
Abstract
Background
Bipolar disorder (BD) is a psychiatric illness defined by pathological alterations between the mood states of mania and depression, causing disability, imposing healthcare costs and elevating the risk of suicide. Although effective treatments for BD exist, variability in outcomes leads to a large number of treatment failures, typically followed by a trial and error process of medication switches that can take years. Pharmacogenetic testing (PGT), by tailoring drug choice to an individual, may personalize and expedite treatment so as to identify more rapidly medications well suited to individual BD patients.
Discussion
A number of associations have been made in BD between medication response phenotypes and specific genetic markers. However, to date clinical adoption of PGT has been limited, often citing questions that must be answered before it can be widely utilized. These include: What are the requirements of supporting evidence? How large is a clinically relevant effect? What degree of specificity and sensitivity are required? Does a given marker influence decision making and have clinical utility? In many cases, the answers to these questions remain unknown, and ultimately, the question of whether PGT is valid and useful must be determined empirically. Towards this aim, we have reviewed the literature and selected drug-genotype associations with the strongest evidence for utility in BD.
Summary
Based upon these findings, we propose a preliminary panel for use in PGT, and a method by which the results of a PGT panel can be integrated for clinical interpretation. Finally, we argue that based on the sufficiency of accumulated evidence, PGT implementation studies are now warranted. We propose and discuss the design for a randomized clinical trial to test the use of PGT in the treatment of BD.
Similar content being viewed by others

Background
Bipolar disorder (BD) is a psychiatric illness that affects 3% to 5% of the population [1], and is characterized by recurring and severe changes in mood, leading to significant impairment, and increased risk for suicide. The estimated direct and indirect costs of BD in the US are estimated at $15B [2]. Mood stabilizers are considered the treatment of choice for managing BD. However, evidenced-based treatment guidelines include a wide range of medications, such as antipsychotics, antidepressants, anxiolytics and multi-drug combinations [3, 4]. Despite the help of guidelines, psychiatrists face tremendous challenges in treating BD. First, the presentation of BD is heterogeneous, and the diagnosis of BD is often difficult. Psychiatric co-morbidity is common, and the typical patient with BD is misdiagnosed an average of four times [5]. After the diagnosis is established, treatment response is often inadequate, and the rate of remission is poor, particularly among those in the depressive phase [6]. Finally, many drugs are poorly tolerated, and unwanted medication side effects are common. Therefore, while there are broadly accepted best practices for treating BD, their application yields variable, and often unacceptable, outcomes, leaving many patients to suffer prolonged and unsuccessful drug trials before responding to treatment.
A challenge in treating BD is heterogeneity among patient responses. The same drug may have different outcomes in two otherwise similar BD patients, successfully treating one, but necessitating a search for an alternative treatment in the other. For this reason, a typical course of treatment is extensive, consisting of serial medication trials until an effective drug or drug combination is identified. Variability in treatment responses may be related to differences in illness pathophysiology and drug metabolism, both factors thought to be influenced by an individual’s genetic background. Therefore, understanding the relationship between genetic factors and treatment response may allow for the development of objective pharmacogenetic tests (PGT) to guide the physician rationally and rapidly towards effective drug treatments for BD.
Recently, many genetic variants have been associated with response-related psychiatric phenotypes, including many in BD. While the strength of this evidence varies, some are now considered reliable. Despite this progress, implementation of this knowledge in the clinic has been limited. It remains unclear if association to response will necessarily translate into improved outcomes, and there has been a reluctance to apply these findings clinically. Other medical disciplines have increasingly demonstrated the utility of personalized medicine [7] with PGT showing advantages in warfarin dosing [8], thiopurine myelosuppression in leukemia [9, 10] and abacavir hypersensitivity in HIV [11, 12]. However, these fields are experiencing similar inertia, even in cases where the supporting evidence is strong [13].
Questions have been raised in the psychiatric literature regarding the appropriateness of implementing PGT in the clinic, most of which remain unanswered [14]. However, unlike genetic association studies which cannot address clinical utility, implementation studies may provide empirical answers to some of these pertinent issues [Box 1]. Hence, they are urgently needed. In this opinion, we conclude that a few PGT markers, while perhaps not perfect are sufficiently well-established to advocate for research into their implementation to determine if they have clinical value. A preliminary path forward and discussion of the anticipated benefits and obstacles is presented.
Discussion
Pharmacogenetic association studies
A large number of genetic markers have been associated with psychotropic response in psychiatry, including many relevant to BD. A number of reviews have been published in recent years [14, 15], focused primarily on lithium. However, many drugs used to treat major depression (MDD) or schizophrenia (SCZ) are also effective in BD. Therefore, in organizing this opinion around implementation, we have broadened the scope of PGT in BD to consider these options in addition to lithium. PubMed and the PharmGKB [16] database were searched for pharmacogenetic reports for lithium, anti-seizure drugs, antipsychotics and antidepressants. We then devised criteria to rank these results based on strength of evidence and clinical utility. In doing so, we focused on variants that have been independently replicated in large cohorts. In some cases, the studies were performed in MDD or SCZ. We developed standardized criteria by which genetic markers were assessed. Those categorized as evidence Level 1 were replicated at least once with a P-value of <0.05 after correction for multiple comparisons, in a total population of ≥500 cases of similar ethnicity. Level 2 evidence required replication with P-values <0.05 after correction and at least one population of 100 to 499. Studies with P-values <0.05, but without replication, or in samples <100 were categorized as Level 3. Our search yielded a set of 16 genetic markers that were classified as Level 1 (Table 1). We also included a small number of variants that were compelling candidates based upon convergent animal or pre-clinical studies that met the threshold for Level 2 evidence. Each genotype-drug association is discussed below.
Pharmacodynamics
Lithium response
Lithium is the most widely used mood stabilizer, greatly decreasing suicide risk and BD symptoms during acute mania, depression and maintenance [17, 18]. Clinical features have been associated with lithium response [19, 20], leading some to argue that lithium responsive BD is a distinct illness subtype that can be defined in part by its sensitivity to the drug [21]. However, in a long term prospective study [22], while lithium response was identified as an enduring trait, the classical clinical profile failed to discriminate lithium responders from non-responders. For this reason, efforts have been directed towards pharmacogenetic approaches predicting lithium response. Table 2 summarizes some of the genetic markers reported to be associated to mood stabilizer response.
BDNF and NTRK2
Brain-derived neurotrophic factor (BDNF), plays a crucial role in neuronal survival, differentiation and plasticity in the brain [23–25]. BDNF binds to the TrkB receptor, the protein product of NTRK2. The BDNF/TrkB signaling pathway is involved in a wide range of intracellular signaling cascades [26] and is thought to play an important role in mediating the therapeutic effects of lithium [27, 28]. Past evidence has implicated BDNF in the pathogenesis of BD [29–31], and the BDNF Val66Met polymorphism (rs6265) has been associated with lithium response, whereby carriers of the Met allele had better treatment outcomes [32, 33]. The lithium response association with BDNF was recently replicated in a sample of Chinese patients with BD [34], but others have failed to replicate the result [35]. NTRK2 polymorphisms have been implicated as genetic factors underlying BD in a genomewide association study (GWAS) [36] and associated with lithium response in two independent studies. In the first, two SNPs in NTRK2 were associated with response specifically in patients with euphoric mania [37]. This association has been subsequently replicated in an independent prospective trial [38]. More recently, another independent study again implicated NTRK2, using a different variant [39]. However, not all studies have replicated the NTRK2 association with lithium response [32]. Different variants in NTRK2 have been associated with risk for suicide attempts, which is particularly interesting in the light of lithium’s known anti-suicide properties [40].
CREB
The cAMP response element-binding protein (CREB1) is a transcription factor that plays important roles in neuroplasticity, cell survival and neuronal modulation by lithium and antidepressants [41–43]. An association between variants in CREB1 and lithium response was reported in a prospective association study conducted on a sample of 258 subjects followed over three years, in which the BD subjects were treated with lithium monotherapy [44]. Of interest, independent CREB1 haplotypes have been associated with selective serotonin receptor inhibitor (SSRI) remission [45], emergent suicidal ideation during SSRI treatment [46] and treatment resistant depression [47], features previously linked to latent bipolarity among depressed subjects.
GRIA2, ODZ4/TENM4
In a GWAS of lithium response conducted using subjects from the Systematic Treatment Enhancement Program for Bipolar Disorder (STEP-BD), five SNPs showed association with P values of <5 × 10ˉ4 and were independently replicated in a cohort of 359 BD patients. Among these was a variant in GRIA2, a glutamate receptor subunit gene [48]. Glutamate has been strongly implicated in the pathogenesis of BD, and GRIA2 was previously shown to be regulated by lithium in hippocampal neurons [49]. ODZ4 (also named TENM4), has been associated with BD susceptibility in the largest published GWAS to date and was also found to be associated with lithium response [50, 51].
GSK3B
Glycogen synthase kinase 3β (GSK3B), is an enzyme involved in neuronal development and survival, and is inhibited by lithium [52, 53]. A pharmacogenetic study of 88 BD patients identified a functional SNP associated with lithium response in the GSK3B promoter [54]. Similar results were obtained in a cohort of 138 Taiwanese BD subjects [55] and a mixed cohort of BD/MDD receiving augmentation of antidepressants with lithium [56]. However, other studies have failed to detect a similar association [57, 58].
Carbamazepine response
The anticonvulsant carbamazepine (CBZ) is a mainstay of treatment in BD patients [59, 60]; however, no pharmacogenetic studies to date have evaluated response to carbamazepine. Clinical features associated with CBZ response include those with BPII disorder, dysphoric mania, comorbid substance abuse, mood incongruent delusions, negative family history of BD in first-degree relatives, and in those not tolerant to other treatments due to side effects (for example, weight gain, tremor, diabetes insipidus, or polycystic ovarian syndrome) [61].
There has been a strong association reported between the HLA-B*1502 haplotype and the severe life-threatening cutaneous drug reactions, Stevens-Johnson syndrome (SJS) and toxic epidermal necrolysis (TEN) [62]. Two studies conducted on Han Chinese patients reported that HLA-B*1502 was present in 100% (44/44) and 98.3% (59/60) of CBZ-induced SJS patients in contrast to 3% (3/101) and 4.2% (6/144) of CBZ-tolerant patients [63, 64]. While the risk-associated haplotype is found in 5% to 15% of Asians, clinical guidelines in some healthcare institutions suggest avoiding carbamazepine in all patients of Asian background, thereby potentially depriving the majority of patients in this racial group a proven treatment for BD. Hence, the adaptation of PGT for HLA-B has a huge potential for impact in this group and HLA-B PGT for carbamazepine treatment is now recommended by the Clinical Pharmacogenetics Implementation Consortium (CPIC) [65].
Valproic acid response
Relatively little work has been done on the pharmacogenetic response to the anticonvulsant mood stabilizer, valproic acid, and no valproic acid study meets the requirements for inclusion in our implementation list. However, valproic acid is a first line treatment for BD, and its omission constitutes an important gap. Valproic acid pharmacogenetics is likely to be a priority for future research.
Antipsychotic response
Antipsychotics are commonly used in BD, both as a first-line treatment in acute mania [66] and depression [67]. However, psychiatrists are increasingly reluctant to use them due to their unfavorable long-term side effect profile, especially weight gain [68]. In addition to metabolic problems, the risk of extra-pyramidal side effects (EPS) associated with second generation antipsychotics is estimated to be 13% to 17% and remains a concern.
Because the majority of the pharmacogenetic studies of antipsychotics have been done with SCZ patients, it requires extrapolation to BD. For this reason, caution is required in interpreting these results. However, many of these data likely apply to BD. First, there is substantial symptom overlap and shared genetic risk between SCZ and BD [50, 69], suggesting that underlying illness mechanisms are shared. Moreover, because side effects such as weight gain are assumed to be due to ‘off target’ effects, side effect mechanisms are likely similar across disorders. To be sure, research extending PGT of antipsychotics to BD is required, not only with regard to psychotic symptoms, but also with respect to mood. Genetic variants reported to be associated with antipsychotic response are listed in Table 3.
DRD2/ANKK1
The D2 dopamine receptor encoded from DRD2 is the primary target of most antipsychotic medications [70, 71]. The -141C insertion/deletion polymorphism located in the DRD2 promoter, has been shown to have a functional effect on expression and has been studied on several occasions with respect to antipsychotic outcomes. In a meta-analysis of 687 SCZ patients from six studies, the -141C variant demonstrated an association with favorable antipsychotic response (>50% reduction in symptoms) at eight weeks [72]. The ankyrin repeat and kinase domain containing 1 gene (ANKK1) is located 10 kb from DRD2 [73], and has been associated with tardive dyskinesia (TD). In a meta-analysis of 1,256 SCZ subjects from six studies, ANKK1 genotype was associated with TD, with odds ratios of 1.30 to 1.50 [74]. A decrease in DRD2 expression was also associated with a risk conferring allele [75, 76], perhaps explaining the effect of ANKK1 genotype on TD risk [77].
HTR2A
Many antipsychotic drugs alter serotonin signaling by blocking 5HT2A receptors, encoded by HTR2A [78]. Several studies demonstrated a less favorable response to olanzapine and clozapine among carriers of the rare functional promoter variant, A-1438G in HTR2A [79–81].
HTR2C
In attempts to identify genetic vulnerability to antipsychotic induced weight gain and metabolic syndrome, HTR2C, encoding the 5-HT2C receptor, has yielded the most reliable associations. A meta-analysis of eight studies showed a significant association of C759T HTR2C SNP, with a lower risk of weight gain with antipsychotics [82]. Similarly, ten independent studies on schizophrenic patients have shown a significant association between the C-allele of the same SNP and higher risk of antipsychotic-induced weight gain [77].
MC4R
MC4R, one of the most important genes associated with weight gain and increased risk for obesity [83, 84], has been shown to play a role in the modulation of food intake and energy homeostasis [85, 86]. It has also been associated with atypical antipsychotics-induced weight gain in a GWAS conducted on 139 pediatric subjects, with replication in three additional cohorts [87]. Another SNP, previously associated with weight gain [83] yielded similar results [88].
Antidepressant response
Although controversial [89], SSRIs are widely used in conjunction with mood stabilizers or antipsychotics for depression in BD, appearing in evidence-based psychopharmacology guidelines [90, 91]. However, because of their questionable efficacy and potential for inducing mania, there is a need to identify genetic variants associated with response and adverse events, such as manic switch and rapid cycling. SSRI response has been primarily studied in MDD or mixed BD/MDD samples. Therefore, our extrapolation from MDD to BD may have important caveats in the use of these markers. Table 4 summarizes genes associated with antidepressant response.
SLC6A4 (5-HTTLPR)
The 5-HTTLPR is a 44 bp insertion/deletion within the promoter of SLC6A4, the gene encoding the serotonin transporter [92]. Transcriptional activity among carriers of the short allele (S) has been shown to be lower compared to carriers of the long allele (L) [92, 93]. Fifteen studies encompassing 1,435 MDD and BD patients were analyzed for association with SSRI response [94]. The L variant was associated with a better response, while SS genotype was linked to lower rates of remission and longer response times. BD patients carrying the S allele were also more susceptible to developing anti-depressant-induced mania (AIM) with a 35% increase in risk [95].
GRIK4
The Sequenced Treatment Alternatives to Relieve Depression (STAR*D) study included an initial period of citalopram monotherapy. Of these SSRI-treated subjects, 1,816 were genotyped in a candidate gene study of 768 SNPs, identifying an association between the GRIK4 SNP rs1954787 and therapeutic response [96]. GRIK4 is a component of the ionotropic kainate/glutamate receptor. An attempt to replicate this finding in 387 BD/MDD subjects found supportive evidence for a GRIK4 association, but not at the same SNP, and required a gene x gene interaction [97].
HTR2A
Since the serotonin transporter is a direct target of SSRIs, modulation of serotonin transmission has long been thought a key mechanism of action. A number of serotonin receptors have been studied and, in the STAR*D sample, an analysis of 1,953 patients revealed a strong association between the intronic HTR2A SNP rs7997012 and treatment response [98]. In a synergistic manner, homozygous carriers of the protective alleles of both GRIK4 and HTR2A were 23% more likely to respond to citalopram than participants carrying neither of these alleles [96].
FKBP5
FKBP5 has been implicated in psychiatric disorders because of its role encoding a co-chaperone protein for the glucocorticoid receptor. It has been shown to affect the hypothalamic–pituitary–adrenal (HPA) [99, 100] and modulate Akt activity [101], thereby altering numerous neuronal functions [102, 103]. Variation in FKBP5 was first associated with antidepressant response in two independent samples [104]. In a subsequent meta-analysis of eight studies including more than 2,199 patients, this association was replicated [105].
Genome-wide association studies
Because the results have been better replicated, most of the markers discussed above come from candidate gene studies. However, by surveying the entire genome, GWAS have the ability to identify previously unrecognized pharmacogenetic markers that could not be predicted based on candidate hypotheses. While some of these studies require replication or have failed to achieve genome-wide significance, several large GWAS of drug response have been conducted and are worthy of mention.
A GWAS of lithium response recently reported very strong evidence of association (P = 10-37) for a variant in the gene glutamic acid decarboxylase like 1 (GADL1) in a sample of 294 Taiwanese subjects [106]. This result was then replicated in smaller samples of 100 and 24 subjects by the same investigators. This is an exciting result awaiting independent replication. A GWAS analysis of citalopram response in the STAR*D cohort yielded suggestive associations for markers in RORA, UBE3C and BMP7, but none that met genome wide thresholds for significance [107]. A similar analysis revealed a number of suggestive associations of citalopram-induced side effects, most prominently a marker in EMID2, associated with altered vision and hearing [108]. More recently, data emerged from a meta-analysis of >2,200 MDD patients from the STAR*D, Genome-Based Therapeutic Drugs for Depression (GENDP) and Munich Antidepressant Response Signature (MARS) trials [109]. In this study, a number of suggestive markers were associated with various response indicators, but none met genome-wide thresholds for significance. Taking a different approach, GWAS analysis for copy number variation using the STAR*D sample and a health system repository revealed a modest enrichment of chromosomal duplications among treatment refractory depression cases, and a deletion in PABPC4L uniquely affecting treatment resistant MDD patients, but was restricted to only a small number of subjects [110].
As with case–control studies of BD, MDD and SCZ, GWAS approaches have generally not supported previously reported candidate gene associations. While the reasons for this discrepancy are unclear, it does underscore the relative strengths and weaknesses of candidate gene studies and GWAS. Candidate gene studies are limited in scope, focusing on individual genes, while GWAS surveys the entire genome. Yet because of this focus, candidate gene studies often have greater statistical power with smaller sample sizes for any individual gene. Practically, however, these studies do not generally correct for the total number of SNPs examined in the same sample. The price of the wide scope of GWAS is the large number of statistical tests and the very large sample sizes required to achieve statistical significance. Such large sample sizes are particularly problematic for pharmacogenetics where the cost of assessing the phenotype, via a prospective clinical trial, is very high, and uniformity of treatment among subjects is rare. Future GWAS with larger samples will likely identify many new drug response loci. Until then, we argue that the strongest candidate gene markers likely provide valid, but incomplete, answers that warrant testing for utility.
Pharmacokinetics
CYP450 enzymes
Cytochrome P450 enzymes constitute a major component of the human drug metabolism system, activating/deactivating and facilitating the elimination of compounds [111, 112]. Many drugs used to treat BD are eliminated by CYP450 enzymes, and knowledge of a patient’s CYP450 genotype can be invaluable in selecting medications or doses. While pharmacokinetics have been largely neglected in previous reviews of the pharmacogenetics of BD, CYP450 genotyping is now approaching mainstream use, with FDA approval of CYP450 testing for 27 alleles in CYP2D6 and three alleles in CYP2C19 [113, 114]. CYP450 genotypes are highly variable, with numerous functionally distinct haplotypes, but are frequently organized by metabolic activity into different phenotypic categories. For example, 2D6 phenotypes are commonly classified as: poor metabolizers (PM) with completely absent enzymatic activity; intermediate metabolizers (IM) with decreased enzymatic activity; extensive metabolizers (EM) with normal enzymatic activity; and ultra-rapid metabolizers (UM) with increased enzymatic activity [115]. The relative frequency of minor allelic variants differs greatly by ethnicity [116–118]. For example, among East Asians approximately 30% carry the null CYP2C19 haplotypes *2 and *3, that lead to a total absence of CYP2C19 activity. In contrast, the frequency in Caucasians ranges from 4% to 13% [119]. On the other hand, <5% of East Asians possesses the CYP2C19 *17 allele that increases activity, whereas the rate in Northern European Caucasians is 18% [120, 121].
CYP2D6
CYP2D6 is involved in the metabolism of more than 70 drugs, including many anti-depressants and anti-psychotics. The CYP2D6 gene is located at 22q13.1, and encodes the CYP2D6 enzyme [122, 123].
CYP2D6 and antidepressants
CYP2D6 genotype has been shown to be associated with antidepressant outcomes across several dimensions [124–126]. Response to venlafaxine was significantly greater in CYP2D6 EM subjects who metabolize the drug normally compared IM subjects who require lower doses [127]. MDD patients showed higher rates of remission among CYP2D6 IMs compared to PMs, after eight weeks of escitalopram treatment [128]. CYP2D6 UM status contributed to non-response by increasing early dropout rates [129, 130], and CYP2D6 UM status was associated with a higher risk of suicide [131–133]. Finally, CYP2D6 genotype predicts the risk of adverse effects as shown among PMs treated with venlafaxine and tricyclic antidepressants (TCAs) [134, 135]. Most dramatically, cases have been reported of PMs being linked to fatal responses to anti-depressants [136, 137]. While compelling evidence links functional CYP2D6 haplotypes to drug levels [138], other studies failed to determine an association between CYP2D6 polymorphisms and treatment response [139–141], leading the Evaluation of Genomic Applications in Practice and Prevention (EGAPP) group to conclude that the evidence in support of CYP2D6 genotyping for guiding antidepressant treatment is inconclusive, and recommending implementation clinical trials in order to show the benefits from CYP450 genotyping [142].
CYP2D6 and antipsychotics
CYP2D6 mediates the metabolism of many antipsychotics, making the use of genetic information about this locus a rational strategy for personalized medicine [143–146]. However the utility of CYP2D6 genotyping in predicting clinical response to antipsychotics is relatively unexplored. CYP2D6 genotype did predict tolerability to risperidone with a higher risk of adverse effects among PMs [147, 148].
CYP2C19
CYP2C19 is involved in the metabolism of a wide range of anti-depressants and benzodiazepines [149, 150]. The CYP2C19 gene is located at 10q24.1-q24.3.
CYP2C19 and antidepressants
CYP2C19 has been shown to be the primary metabolic enzyme for citalopram, escitalopram, amitriptyline and clomipramine [115, 151–153]. Functional CYP2C19 haplotypes have been associated with serum concentrations of citalopram [151, 154] and escitalopram [138, 155]. Analysis of the Caucasian subset of the STAR*D sample revealed an association between the inactive *2 allele and tolerance to citalopram [156].
Other pharmacokinetic targets
ABCB1
P-glycoprotein (P-gp), one of the ATP-binding cassette (ABC) transporter proteins, actively transports drugs, including antidepressants, across the blood–brain barrier [157, 158]. Multiple SNPs in ABCB1, coding for P-gp, were associated with response to citalopram, paroxetine, amitriptyline and venlafaxine, substrates of P-gp [159]. Two of the latter were replicated in a geriatric sample receiving paroxetine [160] and associated with SSRI-related adverse effects in a separate study [161].
Pharmacogenetics and clinical practice: are we there yet?
Psychiatry lacks objective biological disease markers to guide diagnosis and treatment, creating a situation analogous to cardiologists relying on subjective descriptions of chest pain, without the aid of electrocardiograms, biochemical markers, or blood pressure cuffs to differentiate among syndromes or track recovery. While the discovery of predictive genetic markers is just beginning, evidence already exists for a number of well replicated PGT markers. This has raised a number of questions in the psychiatric literature [162], including: How strong must the supporting evidence be? How large is a clinically relevant effect? What degree of specificity and sensitivity are required? Does a given marker influence decision making and have clinical utility? In short, can the existing genetic data be translated from statistical associations to clinically informative tools? The answer remains unclear. A genetic marker can correlate with an outcome, but be deemed clinically useless because of low predictive value, poor specificity or limited external validity [163, 164]. Some have argued against implementation [162–165], concluding that PGT markers are not yet sufficiently sensitive or specific [165]. However, the utility or lack of utility of PGT is an empirical question that has remained largely untested.
Pharmacogenetic implementation studies: design and execution
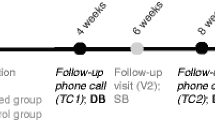
The gold standard for determining the utility of a therapeutic intervention is the randomized clinical trial. This method is readily applied to PGT by comparing the outcomes of PGT guided treatment against treatment as usual (TAU). Figure 1 illustrates a simple, two arm design that could test the clinical utility of PGT. Outcomes could be measured across a number of dimensions including response magnitude, time to response, symptom burden, side effect burden, disability and cost. In principle, improvement on even a single dimension could constitute a successful trial.

A pharmacogenetics implementation design. Patients are randomized to pharmacogenetic test (PGT) guided treatment or treatment as usual (TAU). For the PGT group, the physician incorporates the results of the test to make treatment decisions; in the TAU group, the physician treats according to usual practice based on evidence-based treatment guidelines. Subjects are assessed longitudinally and outcome compared after the specified treatment interval.
Designing the test panel
The design of PGT panels is likely to evolve rapidly. Costs for whole genome sequencing are falling rapidly, and it is expected that this technology will be widely available once the cost drops below $1,000 [166]. Therefore, in the near future, costs of whole genome sequencing will be comparable to other common medical tests, allowing for the patient’s entire genetic sequence and interpretation to be part of the electronic medical record. In the interim, candidate gene panels composed of a limited set of markers, targeting key biological functions offer a cost effective and technically plausible format for focused genotyping. For illustrative purposes, we have selected the well replicated markers described above to show how a candidate gene variant panel might be selected, configured and implemented.
Reporting and recording genetic results
Most psychiatrists lack training in advanced genetics and may have difficulty understanding PGT results. Therefore, in the design of a PGT, it is important to convey results in a simple manner that can be understood and quickly incorporated into clinical decision making without losing pertinent detail. To address the dilemma presented by these competing interests, a PGT report may require multiple layers, each coherent and internally consistent, that presents information with increasing levels of detail, starting with general drug recommendations and ending with the raw genotype results and technical details of the assay.
An algorithm for integrating genetic results
Frequently, a medication may have multiple, relevant genetic marker associations (for example, one for response, others for side effects), a genetic marker may be relevant to multiple medications, and different genetic markers may suggest opposite actions. Therefore, the PGT results for each variant need to be reconciled and consolidated into a single, overall recommendation. The process of synthesizing PGT results from multiple markers into coherent treatment recommendations for the physician may prove challenging. One solution to this challenge is to develop algorithms that prioritize and apply differential weight to potential clinical outcomes (Figure 2). We approached this by first classifying all relevant drug-marker combinations into four clinical recommendations: 1) use with caution; 2) potential limitations to use; 3) use as directed; and 4) preferred use. We then developed an algorithm (Figure 2), that generates an overall recommendation for each drug based on genotype. In this algorithm, drugs are serially considered in descending order of expected adverse events, starting with the most severe. For example, genotypes that predict high risk for life-threatening/serious adverse effects are considered first, thereby removing drugs that could present imminent danger to the subject (for example, HLA-B1502 and SJS). Medications are then considered with respect to genetic risk of long-term side effects and/or higher dosing requirements (for example, CYP450 UMs). Finally, drugs are assessed in terms of genetic associations with symptom response. The set of drugs with minimal side effect associations, but no information on response will be classified for ‘Use as directed’. Those with minimal/no side effect associations predicted to show a good response are classified for ‘Preferred use’. Given the common nature of many of the risk-associated markers that preclude ‘preferred’ status, this latter set of drugs will typically be small, (perhaps even nonexistent for patients with some genotypes), but optimally matched to an individual, narrowing the available choices for making ‘the best decision’, and eliminating choices that are less likely to work or to be poorly tolerated. Importantly, the algorithm does not replace clinical judgment, and the physician is free to incorporate relevant information from other sources (for example, clinical features, drug-drug interactions) to weigh options alternatively, or, when indicated, to override the algorithm.

Integrating pharmacogenetic test results. An algorithm for translating genotypes into specific recommendations for drugs commonly used in BD is illustrated. In making an overall treatment recommendation, all possible drug-genotype combinations are classified into four outcome categories. The overall recommendation is optimized to avoid the worst outcome predicted by PGT. Drug-genotype combinations associated with serious and/or potentially life threatening outcomes are given lowest priority (Use with caution). Drug-genotype combinations with an elevated risk of long term side effects or that are predicted to require higher dosing requirements are given the next lowest priority (Potential limitations to use). Drug-genotype combinations that are not associated with an increase in adverse events are recommended for use in accordance with standard practices (Use as directed), and those without an elevated risk for adverse events, and an association with good psychiatric outcomes are given highest priority (Preferential use). EM, extensive metabolizer; IM, intermediate metabolizer; NA, not available; PM, poor metabolizer; TD, tardive dyskinesia; UM, ultra-rapid metabolizer; UNKN: unknown.
Special considerations in clinical trial design
There are several factors that differ between a PGT implementation study and a randomized clinical trial (for example, for a medication) or genetic association study that warrant special consideration. First, in designing an implementation study, a panel of genetic markers is evaluated, not a single genetic marker, and the efficacy of the panel as a whole is tested. Not all markers will be relevant to a given patient or decision, but the breadth of multi-marker panels affords the clinician an opportunity to survey several low frequency alleles with good efficiency, offering broad utility in a naturalistic environment. This approach does have limited ability to test the benefit of any single genetic association included in the panel. It is assumed that not every result will support a previously established genetic association, but that in aggregate, treatment outcomes will be improved based on the PGT results. Over time, data can be collected regarding clinician choices and specific markers. In this manner, insight into which components of the test are most useful can be developed.
In an implementation study, the effectiveness of treatment, regardless of the specific drug(s) used is the most important variable. The hypothesis is that outcomes in PGT are superior to TAU as a result of genetic information being conveyed to the physician, not that a specific drug is better. Appropriate clinical use of PGT data will differ among clinicians, and this variability must be controlled. The use of evidence-supported clinical treatment guidelines can standardize some practices. However, ‘real world patients’, particularly those with treatment refractory symptoms, often have extensive treatment histories that can make it difficult to fit them into standardized algorithms. To mitigate this difficulty, experimental blinding is essential. Since the physician is required to interpret genetic data and make decisions based upon the results, the physician cannot be blinded. However, by obtaining DNA on all subjects, patients can be blinded if their data are withheld. Independent raters can also be blinded to assess outcomes. Many other clinical trial designs are possible, and their respective strengths and weaknesses have been recently reviewed [162].
Early implementation studies
Using a panel of five genetic markers and a design similar to the one outlined above, a PGT implementation study of 44 MDD patients was completed using a commercially available test, yielding promising results [167]. Treatment refractory patients with MDD were divided into PGT and TAU groups. Depressive symptoms were significantly decreased in the PGT group compared to TAU, as shown by greater reductions in QIDS-C16 and HAM-D17 scores at the eighth week. More recently, similar differences were shown by the same group using a larger replication sample of 227 MDD patients [168]. The same test was retrospectively applied to 97 subjects for whom health insurance records were available. In this way, genetic testing predicted healthcare utilization and costs. When patients were prescribed medications later found to be poorly matched to genotype, they required more frequent visits, took more medication and required greater expenditures [169]. In all three of these reports, differences in outcome were driven primarily by the genotypes expected to have the most severe outcomes, primarily those expected to metabolize medications poorly, resulting in more adverse effects. Strikingly, these most severe mismatches were commonly encountered, affecting approximately 25% of the subjects in one study [168]. Several limitations in these studies warrant mention. First, both efficacy trials were open label and not randomized, meaning that patients were aware of their group assignment. Second, the samples were small, ethnically homogenous and collected from single sites, potentially limiting the external validity of the results. Nonetheless, the improvement over TAU is particularly striking given the nature of the subjects, many of whom suffered from chronic refractory depression. To date, no trials in BD have been conducted.
Summary
Statistically significant, but clinically significant?
The findings summarized indicate that a number of PGT markers are reliably associated with clinically salient treatment outcomes. Although this is a very early stage in the discovery of PGT markers in BD, this set of genes is expected to be refined and enlarged over time, and we argue that there are already enough potentially informative results to warrant implementation studies to determine their clinical utility.
Whether or not the pharmacogenetic panel presented here can be used to improve outcomes in clinical practice is an untested question. In clinical trials, the concepts of effect size, sensitivity (labeling a true positive as positive) and specificity (labeling a true negative as negative) are used to measure the value of a biological test. Psychiatric PGT has been criticized for individual allelic associations falling short on these measures. However, three counter-points can be offered. First, PGT implementation takes advantage of multiple genetic markers, and while individual markers may be non-specific, limited in applicability, or yield small effects, a more comprehensive panel, utilizing multiple markers may prove to be more robust. Second, in the absence of objective markers to guide decisions, medication choice in BD is presently made in a largely trial and error fashion. In this case, even small improvements in care could represent a significant advance. Third, the interactions among genetic variants, medications and individual patients are sufficiently complex that a priori estimates of sensitivity and specificity may not accurately predict the outcome of a PGT trial. Only empirical data can determine the value of PGTs in clinical practice. Hence, we conclude that the potential for benefit from PGT is high, and will only increase as whole genome sequence information becomes widely incorporated into newer PGT panels and new genetic associations are discovered.
On the other side of the equation, the costs of repeated medication trials, prolonged illness, clinician time and unanticipated adverse drug events are also high, while the cost of genotyping, incurred only once, is relatively low, and likely to drop further. Therefore, while the potential for therapeutic gains may be modest in the first iterations of PGT, the downside risk imposed upon the patient is minimal, making the cost-benefit ratio strongly favorable. Therefore, carefully designed implementation studies constitute an essential and effective tool in addressing these concerns while playing an instrumental role in the validation process of genetic tests and their introduction into routine psychiatry practice. Implementation studies, as proposed here, will likely be a useful approach in deciding the value of a genetic test in real world clinical situations [162].
Box 1: Pharmacogenetic association studies versus implementation studies
Genetic association studies have been used widely in psychiatric pharmacogenetics to determine statistical associations between genetic markers and a phenotype related to treatment outcome, typically treatment response, or a major side effect (for example, sexual dysfunction, Stevens-Johnson rash). These are done either as candidate gene studies where a specific hypothesis is tested or as GWAS in which associations sampled from across the whole genome are examined independent of a specific hypothesis. In association studies, patients are determined to be responder or non-responder in categorical or quantitative terms, an assessment that can be determined either prospectively or retrospectively. There is typically no comparator treatment used in association studies.
bibuIn comparison, genetic implementation studies are relatively rare in the psychiatry literature. These studies evaluate the clinical utility of a genetic test(s) versus a control treatment that does not utilize genetic information. Here, the association between the genetic marker to the phenotype is assumed, and the hypothesis tested is that the information provided by the genetic marker will allow for better drug selection than would occur in the absence of this information. Implementation studies have to be prospective in order to determine the effects of adding the information. The endpoints would be treatment response and/or side effect burden at the end of the trial.
Abbreviations
- ABCB1:
-
gene for an ATP binding cassette transporter protein
- AIM:
-
antidepressant-induced mania
- ANKK1:
-
ankyrin repeat and kinase domain containing 1
- BD:
-
bipolar disorder
- BDNF:
-
brain-derived neurotrophic factor
- bp:
-
base pair
- CBZ:
-
carbamazepine
- CREB:
-
cyclic AMP response element
- CYP450:
-
family of proteins involved in drug metabolism
- DRD2:
-
gene for the D2 dopamine receptor
- epS:
-
extrapyramidal symptoms
- FKBP5:
-
gene for a co-chaperone protein for the glucocorticoid receptor
- GRIA2:
-
AMPA type glutamate receptor subunit
- GRIK4:
-
gene for the ionotropic kainate glutamate receptor
- GSK3B:
-
glycogen synthase kinase beta
- GWAS:
-
genomewide association study
- HTR2A:
-
gene for the serotonin 2A receptor
- HTR2C:
-
gene for the serotonin 2C receptor
- MC4R:
-
gene for the melanocortin 4 receptor
- MDD:
-
major depressive disorder
- NTRK2:
-
gene name for the TrkB receptor
- ODZ4:
-
gene for Odd Oz/Ten-m Homolog 4
- PGT:
-
pharmacogenetic guided treatment
- SCZ:
-
schizophrenia
- SJS:
-
Stevens-Johnson syndrome
- SLC6A4:
-
gene for the serotonin transporter
- SNP:
-
single nucleotide polymorphism
- SSRI:
-
selective serotonin reuptake inhibitor
- TAU:
-
treatment as usual
- TrkB:
-
tropomyosin related kinase B.
References
Kessler RC, Berglund P, Demler O, Jin R, Merikangas KR, Walters EE: Lifetime prevalence and age-of-onset distributions of DSM-IV disorders in the National Comorbidity Survey Replication. Arch Gen Psychiatry. 2005, 62: 593-602. 10.1001/archpsyc.62.6.593.
Begley CE, Annegers JF, Swann AC, Lewis C, Coan S, Schnapp WB, Bryant-Comstock L: The lifetime cost of bipolar disorder in the US: an estimate for new cases in 1998. Pharmacoecon. 2001, 19: 483-495. 10.2165/00019053-200119050-00004.
Yatham LN, Kennedy SH, Schaffer A, Parikh SV, Beaulieu S, O’Donovan C, MacQueen G, McIntyre RS, Sharma V, Ravindran A, Young LT, Young AH, Alda M, Milev R, Vieta E, Calabrese JR, Berk M, Ha K, Kapczinski F: Canadian Network for Mood and Anxiety Treatments (CANMAT) and International Society for Bipolar Disorders (ISBD) collaborative update of CANMAT guidelines for the management of patients with bipolar disorder: update 2009. Bipolar Disord. 2009, 11: 225-255. 10.1111/j.1399-5618.2009.00672.x.
Suppes T, Dennehy EB, Hirschfeld RM, Altshuler LL, Bowden CL, Calabrese JR, Crismon ML, Ketter TA, Sachs GS, Swann AC: The Texas implementation of medication algorithms: update to the algorithms for treatment of bipolar I disorder. J Clin Psychiatry. 2005, 66: 870-886. 10.4088/JCP.v66n0710.
Hirschfeld RM, Lewis L, Vornik LA: Perceptions and impact of bipolar disorder: how far have we really come? Results of the national depressive and manic-depressive association 2000 survey of individuals with bipolar disorder. J Clin Psychiatry. 2003, 64: 161-174. 10.4088/JCP.v64n0209.
Nierenberg AA, Ostacher MJ, Calabrese JR, Ketter TA, Marangell LB, Miklowitz DJ, Miyahara S, Bauer MS, Thase ME, Wisniewski SR, Sachs GS: Treatment-resistant bipolar depression: a STEP-BD equipoise randomized effectiveness trial of antidepressant augmentation with lamotrigine, inositol, or risperidone. Am J Psych. 2006, 163: 210-216. 10.1176/appi.ajp.163.2.210.
Ritchie MD: The success of pharmacogenomics in moving genetic association studies from bench to bedside: study design and implementation of precision medicine in the post-GWAS era. Hum Genet. 2012, 131: 1615-1626. 10.1007/s00439-012-1221-z.
Johnson JA, Gong L, Whirl-Carrillo M, Gage BF, Scott SA, Stein CM, Anderson JL, Kimmel SE, Lee MT, Pirmohamed M, Wadelius M, Klein TE, Altman RB, Clinical Pharmacogenetics Implementation Consortium: Clinical pharmacogenetics implementation consortium guidelines for CYP2C9 and VKORC1 genotypes and warfarin dosing. Clin Pharmacol Ther. 2011, 90: 625-629. 10.1038/clpt.2011.185.
van den Akker-van Marle ME, Gurwitz D, Detmar SB, Enzing CM, Hopkins MM, Gutierrez De Mesa E, Ibarreta D: Cost-effectiveness of pharmacogenomics in clinical practice: a case study of thiopurine methyltransferase genotyping in acute lymphoblastic leukemia in Europe. Pharmacogenomics. 2006, 7: 783-792. 10.2217/14622416.7.5.783.
Schaeffeler E, Fischer C, Brockmeier D, Wernet D, Moerike K, Eichelbaum M, Zanger UM, Schwab M: Comprehensive analysis of thiopurine S-methyltransferase phenotype-genotype correlation in a large population of German-Caucasians and identification of novel TPMT variants. Pharmacogenetics. 2004, 14: 407-417. 10.1097/01.fpc.0000114745.08559.db.
Mallal S, Phillips E, Carosi G, Molina JM, Workman C, Tomazic J, Jagel-Guedes E, Rugina S, Kozyrev O, Cid JF, Hay P, Nolan D, Hughes S, Hughes A, Ryan S, Fitch N, Thorborn D, Benbow A, PREDICT-1 Study Team: HLA-B*5701 screening for hypersensitivity to abacavir. N Engl J Med. 2008, 358: 568-579. 10.1056/NEJMoa0706135.
Martin MA, Klein TE, Dong BJ, Pirmohamed M, Haas DW, Kroetz DL: Clinical pharmacogenetics implementation consortium guidelines for HLA-B genotype and abacavir dosing. Clin Pharmacol Ther. 2012, 91: 734-738. 10.1038/clpt.2011.355.
Crews KR, Hicks JK, Pui CH, Relling MV, Evans WE: Pharmacogenomics and individualized medicine: translating science into practice. Clin Pharmacol Ther. 2012, 92: 467-475.
McCarthy MJ, Leckband SG, Kelsoe JR: Pharmacogenetics of lithium response in bipolar disorder. Pharmacogenomics. 2010, 11: 1439-1465. 10.2217/pgs.10.127.
Rybakowski JK: Genetic influences on response to mood stabilizers in bipolar disorder: current status of knowledge. CNS Drugs. 2013, 27: 165-173. 10.1007/s40263-013-0040-7.
Klein TE, Altman RB: PharmGKB: the pharmacogenetics and pharmacogenomics knowledge base. Pharmacogenomics J. 2004, 4: 1.
Tondo L, Hennen J, Baldessarini RJ: Lower suicide risk with long-term lithium treatment in major affective illness: a meta-analysis. Acta Psychiatr Scand. 2001, 104: 163-172. 10.1034/j.1600-0447.2001.00464.x.
Smith LA, Cornelius V, Warnock A, Bell A, Young AH: Effectiveness of mood stabilizers and antipsychotics in the maintenance phase of bipolar disorder: a systematic review of randomized controlled trials. Bipolar Disord. 2007, 9: 394-412. 10.1111/j.1399-5618.2007.00490.x.
Kessing LV, Hellmund G, Andersen PK: Predictors of excellent response to lithium: results from a nationwide register-based study. Int Clin Psychopharmacol. 2011, 26: 323-328. 10.1097/YIC.0b013e32834a5cd0.
Smith DJ, Evans R, Craddock N: Predicting response to lithium in bipolar disorder: a critical review of pharmacogenetic studies. J Ment Health. 2010, 19: 142-156. 10.3109/09638230903469103.
Grof P: Selecting effective long-term treatment for bipolar patients: monotherapy and combinations. J Clin Psychiatry. 2003, 64: 53-61. 10.4088/JCP.v64n0111.
Berghofer A, Alda M, Adli M, Baethge C, Bauer M, Bschor T, Glenn T, Grof P, Muller-Oerlinghausen B, Rybakowski J, Suwalska A, Pfennig A: Long-term effectiveness of lithium in bipolar disorder: a multicenter investigation of patients with typical and atypical features. J Clin Psychiatry. 2008, 69: 1860-1868. 10.4088/JCP.v69n1203.
Lewin GR, Barde YA: Physiology of the neurotrophins. Annu Rev Neurosci. 1996, 19: 289-317. 10.1146/annurev.ne.19.030196.001445.
Asztely F, Kokaia M, Olofsdotter K, Ortegren U, Lindvall O: Afferent-specific modulation of short-term synaptic plasticity by neurotrophins in dentate gyrus. Eur J Neurosci. 2000, 12: 662-669. 10.1046/j.1460-9568.2000.00956.x.
Alsina B, Vu T, Cohen-Cory S: Visualizing synapse formation in arborizing optic axons in vivo: dynamics and modulation by BDNF. Nat Neurosci. 2001, 4: 1093-1101. 10.1038/nn735.
Shaltiel G, Chen G, Manji HK: Neurotrophic signaling cascades in the pathophysiology and treatment of bipolar disorder. Curr Opin Pharmacol. 2007, 7: 22-26. 10.1016/j.coph.2006.07.005.
Tseng M, Alda M, Xu L, Sun X, Wang JF, Grof P, Turecki G, Rouleau G, Young LT: BDNF protein levels are decreased in transformed lymphoblasts from lithium-responsive patients with bipolar disorder. J Psychiatry Neurosci. 2008, 33: 449-453.
Hashimoto R, Takei N, Shimazu K, Christ L, Lu B, Chuang DM: Lithium induces brain-derived neurotrophic factor and activates TrkB in rodent cortical neurons: an essential step for neuroprotection against glutamate excitotoxicity. Neuropharmacology. 2002, 43: 1173-1179. 10.1016/S0028-3908(02)00217-4.
Sklar P, Gabriel SB, McInnis MG, Bennett P, Lim YM, Tsan G, Schaffner S, Kirov G, Jones I, Owen M, Craddock N, DePaulo JR, Lander ES: Family-based association study of 76 candidate genes in bipolar disorder: BDNF is a potential risk locus. Brain-derived neutrophic factor. Mol Psychiatry. 2002, 7: 579-593. 10.1038/sj.mp.4001058.
Sears C, Markie D, Olds R, Fitches A: Evidence of associations between bipolar disorder and the brain-derived neurotrophic factor (BDNF) gene. Bipolar Disord. 2011, 13: 630-637. 10.1111/j.1399-5618.2011.00955.x.
Kremeyer B, Herzberg I, Garcia J, Kerr E, Duque C, Parra V, Vega J, Lopez C, Palacio C, Bedoya G, Ospina J, Ruiz-Linares A: Transmission distortion of BDNF variants to bipolar disorder type I patients from a South American population isolate. Am J Med Genet B Neuropsychiatr Genet. 2006, 141B: 435-439. 10.1002/ajmg.b.30354.
Dmitrzak-Weglarz M, Rybakowski JK, Suwalska A, Skibinska M, Leszczynska-Rodziewicz A, Szczepankiewicz A, Hauser J: Association studies of the BDNF and the NTRK2 gene polymorphisms with prophylactic lithium response in bipolar patients. Pharmacogenomics. 2008, 9: 1595-1603. 10.2217/14622416.9.11.1595.
Rybakowski JK, Suwalska A, Skibinska M, Szczepankiewicz A, Leszczynska-Rodziewicz A, Permoda A, Czerski PM, Hauser J: Prophylactic lithium response and polymorphism of the brain-derived neurotrophic factor gene. Pharmacopsychiatry. 2005, 38: 166-170. 10.1055/s-2005-871239.
Wang Z, Li Z, Chen J, Huang J, Yuan C, Hong W, Yu S, Fang Y: Association of BDNF gene polymorphism with bipolar disorders in Han Chinese population. Genes Brain Behav. 2012, 11: 524-528. 10.1111/j.1601-183X.2012.00797.x.
Masui T, Hashimoto R, Kusumi I, Suzuki K, Tanaka T, Nakagawa S, Suzuki T, Iwata N, Ozaki N, Kato T, Kunugi H, Koyama T: Lithium response and Val66Met polymorphism of the brain-derived neurotrophic factor gene in Japanese patients with bipolar disorder. Psychiatr Genet. 2006, 16: 49-50. 10.1097/01.ypg.0000180680.72922.57.
Smith EN, Bloss CS, Badner JA, Barrett T, Belmonte PL, Berrettini W, Byerley W, Coryell W, Craig D, Edenberg HJ, Eskin E, Foroud T, Gershon E, Greenwood TA, Hipolito M, Koller DL, Lawson WB, Liu C, Lohoff F, McInnis MG, McMahon FJ, Mirel DB, Murray SS, Nievergelt C, Nurnberger J, Nwulia EA, Paschall J, Potash JB, Rice J, Schulze TG, et al: Genome-wide association study of bipolar disorder in European American and African American individuals. Mol Psychiatry. 2009, 14: 755-763. 10.1038/mp.2009.43.
Bremer T, Diamond C, McKinney R, Shehktman T, Barrett TB, Herold C, Kelsoe JR: The pharmacogenetics of lithium response depends upon clinical co-morbidity. Mol Diagn Ther. 2007, 11: 161-170. 10.1007/BF03256238.
Kelsoe JR: Genetic variation in the NTRK2 gene is associated with lithium response in bipolar disorder in both retrospective and prospective samples. Biol Psychiatr. 2012, 71: 24S.
Wang Z, Fan J, Gao K, Li Z, Yi Z, Wang L, Huang J, Yuan C, Hong W, Yu S, Fang Y: Neurotrophic tyrosine kinase receptor type 2 (NTRK2) gene associated with treatment response to mood stabilizers in patients with bipolar I disorder. J Mol Neurosci. 2013, 50: 305-310. 10.1007/s12031-013-9956-0.
Kohli MA, Salyakina D, Pfennig A, Lucae S, Horstmann S, Menke A, Kloiber S, Hennings J, Bradley BB, Ressler KJ, Uhr M, Müller-Myhsok B, Holsboer F, Binder EB: Association of genetic variants in the neurotrophic receptor-encoding gene NTRK2 and a lifetime history of suicide attempts in depressed patients. Arch Gen Psychiatry. 2010, 67: 348-359. 10.1001/archgenpsychiatry.2009.201.
Thome J, Sakai N, Shin K, Steffen C, Zhang YJ, Impey S, Storm D, Duman RS: cAMP response element-mediated gene transcription is upregulated by chronic antidepressant treatment. J Neurosci. 2000, 20: 4030-4036.
Kopnisky KL, Chalecka-Franaszek E, Gonzalez-Zulueta M, Chuang DM: Chronic lithium treatment antagonizes glutamate-induced decrease of phosphorylated CREB in neurons via reducing protein phosphatase 1 and increasing MEK activities. Neuroscience. 2003, 116: 425-435. 10.1016/S0306-4522(02)00573-0.
Grimes CA, Jope RS: CREB DNA binding activity is inhibited by glycogen synthase kinase-3 beta and facilitated by lithium. J Neurochem. 2001, 78: 1219-1232. 10.1046/j.1471-4159.2001.00495.x.
Mamdani F, Alda M, Grof P, Young LT, Rouleau G, Turecki G: Lithium response and genetic variation in the CREB family of genes. Am J Med Genet B Neuropsychiatr Genet. 2008, 147B: 500-504. 10.1002/ajmg.b.30617.
Calati R, Crisafulli C, Balestri M, Serretti A, Spina E, Calabro M, Sidoti A, Albani D, Massat I, Hofer P, Amital D, Juven-Wetzler A, Kasper S, Zohar J, Souery D, Montgomery S, Mendlewicz J: Evaluation of the role of MAPK1 and CREB1 polymorphisms on treatment resistance, response and remission in mood disorder patients. Prog Neuropsychopharmacol Bol Psychiatry. 2013, 44: 271-278.
Perlis RH, Purcell S, Fava M, Fagerness J, Rush AJ, Trivedi MH, Smoller JW: Association between treatment-emergent suicidal ideation with citalopram and polymorphisms near cyclic adenosine monophosphate response element binding protein in the STAR*D study. Arch Gen Psychiatry. 2007, 64: 689-697. 10.1001/archpsyc.64.6.689.
Serretti A, Chiesa A, Calati R, Massat I, Linotte S, Kasper S, Lecrubier Y, Antonijevic I, Forray C, Snyder L, Bollen J, Zohar J, De Ronchi D, Souery D, Mendlewicz J: A preliminary investigation of the influence of CREB1 gene on treatment resistance in major depression. J Affect Disord. 2011, 128: 56-63. 10.1016/j.jad.2010.06.025.
Perlis RH, Smoller JW, Ferreira MA, McQuillin A, Bass N, Lawrence J, Sachs GS, Nimgaonkar V, Scolnick EM, Gurling H, Sklar P, Purcell S: A genomewide association study of response to lithium for prevention of recurrence in bipolar disorder. Am J Psychiatry. 2009, 166: 718-725. 10.1176/appi.ajp.2009.08111633.
Seelan RS, Khalyfa A, Lakshmanan J, Casanova MF, Parthasarathy RN: Deciphering the lithium transcriptome: microarray profiling of lithium-modulated gene expression in human neuronal cells. Neuroscience. 2008, 151: 1184-1197. 10.1016/j.neuroscience.2007.10.045.
Psychiatric GWAS Consortium Bipolar Disorder Working Group: Large-scale genome-wide association analysis of bipolar disorder identifies a new susceptibility locus near ODZ4. Nat Genet. 2011, 43: 977-983. 10.1038/ng.943.
Green EK, Hamshere M, Forty L, Gordon-Smith K, Fraser C, Russell E, Grozeva D, Kirov G, Holmans P, Moran JL, Purcell S, Sklar P, Owen MJ, O’Donovan MC, Jones L, Jones IR, Craddock N, WTCCC: Replication of bipolar disorder susceptibility alleles and identification of two novel genome-wide significant associations in a new bipolar disorder case–control sample. Mol Psychiatry. 2013, 18: 1302-1307. 10.1038/mp.2012.142.
Klein PS, Melton DA: A molecular mechanism for the effect of lithium on development. Proc Natl Acad Sci U S A. 1996, 93: 8455-8459. 10.1073/pnas.93.16.8455.
Gould TD, Chen G, Manji HK: In vivo evidence in the brain for lithium inhibition of glycogen synthase kinase-3. Neuropsychopharmacology. 2004, 29: 32-38. 10.1038/sj.npp.1300283.
Benedetti F, Serretti A, Pontiggia A, Bernasconi A, Lorenzi C, Colombo C, Smeraldi E: Long-term response to lithium salts in bipolar illness is influenced by the glycogen synthase kinase 3-beta -50 T/C SNP. Neurosci Lett. 2005, 376: 51-55. 10.1016/j.neulet.2004.11.022.
Lin YF, Huang MC, Liu HC: Glycogen synthase kinase 3beta gene polymorphisms may be associated with bipolar I disorder and the therapeutic response to lithium. J Affect Disord. 2012, 147: 401-406.
Adli M, Hollinde DL, Stamm T, Wiethoff K, Tsahuridu M, Kirchheiner J, Heinz A, Bauer M: Response to lithium augmentation in depression is associated with the glycogen synthase kinase 3-beta -50 T/C single nucleotide polymorphism. Biol Psychiatry. 2007, 62: 1295-1302. 10.1016/j.biopsych.2007.03.023.
Michelon L, Meira-Lima I, Cordeiro Q, Miguita K, Breen G, Collier D, Vallada H: Association study of the INPP1, 5HTT, BDNF, AP-2beta and GSK-3beta GENE variants and restrospectively scored response to lithium prophylaxis in bipolar disorder. Neurosci Lett. 2006, 403: 288-293. 10.1016/j.neulet.2006.05.001.
Szczepankiewicz A, Rybakowski JK, Suwalska A, Skibinska M, Leszczynska-Rodziewicz A, Dmitrzak-Weglarz M, Czerski PM, Hauser J: Association study of the glycogen synthase kinase-3beta gene polymorphism with prophylactic lithium response in bipolar patients. World J Biol Psychiatry. 2006, 7: 158-161. 10.1080/15622970600554711.
Ballenger JC, Post RM: Carbamazepine in manic-depressive illness: a new treatment. Am J Psychiatry. 1980, 137: 782-790.
Weisler RH, Keck PE, Swann AC, Cutler AJ, Ketter TA, Kalali AH: Extended-release carbamazepine capsules as monotherapy for acute mania in bipolar disorder: a multicenter, randomized, double-blind, placebo-controlled trial. J Clin Psychiatry. 2005, 66: 323-330. 10.4088/JCP.v66n0308.
Post RM, Ketter TA, Uhde T, Ballenger JC: Thirty years of clinical experience with carbamazepine in the treatment of bipolar illness: principles and practice. CNS Drugs. 2007, 21: 47-71. 10.2165/00023210-200721010-00005.
Leeder JS: Mechanisms of idiosyncratic hypersensitivity reactions to antiepileptic drugs. Epilepsia. 1998, 39: S8-S16. 10.1111/j.1528-1157.1998.tb01679.x.
Chung WH, Hung SI, Hong HS, Hsih MS, Yang LC, Ho HC, Wu JY, Chen YT: Medical genetics: a marker for Stevens-Johnson syndrome. Nature. 2004, 428: 486-10.1038/428486a.
Hung SI, Chung WH, Jee SH, Chen WC, Chang YT, Lee WR, Hu SL, Wu MT, Chen GS, Wong TW, Hsiao PF, Chen WH, Shih HY, Fang WH, Wei CY, Lou YH, Huang YL, Lin JJ, Chen YT: Genetic susceptibility to carbamazepine-induced cutaneous adverse drug reactions. Pharmacogenet Genomics. 2006, 16: 297-306. 10.1097/01.fpc.0000199500.46842.4a.
Leckband SG, Kelsoe JR, Dunnenberger HM, George AL, Tran E, Berger R, Muller DJ, Whirl-Carrillo M, Caudle KE, Pirmohamed M: Clinical pharmacogenetics implementation consortium guidelines for HLA-B genotype and carbamazepine dosing. Clin Pharmacol Ther. 2013, 94: 324-328. 10.1038/clpt.2013.103.
Malhi GS, Tanious M, Berk M: Mania: diagnosis and treatment recommendations. Curr Psychiatry Rep. 2012, 14: 676-686. 10.1007/s11920-012-0324-5.
Sanford M, Keating GM: Quetiapine: a review of its use in the management of bipolar depression. CNS Drugs. 2012, 26: 435-460. 10.2165/11203840-000000000-00000.
Lieberman JA, Stroup TS, McEvoy JP, Swartz MS, Rosenheck RA, Perkins DO, Keefe RS, Davis SM, Davis CE, Lebowitz BD, Severe J, Hsiao JK, Clinical Antipsychotic Trials of Intervention Effectiveness (CATIE) Investigators: Effectiveness of antipsychotic drugs in patients with chronic schizophrenia. N Engl J Med. 2005, 353: 1209-1223. 10.1056/NEJMoa051688.
Steinberg S, de Jong S, Mattheisen M, Costas J, Demontis D, Jamain S, Pietilainen OP, Lin K, Papiol S, Huttenlocher J, Sigurdsson E, Vassos E, Giegling I, Breuer R, Fraser G, Walker N, Melle I, Djurovic S, Agartz I, Tuulio-Henriksson A, Suvisaari J, Lönnqvist J, Paunio T, Olsen L, Hansen T, Ingason A, Pirinen M, Strengman E, Hougaard DM, Orntoft T, et al: Common variant at 16p11.2 conferring risk of psychosis. Mol Psychiatry. 2014, 19: 108-114. 10.1038/mp.2012.157.
Kapur S, Seeman P: Does fast dissociation from the dopamine d(2) receptor explain the action of atypical antipsychotics?: a new hypothesis. Am J Psychiatry. 2001, 158: 360-369. 10.1176/appi.ajp.158.3.360.
Kapur S, Mamo D: Half a century of antipsychotics and still a central role for dopamine D2 receptors. Prog Neuropsychopharmacol Biol Psychiatry. 2003, 27: 1081-1090. 10.1016/j.pnpbp.2003.09.004.
Zhang JP, Lencz T, Malhotra AK: D2 receptor genetic variation and clinical response to antipsychotic drug treatment: a meta-analysis. Am J Psychiatry. 2010, 167: 763-772. 10.1176/appi.ajp.2009.09040598.
Neville MJ, Johnstone EC, Walton RT: Identification and characterization of ANKK1: a novel kinase gene closely linked to DRD2 on chromosome band 11q23.1. Hum Mutat. 2004, 23: 540-545. 10.1002/humu.20039.
Zai CC, De Luca V, Hwang RW, Voineskos A, Muller DJ, Remington G, Kennedy JL: Meta-analysis of two dopamine D2 receptor gene polymorphisms with tardive dyskinesia in schizophrenia patients. Mol Psychiatry. 2007, 12: 794-795. 10.1038/sj.mp.4002023.
Ritchie T, Noble EP: Association of seven polymorphisms of the D2 dopamine receptor gene with brain receptor-binding characteristics. Neurochem Res. 2003, 28: 73-82. 10.1023/A:1021648128758.
Jonsson EG, Nothen MM, Grunhage F, Farde L, Nakashima Y, Propping P, Sedvall GC: Polymorphisms in the dopamine D2 receptor gene and their relationships to striatal dopamine receptor density of healthy volunteers. Mol Psychiatry. 1999, 4: 290-296. 10.1038/sj.mp.4000532.
Zhang JP, Malhotra AK: Pharmacogenetics and antipsychotics: therapeutic efficacy and side effects prediction. Expert Opin Drug Metab Toxicol. 2011, 7: 9-37. 10.1517/17425255.2011.532787.
Bymaster FP, Calligaro DO, Falcone JF, Marsh RD, Moore NA, Tye NC, Seeman P, Wong DT: Radioreceptor binding profile of the atypical antipsychotic olanzapine. Neuropsychopharmacology. 1996, 14: 87-96. 10.1016/0893-133X(94)00129-N.
Arranz MJ, Munro J, Owen MJ, Spurlock G, Sham PC, Zhao J, Kirov G, Collier DA, Kerwin RW: Evidence for association between polymorphisms in the promoter and coding regions of the 5-HT2A receptor gene and response to clozapine. Mol Psychiatry. 1998, 3: 61-66. 10.1038/sj.mp.4000348.
Ellingrod VL, Lund BC, Miller D, Fleming F, Perry P, Holman TL, Bever-Stille K: 5-HT2A receptor promoter polymorphism, -1438G/A and negative symptom response to olanzapine in schizophrenia. Psychopharmacol Bull. 2003, 37: 109-112.
Turecki G, Briere R, Dewar K, Antonetti T, Lesage AD, Seguin M, Chawky N, Vanier C, Alda M, Joober R, Benkelfat C, Rouleau GA: Prediction of level of serotonin 2A receptor binding by serotonin receptor 2A genetic variation in postmortem brain samples from subjects who did or did not commit suicide. Am J Psychiatry. 1999, 156: 1456-1458.
De Luca V, Mueller DJ, de Bartolomeis A, Kennedy JL: Association of the HTR2C gene and antipsychotic induced weight gain: a meta-analysis. Int J Neuropsychopharmacol. 2007, 10: 697-704.
Loos RJ, Lindgren CM, Li S, Wheeler E, Zhao JH, Prokopenko I, Inouye M, Freathy RM, Attwood AP, Beckmann JS, Berndt SI, Jacobs KB, Chanock SJ, Hayes RB, Bergmann S, Bennett AJ, Bingham SA, Bochud M, Brown M, Cauchi S, Connell JM, Cooper C, Smith GD, Day I, Dina C, De S, Dermitzakis ET, Doney AS, Elliott KS, Prostate, Lung, Colorectal, and Ovarian (PLCO) Cancer Screening Trial: Common variants near MC4R are associated with fat mass, weight and risk of obesity. Nat Genet. 2008, 40: 768-775. 10.1038/ng.140.
Chambers JC, Elliott P, Zabaneh D, Zhang W, Li Y, Froguel P, Balding D, Scott J, Kooner JS: Common genetic variation near MC4R is associated with waist circumference and insulin resistance. Nat Genet. 2008, 40: 716-718. 10.1038/ng.156.
Mountjoy KG, Mortrud MT, Low MJ, Simerly RB, Cone RD: Localization of the melanocortin-4 receptor (MC4-R) in neuroendocrine and autonomic control circuits in the brain. Mol Endocrinol. 1994, 8: 1298-1308.
Horvath TL: The hardship of obesity: a soft-wired hypothalamus. Nat Neurosci. 2005, 8: 561-565. 10.1038/nn1453.
Malhotra AK, Correll CU, Chowdhury NI, Muller DJ, Gregersen PK, Lee AT, Tiwari AK, Kane JM, Fleischhacker WW, Kahn RS, Ophoff RA, Meltzer HY, Lencz T, Kennedy JL: Association between common variants near the melanocortin 4 receptor gene and severe antipsychotic drug-induced weight gain. Arch Gen Psychiatry. 2012, 69: 904-912. 10.1001/archgenpsychiatry.2012.191.
Czerwensky F, Leucht S, Steimer W: Association of the common MC4R rs17782313 polymorphism with antipsychotic-related weight gain. J Clin Psychopharmacol. 2013, 33: 74-79. 10.1097/JCP.0b013e31827772db.
Sachs GS, Nierenberg AA, Calabrese JR, Marangell LB, Wisniewski SR, Gyulai L, Friedman ES, Bowden CL, Fossey MD, Ostacher MJ, Ketter TA, Patel J, Hauser P, Rapport D, Martinez JM, Allen MH, Miklowitz DJ, Otto MW, Dennehy EB, Thase ME: Effectiveness of adjunctive antidepressant treatment for bipolar depression. N Engl J Med. 2007, 356: 1711-1722. 10.1056/NEJMoa064135.
Brown EB, McElroy SL, Keck PE, Deldar A, Adams DH, Tohen M, Williamson DJ: A 7-week, randomized, double-blind trial of olanzapine/fluoxetine combination versus lamotrigine in the treatment of bipolar I depression. J Clin Psychiatry. 2006, 67: 1025-1033. 10.4088/JCP.v67n0703.
McElroy SL, Weisler RH, Chang W, Olausson B, Paulsson B, Brecher M, Agambaram V, Merideth C, Nordenhem A, Young AH: A double-blind, placebo-controlled study of quetiapine and paroxetine as monotherapy in adults with bipolar depression (EMBOLDEN II). J Clin Psychiatry. 2010, 71: 163-174. 10.4088/JCP.08m04942gre.
Heils A, Teufel A, Petri S, Stober G, Riederer P, Bengel D, Lesch KP: Allelic variation of human serotonin transporter gene expression. J Neurochem. 1996, 66: 2621-2624.
Philibert RA, Sandhu H, Hollenbeck N, Gunter T, Adams W, Madan A: The relationship of 5HTT (SLC6A4) methylation and genotype on mRNA expression and liability to major depression and alcohol dependence in subjects from the Iowa Adoption Studies. Am J Med Genet B Neuropsychiatr Genet. 2008, 147B: 543-549. 10.1002/ajmg.b.30657.
Serretti A, Kato M, De Ronchi D, Kinoshita T: Meta-analysis of serotonin transporter gene promoter polymorphism (5-HTTLPR) association with selective serotonin reuptake inhibitor efficacy in depressed patients. Mol Psychiatry. 2007, 12: 247-257.
Daray FM, Thommi SB, Ghaemi SN: The pharmacogenetics of antidepressant-induced mania: a systematic review and meta-analysis. Bipolar Disord. 2010, 12: 702-706. 10.1111/j.1399-5618.2010.00864.x.
Paddock S, Laje G, Charney D, Rush AJ, Wilson AF, Sorant AJ, Lipsky R, Wisniewski SR, Manji H, McMahon FJ: Association of GRIK4 with outcome of antidepressant treatment in the STAR*D cohort. Am J Psychiatry. 2007, 164: 1181-1188. 10.1176/appi.ajp.2007.06111790.
Horstmann S, Lucae S, Menke A, Hennings JM, Ising M, Roeske D, Muller-Myhsok B, Holsboer F, Binder EB: Polymorphisms in GRIK4, HTR2A, and FKBP5 show interactive effects in predicting remission to antidepressant treatment. Neuropsychopharmacology. 2010, 35: 727-740. 10.1038/npp.2009.180.
McMahon FJ, Buervenich S, Charney D, Lipsky R, Rush AJ, Wilson AF, Sorant AJ, Papanicolaou GJ, Laje G, Fava M, Trivedi MH, Wisniewski SR, Manji H: Variation in the gene encoding the serotonin 2A receptor is associated with outcome of antidepressant treatment. Am J Hum Genet. 2006, 78: 804-814. 10.1086/503820.
Denny WB, Valentine DL, Reynolds PD, Smith DF, Scammell JG: Squirrel monkey immunophilin FKBP51 is a potent inhibitor of glucocorticoid receptor binding. Endocrinology. 2000, 141: 4107-4113.
Holsboer F: The rationale for corticotropin-releasing hormone receptor (CRH-R) antagonists to treat depression and anxiety. J Psychiatr Res. 1999, 33: 181-214. 10.1016/S0022-3956(98)90056-5.
Pei H, Li L, Fridley BL, Jenkins GD, Kalari KR, Lingle W, Petersen G, Lou Z, Wang L: FKBP51 affects cancer cell response to chemotherapy by negatively regulating Akt. Cancer Cell. 2009, 16: 259-266. 10.1016/j.ccr.2009.07.016.
Engelman JA, Luo J, Cantley LC: The evolution of phosphatidylinositol 3-kinases as regulators of growth and metabolism. Nat Rev Genet. 2006, 7: 606-619.
Beaulieu JM, Gainetdinov RR, Caron MG: Akt/GSK3 signaling in the action of psychotropic drugs. Annu Rev Pharmacol Toxicol. 2009, 49: 327-347. 10.1146/annurev.pharmtox.011008.145634.
Binder EB, Salyakina D, Lichtner P, Wochnik GM, Ising M, Putz B, Papiol S, Seaman S, Lucae S, Kohli MA, Nickel T, Künzel HE, Fuchs B, Majer M, Pfennig A, Kern N, Brunner J, Modell S, Baghai T, Deiml T, Zill P, Bondy B, Rupprecht R, Messer T, Köhnlein O, Dabitz H, Brückl T, Müller N, Pfister H, Lieb R, et al: Polymorphisms in FKBP5 are associated with increased recurrence of depressive episodes and rapid response to antidepressant treatment. Nat Genet. 2004, 36: 1319-1325. 10.1038/ng1479.
Zou YF, Wang F, Feng XL, Li WF, Tao JH, Pan FM, Huang F, Su H: Meta-analysis of FKBP5 gene polymorphisms association with treatment response in patients with mood disorders. Neurosci Lett. 2010, 484: 56-61. 10.1016/j.neulet.2010.08.019.
Chen CH, Lee CS, Lee MT, Ouyang WC, Chen CC, Chong MY, Wu JY, Tan HK, Lee YC, Chuo LJ, Chiu NY, Tsang HY, Chang TJ, Lung FW, Chiu CH, Chang CH, Chen YS, Hou YM, Chen CC, Lai TJ, Tung CL, Chen CY, Lane HY, Su TP, Feng J, Lin JJ, Chang CJ, Teng PR, Liu CY, Chen CK, et al: Variant GADL1 and response to lithium therapy in bipolar I disorder. N Engl J Med. 2014, 370: 119-128. 10.1056/NEJMoa1212444.
Garriock HA, Kraft JB, Shyn SI, Peters EJ, Yokoyama JS, Jenkins GD, Reinalda MS, Slager SL, McGrath PJ, Hamilton SP: A genomewide association study of citalopram response in major depressive disorder. Biol Psychiatry. 2010, 67: 133-138. 10.1016/j.biopsych.2009.08.029.
Adkins DE, Clark SL, Aberg K, Hettema JM, Bukszar J, McClay JL, Souza RP, van den Oord EJ: Genome-wide pharmacogenomic study of citalopram-induced side effects in STAR*D. Transl Psychiatry. 2012, 2: e129-10.1038/tp.2012.57.
GENDEP Investigators, MARS Investigators, STAR*D Investigators: Common genetic variation and antidepressant efficacy in major depressive disorder: a meta-analysis of three genome-wide pharmacogenetic studies. Am J Psych. 2013, 170: 207-217.
O’Dushlaine C, Ripke S, Ruderfer DM, Hamilton SP, Fava M, Iosifescu DV, Kohane IS, Churchill SE, Castro VM, Clements CC, Blumenthal SR, Murphy SN, Smoller JW, Perlis RH: Rare copy number variation in treatment-resistant major depressive disorder. Biol Psychiatry. 2014, doi:10.1016/j.biopsych.2013.10.028
Guengerich FP: Cytochrome p450 and chemical toxicology. Chem Res Toxicol. 2008, 21: 70-83. 10.1021/tx700079z.
Groves JT, McClusky GA: Aliphatic hydroxylation by highly purified liver microsomal cytochrome P-450. Evidence for a carbon radical intermediate. Biochem Biophys Res Commun. 1978, 81: 154-160. 10.1016/0006-291X(78)91643-1.
de Leon J: AmpliChip CYP450 test: personalized medicine has arrived in psychiatry. Expert Rev Mol Diagn. 2006, 6: 277-286. 10.1586/14737159.6.3.277.
de Leon J, Susce MT, Murray-Carmichael E: The AmpliChip CYP450 genotyping test: integrating a new clinical tool. Mol Diagn Ther. 2006, 10: 135-151. 10.1007/BF03256453.
Kirchheiner J, Nickchen K, Bauer M, Wong ML, Licinio J, Roots I, Brockmoller J: Pharmacogenetics of antidepressants and antipsychotics: the contribution of allelic variations to the phenotype of drug response. Mol Psychiatry. 2004, 9: 442-473. 10.1038/sj.mp.4001494.
Johansson I, Oscarson M, Yue QY, Bertilsson L, Sjoqvist F, Ingelman-Sundberg M: Genetic analysis of the Chinese cytochrome P4502D locus: characterization of variant CYP2D6 genes present in subjects with diminished capacity for debrisoquine hydroxylation. Mol Pharmacol. 1994, 46: 452-459.
Ingelman-Sundberg M: Genetic polymorphisms of cytochrome P450 2D6 (CYP2D6): clinical consequences, evolutionary aspects and functional diversity. Pharmacogenomics J. 2005, 5: 6-13. 10.1038/sj.tpj.6500285.
Yu A, Kneller BM, Rettie AE, Haining RL: Expression, purification, biochemical characterization, and comparative function of human cytochrome P450 2D6.1, 2D6.2, 2D6.10, and 2D6.17 allelic isoforms. J Pharmacol Exp Ther. 2002, 303: 1291-1300. 10.1124/jpet.102.039891.
Man M, Farmen M, Dumaual C, Teng CH, Moser B, Irie S, Noh GJ, Njau R, Close S, Wise S, Hockett R: Genetic variation in metabolizing enzyme and transporter genes: comprehensive assessment in 3 major East Asian subpopulations with comparison to Caucasians and Africans. J Clin Pharmacol. 2010, 50: 929-940. 10.1177/0091270009355161.
Sim SC, Risinger C, Dahl ML, Aklillu E, Christensen M, Bertilsson L, Ingelman-Sundberg M: A common novel CYP2C19 gene variant causes ultrarapid drug metabolism relevant for the drug response to proton pump inhibitors and antidepressants. Clin Pharmacol Ther. 2006, 79: 103-113. 10.1016/j.clpt.2005.10.002.
Ramsjo M, Aklillu E, Bohman L, Ingelman-Sundberg M, Roh HK, Bertilsson L: CYP2C19 activity comparison between Swedes and Koreans: effect of genotype, sex, oral contraceptive use, and smoking. Eur J Clin Pharmacol. 2010, 66: 871-877. 10.1007/s00228-010-0835-0.
Gonzalez FJ, Vilbois F, Hardwick JP, McBride OW, Nebert DW, Gelboin HV, Meyer UA: Human debrisoquine 4-hydroxylase (P450IID1): cDNA and deduced amino acid sequence and assignment of the CYP2D locus to chromosome 22. Genomics. 1988, 2: 174-179. 10.1016/0888-7543(88)90100-0.
Kroemer HK, Eichelbaum M: “It’s the genes, stupid”. Molecular bases and clinical consequences of genetic cytochrome P450 2D6 polymorphism. Life Sci. 1995, 56: 2285-2298. 10.1016/0024-3205(95)00223-S.
Kootstra-Ros JE, Van Weelden MJ, Hinrichs JW, De Smet PA, van der Weide J: Therapeutic drug monitoring of antidepressants and cytochrome p450 genotyping in general practice. J Clin Pharmacol. 2006, 46: 1320-1327. 10.1177/0091270006293754.
Kirchheiner J, Brosen K, Dahl ML, Gram LF, Kasper S, Roots I, Sjoqvist F, Spina E, Brockmoller J: CYP2D6 and CYP2C19 genotype-based dose recommendations for antidepressants: a first step towards subpopulation-specific dosages. Acta Psychiatr Scand. 2001, 104: 173-192. 10.1034/j.1600-0447.2001.00299.x.
de Leon J, Armstrong SC, Cozza KL: Clinical guidelines for psychiatrists for the use of pharmacogenetic testing for CYP450 2D6 and CYP450 2C19. Psychosomatics. 2006, 47: 75-85. 10.1176/appi.psy.47.1.75.
Lobello KW, Preskorn SH, Guico-Pabia CJ, Jiang Q, Paul J, Nichols AI, Patroneva A, Ninan PT: Cytochrome P450 2D6 phenotype predicts antidepressant efficacy of venlafaxine: a secondary analysis of 4 studies in major depressive disorder. J Clin Psychiatry. 2010, 71: 1482-1487. 10.4088/JCP.08m04773blu.
Tsai MH, Lin KM, Hsiao MC, Shen WW, Lu ML, Tang HS, Fang CK, Wu CS, Lu SC, Liu SC, Chen CY, Liu YL: Genetic polymorphisms of cytochrome P450 enzymes influence metabolism of the antidepressant escitalopram and treatment response. Pharmacogenomics. 2010, 11: 537-546. 10.2217/pgs.09.168.
Kawanishi C, Lundgren S, Agren H, Bertilsson L: Increased incidence of CYP2D6 gene duplication in patients with persistent mood disorders: ultrarapid metabolism of antidepressants as a cause of nonresponse. A pilot study. Eur J Clin Pharmacol. 2004, 59: 803-807. 10.1007/s00228-003-0701-4.
Penas-Lledo EM, Trejo HD, Dorado P, Ortega A, Jung H, Alonso E, Naranjo ME, Lopez-Lopez M, Llerena A: CYP2D6 ultrarapid metabolism and early dropout from fluoxetine or amitriptyline monotherapy treatment in major depressive patients. Mol Psychiatry. 2013, 18: 8-9. 10.1038/mp.2012.91.
Penas-Lledo EM, Dorado P, Aguera Z, Gratacos M, Estivill X, Fernandez-Aranda F, Llerena A: High risk of lifetime history of suicide attempts among CYP2D6 ultrarapid metabolizers with eating disorders. Mol Psychiatry. 2011, 16: 691-692. 10.1038/mp.2011.5.
Stingl JC, Viviani R: CYP2D6 in the brain: impact on suicidality. Clin Pharmacol Ther. 2011, 89: 352-353. 10.1038/clpt.2010.239.
Zackrisson AL, Lindblom B, Ahlner J: High frequency of occurrence of CYP2D6 gene duplication/multiduplication indicating ultrarapid metabolism among suicide cases. Clin Pharmacol Ther. 2010, 88: 354-359. 10.1038/clpt.2009.216.
Lessard E, Yessine MA, Hamelin BA, O’Hara G, LeBlanc J, Turgeon J: Influence of CYP2D6 activity on the disposition and cardiovascular toxicity of the antidepressant agent venlafaxine in humans. Pharmacogenetics. 1999, 9: 435-443.
Bertilsson L, Dahl ML, Dalen P, Al-Shurbaji A: Molecular genetics of CYP2D6: clinical relevance with focus on psychotropic drugs. Br J Clin Pharmacol. 2002, 53: 111-122. 10.1046/j.0306-5251.2001.01548.x.
Sallee FR, DeVane CL, Ferrell RE: Fluoxetine-related death in a child with cytochrome P-450 2D6 genetic deficiency. J Child Adolesc Psychopharmacol. 2000, 10: 27-34. 10.1089/cap.2000.10.27.
Koski A, Ojanpera I, Sistonen J, Vuori E, Sajantila A: A fatal doxepin poisoning associated with a defective CYP2D6 genotype. Am J Forensic Med Pathol. 2007, 28: 259-261. 10.1097/PAF.0b013e3180326701.
Hodgson K, Tansey K, Dernovsek MZ, Hauser J, Henigsberg N, Maier W, Mors O, Placentino A, Rietschel M, Souery D, Smith R, Craig IW, Farmer AE, Aitchison KJ, Belsy S, Davis OS, Uher R, McGuffin P: Genetic differences in cytochrome P450 enzymes and antidepressant treatment response. J Psychopharmacol. 2014, 28: 133-141. 10.1177/0269881113512041.
Serretti A, Calati R, Massat I, Linotte S, Kasper S, Lecrubier Y, Sens-Espel R, Bollen J, Zohar J, Berlo J, Lienard P, De Ronchi D, Mendlewicz J, Souery D: Cytochrome P450 CYP1A2, CYP2C9, CYP2C19 and CYP2D6 genes are not associated with response and remission in a sample of depressive patients. Int Clin Psychopharmacol. 2009, 24: 250-256. 10.1097/YIC.0b013e32832e5b0d.
Gex-Fabry M, Eap CB, Oneda B, Gervasoni N, Aubry JM, Bondolfi G, Bertschy G: CYP2D6 and ABCB1 genetic variability: influence on paroxetine plasma level and therapeutic response. Ther Drug Monit. 2008, 30: 474-482.
Peters EJ, Slager SL, Kraft JB, Jenkins GD, Reinalda MS, McGrath PJ, Hamilton SP: Pharmacokinetic genes do not influence response or tolerance to citalopram in the STAR*D sample. PLoS One. 2008, 3: e1872-10.1371/journal.pone.0001872.
Evaluation of Genomic Applications in Practice and Prevention (EGAPP) Working Group: Recommendations from the EGAPP Working Group: testing for cytochrome P450 polymorphisms in adults with nonpsychotic depression treated with selective serotonin reuptake inhibitors. Genet Med. 2007, 9: 819-825.
Dahl ML: Cytochrome p450 phenotyping/genotyping in patients receiving antipsychotics: useful aid to prescribing?. Clin Pharmacokinet. 2002, 41: 453-470. 10.2165/00003088-200241070-00001.
Brockmoller J, Kirchheiner J, Schmider J, Walter S, Sachse C, Muller-Oerlinghausen B, Roots I: The impact of the CYP2D6 polymorphism on haloperidol pharmacokinetics and on the outcome of haloperidol treatment. Clin Pharmacol Ther. 2002, 72: 438-452. 10.1067/mcp.2002.127494.
Olesen OV, Linnet K: Identification of the human cytochrome P450 isoforms mediating in vitro N-dealkylation of perphenazine. Br J Clin Pharmacol. 2000, 50: 563-571.
Yoshii K, Kobayashi K, Tsumuji M, Tani M, Shimada N, Chiba K: Identification of human cytochrome P450 isoforms involved in the 7-hydroxylation of chlorpromazine by human liver microsomes. Life Sci. 2000, 67: 175-184. 10.1016/S0024-3205(00)00613-5.
Rau T, Wohlleben G, Wuttke H, Thuerauf N, Lunkenheimer J, Lanczik M, Eschenhagen T: CYP2D6 genotype: impact on adverse effects and nonresponse during treatment with antidepressants-a pilot study. Clin Pharmacol Ther. 2004, 75: 386-393. 10.1016/j.clpt.2003.12.015.
de Leon J, Susce MT, Pan RM, Fairchild M, Koch WH, Wedlund PJ: The CYP2D6 poor metabolizer phenotype may be associated with risperidone adverse drug reactions and discontinuation. J Clin Psychiatry. 2005, 66: 15-27. 10.4088/JCP.v66n0103.
Gray IC, Nobile C, Muresu R, Ford S, Spurr NK: A 2.4-megabase physical map spanning the CYP2C gene cluster on chromosome 10q24. Genomics. 1995, 28: 328-332. 10.1006/geno.1995.1149.
Gardiner SJ, Begg EJ: Pharmacogenetics, drug-metabolizing enzymes, and clinical practice. Pharmacol Rev. 2006, 58: 521-590. 10.1124/pr.58.3.6.
Herrlin K, Yasui-Furukori N, Tybring G, Widen J, Gustafsson LL, Bertilsson L: Metabolism of citalopram enantiomers in CYP2C19/CYP2D6 phenotyped panels of healthy Swedes. Br J Clin Pharmacol. 2003, 56: 415-421. 10.1046/j.1365-2125.2003.01874.x.
Ulrich S, Northoff G, Wurthmann C, Partscht G, Pester U, Herscu H, Meyer FP: Serum levels of amitriptyline and therapeutic effect in non-delusional moderately to severely depressed in-patients: a therapeutic window relationship. Pharmacopsychiatry. 2001, 34: 33-40. 10.1055/s-2001-15207.
Steimer W, Zopf K, von Amelunxen S, Pfeiffer H, Bachofer J, Popp J, Messner B, Kissling W, Leucht S: Allele-specific change of concentration and functional gene dose for the prediction of steady-state serum concentrations of amitriptyline and nortriptyline in CYP2C19 and CYP2D6 extensive and intermediate metabolizers. Clin Chem. 2004, 50: 1623-1633. 10.1373/clinchem.2003.030825.
Sindrup SH, Brosen K, Hansen MG, Aaes-Jorgensen T, Overo KF, Gram LF: Pharmacokinetics of citalopram in relation to the sparteine and the mephenytoin oxidation polymorphisms. Ther Drug Monit. 1993, 15: 11-17. 10.1097/00007691-199302000-00002.
Huezo-Diaz P, Perroud N, Spencer EP, Smith R, Sim S, Virding S, Uher R, Gunasinghe C, Gray J, Campbell D, Hauser J, Maier W, Marusic A, Rietschel M, Perez J, Giovannini C, Mors O, Mendlewicz J, McGuffin P, Farmer AE, Ingelman-Sundberg M, Craig IW, Aitchison KJ: CYP2C19 genotype predicts steady state escitalopram concentration in GENDEP. J Psychopharmacol. 2012, 26: 398-407. 10.1177/0269881111414451.
Mrazek DA, Biernacka JM, O’Kane DJ, Black JL, Cunningham JM, Drews MS, Snyder KA, Stevens SR, Rush AJ, Weinshilboum RM: CYP2C19 variation and citalopram response. Pharmacogenet Genomics. 2011, 21: 1-9. 10.1097/FPC.0b013e328340bc5a.
Cordon-Cardo C, O’Brien JP, Casals D, Rittman-Grauer L, Biedler JL, Melamed MR, Bertino JR: Multidrug-resistance gene (P-glycoprotein) is expressed by endothelial cells at blood–brain barrier sites. Proc Natl Acad Sci U S A. 1989, 86: 695-698. 10.1073/pnas.86.2.695.
Ambudkar SV, Dey S, Hrycyna CA, Ramachandra M, Pastan I, Gottesman MM: Biochemical, cellular, and pharmacological aspects of the multidrug transporter. Annu Rev Pharmacol Toxicol. 1999, 39: 361-398. 10.1146/annurev.pharmtox.39.1.361.
Uhr M, Tontsch A, Namendorf C, Ripke S, Lucae S, Ising M, Dose T, Ebinger M, Rosenhagen M, Kohli M, Kloiber S, Salyakina D, Bettecken T, Specht M, Pütz B, Binder EB, Müller-Myhsok B, Holsboer F: Polymorphisms in the drug transporter gene ABCB1 predict antidepressant treatment response in depression. Neuron. 2008, 57: 203-209. 10.1016/j.neuron.2007.11.017.
Sarginson JE, Lazzeroni LC, Ryan HS, Ershoff BD, Schatzberg AF, Murphy GM: ABCB1 (MDR1) polymorphisms and antidepressant response in geriatric depression. Pharmacogenet Genomics. 2010, 20: 467-475. 10.1097/FPC.0b013e32833b593a.
de Klerk OL, Nolte IM, Bet PM, Bosker FJ, Snieder H, den Boer JA, Bruggeman R, Hoogendijk WJ, Penninx BW: ABCB1 gene variants influence tolerance to selective serotonin reuptake inhibitors in a large sample of Dutch cases with major depressive disorder. Pharmacogenomics J. 2013, 13: 349-353. 10.1038/tpj.2012.16.
Perlis RH: Translating biomarkers to clinical practice. Mol Psychiatry. 2011, 16: 1076-1087. 10.1038/mp.2011.63.
Perlis RH, Patrick A, Smoller JW, Wang PS: When is pharmacogenetic testing for antidepressant response ready for the clinic? A cost-effectiveness analysis based on data from the STAR*D study. Neuropsychopharmacology. 2009, 34: 2227-2236. 10.1038/npp.2009.50.
Braff DL, Freedman R: Clinically responsible genetic testing in neuropsychiatric patients: a bridge too far and too soon. Am J Psychiatry. 2008, 165: 952-955. 10.1176/appi.ajp.2008.08050717.
Simon GE, Perlis RH: Personalized medicine for depression: can we match patients with treatments?. Am J Psych. 2010, 167: 1445-1455. 10.1176/appi.ajp.2010.09111680.
Mardis ER: Anticipating the 1,000 dollar genome. Genome Biol. 2006, 7: 112-10.1186/gb-2006-7-7-112.
Hall-Flavin DK, Winner JG, Allen JD, Jordan JJ, Nesheim RS, Snyder KA, Drews MS, Eisterhold LL, Biernacka JM, Mrazek DA: Using a pharmacogenomic algorithm to guide the treatment of depression. Transl Psychiatry. 2012, 2: e172-10.1038/tp.2012.99.
Hall-Flavin DK, Winner JG, Allen JD, Carhart JM, Proctor B, Snyder KA, Drews MS, Eisterhold LL, Geske J, Mrazek DA: Utility of integrated pharmacogenomic testing to support the treatment of major depressive disorder in a psychiatric outpatient setting. Pharmacogenet Genom. 2013, 23: 535-548. 10.1097/FPC.0b013e3283649b9a.
Winner J, Allen JD, Altar CA, Spahic-Mihajlovic A: Psychiatric pharmacogenomics predicts health resource utilization of outpatients with anxiety and depression. Transl Psychiatry. 2013, 3: e242-10.1038/tp.2013.2.
Acknowledgements
This research was supported by grants from the Department of Veterans Affairs Office of Research and Development to MJM (1IK2BX001275) and JRK (I01CX000363). Support was also provided to JRK by the NIMH, the Pharmacogenomics Research Network (MH094483 and MH092758) and the Brain Behavior Research Foundation. Support was also provided by the NIH funded UCSD Clinical Translational Research Institute (UL1TR000100). The funders had no role in the analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare they have no competing interests.
Authors’ contributions
NS conducted literature searches and wrote portions of the manuscript; MM was involved in conceptualization of the paper and wrote portions of the manuscript; SL conducted literature searches and helped draft the manuscript; JK helped in conceiving the paper and wrote portions of the manuscript. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Salloum, N.C., McCarthy, M.J., Leckband, S.G. et al. Towards the clinical implementation of pharmacogenetics in bipolar disorder. BMC Med 12, 90 (2014). https://doi.org/10.1186/1741-7015-12-90
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1741-7015-12-90