
Abstract
The application of supervised learning machines trained to minimize the Cross-Entropy error to radar detection is explored in this article. The detector is implemented with a learning machine that implements a discriminant function, which output is compared to a threshold selected to fix a desired probability of false alarm. The study is based on the calculation of the function the learning machine approximates to during training, and the application of a sufficient condition for a discriminant function to be used to approximate the optimum Neyman–Pearson (NP) detector. In this article, the function a supervised learning machine approximates to after being trained to minimize the Cross-Entropy error is obtained. This discriminant function can be used to implement the NP detector, which maximizes the probability of detection, maintaining the probability of false alarm below or equal to a predefined value. Some experiments about signal detection using neural networks are also presented to test the validity of the study.
Similar content being viewed by others

Introduction
In this article, an extension of the theoretical study presented in[1] about the capability of supervised learning machines to approximate the Neyman–Pearson (NP) detector is presented. This detector can be implemented by comparing the likelihood ratio, Λ(z), to a detection threshold fixed taking into account Probability of False Alarm (P FA) requirements, as stated in expression (1)[2, 3], being f(z|H i ), i ∈ {0,1}, the likelihood functions under both, the null (H 0) and the alternative (H 1) hypothesis.
The NP criterion has been widely used in radar applications. The robustness of the likelihood ratio detector for moderately fluctuating targets was studied in[4]. In the last years, considering also radar applications, the NP criterion has been applied in MIMO radars[5, 6], distributed radar sensor networks[7], and for the detection of ships in marine environments[8]. The NP criterion has also been applied in some other topics: watermarking[9, 10], fault-induced dips detection[11], detection in sensor networks[12], disease diagnosis[13, 14], biometric[15], or gravitational waves detection[16]. Great efforts are being made nowadays to solve a number of problems related to signal detection in noise[17].
For the NP detector to be implemented, both likelihood functions must be known. Usually, statistical models of interference and targets are assumed and their parameters are estimated using the available data. Obviously, detection losses are expected when the interference or target statistical properties vary from those assumed in the design. In addition, when some of the parameters are random, and the composite hypothesis tests must be used, the average likelihood ratio can lead to intractable integrals that should be solved by numerical approximations. The usage of learning machines based detectors, allows us to approximate the NP detector, just using training data obtained experimentally, without knowledge of the likelihood functions. The main advantage of this approach is that no statistical models have to be assumed during the design, and if a suitable error function is used during training, a good approximation to the optimal NP detector is obtained[1]. The main drawback is the difficulty of obtaining representative training samples, and the definition of the most suitable learning machine architecture.
The application of supervised learning machines to approximate the NP detector has already been studied. The easiest way is to use a learning machine with only one output, which is compared to a threshold in order to decide in favor of the null or the alternative hypothesis. The threshold is used to fix the desired P FA. This scheme has been used previously is several works[1, 18–20]. An equivalent implementation consist in varying the bias of the output neuron[21, 22]. A different approach is used in[23]: a two-output NN with outputs in (0,1) was used, comparing the subtraction of both outputs to a threshold. This approach is equivalent to using a NN with only one output and desired outputs {−1,1}[24]. More recently, Radial Basis Function Neural Networks (RBFNN) have also been applied to approximate the NP detector[25–27]. Support Vector Machines (SVMs) have been applied to signal detection in background noise[28]. Finally, detectors based on committee machines have also been proposed[29–32].
The possibility of approximating the NP detector using adaptive systems trained in a supervised manner was studied in[33]. A sufficient condition for a discriminant function to be suitable for implementing the NP detector was obtained. In[1], those results were used to carry out a more general study about the capability of learning machines to approximate the NP detector when they are trained in a supervised manner to minimize an error function, demonstrating that the Sum-of-Squares error is suitable to approximate the NP detector, and the Minkowski error with R = 1 is suitable to approximate the minimum probability of error classifier. With R = 1, the Minkowski error reduces to the mean absolute deviation.
The Sum-of-Squares error is optimal for training supervised learning machines in order to detect or to classify Gaussian signals. If non-Gaussian interference is assumed in the radar, probably there exists some other error functions which give rise to better results, motivating the study to know if they fulfil the sufficient condition established in[1, 33]. In this article, one more error function is considered, the Cross-Entropy error. The study demonstrates that the Cross-Entropy error is also suitable to be used for training supervised learning machines in order to approximate the NP detector, even improving the performance of learning machines trained with the Sum-of-Squares error.
The article is structured as follows: In Section 2, the problem this article deals with is presented. The function that a learning classifier with one output approximates to, when has been trained to minimize the Cross-Entropy error, is calculated in Section 3. The condition stated in[1] is applied to demonstrate that the approximated function is useful to approximate the NP detector. In Section 4, some experiments are presented to illustrate the previous theoretical studies. Finally, in Section 5 the main contributions of this article are summarized, and conclusions are extracted.
Problem statement
The usefulness of supervised learning machines trained to minimize the Sum-of-Squares error to approximate the NP detector, and the usefulness of the Minkowski error with R = 1 to approximate the minimum probability of error classifier, have been demonstrated in[1]. In this article, we extend the study to the Cross-Entropy error. The discriminant function the learning machine approximates to after training is obtained, and the sufficient condition stated in[33] is applied. The detector is implemented by comparing the output of the discriminant function to a threshold. The final approximation error will depend on the selected error function, the selected training and validation sets, the system structure, and the training algorithm[34]. In order to obtain a good approximation, the training set must be a representative subset of the input space, the function implemented by the learning machine must be sufficiently general that there is a choice of adaptive parameters which makes the error function sufficiently small, and the learning algorithm must be able to find the appropriate minimum of the error function[35].
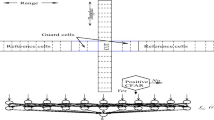
In our study, a learning machine with one output is considered, that is used to classify input vectors into two hypotheses or classes, H 0 and H 1, which stand for the absence of target and for its presence, respectively, in radar detection problems. The basic detector scheme is represented in Figure1.

Scheme of the learning classifier-based detector to approximate the NP optimum detector.
Given a decision rule, let be the set of all possible input vectors that will be assigned to hypothesis H i , and the ensemble of all possible input vectors (). The output of the learning machine is represented by F(z), and the desired output by. A training set, =0∪1, where 1 is composed of N 1 training patterns from hypothesis H 1, and 0 is composed of N 0 training patterns from hypothesis H 0 (N = N 1 + N 0), is available.
In order to study the suitability of the error function to be used to approximate the NP detector, the same strategy applied in[1] is used. The function the learning machine approximates to after training is obtained, as a function of the likelihood functions and the prior probabilities. The implemented detector compares the learning machine output to a threshold η 0, which varies to fix the P FA. The NP detector is usually implemented by comparing the likelihood ratio to a threshold η l r , fixed according to the required P FA. A sufficient condition has been established in[1, 33], which states that for a learning machine to approximate the NP detector, the relation between η l r and η 0 doesn’t depend on the input vector.
In the following sections, in order to obtain the function the learning machine approximates to after training, the strong law of large numbers is going to be applied[36]. It asserts that if 〈X i 〉 is a sequence of independent and identically distributed random variables which has an expectation μ, then:
Discriminant function approximated by a learning-machine trained to minimize the cross-entropy error
The error function to be studied is the Cross-Entropy Error[34, 37], defined in the following expression, when a one output learning machine is considered, the desired outputs are one and zero, and (the function implemented by the system maps into the interval (0,1)):
If the number of patterns tends to infinity (N → ∞), the error can be expressed as follows:
Applying the strong law of large numbers, expression (5) is obtained:
The function F(z) that minimizes E m , which will be denoted by F 0(z), is obtained using calculus of variations, and particularly the Euler-Lagrange differential equation[38, 39]. The calculus of variations can be used to find the function F(z) that minimizes the functional J(F) defined as follows:
where z =[z 1,z 2,…,z L ]T, I is twice differentiable with respect to the indicated arguments, and F is a function in that assumes prescribed values at all points of the boundary of the domain. The function F that minimizes J(F) can be obtained by solving the Euler-Lagrange equation (7), where.
In our problem, J(F) = E m (F), and I(z,F(z)) = −P(H 1)f(z|H 1) ln(F(z)) − P(H 0)f(z|H 0) ln(1 − F(z)), which does not depend on the first derivatives of F. Therefore, F only needs to be defined in and the Euler-Lagrange equation reduces to:
The function F 0(z) that minimizes E m is given in (9) and the detection rule is obtained by comparing F 0(z) to η 0 (10).
Dividing the numerator and denominator of the left side of rule (10) by f(z|H 0), an equivalent rule can be obtained, which is a function of the likelihood ratio:
Extracting the likelihood ratio, a new equivalent rule (12) can be derived, which compares the likelihood ratio to a new threshold, η l r . The expression which relates η l r and η 0 is presented in (13):
The relation between η l r and η 0 does not depend on the input vector, z. Thus, according to the sufficient condition proposed in[1, 33], the detection rule (10) is an implementation of the NP detector.
Experiments
In this section, detectors based on Multilayer Perceptrons (MLPs) are designed for three cases studies: detection of colored Gaussian signals in white Gaussian interference, detection of colored Gaussian signals in correlated Gaussian clutter plus white Gaussian noise, and detection of non-fluctuating targets in K-distributed interference[40, 41]. In practical situations, the statistical properties of the interference can be estimated and tracked to some degree, but the target parameters are very difficult to estimate. When the target parameters are unknown, the NP detector is built with the Average-Likelihood ratio, that is compared to a threshold. The three cases study have been selected because the optimum NP detector can be easily approximated using a Maximum Likelihood estimator of the Average-Likelihood ratio.
Two strategies are followed to check the performance of the proposed detectors:
-
First, the supervised learning machine-based detectors are compared with an approximation of the NP detector. The Average-Likelihood ratio is approximated by a Maximum-Likelihood estimator, based on the Constrained Generalized Likelihood Ratio (CGLR)[42]. The CGLR is built with a number of filters equal to the dimension of the input vector (L). An increase in the number of filter does not produce a significant improvement in the performance of the CGLR.
-
Second, the detectors obtained after training the MLPs with the Cross-Entropy error, are compared with the equivalent obtained after training with the Sum-of-Squares error, and the Minkowski error with R=1. These comparisons are only performed for the first case study, due to space limitations, but similar comparative results are obtained in the other two cases study. The comparison is completed with a representation of P D versus SNR for the best detectors obtained with the different error functions, for the first case study.
The Receiver Operating Characteristic (ROC) curves of all the considered detectors are represented, to show the validity of our approach.
Considered detection problems
The following detection problems are studied in this article, to assess the capability of learning machines trained to minimize the Cross-Entropy error to implement good approximations of the NP optimum detector:
-
Case study 1: Detection of Gaussian fluctuating targets in presence of Additive White Gaussian Noise (AWGN). This case corresponds to target detection in the clear conditions. This case study has been subdivided into two:
-
Detection of Gaussian targets with unknown correlation coefficient.
-
Detection of Swerling I (SWI) targets with unknown Doppler shift.
-
-
Case study 2: Detection of Gaussian fluctuating targets in presence of correlated Gaussian clutter and AWGN. This model can be used for target detection in AWGN and sea/land clutter with low resolution radar systems, or high resolution radar systems with incidence angle higher than 10 degrees. Again, this case study has been subdivided into two:
-
Detection of Gaussian targets with unknown correlation coefficient.
-
Detection of SWI targets with unknown Doppler shift.
-
-
Case study 3: Detection of non fluctuating targets in presence of spiky K-distributed clutter (ν=0.5, where ν is the shape parameter of the K-distribution). This model is suitable for target detection in sea/land clutter with high resolution radar systems and low grazing angles. In this case, the problem of detecting Swerling V (SWV) targets with unknown Doppler shift is considered.
Detectors architecture, training and test parameters
Multilayer Perceptrons with real arithmetic are designed. Each MLP has an input layer, one hidden layer, and one output. In these examples, a pulsed radar which provides eight complex-valued echoes in each exploration, due to antenna rotation and beamwidth, is considered (this is the usual case in air traffic control radars). Each complex valued echo consist of the in-phase and quadrature components. Considering that the input vector is composed of eight complex valued echoes, L = 16 real inputs are required. The dependence of performance on the number of neurons in the hidden layer (M) is studied. The output is compared to a hard threshold, selected according to P FA (Figure1). According to this, the architectures of the MLPs are labeled with MLP L/M/1. The activation function of the processing units is the sigmoidal one.
For training the different MLPs, a training set composed of 50,000 patterns has been used. The training set consists of patterns belonging to both hypothesis, that are considered with equal prior probabilities (the same number of patters for H 0 and H 1). A cross-validation strategy has been used during training to avoid over-fitting, following the k-fold approach with k = 5. The validation set is composed of 10,000 patterns, 5,000 from each hypothesis.
For testing, a different set of patterns has been used. The number of patterns under hypothesis H 0 is 2·107, to estimate P FA values higher than 10−6 using conventional Monte-Carlo simulation with a relative error lower than 10%, while the number of patterns under hypothesis H 1 is 5·104, to estimate P D .
The algorithm used for training with the Cross-Entropy error is the one described in[43], while the algorithm used for training with the Sum-of-Squares error and the Minkowski error (R = 1), is the Conjugate Gradient method[44].
Results
In this subsection the results obtained for the above mentioned detection problems are presented. Different Signal to Interference Ratios (SIR) are considered in the experiments to obtain P D > 0.8 for P FA values of interest in radar applications. The SIR becomes the Signal to Noise Ratio (SNR), when the interference is only noise, and Signal to Clutter Ratio (SCR), when the interference is only clutter. For the MLPs, the influence of the number of hidden neurons, and therefore, the influence of the learning machine architecture is studied too. In some of the cases, the results are better when the number of hidden neurons is higher, but for detecting targets in spiky K-distributed clutter, very good results are obtained even with a low number of neurons in the hidden layer. This is because the surface which separates the acceptance regions of both hypothesis in the optimum detector can be approximated with a simpler architecture. In all the cases, there exists an architecture of the neural network that guarantees a very good approximation to the optimum detector, when the neural network is trained with the Cross-Entropy error.
Detection of Gaussian fluctuating targets in AWGN
First, the detection of Gaussian fluctuating targets with unknown correlation coefficient in AWGN is studied. In this case, the SNR is 7 dB. MLPs with a number of hidden neurons which varies from 14 to 23, in steps of 3, have been trained and tested. The ROC curves of the detectors based on MLPs trained with the Cross-Entropy error are presented in Figure2. As higher the number of neurons, better the approximation to the CGLR detector, demonstrating that the optimum detector can be approximated with a MLP if the number of freedom parameters of the architecture to be fitted during training is high enough for the considered detection problem.

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Cross-Entropy error for detecting Gaussian targets with unknown correlation coefficient in AWGN.
For comparison purposes, MLPs have been trained to minimize the Sum-of-Squares error and the Minkowski error (R = 1). The ROC curves are presented in Figures3 and4, respectively. The results training with the Sum-of-Squares error show high variability, and the results training with the Minkowski error (R = 1) are clearly worse, as expected from the theoretical study presented in[1], and with high variability too. To show the dependence with SNR, the best MLP-based detectors have been selected, and tested with different SNR values. The results are presented in Figure5.

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Sum-of-Squares error for detecting Gaussian targets with unknown correlation coefficient in AWGN.

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Minkowski error ( R =1 ) for detecting Gaussian targets with unknown correlation coefficient in AWGN.

Variation of P D versus SNR, for the best detectors obtained training with the Cross-Entropy error ( MLP ent ), the Sum-of-Squares error ( MLP mse ), and the Minkowski error ( R =1 ) ( MLP mae ).
In a second experiment, the SWI targets with unknown Doppler shift in AWGN is considered. The Doppler shift is modeled as a uniform random variable in the interval [0,2Π). In this case, the SNR is 10 dB. Again, MLPs with different number of hidden neurons have been trained and tested with the Cross-Entropy error, the Sum-of-Squares error, and the Minkowski error (R = 1), to study the dependence of performance on the network architecture. The number of hidden neurons that has been considered varies from 14 to 23, in steps of 3. The ROC curves are presented in Figures6,7 and8.

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Cross-Entropy error for detecting Swerling I targets with unknown Doppler shift in AWGN.

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Sum-of-Squares error for detecting Swerling I targets with unknown Doppler shift in AWGN.

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Minkowski error (R = 1) for detecting Swerling I targets with unknown Doppler shift in AWGN.
The results obtained training with the Cross-Entropy error are clearly the best. The results obtained training with the Sum-of-Squares error show higher variability and are slightly worse. The results obtained training with the Minkowski error (R = 1) are clearly the worst, as expected.
Detection of Gaussian fluctuating targets in presence of correlated Gaussian clutter and AWGN
In this section, we focus on the study of the Cross-Entropy error function. The results obtained with the other two above mentioned error functions are not presented, due to space limitations, but similar conclusions could be extracted in this case. Now, the number of hidden neurons varies from 14 to 20, in steps of 3, because a good approximation to the NP detector can be obtained with a simpler architecture.
In this case, the detection of Gaussian fluctuating targets in correlated Gaussian clutter and AWGN is considered. The level of interference is expressed with the SIR, but the clutter to noise ratio (CNR) should also be known. Again, two different kinds of targets are considered: those with unknown correlation coefficient (ρ t ), and Swerling I targets with unknown Doppler shift (the Doppler shift is modeled as a uniform random variable in the interval [0,2Π)).
The results for the detection of correlated Gaussian targets in correlated Gaussian clutter and AWGN are presented in Figures9 and10. In both figures, the CNR = 20dB, and ρ t is unknown, modeled as a uniform random variable in the interval [0,1]. In Figure9, ρ c = 0.7 and SIR = 0dB. In Figure10, ρ c = 0.995 and SIR = −10dB.

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Cross-Entropy error for detecting Gaussian targets with unknown ρ t in Gassian clutter plus AWGN ( C N R = 2 0 d B , ρ c = 0 . 7, S I R = 0 d B ).

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Cross-Entropy error for detecting Gaussian targets with unknown ρ t in Gassian clutter plus AWGN ( C N R = 2 0 d B , ρ c = 0 . 9 9 5 , S I R = − 1 0 d B ).
The results for the SWI targets with unknown Doppler shift in correlated Gaussian clutter and AWGN are presented in Figures11 and12. In both figures, the CNR = 20 dB, and the Doppler shift is unknown, modeled as a uniform random variable in the interval [0,2Π). In Figure11, ρ c = 0.7 and SIR = 13 dB. In Figure12, ρ c = 0.995 and SIR = 1 dB. Again, training with the Cross-Entropy error, as higher the number of hidden neurons, better the obtained approximation to the CGLR detector taken as reference.

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Cross-Entropy error for detecting Swerling I targets with unknown Doppler shift in Gassian clutter plus AWGN ( CNR = 20 d B, ρ c = 0.7, S I R = 1 3 d B ).

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Cross-Entropy error for detecting Swerling I targets with unknown Doppler shift in Gassian clutter plus AWGN ( C N R = 2 0 d B, ρ c = 0.995, S I R = 1 d B.
Detection of non fluctuating targets in presence of spiky K-distributed clutter
In this case, the results obtained with MLPs with different number of hidden neurons for detecting non-fluctuating targets in spiky K-distributed clutter are presented. These experiments have been included to show the utility of our approach for detection purposes with high resolution radars and low grazing angles. In this case, the considered interference is only clutter (ρ c = 0 and SCR = 9 dB in Figure13, and ρ c = 0.9 and SCR = −3 dB in Figure14). The good approximation to the reference detector can be observed in all cases, even for very low P FA values, and with a reduced number of neurons in the hidden layer.

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Cross-Entropy error for detecting non-fluctuating targets in spiky K -distributed clutter ( SCR = 9 d B, ρ c = 0 ).

ROC curves of the MPLs with different number of hidden neurons, trained to minimize the Cross-Entropy error for detecting non-fluctuating targets in spiky K -distributed clutter ( S C R = − 3 d B, ρ c = 0 . 9 ).
Conclusions
In this article, the possibility of approximating the NP detector using learning machines trained in a supervised manner to minimize the Cross-Entropy error has been studied.
Conventional coherent radar detectors usually apply Doppler processors (MTD, Moving Target Detectors, or MTI, Moving target Indicators) to reduce the clutter in the received signal. Most of these approaches assume Gaussian statistics, and are implemented with linear filters. The modulus of the filtered observation vector is obtained, and finally compared to a detection threshold. Due to clutter residuals, Constant False Alarm (CFAR) techniques are applied to fulfil P FA requirements. Many of the proposed solutions, assume a Gaussian distributed background. In the literature, the detection of radar targets in non-Gaussian clutter has also been addressed, but most of the approaches are based on the design of CFAR detectors that assume a specific probability density function of the clutter, and try to estimate the detection threshold for maintaining the desired P FA. In this article, the learning capabilities of supervised learning machines are exploited to approximate the NP detector in cases where not only the clutter but also target parameters, are unknown. This is the general case study in a radar problem, where detection is formulated as a composite hypothesis test. Instead of using the Sum-of-Squares error, the Cross-Entropy error is considered for training, in order to exploit its better properties with respect to the sensitivity to the presence of outlayers in the training set.
The function approximated by the learning machine after training has been calculated using the calculus of variations, with the objective of finding the function that minimises the formulated Cross-Entropy error.
Once the function the supervised learning machines approximates to after training has been obtained, the method proposed in[33] has been applied to demonstrate that this function can be used to implement the NP detector by comparing the trained learning machine output to a threshold, selected according to P FA requirements.
This theoretical result has been assessed with some experiments. Neural networks based detectors have been considered for detecting different types of signals in different types of interferences. Results prove that an MLP trained to minimize the Cross-Entropy error, can implement a very good approximation to the NP detector for the considered detection problems, even for low P FA values.
Different experiments have been performed for detecting fluctuating radar targets (Gaussian targets with unknown correlation coefficient and Swerling I target with unknown Doppler shift) in AWGN, and in correlated Gaussian clutter plus AWGN. Also, the detection of non-fluctuating targets in spiky K-distributed clutter has been studied. In all the cases, the capability of learning machines (particularly, MLPs) trained to minimize the Cross-Entropy error, to approximate the optimum detector in the NP sense, has been demonstrated. To obtain a good approximation, the number of hidden neurons must be high enough. This number is related to the minimum number of hyperplanes necessary to enclose the acceptance regions of the detection problem, but this theoretical study is beyond the objective of this article.
For comparison purposes, some experiments have been carried out with MLPs trained to minimize the Sum-of-Squares error, and the Minkowski error with R=1. The results obtained training with the Cross-Entropy error are better than the results obtained training with the Sum-of-Squares error, but both can be used to approximate the NP detector. The detectors trained with the Minkowski error with R=1 are the worst, and this detector is very far from the NP optimum detector.
Compared with conventional radar detectors, this approach has the following advantages:
-
Good approximations to the optimal NP detector can be obtained if a suitable error function is selected, if a representative training set is available, if the learning machine architecture has a high enough number of free parameters, and finally, if a good training algorithm is used.
-
No statistical models have to be assumed during the design. On the contrary, most of the CFAR detectors that can be found in the literature assume some statistical model for the interference that is used to adjust the detection threshold to maintain the desired P FA.
-
The implementation of the NP detector based on the Average-Likelihood ratio, when some of the parameters or the statistical models assumed in the design are random, can lead to intractable integrals. When supervised learning machines are used to approximate the NP detector, only training data obtained experimentally are necessary, without knowledge of the statistical distributions, and without solving those integrals.
Obviously, supervised learning machines are not an ideal solution in radar detection problems. The main drawback is the difficulty of obtaining representative training samples, and the definition of the most suitable learning machine architecture.
References
Jarabo-Amores M, Rosa-Zurera M, Gil-Pita R, López-Ferreras F: Study of two error functions to approximate the Neyman–Pearson detector using supervised learning machines. IEEE Trans. Signal Proces 2009, 57(11):4175-4181.
Neyman J, Pearson K: On the problem of the most efficient test of statistical hypotheses. Philosph. Trans. Roy. Soc. Lond. A 231 1933, 492-510.
Trees HV: Detection, estimation, and modulation theory. New York: Wiley; 1968.
di Vito A, Naldi M: Robustness of the likelihood ratio detector for moderately fluctuating radar targets. IEE Proc. Radar Sonar Navig 1999, 146(2):107-122. 10.1049/ip-rsn:19990261
He Q: MIMO radar diversity with Neyman–Pearson signal detection in non-Gaussian circumstance with non-orthogonal waveforms. In Proceedings of IEEE-ICASSP. Prague, Czech Republic; 2011:2764-2767.
He Q, Blum R: Diversity gain for MIMO Neyman–Pearson signal detection. IEEE Trans. Signal Proces 2011, 59(3):869-881.
Yang Y, Blum R, Sadler B: A distributed and energy-efficient framework for Neyman-Pearson detection of fluctuating signals in large-scale sensor networks. IEEE J. Sel. Areas Commun 2010, 28(7):1149-1158.
Vicen-Bueno R, Carrasco-Alvarez R, Jarabo-Amores M, Nieto-Borge J, Alexandre-Cortizo E: Detection of ships in marine environments by square integration mode and multilayer perceptrons. IEEE Trans. Instrum. Meas 2011, 60(3):712-724.
Furon T, Josse J, le Squin S: Some theoretical aspects of watermarking detection. Proc. SPIE 2006, 6072: 553-564.
Ng T, Garg H: Maximum-likelihood detection in DWT domain image watermarking using Laplacian modeling. IEEE Signal Process. Lett 2005, 12: 285-288.
Gu I, Ernberg N, Styvaktakis E, Bollen M: A statistical-based sequential method for fast online detection of fault-induced voltage dips. IEEE Trans. Power Del 2004, 19: 497-504. 10.1109/TPWRD.2003.823199
Chamberland J, Veeravalli V: Decentralized detection in sensor networks. IEEE Trans. Signal Proces 2003, 139: 407-416.
Sebastiani P, Gussoni E, Kohane I, Ramoni M: Statistical challenges in functional genomics. Stat. Sci 2003, 18: 33-60. 10.1214/ss/1056397486
Dudoit S, Fridlyand J, Speed T: Comparison of discrimination methods for the classification of tumors usign gene expression data. J. Am. Stat. Assoc 2002, 97: 77-87. 10.1198/016214502753479248
Nandakumar K, Chen Y, Dass S, Jain A: Likelihood ratio-based biometric score fusion. IEEE Trans. Pattern Anal. Mach. Intell 2008, 30(2):342-347.
Prix R, Krishnan B: Targeted search for continuous gravitational waves: Bayesian versus maximum-likelihood statistics. Class. Quant. Grav 2009., 26(20): 10.1088/0264-9381/26/20/204013
Sung Y, Tong L, Poor H: Neyman–Pearson detection of Gauss–Markov signals in noise: closed-form error exponent and properties. IEEE Trans. Inf. Theory 2006, 52: 1354-1365.
Andina D, Sanz-González J, Jiménez-Pajares J: A comparison of criterion functions for a neural network applied to binary detection. In Proc. IEEE Int. Conf. Neural Netw. Perth, WA; 1995:329-333.
Andina D, Sanz-González J, Rodríguez-Martín O: Performance improvements for a neural network detector. In Proc. IEEE Int. Conf. Neural Netw. Perth, WA, Australia; 1995:492-495.
Burian A, Kuosmanen P, Saarinen J: Neural detectors with variable threshold. In Proc. ISCAS. Orlando, FL, USA; 1999:599-602.
Ramamurti V, Rao SS, Gandhi PP: Neural detectors for signals in non-gaussian noise. In Proc. ICASSP. Minneapolis, MN, USA; 1993:481-484.
Gandhi P, Ramamurti V: Neural networks for signal detection in non-gaussian noise. IEEE Trans. Signal Process 1997, 45: 2846-2851. 10.1109/78.650111
Munro D, Ersoy O, Bell M, Sadowsky J: Neural network learning of low-probability events. IEEE Trans. Aerosp. Electron. Syst 1996, 32: 898-910.
Ruck D, Rogers S, Kabrisky M, Oxley M, Suter B: The multilayer perceptron as an approximation to a Bayes optimal discriminant function. IEEE Trans. Neural Netw 1990, 1: 296-298. 10.1109/72.80266
Casasent D, Chen X: New training strategies for RBF neural networks for X-ray agricultural product inspection. Pattern Recogn 2003, 36: 535-547. 10.1016/S0031-3203(02)00058-4
Casasent D, Chen X: Radial basis function neural networks for nonlinear Fisher discrimination and Neyman Pearson classification. Neural Netw 2003, 16: 529-535. 10.1016/S0893-6080(03)00086-8
Jarabo-Amores P, Gil-Pita R, Rosa-Zurera M, López-Ferreras F: MLP and RBFN for detecting white Gaussian signals in white Gaussian interference. Lecture Notes in Computer Science vol. 2687. Maó, Spain; 2003:790-797.
Davenport M, Baraniuk R, Scott C: Controling false alarms with support vector machines. In Proc. of ICASSP. Toulouse, France; 2006:589-592.
Haykin S, Thomson D: Signal detection in a nonstationary environment reformulated as an adaptive pattern classification problem. IEEE Trans. Signal Proces 1998, 85(11):2325-2344.
Fernandes AM, Utkin AB, Lavrov AV, Vilar RM: Development of neural network committee machines for automatic forest fire detection using lidar. Pattern Recogn 2004, 37: 2039-2047. 10.1016/j.patcog.2004.04.002
Mata-Moya D, Jarabo-Amores P, Vicen-Bueno R, Rosa-Zurera M, López-Ferreras F: Neural network detectors for composite hypothesis tests. Lecture Notes in Computer Science, vol. 4224. Burgos, Spain; 2006:298-305.
Mata-Moya D, Jarabo-Amores P, Rosa-Zurera M, Nieto-Borge J, López-Ferreras F: Combining MLPs and RBFNNs to detect signals with unknown parameters. IEEE Trans. Instrum. Meas 2009, 58(9):2989-2995.
Jarabo-Amores P, Rosa-Zurera M, Gil-Pita R, López-Ferreras F: Sufficient condition for an adaptive system to approximate the Neyman–Pearson detector. In 2005 IEEE/SP 13th Workshop on Statistical Signal Processing. Bordeaux, France; 2005:295-230.
Bishop CM: Neural Networks for Pattern Recognition. Oxford, UK: Oxford University Press; 1995.
Saerens M, Latinne P, Decaestecker C: Any reasonable cost function can be used for a posteriori probability approximation. IEEE Trans. Neural Netw 2002, 13: 1204-1210. 10.1109/TNN.2002.1031952
Slivka J, Severo N: On the strong law of large numbers. Proc. Am. Math. Soc 1970, 24: 729-734. 10.1090/S0002-9939-1970-0259993-9
Hampshire J, Pearlmutter B: Equivalence proofs for multilayer perceptron classifiers and the Bayesian discriminant function. In Proc. of 1990 Connectionist Models Summer School. Edited by: Touretzky DS, Elman JL, Sejnowski TJ, Hinton GE. San Diego, CA, USA; 1990:159-172.
Gelfand I, Fomin S: Calculus of Variations. Mineola, New York: Courier Dover Publications; 2000.
Weinstock R: Calculus of Variations with Applications to Physics and Engineering. New York: McGraw Hill; 1952.
Conte E, Longo M, Lops M, Ullo S: Radar detection of signals with unknown parameters in K-distributed clutter. IEE Proc. F Radar Signal Process 1991, 138(2):131-138. 10.1049/ip-f-2.1991.0019
Conte E, Lops M, Ricci G: Radar detection in K-distributed clutter. IEE Proc. Radar Sonar Navig 1994, 141(2):116-118. 10.1049/ip-rsn:19949882
Nayebi MM, Aref MR, Bastani MH: Detection of coherent radar signals with unknown Doppler shift. IEE Proc. Radar Sonar Navig 1996, 143(2):79-86. 10.1049/ip-rsn:19960158
El-Jaroudi A, Makhoul J: A new error criterion for posterior probability estimation with neural nets. In Proc. of Int. Conf. on Neural Networks IJCNN. San Diego, CA, USA; 1990:185-192.
Charalambous C: Conjugate gradient algorithm for efficient training of artificial neural networks. IEEE Proc. Circ. Dev. Syst 1992, 51(3):301-310.
Acknowledgements
This work has been partially funded by the Spanish Ministry of Economy and Competitiveness with project TEC2012-38701.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The author declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Jarabo-Amores, MP., la Mata-Moya, D.d., Gil-Pita, R. et al. Radar detection with the Neyman–Pearson criterion using supervised-learning-machines trained with the cross-entropy error. EURASIP J. Adv. Signal Process. 2013, 44 (2013). https://doi.org/10.1186/1687-6180-2013-44
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-6180-2013-44