
Abstract
Detecting human beings accurately in a visual surveillance system is crucial for diverse application areas including abnormal event detection, human gait characterization, congestion analysis, person identification, gender classification and fall detection for elderly people. The first step of the detection process is to detect an object which is in motion. Object detection could be performed using background subtraction, optical flow and spatio-temporal filtering techniques. Once detected, a moving object could be classified as a human being using shape-based, texture-based or motion-based features. A comprehensive review with comparisons on available techniques for detecting human beings in surveillance videos is presented in this paper. The characteristics of few benchmark datasets as well as the future research directions on human detection have also been discussed.
Similar content being viewed by others

1. Review
1.1 Introduction
Over the recent years, detecting human beings in a video scene of a surveillance system is attracting more attention due to its wide range of applications in abnormal event detection, human gait characterization, person counting in a dense crowd, person identification, gender classification, fall detection for elderly people, etc.
The scenes obtained from a surveillance video are usually with low resolution. Most of the scenes captured by a static camera are with minimal change of background. Objects in the outdoor surveillance are often detected in far field. Most existing digital video surveillance systems rely on human observers for detecting specific activities in a real-time video scene. However, there are limitations in the human capability to monitor simultaneous events in surveillance displays [1]. Hence, human motion analysis in automated video surveillance has become one of the most active and attractive research topics in the area of computer vision and pattern recognition.
An intelligent system detects and captures motion information of moving targets for accurate object classification. The classified object is being tracked for high-level analysis. In this study, we focus on detecting humans and do not consider recognition of their complex activities. Human detection is a difficult task from a machine vision perspective as it is influenced by a wide range of possible appearance due to changing articulated pose, clothing, lighting and background, but prior knowledge on these limitations can improve the detection performance.
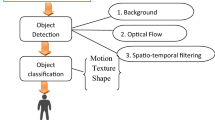
The detection process generally occurs in two steps: object detection and object classification. Object detection could be performed by background subtraction, optical flow and spatio-temporal filtering. Background subtraction is a popular method for object detection where it attempts to detect moving objects from the difference between the current frame and a background frame in a pixel-by-pixel or block-by-block fashion. There are few available approaches to perform background subtraction. The most common ones are adaptive Gaussian mixture [2–10], non-parametric background [11–17], temporal differencing [18–20], warping background [21] and hierarchical background [22] models. The optical flow-based object detection technique [18, 23–26] uses characteristics of flow vectors of moving objects over time to detect moving regions in an image sequence. Apart from their vulnerability to image noise, colour and non-uniform lighting, most of the flow computation methods have large computational requirements and are sensitive to motion discontinuities. For motion detection based on the spatio-temporal filter methods, the motion is characterized via the entire three-dimensional (3D) spatio-temporal data volume spanned by the moving person in the image sequence [27–37]. Their advantages include low computational complexity and a simple implementation process. However, they are susceptible to noise and variations of the timings of movements.
The object classification methods could be divided into three categories: shape-based, motion-based and texture-based. Shape-based approaches first describe the shape information of moving regions such as points, boxes and blobs. Then, it is commonly considered as a standard template-matching issue [18, 23, 38–43]. However, the articulation of the human body and the differences in observed viewpoints lead to a large number of possible appearances of the body, making it difficult to accurately distinguish a moving human from other moving objects using the shape-based approach. This challenge could be overcome by applying part-based template matching [39]. Texture-based methods such as histograms of oriented gradient (HOG) [44] use high dimensional features based on edges and use support vector machine (SVM) to detect human regions.
A large number of studies described in this review use publicly available datasets that are specifically recorded for training and evaluation. KTH human motion dataset [45] contains six activities, whereas Weizmann human action dataset [46] and INRIA XMAS multi-view dataset [47] contains 10 and 11 actions, respectively. Performance Evaluation of Tracking and Surveillance (PETS) datasets [48–59] have a number of datasets for different purposes of vision-based research. Each year, PETS run an evaluation framework on specific datasets with specific objective. The Institute of Automation, Chinese Academy of Sciences (CASIA) provides the CASIA Gait Database [60] for gait recognition and related research.
The key purpose of this paper is to provide a comprehensive review on studies conducted in the area of human detection process of a visual surveillance system. A flow chart of the human detection process is illustrated in Figure 1. Various available techniques are reviewed in Section 1.2. Details of several benchmark databases are presented in Section 1.3. Several major applications are reviewed in Section 1.4. We present a review and analyses of recent developments and highlight future directions of research in the area of human detection in visual surveillance. Future directions are discussed in Section 1.5. The main contributions of this paper are as follows:
-
Object detection and object classification are discussed in a clearly organized manner according to the general framework of visual surveillance. This, we believe, can help readers, especially newcomers to this area, to obtain an understanding of the state of the art in visual surveillance and the scope of its application in the real world.
-
The pros and cons of a variety of different algorithms for motion detection and classification are discussed.
-
We provide a discussion on future research directions in human detection in visual surveillance.

Flow chart of human detection.
1.2 Techniques
Human detection in a smart surveillance system aims at making distinctions among moving objects in a video sequence. The successful interpretations of higher level human motions greatly rely on the precision of human detection [61–63]. The detection process occurs in two steps: object detection and object classification.
1.2.1 Object detection
An object is generally detected by segmenting motion in a video image. Most conventional approaches for object detection are background subtraction, optical flow and spatio-temporal filtering method. They are outlined in the following subsections.
1.2.1.1 Background subtraction
Background subtraction is a popular method to detect an object as a foreground by segmenting it from a scene of a surveillance camera. The camera could be fixed, pure translational or mobile in nature [63]. Background subtraction attempts to detect moving objects from the difference between the current frame and the reference frame in a pixel-by-pixel or block-by-block fashion. The reference frame is commonly known as ‘background image’ , ‘background model’ or ‘environment model’. A good background model needs to be adaptive to the changes in dynamic scenes. Updating the background information in regular intervals could do this [64], but this could also be done without updating background information [65]. Few available approaches have been discussed in this section:
-
Mixture of Gaussian model. Stauffer and Grimson [2] introduced an adaptive Gaussian mixture model, which is sensitive to the changes in dynamic scenes derived from illumination changes, extraneous events, etc. Rather than modelling the values of all the pixels of an image as one particular type of distribution, they modelled the values of each pixel as a mixture of Gaussians. Over time, new pixel values update the mixture of Gaussian (MoG) using an online K-means approximation. In the literature, many approaches are proposed to improve the MoG [3–11]. In [4], an effective learning algorithm for MoG is proposed to overcome the requirement of the prior knowledge about the foreground and background ratio. In [5], authors presented an algorithm to control the number of Gaussians adaptively in order to improve the computational time without sacrificing the background modelling quality. In [6], each pixel is modelled by support vector regression. Kalman filter is used for adaptive background estimation in [7]. In [8], a framework for hidden Markov Model (HMM) topology and parameter estimation is proposed. In [9], colour and edge information are fused to detect foreground regions. In [10], normalized coefficients of five kinds of orthogonal transform (discrete cosine transformation, discrete Fourier transformation (DFT), Haar transform, single value decomposition and Hadamard transform) are utilized to detect moving regions. In [11], each pixel is modelled as a group of adaptive local binary pattern histograms that are calculated over a circular region around the pixel.
-
Non-parametric background model. Sometimes, optimization of parameters for a specific environment is a difficult task. Thus, a number of researchers introduced non-parametric background modelling techniques [12–17]. Non-parametric background models consider the statistical behaviour of image features to segment the foreground from the background. In [13], a non-parametric model is proposed for background modelling, where a kernel-based function is employed to represent the colour distribution of each background pixel. The kernel-based distribution is a generalization of MoG [4], which does not require parameter estimation. The computational requirement is high for this method. Kim and Kim [12] proposed a non-parametric method, which was found effective for background subtraction in dynamic texture scenes (e.g. waving leaves, spouting fountain and rippling water). They proposed a clustering-based feature, called fuzzy colour histogram (FCH) to construct the background model by computing the similarity between local FCH features with an online update procedure. Although the processing time was high in comparison with the adaptive Gaussian mixture model [2], the false positive rate of detection is significantly low at high true positive rates.
-
Temporal differencing. The temporal differencing approach [19] involves three important modules: block alarm module, background modelling module and object extraction module (see Figure 2). The block alarm module efficiently checked each block for the presence of either a moving object or background information. This was accomplished using temporal differencing pixels of the Laplacian distribution model and allowed the subsequent background modelling module to process only those blocks that were found to contain background pixels. Next, the background modelling module is employed in order to generate a high-quality adaptive background model using a unique two-stage training procedure and a mechanism for recognizing changes in illumination. As the final step of their process, the proposed object extraction module computes the binary object detection mask by applying suitable threshold values. This is accomplished using their proposed threshold training procedure.

Flowchart of motion detection approach by Cheng et al.[19].
The performance evaluation of their proposed method is accomplished by quantitative and qualitative processes. The overall results showed that their proposed method attained a substantially higher degree of efficacy.
-
Warping background. Ko et al. [21] presented a background model that differentiates between background motion and foreground objects. Unlike most models that represent the variability of pixel intensity at a particular location in the image, they modelled the underlying warping of pixel locations arising from background motion. The background is modelled as a set of warping layers where at any given time, different layers may be visible due to the motion of an occluding layer. Foreground regions are thus defined as those that cannot be modelled by some composition of some warping of these background layers.
-
Hierarchical background model. Chen et al. [22] proposed a hierarchical background model, which is based on region segmentation and pixel descriptors to detect and track foreground. It first segments the background images into several regions by the mean-shift algorithm. Then, a hierarchical model, which consists of the region models and pixel models, is created. The region model is one kind of approximate Gaussian mixture model extracted from the histogram of a specific region. The pixel model is based on the co-occurrence of image variations described by HOG of pixels in each region. Benefiting from the background segmentation, the region models and pixel models corresponding to different regions can be set to different parameters. The pixel descriptors are calculated only from neighbouring pixels belonging to the same object. The hierarchical models first detect the regions containing foreground and then locate the foreground only in these regions, thus avoid detection failure in other regions and reduce the time and cost. A similar two-stage hierarchical method has been introduced earlier by Chen [66] where the block-based stage provides a course foreground segmentation followed by the pixel-based stage for finer segmentation. The method showed promising results when compared with MoG. Recent application of this approach can be seen in the study of Quan [67] where the hierarchical background model (HBM) is combined with the codebook [68] technique.
1.2.1.2 Optical flow
Optical flow is a vector-based approach [18, 23, 26] that estimates motion in video by matching points on objects over image frame(s). Under the assumption of brightness constancy and spatial smoothness, optical flow is used to describe coherent motion of points or features between image frames. Optical flow-based motion segmentation uses characteristics of flow vectors of moving objects over time to detect moving regions in an image sequence. One key benefit of using optical flow is that it is robust to multiple and simultaneous cameras and object motions, making it ideal for crowd analysis and conditions that contain dense motion. Optical flow-based methods can be used to detect independently moving objects even in the presence of camera motion. Apart from their vulnerability to image noise, colour and non-uniform lighting, most of flow computation methods have large computational requirements and are sensitive to motion discontinuities. A real-time implementation of optical flow will often require a specialized hardware due to the complexity of the algorithm and moderately high frame rate for accurate measurements [18].
1.2.1.3 Spatio-temporal filter
For motion recognition based on spatio-temporal analysis, the action or motion is characterized via the entire 3D spatio-temporal data volume spanned by the moving person in the image sequence. These methods generally consider motion as a whole to characterize its spatio-temporal distributions [27, 37]. Zhong et al. [27] processed a video sequence using a spatial Gaussian and a derivative of Gaussian on the temporal axis. Due to the derivative operation on the temporal axis, the filter shows high responses at regions of motion. These responses were then used to generate thresholds to yield a binary motion mask, followed by aggregation into spatial histogram bins. Such a feature encodes motion and its corresponding spatial information compactly and is useful for far-field and medium-field surveillance videos. As these approaches are based on simple convolution operations, they are fast and easy to implement. They are quite useful in scenarios with low-resolution or poor-quality video where it is difficult to extract other features such as optical flow or silhouettes. Spatio-temporal motion-based methods are able to better capture both spatial and temporal information of gait motion. Their advantage is low computational complexity and a simple implementation. However, they are susceptible to noise and to variations of the timings of movements.
1.2.1.4 Performance comparisons of detection techniques
A generic comparison among object detection methods in terms of accuracy and computational time is presented in Table 1. The table shows accuracy and computational time of different object detection techniques in terms of three criteria, namely low, moderate and high. It is very difficult to generalize the accuracy and computational time of different techniques in each category by three simple attributes because there are several techniques in each category, and each technique has its own accuracy and computational time. We have provided the general trends of these techniques in each category based on various available comparative studies. The readers will have a general understanding about their performances using this table. This should act as a guide for the readers and practitioners to conduct further investigation to find the appropriate technique suitable for their specific contexts.
The MoG-based models compute at pixel level (or small block level) and provide moderate accuracy and relatively low computational time [2]. It has been applied widely, and several improved models are introduced based on MoG. The MoG models are widely used as base model for performance comparisons of new models. The general non-parametric techniques provide high accuracy in dynamic background scenarios but require lower computational time [13]. Temporal differencing technique attained between 10% and 25% more accuracy than some well-known techniques including MoG and has excellent capabilities to handle sudden illumination issues [19]. Warping background techniques provide significantly better results (between 10% and 40% for various datasets) for separating background motion from foreground motion using neighbouring pixel information compared to few classic methods including the non-parametric technique, and the implicit version claims to require less computational overhead [21]. The HBM method provides high accuracy (about 5% to 15% less error) compared to some classic methods including MoG and requires slightly less computational time compared to MoG-based methods as it uses hybrid techniques [22].
Optical flow methods have distinct advantages in moving object detection compared to background subtraction methods as they can handle camera motion and perform well in crowd detection; however, they require higher computational time and special hardware for real-time applications [18, 23]. A comprehensive comparative study among several classic optical flow techniques can provide in-depth understanding to interested readers [24].
Spatio-temporal-based methods are better in accuracy where noise is less as they consider motion in a holistic way. These methods showed promising results in unusual event detection scenarios, and they are good in terms of computational time [27–37]. Recently, a new texture descriptor and hysteresis thresholding-based object detection technique has been introduced by Lai et al. [70] which shows better performance than traditional MoG in challenging conditions such as illumination, shadow- and motion-induced problems.
A modified MoG-based approach by replacing the mean pixel intensity value with the recent pixel intensity value in background frame generation performs better to detect object in a general situation [71] compared to other approaches. A number of video-coding techniques also used the MoG-based approach to generate a background frame and use an additional reference frame to encode uncovered/occluded regions of a frame for better coding efficiency [72–75]. Due to computational time, implementation issues, accuracy and memory requirement, it is very difficult to incorporate other approaches into video-coding applications to encode uncovered/occluded regions.
1.2.1.5 A comparison study
In order to demonstrate the comparison technique, we have conducted a comparison study using a readily available software tool MFC BGS Library x86 1.3.0[76]. The tool provides a wide array of background subtraction methods. In this comparison test, we have chosen the MoG [2], the NP-KDE [13], the temporal median [77] and the frame difference [78] methods. We have chosen these four methods due to their class leading reputations and applications by a large number of researchers.
For this study, we have used the Wallflower dataset [78, 79]. A total of 248 frames were provided as input to the MFC BGS Library x86 1.3.0 tool which provided the detected foreground frames for each input frame. A hand-drawn ground truth has been provided for frame 248 with the Wallflower data. We have compared the foreground for frame 248 with the ground truth. The results are shown in Table 2. From the output detection pictures and the numeric results for false positive (FP) and false negative (FN), we can observe that the non-parametric (NP) one has been most successful in detecting the moving tree in the background from the foreground. The temporal median method has been most successful in identifying the foreground regions but was not as good as the NP in detecting the moving tree as background.
Although this is a simple and short study, it provides a general guidance to the readers regarding the process of such comparative studies. Software tools such as MFC BGS Library x86 1.3.0 or self-implemented tools can be used for such comparative studies. Although we have chosen only four methods, they are the initial ones in their respective category. We would like to highlight the fact that a significant number of new methods have been proposed by researchers with modification to these methods, most of which require some post-processing work such as noise reduction. A comprehensive comparison with all the methods is time consuming and may not be very useful as all the methods may not be suitable for a particular application. Researchers and practitioners are thus recommended to research on comparative studies such as [78, 80–84] to identify potential methods suitable for their intended applications. A comparative study can then be conducted to find the most suitable one among the potential methods.
Object classification. An object in motion needs to be classified accurately for its recognition as a human being. The available classification methods could be divided into three main categories: shape-based method, motion-based method and texture-based method.
1.2.1.6 Shape-based method
Shape-based approaches first describe the shape information of moving regions such as points, boxes and blobs. Then, it is commonly considered as a standard pattern recognition issue [18, 23, 38, 43]. However, the articulation of the human body and differences in observed viewpoints lead to a large number of possible appearances of the body, making it difficult to accurately distinguish a moving human from other moving objects using the shape-based approach. Eishita et al. [43] proposed a simple but effective method for object tracking after full or partial occlusion using shape, colour and texture information even if the colour and textures are the same for the objects. Wang et al. [38] investigated how the deformations of human silhouettes (or shapes) during articulated motion could be used as discriminating features to implicitly capture motion dynamics and exploited the applicability of discrete wavelet transform and DFT for the purpose of human motion characterization and recognition (see Figure 3).

Extraction and representation of moving shapes [5]. (a) Normalized silhouette images and (b) shape Fourier descriptors.
Huang et al. [85] presented a performance evaluation of shape similarity metrics for 3D video sequences of people with unknown temporal correspondence. Lin and Davis [40] proposed a shape-based, hierarchical part-template-matching approach to simultaneous human detection and segmentation combining local part-based and global shape-template-based schemes. Their approach relied on the key idea of matching a part-template tree to images hierarchically to detect humans and estimate their poses. One major disadvantage of the shape-based method is that it cannot capture the internal motion of the object within the silhouette region. Even state-of-the-art background subtraction techniques do not always reliably recover precise silhouettes, especially in dynamic environments. This reduces the robustness of techniques in this method.
1.2.1.7 Motion-based method
This classification method is based on the idea that object motion characteristics and patterns are unique enough to distinguish between objects. Motion-based approaches directly make use of the periodic property of the captured images to recognize human beings from other moving objects. Bobick and Davis [86] developed a view-based approach for the recognition of human movements by constructing a vector image template comprising two temporal projection operators: binary motion-energy image and motion-history image. Cutler et al. [87] presented a self-similarity-based time-frequency technology to detect and analyze periodic motion for human classification. Unfortunately, methods based on periodicity are restricted to periodic motion. Efros et al. [26] characterized the human motion within a spatio-temporal volume by a descriptor, which was based on computing the optical flow, projecting the motion onto a number of motion channels and blurring with a Gaussian. Recognition was performed in a nearest-neighbour framework. By computing a spatio-temporal cross correlation with a stored database of previously labelled action fragments, the most similar to the motion descriptor of the query action fragment could be found.
1.2.1.8 Texture-based method
Local binary pattern (LBP) is a texture-based method that quantifies intensity patterns in the neighbourhood of the pixel [88]. Zhang et al. [89] proposed the multi-block local binary pattern (MB-LBP) to encode intensities of the rectangular regions by LBP. HOG [44] introduced another texture-based method which uses high-dimensional features based on edges and then applies SVM to detect human body regions. This technique counts the occurrences of gradient orientation in localized portions of an image, is computed on a dense grid of uniformly spaced cells and uses overlapping local contrast normalization for improved accuracy. Zhu et al. [90] applied the HOG descriptors in combination with the cascade of rejecters algorithm and introduced blocks that vary in size, location and aspect ratio. In order to isolate the blocks best suited for human detection, they applied the AdaBoost algorithm to select those blocks to be included in the rejecter cascade. Moctezuma et al. [91] proposed HOG with Gabor filter and showed improved performances in both person counting and identification.
1.2.1.9 Detection of non-moving human
We have focused on motion-based human detection in this study due to the fact that some unique human motion features aid in better identification of human beings from other objects [92]. The method for human detection from static images has also a number of applications such as smart rooms and visual surveillance. A human detection scheme in a crowded scene from static images is described in [93]. The method models an individual human as an assembly of natural body parts using edgelet features, which are a new type of silhouette-oriented features. Local body part and global shape-based approach showed promising results [40]. Probability part detector has been used successfully for human detection [94]. A learning-based human detection framework was proposed earlier by Papageorgiou et al. [95]. Recently, motionless human detection based on sensor data has been proposed with particular application interests in the area of aged care support [96, 97].
1.2.1.10 Comparisons of classification techniques
A comparison among object classification methods in terms of accuracy and computational time is presented in Table 3. The table shows accuracy and computational time of different object classification techniques in terms of three criteria, namely low, moderate and high. As we have mentioned earlier, it is very difficult to conclude the accuracy and computational time of different techniques in each category by three simple attributes (e.g. low, moderate and high) because in each category, there are a number of techniques and each technique has its own accuracy and computational time. However, we have provided average or normal trend of the techniques in each category to give an overall understanding of a category.
The main criticism of the shape-based approach with templates for human detection is that local deformation of body parts due to motion could not be captured properly thus provides less accurate performance compared to other methods. However, if the methods use fixed templates, they might provide a slightly better performance than SVM-based variations and process reasonably faster [40]. The motion-based approaches use predefined actions to recognize the human motions. As these approaches need to process motion and then categorize the object, they need more computational time. The texture-based approaches also work similar to motion-based approaches but with the help of texture pattern recognition. They provide better accuracy (around 10%) [91, 98] but may require more time, which can be improved using some fast techniques [90].
1.3 Benchmark datasets for indoor and outdoor
In this section, a brief overview of few datasets for surveillance-based research has been presented.
1.3.1 KTH human motion dataset
KTH dataset [45] is the largest available and most standard dataset widely used for benchmarking results for human action classification. The dataset contains six activities (boxing, hand waving, handclapping, running, jogging and walking) performed by 25 subjects in four different scenarios: outdoors (s1), outdoors with scale variation (s2), outdoors with different clothes (s3) and indoors (s4).There are 25 × 6 × 4 = 600 video files for each combination of 25 subjects, six actions and four scenarios. All sequences were taken over homogeneous backgrounds with a static camera with 25 frames per second (fps) frame rate. The sequences were then down-sampled to the spatial resolution of 160 × 120 pixels and have a length of 4 s in average. Some sample sequences are shown in Figure 4.

Sample sequences from KTH human motion dataset.
1.3.2 Weizmann human action dataset
Weizmann human action dataset [46] contains a total of ten actions performed by nine people, to provide a total of 90 videos. Sample sequences are shown in Figure 5. The dataset contains videos with a static camera unlike that of the KTH dataset, where some of the videos had zooming and also have simple background. As this dataset contains ten activities, which is more comparative to the six activities of the KTH dataset, it provides a good test to the approach in the setting in which the number of activities are increased.

Example sequences from Weizmann dataset (jack, walk, wave1, skip, side, bend, p-jump, wave2, run and jump).
1.3.3 PETS dataset
PETS datasets [48] have a number of datasets for different purposes of vision-based research. Each year, PETS run an evaluation framework on specific datasets with specific objective. PETS'2000 [49] and PETS'2001 [50] datasets are designed for tracking outdoor people and vehicles. PETS'2000 used a single camera, while PETS'2001 used two synchronized views. The later datasets are significantly more challenging than the previous one in terms of significant lighting variation, occlusion, scene activity and use of multi-view data. Two sample images are shown in Figure 6. PETS'2002 [51] has indoor people tracking (and counting) and hand posture classification data. PETS-ICVS'2003 [52] has annotations of a smart meeting, which includes facial expressions, gaze and gesture/action. VS-PETS'2003 [53] has outdoor people tracking - football data from two synchronized camera views. PETS-ECCV'2004 [54] has a number of video clips recorded for the CAVIAR project. These include people walking alone, meeting with others, window shopping, fighting and passing out and, last but not least, leaving a package in a public place. All video clips were filmed for the CAVIAR project with a wide-angle camera lens in the entrance lobby of the INRIA Labs at Grenoble, France. PETS'2006 [55] has surveillance data of public spaces and detection of left luggage events. PETS'2007 [56] considers both volume crime (theft) and a threat scenario (unattended luggage.) The datasets for PETS'2009 [57], PETS'2010 [58] and PETS'2012 [59] consider crowd image analysis and include crowd count and density estimation, tracking of individual(s) within a crowd and detection of separate flows and specific crowd events.

Sample images from PETS'2001 dataset.
1.3.4 INRIA XMAS multi-view dataset
Weinland et al. [47] introduced the INRIA XMAS dataset that contains actions captured from five viewpoints. A total of 11 persons perform 14 actions (check watch, cross arms, scratch head, sit down, get up, turn around, walk, wave, punch, kick, point, pick up, throw over head and throw from bottom up). The actions are performed in an arbitrary direction with regard to the camera set-up. The camera views are fixed, with a static background and illumination settings. Silhouettes and volumetric voxel representations are part of the dataset.
1.3.5 Other datasets
The Institute of Automation, Chinese Academy of Sciences provides the CASIA Gait Database for gait recognition and related research. The database consists of three datasets: dataset A, dataset B (multi-view dataset) and dataset C (infrared dataset). The details of these databases are found in [60].
The Hollywood human action dataset [99] contains eight actions (answer phone, get out of car, handshake, hug, kiss, sit down, sit up and stand up), which are extracted from movies and performed by a variety of actors. A second version of the dataset includes four additional actions (drive car, eat, fight and run) and an increased number of samples for each class. One training set is automatically annotated using scripts of the movies; another is manually labelled. There is a huge variety of performance of the actions, both spatially and temporally. Occlusions, camera movements and dynamic backgrounds make this dataset challenging. Most of the samples are at the scale of the upper body, but some show the entire body or a close up of the face.
The UCF sports action dataset [100] contains 150 sequences of sport motions (diving, golf swinging, kicking, weightlifting, horseback riding, running, skating, swinging a baseball bat and walking). Bounding boxes of the human figure are provided with the dataset. For most action classes, there is considerable variation in action performance, human appearance, camera movement, viewpoint, illumination and background.
The Wallflower dataset [79] contains seven scenarios: one on them is outdoor, and six are indoor. The scenarios include moved object, time of day, light switch, waving tree, camouflage, bootstrapping and foreground aperture. In this dataset, for each scenario, training and test sequences are provided along with hand-drawn ground truth for one specific frame.
1.4 Applications
For an intelligent video surveillance system, the detection of a human being is important for abnormal event detection, human gait characterization, people counting, person identification and tracking, pedestrian detection, gender classification, fall detection of elderly people, etc.
1.4.1 Abnormal event detection
The most obvious application of detecting humans in surveillance video is to early detect an event that is not normal. Candamoo et al. [18] classified the abnormal events as single-person loitering, multiple-person interactions (e.g. fighting and personal attacks), person-vehicle interactions (e.g. vehicle vandalism), and person-facility/location interactions (e.g. object left behind and trespassing). Detecting sudden changes and motion variations in the points of interest and recognizing human action could be done by constructing a motion similarity matrix [26] or adopting a probabilistic method [101]. Methods based on probability statistics use the minimum change of time and space measure to model the method of probability. The most representative probability chart model is HMM. In addition, also there is conditional random field, the maximum entropy Markov model and dynamic Bayesian network. More information on human action recognition techniques for abnormal event detection can be found in [102].
1.4.2 Human gait characterization
Ran et al. [103] detected humans in walking by extracting double helical signatures (DHS) from surveillance video sequences. They found that DHS is robust to size, viewing angles, camera motion and severe occlusion for simultaneous segmentation of humans in periodic motion and labelling of body parts in cluttered scenes. They used the change in DHS symmetry for detecting humans in normal walking, carrying an object with one hand, holding an object in both hands, attaching an object to the upper body and attaching an object to the legs. Although DHS is independent of silhouettes or landmark tracking, it is ineffective when the target walks toward the camera as the DHS degenerates into ribbon and no strong symmetry can be observed. Cutler et al. [87] used the area-based image similarity technique to address this issue and detected the motion of a person who was walking at approximately 25° offset the camera's image plane from a static camera. They segmented the motion and track objects in the foreground. Each object was then aligned along the temporal axis (using the object's tracking results), and the object's self-similarity was computed as it evolves in time. For periodic motions, the self-similarity metric is periodic, and they apply time-frequency analysis to detect and characterize the periodicity.
1.4.3 Person detection in dense crowds and people counting
Detecting and counting persons in a dense crowd is challenging due to occlusions. Eshel and Moses [104] used multiple height homographies for head top detection to overcome this problem. Yao and Odobez [105] proposed to take advantage of the stationary cameras to perform background subtraction and jointly learn the appearance and the foreground shape of people in videos. Sim et al. [106] proposed a representation called the colour bin image which is extracted from the initially detected windows, and they use it for training a classifier to improve the performance of the initial detector. The proposed system was applied for detecting individual heads in dense crowds of 30 to 40 people against cluttered backgrounds from a single video frame. However, the performance of their approach may be challenged by the colour intensities of the heads to be detected. Chen et al. [107] proposed an online people counting system for electronic advertising machines. A vision-based people counting model was proposed by Chih-Wen et al. [108]. The cross camera people counting model proposed by Lin et al. [109] was composed of a pair of collaborative Gaussian processes, which were respectively designed to count people by taking the visible and occluded parts into account. Weng et al. [110] also presented an algorithm for accomplishing cross camera correspondence and proposed a counting model which was composed of a pair of collaborative regressors. A multi-camera people counting technique with occlusion handling is presented by Weng et al. [70]. Recently, Chen and Huang proposed two crowd behaviour detection models based on motion [111] and visual with graph and matching [112].
1.4.4 Person tracking and identification
A person in a visual surveillance system can be identified using face recognition [85, 113–122] and gait recognition [123–131] techniques. The detection and tracking of multiple people in cluttered scenes at public places is difficult due to a partial or full occlusion problem for either a short or long period of time. Leibe et al. [132] tried to address this issue using trajectory estimation while Andriluka et al. [133] used a tracklet-based detector, which was capable of detecting several partially occluded people that cannot be detected in a single frame alone. Yilmaz et al. [134] made a comprehensive survey on tracking methods and categorized them on the basis of the object and motion representations used. The wider application of human detection is not only limited to analysis surveillance videos but also extended to player tracking and identification in sport videos. The system introduced by Lu et al. [135] identified players in broadcast sports videos using conditional random fields and achieved a player recognition accuracy up to 85% on unlabeled NBA basketball clips. Sun et al. [136] proposed an individual level sports video indexing scheme, where a principal axis-based contour descriptor is used is to solve the jersey number recognition problem. Lu et al. [137] proposed a novel linear programming relaxation algorithm for predicting player identification in a video clip using weakly supervised learning with play-by-play texts, which greatly reduced the number of labelled training examples required.
1.4.5 Gender classification
Gender classification is another application of human detection in surveillance cameras. The classification could be carried out by fusion of similarity measures from multi-view gait sequences [138], exploiting separability of features from different views [139] and training a linear SVM classifier based on the averaged gait image [140]. Cao et al. [141] introduced a part-based gender recognition algorithm using patch features for modelling different body parts, which could recognize the gender from either a single frontal or back view image with the accuracy of 75.0% and is robust to tolerate small misalignment errors. Recently, Hu et al. [142] integrated shape appearance and temporal dynamics of both genders into a sequential model called mixed conditional random field (MCRF). By fusion of shape descriptors and stance indexes, the MCRF is constructed in coordination with intra- and inter-gender temporary Markov properties. Their results showed the superior performance of the MCRF over HMMs and separately trained conditional random field. A new face-based gender recognition technique has been proposed by Chen and Hsieh which shows strong gender recognition capabilities [143].
1.4.6 Pedestrian detection
Pedestrian detection is another important application of human detection. Viola et al. [144] described a pedestrian detection system that integrates image intensity information with motion information. Their detector was built over two consecutive frames of a video sequence and was based on motion direction filters, motion shear filters, motion magnitude filters and appearance filters. Their system detected pedestrians from a variety of viewpoints with a low false positive rate using multiple classifiers with cascade architecture. A pedestrian could also be detected by extracting regions of interest (ROI) from an image and then sending it to a classification module for detection. However, ROIs must fulfil the pedestrian size constraints, i.e. the aspect ratio, size and position, to be considered to contain a pedestrian [145]. Chen [146] proposed the orientation filter-enhanced detection technique based on the combination of AdaBoost learning with a local histogram's features which shows better performance and robustness.
1.4.7 Fall detection for elderly people
Automatic detection of a fall for elderly people is one of the major applications of human detection in surveillance videos. Nasution and Emmanuel [147] used the projection histograms of segmented human body silhouette as the main feature vector posture classification and used the speed of fall to differentiate real fall incident and an event where a person is simply lying without falling. Thome and Miguet [148] proposed a multi-view (two-camera) approach to address occlusion and used a layered HMM for motion modelling where the hierarchical architecture decoupled the motion analysis into different temporal granularity levels, which made the algorithm able to detect very sudden changes.
1.5 Discussion
A significant amount of work has been done with a view to detect human beings in a surveillance video. However the low-resolution images from the surveillance cameras always make this work challenging. Most of the object detection methods rely on known operation environments. The model adaptation speed based on observed scene statistics could be improved in the future for faster adaptation of changed background and better persistency. However, occlusion is a major problem for background segmentation technique. Optical flow and spatio-temporal filter techniques address this issue to some extent where the object of interest is occluded by a fixed object, but it is always difficult to detect an object in motion which is occluded by objects with similar shape and motion. One solution could be constructing a 3D image for a 3D system using volume information obtained from multiple cameras.
From the machine vision perspective, it is hard to distinguish an object as a human due to its large number of possible appearances [102]. Moreover, the human motion is not always periodic, but a combination of features could be useful in identifying humans. Interesting progress is being made using a local-based approach [149] for human detection. Future models based on LBP and HOGs might have several benefits over other descriptor methods as they work on localized parts of the image and hence are capable of addressing occlusion problems.
2 Conclusions
Detecting human beings accurately in a surveillance video is one of the major topics of vision research due to its wide range of applications. It is challenging to process the image obtained from a surveillance video as it has low resolution. A review of the available detection techniques is presented. The detection process occurs in two steps: object detection and object classification. In this paper, all available object detection techniques are categorized into background subtraction, optical flow and spatio-temporal filter methods. The object classification techniques are categorized into shape-based, motion-based and texture-based methods. The characteristics of the benchmark datasets are presented, and major applications of human detection in surveillance video are reviewed.
At the end of this paper, a discussion is made to point the future work needed to improve the human detection process in surveillance videos. These include exploiting a multi-view approach and adopting an improved model based on localized parts of the image.
References
Sulman N, Sanocki T, Goldgof D, Kasturi R: How effective is human video surveillance performance? In 19th International Conference on Pattern Recognition, (ICPR 2008). Piscataway: IEEE; 2008:1-3.
Stauffer C, Grimson W: Adaptive background mixture models for real-time tracking. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR 1999). Piscataway: IEEE; 1999:246-252.
Tian YL, Feris RS, Liu H, Hampapur A, Sun M-T: Robust detection of abandoned and removed objects in complex surveillance videos. Syst. Man Cybern. Part C Appl. Rev. IEEE Trans. 2011, 41(5):565-576.
Lee DS: Effective Gaussian mixture learning for video background subtraction. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27(5):827-835.
Shimada A, Arita D: Dynamic control of adaptive mixture-of-Gaussians background model. In IEEE International Conference on Video and Signal Based Surveillance (AVSS'06). Piscataway: IEEE; 2006:5.
Wang J, Bebis G, Miller R: Robust video-based surveillance by integrating target detection with tracking. In IEEE Computer Vision and Pattern Recognition Workshop (CVPRW '06). Piscataway: IEEE; 2006:137.
Ridder C, Munkelt O, Kirchner H: Adaptive Background Estimation and Foreground Detection Using Kalman-Filtering. In Recent Advances in Mechatronics. ICRAM 95: Proc. Int'l Conf; 1995:193-199.
Stenger B, Ramesh V, Paragios N, Coetzee F, Buhmann JM: Topology free hidden Markov models: application to background modeling. In IEEE International Conference on Computer Vision (ICCV 2001). Piscataway: IEEE; 2001:294-301.
Jabri S, Duric Z, Wechsler H, Rosenfeld A: Detection and location of people in video images using adaptive fusion of color and edge information. In 15th International Conference on Pattern Recognition (ICPR2000). Piscataway: IEEE; 2000:627-630.
Zhang W, Zhong X, Xu FY: Detection of moving cast shadows using image orthogonal transform. In 18th International Conference on Pattern Recognition (ICPR'06). Piscataway: IEEE; 2006:626-629.
Heikkilä M, Pietäikinen M: A texture-based method for modeling the background and detecting moving objects. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28: 657-662.
Kim W, Kim C: Background subtraction for dynamic texture scenes using fuzzy color histograms. Signal Process. Lett. IEEE 2012, 19(3):127-130.
Elgammal A, Harwood D, Davis L: Non-parametric model for background subtraction. In 6th European Conference on Computer Vision - Part II (ECCV '00). London: Springer; 2000:751-767.
Elgammal A, Duraiswami R, Davis L: Efficient kernel density estimation using the fast Gauss transform with applications to color modeling and tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25: 1499. 10.1109/TPAMI.2003.1240123
Han B, Comaniciu D, Davis L: Sequential kernel density approximation through mode propagation: Applications to background modeling. In Asian Conference on Computer Vision. Jeju Island: Korea; 2004.
Li L, Huang W, Gu IY-H, Tian Q: Statistical modeling of complex backgrounds for foreground object detection. IEEE Trans. Image Process. 2004, 13: 1459-1472. 10.1109/TIP.2004.836169
Lanza A: Background subtraction by non-parametric probabilistic clustering. In 8th IEEE International Conference on Advanced Video and Signal-Based Surveillance. Piscataway: IEEE; 2011:243-248.
Candamo J, Shreve M, Goldgof DB, Sapper DB, Kasturi R: Understanding transit scenes: A survey on human behavior-recognition algorithms. IEEE Trans. Intell. Transp. Syst. 2010, 11(1):206-224.
Cheng F-C, Huang S-C, Ruan S-J: Scene analysis for object detection in advanced surveillance systems using Laplacian distribution model. Syst. Man Cybern. Part C Appl. Rev. IEEE Trans. 2011, 41(5):589-598.
Tsai D-M, Lai S-C: Independent component analysis-based background subtraction for indoor surveillance. IEEE Trans. Image Process. 2009, 18(1):158-167.
Ko T, Soatto S, Estrin D: Warping background subtraction. In 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2010). Piscataway: IEEE; 2010:1331-1338.
Chen S, Zhang J, Li Y, Zhang J: A hierarchical model incorporating segmented regions and pixel descriptors for video background subtraction. IEEE Trans. Ind. Inform. 2012, 8(1):118-127.
Xiaofei J, Honghai L: Advances in view-invariant human motion analysis: a review. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 40(1):13-24.
Barren JL, Fleet DJ, Beauchemin SS, Burkitt TA: Performance of optical flow techniques. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR ‘92). Piscataway: IEEE; 1992:236-242.
Jeon H, Jeong J, Bang J, Hwang C: The efficient features for tracking. In 20th IEEE International Conference on Tools with Artificial Intelligence, 2008 (ICTAI '08). Piscataway: IEEE; 2008:241-244.
Efros A, Berg A, Mori G, Malik J: Recognizing action at a distance. In Ninth IEEE International Conference on Computer Vision (ICCV 2003). Piscataway: IEEE; 2003:726-733.
Zhong H, Shi J, Visontai M: Detecting unusual activity in video. In 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2004). Piscataway: IEEE; 2004:819-826.
Laptev I: On space-time interest points. Int. J. Comput. Vis. 2005, 64(2–3):107-123.
Dollár P, Rabaud V, Cottrell G, Belongie S: Behavior recognition via sparse spatio-temporal features. In 2nd IEEE Joint International Workshop Visual Surveillance and Performance Evaluation of Tracking Surveillance. Piscataway: IEEE; 2005:65-72.
Niyogi SA, Adelson EH: Analyzing and recognizing walking figures in XYT. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition 1994 (CVPR '94). Piscataway: IEEE; 1994:469-474.
Niyogi SA, Adelson EH: Analyzing gait with spatio-temporal surface. In 1994 IEEE Workshop on Motion of Non-Rigid and Articulated Objects. Piscataway: IEEE; 1994:64-69.
BenAbdelkader C, Cutler R, Nanda H, Davis L: EigenGait: motion-based recognition of people using image self-similarity. Third International Conference, AVBPA 2001 Halmstad, Sweden, 6–8 June 2001. Lecture notes in Computer Science, vol. 2091. In Audio- and Video-Based Biometric Person Authentication. Edited by: Bigun J, Smeraldi F. Heidelberg: Springer; 2001:312-317.
Kale A, Rajagopalan A, Cuntoor N, Kruger V: Gait-based recognition of humans using continuous HMMs. In 5th IEEE International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE; 2002:336-341.
BenAbdelkader C, Culter R, Davis L: Motion-based recognition of people in eigengait space. In 5th IEEE International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE; 2002:267-274.
Collins R, Gross R, Shi J: Silhouette-based human identification from body shape and gait. In 5th IEEE International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE; 2002:366-371.
Wang L, Ning HZ, Hu WM: Gait recognition based on procrustes statistical shape analysis. In 2002 International Conference on Image Processing (ICIP2002). Piscataway: IEEE; 2002:433-436.
Piroddi R, Vlachos T: A simple framework for spatio-temporal video segmentation and delayering using dense motion fields. IEEE Signal Process. Lett. 2006, 13(7):421.
Wang L, Geng X, Leckie C, Kotagiri R: Moving shape dynamics: a signal processing perspective. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2008). Piscataway: IEEE; 2008:1-8.
Singh M, Basu A, Mandal MK: Human activity recognition based on silhouette directionality. IEEE Trans. Circuits Syst. Video Technol. 2008, 18(9):1280-1292.
Lin Z, Davis LS: Shape-based human detection and segmentation via hierarchical part-template matching. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32(4):604-618.
Wu B, Nevatia R: Detecting and tracking of multiple, partially occluded humans by Bayesian combination of edgelet based part detectors. Int. J. Comput. Vision (IJCV) 2007, 75(2):247-266. 10.1007/s11263-006-0027-7
Gavrilla DM: A Bayesian, exemplar-based approach to hierarchical shape matching. PAMI 2007, 29(8):1408-1421.
Eishita FZ, Rahman A, Azad SA, Rahman A: Occlusion handling in object detection. Multidisciplinary computational intelligence techniques: applications in business, engineering, and medicine. IGI Global. 2013.
Dalal N, Triggs B: Histograms of oriented gradients for human detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2005). Piscataway: IEEE; 2005:886-893.
Schuldt C, Laptev I, Caputo B: Recognizing human actions: a local SVM approach. In 17th International Conference on Pattern Recognition (ICPR 2004). Piscataway: IEEE; 2004:32-36.
Blank M, Gorelick L, Shechtman E, Irani M, Basri R, Blank M, Gorelick L, Shechtman E, Irani M, Basri R: Actions as space-time shapes. In Tenth IEEE International Conference on Computer Vision (ICCV ’05). Piscataway: IEEE; 2005:1395-1402.
Weinland D, Ronfard R, Boyer E: Free viewpoint action recognition using motion history volumes. Comput. Vision Image Understanding (CVIU) 2006, 104(2–3):249-257.
PETS: Performance Evaluation of Tracking and Surveillance. . Accessed on 17 Nov 2013 http://www.cvg.rdg.ac.uk/slides/pets.html
PETS 2000.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
PETS 2001.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
PETS 2002.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
PETS ICVS 2013.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
VS PETS 2013.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
Fisher R: CAVIAR test case scenarios. 2007.http://groups.inf.ed.ac.uk/vision/CAVIAR/CAVIARDATA1/ . Accessed 17 Nov 2013
PETS 2006.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
PETS 2007.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
PETS 2009.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
PETS 2010.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
PETS 2012.http://ftp.pets.rdg.ac.uk . Accessed 17 Nov 2013
CBSR, CASIA Gait Database 2005.http://www.cbsr.ia.ac.cn/english/Gait%20Databases.asp . Accessed 17 Nov 2013
Turaga P, Chellappa R, Subramanian VS, Udrea O: Machine recognition of human activities: a survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18(11):1473-1488.
Lavee G, Rivlin E, Rudzsky M: Understanding video events: a survey of methods for automatic interpretation of semantic occurrences in video. IEEE Trans. Syst., Man, Cybern. C 2009, 39(5):489-504.
Hu W, Tan T, Wang L, Maybank S: A survey on visual surveillance of object motion and behaviors. IEEE Trans. Syst., Man, Cybern. Part C, Appl. Rev. 2004, 34(3):334-352. 10.1109/TSMCC.2004.829274
Lin H-H, Liu T-L, Chuang J-H: Learning a scene background model via classification. IEEE Trans. Signal Process. 2009, 57(5):1641-1654.
Du-Ming T, Shia-Chih L: Independent component analysis-based background subtraction for indoor surveillance. IEEE Trans. Image Process. 2009, 18(1):158-167.
Chen Y-T, Chu-Song C, Chun-Rong H, Yi-Ping H: Efficient hierarchical method for background subtraction. Pattern Recognit. 2007, 40: 2706-2715. 10.1016/j.patcog.2006.11.023
Quan S, Zhixing T, Songchen H: Hierarchical CodeBook for background subtraction in MRF. Infrared Phys. Technol. 2013, 61: 259-264.
Kim K, Chalidabhongse TH, Harwood D, Davis L: Real-time foreground–background segmentation using codebook model. Real-time Imaging 2005, 11(3):172-185. 10.1016/j.rti.2004.12.004
Lipton AJ, Fujiyoshi H, Patil RS: Moving target classification and tracking from real-time video. In Fourth IEEE Workshop on Applications of Computer Vision (WACV'98). Piscataway: IEEE; 1998:8-14.
Lai H-E, Lin C-Y, Chen M-K, Kang L-W, Yeh C-H: Moving objects detection based on hysteresis thresholding. Adv. Intell. Syst. Appl. 2013, 2: 289-298.
Haque M, Murshed M, Paul M: A hybrid object detection technique from dynamic background using Gaussian mixture models. In IEEE 10th Workshop on Multimedia Signal Processing. Piscataway: IEEE; 2008:915-920.
Paul M, Evans C, Murshed M: Disparity-adjusted 3D multi-view video coding with dynamic background modelling. In IEEE International Conference on Image Processing (ICIP 2013). Piscataway: IEEE; 2013.
Paul M, Murshed M: Video coding focusing on block partitioning and occlusions. IEEE Trans. Image Process. 2010, 19(3):691-701.
Paul M, Lin W, Lau CT, Lee BS: Explore and model better I-frame for video coding. IEEE Trans. Circuits Syst. Video Technol. 2011, 21: 1242-1254.
Paul M, Lin W, Lau CT, Lee BS: Video coding with dynamic background. EURASIP J. Adv. Signal Process. 2013. doi:10.1186/1687-6180-2013-11
Sobral A: BGSLibrary: an OpenCV C++ background subtraction library. 2010.https://code.google.com/p/bgslibrary/ . Accessed 17 Nov 2013
Cucchiara R, Grana C, Piccardi M, Prati A: Detecting moving objects, ghosts, and shadows in video streams. Pattern Anal. Mach. Intell. IEEE Trans. 2003, 25(10):1337-1342. 10.1109/TPAMI.2003.1233909
Toyama K, Krumm J, Brumitt B, Meyers B: Wallflower: principles and practice of background maintenance. In Seventh IEEE International Conference on Computer Vision (ICCV 1999). Piscataway: IEEE; 1999:255-261.
Krumm J: Test images for Wallflower paper. 1999.http://research.microsoft.com/en-us/um/people/jckrumm/wallflower/testimages.htm . Accessed 17 Nov 2013
Parks DH, Fels SS: Evaluation of background subtraction algorithms with post-processing. In IEEE Fifth International Conference on Advanced Video and Signal Based Surveillance (AVSS '08). Piscataway: IEEE; 2008:192-199.
Cheung S-CS, Kamath C: Robust techniques for background subtraction in urban traffic video. SPIE04 2004, 5308: 881-892.
Cheung S-CS, Kamath C: Robust background subtraction with foreground validation for urban traffic video. JASP05 2005, 14: 2330-2340.
Wang T, Gong S, Liu C, Ji Y: An improved warping background subtraction model for moving object detection. In 2011 International Conference on Transportation, Mechanical, and Electrical Engineering (TMEE). Piscataway: IEEE; 2011:668-672.
Chalidabhongse TH, Kim K, Harwood D, Davis L: A perturbation method for evaluating background subtraction algorithms. In Joint IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance. Piscataway: IEEE; 2011:11-12.
Huang P, Hilton A, Starck J: Shape similarity for 3D video sequences of people. Int. J. Comput. Vision 2010, 89(2–3):362-381.
Bobick AF, Davis JW: The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23(3):257-267. 10.1109/34.910878
Cutler R, Davis LS: Robust real-time periodic motion detection, analysis, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22(8):781-796. 10.1109/34.868681
Ojala T, Pietikinen M, Maenpaa T: Multi-resolution grayscale and rotation invariant texture classification with local binary patterns. PAMI 2002, 24(7):971-987. 10.1109/TPAMI.2002.1017623
Zhang L, Li SZ, Yuan X, Xiang S: Real-time object classification in video surveillance based on appearance learning. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2007 (CVPR 2007). Piscataway: IEEE; 2007:1-8.
Zhu Q, Avidan S, Yeh M-C, Cheng K-T: Fast human detection using a cascade of histograms of oriented gradients. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2006 (CVPR '06). Piscataway: IEEE; 2006:1491-1498.
Moctezuma D, Conde C, Diego IM, Cabello E: Person detection in surveillance environment with HoGG: Gabor filters and histogram of oriented gradient. In ICCV Workshops. Piscataway: IEEE; 2011:1793-1800.
Dalal N, Triggs B, Schmid C: Human detection using oriented histograms of flow and appearance. In Computer Vision–ECCV. Heidelberg: Springer; 2006:428-441.
Wu B, Nevatia R: Detection of multiple, partially occluded humans in a single image by Bayesian combination of edgelet part detectors. In IEEE International Conference on Computer Vision (ICCV 2005). Piscataway: IEEE; 2005:90-97.
Mikolajczyk K, Schmid C, Zisserman A: Human detection based on a probabilistic assembly of robust part detectors. In Computer Vision-ECCV 2004. Heidelberg: Springer; 2004:69-82.
Papageorgiou CP, Oren M, Poggio T: A general framework for object detection. In IEEE Sixth International Conference on Computer Vision. Piscataway: IEEE; 1998:555-562.
Zhang S, McCullagh P, Nugent C, Zheng H: A theoretic algorithm for fall and motionless detection. In IEEE Third International Conference on Pervasive Computing Technologies for Healthcare. Piscataway: IEEE; 2009:1-6.
Curone D, Bertolotti GM, Cristiani A, Secco EL, Magenes G: A real-time and self-calibrating algorithm based on triaxial accelerometer signals for the detection of human posture and activity. IEEE Trans. Info. Technol. Biomed. 2010, 14: 1098-1105.
Conde C, Moctezuma D, Martín De Diego I, Cabello E: HoGG: Gabor and HoG-based human detection for surveillance in non-controlled environments. Neurocomputing 2013, 100: 19-30.
Marszalek M, Laptev I, Schmid C: Actions in context. In Conference on Computer Vision and Pattern Recognition (CVPR’09). Piscataway: IEEE; 2009:2929-2936.
Rodriguez MD, Ahmed J, Shah M: Action MACH: a spatiotemporal maximum average correlation height filter for action recognition. In Conference on Computer Vision and Pattern Recognition (CVPR’08). Piscataway: IEEE; 2008:1-8.
Bobick AF, Ivanov YA: Action recognition using probabilistic parsing. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR’08). Piscataway: IEEE; 2008:196-202.
Poppe R: A survey on vision-based human action recognition. Image Vision Comput. 2010, 28: 976-990. 10.1016/j.imavis.2009.11.014
Ran Y, Zheng Q, Chellappa R, Strat TM: Applications of a simple characterization of human gait in surveillance. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40(4):1009-1020.
Eshel R, Moses Y: Homography based multiple camera detection and tracking of people in a dense crowd. In Conference on Computer Vision and Pattern Recognition (CVPR’08). Piscataway: IEEE; 2008:1-8.
Yao J, Odobez JM: Fast human detection from joint appearance and foreground feature subset covariances. Comput. Vision Image Understanding 2011, 115: 1414-1426. 10.1016/j.cviu.2011.06.002
Sim C-H, Rajmadhan E, Ranganath S: Detecting people in dense crowds. Mach. Vision Appl. 2012, 23: 243-253. 10.1007/s00138-010-0280-1
Chen D-Y, Su C-W, Zeng Y-C, Sun S-W, Lai W-R, Mark Liao H-Y: An online people counting system for electronic advertising machines. In IEEE International Conference on Multimedia and Expo (ICME 2009). Piscataway: IEEE; 2009:1262-1265.
Su C-W, Liao H-YM, Tyan H-R: A vision-based people counting approach based on the symmetry measure. In IEEE International Symposium on Circuits and Systems (ISCAS 2009). Piscataway: IEEE; 2009:2617-2620.
Lin TY, Lin YY, Weng MF, Wang YCF, Hsu YF, Liao HYM: Cross camera people counting with perspective estimation and occlusion handling. In 2011 IEEE International Workshop on Information Forensics and Security (WIFS 2011). Piscataway: IEEE; 2011:1-6.
Weng M-F, Lin Y-Y, Tang NC, Mark Liao H-Y: Visual knowledge transfer among multiple cameras for people counting with occlusion handling. In 20th ACM international conference on Multimedia Pages. New York: ACM; 2012:439-448.
Chen D-Y, Huang P-C: Motion-based unusual event detection in human crowds. J. Visual Commun. Image Represent. 2011, 22(2):178-186. 10.1016/j.jvcir.2010.12.004
Duan-Yu C, Po-Chung H: Visual-based human crowds behavior analysis based on graph modeling and matching. Sens. J. IEEE 2013, 13(6):2129-2138.
Samal A, Iyengar PA: Automatic recognition and analysis of human faces and facial expressions: a survey. Pattern Recognit. 1992, 25(1):65-77. 10.1016/0031-3203(92)90007-6
Chellappa R, Wilson CL, Sirohey S: Human and machine recognition of faces: a survey. Proc. IEEE 1995, 83: 705-741. 10.1109/5.381842
Swets D, Weng J: Discriminant analysis and eigenspace partition tree for face and object recognition from views. In Second International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE; 1996:182-187.
Moghaddam B, Wahid W, Pentland A: Beyond eigenfaces: probabilistic matching for face recognition. In Third IEEE International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE; 1998:30-35.
Guo G, Li S, Chan K: Face recognition by support vector machines. In Fourth IEEE International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE; 2000:196-201.
Rowley H, Baluja S, Kanade T: Neural network based face detection. IEEE Trans. Pattern Anal. Machine Intell. 1998, 20: 23-38. 10.1109/34.655647
Garcia C, Tziritas G: Face detection using quantified skin color regions merging and wavelet packet analysis. IEEE Trans. Multimedia 1999, 1: 264-277. 10.1109/6046.784465
Menser B, Wien M: Segmentation and tracking of facial regions in color image sequences. Proc. SPIE Visual Communications and Image Processing 2000, 4067: 731-740.
Saber A, Tekalp AM: Frontal-view face detection and facial feature extraction using color, shape and symmetry based cost functions. Pattern Recognit. Lett. 1998, 19(8):669-680. 10.1016/S0167-8655(98)00044-0
Xu G, Sugimoto T: Rits Eye: a software-based system for real-time face detection and tracking using pan-tilt-zoom controllable camera. In Fourteenth International Conference on Pattern Recognition (ICPR 1998). Piscataway: IEEE; 1998:1194-1197.
Cunado D, Nixon MS, Carter JN: Using gait as a biometric: via phase-weighted magnitude spectra. In First International Conference on Audio- and Video-Based Biometric Person Authentication. London: Springer; 1997:95-102.
Cunado D, Nixon MS, Carter JN: Extracting a human gait model for use as a biometric. Proc. Inst. Elect. Eng. (IEE) Colloq. Computer Vision for Virtual Human Modelling 1998, 11: 1-4.
Nash JM, Carter JN, Nixon MS: Dynamic feature extraction via the velocity Hough transform. Pattern Recognit. Lett. 1997, 18(10):1035-1047. 10.1016/S0167-8655(97)00128-1
Yam CY, Nixon MS, Carter JN: Extended model-based automatic gait recognition of walking and running. In International Conference on Audio- and Video-Based Biometric Person Authentication. Heidelberg: Springer; 2001:278-283.
Yam CY, Nixon MS, Carter JN: Gait recognition by walking and running: a model-based approach. In Fifth Asian Conference Computer Vision (ACCV2002). Melbourne: ; 2002.
Cunado D, Nash J, Nixon MS, Carter JN: Gait extraction and description by evidence gathering. In Second International Conference on Audio- and Video-Based Biometric Person Authentication (AVBPA99). Washington, DC: ; 1999.
Tanawongsuwan R, Bobick A: Gait recognition from time-normalized joint-angle trajectories in the walking plane. In 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001). Piscataway: IEEE; 2011:726-731.
Murase R: Sakai, Moving object recognition in eigenspace representation: gait analysis and lip reading. Pattern Recognit. Lett. 1996, 17(2):155-162. 10.1016/0167-8655(95)00109-3
Huang PS, Harris CJ, Nixon MS: Human gait recognition in canonical space using temporal templates. Proc. Inst. Elect. Eng. (IEE) Vision Image and. Signal Process. 1999, 146(2):93-100.
Leibe B, Seemann E, Schiele B: Pedestrian detection in crowded scenes. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005). Piscataway: IEEE; 2005:878-885.
Andriluka M, Roth S, Schiele B: People-tracking-by-detection and people-detection-by-tracking. In IEEE Conference on Computer Vision and Pattern Recognition, 2008. Piscataway: IEEE; 2008:1-8.
Yilmaz A, Javed O, Shah M: Object tracking: a survey. ACM Comput. Surv. 2006, 38: 4. 10.1145/1132956.1132957
Lu W-L, Ting J-A, Murphy KP, Little JJ: Identifying players in broadcast sports videos using conditional random fields. In IEEE Conference on Computer Vision and Pattern Recognition, 2008. Piscataway: IEEE; 2008:3249-3256.
Sun S-W, Cheng W-H, Hung Y-L, Fan I, Liu C, Hung J, Lin C-K, Mark Liao H-Y: Who's who in a sports video? An individual level sports video indexing system. In 2012 IEEE International Conference on Multimedia and Expo (ICME). Piscataway: IEEE; 2012:937-942.
Lu W-L, Ting J-A, Little JJ, Murphy KP: Learning to track and identify players from broadcast sports videos. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35(7):1704-1716.
Huang G, Wang Y: Gender classification based on fusion of multi-view gait sequences. In 8th Asian Conference on Computer Vision (ACCV'07). Heidelberg: Springer; 2007:462-471.
Zhang D, Wang Y: Investigating the separability of features from different views for gait based gender classification. In 19th IEEE International Conference on Pattern Recognition. Piscataway: IEEE; 2008:1-4.
Li X, Maybank SJ, Yan S: Gait components and their application to gender recognition. IEEE Trans. Syst. Man Cybern. 2008, 38(2):145-154.
Cao L, Dikmen M, Fu Y, Huang TS: Gender recognition from body. In 16th ACM International Conference on Multimedia (MM '08). Yew York: ACM; 2008:725-728.
Hu M, Wang Y, Zhang Z, Zhang D: Gait-based gender classification using mixed conditional random field. Syst. Man Cybern Part B Cybern. IEEE Trans. 2011, 41(5):1429-1439.
Chen D-Y, Hsieh P-C: Face-based gender recognition using compressive sensing. In IEEE International Symposium on Intelligent Signal Processing and Communications Systems (ISPACS). Piscataway: IEEE; 2012:157-161.
Viola P, Jones M, Snow D: Detecting pedestrians using patterns of motion and appearance. Int. J. Comput. Vis. 2005, 63(2):153-161. 10.1007/s11263-005-6644-8
Gerónimo D, Sappa A, López A, Ponsa D: Adaptive image sampling and windows classification for on-board pedestrian detection. In Fifth International Conference on Computer Vision Systems. Bielefeld: Bielefeld University; 2007.
Chen D-Y: Orientation filter enhanced pedestrian detection. Electron. Lett. 2010, 46(20):1377-1379. 10.1049/el.2010.8448
Nasution AH, Emmanuel S: Intelligent video surveillance for monitoring elderly in home environments. In IEEE 9th Workshop on Multimedia Signal Processing (MMSP 2007). Piscataway: IEEE; 2007:203-206.
Thome N, Miguet S: A real-time, multiview fall detection system: a LHMM-based approach. TCSVT 2008, 18(11):1522-1532.
Ta A, Wolf C, Lavoue G, Baskurt A, Jolion J: Pairwise features for human action recognition. In 20th International Conference on Pattern Recognition (ICPR 2010). Piscataway: IEEE; 2010:3224-3227.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Paul, M., Haque, S.M.E. & Chakraborty, S. Human detection in surveillance videos and its applications - a review. EURASIP J. Adv. Signal Process. 2013, 176 (2013). https://doi.org/10.1186/1687-6180-2013-176
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-6180-2013-176