
Abstract
This article presents an algorithm for moving object detection (MOD) in robot visual simultaneous localization and mapping (SLAM). This MOD algorithm is designed based on the defining epipolar constraint for the corresponding feature points on image plane. An essential matrix obtained using the state estimator is utilized to represent the epipolar constraint. Meanwhile, the method of speeded-up robust feature (SURF) is employed in the algorithm to provide a robust detection for image features as well as a better description of landmarks and of moving objects in visual SLAM system. Experiments are carried out on a hand-held monocular camera to verify the performances of the proposed algorithm. The results show that the integration of MOD and SURF is efficient for robot navigating in dynamic environments.
Similar content being viewed by others


1. Introduction
In recent years, more and more researchers solve the simultaneous localization and mapping (SLAM) as well as the moving object tracking (MOT) problems concurrently. Wang et al. [1] developed a consistency-based moving object detector and provided a framework to solve the SLAMMOT problems. Bibby and Reid [2] proposed a method that combines sliding window optimization and least-squares together with expectation maximization to do reversible model selection and data association that allows dynamic objects to be included directly into the SLAM estimation. Zhao et al. [3] used GPS data and control inputs to achieve global consistency in dynamic environments. There are many advantages to cope with SLAM and MOT problems simultaneously: for example, mobile robots might navigate in a dynamic environment crowded with moving objects. In this case the SLAM could be corrupted with the inclusion of moving entities if the information of moving objects is not taken account. Furthermore, the robustness of robot localization and mapping algorithms can be improved if the moving objects are discriminated from the stationary objects in the environment.
Using cameras to implement SLAM is the current trend because of their light weight and low-cost features, as well as containing rich appearance and texture information of the surroundings. However, it is still a difficult problem in visual SLAM to discriminate the moving objects from the stationary landmarks in dynamic environments. To deal with this problem, we propose the moving object detection (MOD) algorithm based on the epipolar constraint for the corresponding feature points on image plane. Given an estimated essential matrix it is possible to investigate whether a set of corresponding image points satisfy the defining epipolar constraint in image plane. Therefore, the epipolar constraint can be utilized to distinguish the moving objects from the stationary landmarks in dynamic environments.
For visual SLAM systems, the features in the environment are detected and extracted by analyzing the image taken by the robot vision, and then the data association between the extracted features and the landmarks in the map is investigated. Many researchers [4, 5] employed the concept by Harris and Stephens [6] to extract apparent corner features from one image and tracked these point features in the consecutive image. The descriptors of the Harris corner features are rectangle image patches. When the camera translates and rotates, the scale and orientation of the image patches will be changed. The detection and matching of Harris corner might fail in this case, unless the variances in scale and orientation of the image patches are recovered. Instead of detecting corner features, some works [7, 8] detect the features by using the scale-invariant feature transform (SIFT) method [9] which provides a robust image feature detector. The unique properties of image features extracted by SIFT method are further described by using a high-dimensional description vector [9]. However, the feature extraction by SIFT requires more computational cost than that by Harris's method [6]. To improve the computational speed, Bay et al. [10] introduced the concept of integral images and box filter to detect and extract the scale-invariant features, which they dubbed speeded-up robust features (SURF). The extracted SURF must be matched with the landmarks in the map of a SLAM system. The nearest-neighbor (NN) searching method [11] can be utilized to match high-dimensional data sets of description vectors.
In this article, an online SLAM system with a moving object detector is developed based on the epipolar constraint for the corresponding feature points on image plane. The corresponding image features are obtained using the SURF method [10] and the epipolar constraint is calculated using an estimated essential matrix. Moving object information is detected in image plane and integrated into the MOT process such that the robustness of SLAM algorithm can be considerably improved, particularly in highly dynamic environments where surroundings of robots are dominated by non-stationary objects. The contributions in this article are twofold. First, we develop an algorithm to solve the problems for MOD in image plane, and then the algorithm is integrated with the robot SLAM to improve the robustness of state estimation and mapping processes. Second, the improved SLAM system is implemented on a hand-held monocular camera which can be utilized as the sensor system for robot navigation in dynamic environments.
The SLAM problem with monocular vision will be briefly introduced in Section 2. In Section 3, the proposed algorithm of MOD is explained in detail. Some examples to verify the performance of the data association algorithm are described in Section 4. Section 5 is the concluding remarks.
2. SLAM with a free-moving monocular vision
SLAM is a target tracking problem for the robot system during navigating in the environment [12]. The targets to be tracked include the state of the robot itself as well as of the landmarks and moving objects in the environment. The state sequence of the SLAM system at time step k can be expressed as
where x k is the state vector; u k is the input; w k is the process noise. The objective of the tracking problem is to recursively estimate the state x k of the target according to the measurement z k at time step k,
where v k is the measurement noise. A hand-held monocular vision, as shown in Figure 1, is utilized in this article as the only sensing device for the measurement in SLAM system. We treat this hand-held vision sensor as a free-moving robot system with unknown inputs. The states of the system are estimated by solving the recursive SLAM problem using the extended Kalman filter (EKF) [12]

A free-moving monocular vision sensor.
where xk|k-1and xk|krepresent the predicted and estimated state vectors, respectively; K k is Kalman gain matrix; P denotes the covariance matrix, respectively; A k and W k are the Jacobian matrices of the state equation f with respect to the state vector x k and the noise variable w k , respectively; H k and V k are the Jacobian matrices of the measurement g with respect to the state vector x k and the noise variable v k , respectively.
2.1. Motion model
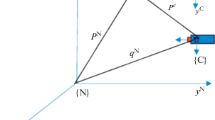
Two coordinate systems are set at the world frame {W} and the camera frame {C}, as shown in Figure 2. The state vector of the SLAM system with MOT in Equation (1) is arranged as

Coordinate setting for the camera system.
x C is a 12 × 1 state vector of the camera including the three-dimensional vectors of position r, rotational angle ϕ, linear velocity v, and angular velocity ω, all in world frame; m i is the three-dimensional (3D) coordinates of i th stationary landmark in world frame; O j is the state vector of j th moving object; n and l are the number of the landmarks and of the moving objects, respectively.
The motion of the hand-held camera is presumed to be at constant velocity (CV), and the acceleration is caused by an impulse noise from the external force. Therefore, the state x C of the camera with a CV motion model at time step k is expressed as:
where w v and w ω are linear and angular velocity noise caused by acceleration, respectively. The state of i th stationary landmark at time step k is represented by 3D coordinates in space,
In the motion model of MOT, the targets to be tracked include the state and motion mode of the moving object in the environment. The state of the MOT system at time step k can be expressed as
where o jk and s jk are the state and motion mode of j th moving object, respectively. The MOT problem can be expressed as a probability density function (pdf) in Bayesian probability
where p(o k |s k ,z1:k) is state inference; z1:kis the set of measurements for time t = 1 to k; p(s k |z1:k) is the mode learning. The EKF-based interacting multiple model (IMM) estimator [13] can be utilized to estimate the motion mode of a moving object. The state is computed at time step k under each possible current model using r filters, with each filter using a different combination of the previous model-conditioned estimates. The mode Mj at time step k is assumed to be among the possible r modes
Given r motion models, the object state o k in Equation (7) is estimated. Instead of using the IMM estimator, a single CV model is utilized in the paper. That is, the moving objects are also presumed to move at a CV motion model. Their coordinates in 3D space are defined as
where p jk and v jk are the vectors of the position and linear velocity of j th moving object at time step k, respectively.
2.2. Vision sensor model
The measurement vector of the monocular vision system is expressed as
m is the number of the observed image features in current measurement. The perspective projection method [14] is employed to model the transformation from 3D space coordinate system to 2D image plane. For one observed image feature, the measurement is denoted as
where f u and f v are the focal lengths of the camera denoting the distance from the camera center to the image plane in u- and v-axis, respectively; (u0, v0) is the offset pixel vector of the pixel image plane; α C is the camera skew coefficient; is the ray vector of i th image feature in camera frame. The 3D coordinates of i th image feature or landmark in world frame, as shown in Figure 2, is given as
is the rotational matrix from world frame to camera frame, represented by using the elementary rotations [15],
where cϕ = cosϕ and sϕ = sinϕ; ϕ x , ϕ y and ϕ z are the corresponding rotational angles in world frame. We can utilize Equatoin (10) to calculate the ray vector of an image feature in camera frame. The coordinates of the feature in image plane are obtained by substituting Equations (10) and (11) into Equation (9) with α C = 0
Moreover, the elements of the Jacobian matrices H k and V k are determined by taking the derivative of z i with respect to the state x k and the measurement noise v k . The Jacobian matrices are obtained for the purpose of calculating the innovation covariance matrix in EKF estimation process [16].
2.3. Feature initialization
Because of the lack of one-dimensional range information in image, how to initialize features becomes an important topic. Some researchers have successfully solved this problem either in time-delayed method [16] or un-delayed method [17]. The un-delayed method will be utilized in this research. When an image feature is selected, the spatial coordinates of the image feature are calculated by employing the method of inverse depth parameterization [17]. Assume that there are m image features with 3D position vectors, y i , i = 1,...,m, which is described by the 6D state vector
indicates the estimated state of the camera when the feature was observed, as shown in Figure 2; is the estimated image depth of the feature; and are the longitude and latitude angles of the spherical coordinate system which locates at the camera center. To compute the longitude and latitude angles, a normalized vector in the direction of the ray vector is constructed by using the perspective project method:
Therefore, from Figure 2, the longitude and latitude angles of the spherical coordinate system can be obtained as
When image features are selected to be new landmarks or moving objects, the inverse depth parameterization vector in Equation (13) is assigned to be new augmented states in the EKF-based SLAM. Meanwhile, for each new state variable y i , the corresponding covariance matrix are initialized according to
where R i is the covariance of the measurement noise; σρ is the deviation of the estimated image depth. However, the inverse depth coordinates are 6D and computational costly. A switching criterion is established in reference [17] based on a linearity index L d . If L d > Ld 0, the inverse depth parameterization in Equation (13) is utilized as the augmented states; where Ld 0is the threshold value of the index defined in [17]. On the other hand, if L d ≤ Ld 0, then the state vector in Equation (10) is chosen and modified as
where is the unit ray vector. In this case, the corresponding covariance matrix is rearranged as
Furthermore, for each new state variable υ i , the correspondent elements of the Jacobian matrix H k are modified as:
The derivative is taken at and v k = 0.
2.4. Speeded-up robust features (SURF)
The basic concept of a scale-invariant method is to detect image features by investigating the determinant of Hessian matrix H in scale space [18]. In order to speed up the detection of image features, Bay et al. [10] utilize integral images and box filters to process on the image instead of calculating the Hessian matrix, and then the determinant of Hessian matrix is approximated by
where D ij are the images filtered by the corresponding box filters; w is a weight constant. The interest points or features are extracted by examining the extreme value of determinant of Hessian matrix. Furthermore, the unique properties of the extracted SURF are described by using a 64-dimensional description vector as shown in Figure 3 [9, 19].

64-dimensional description vector for SURF.
2.5. Implementation of SLAM
The SLAM is implemented on the free-moving vision system by integrating the motion and sensor models, as well as the extraction of SURF. A flowchart for the developed SLAM system is depicted in Figure 4. The images are captured by the monocular camera and features are extracted using SURF method. In the SLAM flowchart, data association in between the landmarks in the database and the image features of the extracted SURF is carried out using the NN ratio matching strategy [9]. A map managerial tactic is designed to manage the newly extracted features and the bad features in the system. The details of the map management have been explained in previous article [19]. The properties of the newly extracted features are investigated and the moving objects will be discriminated from the stationary objects by using a proposed detection algorithm which will be described in next section. All the stationary landmarks and moving objects are included in the state vector. On the other hand, those features which are not continuously detected at each time step will be treated as bad features and erased from the state vector in Equation (4).

Flowchart of EKF-based visual SLAM.
3. Moving object detection and tracking
In the flowchart of Figure 4, the function block of MOD is designed based on the concept of the pixel coordinate constraint of a static object in image plane. An object in space is represented by the corresponding features in two consecutive images. The pixel coordinate constraint equation for these corresponding image features can be expressed as
where and are the homogenous normalized image coordinates of the corresponding features abstracted from two consecutive images, images 1 and 2, respectively. They are defined as
K C is the matrix of camera intrinsic parameters which can be obtained from Equation (9). Note that the image coordinates are defined in camera frame. The essential matrix E in Equation (24) is defined as [20]
where R is the rotation matrix and t is the translation vector of the camera frame with respect to world frame; [t]× is the matrix representation of the cross product with t. The rotation matrix and translation vector would be determined using EKF estimator. Therefore, the essential matrix E can be calculated accordingly. Usually, the pixel coordinate constraint in Equation (24) is utilized to estimate the state vector and according essential matrix. Given a set of corresponding image points, it is possible to estimate the state vector and the essential matrix which optimally satisfy the pixel coordinate constraint. The most straight-forward approach is to set up a total least squares problem, commonly known as the eight-point algorithm [21]. On the contrary in SLAM problem, the state vector and the essential matrix is obtained using the state estimator. We could further utilize the estimated state vector and the essential matrix to investigate whether a set of corresponding image points satisfy the pixel coordinate constraint in Equation (24). First, define the known quantities in Equation (24) as a constant vector
Equation (26) is further rearranged as an equation of the epipolar line constraint in image plane for two corresponding points [22], as shown in Figure 5

Epiploar plane of two camera views.
Equation (27) indicates that the pixel coordinate of the corresponding feature in second image will be constrained on the epipolar line.
Simulation of pixel constraint on the corresponding features for the cases of camera translation and rotation is carried out and depicted in Figure 6. Assume that the image feature of a static object in first image is located at (I x , I y ) = (80,60). In the first simulation, the camera translates 1 cm along x c -axis direction, the corresponding image feature in the second image must be restricted in the epipolar line 1, as shown in Figure 6. Similarly, if the camera translates 1 cm along y c - or z c -axis direction, the corresponding features in the second image must be located on the epipolar line 2 or 3, respectively. In the second simulation, the camera first moves 1 cm in x c -axis and then rotates ϕ x = 15° about x c -axis, the corresponding feature in second image must be located on the epipolar line 4, as shown in Figure 6. If the camera first moves 1 cm in x c -axis and then rotates ϕ y = 15° about y c -axis or ϕ z = 15° about z c -axis, the corresponding features in the second image must be located on the epipolar line 5 or 6, respectively.

Epipolar lines.
Motion and measurement noise is involved in the state estimation process. If the measurement of image points is subject to noise, which is the common case in any practical situation, it is not possible to find a corresponding feature point which satisfies the epipolar constraint exactly. That is, the corresponding feature point might not be constrained on the epipolar line because of the presence of noise. Define the distance D to represent the pixel deviation of the corresponding point from the epipolar line in image plane, as shown in Figure 7,

Deviation from the epipolar line.
D is utilized in this article to denote the pixel deviation from the epipolar line which is induced by the motion and measurement noise in state estimation process. Depending on how the noise related to each constraint is measured, it is possible to design a threshold value in Equation (28) which satisfies the epipolar constraint for a given set of corresponding image points. For example, the image feature of a static object in the first image is located at (I x , I y ) = (50,70) and then the camera moves 1 cm in z c -axis. If the corresponding image feature in the second image is constrained within a deviation is limited in a range, as shown in Figure 7, as varying from 1 to 320.
There are two situations that the pixel coordinate constraint in Equation (24) will result in trivial solutions. First, if the camera is motionless between two consecutive images, we can see from Equation (25) that the essential matrix becomes a zero matrix. Therefore, the object status could not be obtained by investigating the pixel coordinate constraint. In this case, we assume the camera being stationary in space and compute the pixel distance in between the corresponding features in two consecutive images to determine the object status. Second, if the image feature of a static object in the first image is located near the center of image plane (I x , I y ) = (160,120), the coefficients of the epipolar line obtained from Equation (26) are zero. Therefore, any point in the second image will satisfy the equation of the epipolar line in Equation (27). This situation is simulated and the result is depicted in Figure 8. In the simulation, the pixel coordinate in the first image I x varies from 0 to 320 and I y is fixed at 120. The corresponding feature in the second image is limited within the pixel coordinate constraint . We can see that the range of the corresponding is unlimited when (I x , I y ) is close to (160,120), as shown in Figure 8. In real applications, those features located in a small region near the center of the image plane need a special treatment because the epipolar line constraint is not valid in this situation.

Deviation from epipolar line.
4. Experimental results
In this section, the experimental works of the online SLAM with a moving object detector are implemented on a laptop computer running Microsoft Window XP. The laptop computer is Asus U5F with Intel Core 2 Duo T5500 (1.66 GHz), Mobile Intel i945GM chipset and 1 Gb DDR2. The free-moving monocular camera utilized in this work is Logitech C120 CMOS web-cam with 320 × 240-pixels resolution and USB 2.0 interface. The camera is calibrated using the Matlab tool provided by Bouquet [23]. The focal lengths are f u = 364.4 pixels and f v = 357.4 pixels. The offset pixels are u0 = 156.0 pixels and v0 = 112.1 pixels, respectively. We carried out three experiments including the SLAM task in a static environment, SLAM with MOT, and people detection and tracking.
4.1. SLAM in static environment
In this experiment, the camera is carried by a person to circle around a bookshelf (1.5 m × 2 m floor dim.) in our laboratory. The resultant map and the camera pose estimation are plotted in Figure 9. In this figure, the estimated states of the camera and landmarks are illustrated in a 3D plot. The ellipses in the figure indicate the uncertainty of the landmarks obtained from the extracted image features. The rectangular box represents the free-moving monocular camera and the solid line depicts the trajectory of the camera. More detail image frames of the experimental results are illustrated in Figures 10, 11, 12, 13, 14, 15, 16, and 17. For each figure, the captured image is shown in the left panel and the top-view plot is depicted in the right panel. The (blue) circular marks in the left panel of the figures indicate the landmarks extracted from the captured image with an unknown image depth, while the (red) square marks represent the landmarks with a known and stable image depth. In the right panel of the figures, the estimated states of the camera and landmarks are illustrated in a 2D plot. The red (dark) ellipses represent the uncertainty of the landmarks which have known image depths and the green (light) ellipses denote the uncertainty of the landmarks which have unknown image depths. Meanwhile, the rectangular box represents the free-moving camera and the trajectory of the estimated camera pose is plotted as solid lines. As shown in the right panel of Figure 10 for the 31st image frame, the SLAM system starts up and captures four image features with known positions. These features will help to initialize the map scale. After the start-up, more image features are extracted and treated as landmarks with unknown image depth, as indicated in circular marks in Figure 11 for the 32nd frame. In Figure 12 for the 71st frame, the uncertainty of the image depth of feature 10 is reduced to a small region (red ellipse). The SLAM system builds the environment map and estimates the camera pose concurrently, when the camera is carried to circle around the laboratory, as shown in Figure 13 for the 645th frame. In Figures 14 and 15 for the 2265th and 2340th frames, the camera comes to the place it had visited before and the trajectory loop is closing. Some old landmarks (with number less than 100) are captured again and the covariance of the state vector is reduced gradually. The second and third times of loop-closure are depicted in Figures 16 and 17 for the 3355th and 4254th frames. In these frames, old landmarks are visited again and the covariance of the state vector is reduced further.

Three-dimensional map and camera pose estimation.

31st frame: the SLAM system starts up with four known features, 0, 1, 2, 3.

32nd frame: some new features are detected and initialized.

71st frame: the image depth uncertainty of feature 10 decreases to a small region.

645th frame: the SLAM system maps the environment and estimates the camera pose concurrently.

2265th frame: before the loop is closing.

2340th frame: the first time the camera reaches the loop-closure.

3355th frame: the second time the camera reaches the loop-closure.

4254th frame: the third time the camera reaches the loop-closure.
The map size and the sampling frequency (Hz) at each frame are depicted in Figure 18. The map size increases to about 145 features at the first loop-closure and remains at almost constant size (about 200 features at the third loop-closure). That is, the SLAM can rely on the map with old landmarks for localization when it repeats visiting the same environment. The high sampling frequency in Figure 18 is about 20 Hz when the map size is small. When the map size increases, the low sampling frequency keeps at about 5 Hz.

Map size and sampling frequency.
The deviations of the camera pose in xyz-axis are plotted in Figure 19. The camera pose deviations decrease suddenly at each loop-closure, because the old landmarks are revisited and the camera pose and landmark locations are updated accordingly. We also can see from Figure 19 that the lower-bound of the pose deviation is further decreased after each loop-closure.

The deviation of the camera pose estimation.
4.2. SLAM with MOT
The camera is carried to move around at one corner of our laboratory in this example. Meanwhile, the SLAM is implemented to map the environment and estimate the camera pose, as well as to detect and track a moving object. The estimated camera pose and landmarks are illustrated in a 3D plot as shown in Figure 20. The ellipses in the figure indicate the landmarks obtained from the extracted image features. The rectangular box represents the free-moving monocular camera and the solid line depicts the trajectory of the camera. More detail image frames of experimental results are illustrated in Figures 21, 22, 23, 24, 25, 26, 27, 28, 29 and 30. For each figure, the captured image is shown in the left panel and the top-view plot is depicted in the right panel of each figure. As shown in Figure 21 for the 52nd image frame, the SLAM system starts up and captures four image features with known 3D coordinates. After the start-up, some stationary features with unknown status are extracted and treated as new landmarks for mapping, as shown in the 98th frame in Figure 22. These stationary landmarks are initialized using inverse depth parameterization [17]. The system demonstrates a stable implementation of SLAM as shown in Figures 22, 23, 24, and 25. In Figure 26, soon after the feature no. 30 is detected, it is discriminated from the stationary features using the proposed MOD algorithm and then treated as a moving object. This moving object is tracked in the image plane and encircled by a rectangle in Figures 26, 27, 28, 29 and 30. Therefore, the developed system demonstrates the capability of simultaneous localization, mapping and MOT.

Three-dimensional map and camera pose estimation.

52nd frame: system start-up with four known features, 0, 1, 2, 3.

98th frame: three new features are initialized.

330th frame: SLAM.

526th frame: SLAM.

563rd frame: one object (the box) is moving to right direction.

615th frame: feature 30 on the object is deteced and initialized with large image depth uncertainty.

621st frame: the object stops moving and the image depth uncertainty of the feature is reduced.

634th frame: the image depth uncertainty of the tracked feature is further reduced and treated as a 3D point.

657th frame: the object moves to the right again and the covariance increases.

684th frame: the object keeps moving to the right and the covariance increases further.
4.3. People detection and tracking
In this experiment, the SLAM system with MOD is utilized to detect and track a moving people in the environment. The camera is carried to move around at a corner of our laboratory. The estimated states of the camera pose, the landmarks, and the moving people are illustrated in a 2D top-view plot in the right panel of Figures 31, 32, 33, 34, and 35. The captured image is shown in the left panel of each figure. As shown in Figure 31 for the 350th image frame, the SLAM system builds the environment map and estimates the camera pose concurrently and stably. The ellipses in the right panel indicate the landmarks obtained from the extracted image features. The rectangular box represents the free-moving monocular camera and the thin solid line depicts the trajectory of the camera. One person gets in the scene, as shown in the 365th frame in Figure 32, and two image features on the human body are detected. These image features are discriminated from the stationary features using the proposed MOD algorithm, and are further initialized in state vector and tracked using Equation (8). The SLAM system continuously tracks the moving people until he goes out the scene, as shown in Figures 33, 34, and 35. The trajectory of the moving people is depicted as a thick solid line in the right panel of each figure. Hence, the developed system also demonstrates the capability of simultaneous localization, mapping, and moving people tracking.

350th frame: the system performing SLAM.

365th frame: moving objects are detected.

386th frame: the detected moving objects are tracked.

392nd frame: the system performs SLAM and MOT.

410th frame: MOT.
5. Conclusions
In this research, we developed an algorithm for detection and tracking of moving objects to improve the robustness of robot visual SLAM system. SURFs are also utilized to provide a robust detection of image features and a stable description of the features. Three experimental works have been carried out on a monocular vision system including SLAM in a static environment, SLAM with MOT, and people detection and tracking. The results showed that the monocular SLAM system with the proposed algorithm has the capability to support robot systems simultaneously navigating and tracking moving objects in dynamic environments.
References
Wang CC, Thorpe C, Thrun S, Hebert M, Durrant-Whyte H: Simultaneous localization, mapping and moving object tracking. Int J Robot Res 2007, 26(9):889-916. 10.1177/0278364907081229
Bibby C, Reid I: Simultaneous Localisation and Mapping in Dynamic Environments (SLAMIDE) with Reversible Data Association. In Proceedings of Robotics: Science and Systems III. Georgia Institute of Technology, Atlanta; 2007.
Zhao H, Chiba M, Shibasaki R, Shao X, Cui J, Zha H: SLAM in a Dynamic Large Outdoor Environment using a Laser Scanner. In Proceedings of the IEEE International Conference on Robotics and Automation. Pasadena, California; 2008:1455-1462.
Davison AJ, Reid ID, Molton ND, Stasse O: MonoSLAM: Real-time single camera SLAM. IEEE T Pattern Anal 2007, 29(6):1052-1067.
Paz LM, Pinies P, Tardos JD, Neira J: Large-Scale 6-DOF SLAM with Stereo-in-Hand. IEEE T Robot 2008, 24(5):946-957.
Harris C, Stephens M: A combined corner and edge detector. In Proceedings of the 4th Alvey Vision Conference. University of Mancheter; 1988:147-151.
Karlsson N, Bernardo ED, Ostrowski J, Goncalves L, Pirjanian P, Munich ME: The vSLAM Algorithm for Robust Localization and Mapping. In Proceedings of the IEEE International Conference on Robotics and Automation. Barcelona, Spain; 2005:24-29.
Sim R, Elinas P, Little JJ: A Study of the Rao-Blackwellised Particle Filter for Efficient and Accurate Vision-Based SLAM. Int J Comput Vision 2007, 74(3):303-318. 10.1007/s11263-006-0021-0
Lowe DG: Distinctive image features from scale-invariant keypoints. Int J Comput Vision 2004, 60(2):91-110.
Bay H, Tuytelaars T, Van Gool L: SURF: Speeded up robust features. In Proceedings of the ninth European Conference on Computer Vision. Springer-Verlog, Berlin, German; 2006:404-417. Lecture Notes in Computer Science 3951
Shakhnarovich G, Darrell T, Indyk P: Nearest-Neighbor Methods in Learning and Vision. MIT Press, Cambridge, MA; 2005.
Smith R, Self M, Cheeseman P: Estimating Uncertain Spatial Relationships in Robotics. In Autonomous Robot Vehicles. Edited by: Cox IJ, Wilfong GT. Springer-Verlag, New York; 1990:167-193.
Blom AP, Bar-Shalom Y: The interacting multiple-model algorithm for systems with Markovian switching coefficients. IEEE T Automat Control 1988, 33: 780-783. 10.1109/9.1299
Hutchinson S, Hager GD, Corke PI: A tutorial on visual servo control. IEEE T Robot Automat 1996, 12(5):651-670. 10.1109/70.538972
Sciavicco L, Siciliano B: Modelling and Control of Robot Manipulators. McGraw-Hill, New York; 1996.
Wang YT, Lin MC, Ju RC: Visual SLAM and Moving Object Detection for a Small-size Humanoid Robot. Int J Adv Robot Syst 2010, 7(2):133-138.
Civera J, Davison AJ, Montiel JMM: Inverse Depth Parametrization for Monocular SLAM. IEEE Trans Robot 2008, 24(5):932-945.
Lindeberg T: Feature detection with automatic scale selection. Int J Comput Vision 1998, 30(2):79-116. 10.1023/A:1008045108935
Wang YT, Hung DY, Sun CH: Improving Data Association in Robot SLAM with Monocular Vision. J Inf Sci Eng 2011, 27(6):1823-1837.
Longuet-Higgins HC: A computer algorithm for reconstructing a scene from two projections. Nature 1981, 293: 133-135. 10.1038/293133a0
Hartley RI: In Defense of the Eight-Point Algorithm. IEEE T Pattern Anal 1997, 19(6):580-593. 10.1109/34.601246
Luong QT, Faugeras OD: The Fundamental Matrix: Theory, Algorithms, and Stability Analysis. Int J Comput Vision 1996, 17(1):43-75. 10.1007/BF00127818
Bouguet JY: Camera Calibration Toolbox for Matlab.2011. [http://www.vision.caltech.edu/bouguetj/calib_doc/]
Acknowledgements
This article was partially supported by the National Science Council in Taiwan under grant no. NSC100-2221-E-032-008 to Y.T. Wang.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Wang, YT., Sun, CH. & Chiou, MJ. Detection of moving objects in image plane for robot navigation using monocular vision. EURASIP J. Adv. Signal Process. 2012, 29 (2012). https://doi.org/10.1186/1687-6180-2012-29
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-6180-2012-29