
Abstract
The field of perceptual quality assessment has gone through a wide range of developments and it is still growing. In particular, the area of no-reference (NR) image and video quality assessment has progressed rapidly during the last decade. In this article, we present a classification and review of latest published research work in the area of NR image and video quality assessment. The NR methods of visual quality assessment considered for review are structured into categories and subcategories based on the types of methodologies used for the underlying processing employed for quality estimation. Overall, the classification has been done into three categories, namely, pixel-based methods, bitstream-based methods, and hybrid methods of the aforementioned two categories. We believe that the review presented in this article will be helpful for practitioners as well as for researchers to keep abreast of the recent developments in the area of NR image and video quality assessment. This article can be used for various purposes such as gaining a structured overview of the field and to carry out performance comparisons for the state-of-the-art methods.
Similar content being viewed by others


1 Review
1.1 Introduction
There has been a tremendous progress recently in the usage of digital images and videos for an increasing number of applications. Multimedia services that have gained wide interest include digital television broadcasts, video streaming applications, and real-time audio and video services over the Internet. The global mobile data traffic grew by 81% in 2013, and during 2014, the number of mobile-connected devices will exceed the number of people on earth, according to predictions made by Cisco. The video portion of the mobile data traffic was 53% in 2013 and is expected to exceed 67% by 2018[1]. With this huge increase in the exposure of image and video to the human eye, the interest in delivering quality of experience (QoE) may increase naturally. The quality of visual media can get degraded during capturing, compression, transmission, reproduction, and displaying due to the distortions that might occur at any of these stages.
The legitimate judges of visual quality are humans as end users, the opinions of whom can be obtained by subjective experiments. Subjective experiments involve a panel of participants which are usually non-experts, also referred to as test subjects, to assess the perceptual quality of given test material such as a sequence of images or videos. Subjective experiments are typically conducted in a controlled laboratory environment. Careful planning and several factors including assessment method, selection of test material, viewing conditions, grading scale, and timing of presentation have to be considered prior to a subjective experiment. For example, Recommendation (ITU-R) BT.500[2] provides detailed guidelines for conducting subjective experiments for the assessment of quality of television pictures. The outcomes of a subjective experiment are the individual scores given by the test subjects, which are used to compute mean opinion score (MOS) and other statistics. The obtained MOS, in particular, represents a ground truth for the development of objective quality metrics. In ITU-R BT.500 and related recommendations, various types of subjective methods have been described. These types include either single stimulus or double stimulus-based methods. In single stimulus methods, the subjects are shown variants of the test videos and no reference for comparison is provided. In some situations, a hidden reference can be included but the assessment is based only on a no-reference scoring of the subjects.
Due to the time-consuming nature of executing subjective experiments, large efforts have been made to develop objective quality metrics, alternatively called as objective quality methods. The purpose of such objective quality methods is to automatically predict MOS with high accuracy. Objective quality methods may be classified into psychophysical and engineering approaches[3]. Psychophysical metrics aim at modeling the human visual system (HVS) using aspects such as contrast and orientation sensitivity, frequency selectivity, spatial and temporal pattern, masking, and color perception. These metrics can be used for a wide variety of video degradations but the computation is generally demanding. The engineering approach usually uses simplified metrics based on the extraction and analysis of certain features or artifacts in a video but do not necessarily disregard the attributes of the HVS as they often consider psychophysical effects as well. However, the conceptual basis for their design is to do analysis of video content and distortion rather than fundamental vision modeling.
A set of features or quality-related parameters of an image or video are pooled together to establish an objective quality method which can be mapped to predict MOS. Depending on the degree of information that is available from the original video as a reference in the quality assessment, the objective methods are further divided into full reference (FR), reduced reference (RR), and no-reference (NR) as follows:
-
FR methods: With this approach, the entire original image/video is available as a reference. Accordingly, FR methods are based on comparing distorted image/video with the original image/video.
-
RR methods: In this case, it is not required to give access to the original image/video but only to provide representative features about texture or other suitable characteristics of the original image/video. The comparison of the reduced information from the original image/video with the corresponding information from the distorted image/video provides the input for RR methods.
-
NR methods: This class of objective quality methods does not require access to the original image/video but searches for artifacts with respect to the pixel domain of an image/video, utilizes information embedded in the bitstream of the related image/video format, or performs quality assessment as a hybrid of pixel-based and bitstream-based approaches.
1.2 Applications of no-reference image and video quality assessment
In recent years, there has been increasing interest in the development of NR methods due to the widespread use of multimedia services in the context of wireless communications and telecommunication systems. Applications of NR methods include the following areas:
-
Network operators and content providers have a strong interest to objectively quantify the level of service quality delivered to the end user and inside the network nodes. NR methods will provide the data needed to adopt network settings such that customer satisfaction is secured and hence churn can be avoided.
-
The involvement of multiple parties between content providers and the end users gives rise to establish service-level agreements (SLA) under which an agreed level of quality has to be guaranteed. In this respect, NR methods are a suitable choice for in-service quality monitoring in live systems.
-
In general, NR methods are well suited to perform real-time objective quality assessment where resources are limited such as frequency spectrum in wireless communications. In such cases, RR methods have limited application as an ancillary channel is required to transmit the required features of the original video.
-
Real-time communication and streaming services require quality adaptations using NR methods for collecting statistics of the delivered quality.
1.2.1 Related work: published reviews of objective visual quality methods
According to the framework introduced in[4] for NR visual quality estimation, three stages are present in an NR quality estimation approach. These stages are measurement of a physical quantity relevant for visual quality, also called as feature, pooling the measured data over space and/or time, and mapping the pooled data to an estimate of perceived quality. A survey of the measurement stage, which is essentially the main focus in much of the work done in NR quality estimation, has been provided in the same contribution. The survey in[4] divides the literature review into two main categories. In the first category, the methods estimating mean square error (MSE) caused by block-based compression, MSE caused by packet loss errors, and noise estimation methods to compute MSE have been discussed. The second category encompasses the approaches that are termed as feature-based. The feature-based methods are based on either a model developed for particular artifacts related to a visible degradation, or a model developed to quantify the impact of degradations on a specific set of attributes of the original uncorrupted image or video. A brief survey of NR methods of image quality assessment (IQA) based on the notion of quantifying the impact of distortions on natural scene statistics (NSS) is provided in[5]. Some NR methods of visual quality are discussed in[6] also under the categorization of features and artifacts detection. Similarly, a review of the objective methods of video quality assessment (VQA) is provided in[7] including a classification of objective methods in general without specifying it for no-reference methods. In[7], the objective methods are classified as data metrics, pictures metrics, and packet or bitstream-based metrics. The review and performance comparison of video quality assessment methods in[8] present a classification of FR and RR methods only. A survey on visual quality assessment methods that are based on information theory is given in[9]. It was observed that information theory-based research for the development of NR methods is rather limited. The type of NR methods surveyed in[9] relies on an approach that employs Rényi entropy for determining the amount of randomness in the orientation of local structures in an image. NR methods have been reviewed in[10] by classifying them following three approaches. Firstly, a review of NR methods has been performed by classifying them based on the type of distortion that is estimated to formulate a quality value. The second approach used for the classification is based on methods that are designed for quantifying the artifacts produced by a specific compression standard. Lastly, a review of methods that are not designed specifically for a particular distortion has been performed. A broad survey of image and video quality methods, as well as a classification of the methods, was published during 2007 in[11]. This includes both NR and RR methods, and our article focuses on a classification and review of NR methods of IQA and VQA published after[11].
1.2.2 Our proposed classification
The current literature in the area of methods of NR image/video quality assessment is quite diverse. Hence, it is a challenging task to classify these methods into a well-structured and meaningful categorization. A good categorization of such methods should be concise enough to be properly understandable and also comprehensive enough to present most of the relevant methodologies. The aforementioned types of classifications cover a range of NR methods, but there is a need to broaden the categorization approaches in order to review currently existing methods in this area. Reibman et al.[12] classify NR methods as either stemming from statistics derived from pixel-based features and call them NR pixel (NR-P) type or computed directly from the coded bitstream and call them NR bitstream (NR-B) type. We believe that this is a useful classification which can serve as an effective basis for constructing a broader classification.
In the case of NR-P-based methods, one relevant method to classify available approaches is to investigate these in terms of the employment of certain artifacts that are related to a specific kind of degradation of the visual quality. Quantification of such artifacts has been used as a measure for the quality assessment. The quality values may depend only on a single artifact or it may depend upon a combination of many artifacts. It is common that single artifact measure-based methods are developed by considering a given model of degradation, often simulated artifacts, and sometimes their performance remains unknown for realistic or more general scenarios. For example, most of the available blur methods are based on Gaussian or linear blur models, which may not adequately measure the blur produced by a complex relative motion between image capturing device and the object. Moreover, single-artifact-based quality methods may not have satisfactory performance in the assessment of the overall quality, in the presence of other artifacts. Therefore, methods have been introduced where estimation of a combination of artifacts is fused to generate a single quality score. Also, in the domain of NR-P-based methods, there are many methods which work beyond simple artifacts computation and the quality assessment is derived from the impact of distortions upon NSS (referring to statistical characteristics commonly found in natural images). Moreover, some quality-relevant features can be computed from the image/video pixels to formulate an estimation of the perceptual quality.
The NR-B-based methods are relatively simpler to compute than NR-P-based methods, and the quality values can often be computed in the absence of a full decoder. However, such methods can have limited scope of application as they are usually designed for a particular coding technique and bitstream format, e.g., H.264/AVC standard. Such methods are based on either the encoding information derived from the bitstream or the packet header information or a combination of both. These methods are quite suitable for network video applications such IPTV and video conferencing.
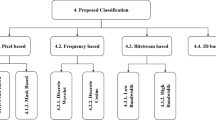
Quality assessment performance can be compromised in NR-B-based methods to gain reduction in the computational complexity as compared to the NR-P-based methods. The performance of NR-B-based methods of quality assessment can be improved by adopting an approach of adding some input from NR-P-based quality assessment. Such composites of NR-P- and NR-B-based methods are called hybrid methods. These methods inherit the computational simplicity of NR-B-based methods and depend on NR-P-related data to gain further robustness.In light of the aforementioned discussion, our approach of a meaningful classification of NR objective visual quality methods is outlined in Figure1. This classification is formulated by considering the type and granularity of usage of the image or video data for the design of an objective method of quality. Thus, it offers the opportunity to present a discussion of most of recently published techniques of the NR visual quality assessment. It is to be noted that the main focus of this article is to review, in a systematic and structured manner, recent advancements in this area. Hence, a performance comparison of the reviewed methods on a comprehensive test database is out of the scope of this paper.

An overview of NR image and video quality assessment methods. The second row of boxes gives a division into three main categories, further divided into subcategories in the next row. The bottom row gives examples of extracted features or information used for processing in each subcategory.
1.2.3 The preliminaries and organization of this paper
Most of the existing NR quality methods fall into NR-P or NR-B type methods or a hybrid of these two approaches. As shown in Figure1, the following sections present an overview of the different classes of NR methods of IQA and VQA. In each section, we have presented a general idea used in computation of various types of methods of quality estimation using block diagrams. Summaries of most of the discussed methods are shown in tables throughout the paper and in dedicated discussion sections. Mostly, the performance of an objective quality prediction model is reported by using measure of prediction accuracy, i.e., Pearson’s linear correlation coefficient, and measure of monotonicity, i.e., Spearman’s rank order correlation coefficient, as recommended by Video Quality Expert Group (VQEG)[13]. These measures have been used to report the performance of the reviewed methods in the tables. In these tables, some cells have been marked with a hyphen (-) in cases where the corresponding value has not been reported in the reference or some uncommon measure of performance has been used. Other than the explicit numerical values of the number of pixels used for stating the resolution of the test data, the following short forms are used:
-
QCIF, Quarter Common Intermediate Format (176 × 144)
-
CIF, Common Intermediate Format (352 × 288)
-
SIF, Standard Interchange Format (320 × 240)
-
SD, Standard Definition (720 × 480 or 720 × 576)
-
HD, High Definition (1920 × 1080 or 1280 × 720)
For validation of the proposed method, some publicly available databases of images and videos have been used in most of the reference papers. In this article, the reference to a public database of test media indicates that either a subset or the complete set of the available media has been used. These sources of the test media include the following:
-
Laboratory for Image and Video Engineering (LIVE): LIVE offers databases of compressed images and videos with the corresponding data of the subjective assessment. The images have been encoded using Joint Photographic Experts Group (JPEG) and JPEG2000 standards. Moreover, some images have been generated using simulated conditions of certain artifacts such as Gaussian blur and white noise. The video database contains sets of videos encoded using Moving Picture Experts Group (MPEG)-2 and H.264/AVC. While we refer to the usage of test data from LIVE in the tables, the standard used for encoding shown in the column Processing indicates whether the used data is an image or a video. References to the publications based on the use of these databases have been provided at the source website[14].
-
Video Quality Experts Group (VQEG): VQEG has released its test data for public use which is available on their website[15]. The data contains standard definition television videos and the corresponding values of the subjective assessment.
-
Tampere Image Database 2008 (TID2008): This database contains test data produced from 17 different types of distortion introduced in the given 25 reference images. The test images have been provided with the corresponding subjective assessment scores and values of many objective methods of quality estimation. More information on it is found in[16].
-
Images and Video Communications (IVC): The IVC database contains a set of ten original images distorted by four types of processing and is supported by the corresponding quality scores as available in[17].
-
Toyoma: This database consists of subjective assessment data and test stimuli generated through processing of 14 reference images using JPEG and JPEG2000[18].
This article is organized as follows. For the pixel-based approaches, the methods that apply direct estimation of single and multiple artifacts are reviewed in Sections 1.3 and 1.4, respectively. The methods based on computation of various features and an evaluation of impacts of pertinent artifacts upon NSS are discussed in Section 1.5. Bitstream-based NR methods are reviewed in Section 1.6. The methods constructed as hybrids of pixel and bitstream-based approaches are discussed in Section 1.7. Finally, some conclusive remarks and a brief outlook of possible future works in this area are presented in Section 2.
1.3 Single artifact NR-P-based methods
Blurring, blocking, and ringing are considered to be the most commonly found spatial domain artifacts in images/videos compressed by lossy encoders[19]. Moreover, noise is also a common source of annoyance in images and videos. Transmission of videos over lossy networks gives rise to temporal artifacts such as frame freeze. In the following, we examine the recent methods which adopt the approach of quantifying a single artifact for perceptual quality estimation. The section is divided into subsections for each of these artifacts, and an overall discussion is provided at the end.
1.3.1 Blurring
Winkler defines blur as an artifact which appears as a loss of spatial detail and a reduction of edge sharpness[20]. The reasons for the occurrence of blur can be many, originating in the acquisition, processing, or compression[21]. The primary source of blur in compression techniques is the truncation of high-frequency components in the transform domain of an image. Other possible reasons of the blurring of an image or video can be out-of-focus capturing, relative motion between the camera and the object being captured, or limitations in the optical system. Traditional no-reference blur methods usually focus on a particular coding artifact for quality prediction and hence their performance is compromised in circumstances of more general blur. Moreover, there has been little work carried out to build methods which have the capability of assessing blur in natural scenarios, rather, most of the work is focused on the simulated blur. A basic schematic of NR blur assessment is shown by the flowchart given in Figure2. In many NR methods of estimating the impact of blur on visual quality, the computations begin with measuring the spread of pixels present on the edges in an image. Usually, it involves the application of commonly used edge detectors such as Sobel and/or Canny for finding the edges in the image. The next step is typically the computation of the edge distortion value that can be used towards finding an estimate of the blur. Some methods, however, make use of HVS adaptation to the value of edge distortion to classify it as perceivable or not perceivable by a human subject.

A basic scheme for NR-P-based assessment of blur.
A paradigm for blur evaluation has been presented in[22] that is mainly composed of four methods of blur quantification, given in[23–25] and[26], which have been integrated by an artificial neural network (ANN) powered multifeature classifier. In the method given in[23], an image quality measurement method in terms of global blur has been proposed. The method relies on histograms of discrete cosine transform (DCT) coefficients present in MPEG and JPEG encoded data to qualitatively encompass the distribution of null coefficients, given the fact that blurred images usually end up having a lot of high-frequency coefficients set to zero. This algorithm provides results which align with subjective assessment but it focuses only on out-of-focus blur and it does not perform well when there is a uniform background present or when an image is over-illuminated. The blur assessment algorithm proposed in[24] exploits the ability of the Haar wavelet transform (HWT) to distinguish edge types, and the method works both for out-of-focus and linear-motion blur. This method is however not tested for realistic blur. The method proposed in[25] presents a framework where global blur is measured in terms of averaged edge lengths. The authors considered only a small set of Gaussian blurred images for its evaluation. Nonetheless, the method has good correlation with subjective scores. An improved version of[25] is found in[26] where HVS properties have been added to get weighted edge lengths. It is to be noted that none of these four reference methods quantify realistic blur situations, but Ciancio et al.[22] have shown their method to be useable for measuring naturally occurring blur. Overall,[22] uses local phase coherence, mean brightness level, and variance of the HVS frequency response and contrast as additional inputs, together with the earlier mentioned four methods, to various ANN models designed for quality estimation. For input calibration, a five-parameter nonlinear mapping function was used for the types of blur including simulated Gaussian, simulated linear motion, a combination of both, and real blur. The proposed method outperforms the given four reference methods when tested on a fairly large database of 6,000 images corrupted by blur. Although the proposed method does not correlate so well with subjective scores in realistic blur scenarios, with a Pearson’s correlation coefficient of approximately 0.56, it performs better than the reference methods with respect to subjective rating. In an earlier paper, the same authors have used the idea of estimating image blur using local phase coherence[27] and a similar method proposed by Hassen et al. is found in[28].
It has been argued in[29] that blur below a certain threshold value remains unperceived by the HVS and such a threshold value is termed as just noticeable blur (JNB). By incorporating the response of the HVS to sharpness at various contrast levels, the authors have proposed a measure of image sharpness. It is suggested that most of the existing no-reference blur assessment methods do not perform well for a variety of images and are rather limited to assess varying blur in a certain image. They have validated this argument by testing a set of 13 contemporary reference methods, which are based on different techniques of blur assessment used for quality assessment such as pixel-based techniques, statistical properties, edge-detection-based, and derivative-based techniques. The proposed method has higher correlation with subjective MOS than the given 13 objective methods of quality assessment when it has been tested on a public database of test images. In[29], the block size used for finding edge pixels is 64 × 64, and a similar contribution based on JNB from the same authors is reported in[30] where a block size of 8 × 8 has been used for finding the edge pixels. The method proposed in[30] has been improved in[31] by adding the impact of saliency-weighting in foveated regions of an image. Specifically, more weighting is given to the local blur estimates that belong to salient regions of an image, while spatial blur values are pooled together to compute an overall value of blur for the whole image.
A similar method found in[21, 32] improves[29] by addition of the concept of commutative probability of blur detection (CPBD) so that the method should estimate the quality by including the impact of HVS sensitivity towards blur perception at different contrast levels. Testing the proposed method upon three public image databases having different blur types reveals that the method performance is considerably better than some of the contemporary sharpness/blur methods. However, this method gives a quality index in a continuous range of 0 to 1 and the authors have modified it in[33] where it gives a quality value on a discrete scale of 1 to 5, the usual five quality classes which are described from Bad to Excellent. Given that blur estimation methods most often work on the idea of measurement of edge-spread and blur manifests itself in smooth or diminished edges, some edges may remain undetected. Varadarajan et al.[34] improved the method proposed in[29] by incorporating an edge refinement method to enhance the edge detection and hence outperformed the blur assessment. The authors achieved as much as 9% increase in Pearson’s correlation coefficient.
In contrast to usual schemes of blur detection at the edges, the method proposed in[35] does an estimation of blur at the macroblock (MB) boundaries. The overall blur of an image can be calculated by averaging the block level measure for the whole image. The authors have also used a content-sensitive masking approach to compensate the impact of image texture. As the method was designed for videos encoded following the H.264/AVC standard, it mainly quantifies the blurring effects from quantization and de-blocking filter. This method is essentially based on a method proposed for images[36] where an estimation of the blur in a video is made by taking an average measure of blur values for each frame.
A wavelet-based noise-resilient color image sharpness method is presented in[37]. The procedure is to compute a multiscale wavelet-based structure tensor which represents the multiscale gradient information of local areas in a color image (image gradient is defined as the directional change in the intensity or color in an image). The proposed tensor structure preserves edges even in the presence of noise. Thus, the sharpness method is defined by calculating the eigenvalues of the multiscale tensor once edges have been identified. A competitive correlation with subjective MOS is achieved when the proposed method is tested on LIVE image database[14], in comparison to a similar sharpness method.
Out-of-focus blur estimation without using any reference information has been given in[38] using the point spread function (PSF) which is derived from edge information. As the proposed algorithm works in the spatial domain, avoiding any iterations or involvement of complex frequencies, it is expected to operate fast and possible to be deployed in real-time perceptual applications. Based on the similar approach in[39], the method has been made workable to assess blurriness of conditions like added blur, realistic blur, and noise contamination.
Chen et al.[40] have claimed that their method works for any kind of blurriness, without being sensitive to the source of the blur. A gradient image is calculated from the given image pixel array. A Markov model is used and a transition probability matrix is computed. Finally, a pooling strategy is applied to the probabilistic values to obtain the blurriness measure.
Some of the other recently introduced no-reference blur assessment methods include the following: In[41] a method based on multiscale gradients and wavelet decomposition of images is given, an image sharpness based on Riemannian tensor mapping into a non-Euclidean space has been found in[42], radial analysis of blurred images in frequency domain is done in[43] to set an image quality index for blur estimation, and reference[44] presents a perceptual blur method to assess quality of Gaussian blurred images. A method based on blur measure in salient regions has been presented in[45]. The perceptually relevant areas in an image are identified through elements of visual attention, namely, color contrast, object size, orientation, and eccentricity. Quality values in correlation with subjective scores are produced by localizing the degradation measure in these elements.
1.3.2 Blocking
Blocking is an artifact which manifests itself as a discontinuity between adjacent blocks in images and video frames[3]. It is a predominant degradation that occurs after employment of block-based processing and compression techniques at high compression ratio conditions. In such techniques, transform is usually followed by quantization of each block individually leading to incoherent block boundaries in the reconstructed images or frames. Blockiness can be estimated in a region of an image, in general, by computing the difference between neighboring blocks and the amount of brightness around those blocks as shown in Figure3. After the value of blockiness is determined in a certain region, it is important to estimate whether it would be significant for human perception or not by taking into account the impact from masking effects. This way, certain features that represent the input from HVS can be calculated. In general, blocking perception is affected by various factors including the blockiness strength (i.e., the difference between adjacent blocks), the local brightness around the blocks, and the local texture present in an image.

A basic scheme for NR-P-based assessment of blocking.
A frequency domain pixel-based bi-directional (horizontal and vertical) measure used to gauge blocking in images is presented in[46]. The authors claim that the proposed method can be used for any image or video format. Unlike the traditional no-reference blocking measures, this method does not require any a priori information about block origin, block offset or block-edge detection. The method has been evaluated on a large set of LIVE image and video database available as JPEG encoded images and MPEG-2 encoded videos. It outperforms a set of 13 contemporary blockiness methods in terms of prediction accuracy and monotonicity.
Liu et al.[47] presented an HVS-based blocking method to assess image quality using a grid detector to locate blocking. A local pixel-based blockiness measure which is calculated on the detected degraded regions is averaged to provide a blockiness value for the whole image. The main strength of this method in terms of computational efficiency and relevance to HVS response lies in the application of visual masking which makes the calculations perform only in the areas of blockiness visible to human perception. The authors took up the same method for further extensive evaluation in[48] under various conditions of comparison of performance where, for example, HVS models and grid detector are omitted or included. The results show that the proposed method performs better than some contemporary methods and can be a good candidate for real-time applications due to its simplified HVS model.
In[49], a blockiness assessment method is presented for block-based discrete cosine transform (BDCT) coded images. It is based on the estimation of noticeable blockiness. The so-called noticeable blockiness map is derived from luminance adaptation and texture masking in line with HVS response combined with a discontinuity map to quantify the visual quality. Along with its validated usability for deblocking of JPEG images, it has the potential of optimizing the codec parameters and similar other post-processing techniques.
Babu et al. presented their HVS related features-based blocking method in[50]. Blockiness as perceived by humans in JPEG encoded images is affected by a number of features such as edge amplitude around the borders of DCT blocks and edge length; the value of these increase in amount as compression rate is increased. It is also affected by the amount of background activity and background luminance as these have masking impact on possible blocking artifacts. The authors have used a sequential learning algorithm in a growing and pruning radial basis function (GAP-RBF) network to estimate the relationship between the mentioned features and the corresponding quality measure. Babu et al. also proposed a method of determining block-edge impairment[51] using the idea that edge gradients of blocks in the regions of low spatial details would contribute towards the overall blocking in an image. The level of spatial details is estimated through edge activity that is computed through standard deviation measurement of each edge.
Other methods in this area include the blind measurement of blocking in low bit rate H.264/AVC encoded videos based on temporal blocking artifact measure between successive frames of a video presented in[52]. A weighted Sobel operator-based blocking method is presented in[53], in which the computation involves luminance gradient matrices of DCT-coded images. A method where a rather simple approach of taking abrupt change in pixel values as a signal of blocking has been proposed in[54] and it can be implemented both in pixel and DCT domain, and a method of blockiness estimation in natural scene JPEG compressed images has been presented in[55] which was influenced by the impact of multineural channels pattern of HVS for vision sensing.
1.3.3 Ringing
The ringing artifact is associated with Gibbs phenomenon and is observed along edges in otherwise smooth texture areas[20]. It has yet been relatively less investigated for NR perceptual quality measurements. This kind of degradation is caused by rough quantization of the high-frequency transform coefficients and is observed in the form of ripples around high contrast edges. A schematic block diagram of commonly used approaches for the estimation of perceptual ringing is shown in Figure4. Certain features can be extracted from the edge maps to classify the image areas in terms of relevance towards ringing artifact. Masking effects of textured regions can be examined to check if the ringing would be visible to HVS perception. From the obtained data, a ringing map is generated for various regions and an overall value of perceptual ringing is obtained for the whole image. We have not found any publication on the NR estimation of ringing in videos.

A basic scheme for NR-P-based assessment of ringing.
Liu et al. have put forward HVS-based quality assessment methods which quantify ringing in compressed images in[56, 57]. The work in[56] does not incorporate the masking effects of HVS properties. However, in[57], Liu et al. have improved the already existing method in multiple aspects. Edge detection is crucial for locating the possible ringing artifact and is used along with consideration of HVS masking in designing of such a method. The HVS masking is integrated by adding human visibility index of ringing nuisance estimate inside the already detected distorted regions. This method has a performance level comparable to a full reference method and it outperforms the two given no-reference methods of ringing assessment while tested on JPEG compressed images. As the method does not use coding parameters like DCT coefficients, the authors argue that a slightly tuned version of the same method should perform similarly well when employed on other types of compressed images, e.g., JPEG2000.
Ringing may occur also as a result of an image restoration process, unlike the other artifacts which usually occur during compression. The ringing that occurs due to image restoration has different characteristics as compared to the one that occurs due to compression. Iterations of blind deconvolution in the image restoration process are likely to result in the generation of ringing[58]. A quality method to assess perceived ringing as a result of application of blind deconvolution methods for image restoration is proposed in[58] and in[59]. The authors claim that these methods evaluate ringing with no sensitivity to the image content type and any specific ringing process. In the method proposed in[58], a 2D Gabor wavelet filter and a line detector were used to quantify ringing in restored images. A similar approach with enhancement is found in[59] where the authors have proposed to assess the degradation on image boundaries and image edges separately and then fuse the weighted results of the two values to have the overall ringing value. A 2D Gabor filter response image is used to calculate the perceived ringing at boundaries, and a Canny edge detector is used for locating ringing around edges in the image. The proposed method was tested on gray scale images restored from simulated blur. It has been found that the reported results are in line with subjective scores of quality assessment.
1.3.4 Noise
Besides the aforementioned unwanted components of an image or video that affect the perceptual quality, there can be other types of spatial noise as well. The mostly occurring types of spatial noise include salt and pepper noise, quantization noise, Gaussian noise, and speckle in coherent light situations. Mostly, the noise is considered to be an additive component, e.g., Gaussian noise, but in some situations the noise component is multiplicative, e.g., speckle noise[60]. Noise can be introduced during the image/video acquisition, recording, processing, and transmission[61]. Estimation of noise is required due to numerous reasons and applications in image processing such as denoising, image filtering, image segmentation, and feature extraction. For the estimation of noise signal, in most cases, it is assumed to be independent, identically distributed additive and stationary zero-mean signal, i.e., white noise[62]. Image noise estimation methods can be categorized into either smoothing-based approaches, where noise is computed using the difference between the input image and a smoothed version of it, or block-based approaches, where block variances of the most homogenous block in a set of image blocks is taken as noise variance[63]. Similar to the approaches used for estimation of other artifacts, computation of noise characteristics depends on the extraction of some features that are affected by noise. Figure5 shows the basic scheme of a block-based approach of noise estimation where an image is divided into smooth areas. A variance higher than a certain threshold in those areas gives an estimate of the noise.

A basic scheme for NR-P-based assessment of noise.
A block-based approach proposed in[64] uses statistical analysis of a histogram of local signal variances to compute an estimation of image noise variance. However, this method is challenged by high computational requirements due to its iterative processing, and[65] simplifies this technique by taking image structure into consideration. It uses high-pass directional operators to determine the homogeneity of blocks besides using average noise variances. The performance of the improved method has been verified using highly noisy as well as good quality images. This method requires a full search of an image to determine the homogeneous areas in it. At the expense of decreased accuracy, spatial separations between blocks can be used to reduce the computational complexity. This approach has been adopted in[66] where particle filtering techniques have been used in the process of localization of the homogeneous regions. It has been shown that the proposed method reduces the number of required computations for homogeneity measurements while it outperforms[65] in accuracy. More examples of block-based approaches are found in[67–69] where noise level is computed by performing principal component analysis (PCA) of the image blocks.
1.3.5 Temporal impairments
Temporal impairments can be divided into two main categories: impairments caused by the encoding process and impairments caused by network perturbations. The typical temporal impairments caused by the encoding process come from temporal downsampling which can be performed uniformly or non-uniformly, depending on different underlying reasons. The impairments generated by network perturbations come from delay or packet loss[70]. These different impairments can be categorized as the following[3, 4, 71, 72]:
-
Jerkiness: non-fluent and non-smooth presentation of frames as a result of temporal downsampling
-
Frame freeze: frame halts as a result of unavailability of new frames to present due to network congestion or packet loss etc.
-
Jitter: perceived as unnatural motion due to variations in transmission delay as a result of, e.g., fluctuations in the available bandwidth or network congestion
-
Flickering: noticeable discontinuity between consecutive frames as a result of a too-low frame rate together with high texture, coding artifacts, or motion content
-
Mosquito noise: appears as temporal shimmering seen mostly in smooth textured areas produced by ringing and prediction error due to motion compensation mismatchJerkiness is the impairment perceived by the user, while jitter and frame freezes are the technical artifacts which produce jerkiness. Figure6 presents an overview of how temporal impairments are computed in most of the contemporary methods. Generally, the first step is to compute the inter-frame difference of pixel intensities (usually the luminance channel only) and the obtained value can be used as it is or a mean square value can be calculated. Afterwards, various techniques can be applied to determine the location and possibility of frame freeze or frame drops. Some kind of thresholding is then useful to obtain more information about the occurrence of a potential temporal artifact. Finally, a suitable pooling mechanism is used to compute an overall value of the artifact under consideration.

A basic scheme for NR-P-based assessment of temporal artifacts.
Borer[71] presented a model based on the mean square difference (MSD) of frames for measuring jerkiness (both frame jitter and frame freeze) which proved its potential for quality assessment of videos with resolution ranging from QCIF up to HD. This model calculates jerkiness as an accumulative result of multiplication of three functions called relative display time, a monotonic function of display time, and motion intensity of all frames. The display time and motion intensity values are parameterized through a mapping S-shaped function, which is equivalent to a sigmoid function. Besides the fact that the proposed model has reasonable correlation with MOS, it does not take into account the value of the motion intensity at the start of a freezing interval.
An earlier proposed temporal quality method which is centered around measuring the annoyance of frame freeze duration is given in[72]. This method uses MSD value to mark freeze events and builds a mapping function based on such durations of freeze to estimate the subjective MOS. The method is a part of ITU-T Recommendation J.247 Annex C[73] for the objective perceptual quality measurement of video. Although the quality method has not been compared for performance against other methods, it has promising values of correlation with the subjective scores. However, the blind frame freeze detection system proposed in[74] claims to outperform the model[72] in terms of precision of correctly signaling a zero MSD event as a frame freeze event or not. They have presented an algorithm for thresholding such as zero MSD events to be classified as frame freeze events or the absence of it. The proposed method is reported to be equally good in performance for videos encoded using low or high quantization parameter (QP) values.
Wolf proposed an approach to accurately detect video frame dropping in[75]. One of the salient features of this approach is its use in a RR method where an adaptive threshold value is determined to avoid detection of very low amount of motion (e.g., lips movement) as a potential frame drop event. Similar to the temporal-artifact-based methods discussed before, this method also derives its computations from the basic difference in pixel values between frames to check for possible frame drops.
A method for visual quality distortion due to arbitrary frame freeze is discussed in[76]. It recursively aggregates arbitrary freeze distortions in the video under test using a method which they proposed earlier in[77]. Essentially, the approach presented in[77] replaces the sum of various freeze distortions with an equivalent single freeze length for predicting the video quality.
Yang et al. targeted their research to assess both consistent and inconsistent frame drops as a measure of perceptual quality in their contribution found in[78]. The constituents of the quality method are the amount of frame drops, motion of various objects in a video, and localized contrast of temporal quality. Instead of relying on frame rate to be used as a basis for temporal quality method, the event length of frame losses has been used. The proposed method correlates well with subjective MOS for test sequences with a range of frame rates and a variety of motion contents.
A rather general model was proposed in[79] for several fluidity break conditions: isolated, regular, irregular, sporadic, and varying discontinuity durations with different distributions and densities. Similarly, the temporal quality method proposed in[80] accounts for the impact of various frame dropping situations and spatio-temporal luminance variations due to motion.
In[81], the authors have shared their preliminary findings on estimation of the effects of lost frames on visual quality by analyzing the inter-frame correlation present at the output of the rendering application. As the lost frames are replaced by a repetition of the previous frame, this results in high temporal correlation at those locations. Analysis of this correlation results in temporal and distortion maps.
1.3.6 Discussion
Except for temporal impairments, most of the methods reviewed in this section have been proposed and tested for images and not for videos. For example, blockiness is a common artifact at high compression rates and some coding standards such as H.264/AVC include the use of a deblocking filter while the videos are being processed by the codec. The blockiness methods proposed for images can be used in the case of videos as well where a suitable temporal pooling scheme needs to be used. We believe that development and testing of more NR methods of blockiness estimation for videos would be beneficial. For the case of spatial-artifacts-based methods, it is evident that most of the research focus has been aimed at the development of techniques that are based on a specific coding technique or image compression standard. This fact necessitates the focus towards unraveling cross-encoder methodologies. Considering the available methods related to the quantification of perceptual impacts of various temporal artifacts, it is noted that more diverse methods are required in this area that can be applied for a variety of video resolutions and frame rates. It has also been observed that many methods employ some commonly used test database of images and videos which in turn gives an opportunity to compare the performance of competitive methods on the common benchmarks of quality. One important strength of the methods that are tested for the performance using test databases such as LIVE (image or video) is their higher applicability because the media present in such databases have been assessed for overall perceptual quality and not for a particular artifact. However, the test databases should be enriched with new demanding areas such as higher-resolution images and videos (HD and above). Besides declaring the performance of the proposed methods, finding some common approaches for reporting the computational complexity would be interesting. Table1 presents a summary of the methods discussed in the subsections regarding blurring, blocking, ringing, and temporal artifacts. It is noted that a very low number of methods have been tested for HD resolution images. Competitive methods can be seen at a glance by observing the significantly high values of the performance indicators.
1.4 Multiple artifacts NR-P-based methods
Various artifacts found in images and videos, incurred due to compression or other reasons, can be combined to predict the overall perceived quality. As shown in Figure7, an image or video can be processed for the extraction of features relevant to different artifacts. A suitable pooling mechanism can be employed to combine the results of different artifact measurements, to make an estimate of overall perceptual quality.

A basic scheme for NR-P-based assessment of multiple artifacts.
Blurring and ringing are the main associated degradations when JPEG2000 coding is operated at low bitrate conditions. The quality method proposed in[19] predicts quality of JPEG2000 coded images by combining blur and ringing assessment methods. Based on the local image structures, a gradient profile sharpness histogram is calculated for evaluation of a blur estimation method, and a ringing method is generated from regions associated with gradients profiles. Here, a gradient profile is essentially the distribution of the gradient magnitude along the gradient direction. It has been argued that the underlying proposed blur method is insensitive to the inherent blur found in natural images, e.g., out-of-focus blur. The performance of the method is similar to or better than a number of competitive methods while tested on LIVE JPEG2000 and TID2008 datasets.
A rule-based VQA method given in[82] relies on a group of pixel domain features of a video. It includes blockiness and blurriness as well as spatial activity, temporal predictability, edge continuity, motion continuity, and color continuity. The authors have used already available methods to measure the first five features and have proposed their own methods for the estimation of the motion continuity and color continuity. A multivariate data analysis technique has been used to combine all the features for computing a single quality score. The earliest mentioned three features (blockiness, blurriness, and spatial activity) are measured on a single frame and the rest is calculated on an inter-frame basis. The used approach is to segregate the given set of videos into one of the given feature models and then estimate an initial prediction of the quality measure. After that, using a low-quality version of the video, a correction value is added to the initial quality estimate of the original videos. The authors claim that at the time of publication, this is the first reference-free quality method for H.264/AVC encoded videos which have been tested on a relatively large test database.
Noise is an artifact found in images in the form of a random variation of brightness and color information (see Section 1.3.4 for more details on noise). An empirical formulation of the objective measure of image quality based on blur and noise has been proposed in[83]. The method is based on the level of image intensity variations around its edges. The authors argue that in modern digital cameras, the image signal processor (ISP) enhances the image by removing noise but in doing so, it may deteriorate the image texture. Hence, there is a need of finding a trade-off between noise and blur and it provides a rationale for combining the estimation of noise and blur in the same method. Specifically, this method considers simulated conditions of white noise as source of the noise artifact in the test stimuli.
Another joint method for noise and blur estimation is found in[84]. It estimates the amount of degradations introduced by additive white noise, Gaussian blur, and defocus blur on the quality of an image. Given the fact that noise disturbs virtually all the spatial frequencies of an image and causes an adverse rise in the higher frequencies while blur has attenuation effect on them, it is justified to study the joint impact of noise and blur on the perceptual quality. The authors have evaluated the impact of noise in both spatial and frequency domain while only the frequency domain is used for blur estimation. The central idea is to influence the power spectra of the image in order to highlight the impact of the distortions on the spectrum properties. The source of noise in the test stimuli used in this work is also white noise. The proposed method has not been tested for its correlation with subjective assessment but it has a competitive performance in comparison with a contemporary method[85] of blind image quality evaluation.
In[86], a sharpness method is presented which is sensitive to the prevailing blur and noise in an image. The mathematical formulation of the method is based on image gradients computed through singular value decomposition (SVD) rather than edge detection as commonly found in contemporary pixel-based structure measures. However, it requires a prior estimate of noise variance. This issue has been resolved in the authors’ later contribution[87]. Simulations on realistic noise data have substantiated the potential usage of this method in parameter optimization issues of image restoration such as applications for denoising. The support vector regression (SVR)-based method reported in[88] uses singular vectors from the SVD data instead of using singular values as in[87]. Various artifacts would modify the singular vectors, and hence the geometry of the distorted image will be changed leading to visual annoyance as perceived by humans. The usefulness of the method was tested on multiple image databases with a variety of artifacts. The results were found to be in accordance with subjective ratings.
Another quality method based on gradient statistics of JPEG and JPEG2000 images, degraded by blockiness and blur, is presented in[89]. This method differs from the methods given above in one way that it does not combine the estimated amount of artifacts to yield a single quality score. Instead, it uses the same approach of calculation of local features in gradient domain for both of JPEG and JPEG2000 images and then estimates the quality of the two sets separately. The obtained results lie in accordance with some contemporary methods of blocking estimation in JPEG images and blur estimation in JPEG2000 images. Further, an artificial neural network has been used in[90] to combine a blocking method, a blurring method, and a ringing method to estimate the overall quality of an image. Quality estimators targeted for images encoded by JPEG2000 usually quantify ringing only, but such images may contain blur as well. The method proposed in[91] first determines the type of distortion by using an ANN classifier and then, depending on these results, either uses a ringing[92] or blur[43] method for the quality assessment.
Different from the aforementioned IQA methods, another example of a composite method has been proposed for videos[93]. This method is based on blocking and flickering measure of H.264/AVC encoded videos. It correlates well with subjective quality assessment and also with the structural similarity (SSIM) index[94].
Most of the VQA methods are processed in the luminance plane only to simplify the computational complexity. However, the method proposed in[95] computes three artifacts both in the luminance and chrominance planes of a video. In this method, they compute the significance of the direction in which an artifact is calculated for determining its contribution to perceptual quality assessment. Hence, for example, the value of blur in vertical direction has been given more weighting than the same in horizontal direction. In this method, blocking is measured by computing boundary smoothness between 8 × 8 blocks and block visibility detection. The third impairment which is considered is jitter/jerkiness. Finally, a multiple regression scheme is employed for weighted integration of the six feature values towards the corresponding quality value. The suggested quality predictor bears competitive correlation with subjective MOS when compared with some contemporary methods as tested on standard-definition television (SDTV) sequences found in VQEG Phase 1 database.
A modular method of combining artifacts both from spatial and temporal domain for quality estimation has been proposed in[80]. The method accounts for frame freeze/jerkiness and clearness/sharpness in MPEG-4 encoded videos. It has been claimed that the combined model is an estimator of global visual quality.
1.4.1 Discussion
Given the fact that a certain type of processing, e.g., JPEG2000 coding, can introduce more than one kind of artifacts, it is imperative to have quality estimators that can assess the impact of more than one artifact. The application of the estimation of multiple artifacts becomes even more interesting when a certain processing that involves removal of an artifact, such as denoising, can produce another artifact due to its underlying methodology. The popularity of digital cameras in the recent years increases the demand of a quality estimation mechanism to compute multiple artifacts that can be used as an aid to improve the photography experience. Global visual quality estimators such as in[80] are a useful contribution towards making an overall assessment of a video signal as it can be impaired by spatial artifacts like blurring and temporal artifacts like jerkiness at the same time. Table2 presents a summary of some of the existing methods of quality assessment that are based on the estimation of multiple artifacts. Overall, it is noted that these methods should be tested on higher-resolution images/videos to account for the requirements of the new display devices with capability of presenting resolutions of HD and above.
1.5 Features measures-based methods
An image or video signal can be decomposed to obtain various features that may be used in the process of estimating the perceptual quality of an image or a video. Generally, such features can represent a particular aspect of the visual signal and its relation to the corresponding perceptual quality. Depending upon the nature of the feature with regards to its relation to perceptual quality, a certain feature can be a desired or an unwanted component of an image or video. For instance, the presence of sharpness in an image can be perceptually preferred in many cases and hence it may be considered as a wanted feature. On the other hand, an image with pixel distortions could be considered as of low quality. In addition, certain features represent different characteristics of an image or video and can be used as complementary information besides other features for making an estimate of quality. For example, the amount of spatio-temporal information content of a video can be used to characterize the masking effect on various artifacts that may be present in the signal. More examples of visual quality relevant features include local contrast, brightness, colorfulness, and structural activity[96, 97].
Moreover, it has been described in[98] that natural images possess a common statistical behavior. This behavior has been termed as NSS, and it has been found to be a useful feature for the description of image quality. There have been numerous applications of NSS including image segmentation, denoising, and texture analysis and synthesis. Although it was concluded in[98] that the major usage of scene statistics would be in the investigation of visual sensory processing, these have recently been proved to be quite useful in the design of no-reference quality methods. It has been found that such common statistical characteristics get distorted by image processing applications like image compression, and a quantitative measure of this distortion can yield the relevant variations in the image quality. Thus, an NSS-driven NR quality assessment method would provide the measure of the unnaturalness introduced into the natural scene statistics under the effect of image distortions. Figure8 shows a basic schematic block diagram of feature-based methods. We have divided the review of such methods into three subsections: (i) Natural scene statistics, (ii) Pixel-based features, and (iii) Pixel-based features and artifacts.

A basic scheme for NR-P-based assessment of visual quality using measures of various features.
1.5.1 Natural scene statistics
It has been claimed in[92] that the distortion introduced in the nonlinear dependencies found in natural images can be quantified for making an estimate of perceptual quality. Based on that notion, the authors presented an NSS-driven approach for quality assessment of images processed by wavelet-based compression standards like JPEG2000.
Similarly, the NSS-based image quality prediction approach presented in[99] is also limited to be applicable only to JPEG2000. The authors have used a neural network to regress between inputs from NSS-based spectral amplitude fall-off curves in combination with positional similarity measure of wavelet coefficients and the corresponding quality value.
Harnessed by the measures to keep the model attributes unaffected by image content variations, the method proposed in[100] uses a contourlet transform[101] to quantify the degradations incurred on NSS. The authors show that wavelet transform does not completely exhibit the artifacts present in the image and the effect of degradations is visible in all the subbands of the contourlet domain. Hence, the contourlet domain can be more effective in image quality assessment. The proposed method has a clear advantage in precisely predicting the image quality while tested for images degraded by JPEG2000 and JPEG compression and distortions like Gaussian blur, fast fading channel, and white noise. Similarly, a statistical relationship between the characteristics of NSS in images and the corresponding quality values was studied in[102] to engineer a reference-free quality method. In order to provide the quality ranking of the filtered natural images, a histogram of a combination of image transforms, namely, curvelet, wavelet, and cosine transform is computed. The considered distortions include noise, blur, and artifacts introduced by compression using JPEG2000 and JPEG. As the authors pointed out, this is one of the few quality methods which can quantify the perceptual impact of such a broad range of degradation types. The additional advantage of this method is its ability to classify images on the basis of the presence of one or more of these artifacts. The proposed method was tested on a large set of images from the LIVE image database as well as authors’ own test set of images. As a result, a promising level of correlation with subjective quality assessment was obtained.
The distortion identification-based image quality estimation method proposed in[103] offers an NSS-based approach of image quality prediction framework and algorithm. Firstly, the pertinent distortion is identified. Then, NSS features are used to quantify the relevant quality value which is largely independent of the distortion type present in the image. The used feature set describes (i) scale and orientation selective statistics, (ii) orientation selective statistics, (iii) correlations across scales, (iv) spatial correlation, and (v) across orientation statistics. Support vector regression is used to train the model, and the proposed method is proved to be comparable in precision of assessment to full reference methods such as peak signal-to-noise ratio (PSNR) and SSIM. The method was evaluated on images found in TID2008 and LIVE databases. It was found quite closely correlated to subjective assessment of image quality and hence proved itself to be test-set independent.
The idea of the impact of distortions on NSS has been used in[104] for prediction of video quality where each frame of the video is decomposed into a Laplacian pyramid of a number of subbands. Intra-subband statistics including mean, variance, skewness, kurtosis, energy, entropy, and inter-subband statistics, namely, Jensen Shannon divergence, SSIM, and smoothness are computed. A Minkowski pooling scheme is adopted to yield a single value out of the aforementioned statistics. The proposed method is reported to perform better than some FR metrics while tested on the LIVE video quality database.
Similar to NSS, a basic model is presented in[105] to develop an NR quality method based on temporal statistics of videos called as natural motion statistics (NMS). The theory of independent component analysis (ICA) has been applied in order to compute NMS. The authors have shown that independent components calculated from the optical flow vectors of a video signal follow the Laplacian distribution. Consequently, it has been observed that the root mean square (RMS) error of the fit between the extracted independent components and Laplacian distribution can be used as an indicator of video quality.
Saad et al. have presented their DCT statistics-based image integrity index in[106]. The central idea is to track the change in particular statistics of an image while it traverses from being original to a distorted one. The proposed framework is mainly DCT based. Owing to the perceptual relevance, some features representing structural information and contrast of an image have been extracted from the DCT values at two levels of spatial sampling. An improved version of this approach is found in[107] where the impact of NSS features for various perceptual degrees of degradation has been added.
In contrast to most of the approaches mentioned before that involve transformation of an image into another domain such as DCT, the NSS-based quality estimator presented in[108] performs in the spatial domain. Locally normalized luminance and its products-based empirical distribution is used to compute quality relevant features for building a spatial NSS model. The performance of the proposed method has been found to be better than FR methods such as PSNR and SSIM. The authors have validated the NR application of this method by employing it in an image denoising system. A similar approach has been adopted in[109] to define latent quality factors that were used to estimate the image quality.
The idea of NSS features-based quality estimator has been used in the case of stereoscopic images as well. In reference[110], 2D- and 3D-based statistical features are extracted from stereopsis to estimate the image quality. A support vector machine model has been trained using these features, and the model has been tested using the LIVE 3D database.
1.5.2 Pixel-based features
There are some methods of no-reference quality estimation which rely on certain statistics, mainly spatial features, derived from pixels of an image or video to perform the corresponding perceptual quality evaluation. In[111], the authors present an example where they have used objective features related to energy, entropy, homogeneousness, and contrast from the color correlogram of an image. These features have been used to train an ANN which serves as a prediction model. Li et al.[112] have also deployed an ANN-based model to devise a quality estimation method using perceptually relevant image features including phase congruency, entropy of the degraded image, and gradient of the degraded image. The importance of phase of an image for its fidelity representation is well known, and the gradient of an image is an implication of changes in the luminance of an image. An ANN model is also used in the image semantic quality method presented in[96] where a variety of quality descriptive features have been used. The authors argue that the overall visual quality can be seen in terms of the usefulness and naturalness of an image. Sharpness and clarity are considered as the representatives of usefulness of an image, whereas brightness and colorfulness represent naturalness. These four representations of usefulness and brightness are further branched into a large set of pixel-based features; edge pixel distribution, contrast, mean brightness, and color dispersion are a few of the used 14 features. The advantage of using higher number of features has been shown by better performance of the predictor.
Compared to the aforementioned methods that rely on the process of training a particular model by using an extracted set of features, the pixel-activity-based method proposed in[113] does not use such methodology. The focus here is on the activity map of an image, essentially controlled by features, namely, monotone-changing, zero-crossing (ZC), and the existence of inactive pixels, which are calculated for non-overlapping image blocks. The concept of ZC has been used to refer to the places in the Laplacian of an image where the value of the Laplacian passes through zero, i.e., the points where the Laplacian changes sign. Such points often occur at edges in an image. The use of ZC as a constituent of an activity map is justified as the method was proposed for JPEG2000 encoded images; and ringing, which can be caused by JPEG2000-based compression, has the potential of generating ZC around contours. Moreover, spatial features consisting of edge information and pixel distortion have been used to predict quality of JPEG2000 encoded images in[114]. Pixel distortion is computed using standard deviation of a central pixel and a measure of difference between central pixel and its closest neighbor pixels. Edge information relies on zero-crossing rate and a histogram measure. Particle swarm optimization has been employed to integrate these features into a single quality index. The authors have presented a similar method in their contribution[115].
The notion of quality estimation with regards to structural changes in images as a result of distortions has gained widespread attention. The FR method SSIM[94] is a commonly used representative method of this area. Zhang et al.[97] have put forward a similar approach of quality estimation based on structural changes. However, the nature of the particular distortion should be known beforehand. This method can be used to evaluate degradation caused by the following artifacts but one set at a time: (i) Gaussian blur and noise, (ii) blur and ringing, and (iii) blockiness. In a nutshell, local structural activity is taken in the form of direction spread whereas structural activity weight is computed through a measure of structural strength and zero-crossing activity.
Some feature-based methods make use of the properties of HVS to govern the performance of the method for better correlation with subjective assessment. A 3D multispectral wavelet transform-based method of NR quality estimation for color video has been given in[116]. Various channels of the HVS have been represented by wavelet decomposition of the video. To invoke the impact of the HVS, a perceptual mask of sensitivity with integrated impacts of spatio-temporal contrast and luminance has been applied to all wavelet bands. The final step is to draw a perceptual mask weighted flow tensor between successive frames to define the method. An ANN has been used in[117] with an extreme learning machine (ELM) algorithm for determining the relationship between spatial statistics of an image and its corresponding quality. These statistics are mainly HVS-inspired features, namely, edge amplitude, edge length, background activity, and background luminance of an image. As the proposed method is basically targeted at JPEG encoded images, some of the underlying methodologies which help calculate these features are focused on computation of blockiness. Since DCT coding is used in video coding also, the proposed algorithm can be generalized to be workable for video quality assessment.
In the experiments on determining the visual interest for different objects and locations inside an image, it has been found that HVS perception is not spatially uniform. Instead, there are specific areas called region of interest (ROI), which draw more attention and hence contribute more towards overall quality assessment of an image. Treisman et al.[118] observed that the visual system notices and codes different features in parallel channels before the observer actually recognizes the objects in an image. Features such as color, brightness, and orientation can be pooled together to form a unique entity to be observed. Based on this observation, there exist IQA methods which assess perceptual quality of an image by focusing mainly on those ROIs. One such method is proposed in[119] where the impact of importance of various ROIs in a video frame has been integrated into a wavelet-based just noticeable difference (JND) profile of visual perception. The proposed method works better than some contemporary methods when it was tested on the VQEG Phase I database.
In order to estimate the impact of packet loss impairments on video quality, a method based on edge strength around macroblock boundaries is proposed in[51]. Edge strength values are processed through a low-pass filter, and a threshold value is applied to compute the edge maps of adjacent rows. Finally, the impact of packet loss is computed through a difference between these edge maps.
In order to quantify the quality of enhanced images, the method given in[120] divides an image into smooth and textured areas. A JND formulation of perception is derived based on the local average brightness and local spatial frequency. The effect of enhancement is monitored through a comparison of local brightness and a JND threshold. The performance of the proposed method is reported to be better than that of conventional average local variance-based methods.
Features-based assessment of the content of an image or video can be used in the estimation of perceptual quality. Ries et al. have shown the relevance of the content class of videos in the process of determination of the visual quality in[121]. The authors classify a given set of videos into five groups based on the content. One of such group, called class here, contains videos which have a small moving ROI with a still scene in the background. Another content class has videos with huge spread of angle of movie capturing device and is called panorama. These content classes are created based on the statistics that are mainly related to motion dynamics of a video. Values of zero motion vector ratio, mean size of motion vector, uniformity of the movement, horizontalness of movement, and greenness are the classification parameters which are used to segregate the set of videos into different content classes. The central idea of the method is to first check the content class of a video and then estimate the visual quality based on bitrate and frame rate. The authors continued working on the same idea in their contribution found in[122] where they have presented a method aimed at the most common content classes of videos for handheld devices. Khan et al. have proposed a content-based method to combine encoding and transmission level parameters to predict video quality in[123]. Based on spatio-temporal features, the videos are first divided into content-based groups using cluster analysis. Adaptive network-based fuzzy inference system (ANFIS) and a regression model have been used separately to estimate the quality score. As per their results, transmission parameters like packet error rate have more impact on the quality than the compression parameters such as frame rate etc. The underlying techniques of ANFIS model and content clustering have been used in the authors’ other contributions as given in[124, 125].
1.5.3 Pixel-based features and artifacts
Some of the existing no-reference perceptual quality assessment methods are composed of a set of spatial features combined with some measurement of artifacts. A set of spatial artifacts has been combined with some spatial image features to estimate perceptual image quality in[126]. An ANN model was trained with these features for the quality prediction. Working on a similar approach, the method presented in[127] integrates spatial features such as picture entropy (represents the amount of information of a picture) and frequency energy (distribution of frequency energy in images) with artifacts, namely, blur and blockiness. The proposed method seems prominent because of its use of the chrominance information also while most of the contemporary quality measures are based on statistics from the luminance channel only. In this contribution, it has been shown that extraction of these features from ROI further improves the value of correlation with subjective scores. Five features of quality significance have been used to model an ANN-based quality predictor in[128] where the features set constitutes a measure of artifacts such as blocking and ringing and spatial statistics such as zero-crossing rate, edge activity measure, and z-score. Another method built on similar principle is found in[129] where the amount of blurring and blocking has been combined with spatial activity in an image and predictability of an image. A partial least square regression (PLSR) approach has been used to determine the function between these features and the quality value.
The approach given in[130] uses local segmented features related to degradation and dissimilarity for quality estimation of 3D images. In fact, the essential methodology used in[114] for 2D images have been extended to be employed for 3D images in[130]. One of the key means used to check disparity in left and right images of a stereoscopic image is the block-based edge information measure.
The authors in[131] propose a method for the assessment of facial image quality. Eye-detection, sharpness, noise, contrast, and luminance values of a test image are calculated. A weighted sum of these quantities constitutes the value of the quality method. In view of the discussion presented in[132], relatively more weighting has been given to sharpness and eye-detection as they are more important for determining facial image quality.
In[133], a set of artifacts, namely, blocking, ringing, truncation of the number of bits for image values, and noise is combined with a set of features including contrast and sharpness for designing a video quality prediction method. Each of these parameters is fitted separately in a functional relationship with subjective assessment of quality such that the correlation between the parameter values and subjective scores is maximized. Subsequently, these individual fitting functions are merged together to form a joint relationship with the perceptual quality. The data used for training includes original videos as well as different combinations of sharpness-enhanced and noise-contaminated videos. The trained model is tested on another data set which reveals a promising correlation with subjective scores.
Unlike the aforementioned NR-P-based artifacts or features measures-based methods, the mean square error distortion due to network impairments for a H.264/AVC encoded video is computed in[134]. An estimate of MSE is computed using the pattern of lost macroblocks due to an erroneous transmission of the video. Information about the lost macroblocks is estimated through the traces of the error concealment process. The same methodology has been enhanced in[135] for more general application scenarios such as no assumption is done about a certain error concealment algorithm and it does not require the knowledge of exact slicing structure.
1.5.4 Discussion
From the review of the features measures-based methods, we can make some general observations. The approach of estimating visual quality by quantifying the impact of distortions on natural scene statistics has gained a wide interest to gauge degradations due to different image processing techniques including compression. However, more of such approaches should be tested in the case of videos as well. Moreover, assessment of quality degradation due to network impairments using NSS-based approaches could be useful. The pixel-based and features-based approaches can be seen as composed of techniques that rely on a variety of spatial features including those related to edges, contrast, and some measures of structural information. The performance of these approaches can be enhanced by adapting the computational procedure with regards to the input of HVS preferences. Additionally, including the impact of mostly occurring artifacts such as blurring, blocking, or noise could be an advantage. We observe that most of the pixel domain features-based approaches have been designed for images and it is desirable to generalize the relevant methods for applications in the case of videos. Temporal pooling quality methods such as Minkowski summation or other methods such as adaptive to perceptual distortion[136] can be used for this purpose. Table2 presents a summary of some of the methods discussed in this section. It is evident that most of the methods in this category exhibit very promising performance, with correlation coefficient values equal to or higher than 0.85.
1.6 Bitstream-based methods
An estimate of the quality of an encoded video can be made by parsing the coded bitstream to deliver readily available features such as encoding parameters and network quality of service (QoS)-related parameters. The methods that adopt the usage of the bitstream data for quality estimation avoid the computational complexity of processing the full video data, as full decoding of the input video is not usually required in the case of bitstream-based methods. Another advantage of this type of methods is the use of readily available information from the bitstream that is significant for the quality estimation, for example, the motion vectors, coding modes, and quantization parameter values. However, these methods are inherently coding standard specific as different encoders have different formats of bitstream. There is a range of quality relevant features that can be extracted by partial decoding or primary analysis of the bitstream data. The performance of such methods significantly depends upon the level of access to the bitstream[137]. A block diagram of general framework in bitstream-based methods is given in Figure9. We have divided the discussion of these methods into three categories based on the level of information used for processing, in accordance with the standardized models recommended by telecommunication standardization sector of International Telecommunication Union (ITU-T), as discussed in[138, 139]. This includes parametric models (parametric planning model and parametric packet-layer model) and bitstream layer model. In the former type, extrinsic features of a video that are of parametric nature such as bitrate, frame rate, and packet loss rate are used. Bitstream layer models have detailed access to the payload and intrinsic features related to a video such as coding modes, quantization parameter, and DCT coefficients. The standardization of these models includes the methods designed for estimation of audio quality as well, but our discussion is limited to video quality only.

A basic scheme used for video quality assessment methods based on bitstream-based features.
1.6.1 Parametric planning model
The parametric planning models have rather low complexity as they do not access the bitstream and utilize bitrate, codec type, and packet loss rate for making a crude estimation of video quality. The work item related to this category in ITU-T is known as Opinion model for video-telephony applications, G.1070[140]. ITU-T Recommendation G.1070 proposes a method for the assessment of videophone quality, based on speech and video parameters, that can be used by the network performance planners for ensuring the given level of end-to-end quality of the service. A quality prediction model for MPEG-2 and H.264/AVC encoded videos for IPTV is presented in[141]. The model takes some parameters related to encoding information, packet information and client information to assess the overall quality. In reference[142], a parametric model is proposed that is based on a simple method of estimating MSE that occurs due to a given pattern of packet loss. The authors derived a relationship between average motion vector length and MSE and this relation gives a fair estimate of the actual MSE.
1.6.2 Parametric packet-layer model
The packet layer models have access to the packet header of the bitstream and can extract a limited set of parameters including bitrate on sequence or frame level, frame rate and type, and packet loss rate. Parametric packet-layer models are also known as QoS-based methods. The work item related to this category in ITU-T is known as non-intrusive parametric model for the assessment of performance of multimedia streaming (P.NAMS)[143]. The visual quality estimation method proposed in[144] presents an approach where it is not required to decode the video at any level, suitable for situations where the encoded video is encrypted. Given the observation that error concealment is more effective when there is less motion in the video, an estimation of the motion dynamics of a particular video is required to assess the effectiveness of an error concealment strategy. In this method, the ratio of the average of the B (bi-predictive coded) frame data size to the average of the size of all frames is compared with a predetermined threshold to adjust the value of the video quality score. The results obtained from the effectiveness of error concealment are refined by adjusting the values in accordance with the importance of the region in which the error has occurred.
The models in[141, 145] are designed for H.264/AVC coded SD and HD videos where a support vector machine (SVM) classifier has been used to assess the video quality based on the visibility of packet loss. By the same research group, the packet layer model presented in[146] uses video resolution, bitrate, packet loss rate, and some information of the codec settings to design a quality estimator for H.264/AVC- and MPEG-2-based encoded videos. An improvement on such statistical parameters-based models is found in[147] where temporal and spatial characteristics of a video are estimated from the packet header to build a content-adaptive model for quality assessment. The no-reference method presented in[148] is based on a nonlinear relationship between an objective quality metric and the quality-related parameters. To make it computationally simple, the authors have used only two parameters, namely, packet loss rate and the value of the interval between intra-frames of a video.
In[149], the authors have presented preliminary results of their investigation into streamlining the impacts of different conditions of packet loss over visible degradation to classify packet loss as visible or invisible. The parameters used in the decision making are extracted from the encoded bitstream. This model was tested for SD resolution H.264/AVC coded videos. If 25% or less subjects perceived an artifact, such a packet loss event was classified as invisible. If 75% or more subjects perceived an artifact, the corresponding packet loss event was classified as visible. In this case, the artifacts perceived by subjects between 25% and 75% were not accounted for at all. This issue was addressed in the authors’ later contribution[150] where all artifacts perceived by less than 75% subjects were classified as invisible. Moreover, they extended the model by including more quality-relevant parameters and generalized it by testing it on HD videos. The authors applied the same model for High Efficiency Video Coding (HEVC) encoded videos to examine its cross-standard performance, as reported in[151]. It was observed that the artifact visibility slightly increases while changing from H.264/AVC to HEVC-based video coding.
1.6.3 Bitstream layer model
In the bitstream-based methods, bitstream layer models have access to most of the data that can be used for the video quality estimation. The work item parametric non-intrusive bitstream assessment of video media streaming quality (P.NBAMS)[152] in its mode 1 (parsing mode) is related to the bitstream layer models. In this mode, it is allowed to do any kind of analysis of the bitstream except the usage of the pixel data. The input information includes parameters extracted from the packet header and payload. Besides the parameters included in the parametric models, this model uses QP, DCT coefficients of the coded video, and pixel information. This makes the model comparatively more complex but it generally offers better performance. A low-complexity solution of video quality prediction based on bitstream extracted parameters is found in[153]. The features used are mainly related to the encoding parameters and are taken on sequence level. Low complexity has been achieved by using a simple multilinear regression system for building the relationship between the parameters and quality values. An improvement of this approach is presented in[154] where the required number of parameters has been reduced for computational efficiency and the prediction accuracy has been improved by the virtue of the usage of an ANN. A further improvement is found in[155] where a larger features set is used and the prediction of subjective MOS is also performed. A set of 48 bitstream parameters related to slice coding type, coding modes, various statistics of motion vectors, and QP value was used in[156] to predict the quality of high-definition television (HDTV) video encoded by H.264/AVC. PLSR was used as tool for regression between the feature set and subjective assessment. This method outperformed the authors’ earlier contribution[129] and some contemporary objective methods of visual quality assessment.
H.264/AVC employs an in-loop filter to suppress blocking, and this filter has a specific parameter called boundary strength (BS) assigned to transform blocks. Statistics of BS combined with QP and average bitrate has been used in[157] to predict quality of H.264/AVC encoded videos. The proposed method formulates a linear combination of these parameters and a linear regression was conducted to determine its relationship with the subjective assessment scores. A motion-based visual quality estimation method was proposed in[158] for H.264/AVC encoded videos. In this method, some statistical features related to motion vectors along with bitrate and frame rate are calculated. PCA is used to identify the parameters most influential in the estimation of video quality value. Finally, the selected set of features is fed to an equation of quality computation. The inclusion of motion features into the reference-free quality assessment is justified by the fact that the reduction in visual quality is less for a certain level of compression when the motion is low, for example, the case of videos with static scenes.
A PSNR estimator for H.264/AVC encoded video is presented in[159] where bitrate, QP value, and coding mode are used as the features for quality prediction. The method given in[160] uses QP and block coding mode parameters for quality prediction of H.264/AVC encoded videos.
Based on an opinion model from ITU-T[140], an automatic QoE monitoring method is proposed in[161]. It depends on the network level information derived from packet loss pattern and loss rank of a frame in a group of pictures (GOP) and a measure of motion vectors to represent motion activity to train an ANN model against subjective scores of expert viewers.
In[162], the authors proposed a framework for quality estimation where a QoS parameter, packet loss rate, is combined with spatial and temporal complexities of a video. Usually, a complete decoding of the video is required to estimate its spatial and temporal complexity as these complexity values are generally obtained by an average measure of the pixel variance of codeblocks in a frame. However, the authors have proposed a method of estimating spatial and temporal complexity from the bitstream information only. Specifically, they have developed a rate-distortion model for QP value and bitrate which helps in estimating the complexity measure. Combining this complexity estimate with effects of packet loss delivers a measure of frame quality. Temporal domain quality degradation is computed through occurrences of frame freeze or frame loss. An overall estimate of the video quality is made by a pooling scheme which integrates the spatial and temporal quality indicators. The authors have argued that the suggested method can be used for real-time video services due to its fair accuracy and efficiency in computational cost.
In[163], the impact of compression on quality estimated through MSE prediction using DCT coefficients data[164] is combined with (i) a packet loss model similar to the one presented in ITU-T Recommendation G. 1070[140], (ii) a frame type-dependent packet loss model, and (iii) a frame type- and error pattern-dependent model separately. It was concluded from the obtained results that a combination of[164] and (iii) offers the best prediction of visual quality of these three combinations.
Bitstream layer methods can also utilize the DCT coefficients data of the encoded image or video, as it can be obtained by partial decoding[138]. There are several such methods which make a quality estimate based on the statistics of the DCT coefficient values. Eden[165] has proposed an algorithm for estimation of PSNR using the assumption that the probability distribution function (pdf) of DCT coefficients follows Laplacian distribution for H.264/AVC encoded videos. A modified Laplacian model for estimation of DCT coefficients distribution has been presented in[166] for JPEG images. The authors proposed to use maximum likelihood with linear prediction estimates to compute the parameter λ (lambda) of the Laplacian pdf, where λ is a parameter of the distribution. Investigation of the correlation between distribution parameters at adjoining frequencies and integration of the prediction results using maximum-likelihood parameters are the key components of this method. They have also used Watson’s model[167] for perceptual weighting of local error estimates in an image. The method given in[166] has been upgraded to be workable for videos in[168]. Here, the video quality predictor has a local error assessment unit, besides having statistics from motion vectors. These values are passed to a perceptual spatio-temporal model that incorporates the HVS sensitivity to produce the visual quality score. Two more methods based on the similar approach from these authors are PSNR estimation for H.264/AVC encoded videos[169] and PSNR estimation for MPEG-2 encoded videos as given in[170].
Contrary to the assumption of Laplacian distribution to model DCT coefficients, it has been argued in[171] that a Cauchy distribution better suits the H.264/AVC encoded data in the process of quality estimation. The proposed approach has been found to be better than the Laplacian distribution[165] in terms of bias between the actual and estimated values of PSNR.
The authors in[172] have used DCT basis functions to evaluate kurtosis measure of images for quality assessment. Three different kinds of kurtosis measures have been made, namely, 1D kurtosis based on frequency band, basis function-based 1D kurtosis, and 2D kurtosis. However, the proposed scheme is meant only for images degraded by blur and it has been tested on LIVE[14] data set JPEG2000 encoded images.
Nishikawa et al. presented a PSNR estimation method of JPEG2000 coded videos in[173] which is actually a no-reference version of their earlier article that needed reference information[174]. The method estimates the PSNR by using wavelet coefficients from the neighboring frames of the frame which has lost some compressed codeblocks. It is assumed that the effect of packet loss upon codeblocks is possible to compute at the receiver end, given that only packet loss occurs and no bit errors exist.
1.6.4 Discussion
Bitstream-based methods of VQA have recently received a significant attention for their computational simplicity and applications in the online quality monitoring. Potentially, the main advantage of these methods is the variety in choice of the features which can be used for quality estimation that in turn means the privilege of adapting to the desired level of complexity. As compared to pixel-based processing, the bitstream-based methods have special advantage of having access to readily available information such as bitrate, frame rate, QP, motion vectors, and various types of information regarding the impacts of network impairments. However, these methods are coding scheme specific that makes them less generally applicable. In the case of parametric planning models, the performance of quality estimation remains limited due to the constraints of the information that can be obtained from the allowed level of access to the bitstream. Packet layer models have better performance with popular application in intermediate nodes of a network as they do not need complex processing and decryption of the data. Bitstream layer models are superior in the performance and the complexity can be flexible depending upon the desired level of accuracy. For possible future works in this area, some comparative performance reports of various models, such as the ones presented in[139, 175] would be useful to further accelerate the research in designing better bitstream-based VQA approaches. As we notice in the summary of bitstream-based methods in Table3, the research community has mostly embraced H.264/AVC-based coding for the design of such methods. It would be advantageous to develop such methods for other popular coding standards as well. Moreover, analysis of the features relevant for quality estimation for the recently approved ITU-T standard of video coding, namely, H.265/HEVC[176] would be useful. For example, in[177], it has been shown that the existing methods of MSE estimation are not feasible for HEVC as it has significantly different coding structure as compared to the previous standards.
1.7 Hybrid of NR-P and NR-B methods
There are no-reference visual quality estimation methods which combine features from the coded bitstream and some statistics from the decoded media. This type of methods inherits the simplicity of computation from the bitstream-based approaches, and further accuracy in quality estimation is achieved by adding input from the pixel-based approaches. Therefore, such methods can avoid some of the difficulties involved in the pixel and bitstream-based methods[178]. One such example is the fusion of artifacts like blocking or blurring with parameters derived from motion vectors to build up a quality estimation method. The work item P.NBAMS[152] in its mode 2 (full decoding mode) is related to the hybrid models where the information from the coded bitstream as well as reconstructed video can be used. Figure10 gives an overview of the methodology used in this type of methods. Essentially, the choice of the features for extraction from bitstream or pixel domain depends on the design requirements of a method, the availability of a certain type of data for quality estimation, and the encoding scheme. The discussion on this class of methods is divided into two categories, namely, pixel-based and bitstream-based features or artifacts, and statistics of transform coefficients.

A basic scheme for quality assessment methods based on hybrid of NR-P- and NR-B-based approaches.
1.7.1 Pixel-based and bitstream-based features or artifacts
Video quality-related features and measures of artifacts can be computed both from the pixel and bitstream data and can be pooled for an overall quality estimate. One such method which focuses on quantifying the perceptual quality of H.264/AVC encoded videos degraded by loss of packets in the IP networks is presented in[179]. The error incurred due to packet loss becomes propagative due to the two types of coding predictions involved in H.264/AVC encoders, namely, intra-prediction (spatial) and inter-prediction (temporal) at the encoder end. Even more errors can be introduced while the decoder tries to conceal for the prediction residuals and/or motion vectors lost due to missing packets in the IP bitstream. For simulating the packet loss conditions, a packet loss rate in the range [0.1, 20]% with error patterns generated using a two-state Gilbert model set for average burst length of three packets was used. Quantitatively, the measures involved in the modeling of the proposed method encompass the impact of errors due to concealment, errors propagated due to loss of reference MBs, and the channel-induced degradation due to H.264/AVC-specific coding techniques. The calculations of these distortions are done on the macroblock level, and the resulting values are summed up to frame and sequence levels. It has been observed that the proposed method yields results which bear good correlation with SSIM[94]. Another method was presented by the same authors in their earlier published contribution[180] where the effects of loss of motion vector information and prediction residuals were incorporated for quality estimation. A method in which transmission and compression artifacts are integrated for VQA is presented in[181]. The constituents of the method are estimations of blockiness, blurring, and packet loss ratio.
Two MPEG-4 encoded video quality prediction methods based on several MB level statistics, derived from bitstream and reconstructed videos, are reported in[182] for PSNR and in[183] for SSIM. A plethora of bitstream-based and pixel-based features at macroblock level have been used in these two methods. One of the distinctive aspects of these two contributions is the usage of different models for system identification between the parameters and the corresponding quality index. In the method targeted for PSNR estimation, spectral regression and reduced model polynomial network have been employed. A multipass prediction system based on stepwise regression has been used in the estimation of SSIM method. The statistical features in both of the methods constitute mainly the coding information of an MB, some relative measures of motion vector of neighboring MBs, and some numerical values related to the texture of an MB.
Average QP values were combined with pixel difference contrast measure values to offer a visual quality method in[184]. The authors have shown that the method outperforms PSNR for a wide range of bitrates of H.264/AVC encoded videos. Similarly, two parametric models have been combined in[185] to design a hybrid model of perceptual quality for H.264/AVC encoded videos. This method uses average value of QP and an average measure of contrast from the decoded video, besides having input from noise masking property of the video content.
A hybrid of bitstream-based and pixel domain quality estimator is proposed in[186]. It has been argued that a video quality estimation merely based on the amount of impaired macroblocks could be erroneous as, in modern video decoders, some error concealment methods are applied to cure the impaired macroblocks and this concealment is not accounted for in such estimations. As the error concealment may not always be effective, the proposed method uses motion intensity and luminance discontinuity measures to estimate the number of impaired macroblocks for which error concealment remains ineffective. In essence, the visual quality, in terms of MSE, is estimated directly based on the macroblocks for which the error concealment could not perform well. The same authors have generalized this approach for three methods of error concealment and a different value of packet length in[187].
In order to estimate the impact of transmission errors on the quality of H.264/AVC encoded videos, a saliency map-based method is proposed in[188]. Color, contrast, and luminance information has been used to compute spatial saliency map, while motion vector information, readily available in coded bitstream of a video, has been exploited for the computation of temporal saliency maps. A squared sum of spatial and temporal saliency maps has been used to pool them together for computing the overall spatio-temporal map. Accordingly, this map is used for weighting of an error map for each video frame to calculate the value of the proposed model.
Another hybrid method of perceptual quality measurement, which is based on information from the bitstream and spatio-temporal image features, is presented in[189]. The weighted Minkowski method is employed to integrate the average quantization scale with their proposed measures of flickering and blocking for H.264/AVC encoded videos.
A framework for a hybrid method for videos transmitted over long term evolution (LTE) networks is proposed in[190]. It suggests to include parameters from packet layer (packet loss rate, packet size), bitstream layer (frame error, frame duration), and media layer (blurring, blocking) for estimation of the quality. However, a suitable pooling scheme to integrate these parameters into a quality indication value remains as a future work.
1.7.2 Statistics of transform coefficients
In some cases, the transform coefficients can be obtained through partial decoding of the coded bitstream data and features from bitstream as well as pixel domain can be combined for the quality estimation. One such example is found in[191] where an estimate of PSNR has been computed for MPEG-2 coded videos using DCT coefficients. This is actually an improved version of the authors’ earlier contribution[192] in which they modeled the distribution of DCT coefficients as a Laplacian pdf to calculate PSNR of the video frames one-by-one for all types, i.e., I, P, and B frames. However, it lacks in accuracy of assessment for B frames. Therefore, the authors conjectured that this happens as a result of fall in the amount of DCT coefficients information which is available for B frames due to processes of rate control and motion compensation. Henceforth, a hybrid approach to resolve this issue has been found in[191] where picture energy has also been used in addition to DCT coefficients. There is a significant improvement of correlation with estimated and actual PSNR, in the case when the proposed method was tested on SDTV and HDTV sequences.
1.7.3 Discussion
The hybrid methods use not only pixel-based information but also bitstream-based information, which in turn makes the hybrid framework having a potential of being the most accurate quality estimator as compared to the other approaches[193]. Thus, the importance of careful combination of the features from pixel and bitstream domains is evident. Further studies are needed to investigate the interaction among various types of artifacts due to compression and transmission and the joint impact towards the video quality.
Various approaches exist on how to combine the impact of various sources of degradation into one representative value for all the artifacts under consideration. In the recommendation ITU-T P.1202.1 that presents a complementary algorithm of NR quality assessment for the recommendation P.NBAMS[152], four types of degradations are sorted with respect to their impact on quality. The values of the two most significant artifact types are pooled together through a linear combination. A higher weighting is applied to the artifact value that is found to be the most significant out of the four types. As different artifact types can exist in different range of values, it is important that all of them are aligned to the same scale before the sorting is applied. Besides linear combination, some contributions[189] adopt the Minkowski metric[3] for pooling the values of different artifacts into a single quantity.
With regards to the preference on which a pooling strategy should be chosen it may depend on many factors including relative severity of different artifacts, spatio-temporal characteristics of the contents, and the presence of masking effects. Linear combination is more valid if the constituents can be related to the quality value through a linear regression. While combining different artifacts through a linear relation, different artifacts can be given different significance. For example, more weight is given to the impact of bitstream layer features than to media-layer features in the hybrid model given in[194]. On the other hand, the Minkowski metric of summation has its roots in additive properties of low-level vision. Therefore, it is required to find the suitable value of its exponent through measurements.
Most of the aforementioned hybrid methods make an assessment of quality in terms of MSE but this measure of quality is known to be rather inaccurate in representing the perceptual quality[195]. This fact necessitates the desire of enhancing such methods for better correlation with subjective quality assessment. As can be seen from the summary of hybrid methods in Table3, the main focus of the development of hybrid methods has been on videos.
2 Conclusions
Motivated by the growing interest in NR methods of quality assessment for images and videos, we have presented a classification and review of recent approaches proposed in this research area. The available contributions have been classified into different categories based on the methodologies used in the design. Recognized classifications and standardizations in the area have been extrapolated to introduce our approach of classification. The new classification enabled us to present a review of a large amount of recently published work. On the highest tier, three categories have been identified to group the existing NR methods. The NR methods that employ pixel domain approaches for quality assessment are called NR-P-based methods, and the methods that employ encoded bitstream and parametric information of the media signal are called NR-B-based methods. The third category is called hybrid methods which are designed by a composite of NR-P- and NR-B-based methods. A further subcategorization has been presented to organize the discussion of the review.
It is observed that the majority of the publications introduce methods that are processed in the pixel domain. This trend can be attributed to the rich heritage of work in the image processing area. In most cases, pixel-based methods require more processing power than bitstream-based methods. NR quality estimation is a widely adopted application in the area of online quality monitoring. It is thus required to employ computationally less complex methods. This fact necessitates to focus towards designing bitstream-based or hybrid methods. The distortions present in a network can introduce a variety of temporal perturbations in a video transmitted through it. Such perturbations have to be monitored by service providers to ensure a given threshold of visual quality at the end users’ premises. This can be performed using NR metrics which estimate the impact of degradation in the temporal domain. Unfortunately, most of the existing methods are designed to account for a single or a limited set of degradations. Therefore, it is not easy to make an estimate of the overall loss of visual quality. Hence, methods which can make a complete assessment of the quality are desirable. Similarly, attention can be drawn towards designing less complex methods which are not application specific, such as the methods that are not limited to a particular coding standard.
In the context of the reviewed methods, it is interesting to compare the approaches adopted in case of IQA and VQA methods. In case of IQA, the main focus has been on addressing the most occurring spatial artifacts such as blocking, blurring, and ringing as a result of popular compression techniques such as JPEG and JPEG2000. Besides many methods that are specifically designed for particular artifacts and hence have limited application, it is exciting to see many methods that are not restricted to a specific artifact type and have a wider application area. In such methods of global application, the mostly adopted approach is based on computing the impact of distortions on natural scene statistics of natural images. This also suggests that such approaches may not be applied to artificial images (such as animations and cartoons). This issue can be considered as a challenge for future work in IQA. More focus has been seen on the development of bitstream-based approaches in the case of VQA methods. This is of advantage in the sense that bitstream-based approaches have relatively low computational complexity. However, they face the drawbacks of being coding scheme specific and sometimes less accurate. We believe that the development of more robust approaches based on hybrids of NR-P and NR-B methods may be beneficial to meet these challenges associated with the NR VQA area.
We observe that many of the existing contributions in NR IQA and VQA have reported the results of the proposed methods therein by doing the relevant performance tests on the publicly available test databases. This is useful for independent benchmarking and performance comparison tests of these methods by other researchers. Therefore, more variety in the content and resolution of the media available through public test databases would be of great value. On the other hand, one general drawback of many existing methods of NR quality assessment lies in the limited use of the test data, as the data used for the designing or training of a metric is often also used for its performance verification. This drawback actually does not allow to draw meaningful results from such studies. Also, it has been observed that most of the existing methods for video quality assessment are limited to one encoder implementation or rather one particular setting of an encoder. Hence, cross-encoder design of VQA metrics would be a useful contribution. Moreover, we enlist the following trends and directions towards future research in the area of NR quality assessment:
-
The trend of contribution in the NR quality estimation has been settling towards finding approaches of lesser complexity as shown by the growing interest in the bitstream-based methods. However, bitstream-based methods face the challenge of being limited for a specific codec. Given the fact that such methods have been shown to have promising performance by having reasonable values of correlation with subjective quality assessment, it would be advantageous to generalize the methodologies of these methods for diverse coding schemes.
-
The performance of the bitstream-based methods has been found to be largely content dependent, as the spatio-temporal perceptual complexities vary with varying content, and, in turn, the nature of the features used for quality estimation also changes. However, in the case of pixel-based methods, it is relatively easier to differentiate the content characteristics. Thus, it is required for bitstream-based models to be trained on a sufficiently high variety in content, enabling them to be used in practice. Future inventions can focus on the development of methods that can be applied in more general scenarios with the desired amount of variety in content.
-
The existing NR methods are usually designed and tested for cases where the quality difference is beyond the threshold of perception of an artifact, i.e., rather clearly visible. However, attention needs to be paid to scenarios where the test stimuli may already be of high quality. Future developments should therefore envisage the degradations that are considered in the category of subthreshold artifacts. The need of such methods becomes even more important with regards to the newly approved HEVC standard that supports ultra-high definition video resolutions of 4K and beyond.
-
It has been observed that emphasis is being put towards making the quality estimation more in line with the perceived quality by HVS. In the future, the NR quality assessment methods should continue to adapt for HVS parameters and further advancements in the understanding of HVS, such as attention-driven foveated quality assessment models[196] should be taken into consideration.
-
A robust combination of audio-visual quality estimators can be devised for designing scenario-dependent models. For example, in quality monitoring of sports video, more emphasis can be put on the visual component than audio as the viewers might be interested more in video. For example, a video of a football match would draw more focus towards visual scene than audio, as compared to news or head and shoulder scenario. Moreover, audio-visual quality estimation is challenging due to the complex interplay of HVS preferences. In terms of the mutual impact of audio-visual subjective quality, some studies report an average cross-modal interaction level of 0.5 MOS[197] to above 2 MOS points[198] on a scale of 1 to 5 quality rating.
-
Given the presented comprehensive literature review, it has been observed that developments of NR methods that consider visual attention are rather limited, especially, in the case of videos. As noted in[199], visual attention models can be integrated into existing NR methods to make them more robust. Generally, the advantage of including visual attention-based modeling appears to be larger for methods designed for video quality assessment than for image quality assessment methods. Visual attention becomes more significant in scenarios of audio-visual stimuli, as it is required to account for the cues from visual channels as well as auditory channels.
-
To make the quality estimation closer to the subjective assessment, intelligent methods are needed that consider the content preference and expectations of humans in a given scenario. For example, the subjective quality assessment results mentioned in[200] indicate that desirable content is rated significantly higher than the undesirable and neutral contents.
-
The task of finding the optimal trade-off between temporal and spatial resolution, and the level of quantization for its impacts on the perceptual quality in different scenarios of application, is challenging[201]. This issue should be taken into consideration for the future development of NR methods.
-
In order to combine independent and isolated approaches for the development of hybrid NR VQA methods, a five-point agenda has been identified by joint effort group (JEG) at VQEG[202]. We believe that such collaborative works will be instrumental in paving the ways of NR VQA towards a measurable evolution.
We believe that our contribution in this article can be utilized and extended in various ways. One can use this review as a systematic literature review to perform comparisons on a class of NR methods using the same image or video test database to highlight the state-of-the-art. Furthermore, this review can be very useful for the beginner researchers in this area to achieve a concise yet comprehensive overview of the field. This way, we expect this contribution to be instrumental for future research and development in the area of NR visual quality assessment. Moreover, a possible future work is to survey the contributions for audio-visual quality assessment based on NR paradigm, similar to[203] that deals with FR methods of audio-visual quality assessment.
References
Cisco Visual Networking Index: Global mobile data traffic forecast update, 2013-2018. Cisco white paper 2014.
ITU: ITU-R Recommendation BT.500-13 Methodology for the subjective assessment of the quality of the television pictures. . Accessed 4 November 2013 http://www.itu.int/rec/R-REC-BT.500-13-201201-I/en
Wu HR, Rao KR: Digital Video Image Quality and Perceptual Coding (Signal Processing and Communications). CRC, Boca Raton; 2005.
Hemami SS, Reibman AR: No-reference image and video quality estimation: applications and human-motivated design. Signal Process. Image Commun 2010, 25(7):469-481. 10.1016/j.image.2010.05.009
Wang Z, Bovik AC: Reduced- and no-reference image quality assessment. IEEE Signal Process. Mag 2011, 28(6):29-40.
Lin W, Jay Kuo C-c: Perceptual visual quality metrics: a survey. J. Vis. Commun. Image Representation 2011, 22(4):297-312. 10.1016/j.jvcir.2011.01.005
Vranješ M, Rimac-Drlje S, Grgić K: Review of objective video quality metrics and performance comparison using different databases. Signal Process. Image Commun 2013, 28(1):1-19. 10.1016/j.image.2012.10.003
Chikkerur S, Sundaram V, Reisslein M, Karam LJ: Objective video quality assessment methods: a classification, review, and performance comparison. IEEE Trans. Broadcasting 2011, 57(2):165-182.
Soundararajan R, Bovik A: Survey of information theory in visual quality assessment. Signal, Image Video Process 2013, 7(3):391-401. 10.1007/s11760-013-0442-5
Chandler DM: Seven challenges in image quality assessment: past, present, and future research. ISRN Signal Processing 2013, 53. (doi:10.1155/2013/905685)
Engelke U, Zepernick H-J: Perceptual-based quality metrics for image and video services: a survey. In EuroNGI Conference on Next Generation Internet Networks. Trondheim; 21–23 May 2007:190-197.
Reibman AR, Sen S, der Merwe JV: Analyzing the spatial quality of internet streaming video. In International Workshop on Video Processing and Quality Metrics for Consumer Electronics. Scottsdale; January 2005.
VQEG: Final report from the Video Quality Experts Group on the validation of objective models of multimedia quality assessment, phase I. 2008.http://www.its.bldrdoc.gov/vqeg/projects/multimedia-phase-i/multimedia-phase-i.aspx . Accessed 11 April 2014
Sheikh HR, Wang Z, Cormack L, Bovik AC: LIVE Image Quality Assessment Database. . Accessed 11 April 2014 http://live.ece.utexas.edu/research/quality
Video Quality Experts Group (VQEG) . Accessed 11 April 2014 http://www.its.bldrdoc.gov/vqeg/downloads.aspx
Ponomarenko N, Lukin V, Zelensky A, Egiazarian K, Carli M, Battisti F: TID2008 - a database for evaluation of full reference visual quality assessment metrics. Adv. Modern Radioelectron 2009, 10: 30-45.
Callet PL, Autrusseau F: Subjective quality assessment IRCCyN/IVC database. 2005.http://www.irccyn.ec-nantes.fr/ivcdb . Accessed 11 April 2014
Sazzad ZMP, Kawayoke Y, Horita Y: Image Quality Evaluation Database. . Accessed 11 April 2014 http://mict.eng.u-toyama.ac.jp/mictdb.html
Liang L, Wang S, Chen J, Ma S, Zhao D, Gao W: No-reference perceptual image quality metric using gradient profiles for JPEG2000. Signal Process. Image Commun 2010, 25(7):502-516. 10.1016/j.image.2010.01.007
Winkler S: Digital Video Quality: Vision Models and Metrics. Wiley, Chichester; 2005.
Narvekar N, Karam L: A no-reference image blur metric based on the cumulative probability of blur detection (CPBD). IEEE Trans. Image Process 2011, 20(9):2678-2683.
Ciancio A, da Costa ALNT, da Silva EAB, Said A, Samadani R, Obrador P: No-reference blur assessment of digital pictures based on multifeature classifiers. IEEE Trans. Image Process 2011, 20(1):64-75.
Marichal X, Ma W-Y, Zhang H: Blur determination in the compressed domain using DCT information. In IEEE International Conference on Image Processing. Kobe; 24–28 October 1999:386-390.
Tong H, Li M, Zhang H, Zhang C: Blur detection for digital images using wavelet transform. In IEEE International Conference on Multimedia and Expo. Taipei; 27–30 June 2004:17-20.
Marziliano P, Dufaux F, Winkler S, Ebrahimi T: Perceptual blur and ringing metrics: application to JPEG2000. Signal Process. Image Commun 2004, 19(2):163-172. 10.1016/j.image.2003.08.003
Ferzli R, Karam LJ: Human visual system based no-reference objective image sharpness metric. IEEE International Conference on Image Processing 2006, 2949-2952.
Ciancio A, da Costa ALN, da Silva EAB, Said A, Samadani R, Obrador P: Objective no-reference image blur metric based on local phase coherence. Electron. Lett 2009, 45(23):1162-1163. 10.1049/el.2009.1800
Hassen R, Wang Z, Salama M: No-reference image sharpness assessment based on local phase coherence measurement. In IEEE International Conference on Acoustics Speech and Signal Processing. Dallas; 14–19 March 2010:2434-2437.
Ferzli R, Karam LJ: No-reference objective image sharpness metric based on the notion of just noticeable blur (JNB). IEEE Trans. Image Process 2009, 18(4):717-728.
Ferzli R, Karam LJ: A no-reference objective image sharpness metric based on just-noticeable blur and probability summation. In IEEE International Conference on Image Processing. San Antonio, TX, USA; 16–19 September 2007:445-448.
Sadaka NG, Karam LJ, Ferzli R, Abousleman GP: A no-reference perceptual image sharpness metric based on saliency-weighted foveal pooling. In 15th IEEE International Conference on Image Processing. San Diego; 12–15 October 2008:369-372.
Narvekar ND, Karam LJ: A no-reference perceptual image sharpness metric based on a cumulative probability of blur detection. In International Workshop on Quality of Multimedia Experience. San Diego; 29–31 July 2009:87-91.
Narvekar N, Karam LJ: An improved no-reference sharpness metric based on the probability of blur detection. In Workshop on Video Processing and Quality Metrics. Scottsdale; 13–15 January 2010.
Varadarajan S, Karam LJ: An improved perception-based no-reference objective image sharpness metric using iterative edge refinement. In IEEE International Conference on Image Processing. San Diego; 12–15 October 2008:401-404.
Debing L, Zhibo C, Huadong M, Feng X, Xiaodong G: No reference block based blur detection. In International Workshop on Quality of Multimedia Experience. San Diego; 29–31 July 2009:75-80.
Marziliano P, Dufaux F, Winkler S, Ebrahimi T: A no-reference perceptual blur metric. In Proceedings of the International Conference on Image Processing 2002. Rochester, New York; 22–25 September 2002:57-60.
Maalouf A, Larabi M-C: A no reference objective color image sharpness metric. In The European Signal Processing Conference. Aalborg; 23–27 August 2010:1019-1022.
Wu S, Lin W, Lu Z, Ong EP, Yao S: Blind blur assessment for vision-based applications. In IEEE International Conference on Multimedia and Expo. Beijing; 2–5 July 2007:1639-1642.
Wu S, Lin W, Xie S, Lu Z, Ong EP, Yao S: Blind blur assessment for vision-based applications. J. Vis. Commun. Image Representation 2009, 20(4):231-241. 10.1016/j.jvcir.2009.03.002
Chen C, Chen W, Bloom JA: A universal reference-free blurriness measure. SPIE J. Image Q. Syst. Performance VIII 2011, 7867: 78670-7867014.
Chen M-J, Bovik AC: No-reference image blur assessment using multiscale gradient. In International Workshop on Quality of Multimedia Experience. San Diego; 29–31 July 2009:70-74.
Ferzli R, Karam L: A no reference objective sharpness metric using riemannian tensor. In International Workshop on Video Processing and Quality Metrics for Consumer Electronics. Scottsdale; 25–26 January 2007:25-26.
Chetouani A, Beghdadi A, Deriche M: A new reference-free image quality index for blur estimation in the frequency domain. In IEEE International Symposium on Signal Processing and Information Technology. Ajman; 14–17 December 2009:155-159.
Hua Z, Wei Z, Yaowu C: A no-reference perceptual blur metric by using OLS-RBF network. In Pacific-Asia Workshop on Computational Intelligence and Industrial Application. Wuhan; 19–20 December 2008:1007-1011.
Oprea C, Pirnog I, Paleologu C, Udrea M: Perceptual video quality assessment based on salient region detection. In Advanced International Conference on Telecommunications. Venice; 24–28 May 2009:232-236.
Chen C, Bloom JA: A blind reference-free blockiness measure. In Proceedings of the Pacific Rim Conference on Advances in Multimedia Information Processing: part I. Shanghai; 21–24 September 2010:112-123.
Liu H, Heynderickx I: A no-reference perceptual blockiness metric. In IEEE International Conference on Acoustics, Speech and Signal Processing. Las Vegas; 31 March to 4 April 2008:865-868.
Liu H, Heynderickx I: A perceptually relevant no-reference blockiness metric based on local image characteristics. EURASIP J. Adv. Signal Process 2009, 2009: 1-15.
Zhai G, Zhang W, Yang X, Lin W, Xu Y: No-reference noticeable blockiness estimation in images. Signal Process. Image Commun 2008, 23(6):417-432. 10.1016/j.image.2008.04.007
Babu RV, Suresh S, Perkis A: No-reference JPEG-image quality assessment using GAP-RBF. Signal Process 2007, 87: 1493-1503. 10.1016/j.sigpro.2006.12.014
Babu RV, Bopardikar AS, Perkis A, Hillestad OI: No-reference metrics for video streaming applications. In International Workshop on Packet Video. Irvine; 13–14 December 2004.
Zhang Z, Shi H, Wan S: A novel blind measurement of blocking artifacts for H.264/AVC video. In International Conference on Image and Graphics. Xian; 20–23 September 2009:262-265.
Hua Z, Yiran Z, Xiang T: A weighted Sobel operator-based no-reference blockiness metric. In Pacific-Asia Workshop on Computational Intelligence and Industrial Application. Wuhan; 19–20 December 2008:1002-1006.
Park C-S, Kim J-H, Ko S-J: Fast blind measurement of blocking artifacts in both pixel and DCT domains. J. Math. Imaging Vis 2007, 28: 279-284. 10.1007/s10851-007-0019-4
Suthaharan S: No-reference visually significant blocking artifact metric for natural scene images. Signal Process 2009, 89(8):1647-1652. 10.1016/j.sigpro.2009.02.007
Liu H, Klomp N, Heynderickx I: A perceptually relevant approach to ringing region detection. IEEE Trans. Image Process 2010, 19(6):1414-1426.
Liu H, Klomp N, Heynderickx I: A no-reference metric for perceived ringing artifacts in images. IEEE Trans. Circuits Syst. Video Technol 2010, 20(4):529-539.
Zuo B-X, Tian J-W, Ming D-L: A no-reference ringing metrics for images deconvolution. In International Conference on Wavelet Analysis and Pattern Recognition. Hong Kong; 30–31 August 2008:96-101.
Zuo B-X, Ming D-L, Tian J-W: Perceptual ringing metric to evaluate the quality of images restored using blind deconvolution algorithms. SPIE J. Opt. Eng 2009, 48(3):037004. 10.1117/1.3095766
Bovik AC: Handbook of Image and Video Processing. Elsevier Academic, Burlington; 2005.
Amer A, Dubois E: Fast and reliable structure-oriented video noise estimation. IEEE Trans. Circuits Syst. Video Technol 2005, 15(1):113-118.
Tian J, Chen L: Image noise estimation using a variation-adaptive evolutionary approach. IEEE Signal Process. Lett 2012, 19(7):395-398.
Olsen SI: Estimation of noise in images: an evaluation. CVGIP: Graph. Models Image Process 1993, 55(4):319-323. 10.1006/cgip.1993.1022
Rank K, Lendl M, Unbehauen R: Estimation of image noise variance. IEE Proc. Vis. Image Signal Process 1999, 146(2):80-84. 10.1049/ip-vis:19990238
Amer A, Dubois E: Fast and reliable structure-oriented video noise estimation. IEEE Trans. Circuits Syst. Video Technol 2005, 15(1):113-118.
Ghazal M, Amer A: Homogeneity localization using particle filters with application to noise estimation. IEEE Trans. Image Process 2011, 20(7):1788-1796.
Liu X, Tanaka M, Okutomi M: Noise level estimation using weak textured patches of a single noisy image. In 19th IEEE International Conference on Image Processing (ICIP). Orlando; 30 September to 3 October 2012:665-668.
Liu X, Tanaka M, Okutomi M: Single-image noise level estimation for blind denoising. IEEE Trans. Image Process 2013, 22(12):5226-5237.
Pyatykh S, Hesser J, Zheng L: Image noise level estimation by principal component analysis. IEEE Trans. Image Process 2013, 22(2):687-699.
Huynh-Thu Q, Ghanbari M: Temporal aspect of perceived quality in mobile video broadcasting. IEEE Trans. Broadcasting 2008, 54(3):641-651.
Borer S: A model of jerkiness for temporal impairments in video transmission. In International Workshop on Quality of Multimedia Experience. Trondheim; 21–23 June 2010:218-223.
Huynh-Thu Q, Ghanbari M: No-reference temporal quality metric for video impaired by frame freezing artefacts. In IEEE International Conference on Image Processing. Cairo; 7–10 November 2009:2221-2224.
ITU-T Recommendation J.247: objective perceptual multimedia video quality measurement in the presence of a full reference . Accessed 4 November 2013 http://www.itu.int/rec/T-REC-J.247/en
Yammine G, Wige E, Simmet F, Niederkorn D, Kaup A: Blind frame freeze detection in coded videos. In Picture Coding Symposium. Krakow; 7–9 May 2012:341-344.
Wolf S: A no reference (NR) and reduced reference (RR) metric for detecting dropped video frames. In International Workshop on Video Processing and Quality Metrics for Consumer Electronics. Scottsdale; 15–16 January 2009.
Watanabe K, Okamoto J, Kurita T: Objective video quality assessment method for evaluating effects of freeze distortion in arbitrary video scenes. Proc. SPIE-Image Qual. Syst. Perform. IV 2007, 6494: 64940-1649408.
Watanabe K, Okamoto J, Kurita T: Objective video quality assessment method for freeze distortion based on freeze aggregation. Proc. SPIE- Image Qual. Syst. Perform. III 2007, 6059: 1-8.
Yang K-C, Guest CC, El-Maleh K, Das PK: Perceptual temporal quality metric for compressed video. IEEE Trans. Multimedia 2007, 9(7):1528-1535.
Pastrana-Vidal RR, Gicquel J-C: Automatic quality assessment of video fluidity impairments using a no-reference metric. In International Workshop on Video Processing and Quality Metrics for Consumer Electronics. Scottsdale; 22–24 January 2006.
Pastrana-Vidal RR, Gicquel J-C: A no-reference video quality metric based on a human assessment model. In International Workshop on Video Processing and Quality Metrics for Consumer Electronics. Scottsdale; 25–26 January 2007.
Battisti F, Carli ANM: No-reference quality metric for color video communication. In International Workshop on Video Processing and Quality Metrics for Consumer Electronics. Scottsdale; 19–20 January 2012.
Oelbaum T, Keimel C, Diepold K: Rule-based no-reference video quality evaluation using additionally coded videos. IEEE J. Select. Topics Signal Process 2009, 3(2):294-303.
Choi MG, Jung JH, Jeon JW: No-reference image quality assessment using blur and noise. Int. J. Comput. Sci. Eng 2009, 3(2):76-80.
Cohen E, Yitzhaky Y: No-reference assessment of blur and noise impacts on image quality. Signal, Image Video Process 2010, 4(3):289-302. 10.1007/s11760-009-0117-4
Gabarda S, Cristóbal G: Blind image quality assessment through anisotropy. J. Opt. Soc. Am. A 2007, 24(12):42-51. 10.1364/JOSAA.24.000B42
Zhu X, Milanfar P: A no-reference sharpness metric sensitive to blur and noise. In International Workshop on Quality of Multimedia Experience. San Diego; 29–31 July 2009:64-69.
Zhu X, Milanfar P: A no-reference image content metric and its application to denoising. In IEEE International Conference on Image Processing. Hong Kong; 26–29 September 2010:1145-1148.
Narwaria M, Lin W: Objective image quality assessment based on support vector regression. IEEE Trans. Neural Netw 2010, 21(3):515-519.
Liu H, Redi J, Alers H, Zunino R, Heynderickx I: No-reference image quality assessment based on localized gradient statistics: application to JPEG and JPEG2000. In SPIE Proceedings-Human Vision and Electronic Imaging Edited by: Rogowitz BE, Pappas TN. 2010, 75271-75271.
Ferzli R, Karam L: A novel free reference image quality metric using neural network approach. In International Workshop on Video Processing and Quality Metrics for Consumer Electronics. Scottsdale; 13–15 January 2010:1-4.
Chetouani A, Beghdadi A: A new image quality estimation approach for JPEG2000 compressed images. In IEEE International Symposium on Signal Processing and Information Technology. Bilbao; 14–17 December 2011:581-584.
Sheikh HR, Bovik AC, Cormack L: No-reference quality assessment using natural scene statistics: JPEG2000. IEEE Trans. Image Process 2005, 14(11):1918-1927.
Romaniak P, Janowski L, Leszczuk MI, Papir Z: Perceptual quality assessment for H.264/AVC compression. In IEEE International Workshop on Future Multimedia Networking. Las Vegas; 14–17 January 2012.
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process 2004, 13(4):600-612. 10.1109/TIP.2003.819861
Liu X, Chen M, Wan T, Yu C: Hybrid no-reference video quality assessment focusing on codec effects. Korea Internet Inform. Soc. Trans. Internet Inform. Syst 2011, 5(3):592-606.
Ouni S, Zagrouba E, Chambah M, Herbin M: No-reference image semantic quality approach using neural network. In IEEE International Symposium on Signal Processing and Information Technology. Bilbao; 14–17 December 2011:106-113.
Zhang J, Le TM, Ong SH, Nguyen TQ: No-reference image quality assessment using structural activity. Signal Process 2011, 91(11):2575-2588. 10.1016/j.sigpro.2011.05.011
Ruderman DL: The statistics of natural images. Network: Comput. Neural Syst 1994, 5(4):517-548. 10.1088/0954-898X/5/4/006
Zhou J, Xiao B, Li Q: A no reference image quality assessment method for JPEG2000. In IEEE International Joint Conference on Neural Networks. Hong Kong; 1–8 June 2008:863-868.
Lu W, Zeng K, Tao D, Yuan Y, Gao X: No-reference image quality assessment in contourlet domain. Neurocomputing 2010, 73: 784-794. 10.1016/j.neucom.2009.10.012
Do MN, Vetterli M: The contourlet transform: an efficient directional multiresolution image representation. IEEE Trans. Image Process 2005, 14(12):2091-2106.
Shen J, Li Q, Erlebacher G: Hybrid no-reference natural image quality assessment of noisy, blurry, JPEG2000, and JPEG images. IEEE Trans. Image Process 2011, 20(8):2089-2098.
Moorthy AK, Bovik AC: Blind image quality assessment: from natural scene statistics to perceptual quality. IEEE Trans. Image Process 2011, 20(12):3350-3364.
Zhu K, Hirakawa K, Asari V, Saupe D: A no-reference video quality assessment based on Laplacian pyramids. In 20th IEEE International Conference on Image Processing (ICIP). Melbourne; 15–18 September 2013:49-53.
Saad MA, Bovik AC: Natural motion statistics for no-reference video quality assessment. In International Workshop on Quality of Multimedia Experience. San Diego; 29–31 July 2009:163-167.
Saad MA, Bovik AC, Charrier C: A DCT statistics-based blind image quality index. IEEE Signal Process. Lett 2010, 17(6):583-586.
Saad MA, Bovik AC, Charrier C: DCT statistics model-based blind image quality assessment. In IEEE International Conference on Image Processing. Brussels; 11–14 September 2011:3093-3096.
Mittal A, Moorthy A, Bovik A: No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process 2012, 21(12):4695-4708.
Mittal A, Muralidhar GS, Ghosh J, Bovik AC: Blind image quality assessment without human training using latent quality factors. IEEE Signal Process. Lett 2012, 19(2):75-78.
Chen M-J, Cormack LK, Bovik AC: No-reference quality assessment of natural stereopairs. IEEE Trans. Image Process 2013, 22(9):3379-3391.
Gastaldo P, Parodi G, Redi J, Zunino R: No-reference quality assessment of JPEG images by using CBP neural networks. In 17th International Conference Artificial Neural Networks. Porto; 9–13 September 2007. Lecture Notes in Computer Science, vol. 4669, (Springer, Heidelberg), pp. 564–572
Li C, Bovik AC, Wu X: Blind image quality assessment using a general regression neural network. IEEE Trans. Neural Netw 2011, 22(5):793-799.
Zhang J, Le TM: A new no-reference quality metric for JPEG2000 images. IEEE Trans. Consumer Electron 2010, 56(2):743-750.
Sazzad ZMP, Kawayoke Y, Horita Y: No reference image quality assessment for JPEG2000 based on spatial features. Image Commun 2008, 23: 257-268.
Sazzad ZMP, Kawayoke Y, Horita Y: Spatial features based no reference image quality assessment for JPEG2000. In IEEE International Conference on Image Processing. San Antonio; 16–19 September 2007:517-520.
Maalouf A, Larabi M-C: A no-reference color video quality metric based on a 3D multispectral wavelet transform. In International Workshop on Quality of Multimedia Experience. Trondheim; 21–23 June 2010:11-16.
Suresh S, Venkatesh Babu R, Kim HJ: No-reference image quality assessment using modified extreme learning machine classifier. Appl. Soft Comput 2009, 9: 541-552. 10.1016/j.asoc.2008.07.005
Treisman AM, Gelade G: A feature-integration theory of attention. Cognit. Psychol 1980, 12(1):97-136. 10.1016/0010-0285(80)90005-5
Yao S, Ong E, Loke MH: Perceptual distortion metric based on wavelet frequency sensitivity and multiple visual fixations. In IEEE International Symposium on Circuits and Systems. Seattle; 18–21 May 2008:408-411.
Wang X-H, Ming Z: A new metric for objectively assessing the quality of enhanced images based on human visual perception. J. Optoelectron. Laser 2008, 19(2):254-262.
Ries M, Crespi C, Nemethova O, Rupp M: Content based video quality estimation for H.264/AVC video streaming. In IEEE Conference on Wireless Communications and Networking. Kowloon; 11–15 March 2007:2668-2673.
Ries M, Nemethova O, Rupp M: Performance evaluation of mobile video quality estimators. In European Signal Processing Conference. Poznan; 3–7 September 2007.
Khan A, Sun L, Ifeachor E: Content-based video quality prediction for MPEG4 video streaming over wireless networks. J. Multimedia 2009, 4(4):228-239.
Khan A, Sun L, Ifeachor E: An ANFIS-based hybrid video quality prediction model for video streaming over wireless networks. In International Conference on Next Generation Mobile Applications, Services and Technologies. Cardiff; 16–19 September 2008:357-362.
Khan A, Sun L, Ifeachor E: Content clustering based video quality prediction model for MPEG4 video streaming over wireless networks. In IEEE International Conference on Communications. Dresden; 14–18 June 2009:1-5.
Engelke U, Zepernick H-J: An artificial neural network for quality assessment in wireless imaging based on extraction of structural information. In IEEE International Conference on Acoustics, Speech and Signal Processing. Honolulu; 15–20 April 2007:1249-1252.
Jiang X, Meng F, Xu J, Zhou W: No-reference perceptual video quality measurement for high definition videos based on an artificial neural network. In International Conference on Computer and Electrical Engineering. Phuket; 20–22 December 2008:424-427.
Ćulibrk D, Kukolj D, Vasiljević P, Pokrić M, Zlokolica V: Feature selection for neural-network based no-reference video quality assessment. Lecture Notes Comput. Sci 2009, 5769: 633-642. 10.1007/978-3-642-04277-5_64
Keimel C, Oelbaum T, Diepold K: No-reference video quality evaluation for high-definition video. In IEEE International Conference on Acoustics, Speech and Signal Processing. Taipei; 19–24 April 2009:1145-1148.
Sazzad ZMP, Yamanaka S, Kawayokeita Y, Horita Y: Stereoscopic image quality prediction. International Workshop on Quality of Multimedia Experience 2009, 180-185.
Bhattacharjee D, Prakash S, Gupta P: No-reference image quality assessment for facial images. In International Conference on Advanced Intelligent Computing Theories and Applications. With Aspects of Artificial Intelligence, Zhengzhou. Springer, Heidelberg, Germany; 11–14 August 2011:594-601.
Castillo OYG: Survey about facial image quality. Technical Report. Fraunhofer Institute for Computer Graphics Research (2007), Darmstadt, Germany, (2006)
Caviedes JE, Oberti F: No-reference quality metric for degraded and enhanced video. In Proceedings of SPIE 5150, Visual Communications and Image Processing. Lugano; 8 July 2003:621-632.
Valenzise G, Magni S, Tagliasacchi M, Tubaro S: Estimating channel-induced distortion in H.264/AVC video without bitstream information. In Second International Workshop on Quality of Multimedia Experience (QoMEX). Trondheim; 21–23 June 2010:100-105.
Valenzise G, Magni S, Tagliasacchi M, Tubaro S: No-reference pixel video quality monitoring of channel-induced distortion. IEEE Trans. Circuits Syst. Video Technol 2012, 22(4):605-618.
Park J, Seshadrinathan K, Lee S, Bovik AC: Video quality pooling adaptive to perceptual distortion severity. IEEE Trans. Image Process 2013, 22(2):610-620.
Reibman AR, Vaishampayan VA, Sermadevi Y: Quality monitoring of video over a packet network. IEEE Trans. Multimedia 2004, 6(2):327-334. 10.1109/TMM.2003.822785
Takahashi A, Hands D, Barriac V: Standardization activities in the ITU for a QoE assessment of IPTV. IEEE Commun. Mag 2008, 46(2):78-84.
Yang F, Wan S: Bitstream-based quality assessment for networked video: a review. IEEE Commun. Mag 2012, 50(11):203-209.
ITU-T: ITU-T Recommendation G.1070: opinion model for video-telephony applications. 2012.http://www.itu.int/rec/T-REC-G.1070 . Accessed 11 April 2014
Raake A, Garcia MN, Moller S, Berger J, Kling F, List P, Johann J, Heidemann C: T-V-model: parameter-based prediction of IPTV quality. In IEEE International Conference on Acoustics, Speech and Signal Processing. Las Vegas; 31 March to 4 April 2008:1149-1152.
Han J, Kim Y-H, Jeong J, Shin J: Video quality estimation for packet loss based on no-reference method. In IEEE International Conference on Advanced Communication Technology. Phoenix Park, Dublin; 7–10 February 2010:418-421.
ITU: ITU-T Recommendation P.1201: Parametric non-intrusive assessment of audiovisual media streaming quality. 2012.http://handle.itu.int/11.1002/1000/11727 . Accessed 11 April 2014
Yamada T, Yachida S, Senda Y, Serizawa M: Accurate video-quality estimation without video decoding. In IEEE International Conference on Acoustics Speech and Signal Processing. Dallas; 14–19 March 2010:2426-2429.
Argyropoulos S, Raake A, Garcia M-N, List P: No-reference bit stream model for video quality assessment of H.264/AVC video based on packet loss visibility. In IEEE International Conference on Acoustics, Speech and Signal Processing. Prague; 22–27 May 2011:1169-1172.
Garcia M-N, Raake A: Parametric packet-layer video quality model for IPTV. In 10th International Conference on Information Sciences Signal Processing and Their Applications (ISSPA). Kuala Lumpur; 10–13 May 2010:349-352.
Yang F, Song J, Wan S, Wu HR: Content-adaptive packet-layer model for quality assessment of networked video services. IEEE J. Select. Topics Signal Process 2012, 6(6):672-683.
Sedano I, Brunnström K, Kihl M, Aurelius A: Full-reference video quality metric assisted the development of no-reference bitstream video quality metrics for real-time network monitoring. EURASIP J. Image Video Process 2014. doi:10.1186/1687-5281-2014-4
Staelens N, Vercammen N, Dhondt Y, Vermeulen B, Lambert P, Van de Walle R, Demeester P: VIQID: a no-reference bit stream-based visual quality impairment detector. In International Workshop on Quality of Multimedia Experience. Trondheim; 21–23 June 2010:206-211.
Staelens N, Van Wallendael G, Crombecq K, Vercammen N, De Cock J, Vermeulen B, Van de Walle R, Dhaene T, Demeester P: No-reference bitstream-based visual quality impairment detection for high definition H.264/AVC encoded video sequences. IEEE Trans. Broadcasting 2012, 58(2):187-199.
Van Wallendael G, Staelens N, Janowski L, De Cock J, Demeester P, Van de Walle R: No-reference bitstream-based impairment detection for high efficiency video coding. In Fourth International Workshop on Quality of Multimedia Experience. Yarra Valley; 5–7 July 2012:7-12.
ITU: ITU-T Recommendation P.1202: parametric non-intrusive bitstream assessment of video media streaming quality. 2012.http://handle.itu.int/11.1002/1000/11730 . Accessed 11 April 2014
Rossholm A, Lövström B: A new low complex reference free video quality predictor. In IEEE Workshop on Multimedia Signal Processing. Cairns; 8–10 October 2008:765-768.
Shahid M, Rossholm A, Lövström B: A reduced complexity no-reference artificial neural network based video quality predictor. In International Congress on Image and Signal Processing. Shanghai; 15–17 October 2011:517-521.
Shahid M, Rossholm A, Lövström B: A no-reference machine learning based video quality predictor. In Fifth International Workshop on Quality of Multimedia Experience (QoMEX). Klagenfurt; 3–5 July 2013:176-181.
Keimel C, Klimpke M, Habigt J, Diepold K: No-reference video quality metric for HDTV based on H.264/AVC bitstream features. In IEEE International Conference on Image Processing. Brussels; 11–14 September 2011:3325-3328.
Lee S-O, Jung K-S, Sim D-G: Real-time objective quality assessment based on coding parameters extracted from H.264/AVC bitstream. IEEE Trans. Consumer Electron 2010, 56(2):1071-1078.
Ries M, Nemethova O, Rupp M: Motion based reference-free quality estimation for H.264/AVC video streaming. In International Symposium on Wireless Pervasive Computing. San Juan; 5–7 February 2007.
Slanina M, Ricny V, Forchheimer R: A novel metric for H.264/AVC no-reference quality assessment. In EURASIP Conference on Speech and Image Processing Multimedia Communications and Services. Maribor; 27–30 June 2007:114-117.
Park I, Na T, Kim M: A noble method on no-reference video quality assessment using block modes and quantization parameters of H.264/AVC. In Proceedings of SPIE-Image Quality and System Performance VIII. San Francisco Airport; 23 January 2011:78670-7867011.
Singh KD, Rubino G: No-reference quality of experience monitoring in DVB-H networks. In Wireless Telecommunications Symposium. Tampa; 21–23 April 2010:1-6.
Yang F, Wan S, Xie Q, Wu HR: No-reference quality assessment for networked video via primary analysis of bit stream. IEEE Trans. Circuits Syst. Video Technol 2010, 20(11):1544-1554.
Chin M, Brandão T, Queluz MP: Bitstream-based quality metric for packetized transmission of H.264 encoded video. In International Conference on Systems, Signals and Image Processing. Vienna; 11–13 April 2012:312-315.
Brandão T, Chin M, Queluz MP: From PSNR to perceived quality in H.264 encoded video sequences. In Proceedings of EuroITV. Lisbon; 29 June to 1 July 2011.
Eden A: No-reference estimation of the coding PSNR for H.264-coded sequences. IEEE Trans. Consumer Electron 2007, 53(2):667-674.
Brandão T, Maria PQ: No-reference image quality assessment based on DCT domain statistics. Signal Process 2008, 88(4):822-833. 10.1016/j.sigpro.2007.09.017
Watson AB: DCT quantization matrices visually optimized for individual images. In Proceedings of SPIE, Human Vision, Visual Processing, and Digital Display IV. San Jose; 31 January 1993:202-216.
Brandão T, Maria PQ: No-reference quality assessment of H.264/AVC encoded video. IEEE Trans. Circuits Syst. Video Technol 2010, 20(11):1437-1447.
Brandão T, Maria PQ: No-reference PSNR estimation algorithm for H.264 encoded video sequences. In European Signal Processing Conference. Laussane; 25–29 August 2008.
Brandão T, Maria PQ: Blind PSNR estimation of video sequences using quantized DCT coefficient data. In Picture Coding Symposium. Lausanne; 12–13 November 2007.
Shim S-Y, Moon J-H, Han J-K: PSNR estimation scheme using coefficient distribution of frequency domain in H.264 decoder. Electron. Lett 2008, 44(2):108-109. 10.1049/el:20082512
Zhang J, Ong SH, Le TM: Kurtosis-based no-reference quality assessment of JPEG2000 images. Image Commun 2011, 26: 13-23.
Nishikawa K, Munadi K, Kiya H: No-reference PSNR estimation for quality monitoring of motion JPEG2000 video over lossy packet networks. IEEE Trans. Multimedia 2008, 10(4):637-645.
Nishikawa K, Nagawara S, Kiya H: QoS estimation method for JPEG2000 coded image at RTP layer. IEICE Trans 2006, E89-A(8):2119-2128. doi:10.1093/ietfec/e89-a.8.2119 10.1093/ietfec/e89-a.8.2119
Joskowicz J, Sotelo R, Ardao JCL: Towards a general parametric model for perceptual video quality estimation. IEEE Trans. Broadcasting 2013, 59(4):569-579.
ITU: ITU-T Recommendation H.265/high efficiency video coding. . Accessed 11 April 2014 http://www.itu.int/rec/T-REC-H.265-201304-I
Lee B, Kim M: No-reference PSNR estimation for HEVC encoded video. IEEE Trans. Broadcasting 2013, 59(1):20-27.
Winkler S, Mohandas P: The evolution of video quality measurement: from PSNR to hybrid metrics. IEEE Trans. Broadcasting 2008, 54(3):660-668.
Naccari M, Tagliasacchi M, Tubaro S: No-reference video quality monitoring for H.264/AVC coded video. IEEE Trans. Multimedia 2009, 11(5):932-946.
Naccari M, Tagliasacchi M, Pereira F, Tubaro S: No-reference modeling of the channel induced distortion at the decoder for H.264/AVC video coding. In IEEE International Conference on Image Processing. San Diego; 12–15 October 2008:2324-2327.
Farias MCQ, Carvalho MM, Kussaba HTM, Noronha BHA: A hybrid metric for digital video quality assessment. In IEEE International Symposium on Broadband Multimedia Systems and Broadcasting. Nuremberg; 8–10 June 2011:1-6.
Shanableh T: No-reference PSNR identification of MPEG-4 video using spectral regression and reduced model polynomial networks. IEEE Signal Process. Lett 2010, 17(8):735-738.
Shanableh T: Prediction of structural similarity index of compressed video at a macroblock level. IEEE Signal Process. Lett 2011, 18(5):335-338.
Davis AG, Bayart D, Hands DS: Hybrid no-reference video quality prediction. In IEEE International Symposium on Broadband Multimedia Systems and Broadcasting. Bilbao; 13–15 May 2009:1-6.
Yamagishi K, Kawano T, Hayashi T: Hybrid video-quality-estimation model for IPTV services. In IEEE Global Telecommunications Conference, (GLOBECOM). Honolulu; 30 November to 4 December 2009:1-5.
Yamada T, Miyamoto Y, Serizawa M: No-reference video quality estimation based on error-concealment effectiveness. In International Workshop on Packet Video. Lausanne; 12–13 November 2007:288-293.
Yamada T, Miyamoto Y, Nishitani T: No-reference quality estimation for video-streaming services based on error-concealment effectiveness. IEICE Trans. Fundamentals Electron. Commun. Comput. Sci 2012, E95-A(11):2007-2014. 10.1587/transfun.E95.A.2007
Boujut H, Benois-Pineau J, Ahmed T, Hadar O, Bonnet P: A metric for no-reference video quality assessment for HD TV delivery based on saliency maps. In IEEE International Conference on Multimedia and Expo (ICME). Barcelona; 11–15 July 2011:1-5.
Sugimoto O, Naito S, Sakazawa S, Koike A: Objective perceptual video quality measurement method based on hybrid no reference framework. In IEEE International Conference on Image Processing. Cairo; 7–10 November 2009:2237-2240.
Zhao S, Jiang H, Cai Q, Sherif S, Tarraf A: Hybrid framework for no-reference video quality indication over LTE networks. In 23rd Wireless and Optical Communication Conference (WOCC). Newark; 9–10 May 2014:1-5.
Ichigaya A, Nishida Y, Nakasu E: Nonreference method for estimating PSNR of MPEG-2 coded video by using DCT coefficients and picture energy. IEEE Trans. Circuits Syst. Video Technol 2008, 18(6):817-826.
Ichigaya A, Kurozumi M, Hara N, Nishida Y, Nakasu E: A method of estimating coding PSNR using quantized DCT coefficients. IEEE Trans. Circuits Syst. Video Technol 2006, 16(2):251-259.
VQEG: Draft VQEG Testplan: Hybrid Perceptual/Bitstream Group. 2012.http://www.its.bldrdoc.gov/vqeg/projects/hybrid-perceptual-bitstream/hybrid-perceptual-bitstream.aspx . Accessed 11 April 2014
Keimel C, Habigt J, Diepold K: Hybrid no-reference video quality metric based on multiway PLSR. In Proceedings of the 20th European Signal Processing Conference (EUSIPCO). Bucharest; 27–31 August 2012:1244-1248.
Wang Z, Bovik AC: Mean squared error: love it or leave it? A new look at signal fidelity measures. IEEE Signal Process. Mag 2009, 26(1):98-117.
You J, Ebrahimi T, Perkis A: Attention driven foveated video quality assessment. IEEE Trans. Image Process 2014, 23(1):200-213.
Belmudez B, Möller S: Audiovisual quality integration for interactive communications. EURASIP J. Audio Speech Music Process 2013., 2013(1): 10.1186/1687-4722-2013-24
Rimell AN, Hollier MP, Voelcker RM: The influence of cross-modal interaction on audio-visual speech quality perception. In Audio Engineering Society Convention 105. San Francisco; 26–29 September 1998.
Engelke U, Kaprykowsky H, Zepernick H-J, Ndjiki-Nya P: Visual attention in quality assessment. IEEE Signal Process. Mag 2011, 28(6):50-59.
Kortum P, Sullivan M: The effect of content desirability on subjective video quality ratings. Hum. Factors: J. Hum. Factors Ergonom. Soc 2010, 52: 105-118. 10.1177/0018720810366020
Rossholm A, Shahid M, Lövström B: Analysis of the impact of temporal, spatial, and quantization variations on perceptual video quality. In IEEE Network Operations and Management Symposium (NOMS). Krakow; 5–9 May 2014:1-5.
Barkowsky M, Sedano I, Brunnström K, Leszczuk M, Staelens N: Hybrid video quality prediction: re-viewing video quality measurement for widening application scope. Multimedia Tools Appl 2014. doi:10.1007/s11042-014-1978-2
You J, Reiter U, Hannuksela MM, Gabbouj M, Perkis A: Perceptual-based quality assessment for audio-visual services: a survey. Signal Process. Image Commun 2010, 25(7):482-501. 10.1016/j.image.2010.02.002
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
MS prepared the database of the publications in the area, streamlined the publications to be reviewed in the paper, planned the structure of the paper in consultation with co-authors, and wrote the main draft of the paper. AR participated in writing some parts of the paper and involved in the discussions on improving the manuscript. BL took part in the initial discussions on the paper topic and gave feedback during the writing process on the structure, the content and its revisions, and wrote the first draft of the conclusions. HJZ helped with refining and structuring the content of the review; participated in drafting, correcting, and revising the article; and helped with assessing the reviewed approaches. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Shahid, M., Rossholm, A., Lövström, B. et al. No-reference image and video quality assessment: a classification and review of recent approaches. J Image Video Proc 2014, 40 (2014). https://doi.org/10.1186/1687-5281-2014-40
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-5281-2014-40