
Abstract
This paper studies the problem of a guaranteed cost control for a class of stochastic delayed neural networks. The time delay is a continuous function belonging to a given interval, but it is not necessarily differentiable. A cost function is considered as a nonlinear performance measure for the closed-loop system. The stabilizing controllers to be designed must satisfy some mean square exponential stability constraints on the closed-loop poles. By constructing a set of augmented Lyapunov-Krasovskii functional, a guaranteed cost controller is designed via memory less state feedback control, and new sufficient conditions for the existence of the guaranteed cost state-feedback for the system are given in terms of linear matrix inequalities (LMIs). A numerical example is given to illustrate the effectiveness of the obtained result.
Similar content being viewed by others

1 Introduction
Stability and control of neural networks with the time delay have attracted considerable attention in recent years [1–8]. In many practical systems, it is desirable to design neural networks, which are not only asymptotically or exponentially stable, but can also guarantee an adequate level of system performance. In the area of control, signal processing, pattern recognition and image processing, and delayed neural networks have many useful applications. Some of these applications require that the equilibrium points of the designed network be stable. In both biological and artificial neural systems, time delays due to integration and communication are ubiquitous and often become a source of instability. The time delays in electronic neural networks are usually time-varying, and sometimes vary violently with respect to time due to the finite switching speed of amplifiers and faults in the electrical circuitry. A guaranteed cost control problem [9–12] has the advantage of providing an upper bound on a given system performance index, and, thus, the system performance degradation, incurred by the uncertainties or time delays, is guaranteed to be less than this bound. The Lyapunov-Krasovskii functional technique has been among the popular and effective tools in the design of guaranteed cost controls for neural networks with time delay. Nevertheless, despite such diversity of results available, most existing works either assumed that the time delays are constant or are differentiable [13–16]. Although, in some cases, the delay-dependent guaranteed cost control for systems with time-varying delays was considered in [12, 13, 15], the approach used there cannot be applied to the systems with interval, nondifferentiable time-varying delays. To the best of our knowledge, the guaranteed cost control and state feedback stabilization for stochastic neural networks with interval, nondifferentiable time-varying delays have not been fully studied yet (see, e.g., [4–16] and the references therein), which are important in both theories and applications. This motivates our research.
In this paper, we investigate the guaranteed cost control for stochastic delayed neural networks problem. The novel features here are that the delayed neural network under consideration is with various globally Lipschitz continuous activation functions, and the time-varying delay function is interval, nondifferentiable. A nonlinear cost function is considered as a performance measure for the closed-loop system. The stabilizing controllers to be designed must satisfy some mean square exponential stability constraints on the closed-loop poles. Based on constructing a set of augmented Lyapunov-Krasovskii functional, new delay-dependent criteria for guaranteed cost control via memoryless feedback control is established in terms of LMIs, which allow simultaneous computation of two bounds that characterize the mean square exponential stability rate of the solution and can be easily determined by utilizing MATLABs LMI control toolbox.
The outline of the paper is as follows. Section 2 presents definitions and some well-known technical propositions, needed for the proof of the main result. LMI delay-dependent criteria for the guaranteed cost control and a numerical example showing the effectiveness of the result are presented in Section 3. The paper ends with the conclusions and cited references.
2 Preliminaries
The following notation will be used in this paper. denotes the set of all real non-negative numbers; denotes the n-dimensional space with the scalar product or of two vectors x, y, and the vector norm ; denotes the space of all matrices of -dimensions. denotes the transpose of matrix A; A is symmetric if ; I denotes the identity matrix; denotes the set of all eigenvalues of A; . , ; denotes the set of all -valued continuously differentiable functions on ; denotes the set of all the -valued square integrable functions on .
Matrix A is called semi-positive definite () if for all ; A is positive definite () if for all ; means . The notation stands for a block-diagonal matrix. The symmetric term in a matrix is denoted by ∗.
Consider the following stochastic neural networks with interval time-varying delay:
where is the state of the neurons, is the control; n is the number of neurons, and
are the activation functions; , represents the self-feedback term; is control input matrix; , denote the connection weights, the delayed connection weights.
is a scalar Wiener process (Brownian motion) on with
and is the continuous function, and is assumed to satisfy that
where and are known constant scalars. For simplicity, we denote by σ.
The time-varying delay function satisfies the condition
The initial functions , with the norm
In this paper, we consider various activation functions and assume that the activation functions , are Lipschitzian with the Lipschitz constants :
The performance index, associated with the system (2.1), is the following function
where is a nonlinear cost function satisfying
for all and , are given symmetric positive definite matrices. The objective of this paper is to design a memoryless state feedback controller for system (2.1) and the cost function (2.5) such that the resulting closed-loop system
is mean square exponentially stable, and the closed-loop value of the cost function (2.5) is minimized.
Definition 2.1 Given . The zero solution of a closed-loop system (2.7) is α-stabilizable in the mean square if there exists a positive number such that every solution satisfies the following condition:
Definition 2.2 Consider the control system (2.1). If there exist a memoryless state feedback control law and a positive number such that the zero solution of the closed-loop system (2.7) is mean square exponentially stable and the cost function (2.5) satisfies , then the value is a guaranteed constant and is a guaranteed cost control law of the system and its corresponding cost function.
We introduce the following technical well-known propositions, which will be used in the proof of our results.
Proposition 2.1 (Integral matrix inequality [17])
For any symmetric positive definite matrix , scalar and vector function such that the integrations concerned are well defined, the following inequality holds
3 Design of guaranteed cost controller
In this section, we give a design of memoryless guaranteed feedback cost control for stochastic neural networks (2.1). Let us set
Theorem 3.1 Consider the control system (2.1) and the cost function (2.5). Given . If there exist symmetric positive definite matrices P, U, , , , , and diagonal positive definite matrices , , satisfying the following LMIs
then
is a guaranteed cost control, and the guaranteed cost value is given by
Moreover, the solution of the system satisfies
Proof Let , . Using the feedback control (2.7), we consider the following Lyapunov-Krasovskii functional taking the mathematical expectation
It easy to check that
Taking the derivative of , , and taking the mathematical expectation, we have
Applying Proposition 2.1 and , we have for ,
Note that
Applying Proposition 2.1 gives
Since , we have
then
Similarly, we have
Then, we have
Using equation (2.7)
multiplying both sides with , and taking the mathematical expectation, we have
Adding all the zero items of (3.6) and , respectively into (3.5), applying assumptions (2.2), (2.3), using the condition (2.6) for the following estimations, and taking the mathematical expectation
we obtain
where , and
Therefore, by condition (3.1), we obtain from (3.7) that
Integrating both sides of (3.8) from 0 to t, we obtain
Furthermore, taking condition (3.3) into account, we have
then
which concludes the mean square exponential stability of the closed-loop system (2.7). To prove the optimal level of the cost function (2.5), we derive from (3.7) and (3.1) that
Integration of both sides of (3.9) from 0 to t leads to
due to . Hence, letting , we have
This completes the proof of the theorem. □
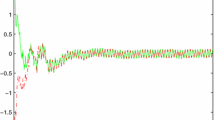
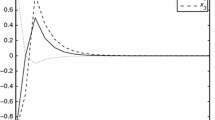
Example 3.1 Consider the stochastic neural networks with interval time-varying delays (2.1), where
Note that is nondifferentiable, therefore, the stability criteria proposed in [5–7, 12, 15] are not applicable to this system. Given , , , , , by using the Matlab LMI toolbox, we can solve for P, U, , , , , , and , which satisfy the condition (3.1) in Theorem 3.1. A set of solutions are
Then
is a guaranteed cost control law and the cost given by
Moreover, the solution of the system satisfies
4 Conclusion
In this paper, the problem of guaranteed cost control for stochastic neural networks with the interval nondifferentiable time-varying delay has been studied. A nonlinear quadratic cost function is considered as a performance measure for the closed-loop system. The stabilizing controllers to be designed must satisfy some mean square exponential stability constraints on the closed-loop poles. By constructing a set of time-varying Lyapunov-Krasovskii functional, a memoryless state feedback guaranteed cost controller design has been presented and sufficient conditions for the existence of the guaranteed cost state-feedback for the system have been derived in terms of LMIs.
References
Hopfield JJ: Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79: 2554–2558. 10.1073/pnas.79.8.2554
Kevin G: An Introduction to Neural Networks. CRC Press, Boca Raton; 1997.
Wu M, He Y, She JH: Stability Analysis and Robust Control of Time-Delay Systems. Springer, Berlin; 2010.
Arik S: An improved global stability result for delayed cellular neural networks. IEEE Trans. Circuits Syst. 2002, 499: 1211–1218.
He Y, Wang QG, Wu M: LMI-based stability criteria for neural networks with multiple time-varying delays. Physica D 2005, 112: 126–131.
Kwon OM, Park JH: Exponential stability analysis for uncertain neural networks with interval time-varying delays. Appl. Math. Comput. 2009, 212: 530–541. 10.1016/j.amc.2009.02.043
Phat VN, Trinh H: Exponential stabilization of neural networks with various activation functions and mixed time-varying delays. IEEE Trans. Neural Netw. 2010, 21: 1180–1185.
Botmart T, Niamsup P: Robust exponential stability and stabilizability of linear parameter dependent systems with delays. Appl. Math. Comput. 2010, 217: 2551–2566. 10.1016/j.amc.2010.07.068
Chen WH, Guan ZH, Lua X: Delay-dependent output feedback guaranteed cost control for uncertain time-delay systems. Automatica 2004, 40: 1263–1268. 10.1016/j.automatica.2004.02.003
Palarkci MN: Robust delay-dependent guaranteed cost controller design for uncertain neutral systems. Appl. Math. Comput. 2009, 215: 2939–2946.
Park JH, Kwon OM: On guaranteed cost control of neutral systems by retarded integral state feedback. Appl. Math. Comput. 2005, 165: 393–404. 10.1016/j.amc.2004.06.019
Park JH, Choi K: Guaranteed cost control of nonlinear neutral systems via memory state feedback. Chaos Solitons Fractals 2005, 24: 183–190.
Fridman E, Orlov Y: Exponential stability of linear distributed parameter systems with time-varying delays. Automatica 2009, 45: 194–201. 10.1016/j.automatica.2008.06.006
Xu S, Lam J: A survey of linear matrix inequality techniques in stability analysis of delay systems. Int. J. Syst. Sci. 2008, 39(12):1095–1113. 10.1080/00207720802300370
Xie JS, Fan BQ, Young SL, Yang J: Guaranteed cost controller design of networked control systems with state delay. Acta Autom. Sin. 2007, 33: 170–174.
Yu L, Gao F: Optimal guaranteed cost control of discrete-time uncertain systems with both state and input delays. J. Franklin Inst. 2001, 338: 101–110. 10.1016/S0016-0032(00)00073-9
Gu K, Kharitonov V, Chen J: Stability of Time-Delay Systems. Birkhäuser, Berlin; 2003.
Acknowledgements
This work was supported by the Thailand Research Fund Grant, the Higher Education Commission and Faculty of Science, Maejo University, Thailand. The author thanks anonymous reviewers for valuable comments and suggestions, which allowed to improve the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The author declares that they have no competing interests.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Rajchakit, G. Delay-dependent optimal guaranteed cost control of stochastic neural networks with interval nondifferentiable time-varying delays. Adv Differ Equ 2013, 241 (2013). https://doi.org/10.1186/1687-1847-2013-241
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-1847-2013-241