
Abstract
Background
Frequency selectivity (FS) is an important aspect of auditory function, and is typically described by a tuning curve function. Sharply tuned curves represent a higher acuity in detecting frequency differences, and conversely, broadly tuned curves demonstrate a lower acuity. One way of obtaining tuning curves is from techniques based on subjective behavioral responses, which yields psychophysical tuning curves (PTCs). In contrast, other methods rely on objective auditory responses to sound, such as neuron responses and otoacoustic emissions, amongst others. The present study introduces an objective method that uses stimulus frequency otoacoustic emissions (SFOAEs) to assemble suppression tuning curves (STCs). Finding an objective method of accurately measuring human FS is very important, as it would permit the FS to be assayed in non-responsive patients (e.g., neonates or comatose patients). However, before the objective method can be applied, it must be demonstrated that its ability to estimate the FS, gives comparable results to those obtained by subjective procedures i.e. PTCs.
Methods
SFOAEs responses, generated in the peripheral auditory system, were used to produce STCs. PTCs were measured by behavioral responses. The validity of the objective measures of human FS were determined by comparing stimulus frequency otoacoustic emission suppression tuning curves (SFOAE STCs) to PTCs at common stimulus parameters in 10 individuals with normal hearing, at low probe-tone levels.
Results
The average Q10 ratios measured between PTCs and SFOAE STCs from subjects were close to 1 at various center frequencies (F 2,24 = .15, p = .858). The estimates of FS provided by SFOAE STCs and PTCs were similar.
Conclusions
This system could be used to estimate auditory FS by both objective and subjective methods. SFOAE STCs have the potential to provide an objective estimate of auditory FS.
Similar content being viewed by others


Background
Frequency selectivity (FS) refers to the ability of the auditory system to identify tonal components in complex sound [1]. It largely depends on the filtering ability of the cochlea [2], and its tuning properties are determined by the amplification mechanisms of the cochlear outer hair cells (OHCs) at low stimulus levels [3–5]. Damage to the OHCs will reduce both the FS and the sensitivity of the auditory system [6–11], with far-reaching consequences for complex sound perception [12]. The reduction or abolition of other OHC-related phenomena, such as two-tone suppression [13, 14] or otoacoustic emissions [15], will also damage cochlear FS. Consequently, the estimation of FS can indirectly assess OHC function and has a significant effect on complex sound perception.
The evaluation of FS is actually a measurement of the bandwidth of the auditory filter on the basilar membrane. Fletcher [16] measured the threshold of a sinusoidal signal as a function of the bandwidth of a band-pass noise masker, referring to the bandwidth of the auditory filter as the “critical bandwidth”, a term that was adopted in later studies [17–20]. Auditory masking can be used to estimate auditory filter shapes [21]. Psychophysical tuning curves (PTCs) can assess FS by using the psychoacoustic detection of masked signals to obtain tuning curves. Since a behavioral response of sound perception is required from the subject, this is considered a subjective hearing evaluation. In humans, forward masking PTCs are more sharply tuned than simultaneous masking PTCs [22], probably because forward masking PTCs overestimate the sharpness of the frequency tuning [23]. The traditional method of obtaining PTCs is time-consuming, because it requires a series of stimulus generation and feedback steps to find the masker intensity at each frequency. However, in 2005, Sek et al. developed a faster method for determining PTCs by using a narrowband noise filter with a center frequency being swept from low to high frequencies [24]. This method only takes 8 minutes to perform. Despite this time-efficient way of obtaining PTCs, their interpretation is influenced by non-auditory factors such as attention [25], therefore it cannot be used for difficult-to-test populations (e.g., age < 3 years, especially neonates).
Otoacoustic emissions (OAEs) are weak acoustic signals produced in the cochlea. They arise from non-linear inner ear mechanics and are detected as acoustic signals in the ear canal [26], making them a useful noninvasive measurement. Stimulus frequency otoacoustic emissions (SFOAEs) are evoked OAEs that have the same frequency as the stimulus. SFOAEs can be evoked within a wide frequency range for subjects with normal hearing or with moderate hearing impairment. The SFOAE suppression tuning curves (SFOAE STCs) are detected by using a suppression-based mode similar to simultaneous masking. Kemp and Chum [27] found that a subject’s SFOAE STCs and PTCs showed a similar filter shape, suggesting that SFOAE STCs could potentially be used to evaluate the periphery auditory system objectively. However, this possibility has not been sufficiently explored in the literature. Siegel et al. [28] obtained the SFOAE STCs of a chinchilla at a stimulus frequency of 9 kHz, which were similar to the STCs constructed from the suppressed discharge patterns of the auditory nerve fibers obtained by Temchin, Rich & Ruggero [29]. Keefe et al. [30] predicted that the two-tone suppression of SFOAEs in the human ear would resemble the results of a simultaneous masking behavioral test. Cheatham et al. [31] found that the tuning characteristics of SFOAEs provided signal processing information prior to inner hair cell stimulation and auditory nervous activation. Charaziak et al. [32] compared the average SFOAE STCs and PTCs in 10 normal-hearing subjects for a probe frequency centered around 1,000 and 4,000 Hz, at low probe levels. They concluded that SFOAE STCs are useful for estimating behavioral tuning noninvasively at the group level, but not at the individual level because of the variability in individual SFOAE STCs.
In the aforementioned studies, the relationships of factors such as Q10 ratio and tip offset were not quantified between PTCs and SFOAE STCs. In the present study, we sought to develop an assessment system for human auditory FS containing both objective detection of the SFOAE STCs and subjective detection of the simultaneous masking PTCs. We investigated the relationships between the two tests, at low probe level (30 dB SPL) in 10 normal hearing subjects, based on the statistical analysis of the tuning curve parameters. Similarities were found between the estimates of FS provided by the SFOAE STCs and the PTCs.
Methods
Subjects
Ten subjects (20–26 years old, 6 females, 4 males) were included in the study, all of whom were native Chinese speakers and college students at Tsinghua University. In accordance with the inclusion criteria, all participants had normal otoscopic examination results, normal hearing thresholds (<15 dB HL for octave frequencies of 250–8,000 Hz), no spontaneous OAEs (SOAEs) in the frequency range of interest (to avoid interference with the detection signal), and no history of neurological or psychiatric illness. All subjects gave their written informed consent to participate, in compliance with a protocol (IRB00008273) approved by the institutional review board at Tsinghua University.
System set-up
All experiments were conducted in an acoustic booth. Stimulus generation, signal acquisition, and processing were performed through an external soundcard (Fire face 800, RME, Haimhausen, German, 24-bit resolution, 192 kHz sampling rate) controlled by a Windows-based computer system. An audio stream input/output (ASIO, Steinberg, Hamburg, German) is a computer soundcard driver protocol for digital audio, allowed us to access external hardware directly, without using Microsoft’s DirectSound. It was used to provide a low-latency and high-fidelity interface between the assessment system and soundcard. A probe, containing miniature loudspeakers and a microphone, was inserted into the subject’s ear. The external soundcard converted a computer-generated digital signal to an analog voltage signal, which was transduced to an acoustic signal by the loudspeakers (ER-2, Etymotic Research, London, USA) and delivered to the ear via tubes. A miniature microphone (ER-10B+, Etymotic Research, London, USA) transduced the acoustic signal collected in the ear canal to an analog voltage signal, which was amplified by 20 dB (ER-10B+ preamplifier, Etymotic Research, London, USA), converted to a digital signal via the external soundcard, and sent back to the main control computer. In the detection of PTCs, the subject indicated the detection of a probe tone by pressing a USB handle button. The assessment system was based on the C sharp programming language (Microsoft Inc., Redmond, Washington, USA) and embedded within Matlab (MathWorks Inc., Natick, MA, USA) for cross-programming. Analysis of variance (ANOVA) and paired-sample t tests were conducted in SPSS (SPSS Inc., Chicago, IL, USA).
Calibration
Calibration was conducted in a Brüel & Kiær ear simulator (type 4157) at the frequencies of 125, 250, 500, 1000, 2000, 3000, 4000, 6000 and 8000 Hz, for both tone and narrowband noise. At each frequency and intensity, six input–output (I/O) signals were recorded, including the digital output generated from the computer, the analog output delivered from soundcard, the sound pressure in the ear simulator, the sound pressure collected in the miniature microphone, the analog input collected by soundcard and the digital input gathered by computer. The I/O functions of the system were calculated by interpolation or extrapolation of the calibration data. The sound pressure level (SPL) measured in decibels (dB), was referenced to 20 μPa.
Experimental procedure
A flowchart of the experimental procedure is shown in Figure 1. Pure tone audiometry (PTA) and SOAEs tests were examined to select eligible subjects. SFOAE fine structure was a high-resolution (40-Hz steps) SFOAE recording in the frequency range of ±200 Hz (relative to the center frequency, CF) to define the best frequency of the probe for testing the SFOAE STCs and PTCs. The best frequency, denoted as f p in the subsequent tests, is the one that can evoke the largest SFOAE. The probe level, L p , was 30 dB SPL. The suppressor frequency, f s , was 47 Hz below the f p and had an intensity, L s , of 70 dB SPL. SFOAE amplitudes were plotted as a function of L p (5–50 dB SPL in 5-dB steps) in SFOAE I/O function testing to determine the suppression criterion in the testing of SFOAE STCs. The suppression criterion is defined as the SFOAE decrease relative to the total SFOAE [30]. In this study, the suppression criterion was −6 dB, corresponding to an SFOAE amplitude decrease relative to the total SFOAE by a factor of 1/2, because 20log10 (1–1/2) = −6 dB. Finally, the SFOAE STCs testing and PTCs testing were conducted separately and then compared. For ease of comparison, the same f p and L p were adopted in both tests. The SFOAE STCs f s was varied from 0.5f p to 2.5f p with a resolution of 10 points/octave at a CF of 1,000 Hz and from 0.5f p to 1.75f p at CFs of 2,000 and 4,000 Hz, respectively.

Flowchart of the experimental procedure. A flowchart of the experimental procedure.
Design of a faster PTC detection algorithm
The methods of Sek et al. [24] and Malicka et al. [25] formed the basis of the PTC measurements. A simultaneous masking PTC was constructed from different masker intensities at each masker frequency, by fixing the probe frequency and intensity. At each masker tone, the intensity was varied at a rate of 2 dB/s until the subject could not hear the probe tone. The determination of the critical masker intensity was repeated at each masker frequency, and a plot of the masker level at each test frequency yielded the PTC [33].
Stimuli
The stimuli comprised the probe and masker tones, delivered by two different speakers. One speaker produced a constant probe tone at a fixed frequency and sound level, whilst the other speaker simultaneously produced a narrowband masking noise with slowly changing center frequency (from low to high: upward sweeps, or from high to low: downward sweeps) and changing sound level as a masker. Each probe cycle was 700 ms, made up of a 200-ms interval and a 500-ms tone, for a total duration of 245 s within 350 cycles. To help the subjects maintain their attention, the probe was pulsed on and off at a fixed rate, with an interval of 200 ms. The 500-ms tone consisted of a 20-ms rise and decay time that reduced the spectral splatter of a rapidly changing tonal intensity. The rise and decay of the envelope of the tone was windowed by a cosine gate function. A 240-s masker was generated 5 s after the probe, to enable the subject to confirm the target signal. The influence of beat detection or an overly wide noise bandwidth can result in a broadened tip of the PTC. Therefore, the bandwidth of the noise masker, at ≤ 90 dB SPL, was 0.2 times the frequency of the probe tone (but always ≤ 320 Hz) [24]. Subjects were instructed to press/release a button when the probe was audible/inaudible. The level of the masking noise was decreased/increased at a fixed rate (2 dB/s). A 245-s downward sweep was made immediately after the 245-s upward sweep to minimize the effects of the narrowband noise sweep. The final PTC was averaged over both the downward and upward sweep procedures.
Masker synthesis
The 240-s narrowband noise masker sweep, S(t), in the faster PTC consisted of 750 segments, S i(t), of 640-ms duration. The two adjacent segments were overlapped in time by 50%, as shown in Equation (1).
where
is the Hanning window and T is the period (0.64 s). Each segment, S i(t), is the narrowband noise with a fixed center frequency. There was a slight difference between the two neighboring segments (f i + 1 is 1.00185 times f i in the upward sweep), which indicated that the center frequency of the masker changed ±1 octave relative to the probe frequency in 750 segments. For each 640-ms segment the bandwidth was too low to obtain the ideal band-pass filter, so narrowband noise was the inverse fast Fourier transform of a low-pass noise, modulated by multiplying by a sine signal with the same frequency as the center frequency of the narrowband noise.
Estimation of tip frequency
The two-point average smoothing method was used to find the trend and estimate the tip frequency of the raw jagged masker intensity curves for upward/downward sweep. The first step was to find the turning points of the raw jagged data, which is hard to quantitatively analyze, and the second step was average smoothing. As the raw data was discrete and the derivative of the two turning points changed sign, the turning points were identified as the non-zero points after the raw data convoluting the filtering operator [1,-2, 1]. Then the smoothed data was set up of the midpoints of the two adjacent turning points. Tip frequency was estimated from the smoothed data. For upward and downward sweeps, each frequency axis was normalized by the tip frequency. Finally, the PTC was the average of both upward and downward sweeps.
Design of the SFOAE detection method
SFOAE fine structure, I/O function and STC were derived from the recorded SFOAEs with a procedure based on the two-tone suppression method of Brass et al. [34, 35]. Those studies used the summation of a four-interval sequence to cancel the probe and suppressor, leaving a residual arising from the nonlinear interactions between the probe and suppressor. In our modified procedure, a single SFOAE detection consisted of stimulation-acquisition, signal detection, data filtering and superposed averaging. At each suppressor tone, the level was varied until the SFOAE was suppressed by the same amount. The determination of the critical suppressor level was repeated at each suppressor frequency, and a plot of the suppressor level at each test frequency yielded the SFOAE STC.
Stimuli
Figure 2 shows the stimuli synthesis for a single SFOAE stimulation-acquisition procedure. To eliminate the effects of system delay and SFOAE latency, section M and N were added to the traditional four-section stimuli paradigm. The stimuli consisted of six sections (except for the last 5 ms). There was one section of 2T d followed by five sections of T w (50 ms) in duration. T d is the system delay from sound-output to signal-input (14.5 ms). The stimuli comprised the probe and suppressor delivered by two different speakers. The probe was a continuous pure tone, with the same polarity in sections A, B, C, D and N. The suppressor was a tone burst, with the rise and decay time of the suppressor envelope windowed by a 5-ms cosine window. Between the rise and decay time of the suppressor tone, the plateau intensity was kept constant. The suppressor in section D was inverted relative to section C.

Stimuli synthesis in a single SFOAE stimulation-acquisition procedure. The probe signal comprises six sections. The duration of first section is 2T d, followed by five sections of duration T w.
SFOAE detection
Excepting the background noise, the resultant sound in the ear canal consisted of probe artifact, Rp, suppressor artifact, Rs, the evoked SFOAE signal caused by the probe, SFE, the evoked SFOAE caused by the suppressor, SFEs, and the remaining SFOAE caused by the probe after suppression, SFE’. The collected signals from the ear canal evoked by stimuli in section A to D were stored in four buffers, A to D, respectively. Both buffers A and B contained Rp and SFE. Buffer C contained Rp, Rs, SFEs and SFE’, whilst buffer D contained Rp, −Rs, −SFEs and SFE’. The final result, the suppressed SFOAE, is the subtraction of the sound field in sections (A + B) and (C + D) (see Equation 3). It can be seen that the subtraction cancels out the Rp, Rs, and SFEs. If SFOAE can be suppressed completely, whereby SFE’ equals zero, then the results of sub-averaging only leave a suppressed SFOAE that equals the SFOAE evoked by the probe tone.
Equation 3 describes an operation over raw data in the time domain. The resulting waveform of SFOAE was a signal in the frequency domain after a fast Fourier transform of a suppressed SFOAE. After each stimulation-acquisition process, a zero phase shift high-pass filter (cut-off f = 500 Hz) was used to filter low-frequency background noise from the signal. Normally, 64 sub-averages were superposed and averaged after data filtering.
SFOAE STCs
A SFOAE STC is a plot of the critical level suppressed the evoked SFOAE to the same criterion as a function of suppressor frequency, at fixed probe frequency and probe level. In our study, the criterion was −6 dB, which means the evoked SFOAE was 50% suppressed. The SFOAE STC took about 30 min to obtain, at a frequency resolution of 10 points/octave.
Results
Test results
PTCs
Figure 3 shows the faster PTC results for one subject. The results in the faster PTC show the approximate V-shaped curve with a tail, which agrees with the results of Sek et al. [24] and Malicka et al. [25]. The tips of the upward and downward sweeps trended towards high and low frequencies, respectively, owing to the interference of the sweeping direction. It can be resolved by two-direction averaging (see Figure 3C). The results of subjectively measured PTC may be influenced by non-auditory factors, such as if the subject concentrated on the test and reacted rapidly. It would mean that if the jagged raw data fluctuated more slightly, a better tuning curve could be extracted. However, if the jagged raw data fluctuated too much, then it would be difficult to extract tuning curves accurately.

Example of a fast PTC obtained from one participant with normal hearing. (A) Upward sweep PTC. (B) Downward sweep PTC. (C) Averaged PTC. Probe frequency and level are indicated by stars. Dashed jagged lines indicate raw data. Solid lines indicate smoothed data.
SFOAEs
Figure 4 presents an example of the SFOAE test results at a CF of 4 kHz and L p of 30 dB SPL. The amplitude spectrum contains information in the frequency domain at a f p of 4,200 Hz which evoked the largest SFOAE in the test of SFOAE fine structure. Extracted SFOAEs had high signal to noise ratios. For this subject, the SFOAE fine structure results showed a best frequency at 4,200 Hz (for a CF of 4 kHz). From 5 to 50 dB SPL, the testing of the SFOAE I/O function shows an increasing function that begins to exhibit a saturation. The results of SFOAE I/O function offered the intensity of the evoked SFOAEs at the probe frequency and probe level, which can be used to choose the appropriate criterion in the test of SFOAE STCs.

SFOAE test results for one participant at a CF of 4 kHz. (A) SFOAE amplitude spectrum. (B) SFOAE fine structure. (C) SFOAE I/O function. Solid lines indicate SFOAEs. Dotted lines indicate noise. The L p is 30 dB SPL.
Comparison between SFOAE STCs and PTCs
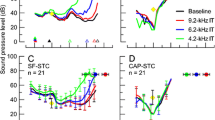
Using a logarithmic frequency axis and decibel intensity axis, we compared the SFOAE STCs and PTCs for all subjects at a suppression criterion of −6 dB (Figure 5). The results show that SFOAE STCs shift higher relative to f p , whilst PTCs shift similarly to f p. The overall shapes of the SFOAE STCs and PTCs of all subjects showed similar trends, except for a shift of the tip, which suggests that a potential use of SFOAE STCs may be as an objective measure of FS, equivalent to PTCs.

Comparison between SFOAE STCs (blue) and PTCs (red) for all subjects. (A) CF = 1 kHz. (B) CF = 2 kHz. (C) CF = 4 kHz. The probe frequency and level are indicated by black stars.
Q10 values
The Q10 value was calculated as the ratio between the tip frequency of the tuning curve and the bandwidth of the tuning curve 10 dB above the tip. Q10 values of SFOAE STCs and PTCs for all subjects are shown in Table 1. Mean Q10 values increased for both SFOAE STCs and PTCs as a function of CFs (Figure 6A). For both SFOAE STCs and PTCs, Q10 values at a CF of 1 kHz are closer to the values at a CF of 2 kHz, but Q10 values at a CF of 4 kHz are much larger. The paired t test indicates that Q10 values of SFOAE STCs and PTCs are significantly different (M D = −.5, SD = 1.20, t = −2.419, p = .022). Q10 values of PTCs are larger than SFOAE STCs at all CFs.

Q 10 values and Q 10 ratio for SFOAE STCs and PTCs. (A) Q10 values (circles) and mean Q10 values (dotted lines) for SFOAE STCs (black) and PTCs (red) as a function of probe frequency. (B) Q10 ratio (black circles) and mean Q10 ratio (dotted line) as a function of probe frequency. Aberrant points indicated by triangles. Error bars denoted as ± 1 SE.
Q10 ratio
To explore the relationship between the frequency selectivity of SFOAE STCs and PTCs, we calculated Q10 ratios (Q10 values of the PTCs divided by the Q10 values of the SFOAE STCs).The mean values of the Q10 ratios remain relatively constant across CFs at low probe levels (F 2,24 = .15, p = .858), except for the aberrant points indicated by triangles (Figure 6B). At all CFs, the mean Q10 ratios are approximately 1 (M = 1.059, SD = .168 at a CF of 1 kHz; M = 1.099, SD = .202 at a CF of 2 kHz; M = 1.054, SD = .190 at a CF of 4 kHz), which suggests that the frequency selectivity of SFOAE STCs is similar to that of PTCs.
Offset ratio
The horizontal and vertical offset ratios are the percentages of the difference of frequency, f tip, and tip level, L tip, relative to f p and L p, as shown in Equations (4) and (5) respectively.
The differences between tip frequencies and levels were calculated as f tip-f p and L tip-L p, respectively. The horizontal and vertical offsets could reflect the features of the site with the sharpest tuning on the basilar membrane. At different CFs, horizontal and vertical offset ratios are not significantly different for either SFOAE STCs or PTCs (SFOAE STCs: F 2,27 = .22, p = .806 for horizontal offset ratio, F 2,27 = 1.15, p = .331 for vertical offset ratio; PTCs: F 2,27 = .83, p = .449 for horizontal offset ratio, F 2,27 = 3.02, p = .065 for vertical offset ratio). For horizontal offset ratios, SFOAE STCs are significantly larger than PTCs (M D = 11.1, SD = 8.32, t = 7.335, two-tailed t test p < .001), and PTCs are mostly scattered around 0 (Figure 7A). SFOAE STCs shift higher relative to f p , but the PTCs shift always coincided with f p. For vertical offset ratios, the SFOAE STCs and PTCs are both shifted higher relative to L p (M D = −9.7, SD = 26.86, t = −1.969, two-tailed t test p = .059). SFOAE STCs are similar to PTCs at CFs of 1 and 2 kHz, but much smaller than PTCs at a CF of 4 kHz (Figure 7B).

Offset ratios for SFOAE STCs and PTCs as a function of f p . Horizontal (A) and vertical (B) offset ratio for SFOAE STCs (black) and PTCs (red) at different CFs. Offset ratios, circles; mean offset ratios, solid lines.
Discussion
Effectiveness
The SFOAE STC measurement took 30 min at a frequency resolution of 10 points/octave, and 15 min at a frequency resolution of 5 points/octave. The fast PTC took ~ 8 min to obtain, with the masker frequency changing ±1 octave relative to the probe frequency. The SFOAE STC was therefore more time-consuming. However, at a CF of 4,000 Hz, the tip masker level of the PTC was much larger than the SFOAE STC (Figure 7B). This indicates that the subject will feel more uncomfortable during the detection of PTCs at higher masker frequency. The interpretation of PTCs was influenced by non-auditory factors whilst the SFOAE determination was not. Therefore, SFOAE STCs have more potential for auditory function assessment when compared with PTCs.
Q10 value
The result indicates that the mean values of Q10 ratios of PTCs to SFOAE STCs were around 1, and remained relatively constant across CFs at low probe levels. However, Q10 values of PTCs were still a little larger than SFOAE STCs at all CFs which seems that PTCs are more sharply tuned than SFOAE STCs. It may be reasonable because PTCs reflect the FS characteristic of the auditory propagation pathway as a subjective measurement, but SFOAE STCs reflect the FS of auditory periphery as an objective measurement.
Tip frequency offset
The tip frequency of SFOAE STCs shifted higher than f p , but the shift of PTCs always coincided with f p (Figure 7A). Our findings are similar to those of other SFOAE studies [30, 32]. The mean tip frequency offset of SFOAE STCs was 12.36% (M = 11.13%, SD = 10.008 at a CF of 1 kHz; M = 12.97%, SD = 5.920 at a CF of 2 kHz; M = 12.99%, SD = 4.744 at a CF of 4 kHz), which is a shift of 1.12f p . This demonstrates that the more sharply tuned frequencies were located basal to the characteristic place of the probe frequency.
Conclusion
We designed an assessment method of human auditory FS using the detection of both PTCs and SFOAE STCs. The effectiveness of the objective SFOAE STCs method to the subjective PTCs method was compared in 10 individuals with normal hearing at low probe levels. Our results showed that estimates of FS provided by the SFOAE STCs were similar to those provided by behavioral measures of PTCs, suggesting that SFOAE STCs have the potential to assess frequency selectivity in a noninvasive, objective and effective way.
References
Moore BCJ: Frequency Selectivity, Masking and the Critical Band. In An introduction to the psychology of hearing. 5th edition. Edited by: Moore BCJ. San Diego: Academic; 2004:65–67.
Evans EF: Latest comparisons between physiological and behavioural frequency selectivity. In Proceedings of the 12th international symposium on hearing: 4–9 August 2000; Mierlo, the Netherlands. Edited by: Breebaart DJ, Houtsma AJM, Kohlrausch AG, Prijs VF, Schoonhoven R. Maastricht: Shaker Publishing; 2001:382–387.
Brownell WE, Bader CR, Bertrand D, de Ribaupierre Y: Evoked mechanical responses of isolated cochlear outer hair cells. Science 1985,227(4683):194–196. 10.1126/science.3966153
Dallos P, Wu X, Cheatham MA, Gao J, Zheng J, Anderson CT, Jia S, Wang X, Cheng WH, Sengupta S, He DZ, Zuo J: Prestin-based outer hair cell motility is necessary for mammalian cochlear amplification. Neuron 2008,58(3):333–339. 10.1016/j.neuron.2008.02.028
Ruggero MA, Rich NC: Furosemide alters organ of corti mechanics: evidence for feedback of outer hair cells upon the basilar membrane. J Neurosci 1991,11(4):1057–1067.
Dallos P, Harris D: Properties of auditory nerve responses in absence of outer hair cells. J Neurophysiol 1978,41(2):365–383.
Evans EF, Harrison RV: Correlation between cochlear outer hair cell damage and deterioration of cochlear nerve tuning properties in the guinea-pig [abstract]. J Physiol Lond 1976,256(1):43–44.
Florentine M, Buus S, Scharf B, Zwicker E: Frequency selectivity in normally-hearing and hearing-impaired observers. J Speech Hear Res 1980,23(3):646–669. 10.1044/jshr.2303.646
Kiang NYS, Liberman MC, Levine RA: Auditory-nerve activity in cats exposed to ototoxic drugs and high-intensity sounds. Ann Otol Rhinol Laryngol 1976, 85: 752–768. 10.1177/000348947608500605
Zhang M, Evans BN, Dallos P: Further characterization of voltage-dependent stereociliary stiffness in cochlear outer hair cells [abstract]. Assoc Res Otolaryngol Abstr 1998, 21: 19.
Zhang M, Surles JG: Voltage-dependent outer hair cell stereocilia stiffness at acoustic frequencies. NeuroReport 2008,19(8):855–859. 10.1097/WNR.0b013e3282ff84e8
Moore BCJ: Cochlear Hearing Loss: Physiological, Psychological and Technical Issues. 2nd edition. UK: Wiley Press; 2007.
Dallos P, Harris DM, Relkin E, Cheatham MA: Two-Tone Suppression and Intermodulation Distortion in the Cochlea: Effects of Outer Hair Cell Lesions. In Proceedings of the 5th International Symposium on Hearing: 8–12 April 1980; Noordwikjkerhout, The Netherlands. Edited by: Van den Brink G, Bilsen FA. Delft: Delft University Press; 1980:242–249.
Ruggero MA, Robles L, Rich NC: Two-tone suppression in the basilar membrane of the cochlea: mechanical basis of auditory-nerve rate suppression. J Neurophysiol 1992, 68: 1087–1099.
Martin GK, Ohlms LA, Franklin DJ, Harris FP, Lonsbury-Martin BL: Distortion product emissions in humans. III. Influence of sensorineural hearing loss. Ann Otol Rhinol Laryngol 1990,147(Suppl):30–42.
Fletcher H: Auditory patterns. Rev Mod Phys 1940,12(1):47–65. 10.1103/RevModPhys.12.47
Hamilton PM: Noise masked thresholds as a function of tonal duration and masking noise bandwidth. J Acoust Soc Am 1957, 29: 506–511. 10.1121/1.1908942
Greenwood DD: Critical bandwidth and the frequency coordinates of the basilar membrane. J Acoust Soc Am 1961,33(10):1344–1356. 10.1121/1.1908437
Schooneveldt GP, Moore BCJ: Comodulation masking release (CMR) as a function of masker bandwidth, modulator bandwidth and signal duration. J Acoust Soc Am 1989,85(1):273–281. 10.1121/1.397734
Spiegel MF: Thresholds for tones in maskers of various bandwidths and for signals of various bandwidths as a function of signal frequency. J Acoust Soc Am 1981,69(3):791–795. 10.1121/1.385590
Patterson RD: Auditory filter shapes derived with noise stimuli. J Acoust Soc Am 1976,59(3):640–654. 10.1121/1.380914
Moore BCJ: Psychophysical tuning curves measured in simultaneous and forward masking. J Acoust Soc Am 1978,63(2):524–532. 10.1121/1.381752
Ruggero MA, Temchin AN: Unexceptional sharpness of frequency tuning in the human cochlea. Proc Natl Acad Sci 2005,102(51):18614–18619. 10.1073/pnas.0509323102
Sęk A, Alcántara J, Moore BCJ, Kluk K, Wicher A: Development of a fast method for determining psychophysical tuning curves. Int J Audiol 2005,44(7):408–420. 10.1080/14992020500060800
Malicka AN, Munro KJ, Baker RJ: Fast method for psychophysical tuning curve measurement in school-age children. Int J Audiol 2009,48(8):546–553. 10.1080/14992020902845899
Kemp DT: Stimulated acoustic emissions from within the human auditory system. J Acoust Soc Am 1978,64(5):1386–1391. 10.1121/1.382104
Kemp DT, Chum RA: Observations on the Generator Mechanism of Stimulus Frequency Acoustic Emissions–two Tone Suppression. In Proceedings of the 5th International Symposium on Hearing: 8–12 April 1980; Noordwikjkerhout, The Netherlands. Volume 5. Edited by: Van den Brink G, Bilsen FA. Delft: Delft University Press; 1980:34–41.
Siegel JH, Temchin AN, Ruggero MA: Empirical estimates of the spatial origin of stimulus-frequency otoacoustic emissions [abstract]. Assoc Res Otolaryngol Abstr 2003, 26: 679.
Temchin AN, Rich NC, Ruggero MA: Threshold tuning curves of chinchilla auditory-nerve fibers. I. Dependence on characteristic frequency and relation to the magnitudes of cochlear vibrations. J Neurophysiol 2008,100(5):2889–2898. 10.1152/jn.90637.2008
Keefe DH, Ellison JC, Fitzpatrick DF, Gorga MP: Two-tone suppression of stimulus frequency otoacoustic emissions. J Acoust Soc Am 2008,123(3):1479–1494. 10.1121/1.2828209
Cheatham MA, Katz ED, Charaziak K, Siegel JH: Using Stimulus Frequency Emissions to Characterize Cochlear Function in Mice. In Proceedings of the 11th International Mechanics of Hearing Workshop: 16–22 July 2011; Massachusetts, USA. Volume 1403(1). Edited by: Shera CA, Olson ES. Maryland: American Institute of Physics; 2011:383–388.
Charaziak KK, Souza P, Siegel JH: Stimulus-frequency otoacoustic emission suppression tuning in humans: comparison to behavioral tuning. JARO 2013,14(6):843–862. 10.1007/s10162-013-0412-1
Nelson DA, Fortune TW: High-level psychophysical tuning curves: simultaneous masking by pure tones and 100-Hz-wide noise bands. J Speech Hear Res 1991,34(2):360–373. 10.1044/jshr.3402.360
Brass D, Kemp DT: Time-domain observation of otoacoustic emissions during constant tone stimulation. J Acoust Soc Am 1991,90(5):2415–2427. 10.1121/1.402046
Brass D, Kemp DT: Suppression of stimulus frequency otoacoustic emissions. J Acoust Soc Am 1993,93(2):920–939. 10.1121/1.405453
Acknowledgements
The authors are grateful for the support of the National Natural Science Foundation of China under the grant no. 61271133, Basic Development Research Key program of Shenzhen under grant no. JC 201105180808A, Specialized Research Fund for the Doctoral Program of Higher Education under grant no.20120002110054, Tsinghua National Laboratory for Information Science and Technology (TNList) Cross-discipline Foundation.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
QG developed original concept for the study, and is the corresponding author. She designed the experiments and was responsible for manuscript revision. YW finished the experiments, analyzed the data and drafted the manuscript. MX set up the testing system, designed and developed the algorithm. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Gong, Q., Wang, Y. & Xian, M. An objective assessment method for frequency selectivity of the human auditory system. BioMed Eng OnLine 13, 171 (2014). https://doi.org/10.1186/1475-925X-13-171
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1475-925X-13-171