
Abstract
Background
The electroencephalography (EEG) signals are known to involve the firings of neurons in the brain. The P300 wave is a high potential caused by an event-related stimulus. The detection of P300s included in the measured EEG signals is widely investigated. The difficulties in detecting them are that they are mixed with other signals generated over a large brain area and their amplitudes are very small due to the distance and resistivity differences in their transmittance.
Methods
A novel real-time feature extraction method for detecting P300 waves by combining an adaptive nonlinear principal component analysis (ANPCA) and a multilayer neural network is proposed. The measured EEG signals are first filtered using a sixth-order band-pass filter with cut-off frequencies of 1 Hz and 12 Hz. The proposed ANPCA scheme consists of four steps: pre-separation, whitening, separation, and estimation. In the experiment, four different inter-stimulus intervals (ISIs) are utilized: 325 ms, 350 ms, 375 ms, and 400 ms.
Results
The developed multi-stage principal component analysis method applied at the pre-separation step has reduced the external noises and artifacts significantly. The introduced adaptive law in the whitening step has made the subsequent algorithm in the separation step to converge fast. The separation performance index has varied from -20 dB to -33 dB due to randomness of source signals. The robustness of the ANPCA against background noises has been evaluated by comparing the separation performance indices of the ANPCA with four algorithms (NPCA, NSS-JD, JADE, and SOBI), in which the ANPCA algorithm demonstrated the shortest iteration time with performance index about 0.03. Upon this, it is asserted that the ANPCA algorithm successfully separates mixed source signals.
Conclusions
The independent components produced from the observed data using the proposed method illustrated that the extracted signals were clearly the P300 components elicited by task-related stimuli. The experiment using 350 ms ISI showed the best performance. Since the proposed method does not use down-sampling and averaging, it can be used as a viable tool for real-time clinical applications.
Similar content being viewed by others


Background
The first recording of the electric field of a human brain was made by the German psychiatrist Hans Berger in Jena, Germany, in 1924. He named the recorded signals electroencephalograms (EEGs) [1]. Over the past few decades, this signal has attracted very considerable interest and attention in the study of cognitive processes in both clinical [2–9] and research areas [10–16]. Its main advantages are non-invasive measurement, superior temporal resolution, easy implementation, and low cost [17, 18]. An event-related potential (ERP), as a derivative of the EEG, is a measured brain response directly resulted from a thought or perception. In 1964 and 1965, respectively, two groups (Chapman and Bragdon [19] and Sutton et al. [20]) independently discovered a P300 component (a wave peak approximately 300 milliseconds (ms) after a task-relevant stimulus). Recently, a great variety of potential applications of the ERP-based P300 component have been widely studied [21–26].
Ideally, the EEG machine records, along the scalp, the electrical activities generated by the firing of neurons within the brain. The present problem is that EEG signals contain the neurons' activities located in some significant distances away from the sensors (electrodes). Therefore, given the distance between the electrode and the neuronal activities, the EEG signal collected at any point on a person's scalp is a nonlinear mixture of the activities generated over a large brain area. In this paper, the recorded EEG data are assumed to be a linear mixture of neuronal activities for brevity. Certainly, dealing with the typical low-amplitude and low signal-to-noise ratio (SNR) potentials, the removal of other biological signals becomes one of the major challenges in the study of ERPs. To resolve this problem, down-sampling and averaging methods of EEG data over multiple trials are usually required. However, the down-sampling method can cause some signals to become indistinguishable and distorted, which implies an alteration of the original characteristics of the waveform of information. Also, the averaging method assumes that the signals are long-time stationary and deterministic relative to the stimulus onset. This assumption might cause the loss of time resolution specifically for dissimilar trials. Also, the stationarity and determinacy assumption on EEG signals might not work, because one must consider other factors such as maturation, age, sex, state-of-consciousness, psychiatric and neurological disorders, etc [27].
In this paper, a more efficient means of feature extraction is developed to cope with the drawbacks of the down-sampling and averaging method. Previous research has shown that several aspects of the ERP (especially the latency, magnitude, and topography) are highly variable across trials [27, 28]. Many techniques [29–33] appeared in research area to resolve the problem of EEG (specifically for obtaining P300 components) are not sufficiently standardized for clinical usage. Moreover, those techniques usually have been performed off-line. In this paper, a real-time feature extraction method for P300 components using an adaptive nonlinear principal component analysis (ANPCA) incorporating the multilayer neural network (MNN) is proposed. The MNN technique has been widely adopted in the fields of information and neural sciences (i.e., feature extraction, classification, modeling, etc.) [34–39]. The experimental results in this paper show that the implementation of the proposed method achieves a very significant statistical improvement in extracting P300 components.
The main contributions of this paper are the following. (i) The developed multi-stage principal component analysis (PCA) applied at the pre-separation step reduces external noises and artifacts significantly, and separates the colored source in the measured EEG signals. (ii) The designed adaptive rule in the whitening step makes the subsequent separation algorithm to converge fast. (iii) The combination of the proposed ANPCA method and the MNN for feature extraction can identify the P300 components in real-time (i.e., without down-sampling and averaging). (iv) Furthermore, the proposed method can become a viable tool in both research and clinical applications.
Methods
Data acquisition
Figures 1(a) and 1(b) show the overall schematic and block diagram, respectively, of the proposed real-time feature extraction method. In the experiment, two masters students and five Ph.D. students (all males, age 32 ± 5 years, none of whom had any known neurological deficits) have participated. A seven-choice signal paradigm (i.e., forward, turn right, turn left, backward, backward right, backward left, and stop) is used to stimulate the seven subjects. They sit in a comfortable chair in front of a computer monitor located at 60 cm away from their eyes. The subjects are asked to count silently the number of times of the flashes of a preselected image on the screen while imagining a car moving in the direction of the flashed signal. Four seconds after a starting tone, seven different images flash in random order, one image at a time. A software program (E-Prime 2.0, developer: Schneider, Sharpsburg-USA) is employed for presenting stimuli.

The proposed scheme for real-time feature extraction (the seven traffic signals flash one at a time to evoke P300): (a) the overall scheme, (b) block diagram. The configurations of the ANPCA algorithm incorporated with the MNN scheme for real-time feature extraction of the independent components according to the P300 component.
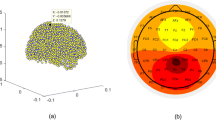
The left-hand side box in Figure 1(a) shows a g-MOBIlab+ biosignal acquisition device (Christoph Guger, Austria), with which the EEG signals are recorded continuously and digitized at a 256 Hz sampling rate. Figure 2 depicts the positioning of the eight electrodes (channels) at Fz, Cz, Pz, Oz, P7, P3, P4, P8 by following the 10-20 International System [40] and the linked-ears reference. The ground electrode is placed at the center of the forehead. The impedance at each location is kept below 5 kΩ. The participants are supposed not to have any eye and head movements during the EEG recording. Each subject records four sessions; four different image-flash durations (i.e., 25 ms, 50 ms, 75 ms, and 100 ms, respectively) followed by a 300 ms blank screen. Hence, the inter-stimulus intervals (ISIs) in this work range from 325 ms to 400 ms.

The eight-electrodes configuration. The standard positions (i.e., Fz, Cz, Pz, Oz, P7, P3, P4, and P8) prescribed by the 10-20 International System with a linked-ears reference.
Real-time feature extraction
Let M be the number of measured EEG signals and N be the number of unknown input sources. Then, the measured signal at channel i, x i (k), can be represented as a linear combination of N unknown mutually statistically independent source signals s j (k), j = 1,2, ..., N, as follows (typically M ≥ N) [41, 42].
or in matrix form,
where x(k) = [x 1(k), x 2(k), ..., x M (k)] T ∈ RMis the vector of EEG signals, A ∈ RM × Nwith entries a ij is the unknown M × N mixing matrix, s(k) = [s 1(k), s 2(k), ..., s N (k)] T ∈ RN is the unknown vector of colored source signals, and n(k) ∈ RMis the vector of additive noises. The objective of this work is to estimate both A and s(k). The following assumptions are made: Individual components of the source vector s(k) are statistically independent of one another; the matrix A is invertible and has full rank; each component in s(k) is a stationary; and the noise vector n(k) is white with Gaussian distribution. The P300 extraction is made in the following steps: pre-separation, whitening, separation, and estimation without ignoring the additive noise signal n(k).
Pre-separation step
The pre-separation step uses a multi-stage PCA to separate the sources and also to reduce external noises and artefacts from the measured signal vector. The eigenvalue decomposition of the correlation matrix R xx of the measured signal x(k) is given by [42]
where Λ ∈ RM × Nis a pseudo-diagonal matrix. On the basis of the largest eigenvalues, the spatial whitening procedures can be written as
where Λ j = diag{λ 1 , λ 2 , ..., λ N } with λ 1 ≥ λ 2 ≥ ... ≥ λ N and V j = {v 1, v 2,...v N } ∈ RN×M. Therefore, the PCA is performed for a new vector of signals, which is defined [41, 42]
where τ is an arbitrary time delay. The covariance matrix of the vector is expressed as
where , under the assumption that H = BA is orthogonal and R SS = I and
Hence, the matrix decomposition can be written
where D(τ)is a diagonal matrix expressed as
with diagonal elements d ii (τ) = 2(1+E{s i (k)s i (k-τ)}) If the diagonal elements are distinct, the eigenvalue decomposition is unique. Thus, the mixing matrix and the input vector , respectively, can be estimated as and
Assume that the process comprises a zero-mean sequence whose covariance matrix is defined as in (3), and that we are going to extract its complex-values eigenvectors v i and corresponding principal components (PCs) in real-time. Employing a self-supervising principle and hierarchical neural network architecture, the PCs() are extracted sequentially as
The vector v i should be determined in such a way that the reconstructed vector will reproduce the input vector according to a suitable optimization. For this purpose, let us define a complex-valued instantaneous error vector as
where I is the identity matrix, and are the real part and imaginary parts of the error vector e i (t), respectively, and . In order to find the optimal value of the vector v i , we can define the following standard 2-norm cost function.
where is the p th element of . The minimization of the cost function (13), according to the standard gradient descent approach for the real and imaginary parts of the vector , leads to a set of differential equations as
where β i > 0 is the learning rate, , , , , , and . Combining (14) and (15) and taking into account that , the adaptation law for updating the parameters is obtained as
which can be written in matrix form as
for any v i (0) ≠ 0, β i (t) > 0. Since the second term in (17), which can be written , tends quickly to zero as tends to 1 with t→∝ it can be neglected. The adaptation law in (17) can be further simplified to
where (.)* denotes a complex conjugate. In discrete time, the adaptation law in (18) can be written
where .
Whitening step
The whitening step uses the PCA to transform the data into an appropriate space and to reduce the redundancy of the observed data. The separated input vector is whitened in the second step by applying the following transformation.
where u(k) is the whitened k vector, and P is the whitening matrix, which is determined using the neural learning approach. The objective is to find a simple adaptive algorithm for estimating the whitening matrix P, such that the covariance matrix of the whitened signals u(k) will be a diagonal matrix, that is, R uu = E{uuT } = diag{λ 1, λ 2, ..., λ N} = I N , and will be mutually uncorrelated if all of the cross-correlations are zero, that is, r ij = E{u i u j } = 0, for all i ≠ j, with non-zero autocorrelations . Therefore, the minimization function can be formulated in the following 2-norm.
To derive an adaptive learning algorithm, the following transformation
is used, where B = PA is the global transformation matrix from s to u. Without loss of generality, R ss = E{ssT } = I N is assumed. By substituting (22) into (21), the optimization criterion can be written as
Applying the standard gradient descent approach and the chain rule, the derivative of (23) is obtained as
Taking into account that B = PA and assuming that A varies very slowly in time (i.e., dA/dt≈0), we have
Using the simple Euler formula, the corresponding discrete-time adaptive learning algorithm can be written as
where η(k) is the learning parameter to be adjusted according to , and ξ is the forgetting factor (i.e., 0 < ξ < 1). The covariance matrix R uu can be estimated as
where .
Separation step
The separation of the whitened signals u(k) is the third step of the proposed algorithm, which is accomplished by applying the nonlinear principal component analysis (NPCA) learning rule. The multichannel linear separation transformation is given in the following form.
where W(k) is the separation matrix, whose values are updated through the NPCA learning rule. If the independent signals are zero-mean, the generalized covariance matrix of f(y i ) and g(y j ) (f(y i ) and g(y j ) are different and odd nonlinear activation functions such that f(y) = y3 and g(y) = tanh(y)) is a non-singular diagonal matrix R fg = E{f(y)gT (y)}-E{f(y)}E{gT (y)}. On the basis of the independence criterion, the nonlinear covariance matrix is given as [41, 43]
where f(y) = [f(y 1), f(y 2), ..., f(y N )] T and g(y) = [g(y 1), g(y 2), ..., g(y N )] T , provided that E{f(y i )} = 0 or E{g(y i )} = 0. To satisfy these conditions for arbitrary distributed sources, the nonlinearities are selected as f i (y i ) = φ i (y i ), g i (y i ) = y i or f i (y i ) = y i , g i (y i ) = φ i (y i ), where φ i (y i ) are suitably designed nonlinear functions, defining g(y) as an odd function and f(y) = g(y)-y. Therefore, similarly to (21)-(26), a real-time implementation algorithm can be derived as
where gT y = (fT y(k)-yT (k)). Since the separation matrix W(k) is assumed to be orthogonal (i.e., WT (k)W(k) = I), the real-time adaptation rule can be rewritten as
where y(k) is the separated signal and the output of the second step, W b = (uT (k)-fT y(k)), μ(k) is the learning parameter (it is adjusted according to with the forgetting factor 0 < γ < 1), and f(.)is a suitably chosen nonlinear function that is usually selected to be odd in order to ensure both stability and signal separations. These nonlinear functions require the use of high-order statistics (HOS). In the present study, f(.)was chosen as f(t) = tanh(t). Finally, since f(t) = dg(t)/dt, g(t) = In[cosh(t)].
Estimation step
The final step is the estimation of the independent component basis vector of the mixing matrix A(k). The estimate of the observed data is given by
Comparing (32) with (2), and since (i.e., is the estimated source signal s(k)), it can be concluded that . Therefore, the columns of the matrix Q(k) are the estimates of the columns of the matrix . Since Q(k) is the estimation matrix, its values (similarly to (26)) are updated through the adaptation law as
where . The quality of the source estimate in y(k) can be measured using the zero-forcing solution. Such a solution attempts to adapt the demixing matrix such that
where C(k) = W(k)P(k)V(k), Φ is a (M × M) permutation matrix with one unity entry in any row or column, and D is a diagonal nonsingular scaling matrix. In this case, it becomes
for some non-replicative assignment j→i for 1 ≤ i ≤ N and 1 ≤ j ≤ M Thus, each element of y(k) is the sum of a single unique source in s(k) and a noise term. In each simulation run, the performance index (PI) is evaluated using the following equation [44].
where , , c ij denotes the (i, j)th element of the matrix in C(k), corresponding to the j th independent component (IC) in the desired subset of sources. This dimensionless performance metric measures the deviation of the combined system from a diagonally scaled permutation matrix (i.e., 0 ≤ PI(k) ≤ 1 for all matrices C(k), PI(k) is one when the sources maximally mixed in the outputs, and PI(k) is zero when the desired subset of the ICs is perfectly separated). The first term in (36) gives the error of the separation of the output component y i (k) in (35) with respect to the sources and the second term measures the degree of the desired IC, c j , appearing multiple times at the output. The integration of the four steps is called the adaptive nonlinear principal component analysis (ANPCA) method. In order to improve the flexibility, efficiency, and performance of blind signals separation or extraction, the proposed ANPCA scheme is run upon a multilayer neural network. The multiple layers of neurons with nonlinear transfer functions allow the network to learn both linear and nonlinear relationships between input and output vectors. Furthermore, this allows us to combine second-order statistics (SOS) and the HOS algorithm to extract features having different statistical properties, existing at various layers, and originating from various sources. The synaptic weights in each layer are updated by employing the algorithm described above.
Results
Preparatory to an analysis of the features of P300 components from EEG signals in real-time, actual signals were recorded in an eight-channel (Fz, Cz, Pz, Oz, P7, P3, P4, and P8) configuration. Figure 3 shows the observed EEG signals with background signal amplitudes of around 300 micro volts. Figure 4 shows the pre-processed signals with amplitudes of around 25 micro volts, which were filtered using a sixth-order BPF with cut-off frequencies of 1 Hz and 12 Hz. One way of gaining further insights into EEG signals is by introducing ANPCA techniques. The present model of EEG analysis consists of four main steps: pre-separation (learning rate β of 0.6), whitening (forgetting factor η of 0.01), separation (forgetting factor γ of 0.002), and estimation (learning rate α of 0.3). In this algorithm, the pre-separation and the whitening steps enable faster adaptation at the separation step. The performance of the component separation of the ANPCA algorithm in the output was evaluated using (36). The evolutions of PI(Ni) for six different run of the proposed method generated from the data with 350 ms ISI is given in Figure 5. It can be seen that the algorithm takes between four and ten epochs to converge. Depending on the simulation run, the performance factor varies from -22 dB to -33 dB, due to random differences in the source signals. The robustness of the ANPCA was evaluated by comparing its separation performance with suggested algorithms (i.e., NPCA [45], Nonstationary Source Separation-Joint Diagonalization (NSS-JD) [42], Joint Approximate Diagonalization of Eigen-matrices (JADE) [46], and Second-Order Blind Identification (SOBI) [47]) as shown in Figure 6. Figures 7, 8, 9, and 10 show the real-time-extracted signals from eight-electrode of the P300 component using the ANPCA algorithm using ISI of 325 ms, 350 ms, 375 ms, and 400 ms, respectively. The P300 amplitudes of individual subject, taken from Fz electrode, for ISI of 325 ms, 350 ms, 375 ms, and 400 ms, respectively, is shown in Figure 11 (a) P300 amplitude upon a single stimulus and (b) P300 upon multiple stimuli. By averaging the eight extracted signals from the eight-electrode, the P300 components were not detected in some periods as indicated in Figure 12. This signal was averaged using the 350 ms ISI data. Comparative plots of the classification accuracies along seven stimuli for all subjects (subjects 1-7) are provided in Figure 13. The best classification accuracy was achieved using ISI 350 ms. The average value of the classification accuracies upon seven block stimuli for all of the subjects is given in Table 1. The classification using ISI 350 ms gave the the higher average value with smallest standard deviation.

The measured raw EEG signals. The EEG signals recorded continuously and digitized at a 256 Hz sampling rate using a g-MOBIlab+biosignal acquisition device.

The pre-processed EEG signals that were band-passed. The EEG signals were pre-processed using a sixth-order BPF with cut-off frequencies of 1 Hz (i.e., to remove the trend from low frequency bands) and 12 Hz (i.e., to remove unimportant information from high frequency bands).

Evolutions of PI ( Ni ) for six different runs of the ANPCA algorithm using 350 ms ISl. The performance of the ANPCA algorithm in (31) was evaluated using (35), where W(0) = I. A single block of N= 7000 samples has been used to compute all coefficient updates for six run, where for all integer values i ≥ 0 and i ≤ k ≤ N-1.

Comparison of separation performance indices: the proposed method (ANPCA) vs. other algorithms (NPCA, NSS-JD, JADE, and SOBI). To evaluate the robustness of the ANPCA against background noise, the separation performance indices of the ANPCA is compared with others well known algorithms (i.e., NPCA, NSS-JD, JADE, and SOBI algorithms).

Extracted P300 components in real time (325 ms ISI). For the ISI of about 325 ms, it was found that the amplitude of the P300 component was higher than for the other ISI but noisier than for the higher ISI.

Extracted P300 components in real time (350 ms ISI). For the ISI of about 350 ms, the target and non-target amplitudes were clearer and easier to distinguish than for the other ISI.

Extracted P300 components in real time (375 ms ISI). For the ISI of about 375 ms, it was found that in some sessions the non-target amplitudes were higher than the target ones.

Extracted P300 components in real time (400 ms ISI). For the ISI of about 400 ms, it was found that none of the channels showed similar behaviour.

Comparison of P300 amplitudes for four different ISIs (Fz channel): (a) P300 amplitude upon a single stimulus, (b) P300 upon multiple stimuli. The amplitudes of the P300 component for each ISI, which indicates that the short ISI could increase both the target and non-target amplitudes. The ISI of about 350 ms shows better performance.

The averages of eight-electrode data in Figure 8 (350 ms ISI): P300s are not detected in some periods. By averaging, the amplitude of a target gets bigger compared to that of a non-target, if the signal is long time stationary. But, this will fail for dissimilar trials as indicated with the ellipse mark (i.e., solid circle for the target and dash circle for the non-target).

Comparison of classification accuracies along seven stimuli (four ISIs, seven subjects): ISI 350 ms was the best out of four. All subjects achieved an average classification accuracy of 100% after three blocks of stimulus presentations were averaged (i.e., 8 s). In this regard, the subject intention will be recognized after eight seconds of the first given stimulus.
Discussion
The ability to measure and classify single-trial responses in real-time from specific brain regions has important theoretical and practical implications for both clinical and research applications. In this study, the amplitude of the background signal was around 300 micro volts as shown in Figure 3. Since the amplitude of the P300 component is very small (around 1.5 micro volts) compared with that of the background, the pre-processing filtering is required. These EEG signals were filtered using a sixth-order BPF with cut-off frequencies of 1 Hz (i.e., to remove the trend from low frequency bands) and 12 Hz (i.e., to remove unimportant information from high frequency bands), respectively. However, as shown in Figure 4, the signals nonetheless were corrupted by noises with background signal amplitudes of around 25 micro volts. Although there were some noticeable improvements, classification of the signals with respect to the given stimulus remained difficult. Therefore, an ANPCA-algorithm-based multilayer neural network model that can be used to analyzed complex P300 component from EEG signals in real-time is proposed. The MNN model with back-propagation training algorithm has five layers: the input and output layers have the same number of units N; the first and third layers are nonlinear (a sigmoid function as a universal approximation), and the second and fourth layers are linear. Layer 2 contains M units, that is, as many as there are nonlinear PCs. The activations of the neurons in Layer 2 are the nonlinear PCs of the input data. The back-propagation algorithm with an adaptive learning rate and momentum was used to train the neural networks. The values of the learning rate and the momentum were estimated by trial and error until no further improvement in the performance index could be obtained. The parameter values chosen were 0.3 and 0.8, respectively. The networks were trained before the EEG signals are recorded for one session. The time length for the training was range from 15.925 s to 19.6 s for each ISI.
Figure 5 shows the evolution of PI(Ni) for six different simulation runs in one implementation of the proposed method. The performance of the ANPCA algorithm in (30) was evaluated using (36) with W(0) = I. A single block of N = 7000 samples has been used to compute all coefficient updates for six run, where for all integer values i ≥ 0 and i ≤ k ≤ N-1. As it can be seen, the algorithm took between four and ten epochs to converge. Depending on the simulation run, the performance factor varies from -22 dB to -33 dB, due to random differences in the source signals. The accuracy of the method generally improves for increasing values of block length N. It can be confirmed that the ANPCA algorithm successfully separates the mixture of source signals. To evaluate the robustness of the ANPCA against background noise, the separation performance indices of the ANPCA were compared with the suggested algorithms (i.e., NPCA, JADE, NSS-JD, and SOBI). The accuracy of the recovered independent components compared to the sources was measured according to the specified performance function in (36). Figure 6 shows the overall performance of all algorithms. For data iterations longer than 5000 iterations, the performance index was not much better, but was more and more time consuming. The quality of separation increases dramatically after 1500 length of iterations for the proposed method (ANPCA) and after 4000 length of iterations for other algorithms. It's clear that the proposed method present the shortest iteration time performance index about little over 0.03 (an acceptable level for separation). Upon this, it is asserted that the ANPCA algorithm successfully separates mixed source signals. The same accuracy level of separation was achieved after 4000 iterations by using other algorithms.
The ICs that were produced from the observed data using the ANPCA algorithm (for ISI of about 325 ms, 350 ms, 375 ms, and 400 ms) are shown in Figures 7, 8, 9, and 10. Although the signals were still corrupted by noises (manifested as the high amplitudes of non-targets in some sessions), the behaviours of the extracted signals clearly represented the P300 components. The observed signal was of the P300 event-related potential signal form. For the ISI of about 325 ms (Figure 7), it was found that the amplitude of the P300 component was higher than for the other ISI, as shown in Figure 11 (a), but noisier than for the higher ISI. As noted in Figure 7, the non-target amplitudes were roughly similar to the target amplitudes. For the ISI of about 350 ms (Figure 8), the target and non-target amplitudes were clearer and easier to distinguish than for the other ISI. For the ISI of about 375 ms (Figure 9), it was found that in some sessions the non-target amplitudes were higher than the target ones. For the ISI of about 400 ms, it was found that none of the channels showed similar behavior, as indicated in Figure 10. In this case the assumption of long stationary segment for averaging method will cause loss of the time resolution. Figures 7, 8, 9, and 10 show that the extracted signal amplitudes decreased (i.e., from the Fz to the P8 channel) as the distance of the electrodes increased. Figure 11(a) plots the amplitudes of the P300 component for four different ISIs (Fz channel) upon a single stimulus (scale of 700 ms) and indicate that the short ISI could increase both a target and a non-target amplitudes. Figure 11(b) plots the amplitudes of the P300 component for four different ISIs upon multiple stimuli (scale of 60 s) and indicate the peak shifting of the P300 component with respect to the various ISIs. The experiment using 350 ms ISI showed the best performance. Figure 12 displays the averages of the signals extracted from the eight-channel with ISI 350 ms. By averaging, the amplitude of a target gets bigger compared to that of a non-target, if the signal is long time stationary. But, this will fail for dissimilar trials, as indicated in Figure 12 (i.e., solid circle for the target and dashed circle for the non-target). This is one of the main reasons why the proposed method does not use the averaging scheme.
Comparative plots of the classification accuracies for the seven subjects were provided in Figure 13. All subjects achieved an average classification accuracy of 100% after three blocks of stimulus presentations were averaged (i.e., 8 s). In this regard, the subject intention was be recognized after eight seconds of the first given stimulus. Shown alongside the average value of the classification accuracies upon seven block stimuli for all of the subjects, in Table I, are the corresponding 85% confidence intervals. According to Table 1, the experiment with ISI 350 ms provides the highest average classification accuracies (88.921%) and smallest standard deviation (1.807) over all subjects. By contrast, ISI 400 ms showed the worst classification accuracies (84.839%). However, the worst standard deviation (4.959) was given by the experiment with ISI 325 ms. These results reflect the fact that the best performance was obtained through the experiment with ISI 350 ms.
Routine P300 component of EEG signals has been widely used in the clinical circumstances [21–26]. In this context, the use of physiological signals rather than behavioral responses of patient are often advisable, albeit challenging. Overall, the P300 component has sparked considerable interest as a clinical-application diagnostic tool. The most efficient method of implementing the diagnostic tool is through real-time detection. The amplitude of different waveforms at a single point can also be displayed in a similar format. This type of display provides a more objective analysis of the EEG activity compared to a subjective visual analysis by a physician. Simultaneous video monitoring of the patient during the EEG recording is becoming more popular. It allows the physician to closely correlate EEG waveforms with the patient's activity and may help produce a more accurate diagnosis.
Conclusions
The applicability of the proposed ANPCA method for extracting the P300 waves included in the EEG signals for real-time without down-sampling and averaging of the original signals was demonstrated. The separation performance factor of the ANPCA varied from -22 dB to -33 dB due to the randomness of source signals. In comparison with other algorithms (i.e., NPCA, NSS-JD, JADE, and SOBI), the ANPCA presented the shortest iteration time with performance index about 0.03. Since all the computations are done in real time, the ANPCA can be used as a viable tool for clinical applications.
References
Berger H: Uber das elektroenkephalogram des menschen. Archiv fur Psychiatrie und Nervenkrankheiten 1929, 87: 527–570. 10.1007/BF01797193
Niedermeyer E, da Silva FL: Electroencephalography: Basic principles, clinical applications, and related fields. 5th edition. Lippincot Williams & Wilkins; 2004.
Wang JT, Young GB, Connolly JF: Prognostic value of evoked responses and eventrelated brain potentials in coma. Can J Neurol Sci 2004, 31: 438–450.
Rousseff RT, Tzvetanov P, Atanassova PA, Volkov I, Hristova I: Correlation between cognitive P300 changes and the grade of closed head injury. Electromyogr Clin Neurophysiol 2006, 46: 275–282.
Pritchett S, Zilberg E, Xu ZM, Myles P, Brown I, Burton D: Peak and averaged bicoherence for different EEG patterns during general anaesthesia. Biomedical Engineering Online 2010, 9: 76. 10.1186/1475-925X-9-76
Lorenz J, Kunze K, Bromm B: Differentiation of conversive sensory loss and malingering by P300 in a modified oddball task. Neuroreport 1998, 9: 187–191. 10.1097/00001756-199801260-00003
Towle VL, Sutcliffe E, Sokol S: Diagnosing functional visual deficits with the P300 component of the visual evoked potential. Arch Ophthalmol 1985, 103: 47–50.
Rosenfeld JP, Cantwell B, Nasman VT, Wojdac V, Ivanov S, Mazzeri L: A modified, event-related potential-based guilty knowledge test. Int J Neurosci 1988, 42: 157–161. 10.3109/00207458808985770
Abootalebi V, Moradi MH, Khalilzadeh MA: A new approach for EEG feature extraction in P300-based lie. Computer Methods and Programs in Biomedicine 2009, 94: 48–57. 10.1016/j.cmpb.2008.10.001
Roberts SJ, Penny WD: Real-time brain computer interfacing: A preliminary study using bayesian learning. Med Biol Eng Comput 2000, 38: 56–61. 10.1007/BF02344689
Takano K, Kamatsu T, Hata N, Nakajima Y, Kansaku K: Visual stimuli for the P300 brain-computer interface: A comparison of white/gray and green/blue flicker matrices. Clinical Neurophysiology 2009, 120: 1562–1566. 10.1016/j.clinph.2009.06.002
Hazrati MKh, Erfanian A: An online EEG-based brain-computer interface for controlling hand grasp using an adaptive probabilistic neural network. Medical Engineering & Physics 2010, 32: 730–739. 10.1016/j.medengphy.2010.04.016
Lv J, Li Y, gu Z: Decoding hand movement velocity from electroencephalogram signals during a drawing task. Biomedical Engineering Online 2010, 9: 64. 10.1186/1475-925X-9-64
Lee Y, Lee H, Kim J, Shin HC, Lee M: Classification of BMI control commands from rat's neural signals using extreme learning machine. Biomedical Engineering Online 2009, 9: 29.
Shen TW, Tompkins WJ, Hu YH: Implementation of a one-lead ECG human identification system on a normal population. Journal of Engineering and Computer Innovations 2011, 2: 12–21.
Lewis D, Brigder D: Market researchers make increasing use of brain imaging. Advances in Clinical Neuroscience & Rehabilitation 2005, 5: 35–36.
Etevenon P, Lebrun N, Clochon P, Perchey G, Eustache F, Baron JC: High temporal resolution dynamic mapping of instantaneous EEG amplitude modulation after tone-burst auditory stimulation. Brain Topography 1999, 12: 129–137. 10.1023/A:1023466312686
Davidson PR, Jones RD, Peiris MT: EEG-based lapse detection with high temporal resolution. IEEE Trans Biomed Eng 2007, 4: 832–841.
Chapman RM, Bragdon HR: Evoked responses to numerical and non-numerical visual stimuli while problem solving. Nature 1964, 203: 1155–1157. 10.1038/2031155a0
Sutton S, Braren M, John ER, Zubin J: Evoked potential correlates of stimulus uncertainty. Science 1965, 150: 1187–1188. 10.1126/science.150.3700.1187
Ma Q, Shen Q, Xu Q, Li D, Shu L, Weber B: Empathic responses to others' gains and losses: An electrophysiological investigation. Neuroimage 2011, 54: 2472–2480. 10.1016/j.neuroimage.2010.10.045
Bauer LO: Interactive effects of HIV/AIDS, body mass, and substance abuse on the frontal brain: A P300 study. Psychiatry Research 2011, 185: 232–237. 10.1016/j.psychres.2009.08.020
Kessels LT, Ruiter RA, Brug J, Jansma BM: The effects of tailored and threatening nutrition information on message attention. Evidence from an event-related potential study. Appetite 2011, 56: 32–38. 10.1016/j.appet.2010.11.139
Lahteenmaki PM, Holopainen I, Krause CM, Helenius H, Salmi TT, Heikki LA: Cognitive functions of adolescent childhood cancer survivors assessed by event related potentials. Med Pediatr Oncol 2001, 36: 442–50. 10.1002/mpo.1108
Luijten M, van Meel CS, Franken IHA: Diminished error processing in smokers during smoking cue exposure. Pharmacology Biochemistry and Behavior 2011, 97: 514–520. 10.1016/j.pbb.2010.10.012
Heinrich SP, Marhofer D, Bach M: Cognitive visual acuity estimation based on the event-related potential P300 component. Clinical Neurophysiology 2010, 121: 1464–1472. 10.1016/j.clinph.2010.03.030
Polich J, Howard L, Starr A: Effects of age on the P300 component of the event-related potential from auditory stimuli: Peak definition, variation, and measurement. The Journal of Gerontology 1985, 40: 721–726.
Brazier MAB: Evoked responses recorded from the depths of the human brain. Annals of the New York Academy of Sciences 1964, 112: 33–59.
Yeah CL, Chang HC, Wu CH, Lee PL: Extraction of single-trial cortical beta oscillatory activities in EEG signals using empirical mode decomposition. Biomedical Engineering Online 2009, 9: 25.
Graichen U, Witte H, Haueisen J: Analysis of induced components in electroencephalograms using a multiple correlation method. Biomedical Engineering Online 2009, 9: 21.
LeVan P, Gotman J: Independent component analysis as a model-free approach for the detection of bold changes related to epileptic spikes: A simulation study. Human Brain Mapping 2009, 30: 2021–2031. 10.1002/hbm.20647
Sabeti M, Katebi SD, Boostani R, Price GW: A new approach for EEG signal classification of schizophrenic and control participants. Expert Systems with Applications 2011, 38: 2063–2071. 10.1016/j.eswa.2010.07.145
Wessel JR, Ullsperger M: Selection of independent components representing event-related brain potentials: A data-driven approach for greater objectivity. NeuroImage 2011, 54: 2105–2115. 10.1016/j.neuroimage.2010.10.033
Mahmoudi Z, Rahati S, Chasemi MM, Asadpour V, Tayarani H, Rajati M: Classification of voice disorder in children with cochlear implantation and hearing aid using multiple classifier fusion. Biomedical Engineering Online 2011, 10: 3. 10.1186/1475-925X-10-3
Kim J, Shin HS, Shin K, Lee M: Robust algorithm for arrhythmia classification in ECG using extreme learning machine. Biomedical Engineering Online 2009, 8: 31. 10.1186/1475-925X-8-31
Yuenyong S, Nishihara A, Kongprawechnon W, Tungpimolrut K: A framework for automatic heart sound analysis without segmentation. Biomedical Engineering Online 2011, 10: 13. 10.1186/1475-925X-10-13
Kulkarni S, Reddy NP, Hariharan SI: Facial expression (mood) recognition from facial images using committee neural networks. Biomedical Engineering Online 2009, 10: 16.
Shrirao NA, Reddy NP, Kosuri DR: Neural network committees for finger joint angle estimation from surface EMG signals. Biomedical Engineering Online 2009, 8: 2. 10.1186/1475-925X-8-2
Hu XS, Hong KS, Ge SS, Jeong MY: Kalman estimator- and general linear model-based on-line brain activation mapping by near-infrared spectroscopy. BioMedical Engineering OnLine 2010, 9: 82. 10.1186/1475-925X-9-82
Jasper HH: Report of the committee on methods of clinical examination in electroencephalography. Electroenceph Clin Neurophysiol 1958, 10: 370–375.
Choi S, Cichocki A: Blind separation of nonstationary sources in noisy mixtures. Electronics Letters 2000, 36: 848–849. 10.1049/el:20000623
Cichocki A, Amari SI: Adaptive Blind Signal and Image Processing: Learning Algorithms and Applications. John Wiley & Sons, LTD, England; 2002.
Oja E: The nonlinear PCA learning rule in independent component analysis. Neurocomputing 1997, 17: 25–45. 10.1016/S0925-2312(97)00045-3
Hu YH, Hwang JN: Handbook of Neural Network Signal Processing. CRC Press, New York, Washington, D.C.; 2002.
Turnip A, Hong KS, Jeong MY: Real time feature extraction of EEG-based P300 using nonlinear principal component analysis. In 17th Annual Meeting of the Organization for Human Brain Mapping, June 26–30, 2011. Quebec City, Canada;
Naraharisetti KVP: Removal of ocular artifacts from EEG signal using joint approximate diagonalization of eigen matrices (JADE) and wavelet transform. Canadian Journal on Biomedical Engineering & Technology 2010, 1: 56–60.
Gharieb RR, Cichocki S: Second-order statistics based blind source separation using a bank of subband filters. Digital Signal Processing 2003, 13: 252–274. 10.1016/S1051-2004(02)00034-9
Acknowledgements
This research was supported by the World Class University program funded by the Ministry of Education, Science and Technology through the National Research Foundation of Korea (grant no. R31-20004).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
AT carried out data acquisition and processing and drafted the manuscript. KSH supervised the project and corrected the manuscript. MYJ provided suggestions to improve the manuscript. All of the authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Turnip, A., Hong, KS. & Jeong, MY. Real-time feature extraction of P300 component using adaptive nonlinear principal component analysis. BioMed Eng OnLine 10, 83 (2011). https://doi.org/10.1186/1475-925X-10-83
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1475-925X-10-83