
Abstract
Background
A reliable prediction of the Xaa-Pro peptide bond conformation would be a useful tool for many protein structure calculation methods. We have analyzed the Protein Data Bank and show that the combined use of sequential and structural information has a predictive value for the assessment of the cis versus trans peptide bond conformation of Xaa-Pro within proteins. For the analysis of the data sets different statistical methods such as the calculation of the Chou-Fasman parameters and occurrence matrices were used. Furthermore we analyzed the relationship between the relative solvent accessibility and the relative occurrence of prolines in the cis and in the trans conformation.
Results
One of the main results of the statistical investigations is the ranking of the secondary structure and sequence information with respect to the prediction of the Xaa-Pro peptide bond conformation. We observed a significant impact of secondary structure information on the occurrence of the Xaa-Pro peptide bond conformation, while the sequence information of amino acids neighboring proline is of little predictive value for the conformation of this bond.
Conclusion
In this work, we present an extensive analysis of the occurrence of the cis and trans proline conformation in proteins. Based on the data set, we derived patterns and rules for a possible prediction of the proline conformation. Upon adoption of the Chou-Fasman parameters, we are able to derive statistically relevant correlations between the secondary structure of amino acid fragments and the Xaa-Pro peptide bond conformation.
Similar content being viewed by others

Background
The peptide bond has a partial double bond character which results in the plane arrangement of the six backbone atoms Cα(i-1), C'(i-1), O(i-1), N(i), H(i), Cα(i). The angles Ψ, Φ and Ω readily describe the arrangement of the six atoms in three-dimensional space: Ψ defines the angle of the N – Cα bond and Φ is given by the Cα-C' bond of the same residue whereas the Ω angle is defined between the C' and N atoms of adjacent residues. For Ω only two conformations are energetically and sterically preferred. The trans conformation is defined by an Ω angle of 180° while the cis conformation ideally displays an Ω angle of 0°. The cis conformation occurs rarely in polypeptides because of the higher intrinsic energy compared to the trans conformation [1]. In contrast to other amino acids proline has a higher propensity for the cis conformation. This can be explained by the smaller energy difference between the cis and trans isomer which is 2 kcal/mol higher for the cis as compared to the trans imide bond. The functional relevance of the proline cis/trans equilibrium is supported by the existence of special enzymes called peptidyl-prolyl isomerases which catalyze the cis/trans isomerization of Xaa-Pro bond [2, 3]. The action of these enzymes is thought to be important for the proper functioning of biological processes such as protein folding [4, 5] and splicing [6]. In addition, cis prolines act possibly as molecular switches [7] and are frequently present in turn regions of water-soluble proteins [8].
Nuclear magnetic resonance (NMR) experiments have shown that the cis/trans ratio depends on the amino acid sequence adjacent to the proline. More specifically, a correlation has been found between the isomerization rate and the bulkiness of the side chain of the residue preceding proline. The isomerization rate becomes smaller as the bulkiness of the side chain increases. For example, aromatic residues cause an approximately tenfold reduction in isomerization rate in comparison to alanine [9]. Further NMR studies [10] demonstrated that the cis/trans ratio is influenced by the nature of the succeeding amino acid. Positively charged side chains seem to destabilize cis relative to trans whereas aspartate, asparagine and glycine stabilize the cis form.
Cis and trans isomers show different tendencies to be present in certain secondary structure elements: While the trans conformations can be found in all classes of secondary structure (in helices at the beginning or the end and in the center of helices causing a sharp kink of ≥ 20°) [11], the cis isomer is usually confined to bend and turn regions within proteins. However, a systematic analysis of these findings has been elusive.
The goal of our study is to derive statistically relevant propensities for predicting the relative occurrence of cis and trans proline conformations in proteins with respect to their sequential and structural properties.
For the analysis of the data set, different statistical methods such as calculation of the Chou-Fasman parameters [12] and occurrence matrices were used.
Results and discussion
Chou-Fasman parameters
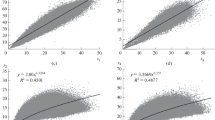
Figure (1) shows the comparison of the relative natural occurrence of the secondary structure types for cis and trans conformations of the Xaa-Pro peptide bond based on the PDB analyses (see Materials and Methods). Interestingly, cis prolines mostly occur in bend structures and almost never in helix or strand whereas trans prolines are mostly found in coil and to a smaller degree in turn, bend, helix or strand structures.

Occurrence of secondary structure. Relative occurrence of the secondary structure types compared for cis and trans prolines.
This observation is confirmed by analysis of the data with the modified Chou-Fasman parameters (equations 1–3 in the Methods section). The

values obtained from this analysis (Table (1)) show that the parameter values are close to one for the trans proline, indicating no significant preference for any given secondary structure type. In contrast, the value is high for cis prolines within the bend structure type (4.249) while it is very small for helix (0.036) or strand (0.051) elements.
In addition, the Chou-Fasman parameters of the secondary structures of the two amino acids adjacent to proline (i-1 and i+1) are calculated and illustrated in Table (2). Similar to the results for the central proline position (Table (1)), the trans conformation of the proline is almost equally distributed amongst the different secondary structure types for these two positions (values close to 1). For cis prolines, the Chou-Fasman parameter at positions (i-1) and (i+1) show a strong bias against helical secondary structure, albeit not as strong as for the proline itself (0.086 and 0.321, respectively). The low propensity for the strand structure seen for the central cis proline is not observed for the preceding residue and is above 1 for the residue following proline. The preference for the bend structure is attenuated for the adjacent residues (2.054 and 1.263, respectively) as compared to the central cis proline (4.249). Interestingly, the propensity for the residue preceding cis proline to be part of a turn structure is higher than to be part of a bend structure (2.261 and 2.054, respectively). For the cis proline itself, the order is reverse.
Occurrence matrix
A matrix of residue occurrence of the five-piece fragments (Table (3)) reveals the different preferences of residues adjacent to proline. On the left side all residue combinations with a trans proline in the mid-position are listed and on the right side all combinations with a cis proline in this position are reported. Rows indicate the amino acid types and columns contain the absolute and relative occurrences of the amino acids in the five-pieces fragments with proline in the central position.
Table (3) illustrates the significant changes of the natural occurrence of the amino acids at different positions. The calculated natural occurrences (column 2) correspond to the results by [13].
The observed relative occurrences were normalized in respect to the natural occurrence at each position for each amino acid type (Table (4)). The normalized occurrences for cis and trans (trans proline conformation Htrans and cis proline conformation Hcis) show the preference for certain amino acid sequence patterns. Amino acids with a relative occurrence greater one are shown in bold face. We considered a relative occurrence difference as almost equal (≈) if ΔH was smaller than 0.05. ΔH values larger than 0.5 were of particular significance (>>). The following observations can be made: For the normalized occurrences (Htrans/cis) of the trans conformations at the position i-2 the amino acids P≈G>F>Y≈W>T = N≈L are preferred in comparison to the cis conformation where C>>Q>P>S≈M>K≈G>V are favored in position i-2. For position i-1 the amino acids C>N>I = H>T = D≈L≈K≈Q≈R are predominant for the trans conformation while the order W>Y>>G>F>C>N>P≈Q≈A was found for the cis conformation. For the succeeding residue of Pro (residue i+1) the preferences E>Q = A≈D≈V = G≈R are observed for the trans conformation and the order Y≈ F>A>W = C>H>G≈S≈P = L≈Q resulted for the cis conformation. The most favorable amino acids are P≈W = G≈S≈M≈A≈F≈L for the trans conformation (although the highest ΔH value of P is only 1.09 indicating that this position has almost no preference for any amino acid) and P>C>>T>N>G≈R = K≈V for the cis conformation at position i+2.
By analyzing the individual positions, it appears that certain amino acids occur in the cis and in the trans sets with high propensity (in position i-2: G and P, in position i-1: C, N and Q, in position i+1: G, A and Q and in position i+2: P and G). Besides those amino acids a number of amino acids occur more exclusively at distinct positions for either the cis or the trans conformation. Interestingly, certain properties seem to dominate at particular positions. For cis, aromatic residues are very likely at position i-1 and i+1 whereas for trans aromatic residues occur with high propensity at position i-2.
In Table (5) the occurrences of the secondary structure types of proline in the cis and trans conformation are shown. For the five secondary structure elements (bend, coil, helix, strand and turn) we analyzed the surrounding of the fixed proline in the mid-position. Rows indicate the secondary structure type with fixed secondary structure of the proline. Columns show the relative occurrence of the secondary structure at the 4 positions around proline. Based on the relative occurrence of the secondary structure of the proline we can specify typical secondary structure pattern for cis and trans Xaa-Pro peptide bond conformation.
For example, if the cis proline is located in a bend or coil secondary structure type the amino acid at the position i-1 is never an element of a helix or turn. Furthermore, in the rare case where cis proline is part of a helix it is never found at the beginning or the end of the helix. In the case of the cis proline being present in a turn we never found a helix or bend structure element at the position i-1. However, residues in a turn occurred relatively often (378 times at the position i-1).
The 10 most frequently occurring secondary structure fragments with a cis proline at the mid position are presented in the second and third column of Table (6). For comparison, the occurrences of the corresponding fragments with trans proline are shown in column 4 and 5. In contrast, Table (7) shows the 10 most frequently occurring secondary structure fragments of trans proline and the corresponding occurrence of cis prolines. Here, the amount of helical regions in the environment of proline increases dramatically whereas in the cis case the helix structure occurs very rarely. Most of the trans prolines of the five-piece fragments in helical regions appear as the first helix element in contrast to the helical cis prolines which do never occur as the first element of a helix (Table (5)).
All previous results from the different approaches are compared with the content of the "Top 10" tables (Tables (6)(7)) in order to confirm the observed dependencies of sequence and secondary structure on the cis/trans peptide bond conformation of proline.
As a control parameter for the estimation of cis and trans conformations the sum of the Chou-Fasman parameter can be used (Table (1) and (2)). The sum of the at the positions (i-1, i, i+1) leads to the same ranking in comparison to the "TOP 10" tables considering only 3 positions. For the pattern bbc in the cis case the sum is 7.746 and for trans conformation it is 2.541. In contrast the pattern ccc leads to 3.071 for trans and 2.275 for the cis conformation. On the basis of separated data sets for cis and trans proline conformation we derived the occurrence for the secondary structure elements and sequence pattern from so-called occurrence matrices (Table (3)(4) and (5)).
The output from the "TOP 10" tables can be verified in the occurrence matrices (Table (5)). The cbbcc pattern is most probable for the cis conformation and for trans conformation it is the ccccc pattern. They coincide as most probable secondary structure combination in Table (5) as highlighted by bold face. For example, for the secondary structure element bend in position i, ccbbc results as most probable for the trans proline and the cbbcc pattern for cis. For coil as secondary structure element in the position i ccccs results for the cis case whereas ccccc occurs for trans.
In order to evaluate the significance of Table (3) and (4), we analyzed the ccccc secondary structure pattern for the middle proline in trans peptide bond conformation in terms of the most probable amino acid in the 4 positions (H > 1). We found the following preferences: position i-2: P>M>Q>A>Y>T>R>S, position i-1: P>S>A>Q>R>K>M>C>L>T, position i+1: P>R>T>E>S>Q>A>V>K position i+2: P>S>K>R>Y>A>V>E. However, if those amino acids are compared with the most probable amino acids for trans or cis peptide bond conformation with proline in position i, no unambiguous sequence pattern remains.
We conclude that the influence of the secondary structure on a possible prediction of the Xaa-Pro peptide bond conformation is more significant than the sequence information of the residues surrounding proline.
Analysis of the solvent accessible surface
The relationship between the relative solvent accessibility and the relative occurrence of prolines in our PDB data set was investigated. In the range from 0% to 20% of solvent accessibility 62.7% of the trans entries can be found compared to 56.1% cis entries whereas 43.9% cis instances occur in the range above the threshold of 20 % accessibility rate in contrast to 37.3% trans. These numbers suggest that proline in the cis conformation is slightly more frequently found in surface accessible areas compared to the trans proline.
The reason for the difference can be explained by the finding that cis prolines are more frequently found in solvent-exposed turn and bend structures, whereas trans prolines mostly occur in either helix or strand secondary structure elements. The relatively high frequency of exposed cis-prolines in conjunction with the relatively low energy barrier for the cis to trans conversion as compared to other amino acids mark proline as a preferred site for conformational switch mechanism in proteins. For example, PPIases catalyze the isomerization rate and thereby may regulate biological responses by alternative conformations of loop regions [14].
Conclusion
In this work, we have analyzed more than 15000 proline residues within PDB-deposited protein structures in regard to their peptide bond conformation (cis or trans). We extracted fragments of 5 residues in length with proline in the mid-position. The PDB-derived secondary structure and the sequence information were used in a further statistical analysis of the 15778 fragments.
The calculation and interpretation of occurrence matrices reveal distinct preferences for the cis and for the trans conformation in dependence of secondary structure types. By the use of the modified Chou-Fasman parameter at the positions (i-1), (i) and (i+1) (equations 1–3) propensities for the proline peptide bond conformation can be derived from the secondary structure pattern. It is conceivable that an implementation of the modified Chou-Fasman parameters can be used for the prediction of proline peptide bond conformation in fragments with known secondary structure. An application of the new Chou-Fasman parameters for other naturally occurring amino acids is possible and leads to statistically relevant propensities for the prediction of the peptide conformation of any of the 20 amino acids in proteins. A prediction algorithm is presented on our website http://www.fmp-berlin.de/nmr/cops.
Finally the relationship between the relative solvent accessibility of proline and its peptide bond conformation shows that cis prolines occur more frequently in surface accessible areas compared to the prolines in trans conformation.
Methods
Materials
For data acquisition the PDB [15] was used by iterating over those protein entries who's PDB IDs are in a set of 3722 nonredundant proteins. All these proteins fulfill the following conditions: they share a maximum sequence identity of 25%, they have been solved to a resolution of 4.0 Å or less, they display a maximum R-value of 1.0 and a maximal chain length of 10000 amino acids (given by the PISCES [16] protein sequence culling service at http://www.fccc.edu/research/labs/dunbrack/pisces.
From these proteins the coordinate section was extracted to calculate the Ω dihedral angle between adjacent residues. A Perl script using the angle calculation algorithm of the PDB tool dihedrl.for was used for this calculation. A peptide bond was defined to be in cis conformation if the Ω angle was between -30° and +30° whereas angles outside of this range are assumed to be trans. The resulting file contains the PDB ID, the chain notation, the position of the cis residue in the sequence, its amino acid three letter code and the calculated Ω angle.
The resulting set of the calculation comprised 954 proteins containing at least one peptide backbone conformation of cis. The adjacent residues and the secondary structure were extracted from the locally installed PDB files pdb_seqres.txt and ss.txt. In this way fragments of five amino acids were created with two residues flanking the proline at the mid-position on each side. The secondary structure of these five-residue segments were derived from the ss.txt of the respective PDB file and was calculated on the basis of the hydrogen bonding pattern by DSSP [17] denoting H as helix, B as beta bridge, E as strand, G as 3.1 helix, I as pi-helix, T as turn, S as bend and a blank space as coil structure. We grouped the DSSP derived structural information into the following five types: {b(end) = S, c(oil) = {B, }, h(elix) = {H, G, I}, s(trand) = E, t(urn) = T}. The resulting data set contained 15778 entries including 1390 fragments containing cis prolines. Each entry of the data set comprised the amino acid types at each position, the secondary structure information and the classification (cis/trans) (for example "R, S, P, F, T, c, b, b, c, t, cis").
Chou-Fasman parameter
The correlation between secondary structure type and the conformation of proline can be calculated from the Chou Fasman parameters. We have applied the Chou-Fasman algorithm to elucidate this correlation by using the following formulas:



where f
s
denotes the occurrence of a certain secondary structure type with proline whether in the cis or trans conformation relative to the total occurrence of the same structure type. f
class
is the relation of the number of prolines in a specific conformation and the total number of prolines in the data set. then describes the altered Chou-Fasman parameter for the probability of the cis or trans conformation of proline to be present in the individual secondary structure types.
Solvent accessible area
The solvent accessible area was calculated for the whole protein with DSSP [17]. The DSSP algorithm provides information of the secondary structure based on the hydrogen bond pattern and of the solvent accessible area [18] of the different amino acids in the sequences. For the normalization of the accessible surface area of the prolines, the values obtained by DSSP were divided by the maximum solvent accessible area of an isolated proline residue (269 A2). The calculated relative accessibilities were in the range from 0% to 78%.
References
Ramachandran G, Mitra A: An explanation for the rare occurrence of cis peptide units in proteins and polypeptides. J Mol Biol 1976, 107: 85–92.
Fischer G, Bang H, Mech C: Determination of enzymatic catalysis for the cis-trans-isomerization of peptide binding in proline-containing peptides. Biomed Biochim Acta 1984, 43: 1101–11.
Pal D, Chakrabarti P: Cis peptide bonds in proteins: residues involved, their conformations, interactions and locations. J Mol Biol 1999, 294: 271–88. 10.1006/jmbi.1999.3217
Lang K, Schmid F, Fischer G: Catalysis of protein folding by prolyl isomerase. Nature 1987, 329: 268–70. 10.1038/329268a0
Wedemeyer W, Welker E, Scheraga H: Proline cis-trans isomerization and protein folding. Biochemistry 2002, 41: 14637–44. 10.1021/bi020574b
Horowitz D, Lee E, Mabon S, Misteli T: A cyclophilin functions in pre-mRNA splicing. EMBO J 2002, 21: 470–80. 10.1093/emboj/21.3.470
Reimer U, Fischer G: Local structural changes caused by peptidyl-prolyl cis/trans isomerization in the native state of proteins. Biophys Chem 2002, 96: 203–12. 10.1016/S0301-4622(02)00013-3
Stewart D, Sarkar A, Wampler J: Occurrence and role of cis peptide bonds in protein structures. J Mol Biol 1990, 214: 253–60.
Grathwohl C, Wuthrich K: Nmr studies of the rates of proline cis-trans isomerization in oligopeptides. Biopolymers 1981, 20: 2623–2633. 10.1002/bip.1981.360201209
Dyson H, Rance M, Houghten R, Wright P, Lerner R: Folding of immunogenic peptide fragments of proteins in water solution. II. The nascent helix. J Mol Biol 1988, 201: 201–17. 10.1016/0022-2836(88)90447-0
MacArthur M, Thornton J: Influence of proline residues on protein conformation. J Mol Biol 1991, 218: 397–412. 10.1016/0022-2836(91)90721-H
Chou P, Fasman G: Prediction of protein conformation. Biochemistry 1974, 13: 222–45. 10.1021/bi00699a002
Jones D, Taylor W, Thornton J: The rapid generation of mutation data matrices from protein sequences. Comput Appl Biosci 1992, 8: 275–82.
Brazin K, Mallis R, Fulton D, Andreotti A: Regulation of the tyrosine kinase Itk by the peptidyl-prolyl isomerase cyclophilin A. Proc Natl Acad Sci U S A 2002, 99: 1899–904. 10.1073/pnas.042529199
Berman H, Westbrook J, Feng Z, Gilliland G, Bhat T, Weissig H, Shindyalov I, Bourne P: The Protein Data Bank. Nucleic Acids Res 2000, 28: 235–42. 10.1093/nar/28.1.235
Wang G, Dunbrack R: PISCES: a protein sequence culling server. Bioinformatics 2003, 19: 1589–91. 10.1093/bioinformatics/btg224
Kabsch W, Sander C: Dictionary of protein secondary structure: pattern recognition of hydrogen-bonded and geometrical features. Biopolymers 1983, 22: 2577–637. 10.1002/bip.360221211
Shrake A, Rupley J: Environment and exposure to solvent of protein atoms. Lysozyme and insulin. J Mol Biol 1973, 79: 351–71. 10.1016/0022-2836(73)90011-9
Acknowledgements
We are grateful for the financial support of this work by the BMBF-Leitprojekt "Strukturanalyse mit hohem Durchsatz für medizinisch relevante Proteine – Proteinstrukturfabrik" (Fk.01GG9812). C.F. acknowledges a grant from the Volkswagen Stiftung related to this work (I/77955). The authors thank Urs Wiedeman for helpful discussion and careful reading of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Authors' contributions
DP, DLe, DLa, CF are responsible for data mining, statistical analysis and the manuscript preparation. DP & DLa programmed the scripts. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article
Cite this article
Pahlke, D., Freund, C., Leitner, D. et al. Statistically significant dependence of the Xaa-Pro peptide bond conformation on secondary structure and amino acid sequence. BMC Struct Biol 5, 8 (2005). https://doi.org/10.1186/1472-6807-5-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1472-6807-5-8