
Abstract
Background
The recent settlement of cattle in West Africa after several waves of migration from remote centres of domestication has imposed dramatic changes in their environmental conditions, in particular through exposure to new pathogens. West African cattle populations thus represent an appealing model to unravel the genome response to adaptation to tropical conditions. The purpose of this study was to identify footprints of adaptive selection at the whole genome level in a newly collected data set comprising 36,320 SNPs genotyped in 9 West African cattle populations.
Results
After a detailed analysis of population structure, we performed a scan for SNP differentiation via a previously proposed Bayesian procedure including extensions to improve the detection of loci under selection. Based on these results we identified 53 genomic regions and 42 strong candidate genes. Their physiological functions were mainly related to immune response (MHC region which was found under strong balancing selection, CD79A, CXCR4, DLK1, RFX3, SEMA4A, TICAM1 and TRIM21), nervous system (NEUROD6, OLFM2, MAGI1, SEMA4A and HTR4) and skin and hair properties (EDNRB, TRSP1 and KRTAP8-1).
Conclusion
The main possible underlying selective pressures may be related to climatic conditions but also to the host response to pathogens such as Trypanosoma(sp). Overall, these results might open the way towards the identification of important variants involved in adaptation to tropical conditions and in particular to resistance to tropical infectious diseases.
Similar content being viewed by others


Background
Cattle are still playing a major role in Africa for food supply, to generate income and draught power or for ceremonial purposes. Archaeological, historical and anthropological evidence combined with recent genetic data [1] have provided insights into the complex origins of present day West-African cattle diversity. Indeed, although their wild ancestor Bos primigenius was not native to sub-Saharan Africa, West African cattle populations are representative of both shorthorn (Bos taurus brachyceros) and longhorn (Bos taurus longifrons) humpless taurines, humped zebus (Bos indicus) and zebu/taurine hybrid cattle. This early suggested that West African cattle has originated from several successive and recent colonization events [2, 3]. Briefly, shorthorn taurines were introduced from the Middle-East and possibly North Africa around 4,000 years BP [3, 4] while longhorn taurine probably arrived at an earlier period (5,000 years BP) following different migration routes [3]. Although, zebu cattle first penetrated through the Horn of Africa in the late 2nd millennium BC, the major wave of indicine introgression really started with the Arab settlements along the East Coast of Africa from the end of the 7th century AD. Zebu cattle spread even more recently over West Africa with movements of pastoralist people such as the Fulani [1].
As a consequence of their remote origin, West African cattle populations have been subjected in recent times to new environmental pressures imposing strong adaptive constraints [5]. Indeed, tropical climate conditions might have affected several traits such as reproduction, grazing behavior, feed/water intake and utilization, milk production and growth. For instance, some West African shorthorn cattle which are exposed to very harsh conditions have been subjected to a marked reduction in size [3]. In addition, cattle were exposed to new pathogens in particular parasites. A well described example of newly acquired adaptation to parasitic disease is the ability, known as trypanotolerance, of taurine cattle to survive, reproduce and remain productive within the tsetse infested sub-tropical zone characterized by a high prevalence of trypanosomiasis (Figure 1) [6]. This might have in turn limited the introgression in these areas of zebus which are trypanosusceptible (Figure 1).

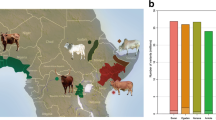
Origin of the West African population samples. A) N'Dama ND2 samples (n = 17) originated from the Samandeni ranch in Burkina Faso [64]; B) Baoulé (BAO) samples (n = 29) and N'Dama ND1 (n = 14) originated from the Gaoua Ranch in Burkina-Faso [64]; C) and D) Somba (SOM) samples (n = 44) originated from Boukombe (Benin) and Nadoba (Togo) regions [65]; E) Lagune (LAG) samples (n = 44) originated from the Porto Novo region in Benin [65]; F) Borgou (BOR) samples (n = 45) originated from the Parakou district in Benin [65]; G) Sudanese Fulani (ZFU) samples (n = 43) originated from the Malanville region in Benin [65]; H) Kuri (KUR) samples (n = 47) were collected in Lake Chad islands [64] and I) Choah zebu (ZCH) samples originated from the Bol district in Chad [64]. The tsetse infested region is colored in green on the map.
West African cattle populations thus represent an appealing model to unravel the genome response to adaptation to tropical conditions. The purpose of this study was to perform a whole genome scan for footprints of adaptive selection based on a newly collected genotyping data set containing 36,320 SNPs genotyped on 9 West African cattle populations from different bovine sub-species and agro-ecological areas (Figure 1). In particular, we sampled populations on both side of the tsetse infested zone. Based on this large data set, we first carried out a detailed analysis of the genetic structure of these populations. We next performed a scan for differentiation among SNPs under a full Bayesian framework [7, 8] for which we proposed additional extensions to improve the detection of loci under selection. We then annotated regions containing SNPs subjected to selection, adopting a systems biology approach to highlight the main underlying physiological functions.
Results and Discussion
SNP polymorphism
In total, 437 individuals belonging to 12 different cattle populations, nine of which originating from West Africa (Figure 1), were genotyped for the BovineSNP50 chip assay containing 54,001 SNPs mainly derived from sequences available in European cattle breeds [9]. Among the autosomal SNPs that passed Quality Control analyses (see Methods), we retained the 36,320 SNPs polymorphic (Minor Allele Frequency or MAF above 0.01) in at least one West-African taurine and one West African zebu populations. As expected and shown in Figure S1A (additional file 1), this SNP selection procedure, leading mainly to the elimination of SNPs from European origin, resulted in a relative increase in calculated heterozygosity for all but outgroup taurine populations (Aubrac or AUB and Oulmès Zaer or OUL). In addition, as revealed by the distribution of the MAF for the different populations (Figure S1B in additional file 1), the remaining differences in heterozygosity among populations were mainly explained by the proportion of SNPs with rare variants (MAF < 0.05). In particular, marker polymorphism remained clearly lower in West African taurine populations (ND1, ND2, LAG, SOM and BAO), the proportion of SNPs with a MAF < 0.05 being the highest (36%) in LAG which also displayed the lowest average heterozygosity (0.118). These observations are in agreement with previous studies based on microsatellite markers on the same populations [10] and might essentially be explained by the recent demographic history of West African taurine cattle characterized by a marked isolation associated with a strong effective population size decrease (e.g. [11]). Although West African zebus (ZFU and ZCH) and hybrids (BOR and KUR) displayed more genetic diversity than West African taurines in our study (Figure S1 in additional file 1), ZFU, ZCH and ZMA levels of polymorphism were clearly lower than, and BOR and KUR ones similar to the taurine outgroup (AUB and OUL) ones (Figure S1A in additional file 1). Nevertheless, studies based on microsatellite data (e.g. [10]) revealed that heterozygosities of ZCH, ZFU, BOR and KUR were higher than European breeds' ones (AUB) which were themselves similar to ZMA. The lack of zebu specific sequences in the SNP discovery process might explain these apparent discrepancies.
Analysis of Population Structure
The neighbor-joining tree based on Allele Sharing Distances (ASD) [12] allowed us to unambiguously separate individuals according to their population of origin (Figure S2 in additional file 1). West African individuals branched in their expected intermediary position relatively to the taurine (OUL and AUB) and zebu (ZMA) outgroups. Moreover, West African zebus (ZFU and ZCH) were closer to ZMA while West African taurines (LAG, ND1, ND2, BAO and SOM) were closer to OUL and AUB. KUR and BOR individuals branched between West African taurines and zebus. To go further in the characterization of the population relationships we carried out a principal component analysis (PCA) [13] based on all available SNP information [14]. As shown in Figure 2A and in agreement with previous published studies [1, 4, 15, 16], the first component which accounted for 7.88% of variation separated West African populations according to a zebu/taurine gradient while the second (accounting for 4.58% of the total variance) could be associated to an Africa/Europe gradient, the North African OUL being closer to the European AUB. A similar PCA performed after removing the three outgroup populations (ZMA, OUL and AUB) allowed to distinguish West African populations according to the same zebu/taurine gradient on the first axis (which accounted for 8.25% of the total variance). The second and third components (which accounted respectively for 2.59% and 1.41% of the total variance) separated respectively LAG and ND2 from the other West African taurines (BAO, ND1 and SOM) (Figure 2B). The position of ND1 along the third axis suggested a certain level of admixture with shorthorn populations, most probably of BAO origin, according to their sampling area (Figure 1), although pairwise F ST divergence was smaller when compared to SOM (Table S1 in additional file 2). Finally, the fourth component (which accounted for 1.10% of the total variance) separated both West-African hybrids (BOR and KUR) and zebus (ZFU and ZCH) (Figure 2C). Overall, these results demonstrated a clear partition of the West African populations considered. F ST between pairs of populations (Table S1 in additional file 2) were all found significantly non null (P << 0.00001) and ranged between 0.013 (for ZFU compared to ZCH) and 0.28 (for LAG compared to ZFU).

PCA results. Plots of the individuals according to their coordinates on the first two principal components on the eigenanalysis with (A) and without (B) the three outgroup populations (AUB, OUL and ZMA). Plots on the third and fourth components for this latter analysis are shown on Figure 2C. Ellipses characterize the dispersion of each breed around its center of gravity (assuming the cloud is a random sample distributed according to a bivariate gaussian distribution, the probability for an individual to be within the ellipse is 0.9).
As reported in Table S1 (additional file 2), within population F IS were almost null (< 0.006) for ZFU and BOR or very close to zero (from -0.0121 to 0.0198) for ND1, BAO, KUR and ZCH. The slightly positive F IS (0.0421) observed in SOM might result from the sampling area being apart the border between Togo and Benin. The positive F IS (0.0414) of similar magnitude observed in LAG might rather originate from a higher level of inbreeding as suggested by the extent of Linkage Disequilibrium (LD) within this population (see below). Conversely, for ND2, the negative F IS (-0.108) might be explained by recent outcrossing events. Indeed ND2 individuals derived from founders recently collected in different and distant Ivorian villages (see Methods). This hypothesis is also in agreement with their higher dispersion compared to other West African taurines in the PCA (Figure 2) and a higher level of overall extent of LD (see below). Nevertheless, the global F IS coefficient remained close to zero (0.0103) while the global F ST and F IT were respectively equal to 0.132 and 0.141. Such a level of differentiation among the West African populations was in agreement with the one computed based on microsatellite markers [10] suggesting a low impact of the SNP ascertainment procedure on these estimates.
Bayesian scan for differentiation among SNPs
We further studied the differentiation among SNPs and populations based on a Bayesian hierarchical model derived from [7] and presented in more details in the Methods section. Among the factors influencing population differences in allele counts (differentiation), the model aims at distinguishing locus-specific from population-specific factors, such as migration or drift [17]. Because most SNPs originated prior to breed differentiation, the effect of different mutation rates across loci might be negligible and the SNP-specific effect in the model is mainly related to selection. Notice that the model assumed the F IS to be null within each population which appeared sound given the characteristics of our data (see Figure S3 in additional file 1 and Methods). We also ignored ascertainment biases originating both from the SNP discovery process and our selection of SNPs "informative" in West African populations. These two different sources are expected to favour polymorphic SNPs of ancient origin (co-segregating in European and African cattle breeds) and thus modifies to some extent the distribution of allele frequencies in the gene pool (x following our model notations) [18]. Recently, efficient algorithms were proposed to account for ascertainment biases [19], providing it can be modelled (which is difficult in our case at least for the first identified source). Nevertheless, for the purpose of this study we were mainly concerned with possible biases introduced in the locus-specific effect estimation which might not be of importance [18]. At least for our second source of ascertainment bias, simulated data allowed to confirm this statement (Figure S4 in additional file 1) since estimation of x was found robust to departure from the prior distribution assumed. Similarly, although more variable, locus-specific effect estimates were highly correlated with their corresponding simulated values (r > 0.8).
To identify loci subjected to selection we thus focused on the posterior estimates of the SNP effect and evaluated the significance of its departure to the null value (expected under the neutral hypothesis). In Figure 3, we plotted the posterior SNP specific F ST estimate against its Bayes Factor (BF) expressed in deciban units (dB). BF compare models with and without the locus effect in terms of posterior to prior odds ratios, thus providing a basis for a decision rule to identify SNPs under selection (see Methods). The mean (standard deviation) of the posterior distribution for the proportion P of SNPs under selection (computed as the average over loci of the indicator variable δ i associated to the SNP effect in the hierarchical model) was equal to 0.186 (2.7 × 10-3). Analyses of four simulated data sets (with respectively 0.1%, 1%, 10% and 18.6% of the SNPs under selection) revealed that such estimates were extremely robust to the prior distribution of P (Figure S5 in additional file 1). The high proportion of SNPs under selection confirmed that selection had a non negligible role in the differentiation of these populations.

Plot of the estimate of the locus F ST against Bayes Factor. The three dashed lines represent the 15, 20 and 25 BF threshold.
To provide insights into the decision rule criterion (in terms of BF threshold) to declare SNPs as subjected to selection, we subsequently investigated the power and the robustness of the model using simulated data (see Methods). For each of the four previously mentioned simulated data sets, we estimated False Discovery Rates (FDR) and False Negative Rate (FNR) (Table 1). Application of the Jeffreys' rule (see Methods) proved efficient since the FDR, although slightly increasing with the simulated P, was always less than 0.5% when considering a threshold of 20 on BF (i.e. decisive evidence). However, for such stringent a threshold, the FNR was very high across the four simulated data sets (>80%), a detailed inspection (Table S2 in additional file 2) showing that most non discovered SNPs were those with the smallest simulated effects (α i following our notations). More precisely, for SNPs under positive selection, the FNR was less than 30% (<10%) when α i >2 (α i >4) while above 98% when α i <1. In addition, as expected from previous studies [7, 8, 20] and from our overall relatively low level of differentiation, the model was less powerful to detect SNPs under balancing selection. The observed FNR remained high even for very large (in absolute value) α i (FNR>60% when α i <-4). Decreasing the threshold to a less stringent value such as 15 ("very strong evidence" according to Jeffreys' rule) reduced substantially the FNR (FNR<31% when α i <-4 and FNR<51% when α i <-2) and increased only slightly the FDR. To illustrate how these values of α i can be related to a coefficient of selection s we finally performed simulations under a Wright-Fisher island model with selection for various s and types of selection [20]. For SNPs under positive selection, α i >2 was achieved for loci with s >0.05 (under a dominant model) while for SNPs under balancing selection α i remained low even for large s (α i = -1.40 for s = 0.5) (Table 2). This confirmed that given our overall level of differentiation, the approach is expected to be powerful for positively selected SNPs with moderate to high effect but might lack some power even for those under high balancing selection.
A Genome map of regions under adaptive differentiation
Whole genome maps of adaptively differentiated loci in West African populations are given in Figure 4 for four different thresholds on BF value. In total, 2,054 (5.7%), 1,119 (3.1%), 619 (1.7%) and 375 (1.0%) of the 36,320 SNPs displayed a BF above 15, 20, 25 and 30 respectively (Table S3 in additional file 2). As expected (see above) most of the SNPs displaying high evidence of selection were highly differentiated suggesting they were subjected to positive selection (Figures 3 and 4). More precisely, among the SNPs with a BF value above 15, 537 were under balancing selection with a F ST < 0.011 while 1517 were clearly under positive selection with a F ST > 0.28. At a more stringent threshold on BF of 30, 3 SNPs remained under balancing selection (F ST < 0.0013) and 372 under positive selection (F ST > 0.33). Interestingly, the whole genome distribution of SNPs declared under selection appeared less uniform as the threshold on BF increased (Figure 4). This might be explained by the effect of selection which tends to increase LD between markers [21]. Yet, we did not include in the model any spatial structure, which may take into account the LD among SNPs, as recently proposed ().().(.)[22]. Within the different West African populations and at the distance of 70 kb corresponding to our average marker spacing (Figure S6 in additional file 1 and Methods), r2 was close to the asymptotic value (<0.1 in all populations except ND2) (Figure S7 in additional file 1) which is related to the current effective population size [23]. As a result, the level of association between most SNP pairs was expected to be of similar magnitude to the one between unlinked markers as illustrated by the correlations of the estimated F ST and BF between pairs of SNPs which quickly dropped towards 0 as they were more distantly related (Table S4 in additional file 2).

Genome position of the locus declared under selection. For each BF thresholds, the color indicates whether the SNP is neutral (grey), under positive selection (red) or balancing selection (blue). The type of selection (balancing or positive) is deduced from the SNP F ST value (< 0.1 or > 0.1).
As an attempt to identify those genomic regions with unexpectedly high proportions of selected SNPs, we smoothed individual SNP BF values over each chromosome (see Methods). This empirical, non parametric approach can efficiently combine information from several neighboring SNPs and allows the identification of significantly differentiated regions. This strategy might provide in turn a first empirical attempt to correct for false positives as expected when a hierarchical structure exists among populations under study i.e. when some populations share a recent ancestry or there are barriers to gene flow between some of them [24]. As shown in Figure 5 and Table 3, 53 significant regions were identified at the 5% local FDR (q-value) threshold. In agreement with strong hitchhiking effects, these regions together contained 49.9% of the SNPs with a BF larger than 30 and 24.9% of the SNPs with a BF larger than 15. In addition, most of these SNPs were subjected to positive selection (F ST > 0.1) although a notable exception is represented by the region on the middle of BTA23 which was exclusively composed of SNPs under balancing selection. Interestingly, this region contains BoLA, the bovine Major Histocompatibility Complex (MHC) for which balancing selection has already been extensively reported in other species [25, 26] and also in other cattle populations [15]. To a lesser extent, a few other regions, such as the ones localized on the centromeric part of BTA01, the telomeric part of BTA06 and the middle of BTA22 (Figure 5) contained a high proportion of SNPs under balancing selection. This might be related to the maintenance of several haplotypes containing variants under positive selection within different populations. Alternatively, the fixation of the same variant in some populations could also lead to such a trend because of the low level of LD across populations [11].

Whole genome map of regions under selection at the 5% local FDR (q-value) threshold. For each of the 29 bovine autosomes, the smoothed BF is plotted against the chromosomal position (green line). For significant positions, non smoothed SNP BF are indicated by a black star. At the corresponding positions, a red (blue) bar is represented on the top of each graph if the SNP was under positive (balancing) selection i.e. displayed a (non smoothed) BF > 15 and a F ST > 0.1 (F ST < 0.1).
Functional annotation of regions under selection
The 36,320 SNPs were representative of about 7,177 different genes corresponding to approximately one third of the total number expected in the genome. For each of these, Table S5 (additional file 2) summarizes the number of SNPs they contained and results from the differentiation analysis. Individual SNP information made it nevertheless difficult to propose a list of genes subjected to selection and this strategy might be more sensitive to possible false positives introduced by hierarchical structure among the populations under study [24]. Alternatively, a great proportion of such genes could include SNPs appearing as significantly differentiated as a result of hitchhiking with a favourable variant located nearby (see above). Hence, among the 191 (853) genes containing or close to at least one SNP with a BF > 30 (BF > 15), 103 (237) mapped within one of the 53 regions identified above. For functional and network analyses, we thus decided to mainly concentrate on the 42 genes which were located for 25 of them (represented in Table S5 in additional file 2), under the peak of each region, or for the remaining 17 less than 50 kb from the peak of each region (Table 3) (and not represented by any of the 36,320 SNPs surveyed). These 42 genes were viewed as the strongest candidates underlying the observed footprints of selection. Among these, 37 genes were eligible for network analysis, 29 being also eligible for functional analysis. The five remaining ones (CCDC46, CTXN3, KRTAP8-1, RNF180, TEKT3) were not eligible for any network or functional analyses.
Four significant networks namely N1, N2, N3 and N4 (Table S6 in additional file 2) were identified. Three of them (N1, N2 and N4) were interconnected and further merged into a single network (N). Networks N and N3 are represented in Figure 6 and their functional annotations detailed in Table S7 (additional file 2). The main hubs of N corresponded to genes encoding cytokines (CSF2, IFNG, IL4, IL13, IL6, TGFB1 and TNF) and protein kinases (Akt and Erk). Network N contained 22 of our candidate genes (ALK, ANTXR2, CAC3, CCDC71, CD79A, CXCR4, DLK1, DYRK2, EDNRB, HTR4, MAGI1, MATR3, MINK1, MYL2, PADI4, RFX3, RNF220, SEMA4A, SRCAP, TICAM1, TRIM21 and TRPS1), some of them being involved in innate and adaptive immune response (Figure 6A, Table S7 in additional file 2). Network N3 contained molecules mainly involved in cancer, cellular function and maintenance, and neurological disease, and among them nine candidate genes (CDC16, DIS3L2, FTSJ3, NEUROD6, OLFM2, PDE1B, RBMS2, RPL3A and SNRPG). Six other candidate genes (AMZ1, BSFP2, CLDN9, EPDR1, ERGIC1 and KIAA0391) were eligible for network analysis but were included neither in N nor N3. Overall, the functional annotation suggested that the three main physiological functions targeted by selection in the breeds we studied were related to i) immune response, ii) nervous system and iii) skin and hair development which we discuss in the following.

Representation of the N (A) and N3 (B) gene networks. Symbols corresponding to candidate genes are colored in red.
Immune response genes under selection
Several candidate genes (such as CD79A, CXCR4, DLK1, RFX3, SEMA4A, TICAM1 and TRIM21) belonging to N directly participate in antigen recognition, a key process underlying the development of immune response. For instance, TRIM21, a newly identified type of IgG Fc receptors [27] participates to both the host anti-viral response through the modulation of IRF3 functions [28] and mediation of autoimmune diseases. Footprints of selection were recently reported in primates within another member of the same tripartite motif (TRIM) family of proteins which has antiretroviral properties [29, 30]. TICAM1 is a Toll like receptor (TLR) adapter and thus plays a role in innate immunity. It possesses, in particular, a high IFN type I inducing activity during viral infection [31]. DLK1, a member of the epidermal growth factor-like gene family, has been shown in mouse to be involved in B lymphocytes differentiation and function [32]. More specifically, other genes (such as CD79A, CXCR4, RFX3 and SEMA4A) are related to antigen presentation to T cells in the context of MHC. Although no MHC genes were present in the list analyzed, the corresponding region (#49 in Table 3) and a SNP (with BF = 17 and F ST = 0.005) within the bovine HLA-DMB ortholog (Table S4 in additional file 2) were found under strong balancing selection. Among the molecules participating to antigen presentation, the chemokine receptor CXCR4 is co-recruited with CCR5 in the immunological synapse, and it participates to modulation of T cells response [33]. These two molecules were shown to act as co-receptors for HIV entry in human cells [34]. A strong signature of balancing selection was reported in the 5' cis-regulatory region of CCR5 in human [35], this region displaying as well a selective sweep in chimpanzee [36]. We also recently observed a significant signal of selection on a microsatellite located less than 1 Mb from CXCR4 in West African taurine [10] and defining the boundary of a QTL underlying the trypanotolerance trait in cattle [37]. Similarly, RFX3 (43.235-43.563 Mb on BTA08) is located within another QTL identified in this latter study [37]. This member of the regulatory factor X (RFX) gene family participates with CIITA in the regulation of MHC genes [38–40]. CD79A via CD79α-CD79β heterodimer located on the surface of B cells is required for antigen presentation through MHC class II [41]. SEMA4A a semaphorin expressed on dendritic cells and B cells is involved in T cell priming and Th1 differentiation through its interaction with Tim2 expressed on T cells [42].
Although heat stress response may have imposed immunological parameter modifications [5], infectious and parasitical diseases are likely to have represented selective pressures acting on genes involved in such functions [43]. As previously mentioned, trypanosomiasis represents one of the well known examples of such selective pressure. Nevertheless, the importance of other diseases such as tick-borne diseases (anaplasmosis, babesiosis, cowdriosis) or anthrax should not be overlooked. For instance, anthrax is hyperendemic (especially in Chad, Togo and Ivory Coast) or endemic in West Africa http://www.vetmed.lsu.edu/whocc/mp_world.htm. Notice that the ANTRXR2, a receptor of the anthrax toxin was among our candidate genes (see network N, Figure 6).
Neural genes under selection
In addition to the exposure to new pathogens, the recent settlement of cattle to Sub Saharan Africa might have imposed a dramatic change in their environmental conditions [5]. Hence, cattle (in particular taurine) were exposed to warmer temperature, to a thermal amplitude decrease, to a day length change, to differences in solar radiation and also to new feeding conditions. As a result, adaptations needed modifications in global appearance (such as morphology or coat color), in body temperature regulation, in circadian clock and also in reproductive behaviour and abilities. Such selective pressures might partly explain the physiological functions related to nervous system (neurogenesis and eyesight). Alternatively, neurotropism of several parasites such as Trypanosoma(sp) have been demonstrated at least in human. Some of the candidate genes related to nervous system development and function belonged to N3 (e.g. NEUROD6 and OLFM2) or N (e.g. MAGI1, SEMA4A, HTR4 and EDNRB). NEUROD6 is a member of the neurogenic differentiation transcription factor family [44] while OLFM2 is a secreted glycoprotein belonging to the noelins family which modulate the timing of neuronal differentiation during development [45]. Interestingly, MAGI1 is a scaffolding protein present in tight junction of epithelial cells [46], some transcripts of the corresponding gene being only expressed in brain. Moreover it is located within a QTL underlying the trypanotolerance trait [37]. Besides their role in immune response (see above), semaphorins represented by SEMA4A were initially characterized for their role in the guidance of axonal migration during neuronal development. Mutations in the conserved semaphorin domain of SEMA4A are associated with two retinal degenerative diseases, retinis pigmentosa and cone-rod dystrophy [47]. Of more particular interest is HTR4 which is a serotonin receptor participating to the serotonergic system. Recently, a mutation within HTR2A, a receptor of the same family was reported associated with the chronic fatigue syndrome corresponding to a dysregulation of hypothalamic-pituitary-adrenal (HPA) axis and serotonergic system [48]. A reduced responsiveness of the HPA axis after corticotropin-releasing hormone (CRH) challenge was observed in Boran cattle infected with Trypanosoma congolense [49]. Taken together, a possible involvement of HTR4 in trypanotolerance/susceptibility in cattle might be hypothesized though we cannot exclude an implication of this serotonin receptor in more general aspects of circadian rythmicity [50].
Genes under selection involved in skin and hair properties
Although EDNRB plays an essential role in the development of enteric neurons, it is also involved in the development of epidermal melanocytes, both cell lineages being derived from the neural crest [51]. As an illustration, several EDNRB mutations are associated with an auditory pigmentary syndrome caused by the absence of melanocytes [52]. However, given the variety of cattle populations surveyed (Figure 1), the footprint of selection observed in the EDNRB region is more likely related to differences in coat color and more particularly to the spotting pattern (SOM, BAO and LAG) or the white color (KUR and ZFU). Indeed, EDNRB is also referred to as piebald or S locus in mouse [53] and a null mutation induce a white coat color in rat [51]. In the Hereford cattle breed, although not yet fully characterized, locus S seems responsible for white spotting pattern [53]. In addition to EDNRB involved in skin and hair pigmentation, other genes such as TRSP1 which belonged to N and KRTAP8-1 which was not eligible for network analysis play a role in hair development in human and mouse. Indeed, TRPS1 is a zinc finger transcription factor implicated in growth and trichosis, some of its variants being associated with trichorhinophalangeal syndromes [54, 55]. It is down-regulated in patients affected by hypertrichosis and in a mouse model of hypertrichosis [56]. KRTAP8-1, a keratin associated protein, plays a role in the formation of hair shafts [57].
The skin color and thickness, the hair size and sleekness and the number of sweat glands directly influence thermo-resistance of cattle living in the tropics [5]. Compared to European taurine breeds, zebus which have a higher density of sweat glands and a smoother and shinier hair coat were reported to better regulate body temperature and more efficiently maintain cellular function during heat stress [58]. Similarly, slick-haired Holstein cattle are more able to regulate their body temperature than wild-type [59]. Some skin and hair properties might also confer higher resistance to tick infestation [60, 61]. Interestingly, some genes involved in hair development also participate in cornification. Hence the observed footprint of selection within the cluster of keratin associated proteins (represented in the candidate genes list by KRTPA8-1, the closest to the peak) might thus also be related to horn morphology differences [62]. A striking example is the floating horns of KUR which could represent original adaptation facilitating swimming in their swamp living area [3]. Note that the identified region is also localized less than 5 Mb from the bovine polled locus [63]
Conclusion
West African cattle provide a valuable resource to better understand the genomic response to selective pressure arising in tropical conditions. This large-scale whole genome Bayesian scan for adaptive differentiation in populations representative of the current breed diversity allowed us to identify candidate genes involved in several key physiological functions. These results might open the way towards the identification of variants underlying these footprints of selection, in particular those involved in the resistance to tropical infectious diseases in cattle but also in other mammals such as human populations subjected to similar pressures.
Methods
Animal Material
Figure 1 provides information on the origin of the nine different West African populations sampled in our study and representatives of the three main types of cattle found in this area. Longhorn taurines were represented by N'Dama individuals from two distinct origins (ND1 and ND2). ND1 individuals (n = 14) originated from the Gaoua herd constituted by acquisitions coming from different villages in the Pays Lobi (Burkina Faso). ND2 (n = 17) samples were collected in the Samandeni herd (Burkina Faso) which was constituted in the early eighties by acquisitions from the Marahoue ranch (Ivory Coast) and originated from northwestern villages from Ivory Coast where zebu had not been introduced [64]. Shorthorn taurines were represented by three different breeds: Baoulé (BAO) samples (n = 29) originated, as ND1, from the Gaoua herd [64], Somba (SOM) individuals (n = 44) were sampled in the breed birthplace across the border near Nadoba (Togo) and Boukoumbe (Benin), and Lagune (LAG) individuals (n = 44) were sampled in the Porto Novo district (Benin) [65]. West African zebus were represented by two populations: Sudanese Fulani or ZFU (n = 43) which was sampled in the Malanville region in Benin [65] and Choah zebus or ZCH (n = 59) which was sampled in the Bol district (Chad) [64]. This latter population was initially sub-divided into two breeds (M'Bororo and Choah Zebus), however, as previously shown [10] and confirmed in our analysis with a dense marker set, no clear differentiation appeared among these. Finally, two hybrid populations were considered: Borgou or BOR (n = 45) which is a stabilized crossbred between shorthorn taurines (LAG or BAO) and was sampled in its region of origin around Parakou in Benin [65] and Kuri or KUR (n = 47) which was sampled from different islands of Lake Chad around Bol [64]. This latter breed was sometimes referred to as a particular longhorn taurine [3], however, several molecular analyses showed a high level of Zebu admixture in it [4, 10]. Moreover, unlike West African taurines, KUR is known to be trypano-susceptible. Three other breeds were considered as outgroups for the detailed genetic structure analysis: ZMA (n = 35) sampled in the Madagascar Island [66] and representing pure zebu [1], AUB (n = 20) sampled in the birthplace of the breed [67] and representing European taurine, and OUL (n = 40) sampled in the North of Morocco to represent North African taurine cattle.
Genotyping data
Individuals were genotyped on the Illumina BovineSNP50 chip assay [9] at the Centre National de Génotypage (CNG) platform (Evry, France) using standard procedures http://www.illumina.com. Among the 54,001 SNPs included in the chip, only the 51,581 mapping to a bovine autosome on the latest bovine genome assembly Btau_4.0 [68] were retained for further analysis. To limit ascertainment bias favouring SNPs from European origin, we subsequently discarded 13,786 SNPs (~25%) which were not polymorphic (MAF > 0.01) in at least one West African taurine (ND1, ND2, LAG, SOM or BAO) and one West African zebu (ZCH or ZFU). Among the remaining ones, 1,422 SNPs which were genotyped on less than 85% of the individuals from at least one of the nine West African breeds, were also eliminated. An exact test for Hardy-Weinberg Equilibrium (HWE) [69] was subsequently carried out within each breed separately. Based on the obtained p-values, q-values [70] were estimated for each SNP using the R package qvalue http://cran.r-project.org/web/packages/qvalue/index.html. Fifty three SNPs with a q-value < 0.01 in at least one breed were then discarded from further analysis. In total, 36,320 SNPs were finally considered for the study leading to an average marker density of 1 SNP every 70 kb over the genome (Table S8 in additional file 2). Moreover, as shown in Figure S6 (additional file 1) and detailed in Table S8 (additional file 2), the genome coverage was homogeneous with a median distance between consecutive SNPs equal to 47.54 kb. Few large gaps between SNPs were present since the 95th (99th) percentile of this distance was 189 kb (385 kb), the largest gap localized on BTA10 being 2 Mb long. Conversely, less than 0.5% of the distances between successive SNPs were shorter than 20 kb. Genotyping data are given in additional file 3.
Analysis of Population Structure and characterization of the extent of LD
ASD were computed for each pair of individuals using all available SNP information by a simple counting algorithm: for a given pair of individuals i and j, ASD was defined as 1-x ij where x ij represents the proportion of alleles alike in state averaged over all genotyped SNPs. A neighbor-joining tree was computed based on the resulting distance matrix using the R package APE [71]. We subsequently performed a PCA based on all available SNP information using the SMARTPCA software package [14]. As suggested by Patterson et al. [14], we performed LD correction by replacing individual SNP values with the residuals from a multivariate regression without intercept on the two preceding SNPs on the map, providing they were less than 200 kb apart. Results were further visualized using functionalities available in the R package ade4 [72]. The global F-statistics F IT , F ST and F IS were estimated respectively in the form of F, θ and f [73] using the program GENEPOP 4.0 [74]. GENEPOP 4.0 was also used to estimate diversity for each locus and population both within individuals and among individuals within a population. The within breed F IS was derived from the average of these two quantities over all the SNPs. In order to evaluate the reliability of the F IS estimates we computed the mean and standard deviation over 10,000 samples of 5,000 randomly chosen SNPs. F ST statistics between populations were estimated using both SMARTPCA [14] and GENEPOP [74] which are based on two different models of population divergence.
In order to characterize the extent of LD, we computed the r2 measure [23] between each marker pair within each breed separetely using Haploview 4.1 [75].
Bayesian Model to analyze Differentiation among SNPs
Individual genotyping data were modelled according to the reparameterized extension, recently proposed by Riebler et al. [8], of the initial Bayesian hierarchical model developed by Beaumont and Balding [7]. Briefly and in the bi-allelic SNP case, let a ij be the observed reference allele (defined arbitrarily) count in population j = 1, ..., J at locus i = 1, ..., I. The conditional distribution given the true (unobserved) allele frequency p ij in that population at that locus is assumed to be binomial with parameters n ij (twice the number of genotyped individuals in population j at locus i) and p ij : a ij | p ij ~Bin(n ij , p ij ) (1). Note that 1) implicitly assumes populations are in HWE or their respective inbreeding coefficients (F IS ) are null. Non null F IS could be taken into account in the model by considering instead that the three possible genotypes are drawn from a multinomial distribution with parameters corresponding to the number of individuals genotyped and genotype probabilities: (1-F IS j)p ij 2 + F IS jp ij ; 2(1-F IS j)p ij (1-p ij ) and (1-F IS j)(1-p ij )2 + F IS j(1-p ij ) [18]. Nevertheless, for co-dominant markers such as SNP and given the range of F IS values in our study (see Results), the binomial distribution seems to be reasonable (Figure S3 in additional file 1). The second step assumes that the true allele frequencies p ij are themselves sampled from a Beta distribution: p ij | λ ij , x i ~Beta(λ ij x i , λ ij (1-x i )) (2). This distribution relies on an infinite Wright island model involving mutation, drift and migration at its equilibrium state [76, 77]. Under this model, x i might be interpreted as the frequency of the chosen reference allele at locus i in the gene pool from which each allele frequency p ij is sampled. The scaling parameter λ ij reflects the gene flow from the gene pool to population j. Under Wright's model, this parameter is specific to each population j but remains homogeneous over loci so that any departure from that property may indicate that locus i is no longer neutral. Note that under the Beta distribution, the first two moments can be simply expressed as E(p ij ) = x i and Var(p ij ) = x i (1-x i )(1+λ ij )-1. Actually (1+λ ij )-1 can be identified as a F ST ijcoefficient [17]. The next level of the model consists of specifying the distributions of λ ij (or F ST ij) and of x i . These frequencies are nuisance parameters and uncertainty about them will be taken into account by assigning to them non informative prior such as a Beta(1,1) distribution (e.g. [78]). Following Beaumont and Balding [7], the λ ij 's are modelled via a linear model on the logistic transformation of the F ST ij. Since F ST ij/(1-F ST ij) = 1/λ ij , we can write this model in terms of η ij = log(F ST ij/(1-F ST ij)) = -log(λ ij ) as: η ij = α i + β j + γ ij where α i is a locus effect, β j a population effect and γ ij an error term corresponding to a departure of the logit of F ST ijfrom the additive decomposition. For theoretical and computational reasons, it is more efficient to consider the previous decomposition under a hierarchical Bayesian structure than under its basic form, and implement it as follows: η ij | α i , β j , σ γ 2~ iid N(α i + β j , σ γ 2) with β j | μ β , σ β 2~ iid N(μ β , σ β 2) and α i | σ α 2~ iid N(0, σ α 2). Introduction of additional levels by defining priors on the variance components σ α 2, σ β 2 and σ γ 2 is straightforward but adds marginal gain in the estimates and requires high supplementary computational costs (Gautier and Foulley, unpublished data). We thus gave for these components the known values proposed initially by Beaumont and Balding (2004): σ α 2 = 1, σ β 2 = 3.24 and σ γ 2 = 0.25. The prior mean μ for the β j was also taken as -2.0. Recently, Riebler et al. [8] introduced in the above logistic model an auxiliary indicator variable δ i attached to each locus specifying whether it can be regarded as selected (δ i = 1) or neutral (δ i = 0). They demonstrated the efficiency of this approach for improving the power of the statistical procedure, particularly for the detection of loci under balancing selection. Under this reparameterized model, the previous parameters α i are written as: α i = δ i α i * with α i * | σ α *2~ iid N(0, σ α *2). The model further assumes a Bernoulli distribution for the indicator δ i variable with parameter P: δ i | P ~Bin(1, P). P is itself assumed to be Beta distributed to take into account uncertainty on this crucial parameter. Here we took P ~Beta(0.2,1.8) [8], thus assuming that a priori 10% of the loci are on average under selection, but within a very large range of possible values as the 95% credibility interval goes from almost 0 to 65%. Note that the value σ α *2 can be derived from σ α 2 since by construction σ α 2 = E(P) σ α *2 (hence σ α *2 = 10).
The posterior distributions of the different parameters of interest were estimated via MCMC procedures as previously described [8] from 10,000 post burn-in samples (with a burn-in period of 3,000 iterations) and a thinning interval of k = 25. Convergence was checked using standard criterion. Parameter estimates for the F ST ijwere taken as the median of the posterior distribution.
Decision rule to identify non neutral loci
In order to identify outlier loci, we decided to base the decision rule on a Bayes Factor BF i defined as the ratio of the posterior to the prior odds that locus i is selected:

As δ i is an indicator variable, the prior and posterior probabilities that δ i = 1 are easy to compute since they reduce to expectations as shown below:

where π(P) is the density of the distribution of P defined above. To make interpretation of the BF i easier, we expressed them in deciban units (dB) ie dB i = 10log10(BF i ) so that 10 dB corresponds to an odds ratio of 10, 20 dB to an odds ratio of 100, 30 dB to an odds ratio of 1,000 and so forth. We then applied the Jeffreys' rule [79] which quantifies the strength of evidence (here to consider a SNP as being under selection) based on BF using the following scale: "strong evidence" when 10<dB i <15, "very strong evidence" when 15<dB i <20 and "decisive evidence" when dB i >20. Notice that the BF captures the change in the odds in favor of δ i = 1 as we move from the prior to the posterior. In that way, it makes this criterion independent of the prior distribution of δ i and thus guarantees some robustness.
Simulated data
Following Foll and Gaggiotti [20], four data sets each comprising 50,000 (unlinked) SNPs with respectively 9300 (P = 0.186), 5000 (P = 0.1), 500 (P = 0.01) and 50 (P = 0.001) under selection (α i ≠ 0) were simulated under the inference model. To mimic characteristics of our samples, we considered 9 populations with parameters β j equal to the ones estimated on the real data (mean of the corresponding posterior distribution). For each pair of simulated locus/population, we subsequently simulated the η ij parameter by adding to the corresponding β j , a value of γ ij sampled from a Gaussian distribution (γ ij ~N(0,0.25)) and a value for α i equal to 0 if the locus was neutral or sampled from a Gaussian distribution (α i ~N(0,10)) if the locus was under selection. The frequency x i in the ancestral population (or migrant gene pool) was sampled from a Beta distribution with parameters equal to 0.7. This is equivalent to assume the ancestral population was at equilibrium with 4Nμ = 0.7 where N is the effective population size and μ the mutation rate [80]. Based on these simulated values for x i and η ij we subsequently derived the p ij parameter of the binomial distribution from which the simulated observed a ij was sampled (taking n ij = 80 for all i and j). Only SNPs displaying MAF>0.01 in at least one simulated West-African taurine and one West-African zebu (identified according to the simulated β j ) were conserved which led to the exclusion of few SNPs (displaying α i too high in general). To a first approximation, this also allowed the mimicking of the ascertainment bias introduced by the SNP selection criterion. The posterior distributions of the different parameters of interest were then estimated as described above from 1,000 post burn-in samples (with a burn-in period of 3,000 iterations) and a thinning interval of k = 25. BF i for each simulated loci were then computed (see above) and used to compute the (true) FDR and FNR for a given threshold. To investigate relationships between the coefficient of selection and the magnitude of the locus effect α i we performed simulations under a simplified version (without mutation) of the Wright-Fisher island model with selection proposed by Beaumont and Balding [7]. Briefly, 10 random mating populations with a constant size of 1,000 individuals and deriving from the same ancestral population were reproduced for 500 generations assuming a global F ST of 0.15. In total, 5,000 neutral SNPs and 500 SNPs for each investigated coefficient and mode of selection were simulated. Initial allele frequencies were drawn from a Beta distribution with both parameters equal to 0.7. At the end of the process, SNPs displaying a MAF <0.01 in at least 2 populations were discarded. Locus specific F ST were then computed following Weir and Cockerham [73]. Following Foll and Gaggiotti [20], for each type of selection considered, the corresponding average F ST was compared to the one obtained under neutrality (α i = 0) to estimate the average SNP effect.
Annotation of the SNPs
Because the annotation of the bovine genome is still sparse, the gene content information was derived from the TransMap cross-species alignments available in the UCSC Genome Browser http://genome.ucsc.edu/. For closer evolutionary distances, the alignments are created using syntenically filtered BLASTZ alignment chains, resulting in a prediction of the orthologous genes in cow. In total, 46,598 different RefSeq identifiers were anchored to the Btau_4.0 bovine genome assembly http://genome.ucsc.edu/. Considering that most consecutive SNPs on the map were separated by more than 20 kb and the relatively high level of LD at shorter distance (see Results and [11]) a SNP was considered as representative of a gene if it was localized within the boundary positions of the gene that extended by 15 kb upstream and downstream. According to this criterion, 15,360 out of the 36,320 SNPs were representative of 17,190 different TransMap RefSeq identifiers. Subsequent annotation and analyses were carried out with the Ingenuity Pathway Analysis (IPA) software v7.0 (Ingenuity Systems Inc., USA, http://www.ingenuity.com/). Among the 17,190 different TransMap RefSeq identifiers, 17,151 identifiers (99.7%) were represented in the Ingenuity Pathway Knowledge Base (IPKB) and corresponded to 7,177 different genes further considered as the reference set. Finally, 15,336 SNPs were located within a gene, leading to an average of 2.21 SNPs per annotated gene. Notice that 421 of these SNPs were representative of more than one gene.
Functional and Network Analyses
Functional and Networks analyses were carried out using an approach similar to the one described in [81]. Based on the information contained in the IPKB, IPA allows performing both functional and network analyses. The functional analysis aims at identifying the most significant biological functions represented in the candidate gene list from the reference set. Note that among the genes under selection, only those associated with at least one functional annotation in IPKB were eligible for functional analysis. The most significant functions are then obtained by comparing functions associated with eligible genes against functions associated with all the genes in the reference set using the right-tailed Fisher's exact test. The network analysis aims at searching for interactions (known from the literature) between candidate genes and all other IPKB molecules (genes, gene products or small molecules) and result in the definitions of networks which contains at most 35 molecules (including candidate genes). For each network, a score S is computed based on a right-tailed Fisher exact test for the overrepresentation of candidate genes (S = -log(p-value)). In our study, networks were considered as significant when S>3 and their associated top functions and diseases were further reported.
Identification of regions under selection
In order to identify regions under selection (with an unexpectedly high proportions of SNPs subjected to selection), we followed the locally adaptive procedure which allows to account for variations in distance between the different tested positions [81, 82]. Individual SNP BF values were first smoothed over each chromosome with a local variable bandwidth kernel estimator [83]. We further performed 250,000 permutations to estimate local p-values which were corrected for multiple testing by computing q-values (see above).
Abbreviations
- Breed Codes :
-
AUB: Aubrac
- BAO:
-
Baoulé
- BOR:
-
Borgou
- KUR:
-
Kuri
- LAG:
-
Lagune
- ND1:
-
N'Dama (first population)
- ND2:
-
N'Dama (second population)
- OUL:
-
Oulmès Zaer
- SOM:
-
Somba
- ZCH:
-
Choah zebu
- ZFU:
-
White Fulani Zebu
- ZMA:
-
Zebu from Madagascar.
- ASD:
-
: Allele Sharing Distance
- BF:
-
Bayes Factor
- BTA:
-
Bos TAurus chromosome
- dB:
-
deciban unit
- HWE:
-
Hardy-Weinberg Equilibrium
- IPA:
-
Ingenuity Pathway Analysis
- IPKB:
-
Ingenuity Pathway Knowledge database
- FDR:
-
False Discovery Rate
- FNR:
-
False Negative Rate
- LD:
-
Linkage Disequilibrium
- MAF:
-
Minor Allele Frequency
- MHC:
-
Major Histocompatibility Complex
- PCA:
-
Principal Component Analysis
- SNP:
-
Single Nucleotide Polymorphism.
References
Hanotte O, Bradley DG, Ochieng JW, Verjee Y, Hill EW, Rege JE: African pastoralism: genetic imprints of origins and migrations. Science. 2002, 296 (5566): 336-339. 10.1126/science.1069878.
Epstein H: The Origins of the Domestic Animals of Africa. 1971, London: Africana Publishing Corporation, 1:
Payne WJA, Hodges J: Tropical Cattle, Origins, Breeds and Breeding Policies. 1997, Oxford: Blackwell Science Ltd
Freeman AR, Meghen CM, Machugh DE, Loftus RT, Achukwi MD, Bado A, Sauveroche B, Bradley DG: Admixture and diversity in West African cattle populations. Mol Ecol. 2004, 13 (11): 3477-3487. 10.1111/j.1365-294X.2004.02311.x.
Williamson G, Payne WJA: An introduction to Animal Husbandry in the Tropics. 1984, English Language Book Service/Longman
Rege JEO, Aboagye GS, Tawah CL: Shorthorn cattle of West and Central Africa. I. Origin, distribution, classification and population statistics. World Anim Rev. 1994, 78: 1-14.
Beaumont MA, Balding DJ: Identifying adaptive genetic divergence among populations from genome scans. Mol Ecol. 2004, 13 (4): 969-980. 10.1111/j.1365-294X.2004.02125.x.
Riebler A, Held L, Stephan W: Bayesian variable selection for detecting adaptive genomic differences among populations. Genetics. 2008, 178 (3): 1817-1829. 10.1534/genetics.107.081281.
Matukumalli LK, Lawley CT, Schnabel RD, Taylor JF, Allan MF, Heaton MP, O'Connell J, Moore SS, Smith TPL, Sonstegard TS, et al: Development and Characterization of a High Density SNP Genotyping Assay for Cattle. PLoS ONE. 2009, 4 (4): e5350-10.1371/journal.pone.0005350.
Dayo GK, Thevenon S, Berthier D, Moazami-Goudarzi K, Denis C, Cuny G, Eggen A, Gautier M: Detection of selection signatures within candidate regions underlying trypanotolerance in outbred cattle populations. Mol Ecol. 2009, 18 (8): 1801-1813. 10.1111/j.1365-294X.2009.04141.x.
Gautier M, Faraut T, Moazami-Goudarzi K, Navratil V, Foglio M, Grohs C, Boland A, Garnier JG, Boichard D, Lathrop GM, et al: Genetic and haplotypic structure in 14 European and African cattle breeds. Genetics. 2007, 177 (2): 1059-1070. 10.1534/genetics.107.075804.
Bowcock AM, Ruiz-Linares A, Tomfohrde J, Minch E, Kidd JR, Cavalli-Sforza LL: High resolution of human evolutionary trees with polymorphic microsatellites. Nature. 1994, 368 (6470): 455-457. 10.1038/368455a0.
Cavalli-Sforza LL, Menozzi P, Piazza A: The History and Geography of Human Genes. 1994, Princeton, NJ: PrincetonUniversity Press
Patterson N, Price AL, Reich D: Population structure and eigenanalysis. PLoS Genet. 2006, 2 (12): e190-10.1371/journal.pgen.0020190.
Gibbs RA, Taylor JF, Van Tassell CP, Barendse W, Eversole KA, Gill CA, Green RD, Hamernik DL, Kappes SM, Lien S, et al: Genome-wide survey of SNP variation uncovers the genetic structure of cattle breeds. Science. 2009, 324 (5926): 528-532. 10.1126/science.1167936.
Moazami-Goudarzi K, Laloe D: Is a multivariate consensus representation of genetic relationships among populations always meaningful?. Genetics. 2002, 162 (1): 473-484.
Balding DJ: Likelihood-based inference for genetic correlation coefficients. Theor Popul Biol. 2003, 63 (3): 221-230. 10.1016/S0040-5809(03)00007-8.
Foll M, Beaumont MA, Gaggiotti O: An approximate Bayesian computation approach to overcome biases that arise when using amplified fragment length polymorphism markers to study population structure. Genetics. 2008, 179 (2): 927-939. 10.1534/genetics.107.084541.
Guillot G, Foll M: Correcting for ascertainment bias in the inference of population structure. Bioinformatics. 2009, 25 (4): 552-554. 10.1093/bioinformatics/btn665.
Foll M, Gaggiotti O: A genome-scan method to identify selected Loci appropriate for both dominant and codominant markers: a bayesian perspective. Genetics. 2008, 180 (2): 977-993. 10.1534/genetics.108.092221.
McVean G: The structure of linkage disequilibrium around a selective sweep. Genetics. 2007, 175 (3): 1395-1406. 10.1534/genetics.106.062828.
Guo F, Dey DK, Holsinger KE: A Bayesian hierarchical model for analysis of SNP diversity in multilocus, multipopulation samples. J Am Stat Assoc. 2009, 104 (485): 142-154. 10.1198/jasa.2009.0010.
Hill WG, Robertson A: Linkage disequilibrium in finite populations. Theoretical and Applied Genetics. 1968, 38: 226-231. 10.1007/BF01245622.
Excoffier L, Hofer T, Foll M: Detecting loci under selection in a hierarchically structured population. Heredity. 2009, 103 (4): 285-298. 10.1038/hdy.2009.74.
Garrigan D, Hedrick PW: Perspective: detecting adaptive molecular polymorphism: lessons from the MHC. Evolution. 2003, 57 (8): 1707-1722.
Hedrick PW: Balancing selection and MHC. Genetica. 1998, 104 (3): 207-214. 10.1023/A:1026494212540.
Keeble AH, Khan Z, Forster A, James LC: TRIM21 is an IgG receptor that is structurally, thermodynamically, and kinetically conserved. Proc Natl Acad Sci USA. 2008, 105 (16): 6045-6050. 10.1073/pnas.0800159105.
Yang K, Shi HX, Liu XY, Shan YF, Wei B, Chen S, Wang C: TRIM21 is essential to sustain IFN regulatory factor 3 activation during antiviral response. J Immunol. 2009, 182 (6): 3782-3792. 10.4049/jimmunol.0803126.
Johnson WE, Sawyer SL: Molecular evolution of the antiretroviral TRIM5 gene. Immunogenetics. 2009, 61 (3): 163-176. 10.1007/s00251-009-0358-y.
Newman RM, Hall L, Connole M, Chen GL, Sato S, Yuste E, Diehl W, Hunter E, Kaur A, Miller GM, et al: Balancing selection and the evolution of functional polymorphism in Old World monkey TRIM5alpha. Proc Natl Acad Sci USA. 2006, 103 (50): 19134-19139. 10.1073/pnas.0605838103.
Seya T, Oshiumi H, Sasai M, Akazawa T, Matsumoto M: TICAM-1 and TICAM-2: toll-like receptor adapters that participate in induction of type 1 interferons. Int J Biochem Cell Biol. 2005, 37 (3): 524-529. 10.1016/j.biocel.2004.07.018.
Raghunandan R, Ruiz-Hidalgo M, Jia Y, Ettinger R, Rudikoff E, Riggins P, Farnsworth R, Tesfaye A, Laborda J, Bauer SR: Dlk1 influences differentiation and function of B lymphocytes. Stem Cells Dev. 2008, 17 (3): 495-507. 10.1089/scd.2007.0102.
Contento RL, Molon B, Boularan C, Pozzan T, Manes S, Marullo S, Viola A: CXCR4-CCR5: a couple modulating T cell functions. Proc Natl Acad Sci USA. 2008, 105 (29): 10101-10106. 10.1073/pnas.0804286105.
Lusso P: HIV and the chemokine system: 10 years later. Embo J. 2006, 25 (3): 447-456. 10.1038/sj.emboj.7600947.
Bamshad MJ, Mummidi S, Gonzalez E, Ahuja SS, Dunn DM, Watkins WS, Wooding S, Stone AC, Jorde LB, Weiss RB, et al: A strong signature of balancing selection in the 5' cis-regulatory region of CCR5. Proc Natl Acad Sci USA. 2002, 99 (16): 10539-10544. 10.1073/pnas.162046399.
Wooding S, Stone AC, Dunn DM, Mummidi S, Jorde LB, Weiss RK, Ahuja S, Bamshad MJ: Contrasting effects of natural selection on human and chimpanzee CC chemokine receptor 5. Am J Hum Genet. 2005, 76 (2): 291-301. 10.1086/427927.
Hanotte O, Ronin Y, Agaba M, Nilsson P, Gelhaus A, Horstmann R, Sugimoto Y, Kemp S, Gibson J, Korol A, et al: Mapping of quantitative trait loci controlling trypanotolerance in a cross of tolerant West African N'Dama and susceptible East African Boran cattle. Proc Natl Acad Sci USA. 2003, 100 (13): 7443-7448. 10.1073/pnas.1232392100.
Nagarajan UM, Long AB, Harreman MT, Corbett AH, Boss JM: A hierarchy of nuclear localization signals governs the import of the regulatory factor X complex subunits and MHC class II expression. J Immunol. 2004, 173 (1): 410-419.
Krawczyk M, Peyraud N, Rybtsova N, Masternak K, Bucher P, Barras E, Reith W: Long distance control of MHC class II expression by multiple distal enhancers regulated by regulatory factor X complex and CIITA. J Immunol. 2004, 173 (10): 6200-6210.
Gobin SJ, Peijnenburg A, van Eggermond M, van Zutphen M, Berg van den R, Elsen van den PJ: The RFX complex is crucial for the constitutive and CIITA-mediated transactivation of MHC class I and beta2-microglobulin genes. Immunity. 1998, 9 (4): 531-541. 10.1016/S1074-7613(00)80636-6.
Siemasko K, Eisfelder BJ, Stebbins C, Kabak S, Sant AJ, Song W, Clark MR: Ig alpha and Ig beta are required for efficient trafficking to late endosomes and to enhance antigen presentation. J Immunol. 1999, 162 (11): 6518-6525.
Kumanogoh A, Marukawa S, Suzuki K, Takegahara N, Watanabe C, Ch'ng E, Ishida I, Fujimura H, Sakoda S, Yoshida K, et al: Class IV semaphorin Sema4A enhances T-cell activation and interacts with Tim-2. Nature. 2002, 419 (6907): 629-633. 10.1038/nature01037.
Hill AV: Aspects of genetic susceptibility to human infectious diseases. Annu Rev Genet. 2006, 40: 469-486. 10.1146/annurev.genet.40.110405.090546.
Guo L, Jiang M, Ma Y, Cheng H, Ni X, Jin Y, Xie Y, Mao Y: Cloning, chromosome localization and features of a novel human gene, MATH2. J Genet. 2002, 81 (1): 13-17. 10.1007/BF02715865.
Moreno TA, Bronner-Fraser M: Noelins modulate the timing of neuronal differentiation during development. Dev Biol. 2005, 288 (2): 434-447. 10.1016/j.ydbio.2005.09.050.
Laura RP, Ross S, Koeppen H, Lasky LA: MAGI-1: a widely expressed, alternatively spliced tight junction protein. Exp Cell Res. 2002, 275 (2): 155-170. 10.1006/excr.2002.5475.
Abid A, Ismail M, Mehdi SQ, Khaliq S: Identification of novel mutations in the SEMA4A gene associated with retinal degenerative diseases. J Med Genet. 2006, 43 (4): 378-381. 10.1136/jmg.2005.035055.
Smith AK, Dimulescu I, Falkenberg VR, Narasimhan S, Heim C, Vernon SD, Rajeevan MS: Genetic evaluation of the serotonergic system in chronic fatigue syndrome. Psychoneuroendocrinology. 2008, 33 (2): 188-197. 10.1016/j.psyneuen.2007.11.001.
Abebe G, Eley RM, ole-MoiYoi OK: Reduced responsiveness of the hypothalamic-pituitary-adrenal axis in Boran (Bos inducus) cattle infected with Trypanosoma congolense. Acta Endocrinol (Copenh). 1993, 129 (1): 75-80.
Morin LP: Serotonin and the regulation of mammalian circadian rhythmicity. Ann Med. 1999, 31 (1): 12-33. 10.3109/07853899909019259.
Gariepy CE, Cass DT, Yanagisawa M: Null mutation of endothelin receptor type B gene in spotting lethal rats causes aganglionic megacolon and white coat color. Proc Natl Acad Sci USA. 1996, 93 (2): 867-872. 10.1073/pnas.93.2.867.
Read AP, Newton VE: Waardenburg syndrome. J Med Genet. 1997, 34 (8): 656-665. 10.1136/jmg.34.8.656.
Seo K, Mohanty TR, Choi T, Hwang I: Biology of epidermal and hair pigmentation in cattle: a mini-review. Vet Dermatol. 2007, 18 (6): 392-400. 10.1111/j.1365-3164.2007.00634.x.
Hilton MJ, Sawyer JM, Gutierrez L, Hogart A, Kung TC, Wells DE: Analysis of novel and recurrent mutations responsible for the tricho-rhino-phalangeal syndromes. J Hum Genet. 2002, 47 (3): 103-106. 10.1007/s100380200010.
Momeni P, Glockner G, Schmidt O, von Holtum D, Albrecht B, Gillessen-Kaesbach G, Hennekam R, Meinecke P, Zabel B, Rosenthal A, et al: Mutations in a new gene, encoding a zinc-finger protein, cause tricho-rhino-phalangeal syndrome type I. Nat Genet. 2000, 24 (1): 71-74. 10.1038/71717.
Fantauzzo KA, Tadin-Strapps M, You Y, Mentzer SE, Baumeister FA, Cianfarani S, Van Maldergem L, Warburton D, Sundberg JP, Christiano AM: A position effect on TRPS1 is associated with Ambras syndrome in humans and the Koala phenotype in mice. Hum Mol Genet. 2008, 17 (22): 3539-3551. 10.1093/hmg/ddn247.
Wu DD, Irwin DM, Zhang YP: Molecular evolution of the keratin associated protein gene family in mammals, role in the evolution of mammalian hair. BMC Evol Biol. 2008, 8: 241-10.1186/1471-2148-8-241.
Hansen PJ: Physiological and cellular adaptations of zebu cattle to thermal stress. Anim Reprod Sci. 2004, 82-83: 349-360. 10.1016/j.anireprosci.2004.04.011.
Dikmen S, Alava E, Pontes E, Fear JM, Dikmen BY, Olson TA, Hansen PJ: Differences in thermoregulatory ability between slick-haired and wild-type lactating Holstein cows in response to acute heat stress. J Dairy Sci. 2008, 91 (9): 3395-3402. 10.3168/jds.2008-1072.
Martinez ML, Machado MA, Nascimento CS, Silva MV, Teodoro RL, Furlong J, Prata MC, Campos AL, Guimaraes MF, Azevedo AL, et al: Association of BoLA-DRB3.2 alleles with tick (Boophilus microplus) resistance in cattle. Genet Mol Res. 2006, 5 (3): 513-524.
Mattioli RC, Pandey VS, Murray M, Fitzpatrick JL: Immunogenetic influences on tick resistance in African cattle with particular reference to trypanotolerant N'Dama (Bos taurus) and trypanosusceptible Gobra zebu (Bos indicus) cattle. Acta Trop. 2000, 75 (3): 263-277. 10.1016/S0001-706X(00)00063-2.
Tomlinson DJ, Mulling CH, Fakler TM: Invited review: formation of keratins in the bovine claw: roles of hormones, minerals, and vitamins in functional claw integrity. J Dairy Sci. 2004, 87 (4): 797-809.
Drogemuller C, Wohlke A, Momke S, Distl O: Fine mapping of the polled locus to a 1-Mb region on bovine chromosome 1q12. Mamm Genome. 2005, 16 (8): 613-620. 10.1007/s00335-005-0016-0.
Souvenir-Zafindrajaona P, Zeuh V, Moazami-Goudarzi K, Laloë D, Bourzat D, Idriss A, Grosclaude F: Etude du statut phylogénétique du bovin Kouri du lac Tchad à l'aide de marqueurs moléculaires. Revue Elev Méd Vét Pays trop. 1999, 52 (2): 155-162.
Moazami-Goudarzi K, Belemsaga DMA, Ceriotti G, Laloë D, Fagbohoun F, Kouagou NT, Sidibé I, Codjia V, Crimella MC, Grosclaude F, et al: Caractérisation de la race bovine Somba à l'aide de marqueurs moléculaires. Revue Elev Méd Vét Pays trop. 2001, 54 (2): 129-138.
Souvenir-Zafindrajaona P, Lauvergne JJ: Comparaison de populations de zébu malgache à l'aide des distances génétiques. Genetics, Selection, Evolution: GSE. 1993, 25: 373-395. 10.1186/1297-9686-25-4-373.
Beja-Pereira A, Alexandrino P, Bessa I, Carretero Y, Dunner S, Ferrand N, Jordana J, Laloe D, Moazami-Goudarzi K, Sanchez A, et al: Genetic characterization of southwestern European bovine breeds: a historical and biogeographical reassessment with a set of 16 microsatellites. Journal of Heredity. 2003, 94 (3): 243-250. 10.1093/jhered/esg055.
Elsik CG, Tellam RL, Worley KC, Gibbs RA, Muzny DM, Weinstock GM, Adelson DL, Eichler EE, Elnitski L, Guigo R, et al: The genome sequence of taurine cattle: a window to ruminant biology and evolution. Science. 2009, 324 (5926): 522-528. 10.1126/science.1169588.
Wigginton JE, Cutler DJ, Abecasis GR: A note on exact tests of Hardy-Weinberg equilibrium. Am J Hum Genet. 2005, 76 (5): 887-893. 10.1086/429864.
Storey JD, Tibshirani R: Statistical significance for genomewide studies. Proc Natl Acad Sci USA. 2003, 100 (16): 9440-9445. 10.1073/pnas.1530509100.
Paradis E, Claude J, Strimmer K: APE: Analyses of Phylogenetics and Evolution in R language. Bioinformatics. 2004, 20 (2): 289-290. 10.1093/bioinformatics/btg412.
Dray S, Dufour AB: The ade4 package: implementing the duality diagram for ecologists. Journal of Statistical Software. 2007, 22 (4): 1-20.
Weir BS, Cockerham CC: Estimating F-statistics for the analysis of population structure. Evolution. 1984, 19: 395-420.
Rousset F: GenePop'007: a complete re-implementation of the GenePop software for Windows and Linux. Molecular Ecology Resources. 2008, 8: 103-106. 10.1111/j.1471-8286.2007.01931.x.
Barrett JC, Fry B, Maller J, Daly MJ: Haploview: analysis and visualization of LD and haplotype maps. Bioinformatics. 2005, 21 (2): 263-265. 10.1093/bioinformatics/bth457.
Rousset F: Inferences from Spatial Population Genetics. Handbook of Statistical Genetics. Edited by: Balding DJ, Bishop M, Cannings C. 2008, Wiley-Interscience, 2: 945-979. 3
Wright S: Isolation by Distance. Genetics. 1943, 28 (2): 114-138.
Pritchard JK, Stephens M, Donnelly P: Inference of population structure using multilocus genotype data. Genetics. 2000, 155 (2): 945-959.
Jeffreys H: Theory of Probability, 3rd edition. 1961, Oxford University Press
Wright S: Evolution in Mendelian Populations. Genetics. 1931, 16 (2): 97-159.
Flori L, Fritz S, Jaffrezic F, Boussaha M, Gut I, Heath S, Foulley JL, Gautier M: The genome response to artificial selection: a case study in dairy cattle. PLoS One. 2009, 4 (8): e6595-10.1371/journal.pone.0006595.
Callegaro A, Basso D, Bicciato S: A locally adaptive statistical procedure (LAP) to identify differentially expressed chromosomal regions. Bioinformatics. 2006, 22 (21): 2658-2666. 10.1093/bioinformatics/btl455.
Herrmann E: Local bandwidth choice in kernel regression estimation. J Graphic Comput Statist. 1997, 6: 35-54. 10.2307/1390723.
Acknowledgements
The authors wish to thank the farmers, the persons in charge of breeding programmes and the CIRDES (Burkina-Faso) team for their precious help in providing the samples from Burkina-Faso, Togo and Benin and Pr Lahoussine Ouragh from the Rabat Institute of Morocco for providing samples from Oulmès-Zaer breed. They also wish to thank anonymous referees for helpful corrections. The genotyping was supported by the French Ministry of Education and Research and the National Institute of Agronomic Research (INRA AIP "Bio-Ressources").
Author information
Authors and Affiliations
Corresponding author
Additional information
Authors' contributions
All authors read and approved the final manuscript. MG conceived the study, analyzed the data and drafted the paper. LF performed functional and network analyses and drafted the paper. AR, FJ, DL and JLF contributed to analyses. KMG provided samples and IG oversaw genotyping and quality control of genotyping results.
Electronic supplementary material
12864_2009_2434_MOESM1_ESM.PDF
Additional file 1: Supplementary Figures. This additional file is a pdf document with seven pages each corresponding to the following supplementary figures: Figure S1 (page 1): SNP Polymorphism within each population. A) Plot of heterozygosities averaged across all the 36,320 selected SNPs against the corresponding relative increase after removing non informative SNPs from the full data set B) Distribution of the number of SNPs per population for different MAF range. Figure S2 (page 2): Neighbor-Joining tree relating the 437 individuals. The tree was constructed using allele sharing distances averaged over 36,320 SNPs. Edges are colored according to the individual breed of origin. Figure S3 (page 3): Distribution of allele counts for different F IS , allele frequency and number of genotyped individuals. Figure S4 (page 4): Comparison of the distribution of estimated and simulated allele frequencies in the gene pool in four simulated data sets. P represents the proportion of SNP under selection simulated and Alpha the locus effect. Figure S5 (page 5): Posterior distribution of the proportion P of loci under selection. Distributions for the real data set and the four different simulated data sets (with known P) are represented. Figure S6 (page 6): Distribution of distances separating consecutive SNPs. Figure S7 (page 7): Decay of average pairwise r2 with inter-marker distance for the different populations. A vertical dotted line indicates the average marker spacing of 70 kb in the study. (PDF 6 MB)
12864_2009_2434_MOESM2_ESM.XLS
Additional file 2: Supplementary Tables. This additional file is an excel file containing 7 sheets each corresponding to the following supplementary tables: Table S1: Differentiation between populations. Estimates of F ST between pairs of population computed with SMARTPCA (GENEPOP) software are below (above) the diagonal. Diagonal elements are estimates of population F IS . Standard deviations of the estimates are given in parenthesis. Table S2: Power to detect loci under selection as a function of the simulated locus effect. Table S3: BF and F ST estimates for each SNP considered in the study. Table S4: Correlation of BF and F ST between pair of SNPs for different inter-marker distance bins. Table S5: Description of the 7,177 genes represented by analyzed SNPs. Table S6: Description of significant gene networks. Table S7: Functional annotation of N and N3 networks. Table S8: Genome Coverage of the SNPs. (XLS 6 MB)
12864_2009_2434_MOESM3_ESM.BZ2
Additional file 3: Genotyping Data. This file is a bzipped archive containing the genotyping data (437 individuals and 36,320 SNPs) in the Haploview format (see Methods). (BZ2 6 MB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Gautier, M., Flori, L., Riebler, A. et al. A whole genome Bayesian scan for adaptive genetic divergence in West African cattle. BMC Genomics 10, 550 (2009). https://doi.org/10.1186/1471-2164-10-550
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2164-10-550