
Abstract
Background
Transmembrane proteins (TMPs) constitute about 20~30% of all protein coding genes. The relative lack of experimental structure has so far made it hard to develop specific alignment methods and the current state of the art (PRALINE™) only manages to recapitulate 50% of the positions in the reference alignments available from the BAliBASE2-ref7.
Methods
We show how homology extension can be adapted and combined with a consistency based approach in order to significantly improve the multiple sequence alignment of alpha-helical TMPs. TM-Coffee is a special mode of PSI-Coffee able to efficiently align TMPs, while using a reduced reference database for homology extension.
Results
Our benchmarking on BAliBASE2-ref7 alpha-helical TMPs shows a significant improvement over the most accurate methods such as MSAProbs, Kalign, PROMALS, MAFFT, ProbCons and PRALINE™. We also estimated the influence of the database used for homology extension and show that highly non-redundant UniRef databases can be used to obtain similar results at a significantly reduced computational cost over full protein databases. TM-Coffee is part of the T-Coffee package, a web server is also available from http://tcoffee.crg.cat/tmcoffee and a freeware open source code can be downloaded from http://www.tcoffee.org/Packages/Stable/Latest.
Similar content being viewed by others

Background
Transmembrane proteins (TMPs) are non-soluble proteins anchored in a cell membrane and containing one or more membrane-spanning segments separated with intra or extra-cellular domains of variable length. This figure reflects the bi-layer membrane width, though the segments can also be tilted within the membrane, thus requiring more amino acids to span the interval (up to 30). TMPs constitute about 20~30% of all protein coding genes in prokaryotic and eukaryotic organisms [1, 2]. The problem of generating multiple sequence alignments (MSAs) of TMPs was first addressed by [3], and over the last years several packages have been published, specifically designed for that task [4–6]. To our knowledge PRALINE™ is the only TMPs multiple aligner currently available. PRALINE™ belongs to a category of aligners using the process of homology extension. PROMALS [7] and PSI-Coffee [8] also belong to this category. Homology extension is a method that involves using database searches to replace each sequence with a profile made of close homologues. As a result, in any sequence, each position becomes a column in a multiple alignment, thus reflecting the pattern of acceptable mutations. These patterns are very informative, as they tend to reflect the sum of constraints (mostly functional and structural) that have shaped the diversity observed along the proteins of the same family. A natural consequence of these patterns conservation is the high sensitivity of profile-profile comparisons when doing remote homology search [9].
In this paper we show that the PSI-Coffee homology extension can also be used to reveal and use specific conservation patterns of TMPs like the amphiphilic properties of transmembrane alpha helices and thus yield significant improvements when aligning TMPs. A critical parameter when doing homology extension is to determine the influence of the database used to make the extension. Typical homology extension involves performing BLAST or PSI-BLAST [10] against the NR database [11]. This step is time consuming and results in a prohibitive cost for homology extension, as compared with faster methods. We show here that one can go over this problem by using smaller non-redundant databases. We go even further by showing that a TMP specific database can be used for homology extension at a much lower CPU cost and without any significant reduction in alignment accuracy.
Methods
Homology extension
The process of homology extension involves replacing individual sequences with a set of multiply aligned homologues. Given a dataset, this procedure involves performing BLAST for each individual sequence against a protein database and turning the resulting output into a one-against-all MSA (i.e. query against hits). These MSAs (one per sequence in the original dataset) are then turned into profiles. The purpose of homology extension is to reveal the evolutionary variability associated with each site of the considered sequences thus producing more accurate pair-wise alignments [7]. We used blast+ (version 2.2.25) against various databases (see next section). In practice, homology extension is made automatically by T-Coffee [12] either using the public web service maintained by the European Bioinformatics Institute (default) or using a locally installed BLAST against locally maintained databases.
Databases
Homology extension was carried out against two databases: NR and UniRef [13]. In order to check the effect of redundancy, we used the versions of UniRef non-redundant database (UniRef100, UniRef90 and UniRef50) trimmed at various levels of redundancy. In these versions, the database is modified so as to make sure that no pair of sequences exists with an identity higher than the specified level. UniRef100-TM, UniRef90-TM and UniRef50-TM are even smaller databases produced by filtering the corresponding UniRef dataset with the following query string: "keyword:transmembrane". These TMP specific databases are typically 20% of the size of their sources.
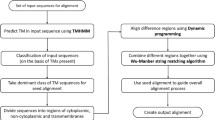
TM-Coffee algorithm
TM-Coffee uses the PSI-Coffee (Position Specific Iterative T-Coffee) mode of T-Coffee to multiply align TMPs. The algorithm can be summarized as follows:
-
1.
Perform BLAST for each query sequence against the selected database with default parameters.
-
2.
Keep hits having a level of identity between 50% and 90% and a coverage higher than 70%.
-
3.
Turn the BLAST output into a profile by removing all columns corresponding to positions unaligned to the query (i.e. gaps in the query) and by filling with gaps query positions unmatched by BLAST.
-
4.
Produce a T-Coffee library by aligning every pair of profiles with a pair-HMM. When doing so, every pair of matched column with a posterior probability of being aligned higher than 0.99 is added to the library. The pair-HMM is adapted from the ProbCons pair-HMM [14] in order to deal with profiles. It uses the ProbCons bi-phasic gap penalty set (i.e. two distinct sets of gap opening and extension penalties for short and longer gaps). The parameter values are those initially reported [14].
Benchmarking
We used as a gold standard the reference 7 of BAliBASE2 [15]. This dataset is made of 435 alpha-helical TMPs classified into eight distinct families that can be multiply aligned. The core regions of BAliBASE defined by the authors examine the alignment of structurally equivalent residues only (Additional file 1). Evaluation is made by assessing the capacity of the methods to recapitulate these core regions, mostly made of alpha helices. Two metrics are used to assess accuracy: the Sum of Pairs score (SP) that estimates the fraction of residue pairs from the reference core identically aligned in the target and the reference MSA and the Total Column score (TC) that estimates the fraction of columns identically aligned in the target and the reference.
Aligners
We used BAliBASE-ref7 dataset to compare PSI-Coffee with the six most accurate methods currently available, MSAProbs 0.9.4 [16], Kalign 2.04 [17], PROMALS, MAFFT 6.815 [18], ProbCons 1.12 and PRALINE™. All methods were run using default parameters. PSI-Coffee is part of the T-Coffee suite (Version 8.99). It was run with default parameters except for the database used for homology extension. This was done with the following command line:
t_coffee <seq.fasta> -mode psicoffee -blast_server LOCAL -protein_db <database> -template_file PSITM
The PSITM template file mode is used here to display a coloured MSA version (.tm_html output file, Figure 1) reflecting predictions carried out by HMMTOP [19] using the profile associated with each sequence. This prediction is only used for display purposes and is not required by the alignment procedure.

Typical colour output (tm_html). In this example, the protein Or9a of Drosophila melanogaster and its orthologues of other Drosophila species were aligned with PSITM template. The colour code corresponds to prediction by HMMTOP, where yellow: in loop, red: TM helix, blue: out loop. Notably, the predicted topology of the Or9a set is consistent with the Benton et al.'s conclusion [20].
Results
We first asked whether applying the PSI-Coffee homology extension algorithm on our reference dataset of TMPs could lead to some improvement over existing alignment methods. We did so using the NR database for homology extension. Results (Table 1) show that TM-Coffee outperforms the other methods, most notably when considering entire columns (TC comparison). When doing so, we find an improvement of nearly 10% over PRALINE™. Owing to the small dataset size (eight families), the observed differences are not highly statistically significant, although the differences between PSI-Coffee and the other methods are consistently more marked than the differences between the other methods (Table 2). This increased accuracy comes, however, at a significant computational cost. One may therefore argue that the over-head for turning single sequences into profiles is so significant that it is not worth using this approach for large-scale analysis. In order to address this problem we asked whether one could achieve a similar level of accuracy while doing the homology extension on smaller databases.
When using PSI-Coffee, profiles are built by performing BLAST search for each sequence against NR. This procedure defines the database as a key ingredient of homology extension. It is therefore an interesting question to ask how this parameter may affect the overall accuracy of the procedure. We did so by providing PSI-Coffee with databases of various redundancy levels (UniRefXX), all built upon UniProt, and then realigning the reference datasets. Results (Table 3 and 4, detailed performance per family in Additional file 2) show that the difference in accuracy is very small when comparing to NR. Overall, the accuracy level of PSI-Coffee remains high regardless of the redundancy level. In practice, however, using a UniRef50 means using a database with 50% redundancy and approximately 3.5 times smaller than the full database. As one would expect the CPU requirements of the extension process decrease accordingly and the time required by the alignment goes down to 26,442 as compared with the 72,199 seconds required when using the full database (2.7 times faster).
Even so, the CPU requirements can be considered excessive when compared with the time needed by the default T-Coffee (that does not need to do any extension), we therefore decided to take advantage of the observation that when doing homology extension with TMPs, one spends a lot of CPU time searching databases mostly made of unlikely TMPs homologues. Indeed, 80% of the proteins in UniRef are non TMPs. We therefore asked if a simple database, built by filtering UniRef on keywords could be used instead of the full DB. This database, named UniRefXX-TM is significantly more compact than its source. UniRef50-TM contains about 100 times fewer sequences than the full UniProt. Results obtained on this database show that using such a reduced protein set for the extension does not result in any trade-off between accuracy and efficiency. The level accuracy is comparable and even superior to that achieved with the default PSI-Coffee while the CPU time requirements are dramatically decreased by a factor 10. We named TM-Coffee the flavour of PSI-Coffee running homology extension against UniRef50-TM. Table 5 shows that TM-Coffee remains relatively slower than non-homology extension based methods but dramatically faster than PROMALS, a well-known aligner using homology extension.
We finally asked whether one can alter the effect of homology extension by filtering the BLAST output based on e-value and removing distantly related sequences (i.e. remote homologues) that are likely to be inaccurately or only partially aligned. Results are shown in Figure 2. As one can see, no benefit is gained from filtering the BLAST output and the overall accuracy tends to increase when more hits are included. The slight drop on the curve is not statistically significant and can be attributed to a single misaligned sequence. Overall this result indicates that using the default BLAST parameters (NONE in Figure 2) leads to profiles where low quality hits only have a negligible impact on the overall alignment accuracy, probably because remote homologues tend to be filtered out through their low coverage.

Line chart of the average TC respect to different e -value thresholds on UniRef50-TM database. The number of homologues is counted by summing all homologues found in eight families and plotted in log10 scale. The standard error of TC score cross eight families is the range of dash line. SP is skipped due to minor change respect to different e-value thresholds.
Discussion and conclusions
In this work we show that homology extension can be used to significantly increase the accuracy of transmembrane protein multiple sequence alignments. When considering entire columns (the most stringent measure of multiple alignment accuracy), our results suggest that PSI-Coffee is about 10% more accurate than MSAProbs, the next best method. This improvement comes, however, at a cost and we show that the default PSI-Coffee requires about 30 times more CPU time than simpler methods. We therefore explored the possibility of using more compact non-redundant databases and found that when using a database trimmed to 50% redundancy and containing only sequences annotated as TMPs, we could achieve the same level of accuracy as PSI-Coffee while only requiring a tenth of the CPU time. This new protocol is named TM-Coffee.
Regardless of the improvement reported here in terms of CPU, TM-Coffee remains a relatively slow method. One may argue whether the increased computation cost is worth the improvement reported here. There is no simple answer to this question. For instance, if we consider Kalign and TM-Coffee, the difference in CPU requirement is about a thousand fold. The difference in accuracy at the column level, however, is about 28%. These are major differences, bound to dramatically affect any modelling based on an MSA. Of course, one may argue that the column score can be affected by a single misaligned sequence and is therefore an amplification of reality. This is probably true for some applications of MSAs, yet many circumstances exist like homology or phylogenetic modelling where the misalignment of a single sequence can have a major impact on the conclusion drawn upon the analysis of a dataset.
Abbreviations
- TMPs:
-
transmembrane proteins
- MSAs:
-
multiple sequence alignments
- SP:
-
the Sum of Pairs score
- TC:
-
the Total Column score.
References
Martin-Galiano AJ, Frishman D: Defining the fold space of membrane proteins: the CAMPS database. Proteins 2006, 64: 906–922. 10.1002/prot.21081
Wallin E, von Heijne G: Genome-wide analysis of integral membrane proteins from eubacterial, archaean, and eukaryotic organisms. Protein Sci 1998, 7: 1029–1038.
Cserzo M, Bernassau JM, Simon I, Maigret B: New alignment strategy for transmembrane proteins. J Mol Biol 1994, 243: 388–396. 10.1006/jmbi.1994.1666
Pirovano W, Feenstra KA, Heringa J: PRALINETM: a strategy for improved multiple alignment of transmembrane proteins. Bioinformatics 2008, 24: 492–497. 10.1093/bioinformatics/btm636
Forrest LR, Tang CL, Honig B: On the accuracy of homology modeling and sequence alignment methods applied to membrane proteins. Biophys J 2006, 91: 508–517. 10.1529/biophysj.106.082313
Shafrir Y, Guy HR: STAM: simple transmembrane alignment method. Bioinformatics 2004, 20: 758–769. 10.1093/bioinformatics/btg482
Pei J, Grishin NV: PROMALS: towards accurate multiple sequence alignments of distantly related proteins. Bioinformatics 2007, 23: 802–808. 10.1093/bioinformatics/btm017
Kemena C, Notredame C: Upcoming challenges for multiple sequence alignment methods in the high-throughput era. Bioinformatics 2009, 25: 2455–2465. 10.1093/bioinformatics/btp452
Soding J, Remmert M, Biegert A, Lupas AN: HHsenser: exhaustive transitive profile search using HMM-HMM comparison. Nucleic Acids Res 2006, 34: W374–378. 10.1093/nar/gkl195
Altschul SF, Madden TL, Schäffer AA, Zhang J, Zhang Z, Miller W, Lipman DJ: Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res 1997, 25: 3389–3402. 10.1093/nar/25.17.3389
Pruitt KD, Tatusova T, Klimke W, Maglott DR: NCBI Reference Sequences: current status, policy and new initiatives. Nucleic Acids Res 2009, 37: D32–36. 10.1093/nar/gkn721
Notredame C, Higgins DG, Heringa J: T-Coffee: A novel method for fast and accurate multiple sequence alignment. J Mol Biol 2000, 302: 205–217. 10.1006/jmbi.2000.4042
Suzek BE, Huang H, McGarvey P, Mazumder R, Wu CH: UniRef: comprehensive and non-redundant UniProt reference clusters. Bioinformatics 2007, 23: 1282–1288. 10.1093/bioinformatics/btm098
Do CB, Mahabhashyam MS, Brudno M, Batzoglou S: ProbCons: Probabilistic consistency-based multiple sequence alignment. Genome Res 2005, 15: 330–340. 10.1101/gr.2821705
Bahr A, Thompson JD, Thierry JC, Poch O: BAliBASE (Benchmark Alignment dataBASE): enhancements for repeats, transmembrane sequences and circular permutations. Nucleic Acids Res 2001, 29: 323–326. 10.1093/nar/29.1.323
Liu Y, Schmidt B, Maskell DL: MSAProbs: multiple sequence alignment based on pair hidden Markov models and partition function posterior probabilities. Bioinformatics 2010, 26: 1958–64. 10.1093/bioinformatics/btq338
Lassmann T, Sonnhammer EL: Kalign--an accurate and fast multiple sequence alignment algorithm. BMC Bioinformatics 2005, 6: 298. 10.1186/1471-2105-6-298
Katoh K, Toh H: Recent developments in the MAFFT multiple sequence alignment program. Brief Bioinform 2008, 9: 286–298. 10.1093/bib/bbn013
Tusnady GE, Simon I: The HMMTOP transmembrane topology prediction server. Bioinformatics 2001, 17: 849–850. 10.1093/bioinformatics/17.9.849
Benton R, Sachse S, Michnick SW, Vosshall LB: Atypical membrane topology and heteromeric function of Drosophila odorant receptors in vivo. PLoS Biol 2006, 4: e20. 10.1371/journal.pbio.0040020
Acknowledgements
JMC, PDT, JFT and CN are funded by the Centre de Regulacio Genomica (CRG), the Plan Nacional (BFU2008-00419) from the Spanish Ministry of Science. JMC is also funded by "la Caixa" pre-doctoral fellowship. This work was also co-financed by the European Commission, within the 7th Framework Programme, Leishdrug (223414) and Quantomics (222664) and SGR-951 grant from the Catalan Government.
This article has been published as part of BMC Bioinformatics Volume 13 Supplement 4, 2012: Italian Society of Bioinformatics (BITS): Annual Meeting 2011. The full contents of the supplement are available online at http://www.biomedcentral.com/1471-2105/13/S4.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
JMC and CN conceived of the experiments and drafted the manuscript. JFT and PDT constructed web service and open source code. All authors read and approved the final manuscript.
Electronic supplementary material
12859_2012_5098_MOESM1_ESM.pdf
Additional file 1: The core region of BAliBASE 2. For BAliBASE 2, authors did not publish the XML file allowing automated use of these blocks. The location of the block is only available in HTML file, the uppercase of character (i.e., http://bips.u-strasbg.fr/en/Products/Databases/BAliBASE2/ref7/test/msl_ref7.html). We have generated the XML following the original BAliBASE annotation. (PDF 1 MB)
12859_2012_5098_MOESM2_ESM.pdf
Additional file 2: The performance of each TMP family by individual database. default means T-Coffee without homology extension. Others are PSI-Coffee searching against corresponding databases. The construction of databases is explained in "Methods" section. (PDF 86 KB)
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Chang, JM., Di Tommaso, P., Taly, JF. et al. Accurate multiple sequence alignment of transmembrane proteins with PSI-Coffee. BMC Bioinformatics 13 (Suppl 4), S1 (2012). https://doi.org/10.1186/1471-2105-13-S4-S1
Published:
DOI: https://doi.org/10.1186/1471-2105-13-S4-S1