
Abstract
Background
The Bayesian shrinkage technique has been applied to multiple quantitative trait loci (QTLs) mapping to estimate the genetic effects of QTLs on quantitative traits from a very large set of possible effects including the main and epistatic effects of QTLs. Although the recently developed empirical Bayes (EB) method significantly reduced computation comparing with the fully Bayesian approach, its speed and accuracy are limited by the fact that numerical optimization is required to estimate the variance components in the QTL model.
Results
We developed a fast empirical Bayesian LASSO (EBLASSO) method for multiple QTL mapping. The fact that the EBLASSO can estimate the variance components in a closed form along with other algorithmic techniques render the EBLASSO method more efficient and accurate. Comparing with the EB method, our simulation study demonstrated that the EBLASSO method could substantially improve the computational speed and detect more QTL effects without increasing the false positive rate. Particularly, the EBLASSO algorithm running on a personal computer could easily handle a linear QTL model with more than 100,000 variables in our simulation study. Real data analysis also demonstrated that the EBLASSO method detected more reasonable effects than the EB method. Comparing with the LASSO, our simulation showed that the current version of the EBLASSO implemented in Matlab had similar speed as the LASSO implemented in Fortran, and that the EBLASSO detected the same number of true effects as the LASSO but a much smaller number of false positive effects.
Conclusions
The EBLASSO method can handle a large number of effects possibly including both the main and epistatic QTL effects, environmental effects and the effects of gene-environment interactions. It will be a very useful tool for multiple QTL mapping.
Similar content being viewed by others

Background
Quantitative traits are usually controlled by multiple quantitative trait loci (QTLs) and environmental factors. Interactions among QTLs or between genes and environmental factors make a substantial contribution to variation in complex traits [1]. The goal of QTL mapping is to infer genomic loci that are associated with the trait and to estimate the genetic effects of these loci including their main effects and gene-gene (epistasis) and gene-environment (G × E) interactions. Due to the physical linkage of and/or epistatic interactions among multiple QTLs, it is highly desirable to analyze a large number of loci simultaneously. Since hundreds or thousands of genomic loci or markers are usually genotyped and involved in QTL mapping studies, including all these markers and their possible interactions in a model leads to a huge number of model variables, typically much larger than the sample size. Two general techniques often employed to handle such oversaturated models are variable selection and shrinkage.
Variable selection attempts to identify a subset of all possible genetic effects that best explain the phenotypic variation, typically using a stepwise search procedure in conjunction with a selection criterion such as the Bayesian information criterion (BIC) [2]. On the other hand, a shrinkage method includes all variables in the model but uses a penalty function of the variables or appropriate prior distributions on the variables to shrink most non-effect variables toward zero. Early shrinkage methods include ridge regression [3] and the least absolute shrinkage and selection operator (LASSO) [4]. More recently, Bayesian shrinkage method [5] has received considerable attention and been applied to multiple QTL mapping [6–10]. All these works employ Markov chain Monte Carlo (MCMC) simulation to fit the Bayesian model and provide comprehensive information about the model drawing from the posterior distribution of the model variables. Despite the advances in the development of the MCMC simulation algorithms [11], MCMC simulations are computationally intensive and time consuming.
In order to reduce the computational burden of the fully Bayesian approach relying on MCMC simulation, one of the authors of this paper developed an empirical Bayes (EB) method [12] that uses a properly chosen prior distribution for the model variables to shrink variables toward zero. It was demonstrated that the EB method can handle a large number of model variables simultaneously. More recently, the EB method has been extended to handle classification predictor variables [13]. Although the EB method [12] requires much less computation comparing to the fully Bayesian approach, its efficiency is limited by the fact that a numerical optimization algorithm such as the simplex algorithm [14] is needed to estimate the variance components. On the other hand, a very efficient EB method, named relevance vector machine (RVM), for learning a linear model was developed in the machine learning community [15, 16]. The RVM can estimate the variance components in a closed form, which along with other algorithmic techniques make it a very fast algorithm. The RVM assumes a uniform prior distribution for the variance components. Although this choice of the prior distribution gets rid of any hyperparameters to be pre-specified, it lacks the flexibility of adjusting the degree of shrinkage needed for analyzing a specific data set. Particularly, its uniform prior distribution may not provide enough shrinkage in multiple QTL mapping that includes a very large number of possible effects, often resulting in a large number of false effects [13].
In this paper, capitalizing on the idea of RVM, we developed a fast empirical Bayesian LASSO (EBLASSO) algorithm based on the Bayesian LASSO model [10, 17] with an exponential prior distribution for the variance components in contrast to the inverse chi-square distribution for the variance components used by the EB method [12]. Simulation studies demonstrate that our EBLASSO method can provide a speed up to orders of magnitude faster than the EB method and can detect more true QTL effects without increasing the false positive rate. Real data analysis also show that the EBLASSO method is able to detect some effects when the EB method fails.
Methods
Linear model of multiple QTLs
Let y i be the phenotypic value of a quantitative trait of the i th individual in a mapping population. Suppose we observe y i , i = 1, ⋯, n of n individuals and collect them into a vector y = [y1, y2, ⋯, y n ] T . Considering environmental effects, main and epistatic effects of all markers and gene-environment (G × E) interactions, we have the following linear regression model for y:

where μ is the population mean, vectors β
E
and β
G
represent the environmental effects and the main effects of all markers, respectively, vectors β
GG
and β
GE
capture the epistatic effects and the G × E interactions, respectively, X E, X G, X
GG
and X
GE
are the corresponding design matrices of different effects, and e is the residual error that follows a normal distribution with zero-mean and covariance 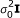 . Throughout the paper we use I to denote an identity matrix whose size can be clearly identified from the context.
. Throughout the paper we use I to denote an identity matrix whose size can be clearly identified from the context.
The design matrix X G depends on a specific genetic model. We adopt the widely used Cockerham genetic model as also used by [18] in their generalized linear model for multiple QTL mapping. For a back-cross design, the Cockerham model defines the values of the main effect of a marker as -0.5 and 0.5 for two genotypes at the marker. For an intercross (F2) design, there are two possible main effects named additive and dominance effects. The Cockerham model defines the values of the additive effect as -1, 0 and 1 for the three genotypes and the values of the dominance effect as -0.5 and 0.5 for homozygotes and heterozygotes, respectively. The columns of the design matrix X GG are obtained as the element-wise product of any two different columns of X G , and similarly the columns of X GE are constructed as the element-wise product of any pair of columns from X E and X G .
Defining 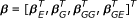 , X = [X
E
, X
G
, X
GG
, X
GE
], we can write (1) in a more compact form:
, X = [X
E
, X
G
, X
GG
, X
GE
], we can write (1) in a more compact form:

Suppose that there are p environmental covariates and q markers whose main effects are additive, then the size of matrix X is n × k where k = p + q(q + 1)/2 + pq. Typically, we have k ≫ n. If dominance effects of the markers are considered, k is even larger. Our goal is to estimate all possible environmental and genetical effects on y manifested in the regression coefficients β, which is a challenging problem because k ≫ n. However, we would expect that most elements of β are zeros and thus we have a sparse linear model. Taking into account this sparsity, we will adopt the Bayesian LASSO model [10] where appropriate prior distributions are assigned to the elements of β as described in the next section.
Prior and posterior distributions
The unknown parameters in model (2) are, μ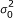 and β. While our main concern is β, parameters μ and need to be estimated so that we can infer β. To this end, we assign a noninformative uniform prior μ to and , i.e., p(μ) ∝ 1 and p() ∝ 1. Following the Bayesian LASSO model [10], we assume a three-level hierarchical model for β. Let us denote the elements of β as β
i
, i = 1, 2, ⋯, k. At the first level, β
i
, i = 1, 2, ⋯, k follow independent normal distributions with mean zero and unknown variance
and β. While our main concern is β, parameters μ and need to be estimated so that we can infer β. To this end, we assign a noninformative uniform prior μ to and , i.e., p(μ) ∝ 1 and p() ∝ 1. Following the Bayesian LASSO model [10], we assume a three-level hierarchical model for β. Let us denote the elements of β as β
i
, i = 1, 2, ⋯, k. At the first level, β
i
, i = 1, 2, ⋯, k follow independent normal distributions with mean zero and unknown variance 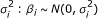 . At the second level,
. At the second level,  , follow independent exponential distribution with a common parameter
, follow independent exponential distribution with a common parameter 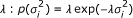 . For a given λ, the distribution of β
i
is found to be the Laplace distribution:
. For a given λ, the distribution of β
i
is found to be the Laplace distribution: 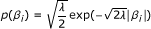 , which is known to encourage the shrinkage of β
i
toward zero [4]. However, the degree of shrinkage strongly depends on the value of λ. To alleviate the problem of choosing an inappropriate value for λ, we add another level to the hierarchical model at which we assign a conjugate Gamma prior Gamma(a, b) with a shape parameter a > 0 and an inverse scale parameter b > 0 to the parameter λ. As discussed in [10], we can pre-specify appropriate values for a and b so that the Gamma prior for λ is essentially noninformative.
, which is known to encourage the shrinkage of β
i
toward zero [4]. However, the degree of shrinkage strongly depends on the value of λ. To alleviate the problem of choosing an inappropriate value for λ, we add another level to the hierarchical model at which we assign a conjugate Gamma prior Gamma(a, b) with a shape parameter a > 0 and an inverse scale parameter b > 0 to the parameter λ. As discussed in [10], we can pre-specify appropriate values for a and b so that the Gamma prior for λ is essentially noninformative.
Let us define vector 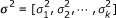 . The joint posterior distribution of all the parameters (μ, , β, σ2, λ) can be easily found [10]. In principle, MCMC simulation can be employed to draw samples from the posterior distribution for each parameter. However, since the number of parameters 2k + 3 in our model can be very large, the fully Bayesian approach based on MCMC sampling requires a prohibitive computational cost. To avoid this problem, Xu developed an empirical Bayes method for inferring β[12]. Our goal here is to develop a much faster and more accurate empirical Bayes method that can easily handle tens of thousands of variables.
. The joint posterior distribution of all the parameters (μ, , β, σ2, λ) can be easily found [10]. In principle, MCMC simulation can be employed to draw samples from the posterior distribution for each parameter. However, since the number of parameters 2k + 3 in our model can be very large, the fully Bayesian approach based on MCMC sampling requires a prohibitive computational cost. To avoid this problem, Xu developed an empirical Bayes method for inferring β[12]. Our goal here is to develop a much faster and more accurate empirical Bayes method that can easily handle tens of thousands of variables.
Maximum a posteriori estimation of variance components
Similar to the EB method of [12], our EBLASSO first estimates σ2, and μ, and then finds the posterior distribution of β based on the estimated parameters. Since λ is a parameter that we do not want to estimate, we can find the prior distribution of 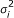 independent of λ as follows
independent of λ as follows
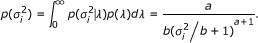
The posterior distribution of μ, β, σ2 and is given by
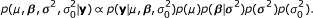
The marginal posterior distribution of μ, σ2 and can then be written as
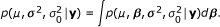
Let us define the precision of β
i
as 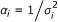 , i = 1, 2, ..., k and let α= [α1, α2, ⋯, α
k
]. It turns out to be more convenient to estimate α rather than σ2 as will be shown shortly. Let us collect all parameters that need to be estimated as θ= (μ, σ0, α). The log marginal posterior distribution of θ can be found from (5) as follows
, i = 1, 2, ..., k and let α= [α1, α2, ⋯, α
k
]. It turns out to be more convenient to estimate α rather than σ2 as will be shown shortly. Let us collect all parameters that need to be estimated as θ= (μ, σ0, α). The log marginal posterior distribution of θ can be found from (5) as follows

where 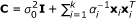 is the covariance matrix of y with a given α.
is the covariance matrix of y with a given α.
Similar to the EB method [12] and the RVM [15, 16], we will iteratively estimate each parameter by maximizing the log marginal posterior distribution L(θ) with the other parameters being fixed. Since it is not difficult to find the optimal μ and in each iteration as shown in [12, 15], we will give the expressions for μ and later but focus on the estimation of α now. Let us define 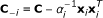 and
and 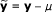 . Then following the derivations in [16], we can write L(θ) in (6) as L(θ) = L(θ-i) + L(α
i
), where L(θ-i) does not depend on α
i
and L(α
i
) is given by
. Then following the derivations in [16], we can write L(θ) in (6) as L(θ) = L(θ-i) + L(α
i
), where L(θ-i) does not depend on α
i
and L(α
i
) is given by
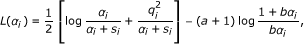
with 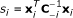 and
and  . If we assume a > -1.5 and b > 0, we prove in Additional file 1 that L(α
i
) has a unique global maximum and that the optimal α
i
maximizing L(α
i
) is given by
. If we assume a > -1.5 and b > 0, we prove in Additional file 1 that L(α
i
) has a unique global maximum and that the optimal α
i
maximizing L(α
i
) is given by
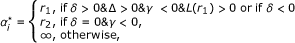
where we have defined 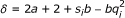 ,
, 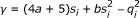 ,
,  ,
,  and
and 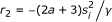 . Note that the Gamma distribution requires that a > 0 and b > 0 as we mentioned earlier. When -1.5 <a ≤ 0 as assumed here, we essentially use an improper distribution. In Additional file 1, we show that this improper distribution appears appropriate for getting a point estimation of α
i
given in (8). It turns out that negative values of a give one more degree of freedom to adjust the shrinkage as will be demonstrated later in the Results section. Moreover, if a = -1, the last term in the right hand side of (7) disappears. In this case, we essentially use a noninformative uniform prior. Then it is not difficult to verify that (8) gives the optimal α
i
derived in [16]:
. Note that the Gamma distribution requires that a > 0 and b > 0 as we mentioned earlier. When -1.5 <a ≤ 0 as assumed here, we essentially use an improper distribution. In Additional file 1, we show that this improper distribution appears appropriate for getting a point estimation of α
i
given in (8). It turns out that negative values of a give one more degree of freedom to adjust the shrinkage as will be demonstrated later in the Results section. Moreover, if a = -1, the last term in the right hand side of (7) disappears. In this case, we essentially use a noninformative uniform prior. Then it is not difficult to verify that (8) gives the optimal α
i
derived in [16]:
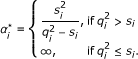
Note that α* in (8) and (9) depends on other unknown parameters through s
i
and q
i
, and thus, α
i
will be estimated iteratively as detailed in the EBLASSO algorithm described in the next section. Comparing with the EB method [12], our method finds each α
i
(and equivalently ) in a closed form, whereas the EB method generally needs to employ a numerical optimization algorithm to find each . Therefore, our method not only saves much computation but also gives more accurate estimate of each α
i
. Moreover, exploiting the similar techniques used in the RVM [16], we can further increase computational efficiency as described in the ensuing section.
Fast Empirical Bayesian LASSO algorithm
Note that when α
i
= ∞, we have β
i
= 0. Therefore, in each iteration, we can construct a reduced model of (2) that includes only nonzero β
i
s and the corresponding columns of X. Let x
i
be the i th column of X. If α
i
= ∞ in the previous iteration but 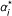 is finite in the current iteration, then we add x
i
to the model and set
is finite in the current iteration, then we add x
i
to the model and set  ; if α
i
is finite in the previous iteration but
; if α
i
is finite in the previous iteration but 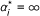 in the current iteration, we delete x
i
from the model and set α
i
= ∞; if both α
i
and are finite, we retain x
i
in the model and update α
i
as . This can be done for all i s in a pre-specified order in each iteration. Alternatively, we can employ a greedy and potentially more efficient method to construct the model as described in the following. We define two iteration loops: an outer iteration loop and an inner iteration loop. In each outer iteration, we estimate μ and . In the inner iterations, assuming μ and are known and fixed, we estimate each α
i
and construct the model. Specifically, in each inner iteration, we first calculate each from (8) and hen find
in the current iteration, we delete x
i
from the model and set α
i
= ∞; if both α
i
and are finite, we retain x
i
in the model and update α
i
as . This can be done for all i s in a pre-specified order in each iteration. Alternatively, we can employ a greedy and potentially more efficient method to construct the model as described in the following. We define two iteration loops: an outer iteration loop and an inner iteration loop. In each outer iteration, we estimate μ and . In the inner iterations, assuming μ and are known and fixed, we estimate each α
i
and construct the model. Specifically, in each inner iteration, we first calculate each from (8) and hen find 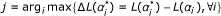 , where α
i
stands for the value of α
i
obtained in the previous inner iteration. This step basically identifies the x
j
that gives the largest increase in the log posterior distribution. Then we add, delete or retain x
j
as described early. The inner iterations can run until a local convergence criterion is satisfied. Let vector
, where α
i
stands for the value of α
i
obtained in the previous inner iteration. This step basically identifies the x
j
that gives the largest increase in the log posterior distribution. Then we add, delete or retain x
j
as described early. The inner iterations can run until a local convergence criterion is satisfied. Let vector  contain all finite α
i
s, vector
contain all finite α
i
s, vector 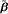 consist of the corresponding β
i
s and matrix
consist of the corresponding β
i
s and matrix 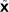 contain the corresponding columns of X. Then we essentially construct the following reduced model:
contain the corresponding columns of X. Then we essentially construct the following reduced model:

where the number of columns of , k
r
, is typically much less than the number of rows, n. This property will be used to reduce computation.
To calculate in (8), we need to first calculate s
i
and q
i
which requires 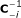 . Since C-iis different for different i, it may need large computation to calculate all . However, it was shown in [16] that we can calculate s
i
and q
i
as follows
. Since C-iis different for different i, it may need large computation to calculate all . However, it was shown in [16] that we can calculate s
i
and q
i
as follows

where 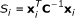 and
and  . This requires only one matrix inversion in each iteration for calculating all s
i
and q
i
, i = 1, ⋯, k. However, since C is a relatively large matrix of size n × n, direct calculation of C-1 may still require large computation. To avoid this problem, we can use the Woodbury matrix identity to derive an expression for C-1:
. This requires only one matrix inversion in each iteration for calculating all s
i
and q
i
, i = 1, ⋯, k. However, since C is a relatively large matrix of size n × n, direct calculation of C-1 may still require large computation. To avoid this problem, we can use the Woodbury matrix identity to derive an expression for C-1:

where

with 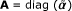 . The size of matrix ∑ is k
r
× k
r
which is typically much smaller than the size of C. Since inverting a matrix of N × N using an efficient method such as QR decomposition needs computation of O(N3), calculating ∑ requires much less computation than directly inverting C. Using (12), we can calculate S
i
and Q
i
as follows:
. The size of matrix ∑ is k
r
× k
r
which is typically much smaller than the size of C. Since inverting a matrix of N × N using an efficient method such as QR decomposition needs computation of O(N3), calculating ∑ requires much less computation than directly inverting C. Using (12), we can calculate S
i
and Q
i
as follows:

So far we have derived the method for efficiently estimating α. Other two unknown parameters μ and can be obtained by setting  and
and 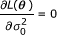 . This gives
. This gives
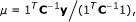
where 1 is a vector whose elements are all 1, and [15]
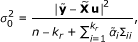
where ∑ ii is the i th diagonal element of ∑ and
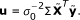
After we get estimates of μ, and α, we finalize the model (10), where the prior distribution of 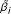 is now
is now 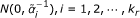 . For those x
i
s not in the model, we can declare that they do not affect the quantitative trait because their regression coefficient is zero. For those x
i
s in the matrix , the posterior distribution of their regression coefficients is Gaussian with covariance ∑ in (13) and mean u in (17) [15]. We can then use the z-score or more conservative t-statistics to test if
. For those x
i
s not in the model, we can declare that they do not affect the quantitative trait because their regression coefficient is zero. For those x
i
s in the matrix , the posterior distribution of their regression coefficients is Gaussian with covariance ∑ in (13) and mean u in (17) [15]. We can then use the z-score or more conservative t-statistics to test if  at certain significance level. In this paper, the posterior mean u
j
of the j th effect is reported as the empirical Bayes estimate of β
j
, denoted by
at certain significance level. In this paper, the posterior mean u
j
of the j th effect is reported as the empirical Bayes estimate of β
j
, denoted by  , and the posterior standard deviation,
, and the posterior standard deviation,  , is used as the standard error of .
, is used as the standard error of .
We now summarize our fast EBLASSO algorithm as follows.
Algorithm 1 (EBLASSO algorithm)
1. Initialize parameters: choose a > -1.5 and b > 0, calculate μ = 1Ty/n, and setto be a small number, e.g., 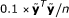 .
.
2. Initialize the model: Find , and calculate α j from (9), set all other α i s to be ∞ and .
3. Calculate ∑ from (13), S i and Q i , ∀i, from (14).
4. Update the model
while the local convergence criterion is not satisfied
Calculate q i and s i from (11), ∀i.
Calculatefrom (8), ∀i.
Find  .
.
if

if x j is in the model, delete it and update ∑ , S i and Q i , ∀i.
else
if x
j
is in the model, set and update ∑ , S
i
and Q
i
, ∀i.
and update ∑ , S
i
and Q
i
, ∀i.
if
x
j
is not in the model, add it, set
and update
∑
, S
i
and Q i , ∀i.
end if
end while
5. Update the residual varianceusing (16).
6. Calculate ∑ from (13) and C-1from (12).
7. Update the fixed effects μ using (15) and update.
8. Calculate S i and Q i from (14).
9. If the global convergence criterion is not satisfied, go to step 4.
10. Find the posterior mean offrom (17) and the posterior variance ∑
ii
from (13).
11. Use t-statistics to test if.
The parameters a and b can be set to be a small number (e.g., a = b = 0.01) so that the Gamma prior distribution is essentially noninformative [10]. Alternatively, we can use the predicted error (PE) obtained from cross-validation [4] to choose the values of a and b. As done in [16], the initial value of is chosen in step 1 to be a small number and the initial model is selected in step 2 to have a single effect that corresponds to the maximum L(α
i
) with a = -1. The outer iteration loop consists of steps 4-9, while the inner iteration loop is step 4, where we use the greedy method described earlier to update the model. In step 4, we use the method given in the Appendix of [16] to efficiently update ∑, S
i
and Q
i
after a x
j
is added to or deleted from the model or after α
j
is updated. The local convergence criterion can be defined as the simultaneous satisfaction of the following three conditions: 1) no effect can be added to or deleted from the model, 2) the change of L(θ) between two consecutive inner iterations is smaller than a pre-specified small value, and 3) the change of between two consecutive inner iterations is less than a pre-specified value. The global convergence criterion can be defined as the simultaneous satisfaction of the following two conditions: the change of L(θ) between two consecutive outer iterations is smaller than a pre-specified small value, and 2) the total change in μ, and between two consecutive outer iterations is less than a pre-specified value. A Matlab program has been developed to implement the algorithm; and a more efficient C++ program is under development.
Results
Simulation study
We simulated a single large chromosome of 2400 centiMorgan (cM) long covered by evenly spaced q = 481 markers with a marker interval of 5 cM. The simulated population was an F2 family derived from the cross of two inbred lines with a sample size n = 1000. The genotype indicator variable for individual i at marker k is defines as X
ik
= 1, 0, -1 for the three genotypes, A1A1, A1A2 and A2A2, respectively. Twenty markers are QTLs with main effects and 20 out of the 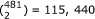 marker pairs have interaction effects. The locations and effects of the markers and maker pairs are shown in Table 1. Environmental effects and G × E effects were not simulated. The true population mean is μ = 100 and the residual variance is
marker pairs have interaction effects. The locations and effects of the markers and maker pairs are shown in Table 1. Environmental effects and G × E effects were not simulated. The true population mean is μ = 100 and the residual variance is 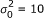 .
.
The total phenotypic variance for the trait can be written as
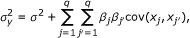
where cov(x
j
, xj') is the covariance between X
j
and Xj'if j ≠ j' or the variance of X
j
if j = j', which can be estimated from the data. The total phenotypic variance was calculated from (18) to be 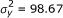 and the total genetic variance contributed by the main and epistatic effects of the markers was calculated from the second term of the right hand side of (18) to be 88.67. If we ignore the contributions from the covariance terms which are relatively small, the proportions of the phenotypic variance explained by a particular QTL effect j can be approximated by
and the total genetic variance contributed by the main and epistatic effects of the markers was calculated from the second term of the right hand side of (18) to be 88.67. If we ignore the contributions from the covariance terms which are relatively small, the proportions of the phenotypic variance explained by a particular QTL effect j can be approximated by
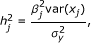
where var(x
j
) is the variance of X
j
. In the simulated data, the proportion of contribution from an individual QTL varied from 0.30% to 9.75%, whereas the proportion of contribution from a pair of QTLs ranged from 0.26% to 7.25%, as shown in Table 1. Some of the markers had only main or epistatic effect, while the others had both main and epistatic effects. The QTL model contained a total of  possible effects, a number about 115 times of the sample size.
possible effects, a number about 115 times of the sample size.
The data were analyzed in Matlab on a personal computer (PC) using the EBLASSO algorithm, the EB method, the RVM and the LASSO. The Matlab program SPARSEBAYES for the RVM was downloaded from http://www.miketipping.com. We translated the original SAS program for the EB method [12] into Matlab, and slightly modified the program to avoid possible memory overflow due to the large number of possible effects. We also got the program glmnet [19] that is a very efficient program implementing the LASSO and other related algorithms. The PC version of glmnet uses Matlab to initialize and call the core LASSO algorithm that is implemented efficiently with Fortran code.
We used the PE [4] obtained from ten-fold cross validation to select the values of hyperparameters a and b in our EBLASSO algorithm. Ideally, we should test a large set of values for a ≥ -1 and b > 0, but this may be time consuming. Therefore, we first ran cross-validation for the following values: a = b = 0.001, 0.01, 0.05, 0.1, 0.5, 1; the degree of shrinkage generally decreases along this path. Table 2 lists the PEs and the standard errors of the PEs for different values of a and b. It is seen that the PE for a = b = 0.1 is the smallest, although it is close to the PEs for a = b = 0.05 and 0.5 but relatively smaller than PEs for the other values of a and b. To see if a = b = 0.1 is the best set of values, we further ran cross-validation with b = 0.1 and a = 0.5 or -0.01. For a fixed b, the degree of shrinkage decreases when a decreases. It is seen from Table 2 that the PE for b = 0.1 and a = 0.5 or -0.01 is greater than that for a = b = 0.1. Therefore, cross-validation gave a = b = 0.1 as the best set of values. Table 2 also lists the number of effects detected with different values of a and b. All 30 effects detected with a = b = 0.1 are presented in Table 1 and shown in Figures 1 and 2.

Main effects estimated with the EBLASSO for the simulated data with main and epistatic effects.

Epistatic effects estimated with the EBLASSO for the simulated data with main and epistatic effects. The horizontal axis is scaled as 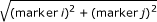 for each marker pair (marker i, marker j).
for each marker pair (marker i, marker j).
To test the performance of the EB method, we ran the program with the following parameter values: τ = -1, ω = 0.0001, 0.0005, 0.001 and 0.01, which yielded 14, 13, 22, and 8 true simulated effects, respectively, and 1, 1, 1, and 0 false effects, respectively, as shown in Table 2. Cross-validation was not done because it was too time-consuming, and thus, the optimal values for the parameters could not be determined. Nevertheless, we listed 22 true positive effects estimated with τ = -1 and ω = 0.001 in Table 1, which reflects the best performance of the EB method with the set of parameters values tested. We also plotted these 22 effects in Figures 3 and 4. Comparing the effects detected by EBLASSO and EB methods shown in Table 1 and in Figures 1, 2, 3 and 4, the EBLASSO method detected 13 (17) true main (epistatic) effects, whereas the EB method detected 15 (7) true main (epistatic) effects. Overall, the EBLASSO detected 8 more true effects than the EB method without any false positive effects, whereas the EB method gave one false positive effect. We would like to emphasize here that the EB method may detect less number of true effects in practice because as we mentioned earlier it is too time-consuming to choose the optimal values for the parameters τ and ω. To see if EBLASSO could estimate QTL effects robustly, we simulated three replicates of the data: each replicate consists of 1000 individuals whose genotypes at 481 markers were independently generated and whose phenotypes were calculated from (2) with e independently generated from Gaussian random variables with zero mean and covariance 10I. We performed cross-validation and determined the best values of a and b for each replicate. Using these values, we ran the EBLASSO and identified 35, 38, 34 true positive effects and 4, 6, 2 false positive effects, respectively, for three replicates. These results showed that the EBLASSO could detect QTL effects robustly.

Main effects estimated with the EB method for the simulated data with main and epistatic effects.

Epistatic effects estimated with the EB method for the simulated data with main and epistatic effects. The horizontal axis is scaled for each marker pair (marker i, marker j).
The EBLASSO took about 3.4 minutes of CPU time for each set of values of a and b listed in Table 2, whereas the EB took 249 hours of CPU time for τ = -1 and ω = 0.001 and about 46, 69, 46 hours for τ = -1 and ω = 0.0001, 0.0005, 0.01, respectively. This simulation study showed that the EBLASSO method not only can detect more effects, but also offers a huge advantage in terms of computational time. Note that all simulations were done in Matlab. It is expected that the EBLASSO algorithm will be even faster, after its implementation in C++ is completed.
We wished to test the performance of the RVM and the LASSO on the simulated data. To this end, we replaced the inner iteration in our EBLASSO algorithm with the program SPARSEBAYES that implemented the RVM. Although we carefully modified SPARSEBAYES to avoid possible memory overflow due to the large number of possible effects, the program ran out of memory after one or two outer iterations. Hence, we did not get any results from the RVM method. Considering the QTL model in (2), the LASSO tries to estimate μ and the QTL effects β as follows

where λ is a positive constant that can be determined with cross-validation [4]. We tried to run the program glmnet [19] with the simulated data. However, glmnet could not handle the big design matrix X of 1, 000 × 115, 922 in our QTL model, and we did not get any results from glmnet.
In order to compare the performance of our EBLASSO algorithm with that of the RVM and the LASSO, we simulated a new set of data by deleting the 20 epistatic effects in the previous set of simulated data, and then used a QTL model that only contained 481 possible main effects to estimate QTL effects, i.e., the design matrix X in (2) was 1000 × 481. The small number of possible effects was chosen to avoid the memory overflow problem of the RVM and glmnet. The results of the EBLASSO, EB, RVM and LASSO for this data set are summarized in Table 3. To choose the values of a and b for the EBLASSO, we ran ten-fold cross validation with the following parameters: a = b = 0.001, 0.01, 0.05, 0.1, 0.5, 1. Since a = b = 0.1 yielded the smallest PE, we further performed cross-validation with b = 1, and a = -0.95, -0.75, -0.5, 0.5. This gave the smallest PE at a = -0.75 and b = 0.1. Finally, we used a = -0.75 and b = 0.1 to run the EBLASSO algorithm on the whole data set, which identified all 20 true effects but also 5 false positive effects. In fact, since the EBLASSO program ran very fast on this data set, we did ten-fold cross validation for 165 sets of values for a and b obtained by combining the following values: a = -1, -0.95, -0.85, -0.75, -0.5, -0.1, -0.05, -0.01, -0.001, 0.001, 0.01, 0.05, 0.1, 0.5, 1 and b = 0.001 0.01 0.05 0.1, 0.5, 1, 2.5, 5, 10, 15, 20. The smallest average PE and standard error were 10.49 ± 0.5444 achieved at a = 0.05 and b = 10. With this set of values, the EBLASSO identified all 20 true effects and also 6 false positive effects, which is similar to that identified at a = -0.75 and b = 0.1. This study showed that the two-step cross-validation approach, where cross-validation was run with a = b = 0.001, 0.01, 0.05, 0.1, 0.5, 1 and then with a fixed b but a varying a, performed well and could save much time. We further simulated three replicates of the data in the same way described earlier for the model with epistatic effects. We then repeated the two-step cross-validation for each replicate. Using the values of a and b determined in cross-validation, the EBLASSO detected 20, 19, 19 true effects, and 4, 1 and 2 false positive effects, respectively, for three replicates. This again showed that our EBLASSO could estimate the effects robustly.
The optimal values for the parameters of the EB method were τ = -1 and ω = 0.01, since they gave the smallest PE in cross-validation as listed in Table 3. With τ = -1 and ω = 0.01, the EB method detected 19 true effects and 4 false positive effects. The RVM detected all 20 true effects as the EBLASSO did, but it also output a large number of 42 false positive effects. This result is consistent the observation [13] that the uniform prior distribution used in the RVM usually yields many false positive effects. To choose the optimal value of λ for the LASSO, we ran ten-fold cross validation starting from λ = 4.9725 (which gave only one nonzero effect) and then decreasing λ to 0.0025 with a step size of 0.0768 on the logarithmic scale (Δ ln(λ) = 0.0768). The smallest PE was achieved at λ = 0.0675. We then used this value to run glmnet on the whole data set, which yielded 97 nonzero effects. For each of these nonzero effects, we calculated their standard error using equation (7) in [4], and then calculated the p-value of each nonzero effect. This gave 20 true effects and 48 false positive effects with a p-value less than 0.05. Comparing the number of effects detected by the EBLASSO, EB, RVM and LASSO, the EBLASSO offered the best performance because it detected all true effects and a very small number of false positive effects.
It is seen from Table 3 that the EBLASSO and the LASSO took much less time than the EB method and the RVM on analyzing this data set. It is expected that the EBLASSO is much faster than the EB method because as we discussed earlier the EB needs a numerical optimization procedure. The RVM and EBLASSO generally should have similar speed because two algorithms use the similar technique to estimate effects. However, when applying to the same data set, the RVM often yields a model with much more nonzero effects than the EBLASSO as is the case here, because the RVM does not provide sufficient degree of shrinkage. Due to this reason, the RVM algorithm requires more time than the EBLASSO. The LASSO took slightly less CPU time than the EBLASSO in this example. However, we would emphasize that the LASSO was implemented with Fortran but our EBLASSO was implemented with Matlab. The speed of EBLASSO is expected to increase significantly once it is implemented in C/C++.
Real data analysis
This dataset was obtained from [20]. This dataset consists of n = 150 double haploids (DH) derived from the cross of two spring barley varieties Morex and Steptoe. The total number of markers was q = 495 distributed along seven pairs of chromosomes of the barley genome, covering 206 cM of the barley genome. The phenotype was the spot blotch resistance measured as the lesion size on the leaves of barley seedlings. Note that spot blotch is a fungus named Cochliobolus sativus. This dataset was used as an example for the application of the EBLASSO method. Genotype of the markers were encoded as +1 for genotype A (the Morex parent), -1 for genotype B (the Steptoe parent), and 0 for missing genotype. Ideally, the missing genotypes should be imputed from known genotypes of neighboring markers. For simplicity, we replaced the missing genotypes with 0 in order to use the phenotypes of the individuals with missing genotypes. The total missing genotypes only account for about 4.2% of all the genotypes. Including the population mean, the main and the pair-wise epistatic effects, the total number of model effects was 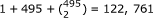 , about 818 times as large as the sample size.
, about 818 times as large as the sample size.
Table 4 gives the average PE and the standard error obtained from 5-fold cross validation, the residual variance and the number of effects detected by the EBLASSO method for different values of a and b. It is seen that the PEs for a = b = 0.001, 0.01.0.05 are almost the same but are smaller than the PEs for other larger a and b. However, when a = b = 0.001 or 0.01, only one or two effects were detected. When a = b = 0.1, 0.5 or 1, the residual variance is very small, implying that the model is likely over-fitted. Specifically, the number of columns of matrix in the model (10) is equal to the total number nonzero effects, which is more than 120 for a = b = 0.1, 0.5 or 1 as indicated in Table 4. Hence, since the number of samples (150) is relative small, y - μ can be almost completely in the column space of , which results in very small residual variance. Based on these observations, it seems that a = b = 0.05 gives reasonable results, because the PE is among the smallest and the residual variance is relatively but not unreasonably small. Nevertheless, in order to estimate effects more reliably, we searched over all effects detected with a = b = 0.05, 0.07, 0.1, 0.5 or 1, and found eight effects are detected with all these values. Markers or marker pairs of these eight effects and their values estimated with a = b = 0.05 were listed in Table 5. All 11 effects estimated with a = b = 0.05 were also plotted in Figure 5. As seen from Table 5, one single QTL at marker 446 contributes most of the phenotypic variance (about 76%), while the other QTL effects contribute from about 0.8% to 2.6% of the variance. We also analyzed the data with the EB method. One effect at marker 446 was detected with a p-value < 0.05 when τ = -1, ω = 0.0001 or 0.0005, no effect was detected with p-value ≤ 0.05 when τ = -1, ω = 0.001 or 0.01. The CPU time of the EB was about 46 minutes for each set of values of τ and ω tested; whereas the CPU time of the EBLASSO method was about 3 minutes for a = b = 0.05.

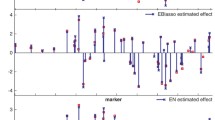
Effects estimated with the EBLASSO algorithm for the real data. Blue bars represent the positive effects, while the red bars represent the absolute values of negative effects.
Discussion
Xu [12] compared several methods for multiple QTL mapping including the EB [12], LASSO [4], penalized likelihood (PENAL) [21] and stochastic search variable selection (SSVS) [22, 23] methods. The SSVS method is much slower than the EB method; whereas LASSO and PENAL methods are faster than the EB method. Although we did not directly compare the speed of our EBLASSO with that of the PENAL method, based on all comparisons with the EB method in [12], we observed that the EBLASSO method is faster than PENAL methods. Direct comparison between the EBLASSO and LASSO showed that the LASSO is slightly faster than the current version of EBLASSO, however, this may not be the case when the EBLASSO is implemented in C/C++ instead of Matlab. Although EB, LASSO, PENAL and SSVS methods all produced satisfactory results in a simulation study [12], the EB method outperformed the other three methods in terms of the mean-squared error. Moreover, when being applied to a real data set, the EB and LASSO detected some effects, whereas the PENAL and SSVS failed to generate any meaningful results [12]. In our simulation studies, we observed that the EBLASSO method detected more true effects than the EB method with almost the same false positive rate, and the same number of true effects as the LASSO but with a much smaller number of false positive effects. When analyzing a real data set, we found that the EBLASSO method detected a reasonable number of effects, but the EB method detected one or zero effect depending on values of the hyperparameters used. These observations in both simulation study and real data analysis demonstrated that the EBLASSO method outperforms the EB method and the LASSO.
The EBLASSO method was built upon the idea of the RVM in machine learning. The EBLASSO and EB methods, as well as the RVM, all are based on a Bayesian hierarchical linear regression model and all estimate the variances of the regression coefficients. The difference of the three methods in the regression model is the different prior distributions for the hyperparameters. The EB method and the RVM employ inverse chi-square and uniform distributions, respectively, for the variances of the regression coefficients, while the EBLASSO assigns exponential distributions to the variance components and uses a Gamma distribution for the parameter of the exponential distribution, which leads to the prior distribution in (3) for the variance components. The uniform prior distribution used by the RVM may not provide enough degree of shrinkage for certain data and thus generate a large number of false positive effects as shown in [13] and as demonstrated in our simulation study.
The prior distributions used by the EBLASSO and RVM methods enable one to estimate the variance components in a closed form, while the EB method generally needs a numerical optimization algorithm to estimate the variance components. This difference has at least two implications: 1) both the EBLASSO and the RVM methods requires much less computation than the EB method to estimate the variance components, and 2) the EBLASSO method and the RVM method can always find the unique optimal estimate of a variance component but the numerical optimization algorithm used by the EB method may not find the optimal value of the variance due to the nonlinearity and non-convexity of the objective function. Another main factor that makes the EBLASSO method and RVM more efficient is an automatic variable selection procedure resulting from the process of estimating variance components, because the variables whose precision is infinity or equivalently whose variance is zero are excluded from the model. This results in an efficient formula in (12) for calculating the inverse of the covariance matrix of the data. This is especially beneficial when the number of samples is relatively large. On the other hand, the EB method in principle can be applied to a linear regression model with any prior distribution for the variances of regression coefficients. Since the prior distribution may play an important role in estimation of the QTL effects, the EB method has its value when one tries to explore different prior distributions.
To get the best performance, the EBLASSO method needs to properly choose values of hyperparameters a and b. In this paper, we selected the values of a and b that gave the smallest average PE resulting from ten-fold cross validation. Ideally, we need to find PEs for a large set of values for a ≥ -1 and b > 0 and then identify the best values for a and b. In our simulation study, we found a two-step cross validation procedure could significantly reduce the number of values to be tested without missing the best values, thereby reducing computational time. In this two-step procedure, we first run cross-validation for the following set of values: a = b = 0.001, 0.01, 0.05, 0.1, 0.5, 1. We identify the values (denoted as a* and b*) from this set of values that yields the smallest PE. We then fixed b to be b* and run cross-validation for several other values of a greater or less than a*. The final best values of a and b are the ones that yield the smallest PE.
The EBLASSO algorithm may still be improved. In the analysis of simulated data with both main and epistatic effects, although the EBLASSO method detected 8 more true effects than the EB method without any false positive effects, it missed three effects that the EB method detected. It is unclear how this discrepancy occurred. One possible reason is the different prior distributions used in the two methods. Although it is difficult for the EBLASSO method to use the scaled inverse chi-square distribution that is used by the EB method, other prior distributions may worth investigation. Another possible reason may be the greedy method used to select the variable to include in or to exclude from the model. In the current algorithm, we choose the variable that gives the largest increase in the likelihood to add to or delete from the model. It may be better to simultaneously add or delete more than one variables. The EBLASSO method presented in this paper assumes continuous quantitative traits. It can also be extended to handle binary or polychotomous traits and the algorithm is under development. The algorithm is currently implemented in Matlab. We are developing programs in C++ to implement the algorithm, which is expected to be much faster and to be capable of running in R and SAS environments.
Conclusions
We have developed a fast empirical Bayesian LASSO method for multiple QTL mapping that can deal with a large number of effects possibly including main and epistatic QTL effects, environmental effects and the effects of environment and gene interactions. Our simulation studies demonstrated that the EBLASSO algorithm needed about 3.4 minutes of CPU time, running in Matlab on a PC with 2.4 GHz Intel Core2 CPU and 2 Gb memory running Windows XP, to analyze a QTL model with more than 105 possible effects, whereas the EB method took more than 2,000 minutes to analyze the same model on the same computer. Our simulation studies also showed that the EBLASSO method could detect more true effects with almost the same false positive rate comparing to the EB method. Our real data analysis demonstrated that the EBLASSO method could output more reasonable effects than the EB method. Comparing with the LASSO, our simulation showed that the current version of the EBLASSO implemented in Matlab was slightly slower than the LASSO implemented with glmnet in Fortran, and that the EBLASSO detected the same number of true effects as the LASSO but a much smaller number of false positive effects. In conclusion, the EBLASSO method will be a useful tool in multiple QTL mapping.
References
Carlborg Ö, Haley CS: Epistasis: too often neglected in complex trait studies? Nat Rev Genet 2004, 5: 618–625. 10.1038/nrg1407
Schwarz G: Estimating the dimension of a model. Ann Stat 1978, 6: 461–464. 10.1214/aos/1176344136
Hoerl AE, Kennard RW: Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12: 55–67. 10.2307/1267351
Tibshirani R: Regression Shrinkage and Selection Via the Lasso. J R Statistical Soc Ser B 1996, 58: 267–288.
O'Hara RB, Sillanpää MJ: A review of Bayesain variable selection methods: what, how and which. Bayesian Analysis 2009, 4: 85–118.
Xu S: Estimating polygenic effects using markers of the entire genome. Genetics 2003, 163(2):789–801.
Wang H, Zhang YM, Li X, Masinde GL, Mohan S, Baylink DJ, Xu S: Bayesian shrinkage estimation of quantitative trait loci parameters. Genetics 2005, 170: 465–480. 10.1534/genetics.104.039354
Hoti F, Sillanpää MJ: Bayesian mapping of genotype × expression interactions in quantitative and qualitative traits. Heredity 2006, 97: 4–18. 10.1038/sj.hdy.6800817
Huang H, Eversley CD, Threadgill DW, Zou F: Bayesian Multiple Quantitative Trait Loci Mapping for Complex Traits Using Markers of the Entire Genome. Genetics 2007, 176(4):2529–2540. 10.1534/genetics.106.064980
Yi N, Xu S: Bayesian LASSO for quantitative trait loci mapping. Genetics 2008, 179(2):1045–1055. 10.1534/genetics.107.085589
Robert CR, Casella G: Monte Carlo Statistical Methods. 2nd edition. Springer; 2004.
Xu S: An Empirical Bayes Method for Estimating Epistatic Effects of Quantitative Trait Loci. Biometrics 2007, 63(2):513–521. 10.1111/j.1541-0420.2006.00711.x
Xu S: An expectation maximization algorithm for the Lasso estimation of quantitative trait locus effects. Heredity 2010, 2010: 1–12.
Nelder JA, Mead R: A Simplex Method for Function Minimization. Comput J 1965, 7: 308–313.
Tipping ME: Sparse Bayesian learning and the relevance vector machine. J Mach Learn Res 2001, 1: 211–244. 10.1162/15324430152748236
Tipping ME, Faul AC: Fast Marginal Likelihood Maximisation for Sparse Bayesian Models. In Proc 9th International Workshop on Artificial Intelligence and Statistics. Key West, FL; 2003.
Park T, Casella G: The Bayesian Lasso. J Amer Stat Assoc 2008, 103(482):681–686. 10.1198/016214508000000337
Yi N, Banerjee S: Hierachical Generalized Linear Models for Multiple Quantitative Trait Locus Mapping. Genetics 2009, 181: 1101–1133. 10.1534/genetics.108.099556
Friedman J, Hastie T, Tibshirani R: Regularization Paths for Generalized Linear Models via Coordinate Descent. J Stat Softw 2010, 33: 1–22.
Luo ZW, Potokina E, Druka A, Wise R, Waugh R, Kearsey MJ: SEP genotyping from Affymetrix arrays is robust but largely detects cis-acting expression regulators. Genetics 2007, 176: 789–800.
Zhang YM, Xu S: A penalized maximum likelihood method for estimating epistatic effects of QTL. Heredity 2005, 95: 96–104. 10.1038/sj.hdy.6800702
George EI, McCulloch RE: Variable Selection Via Gibbs Sampling. Journal of the American Statistical Association 1993, 88(423):881–889. 10.2307/2290777
Yi N, George V, Allison DB: Stochastic Search Variable Selection for Identifying Multiple Quantitative Trait Loci. Genetics 2003, 164: 1129–1138.
Acknowledgements
This work was supported by the National Science Foundation (NSF) under NSF CAREER Award no. 0746882 to XC and by the Agriculture and Food Research Initiative (AFRI) of the USDA National Institute of Food and Agriculture under the Plant Genome, Genetics and Breeding Program 2007-35300-18285 to SX.
Author information
Authors and Affiliations
Corresponding author
Additional information
Authors' contributions
XC conceived the idea of the EBLASSO method, developed the EBLASSO algorithm, participated in the data analysis and drafted the manuscript. AH developed the computer programs and performed the data analysis. SX participated in the development of the EBLASSO algorithm, designed simulation study, participated in the data analysis and helped to draft the manuscript. All authors read and approved the final manuscript.
Electronic supplementary material
12859_2011_4598_MOESM1_ESM.pdf
Additional file 1: Derivation of Equation (8) (PDF 22 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Cai, X., Huang, A. & Xu, S. Fast empirical Bayesian LASSO for multiple quantitative trait locus mapping. BMC Bioinformatics 12, 211 (2011). https://doi.org/10.1186/1471-2105-12-211
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2105-12-211