
Abstract
The Boolean network paradigm is a simple and effective way to interpret genomic systems, but discovering the structure of these networks remains a difficult task. The minimum description length (MDL) principle has already been used for inferring genetic regulatory networks from time-series expression data and has proven useful for recovering the directed connections in Boolean networks. However, the existing method uses an ad hoc measure of description length that necessitates a tuning parameter for artificially balancing the model and error costs and, as a result, directly conflicts with the MDL principle's implied universality. In order to surpass this difficulty, we propose a novel MDL-based method in which the description length is a theoretical measure derived from a universal normalized maximum likelihood model. The search space is reduced by applying an implementable analogue of Kolmogorov's structure function. The performance of the proposed method is demonstrated on random synthetic networks, for which it is shown to improve upon previously published network inference algorithms with respect to both speed and accuracy. Finally, it is applied to time-series Drosophila gene expression measurements.
Similar content being viewed by others
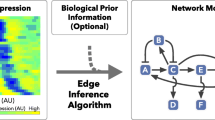

1. Introduction
The modeling of gene regulatory networks is a major focus of systems biology because, depending on the type of modeling, the networks can be used to model interdependencies between genes, to study the dynamics of the underlying genetic regulation, and to provide a basis for the derivation of optimal intervention strategies. In particular, Bayesian networks [12] and dynamic Bayesian networks [34] provide models to elucidate dependency relations; functional networks, such as Boolean networks [5] and probabilistic Boolean networks [6], provide the means to characterize steady-state behavior. All of these models are closely related [7].
When inferring a network from data, regardless of the type of network being considered, we are ultimately faced with the difficulty of finding the network configuration that best agrees with the data in question. Inference starts with some framework assumed to be sufficiently complex to capture a set of desired relations and sufficiently simple to be satisfactorily inferred from the data at hand. Many methods have been proposed, for instance, in the design of Bayesian networks [8] and probabilistic Boolean networks [9]. Here we are concerned with Boolean networks, for which a number of methods have been proposed [10–14]. Among the first information-based design algorithms is the Reveal algorithm, which utilizes mutual information to design Boolean networks from time-course data [11]. Information-theoretic design algorithms have also been proposed for non-time-course data [1516].
Here we take an information-theoretic approach based on the minimum description length (MDL) principle [17]. The MDL principle states that, given a set of data and class of models, one should choose the model providing the shortest encoding of the data. The coding amounts to storing both the network parameters and any deviations of the data from the model, a breakdown that strikes a balance between network precision and complexity. From the perspective of inference, the MDL principle represents a form of complexity regularization, where the intent is generally to measure the goodness of fit as a function of some error and some measure of complexity so as not to overfit the data, the latter being a critical issue when inferring gene networks from limited data. Basically, in addition to choosing an appropriate type, one wishes to select a model most suited for the amount of data. In essence, the MDL principle balances error (deviation from the data) and model complexity by using a cost function consisting of a sum of entropies, one relative to encoding the error and the other relative to encoding the model description [18]. The situation is analogous to that of structural risk minimization in pattern recognition, where the cost function for the classifier is a sum of the resubstitution error of the empirical-error-rule classifier and a function of the VC dimension of the model family [19]. The resubstitution error directly measures the deviation of the model from the data and the VC dimension term penalizes complex models. The difficulties are that one must determine a function of the VC dimension and that the VC dimension is often unknown, so that some approximation, say a bound, must be used. The MDL principle was among the first methods used for gene expression prediction using microarray data [20].
Recently, a time-course-data algorithm, henceforth referred to as Network MDL [10], was proposed based on the MDL principle. The Network MDL algorithm often yields good results, but it does so with an ad hoc coding scheme that requires a user-specified tuning parameter. We will avoid this drawback by achieving a codelength via a normalized maximum likelihood model. In addition, we will improve upon Network MDL's efficiency by applying an analogue of Kolmogorov's structure function [21].
2. Background
2.1. Boolean Networks
Using notation modified from Akutsu et al. [12], a Boolean network is a directed graph  defined by a set
defined by a set  of
of  binary-valued nodes representing genes, a collection of structure parameters
binary-valued nodes representing genes, a collection of structure parameters  indicating their regulatory sets (predecessor genes), and the Boolean functions
indicating their regulatory sets (predecessor genes), and the Boolean functions  regulating their behavior. Specifically, each structure parameter
regulating their behavior. Specifically, each structure parameter  is the collection of indices
is the collection of indices  associated with
associated with  's regulatory nodes. The number
's regulatory nodes. The number  of regulatory nodes for node
of regulatory nodes for node  is referred to as the indegree of
is referred to as the indegree of  . We assume that the nodes are observed over
. We assume that the nodes are observed over  equally spaced time points, and we write
equally spaced time points, and we write  to denote the values of node
to denote the values of node  for
for  . The value of node
. The value of node  progresses according to
progresses according to

for  . Such synchronous updating is perhaps unrealistic in biological systems, but it provides a framework with more easily tractable models and has proven useful in the present context [22]. For ease of notation, we define the inputs of
. Such synchronous updating is perhaps unrealistic in biological systems, but it provides a framework with more easily tractable models and has proven useful in the present context [22]. For ease of notation, we define the inputs of  as the column vector
as the column vector  , allowing us to rewrite (1) as
, allowing us to rewrite (1) as

The fundamental question we face is the estimation of  and
and  . Note that
. Note that  is usually not included as a parameter of
is usually not included as a parameter of  because it can be absorbed into
because it can be absorbed into  , but we choose to write it separately because, under the model we will specify,
, but we choose to write it separately because, under the model we will specify,  completely dictates
completely dictates  , making our interest reside primarily in the structure parameter set
, making our interest reside primarily in the structure parameter set  .
.
As written, (2) provides us with a completely deterministic network, but this is generally considered to be an inadequate description. Measurement error is inescapable in virtually any experimental setting, and, even if one could obtain noiseless data, biological systems are constantly under the influence of external factors that might not even be identifiable, let alone measurable [6]. Therefore, we consider it incumbent to relocate our model of the network mechanisms into a probabilistic framework. By incorporating this philosophy and switching to matrix notation, (2) becomes

where  denotes modulo
denotes modulo  sum,
sum,  acts independently on each column of
acts independently on each column of  , and
, and  is a vector of independent Bernoulli random variables with
is a vector of independent Bernoulli random variables with  . We further assume that the errors for different nodes are independent. We allow
. We further assume that the errors for different nodes are independent. We allow  to depend on
to depend on  because it can be interpreted as the probability that node
because it can be interpreted as the probability that node  disobeys the network rules, and we consider it natural for different nodes to have varying propensities for misbehaving.
disobeys the network rules, and we consider it natural for different nodes to have varying propensities for misbehaving.
Returning to our overall objective, we observe that  and
and  can be estimated separately for each gene. This is possible because, for each evaluation of
can be estimated separately for each gene. This is possible because, for each evaluation of  ,
,  is regarded as fixed and known. Even if a network was constructed so that a gene was entirely self-regulatory, that is,
is regarded as fixed and known. Even if a network was constructed so that a gene was entirely self-regulatory, that is,  , the random vector
, the random vector  is observed sequentially so that any random variable
is observed sequentially so that any random variable  within it is observed and then considered as a fixed value
within it is observed and then considered as a fixed value  before being used to obtain
before being used to obtain  . Therefore, despite the obvious dependencies that would exist for networks containing configurations such as feedback loops and nodes appearing in multiple predecessor sets, the given model stipulates independence between all random variables. Thus, we restrict ourselves to estimating the parameters for one node and rewrite (3) as
. Therefore, despite the obvious dependencies that would exist for networks containing configurations such as feedback loops and nodes appearing in multiple predecessor sets, the given model stipulates independence between all random variables. Thus, we restrict ourselves to estimating the parameters for one node and rewrite (3) as

which we recognize as multivariate Boolean regression. Note that  and
and  now become
now become  and
and  , respectively.
, respectively.
We finalize the specification of our model by extending the parameter space for the error rates by replacing  with
with  where each
where each  corresponds to one of the
corresponds to one of the  possible values of
possible values of  . This allows the degree of reliability of the network function to vary based upon the state of a gene's predecessors. Note that
. This allows the degree of reliability of the network function to vary based upon the state of a gene's predecessors. Note that  is only an upper bound on the number of error rates because we will not necessarily observe all
is only an upper bound on the number of error rates because we will not necessarily observe all  possible regressor values. This model is specified by the predecessor genes composing
possible regressor values. This model is specified by the predecessor genes composing  , the function
, the function  , and the error rates in
, and the error rates in  . Thus, adopting notation from Tabus et al. [23], we refer to the collection of all possible parameter settings as the model class
. Thus, adopting notation from Tabus et al. [23], we refer to the collection of all possible parameter settings as the model class 
2.2. The MDL Principle
Given the model formulation, we use the MDL principle as our metric for assessing the quality of the parameter estimates. As stated in Section 1, the MDL principle dictates that, given a dataset and some class of possible models, one should choose the model providing the shortest possible encoding of the data. In our case, the MDL principle is applied for selecting each node's predecessors. However, as we have noted, this technique is inherently problematic because no unique manner of codelength evaluation is specified by the principle. Letting  when the node in question is predicted incorrectly and
when the node in question is predicted incorrectly and  otherwise, basic coding theory gives us a residual codelength of
otherwise, basic coding theory gives us a residual codelength of  , but the cost of storing the model parameters has no such standard. Thus, we can technically choose any applicable encoding scheme we like, an allowance that inevitably gives rise to infinitely many model codelengths and, as a result, no unique MDL-based solution.
, but the cost of storing the model parameters has no such standard. Thus, we can technically choose any applicable encoding scheme we like, an allowance that inevitably gives rise to infinitely many model codelengths and, as a result, no unique MDL-based solution.
As an example, we refer to the encoding method used in Network MDL, in which the network is stored via probability tables such as Table 1. In this procedure, the model codelength is calculated as the cost of specifying the two predecessor genes plus the cost of storing the probability table. Letting  and
and  denote the number of bits needed to encode integers and subunitary floating point numbers, respectively, the model codelength is
denote the number of bits needed to encode integers and subunitary floating point numbers, respectively, the model codelength is  . Note that we only need
. Note that we only need  of the probabilities since each row in the table adds to
of the probabilities since each row in the table adds to  . This is one of many perfectly reasonable coding schemes, but we present another method that corresponds to our model class and yields a shorter codelength. Also, to demonstrate the risk of using the MDL principle with ad hoc encodings, we compare results obtained by using these two schemes in a short artificial example. Observe that Table 1 corresponds to
. This is one of many perfectly reasonable coding schemes, but we present another method that corresponds to our model class and yields a shorter codelength. Also, to demonstrate the risk of using the MDL principle with ad hoc encodings, we compare results obtained by using these two schemes in a short artificial example. Observe that Table 1 corresponds to  with each
with each  . First, we encode
. First, we encode  as the 4 bits
as the 4 bits  because, providing all predecessor combinations are lexographically sorted, those are the values that
because, providing all predecessor combinations are lexographically sorted, those are the values that  will be with probability
will be with probability  . Assuming we select
. Assuming we select  to minimize the error rates, we can also assume that
to minimize the error rates, we can also assume that  . Since
. Since  bits are sufficient to encode any decimal less than
bits are sufficient to encode any decimal less than  , we really only need
, we really only need  bits to store each
bits to store each  , yielding a model cost of
, yielding a model cost of  .
.
 .
.To show the effect of the encoding scheme we generated one hundred 6-gene networks, each of which was observed over 50 time points.  and
and  were fixed so that one gene would behave according to Table 1. The MDL principle was applied for both of the encoding schemes to determine the predecessors of that gene. The results are displayed in Table 2.
were fixed so that one gene would behave according to Table 1. The MDL principle was applied for both of the encoding schemes to determine the predecessors of that gene. The results are displayed in Table 2.
We find that the two encoding methods can give different structure estimates because the shorter model codelength allows for a greater number of predecessors. Zhao et al. compensate for this nonuniqueness by adjusting the model codelength with a weight parameter, but, while necessary for ad hoc encodings such as the ones discussed so far, the presence of such tuning parameters is undesirable when compared with a more theoretically based method. Moreover, the MDL principle's notion of "the shortest possible codelength" implies a degree of generality that is violated if we rely upon a user-defined value.
2.3. Normalized Maximum Likelihood
One alternative that alleviates these drawbacks is to measure codelength based on universal models. In this approach, we depart from two part description lengths and their ad hoc parameters by evaluating costs using a framework that incorporates distributions over the entire model class. The fundamental idea for such a model is that, assuming a specific model class, we should choose parameters that maximize the probability of the data [21]. Two such models are the mixture universal model and the normalized maximum likelihood (NML) model, the latter of which will command our attention. For  with a fixed
with a fixed  , the NML model is introduced by the standard likelihood optimization problem
, the NML model is introduced by the standard likelihood optimization problem  . The solution is obtained for
. The solution is obtained for  , the maximum likelihood estimate (MLE), but cannot be used as a model because
, the maximum likelihood estimate (MLE), but cannot be used as a model because  does not integrate to unity. Thus, we will use the distribution
does not integrate to unity. Thus, we will use the distribution  such that its ideal codelength
such that its ideal codelength  is as close as possible to the codelength
is as close as possible to the codelength  . This suggests that we should minimize the difference between using
. This suggests that we should minimize the difference between using  in place of
in place of  for the worst case
for the worst case  . The resulting optimization problem,
. The resulting optimization problem,

is solved by the NML density function, defined as  divided by the normalizing constant
divided by the normalizing constant  . Tabus et al. [23] provide the derivations of this NML distribution; the following is a brief outline of the major steps.
. Tabus et al. [23] provide the derivations of this NML distribution; the following is a brief outline of the major steps.
Given a realization  of the random variable
of the random variable  , we have residuals
, we have residuals

Recall that the Bernoulli distribution is defined by

Letting  denote the
denote the  -bit binary representation of integer
-bit binary representation of integer  , combine (6) and (7) to define the probability
, combine (6) and (7) to define the probability  as
as

This representation allows us to formally write our model class as

2.3.1. NML Model for 

Consider any  and fixed
and fixed  . Let
. Let  denote the number of times each unique regressor vector
denote the number of times each unique regressor vector  occurs in
occurs in  , and let
, and let  count the number of times
count the number of times  is associated with a unitary response. As pointed out by Tabus et al. [23], the MLE for this model is not unique. The network could have
is associated with a unitary response. As pointed out by Tabus et al. [23], the MLE for this model is not unique. The network could have  , in which case
, in which case  , or
, or  , giving
, giving  . Either way, the NML model is given by
. Either way, the NML model is given by

where

Of course, this means that our model does not explicitly estimate  . However, considering that
. However, considering that  represents error rates, the obvious choice is to minimize each
represents error rates, the obvious choice is to minimize each  by taking
by taking  whenever
whenever  , and
, and  otherwise. In the event that
otherwise. In the event that  , we set
, we set  if the portion of
if the portion of  corresponding to
corresponding to  is less than
is less than  in binary. Assuming independent errors, this removes any bias that would result from favoring a particular value for
in binary. Assuming independent errors, this removes any bias that would result from favoring a particular value for  when
when  . This effectively reduces the parameter space for each
. This effectively reduces the parameter space for each  from
from  to
to  which, in turn, affects
which, in turn, affects  by halving every
by halving every  . However, we will later show that the algorithm does not change whether or not we actually specify
. However, we will later show that the algorithm does not change whether or not we actually specify  , and we opt not to do so.
, and we opt not to do so.
Also note that computing  exactly may not be feasible. For example, Matlab loses precision for the binomial coefficient
exactly may not be feasible. For example, Matlab loses precision for the binomial coefficient  when
when  . In these cases, we use
. In these cases, we use

an approximation given in [24]. For the sake of efficiency, we compute every  prior to learning the network so that calculating the denominator of (10) takes at most
prior to learning the network so that calculating the denominator of (10) takes at most  operations.
operations.
2.3.2. Stochastic Complexity
We take as the measure of a selected model's total codelength the stochastic complexity of the data, which is defined as the negative base 2 logarithm of the NML density function [21]. As was already the case for the residual codelength, the stochastic complexity is a theoretical codelength and will not necessarily be obtainable in practice, but it is precisely this theoretical basis that frees us from any tuning parameters. Given (10), our stochastic complexity is given by

where  denotes the binary entropy function. Note that the previous and all future logarithms are base 2. Returning to the issue of picking values for
denotes the binary entropy function. Note that the previous and all future logarithms are base 2. Returning to the issue of picking values for  , we recall that doing so halves each
, we recall that doing so halves each  . This translates to a unit reduction in stochastic complexity for each
. This translates to a unit reduction in stochastic complexity for each  , but we observe that it also requires
, but we observe that it also requires  bit to store
bit to store  . Regardless of whether or not we choose to specify
. Regardless of whether or not we choose to specify  , the total codelength remains the same.
, the total codelength remains the same.
The NML model assumes a fixed  to specify the set of predecessor genes, so encoding the network requires that we store this structure parameter as well. The simplest ways to accomplish this are by using
to specify the set of predecessor genes, so encoding the network requires that we store this structure parameter as well. The simplest ways to accomplish this are by using  (the total number of genes) bits as indicators or by using
(the total number of genes) bits as indicators or by using  bits to represent the number of predecessors (assuming a uniform prior on
bits to represent the number of predecessors (assuming a uniform prior on  ) and
) and  bits to select one of the
bits to select one of the  possible sets of size
possible sets of size  . However, the indegrees of genetic networks are generally assumed to be small [25], in light of which we prefer a codelength that favors smaller indegrees and choose to use an upper bound on encoding the integer
. However, the indegrees of genetic networks are generally assumed to be small [25], in light of which we prefer a codelength that favors smaller indegrees and choose to use an upper bound on encoding the integer  to store
to store  with
with  bits [21]. Note that we use
bits [21]. Note that we use  because the given bound only applies for positive integers, and we must accommodate any
because the given bound only applies for positive integers, and we must accommodate any  . Hence, the total codelength is
. Hence, the total codelength is

where

2.4. Kolmogorov's Structure Function
If we compute  for every possible
for every possible  , we can simply select the one that provides the shortest total codelength, thus satisfying the MDL principle; however, this requires computing
, we can simply select the one that provides the shortest total codelength, thus satisfying the MDL principle; however, this requires computing  codelengths. A standard remedy for this problem is assuming a maximum indegree
codelengths. A standard remedy for this problem is assuming a maximum indegree  [12], but, even with
[12], but, even with  , a
, a  -gene network would still result in
-gene network would still result in  possible predecessor sets per gene. Moreover, a fixed
possible predecessor sets per gene. Moreover, a fixed  introduces bias into the method so, while we obviously cannot afford to perform exhaustive searches, we prefer to refrain from limiting the number of predecessors considered.
introduces bias into the method so, while we obviously cannot afford to perform exhaustive searches, we prefer to refrain from limiting the number of predecessors considered.
Instead, we utilize Kolmogorov's structure function (SF) to avoid excessive computations without sacrificing the ability to identify predecessor sets of arbitrary size. The SF was originally developed within the algorithmic theory of complexity and is noncomputable, so, in order to use this theory for statistical modeling, we need a computable alternative. The details are beyond the scope of this paper, but obtaining a computable SF requires, for fixed  , partitioning the parameter space for
, partitioning the parameter space for  so that the Kullback-Leibler distance between any two adjacent partitions, each of which represents a different model, is
so that the Kullback-Leibler distance between any two adjacent partitions, each of which represents a different model, is  for some
for some  [21]. When using an NML model class, this partitioning yields an asymptotically uniform prior so that any model
[21]. When using an NML model class, this partitioning yields an asymptotically uniform prior so that any model  can be encoded with length
can be encoded with length

where  is the number of error estimates in
is the number of error estimates in  [21]. Again, the inequality is necessary for data in which not all possible regressor vectors are observed. The partitioning also increases the noise codelength [21] to
[21]. Again, the inequality is necessary for data in which not all possible regressor vectors are observed. The partitioning also increases the noise codelength [21] to

We refer to  and
and  as the model and noise codelengths, respectively, which together constitute a universal sufficient statistics decomposition of the total codelength. The summation of these values is clearly different from the stochastic complexity, but this is a result of partitioning the parameter space.
as the model and noise codelengths, respectively, which together constitute a universal sufficient statistics decomposition of the total codelength. The summation of these values is clearly different from the stochastic complexity, but this is a result of partitioning the parameter space.
The appropriate analogue of the SF is then defined as

We see that  is a nonincreasing function of the model constraint
is a nonincreasing function of the model constraint  and displays the minimum possible amount of noise in the data if we restrict the model codelength to be less than
and displays the minimum possible amount of noise in the data if we restrict the model codelength to be less than  . Rissanen shows that this criterion is minimized for
. Rissanen shows that this criterion is minimized for  [21], but the optimal
[21], but the optimal  cannot be solved analytically. However, by plotting
cannot be solved analytically. However, by plotting  we obtain a graph similar to a rate-distortion curve (Figure 1), and by making a convex hull we can find a near-optimal predecessor set. Simply select the truncation point at which the magnitude of the slope of the hull drops below
we obtain a graph similar to a rate-distortion curve (Figure 1), and by making a convex hull we can find a near-optimal predecessor set. Simply select the truncation point at which the magnitude of the slope of the hull drops below  . In other words, locate the truncation point at which allowing an additional bit for the model yields less than a
. In other words, locate the truncation point at which allowing an additional bit for the model yields less than a  -bit reduction in the noise codelength because, once past this point, increasing the model complexity no longer decreases the total encoding cost.
-bit reduction in the noise codelength because, once past this point, increasing the model complexity no longer decreases the total encoding cost.

The SF for a single gene. The leftmost point is for k = 0, and each subsequent vertical band corresponds to a unit increase in k. The slope of the SF goes above -1 after k = 2, the same indegree for which the total codelength LM(y,λ,d) + LM (y,λ,d) is minimized.
Of particular use in this scenario is the way in which the model codelength is somewhat stable for each  , producing the distinct bands in Figure 1. The noise codelengths are still widely dispersed so we are required to compute all possible codelengths up to some total number of predecessors. We would like that number to be variable and not arbitrarily specified in advance, but this may not be feasible for highly connected networks. However, as mentioned earlier, the indegrees of genetic networks are generally assumed to be small (hence, the standard
, producing the distinct bands in Figure 1. The noise codelengths are still widely dispersed so we are required to compute all possible codelengths up to some total number of predecessors. We would like that number to be variable and not arbitrarily specified in advance, but this may not be feasible for highly connected networks. However, as mentioned earlier, the indegrees of genetic networks are generally assumed to be small (hence, the standard  ), and, when looking for a single gene's predecessors in a 20-gene network, our method only takes 70 minutes to check every possible set up to size 6. Thus, we are still constrained by a maximum indegree, but we can now increase it well beyond the accepted number that we expect to encounter in practice without risking extreme computational repercussions. Additionally, choosing a
), and, when looking for a single gene's predecessors in a 20-gene network, our method only takes 70 minutes to check every possible set up to size 6. Thus, we are still constrained by a maximum indegree, but we can now increase it well beyond the accepted number that we expect to encounter in practice without risking extreme computational repercussions. Additionally, choosing a  makes
makes  a nondecreasing function of
a nondecreasing function of  , meaning that we can also stop searching if
, meaning that we can also stop searching if  ever becomes larger than the current value of
ever becomes larger than the current value of  . The method is summarized in Algorithm 1.
. The method is summarized in Algorithm 1.
Algorithm 1: The NML MDL method for one gene.
-
(1)
Initialize

-
(2)

-
(3)
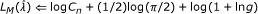
-
(4)
for
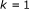 to
to  do
do


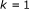 to
to  do
do(5) compute  using (16)
using (16)
(6) if then
then
(7) return
(8) end if
-
(9)
 collection of all
collection of all 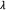 's such that
's such that 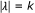
 collection of all
collection of all 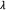 's such that
's such that 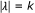
(10) for to
to  do
do
(11)  rows of
rows of  specified by
specified by 
(12) for to
to  do
do
(13) compute  and
and  for
for 
(14) end for
-
(15)
 number of nonzero
number of nonzero 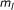 's
's
 number of nonzero
number of nonzero 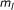 's
's(16) compute  and
and 
using (11), (17), and (18)
(17) end for
(18) use  ,
,  ,
,  , and
, and  to form a convex
to form a convex
hull with truncation points 
(19) 

(20) if isempty ( ) then
) then
(21) return
(22) else
(23) update  , and
, and  using truncation
using truncation
point indexed by 
(24) end if
-
(25)
end for
Note that we termed the resulting predecessors "near-optimal." It is possible to encounter genes for which adding one predecessor does not warrant an increase in model codelength but adding two predecessors does. Nevertheless, these differences tend to be small for certain types of networks. Moreover, depending on the kind of error with which one is concerned, these near-optimal predecessor sets can even provide a better approximation of the true network in the sense that any differences will be in the direction of the SF finding fewer predecessors. Thus, assuming a maximum indegree  , the false positive rate from using the SF can never be higher than that from checking all predecessor sets up to size
, the false positive rate from using the SF can never be higher than that from checking all predecessor sets up to size  .
.
3. Results
3.1. Performance on Simulated Data
A critical issue in performance analysis concerns the class from which the random networks are to be generated. While it might first appear that one should generate networks using the class  composed of all Boolean networks containing
composed of all Boolean networks containing  genes, this is not necessarily the case if one wishes to achieve simulated results that reflect algorithm performance on realistic networks. An obvious constraint is to limit the indegree, either for biological reasons [26] or for the sake of inference accuracy when data are limited. In this case, one can consider the class
genes, this is not necessarily the case if one wishes to achieve simulated results that reflect algorithm performance on realistic networks. An obvious constraint is to limit the indegree, either for biological reasons [26] or for the sake of inference accuracy when data are limited. In this case, one can consider the class  composed of all Boolean networks with indegrees bounded by
composed of all Boolean networks with indegrees bounded by  . Other constraints might include realistic attractor structures [27], networks that are neither too sensitive nor too insensitive to perturbations [28], or networks that are neither too chaotic nor too ordered [29].
. Other constraints might include realistic attractor structures [27], networks that are neither too sensitive nor too insensitive to perturbations [28], or networks that are neither too chaotic nor too ordered [29].
Here we consider a constraint on the functions that is known to prevent chaotic behavior [526]. A canalizing function is one for which there exists a gene among its regulatory set such that if the gene takes on a certain value, then that value determines the value of the function irrespective of the values of the other regulatory genes. For example,  OR
OR  is canalizing with respect to
is canalizing with respect to  because
because  for any values of
for any values of  and
and  . There is evidence that genetic networks under the Boolean model favor this kind of functionality [30]. Corresponding to class
. There is evidence that genetic networks under the Boolean model favor this kind of functionality [30]. Corresponding to class  is class
is class  , in which all functions are constrained to be canalizing.
, in which all functions are constrained to be canalizing.
To evaluate the performance of our model selection method, referred to as NML MDL, on synthetic Boolean networks, we consider sample sizes ranging from  to
to  ,
,  , and
, and  . We test each of the
. We test each of the  combinations on
combinations on  randomly generated networks from
randomly generated networks from  and
and  . Note that
. Note that  is equivalent to
is equivalent to  .
.
We use the Reveal and Network MDL methods as benchmarks for comparison. As mentioned earlier, Network MDL requires a tuning parameter, which we set to  since that paper uses 0.2–0.4 as the range for this parameter in its simulations. Also, its application in [10] limits the average indegree of the inferred network to 3 so we assume this as well. Reveal is run from a Matlab toolbox created by Kevin Murphy, available for download at http://bnt.sourceforge.net/, and requires a fixed
since that paper uses 0.2–0.4 as the range for this parameter in its simulations. Also, its application in [10] limits the average indegree of the inferred network to 3 so we assume this as well. Reveal is run from a Matlab toolbox created by Kevin Murphy, available for download at http://bnt.sourceforge.net/, and requires a fixed  , which we also set to 3. We implement our method with and without including the SF approach to show that the difference in accuracy is often small, especially in light of the reduction in computation time.
, which we also set to 3. We implement our method with and without including the SF approach to show that the difference in accuracy is often small, especially in light of the reduction in computation time.
As performance metrics, we use the number of false positives and the Hamming distance between the estimated and true networks, both normalized over the total number of edges in the true network. False positives are defined as any time a proposed network includes an edge not existing in the real network, and Hamming distance is defined as the number of false positives plus the number of edges in the true network not included in the estimated network.
3.1.1. Random Networks
In this section, we consider performance when the network is generated from  . Figures 2–5 show a selection of the performance-metric results for all four methods and several combinations of
. Figures 2–5 show a selection of the performance-metric results for all four methods and several combinations of  and
and  . The remaining figures can be found in the supporting data, available at http://www.stat.tamu.edu/~jdougherty/nmlmdl.
. The remaining figures can be found in the supporting data, available at http://www.stat.tamu.edu/~jdougherty/nmlmdl.

(a) Hamming distances and (b) false positive counts for random networks generated from  with θ = 0.1 Results are normalized over the true number of connections and averaged over 30 networks.
with θ = 0.1 Results are normalized over the true number of connections and averaged over 30 networks.

Error rates for  and θ = 0.1.
and θ = 0.1.

Error rates for and θ = 0.2.

Error rates for and θ = 0.3.
With respect to false positives, NML MDL is uniformly the best, and there is at most a minor difference between the two modes. NML MDL is also the best overall method when looking at Hamming distances. Figures 2 and 3 show the cases for which it most definitively improves upon Network MDL and Reveal, both of which have  . The way in which the two NML methods diverge as
. The way in which the two NML methods diverge as  increases is a general trend, but both remain below Network MDL. Increasing
increases is a general trend, but both remain below Network MDL. Increasing  to 0.2 narrows the margins between the methods, but the relationships only change significantly for
to 0.2 narrows the margins between the methods, but the relationships only change significantly for  . As shown in Figure 4, NML MDL with the SF loses its edge, but NML MDL with fixed
. As shown in Figure 4, NML MDL with the SF loses its edge, but NML MDL with fixed  remains the best choice. Raising
remains the best choice. Raising  to 0.3 is most detrimental to Reveal, pulling its accuracy well away from the other three methods. Figure 5 shows this for
to 0.3 is most detrimental to Reveal, pulling its accuracy well away from the other three methods. Figure 5 shows this for  , but the plots for smaller values of
, but the plots for smaller values of  look very similar, especially in how the two NML MDL approaches perform almost identically. We point out that this is the worst scenario for NML MDL, but, even then, it is still superior for small
look very similar, especially in how the two NML MDL approaches perform almost identically. We point out that this is the worst scenario for NML MDL, but, even then, it is still superior for small  and only worse than Network MDL for
and only worse than Network MDL for  .
.
In terms of computation time, Reveal was fairly constant for all of the simulation settings, taking an average of 6.35 seconds to find predecessors for gene using Matlab on a Pentium IV desktop computer with 1 GB of memory. NML MDL with  increases slightly with
increases slightly with  in a linear fashion, but its most noticeable increase is with
in a linear fashion, but its most noticeable increase is with  . For
. For  , this method took an average of 0.33 to 0.48 seconds per gene as
, this method took an average of 0.33 to 0.48 seconds per gene as  goes from 20 to 100, but this range increased from 0.59 to 0.73 for
goes from 20 to 100, but this range increased from 0.59 to 0.73 for  . Alternatively, Network MDL's runtime is sporadic with respect to
. Alternatively, Network MDL's runtime is sporadic with respect to  and decreases when
and decreases when  is raised, taking an average of 2.50 seconds per gene for
is raised, taking an average of 2.50 seconds per gene for  but needing only 0.33 second per gene when
but needing only 0.33 second per gene when  , the only case for which it was noticeably faster than NML MDL with fixed
, the only case for which it was noticeably faster than NML MDL with fixed  . However, NML MDL with the SF proved to be the most efficient algorithm in almost every scenario. For
. However, NML MDL with the SF proved to be the most efficient algorithm in almost every scenario. For  and 0.3 it was uniformly the fastest, taking an average of 0.06 and 0.02 seconds per gene, respectively. The runtime begins to increase more rapidly with
and 0.3 it was uniformly the fastest, taking an average of 0.06 and 0.02 seconds per gene, respectively. The runtime begins to increase more rapidly with  for
for  and
and  , but the only observed case when it was not the fastest method was for
, but the only observed case when it was not the fastest method was for  and
and  , and even then the needed time was still less than 1 second per gene.
, and even then the needed time was still less than 1 second per gene.
3.1.2. Canalizing Networks
Next, we impose the canalizing restriction and generate networks from  . The general impact can be seen by comparing Figures 3 and 6. There is essentially no difference in the false positive rates (or runtimes), but the behavior of the Hamming distances is clearly different. We observe that NML MDL with fixed
. The general impact can be seen by comparing Figures 3 and 6. There is essentially no difference in the false positive rates (or runtimes), but the behavior of the Hamming distances is clearly different. We observe that NML MDL with fixed  performs better over all Boolean functions, although invoking the SF yields error rates much closer to the fixed
performs better over all Boolean functions, although invoking the SF yields error rates much closer to the fixed  approach when we are restricted to canalizing functions. This is expected because one canalizing gene can provide a significant amount of predictive power, whereas a noncanalizing function may require multiple predecessors to achieve any amount of predictability.
approach when we are restricted to canalizing functions. This is expected because one canalizing gene can provide a significant amount of predictive power, whereas a noncanalizing function may require multiple predecessors to achieve any amount of predictability.

Error rates for  and θ = 0.1
and θ = 0.1
For example, consider  OR
OR  . If
. If  is found to be the best predecessor set of size 1, adding
is found to be the best predecessor set of size 1, adding  may not give enough additional information to warrant the increased model codelength, in which case NML MDL will miss one connection. Alternatively, if
may not give enough additional information to warrant the increased model codelength, in which case NML MDL will miss one connection. Alternatively, if  XOR
XOR  , either input tells almost nothing by itself, and the SF will probably stop the inference too soon. However, using both inputs will most likely result in the minimum total codelength, in which case NML MDL with fixed
, either input tells almost nothing by itself, and the SF will probably stop the inference too soon. However, using both inputs will most likely result in the minimum total codelength, in which case NML MDL with fixed  will find the correct predecessor set.
will find the correct predecessor set.
For the same reason, we also see that Network MDL is better suited to canalizing functions, but Reveal does better without this constraint. Of particular interest is that, for these methods, the change can be so drastic that they comparatively switch their rankings depending on which network class we use, whereas NML MDL provides the most accurate inference either way. Similar results can be observed for the other cases in the supporting data. Based on these findings, we recommend using the SF primarily for networks composed of canalizing functions and networks too large to run NML MDL with fixed  in a reasonable amount of time. We also suggest using the SF when
in a reasonable amount of time. We also suggest using the SF when  is large because, as pointed out in Section 3.1.1, the performance of the two NML MDL varieties is no longer different when
is large because, as pointed out in Section 3.1.1, the performance of the two NML MDL varieties is no longer different when  .
.
3.2. Application to Drosophila Data
In order to examine the proficiency of NML MDL on real data, we tested it on time-series Drosophila gene expression measurements made by Arbeitman et al. [31]. The dataset in question consists of 4028 genes observed over 67 time points, which we binarized according to the procedure outlined in [10]. We selected 20 of these genes based on type (gap, pair-rule, etc.) and the availability of genetically verified directed interactions in the literature. Of the 32 edges identified by NML MDL (Figure 7), 16 have been previously demonstrated [32–43], and 3 more follow the standard genetic hierarchy [44]. Observe that 3 of the 12 other edges are simply reversals of known relationships and, therefore, could possibly represent unknown feedback mechanisms. Additionally, 5 of the remaining inferred relationships are between genes that are active in the same area such as the central nervous system (Antp/runt) and reproductive organs (Notch/paired) (the Interactive Fly website, hosted by the Society for Developmental Biology).

Inferred gene regulatory network for Drosophila.
4. Concluding Remarks
Using a universal codelength when applying the MDL principle eliminates the relativity of applying ad hoc codelengths and user-defined tuning parameters. In our case, this has resulted in improved accuracy of Boolean network esimation. Using the theoretically grounded stochastic complexity instead of ad hoc encodings genuinely reflects the intent of the MDL principle. In addition, the structure function makes the proposed method faster than other published methods. Computation time does not heavily rely on bounded indegrees and increases only slightly with  .
.
References
Pearl J: Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Morgan Kaufmann, San Francisco, Calif, USA; 1988.
Friedman N, Linial M, Nachman I, Pe'er D: Using Bayesian networks to analyze expression data. Journal of Computational Biology 2000,7(3-4):601-620. 10.1089/106652700750050961
Dean T, Kanazawa K: A model for reasoning about persistence and causation. Computational Intelligence 1989,5(2):142-150. 10.1111/j.1467-8640.1989.tb00324.x
Murphy K: Dynamic Bayesian networks: representation, inference and learning, Ph.D. thesis. Computer Science Division, UC Berkeley, Berkeley, Calif, USA; 2002.
Kauffman SA: Metabolic stability and epigenesis in randomly constructed genetic nets. Journal of Theoretical Biology 1969,22(3):437-467. 10.1016/0022-5193(69)90015-0
Shmulevich I, Dougherty ER, Kim S, Zhang W: Probabilistic Boolean networks: a rule-based uncertainty model for gene regulatory networks. Bioinformatics 2002,18(2):261-274. 10.1093/bioinformatics/18.2.261
Lähdesmäki H, Hautaniemi S, Shmulevich I, Yli-Harja O: Relationships between probabilistic Boolean networks and dynamic Bayesian networks as models of gene regulatory networks. Signal Processing 2006,86(4):814-834. 10.1016/j.sigpro.2005.06.008
Pe'er D, Regev A, Elidan G, Friedman N: Inferring subnetworks from perturbed expression profiles. Bioinformatics 2001,17(supplement 1):S215-S224.
Zhou X, Wang X, Pal R, Ivanov I, Bittner M, Dougherty ER: A Bayesian connectivity-based approach to constructing probabilistic gene regulatory networks. Bioinformatics 2004,20(17):2918-2927. 10.1093/bioinformatics/bth318
Zhao W, Serpedin E, Dougherty ER: Inferring gene regulatory networks from time series data using the minimum description length principle. Bioinformatics 2006,22(17):2129-2135. 10.1093/bioinformatics/btl364
Liang S, Fuhrman S, Somogyi R: Reveal, a general reverse engineering algorithm for inference of genetic network architectures. Pacific Symposium on Biocomputing 1998, 3: 18-29.
Akutsu T, Miyano S, Kuhara S: Identification of genetic networks from a small number of gene expression patterns under the Boolean network model. Pacific Symposium on Biocomputing 1999, 3: 17-28.
Shmulevich I, Saarinen A, Yli-Harja O, Astola J: Inference of genetic regulatory networks via best-fit extensions. In Computational and Statistical Approaches to Genomics. chapter 11, Kluwer Academic Publishers, New York, NY, USA; 2002:197-210.
Lähdesmäki H, Shmulevich I, Yli-Harja O: On learning gene regulatory networks under the Boolean network model. Machine Learning 2003,52(1-2):147-167.
Margolin AA, Nemenman I, Basso K, et al.: ARACNE: An algorithm for the reconstruction of gene regulatory networks in a mammalian cellular context. BMC Bioinformatics 2006,7(supplement 1):S7.
Nemenman I: Information theory, multivariate dependence, and genetic network inference. KITP, UCSB, Santa Barbara, Calif, USA; June 2004.
Rissanen J: Modeling by shortest data description. Automatica 1978,14(5):465-471. 10.1016/0005-1098(78)90005-5
Rissanen J: Stochastic complexity and modeling. Annals of Statistics 1986,14(3):1080-1100. 10.1214/aos/1176350051
Vapnik V: Estimation of Dependencies Based on Empirical Data. Springer, New York, NY, USA; 1982.
Tabus I, Astola J: On the use of MDL principle in gene expression prediction. EURASIP Journal on Applied Signal Processing 2001,2001(4):297-303. 10.1155/S1110865701000270
Rissanen J: Information and Complexity in Statistical Modeling. Springer, New York, NY, USA; 2007.
Wuensche A: Genomic regulation modeled as a network with basins of attraction. Pacific Symposium on Biocomputing 1998, 3: 89-102.
Tabus I, Rissanen J, Astola J: Normalized maximum likelihood models for Boolean regression with application to prediction and classification in genomics. In Computational and Statistical Approaches to Genomics. chapter 10, Kluwer Academic Publishers, New York, NY, USA; 2002:173-196.
Szpankowski W: On asymptotics of certain recurrences arising in universal coding. Problems of Information Transmission 1998,34(2):55-61.
Thieffry D, Huerta AM, Pérez-Rueda E, Collado-Vides J: From specific gene regulation to genomic networks: a global analysis of transcriptional regulation in Escherichia coli . BioEssays 1998,20(5):433-440. 10.1002/(SICI)1521-1878(199805)20:5<433::AID-BIES10>3.0.CO;2-2
Kauffman SA: The Origins of Order. Oxford University Press, Oxford, UK; 1993.
Pal R, Ivanov I, Datta A, Bittner ML, Dougherty ER: Generating Boolean networks with a prescribed attractor structure. Bioinformatics 2005,21(21):4021-4025. 10.1093/bioinformatics/bti664
Shmulevich I, Kauffman SA: Activities and sensitivities in Boolean network models. Physical Review Letters 2004,93(4):-4.
Derrida B, Pomeau Y: Random networks of automata: a simple annealed approximation. Europhysics Letters 1986, 1: 45-49. 10.1209/0295-5075/1/2/001
Harris S, Sawhill B, Wuensche A, Kauffman SA: A model of transcriptional regulatory networks based on biases in the observed regulation rules. Complexity 2002,7(4):23-40. 10.1002/cplx.10022
Arbeitman M, Furlong E, Imam F, et al.: Gene expression during the life cycle of Drosophila melanogaster . Science 2002,297(5590):2270-2275. 10.1126/science.1072152
Bhojwani J, Shashidhara LS, Sinha P: Requirement of teashirt (tsh) function during cell fate specification in developing head structures in Drosophila . Development Genes and Evolution 1997,207(3):137-146. 10.1007/s004270050101
Cimbora DM, Sakonju S: Drosophila midgut morphogenesis requires the function of the segmentation gene odd-paired . Developmental Biology 1995,169(2):580-595. 10.1006/dbio.1995.1171
Fujioka M, Jaynes J, Goto T: Early even-skipped stripes act as morphogenetic gradients at the single cell level to establish engrailed expression. Development 1995,121(12):4371-4382.
González-Gaitan M, Jäckle H: Invagination centers within the Drosophila stomatogastric nervous system anlage are positioned by Notch -mediated signaling which is spatially controlled through wingless . Development 1995,121(8):2313-2325.
Mathies LD, Kerridge S, Scott MP: Role of the teashirt gene in Drosophila midgut morphogenesis: secreted proteins mediate the action of homeotic genes. Development 1994,120(10):2799-2809.
Morimura S, Maves L, Chen Y, Hoffmann FM: Decapentaplegic overexpression affects Drosophila wing and leg imaginal disc development and wingless expression. Developmental Biology 1996,177(1):136-151. 10.1006/dbio.1996.0151
Dréan BS-L, Nasiadka A, Dong J, Krause HM: Dynamic changes in the functions of Odd-skipped during early Drosophila embryogenesis. Development 1998,125(23):4851-4861.
Schaeffer V, Killian D, Desplan C, Wimmer EA: High Bicoid levels render the terminal system dispensable for Drosophila head development. Development 2000,127(18):3993-3999.
Steneberg P, Hemphälä J, Samakovlis C: Dpp and Notch specify the fusion cell fate in the dorsal branches of the Drosophila trachea. Mechanisms of Development 1999,87(1-2):153-163. 10.1016/S0925-4773(99)00157-4
Torres IS, López-Schier H, Johnston DSt: A Notch/Delta-dependent relay mechanism establishes anterior-posterior polarity in Drosophila . Developmental Cell 2003,5(4):547-558. 10.1016/S1534-5807(03)00272-7
Torres-Vazquez J, Park S, Warrior R, Arora K: The transcription factor Schnurri plays a dual role in mediating Dpp signaling during embryogenesis. Development 2001,128(9):1657-1670.
Yin Z, Xu X-L, Frasch M: Regulation of the twist target gene tinman by modular cis -regulatory elements during early mesoderm development. Development 1997,124(24):4971-4982.
Schroeder MD, Pearce M, Fak J, et al.: Transcriptional control in the segmentation gene network of Drosophila . PLoS Biology 2004,2(9):e271. 10.1371/journal.pbio.0020271
Acknowledgments
This work was supported by the Academy of Finland (Application no. 213462, Finnish Programme for Centres of Excellence in Research 2006–2011), and the Tampere Graduate School in Information Science and Engineering. Partial support also provided by the National Cancer Institute (Grant no. CA90301).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Dougherty, J., Tabus, I. & Astola, J. Inference of Gene Regulatory Networks Based on a Universal Minimum Description Length. J Bioinform Sys Biology 2008, 482090 (2008). https://doi.org/10.1155/2008/482090
Received:
Accepted:
Published:
DOI: https://doi.org/10.1155/2008/482090