
Abstract
We extend the qubit-efficient encoding presented in (Tan et al. in Quantum 5:454, 2021) and apply it to instances of the financial transaction settlement problem constructed from data provided by a regulated financial exchange. Our methods are directly applicable to any QUBO problem with linear inequality constraints. Our extension of previously proposed methods consists of a simplification in varying the number of qubits used to encode correlations as well as a new class of variational circuits which incorporate symmetries thereby reducing sampling overhead, improving numerical stability and recovering the expression of the cost objective as a Hermitian observable. We also propose optimality-preserving methods to reduce variance in real-world data and substitute continuous slack variables. We benchmark our methods against standard QAOA for problems consisting of 16 transactions and obtain competitive results. Our newly proposed variational ansatz performs best overall. We demonstrate tackling problems with 128 transactions on real quantum hardware, exceeding previous results bounded by NISQ hardware by almost two orders of magnitude.
Similar content being viewed by others



Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.1 Introduction
Provable asymptotic advantages of quantum computing over classical algorithms have been shown in the fault-tolerant regime ([1, 2]) and quantum computational supremacy ([3]) has been claimed experimentally in circuit sampling tasks ([4–6]).Footnote 1 Methods that promise to extend these computational advantages to relevant problems with available noisy intermediate scale quantum (NISQ) devices have been an active field of research over the past decade. A recent breakthrough in this regard was achieved by IBM Quantum ([8]), claiming evidence for the utility of said NISQ devices by simulating the evolution under an Ising Hamiltonian beyond the reach of standardFootnote 2 classical simulation methods. Most research to this end of useful NISQ algorithms is concerned with problems in Hamiltonian simulation, machine learning or energy minimization/optimization ([12, 13]). This work concerns the latter.
Outline of this paper
In the introduction, we give an overview of quantum optimization in NISQ, summarize different approaches to reduce the number of qubits (1.1) and introduce the transaction settlement problem (1.2). We extend the qubit reduction technique introduced in [14] to find approximate solutions to problem instances larger than previously attempted. We outline the mapping used between the quantum state and the binary variables of the problem (2.2) and how the cost can be estimated using this quantum state (2.3). We introduce a new variational ansatz derived to incorporate symmetries of the encoding scheme (2.4), before concluding with simulation (3.1) and quantum hardware (3.2) results.
1.1 Quantum optimization – quadratic unconstrained binary optimization
The optimization problem we consider in 1.2 will generalize quadratic unconstrained binary optimization (QUBO) problems, which have the form
where I is the number of binary entries of the vector \(\underline {\mathbf {x}}\) and Q is any real (usually symmetric) matrix, \(Q \in \mathbb{R}^{I\times I}\). Finding the vector \(\underline {\mathbf {x}}\) minimizing equ. (1) for general Q is NP hard ([15]). Many combinatorial/graph problems such as MaxCut can be readily mapped to QUBO problems and a wide range of industrial applications is known. This includes training of machine learning models ([16]) and optimization tasks such as assignment problems ([17]), route optimization ([18]) or - the focus of this study - financial transaction settlement ([19]).Footnote 3 This broad applicability and (by benchmarking existing classical solvers) “verifiable” advantage make QUBO problems a great test-bed in the search for a useful quantum advantage.
The solution of equation (1) corresponds to the ground state of an Ising Hamiltonian \(H_{Q}\) on I qubits,
with \(\sigma _{a}^{i}\) referring to the Pauli operator a on qubit i. This allows mapping a QUBO problem on I variables to the problem of finding the ground state of a Hamiltonian on I qubits. We extend equation (2) in Sect. 2.2 and 2.3 by applying the qubit compression from [14] to reduce the number of qubits to \(O(\text{log}I)\) at the cost of losing the formulation (2) as the ground state of a Hermitian operator. Quantum solvers (QS) to the Ising Hamiltonian or more general ground-state problems have been studied extensively. A short overview is given in Table 1 and the following:
Annealing
Introduced as early as 1994 ([21]) and inspired by simulated annealing ([22]), quantum annealing aims to find the ground state of \(H_{Q}\) in (2) by adiabatically transforming \(H_{\text{tot}}(t) = s(t) H_{Q} + (1-s(t))H_{m}\), with the mixing Hamiltonian \(H_{m} = \sum _{j=1}^{I}\sigma ^{x}_{j}\), over a time span \(t \in [0, t_{\text{end}}]\). Here, \(s(t)\) is the annealing schedule, with \(s(0)=0\) and \(s(t_{\text{end}})=1\). Reading out the state of the annealing device at the end of this transformation yields candidates for the optimal solution \(\underline {\mathbf {x}}\). Annealing devices are not guaranteed to find optimal solutions efficiently and can only implement a limited set of Hamiltonians, often restricted in their connectivity (resulting in limitations on the non-zero entries of Q) ([23]). Despite these limitations, general-purpose QUBO solvers based on hybrid classical computation and quantum annealing are commercially available with as many as 5000 (1 million) physical nodes (variables, I in equ. (1)) for D-wave’s AdvantageTM annealer ([24]).Footnote 4
QAOA
Quantum Approximate Optimization Algorithms ([25]) can be regarded as implementing a parametrized, trotterized version of the quantum annealing schedule on gate-model based quantum computers. The parameterized p-layered circuit \(e^{-iH_{Q}\beta _{p}}e^{-iH_{m}\gamma _{p}}...e^{-iH_{Q}\beta _{1}}e^{-iH_{m} \gamma _{1}}\) is applied to  and measured in the computational basis. This yields candidate vectors \(\underline {\mathbf {x}}\) by identifying each binary variable with one qubit. The parameters \(\{\beta _{j}, \gamma _{j}\}\) are classically optimized to minimize equ. (1) (minimize
and measured in the computational basis. This yields candidate vectors \(\underline {\mathbf {x}}\) by identifying each binary variable with one qubit. The parameters \(\{\beta _{j}, \gamma _{j}\}\) are classically optimized to minimize equ. (1) (minimize  ). QAOA provides theoretical guarantees in its convergence to the exact solution for \(p\to \infty \) given optimal parameters. Yet, implementing the evolution of \(H_{Q}\) and reaching sufficient depth p on NISQ devices can be infeasible in the case of many non-zero entries of Q.
). QAOA provides theoretical guarantees in its convergence to the exact solution for \(p\to \infty \) given optimal parameters. Yet, implementing the evolution of \(H_{Q}\) and reaching sufficient depth p on NISQ devices can be infeasible in the case of many non-zero entries of Q.
Hardware-efficient VQA
In this work, we make use of general Variational Quantum Algorithms to minimize a cost estimator (in the context of quantum chemistry often referred to as VQE, variational quantum eigensolver ([26]), and applied beyond Ising Hamiltonians). VQAs are general quantum circuit ansätze parameterized by classical parameters, hence QAOA can be seen as a special case of a VQA. We use the term hardware-efficient VQA loosely for ansätze whose gates, number of qubits and circuit depth suit current NISQ devices. Analogously to QAOA, the parameters of the VQA circuit are optimized classically through evaluation of some classical cost function on the measured bit-vector. As we will see later, this cost function does not necessarily correspond to a Hermitian observable. VQAs are widely studied in the NISQ era beyond their application to combinatorial optimization problems ([27–29]). Challenges, most notably vanishing gradients for expressive circuits ([30–32]) and remedies ([33–41]) exist aplenty but will not play a central role in this paper. While the generality of VQAs allows for tailored hardware-efficient ansätze which are independent of the problem itself, this comes at the cost of losing the remaining theoretical guarantees of QAOA and adiabatic ground state computation.
Non-VQA, quantum-assisted solvers
Other quantum algorithms for solving ground-state problems have been proposed in the literature. Examples include quantum-assisted algorithms, often inspired by methods such as Krylov subspace, imaginary time evolution or quantum phase estimation. For example, quantum computers are used to calculate overlaps between quantum states employed in a classical outer optimization loop ([42–48]). Although some of these approaches are variational in the circuit ansatz, they do not directly correspond to the classical-quantum feedback loop in the VQA setting described above and are beyond the focus of this work.
Classical solvers
It should be noted at this point, that approaches using classical computing for tackling QUBO problems exist. Among themFootnote 5 are general purpose optimization suites such as Gurobi ([49]), CPLEX ([50]) or SCIP ([51]) as well as dedicated approximation algorithms such as simulated annealing ([52]), TABU search ([53])) or the relaxation-based Goemans and Williamson ([54]) algorithm which guarantees an approximation ratio of at least 0.878Footnote 6 for Max-Cut problems. Due to the NP-hardness of the general problem, all classical solvers are either approximations or have no polynomial worst-case runtime guarantees.
NISQ-limitations
Quantum computers are not expected to break NP-hardness (cf. [56, 57] and the lack of any polynomial-time quantum algorithm for an NP-hard problem) and it is often justified to regard quantum approaches to QUBO as heuristics hoped to provide practical advantages rather than general purpose solvers with rigorous runtime and optimality guarantees. This makes benchmarking on relevant problem instances paramount in guiding the search for promising quantum algorithms. Yet, most NISQ-era quantum approaches suffer from a combination of
-
1.
Problem size limited by the number of available qubits
-
2.
Constraints on the problem class (connectivity of Q)
making a direct application of QS to relevant problem instances infeasible on NISQ-devices ([58]). While 1. is a consequence of the limited number of qubits available on NISQ devices, 2. can be seen as a consequence of noise in the qubit and operations: Computations become infeasible due to low coherence times and noisy gates paired with often deep circuits (e.g. arising from the limited lattice-connectivity of devices based on superconducting qubits) upon decomposition into hardware-native gates. Constraints on the problem class can also arise from the fundamental design of the algorithm itself.
How these limitations on problem size and class apply to the different QS is summarized in Table 1. Various work has been done to address these challenges. Improved problem embeddings ([59]), decomposition ([60]), compilation and hardware-efficient ansätze are just some approaches to deal with connectivity issues. A wide variety of qubit-reduction methods has been suggested in the quantum optimization and quantum chemistry literature, see Table 2.
Proposing a solution to the limitations in Table 1 and pushing the boundaries of QUBO problems accessible by QS is a central motivation for this work. We give a detailed description of our qubit-reduction method in Sect. 2.2.
1.2 Financial transaction settlement
We refer to the transaction settlement problem as a computational task, consisting of parties \(\{1,\ldots ,K\}\) with balances \(\{\underline {\mathbf {bal}}_{k}\}\) submitting trades \(\{1,\ldots ,I\}\) to a clearing house. The task faced by the clearing house is to determine the maximal set of transactions that can be executed without any party k falling below its credit limit \(\underline {\mathbf {lim}}_{k}\). An overview of the notation is given in Table 3 and a graph representation of a transaction settlement problem with parties as nodes and transactions as edges is shown in Fig. 1.

Example of a transaction settlement problem constructed using data provided from a regulated financial exchange. Eight transactions (arrows) between seven parties (numbered squares) are depicted. Each party has initial balances for cash ($) and different securities (S1, …). The optimal solution which settles the maximal amount of transactions without violating balance constraints is indicated through  and
and  . The solution is not unique, another optimal solution would settle T2 instead of T3. Even for a problem of only eight transactions, non-trivial dependencies between different transactions exist: For example, T4 can only be settled if T5 is settled which in turn requires T8
. The solution is not unique, another optimal solution would settle T2 instead of T3. Even for a problem of only eight transactions, non-trivial dependencies between different transactions exist: For example, T4 can only be settled if T5 is settled which in turn requires T8
In the case when not all parties have sufficient balances to meet all settlement instructions they are involved with, finding this maximal set can be difficult with classical computing resources. Intuitively, this is because a party’s ability to serve outgoing transactions may depend on its incoming transactions, creating many interdependencies between different parties (cf. Fig. 1). Whilst classical technology is sufficient for current transaction volumes, increases could be expected from more securities in emerging markets and digital tokens, for example. Furthermore, cash shortages make optimization more challenging as it becomes harder to allocate funds optimally among various settlement obligations, determining the priority of different trades and parties and an increased risk of settlement failures. Quantum technologies offer a potential path to mitigate these issues.
Transactions can be conducted both in currencies and securities such as equity and bonds (hence \(\underline {\mathbf {bal}}_{k}\) and \(\underline {\mathbf {lim}}_{k}\) are vector-valued). A financial exchange may, for example, handle as many as one million trades involving 500-600 different securities by up to 100 financial institutions (parties) per day.
QUBO formulation
To obtain a QUBO formulation of the transaction settlement problem, we follow a slightly simplified version of [19]. The mathematical formulation as a binary optimization problem with inequality constraints looks as follows:
where for generality, a weight \(w_{i}\) is given for each transaction i and \(\underline {\mathbf {v}}_{ik}\) represents the balance changes (in cash and securities) for party k in transaction i. In practice one might choose \(w_{i}\) proportional to the transaction value of transaction i, for simplicity, we will always choose \(w_{i} \equiv 1\).
The solution of this linear constrained binary optimization problem equals the solution of the mixed binary optimization (MBO)
for large λ, referred to as the slack parameter. Here, continuous slack variables \(\underline {\mathbf {s}}_{k} \geq 0\) (element-wise) were introduced to capture the inequality constraints as penalty terms in the objective. Note, that by approximating \(\underline {\mathbf {s}}_{k}\) as a binary representation, i.e. \((\underline {\mathbf {s}}_{k})_{i} \approx \sum _{l = -L_{1}}^{l = L_{2}} \tilde{b}_{kil}2^{l}, \tilde{b}_{kil}\in \{0,1\}\), the problem could further be transformed into a QUBO problem without any constraints. For large enough λ, any violation of the constraints (4) will result in a less-than-optimal solution vector. Equation (5) can directly be rewritten:
For fixed \(\underline {\mathbf {s}}\), the minimization over binary \(\underline {\mathbf {x}}\) is a QUBO problem as in equ. (1) with \(Q = A + \textrm{Diag}[\underline {\mathbf {b}}(\underline {\mathbf {s}})]\),Footnote 7 where \(\textrm{Diag}[\underline {\mathbf {b}}]\) is the matrix with the vector \(\underline {\mathbf {b}}\) on the diagonal and zeros elsewhere.
1.3 Contribution of this work
The structure of this work is as follows: In Sect. 2.1, we outline the construction of the transaction settlement instances from data provided by a regulated financial exchange. In Sect. 2.2, we use the encoding scheme listed in [14] to reduce the number of qubits required and extend the ideas to include a new variational cost objective and ansatz. Section 3.1 presents the results, using the transaction settlement instances generated as a testbed for comparing our methods with QAOA and exploring different encodings. Section 3.2 offers comparisons in the solutions obtained when using the exponential qubit reduction to tackle problems with 128 transactions on real quantum hardware by IonQ and IBM Quantum, exceeding previous results using quantum hardware [19]. We present some analysis regarding the results obtained, before concluding with Sect. 4. To the best of our knowledge, this is the first work that tackles mixed binary optimization problems with a qubit-efficient approach on a quantum computer.
2 Methodology
To give an overview of the methodology, we first detail how the financial settlement problem can be constructed using data provided by a regulated financial exchange (2.1). We will then describe the quantum algorithm (Fig. 2) consisting of a heuristic to exponentially reduce the number of qubits (Sect. 2.2), a cost-objective (Sect. 2.3), a parameterized quantum circuit to generate solution bit-vectors (Sect. 2.4) and finally the classical optimization (Sect. 2.5).

Workflow of a quantum-classical hybrid optimization algorithm. The algorithm involves (i) collecting measurements from the parameterized quantum circuit (PQC) with parameters \(\underline {\mathbf {\theta}}^{(n)}\), (ii) calculating the cost function (and potentially its gradients) from the measurement outcomes, and (iii) optimizing the parameters using classical optimization techniques. The steps are further detailed in Sects. 2.3, 2.5 and 2.4
2.1 Problem instance - financial transaction settlement
Dataset
This work uses anonymized transaction data to generate settlement problems of arbitrary size I. The format of the settlement instructions made available for this purpose can be seen in Table 3. To generate a problem instance we proceeded as follows:
-
1.
Fix the number of transactions (I), number of parties (K) and an integer \(R \leq I\).
-
2.
Choose \(I-R\) random transactions from the dataset and randomly assign them to parties (sender and recipient). A single transaction consists of a security being transferred from one party to the other and (if delivery vs payment) a cash transaction in the other direction.Footnote 8
-
3.
As our dataset does not provide account balances or credit limits, we set \(\underline {\mathbf {lim}}_{k} = \underline {\mathbf {0}}\) and choose minimal non-negative balances \(\underline {\mathbf {bal}}_{k}\) for each party k such that all previously chosen transactions can be jointly executed without any party’s balance becoming negative. The balances hence depend on the first \(I-R\) transactions chosen. This choice of \(\underline {\mathbf {bal}}_{k}\) is made by considering the net balance-change for each party if all transactions were conducted.
-
4.
Choose additional R random transactions from the dataset and randomly assign them to parties (without changing the balances assigned in the previous step).
This procedure ensures the optimal solution contains at least \(I-R\) valid transactions. Due to the minimal choice of the balances, most of the R transactions chosen last are expected to be invalid in the optimal solution.
To mitigate large differences in transaction volumes between different parties (\(\text{S}\$~10-10^{6}\)) as well as different units (cash and different securities) in the data samples, we renormalize each party’s balance, credit limit and transaction volume:
which, using equ (3) and (4), does not affect the optimal solution.
We show in lemma 3 (appendix B), that the connectivity for the QUBO matrix of the transaction settlement is bounded by twice the average number of transactions per party, \(\frac{4I}{K}\), plus a variance term which vanishes for d-regular graphs.
2.2 Qubit-efficient mapping
Mapping QUBO to VQA
The underlying idea to solve QUBO problems with VQAs is to use the PQC to generate bit-vectors \(\underline {\mathbf {x}}\). The parameters \(\underline {\mathbf {\theta}}\) of the PQC are then tuned such that the generated \(\underline {\mathbf {x}}\) are likely to approximately minimize equation (1). Formally:
where the right hand side only depends on the marginals \(p_{ij}(\underline {\mathbf {\theta}}) := \text{Prob}_{\underline {\mathbf {\theta}}}(x_{i} = 1, x_{j} = 1)\) and \(p_{i}(\underline {\mathbf {\theta}}) := \text{Prob}_{\underline {\mathbf {\theta}}}(x_{i} = 1)\).
Instead of searching in a discrete space, this turns the problem into the optimization of the continuous parameters of a generator of bit-vectors. This appears similar but is different from relaxation-based approaches, which often replace binary variables through continuous ones to obtain a more tractable optimization problem whose solutions are projected back to a binary format: Here, the model (the PQC) directly generates bit-vectors \(\underline {\mathbf {x}}\) and if it is expressive enough in the distributions \(\text{Prob}_{\underline {\mathbf {\theta}}}(\underline {\mathbf {x}})\) it parameterizes, then an optimal \(\underline {\mathbf {\theta}}\) will generate an optimal bit-vector \(\underline {\mathbf {x}}\) deterministically. The steps to solve this minimization are shown in Fig. 2.
The core of mapping a QUBO problem to a variational minimization problem therefore consists of specifying how to generate bit-vectors \(\underline {\mathbf {x}}\) with a quantum circuit. In standard QAOA or variational approaches, this mapping is straightforward (equation (2)): As the number of qubits \(n_{q}\) equals the number of variables I, we simply measure in the computational basis (Pauli-Z) and associate the outcome 1 (-1) of qubit \(q_{i}\) with the bit \(x_{i}\) equal 0 (1). We use a different mapping, generalizing the qubit-efficient approach in [14]:
Qubit-efficient binary encoding
We use \(n_{a}\) qubits (ancillas) to represent a subset of \(n_{a}\) bits and \(n_{r}\) qubits (register) to provide an address labelling this subset. Compared to the approach for standard QAOA, we (partly) encode the bit-position in a binary encoded number instead of the one-hot encoded qubit-position. Hence the name “binary encoding” in Table 2.
Formally, consider a covering \(\mathcal{A} = \{A_{1}, \ldots, A_{N_{r}}\},~N_{r} = 2^{n_{r}}\) of the set of bit-positions \(B = \{1,\ldots ,I\}\) with \(|A_{i}| \in \{0, n_{a}\}~\forall i\) and each \(A_{i}\) ordered. Regard the quantum state  as corresponding to bit \(A_{r}[l]\) (the \(l^{\text{th}}\) entry of \(A_{r}\)) equal to \(b_{l}~\forall l \in \{1,\ldots , n_{a}\}\). This quantum state fixes only the subset \(A_{r}\) of the bits. In general, we interpret
as corresponding to bit \(A_{r}[l]\) (the \(l^{\text{th}}\) entry of \(A_{r}\)) equal to \(b_{l}~\forall l \in \{1,\ldots , n_{a}\}\). This quantum state fixes only the subset \(A_{r}\) of the bits. In general, we interpret
-
Superpositions in the ancilla state ↔ probabilistic sampling in the computational basis of different bit-vectors \(b_{1}\ldots b_{n_{a}}\)
-
Superpositions in the register state ↔ probabilistic sampling in the computational basis of different bit-sets \(A_{r}\)
resulting in the general form

where we already indicated that the PQC parameterized by \(\underline {\mathbf {\theta}}\) determines the values of the register amplitudes (\(\beta _{r}(\underline {\mathbf {\theta}})\)) and normalized bit-vector amplitudes (\(a_{r}^{b_{1} \ldots b_{n_{a}}}(\underline {\mathbf {\theta}})\)). We achieve an exponential compression from \(n_{q} = I\) qubits to \(n_{q} = n_{a} + \lceil \text{log}_{2}(I/n_{a})\rceil \) in the case of a disjoint covering (also perfect matching). In general, a covering consisting of \(|\mathcal{A}| = R\) bit-sets requires \(n_{a} + \lceil \text{log}_{2}(R)\rceil \) qubits.
For the simplest case of the minimal encoding, defined by \(n_{a} = 1\), each subset consists of just one binary variable with a total of \(n_{r} = I\) subsets. A quantum state in this encoding can be written as

and represents the bit-vector \(\underline {\mathbf {x}}\) if \(|a_{r}^{i}| = \delta _{ix_{r}}\). The total number of qubits required is \(n_{q} = 1 + \lceil \text{log}_{2}(I)\rceil \).
The large decrease in qubits comes with a few drawbacks:
-
A single measurement in the computational basis only specifies a subset \(A_{r}\) of the bit-positions, and it is not immediate how to sample full bit-vectors \(\underline {\mathbf {x}}\).
-
Even arbitrary state-preparation through the PQC may only allow limited distributions on the vector x. Consider for example the minimal encoding: It generates bit-vectors distributed as \(\text{Prob}_{\underline {\mathbf {\theta}}}(\underline {\mathbf {x}}) = \text{Prob}_{\underline {\mathbf {\theta}}}^{1}(x_{1}) \cdot \ldots \cdot \text{Prob}_{\underline {\mathbf {\theta}}}^{I}(x_{I}) = \prod _{r}^{I} |a_{r}^{1}|^{2}\), where \(a_{r}^{1}\) are the coefficients of the ancilla qubits in equation (17), corresponding to a mean-field approximation ([81]).
-
Different from QAOA, the cost objective may no longer correspond to the expectation of a Hermitian observable. This issue and a resolution are discussed in appendix D.
Sampling algorithm
We will adopt a simple greedy approach here, which fixes entries of \(\underline {\mathbf {x}}\) as they are sampled throughout multiple measurements and concludes once every entry is sampled. We furthermore determine the covering \(\mathcal{A}\) through a k-means-inspired clustering on the graph representation of the problem. Given uniform \(\beta _{r}(\underline {\mathbf {\theta}})\) and a disjoint covering \(\mathcal{A}\), the probability of any one register not being sampled after \(n_{\text{shots}}\) measurements is exponentially small, bounded by \(\text{exp}(-\frac{n_{\text{shots}}}{N_{r}})\). In practice, we sample multiple bit-vectors \(\underline {\mathbf {x}}\) to find candidates for the optimal solution. This allows us to reduce the average number of measurements by reusing measurement outcomes (in particular those that were sampled multiple times before conclusion of the algorithm). Nonetheless, the qubit compression comes at the cost of significant sampling overhead.
2.3 Cost function
Having specified how to generate bit-vectors from measurement samples of the PQC fully determines \(\text{Prob}_{\underline {\mathbf {\theta}}}(\underline {\mathbf {x}})\) and hence the minimization problem in equation (15). In practice, we cannot access \(\text{Prob}_{\underline {\mathbf {\theta}}}(\underline {\mathbf {x}})\) directly, but rather obtain finite-shot measurements on the state prepared by the PQC. Hence, we need to specify an estimator of the expected cost \(\mathbb{E}_{\underline {\mathbf {\theta}}}[C]\). We will refer to this estimator as \(\hat{C}(\underline {\mathbf {\theta}})\).
For the explicit formulation of \(\hat{C}(\underline {\mathbf {\theta}})\), we make use of the formulation of \(\mathbb{E}_{\underline {\mathbf {\theta}}}[C]\) in terms of marginal probabilities \(p_{ij}(\underline {\mathbf {\theta}}) = \text{Prob}_{\underline {\mathbf {\theta}}}(x_{i} = 1, x_{j} = 1)\) and \(p_{i}(\underline {\mathbf {\theta}}) = \text{Prob}_{\underline {\mathbf {\theta}}}(x_{i} = 1)\) in equation (15). For the latter, we use heuristic estimators \(\hat{p}_{i}(\underline {\mathbf {\theta}})\) and \(\hat{p}_{ij}(\underline {\mathbf {\theta}})\) which are constructed by counting the number of times a certain bit (or pair of bits) was sampled with value equal to one.
The exact formulas for these estimators are given in appendix C.1 with a derivation for disjoint coverings in appendix C.2. Intuitively,
where \(0\leq \hat{\mu}_{ij} \leq 1\) and the asymptotic convergence
motivates the expressions \(\hat{p}_{i}\) and \(\hat{p}_{ij}\).
Following equation (15), the cost estimator \(\hat{C}(\underline {\mathbf {\theta}})\) for the transaction settlement problem then takes the form
which is optimized with respect to \(\underline {\mathbf {\theta}}\) and the slack variables \(\underline {\mathbf {s}} = (\underline {\mathbf {s}}_{1}, \ldots , \underline {\mathbf {s}}_{K}) \geq 0\). The optimal slack variables can be obtained straightforwardly using
where \(\max (\circ , \circ )\) is to be taken element-wise. The optimal slack variables substitute \(\underline {\mathbf {s}}\) in equ (21), thus removing the need for separate optimization over the slack variables.
Remarks:
-
1.
It is not possible to express equation (21) as the expectation of a Hermitian observable on a state of the form of equation (16) due to denominators in the expressions for p̂, q̂ (equ. (54), (56) in appendix) and \(\hat{\mu}_{ij}\) (equ. (57)) as well as the functional form of \(\hat{\underline {\mathbf {s}}}\). We will show in appendix D how this problem can be resolved for fixed \(\underline {\mathbf {s}}\) given uniform \(\beta _{r}(\underline {\mathbf {\theta}})\).
-
2.
In the limit of the full encoding (\(n_{a} = I\), \(n_{r} = 0\)), we get
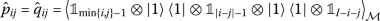
and

resulting in the “standard” cost estimator identical to e.g. QAOA.
-
3.
Runtime and memory cost: The naive run-time for classically computing the cost estimator scales as \(O(n_{\text{shots}}I^{2})\), while the memory required only scales as \(O(n_{\text{shots}}+I^{2})\). Our approach does not require full tomography with memory requirements as high as \(O(4^{I})\). In further extensions, methods such as classical shadows ([82]) may be used to more efficiently estimate the cost and reduce \(n_{\text{shots}}\).
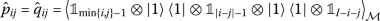

If certain registers are hardly sampled, i.e. \(|\beta _{r}(\underline {\mathbf {\theta}})|^{2}\simeq 0\), we may encounter division by zero in the expressions for \(\hat{p}_{i}\) and \(\hat{q}_{ij}\). In practice, this can be dealt with by setting the corresponding estimators to \(1/2\) whenever estimates for \(|\beta _{r}(\underline {\mathbf {\theta}})|^{2}\) fall below some \(\epsilon > 0\), resulting in indirect penalization. Alternatively, we can add an explicit regularization term \(\hat{R}(\underline {\mathbf {\theta}}) = \eta \sum _{r = 1}^{N_{r}}\left [\hat{r}_{r}( \underline {\mathbf {\theta}}) -\frac{1}{N_{r}} \right ]^{2}\) to the cost function.
2.4 Variational ansatz
In this work, we consider two types of PQC:
-
A hardware-efficient ansatz consisting of RY rotations and entangling CNOT layers.
-
A register-preserving ansatz of conditional RY rotations incorporating constraints and symmetries tailored to the qubit-efficient encoding.
Both variational circuits are depicted in Fig. 3. The hardware-efficient ansatz was used identically in [14], the register-preserving ansatz is one of the main contributions of this work.

One layer of the register-preserving ansatz (left) and the hardware-efficient ansatz (right) used in the result section. To obtain the PQC \(U(\underline {\mathbf {\theta}})\), these circuit layers L are preceded by a Hadamard gate on every qubit and are repeated a chosen number d of times (depth), i.e. \(U(\underline {\mathbf {\theta}}) = L(\underline {\mathbf {\theta}})^{d} H^{\otimes n_{q}}\). Both ansätze contain parameterized rotations followed by a layer of CNOTs. Here, the basis permutation layer of the register-preserving ansatz is identical to the entangling layer of the hardware-efficient ansatz, with the difference that it only acts on register-qubits. Furthermore, in the case of the register-preserving ansatz, parameterized single-qubit \(R_{Y}\) rotations were applied to all ancillas prior to the first layer
We mentioned difficulties arising from vanishing register-amplitudes in the previous section. We will now formally define register-uniform quantum states and register-preserving circuits before discussing the advantages offered by them:
Definition 1
(Register-uniform)
We call a quantum state  register-uniform with respect to the orthonormal basis
register-uniform with respect to the orthonormal basis  of \(\mathcal{H}_{\text{reg}}\), if it can be written as
of \(\mathcal{H}_{\text{reg}}\), if it can be written as

where  is arbitrary with
is arbitrary with  .
.
Definition 2
(Register-preserving)
We call a unitary U acting on \(\mathcal{H}_{\text{anc}}\otimes \mathcal{H}_{\text{reg}}\) register-preserving with respect to the orthonormal basis  of \(\mathcal{H}_{\text{reg}}\) if it always maps register-uniform states to register-uniform states (with respect to the same basis).
of \(\mathcal{H}_{\text{reg}}\) if it always maps register-uniform states to register-uniform states (with respect to the same basis).
The set of register-preserving unitaries with respect to the same basis is closed under concatenation. Our register-preserving ansatz first prepares the register-uniform plus state  (H being the Hadamard gate) and then acts through register-preserving unitaries on it.
(H being the Hadamard gate) and then acts through register-preserving unitaries on it.
Notation
We use the bra-/ket-notation only for normalized states. Furthermore, Latin letters inside bra and ket indicate computational basis states, while Greek letters indicate general quantum states. We will refer to register-preserving circuits as quantum circuits which output register-uniform states with respect to the computational basis (and fix said basis from now on, omitting further mention of it).
The following claims about register-uniform states and register-preserving circuits are proved in appendix B:
Lemma 1
The following is equivalent to a state  being register-uniform:
being register-uniform:

Theorem 1
The following are equivalent for a unitary U acting on \(\mathcal{H}_{\textit{anc}}\otimes \mathcal{H}_{\textit{reg}}\):
-
(i)
U is register-preserving
-
(ii)
 where \(U_{r}\) is a unitary on \(\mathcal{H}_{\textit{anc}}\) ∀r and \(f: \{1,\ldots ,N_{r}\}\to \{1,\ldots ,N_{r}\}\) is bijective.
where \(U_{r}\) is a unitary on \(\mathcal{H}_{\textit{anc}}\) ∀r and \(f: \{1,\ldots ,N_{r}\}\to \{1,\ldots ,N_{r}\}\) is bijective. -
(iii)
U can be written as a sequence of unitary matrices on \(\mathcal{H}_{\textit{anc}}\) conditioned on a subset of register-qubits and basis-permutations on the register.
 where
where Note,Footnote 9 that in theorem 1 we refer to basis-permutations, not qubit-permutations, although former contains the latter.
Theorem 1 provides a list of ingredients that may be used to construct register-preserving variational ansätze. Namely, we can combine conditional unitaries (such as CNOT, Toffoli gates), acting on the ancillas and conditioned on the register-qubits, with arbitrary unitaries that only act on the ancilla qubits. Furthermore, we can permute computational basis states on the register qubits. These permutations could be cryptographic permutation pads [83], binary adder circuits [84] or heuristic constructions from NISQ-friendly gates such as CNOT, SWAP and X gates.
When defining register-preserving circuits, we demand that any register-uniform state is mapped to a register-uniform state. This may not always be necessary. In the case of this work, we always start with the same input state  which allows more general unitaries than theorem 1, as the following lemma demonstrates:
which allows more general unitaries than theorem 1, as the following lemma demonstrates:
Lemma 2
For register-uniform states as in equation (23) with  , a unitary only non-trivially acting on the register-qubits always maps
, a unitary only non-trivially acting on the register-qubits always maps  to a register-uniform state if and only if
to a register-uniform state if and only if
While theorem 1 only allows permutations on the register-qubits, this lemma allows (a single) application of \(\text{exp}\left (-i\frac{\theta}{2}P\right )\) for any self-inverse permutation P, e.g. R\(X^{n}\) rotations or the RBS gate, on the register-qubits. The condition  is trivially fulfilled for states which are a real-valued linear combination of computational basis states such as
is trivially fulfilled for states which are a real-valued linear combination of computational basis states such as  .
.
Our ansatz
The circuits used in this work are shown in Fig. 3. The register-preserving circuit acts with conditional RY rotations on every ancilla-qubit, conditioned on individual register-qubits. The RY rotation on ancilla-qubit b conditioned on register-qubit c can be regarded as a parameterized rotation on b for half the registers (those registers r, for which the binary encoding of r has a 1 at position c). A basis permutation layer consisting of CNOTs is added to ensure consecutive conditional RY rotations act on a different set of registers (this basis permutation layer is omitted if only a single layer is used, \(d=1\)).
In terms of optimization parameters, we optimize \(n_{a}*n_{r}\) parameters per register-preserving layer and \(n_{q} = n_{r}+n_{a}\) for the hardware-efficient ansatz.
Discussion register-preserving ansatz
Only allowing register-preserving gates in the variational ansatz imposes challenges in keeping the variational ansatz both expressive and NISQ-friendly, at least on superconducting hardware (cf. Sect. 3.2). On the other hand, we see the following motivations and advantages for exploring register-preserving circuits:
-
1.
Respect the symmetries of the qubit-efficient approach: In light of challenges associated with barren plateaus for over-expressive ansätze, incorporating symmetries into the circuit architecture – here: register-preservation and real-valued amplitudesFootnote 10 in the computational basis – is promising as it has been shown to help with the problem of vanishing gradients ([40, 80]).
-
2.
Numeric stability: The cost estimator \(\hat{C}(\underline {\mathbf {\theta}})\) (equ. (21)) makes use of estimators for the register-amplitudes \(|\beta (\underline {\mathbf {\theta}})|^{2}\). These can be fixed to \(\frac{1}{N_{r}}\) for a register-preserving circuit, adding numerical stability (especially as the terms affected are in the denominator) and reducing the computational overhead. In Fig. 4, we visualize the variance of the gradient-estimator with respect to shot noise at fixed parameters \(\underline {\mathbf {\theta}}\). The register-preserving ansatz shows much smaller variance, which suggests a lower number of required shots \(n_{\text{shots}}\) (cf. bullet 3.).
Figure 4 
16 Transactions, 12 parties, 6 qubits, \(n_{a} = 4\) | Variance in partial derivatives of cost estimator over ten samples (104 shots each). The variance was in turn averaged over all entries of the gradient. This was done for circuits of different depths (x-axis), for each of which we uniformly sampled 25 different parameters \(\underline {\mathbf {\theta}}\) (scatter). The median over the different parameters is depicted as a solid line, the inter-quartile range as a shaded region
-
3.
Sampling overhead: Register-uniform states minimize the expected number of samples needed to cover each register ([85]). Furthermore, theorem 1\((ii)\) shows, that the net effect of any register-preserving unitary on the register-qubits is a permutation. If this permutation
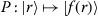 is easily inverted, then the bit-vector sampling can be made deterministic in the register (without otherwise impacting the prediction), by using the input state
is easily inverted, then the bit-vector sampling can be made deterministic in the register (without otherwise impacting the prediction), by using the input state 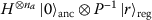 instead of
instead of 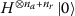 . In any case, we can reduce the number of circuit evaluations needed by using initial states of the form
. In any case, we can reduce the number of circuit evaluations needed by using initial states of the form 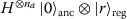 and ensuring that we sample a different register \(f(r)\) in every run by iterating over \(r \in \{1,\ldots , N_{r}\}\).
and ensuring that we sample a different register \(f(r)\) in every run by iterating over \(r \in \{1,\ldots , N_{r}\}\). -
4.
Expression as expectation value of Hermitian observable: As all denominators in the expressions for \(\hat{p}_{i}\), \(\hat{q}_{ij}\) and all of μ̂ are replaced by constants, this allows – for fixed \(\underline {\mathbf {s}}\) – to express \(\hat{C}(\underline {\mathbf {\theta}})\) as the expectation value of a Hermitian observable (although the product \(\hat{p}_{i} \hat{p}_{j}\) requires preparation of a product state, see appendix D). A majority of the literature (including aforementioned classical shadows) and software are tailored primarily for Hermitian expectation values. Areas include theoretical results (e.g. adiabatic theorem), the variational ansatz and optimizer itself, estimation and error mitigation as well as fault-tolerant methods for the evaluation of expectation values. Expressing our cost function as a Hermitian expectation hence widens the cross-applicability of other results and code-bases.

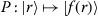 is easily inverted, then the bit-vector sampling can be made deterministic in the register (without otherwise impacting the prediction), by using the input state
is easily inverted, then the bit-vector sampling can be made deterministic in the register (without otherwise impacting the prediction), by using the input state 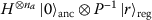 instead of
instead of 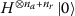 . In any case, we can reduce the number of circuit evaluations needed by using initial states of the form
. In any case, we can reduce the number of circuit evaluations needed by using initial states of the form 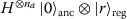 and ensuring that we sample a different register
and ensuring that we sample a different register 2.5 Optimization
Many different optimization procedures have been suggested in the literature to find the optimal parameters for a PQC through classical optimization. This includes the parameter-initialization ([36, 86–89]), choice of meta-parameters ([90]) as well as the parameter update itself ([38, 91–94], an overview of gradient-based and gradient-free optimizers can be found in section D. of [12]).
While the optimization of a PQC has been shown to be NP-hard ([95]) and may well be the most important ingredient to practical advantage for any quantum QUBO solver, the focus of this work is on the qubit-efficient methods rather than on the optimization itself. Our results were obtained with two different commonly used optimizers: The gradient-free optimizer COBYLA (implemented in scipy [96]) as well as standard gradient descent, with gradients calculated through the parameter-shift rule ([92, 97]).
The full optimization step for updating the circuit parameters \(\underline {\mathbf {\theta}}^{(n)}\mapsto \underline {\mathbf {\theta}}^{(n+1)}\) is depicted in Fig. 2.
3 Results and discussion
Here, we present results from applying the methodology presented in Sect. 2 to transaction settlement problems of 16 and 128 transactions. We compare hardware-efficient and register-preserving qubit compression with QAOA. We show results for both a simulator backend (Pennylane [98]) and quantum hardware from IBM Quantum and IonQ. The statistics for uniformly random solution-sampling is also provided for benchmarking. For 16 transactions, this includes the optimal solution. Throughout this section R (see 2.1) was set to \(\lfloor \frac{I}{4}\rfloor \) and we considered only cash and one security (\(J=2\)). We randomly generated three sets of I= 16 transaction instructions with K= 10, 12 and 13 parties respectively and one settlement problem with 128 transaction instructions, \(K = 41\).
3.1 Simulation, 16 transactions – comparison with QAOA
Training convergence
Figure 5 shows the training convergence during the parameter optimization, averaged over different random initial parameters of the PQC. While COBYLA returned optimized parameters within a few hundred steps or less, its cost value is consistently outperformed by gradient descent (DESC), especially for an increasing number of circuit parameters.

16 Transactions, 10 parties, 5 (register-efficient) / 16 (QAOA) qubits, \(n_{a} = 1\), \(2\times 10^{4}\) shots | Cost during parameter optimization for different circuit ansätze (Hardware-efficient, Register-preserving and QAOA) applied to a transaction settlement problem with 16 transactions. Two different optimizers, COBYLA (gradient-free) and gradient descent (DESC) were used in the qubit-efficient approach while only COBYLA was used for QAOA. The depth of the circuit (in number of layers/p-value for QAOA) is given in square brackets. The solid lines depict means over 25 (qubit-efficient) and 10 (QAOA) different training runs with random starting points. The 95% confidence interval is given as a shaded region. Quantitative values against QAOA are not comparable due to different cost functions used for the parameter training
The register-preserving ansatz not only outperforms the hardware-efficient PQC, but also produces solutions with less variance for different starting points. For all the qubit-efficient approaches, deeper circuits also improved the performance.
For QAOA, the substitution in equ (22) to optimize both slack variables and variational parameters simultaneously is infeasible as the variational ansatz depends on the QUBO matrix and by extension, the slack variables (cf. equation (6)). Results for QAOA were obtained by alternating the optimization of slack variables and circuit parameters 50 times, with up to 103 COBYLA-iterations to update the circuit parameters at each cycle. The optimization landscape appears to be dominated by the slack variables, and each update changes the optimization landscape for the variational parameters. This unusual optimization landscape is likely the reason why no significant improvements were observed for increasing p-values.
From our brief comparison, hardware-efficient ansätze appear to be more suited for MBO problems as they are agnostic to changes in the QUBO matrix. Despite these challenges, we maintain our QAOA results for the purposes of comparison and leave the exploration of more effective implementations of the QAOA to MBO to future work.
Bit-vector quality
As the cost estimator used in the optimization is only a proxy for the actual quality of the bit-vectors \(\underline {\mathbf {x}}\) generated, we show the empirical cumulative distribution of the cost associated with bit-vectors generated from the trained PQC in Fig. 6. We normalized the cost for each transaction settlement problem and averaged over different configurations (three settlement problems, \(n_{a} \in \{1,4,8\}\) for 6a, COBYLA and gradient descent, up to 25 training runs), drawing 50 bit-vectors per configuration.

16 Transactions, 10-13 parties, 5-16 qubits, 104 shots | Empirical cumulative distribution function of normalized cost over bit-vectors generated by different trained PQCs: For a given cost x, the empirical probability y of generating bit-vectors with cost at most x is plotted. Due to a rescaling of the x-axis (cost normalization), an x-value of zero corresponds to the optimal bit-vector and a value of one to the bit-vector maximizing the cost. Both can be easily found for a problem with only 16 transactions. Insets show the area with the lowest 5% of the cost. In the calculation of the cost, equation (6) was used with optimal slack-variables \(\underline {\mathbf {s}} (\underline {\mathbf {x}})\) for a given bit-vector \(\underline {\mathbf {x}}\). The distribution for uniformly random bit-vectors is shown as a grey dotted line
Subfigure 6a shows the cumulative distributions for both the qubit-efficient approach and QAOA. Except for the hardware-efficient ansatz with one layer, our qubit-efficient approach performs better than QAOA on average. As in the training traces, no significant differences in the results for QAOA were found by varying the depth (p-value) from one to ten. The register-preserving ansatz performs best for all depths.
In subfigure 6b, weak improvement can be observed by using 8 instead of 1 ancilla qubits and by adding another register-qubit (\(n_{r}+ =1\)).
During the training, we observed that gradient descent yields better minima than COBYLA in the cost estimator but tends to sparse solutions, i.e. the associated distribution on bit-vectors is strongly concentrated around a single value (cf. Fig. 7). Here, redundant encoding of bit-vector-positions in the ancillas (i.e. \(n_{r}+ > 0\)) was found to help in generating more diverse solution candidates.

16 Transactions, 10 parties, 6 qubits, \(d=4\), DESC, \(n_{a} = 4\), disjoint covering | Empirical cumulative distribution function (cf. Fig. 6) of cost (not normalized) over bit-vectors generated by a trained PQC. Executed on a simulator (Simulation), IBMQ quantum computer (ibm_geneva) and IonQ quantum computer (ionq_harmony). Uniformly random bit-vectors are shown by a grey line (Random). For each generator, 1000 bit-vectors were drawn from \(2.4 \times 10^{4}\) shots. Each subfigure corresponds to a single optimization run in which the PQC was optimized using gradient descent. Both runs produce narrow distributions around a fixed bit-vector, resulting in a steep curve (especially in the noise-free simulation)
3.2 Hardware, 16 & 128 transactions – results on IonQ and IBMQ QPUs
To investigate the generation of bit-vectors on real quantum hardware (QPU), we optimized different configurations of both register-preserving and hardware-efficient PQCs on a simulator for 16 and 128 transactions. The pre-trained circuit parameters were then executed on the Geneva/Hanoi QPU provided by IBM Quantum and the Harmony/Aria QPU provided by IonQ.Footnote 11 The resulting cost-distributions of generated bit-vectors for a settlement problem with 16 transactions and 10 parties / 128 transactions and 41 parties are depicted in Fig. 7 and 8.

128 transactions, 41 parties, 19 qubits, hardware-efficient ansatz, \(d=1\), DESC, \(n_{a} = 16\), disjoint covering | Visualization of results for 128 transactions on the ibm_hanoi and ionq_aria backends (\(2.4 \times 10^{4}\) shots, 500 bit-vectors)

128 Transactions (each with security and optional cash payment), 41 parties | Parties and transactions are shown similar to Fig. 1 for a settlement problem generated from data of a regulated financial exchange (same settlement problem as Fig. 8). Transfers of securities (cash) are visualized by dotted (solid) edges and green (blue) arrow-heads. The thickness of the edges scales proportional to the transaction volume. The nodes represent parties and are colored and scaled according to the number of in- and outgoing transfers. The edge-coloring corresponds to the register-mapping, i.e. the sets \(A_{i} \in \mathcal{A}\). For \(n_{a} = 16\) ancilla qubits and \(n_{r} = 3\) register qubits used to generate the register-mapping, we have \(2^{3}=8=|\mathcal{A}|\) different colors
IBMQ vs IonQ
For 4 layers of the register-preserving circuit (7a), the IBMQ results are significantly worse than for IonQ. This can partly be attributed to the connectivity requirements of the long-range conditional Y-Rotations used in the register-preserving ansatz (Fig. 3a). This favours the all-to-all connectivity of ionq_harmony, which forgoes the need for depth-increasing SWAP networks. The hardware-efficient ansatz (7b) on the other hand is compatible with the lattice connectivity of IBMQ devices and shows similar performance for both QPUs.
For 128 transactions, the benchmarked IonQ device (ionq_aria) slightly outperforms IBMQ (ibm_hanoi) even with the hardware-efficient ansatz, the results of which are depicted in Fig. 8.
Impact of noise
In general, the noisy results obtained from real quantum backends yielded worse results than noise-free simulations. However, the additional variation in the generated bit-vectors could also help to generate solutions of lower cost. This is observed in Fig. 8a, where the hardware results yielded bit-vectors of lower cost than the lowest simulated vectors with a probability of more than 10%. Noise does not necessarily move the distribution towards uniform random bit-vectors: On real hardware, the decay into the physical ground state is more likely than the excited state. Depending on the \(\sigma _{z}\)-to-bit mapping, this can result in a larger or smaller number of settled transactions than uniform randomness and, potentially, in performance worse than uniform random (as for ibm_geneva in Fig. 7a).
Figure 8b emphasizes the need for classical post-processing methods that search for feasible solutions in the vicinity of infeasible solutions generated by the PQC (cf. 4): None of the bit-vectors generated by both simulation and real hardware fulfil all the constraints on the security-account balances (cf. equation (4)). Alternatively, the cost penalty λ could be increased to put even higher priority on the balance constraints relative to the maximization of the number of transactions.
4 Conclusion and outlook
Increasing the scope of tractable problems and benchmarking with industry data is important to gauge the applicability of heuristics-reliant variational quantum algorithms to optimization and to find promising applications. In this work, we extended the qubit-efficient encoding in [14] by providing explicit formulas of the cost objective and its gradient for arbitrary number of ancilla qubits. We introduced a new ansatz for uniform register sampling. We argue that register-preserving ansätze have the additional benefits of numerical stability, shot-reductions and selective sampling of individual registers, and expressing the cost estimator as a Hermitian observable.
We demonstrate our methods on mixed binary optimization problems arising from financial transaction settlement [19], benchmarking problems of up to 128 transactions and 41 parties constructed from transaction data provided by a regulated financial exchange. We also showed how the optimal slack variables can be obtained without the need for an outer loop optimization. We observed that our qubit-efficient methods outperformed standard QAOA, even when executed on quantum backends. Our proposed register-preserving ansatz stood out as best in many of the instances considered.
Post-processing
While not explored in this work, post-processing by projecting sampled solutions to valid bit-vectors fulfilling all problem constraints may be a necessity for practical use. One possible method to do so includes projecting a solution bit-vector generated by the QS to the best bit-vector in the vicinity that fulfils all constraints. Restricting the search to a ball of Hamming distance ≤k, solutions can be sampled at the asymptotic runtime of \(O(I^{k})\) (as opposed to \(2^{I}\) for a full search). While without guarantees for the optimality or even existence of a close valid solution, one may hope that if the QS provides solutions of high quality, only small adjustments are needed to obtain a good solution which adheres to all constraints. This search can be refined with heuristics, e.g. by only adjusting transactions involving parties (and potentially their k-nearest-neighbours on the graph) whose balance constraints are violated.
Method exploration
Overall, further exploration of different ancilla-register-mappings, variational (register-preserving) ansätze, optimization algorithms and (scaling of) meta-parameters such as circuit depth, penalty terms and step-size is warranted to validate and refine the qubit-compression approach presented in this work. For example, how the restrictions given by theorem 1 regarding the register-preserving ansatz can best be extended in practice, e.g. by changing the computational basis and keeping track of phases on the ancilla qubits (cf. 2), is still an open question. Another important consideration is the lack of correlation between the individual measurements in the sampling algorithm used in this work. Exploring sample rejection or the addition of hidden layers to the ansatz provides one avenue to extend the probability distributions of \(\underline {\mathbf {x}}\) which our PQC parameterizes.
Our methods, despite being tested on synthetic problems, demonstrated the broad applicability of quantum algorithms beyond small toy examples. Witnessing advantages of our methods over classical solvers would require a comparison to state-of-the-art classical solvers on problem instances faced in real scenarios. Most of our methods are directly applicable beyond the transaction settlement problem to any QUBO problem with linear inequality constraints, setting them apart from other qubit-efficient methods to the best of our knowledge and making them suitable to tasks beyond settling financial transactions.Footnote 12
Data Availability
Given permission by the regulated stock exchange, anonymized transaction data samples used and/or analysed during the current study are available from the corresponding author on reasonable request.
Notes
Although some problem instances have later been shown to be classically simulable, e.g. [7].
For further applications see Chap. 2 in [20].
Note that it is not public how exactly the quantum annealer is used as a subroutine in this hybrid computation.
A more extensive overview can be found in Chap. 11 of [20].
Which is optimal for any polynomial-time classical algorithm assuming the unique games conjecture ([55]).
Here we use: \(\underline {\mathbf {x}}^{T} \text{Diag}[\underline {\mathbf {b}}]\underline {\mathbf {x}} = \sum _{i = 1}^{I} b_{i} x_{i}^{2} \overset{x_{i}^{2} = x_{i}}{=} \underline {\mathbf {b}}^{T}\underline {\mathbf {x}}\).
To avoid confusion, we will refer to transfers instead when only considering a single security or cash transfer.
To avoid confusion with the permutation operator used in quantum physics which refers to permuting particle-labels.
Real-valued amplitudes are the reason we only make use of RY rotations (instead of RX, RZ).
Different backends from both providers were used as ibmq_geneva was retired while this work was in process and ionq_harmony only provides 11 qubits, necessitating the larger ionq_aria device for 128 transactions with 16 ancillas.
For a list of examples see [20] ch. 2.2(.1).
In the case of an undirected graph we can fix any ordering.
In the case of a disjoint covering \(\mathcal{A}\), we have \(\tilde{A}^{(S)}_{r_{i}}= A_{r_{i}}\).
which depending on the graph covering \(\mathcal{A}\) may not be warranted.
References
Grover LK. A fast quantum mechanical algorithm for database search. In: Proceedings of the twenty-eighth annual ACM symposium on theory of computing. STOC’96. New York: Association for Computing Machinery; 1996. p. 212–9. https://doi.org/10.1145/237814.237866.
Shor PW. Algorithms for quantum computation: discrete logarithms and factoring. In: Proceedings 35th annual symposium on foundations of computer science. 1994. p. 124–34. https://doi.org/10.1109/SFCS.1994.365700.
Harrow AW, Montanaro A. Quantum Computational Supremacy. arXiv:1809.07442v1 (2018).
Arute F, et al.. Quantum supremacy using a programmable superconducting processor. Nature. 2019;574:505–10. https://doi.org/10.1038/s41586-019-1666-5.
Zhong H-S, et al.. Quantum computational advantage using photons. Science. 2020;370:1460–3. https://doi.org/10.1126/science.abe8770.
Madsen LS, et al.. Quantum computational advantage with a programmable photonic processor. Nature. 2022;606:75–81. https://doi.org/10.1038/s41586-022-04725-x.
Pan F, Chen K, Zhang P. Solving the sampling problem of the sycamore quantum circuits. Phys Rev Lett. 2022;129:090502. https://doi.org/10.1103/PhysRevLett.129.090502.
Kim Y, et al.. Evidence for the utility of quantum computing before fault tolerance. Nature. 2023;618:500–5. https://doi.org/10.1038/s41586-023-06096-3.
Tindall J, et al. Efficient tensor network simulation of IBM’s kicked Ising experiment. arXiv:2306.14887 (2023).
Kechedzhi K, et al. Effective quantum volume, fidelity and computational cost of noisy quantum processing experiments. arXiv:2306.15970 (2023).
Begušić T, Chan GK-L. Fast classical simulation of evidence for the utility of quantum computing before fault tolerance. arXiv:2306.16372 (2023).
Bharti K, et al.. Noisy intermediate-scale quantum algorithms. Rev Mod Phys. 2022;94:015004. https://doi.org/10.1103/REVMODPHYS.94.015004/FIGURES/7/MEDIUM.
Wei J, et al. NISQ computing: where are we and where do we go? https://doi.org/10.1007/s43673-022-00058-z.
Tan B, et al.. Qubit-efficient encoding schemes for binary optimisation problems. Quantum. 2021;5:454. https://doi.org/10.22331/q-2021-05-04-454.
Barahona F. On the computational complexity of Ising spin glass models. J Phys A, Math Gen. 1982;15:3241–53. https://doi.org/10.1088/0305-4470/15/10/028.
Date P, Arthur D, Pusey-Nazzaro L. QUBO formulations for training machine learning models. Sci Rep. 2021;11:10029. https://doi.org/10.1038/s41598-021-89461-4.
Vikstål P, et al.. Applying the quantum approximate optimization algorithm to the tail assignment problem. Phys Rev Appl. 2020;14:034009. https://doi.org/10.1103/PhysRevApplied.14.034009.
Harwood S, et al.. Formulating and solving routing problems on quantum computers. In: IEEE transactions on quantum engineering. vol. 2. 2021. p. 1–17. https://doi.org/10.1109/TQE.2021.3049230.
Braine L, et al. Quantum Algorithms for Mixed Binary Optimization applied to Transaction Settlement. arXiv:1910.05788 (2019). https://doi.org/10.1109/TQE.2021.3063635.
Punnen AP, editor. The quadratic unconstrained binary optimization problem: theory, algorithms, and applications. Cham: Springer; 2022. https://doi.org/10.1007/978-3-031-04520-2.
Finnila AB, et al.. Quantum annealing: a new method for minimizing multidimensional functions. Chem Phys Lett. 1994;219:343–8. https://doi.org/10.1016/0009-2614(94)00117-0.
Kirkpatrick S. Optimization by simulated annealing: quantitative studies. J Stat Phys. 1984;34:975–86. https://doi.org/10.1007/BF01009452.
Yarkoni S, et al.. Quantum annealing for industry applications: introduction and review. Rep Prog Phys. 2022;85:104001 https://doi.org/10.1088/1361-6633/ac8c54.
D.-Wave Systems Inc. D-wave hybrid solver service + advantage: technology update. Tech. Rep. https://www.dwavesys.com/media/m2xbmlhs/14-1048a-a_d-wave_hybrid_solver_service_plus_advantage_technology_update.pdf.
Farhi E, Goldstone J, Gutmann S. A Quantum Approximate Optimization Algorithm. arXiv:1411.4028 (2014).
Peruzzo A, et al.. A variational eigenvalue solver on a photonic quantum processor. Nat Commun. 2014;5:4213. https://doi.org/10.1038/ncomms5213.
Tilly J, et al.. The variational quantum eigensolver: a review of methods and best practices. Phys Rep. 2022;986:1–128. https://doi.org/10.1016/j.physrep.2022.08.003.
Benedetti M, et al.. Parameterized quantum circuits as machine learning models. Quantum Sci Technol. 2019;4:043001 https://doi.org/10.1088/2058-9565/ab4eb5.
McClean JR, et al.. The theory of variational hybrid quantum-classical algorithms. New J Phys. 2016;18:023023 https://doi.org/10.1088/1367-2630/18/2/023023.
McClean JR, et al.. Barren plateaus in quantum neural network training landscapes. Nat Commun. 2018;9:4812 https://doi.org/10.1038/s41467-018-07090-4.
Arrasmith A, et al.. Effect of barren plateaus on gradient-free optimization. Quantum. 2021;5:558 https://doi.org/10.22331/q-2021-10-05-558.
Wang S, et al.. Noise-induced barren plateaus in variational quantum algorithms. Nat Commun. 2021;12:6961. https://doi.org/10.1038/s41467-021-27045-6
Liu X, et al. Mitigating barren plateaus of variational quantum eigensolvers. arXiv:2205.13539 (2022).
Pesah A, et al.. Absence of barren plateaus in quantum convolutional neural networks. Phys Rev X. 2021;11:041011. https://doi.org/10.1103/PhysRevX.11.041011.
Patti TL, et al.. Entanglement devised barren Plateau mitigation. Phys Rev Res. 2021;3:033090. https://doi.org/10.1103/PhysRevResearch.3.033090.
Grant E, et al.. An initialization strategy for addressing barren plateaus in parametrized quantum circuits. Quantum. 2019;3:214. https://doi.org/10.22331/q-2019-12-09-214
Dborin J, et al. Matrix Product State Pre-Training for Quantum Machine Learning. arXiv:2106.05742 (2021).
Skolik A, et al.. Layerwise learning for quantum neural networks. Quantum Mach Intell. 2021;3:5. https://doi.org/10.1007/s42484-020-00036-4.
Cerezo M, et al.. Cost function dependent barren plateaus in shallow parametrized quantum circuits. Nat Commun. 2021;12:1791. https://doi.org/10.1038/s41467-021-21728-w
Schatzki L, et al. Theoretical Guarantees for Permutation-Equivariant Quantum Neural Networks. arXiv:2210.09974 (2022).
Sack SH, et al.. Avoiding barren plateaus using classical shadows. PRX Quantum. 2022;3:020365. https://doi.org/10.1103/PRXQuantum.3.020365.
Seki K, Yunoki S. Quantum power method by a superposition of time-evolved states. PRX Quantum. 2021;2:010333. https://doi.org/10.1103/PRXQuantum.2.010333.
Kyriienko O. Quantum inverse iteration algorithm for programmable quantum simulators. npj Quantum Inf. 2020;6:1–8. https://doi.org/10.1038/s41534-019-0239-7.
Bharti K, Haug T. Iterative quantum-assisted eigensolver. Phys Rev A. 2021;104:L050401. https://doi.org/10.1103/PhysRevA.104.L050401.
Takeshita T, et al.. Increasing the representation accuracy of quantum simulations of chemistry without extra quantum resources. Phys Rev X. 2020;10:011004. https://doi.org/10.1103/PhysRevX.10.011004.
Motta M, et al.. Determining eigenstates and thermal states on a quantum computer using quantum imaginary time evolution. Nat Phys. 2020;16:205–10. https://doi.org/10.1038/s41567-019-0704-4.
Huggins WJ, et al.. A non-orthogonal variational quantum eigensolver. New J Phys. 2020;22:073009. https://doi.org/10.1088/1367-2630/ab867b.
Stair NH, Huang R, Evangelista FA. A multireference quantum Krylov algorithm for strongly correlated electrons. J Chem Theory Comput. 2020;16:2236–45. https://doi.org/10.1021/acs.jctc.9b01125.
Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual. https://www.gurobi.com (2023).
IBM ILOG Cplex. V12. 1: user’s manual for CPLEX. In: International business machines corporation. vol. 46. 2009. p. 157.
Achterberg T. SCIP: solving constraint integer programs. Math Program Comput. 2009;1:1–41. https://doi.org/10.1007/s12532-008-0001-1.
Kirkpatrick S, Gelatt CD, Vecchi MP. Optimization by simulated annealing. Science. 1983;220:671–80. https://doi.org/10.1126/science.220.4598.671.
Wang Y, et al.. A multilevel algorithm for large unconstrained binary quadratic optimization. In: Beldiceanu N, Jussien N, Pinson É, editors. Integration of AI and OR techniques in contraint programming for combinatorial optimzation problems. Lecture notes in computer science. Berlin: Springer; 2012. p. 395–408. https://doi.org/10.1007/978-3-642-29828-8_26.
Goemans MX, Williamson DP. Improved approximation algorithms for maximum cut and satisfiability problems using semidefinite programming. J ACM. 1995;42:1115–45. https://doi.org/10.1145/227683.227684.
Khot S, Kindler G, Mossel E. Optimal Inapproximability Results for MAX-CUT and Other 2-Variable CSPs? 2005.
Bennett CH, et al.. Strengths and weaknesses of quantum computing. SIAM J Comput. 1997;26:1510–23. https://doi.org/10.1137/S0097539796300933.
Aaronson S. The limits of quantum. Sci Am. 2008;298:62–9.
Guerreschi GG, Matsuura AY. QAOA for max-cut requires hundreds of qubits for quantum speed-up. Sci Rep. 2019;9:6903. https://doi.org/10.1038/s41598-019-43176-9.
Date P, et al.. Efficiently embedding QUBO problems on adiabatic quantum computers. Quantum Inf Process. 2019;18:117. https://doi.org/10.1007/s11128-019-2236-3.
Mitarai K, Fujii K. Overhead for simulating a non-local channel with local channels by quasiprobability sampling. Quantum. 2021;5:388. https://doi.org/10.22331/q-2021-01-28-388
Harrigan MP, et al.. Quantum approximate optimization of non-planar graph problems on a planar superconducting processor. Nat Phys. 2021;17:332–6. https://doi.org/10.1038/s41567-020-01105-y
Otterbach JS, et al. Unsupervised Machine Learning on a Hybrid Quantum Computer. arXiv:1712.05771 (2017).
Pelofske E, Bärtschi A, Eidenbenz S. Quantum Annealing vs. QAOA: 127 Qubit Higher-Order Ising Problems on NISQ Computers. arXiv:2301.00520v1.
Zhu Y, et al.. Multi-round QAOA and advanced mixers on a trapped-ion quantum computer. Quantum Sci Technol. 2022;8:015007. https://doi.org/10.1088/2058-9565/ac91ef.
Shaydulin R, Pistoia M. QAOA with \(N\cdot p\geq 200\). arXiv:2303.02064 (2023).
Dunjko V, Ge Y, Cirac JI. Computational speedups using small quantum devices. Phys Rev Lett. 2018;121:25. https://doi.org/10.1103/PhysRevLett.121.250501.
Glover F, Lewis M, Kochenberger G. Logical and inequality implications for reducing the size and difficulty of quadratic unconstrained binary optimization problems. Eur J Oper Res. 2018;265:829–42. https://doi.org/10.1016/j.ejor.2017.08.025.
Lewis M, Glover F. Quadratic unconstrained binary optimization problem preprocessing: theory and empirical analysis. Networks. 2017;70:79–97. https://doi.org/10.1002/net.21751.
Fujii K, et al. Deep Variational Quantum Eigensolver: a divide-and-conquer method for solving a larger problem with smaller size quantum computers. arXiv:2007.10917 (2022).
Bechtold M, et al. Investigating the effect of circuit cutting in QAOA for the MaxCut problem on NISQ devices. arXiv:2302.01792 (2023).
Peng T, et al.. Simulating large quantum circuits on a small quantum computer. Phys Rev Lett. 2020;125:150504. https://doi.org/10.1103/PhysRevLett.125.150504.
Amaro D, et al.. Filtering variational quantum algorithms for combinatorial optimization. Quantum Sci Technol. 2022;7:015021. https://doi.org/10.1088/2058-9565/ac3e54.
Shee Y, et al.. Qubit-efficient encoding scheme for quantum simulations of electronic structure. Phys Rev Res. 2022;4(2):023154. https://doi.org/10.1103/PhysRevResearch.4.023154.
Glos A, Krawiec A, Zimboras Z. Space-efficient binary optimization for variational quantum computing. npj Quantum Inf. 2022;8:39. https://doi.org/10.1038/s41534-022-00546-y.
Fuchs FG, et al.. Efficient encoding of the weighted MAX k-CUT on a quantum computer using QAOA. SN Comput Sci. 2021;2:89. https://doi.org/10.1007/s42979-020-00437-z.
Fuller B, et al. Approximate Solutions of Combinatorial Problems via Quantum Relaxations. arXiv:2111.03167 (2021).
Teramoto K, et al. Quantum-Relaxation Based Optimization Algorithms: Theoretical Extensions. arXiv:2302.09481 (2023).
Rancic MJ. Noisy intermediate-scale quantum computing algorithm for solving an n-vertex MaxCut problem with log(n) qubits. Phys Rev Res. 2023;5(1):L012021. https://doi.org/10.1103/PhysRevResearch.5.L012021.
Winderl D, Franco N, Lorenz JM. A Comparative Study on Solving Optimization Problems with Exponentially Fewer Qubits. arXiv:2210.11823 (2022).
Guo Liu J, et al.. Variational quantum eigensolver with fewer qubits. Phys Rev Res. 2019;1:023025. https://doi.org/10.1103/PhysRevResearch.1.023025.
Tibor Veszeli M, Vattay G. Mean Field Approximation for solving QUBO problems. arXiv:2106.03238 (2021).
Huang H-Y, Kueng R, Preskill J. Predicting many properties of a quantum system from very few measurements. Nat Phys. 2020;16:1050–7. https://doi.org/10.1038/s41567-020-0932-7.
Kuang R, Barbeau M. Quantum permutation pad for universal quantum-safe cryptography. Quantum Inf Process. 2022;21:21. https://doi.org/10.1007/s11128-022-03557-y.
Draper TG. Addition on a Quantum Computer. Tech. Rep. http://xxx.lanl.gov/quant-ph (2000).
Boneh A, Hofri M. The Coupon-Collector Problem Revisited (1989).
Truger F, et al.. Warm-starting and quantum computing: a systematic mapping study. 2023. arXiv:2303.06133 [quant-ph].
Egger DJ, Mareček J, Woerner S. Warm-starting quantum optimization. Quantum. 2021;5:479 https://doi.org/10.22331/q-2021-06-17-479.
Akshay V, et al.. Parameter concentrations in quantum approximate optimization. Phys Rev A. 2021;104:L010401. https://doi.org/10.1103/PhysRevA.104.L010401.
Mitarai K, Yan T, Fujii K. Generalization of the output of a variational quantum eigensolver by parameter interpolation with a low-depth ansatz. Phys Rev Appl. 2019;11:044087. https://doi.org/10.1103/PhysRevApplied.11.044087.
Thye Goh S, et al.. Techniques to enhance a QUBO solver for permutation-based combinatorial optimization. In: GECCO 2022 companion - proceedings of the 2022 genetic and evolutionary computation conference. Association for Computing Machinery, Inc; 2022. p. 2223–31. https://doi.org/10.1145/3520304.3533982.
Kl Barkoutsos P, et al.. Improving variational quantum optimization using CVaR. Quantum. 2020;4:256. https://doi.org/10.22331/q-2020-04-20-256.
Schuld M, et al.. Evaluating analytic gradients on quantum hardware. Phys Rev A. 2019;99:032331. https://doi.org/10.1103/PhysRevA.99.032331.
Ostaszewski M, Grant E, Benedetti M. Structure optimization for parameterized quantum circuits. Quantum. 2021;5:391. https://doi.org/10.22331/q-2021-01-28-391.
Nakanishi KM, Fujii K, Todo S. Sequential minimal optimization for quantum-classical hybrid algorithms. Phys Rev Res. 2020;2:043158. https://doi.org/10.1103/PhysRevResearch.2.043158.
Bittel L, Kliesch M. Training variational quantum algorithms is NP-hard. Phys Rev Lett. 2021;127:120502. https://doi.org/10.1103/PhysRevLett.127.120502.
Virtanen P, et al.. SciPy 1.0: fundamental algorithms for scientific computing in Python. Nat Methods. 2020;17:261–72. https://doi.org/10.1038/s41592-019-0686-2.
Mitarai K, et al.. Quantum circuit learning. Phys Rev A. 2018;98:032309. https://doi.org/10.1103/PhysRevA.98.032309.
Bergholm V, et al. PennyLane: Automatic differentiation of hybrid quantum-classical computations. arXiv:1811.04968 (2022).
O’Brien TE, et al.. Error mitigation via verified phase estimation. PRX Quantum. 2021;2:020317. https://doi.org/10.1103/PRXQuantum.2.020317.
Endo S, Benjamin SC, Li Y. Practical quantum error mitigation for near-future applications. Phys Rev X. 2018;8:031027. https://doi.org/10.1103/PhysRevX.8.031027.
LaRose R, et al.. Mitiq: a software package for error mitigation on noisy quantum computers. Quantum. 2022;6:774. https://doi.org/10.22331/q-2022-08-11-774
Knill E, Ortiz G, Somma RD. Optimal quantum measurements of expectation values of observables. Phys Rev A. 2007;75:012328. https://doi.org/10.1103/PhysRevA.75.012328.
Ahmed S, Killoran N, Álvarez JFC. Implicit differentiation of variational quantum algorithms. arXiv:2211.13765 (2022).
Acknowledgements
We thank Daniel Leykam for his valuable comments and suggestions. We acknowledge the use of IBM Quantum, IonQ and Amazon Web Services.
Funding
This research is supported by the National Research Foundation, Singapore and A*STAR (#21709) under its CQT Bridging Grant and Quantum Engineering Programme (NRF2021-QEP2-02-P02) and by EU HORIZON-Project101080085—QCFD. We acknowledge IBM Quantum, IonQ and Amazon Web Services.
Author information
Authors and Affiliations
Contributions
E.H. wrote the main manuscript text and conducted the underlying analysis, excluding simulations of QAOA which were conducted by B.T., who in addition contributed to the research design and revised the manuscript. D.A. and P.G. coordinated the project and facilitated contact with the regulated financial exchange. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
The authors consent to publication by EPJ Quantum Technology.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Additional figures
Appendix B: Proofs
In this section, we provide formal proofs of claims made in the main text:
Register-preserving ansatz.
Lemma 1 1
The following is equivalent to a state  being register-uniform:
being register-uniform:

Proof
“⇒”: Given a register-uniform state  , direct calculation shows
, direct calculation shows

“\(\impliedby \)”: Given  with
with  , write
, write  in the computational basis as
in the computational basis as

Then

showing that  is register-uniform. □
is register-uniform. □
Theorem 1 1
The following are equivalent for a unitary U acting on \(\mathcal{H}_{\textit{anc}}\otimes \mathcal{H}_{\textit{reg}}\):
-
(i)
U is register-preserving
-
(ii)
 where \(U_{r}\) is a unitary on \(\mathcal{H}_{\textit{anc}}\) ∀r and \(f: \{1,\ldots ,N_{r}\}\to \{1,\ldots ,N_{r}\}\) is bijective.
where \(U_{r}\) is a unitary on \(\mathcal{H}_{\textit{anc}}\) ∀r and \(f: \{1,\ldots ,N_{r}\}\to \{1,\ldots ,N_{r}\}\) is bijective. -
(iii)
U can be written as a sequence of unitary matrices on \(\mathcal{H}_{\textit{anc}}\) conditioned on a subset of register-qubits and basis-permutations on the register.
 where
where Proof
We will proof in order \((i)\implies (ii)\implies (iii)\implies (i)\).
\((i) \implies (ii)\): The idea in this part is the following: Since the ancilla states for each register are arbitrary, no “mixing” between different registers is allowed as this would result in uncontrollable superpositions on the ancilla subsystems causing a loss of “normalization”. We will first show the following weaker claim:
Claim 1:  , \(1\leq r\leq N_{r}\),
, \(1\leq r\leq N_{r}\),  and \(1\leq \tilde{r}\leq N_{r}\), s.t.
and \(1\leq \tilde{r}\leq N_{r}\), s.t. 
Proof of Claim 1: Assume this was not the case, i.e.  s.t.
s.t.

for some  with \(0<|\lambda | < 1\) and
with \(0<|\lambda | < 1\) and  . We denoted \(\bar{\lambda}:= \sqrt{1-|\lambda |^{2}}\). We note at this point, that adding a complex phase to
. We denoted \(\bar{\lambda}:= \sqrt{1-|\lambda |^{2}}\). We note at this point, that adding a complex phase to  merely adds the same phase to λ and
merely adds the same phase to λ and  but otherwise does not change equation (30).
but otherwise does not change equation (30).
We now apply U to a register-uniform state containing  , resulting in
, resulting in


where  . We will fix
. We will fix  for \(r\neq s\) later. Using that U is register-preserving, we have
for \(r\neq s\) later. Using that U is register-preserving, we have

If we can show that  , then we can choose the phase of
, then we can choose the phase of  such that
such that
-
Case 1: \(\lambda = |\lambda |\)
-
Case 2: \(\lambda = i|\lambda |\)
which results in the contradiction

It remains to show, that we can choose  such that
such that  and real.
and real.
For this consider

Claim 2: 
Proof of Claim 2: Assume this was not the case. Then

Hence span . In particular for \(r\neq s\)
. In particular for \(r\neq s\)

Therefore

which implies

which is not normalized (\(|\lambda |<1\)), in contradiction with U being register-preserving.
Therefore claim 2 holds and it exists  with \(w\neq s\) such that
with \(w\neq s\) such that

We can furthermore fix the phase of  such that the overlap in (40) is real and positive. We can choose all other
such that the overlap in (40) is real and positive. We can choose all other  for \(r \neq w, s\) arbitrary with the condition that if the overlap
for \(r \neq w, s\) arbitrary with the condition that if the overlap  is non-zero, we adjust the phase so that the overlap is real and positive. From this it follows
is non-zero, we adjust the phase so that the overlap is real and positive. From this it follows

which concludes claim 1.
To prove the more restrictive statement \((ii)\), it remains to show:
-
a)
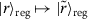 is a well-defined bijective function, \(\tilde{r} = f(r)\), \(f: \{1,\ldots ,N_{r}\}\to \{1,\ldots ,N_{r}\}\)
is a well-defined bijective function, \(\tilde{r} = f(r)\), \(f: \{1,\ldots ,N_{r}\}\to \{1,\ldots ,N_{r}\}\) -
b)
 is unitary
is unitary 
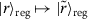 is a well-defined bijective function,
is a well-defined bijective function,  is unitary
is unitary 
To show that f is a well-defined function, we need to show in addition to claim 1 that the registers are mapped independently of the state of the ancilla. Assume this was not the case, i.e.  s.t.
s.t.

with \(\tilde{r}^{1} \neq \tilde{r}^{2}\). Consider two register-uniform states which are identical besides one containing  and the other
and the other  . Then due to linearity, one of the two states is not mapped to a register-uniform state under U. This is a contradiction and hence f is a well-defined function. Because U is register-preserving, f must be surjective and is hence bijective.
. Then due to linearity, one of the two states is not mapped to a register-uniform state under U. This is a contradiction and hence f is a well-defined function. Because U is register-preserving, f must be surjective and is hence bijective.
To show b) we note that for any r the restriction  is unitary.
is unitary.
\((ii) \implies (iii)\): Given \(U_{r}\) and \(f(\circ )\) as in \((ii)\), we can directly define a sequence of conditioned unitaries and a permutation on the registers.
For any r we can condition the unitary \(U_{r}\) acting on \(\mathcal{H}_{\text{anc}}\) on the bitvector-representation of r. Let us call the resulting unitary \(CU_{r}\). Define the permutation  . Then
. Then
\((iii) \implies (i)\): As the set of register-preserving unitaries is closed under composition, it suffices to show that basis-permutations on the registers and unitaries on the ancillas conditioned on register-states are both register-preserving. Both can be verified explicitly by tracking the action on a state of the form  and observing that the normalization of the individual terms in the sum is not compromised. Permutations on the register merely reassign the ancilla states to different addresses while conditional unitaries on the ancillas apply unitary transformations on the ancilla-states for a subset of registers specified through the conditioning. □
and observing that the normalization of the individual terms in the sum is not compromised. Permutations on the register merely reassign the ancilla states to different addresses while conditional unitaries on the ancillas apply unitary transformations on the ancilla-states for a subset of registers specified through the conditioning. □
Lemma 2 1
For register-uniform states as in equation (23) with  , a unitary only non-trivially acting on the register-qubits always maps
, a unitary only non-trivially acting on the register-qubits always maps  to a register-uniform state if and only if
to a register-uniform state if and only if
Proof
We will show the claim by demanding  adhere to definition 1.
adhere to definition 1.
Projecting  on a register s, we obtain
on a register s, we obtain

and therefore

We can split the sum to obtain (using the assumption of real-valued ancilla overlap)

where the first term equals 1 due to  forming an orthonormal basis of \(\mathcal{H}_{\text{reg}}\). As this equations has to hold for all sets
forming an orthonormal basis of \(\mathcal{H}_{\text{reg}}\). As this equations has to hold for all sets  which have real-valued overlap (hence we can engineer them such that exactly one chosen term
which have real-valued overlap (hence we can engineer them such that exactly one chosen term  in the sum is non-zero) and for all s, equation (47) is equivalent to \(\text{Re}\left [(U^{\dagger})_{r_{1}s}U_{sr_{2}}\right ]=0~\forall r_{1},r_{2},s \in \{1,\ldots , N_{r}\} \text{ with } r_{1}< r_{2}\). □
in the sum is non-zero) and for all s, equation (47) is equivalent to \(\text{Re}\left [(U^{\dagger})_{r_{1}s}U_{sr_{2}}\right ]=0~\forall r_{1},r_{2},s \in \{1,\ldots , N_{r}\} \text{ with } r_{1}< r_{2}\). □
The resulting state is register-uniform due to cancellation of phases. While this only holds for real-valued inner product between ancilla-states, it raises the question whether similar results are possible more generally if a record of the phases of the ancilla states is kept. Furthermore, we did not explore the possibility of allowing different register bases for the input and output state in the definition of a register-preserving unitary.
Transaction settlement problem
For some combinatorial graph problems such as MaxCut, the corresponding QUBO matrix Q is in simple correspondence with the graph and its adjacency matrix. This is not the case here, where deciding which transactions to settle corresponds to choosing a subset of edges (not nodes, cf. Fig. 1). Quadratic terms beyond the graph connectivity are common for QUBO problems which incorporate constraints as quadratic penalties. This increase the number of non-zero off-diagonal elements of Q and hence limits the applicability of many NISQ-QS as stressed in Sect. 1.1. For transaction settlements, we can relate the number of non-zero elements per row of Q as follows:
Lemma 3
Given a transaction settlement with \(A, \underline {\mathbf {b}}(\underline {\mathbf {s}})\) as in equations (7) and (8), represented by a graph G with parties as K nodes \(\mathcal{K}\) and transactions as I edges \(\mathcal{I}\) connecting the transacting parties, then: The average number of non-zero entries per row of the matrix \(Q = A + \textrm{Diag}(\underline {\mathbf {b}}(\underline {\mathbf {s}}))\) is bounded by
where \(N_{k}\) is the number of edges connected to node \(k\in \mathcal{K}\).
For d-regular graphs \(\mathbb{V}_{\mathcal{K}}\left [N_{k}\right ]=0\).
Proof
We are looking for an upper-bound of the average number of non-zero elements in the rows of Q. For this assume the diagonal elements are all non-zero. For the off-diagonal elements we only need to consider the contributions of \(A = -\lambda V V^{T}\). As \(V_{il} := (\underline {\mathbf {v}}_{ik(l)})_{j(l)}\) is only non-zero if transaction i changes balance \(j(l)\) of party \(k(l)\), \(A_{ij}\) may only be non-zero if edges i and j share a node. Therefore
Let \(k_{1}(i), k_{2}(i) \in \mathcal{K}\) such that \(i = (k_{1}(i), k_{2}(i))\).Footnote 13 Then
where −1 comes from double-counting the edge i connecting \(k_{1}(i)\) with \(k_{2}(i)\). Plugging this into equ. (49) we get
□
Appendix C: Cost estimator and marginal probability distribution obtained from sampling algorithm
In this section, we give explicit formulas for the estimators in Sect. 2.3 and their gradients. For the special case of a disjoint covering and greedy sampling algorithm, we rigorously prove the heuristic estimators used in the cost objective.
3.1 C.1 Cost estimator
To express \(\hat{p}_{i}\) and \(\hat{p}_{ij}\) through a set of measurements \(\mathcal{M}=\left \{\underline {\mathbf {m}}_{1}, \ldots \underline {\mathbf {m}}_{n_{\text{shots}}} \right \}\) in the computational basis, let \(\tilde{\underline {\mathbf {x}}}(\underline {\mathbf {m}})\) refer to the “bit”-vector \(\in \{-1,0,1\}^{I}\) with the subset \(A_{r(\underline {\mathbf {m}})}\) of entries fixed to \(b(\underline {\mathbf {m}})_{1} \ldots b(\underline {\mathbf {m}})_{n_{a}}\) as described in Sect. 2.2 and all other bits set to −1. Define \(l_{r}(\circ ): A_{r} \to \{1,\ldots ,n_{a}\}\) through \(A_{r}[l_{r}(i)]=i~\forall i \in A_{r}\) (“bit i is mapped to \(l_{r}(i)^{\text{th}}\) ancilla bit of register r”). The estimators are given as follows:
where:
Note, that for disjoint coverings \(\mathcal{A}\), the sums over r collapse to at most a single term as every bit i is contained in exactly one register-set \(A_{r(i)}\). In the definition of \(\tilde{q}_{ij}\) we adopt the convention \(\tilde{q}_{ij}\equiv 0\) if \(\{r: i,j \in A_{r}\}=\emptyset \) (sum contains no terms).
3.2 C.2 Derivation for disjoint covering
To derive the marginal probability distributions \(p_{ij}(\underline {\mathbf {\theta}}) = \text{Prob}_{\underline {\mathbf {\theta}}}(x_{i} = 1, x_{j} = 1)\) and \(p_{i}(\underline {\mathbf {\theta}}) = \text{Prob}_{\underline {\mathbf {\theta}}}(x_{i} = 1)\) that arise from the greedy sampling algorithm, consider the output of the PQC given by equation (16).
We denote the sequence of registers during one run of the sampling algorithm by \(S = \left (r_{i} \right )_{i=1}^{N_{m}}\), where \(r_{i}\) is the register sampled in the \(i^{\text{th}}\) measurement (omitting measurements with not bits being set)and \(N_{m}\) is the number of such calls before termination of the algorithm. Denote by \(\tilde{A}^{(S)}_{r_{i}}\subset A_{r_{i}}\)Footnote 14 the bits set in the \(i^{\text{th}}\) measurement.
Then
where \(\text{Prob}(S)\) is the probability of the sampling algorithm resulting in the register-sequence S and \(p^{(r_{i})}_{\tilde{A}^{(S)}_{r_{i}}}(\underline {\mathbf {x}})\) is defined through the complex ancilla amplitudes compatible with \(\underline {\mathbf {x}}_{\tilde{A}^{(S)}_{i}}\) for the given register \(r_{i}\), i.e.
which simplifies to \(|a^{\underline {\mathbf {x}}_{A_{r}}}|^{2}\) if \(|\tilde{A}^{(S)}_{r_{i}}|=n_{a}\).
For fixed S define \(\tilde{r}(i),~i\in B\) such that \(i\in \tilde{A}^{(S)}_{\tilde{r}(i)}\), as well as \(p_{i}^{(r)} := p_{\{i\}}^{(r)}(\underline {\mathbf {1}}) = \sum _{ \substack{b_{k} \in \{0,1\}\\b_{l_{r}(i)}=1}}|a^{b_{1} ... b_{n_{a}}}_{r}|^{2}\) and \(p_{ij}^{(r)} := p_{\{i,j\}}^{(r)}(\underline {\mathbf {1}}) = \sum _{ \substack{b_{k} \in \{0,1\}\\b_{l_{r}(i)}=b_{l_{r}(j)}=1}}|a^{b_{1} ... b_{n_{a}}}_{r}|^{2}\). Then it follows for the marginals:
In the case of a disjoint covering \(\mathcal{A}\), every register has to be sampled once and \(\tilde{A}^{(S)}_{r_{i}}=A_{r_{i}}~\forall i\in \{1,\ldots ,N_{m}= \frac{I}{n_{a}}\}\). Due to this the sum over S merely consists of different orderings of \(\{1,\ldots ,N_{r}=\frac{I}{n_{a}}\}\). Therefore, \(\text{Prob}(S)=\prod _{i = 1}^{N_{m}}|\beta _{r_{i}}|^{2}=( \frac{I}{n_{a}}!)^{-1}\) is uniform.
For general coverings however, \(\text{Prob}(S)\) is not necessarily uniform and the sum over S is non-trivial. However, we can hope to approximate in the general case
and
(equality holds for disjoint coverings, in which case the sums become trivial). We can regard this as assuming that based on symmetry considerations,Footnote 15 the probability of the sampling algorithm running through the sequence S where entry i is sampled from register \(r\in \{r:~i\in A_{r}\}\)) is proportional to \(|\beta _{r}|^{2}\). Similar considerations are made when looking at bit-pairs \((i,j)\) with the added complexity that they can either be sampled from the same register r or from two different register \(r_{1}, r_{2}\). The probability of the former is estimated as
By further approximating \(\sum _{r_{1}, r_{2}:~i \in A_{r_{1}}, j \notin A_{r_{1}}, j \in A_{r_{2}}} \approx \sum _{r_{1}:~i \in A_{r_{1}}}\sum _{r_{2}:~j \in A_{r_{2}}}\) we obtain
Given this, \(p_{i}\) is estimated by \(\hat{p}_{i}\) (equ. (54)) and \(p_{ij}\) by \(\hat{p}_{ij}\) (equ. (55)), where all “≈” are exact for the case of a disjoint covering.
In summary, we have motivated the cost estimator in Sect. 2.3 as a heuristic for the general case and proven
Lemma 4
For the greedy sampling algorithmand a disjoint covering \(\mathcal{A}\) (perfect matching), equation (21) and \(\mathbb{E}_{\underline {\mathbf {\theta}}}[C]\) from equation (15) are equal in the limit \(n_{\textit{shots}}\to \infty \). In particular
3.3 C.3 Explicit form of cost-gradient
In this section, we will give the explicit form of the derivatives \(\partial _{\theta _{d}}\) of the cost a and register-regularization estimator
When optimizing \(\hat{C}(\underline {\mathbf {\theta}})\) with respect to \(\underline {\mathbf {\theta}}\) we may want to make use of the gradient \(\nabla _{ \underline {\mathbf {\theta }}}\hat{C}\) to update \(\underline {\mathbf {\theta}}\). For this, note that both terms in the quotient for \(\hat{p}_{i}\) and \(\hat{q}_{ij}\) are given as linear combinations of Pauli-expectation values (equation (54) and (56)). For many variational ansätze, in particular those consisting of single-qubit Pauli-rotations used in this paper, this allows to easily calculate gradients \(\nabla _{ \underline {\mathbf {\theta }}}[\hat{p}_{i}]\) and \(\nabla _{ \underline {\mathbf {\theta }}}[\hat{q}_{ij}]\) through the parameter-shift rule ([92, 97]). Similarly, the gradients of \(\hat{\mu}_{ij}\) and \(\hat{r}_{r}\) can be calculated by applying the parameter-shift rule. Through application of the chain-rule, the gradient of \(\hat{C}\left (\{\hat{p}_{i}\}_{i}, \{\hat{q}_{ij}\}_{ij}, \{ \hat{\mu}_{ij}\}_{ij};\{\hat{r}_{r}\}_{r}\right )\) is obtained.
We distinguish between the case of register-preserving ansätze and general circuit ansätze. For simplicity (and motivated by the regularization of the register-probabilities) we will treat \(\hat{\mu}_{ij}\) as constant in \(\underline {\mathbf {\theta}}\) in both cases.
By the chain rule we get
where
with \(V_{(i)}\) being the \(i^{\text{th}}\) row of V. As \(\hat{r}_{r}\) is the expectation of the observable  its partial derivatives can be calculated directly through parameter-shift rules or similar techniques to calculate the gradient of quantum observables. If we consider a register-preserving ansatz, the same holds true for \(\hat{q}_{ij}(\underline {\mathbf {\theta}})\) and \(\hat{p}_{i}(\underline {\mathbf {\theta}})\). Otherwise, the derivatives have to be calculated separately for the nominator and denominator in equation (54) and (56) respectively and recombined using the quotient rule.
its partial derivatives can be calculated directly through parameter-shift rules or similar techniques to calculate the gradient of quantum observables. If we consider a register-preserving ansatz, the same holds true for \(\hat{q}_{ij}(\underline {\mathbf {\theta}})\) and \(\hat{p}_{i}(\underline {\mathbf {\theta}})\). Otherwise, the derivatives have to be calculated separately for the nominator and denominator in equation (54) and (56) respectively and recombined using the quotient rule.
Appendix D: Expressing cost estimator as Hermitian observable
We observed in Sect. 2.2 and 2.3, that our qubit-compression results in a cost-estimator expressed as a function of Pauli-Z measurements that cannot be written straightforwardly as the expectation over a Hermitian operator. Here, we alleviate this issue for register-preserving circuits and fixed slack variables.
We can rewrite the cost as a Hermitian expectation for register-preserving circuits and fixed slack variables \(\underline {\mathbf {s}}\):
-
1.
Substitute denominators in \(\hat{p}_{i}\) and \(\hat{q}_{ij}\) as well as \(\hat{\mu}_{ij}\) by exact counterpart.
-
2.
Define operator \(C(\underline {\mathbf {\theta}})\) such that \(\hat{C}(\underline {\mathbf {\theta}}) = \langle C(\underline {\mathbf {\theta}})\rangle _{ \mathcal{M}}\) by “doubling the Hilbert space”.
1
The denominators in the expressions for \(\hat{p}_{i}\) and \(\hat{q}_{ij}\) (equations (54) and (56)) as well as \(\hat{\mu}_{ij}\) can be replaced by scalar constants by substituting

resulting in (\(n_{i}:=\sum _{\substack{r=1\\i\in A_{r}}}^{N_{r}}1\), \(n_{ij}:=\sum _{\substack{r=1\\i,j\in A_{r}}}^{N_{r}}1\))


where we set \(\hat{p}_{i}=0\) (\(\hat{q}_{ij}=0\)) if \(n_{i} = 0\) (\(n_{ij}=0\)).
2
Equations (78) and (79) suggest defining the Hermitian operators


This would allow us to write \(\hat{C}(\underline {\mathbf {\theta}})\) in the desired form if it weren’t for the terms of the form \(\hat{p}_{i}\hat{p}_{j} = \left \langle P_{i}\right \rangle _{ \mathcal{M}}\left \langle P_{j}\right \rangle _{\mathcal{M}}\). Instead of a quantum state  in the form of equation (16), we consider the product state
in the form of equation (16), we consider the product state  and the following operator acting on it:
and the following operator acting on it:
This requires doubling the number of qubits and circuit width. The cost estimator is then given as this operator’s expectation value

estimated through measurements.
We note:
-
C is Hermitian as it is real-valued and diagonal in the computational basis
-
While we assumed the measured quantum state to be register-uniform in the substitutions of 1., one may consider using the observable in equation (82) even for non-register-preserving circuits if the register-amplitudes are approximately kept constant with a penalty term. The penalty term can be added to C in the same manner as \(P_{i}\otimes P_{j}\).
-
The assumption of a register-preserving circuit comes with a caveat: We need to be careful in applying methods tailored to Hermitian-expectation-minimization which change the variational ansatz itself based on properties of the Hermitian (QAOA being the most prominent example). Still there are relevant results which can be applied to a constrained set of allowed gates, such as optimization techniques ([92, 93]), estimation ([82]) and error mitigation techniques as well as libraries ([99–101]) or fault-tolerant methods for evaluating expectation values (e.g. [102]).
-
Throughout, we assumed constant slack variables \(\underline {\mathbf {s}}\), as expressing the relationship in (22) through an observable is complicated by the non-linearity of the rectified linear unit. Hence, alternating adjustments of \(\underline {\mathbf {s}}\) using (22) and the circuit parameters \(\underline {\mathbf {\theta}}\) through a classical optimizer are needed. Alternatively, both variables could be optimized simultaneously, for which implicit differentiation may be useful ([103]).
Appendix E: Simulation parameters
The configurations used to determine ansatz and for optimizing circuit parameters in Sect. 3 are shown in Table 4. Pennylane ([98]; version: pennylane=0.29.1) was used for quantum computing simulations. For parameter optimization, the SciPy ([96]; version: scipy=1.10.1) implementation of gradient-free optimizer COBYLA as well as standard gradient descent were used. The gradients of the latter were calculated through the chain rule and parameter-shift rule ([92, 97]).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Huber, E.X., Tan, B.Y.L., Griffin, P.R. et al. Exponential qubit reduction in optimization for financial transaction settlement. EPJ Quantum Technol. 11, 52 (2024). https://doi.org/10.1140/epjqt/s40507-024-00262-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjqt/s40507-024-00262-w