
Abstract
In this study, we investigate the potential existence of a non-minimal coupling between dark matter and gravity using a compilation of galaxy clusters. We focus on the disformal scenario of a non-minimal model with an associated coupling length L. Within the Newtonian approximation, this model introduces a modification to the Poisson equation, characterized by a term proportional to \(L^2 \nabla ^2 \rho \), where \(\rho \) represents the density of the DM field. We have tested the model by examining strong and weak gravitational lensing data available for a selection of 19 high-mass galaxy clusters observed by the CLASH survey. We have employed a Markov Chain Monte Carlo code to explore the parameter space, and two different statistical approaches to analyse our results: a standard marginalisation and a profile distribution method. Notably, the profile distribution analysis helps out to bypass some volume-effects in the posterior distribution, and reveals lower Navarro–Frenk–White concentrations and masses in the non-minimal coupling model compared to general relativity case. We also found a nearly perfect correlation between the coupling constant L and the standard Navarro–Frenk–White scale parameter \(r_s\), hinting at a compelling link between these two lengths.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
A notable topic of interest in modern cosmology is to understand Dark Matter (DM) and Dark Energy (DE), whose origin and nature remain elusive. These components hold a significant importance in our Universe, making up a substantial 95% of its energy-matter composition (\(\sim 68\%\) as DE and \(\sim 27\%\) as DM) [1]. The existence of DM was first inferred in the 1930 s by Zwicky. He noticed a discrepancy between the observed dynamical mass of galaxy clusters and the mass derived from theoretical calculations [2]. Subsequent pioneering studies on the rotation curves of spiral galaxies confirmed this inconsistency at galactic scales [3]. These results challenged the previously held assumption that the concentration of a galaxy’s mass is within its central bulge, which contains the majority of its stars and gas. Instead, observations indicated a notably more consistent density extending across the entire gravitational structures. This “hidden” mass which could not be directly observed thus acquired the name of “dark matter”.
Since then, more and more evidence has accumulated supporting the need of DM on both cosmological and astrophysical scales. The enthusiastic exploration driven by particle physics considerations has generated numerous models and a variety of dark matter candidates (check [4, 5] for more information). However, up to the present moment, there has been no evidence supporting the existence of these proposed dark matter particles, and the sole means to detect the presence and characteristics of dark matter comes from observations within the realm of astrophysics and cosmology.
Currently, the dominant cosmological model is the \(\Lambda \)–Cold Dark Matter model (\(\Lambda \)CDM), which is fully based on General Relativity (GR). While the \(\Lambda \)CDM model has been successful in explaining so many observations and closely matches the data we have, it suffers from some problems [6,7,8,9,10,11,12,13]. In the pursuit of understanding the nature of DM and DE, researchers have proposed exploring extended theories of gravity (ETGs) [14, 15]. By embracing the idea that GR is a special case of a more comprehensive theory, we naturally arrive to the realm of ETGs. In certain ETG scenarios, both geometry and matter can undergo modifications, offering us a wider horizon through which to comprehend DM and DE. Over time, a multitude of models have been proposed within the ETG category, each contributing uniquely to our understanding of these phenomena [16,17,18,19].
In this paper, our objective is to investigate the characteristics of the DM fluid considering it to be non-minimally coupled with gravity. One might inquire about the rationale for choosing our perfect fluid to be Non-Minimally Coupled (NMC). In the fundamental concept of fluids in GR, we assume that when we transition from individual particles to a fluid, we are dealing with very small scales that can be expressed with a good approximation as a flat spacetime. However, it is worth exploring the scenario where the scale of the fluid’s mean free path is comparable to the scale at which spacetime curvature undergoes changes. This scenario is quite likely to be applicable to DM, which doesn’t interact with anything, exhibiting at most only very weak (self)interactions. As a result, its mean free path can be potentially as large as the Hubble scale (\(l_{\mathrm {{mfp}}} \sim 10^3\, \textrm{Gpc}\)). As a consequence, DM can be NMC and, consequently, the standard Einstein equations will be modified [20,21,22].
Within the framework of GR, there exists an option to contemplate DM as a Bose–Einstein condensate (BEC) [23]; this approach provides a way to satisfy the aforementioned criteria, as a BEC naturally possesses a characteristic length scale.Footnote 1 Additionally, within the domain of ETGs, modifications to gravity inspired by Born-Infeld theory result in the same modifications [32].
Furthermore, it has been shown that models assuming NMC between DM and gravity can resolve the core-cusp problem of \(\Lambda \)CDM model [27]. This controversy arises from the contrasting findings between cosmological simulations and observations. Cosmological simulations predict that the density distribution of DM near the center of galaxies will exhibit a cusp-like pattern. In contrast, observations on dwarf galaxies have revealed different results, demonstrating a linear increase in velocity as one moves toward their centers, resulting in the eventual development of a central density core (see [33,34,35,36]).
In the Newtonian limit, NMC manifests as an adjustment to the Poisson equation. Specifically, it introduces an additional term proportional to the dark matter density \( \rho \), expressed as \( L^2 \nabla ^2 \rho \), thereby the modified Poisson equation now relies not only on density but also on the gradients of the density [23].
While corrections to Poisson’s equation have been examined on stellar scales [37, 38], there is currently a gap in the analysis at galactic and cluster scales. Here, we try to address this gap by conducting an investigation of these corrections specifically at the scale of galaxy clusters. We will investigate the implications of our modified Poisson equation without making any initial assumptions about the source or magnitude of L.
The structure of our paper is as follows. First, in Sect. 2, we provide a concise overview of the NMC DM model’s underlying theory. Following that, we introduce the fundamental principles of gravitational lensing theory, upon which we base our theoretical predictions. Lastly in this section, we shortly review the specifics of our chosen mass density profile. In Sect. 3 we go through the data set from the CLASH program that has been utilized in our analysis. In Sect. 4 we outline the key aspects of the statistical analysis we have conducted. Finally, in Sect. 5, we provide a comprehensive discussion of our results and present our concluding findings.
2 Theory
We will quickly go over our model’s theoretical foundation in this section (see [20, 39] for more detail).
The general action that describes the NMC case can be written as follows [20]
where, the action \(S_{\textrm{fluid}}\) represents the behavior of dark matter which we will model using the action for a perfect fluid. This reads [20, 40]
where n represents the particle number density and s indicates the entropy assigned to each particle. In addition, \(\alpha ^{A}\) and \(\beta _{A}\), where A takes on values of 1, 2, 3, represent the Lagrangian coordinates for the fluid. The second term introduces some limitations on the perfect fluid’s flow. In addition, \(\psi \) and \(\theta \), have a thermodynamic interpretation in terms of thermodynamic potentials. Furthermore, \(J^{\mu }\) is defined as
and is the conserved current representing particles number conservation, being \(u^{u}\) the four-vector velocity of the fluid.
In Eq. (1), the term \(\rho _c(n,s)R\) represents a conformal coupling term, while \(\rho _d(n,s)R_{\mu \nu }u^\mu u^\nu \) shows a disformal one where our fluid variable couple to the contracted Ricci tensor with the fluid four-vector velocity.
As we will explain below, we are focusing specifically on utilizing the disformal coupling term only. Hence, we retain only the latter term in the total action
In order to derive the Newtonian limit of our theory, it is beneficial to employ fluid approximation [22]. This approach leads to a modification of the Poisson equation of the form [20, 21]
where \(\Phi \) represents the Newtonian potential, and \(\rho _{\textrm{bar}}\) and \(\rho \) denote the mass densities of baryonic matter and dark matter, respectively. The second term of the Eq. (5) represents the non-minimal coupling term: from [20]it can be seen how \(L^2 \propto \alpha _d\) thus being L the non-minimal coupling length; \(\epsilon = \pm 1\) represents the polarity of the coupling. According to [39], the negative polarity \(\epsilon =-1\) is required. In our chosen scenario for disformally coupled fluid, we only have one gravitational potential and no anisotropic stress. Additionally, it’s important to highlight that Eq. (5) is not the most general expression and having extra terms is possible, but most of them have to be close to zero to satisfy the equivalence principle [41, 42].
It is worth mentioning that this kind of modification to the dynamics of GR (Eq. 2) is linked to a “coarse-grained” scenario and doesn’t involve making fundamental modifications to gravitational dynamics. Consequently, L is not a fundamental constant of nature and its value can hence depend on the local environment.
As can be seen in Eq. (5), the modified Poisson equation has a term that is dependent on gradients of density. As a consequence, the impact of this modification becomes more pronounced as the distribution of dark matter becomes increasingly inhomogeneous [21].
According to [43], this modification has an important role in modifying the dynamics of spiral galaxies. In addition, in the mentioned study it has been shown that NMC DM can provide a better fit to the rotation curves of spiral galaxies than NFW.
2.1 Gravitational lensing
Gravitational lensing emerges as a potent tool for probing the distribution of both dark and baryonic matter within galaxy clusters.
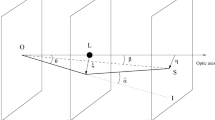
Considering a source that is positioned at an angular diameter distance of \(D_A\), \(D_s\) is the distance from the observer and \(D_{l}\) would be distance from the lens; the distance between the lens and the source is denoted as \(D_{ls}\) in a gravitational lensing setup [44,45,46]. The angular diameter distance which is a function of redshift can be defined as
where, in the context of a \(\Lambda \)CDM (Lambda Cold Dark Matter) model, the Hubble function denoted as H(z) is expressed through the first Freedman equation:
with \(\Omega _{\Lambda } = 1-\Omega _m\) in the case of spatial flatness (\(\Omega _k =0\)). Throughout this work, we are assuming our background cosmology parameters to be given from Planck baseline model [1], with the values: Hubble constant \(H_0 = 67.89\) km s\(^{-1}\) Mpc\(^{-1}\) and the matter density parameter \(\Omega _m = 0.308\). Thus, we are implicitly assuming that the NMC model we are analyzing behaves on cosmological scales as this chosen\(\Lambda \) CDM one, at least effectively, whatever would be the (different) cosmological parameters which would effectively describe it.
Additionally, we assume that this system can be roughly thought of as two-dimensional given the scale differences between \(D_l\) and \(D_{ls}\) distances compared to the physical dimensions of the lens (the “thin-lens” approximation).Footnote 2 In such case, the lens’s primary function is to deflect light beams from the source by an angle called \(\hat{\vec {\alpha }}\), which is defined as
where \(\vec {\nabla }_{\perp }\) represents the two-dimensional gradient operator, which is perpendicular to the path of the light. Additionally, z denotes the coordinate that specifies the position along the path in which the light is propagating.
The deflection angle \(\hat{\vec {\alpha }}\), can be described using the effective lensing potential
where R is the two-dimensional projected radius on the lens plane.
The Laplacian of Eq. (8) gives twice the lensing convergence
where as mentioned earlier R is the two-dimensional projected radius in the lens plane, \(r = \sqrt{R^2+z^2}\) is the three-dimensional radius and \(\Delta _r = \frac{2}{r}\frac{\partial }{\partial r} + \frac{\partial ^2}{\partial ^2 r}\) represents the radial Laplacian in spherical coordinates, where we assume spherical symmetry for simplification. Now, by using the standard Poisson equation
we can establish a connection between the convergence \(\kappa \) and the distribution of mass density \(\rho \) within the lens system, ultimately leading us to another expression for convergence
where \(\Sigma (R)\) is the lens’s two-dimensional surface density and \(\Sigma _{cr}\) is the critical surface density of gravitational lensing and these quantities are expressed as follows, respectively
It should be mentioned that, till this point, our focus has been on the GR case, thus having \(\Phi = \Psi \). Yet, we can broaden our perspective by considering a more general scenario where we have non-zero anisotropic stress, which means the gravitational (\(\Phi \)) and metric potential (\(\Psi \)) are not equal (\(\Phi \ne \Psi \)). In this context, the expression for the convergence can be generalized to
For the model we are focusing on and outlined in Eq. (5), in the case of a disformal coupling, we do have \(\Phi = \Psi \) but with the modified Poisson equation Eq. (5), for which we will have the following convergence for our model
where \(\rho = \rho _{NFW} + \rho _{gas}\) is the total density. In the case of DM, as described in the next section, we considered the Navarro–Frenk–White to describe its density profile; for the hot intracluster gas component, we used the profile \(\rho _{gas}\) described in the following pages.
As can be seen, the new convergence is influenced by the behavior of \(\rho (R,z)\) and the radial Laplacian of only DM, \(\Delta _r \rho _{NFW}(R,z)\). Consequently, notable variations in the density profile may impact the value of the convergence. One should also consider the influence of the parameter L, distinct for each cluster, which further contributes to the overall change in convergence.
2.2 Navarro–Frenk–White profile
The mass distribution within galaxy clusters is frequently represented using spherically symmetric Navarro–Frenk–White (NFW) mass density profile [33]. One might argue that such a distribution, although seemingly generally valid [47], emerges from simulations in the context of standard General Relativity. We thus follow a minimally-conservative approach, in which we explore if the NFW profile is compatible with the modified scenario and still can be used as density profile for DM distribution in galaxy clusters. But we are aware that the only way to check if a different DM distribution would be achieved in the modified scenario we are considering here, would be to run cosmological simulations based on it. But this is out of the scope of this work.
It’s important to note that, in this study, we assume that the mass distribution in galaxy clusters is primarily influenced by DM
where \(\rho _{s}\) represents the characteristic density of the halo, while \(r_{s}\) corresponds to the scale radius. Moreover, \(\rho _{s}\) can be written
where
\(c_{\Delta }\) –the ratio of the size of the halo– is the dimensionless concentration parameter. \(r_{\Delta }\) represents the spherical radius where the average density inside it is equal to \(\Delta \) times the critical density \(\rho _c\) of the Universe at the redshift of the lens which here is the cluster. In addition, we have also \(M_{\Delta }\), which corresponds to the total mass encompassed within the overdensity radius \(r_{\Delta }\)
For our analysis, we have fixed the value of \(\Delta \) to be 200. As a result, the free NFW parameters we have utilized in our study are \(\{c_{200}, M_{200}\}\).
2.3 Hot gas
Although it would be possible to use X-ray observations for the CLASH clusters, which all have related archival data [48], we have decided to not take directly into account them. As it is well known, such type of observables might be biased by non-gravitational local astrophysical phenomena, contrarily to gravitational lensing, which is a neat gravitational probe. Thus, we have decided to sacrifice a bit of precision (X-ray reconstructed masses are generally better than some lensing-based data) for a stronger and lesser biased reconstruction.
Despite this, we consider hot gas in our modelling of the clusters, and we include \(\rho _{gas}\) in the total density appearing in Eq. (15). From the data at our disposal (as discussed in the next section), we fit the gas densities with a double (truncated) \(\beta \) model
Note that the free parameters in this expression are fixed at a preliminary stage, by independent fits, and are not left free in the global analysis.
3 Data
In this study, we have used the data from the CLASH (Cluster Lensing And Supernova survey with Hubble) programFootnote 3 [49].
The goal of the survey was (among others) to analyse the gravitational lensing characteristics of a set of massive galaxy clusters selected in the redshift range \(0.18<z<0.90\) to precisely determine their mass distributions. The sample covers a wide range of masses, \(5\lesssim M_{200}/10^{14}M_\odot \lesssim 30\), and each cluster has both weak- and strong-lensing data from Hubble Space Telescope focusing on the central regions [50, 51] combined with ground-based weak-lensing shear and magnification data from the Subaru Telescope [52]. The radial convergence profiles for 20 clusters [53] is then reconstructed. Out of these 20 clusters, 16 were selected based on X-ray observations, while 4 were chosen through lensing observations.
Our work focuses on a subset of the CLASH sample, consisting of 15 clusters selected based on X-ray observations and 4 clusters chosen through lensing observations, as described in [53]. One of the X-ray-selected clusters, RXJ1532, was excluded from our analysis because its mass reconstruction was based only on wide-field weak-lensing data resulting in too large errors [51]. The clusters in our analysis sample span a redshift range of \(0.187 \le z \le 0.686\), with a median redshift of \(z_\textrm{med}= 0.352\). The resolution limit of the mass reconstruction, determined by the HST lensing data, is typically around 10 arcseconds (\(\approx 35\) h\(^{-1}\) kpc) at the median redshift [54]. It is worth noting that approximately half of the selected clusters in our sample are anticipated to be unrelaxed [54].
In [53], it is mentioned that the average surface mass density (\(\Sigma (R)\)) of the X-ray-selected subset from the CLASH sample is most accurately described by the NFW profile when considering GR. The NFW model is effective in explaining the distribution of dark matter in clusters, as it dominates the overall cluster scale. On the other hand, cluster baryons, including X-ray-emitting hot gas and BCGs, are influenced by non-gravitational and local astrophysical phenomena. Consequently, estimates of the total mass based on hydrostatic methods using X-ray observations are heavily influenced by the dynamic and physical conditions within the cluster. In comparison, gravitational lensing offers a direct means to investigate the projected mass distribution in galaxy clusters.
4 Statistical analysis
In order to constrain the values in the non-minimally coupled model and the variables describing the NFW profile for each cluster, we need to define a \(\chi ^2\) function. Therefore, \(\varvec{\theta } = \{c_{200}, \, M_{200}, \, L \}\) denotes the collection of parameters we see as variables in our theory. Surely, as we switch into the realm of GR, this will change to \(\varvec{\theta } = \{c_{200}, \, M_{200} \}\). The \(\chi ^2\) function is defined as below
where \(\varvec{\kappa ^{obs}}\) refers to the data vector related to the observed convergence values. This vector comprises 15 data elements, each corresponding to the measured value of \(\kappa \) in a specific radial bin. The vector \(\varvec{\kappa ^{theo}}(\varvec{\theta })\) contains the theoretical predictions for the convergence of the model, calculated using Eq. (11) for GR and Eq. (15) for our NMC model. Additionally, \(\textbf{C}\) represents the covariance error matrix [46, 53].
We employed our custom Monte Carlo Markov Chain (MCMC) code to minimize the \(\chi ^{2}\) function. To ensure the convergence of the chains, we followed the approach described in [55]. To assess the credibility of our NMC model compared to standard GR by a meaningful statistical comparison, we calculated the Bayesian Evidence [56], \(\mathcal {E}\), for both models for each of cluster using the nested sampling algorithm explained in [57]. Since the selection of priors may significantly impacts Bayesian evidence [58], we maintained consistency by always choosing the same uninformative flat priors for the parameters.
The posterior distribution \(\mathcal {P}(\varvec{\theta },\mathcal {M}|{D})\), which we get as output from our MCMCs, is defined as
where \(\varvec{\theta }\) is the set of parameters of our models \(\mathcal {M}\) (GR and NMC), having the data D, and \(\mathcal {L}(D|\varvec{\theta },\mathcal {M}) \propto \exp (-\chi ^2 (\varvec{\theta })/2\)) is the likelihood distribution function given the priors distributions \(\pi (\varvec{\theta },\mathcal {M})\). Thus, the Evidence is
We calculate the Bayes Factor (\(\mathcal {B}^{\,i}_{j}\)), defined as the ratio of evidence values between two models
with \(\mathcal {M}_{j}\) being the reference model (in our case, GR). The comparison of models is then conducted employing the empirically calibrated Jeffreys scale [59] which states that: if \(\ln \mathcal {B}_{ij} < 1\), the evidence in favor of model i is weak against model j; if \(1< \ln \mathcal {B}_{ij} < 2.5\) the evidence is substantial; if \(2.5< \ln \mathcal {B}_{ij} < 5\) it is strong; if \(\ln \mathcal {B}_{ij} > 5\) it becomes decisive.
Moreover, in order to be sure to minimize the impact from the applied priors on the Bayesian comparison, we have also resorted on the Suspiciousness, \( \mathcal {S}^{i}_{j}\), introduced in [60,61,62] and defined as
where \(\mathcal {D}_{KL}\) is the Kullback–Leibler (KL) divergence[63]. An interpretation of the suspiciousness, similar to Jeffrey’s scale for the Bayes Ratio, is provided by Fig. 4 of [62]. Specifically, a negative value of \(\log \mathcal {S}^i_j\) should be intended as a sign of tension; a positive value of \(\log \mathcal {S}^i_j\) instead as a sign of concordance.
We anticipate here (a discussion of the reasons behind our choice will be detailed in the next section) that in our statistical analysis we have chosen two different approaches: “standard” marginalisation, as working directly on the MCMCs outputs; and the profile distribution (PD—an extension of the profile likelihood) [64, 65] approach.
5 Results and discussion
In Table 1 we report all the main results of our analysis. In the first step, in the second and third column we show the values for the NFW parameters \(c_{200}\) and \(M_{200}\) in the GR case, which will serve as our benchmark model, and we find a perfect agreement (just as cross-check of our codes) with results from literature [53, 66]. In Table 2 we report some secondary (not directly fitted) quantities which are equally important: the characteristic lengths from GR, namely, \(r_{200}\) and the NFW scaling, \(r_s\).
In both tables, regarding our NMC model, the results we report are obtained both from custom marginalisation, namely, simply “reading” the posteriors which are produced as output by the MCMCs; and after applying a PD procedure. The reason for this double analysis is due to clear volume-effects which we can notice when we take a more close inspection of the \(\chi ^2\) (or, equivalently, \(\mathcal {L}\)) landscape. Indeed, one can easily spot that the results obtained by standard marginalisation for our NMC model exhibit just a statistically not-significant deviation from GR for what concerns the NFW parameters, \(c_{200}\) and \(M_{200}\). On the other hand, when looking carefully at the posterior distribution of the main characterizing NMC parameter, the coupling length L, we note how its peak is generally highly shifted from the value at which we effectively get the minimum \(\chi ^2\), which does should serve as best fit estimation for this parameter. Actually, the region around the minimum is poorly explored with respect to rest of the parameter space because it is quite narrow, thus, volume-effects might be penalizing the physical information we may infer from our analysis and jeopardize our final assessments about the reliability of the NMC model with respect to GR. The PD approach as described in [64] is designed exactly to highlight statistical inference beyond such volume-effects.
Before any conclusion can be drawn, it is important to highlight that the value of \(r_{200}\), as it is possible to check from Table 2, does not change in a statistically significant way when moving from GR to the NMC case. That is important, because it means that the scale at which the concentration and the mass are estimated are the same in both cases and, thus, any difference can be consistently compared.
The difference between the marginalisation and the PD approach is made clear in our figures. For example, in Fig. 1, we present a comparison between the values of \(c_{200}\) and \(M_{200}\) acquired from GR and our NMC model. The left panels illustrates the comparison in the marginalisation case, while the right panel showcases the PD outcomes.
Upon closer look at these figures, a notable trend emerges. In general, the values obtained for \(c_{200}\) and \(M_{200}\) from the marginal analysis align more closely with those derived from GR, while the PD results exhibit more pronounced variations from the GR predictions. More specifically, in the PD analysis we see how both the concentration and the mass of the NFW profile are systematically lower than the GR case. We try to stress even more this trend in Fig. 2, where we do not show error bars for the sake of clarity, and we connect, for each cluster, GR (solid circles) to NMC marginalisation (empty circles) results with solid lines, and NMC marginalisation results to NMC PD ones (bold empty circles) with dashed ones. Thus, the NMC model, at least within the internal \(r_{200}\) region, requires less massive and less concentrated dark matter haloes in order to explain lensing data.

Comparison of the constraints on dark matter parameters for \(c_{200}\) and for \(M_{200}\) obtained from GR and from the NMC model considered in this work. In the left panels, we plot results from the marginalisation procedure; in the right ones, we show results from the profile distribution procedure
It is now interesting to give a look at the parameter which actually characterizes the NMC model, the interaction length L (for numerical reasons, we have chosen to work with \(\log {L}\)). In the case of a marginalized analysis, the estimated value of L appears to be “relatively” small, where the qualitative “relatively” should be clarified. Indeed, we are dealing with clusters which have ranges of the order of few Mpc, and L ranges from 0.1 to \(10^2\) kpc, with a typical average value \(\sim 10\) kpc. The main consequence which could be draw from this result, is that the correction to the Poisson equation introduced by the NMC model is just a small “perturbation” to the standard one. This result prompts further investigation. In our quest for validation, we can compare our results with those of [67], which addresses similar research objectives, albeit with a different data set. Interestingly, their computed value for L is also very small and of the same order of our finding, as shown in their corresponding Fig. 4.
When moving to the PD analysis, things change substantially. In some cases PDs are in full disagreement with the marginalized results: for example, in the case of MACS0416 we move from \(L \sim 10^{-2}\) kpc in the marginalized case to \(L \sim 1\) Mpc in the PD one. This is a general trend: from the PD analysis, which once again we remind highlights the behaviour of the posterior around the maximum of the likelihood, we get systematically larger values for L with respect to the marginalized analysis.
To get even more insight we compare L with the NFW parameters, \(c_{200}\) and \(M_{200}\) and with the other two characteristic lengths from GR, \(r_{200}\) and \(r_s\) in Fig. 3, where the results from marginalized analysis are shown as solid circles and those from PD are empty ones.
In the top left plot, we see again the shift towards smaller values of the concentration which we obtain in the PD analysis, but more strikingly we see an almost perfect anti-correlation between \(c_{200}\) and L. Although, this is not surprising, because in the corrective term induced by the NMC model into the Poisson equation, Eq. (5), we actually have the combination \(L^2\,\rho _s\), with \(\rho _s\) being mostly dependent on \(c_{200}\), as in Eq. (17). The same anti-correlation vs the mass is visible also in the top right panel, although much weaker. Also, we notice how it goes in the opposite direction with respect to what shown in Fig. 4 by [67], although in this reference they do not seem to have performed the PD analysis.

Comparison of the constraints on dark matter parameters \(\{c_{200},M_{200}\}\) obtained from GR and from the NMC model considered in this work. Solid circles are GR; empty circles are from NMC after marginalisation; bold empty circles are from NMC after profile distribution procedure. Solid lines connect GR and NMC after marginalisation; dashed lines connect NMC after marginalisation with NMC after profile distribution procedure. We avoid to plot error bars for the sake of clarity

Comparisons between the NMC characteristic parameter L, and the NFW parameters. In the plot, solid circles represent the Marginalized analysis, and empty circles show the PD ones
In the bottom panels of Fig. 3 we have the most interesting finding. On the left, we compare L with \(r_{200}\), and we notice how moving from the marginalized to the PD analysis leads from \(L \ll r_{200}\) to \(L \sim r_{200}\). This same pattern is even more clearly evident on the right, where the correspondence between L and \(r_s\) seems to be almost perfect, with a tentative weighted fit producing \(\log L \approx (0.964 \pm 0.034) \log r_{s} \). If confirmed by further investigations, these results would state for the NFW scaling \(r_{s}\) a sort of “natural” explanation if connected to the interaction length L of dark matter explained as an NMC fluid.
While the anti-correlation between \(c_{200}\) and L can be easily explained, this latter correlation is more tricky, and interesting. If we expressed the NFW profile and the NMC correction in dimensionless units, \(x=r/r_s\), we would have
This would be also expected from dimensional considerations and by the second derivative nature of the NMC. But in no way it implies the linear correlation between L and \(r_{s}\). If the NMC would contribute in a negligible way, it would be more logical and statistically favoured to expect small values for L. Moreover, the correction is itself a function of the scale, r.
Finally, in Fig. 4 we show the variation in the M(r)) distribution from GR to the NMC model at the best fit derived from the PD statistical analysis. Note that \(\Delta M_{200}\) is defined as \((M_{200,NMC}-M_{200,GR})/M_{200,GR}\), as considering the change in the scale which is due to the differences in the estimated lengths, we normalize the distances from the center to \(r/r_{200}\). It is quite evident to notice how the NMC model requires much less matter and much less concentrated in most of the cases we have considered: in some cases even more than \(70\%\) less dark matter with respect to GR from the inner to the outer regions; in many cases, we require half of the mass in the inner regions, with a difference which is less evident \((\approx 10\%)\) at outer ranges; few cases seem to be outliers and deviate from this general trend.

Difference in the mass distribution between GR and NMC model from the PD statistical analysis. We plot M(r) (left panel; dotted lines for GR, solid lines for the NMC model) and \(\Delta M \equiv (M_{NMC}-M_{GR}) / M_{GR}\) (right panel) as functions of the normalized distance from the center, \(r/r_{200}\)
6 Conclusions
Our investigation centers on exploring the scenario of a non-minimal coupling between dark matter (modeled as a perfect fluid) and gravity. As highlighted earlier, this coupling introduces alterations to the Einstein equations, extending its impact to the Planck mass and the energy-momentum tensor of a fluid, given their reliance on the curvature scale.
By adapting the action and taking the Newtonian limit for the disformal case, one reaches the modified Poisson equation Eq. (5), characterized by an additional term \(L^2 \nabla ^2\rho \). In this equation, the first term represents the density of dark matter and gas, while the additional term involves the coupling length L and the NFW density \(\rho \).
Leveraging both robust strong and weak gravitational lensing data within the CLASH program, we tested the NMC model across 19 high-mass galaxy clusters. It’s noteworthy that our analysis extends beyond dark matter to include the density of gas (X-ray). While the option to incorporate gas data from the CLASH dataset was available, we exercised caution, opting to not consider it due to potential biases.
Our analytical methodology employs two approaches for presenting findings: Marginalisation and Profile Distribution. Recognizing the influence of volume effects in the posterior distribution, we find that the PD is more suitable when working with data. Applying the PD reveals that dark matter necessitates lower mass and concentration to align with observed lensing data. Furthermore, a noteworthy correlation emerges between the coupling constant L and the standard NFW scale parameter \(r_s\) prompting further exploration into the connection between them in future research.
In our forthcoming research, we aim to expand our investigations beyond the exclusive consideration of dark matter and gas. Our focus will encompass additional components, such as galaxies, enhancing our understanding of dark matter characteristics.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: No new data have been produced during the study. All used data are available upon reasonable request to/from Keiichi Umetsu.]
Code Availability Statement
Code/software will be made available on reasonable request. [Authors’ comment: The code/software generated during and/or analysed during the current study is available from the corresponding author on reasonable request.]
Notes
The lens equation is as follows:
$$\begin{aligned} \vec {\beta } = \vec {\theta } - \frac{D_{ls}}{D_s}\, \hat{\vec {\alpha }}(\vec {\theta }), \end{aligned}$$where \((\vec {\beta })\) is the angular position of the source and \((\vec {\theta })\) is the angular position of the observer.
References
N. Aghanim et al. (Planck), Astron. Astrophys. 641, A6 (2020). [Erratum: Astron.Astrophys. 652, C4 (2021)]. https://doi.org/10.1051/0004-6361/201833910. arXiv:1807.06209 [astro-ph.CO]
F. Zwicky, J. Astrophys, 86, 217 (1937). https://doi.org/10.1086/143864
V. C. Rubin, W. K. Ford, Jr., Astrophys. J. 159, 379 (1970). https://doi.org/10.1086/150317
G. Bertone, D. Hooper, J. Silk, Phys. Rept. 405, 279 (2005). https://doi.org/10.1016/j.physrep.2004.08.031. arXiv:hep-ph/0404175
J.L. Feng, Ann. Rev. Astron. Astrophys. 48, 495 (2010). https://doi.org/10.1146/annurev-astro-082708-101659. arXiv:1003.0904 [astro-ph.CO]
N. Aghanim et al., Planck. Astron. Astrophys. 641, A1 (2020). https://doi.org/10.1051/0004-6361/201833880. arXiv:1807.06205 [astro-ph.CO]
S. Alam et al., eBOSS. Phys. Rev. D 103, 083533 (2021). https://doi.org/10.1103/PhysRevD.103.083533. arXiv:2007.08991 [astro-ph.CO]
T.M.C. Abbott et al., DES. Phys. Rev. D 105, 023520 (2022). https://doi.org/10.1103/PhysRevD.105.023520. arXiv:2105.13549 [astro-ph.CO]
T.M.C. Abbott et al., DES. Phys. Rev. D 105, 043512 (2022). https://doi.org/10.1103/PhysRevD.105.043512. arXiv:2107.04646 [astro-ph.CO]
P. Bull et al., Phys. Dark Univ. 12, 56 (2016). https://doi.org/10.1016/j.dark.2016.02.001. arXiv:1512.05356 [astro-ph.CO]
J. Martin, C R Phys. 13, 566 (2012). https://doi.org/10.1016/j.crhy.2012.04.008. arXiv:1205.3365 [astro-ph.CO]
L. Perivolaropoulos, F. Skara, New Astron. Rev. 95, 101659 (2022). https://doi.org/10.1016/j.newar.2022.101659. arXiv:2105.05208 [astro-ph.CO]
E. Di Valentino, O. Mena, S. Pan, L. Visinelli, W. Yang, A. Melchiorri, D.F. Mota, A.G. Riess, J. Silk, Class. Quant. Grav. 38, 153001 (2021). https://doi.org/10.1088/1361-6382/ac086d. arXiv:2103.01183 [astro-ph.CO]
T. Clifton, P.G. Ferreira, A. Padilla, C. Skordis, Phys. Rept. 513, 1 (2012). https://doi.org/10.1016/j.physrep.2012.01.001. arXiv:1106.2476 [astro-ph.CO]
K. Koyama, Rept. Prog. Phys. 79, 046902 (2016). https://doi.org/10.1088/0034-4885/79/4/046902. arXiv:1504.04623 [astro-ph.CO]
S. Nojiri, S.D. Odintsov, V.K. Oikonomou, Phys. Rept. 692, 1 (2017). https://doi.org/10.1016/j.physrep.2017.06.001. arXiv:1705.11098 [gr-qc]
M. Li, X.-D. Li, S. Wang, Y. Wang, Commun. Theor. Phys. 56, 525 (2011). https://doi.org/10.1088/0253-6102/56/3/24. arXiv:1103.5870 [astro-ph.CO]
M. Ishak, Living Rev. Rel. 22, 1 (2019). https://doi.org/10.1007/s41114-018-0017-4. arXiv:1806.10122 [astro-ph.CO]
S. Capozziello, M. De Laurentis, Phys. Rept. 509, 167 (2011). https://doi.org/10.1016/j.physrep.2011.09.003. arXiv:1108.6266 [gr-qc]
D. Bettoni, S. Liberati, JCAP 08, 023 (2015). https://doi.org/10.1088/1475-7516/2015/08/023. arXiv:1502.06613 [gr-qc]
D. Bettoni, S. Liberati, L. Sindoni, JCAP 11, 007 (2011). https://doi.org/10.1088/1475-7516/2011/11/007. arXiv:1108.1728 [gr-qc]
D. Bettoni, V. Pettorino, S. Liberati, C. Baccigalupi, J. Cosmol. Astropart. Phys. 07, 027 (2012). https://doi.org/10.1088/1475-7516/2012/07/027. arXiv:1203.5735 [astro-ph.CO]
D. Bettoni, M. Colombo, S. Liberati, JCAP 02, 004 (2014). https://doi.org/10.1088/1475-7516/2014/02/004. arXiv:1310.3753 [astro-ph.CO]
S.U. Ji, S.J. Sin, Phys. Rev. D 50, 3655 (1994). https://doi.org/10.1103/PhysRevD.50.3655. arXiv:hep-ph/9409267
C.G. Boehmer, T. Harko, JCAP 06, 025 (2007). https://doi.org/10.1088/1475-7516/2007/06/025. arXiv:0705.4158 [astro-ph]
T. Fukuyama, M. Morikawa, T. Tatekawa, JCAP 06, 033 (2008). https://doi.org/10.1088/1475-7516/2008/06/033. arXiv:0705.3091 [astro-ph]
T. Harko, JCAP 05, 022 (2011). https://doi.org/10.1088/1475-7516/2011/05/022. arXiv:1105.2996 [astro-ph.CO]
T. Harko, Mon. Not. Roy. Astron. Soc. 413, 3095 (2011). https://doi.org/10.1111/j.1365-2966.2011.18386.x. arXiv:1101.3655 [gr-qc]
P.-H. Chavanis, Astron. Astrophys. 537, A127 (2012). https://doi.org/10.1051/0004-6361/201116905. arXiv:1103.2698 [astro-ph.CO]
P.-H. Chavanis, Phys. Rev. D 84, 043531 (2011). https://doi.org/10.1103/PhysRevD.84.043531. arXiv:1103.2050 [astro-ph.CO]
T. Rindler-Daller, P. R. Shapiro, P. R. Shapiro, In 4th International Meeting on Gravitation and Cosmology (MGC 4) ( 2014) pp. 163–182. https://doi.org/10.1007/978-3-319-02063-1_12. arXiv:1209.1835 [astro-ph.CO]
J. Beltran Jimenez, L. Heisenberg, G. J. Olmo, D. Rubiera-Garcia. Phys. Rept. 727, 1 (2018). https://doi.org/10.1016/j.physrep.2017.11.001. arXiv:1704.03351 [gr-qc]
J.F. Navarro, C.S. Frenk, S.D.M. White, Astrophys. J. 462, 563 (1996). https://doi.org/10.1086/177173
E.L. Lokas, G.A. Mamon, Mon. Not. Roy. Astron. Soc. 321, 155 (2001). https://doi.org/10.1046/j.1365-8711.2001.04007.x. arXiv:astro-ph/0002395
M. Boylan-Kolchin, C.-P. Ma, Mon. Not. Roy. Astron. Soc. 349, 1117 (2004). https://doi.org/10.1111/j.1365-2966.2004.07585.x. arXiv:astro-ph/0309243
W.J.G. de Blok, Adv. Astron. 2010, 789293 (2010). https://doi.org/10.1155/2010/789293. arXiv:0910.3538 [astro-ph.CO]
J. Casanellas, P. Pani, I. Lopes, V. Cardoso, Astrophys. J. 745, 15 (2012). https://doi.org/10.1088/0004-637X/745/1/15. arXiv:1109.0249 [astro-ph.SR]
P. Pani, T. Delsate, V. Cardoso, Phys. Rev. D 85, 084020 (2012). https://doi.org/10.1103/PhysRevD.85.084020. arXiv:1201.2814 [gr-qc]
G. Gandolfi, A. Lapi, S. Liberati, Astrophys. J. 910, 76 (2021). https://doi.org/10.3847/1538-4357/abe460. arXiv:2102.03873 [astro-ph.CO]
J.D. Brown, Class. Quant. Grav. 10, 1579 (1993). https://doi.org/10.1088/0264-9381/10/8/017. arXiv:gr-qc/9304026
E. Di Casola, S. Liberati, S. Sonego, Am. J. Phys. 83, 39 (2015). https://doi.org/10.1119/1.4895342. arXiv:1310.7426 [gr-qc]
J.D. Bekenstein, Phys. Rev. D 48, 3641 (1993). https://doi.org/10.1103/PhysRevD.48.3641. arXiv:gr-qc/9211017
G. Gandolfi, A. Lapi, S. Liberati, Astrophys. J. 929, 48 (2022). https://doi.org/10.3847/1538-4357/ac5970. arXiv:2203.00572 [astro-ph.CO]
M. Meneghetti, Introduction to Gravitational Lensing: With Python Examples, Lecture Notes in Physics (Springer International Publishing, 2021). https://books.google.it/books?id=hBpFzgEACAAJ
‘ M. Bartelmann, P. Schneider, Phys. Rept. 340, 291 (2001). https://doi.org/10.1016/S0370-1573(00)00082-X. arXiv:astro-ph/9912508
K. Umetsu, Astron. Astrophys. Rev. 28, 7 (2020). https://doi.org/10.1007/s00159-020-00129-w. arXiv:2007.00506 [astro-ph.CO]
J. Wagner, Gen. Rel. Grav. 52, 61 (2020). https://doi.org/10.1007/s10714-020-02715-w. arXiv:2002.00960 [astro-ph.CO]
M. Donahue et al., Astrophys. J. 794, 136 (2014). https://doi.org/10.1088/0004-637X/794/2/136. arXiv:1405.7876 [astro-ph.CO]
M. Postman et al., Astrophys. J. Suppl. Ser. 199, 25 (2012). https://doi.org/10.1088/0067-0049/199/2/25
J. Merten et al., Astrophys. J. 806, 4 (2015). https://doi.org/10.1088/0004-637X/806/1/4. arXiv:1404.1376 [astro-ph.CO]
A. Zitrin, A. Fabris, J. Merten, P. Melchior, M. Meneghetti, A. Koekemoer, D. Coe, M. Maturi, M. Bartelmann, M. Postman, K. Umetsu, G. Seidel, I. Sendra, T. Broadhurst, I. Balestra, A. Biviano, C. Grillo, A. Mercurio, M. Nonino, P. Rosati, L. Bradley, M. Carrasco, M. Donahue, H. Ford, B.L. Frye, J. Moustakas, Astrophys. J. 801, 44 (2015). https://doi.org/10.1088/0004-637X/801/1/44. arXiv:1411.1414 [astro-ph.CO]
K. Umetsu et al., Astrophys. J. 795, 163 (2014). https://doi.org/10.1088/0004-637X/795/2/163. arXiv:1404.1375 [astro-ph.CO]
K. Umetsu, A. Zitrin, D. Gruen, J. Merten, M. Donahue, M. Postman, Astrophys. J. 821, 116 (2016). https://doi.org/10.3847/0004-637X/821/2/116. arXiv:1507.04385 [astro-ph.CO]
M. Meneghetti et al., Astrophys. J. 797, 34 (2014). https://doi.org/10.1088/0004-637X/797/1/34. arXiv:1404.1384 [astro-ph.CO]
J. Dunkley, M. Bucher, P.G. Ferreira, K. Moodley, C. Skordis, Mon. Not. Roy. Astron. Soc. 356, 925 (2005). https://doi.org/10.1111/j.1365-2966.2004.08464.x. arXiv:astro-ph/0405462
D. J. C. MacKay, Information Theory, Inference and Learning Algorithms ( Cambridge University Press, 2003)
P. Mukherjee, D. Parkinson, A.R. Liddle, Astrophys. J. Lett. 638, L51 (2006). https://doi.org/10.1086/501068. arXiv:astro-ph/0508461
S. Nesseris, J. Garcia-Bellido, JCAP 08, 036 (2013). https://doi.org/10.1088/1475-7516/2013/08/036. arXiv:1210.7652 [astro-ph.CO]
H. Jeffreys, The Theory of Probability (Oxford University Press, 1998)
W. Handley, P. Lemos, Phys. Rev. D 100, 043504 (2019). https://doi.org/10.1103/PhysRevD.100.043504. arXiv:1902.04029 [astro-ph.CO]
W. Handley, P. Lemos, Phys. Rev. D 100, 023512 (2019). https://doi.org/10.1103/PhysRevD.100.023512. arXiv:1903.06682 [astro-ph.CO]
B. Joachimi, F. Köhlinger, W. Handley, P. Lemos, Astron. Astrophys. 647, L5 (2021). https://doi.org/10.1051/0004-6361/202039560. arXiv:2102.09547 [astro-ph.CO]
S. Kullback, R. A. Leibler, Ann. Math. Stat. 22, 79 (1951). https://doi.org/10.1214/aoms/1177729694
A. Gómez-Valent, Phys. Rev. D 106, 063506 (2022). https://doi.org/10.1103/PhysRevD.106.063506. arXiv:2203.16285 [astro-ph.CO]
R. Trotta (2017) arXiv:1701.01467 [astro-ph.CO]
F. Bouchè, S. Capozziello, V. Salzano, K. Umetsu, Eur. Phys. J. C 82, 652 (2022). https://doi.org/10.1140/epjc/s10052-022-10586-5. arXiv:2205.03216 [gr-qc]
G. Gandolfi, B.S. Haridasu, S. Liberati, A. Lapi, Astrophys. J. 952, 105 (2023). https://doi.org/10.3847/1538-4357/acd755. arXiv:2305.13974 [astro-ph.CO]
Acknowledgements
The research of S.Z. and V.S. is funded by the Polish National Science Centre grant No. DEC-2021/43/O/ST9/00664. D.B. acknowledge support from projects PID2021-122938NB-I00 funded by the Spanish “Ministerio de Ciencia e Innovación” and FEDER “A way of making Europe” and PIC-2022-02 funded by Salamanca University.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3.
About this article

Cite this article
Zamani, S., Salzano, V. & Bettoni, D. Gravitational lensing from clusters of galaxies to test disformal couplings theories. Eur. Phys. J. C 84, 618 (2024). https://doi.org/10.1140/epjc/s10052-024-13000-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-024-13000-4