
Abstract
The main aim of this paper is to perform a model comparison for some reconstructions of the key properties that describe the dark energy of the Universe i.e. energy density and the equation of state (EoS). We carry out this process by using a binning and a linear interpolation methodologies, and on top of that, we incorporate a correlation function mechanism. An extension of the two of them was also introduced, where internal amplitudes are allowed to vary in height as well as in position. The reconstructions were made with data from the Hubble parameter, Supernovae Type Ia and Baryon Acoustic Oscillations (H+SN+BAO), all of which span a range from \(z=0.01\) to \(z=2.34\). First we perform the parameter estimation for each of the reconstructions to then provide a model selection through the Bayesian Evidence. Throughout our process we found a better fit to the data, up to \(4\sigma \) compared to \(\Lambda \)CDM, and the presence of some interesting features, i.e. an oscillatory behaviour at late times, a decrease in the dark energy density component at early times and a transition to the phantom divide-line in the EoS. To discern these features from noisy contributions, we include a principal component analysis and found that some of these characteristics should be taken into account to satisfy current observations.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Since the discovery of the current accelerated expansion of the Universe, cosmologists have been challenged to explain the cause of this mysterious phenomenon. In order to provide a possible explanation, the idea of a new exotic source was introduced, called dark energy (DE). In addition to the cosmological constant \(\Lambda \), being the simplest assumption to be the dark energy, there is also a still-unknown key component for structure formation in the Universe, coined as Cold Dark Matter (hereafter CDM). These two dark components comprise the basis of the standard cosmological model or \(\Lambda \)CDM. Even though the \(\Lambda \)CDM model has had remarkable achievements, i.e. satisfies most of the current cosmological observations on different scales, it still presents several shortcomings. On the theoretical side, for instance, a disagreement encountered by cosmology and quantum field theory about the vacuum predictions [1]; on the observational side several problems began to arise, for example the discrepancy on the measurements of the Hubble constant \(H_0\) among datasets [2]. This so-called Hubble tension seems to be enhancing as observations become more precise [3] and even a variable \(H_0\) (also named “running”) has also been found [4,5,6,7,8], further indicating the standard model’s inability to reconcile late-time data with high-redshift data. The presence of these issues opens up the possibility to consider alternatives beyond the \(\Lambda \)CDM model. A natural extension to the cosmological constant is to allow a redshift dependency either through the equation of state (EoS) \(w_{{\texttt{DE}}}(z)\) or the energy density \(\rho _{\texttt{DE}}(z)\) for the dark energy. Different proposals with a dynamical behaviour have been presented. Some of them include scalar fields in the form of Quintessence, Phantom [9,10,11] or the two of them combined, called Quintom models [12]; others intent to modify the theory of general gravity known as f(R) models [13], anisotropic massive Brans–Dicke gravity [14] or theories with extra dimensions such as brane world models [15, 16].
On the other hand, in the absence of a fundamental and well defined theory, several parameterizations to cosmological functions have been suggested to get insights of the general DE behaviour and hence to look for possible deviations from the cosmological constant [17]. Some of them include quantities such as the deceleration parameter q(z) [18,19,20], the jerk parameter j(z) [21, 22] or, more predominantly, the dark energy EoS \(w_{{\texttt{DE}}}(z)\). Focusing on the EoS we can find a plethora of parameterizations to express \(w_{{\texttt{DE}}}(z)\) (or \(w_{\texttt{DE}}(t)\)), for instance in terms of power-law, logarithmic, exponential and trigonometric components, or combinations of them [17, 23, 24]. These approaches can even be classified depending on the number of parameters that describe \(w_{{\texttt{DE}}}(z)\), i.e. with a single, two or more parameters [25, 26]. Similarly, there have been, although not as many as for the equation of state (EoS), parameterizations for the dark energy density, i.e. the Generalised Emergent Dark Energy (GEDE) [21, 27, 28], the Graduated Dark Energy (gDE) [29,30,31,32], the Early Dark Energy (EDE) [33] and the Energy–Momentum Log-gravity (EMLG) [34]. Generally, in these models it can be obtained an associated EoS but the main assumptions come from the density, that is, the GEDE considers directly the evolution of the density parameter, and in the gDE model an inertial mass density is introduced which allows a possible transition to negative effective energy densities. Even though these parametric forms usually provide a better fit to the data, they have the limitation of assuming an a priori functional form which may lead to some bias or misleading model-dependent results, regardless of the DE nature. To avoid these possible issues, non-parametric and model-independent techniques are used. They allow us to extract information directly from the data to detect features within cosmological functions. That is, the goal of non-parametric and model-independent approaches is to reconstruct (infer) an unknown quantity without a predefined shape. Non-parametric reconstructions may include Artificial Neural Networks or Gaussian processes, as they have proven to be useful in cosmology as more data become available [35,36,37,38,39,40,41,42,43,44,45,46]. Examples of model-independent ones are higher order terms on a Taylor series [17], Fourier series expansion [47] and the Padé approximation [48], just to mention a few. Another example of a model-independent reconstruction (relevant to this work) was introduced by [49] that considers adding a correlation function term to the data. An interesting result, by using this technique, found that a dynamical form of \(w_{{\texttt{DE}}}(z)\) is preferred over the constant value with a 3.5\(\sigma \) significance level [3]. Also, in [50] this same method was used directly with the DE energy-density, finding a dynamic behavior and even evidence in its favor when compared with the standard model, although this only happened when reducing some of the parameters’ priors. Moreover, a similar path consists of combining the Principal Component Analysis (PCA) with the Goodness of Fit [51], where PCA helps to remove noisy oscillations induced by the reconstruction method to find deviations from the cosmological constant [52]. In a similar fashion, the study in [53] introduced the nodal reconstruction in which a piecewise linear interpolation (or cubic splines) represents the main functional form to be reconstructed. This approach has been utilized to recover the EoS directly from the data [53] and its final form presented a well constrained redshift dependency with a small bump at \(z\approx 1.3\), but beyond \(z\approx 1.5\) the data was too inaccurate to provide a good prescription. Later on, a similar form of this method was also applied in [54, 55] and in [56] (although here it is referred as knot-spline reconstruction) and showed that this type of model-independent approach can be used to find specific features by allowing some central knots to vary both in height and position. More recently an improvement of these methods has been applied to the dark energy EoS [57].
The main aim of this work is to perform model-independent reconstructions of the dark energy features and to provide a model comparison through the Bayesian evidence and goodness-of-fit. Our analysis is carried out among the nodal reconstruction [57], the correlation function method [49], an extension of the two of them where internal amplitudes are allowed to vary in height as well as in position, and finally, for comparison, to include some of the parametric proposals. Even though these techniques are applicable to any function describing the dark energy, we focus on the EoS and the energy density. After the reconstruction is carried out, some of the cosmological functions can therefore be derived, i.e. Hubble parameter H(z), deceleration parameter q(z) and the Om(z) diagnostic. Finally we perform the PCA to discern possible important features from noise contributions. The novelty in this work is the joint study of the EoS and the energy density by using the model-independent approaches (nodal and step functions) to then perform model comparison through the Bayesian evidence, derived some functions in terms of the results and carried out the PCA to find preferred behaviours of DE to then keep, discard or propose other models/parameterizations.
The paper is organized as follows: in Sect. 2 we describe the reconstruction methodology, the PCA method is also introduced and explained. Then in Sect. 3 we provide a brief review of the underlying theory, datasets and some specifications about the parameter estimation and model selection. In Sect. 4 we present the main results, and finally in Sect. 5 we give our conclusions.
2 Reconstruction methodology
One of the primary reconstruction methods used in this paper is built on a set of step functions. In this approach steps or bins are utilized to describe any function f, where the steps are connected together via hyperbolic tangents to preserve continuity. The target function looks like this:
where N is the number of bins, \(f_i\) the amplitude of the bin value, \(z_i\) the position where the bin begins in the z axis and \(\xi \) a smoothness parameter.
Another approach used in this paper is the nodal reconstruction [57]. This type of reconstruction consists of performing interpolations, either by using linear, cubic or higher order splines, to fill in the gaps amongst certain number of nodes. The simplest example is the linear interpolation, that is, given two coordinates \((z_i, f_i)\) and \((z_{i+1}, f_{i+1})\), the interpolated function is as follows
The interpolation could also be made with higher order polynomials (or splines) to preserve smoothness, nonetheless it may present heavy correlations between nodes or introduce unwanted noise to the reconstruction, it may also present numerical problems when the amplitude values are changing too abruptly or when the nodes are positioned too close, as shown in the appendix of [53].

Example of the reconstruction plot for the f(z) function with 8 nodes and bins. We observe the difference in the reconstruction when using two values for the smoothness parameter \(\xi \)
In both types of reconstructions the nodes are located in space at certain positions \(z_i\) and with variable amplitudes \(f_i\). For instance, Fig. 1 displays an arbitrary function f(z) with amplitudes randomly selected \((N=8)\) at fixed equally distant positions and for two values of the smoothness parameter, along with the interpolation method.
A modified version of the binning and nodal reconstruction techniques is to consider the internal positions \(z_i\) be free parameters, which will allow us to capture more specific features at certain places [55, 56]. Notice that in this version, the internal variable positions have to be sorted in a way to avoid possible overlapping in the reconstructions. This approach gives more degrees of freedom (one for each variable \(z_i\)) to the reconstruction. When using the linear interpolation the expected behavior is straightforward, as it only varies the lines between nodes, however in the binning process it will affect the width of the bins, so it would be easier to find specific features on the positions rather than on the amplitudes.
Finally, there exists the possibility of either overfitting by using a very complex model with a large amount of bins (nodes) or underfitting by not capturing enough features due to the use of just few bins (nodes). Both of these possible issues can be managed by performing a model comparison among reconstructions through the Bayesian Evidence, that is, we modulate the impact of additional parameters and their priors to find out the most suitable to the data. This method follows the principle of simplicity and economy of explanation known as Occam’s Razor [58] which states: “the simplest theory compatible with the available evidence ought to be preferred”.
2.1 Correlation function method
This method is applied on top of the binning approach in order to obtain a function that evolves smoothly [59]. The idea behind it is to treat the function in place as a random field evolving along with a correlation function \(\xi \), for instance
with \(\xi (0)\) being the normalization factor and \(z_c\) represents a smoothing distance. The correlation function (3), named CPZ [49], has a characteristic correlation length after which its contribution decreases, hence providing stronger correlations between neighboring bins when they are located at distances smaller than \(z_c\). There exist several alternatives that can reproduce this behaviour up to a certain degree, like the exponential fall-off \(\xi (\delta z) = \xi (0)e^{-\delta z/ z_c}\) or the power law \(\xi (\delta z) = (\delta z/ z_c)^{-n}\), but the CPZ has a more transparent dependency in the parameters \(f_i\), a relatively simpler behaviour and it constrains the high frequency modes better [49]. Throughout this work, we use the following values \(z_c = 0.3\) and \(\xi (0) = 0.1\) since they normalize the shorter wavelength modes of the data [59].
Assuming every amplitude \(f_i\) are equally distributed with the same width-location \(\Delta = z_{i+1} - z_i\), then the average of f(z) over each \(f_i\) is
The variation from the fiducial model averaged over the bin is \(\delta f_i = f_i - f_{\textrm{fid}}\), where the fiducial model is the underlying scheme upon which our reconstruction will be dependant on. In this way the covariance matrix can be obtained by
and therefore the associated prior
Finally, once the prior is given (or equivalently \(\chi _{\textrm{prior}}^2 = -2 \ln P_{\textrm{prior}}\)), our total \(\chi ^2\) to minimize becomes
The fiducial model could be one previously known, for instance in the case of the dark energy EoS, it could be the cosmological constant with \(w_{{\texttt{DE}}}(z)\) \(=-1\) or \(\rho _{\texttt{DE}}(z)\)=constant. However, demanding a behaviour like the cosmological constant may create a bias when performing the reconstruction. The same would be true for any other fixed fiducial model, so we opted for the floating prior proposed by [49], where
here \(z_j\) is the position of the amplitude \(f_j\) and \(N_j\) is the number of amplitudes that fulfill the condition \(|z_j-z_i|\le z_c\). This floating prior makes sure that the parameter values stay continuous by evaluating the mean value of each parameter with its immediate neighbors.
It is important to mention that the correlation function method applied here is used as an “agnostic” way of reducing overfitting, agnostic in the sense that our imposed correlations are mainly obtained via a data-driven approach, not a theory-driven one, i.e. effective field theories (EFTs) such as Quintessence or Horndeski [60,61,62,63,64]. This could provide a small bias against EFTs, particularly Quintessence, as explained in [60]. Also, since this method is being used as a way to diminish overfitting it could even prevent some interesting features to appear or even wither existing ones, such as the disappearance of wiggles in [63, 64] when using a theory prior. To see if any possible bias may arise we will have an instance where we do not use the Correlation Function method (as seen in Fig. 5).
2.2 Bayesian statistics
In order to perform the parameter estimation we follow the definition of the Bayes Theorem
being u the vector of parameters of our hypothesis M (or model) to assess, D is the experimental (observational) data, P(u|D, M) the posterior probability distribution, \({\mathcal {L}}(D|u,M)\) the likelihood, P(u|M) the prior distribution and E(D|M) the Bayesian evidence. Once the Bayesian evidence is computed for two models \(M_1\) and \(M_2\), the Bayes factor is defined as
This quotient, together with the Jeffrey’s scale shown in Table 1 [58, 65], is a great empirical tool for performing model selection, that is, it gives an insight of how good a model \(M_1\) is when compared to model \(M_2\). An example of this method can be seen in [66] where the authors compared some DE models to \(\Lambda \)CDM. In this work, \(M_1\) will correspond to \(\Lambda \)CDM and \(M_2\) will be any of our reconstructions in order to make a direct comparison with the standard model. Even so, it is important to mention that Jeffreys’ scale is empirical in nature and sometimes rule out the true model [67]; added to this we have the dependence of the Bayesian evidence on priors and on model constrains [68]. So, even though it is a great tool for comparison, it should not be taken as completely decisive when performing model selection.
2.3 Principal component analysis
After doing the reconstruction we can perform a process known as Principal Component Analysis (PCA) on the parameter space to draw conclusions about the data and how well they are constraining the parameter space. Once the parameter inference is complete, we compute the Fisher matrix of the parameters \(w_i\), which is \(F=C^{-1}\), where C is the covariance matrix. Then, we diagonalize F to find a basis where the parameters are uncorrelated, so that
where the rows of W are the eigenvectors \(e_i(z)\) of the basis in which our parameters are uncorrelated and D is a diagonal matrix. If \(\vec {p}\) is the vector of the best-fit values of our \(f_i\) then the new uncorrelated parameters are \(\vec {q}=W\vec {p}\). Being \(d_i\) the diagonal elements of D sorted out such that \(d_1>d_2>\cdots >d_N\), and also their corresponding \(e_i(z)\) and \(q_i\). These \(d_i\) are related to the errors as \(\sigma _i =\frac{1}{\sqrt{d_i}}\). Then, we can reconstruct the function in place
with standard deviation
where \(z_n\) is the location for each parameter \(f_i\). Now we can choose any number of principal components (PCs) to reconstruct the function (from one PC up to the original number of parameters in the reconstruction). If we have the same number of PCs as there are bins then the reconstruction will look the same as no variance has been removed, but by removing the PCs with smaller \(d_i\) contribution, then we remove the noisiest aspects of the reconstruction (with the biggest errors \(\sigma _i\)). A common practice is to remove enough PCs to maintain \(95\%\) of the information or variance.
3 Theory and datasets
For a homogeneous and isotropic flat universe given by the Friedmann–Robertson–Walker metric, the Friedmann equation describing the dynamical evolution, in terms of redshift z, can be written as
where the Hubble parameter H(z) represents the expansion rate of the Universe, with \(H_0\) being its value today. Here, we have the components of the Universe written in terms of the dimensionless density parameters \(\Omega _i(z)\equiv \rho _i(z)/\rho _{\texttt{c}}(z)\), where their contribution at the present time (represented by subscript 0) are \(\Omega _{\textrm{r,0}}\) for the relativistic particles, \(\Omega _{\textrm{m,0}}\) describes the matter content (baryons and dark matter) and \(\Omega _{\Lambda , 0}\) is associated to the cosmological constant; \(\rho _{\texttt{c}}\) is the critical density of a spatially flat Universe.
By letting aside the cosmological constant and allowing a dynamical dark energy component, the last term in the Eq. (14) is replaced by \(\Omega _{\Lambda ,0} \rightarrow \) \(\rho _{{\texttt{DE}}}(z)/\rho _{{\texttt{c,0}}}\). Furthermore, if the dark energy is assumed to be a perfect fluid with a barotropic EoS, then once we compute the EoS we are able to derive the energy density through
On the other hand, the dark energy density could, in general, come from an effective model contribution and not necessarily from a physical component. Hence \(\rho _{\texttt{DE}}(z)\) may have any shape (including negative values). Therefore, if the shape of \(\rho _{{\texttt{DE}}}(z)/\rho _{{\texttt{c,0}}}\) is obtained from any process, then we are able to derive its associated equation of state:
Finally, if the shape of the energy density is obtained, either directly or through \(w_{{\texttt{DE}}}(z)\), we are able to compute some derived functions, for instance the Om diagnostic, which provides a null test for the cosmological constant [69]
and the deceleration parameter
3.1 Data sets
The Hubble parameter tells us the expansion rate of the Universe, and it can be expressed as a function of the redshift through the Friedmann equation. This parameter can also be assembled by gathering measurements of old stars known as cosmic chronometers as they work as “standard clocks” in cosmology. That is, H(z) can be obtained by calculating the derivative of the cosmic time with respect to the redshift as
where the rate \(\Delta z/\Delta t\) is measured with the difference in age of the cosmic chronometers. In this work we will use the collection of these cosmic chronometers [70,71,72,73,74,75,76] (written as H in the datasets), which can be found within the repository [77].
Similarly to standard clocks, the type Ia supernovae (SNIa) are coined as the “standard candles”. The distance modulus of the SNIa is derived from the empirical relation when observing light curves
where X is the stretch parameter, C is the color parameter, \(M_B\) is the absolute magnitude, \(m_B^*\) is the B-band apparent magnitude, \(\alpha \) and \(\beta \) are nuisance parameters. The Pantheon Sample measured the apparent magnitude \(m_B=m_B^*+\alpha X - \beta C\), with fix absolute magnitude \(M_B\). Also, for a given cosmological model the distance modulus is
from which the luminosity distance, \(D_L(z)=H_0 d_L(z)\), can be calculated in terms of redshift as \(d_L(z)=(1+z)r(z)\), with r(z) being the comoving distance
In this work we use the full catalogue of 1048 supernovae from the Pantheon SN Ia sample, covering a redshift range of \(0<z<2\) [78] (written as SN in the datasets). The full covariance matrix associated is comprised of a statistical and a systematic part, and along with the data, they are provided in the repository [79].
On the other hand, the baryon acoustic oscillations (BAOs) are used as “standard rulers” in cosmology, as they measure the angular distance \(D_A=r(z)/(1+z)\). The BAO scale is set by the radius of the sound horizon
with \(c_s(z)\) being the sound speed of the baryon-photon fluid and \(z_d\) the drag epoch [80]. Since the size of \(r_d\) depends on the cosmological model, the BAO actually constrains \(D_A(z)/r_d\) (with \(D_A(z)=H_0 d_A(z)\)), \(H(z)/r_d\) and the volume average distance \(D_V(z)/r_d=[(1+z)^2 D_A^2(z)cz/H(z)]^{1/3}\). The sound horizon is calibrated by using Big Bang Nucleosynthesis [81]. The BAO datasets used here contain the SDSS DR12 Galaxy Consensus, BOSS DR14 quasars (and eBOSS), Lyman-\(\alpha \) DR14 auto-correlation, SDSS MGS and 6dFGS located at different redshifts up to 2.36. For a more complete explanation see [82,83,84,85,86,87] and references therein.
To compute the \(\chi ^2\) for each data sample, we have
where \(d_{m}\) and \(d_{\textrm{obs}}\) are our model predictions and the observables respectively; \(C_{\textrm{data}}\) is the covariance matrix associated to each of the datasets. Since observations of each dataset are independent from each other, the joint \(\chi ^2\) can be calculated as
3.2 Models and priors
Since the Bayesian evidence is very susceptible to the number of parameters and their prior distribution, it is worth to be careful when selecting them. A summary of the additional parameters along with their prior ranges is displayed in Table 2.
First, to provide a comparison to the reconstructions, we constrain some parameterization models. For instance, the wCDM model which corresponds to a constant EoS \(w_{{\texttt{DE}}}(z)\)\( = w_c\) and the Chevallier–Polarski–Linder (CPL) EoS [26] in which \(w_{{\texttt{DE}}}(z)\)\(= w_0 + w_a\frac{z}{1+z}\), being \(w_0\), \(w_a\) and \(w_c\) free parameters to be estimated with data. The flat priors for \(w_0\) and \(w_c\) are the same \([-2.0,0.0]\) and the flat prior used for \(w_a\) is \([-2.0, 2.0]\). Then, inspired by the idea of a density capable of performing a possible transition to \(\rho _{\texttt{DE}} \le 0\) at high redshifts, similar to the one introduced by [29], we propose a simple parameterization with the shape of a sigmoid function:
with \(z_{\textrm{cut}}\) the redshift value where the transition may occur and \(k_0=1+\frac{1}{1+e^{10z_{\textrm{cut}}}}\) is a constant which compensates the necessary amount so that \(\rho _{\texttt{DE}}(z=0)/\rho _{\texttt{c,0}}=1-\Omega _{\textrm{m,0}}\), to account for the Friedmann constraint. The parameter \(z_{\textrm{cut}}\) has a flat prior within the range [0.0, 3.0]. The sharp part of this sigmoid function comes from the argument in the exponential, if this number is larger (smaller) its transition to zero would be sharper (smoother).
Throughout all the reconstructions we let the data to decide the level of complexity of the two main functions within the range \(0\le z \le 3\), that is, we place the nodes and bins (free parameters) over this range, and for \(z>3\) we adopt a constant value corresponding to the last amplitude.
In the first set of reconstructions, the position of the nodes and bins are kept fixed and uniformly distributed within \(z=[0,3]\). In both types of reconstructions it is relatively free to choose any number of amplitudes, thus we used from 1 to 6 (and then, without loss of generality, jump to 20) to see the improvement of the fit to the data and how well the Bayesian evidence responded. Notice that the wCDM model is equivalent to the EoS reconstruction with one bin. In particular, we allow the possibility of having negative energy density, hence the amplitudes for the nodes and bins for \(\rho _{{\texttt{DE}}}(z)/\rho _{{\texttt{c,0}}}\) were set to move freely on the ordinate with flat priors [0.0, 1.5] if \(z<1.5\), otherwise the prior is set to \([-1.5,1.5]\), since it is beyond \(z=1.5\) where a switch to negative energy density is generally presented. For the amplitudes in the EoS we have flat priors of \([-2.5, 1.0]\). An important point is that when incorporating the correlation function method with a floating prior (\(\chi ^2_{\textrm{prior}}\)) or CPZ, it is recommended to choose a large number of bins. In our case, we used 20 bins and obtained consistent results.
In the first set of reconstructions, the positions \(z_i\) for each parameter remained fixed, however one may argue that the location of the amplitudes could bias the results. To check this point, in the second set of reconstructions every amplitude varies as well as the internal positions are allowed to move freely, spanning over the z-direction (but without overlapping each other). For the reconstruction of \(w_{{\texttt{DE}}}(z)\) we consider 6 parameters: 4 varying amplitudes and 2 internal positions; similarly for \(\rho _{{\texttt{DE}}}(z)/\rho _{{\texttt{c,0}}}\) we use 5 parameters: 3 amplitudes and 2 internal positions. We will refer to them as 4y2x (3y2x) or simply internal \(z_i\). Whereas the priors for the amplitudes remain the same as in the first set, the priors for the internal \(z_i\) positions are [0.2, 1.4] and [1.6, 2.8] respectively.
Regarding the cosmological parameters, we have: the reduced dimensionless Hubble parameter \(h_0=H_0/100~\text {km}~\text {s}^{-1}~\text {Mpc}^{-1}\) with a flat prior of [0.6, 0.8], the baryon density \(\Omega _{b}h_0^2\) with prior [0.021, 0.024] and the matter density parameter \(\Omega _{\textrm{m,0}}\) with a prior of [0.2, 0.4].
To perform the reconstruction analysis we used a modified version of the SimpleMC code [88] along with dynesty [89], a nested sampling algorithm which allows to compute efficiently the Bayesian evidence. For the number of live points we followed the general rule [90] of using \(50\times ndim\) live points, where the dimensionality ndim corresponds to the number of parameters, so the total number of live points depends on the reconstruction and the amount of bins/nodes. As for the stopping criterion we have an accuracy of 0.01, which indicates the maximum difference between samples. Within the SimpleMC code we have also implemented the Principal Component Analysis and the correlation function method with the floating prior. For the functional posterior confidence contour plots we used a python package named fgivenx [91]. See Ref. [92], and references therein, for an extended review of the cosmological parameter inference and model selection procedure.
4 Results
We present the results in four subsections: regarding the EoS, the energy density, the derived functions in terms of our results and the PCA analysis to distinguish noise from signal. The best-fit parameter values, the logarithm of the Bayes’ factor \((\ln B_{\Lambda \text {CDM},i})\) and the goodness of fit \((\Delta \chi ^2)\) are presented in Table 3; complementary to this table, both quantities are displayed in Fig. 2. The regions of confidence for the parameterizations are shown in Fig. 3, whilst the reconstructions are shown in Figs. 4 and 5.
4.1 Dark energy equation of state
The best-fit values (with standard deviations) for the wCDM and the CPL parameterization, correspond to \(w_c=-0.99\pm 0.06\), \(w_0=-1.01\pm 0.08\) and \(w_a=0.12\pm 0.47\) respectively. That is, the models with one or two parameters, wCDM, CPL and the 2-parameter reconstructions produce very similar results, which means they are statistically consistent with the cosmological constant, within the 68% confidence region (see Fig. 3 and the first column of Fig. 4). Also, these results can be validated when comparing the \(\Delta \chi ^2\) presented in Table 3.

In this graph we show the differences in the \(\Delta \chi ^2\) and the Bayes factor between \(\Lambda \)CDM and our reconstructions for \(w_{\texttt{DE}}(z)\) and \(\rho _{\texttt{DE}}/\rho _{\texttt{c,0}}\). The green shades show the strength-of-evidence according to the Jeffrey’s scale and the orange shades show the 1 to 4-\(\sigma \) levels of statistical significance \(S/N \equiv \sqrt{|\Delta \chi ^2|}\). Ideally we want the upper markers to stay as close as possible to the black line at 0 (preferably to cross it), which it is an indication of a better Bayes’ factor, and the lower ones to be far away from zero, which indicates a better fit to the data. The stars indicate the fitness of the reconstruction of the CPL EoS (top) and the energy density with a sigmoid (bottom), the crosses indicate the internal \(z_i\) reconstructions and the triangles the reconstructions with 20 bins plus correlation function. The binning reconstructions are plotted with blue lines, whereas the nodal with red lines

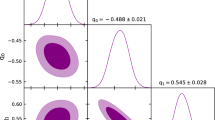
These plots show the functional posterior probability: the probability of \(w_{{\texttt{DE}}}(z)\) or \(\rho _{{\texttt{DE}}}(z)/\rho _{{\texttt{c,0}}}\) as normalised in each slice of constant z, with colour scale in confidence interval values. The 68% \((1\sigma )\) and 95% \((2\sigma )\) confidence intervals are plotted as black lines. From left to right: parameterized equations of state for wCDM and CPL, phenomenological sigmoid and 1-bin energy density reconstructions. The dashed black line corresponds to the standard \(\Lambda \)CDM values

From top to bottom: reconstructed \(w_{\texttt{DE}}(z)\) with bins (and nodes), reconstructed \(\rho _{\texttt{DE}}(z)/\rho _{\texttt{c,0}}\) with bins (and nodes). It is easy to observe there is more structure (more apparent features) in the reconstructions as the number of parameters increases (from left to right)
When computing the Bayes’ factors of all the models (green region of the top panel in Fig. 2) one observes, in general, a moderate evidence against the reconstructions regardless of the number of extra parameters, compared to the standard model. However, in the reconstructions certain features at high redshift become apparent as more parameters are added, and therefore an enhancement in the goodness of fit. For instance, when using three amplitudes (second column of Fig. 4), a bump-like shape appears at \(z\approx 1.5\) and after that the general form prefers a crossing of the phantom-divide-line (PDL), i.e. for \(z\gtrsim 2\) the amplitude values lean toward \(w_{\texttt{DE}}<-1\) outside the 68% confidence region, which represents an improvement of \(\Delta \chi ^2 \sim -3\). If we continue the process of adding amplitudes to the reconstructions, the main trend preserves a bump but now located at about \(z\approx 1.2\) and a crossing of the PDL at \(z\sim 1.5\). This is not true though when having 5 extra parameters (and we will have a similar problem with the density with 4 extra parameters), although the reason for this is mainly related to the reconstruction methodology, for a detailed explanation please refer to Appendix A. We also obtained that the cosmological constant is slightly outside of the 95% confidence contours at several places (see last column of Fig. 4), and according to the Table 3 by using the definition of statistical significance in terms of the standard deviation \(\sigma \), that is, the signal-to-noise ratio \(S/N \equiv \sqrt{|\Delta \chi ^2|}\), it represents a \(\sim 3\sigma \) deviation from \(\Lambda \)CDM based on the improvement in the fit alone. These two features play a key role in identifying the correct dark energy model. If future surveys confirm their existence, the cosmological constant and single scalar field theories (with minimal assumptions) might be in serious problems as they cannot reproduce these essential features, and therefore alternative models should be taken into account. Furthermore, in the internal-\(z_i\) reconstructions the internal positions are able to localize the position for the bump and the PDL, and the results resemble the previous ones, see the last two columns of Fig. 5. Besides the presence of the bump and crossing of the PDL, we notice that at \(z=0\) the 68% confidence contour lays down right below the limits of \(w_{\texttt{DE}}<-1\). An important point to stress out is that the freedom of the internal positions led to a better fit to the data, compared to the reconstructions with the same number of parameters but fixed positions; displayed as the x-markers in the top panel of Fig. 2.
Finally, to corroborate our findings, we include two reconstructions with 20 parameters: binning and binning with CPZ correlation function, shown in the column 1 and 2 of Fig. 5. For these particular reconstructions, we have only focused on the binning method as it provides a better fit to the data. As commented above, the correlation method is incorporated to create a function that evolves smoothly, and in general, they both share the same structure: a bump located at \(z\approx 1.2\), a crossing of the PDL at \(z\approx 1.5\) and a slight preference of \(w_{\texttt{DE}}<-1\) at \(z=0\). Besides these three features (found already in the internal models), there is also an oscillatory behaviour throughout the whole structure, which yields to a deviation of about \(4\sigma \) to the \(\Lambda \)CDM. Even though this result may be considered as an overfitting due to the large number of parameters and small \(\Delta \chi ^2\), its Bayes factor is as good as the reconstruction with fewer amplitudes. Also, the authors in [47] obtained a similar shape by using only three parameters in a Fourier basis and concluded a deviation of about \(3\sigma \) from the cosmological constant, as we did here through a different mechanism.

From left to right: reconstructions with 20 bins, 20 bins with correlation function, internal \(z_i\)-bins and internal \(z_i\)-nodes. Purple figures correspond to the EoS whereas green to the energy density

Derived functions for the reconstructed \(w_{\texttt{DE}}(z)\) and \(\rho _{\texttt{DE}}(z)/\rho _{\texttt{c,0}}\) with 20 bins plus correlation function. The red dotted line in the derived \(w_{\texttt{DE}}(z)\) corresponds to the best-fit values
4.2 Dark energy density
Similarly to the previous section, with one extra parameter, through the \(z_{\texttt{cut}}\) in the sigmoid function for \(\rho _{\texttt{DE}}\), we have got a better fit to the data by more than 1\(\sigma \), and its Bayes’ factor results on a negative value \(B_{\Lambda \text {CDM},i}= -0.124 \pm 0.131\), indicating a slight evidence in its favor, although it is still within the 1\(\sigma \) for the error. The constraints of the \(z_{\texttt{cut}}\) parameter corresponds to \(2.101 \pm 0.413\), which provides an insight of a possible vanishing energy density beyond \(z=2\). This feature is also noticeable when looking at the 1-bin reconstruction where the cosmological constant is on the edge of the 68% confidence contour for \(z>1.5\) (see Fig. 3).
By incorporating additional parameters to the reconstruction of \(\rho _{\texttt{DE}}(z)/\rho _{\texttt{c,0}}\) the fit to the data becomes better than the standard model, as shown by the negative values of the \(\Delta \chi ^2\) on the bottom panel of Fig. 2. Even though this behaviour is expected by the increased of complexity, it is accompanied by a penalization incorporated into the Bayes Factor, shown in the green part of Fig. 2. As the number of nodes/bins increases we expect the values of \(B_{\Lambda \text {CDM},i}\) to do so too, however, an important point to note is the existence of a valley on this factor up to 4 parameters, where the first three have negative values indicating an evidence in favor (but still inconclusive) to our reconstructions, and also reflected on the improvement of the \(\chi ^2\). This may be happening due to the data having a preference for an energy density with a bump located at \(z\approx 1.2\) and then as the redshift becomes larger \(\rho _{\texttt{DE}}(z)\) decreases until reaching a zero value, and even passing through negative values, but still statistically consistent with zero. That is, by having at least two amplitudes our reconstruction methodology is flexible enough to present this behavior, as seen in the first three columns of Fig. 4. As we continue adding more parameters, the presence of a possible sign change in the energy density is more pronounced. This transition occurs near \(z\approx 2\), and in the region around \(z\approx 2.5\) the deviation from the cosmological constant peaks. The general behaviour of our reconstructions is reflected by these two main features, which together provide a deviation up to \(2.8\sigma \) from the standard model.
In the same manner as the reconstruction for the EoS, one may say that the position of these two features (the bump at \(z\sim 1.2\) and the vanishing energy density behaviour for \(z>1.5\)) could be biased because the particular location for the amplitudes. Even so, it is stated in [93] that these particular features and their positions are prompted by the Lyman-\(\alpha \) BAO data (as we will further discuss in the PCA subsection). In order to find an optimal place for the internal positions, we set them free by allowing them to move around the z-axis. Because of this additional freedom, the internal reconstruction (or 3y2x model) is able to localize these features and provides a better fit to the data, compared to the reconstruction with three fixed amplitudes. Moreover, despite having 5 extra parameters, the binning reconstruction has a negative Bayes factor which favours this model over the rest of the reconstructions (displayed as crosses in the bottom panel of Fig. 2).
Lastly, as was made with the EoS, we incorporated a 20 bins and 20 bins with the correlation function reconstructions. Both present more substructures like an oscillatory-like behavior at late times and also have a transition to a null or negative density in \(z>2\), as seen in Fig. 5. Analogous to the guidance offered by the oscillatory demeanor found in the EoS reconstruction, its apparent wavering nature in \(z<1.5\) could encourage the study of an oscillatory basis such as a Fourier series. Looking at the \(\Delta \chi ^2\) we notice a deviation from the \(\Lambda \)CDM of about \(3.4\sigma \), and a Bayes factor comparable with the few-parameter reconstructions.
The drop-off behaviour of \(\rho _{\texttt{DE}}(z)\) and, perhaps, a transition to a negative energy density has been captured in other works [29, 50, 93,94,95,96,97], as it seems to alleviate the tension that arises by estimating the Hubble constant \(H_0\) with different datasets. It was also found in [8] that, when considering flat \(\Lambda \)CDM and binning the data, negative energy densities \((\Omega _{m,0} > 1)\) are expected for higher redshifts. Hence, it may be pertinent to study models with a similar demeanor. This behaviour does not necessarily imply a negative physical energy density per se, but it may be the indication of an effective energy density, i.e. similar to the one generated by the curvature component [98, 99].
In general, and throughout the reconstruction process, we have found different features beyond the cosmological constant, which result in deviations up to \(4\sigma \). One final interesting observation is that the reconstructions when using bins are generally better than with nodes and also the Bayes factor shows an improvement. Likewise, there is a preference for the reconstruction with 20 bins over 20 bins plus the correlation function, reflected on the \(\Delta \chi ^2\), in fact there is a strong evidence against using the 20 bins+prior model, according to the Jeffreys’ scale.
4.3 Derived functions
Once we have obtained the general form of both the EoS and the energy density we proceed to obtain their respective derived functions, these being: the Hubble parameter \(H(z)/(1+z)\), the Om diagnostic and the deceleration parameter q(z). For the reconstructed energy density, we get as a derived the EoS and similarly for the reconstructed EoS, the energy density is an inferred one. These derived functions correspond to the 20 bin reconstruction, which produced the best fit, and their posterior probabilities are displayed in Fig. 6. In general, the functions coming from the energy density show an enhanced oscillatory behaviour, compared to the functions derived from the EoS.
When comparing the reconstructed EoS with the one deduced from \(\rho _{\texttt{DE}}/\rho _{\texttt{c,0}}\) we notice an important difference: we allowed for negative energy density values, hereby the derived EoS presents a discontinuity at about \(z\approx 2\), seen in the best-fit model denoted by the red dotted line in Fig. 6. Such type of discontinuities have been found and studied in other reconstructions and different models, such as [29, 100, 101]. Regarding the derived energy density: when reconstructing \(\rho _{\texttt{DE}}/\rho _{\texttt{c,0}}\) directly its freedom in the parameter space allowed it to reach null values of the energy density, and even negative ones at high redshifts; but when a barotropic EoS is imposed, through the conservation equation, the derived energy density remains always positive with a bump located at \(z\approx 1.5\) and a smooth drop out at high redshifts.
Considering the \(H(z)/(1+z)\), the best-fit reconstructed function passes through the observational H(z) values (red error bars in Fig. 6), \(H_0=69.8\pm 0.8\,\text {km}\,\text {s}^{-1}~\text {Mpc}^{-1}\) from the TRGB [102], consensus Galaxy BAO (from \(z_{\textrm{eff}}=0.38,\,0.51,\,0.61\)) and DR14 Ly-\(\alpha \) BAO (from \(z_{\textrm{eff}}=2.34,\,2.35\)) [83, 85, 87], and hence the best-fit is slightly better compared to the \(\Lambda \)CDM model (black dashed line).
In general, the Om diagnostic shows consistency with several parameterizations and reconstructions [103, 104]. Nevertheless, in our reconstructions we have found a mixed behaviour between quintessence and phantom components, corroborated by the EoS. That is, we have certain places where \(Om(z)> \Omega _{\textrm{m,0}}\) (quintessence) and others with \(Om(z)< \Omega _{\textrm{m,0}}\) (phantom).
Finally, the deceleration parameter q(z) for the reconstructed EoS gives a value for the transition to an accelerated Universe around \(z\sim 0.6\), which is statistically consistent with the \(\Lambda \)CDM value, and with results previously obtained [19, 104, 105]. On the other hand, when q(z) is reconstructed through the energy density, the universe goes through several short periods of acceleration-deceleration (a similar behaviour was seen in [50]), however the main acceleration transition corresponds to \(z\sim 0.45\), unlike in \(\Lambda \)CDM, where the acceleration starts at \(z\sim 0.7\).
4.4 PCA and the Bayes’ factor
By applying the principal component analysis to remove the noisiest modes (enough to preserve \(95\%\) of the variance) of the reconstructions, we see that the biggest changes happened mainly at \(z>2.0\). An example of this can be seen in Fig. 7, where we used the reconstruction with 20 bins for the energy density and the EoS. Since the only information here is coming from the Lyman-\(\alpha \) BAO \((z\sim 2.3)\) it may be reasonable to argue that the main tensions amongst models come from these high-redshift data (as has been also suggested in [106,107,108]), or perhaps it exists the possibility that large systematic errors are present in this dataset. This may be an indication that the dynamical DE behavior, referring to the crossing of the PDL for the EoS and the null energy density at early times, is merely due to noisy data, although this will be confirmed until a significant amount of information is obtained in this redshift region. This also has an effect in the Bayesian Evidence. As the parameters beyond \(z=1.5\) are the least constrained they contribute little to nothing to the final evidence of the reconstruction and thus means that we have to be very careful when utilizing the Bayes’ Factor to directly perform model selection. Added to this is the fact that the Evidence is pretty susceptible to the prior range. Such problems are common when performing reconstructions, but a possible solution has been proposed in [68], although it is still a work in progress.
Nevertheless, something that should be borne in mind is that certain characteristics pointing out to dynamics are still present even when removing the noisiest PCs. These characteristics, in the energy density, are the oscillatory nature at low redshift and the transition to a null or negative energy density in \(z\approx 1.5\); with the EoS the preserved features include the oscillatory behavior, the bump in \(z\approx 1.3\), a preference for values below \(w_{\texttt{DE}}=-1\) at \(z=0\), and the crossing of the phantom divide line in late times.

Applying the principal component technique to our reconstructions of the EoS and the energy density with 20 bins. By eliminating 5 PCs (which add up to about 5% of the total variance for each reconstruction) we obtain the orange figures with slightly overestimated errors localized in \(z>1.5\)
5 Conclusions
Throughout this work we have studied several parametric forms and model-independent reconstructions of two properties of the Dark Energy: the EoS and the energy density. Regarding the parametric forms, we have analyzed the wCDM and CPL models, whereas for the energy density we introduced a simple form given by a sigmoid function to describe a transition behaviour. Then, to introduce more flexibility for the recovered functions, we also included two types of reconstructions: based on step functions smoothly connected (bins) and linear interpolations (nodes). Each of the reconstructions may have several amplitudes as free parameters with fixed locations, as well as variable positions to localize possible features. On the top of the bin reconstruction we incorporated a floating prior that averages the set of neighboring amplitudes to behave as a mean between bins, hence to preserve continuity among heights.
The wCDM and CPL parameterizations of the EoS showed little to no improvement over \(\Lambda \)CDM. However, with just a single parameter, the sigmoid function for the energy density had a better fitness to data as well as a better Bayes’ factor when compared to \(\Lambda \)CDM. Even though this parameterization is phenomenological, it could be an indication that these type of models should be further studied upon.
By adding complexity in the model-independent reconstructions, through extra amplitudes with fixed positions, the general outcome presented a dynamical behavior beyond the cosmological constant. In both reconstructed functions, \(\rho _{\texttt{DE}}(z)\) and \(w_{\texttt{DE}}(z)\), there is a presence of a bump located at about \(z\sim 1.2\). This feature along with a crossing to the phantom-divide-line in the EoS, and a transition to a null energy density (or even negative values) yield to deviations from a constant energy density of about \(3\sigma \). However, for these type of reconstructions the Bayes factor penalized the incorporation of parameters and displayed a moderate evidence against the reconstruction of \(w_{\texttt{DE}}(z)\) and an inconclusive to weak evidence for \(\rho _{\texttt{DE}}(z)\).
In order to avoid a possible bias due to the location of the amplitudes, we have let the internal points to move freely in the z-space. The autonomy of the internal positions led to localize the features, previously mentioned, and to an improvement on the fit of about \(1\sigma \), in comparison to the same number of amplitudes with fixed positions. Another point to stress out about the internal reconstructions, is the enhancement of the Bayes’ factor which could get even negative values, i.e. for \(\rho _{\texttt{DE}}(z)\) with bins and the 3y2x method.
Finally, when considering 20 parameters in the binned reconstruction we noticed an improvement in the fitness up to about \(4\sigma \). Nevertheless, a key result to bear in mind is that for the case of 20 bins+prior the Bayes’s factor showed a strong evidence against this type of reconstruction. This is also reflected on a worse \(\Delta \chi ^2\), when compared to a reconstruction with the same number of parameters.
In general, the derived functions inherited the behaviour from the reconstructed ones: an oscillatory shape. These functions also exhibited consistency with other reconstruction methods. For instance, a dynamical DE behaviour, a different redshift transition from a decelerating universe to an accelerating one, a better agreement to the BAO data. From the energy density reconstruction, the derived EoS presents a discontinuity at redshift around \(z\sim 2\), which is necessary if the energy density transitioned to negative values; found in several models and parameterizations.
By performing a principal component analysis we found that, in both types of reconstructions, the amplitudes beyond \(z=1.5\) are the least constrained, where the predominant data around these redshift values is the BAO Lyman-\(\alpha \). This shows that current Lyman-\(\alpha \) BAO prefers a nearly null or negative energy density, or a transition from quintessence to a phantom dark energy. However, more precise data in this region is necessary to fully discern a dynamical DE, also, considering that the parameters in this region are unconstrained, it directly affects the estimation of the Bayesian Evidence, so any remarks about the Bayes’ Factor should be made carefully. Nevertheless it was found that some features could indeed be considered as signal, like the general oscillatory behaviour, the bump located at \(z\approx 1.2\) and the \(w_{\texttt{DE}}<-1\) at the present redshift.
Some concluding remarks can be summarized as follow: (i) the binned reconstruction provided better results than the node method; (ii) when incorporating the correlation function, the fitness and the Bayes’ Factor worsen considerably, even when the final shape is very much alike; (iii) our model-independent reconstructions resulted in a better fit to the data (up to \(4\sigma \)) and, in some cases a better Bayes’ Factor; (iv) if future surveys confirm our results, the cosmological constant and single scalar field theories (with minimal assumptions) might be in serious problems as they cannot reproduce these essential features. This could be a great incentive to study DE models with this type of dynamical behavior and encourage direct reconstruction of other functions, such as those that may lead to discontinuities in the EoS. Finally, (v) the PCA analysis showed a great promise for some of the reconstructed features, such as the oscillations and a bump at intermediate redshifts.
As a future prospect, it remains the addition of other datasets that contain information from linear perturbations, such as the cosmic microwave background and the matter power spectrum data. Also, with the resulting shape provided by our model-independent reconstructions, we may search for a parameterization or a physical model that incorporates the important characteristics already found. It would also be interesting to study some alternative PCA methods that have a mathematical basis to truly discern important features from noise.
Data availability
This manuscript has no associated data or the data will not be deposited. [Author’s comment: Our code and data used are public and available in https://github.com/ja-vazquez/SimpleMC.]
References
V. Sahni, Class. Quantum Gravity 19, 3435 (2002). https://doi.org/10.1088/0264-9381/19/13/304. arXiv:astro-ph/0202076
P. Bull, Y. Akrami, J. Adamek, T. Baker, E. Bellini, J.B. Jimenez, E. Bentivegna, S. Camera, S. Clesse, J.H. Davis et al., Phys. Dark Universe 12, 56 (2016). https://doi.org/10.1016/j.dark.2016.02.001. arXiv:1512.05356 [astro-ph.CO]
G.-B. Zhao, M. Raveri, L. Pogosian, Y. Wang, R.G. Crittenden, W.J. Handley, W.J. Percival, F. Beutler, J. Brinkmann, C.-H. Chuang et al., Nat. Astron. 1, 627 (2017). https://doi.org/10.1038/s41550-017-0216-z. arXiv:1701.08165 [astro-ph.CO]
K.C. Wong et al., Mon. Not. R. Astron. Soc. 498, 1420 (2020). https://doi.org/10.1093/mnras/stz3094. arXiv:1907.04869 [astro-ph.CO]
C. Krishnan, E.O. Colgáin, M.M. Sheikh-Jabbari, T. Yang, Phys. Rev. D 103, 103509 (2021). https://doi.org/10.1103/PhysRevD.103.103509. arXiv:2011.02858 [astro-ph.CO]
J.-P. Hu, F.Y. Wang, Mon. Not. R. Astron. Soc. 517, 576 (2022). https://doi.org/10.1093/mnras/stac2728. arXiv:2203.13037 [astro-ph.CO]
C. Krishnan, R. Mondol (2022). arXiv:2201.13384 [astro-ph.CO]
E.O. Colgáin, M.M. Sheikh-Jabbari, R. Solomon, M.G. Dainotti, D. Stojkovic (2022). arXiv:2206.11447 [astro-ph.CO]
J.A. Vázquez, D. Tamayo, A.A. Sen, I. Quiros, Phys. Rev. D 103, 043506 (2021). https://doi.org/10.1103/PhysRevD.103.043506. arXiv:2009.01904 [gr-qc]
R.R. Caldwell, Phys. Lett. B 545, 23 (2002). https://doi.org/10.1016/S0370-2693(02)02589-3. arXiv:astro-ph/9908168
R. Caldwell, E.V. Linder, Phys. Rev. Lett. 95, 141301 (2005). https://doi.org/10.1103/PhysRevLett.95.141301. arXiv:astro-ph/0505494
Z.-K. Guo, Y.-S. Piao, X.-M. Zhang, Y.-Z. Zhang, Phys. Lett. B 608, 177 (2005). https://doi.org/10.1016/j.physletb.2005.01.017. arXiv:astro-ph/0410654
S. Nojiri, S.D. Odintsov, Phys. Rep. 505, 59 (2011). https://doi.org/10.1016/j.physrep.2011.04.001. arXiv:1011.0544 [gr-qc]
O. Akarsu, N. Katırcı, N. Özdemir, J.A. Vázquez, Eur. Phys. J. C 80, 32 (2020). https://doi.org/10.1140/epjc/s10052-019-7580-z. arXiv:1903.06679 [gr-qc]
D. Ida, JHEP 09, 014 (2000). https://doi.org/10.1088/1126-6708/2000/09/014. arXiv:gr-qc/9912002
P. Brax, C. van de Bruck, A.-C. Davis, Rep. Prog. Phys. 67, 2183 (2004). https://doi.org/10.1088/0034-4885/67/12/R02. arXiv:hep-th/0404011
V. Sahni, A. Starobinsky, Int. J. Mod. Phys. D 15, 2105 (2006). https://doi.org/10.1142/S0218271806009704. arXiv:astro-ph/0610026
Y.-G. Gong, A. Wang, Phys. Rev. D 75, 043520 (2007). https://doi.org/10.1103/PhysRevD.75.043520. arXiv:astro-ph/0612196
A.A. Mamon, S. Das, Eur. Phys. J. C 77, 495 (2017). https://doi.org/10.1140/epjc/s10052-017-5066-4. arXiv:1610.07337 [gr-qc]
W. Yu-Ting, X. Li-Xin, L. Jian-Bo, G. Yuan-Xing, Chin. Phys. B 19, 019801 (2010). https://doi.org/10.1088/1674-1056/19/1/019801. arXiv:1004.3370 [astro-ph.CO]
A. Hernández-Almada, G. Leon, J. Magaña, M.A. García-Aspeitia, V. Motta, Mon. Not. R. Astron. Soc. 497, 1590 (2020). https://doi.org/10.1093/mnras/staa2052. arXiv:2002.12881 [astro-ph.CO]
A. Mukherjee, N. Banerjee, Phys. Rev. D 93, 043002 (2016). https://doi.org/10.1103/PhysRevD.93.043002. arXiv:1601.05172 [gr-qc]
O. Akarsu, T. Dereli, J.A. Vazquez, JCAP 06, 049 (2015). https://doi.org/10.1088/1475-7516/2015/06/049. arXiv:1501.07598 [astro-ph.CO]
G. Arciniega, M. Jaber, L.G. Jaime, O.A. Rodríguez-López, Phys. Dark Univ. 37, 101069 (2022). https://doi.org/10.1016/j.dark.2022.101069. arXiv:2102.08561 [astro-ph.CO]
W. Yang, S. Pan, E. Di Valentino, E.N. Saridakis, S. Chakraborty, Phys. Rev. D 99, 043543 (2019). https://doi.org/10.1103/PhysRevD.99.043543. arXiv:1810.05141 [astro-ph.CO]
M. Chevallier, D. Polarski, Int. J. Mod. Phys. D 10, 213 (2001). https://doi.org/10.1142/S0218271801000822. arXiv:gr-qc/0009008
X. Li, A. Shafieloo, Astrophys. J. 902, 58 (2020). https://doi.org/10.3847/1538-4357/abb3d0. arXiv:2001.05103 [astro-ph.CO]
W. Yang, E. Di Valentino, S. Pan, A. Shafieloo, X. Li , Phys. Rev. D 104(6), 063521 (2021). https://doi.org/10.1103/PhysRevD.104.063521. arXiv:2103.03815
O. Akarsu, J.D. Barrow, L.A. Escamilla, J.A. Vazquez, Phys. Rev. D 101, 063528 (2020). https://doi.org/10.1103/PhysRevD.101.063528. arXiv:1912.08751 [astro-ph.CO]
G. Acquaviva, O. Akarsu, N. Katirci, J.A. Vazquez, Phys. Rev. D 104, 023505 (2021). https://doi.org/10.1103/PhysRevD.104.023505. arXiv:2104.02623 [astro-ph.CO]
O. Akarsu, S. Kumar, E. Özülker, J.A. Vazquez, Phys. Rev. D 104, 123512 (2021). https://doi.org/10.1103/PhysRevD.104.123512. arXiv:2108.09239 [astro-ph.CO]
O. Akarsu, S. Kumar, E. Özülker, J.A. Vazquez, A. Yadav (2022). arXiv:2211.05742 [astro-ph.CO]
V. Poulin, T.L. Smith, D. Grin, T. Karwal, M. Kamionkowski, Phys. Rev. D 98, 083525 (2018). https://doi.org/10.1103/PhysRevD.98.083525. arXiv:1806.10608 [astro-ph.CO]
O. Akarsu, J.D. Barrow, C.V.R. Board, N.M. Uzun, J.A. Vazquez, Eur. Phys. J. C 79, 846 (2019). https://doi.org/10.1140/epjc/s10052-019-7333-z. arXiv:1903.11519 [gr-qc]
R.E. Keeley, A. Shafieloo, G.-B. Zhao, J.A. Vazquez, H. Koo, Astron. J. 161, 151 (2021). https://doi.org/10.3847/1538-3881/abdd2a. arXiv:2010.03234 [astro-ph.CO]
M. Seikel, C. Clarkson, M. Smith, JCAP 06, 036 (2012). https://doi.org/10.1088/1475-7516/2012/06/036. arXiv:1204.2832 [astro-ph.CO]
T. Holsclaw, U. Alam, B. Sanso, H. Lee, K. Heitmann, S. Habib, D. Higdon, Phys. Rev. Lett. 105, 241302 (2010). https://doi.org/10.1103/PhysRevLett.105.241302. arXiv:1011.3079 [astro-ph.CO]
A. Velásquez-Toribio, J.C. Fabris, Eur. Phys. J. C 80(12), 1210 (2020). https://doi.org/10.1140/epjc/s10052-020-08785-z. arXiv:2008.12741
M. Aljaf, D. Gregoris, M. Khurshudyan, Eur. Phys. J. C 81(6), 544 (2021). https://doi.org/10.1140/epjc/s10052-021-09306-2. arXiv:2005.01891
Y. Yang, Y. Gong, JCAP 06, 059 (2020). https://doi.org/10.1088/1475-7516/2020/06/059. arXiv:1912.07375 [astro-ph.CO]
F. Gerardi, M. Martinelli, A. Silvestri, JCAP 07, 042 (2019). https://doi.org/10.1088/1475-7516/2019/07/042. arXiv:1902.09423 [astro-ph.CO]
T. Yang, Z.-K. Guo, R.-G. Cai, Phys. Rev. D 91, 123533 (2015). https://doi.org/10.1103/PhysRevD.91.123533. arXiv:1505.04443 [astro-ph.CO]
T. Holsclaw, B. Sansó, H.K. Lee, K. Heitmann, S. Habib, D. Higdon, U. Alam, Technometrics 55, 57 (2013)
D. Wang, X.-H. Meng, Phys. Rev. D 95, 023508 (2017). https://doi.org/10.1103/PhysRevD.95.023508. arXiv:1708.07750 [astro-ph.CO]
G.-J. Wang, X.-J. Ma, S.-Y. Li, J.-Q. Xia, ApJ Suppl. 246, 13 (2020). https://doi.org/10.3847/1538-4365/ab620b
I. Gómez-Vargas, J.A. Vázquez, R.M. Esquivel, R. García-Salcedo (2021). arXiv:2104.00595 [astro-ph.CO]
D. Tamayo, J.A. Vazquez, Mon. Not. R. Astron. Soc. 487, 729 (2019). https://doi.org/10.1093/mnras/stz1229. arXiv:1901.08679 [astro-ph.CO]
A. Mehrabi, S. Basilakos, Eur. Phys. J. C 78, 889 (2018). https://doi.org/10.1140/epjc/s10052-018-6368-x. arXiv:1804.10794 [astro-ph.CO]
R.G. Crittenden, G.-B. Zhao, L. Pogosian, L. Samushia, X. Zhang, JCAP 02, 048 (2012). https://doi.org/10.1088/1475-7516/2012/02/048. arXiv:1112.1693 [astro-ph.CO]
Y. Wang, L. Pogosian, G.-B. Zhao, A. Zucca, Astrophys. J. Lett. 869, L8 (2018). https://doi.org/10.3847/2041-8213/aaf238. arXiv:1807.03772 [astro-ph.CO]
H.-R. Yu, S. Yuan, T.-J. Zhang, Phys. Rev. D 88, 103528 (2013). https://doi.org/10.1103/PhysRevD.88.103528. arXiv:1310.0870 [astro-ph.CO]
D. Huterer, G. Starkman, Phys. Rev. Lett. 90, 031301 (2003). https://doi.org/10.1103/PhysRevLett.90.031301. arXiv:astro-ph/0207517
J.A. Vazquez, M. Bridges, M.P. Hobson, A.N. Lasenby, JCAP 06, 006 (2012). https://doi.org/10.1088/1475-7516/2012/06/006. arXiv:1203.1252 [astro-ph.CO]
J.A. Vazquez, M. Bridges, Y.-Z. Ma, M.P. Hobson, JCAP 08, 001 (2013). https://doi.org/10.1088/1475-7516/2013/08/001. arXiv:1303.4014 [astro-ph.CO]
W.J. Handley, A.N. Lasenby, H.V. Peiris, M.P. Hobson, Phys. Rev. D 100(10), 103511 (2019). https://doi.org/10.1103/PhysRevD.100.103511. arXiv:1908.00906
G. Aslanyan, L.C. Price, K.N. Abazajian, R. Easther, JCAP 08, 052 (2014). https://doi.org/10.1088/1475-7516/2014/08/052. arXiv:1403.5849 [astro-ph.CO]
S. Hee, J.A. Vázquez, W.J. Handley, M.P. Hobson, A.N. Lasenby, Mon. Not. R. Astron. Soc. 466, 369 (2017). https://doi.org/10.1093/mnras/stw3102. arXiv:1607.00270 [astro-ph.CO]
R. Trotta, Contemp. Phys. 49, 71 (2008). https://doi.org/10.1080/00107510802066753. arXiv:0803.4089 [astro-ph]
R.G. Crittenden, L. Pogosian, G.-B. Zhao, JCAP 12, 025 (2009). https://doi.org/10.1088/1475-7516/2009/12/025. arXiv:astro-ph/0510293
E.O. Colgáin, M.M. Sheikh-Jabbari, L. Yin, Phys. Rev. D 104, 023510 (2021). https://doi.org/10.1103/PhysRevD.104.023510. arXiv:2104.01930 [astro-ph.CO]
M. Raveri, P. Bull, A. Silvestri, L. Pogosian, Phys. Rev. D 96, 083509 (2017). https://doi.org/10.1103/PhysRevD.96.083509. arXiv:1703.05297 [astro-ph.CO]
J. Espejo, S. Peirone, M. Raveri, K. Koyama, L. Pogosian, A. Silvestri, Phys. Rev. D 99, 023512 (2019). https://doi.org/10.1103/PhysRevD.99.023512. arXiv:1809.01121 [astro-ph.CO]
L. Pogosian, M. Raveri, K. Koyama, M. Martinelli, A. Silvestri, G.-B. Zhao, J. Li, S. Peirone, A. Zucca, Nat. Astron. 6, 1484 (2022). https://doi.org/10.1038/s41550-022-01808-7. arXiv:2107.12992 [astro-ph.CO]
M. Raveri, L. Pogosian, M. Martinelli, K. Koyama, A. Silvestri, G.-B. Zhao, J. Li, S. Peirone, A. Zucca, JCAP 02, 061 (2023). https://doi.org/10.1088/1475-7516/2023/02/061. arXiv:2107.12990 [astro-ph.CO]
B. Efron, A. Gous, R. Kass, G. Datta, P. Lahiri, Lecture Notes-Monograph Series, vol. 208 (2001)
F.X. Linares Cedeño, A. Montiel, J.C. Hidalgo, G. Germán, JCAP 08, 002 (2019). https://doi.org/10.1088/1475-7516/2019/08/002. arXiv:1905.00834 [gr-qc]
S. Nesseris, J. Garcia-Bellido, JCAP 08, 036 (2013). https://doi.org/10.1088/1475-7516/2013/08/036. arXiv:1210.7652 [astro-ph.CO]
R.E. Keeley, A. Shafieloo, Mon. Not. R. Astron. Soc. 515, 293 (2022). https://doi.org/10.1093/mnras/stac1851. arXiv:2111.04231 [astro-ph.CO]
V. Sahni, A. Shafieloo, A.A. Starobinsky, Phys. Rev. D 78, 103502 (2008). https://doi.org/10.1103/PhysRevD.78.103502. arXiv:0807.3548 [astro-ph]
R. Jimenez, L. Verde, T. Treu, D. Stern, Astrophys. J. 593, 622 (2003). https://doi.org/10.1086/376595. arXiv:astro-ph/0302560
J. Simon, L. Verde, R. Jimenez, Phys. Rev. D 71, 123001 (2005). https://doi.org/10.1103/PhysRevD.71.123001. arXiv:astro-ph/0412269
D. Stern, R. Jimenez, L. Verde, M. Kamionkowski, S.A. Stanford, JCAP 02, 008 (2010). https://doi.org/10.1088/1475-7516/2010/02/008. arXiv:0907.3149 [astro-ph.CO]
M. Moresco, L. Verde, L. Pozzetti, R. Jimenez, A. Cimatti, JCAP 07, 053 (2012). https://doi.org/10.1088/1475-7516/2012/07/053. arXiv:1201.6658 [astro-ph.CO]
C. Zhang, H. Zhang, S. Yuan, T.-J. Zhang, Y.-C. Sun, Res. Astron. Astrophys. 14, 1221 (2014). https://doi.org/10.1088/1674-4527/14/10/002. arXiv:1207.4541 [astro-ph.CO]
M. Moresco, Mon. Not. R. Astron. Soc. 450, L16 (2015). https://doi.org/10.1093/mnrasl/slv037. arXiv:1503.01116 [astro-ph.CO]
M. Moresco, L. Pozzetti, A. Cimatti, R. Jimenez, C. Maraston, L. Verde, D. Thomas, A. Citro, R. Tojeiro, D. Wilkinson, JCAP 05, 014 (2016). https://doi.org/10.1088/1475-7516/2016/05/014. arXiv:1601.01701 [astro-ph.CO]
M. Moresco, Astrophys. J. Suppl. https://gitlab.com/mmoresco/CCcovariance
D.M. Scolnic, D. Jones, A. Rest, Y. Pan, R. Chornock, R. Foley, M. Huber, R. Kessler, G. Narayan, A. Riess et al. (Pan-STARRS1), Astrophys. J. 859, 101 (2018). https://doi.org/10.3847/1538-4357/aab9bb. arXiv:1710.00845 [astro-ph.CO]
Jones et al. and Scolnic et al. https://archive.stsci.edu/prepds/ps1cosmo/
S. Dodelson, Modern Cosmology (Elsevier, Amsterdam, 2003)
É. Aubourg, S. Bailey, J.E. Bautista, F. Beutler, V. Bhardwaj, D. Bizyaev, M. Blanton, M. Blomqvist, A.S. Bolton, J. Bovy et al., Phys. Rev. D 92, 123516 (2015)
S. Alam, M. Ata, S. Bailey, F. Beutler, D. Bizyaev, J.A. Blazek, A.S. Bolton, J.R. Brownstein, A. Burden, C.-H. Chuang et al. (BOSS), Mon. Not. R. Astron. Soc. 470, 2617 (2017). https://doi.org/10.1093/mnras/stx721. arXiv:1607.03155 [astro-ph.CO]
V. de Sainte Agathe, C. Balland, H. du Mas des Bourboux, M. Blomqvist, J. Guy, J. Rich, A. Font-Ribera, M.M. Pieri, J.E. Bautista, K. Dawson et al., Astrophys. J. 878, 47 (2019). https://doi.org/10.3847/1538-4357/ab1d49. arXiv:1901.01950 [astro-ph.CO]
M. Ata, F. Baumgarten, J. Bautista, F. Beutler, D. Bizyaev, M.R. Blanton, J.A. Blazek, A.S. Bolton, J. Brinkmann, J.R. Brownstein et al., Mon. Not. R. Astron. Soc. 473, 4773 (2018). https://doi.org/10.1093/mnras/stx2630. arXiv:1705.06373 [astro-ph.CO]
M. Blomqvist, H. du Mas des Bourboux, N.G. Busca, V. de Sainte Agathe, J. Rich, C. Balland, J.E. Bautista, K. Dawson, A. Font-Ribera, J. Guy et al. Astron. Astrophys. 629, A86 (2019). https://doi.org/10.1051/0004-6361/201935641. arXiv:1904.03430
F. Beutler, C. Blake, M. Colless, D.H. Jones, L. Staveley-Smith, L. Campbell, Q. Parker, W. Saunders, F. Watson, Mon. Not. R. Astron. Soc. 416, 3017 (2011). https://doi.org/10.1111/j.1365-2966.2011.19250.x. arXiv:1106.3366 [astro-ph.CO]
L. Anderson, E. Aubourg, S. Bailey, F. Beutler, V. Bhardwaj, M. Blanton, A.S. Bolton, J. Brinkmann, J.R. Brownstein, A. Burden et al. (BOSS), Mon. Not. R. Astron. Soc. 441, 24 (2014). https://doi.org/10.1093/mnras/stu523. arXiv:1312.4877 [astro-ph.CO]
A. Slosar, J.A. Vazquez. https://github.com/ja-vazquez/SimpleMC
J.S. Speagle, Mon. Not. R. Astron. Soc. 493, 3132 (2020). https://doi.org/10.1093/mnras/staa278. arXiv:1904.02180 [astro-ph.IM]
J. Speagle. https://dynesty.readthedocs.io/en/stable/index.html
W. Handley, J. Open Source Soft. 3(28), 849 (2018). https://doi.org/10.21105/joss.00849arXiv:1908.01711
L.E. Padilla, L.O. Tellez, L.A. Escamilla, J.A. Vazquez, Universe 7, 213 (2021). https://doi.org/10.3390/universe7070213. arXiv:1903.11127 [astro-ph.CO]
O. Akarsu, E.O. Colgain, E. Özulker, S. Thakur, L. Yin (2022). arXiv:2207.10609 [astro-ph.CO]
E. Mörtsell, S. Dhawan, JCAP 09, 025 (2018). https://doi.org/10.1088/1475-7516/2018/09/025. arXiv:1801.07260 [astro-ph.CO]
M. Marciu, Phys. Rev. D 93, 123006 (2016). https://doi.org/10.1103/PhysRevD.93.123006
L. Visinelli, S. Vagnozzi, U. Danielsson, Symmetry 11, 1035 (2019). https://doi.org/10.3390/sym11081035. arXiv:1907.07953 [astro-ph.CO]
K. Dutta, Ruchika, A. Roy, A.A. Sen, M.M. Sheikh-Jabbari, Gen. Relativ. Gravit. 52, 15 (2020). https://doi.org/10.1007/s10714-020-2665-4. arXiv:1808.06623 [astro-ph.CO]
W. Handley, Phys. Rev. D 103, L041301 (2021). https://doi.org/10.1103/PhysRevD.103.L041301. arXiv:1908.09139 [astro-ph.CO]
G. Acquaviva, O. Akarsu, N. Katirci, J.A. Vazquez, Phys. Rev. D 104, 023505 (2021). https://doi.org/10.1103/PhysRevD.104.023505. arXiv:2104.02623 [astro-ph.CO]
A. Gomez-Valent, E. Karimkhani, J. Sola, JCAP 12, 048 (2015). https://doi.org/10.1088/1475-7516/2015/12/048. arXiv:1509.03298 [gr-qc]
D. Wang, W. Zhang, X.-H. Meng, Eur. Phys. J. C 79, 211 (2019). https://doi.org/10.1140/epjc/s10052-019-6726-3. arXiv:1903.08913 [astro-ph.CO]
W.L. Freedman et al. (2019). https://doi.org/10.3847/1538-4357/ab2f73. arXiv:1907.05922 [astro-ph.CO]
J.-Z. Qi, S. Cao, M. Biesiada, T. Xu, Y. Wu, S. Zhang, Z.-H. Zhu (2018). arXiv preprint. arXiv:1803.04109
A. Mukherjee, Eur. Phys. J. Plus 136, 300 (2021). https://doi.org/10.1140/epjp/s13360-021-01269-3. arXiv:2002.12063 [astro-ph.CO]
C. Bernal, V.H. Cardenas, V. Motta, Phys. Lett. B 765, 163 (2017). https://doi.org/10.1016/j.physletb.2016.12.008. arXiv:1606.07333 [astro-ph.CO]
N. Aghanim et al. (Planck), Astron. Astrophys. 641, A6 (2020). https://doi.org/10.1051/0004-6361/201833910. arXiv:1807.06209 [astro-ph.CO]. [Erratum: Astron. Astrophys. 652, C4 (2021)]
J. Evslin, JCAP 04, 024 (2017). https://doi.org/10.1088/1475-7516/2017/04/024. arXiv:1604.02809 [astro-ph.CO]
A. Cuceu, J. Farr, P. Lemos, A. Font-Ribera, JCAP 10, 044 (2019). https://doi.org/10.1088/1475-7516/2019/10/044. arXiv:1906.11628 [astro-ph.CO]
Acknowledgements
L.A.E. was supported by CONACyT México. J.A.V. acknowledges the support provided by FOSEC SEP-CONACYT Investigación Básica A1-S-21925, FORDECYT-PRONACES-CON-ACYT/304001/2020 and UNAM-DGAPA-PAPIIT IA104221.
Author information
Authors and Affiliations
Corresponding author
Appendix A: Capturing features with the right amount of parameters
Appendix A: Capturing features with the right amount of parameters
Given the mathematical structure of the binning scheme and linear interpolation of our reconstructions there are some subtleties that are not obvious at first glance. In particular one that has an effect to this work: a bigger number of parameters does not necessarily means a better fitness to the data. We can only guarantee it to be true when the bigger number of parameters is a multiple of the one being compared. For example if we compare a reconstruction with 2 parameters we can only guarantee that the ones with \(2n, n \in {\mathbb {N}}\) parameters will perform better at fitting the data (and this is true for any number of parameters, not only 2). This is because the bins/nodes are all equally spaced in the redshift range [0, 3]. When we use, lets say 2 and 4 parameters, the reconstruction with 2 having parameter positions of (1.5, 3.0) is a special case of the one with 4 with parameters positions of (0.75, 1.5, 2.25, 3.0), and the same is true for any multiple of 2.
This also means that there may be some features that a certain number of bins/nodes will not be able to capture since they are located in a region not accessible by the larger number of bins/nodes. As seen in Fig. 8 where the data (black dots) are being modeled with 2 and 3 bins. The data clearly show a transition in \(z=1.5\) and the 3 bins cannot, by design, correctly model this transition since the positions of the bins interfere. It is also important to note that these problems appear with an interpolation reconstruction (linear, cubic and so forth). This happens almost exclusively to reconstructions with a low number of nodes/bins because as more parameters are utilized the resolution of the reconstruction becomes a lot better.

Visual representation of the possibility of underfitting data with more parameters
Everything here discussed also applies for the nodes in the interpolation and for the reconstructed density.

Functional posteriors of the EoS reconstruction, from up to down, with 4, 5 and 6 bins using only Hubble parameter data
Even if these effects could seem generally unimportant they are quite relevant to this work since they are both present. When reconstructing either the EoS or the density with 4 and 5 parameters we should expect a better fit to the data with 5 parameters because it has more degrees of freedom, but the \(\Delta \chi ^2\) says otherwise. By separating and analyzing the \(\Delta \chi ^2\) in its components via Eq. (25) we see some differences as expected, but the component responsible for the bad fitness when utilizing 5 bins is the \(\Delta \chi ^2_{H}\) with a difference of 3.36 when compared to the 4 bin reconstruction (for reference we also have \(\Delta \chi ^2_{SN}=-1.38\) and \(\Delta \chi ^2_{BAO}=-0.4\) in favor of the 5 bin reconstruction). This indicates that there might be some feature present in the 4 bin reconstruction which favours it specifically with the Hubble parameter data, and it is not present in the 5 bin one. This feature is also present in the 6 bin reconstruction, as represented by its \(\Delta \chi ^2_{H}=5.26\) (when compared with the 5 bin one).
The absent feature becomes obvious when reconstructing the EoS with 4, 5 and 6 bins with only Hubble parameter data, which is the data where 5 bins has trouble with. The functional posterior of these reconstructions can be seen in Fig. 9. Paying attention to the 1\(\sigma \) region of 4 and 6 bins a bump can be seen followed by a slump in the interval \(0.7<z<2.0\). The 5 bin reconstruction is completely missing this bump and subsequent slump. As explained at the start of the appendix, the reason for the inability with 5 bins to reproduce this behaviour comes from its bins’ positions. The important bin is the one that starts in 1.2 and ends in 1.8, since the transition from bump to slump happens in \(z=1.5\) it is impossible for this bin to correctly capture such trait.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3. SCOAP3 supports the goals of the International Year of Basic Sciences for Sustainable Development.
About this article

Cite this article
Escamilla, L.A., Vazquez, J.A. Model selection applied to reconstructions of the Dark Energy. Eur. Phys. J. C 83, 251 (2023). https://doi.org/10.1140/epjc/s10052-023-11404-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-023-11404-2