
Abstract
This paper reports on the development of a resource-efficient FPGA-based neural network regression model for potential applications in the future hardware muon trigger system of the ATLAS experiment at the Large Hadron Collider (LHC). Effective real-time selection of muon candidates is the cornerstone of the ATLAS physics programme. With the planned ATLAS upgrades for the High Luminosity LHC, an entirely new FPGA-based hardware muon trigger system will be installed that will process full muon detector data within a 10 \({\upmu }\text {s}\) latency window. The large FPGA devices planned for this upgrade should have sufficient spare resources to allow deployment of machine learning methods for improving identification of muon candidates and searching for new exotic particles. Our neural network regression model promises to improve rejection of the dominant source of background trigger events in the central detector region, which are due to muon candidates with low transverse momenta. This model was implemented in FPGA using 157 digital signal processors and about 5000 lookup tables. The simulated network latency and deadtime are 122 and 25 ns, respectively, when implemented in the FPGA device using a 320 MHz clock frequency. Two other FPGA implementations were also developed to study the impact of design choices on resource utilisation and latency. The performance parameters of our FPGA implementation are well within the requirements of the future muon trigger system, therefore opening a possibility for deploying machine learning methods for future data taking by the ATLAS experiment.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Machine learning methods have become standard practice in experimental particle physics, see Refs. [1, 2] for recent reviews. They are frequently used to detect rare processes in offline data analysis, where they are typically executed on servers utilising Intel and AMD processor architectures. Recently, several different machine learning methods have been implemented using field-programmable gate array (FPGA) devices for real-time applications in high energy physics [3,4,5,6,7,8,9,10]. The current state of applications and techniques for fast machine learning is summarised in the recently released community report [11].
FPGA-based machine learning algorithms are deployed in situations where software solutions cannot provide sufficiently high bandwidth within a required low latency. For example, experimental trigger systems at the Large Hadron Collider (LHC) are a perfect use case for deploying FPGA-based neural networks. These systems use sophisticated data filtering algorithms (triggers) to select in real-time interesting collision events. First-level hardware components of these systems process a large amount of data at a 40 MHz rate of LHC collisions with microsecond-level latency, thus necessitating hardware-based machine learning solutions. For instance, FPGA-based algorithms have been proposed for searching for new physics phenomena using calorimeter data [12, 13] and kinematic properties of events [14]. FPGAs are also used to accelerate resource-intensive software algorithms for processing data by large server farms [15]. Such accelerators are being studied for potential deployment in high-level software components of the trigger systems at the LHC.
The present work is motivated by future availability of large FPGA devices that will be installed during the planned upgrades of the ATLAS muon trigger system [16, 17]. These FPGA devices will allow deployment of more sophisticated real-time selection algorithms than what is currently possible. Our goal is the development of generic FPGA-based neural network algorithms that can be used to extend physics capabilities of the future ATLAS trigger system. An advantage of using neural networks is that they are capable of accurately approximating multivariate functions [18, 19]. Therefore, the same neural network circuit design can be used for different applications, with differences configured via different network parameter sets. Deploying such FPGA-based machine learning methods for real-time applications requires careful optimisations in order to reach necessary timing and resource utilisation targets. Performing these optimisations in the context of the ATLAS muon trigger upgrades is one of the subjects of the present work.
In this paper, a resource-efficient FPGA-based neural network regression model is developed that meets FPGA resource and latency requirements of the future ATLAS muon trigger system [16]. These FPGA-based networks will be used to improve performance of standard muon trigger algorithms and to search for new exotic particles. For example, a new trigger can be developed to search for slow-moving heavy charged particles using the resistive plate chamber (RPC) detector [20] for time-of-flight measurements [21]. Deploying such triggers for analysing collision data will improve sensitivity of the LHC experiments for detecting new long-lived particles that are predicted by well-motivated extensions of the standard model (e.g., Refs. [22, 23]). The current RPC trigger system [17, 24] does not allow such triggers because it uses application-specific integrated circuits that perform standard muon logic. The current system will be replaced with an FPGA-based system after 2026. Our goal is to deploy resource-efficient neural networks using spare FPGA resources that should be available after implementation of baseline muon trigger algorithms [16] that do not use machine learning methods.
This paper reports on the development of an FPGA-based neural network regression model that aims to improve performance of the RPC trigger system by measuring more precisely muon transverse momentum (\(p_{\text {{T}}} \)) and charge. This model shows promising potential for reducing rates of hardware-based muon trigger algorithms of the future ATLAS trigger system. It was implemented in FPGA code using the hardware description language (HDL). The HDL is used in order to minimise usage of FPGA resources and to achieve better timing performance. Two other FPGA implementations were also developed to study the impact of design choices on resource utilisation and latency. As detailed later, the resource usage, latency and deadtime of our model are well within the requirements of the future ATLAS hardware trigger system. In this context, the deadtime denotes a time period during which an FPGA circuit is busy with calculations and therefore is not available for processing new data. This result creates an opportunity for deploying novel hardware-based trigger algorithms that use machine learning methods with a minimal impact on the new ATLAS trigger system, which is still being designed.
This paper is organised as follows. Section 2 describes the ATLAS detector and RPC muon trigger system. This section describes key detector features that are included in the simple RPC detector simulation model described in Sect. 3. This section also describes the design of the neural network regression model for measuring muon candidate \(p_{\text {{T}}} \) and charge. Section 4 details performance of this model and compares its efficiency for detecting muon candidates with that of the present ATLAS RPC muon trigger. Section 5 details design and performance of the FPGA implementation of this model. Section 6 summarises our results and ideas for the future work.
2 ATLAS experiment and muon trigger system
The ATLAS experiment at the LHC is a general purpose detector observing high energy collisions of protons and heavy ions. The detector is designed for efficient detection of leptons, hadronic jets and missing transverse energy. The ATLAS physics programme includes measurements of the Higgs boson properties, discovered simultaneously with CMS in 2012 [25, 26], measurements of standard model properties, and diverse searches for new physics phenomena. Efficient selection of muon candidates is the crucial requirement of the ATLAS physics programme.
The ATLAS detector [27] consists of several sub-detectors with cylindrical geometry. The LHC beamline serves as the detector z-axis. The detector consists of one central barrel section and two endcap sections. The inner tracking detectors are immersed in 2 T magnetic field allowing precise measurements of the charged particle momenta. The electromagnetic and hadronic calorimeters are located outside the tracking detectors. The muon spectrometer is located outside the calorimeters and immersed in approximately 0.5 T magnetic field generated by three air-core toroidal magnets.
Interesting collision events are selected in real-time by the two-level trigger system. The first level trigger system (L1) uses dedicated hardware algorithms to analyse data from fast muon detectors and partial calorimeter data, operating at the 40 MHz LHC collision rate. The L1 system accepts events at approximately 100 kHz rate for further analysis by a high-level software-based trigger system which uses software algorithms to select events for offline analysis at approximately 1 kHz rate.
The current L1 system uses the RPC detector to select muon candidates in the central (barrel) region of the detector. The RPCs are fast gaseous detectors [20, 28, 29] with space and time resolution of about 1 cm and 1 ns, respectively. The present ATLAS RPCs are arranged into three concentric double layers (doublets) that are located at radii of approximately 6.8 m, 7.5 m and 9.8 m, referred to as RPC1, RPC2 and RPC3, respectively. The RPC-based muon trigger algorithms were implemented using application-specific integrated circuits that were developed specifically for the RPC trigger system [24].
The L1 muon trigger identifies muon candidates and measures their \(p_{\text {{T}}} \) using six thresholds [30]. The primary single muon trigger (MU20) corresponds to the \(p_{\text {{T}}} \) threshold of 20 GeV. This trigger selects events at about 15 kHz rate at the highest instantaneous LHC luminosity achieved in 2018. The majority of muons produced in LHC collisions are due to decays of heavy flavour hadrons and decays of W and Z bosons [31]. The majority of the selected L1 trigger muon candidates are low-\(p_{\text {{T}}} \) muons with mismeasured \(p_{\text {{T}}} \) values [20].
The ATLAS experiment will undergo extensive upgrades over the next several years to prepare for higher collision rates of the High Luminosity LHC, and correspondingly higher backgrounds. In order to maintain efficient trigger selections, an entirely new hardware trigger system will be installed that will select interesting LHC collisions at about 1 MHz rate [16]. New muon trigger algorithms will be executed using powerful FPGA devices which will allow more complex, re-programmable trigger logic [16]. As a part of these upgrades, new thin-gap RPCs and small diameter muon drift tubes (MDTs) will be also installed in the inner barrel region of the muon spectrometer [17]. Figure 1 shows the ATLAS muon spectrometer after the upgrades.
3 RPC simulation model and neural network design
A simple simulation model of the current RPC detector has been developed for designing and testing a neural network regression modelFootnote 1 for measuring muon \(p_{\text {{T}}} \). The geometry of the present detector is used for this study to allow performance comparisons with the current RPC muon trigger [20]. This model includes three cylindrical doublet RPC layers, with each doublet layer made of two parallel detector surfaces separated by 2 cm. Active detector elements are simulated by parallel strips that are 3 cm wide. The simulation model includes only so-called \(\eta \) strips [20] that measure muon deflections in the bending (r, z) plane.

One quadrant of the ATLAS muon spectrometer after the upgrades which will add new thin-gap RPCs and MDTs in the inner barrel region. The z-axis points along the beam direction and the collision point is at the origin
Approximately 100,000 positively and 100,000 negatively charged muons are simulated, originating at the detector centre. Muons are simulated with a uniform \(p_{\text {{T}}}\) distribution in the range of 3–30 GeV, and with a uniform distribution of muon angles in the range of 40\(^{\circ }\)–85\(^{\circ }\) with respect to the z-axis. Muons with \(p_{\text {{T}}} <3\) GeV are typically stopped by the calorimeters and therefore they are not included in the training. Muons with \(p_{\text {{T}}} >30\) GeV cannot be resolved by the RPC system as they look like straight tracks, therefore including them does not help to improve the network performance. Muons are propagated through the uniform toroidal magnetic field of 0.5 T in the detector region with a radius greater than 6 m. No material scattering effects are included in the simulation. The effect of the material scattering on muon trajectories is expected to be smaller than the RPC strip width and therefore should not affect our results. Verifying this assumption with more precise simulation will be one of the subjects of follow up work.
The probability for a muon passing through a given strip to produce a hit in that strip is 95%. In addition, each muon has 25% average probability to produce one additional hit in the closest strip and 5% probability to produce two hits in two nearby strips. These additional hits are referred to as cluster hits. The probability to produce an extra (cluster) hit is 0% at the strip’s centre and increases linearly to 50% at the strip’s edge. Finally, the probability to produce a noise (background) hit in each strip is 0.1%. These noise hits correspond to ionisation events in the real detector due to background particles, such as low momentum photons and neutrons. The above values for cluster and noise hit probability were chosen to approximate the actual detector response [20]. Figure 2 shows an event display of one simulated muon traversing the RPC detector model.
Each simulated event is processed to reconstruct clusters using adjacent hits in each doublet layer. A cluster contains all contiguous hits in nearby strips in the two layers belonging to one doublet layer. A candidate muon is required to contain one cluster in each of three RPC layers. The reconstruction algorithm iterates over all clusters in the RPC2 layer, with each cluster serving as a seed for building a muon candidate. The two selected clusters in the RPC1 and RPC3 layers are clusters that are closest to the straight line starting at the origin and passing through the centre of the RPC2 cluster (referred to as the seed line). The cluster centre is the mean position of all cluster hits. The centres of the selected clusters are required to be within a window of 0.15 m and 0.6 m with respect to the seed line for the RPC1 and RPC3 clusters, respectively. These window sizes were chosen to collect the majority of muons with \(p_{\text {{T}}} >20\) GeV that curve in the magnetic field while still remaining within the window. Each event typically contains one muon candidate. For a small fraction of events, two muon candidates are reconstructed when a noise cluster in one layer matches muon induced clusters in other two layers.

Illustration of one simulated muon candidate traversing the RPC detector. Six horizontal solid black lines represent six layers of the current RPC detector. Small vertical lines along these lines represent strip boundaries. Solid red line represents the muon track. Dotted magenta line passing through the reconstructed cluster in the RPC2 layer is referred to as the seed line in the text. Coloured markers represent simulated RPC hits

Differences of z coordinates between the impact point of the seed line and the cluster position in the RPC1 (top) and RPC3 (bottom) layers. Positively charged muon candidates are shown in blue and negatively charged muon are shown in red. Muon candidates that include a noise cluster are shown in green
Coordinates of the reconstructed clusters are used to compute three input variables for the neural network regression model. The z-coordinate of the RPC2 seed cluster is the first input variable. In RPC1 and RPC3 layers, the z coordinate differences between the impact point of the seed line and the cluster position serve as other two input variables. These two variables are shown in Fig. 3, separately for muon candidates without noise clusters (pure muons), and for muon candidates with a noise cluster (noise muons). Figure 4 plots these variables as a function of the simulated muon \(1/p_{\text {{T}}} \) for muon candidates without noise clusters, and for muon candidates with a noise cluster. There is a clearly visible linear relation between the z differences and \(1/p_{\text {{T}}} \) for the pure muon candidates. For the noise muon candidates, there are no strong correlations due to the randomness of noise hit positions.

Differences of z coordinates between the impact point of the seed line and the cluster position in the RPC3 layer plotted as a function of simulated muon \(1/p_{\text {{T}}} \). Colour coded density map shows candidates with only muon hits. Orange dots show candidates that include at least one noise cluster
The three input variables are linearly transformed to produce distributions with the same mean and standard deviation values in order to improve regression model performance. The inverse of the simulated muon transverse momentum times its charge (\(q/p_{\text {{T}}} \)) is used as the regression target. The network output serves as a prediction of muon q/pT value. The \(q/p_{\text {{T}}} \) target improves numerical stability of the neural network parameter optimisation because deflections of muons with \(p_{\text {{T}}} > 20\) GeV are of the order of the strip width and decrease further with higher \(p_{\text {{T}}} \) values. Therefore, the network cannot distinguish positively charged and negatively charged muons with \(p_{\text {{T}}} >20\) GeV.

Structure of the neural network model
A neural network model is trained using the PyTorch library with the linear loss function, which is defined as the mean of absolute differences between simulated and predicted \(q/p_{\text {{T}}} \) values. Statistically independent samples were used for training and testing different network configurations. Only muon candidates without noise clusters were used in the training. This approach was found to improve network performance and speed up the training convergence.
Several networks with different numbers of neuron nodes per layer were tested and no strong dependence on the network size was observed for configurations with more than 20 nodes per layer. The selected network configuration contains three fully connected hidden layers with 20 nodes in each layer, as illustrated in Fig. 5. The network nodes use the rectified linear unit (ReLU) activation functions. Other activation functions, such as sigmoid and hyperbolic tangent, were also tested. All of the tested activation functions result in similar performance for predicting muon \(q/p_{\text {{T}}} \). Thus, the ReLU function was selected because it can be easily implemented in FPGA logic. The other activation functions can increase latency and may require more logic resources [32].
4 Neural network performance
Figure 6 shows the muon \(q/p_{\text {{T}}} \) values predicted by the neural network plotted as a function of the true simulated \(q/p_{\text {{T}}} \), where muon candidates with and without noise hits are shown separately. The relative differences between simulated and predicted muon \(q\cdot p_{\text {{T}}} \) values are plotted as a function of the simulated muon \(p_{\text {{T}}} \) in Fig. 7. These two figures show that our regression model accurately predicts muon \(q/p_{\text {{T}}} \) values for muon \(p_{\text {{T}}} <20\) GeV. As expected, the \(p_{\text {{T}}} \) resolution is best at low \(p_{\text {{T}}} \) values and then slowly degrades with increasing \(p_{\text {{T}}} \) because muon displacements due to the magnetic field become comparable to the strip width for muon \(p_{\text {{T}}} >20\) GeV.

Output of the neural network plotted as a function of the true simulated muon \(q/p_{\text {{T}}} \) using network trained with events including only muon hits. Colour coded density map shows muon candidates without any noise hits. Orange dots show muon candidates that include at least one noise cluster

Relative differences between predicted and true muon \(q \cdot p_{\text {{T}}} \) plotted as a function of true simulated muon \(1/p_{\text {{T}}} \) using network trained with muon candidates without noise hits. Colour coded density map shows muon candidates without any noise hits. Orange dots show muon candidates that include at least one noise cluster
Performance of the neural network regression model was evaluated by computing the efficiency to select muon candidates with \(p_{\text {{T}}} >20\) GeV. Figure 8 shows the efficiency of selecting muons with \(p_{\text {{T}}} >20\) GeV for muon candidates without noise clusters and for inclusive muon candidates that also include candidates with noise clusters. These two efficiency curves are compared to the reference curve. This curve corresponds to the efficiency of the RPC MU20 trigger which selects muons with \(p_{\text {{T}}} >20\) GeV in the barrel detector region. This reference efficiency [20] was measured using collision data recorded by the ATLAS detector in 2018. The efficiency of the MU20 trigger reaches the plateau at 70% due to the RPC detector coverage gaps because of inefficient modules and presence of support structures [20]. Since the present simulation model does not include these effects, the efficiencies predicted by the regression model are scaled to the same value as the MU20 trigger efficiency curve for \(p_{\text {{T}}} >25\) GeV, in order to allow easier comparisons of efficiency curve shapes.

Efficiency of selecting muon candidates plotted as a function of the muon \(p_{\text {{T}}}\). Shown in orange is the ATLAS data efficiency for the MU20 trigger threshold of the present RPC detector [20]. Shown in green (blue) is efficiency for selecting simulated muons with (without) noise hits. These two curves are scaled to obtain the same efficiency as the MU20 trigger for \(p_{\text {{T}}} >25\) GeV
As discussed previously, several network configurations were tested. Figure 9 shows efficiency for selecting muons with \(p_{\text {{T}}} >20\) GeV for three different network configurations: 32-16-16, 32-16-8, and 32-20-20, where three numbers represent a number of nodes in layers 1, 2 and 3, respectively. A smaller neuron network with 8 nodes in the last layer (32-16-8) results in the worse performance. Two larger networks produce similar results, with 20-20-20 configuration resulting in a slightly better performance. This network was therefore chosen as the final configuration.
The main purpose of the present work is to improve RPC detector resolution for measuring muon \(p_{\text {{T}}} \). Achieving this goal would lead to better rejection of low-\(p_{\text {{T}}} \) muon candidates which dominate the sample of collisions events accepted by the RPC muon trigger [20]. The developed regression model produces the sharper rising efficiency curve than that of the MU20 trigger. This sharper curve would lead to lower trigger acceptance of the low-\(p_{\text {{T}}} \) muons with incorrectly measured \(p_{\text {{T}}} \). However, the present simulation model does not fully account for all effects present in the real detector. For example, there are regions in the ATLAS barrel muon spectrometer where the magnetic field is not uniform or is weaker than what is assumed by our model. Therefore, this potentially better performance of the regression model will be verified in the follow up work using a more precise simulation model and collision data.

Efficiency of selecting muon candidates plotted as a function of the muon \(p_{\text {{T}}}\) for three different neural network configurations
5 FPGA implementation
This section presents details of the implementation of the neural network regression model in FPGA code. Section 5.1 motivates our choice for numerical precision of the FPGA logic implementation. Section 5.2 presents details of the FPGA implementation. Section 5.3 reports measurements of FPGA timing performance, latency, and resource utilisation. Finally, Sect. 5.4 presents results of testing the FPGA logic implementation using simulated events.
5.1 Data precision for FPGA logic implementation
The neural network model was implemented in FPGA using 16-bit binary fixed-point numbers. This choice results in fast network execution speed and low usage of FPGA resources. Prior to the FPGA implementation, the number of bits allocated to integer and decimal (fractional) parts of fixed-point 16-bit numbers were carefully studied. This study was motivated by the requirement of avoiding frequent integer overflows while maintaining sufficient decimal accuracy for 16-bit arithmetic operations.
The output values of neuron activation functions of the hidden layers typically range between \(-8\) and 8. To cover nearly all of neuron output values, at least 5-bit integer part is required for the fixed point calculations. One or two extra bits can be reserved to avoid overflows for addition operations. Therefore, only 9 to 11 bits can be used for the decimal part.
To select the best possible decimal precision, network output values were computed using the network implemented in the custom Python code with three different values of the decimal precision: 9, 10 and 11 bits. These network output values were compared with the values obtained using the same implementation but using 32-bit floating-point precision. Relative errors between each of the three calculations and the 32-bit implementation are shown in Fig. 10. The implementation using 10-bit decimal precision achieves sufficient accuracy so this solution was adopted in order to reserve one extra bit for the integer part. This choice helps to further reduce integer overflows for 16-bit arithmetic operations.

Errors for network output values computed as the relative differences between values obtained using the implementation with 16-bit precision and implementation with 32-bit precision. Three different results with the decimal precision of 9, 10 and 11 bits are compared in the plot
5.2 FPGA logic design
The full neural network was implemented in the FPGA code using HDLFootnote 2. Each layer of this fully connected network represents the multiplication of an input data vector and a matrix containing layer weights. Each neuron performs the inner product of two vectors, one vector representing input data and another representing specific node weights. The FPGA implementation of these operations is built using three main logical blocks that correspond to the three neural network layers. Figure 11 shows the data flow diagram of our neural network implementation. Neuron layers are divided into neuron groups, each containing either 6 or 7 neurons. Each neuron group sends its data serially and simultaneously with other groups in the same layer. In layers 2 and 3, each neuron receives data from all neurons in the previous layers. This data is transferred in parallel by three neuron groups with the receiving neuron processing that data in parallel using three processing elements (PEs). This division of the neurons into three groups reduces the layer latency by a factor of three. The same logic is also used for the output neuron.

FPGA data flow of the neural network logic. Output neuron and each neuron in layers 2 and 3 contain three PEs, denoted A, B, and C. Each PE receives and processes data from the corresponding group in the previous layer
The PE is the basic unit for FPGA implementation of the neural network logic. It contains two logical units: a multiply-add-accumulate (MAC) unit and a random-access memory (RAM) unit, as illustrated in Fig. 12. Input data is processed serially by each PE in order to simplify the circuit design. The MAC unit performs vector multiplication operations and the RAM unit stores weights using distributed FPGA RAM. One digital signal processor (DSP) is used by each MAC unit to perform addition and multiplication operations. In hidden layers, additional logic to perform the ReLU functionality is implemented using one DSP. In order to maximise processing speed and to reduce latency, our design does not use lookup tables and block memory.

FPGA logic design for one processing element (PE). Random access memory unit (RAM) stores node weights. Multiply-add-accumulate unit (MAC) implements arithmetic operations using a single DSP
The overall structure of the hidden layer implementation is shown in Fig. 13. It consists of one input block, twenty neuron blocks, and three output blocks. Data is sent and received when a layer is ready for processing. This ready signal is propagated using dedicated handshake lines between layers. Each layer includes a distributor unit which makes 20 copies of every input data element and transmits them in parallel to PEs. Layer results are stored in the output buffer until a next layer is ready to receive data.

FPGA logic design for one neuron layer
The layer input block receives three data streams from three neuron groups of the previous layer (labelled A, B and C). In each data stream, output data of the seven (or six) neurons is sent serially, with one transmission per clock cycle. Each neuron receives three input data streams in parallel, with one dedicated PE performing arithmetic operations for each data stream. Arithmetic operations of every neuron node are performed in parallel with other nodes since the layer nodes are independent from each other. This parallel design reuses the same basic PE structure and leads to lower latency.
A PE processes its input data within eight clock cycles. One cycle is used by the data preparation step. Seven cycles are used by the neural node logical operations. Results of each neuron group (A, B or C) are organized into a new data stream which is sent serially to a next layer via the group’s output block which functions as a pipeline. The output block sums together outputs of three PEs of each neuron and sends the resulting sum to the ReLU block which prepares a new data stream for a next layer. Two DSPs perform summation operations of the output block within two clock cycles. ReLU calculation takes one clock cycle.

FPGA timing simulation of the full neural network
In addition to the FPGA implementation described so far, two other implementations were developed for comparison purposes and to better understand the impact of design choices on resource utilisation and latency. The same clock frequency of 320 MHz and the same 16 bit precision were used for all three implementations. The first of these additional implementations used a simpler HDL design with only one PE in each neural node. This implementation is referred to as the simplified HDL design. This simpler design was in fact implemented first and then it was optimised to improve timing performance to produce our final design, at a price of somewhat larger resource utilisation. This final design is described earlier in this section and it is referred to as the optimised HDL design.
The third FPGA implementation of our model was performed using the hls4ml project of Ref. [3]. The hls4ml tools translate neuron network models into HLS code for FPGA implementation. It requires significantly less effort to implement multilayer networks or convolutional networks using hls4ml, compared to manually developing a FPGA project using HDL. Our neural network model was transformed into a format compatible with hls4ml. This model was then converted into an HLS project using hls4ml. FPGA firmware implementation was then generated using Vitis HLS. The hls4ml project allows fine tuning resulting FPGA implementation by changing the so-called “reuse” factor, which determines how many multiplications are performed in one single clock period by each DSP. A higher reuse factor uses fewer FPGA resources at a price of higher latency and deadtime. Three different reuse factors were tested: 1, 2 and 4, to produce results reported in the next section.
5.3 Performance of FPGA logic implementation
The full network logic was simulated for the Xilinx XCKU060 FPGA using 320 MHz clock. The latency and deadtime of our optimised HDL implementation are summarised in Table 1, separately for each network layer. The hidden layer deadtime is eight clock cycles, driven by the PE deadtime which has the maximum deadtime among all layer blocks. The input layer contains fewer PEs than the hidden layer because of the smaller input data size. The output layer contains just one neuron without the ReLU logic. As a result, these two layers have smaller latency and deadtime values. The timing simulation of the full network is shown in Fig. 14. The latency and deadtime of the optimised HDL implementation of the full network are \(39\times 3.125~\text {ns} = 121.875~\text {ns}\) and \(8\times 3.125~\text {ns} = 25~\text {ns}\), respectively. The total network latency is the sum of latencies of individual components. The overall network deadtime is determined by the maximum deadtime of individual components.
The latency, deadtime, and resource utilisation are summarised in Table 2 for all three FPGA implementations. For the optimised HDL design, the utilisation of the available DSP resources is less than 6% and the utilisation of the available LUTs is less than 1.5%. For comparison, the fastest HLS design (with reuse factor set to one) uses significantly larger fractions of logic resources, with comparable latency performance. These results demonstrate that carefully tuned HDL designs can produce resource-efficient implementations while maintaining sufficiently fast timing performance. In particular, our optimised HDL design of the full neural network was realised in FPGA hardware with efficient use of its resources, and with low latency and deadtime parameters. This result opens possibilities for real-time machine learning applications in the future ATLAS trigger system.
5.4 Test results of FPGA logic implementation
After the HDL design was finished, the full network circuit has been tested using simulation. Simulated muon events were generated and processed using the methods detailed in Sect. 3. A simulation test project was developed using Questa Advanced Simulator and SystemVerilog language. An interface was designed for communications between software and Verilog blocks. Input data for network evaluation is sent to the Verilog block and network output data is read back through this interface. The generated dataset was adapted for interfacing with the input ports of the FPGA-based neural network.
Candidate muons were evaluated using the FPGA simulation and neural network results produced by this simulation were compared with those obtained using the Python implementation. In total, 200 thousand simulated events were generated and processed, with \(p_{\text {{T}}} \) values uniformly distributed between 3 and 30 GeV and the muon angle uniformly distributed between 40\(^{\circ }\) to 85\(^{\circ }\). The inference result of the FPGA neural network simulation (i.e. predicted value of \(q/p_{\text {{T}}} \)) is compared event by event with the Python result.
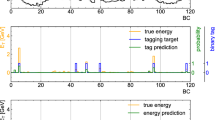
Figure 15 shows the correlations of the results of the FPGA simulation with the Python results. The \(p_{\text {{T}}} \) values predicted by the FPGA simulation are nearly the same as those predicted by the Python implementation for predicted \(p_{\text {{T}}} < 100\) GeV. The output \(p_{\text {{T}}} \) values reach up to and above 50 GeV due to larger errors in measuring a muon transverse momentum for \(p_{\text {{T}}} > 20\) GeV. This is expected since the RPC detector was designed to identify muons with \(p_{\text {{T}}} \) up to 20 GeV. Above this threshold, the muon curvature becomes comparable to the RPC strip width and therefore the RPC detector cannot measure precisely \(p_{\text {{T}}} \) of such muons. Therefore, these differences between the FPGA simulation and Python implementation above 20 GeV do not degrade the performance of the regression model for distinguishing muons with \(p_{\text {{T}}} > 20\) GeV from those with \(p_{\text {{T}}} < 20\) GeV.
The relative error between these two approaches is shown as a function of the muon \(p_{\text {{T}}} \) in Fig. 16. Within the working \(p_{\text {{T}}} \) range of the RPC detector, the errors introduced by the 16-bit arithmetic of the FPGA hardware do not impact the network performance for predicting muon \(p_{\text {{T}}} \). As shown in Fig. 17, the trigger efficiency curve computed by the FPGA simulation is consistent with the result computed by the Python program.

Relative differences between \(p_{\text {{T}}} \) values computed by the software and FPGA plotted as a function of \(p_{\text {{T}}} \) predicted by the software

Standard deviation of the relative differences between \(p_{\text {{T}}} \) values predicted by the python code and by FPGA simulation plotted as a function of \(p_{\text {{T}}} \)

Muon trigger efficiency plotted as a function of the simulated muon \(p_{\text {{T}}} \) for the software (red) and FPGA (blue)
5.5 Discussion of FPGA implementation
Verilog HDL is used in this paper to realise the neural network on the FPGA device. Another approach using HLS was also studied. The major advantage of HLS over HDL is that the HLS programming environment and tools are far more convenient for developing FPGA code. Hence, using the HLS allows implementation of complex algorithms in FPGA hardware with short development cycles. HLS implementations are also usually more flexible, for example allowing non-expert users to easily change a neural network size and numerical precision of its arithmetic operations.
The disadvantages of the HLS tools are also well-known. Circuits designed using the HLS tools often utilise more logic resources than comparable algorithms implemented using well-tuned HDL code. In addition, HLS-designed circuits often run at a lower clock frequency than a maximum available device frequency. For example, Refs. [33, 34] show that the HLS-designed circuits consume a factor of three more FPGA logic resources compared to the circuits which were manually designed using HDL. These observations are also confirmed by our work. The logic utilisation of our HDL implementation is lower compared to that of the HLS design performed using the hls4ml project. This demonstrates the utility of using HDL in situations where neural network performance is constrained by scarcity of available FPGA resources.
In the context of muon trigger upgrades at the LHC, convolutional neural networks (CNNs) were previously applied for detecting muon candidates by the upgraded ATLAS RPC detector [8]. Our approach instead focuses on measuring muon candidate \(p_{\text {{T}}} \) using a neural network regression model. A simple network architecture is deployed to measure more precisely \(p_{\text {{T}}} \) in order to reduce the dominant source of background events due to muons with mismeasured \(p_{\text {{T}}} \). A carefully tuned HDL design is used to implement the neural network model in FPGA firmware. The resulting FPGA implementation has a lower latency compared to that of Ref. [8], while resource usage is approximately similar: more LUTs are used by the CNN while more DSPs were used by our implementation. It is not possible at the present moment to compare directly the resulting trigger efficiency curves since different simulation datasets and detector geometry were used by the two approaches. Another approach [9] by the CMS experiment used boosted decision trees as the regression algorithm for measuring muon \(p_{\text {{T}}} \). This approach requires large memory banks to store lookup tables, with a significantly large memory footprint compared to our FPGA implementation of the neural network regression model.
The ATLAS RPC muon trigger system is currently being designed and exact specifications are still being finalised. The overall latency of the future ATLAS hardware trigger system [16] is fixed at 10 \(\upmu \)s. The latency of the RPC muon trigger logic [16] is expected to be around 300 ns. It is a small fraction of the total latency because extra time is needed for sending data from the on-detector electronics to the counting room and for data processing by other components of the hardware trigger system. XCVU13P FPGAs are being planned for the RPC trigger system [16]. This device has about 12,000 DSPs and about 1.8 million LUTs, which is about a factor of four larger resource availability than that of the XCKU060 FPGA. Therefore, our neural network implementation is capable of meeting the latency and resource requirements of the future RPC trigger system.
6 Conclusions
This paper presents a study that aims to improve performance of the future ATLAS hardware muon trigger system in the barrel detector region. A neural network regression model was developed for estimating transverse momentum (\(p_{\text {{T}}} \)) and charge of muon trigger candidates. A simplified simulation model of the current ATLAS resistive plate chamber (RPC) detector was developed to generate events for training and testing the regression model. Our model promises to provide more precise measurements of the muon trigger candidate \(p_{\text {{T}}} \), when compared to the current RPC muon trigger. This can improve rejection of low-\(p_{\text {{T}}} \) muon candidates, which are the dominant source of background events accepted by the ATLAS RPC muon trigger.
The latency and resource usage of our FPGA implementation of this neural network are well within the requirements of the future ATLAS hardware muon trigger system. This result opens possibilities for deploying machine learning algorithms for new hardware-based triggers. Verifying these results with a more accurate detector simulation model and developing new FPGA trigger algorithms for exotic particle searches will be the subject of our future work.
Data Availability
This manuscript has associated data in a data repository. [Authors’ comment: Source code and data for training and testing the neural network are available at: https://github.com/rustemos/MuonTriggerPhase2RPC. Source code for the optimised HDL implementation of the neural network is available at: https://github.com/rustemos/hdl4nn.]
Notes
Source code is available at https://github.com/rustemos/hdl4nn
References
A. Radovic et al., Machine learning at the energy and intensity frontiers of particle physics. Nature 560(7716), 41–48 (2018). https://doi.org/10.1038/s41586-018-0361-2
G. Carleo et al., Machine learning and the physical sciences. Rev. Mod. Phys. 91, 045002 (2019). https://doi.org/10.1103/RevModPhys.91.045002arXiv:1903.10563 [physics.comp-ph]
J. Duarte et al., Fast inference of deep neural networks in FPGAs for particle physics. JINST 13(07), P07027 (2018). https://doi.org/10.1088/1748-0221/13/07/P07027. arXiv:1804.06913 [physics.ins-det]
N. Nottbeck, C. Schmitt, V. Büscher, Implementation of high-performance, sub-microsecond deep neural networks on FPGAs for trigger applications. JINST 14(09), P09014 (2019). https://doi.org/10.1088/1748-0221/14/09/p09014. arXiv:1903.10201 [physics.ins-det]
C.N. Coelho et al., Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors. Nat. Mach. Intell. 3, 675–686 (2020). https://doi.org/10.1038/s42256-021-00356-5arXiv:2006.10159 [physics.ins-det]
T.M. Hong et al., Nanosecond machine learning event classification with boosted decision trees in FPGA for high energy physics. JINST 16(08), P08016 (2021). https://doi.org/10.1088/1748-0221/16/08/P08016arXiv:2104.03408 [hep-ex]
E. Govorkova et al., Autoencoders on FPGAs for real-time, unsupervised new physics detection at 40 MHz at the Large Hadron Collider . Nature Mach. Intell. 4, 154–161 (2022). https://doi.org/10.1038/s42256-022-00441-3. arXiv:2108.03986 [physics.ins-det]
S. Francescato et al., Model compression and simplification pipelines for fast deep neural network inference in FPGAs in HEP. Eur. Phys. J. C 81(11), 969 (2021). https://doi.org/10.1140/epjc/s10052-021-09770-w
D. Acosta et al., Boosted decision trees in the level-1 muon endcap trigger at CMS. J. Phys. Conf. Ser. 1085(4), 042042 (2018). https://doi.org/10.1088/1742-6596/1085/4/042042
C. Sun et al., Fast muon tracking with machine learning implemented in FPGA (2022). arXiv:2202.04976 [physics.ins-det]
A.M.C. Deiana et al., Applications and techniques for fast machine learning in science. Front. Big Data 5, 787421 (2021). https://doi.org/10.3389/fdata.2022.787421. arXiv:2110.13041 [cs.LG]
J. Alimena, Y. Iiyama, J. Kieseler, Fast convolutional neural networks for identifying long-lived particles in a high-granularity calorimeter. JINST 15(12), P12006 (2020). https://doi.org/10.1088/1748-0221/15/12/P12006arXiv:2004.10744 [hep-ex]
D. Linthorne, D. Stolarski, Triggering on emerging jets. Phys. Rev. D 104(3), 035019 (2021). https://doi.org/10.1103/PhysRevD.104.035019arXiv:2103.08620 [hep-ph]
O. Cerri et al., Variational autoencoders for new physics mining at the large hadron collider. JHEP 05, 036 (2019). https://doi.org/10.1007/JHEP05(2019)036arXiv:1811.10276 [hep-ex]
J. Duarte et al., FPGA-accelerated machine learning inference as a service for particle physics computing. Comput. Softw. Big Sci. 3(1), 13 (2019). https://doi.org/10.1007/s41781-019-0027-2arXiv:1904.08986 [physics.data-an]
ATLAS Collaboration, Technical design report for the phase-II upgrade of the ATLAS trigger and data acquisition system. CERN-LHCC-2017-020 (2018)
ATLAS Collaboration, Technical design report for the ATLAS muon spectrometer phase-II upgrade. CERN-LHCC-2017-017 (2017)
A.R. Barron, Universal approximation bounds for superpositions of a sigmoidal function. IEEE Trans. Inf. Theory 39(3), 930–945 (1993)
K. Hornik, M.B. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators. Neural Netw. 2(5), 359–366 (1989)
ATLAS Collaboration, Performance of the ATLAS RPC detector and Level-1 muon barrel trigger at \(\sqrt{s}\) =13 TeV. JINST 16(07), P07029 (2021). https://doi.org/10.1088/1748-0221/16/07/P07029. arXiv:2103.01029 [physics.ins-det]
ATLAS Collaboration, Search for heavy charged long-lived particles in the ATLAS detector in 36.1 fb\(^{-1}\) of proton–proton collision data at \(\sqrt{s} = 13\) TeV. Phys. Rev. D 99(9), 092007 (2019). https://doi.org/10.1103/PhysRevD.99.092007. arXiv:1902.01636 [hep-ex]
J. Alimena et al., Searching for long-lived particles beyond the Standard Model at the Large Hadron Collider. J. Phys. G 47(9), 090501 (2020). https://doi.org/10.1088/1361-6471/ab4574
D. Curtin et al., Long-lived particles at the energy frontier: the MATHUSLA physics case. Rep. Prog. Phys. 82(11), 116201 (2019). https://doi.org/10.1088/1361-6633/ab28d6arXiv:1806.07396 [hep-ph]
F. Anulli et al., The level-1 trigger muon barrel system of the ATLAS experiment at CERN. JINST 4, P04010 (2009). https://doi.org/10.1088/1748-0221/4/04/P04010
ATLAS Collaboration, Observation of a new particle in the search for the Standard Model Higgs boson with the ATLAS detector at the LHC. Phys. Lett. B 716(1), 1–29 (2012). https://doi.org/10.1016/j.physletb.2012.08.020
CMS Collaboration, Observation of a new boson at a mass of 125 GeV with the CMS experiment at the LHC. Phys. Lett. B 716(1), 30–61 (2012). https://doi.org/10.1016/j.physletb.2012.08.021
ATLAS Collaboration, The ATLAS experiment at the CERN large hadron collider. JINST 3, S08003 (2008). https://doi.org/10.1088/1748-0221/3/08/S08003
R. Santonico, R. Cardarelli, Development of resistive plate counters. Nucl. Instrum. Methods 187, 377–380 (1981). https://doi.org/10.1016/0029-554X(81)90363-3
R. Santonico et al., Progress in resistive plate counters. Nucl. Instrum. Methods A 263, 20–25 (1988). https://doi.org/10.1016/0168-9002(88)91011-X
ATLAS Collaboration, Performance of the ATLAS muon triggers in Run 2. JINST 15(09), P09015 (2020). https://doi.org/10.1088/1748-0221/15/09/p09015. arXiv:2004.13447 [hep-ex]
ATLAS Collaboration, Measurements of the electron and muon inclusive cross-sections in proton–proton collisions at \(\sqrt{s} = 7\) TeV with the ATLAS detector. Phys. Lett. B 707, 438–458 (2012). https://doi.org/10.1016/j.physletb.2011.12.054. arXiv:1109.0525 [hep-ex]
Peter W. Zaki et al., A novel sigmoid function approximation suitable for neural networks on FPGA, in 2019 15th International Computer Engineering Conference (ICENCO) (2019), pp. 95–99. https://doi.org/10.1109/ICENCO48310.2019.9027479
J. Marjanovic, Low vs high level programming for FPGA, in 7th International Beam Instrumentation Conference Proceedings (2019). https://doi.org/10.18429/JACoW-IBIC2018-THOA01
R. Millon, E. Frati, E. Rucci, A comparative study between HLS and HDL on SoC for image processing applications. Revista Elektron 4(2), 100–106 (2020). https://doi.org/10.37537/rev.elektron.4.2.117.2020. arXiv:2012.08320 [cs]
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China, under Grants 11922510 and 11961141014, and by the Fundamental Research Funds for the Central Universities of China, under Grant WK2360000011. We would like to thank Wenqi Lou for the helpful guidance on FPGA implementation using high level synthesis tools.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3
About this article

Cite this article
Ospanov, R., Feng, C., Dong, W. et al. Development of a resource-efficient FPGA-based neural network regression model for the ATLAS muon trigger upgrades. Eur. Phys. J. C 82, 576 (2022). https://doi.org/10.1140/epjc/s10052-022-10521-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-022-10521-8