
Abstract
We present a fast and precise method to approximate the physics model of the Karlsruhe Tritium Neutrino (KATRIN) experiment using a neural network. KATRIN is designed to measure the effective electron anti-neutrino mass \(m_\nu \) using the kinematics of \(\upbeta \)-decay with a sensitivity of 200 meV at 90% confidence level. To achieve this goal, a highly accurate model prediction with relative errors below the \(10^{-4}\)-level is required. Using the regular numerical model for the analysis of the final KATRIN dataset is computationally extremely costly or requires approximations to decrease the computation time. Our solution to reduce the computational requirements is to train a neural network to learn the predicted \(\upbeta \)-spectrum and its dependence on all relevant input parameters. This results in a speed-up of the calculation by about three orders of magnitude, while meeting the stringent accuracy requirements of KATRIN.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In particle physics, a widely used measurement technique is based on parameter inference using a parameterized model on a set of observed data. To obtain precision results, the prediction accuracy of this model, given any choice of parameters, should exceed the statistical uncertainty. In particular for high-precision experiments, such a requirement can easily translate to maximally allowed model errors at the subpercent level. Such accurate model predictions often entail high computational demands, that – at least in some cases – can render a full analysis unfeasible and resorting to approximations or a reduced scope becomes necessary.
Some examples of high computational demand are the Monte Carlo methods used by the ATLAS and CMS collaborations at the Large Hadron Collider [1, 2] to calculate their event predictions and by the Ice Cube Collaboration to analyze small signals in high-statistics neutrino oscillation experiments [3]. The particular example of such a high-precision experiment we want to focus on is the Karlsruhe Tritium Neutrino (KATRIN) experiment, designed to measure the effective electron anti-neutrino mass \(m_\nu \) with an unprecedented sensitivity of 200 meV at 90% confidence level (CL) [4] (note that we use natural units setting \(\hbar = c = 1\) for better readability throughout this paper). This is achieved via a high-precision measurement of the tritium beta decay spectrum close to the endpoint, where the neutrino mass manifests itself as a small shape distortion. To reach this design goal, each spectral data point will be measured with a statistical uncertainty of less than one per mill. This, in turn, puts tight constraints on the required accuracy of the model prediction. The current KATRIN physics model is based on numerical methods including numerical integrations and root searches, making a single model evaluation computationally expensive, taking approximately one CPU second. For parameter inference – be that Frequentist or Bayesian – this model then typically needs to be evaluated repeatedly for different parameter values. For KATRIN analyses, often many millions of model evaluations are needed to achieve convergence, driving the computational costs into tens or hundreds of CPU years. Until now, it was feasible to apply certain approximations, such as reducing the number of parameters by assuming 100% correlations. However, as the statistical precision increases with the upcoming data taking, these approximations may no longer be applicable.
In this article, we introduce the KATRIN physics model, the computational requirements for future analyses, and how current limitations can be overcome. We propose a novel approach to approximate the full KATRIN model by a fast neural network (NN), while retaining the necessary accuracy. The validity of our approach is discussed by applying it to previous data taking campaigns and Monte Carlo data sets modeling the final KATRIN data set.
2 The KATRIN physics model
KATRIN is currently the leading experiment using the kinematics of \(\upbeta \)-decay for the measurement of the absolute neutrino mass scale. Based on the first two data taking campaigns, KATRIN set a limit of \(m_\nu < {0.8}\,\hbox {eV}\) (90% CL) [5]. With the full data set of 1000 days, KATRIN targets a sensitivity close to 0.2 eV at 90% CL [4].
The measurement principle of KATRIN is based on the \(\upbeta \)-decay of tritium [6]. In a \(\upbeta ^-\)-decay a neutron in nucleus X decays into a proton in the daughter nucleus \(Y^+\) emitting an electron \(e^-\), and an electron anti-neutrino \(\bar{\nu }\):
The amount of energy released in the decay Q is shared between the decay products. A low recoil energy \(E_\text {rec}\) of 0.0–1.7 eV is passed to the significantly heavier daughter nucleus \(Y^+\). In the small analysis interval of KATRIN, this recoil energy can be considered constant: \(E_\text {rec} \approx {1.7}\,\hbox {eV}\). The remaining so-called endpoint energy \(E_0 = Q - E_\text {rec} = E + E_\nu \) is shared between the electron (E) and the neutrino (\(E_\nu \)). This corresponds to the maximum energy an electron can receive, assuming a neutrino mass of zero. As \(E_\nu = \sqrt{p_\nu ^2 + m_\nu ^2}\), a non-zero rest-mass of the neutrino reduces the maximal energy the electron can receive. The differential decay rate for an allowed \(\upbeta \)-decay depends on the electron energy and is given by:

Left: impact of non-zero neutrino mass on the differential \(\upbeta \)-spectrum. The smoking gun is the change in curvature near the endpoint. Right: transmission probability of electrons depending on their surplus energy at a retarding potential of \(qU = {18{,}575}\,\hbox {eV}\). The sharp edge at low surplus energies is defined by the transmission properties of the MAC-E filter whereas the bumps starting around 13 electronvolt come from energy losses by inelastic scattering of the electron with tritium molecules in the source
with a constant term C; the Fermi function F with the atomic number \(Z' = 2\); the electron kinetic energy E, momentum p and mass \(m_e\); the endpoint energy \(E_0\); and the effective neutrino mass \(m_\nu \). The Heaviside function \(\Theta \) ensures energy conservation. The impact of the neutrino mass \(m_\nu \) on the spectral shape is maximal near the endpoint \(E_0\) as depicted in Fig. 1 (left).
From Fig. 1 (left) we can also deduce two of the main properties an experiment aiming to measure \(m_\nu \) from \(\upbeta \)-decay must fulfill. First of all, due to the very low rate near the endpoint, an extremely luminous source is required. Furthermore, an energy resolution on the electronvolt-scale must be achieved to resolve the small shape effect of a non-zero neutrino mass. To achieve these two features, KATRIN combines a windowless gaseous tritium source [7] with an electrostatic high-pass filter with magnetic adiabatic collimation (MAC-E filter) as used by its predecessors in Mainz [8] and Troitsk [9].
As KATRIN uses gaseous molecular tritium as a \(\upbeta \)-emitter, the daughter nucleus can end up in a rotational-vibrational or electronic excited state with energy \(V_k\) and corresponding probability \(P_k\) [10]. This modifies the differential decay rate in Eq. 2 as it shifts the maximum energy available for the electron and the neutrino away from the endpoint and smears the spectrum. Introducing \(\epsilon _k = E_0 - E - V_k\), we now have:
Instead of measuring the differential energy spectrum directly, different retarding energies qU, where q denotes the charge of the electron and U the applied voltage, are set in the MAC-E filter. Thus, only electrons with sufficient energy to pass the filter are counted resulting in an integral measurement of the \(\upbeta \)-spectrum. The probability of an electron with energy E to pass the retarding energy qU is given by the response function
shown in Fig. 1 (right). Here, the transmission function T describes the properties of the MAC-E filter which are mainly governed by the magnetic fields in the beamline and the angular distribution of electrons in the source, \(P_s\) is the probability of an electron to scatter s times, and \(g_s(\epsilon )\) describes the probability of an electron to lose the energy \(\epsilon \) in the s-fold scattering process. For further reading on the response function we refer to [6] and details on the measurement of the energy loss function can be found in [11].
The integral count rate is given by integrating the differential spectrum times the response function over the electron energy:
Putting all described components together, we can already see why the calculation of the expected rate R is computationally involved. In the differential spectrum, Eq. 3, we must sum over hundreds of final states. To calculate the response function, Eq. 4, we convolve the transmission over the energy loss function for each scattering s. In the typical neutrino mass interval, up to five scatterings are considered. The transmission function itself consists of a numerical root search combined with an integral, and the energy loss function for s-fold scattering is obtained by convolving g \(s - 1\)-times with itself. Finally, we integrate the differential decay rate over the response function. Combining all these factors leaves us with a computationally expensive model calculation of about one second for each integral rate. Although parts can be precalculated depending on the analysis, we will see in the next section that this leads to very high computing demands which are already on the edge of feasibility.
3 Analysis methods and computing requirements
The KATRIN collaboration follows multiple approaches to infer the value, uncertainty, and thus confidence interval of the neutrino mass [5, 12, 13]. In the following, we will describe why each approach requires excessive computational power and would thus benefit from a fast calculation of the model.
3.1 KATRIN likelihood
As a basis for our analysis method, we first infer the likelihood function used for KATRIN. The likelihood \(\mathcal {L}(\mu (\varvec{\theta }) | \text {data})\) describes how well a set of model parameters \(\varvec{\theta }\) describes the measured data. Building on the integrated tritium spectrum from Eq. 5, we can write our expected model rate as
with a signal normalization \(A_\text {sig}\), a constant background rate B and various parameters impacting the tritium spectrum \(\varvec{\theta }_\text {spec}\). A summary of these spectral parameters can be found in Table 1. In this text we do not enter the details of what each parameter means and where the numbers come from, but would like to give an impression of the amount of parameters and the order of magnitude of their values and constraints. For more information on each parameter, we refer to [13].
During a single spectral measurement, called a scan, a fixed set of retarding energies \(qU_i\) are scanned with the corresponding measurement times \(t_i\), counting the number of electrons \(N_i\) that hit the detector. As the individual measurements at \(qU_i\), called scan steps, are statistically independent and the decay rate in the source is approximately constant during a single scan step (fluctuation \(< {0.1}\%\)), we can describe our likelihood using a product of individual Poisson distributions:
A typical scan contains 40 scan steps, of which about 30 are used for neutrino mass analysis, and takes about two hours. The scan steps currently not used for neutrino mass analysis allow monitoring the source activity as well as possibly extending the analysis interval in the future. In the current neutrino mass analysis interval one scan step takes between 30 s and 10 min and we collect between 50 and 2000 electrons per scan step. The KATRIN detector is segmented into 148 pixels, each measuring an independent spectrum. In simple cases, the pixels can be treated as one detector (uniform), but often segmentation into patches is needed to avoid averaging significantly different models. Typical segmentations are the grouping into 12 rings or 14 ring-like patches which account for misalignment of the detector with respect to the beamline. In a measurement campaign, a so-called period in KATRIN jargon, on the order of 300 scans are performed. For the analysis of a single measurement campaign, one can typically combine the data of all measurements taken at the same qU set points, leading to roughly 30 measurement points for one campaign. In addition to the detector segmentation, the model can differ significantly between various measurement campaigns. We must therefore also split our model and data in time, using one model for each campaign. Some model parameters are individual to each segmentation, while others are shared. Writing out the total likelihood then leads us to:
As an example, we expect roughly 15 periods, each with the 14-patch segmentation, for the total KATRIN measuring time. This gives us \(\approx 15 \cdot 14 \cdot 30 = 6300\) data points and on the order of one thousand likelihood parameters.
3.2 Parameter inference
We now describe various methods used to infer these parameters from the likelihood and to obtain an uncertainty on \(m_\nu ^2\). In the following, we refer to an approach where only the four unconstrained parameters \(\varvec{\theta }_\text {stat}= \{m_\nu ^2, E_0, A_\text {sig}, B\}\) are included as “statistical only”. We label the constrained “systematic” parameters \(\varvec{\theta }_\text {syst}\).
Nuisance parameter method In this approach, we retrieve the parameters best describing our data by maximizing the likelihood (minimizing the negative log-likelihood) with respect to the parameters \(\varvec{\theta }\). To include external constraints, we multiply our likelihood with so-called pull terms. The simplest and most common form of the pull term is a Gaussian centered at the best knowledge value with a standard deviation describing the uncertainty. To calculate the uncertainty of \(m_\nu ^2\), we profile the likelihood searching for the \(\Delta \log \mathcal {L}\) value corresponding to \(1\,\sigma \). This is needed, as the errors in \(m_\nu ^2\) are typically not symmetric and the estimate from the Hesse of the fit is numerically unstable.
Using this approach for all parameters has two important impacts on the computational requirements. Firstly, the dimensionality of our minimization problem is very large, leading to many likelihood- and thus model evaluations in practice. In addition, all parts of our model rate, especially the expensive response function, must be recalculated in every minimization step as they depend on \(\varvec{\theta }\). Analyzing a single measurement campaign, the detector segmented into 12 or 14 parts, already requires on the order of \(10^{10}\) evaluations of the integral spectrum. This estimate includes both the regular function evaluations as well as the numerical estimation of derivatives required for the minimization algorithm. With the numerical model, this can take up to one CPU year with drastic parallelization being difficult due to the serial nature of minimization. The scaling with additional measurement phases is at least quadratic since both the number of points and free parameters increase linearly, making it challenging to use this method as-is for final KATRIN.

Left: output spectral rate for different input parameter values \(\varvec{\theta }_\text {spec}\). The spectra all show the same general trend. Right: the output spectra normalized by the average rate in each qU point. We now see clear shape-effects for the different parameter samples. As an example for the sampled parameter values: for spectrum 0, we have \(m_\nu ^2 = {-3.8}\,\hbox {eV}^{2}\) and \(E_0 = {18{,}573.3}\,\hbox {eV}\); for spectrum 1, \(m_\nu ^2 = {-5.1}\,\hbox {eV}^{2}\) and \(E_0 = {18{,}574.1}\,\hbox {eV}\); and for spectrum 2, \(m_\nu ^2 = {9.2}\,\hbox {eV}^{2}\) and \(E_0 = {18{,}573.9}\,\hbox {eV}\)
Monte Carlo propagation method Another approach used is based upon Monte Carlo propagation of uncertainty. The general idea is to repeat the maximum-likelihood fit multiple times with randomized input values for the systematic parameters \(\varvec{\theta }_\text {syst}\), but to fix them during the minimization. Statistical uncertainty is included by randomizing the data points according to their underlying Poisson distribution in each step. The resulting distribution in \(m_\nu ^2\) describes the uncertainty and can be used to calculate appropriate intervals as well as the best-fit value.
An advantage of this method is that it allows precalculating the expensive response function which depends on \(\varvec{\theta }_\text {syst}\), but not on any of the remaining fit parameters \(\varvec{\theta }_\text {stat}\). The downside is that it requires repeating the fit process thousands of times. This becomes worse when each fit is already expensive, for example when the likelihood has a large number of points due to the necessity of splitting the data over time and over detector segments. This was already an issue when analyzing the second neutrino mass campaign, where the final result with all uncertainties included more than 100,000 individual fits, each with \(10^{8}\) function evaluations, amounting to a total of \(10^{13}\) evaluations of the integrated spectrum. With the applied precalculations, this amounted to a computing requirement of about 50 CPU years. When fitting multiple measurement campaigns together to retrieve the combined neutrino mass value, this quickly becomes unfeasible due to the same quadratic scaling issues as with the nuisance parameter method.
Full Bayesian sampling In addition to the two Frequentist approaches, there is also the option for a full Bayesian analysis. Instead of performing a minimization, we sample the likelihood using a Markov chain Monte Carlo (MCMC). External constraints are included by multiplying the likelihood with the corresponding so-called priors. In this case, similar to the nuisance parameter method, the expensive response function cannot be approximated. A typical result involves more than \(10^{7}\) samples in the posterior, each with hundreds or thousands of calculations of the integral spectrum and an acceptance of \(\approx 0.234\) [14], amounting to around \(10^{11}\) total evaluations. This is more expensive than the nuisance parameter approach and therefore hardly feasible at the current state.
Instead, a model variation approach similar to the Monte Carlo propagation was pursued. Once again, \(\varvec{\theta }_\text {syst}\) are randomized before running a full MCMC chain. Finally, the samples from all chains are combined to incorporate the effect of systematic uncertainty. This approximated hybrid method requires at least the computing time of the Monte Carlo propagation method, and can therefore also not be scaled as-is.
4 Approximating the model estimate with a neural network
As we have seen in the previous section, all analysis approaches would benefit from a fast calculation of the integrated \(\upbeta \)-spectrum \(R(qU; \varvec{\theta }_\text {spec})\), as it is evaluated billions of times. A possible solution to this is to pre-calculate R for many samples of \(\varvec{\theta }_\text {spec}\) and to retrieve R for arbitrary samples within the generated sample range using a multidimensional interpolation algorithm during the analysis. Unfortunately, the high dimensionality in \(\varvec{\theta }_\text {spec}\) of \(\mathcal {O}(10)\) as seen in Table 1, combined with the stringent sub-per mill accuracy requirements, quickly makes traditional interpolation algorithms such as cubic-splines or (k-) nearest-neighbor unfeasible.

Left: layer structure of our neural network. The input layer (left) consists of the parameter values of the spectral parameters such as the neutrino mass squared. Two hidden layers (number of nodes not to scale for better visualization) connect the input layer with the output layer using “mish” as activation function. The output layer (right) gives the count rate at each scan step with a different retarding potential. Right: training loss over iteration for the different samples. Training (blue solid line) and validation (orange dashed line) are for our reference architecture using two hidden layers with 128 nodes. The two match very well, indicating there is no overtraining. Including four hidden layers with 32 nodes (green dotted line) has a similar performance to our reference architecture, showing that the exact architecture does not have a large impact on the performance, as long as there are enough weights to optimize. Using only one hidden layer with 8 nodes (red dash-dotted line) leads to a significantly worse loss
Our approach to this interpolation problem is to use a neural network: we train the network using samples generated with the analytical model to learn the output rate depending on the physical parameters \(\varvec{\theta }_\text {spec}\). In the following we describe the architecture of the network as well as the exact form of input and output layers we propose to achieve the required accuracy.
The inputs we pass to the neural network are the values of the parameters \(\varvec{\theta }_\text {spec}\). As we sample these independently, there is no need for decorrelation, but we normalize each parameter to a mean of zero and a standard deviation of one. As output, we use the predicted count rate \(R(qU; \varvec{\theta }_\text {spec})\) for each point qU in the data spectrum. This allows the neural network to “learn” any correlations between the count rate in neighboring points. As all integrated spectra follow a very similar pattern, see Fig. 2 (left), we divide each spectrum by the average count rate at every given point \(\left<R(qU; \varvec{\theta }_\text {spec})\right>\) adding a constant background rate B to avoid dividing by zero. We then arrive at output samples as shown in Fig. 2 (right).
Between the input and the output layer, we add two hidden layers, each fully connected to both the input/output layer and the next/previous hidden layer. Each hidden layer uses the “mish” function as activation and consists of 128 nodes. As all our rates \(R_i\) and thus also the output values \(\frac{R_i}{\left<R_i\right>}\) are positive, the output layer uses the “softplus” activation function. The final layer structure of the neural network is depicted in Fig. 3 (left). Our described activation functions are defined as:
We train the neural network on \(\mathcal {O}(10\,\text {million})\) input samples which we generate by sampling the parameters within their expected 1-, 3- and 5-sigma range using the N-dimensional \(R_2\) method [15]. For example, we could sample \(m_\nu ^2\) as one input parameter from \({-\,0.15}\, \hbox {eV}^{2}\) to \({+\,0.15}\,\hbox {eV}^{2}\) and \(B_\text {max}\) as another one within its 1 \({\sigma }\) systematic uncertainty. During training, we optimize our loss function with respect to the weights of the network using an interface of scipy’s [16] low-memory BFGS [17, 18] minimizer to the tensorflow [19] front-end keras. We define our loss function as the mean squared error of the net prediction
with the true rate change of each sample \(C_\text {i} = \frac{R_i}{\left<R_i\right>}\) and the corresponding prediction of the neural net \(C_\text {pred,i}\). Here, we follow an iterative approach. In each iteration:
-
we select a random batch of \(\mathcal {O}(1\,\text {million})\) samples from our total of \(\mathcal {O}(10\,\text {million})\) samples, and
-
gradually decrease the minimization tolerance.
After roughly 40 iterations, we see convergence of our loss function as shown in Fig. 3 (right). During training, we split off 10% of our generated samples for validation to check for overfitting. As the validation loss is the same as the training loss, we conclude that the training is successful and no overfitting happens.

Left: spectrum and residuals for the Asimov cross-fit. On the top we see the generated Monte Carlo spectrum (black points) as well as the best-fit using the neural network (orange line). On the bottom we plot the normalized residuals, once with a regular scale, and once with a zoom-in to see the underlying structure. Right: comparison of the likelihood-profile in \(m_\nu ^2\) with statistical uncertainty only. The reference (blue solid) matches the profile of the neural network (orange dashed line)
To generate the samples, we need to evaluate the full integral spectrum about \(30 \cdot 10^{7} = 3 \times 10^{8}\) times, significantly less than for the individual analysis methods. This task is embarrassingly parallel and the required \(< 10\) CPU years can be split upon thousands of CPUs on a computing cluster, allowing us to typically complete this task within a single day. The training is then no longer challenging using a modern GPU and is completed within a few hours. One great advantage of this approach is that this computing time must only be invested once and can then be reused for multiple analyses.
5 Validation and results
To test the numerical accuracy of our neural network, we do a 1:1 comparison of the analytic model to the NN approximation with statistical uncertainties on representative Monte Carlo data. Afterwards, we carry out a full analysis of already analyzed measurement phases comparing to the published results. Finally, we demonstrate that our approach allows the analysis of a large number of datasets as expected for the final KATRIN analysis.
5.1 Asimov cross-fit
As a first check, we generate a single statistically unfluctuated Asimov reference spectrum using the existing numerical analysis framework assuming 1000 days of measurement. The parameter values assumed in this spectrum correspond to the ones summarized in Table 1. We now fit this spectrum with the model obtained from the NN. \(\varvec{\theta }_\text {stat}\) are treated as free parameters in the fit, while the others are fixed to their input value. This simplification of fixing \(\varvec{\theta }_\text {syst}\) allows a detailed comparison with the existing framework. The spectrum and residuals are shown in Fig. 4 (left) while the fit parameter results can be found in Table 2. There is no structure in the residuals when scaled to the usual \(1\,\sigma \) level. Only after zooming in, we can see residuals below the \(0.003\,\sigma \) level, almost three orders of magnitude smaller than the expected statistical uncertainty. This excellent fit is further underpinned by the \(m_\nu ^2\) bias of less than \(1\times 10^{-5}\,\hbox {eV}^{2}\). For the other parameters, we cannot see any deviation on the displayed number of significant digits. Therefore, we conclude that the neural network has no significant bias when fitting unfluctuated spectra.
In addition to the central value, we also check the likelihood profile in \(m_\nu ^2\) which is used to retrieve the uncertainty. The overlay of the two profiles, one using our network, one using the existing methods, is shown in Fig. 4 (right). We can see that the overlay matches and the \(1\,\sigma \) uncertainties differ by less than \(1 \times 10^{-3}\,\hbox {eV}^{2}\). Thus, also the uncertainties are not significantly biased using our neural network.

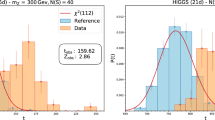
Left: difference of best-fit \(m_\nu ^2\) values using the regular analysis framework and our neural network (orange) compared to the assumed statistical uncertainty of 0.04 \(\hbox {eV}^{2}\) on our 1000 day Monte Carlo spectrum. Both bias (\(-3\times 10^{-4}\,\hbox {eV}^{2}\)) and width (\(4 \times 10^{-4}\,\hbox {eV}^{2}\)) are below the \(1 \times 10^{-3}\,\hbox {eV}^{2} \) level. Right: comparison of our analysis of the first two measurement campaigns using the neural network (blue) with the results published in [5, 12]. The gray dotted line splits the first measurement campaign (top) and the second one (bottom)
5.2 Ensemble test
As a next step, we perform an ensemble test on 1000 statistically fluctuated spectra using the same 1000 day Asimov spectrum as in Sect. 5.1 for the expectation, and the Poisson distribution to randomize it. We then fit each of these 1000 spectra once with the regular framework and once with the neural network. In Fig. 5 (left) we compare the \(m_\nu ^2\) best-fit values of the two methods. The resulting bias (width) in \(m_\nu ^2\) is \(-3 \times 10^{-4}\,\hbox {eV}^{2}\) (\(4 \times 10^{-4}\,\hbox {eV}^{2}\)) and thus two orders of magnitude smaller than the assumed statistical uncertainty around \(0.04\,\hbox {eV}^{2}\). This would only affect a possible final upper limit at the third significant digit. We would also like to point out that the numerical inaccuracies of the current analysis methods can also be similarly large. We thus conclude that the accuracy of the neural network is sufficient to be applied in KATRIN data analysis.
5.3 Application to realistic KATRIN scenarios
Analysis of the first two measurement campaigns As a first step, we reproduce the published results of the first two measurement campaigns [5, 12] using the neural network and the nuisance parameter approach. We include all systematic uncertainties in the official analysis except for an uncertainty on the molecular final states and the source activity fluctuation as these are not parameterized and will be treated differently in future analyses. For both campaigns these neglected uncertainties are minor effects, impacting the final result by less than 1%. Background parameters and uncertainties not shown in Table 1 are included without the use of a neural network as they are simple linear parameters. For the first measurement campaign, we arrive at \(m_\nu ^2 = -1.14_{-1.10}^{+0.91}\,\hbox {eV}^{2}\), consistent at the percent level with the updated value reported in [5]. When analyzing the second measurement campaign using a 12-ring segmentation for the detector, we find \(m_\nu ^2 = 0.27_{-0.33}^{+0.33}\,\hbox {eV}^{2}\) which is within the range of values reported by the analysis teams in [5] where the individual results can differ by around \({0.01}\,\hbox {eV}^{2}\). The various results both from the published analyses and using our neural network are summarized in Fig. 5 (right).
After showing that our method provides consistent results, we can now go beyond what has been published. To combine the two datasets, we perform a combined fit with shared \(m_\nu ^2\) using a uniform detector segmentation for the first period, and a 12-ring segmentation for the second measurement phase. With this approach, we find \(m_\nu ^2 = 0.07_{-0.34}^{+0.30}\,\hbox {eV}^{2}\). This type of combined fit has not been performed before, as it was computationally involved and the ring-wise segmentation of the second measurement campaign is not necessarily required. However, with our neural network-based approach, this fit completes within roughly 10 CPU minutes. A more detailed overview of the various computing times is shown in Table 3.
In addition to the Frequentist approach, we perform a full-Bayesian analysis of the two campaigns sampling both \(\varvec{\theta }_\text {stat}\) and \(\varvec{\theta }_\text {syst}\) during the MCMC. As described in Sect. 3.2, this type of analysis was not feasible with the regular analysis framework. Using a flat positive prior on \(m_\nu ^2\), we find consistent limits of \(m_\nu < {0.90}\,\hbox {eV}\) (first campaign), \(m_\nu < {0.86}\,\hbox {eV}\) (second campaign), and \(m_\nu < {0.75}\,\hbox {eV}\) (both combined) at 90% credibility. Each of these analyses was completed in less than one CPU day with a few million samples in the posterior.
We can also see the re-usability aspect of our neural network play out here, as we used the same two trained networks, one per measurement campaign, for each of these analyses.
Feasibility study for final KATRIN Finally, we perform a study to demonstrate the feasibility of analyzing a dataset similar to what is expected for the final KATRIN analysis. Our dataset is similar with respect to the computational demands due to the assumed data segmentation. However, the actual parameter values and uncertainties as well as the total measuring time are still under evaluation by the KATRIN collaboration and our choice is not meant to reflect the final KATRIN sensitivity. To simulate the expected data, we generate a Monte Carlo dataset consisting of 15 independent measurement phases, each with \(m_\nu ^2 = {0}\,\hbox {eV}^{2}\) as truth and 60 days of measurement time each. We then perform a combined fit, segmenting the detector into 14 patches and including systematic uncertainties with the nuisance parameter approach and uncertainties similar to Table 1. This results in 1336 parameters in the minimization process: 1 shared neutrino mass, 5 parameters shared over detector patch but not the campaign, and 6 parameters individual for each patch and campaign. For the neutrino mass squared, we arrive at \(m_\nu ^2 = 0.000_{-0.049}^{+0.047}\,\hbox {eV}^{2}\) after roughly one CPU day of computing time. The preparation of the required networks, probably one per patch and measurement phase, would take a few weeks at most and can already be done when analyzing the individual campaigns and then reused for all subsequent combined analyses. This shows that a final combined fit with several hundreds of parameters in the minimization is both numerically and computationally feasible with our approach, thus fulfilling the requirements needed to analyze the expected complete KATRIN data in a simultaneous fit.
6 Conclusion
We have presented a method to approximate the KATRIN physics model with a neural network. On a Monte Carlo dataset representing the statistics of 1000 days of KATRIN measurement, we showed that the bias of our model is less than \(1 \times 10^{-3}\,\hbox {eV}^{2}\) and would impact the final limit of KATRIN in the third digit. Our analysis of the first two data taking campaigns is consistent with the results published on the same level as the individual analysis methods pursued [5, 12]. Finally, we demonstrated the computational feasibility of performing an analysis of more than 6000 data points and more than 1000 free parameters, emulating the final KATRIN data set. The presented method will be applied to the forthcoming data taking campaigns of KATRIN, as it offers a solution to overcome the computational limitations of a simultaneous fit of multiple data sets.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: The KATRIN data for the first two measurement campaigns is or will be available via the corresponding publications. Any other data is available from the corresponding author on reasonable request.]
References
ATLAS Collaboration, Atlfast3: the next generation of fast simulation in atlas (2021)
CMS Collaboration, S Sekmen, Recent developments in cms fast simulation (2017)
IceCube Collaboration, M.G. Aartsen et al., Computational techniques for the analysis of small signals in high-statistics neutrino oscillation experiments (2019)
KATRIN Collaboration, Katrin design report 2004. Technical report, Forschungszentrum, Karlsruhe, 2005. 51.54.01; LK 01; Auch: NPI ASCR Rez EXP-01/2005; MS-KP-0501
KATRIN Collaboration, M. Aker et al., First direct neutrino-mass measurement with sub-ev sensitivity (2021)
M. Kleesiek et al., \(\beta \)-decay spectrum, response function and statistical model for neutrino mass measurements with the Katrin experiment . Eur. Phys. J. C (2019). https://doi.org/10.1140%2Fepjc%2Fs10052-019-6686-7
F. Heizmann, H. Seitz-Moskaliuk, KATRIN Collaboration, The windowless gaseous tritium source (wgts) of the katrin experiment. J. Phys. Conf. Ser. 888(1), 012071 (2017)
Ch. Kraus et al., Final results from phase ii of the Mainz neutrino mass search in tritium \(\beta \) decay. Eur Phys J C Part Fields 40(4), 447–468 (2005)
V.N. Aseev et al., Upper limit on the electron antineutrino mass from the Troitsk experiment. Phys. Rev. D 84, 112003 (2011)
A. Saenz, S. Jonsell, P. Froelich, Improved molecular final-state distribution of \({\text{ het }}^{+}\) for the \({{\beta }}\)-decay process of \({T}_{2}\). Phys. Rev. Lett. 84, 242–245 (2000)
M. Aker, A. Beglarian, J. Behrens, A. Berlev, U. Besserer, B. Bieringer, F. Block, B. Bornschein, L. Bornschein, M. Böttcher et al., Precision measurement of the electron energy-loss function in tritium and deuterium gas for the Katrin experiment. Eur. Phys. J. C 81(7), 579 (2021). https://doi.org/10.1140/epjc/s10052-021-09325-z
KATRIN Collaboration, M. Aker et al., Improved upper limit on the neutrino mass from a direct kinematic method by Katrin. Phys. Rev. Lett. 123, 221802 (2019)
KATRIN Collaboration, M. Aker et al., Analysis methods for the first Katrin neutrino-mass measurement. Phys. Rev. D 104, 012005 (2021)
M. Bédard, Optimal acceptance rates for metropolis algorithms: moving beyond 0.234. Stoch. Process. Appl. 118(12), 2198–2222 (2008)
M. Roberts, The unreasonable effectiveness of quasirandom sequences (2018). http://extremelearning.com.au/unreasonable-effectiveness-of-quasirandom-sequences/
P. Virtanen et al., and SciPy 1.0 Contributors, SciPy 1.0: fundamental algorithms for scientific computing in Python. Nat. Methods 17, 261–272 (2020)
J. Nocedal, Updating quasi-newton matrices with limited storage. Math. Comput. 35(151), 773–782 (1980)
D.C. Liu, J. Nocedal, On the limited memory bfgs method for large scale optimization. Math. Program. 45(3), 503–528 (1989)
M. Abadi et al., TensorFlow: large-scale machine learning on heterogeneous systems (2015). Software available from tensorflow.org
Acknowledgements
We thank the support of the Origins Data Science Lab under the lead of A. Caldwell for making this project possible. We would also like to thank Prof. Debarghya Ghoshdastidar from the TUM IT department and his group as well as Ulf Mertens, Sebastian Neubauer, and Felix Wick from Blue Yonder for the fruitful discussions. We extend our thanks to the full KATRIN collaboration for helpful discussions and inputs, and finally their review and approval of our work and this article.
Funding
We acknowledge the support of Helmholtz Association (HGF), the Max Planck Research Group (MaxPlanck@TUM) program, the international Max Planck School (IMPRS), the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) for the SFB-1258 program and especially the ORIGINS Data Science Lab (ODSL) of the ORIGINS Excellence Cluster under Germany’s Excellence Strategy-EXC-2094-390783311, and finally the Munich Data Science Institute (MDSI). This project has received funding from the European Research Council (ERC) under the European Union Horizon 2020 research and innovation programme (Grant agreement no. 852845). We thank the computing cluster support at the Max Planck Computing and Data Facility (MPCDF).
Author information
Authors and Affiliations
Contributions
CK: main author, development of code and application to KATRIN, PE: support for neural network development and optimization, SM: supervisor of CK, initiator of the project. All authors read and approved the final text.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3
About this article

Cite this article
Karl, C., Eller, P. & Mertens, S. Fast and precise model calculation for KATRIN using a neural network. Eur. Phys. J. C 82, 439 (2022). https://doi.org/10.1140/epjc/s10052-022-10384-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-022-10384-z