
Abstract
We discuss a method that employs a multilayer perceptron to detect deviations from a reference model in large multivariate datasets. Our data analysis strategy does not rely on any prior assumption on the nature of the deviation. It is designed to be sensitive to small discrepancies that arise in datasets dominated by the reference model. The main conceptual building blocks were introduced in D’Agnolo and Wulzer (Phys Rev D 99 (1), 015014. https://doi.org/10.1103/PhysRevD.99.015014. arXiv:1806.02350 [hep-ph], 2019). Here we make decisive progress in the algorithm implementation and we demonstrate its applicability to problems in high energy physics. We show that the method is sensitive to putative new physics signals in di-muon final states at the LHC. We also compare our performances on toy problems with the ones of alternative methods proposed in the literature.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the study of the fundamental laws of Nature we face a number of open questions. In the past decades the field of particle physics has produced a set of potential answers that seemed inevitable in their simplicity. The experimental effort inspired by these solutions is now mature and is slowly stripping them of their initial theoretical appeal. As more and more data are collected, the problems that confront us become sharper and harder to solve. We know that the theories that well describe current data are incomplete and should be extended, but our prior beliefs on how the extension should look like and on where to discover it experimentally become less concordant every day. In this paper we show how to interrogate experimental data in a new way, going beyond searches targeted at one specific theoretical model.
We consider the problem of having large multivariate datasets that are seemingly well described by a reference model. Departures from the reference model can be statistically significant, but are caused only by a very small fraction of events. The significance of the discrepancy might stem from the extreme rarity of the discrepant events in the reference model and in this case standard anomaly detection techniques might be employed. Or the discrepancy is due to a small excess (or even a deficit) of events in a region of the space of physical observables that is also populated in the reference model. Our goal is to determine if the experimental dataset does follow the reference model exactly or if it instead contains “small” departures as described above. In the latter case, we also want to know in which region of the space of observables the discrepancy is localized. This problem is relevant to Large Hadron Collider (LHC) datasets that are well described by the Standard Model of particle physics (SM) and CMB datasets that are well described by the standard cosmological model \(\Lambda \)CDM.
Our focus here will be physics cases relevant to the LHC. Many attempts at generalizing traditional new physics searches based on specific models have already been made in this context, developing what are called “model independent” search strategies. As customary in the literature [2,3,4,5,6,7,8,9,10,11,12,13,14,15] by model independent analysis we mean an analysis that does not target a specific new physics model. Typically, analysis techniques of this kind assume that a background model is at hand. This could be obtained from simulation or some simulation-based reweighting of a data control region.Footnote 1 Recent papers (e.g., Ref. [16]) started referring to data-driven background estimates as (background) model-independence, to be accompanied by (signal) model-independence for a truly model-independent approach. We do not employ this latter notion of model independence in this study, and we keep the estimate of the background predictions, with the associated uncertainties, as a separated aspect (see below) from the one of model-independence. Notice that model-independent analyses (no matter which notion of model-independence is adopted) do rely on the choice of the specific final state (reconstructed variables and acceptance cuts) to which they are applied. This obviously restricts the sensitivity only to new physics models that contribute to the specific final state, and reintroduces some amount of model-dependence.
Model-independent analyses typically follow the binned histogram technique, in which one selects a set of bins (i.e. search regions) in the space of observables and compares the amount of data observed in each bin with the reference model (i.e., the SM). The main problem with this approach comes from the fact that, as previously emphasized, the data distribution will be identical to the one predicted by the SM in the vast majority of the phase space. The observed countings in almost all bins will thus be in agreement with the SM expectation, but only up to the unavoidable Poisson fluctuations. Poisson fluctuations from non-discrepant bins do contribute to the binned likelihood, and if there are many non-discrepant bins their contribution will overwhelm the contribution the likelihood receives from the few genuinely discrepant bins. This is not an issue in a binned (or unbinned) analysis targeting a specific new physics model, because the bins where no discrepancies are expected do not contribute to the likelihood (which is the ratio between the new physics and the SM Poisson likelihoods). In the model-independent case instead, Poisson fluctuations from non-discrepant bins easily swamp any potential signal of new physics. Typically this can be mitigated only by paying a high price in flexibility [2, 17].
In this work we apply a new methodology to the problem, expanding on the ideas presented in Ref. [1]. Our technique leverages the progress that the field of machine learning has experienced in the past few years. In particular we exploit the flexibility of neural networks as multidimensional function approximants [18,19,20,21,22,23,24,25]. Here we show that this idea addresses the challenge presented above for realistic multidimensional datasets and physically motivated putative signals. In particular we consider \(\mu ^+\mu ^-\) production at the LHC and we quantify the sensitivity of our method to a resonance \(Z^\prime \rightarrow \mu ^+\mu ^-\) and to a non-resonant signal induced by a four-fermion contact interaction.
It should be stressed that the design of the algorithm is purely based on the knowledge of the reference model with the criteria described in Sect. 2. No optimization was performed based on the putative new physics signals, as appropriate for a model-independent search strategy. We always present the sensitivity of our method in comparison with the “ideal” sensitivity one might obtain with a standard model-dependent search strategy that is instead optimized for the specific model at hand. We will also discuss how the trained neural network can help identifying the physical origin of the observed discrepancy.
At this stage, we assume that the reference dataset provides a perfect representation of the background distribution in real data. In a typical analysis, this is true within the effect of systematic uncertainties, which are controlled by nuisance parameters. The effect of these nuisance parameters can be accounted for in our method, by a straightforward application of the profile likelihood ratio methodology. The practical implementation of this extension of the method will be the topic of a future publication [26]. In this study, we ignore this aspect and concentrate on the more pressing issue of generalizing Ref. [1] to a multivariate problem. This motivates the choice of relatively simple and clean experimental signature: that in fact allows introducing the new method and discussing its strength, knowing that the underlying assumptions (e.g., the possibility of accessing a trustable reference sample with larger statistics than the data sample) will be fulfilled. It is reasonable to expect that extending this method to other final states (e.g., dijet) might imply additional practical problems (e.g., the need of a large reference dataset).
Our results benefit from a crucial methodological advance that we make in this paper compared to Ref. [1]. This consists in an algorithmic procedure to select the regularization parameters of the neural network and the network architecture. We take the regularization parameter to be a hard upper bound (weight clipping) on the magnitude of the weights. While admittedly heuristic (even if based on robust results in statistics), we will see that this procedure uniquely selects the weight clipping and it also gives constraints on the viable neural network architectures.Footnote 2
Machine learning techniques have recently been introduced to solve problems related to the one discussed above [27,28,29,30,31,32,33]. In this paper we also directly compare our sensitivity with that of two related ideas presented in the literature. One has the same goal, but is based on a nearest neighbors estimation of probability distributions [32, 33]. The other targets only resonant signals, with the resonant feature occurring in a pre-specified variable, but leverages in a similar way the capability of multilayer perceptrons to identify correlations in multivariate datasets [17]. For the comparison we employ simple toy benchmark examples defined in the corresponding publications. We study these examples with our method and compare our performances with the published results. This is a first step towards an exhaustive comparison of the different proposals (that also include [27,28,29,30,31,32]), which we consider necessary at this stage given the practical difficulties involved in directly evaluating their respective strengths and weaknesses by just reading published work.
The paper is organized as follows. In Sect. 2, after a brief review of the basic ideas behind our approach (see Ref. [1] for a detailed exposition), we define its detailed implementation. We describe in particular the strategy we adopt to select the neural network architecture and the other hyperparameters. In Sect. 3 we compare our performances with Refs. [17, 32, 33] in the context of toy examples. The rest of the paper is devoted to \(\mu ^+\mu ^-\) production at the LHC. First, in Sect. 4, we introduce the new physics signals and the details of our simulated datasets. We also describe the dedicated analyses that we use to estimate the ideal sensitivity. In Sect. 5 we describe the application of our method and we extensively study its performances. We conclude and outline directions for future work in Sect. 6.
2 Methodology
Neural networks have already found a plethora of successful applications in high energy physics, including jet physics [34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58], optimized new physics searches [17, 59,60,61,62,63,64,65], faster detector simulations [66,67,68,69,70,71] and fits to parton distribution functions [72], where they have been applied successfully for decades [73]. In this work we show the power of these techniques in the context of model-independent new physics searches at the LHC, expanding the framework of Ref. [1].
We first choose a set of variables that describe the data, a range for their values and the integrated luminosity of the dataset. This is the only physics choice that we have to make, which defines the “experiment” we want to analyze. For instance our input space can consist of the momenta of the two leading muons in events with at least two opposite-sign muons within acceptance.
Once we have selected an input space of interest we generate a large reference sample that represents the SM (or, “reference model”) prediction. This simulated dataset has much larger statistics than the actual experimental data, we denote with \(\mathcal {N}_R\) the number of events in this sample, while the expected number of events is \(N(R)\ll \mathcal {N}_R\). We also generate \(N_\mathrm{toy}\) toy datasets that again follow the SM prediction, but have the same statistics as the actual experimental dataset. Namely, they contain a variable number of events, thrown randomly from a Poisson distribution with N(R) expected events. At this point we have prepared the required input for the neural network and we can choose a specific network architecture.
Our neural networks are fully connected, feedforward regressors, trained to learn a likelihood ratio. The training is carried on with a supervised procedure, taking as input the two datasets described above: the large reference dataset that follows the SM (reference) prediction \(\mathcal {R}\) and a smaller dataset that represents the experimental data \(\mathcal {D}\). The training datasets are preprocessed. Input variables allowing negative values, as \(\eta \), are normalized subtracting their mean and dividing by their standard deviation. The other variables, like \(p_T\), are simply divided by their mean. The loss L used to train the network is
Here x is an element of the input space (for example 5 numbers describing the two muons \(p_T\), rapidity and azimuthal angular difference) and f is the output of the network as a function of the free parameters \(\mathbf{w}\) (weights and biases) of the network. The values of these parameters after training will be denoted as \(\widehat{\mathbf{w}}\) in what follows.
The neural network defines a composite hypothesis for the distribution (denoted as \(n(x| \mathbf{w})\)) of the data, namely
where \(n(x|{\mathrm{R}})\) is the distribution (see Table 1 for a summary of our notation) in the reference hypothesis. Our search strategy is constructed as an hypothesis test between the simple hypothesis \(n(x|{\mathrm{R}})\) and the composite (depending on the free parameters \({\mathbf{w}}\)) alternative hypothesis \(n(x| \mathbf{w})\). The loss is constructed [1] to reproduce the maximum log-likelihood ratio (Neyman–Pearson) test statistic \(t(\mathcal {D})\) for composite alternative hypothesis [74]. Namely it is such that
when \({\mathcal {N}}_{\mathcal {R}}\) is much larger than the number of events in \({\mathcal {D}}\). The minimum of the loss at the end of training (or, more precisely, \({t(\mathcal {D})}\)) is thus employed as the statistic of our hypothesis test. Notice that after training, the output of the network is an estimate of the log-ratio of the data distribution over the reference distribution: \(f(x;\widehat{\mathbf{w}})\simeq \log \left[ n(x|\widehat{\mathbf{w}})/n(x|{\mathrm{R}})\right] \), as a function of the input variables x. It can thus be used, in case of tension between the data and the reference model, to identify the most discrepant regions of the phase space.
Armed with the input datasets, the network and loss described above we can analyze the data. The procedure is rather straightforward. The neural network is trained using the reference sample and a data sample collected by the experiment. The loss at the end of training produces a single value \(t_\mathrm{obs}\) for the test statistic. We then train the network again using, instead of the experimental data, the \(N_\mathrm{toy}\) synthetic datasets distributed according to the reference hypothesis, previously described. This gives us \(N_\mathrm{toy}\) values of the test statistic t that populate the distribution of the test statistic in the reference model hypothesis: \(P(t|\mathrm{R})\). Comparing \(t_{\mathrm{obs}}\) with \(P(t|{\mathrm{R}})\) tells us if our dataset is consistent with the reference model. More precisely we can compute a globalFootnote 3p value as
We also define a corresponding Z score as
where \(\Phi ^{-1}\) is the quantile of a Normal distribution with zero mean and unitary variance, so that Z is conveniently expressed as a number of \(\sigma \)’s. The presence of a new physics signal in the experimental dataset would manifest itself as a large value of Z.
The discussion above concisely lays out our data analysis strategy (see Ref. [1] for a more complete exposition), to be put in place once the neural network architecture and the other hyperparameters have been selected. We now describe the criteria and the algorithmic procedure by which this selection is made, which constitute the major methodological advance of the present paper.
2.1 Hyperparameters selection
Our goal is to design an effectively model independent search, so the construction of our method must not assume to know anything specific about the signal that we are looking for. Our selection strategy is thus purely based on the reference model (SM) prediction, and relies on two general criteria.
The first criterion that we adopt is flexibility. Namely we would like the neural network to have as many parameters as possible, free to vary in the largest possible range, in order to be sensitive to the largest possible variety of new physics.
This has to be balanced against a second criterion, based on the following observation. Our method is mathematically equivalent to the Maximum Likelihood hypothesis test strategy where the set of alternative hypotheses is defined by the neural network. Hence we can rely on the classical results by Wilks and Wald [75, 76] (see also [77] for a more recent exposition) according to which the maximum log-likelihood ratio test statistics is distributed in the Asymptotic Limit as a \(\chi ^2\) with a number of degrees of freedom equal to the number of free parameters in the alternative probability model. From here we conclude that the distribution of our test statistic on reference-model toy datasets (i.e., \(P(t|\mathrm{R})\)) approaches in the asymptotic limit a \(\chi ^2\) with a number of degrees of freedom given by the number of parameters of the neural network. Clearly we should not expect this result to hold for a finite dataset. However if it does apply, namely if the distribution does resemble the \(\chi ^2\), we can conclude heuristically that the dataset is sufficiently abundant for the network that is being fitted. If instead the distribution violates the asymptotic formula, it means that the test statistic is sensitive to low-statistics regions of the dataset that are subject to large and uncontrolled fluctuations. We can define this behavior as “overfitting” in our context and restrict ourselves to hyperparameters configurations for which a good compatibility of \(P(t|\mathrm{R})\) with the appropriate \(\chi ^2\) distribution is observed. We will see that combining the two criteria of flexibility and of \(\chi ^2\)-compatibility dramatically restricts the space of viable options.

Quantiles of the test statistic distribution vs training epochs for different choices of weight clipping. The quantiles are obtained from 1000 toy experiments and are a plotted for a 1D example discussed in the text. The architecture of the network is fixed at 1-3-1
In order to illustrate how the optimization strategy works in practice we first need to specify our framework. We restrict ourselves to fully-connected neural networks with logistic sigmoid activation functions in the inner layers. The architecture is characterized by the dimensionality of the input of each of the “L” layers, i.e. by a set of integers \(a_0\)-\(a_1\)-\(\ldots \)-\(a_\mathrm{{L-1}}\), plus the output dimensionality that is fixed to \(a_\mathrm{{L}}=1\) in our case. So for example a 1-3-1 (\(L=2\)) network acts on a one-dimensional feature space (\(a_0=1\)), has one inner layer with three neurons (\(a_1=3\)) and one-dimensional output (\(a_2=1\)). In this notation the total number of parameters (weights and biases) in the network is
We regularize the network by imposing an upper bound (weight clipping) on the absolute value of each weight. In the following we capitalize Weight Clipping when referring to this specific use of the parameter (i.e., an upper bound on each individual weight). The minimization of the loss function in Eq. (2) is performed using ADAM [78] as implemented in Keras [79] (with the TensorFlow [80] backend) with parameters fixed to \(\beta _1=0.9\), \(\beta _2=0.99\), \(\epsilon =10^{-7}\) and initial learning set to \(10^{-3}\). The batch size is always fixed to cover the full training sample. The hyperparameters we want to determine are thus the number of layers and of neurons in each layer (i.e., the architecture of the network), the weight clipping parameter and the number of training epochs.
The first step of the optimization procedure consists in choosing an initial network architecture. This can be done heuristically by considering the dimension of the input space and the number of events in the datasets of interest. Here we consider for illustration a one-dimensional slice (specifically, the momentum of the leading lepton in the x direction) of the SM di-muon dataset described in Sect. 4 with a relatively low expected number of data events \(N({\mathrm{R}})=2000\). The number of events in the reference sample is \({\mathcal{N}}_{\mathcal{R}}=20{,}000\). A small 1-3-1 network is a reasonable starting point in this case. According to the flexibility criterion, the weight clipping parameter should be taken as large as possible in order to maximize the expressive power of the network. However if we take it very large training does not converge even after hundreds of thousands of training epochs. This is not acceptable because reaching the absolute minimum of the loss function as in Eq. (2) is conceptually essential for our strategy. We observe this behaviour in the upper left corner of Fig. 1, where we plot the upper quantiles of P(t|R) as a function of training rounds. The phenomenon is avoided by lowering the weight clipping below a certain threshold \({\mathrm{W}}_{\mathrm{max}}\), which we find to be \({\mathrm{W}}_{\mathrm{max}}\simeq 30\) in the case at hand as shown in the figure.
The test statistic distribution P(t|R) can now be compared with the \(\chi ^2_{N_{\mathrm{par}}}\) distribution, with a number of degrees of freedom equal to the number of parameters of the neural network as in Eq. (5). We have \(N_{\mathrm{par}}=10\) for the 1-3-1 network. The left panel of Fig. 2 displays the evolution with the training rounds of the \(\chi ^2\)-compatibility, defined as a simple Pearson’s \(\chi ^2\) test statistic on the P(t|R) distribution sampled with 1000 toy experiments. We see that requiring an acceptable level of \(\chi ^2\)-compatibility further restricts the allowed range for the weight clipping parameter. The maximum weight clipping for which compatibility is found is 7 in the case at hand. Since the Weight Clipping should be as large as possible to maximize flexibility, this is the value to be selected.

Left: compatibility of the test statistic distribution in the reference hypothesis with a \(\chi ^2\) distribution with \({N_{\mathrm{par}}}=10\) degrees of freedom (1-3-1 network). The plot was made using 100 toy experiments and a 1D example discussed in the text. Note that the \(\chi ^2_\nu \) on the y-axis measures the compatibility between the two distribution and is not related with the \(\chi ^2_{N_{\mathrm{par}}}\) that approximates reference model distribution of t. Right: the test statistic distribution for weight clipping set to 7, compared with the \(\chi ^2_{10}\)
In summary, the strategy we adopt to select the weight clipping parameter is the following:
-
1.
Starting from a large weight clipping, decrease it until the evolution of the 95% quantiles of P(t|R) achieve a plateau as a function of training epochs.
-
2.
In the range of weight clippings below \({\mathrm{W}}_{\mathrm{max}}\) where the plateau is reached, choose the largest Weight Clipping value that gives a good compatibility between P(t|R) and a \(\chi ^2\) distribution whose degrees of freedom are equal the total number of trainable parameters in the network, as shown in Fig. 2.
-
3.
The total number of training epochs should also be fixed. To reduce the computational burden of our procedure this is chosen as the minimum value for which the evolution of the \(\chi ^2\)-compatibility has reached its plateau.

Compatibility of the test statistic distribution in the reference hypothesis with a \(\chi ^2\) distribution with \({N_{\mathrm{par}}}=31\) degrees of freedom (1-10-1 network) as a function of a training rounds and for different choices of the Weight Clipping parameter. A satisfactory level of compatibility is never reached
We should now explore different neural network architectures. In particular we would like to consider more complex architectures than 1-3-1 to increase the expressive power of the network. Complexity can indeed be increased, but not indefinitely as shown in Fig. 3 for a 1-10-1 network. A suitable \({\mathrm{W}}_{\mathrm{max}}\) can be identified below which the quantiles of P(t|R) converge, but P(t|R) fails to fulfil the \(\chi ^2\)-compatibility criterion for any choice of the Weight Clipping parameter. The 1-10-1 network should thus be discarded and the optimal (largest) viable network of the 1-N-1 class sits in the range \(3\le {\text {N}}<10\). By studying the networks in this range we might uniquely select the architecture and all the other hyperparameters that are suited for the problem at hand.
The behaviour described above for the toy one-dimensional dataset has been confirmed in other cases and it is believed to be of general validity. Namely it is generically true that \(\chi ^2\)-compatibility places an upper bound on the network complexity, leaving us with a finite set of options to explore. On the other hand we cannot claim that the our selection strategy always singles out a unique hyperparameters configuration. Even in our one-dimensional example one might extend the complexity of the network by adding also new layers, obtaining several viable options with similar number of parameters. Selecting one of these options would require to introduce a strict notion of neural network “complexity”, to be maximized. Furthermore one might consider departures from the general neural network framework that we are considering. For instance the weight clipping might be imposed on the norm of the weight vector at each layer rather than on each individual weight, and/or a different weight clipping threshold might be imposed on each layer. Even the choice of logistic sigmoid activations and of fully-connected networks might be reconsidered.
While this aspect should be further studied, it is probably unnecessary to consider this extended space of possibilities. This belief is supported by a number of tests that we performed with different activation functions, training methods and architectures. We find that the performances of our strategy in terms of sensitivity to putative new physics signals depend quite weakly on the detailed implementation of the algorithm. Performances are very similar for all the hyperparameters configurations that are reasonably flexible and obey the \(\chi ^2\)-compatibility criterion. Even slight departures from compatibility typically do not change the sensitivity appreciably. Establishing this fact for a number of putative new physics signals and for several neural network configurations selected with our criteria would justify the choice of restricting to a single configuration. Or, alternatively, would allow to combine the p-values obtained from different strategies without loosing sensitivity by the look-elsewhere effect.
Before concluding this section it is worth to point out that the compatibility with the \(\chi ^2_{N_{\mathrm{par}}}\) distribution can be leveraged to compute the p-value without generating a large number of toy experiments
This considerably reduces the computational burden of evaluating the global significance. However one should keep in mind that \(P(t|R)\simeq \chi ^2_{N_{\mathrm{par}}}(t)\) is an approximate statement, which we can only test at a statistical level given by the number of toys that we generated. However in cases where generating a sufficient number of toy samples is unfeasible, as for example the high significance models discussed in Sect. 3, we will be obliged to report estimates of the p-value obtained with this approximation.
We stress that our hyperparameter selection strategy is not based on an a priori assumed new physics model, hence it is not optimal to detect any specific signal. In particular, the network we select with our method might not be expressive enough to be fully sensitive to complex new physics signals. However we will see this is not a problem for the BSM scenarios studied in this paper.

Top: test statistic distribution for the signal and background models considered in [33], obtained with our analysis technique. The plot displays our sensitivity obtained using the toy samples (Z) and the \(\chi ^2\) approximation of P(t|R) (\(Z_\chi ^2\)). The significance quoted in Ref. [33] is \(2.2\sigma \) for \(\hbox {NP}_1\) and \(3.5\sigma \) for \(\hbox {NP}_2\). Bottom: test statistic distribution for the signal and background models considered in [32], obtained with our analysis technique
3 Comparison with related work
In the previous section we have introduced all the ingredients needed to implement our data analysis strategy. In this section and in Sect. 5 we test its performances on a series of examples. This section is devoted to comparisons with other ideas that have related goals.
Machine learning has recently seen a surge of popularity following the latest developments in deep learning and computer vision. A number of works proposing anomaly detection strategies for LHC datasets has appeared in the literature in the past few years [27,28,29,30,31,32,33]. This effort is still relatively recent and the field has not fully matured yet. Ongoing efforts (LHC Olympics [81, 82] and DarkMachines [83]) are establishing benchmarks for common comparison.
We take a step towards making the comparison between different strategies more transparent by testing our methodology on some toy examples present in the literature. We consider three examples: two incarnations of a method that has the same goal, but a very different estimation strategy for the test statistic and a third method that has a narrower scope, but a similar technical approach to the problem, based on multilayer perceptrons trained as classifiers.
The first strategy that we compare with is the nearest neighbors approach of Refs. [32, 33]. This is a truly model-independent approachFootnote 4 that aims at reconstructing the true probability distributions for the data and the reference model, using a nearest neighbors technique [84,85,86]. A comparison to this method is instructive because it allows us to test a completely different approach to the estimation of the likelihood.
We first study the performance of our algorithm on a two-dimensional example, considered in Ref. [33], comprised of events extracted from Normal distributions. The reference model is a two-dimensional Gaussian with mean \(\vec {\mu }=(1,1)\) and covariance matrix \(\Sigma = \mathbf{1}_{2\times 2}\). The number of expected events in the reference model is \(N(\mathrm{R})=20{,}000\).
We consider two different putative new physics (NP) models:
-
\(\hbox {NP}_1\): the data have mean \(\vec {\mu }=(1.12,1.12)\) and covariance matrix \(\Sigma = \mathbf{1}_{2\times 2}\). The number of events predicted is the same as in the reference model: \(N(\mathrm{NP}_1)=20000\).
-
\(\hbox {NP}_2\): the data have mean \(\vec {\mu }=(1,1)\) and covariance matrix \(\Sigma = ((0.95,0.1),(0.1,0.8))\). Again, \(N(\mathrm{NP}_2)=20000\).
The results are shown in Fig. 4 (top) for a 2-5-1 network with weight clipping 1.2 and 150,000 epochs of training. We generated 1000 toy SM samples and 300 data samples distributed according to the new physics hypothesis. The lowest significances that we find, using the \(\chi ^2\) approximation (6) for the reference model test statistic distribution, are \(Z_{\chi ^2}=19\sigma \) for \(\hbox {NP}_1\) and \(Z_{\chi ^2}=24\sigma \) for \(\hbox {NP}_2\). The nearest neighbor approach of [33] finds \(Z=2.2(3.5)\sigma \) for \(\hbox {NP}_1\)(\(\hbox {NP}_2\)) for 5 nearest neighbors and 1000 permutations used to estimate the test statistic distribution in the reference hypothesis.
An alternative implementation of the nearest neighbors approach was proposed in Ref. [32]. The following two-dimensional problem is considered:
-
Reference model (R): the data have mean \(\vec {\mu }=(0,0)\) and covariance matrix \(\Sigma = \mathbf{1}_{2\times 2}\). The number of expected events is \(N(\mathrm{R})=10{,}000\).
-
New Physics (NP): a signal component with \(\vec {\mu }=(1.5,1.5)\) and covariance matrix \(\Sigma = 0.1\,\mathbf{1}_{2\times 2}\) is present in addition to the background (reference) one. The expected signal is \(N({\mathrm{S}})=500\) and the total number of expected events is \(N(\mathrm{NP})=N({\mathrm{S}})+N({\mathrm{R}})=10{,}500\), with the remaining \(10^4\) events generated by the reference model.
For a 2-5-1 network, weight clipping equal to 1.35 and 150,000 epochs, the results of our method are displayed in Fig. 4 (bottom). We generated 1000 toy SM samples and 300 NP samples. The median significance, obtained with a \(\chi ^2\) approximation of the test statistic, is \(20\sigma \), while Ref. [32] quotes between 5 and \(16\sigma \) for the nearest neighbors approach depending on the cut on their discriminating variable. We can conclude that both approaches are sensitive to the simple problem at hand.

The other idea that we compare with is the bump hunter technique in Ref. [17, 87]. This approach does not have the same goal as ours, as it requires prior knowledge of the signal showing up as a peak in a pre-specified variable. It is further assumed that the background distribution of the other variables used in the analysis is the same in the peak and in the sideband regions. Clearly we have a price to pay in sensitivity for signals that satisfy these assumptions, since we discard this knowledge. On the other hand the approach in [17, 87] is much less effective on (or blind to) signals that do not satisfy them. Given these differences, it is instructive to check what is exactly the price that we are paying on resonant signals compared to this refined bump hunter.
We test our strategy on a three-dimensional toy example (see [17, 87]) defined by:
-
Reference model: the three variables m, x and y are uniformly distributed in the ranges \(|m|<2\), \(|x|<0.5\) and \(|y|<0.5\). The number of expected events is \(N(\mathrm{R})=10{,}000\).
-
New Physics (NP): there are \(N(\mathrm{S})=300\) signal events with variables uniformly distributed in the ranges: \(|m|<1\), \(|x|<0.1\) and \(|y|<0.1\) and \(N(\mathrm{R})=10{,}000\) events distributed as the reference model, for a total number of expected events \(N(\mathrm{NP})=N(\mathrm{S})+N(\mathrm{R})=10{,}300\).
Our results are shown in Fig. 5 for a 3-5-1 network with weight clipping 3.4 and 150,000 epochs of training. As in the previous examples, we generated 1000 toy SM samples and 300 NP samples.
We obtain a median significance of \(8.1\sigma \), to be compared with the \(10.8\sigma \) claimed in Ref. [17, 87] for the optimal choice of the neural network discriminant threshold. In the comparison it should be taken into account that \(10.8\sigma \) is a local significance, based on prior knowledge of the peak position and width. The degradation due to the need of scanning over the peak position and width (inherent of the bump hunter approach) and over the neural network threshold (specific of this strategy, see Ref. [87]) should be quantified for a better comparison with our \(8.1\sigma \) significance, which is instead global. However such a refined comparison is unnecessary in this benchmark example because no quantitative meaning should be attached to the asymptotic estimates of such high levels of significance. We can only conclude that our method is sensitive to this toy problem in spite of not being optimized for (and hence limited to) the detection of resonant signals.
4 Benchmark examples
In the previous sections we have introduced our methodology and compared our data analysis strategy with two alternative ideas present in the literature. The comparisons involved toy examples that can not be directly mapped on cases of physical interest.
The natural next step is to study the performances of our strategy on more realistic datasets and new physics examples. We choose to study LHC di-muon production and to consider two well-known new physics scenarios. In this section we describe the signal and background samples used for the analysis. The results of our study are presented in the next section. We consider two distinct possibilities for how new physics can manifest itself a resonant signal, represented by a \(Z^\prime \) decaying to \(\mu ^+\mu ^-\), and a smooth signal given by a contact interaction that we call “EFT”. The samples used to study our performances are:


SM di-muon The reference sample and the SM toy data are composed of SM Drell–Yan events: \(pp\rightarrow \mu ^+\mu ^-\). All events were generated with MadGraph5 [88], showered with Pythia6 [89], simulating proton-proton collision at \(\sqrt{s}=13\) TeV with an average of 20 overlapping collisions per bunch crossing. The events were further processed with Delphes 3 [90]. We use the default CMS detector card. We run the Delphes particle-flow algorithm, which combines the information from different detector components to derive a list of reconstructed particles. The five kinematical variables relevant for the analysis are the \(p_T\)’s and \(\eta \)’s of the two leptons and their \(\Delta \phi \). These are given as input to the neural network after preprocessing. The integrated luminosity of the dataset, corresponding to the number of expected events in the toy SM (and BSM) samples are varied to study the performances of the algorithm as discussed in Sect. 5.
\(\mathbf{Z}^{\prime }\) to di-muon We study a new vector boson with the same couplings to SM fermions as the SM Z boson. We generate events for three different masses: \(m_{Z^\prime }=200, 300\) and 600 GeV. The signal manifest itself as a narrow resonance at the LHC: \(\Gamma _{Z^\prime } \simeq \Gamma _Z m_{Z^\prime }/{m_Z}\). The events are generated using the same software and detector cards as the reference model events described above. The number of events in the data sample and the signal to background ratio \(N(\mathrm{S})/N(\mathrm{R})\) are varied to study the performances of the algorithm and are discussed in Sect. 5. The input variables distribution for three representative signal points are shown in Figs. 6 and 7.
EFT We consider a non-resonant BSM effect due to the presence of a dimension-6 4-fermion contact interaction (see e.g. [91])
where \({J_L}^\mu _a\) is the SU\((2)_L\) SM current and \(\Lambda \) is conventionally set to 1 TeV. We generate di-muon events with the same tools described above (supplemented with a MadGraph5 model for the EFT operator obtained by FeyRules [92]) by varying \(c_W\) in order to study the performances of the algorithm as discussed in Sect. 5. The distribution of the input values for three representative values of \(c_W\) are shown in Figs. 6 and 7.
In Sect. 5 we will extensively study the sensitivity of our method to the BSM scenarios described above. For a meaningful presentation of the results, and in order to compare the performances on different scenarios, we need an absolute measure of how much a given BSM hypothesis is “easy” to detect with a given integrated luminosity. As in Ref. [1], this measure is introduced by the notion of “ideal significance”, described below.
4.1 The ideal significance
The ideal significance is the highest possible median Z-score (\(Z_\mathrm{id}\)) that any search specifically targeted to a given BSM scenario in a given experiment could ever obtain. By the Neyman–Pearson lemma, it is obtained using the “ideal” test statistic
The ideal significance can be reached only in a fully model-dependent search where the exact knowledge of both the new physics distribution \(n(x|\mathrm{NP})\) (see Table 1) and the reference distribution \(n(x|\mathrm{R})\) are available. This knowledge is available, in principle, for the BSM scenarios under examination. However computing \(n(x|\mathrm{NP})/n(x|\mathrm{R})\) is cumbersome. An estimate for it sufficiently accurate to serve as a reference of performance in the present paper (hence quoted as \(Z_\mathrm{ref}\)) is readily obtained as follows.
\(\mathbf{Z}^{\prime }\) to di-muon The signal shows up as a resonant peak in the di-muon invariant mass \(m_{ll}\) around the \(Z^\prime \) mass \(m_{Z^\prime }\). A simple cut-and-count strategy in a suitably designed interval \(m_{ll}\in \left[ m_\mathrm{min}, m_\mathrm{max}\right] \) around \(m_{Z^\prime }\) should provide a reasonable estimate of the ideal reach. The ideal significance is thus estimated as
In the equation, \({\mathrm{CDF}[{\mathrm{P}}_b]}\) denotes the cumulative of the Poisson distribution with mean “b” while \(f_\mathrm{sig}\) and \(f_\mathrm{bkg}\) are respectively the signal and background fractions in the mass-window
The signal fraction is estimated with a Monte Carlo sample consisting of 16,000 signal-only events. The background is computed by fitting a Landau distribution to the tail of a SM sample with 1.6 million events. The boundaries of the mass-window \(\left[ m_\mathrm{min}, m_\mathrm{max}\right] \) are selected by optimizing the significance and reported in Table 2 together with the corresponding signal and background fractions.
In order to validate Eq. (9) as a reasonable estimate of \(Z_\mathrm{id}\) we compared it with the truly “ideal” significance obtained with the Neyman-Pearson test performed on the \(m_{ll}\) variable. We fitted the background Monte Carlo data using two Landau distributions (one for \(250\;\mathrm{GeV}\le m_{ll}<600\; \mathrm{GeV}\), the other for \(m_{ll}\ge 600\;\mathrm{GeV}\)) and a Normal distribution for the \(Z^\prime \) peak. This allowed us to compute the test statistic in Eq. (8) and in turn the ideal significance by toy experiments. Good agreement with Eq. (9) was found. Notice however that the comparison was possible only in configurations with low enough \(Z_\mathrm{ref}\). For cases with \(Z_\mathrm{ref} > rsim 4\), which we do consider in Sect. 5, validation is unfeasible and we exclusively rely on Eq. (9).
EFT Also in this case, the di-muon invariant mass is the most relevant discriminant. Since the excess is spread over the entire spectrum, the ideal significance is estimated through a likelihood ratio (Neyman–Pearson) test on the binned \(m_{ll}\) distribution. The number of expected events in each bin is quadratic in \(c_W\)
with coefficients determined from Monte Carlo simulations at varying \(c_W\), reported in Table 3. The test statistic is the log-ratio for the Poisson distributed observed countings “\(o_i\)” in each bin
and the reference significance is evaluated from the distribution of t in the SM (\(c_W=0\)) extracted from toy experiments.

Probability of finding a \(\alpha =2\sigma , 3\sigma , 5\sigma \) evidence for new physics using our technique as a function of the reference significance of the signal, for the \(Z^\prime \) model described in Sect. 4. (Left) Including the Z-peak in the data. (Right) Without the Z-peak
5 Results on benchmark examples
In this section we study the sensitivity of our data analysis strategy to the physics examples discussed in the previous section. Our main results are:
-
1.
In the examples we studied, in all cases where the estimate of the ideal significance exceeds \(5\sigma \), the probability of finding a \(2\sigma \) tension for the SM using our approach is \(p(\alpha =2\sigma ) > rsim 20\%\) and grows to \(p(\alpha =2\sigma ) > rsim 40\%\) if we exclude the Z-boson peak from the input data by a cut on the invariant mass. The probability of finding a \(3\sigma \) tension is \(p(\alpha =3\sigma ) > rsim 7\%\) and \(p(\alpha =3\sigma ) > rsim 20\%\) including or excluding the Z-peak, respectively (Fig. 8).
-
2.
For any given “experiment” (i.e., at fixed luminosity and input space), the observed significance mostly depends on the ideal significance of the putative signal, while it weakly depends on the type of signal (Fig. 9).
-
3.
The neural network output correctly reconstruct the data to reference likelihood-ratio, finding a good approximation to the properties of the signal in the space of input variables, for all the signals that we consider (Fig. 10).
-
4.
In the examples that we have studied, where the observed significance is not close to saturating the reference significance, the observed significance increases linearly with luminosity, as opposed to the \(\sqrt{L}\) growth of the reference significance. Both significances increase linearly with the number of signal events as expected (Fig. 11).
Properties “1” and “2” make our technique ideally suited to identify an unexpected new physics signal. Because of “3”, if a tension is observed in the data the sensitivity to the signal can be increased with a dedicated analysis on new data, selected using the likelihood ratio learned by the network.
As stated in “2” above, \(Z_\mathrm{obs}\) essentially depends only on the ideal significance (approximated by \(Z_\mathrm{ref}\)) for a given experiment. However in a different experiment (e.g., if we change the luminosity) the relation between \(Z_\mathrm{obs}\) and \(Z_\mathrm{ref}\) changes. The relation becomes more favorable at high luminosity because of point “4”.
Let us now turn to an extensive description of the items above, and of our findings on a few technical points relevant to the implementation of the algorithm. For all the results in this paper the minimization of the loss function is performed using ADAM [78] as implemented in Keras [79] (with the TensorFlow [80] backend) with parameters fixed to: \(\beta _1=0.9\), \(\beta _2=0.99\), \(\epsilon =10^{-7}\), initial learning rate \(=10^{-3}\). The batch size is always fixed to cover the full training sample. Network architecture, size of the weight clipping and number of training rounds were selected following the procedure described in Sect. 2. Where not specified otherwise, the results were obtained with a 5-5-5-5-1 network and \(3\times 10^5\) training rounds, using 100 data samples and 100 toy reference samples. The median observed significance plotted in the Figures and its \(68\%\) C.L. error were obtained approximating P(t|R) with a \(\chi ^2\) distribution with as many degrees of freedom as free parameters in the network as discussed in Sect. 2. We always consider a five-dimensional input space composed of the \(p_T\)’s and \(\eta \)’s of the two leptons and their \(\Delta \phi \). The range of the input variables and their distribution for three representative signal points are shown in Figs. 6 and 7.
Sensitivity The first goal of our study is to show that our technique is sensitive to realistic signals. By realistic we mean having \(N({\mathrm{S}})/N({\mathrm{R}})\ll 1\), i.e. a small number of signal events compared to the total size of the sample, and ideal significances of order a few \(\sigma \)’s. These choices reproduce signals that we might have missed at the LHC so far, if not targeted by a dedicated search. The best way to illustrate the performances of a model-independent strategy is to report the probability it has to identify a tension with respect to the SM if a putative new physics effect is present in the data. This measures the chances that the analysis has to produce an interesting result. In the left panel of Fig. 8 we show the probability of finding evidence for new physics at the \(\alpha =2\sigma , 3\sigma \) and \(5\sigma \) levels given a reference significance for the signal. We consider for illustration the \(Z^\prime \) signal model with \(m_{Z^\prime }=300\) GeV described in the previous section, but similar or better performances are obtained for other masses and for the case of the EFT. The two plots here presented are obtained by fixing the luminosity while the ratio \(N({\mathrm{S}})/N({\mathrm{R}})\) is varied.
On the left panel of the figure, and in the results that follow if not specified otherwise, we applied our algorithm to the entire dataset which includes the SM Z-boson peak. This choice was made in order to challenge our analysis strategy in a situation where the dataset is dominated by the peak, where no new physics effect is present. On the other hand the peak would be excluded in a realistic application of our method to the di-muon final state because it is hard to imagine new physics appearing on the Z peak not excluded by LEP and because detailed analyses of the Z resonant production could be performed separately. If we exclude the Z-peak from the input data, with a cut \(m_{ll}>95\) GeV (whose efficiency is \(10\%\)), the performances of our analysis improve as shown on the right panel of Fig. 8.
Another way to quantify the sensitivity is to report the median significance obtained for different new physics scenarios, still as a function of the ideal significance. The result is shown in Fig. 9, with the error bars representing the 68% C.L. spread of the observed significance distribution. The study was performed for a given experimental setup, namely by fixing \(N({\mathrm{R}})=2\times 10^4\) (and \(\mathcal {N}_R=5\,N({\mathrm{R}})\)), and varying the signal fraction or the EFT Wilson coefficient \(c_W\) as shown in the legend. We observe, similarly to Ref. [1], a good level of correlation between our sensitivity and the ideal one and a weak dependence on the nature of the new physics. This correlation was sharper in the examples studied in Ref. [1], however it should be taken into account that the present study relies on approximate (see Sect. 4) estimates of \(Z_{\mathrm{id}}\) and that high values of \(Z_{\mathrm{obs}}\) are also approximate, being estimated with the Asymptotic \(\chi ^2\) formula (see Sect. 2.1).

Sensitivity (\(Z_\mathrm{obs}\)) to \(Z^\prime \rightarrow \mu ^+\mu ^-\) for \(m_{Z^\prime }=300\) GeV and the EFT signal. We show the sensitivity as a function of the reference significance \(Z_\mathrm{ref}\)
Likelihood Learning It is instructive to study directly what the network has learned during training. The network should learn approximately the log-ratio between the true distribution (\(n(x|{\mathrm{T}})\), see Table 1) of the data and the reference model distribution \(n(x|{\mathrm{R}})\). We should thus be able to get information on the nature of the discrepancy by inspecting the likelihood ratio learned by the network as a function of the physical observables chosen as input or any of their combinations. In the case of a \(Z^\prime \) signal, for instance, we would like to see a bump in the invariant mass distribution as learned by the network.
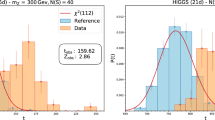
In Fig. 10 we plot the distribution ratio learned by the network as a function of the invariant mass of the dimuon system. In the figure we also show the true likelihood ratio used for the generation of the events and its estimate based on the specific data sample used for training. The signals are the \(Z^\prime \) with a 300 GeV mass with \(N({\mathrm{S}})/N({\mathrm{R}})=2\times 10^{-3}\), \(N({\mathrm{R}})=2\times 10^4\) and \(\mathcal {N}_R=10^5\) and an EFT signal with the same \(N({\mathrm{R}})\) and \(\mathcal {N}_R\) and \(c_W=10^{-6}\). Notice that \(m_{ll}\) is not given to the network, the input variables being the muon \(p_T\)’s, rapidities and \(\Delta \phi \).

Comparison between the ideal invariant mass distribution for the \(Z^\prime \) and EFT signals and the distribution reconstructed by the network and realized in the toy sample taken as input. The probability distribution of the data sample is normalized to the reference one
The ratios in the figure were obtained in the following way. The yellow “ideal” likelihood-ratio was obtained by binning the invariant mass of a large data sample, containing one million events, and of the reference sample and taking the ratio. The red likelihood-ratio pertaining to a specific toy was obtained in the same way, replacing the large data sample with the relevant toy. Finally, the ratio as learned by the network was obtained by reweighting reference sample by \(e^{f(x, {\widehat{\mathbf{w}}})}\), where f is the neural network output after training, binning it and taking the ratio with the reference.
The network is doing a pretty good job in reproducing a peak or a smooth growth (for the \(Z^\prime \) and the EFT, respectively) in the invariant mass. Therefore if one had access to a new independent data set, distributed like the one used for training (i.e., following \(n(x|{\mathrm{T}})\)), one could employ the neural network \(f(x, {\widehat{\mathbf{w}}})\) (trained on the first dataset) as discriminant (for instance, by a simple lower cut), and boost the significance of the observed tension.
In the studies presented so far we have chosen as input to the network five independent kinematic variables that characterize the di-muon final state under examination, paying attention not to include the invariant mass \(m_{ll}\) which is essentially the only relevant discriminant in the new physics scenarios under investigation. This choice was intended to maximize the difficulty of the network task, reproducing the realistic situation where, since the actual signal is unknown, the most discriminant variable cannot be identified and given to the network. However it is interesting to study the potential improvement of the performances that could be achieved with a judicious (but model-dependent) choice of the input variables. The first test we made was to present \(m_{ll}\) to the network in addition to the five variables \(p_{T1,2}\), \(\eta _{1,2}\) and \(\Delta \phi \). This led to no substantial improvement of the performances suggesting that the neural network is already learning to reconstruct \(m_{ll}\) sufficiently well from the five variables and does not need the sixth one. The second test was to trade the variable \(\Delta \phi \) for \(m_{ll}\), considering an alternative five-dimensional parametrization of the phase-space. Notice that \(\Delta \phi \) has no discriminating power whatsoever because the new physics scenarios under examination emerge in \(2\rightarrow 2\) scattering processes where the muons are back-to-back in the transverse plane up to showering and detector effects, as it is the case for the SM. The \(\Delta \phi \) distribution is thus (see Fig. 7) strongly peaked at \(\pi \) and identical in the SM and in BSM. Replacing it with \(m_{ll}\), which is instead the most discriminant one, is thus the strongest test we can make of the robustness of our approach against change of input space parametrization. For the \(m_{Z^\prime }=300\) GeV signal with \(N({\mathrm{S}})/N({\mathrm{R}})=10^{-3}\) and \(N({\mathrm{R}})=2\times 10^4\), whose significance was \(Z_\mathrm{obs}=(0.9^{+1.3}_{-0.9})\sigma \), replacing \(\Delta \phi \) with \(m_{ll}\) increases the observed significance to \(Z_\mathrm{obs}=(2.3^{+1.4}_{-1.1})\sigma \).

Sensitivity (\(Z_\mathrm{obs}\)) to \(Z^\prime \rightarrow \mu ^+\mu ^-\) for \(m_{Z^\prime }=300\) GeV. We show the sensitivity as a function of Luminosity (left panel) and signal fraction (right panel). For reference we plot the reference significance \(Z_\mathrm{ref}\) and a polynomial fit to the sensitivity
Luminosity and signal fraction In the left panel of Fig. 11 we show our performances for the \(Z^\prime \) model with \(m_{Z^\prime }=300\) GeV as a function of \(N({\mathrm{R}})\), i.e. as a function of the integrated luminosity “L” of the dataset. The observed significance shown in the plot is the median over 100 data samples with its \(68\%\) C.L. error. The signal fraction is fixed to \(N({\mathrm{S}})/N({\mathrm{R}})=10^{-3}\), the size of the reference sample is \(\mathcal {N}_R=5 N({\mathrm{R}})\) and we increase \(N({\mathrm{R}})\) from \(10^4\) to \(10^5\). Interestingly, in the regime where these tests are performed, the observed significance increases linearly with the luminosity \(Z_\mathrm{obs}\sim L\), as opposed to the \(\sqrt{L}\) growth of the reference significance. This can be explained by the fact that our analysis technique benefits from having enough statistics in the data to accurately reproduce the likelihood ratio. So increasing L does not only make the signal more abundant and easier to see as in standard model-dependent analyses, but it also helps the learning process to reconstruct the most powerful (likelihood ratio) discriminant to detect it. Note however that at some point this behaviour must change and match the usual \(\sqrt{L}\) scaling; this is expected to happen for very large signals corresponding to very large \(Z_\mathrm{ref}\), somewhat beyond the regimes typically relevant for new physics searches.

(Left) Observed significance as a function of the statistical error on the reference sample in the \(m_{Z^\prime }=300\) GeV case. (Right) Optimized weight clipping as a function of reference size \(\mathcal {N}_R\)
Increasing the signal fraction \(N({\mathrm{S}})/N({\mathrm{R}})\) at fixed luminosity has the only benefit of increasing the ideal significance and its estimate. So both \(Z_\mathrm{obs}\) and \(Z_\mathrm{ref}\) increase linearly with the signal fraction as show in the right panel of Fig. 11. This study was performed on the \(m_{Z^\prime }=300\) GeV sample with \(N({\mathrm{R}})=2\times 10^4\), \(\mathcal {N}_R=10^5\) as for the study of the luminosity in the same figure.
(In)Sensitivity to data selection. As discussed in the Introduction, traditional model-independent strategies based on countings in bins suffer from the presence of regions in the phase space that are insensitive to new physics, because of uncorrelated Poisson fluctuation in the corresponding bins. In our approach this effect is greatly reduced, because the smoothness of the neural network protects it from following the bin-by-bin statistical fluctuations [1]. One particular implication of this fact is that we expect our sensitivity to depend weakly on the presence or on the absence of selection cuts that eliminate signal-free regions of the phase space. This is illustrated by studying the dependence of the observed sensitivity on: 1) a cut on the \(p_T\) of the leading muon and 2) a cut on the invariant mass of the di-muon system. The 300 GeV \(Z^\prime \) model, with \(\mathcal {N}_R=10^5\) and \(N({\mathrm{S}})/N({\mathrm{R}})=1\times 10^{-4}\) (before selection) is considered for this investigation.
We find that the \(p_T\) cut does not alter our sensitivity. For instance the median \(Z_\mathrm{obs}\) remains at \(1\sigma \) after a \(p_T>75\) GeV selection, in spite of the fact that the cut rejects \(96\%\) of the background and only \(5\%\) of the signal. The selection on the invariant mass instead slightly increases our sensitivity. For example \(m_{ll}>95\) GeV (that rejects \(90\%\) of the background and nothing of the signal) increases the median significance to \(Z_\mathrm{obs}=1.4\sigma \).Footnote 5 We have observed this phenomenon already in Figs. 8 and 9.
Reference size and optimal weight clipping An accurate knowledge of known processes in the phase space of interest is crucial for the success of any new physics search. Therefore the size \(\mathcal {N}_R\) of the Reference Sample should be taken as large as possible, compatibly with the computational price for training. To give an idea of the needed reference sample size, we study the performances of our method as a function of \(\mathcal {N}_R/N(R)\). The result on the left panel of Fig. 12 is reassuring: the sensitivity is very stable as a function of this ratio up to \(\mathcal {N}_R/N(R)\approx 1\). Below this value the statistical error on the reference sample in the signal region becomes sizable. If we define \(\varepsilon \equiv 1/\sqrt{\mathcal {N}_R(278\le m \le 322)}\), i.e. counting only events in the invariant mass window populated by the signal (see Sect. 4) then the first point in the left panel of Fig. 12, where Z is degraded, corresponds to \(\varepsilon \sim 1/2\). However this holds for a specific signal (\(m_{Z^\prime }=300\) GeV \(N({\mathrm{S}})/N({\mathrm{R}})=2\times 10^{-3}\) and \(N({\mathrm{R}})=2\times 10^4\)), in general we expect that a degradation of the performances might be observed if \(\mathcal {N}_R\) is not well above \(N({\mathrm{R}})\), because of the result shown on the right panel of Fig. 12. The plot shows the evolution with \(\mathcal {N}_R/N({\mathrm{R}})\) of the weight clipping parameter, selected with the criteria of Sect. 2. The Weight Clipping becomes stable for \(\mathcal {N}_R/N({\mathrm{R}}) > rsim 10\), but it abruptly drops for smaller values of this ratio. Small Weight Clipping reduces the flexibility of the neural network, which is thus less suited to identify complex new physics signals. Employing Reference samples with \(\mathcal {N}_R/N({\mathrm{R}}) > rsim 10\), slightly above the benchmark \(\mathcal {N}_R/N({\mathrm{R}})=5\) we employed here, is thus recommended.
6 Conclusions and outlook
We have discussed a new physics search strategy that is “model-independent” (i.e., not targeted to a given new physics model), with the alternative hypothesis needed for hypothesis testing being provided by a neural network. This approach was proposed in Ref. [1]. In this paper we made progress on its implementation and on the study of its performances.
The main methodological advance, described in Sect. 2.1, consists of a strategy to select the hyperparameters associated with the neural network and its training, prior to the experiment, and without relying on assumptions on the nature of the putative new physics signal. It is crucial to identify one such strategy in order to avoid the look-elsewhere effect from the ambiguities in the choice of the hyperparameters. The one we propose is heuristic, but convincing, and reduces the ensemble of hyperparameters choices to a manageable level. Progress might come on this aspect from a more sharp notion of neural network “flexibility” (or capacity). Notice however that the concrete impact of the hyperparameters on the sensitivity to new physics signal has been observed to be extremely limited in all the examples we studied. Even if no systematic study has been performed, this suggests that residual ambiguities in the hyperparameters selection could be ignored.
It is not easy to quantify the performances of a model-independent search strategy. The assessment unavoidably relies on the selection of putative new physics models that are potentially present in the data, which we can try to make as broad and varied as possible. Once this choice is made, one way to proceed is to compare the sensitivity to other model-independent strategies. This is what we did in Sect. 3, finding that our approach compares favorably to other ideas recently proposed in the literature. This comparison is however highly incomplete because it is based on a few toy problems, which are not representative of realistic LHC datasets and where new physics is extremely easy to see with our method. This is a second direction in which further work is needed.
We also need to quantify the performances in absolute terms. To this end, the most indicative quantity is arguably the probability to observe a tension with the SM if the data follow the new physics distribution. That is, the probability for our analysis to produce an interesting result. This is shown in Fig. 8 for different levels of observed tension and as a function of the ideal median significance of the putative new physics signal. The latter quantity, defined in Ref. [1] and in Sect. 4, serves as an objective measure of how “easy-to-detect” the new physics scenario is. Notice that the ideal significance is not the target of our method. The ideal significance can be reached, because of the Neyman–Pearson lemma, only in a fully model-dependent search where all the details of the new physics scenario are known. It cannot be obtained with any model-independent approach. With this in mind, one can still compare the observed and ideal significance directly as in Fig. 9. The picture displays a good correlation between the ideal and observed significance in a given experiment and a weak dependence on the type of signal that is responsible for the discrepancy. This behavior might have a deep explanation, which is worth trying to identify. Yet another direction for future work is the assessment of the performances presented for more complex final states than dimuon and for more exotic putative signals.
All the items listed above are worth investigating. However the most pressing aspect to be explored in view of the application of our strategy to real data is the inclusion of the systematic uncertainties in the reference (SM) Monte Carlo. This is conceptually straightforward because our method is based on the Maximum Likelihood approach to hypothesis testing, and systematic uncertainties are easily included in that framework as nuisance parameters. All steps needed to turn likelihood maximization into a training problem are straightforwardly repeated in the presence of nuisance parameters, as mentioned in Ref. [1]. The final outcome is simply that training should be performed against a reference Monte Carlo sample where the nuisance parameters are set to their best-fit values for the dataset under consideration. The concrete implementation of the algorithm in the presence of nuisance parameters thus requires two steps. The first one is to fit the nuisance parameters under the SM hypothesis to the observed data, including auxiliary measurements. Since this first step is the same as in any other experimental analysis, it should not pose any specific issue. Implementing the second step is instead problematic because it would require running the Monte Carlo with the nuisance parameters set to the observed best-fit value. Doing so for many toy SM datasets would be computationally very demanding or unfeasible. Potential solutions are either to obtain the reference sample by reweighting (which will require fitting the dependence on the nuisance of the SM likelihood possibly with a neural network) or to employ a reference sample with benchmark nuisance and correct the test statistics by some approximation of the ratio between the best-fit and the benchmark SM likelihood. It is important to verify if and how these solutions work in practice.
Before concluding it is worth outlining that the problem we are addressing is of rather general relevance in data analysis. The methods we are developing could thus find applications outside the specific domain of new physics searches at collider. In abstract terms, the problem can be phrased in terms of two distinct datasets, each of which can be of natural or artificial origin. The first set of data, obeying the “Reference” probability model, must be more abundant than the “Data” because it has to provide both the Reference dataset used for training and the Reference-distributed toy data used to compute the test statistic distribution. In these conditions are met, ours is a strategy to tell if the two datasets are thrown from the same statistical distribution or not, which could be useful in different domains of science. Still remaining in the context of particles physics, other potential applications of our strategies are the comparison of different Monte Carlo generators and data validation.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: The data used for the paper (as a tar.gz file) is uploaded and available on Zenodo: https://zenodo.org/record/4442665#.YAGiaC9h23I].
Notes
Also in the approach we follow in the present paper, both options are viable since we only need a reference data sample distributed as the SM predicts. It might come from a Monte Carlo simulation or from a control region.
While more standard validation procedures like k-folding could be exploited, in this study we only focus on the approach described in Sect. 2.1, specifically designed to fit the proposed methodology.
We stress the fact that our p-values are global. i.e., we do account for the look-elsewhere effect in the specific analysis at hand. On the other hand, there is a residual trial factor, induced by repeating the procedure on multiple final states. This trial factor is difficult to quantify, and analogous to the usually neglected trial factor of the global search effort by an LHC experiment consisting of hundreds of searches in different final states. We do not discuss it further here.
Note that in reality one always needs an alternative hypothesis to obtain a significance. Our use of the term model-independent is explained in the previous section and in Ref. [1].
To face the reduced amount of training data, a less complex neural network is used for this study: the 5-5-5-5-1 architecture is replaced by a 5-5-5-1. Also in this case the weight clipping and the number of training rounds are optimized following the procedure described in Sect. 2.1.
References
R.T. D’Agnolo, A. Wulzer, Learning new physics from a machine. Phys. Rev. D 99(1), 015014 (2019). https://doi.org/10.1103/PhysRevD.99.015014. arXiv:1806.02350 [hep-ph]
G. Choudalakis, On hypothesis testing, trials factor, hypertests and the BumpHunter, in Proceedings, PHYSTAT 2011 Workshop on Statistical Issues Related to Discovery Claims in Search Experiments and Unfolding, CERN, Geneva, 17–20 January 2011 (2011). arXiv:1101.0390 [physics.data-an]
D0 Collaboration, B. Abbott et al., Search for new physics in \(e\mu X\) data at DØ using Sherlock: a quasi model independent search strategy for new physics. Phys. Rev. D 62, 092004 (2000). https://doi.org/10.1103/PhysRevD.62.092004. arXiv:hep-ex/0006011
D0 Collaboration, V.M. Abazov et al., A Quasi model independent search for new physics at large transverse momentum. Phys. Rev. D 64, 012004 (2001). https://doi.org/10.1103/PhysRevD.64.012004. arXiv:hep-ex/0011067
H1 Collaboration, A. Aktas et al., A general search for new phenomena in ep scattering at HERA. Phys. Lett. B 602, 14–30 (2004). https://doi.org/10.1016/j.physletb.2004.09.057. arXiv:hep-ex/0408044
H1 Collaboration, F.D. Aaron et al., A general search for new phenomena at HERA. Phys. Lett. B B674, 257–268 (2009). https://doi.org/10.1016/j.physletb.2009.03.034. arXiv:0901.0507 [hep-ex]
P. Asadi, M.R. Buckley, A. DiFranzo, A. Monteux, D. Shih, Digging deeper for new physics in the LHC data. JHEP 11, 194 (2017). https://doi.org/10.1007/JHEP11(2017)194. arXiv:1707.05783 [hep-ph]
CDF Collaboration, T. Aaltonen et al., Model-independent and quasi-model-independent search for new physics at CDF. Phys. Rev. D 78, 012002 (2008). https://doi.org/10.1103/PhysRevD.78.012002. arXiv:0712.1311 [hep-ex]
CDF Collaboration, T. Aaltonen et al., Global search for new physics with \(2.0~\text{fb}^{-1}\) at CDF. Phys. Rev. D 79, 011101 (2009). https://doi.org/10.1103/PhysRevD.79.011101. arXiv:0809.3781 [hep-ex]
CMS Collaboration, MUSIC—an automated scan for deviations between data and Monte Carlo simulation. CMS-PAS-EXO-08-005
CMS Collaboration, Model unspecific search for new physics in pp collisions at sqrt(s) = 7 TeV. CMS-PAS-EXO-10-021
ATLAS Collaboration, A model independent general search for new phenomena with the ATLAS detector at \(\sqrt{s} = 13\;\text{ TeV }\). ATLAS-CONF-2017-001
ATLAS Collaboration, A general search for new phenomena with the ATLAS detector in pp collisions at sort(s)=7 TeV. ATLAS-CONF-2012-107
ATLAS Collaboration, A general search for new phenomena with the ATLAS detector in pp collisions at \(\sqrt{s}=8\) TeV. ATLAS-CONF-2014-006
C.A. Arguelles, A. Schneider, T. Yuan, A binned likelihood for stochastic models. JHEP 06, 030 (2019). https://doi.org/10.1007/JHEP06(2019)030. arXiv:1901.04645 [physics.data-an]
A. Andreassen, B. Nachman, D. Shih, Simulation assisted likelihood-free anomaly detection. Phys. Rev. D 101 (2020). https://doi.org/10.1103/PhysRevD.101.095004
J.H. Collins, K. Howe, B. Nachman, Extending the search for new resonances with machine learning. Phys. Rev. D 99 (2019). https://doi.org/10.1103/PhysRevD.99.014038
G. Cybenko, Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 2, 303–314 (1989). https://doi.org/10.1007/BF02551274
V.Y. Kreinovich, Arbitrary nonlinearity is sufficient to represent all functions by neural networks: a theorem. Neural Netw. 4(3), 381–383 (1991). https://doi.org/10.1016/0893-6080(91)90074-F
R. Hecht-Nielsen, Neural networks for perception (vol. 2). http://dl.acm.org/citation.cfm?id=140639.140643
K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators. Neural Netw. 2, 359–366 (1989)
S. Liang, R. Srikant, Why deep neural networks for function approximation? arXiv e-prints (2016). arXiv:1610.04161 [cs.LG]
T. Poggio, H. Mhaskar, L. Rosasco, B. Miranda, Q. Liao, Why and when can deep—but not shallow—networks avoid the curse of dimensionality: a review. arXiv:1611.00740 [cs.LG]
F. Bach, Breaking the curse of dimensionality with convex neural networks. arXiv:1412.8690 [cs.LG]
H. Montanelli, Q. Du, Deep ReLU networks lessen the curse of dimensionality. arXiv e-prints (2017). arXiv:1712.08688 [math.NA]
R.T. D’Agnolo, G. Grosso, M. Pierini, A. Wulzer, M. Zanetti, Learning new physics from an imperfect machine (in preparation)
C. Weisser, M. Williams, Machine learning and multivariate goodness of fit. arXiv:1612.07186 [physics.data-an]
A. Blance, M. Spannowsky, P. Waite, Adversarially-trained autoencoders for robust unsupervised new physics searches. J. High Energy Phys. 2019 (2019). https://doi.org/10.1007/JHEP10(2019)047
T. Heimel, G. Kasieczka, T. Plehn, J.M. Thompson, QCD or what? SciPost Phys. 6(3), 030 (2019). https://doi.org/10.21468/SciPostPhys.6.3.030. arXiv:1808.08979 [hep-ph]
O. Cerri, T.Q. Nguyen, M. Pierini, M. Spiropulu, J.-R. Vlimant, Variational autoencoders for new physics mining at the large hadron collider. JHEP 05, 036 (2019). https://doi.org/10.1007/JHEP05(2019)036. arXiv:1811.10276 [hep-ex]
M. Farina, Y. Nakai, D. Shih, Searching for new physics with deep autoencoders. Phys. Rev. D 101 (2020). https://doi.org/10.1103/PhysRevD.101.075021
J. Hajer, Y.-Y. Li, T. Liu, H. Wang, Novelty detection meets collider physics. Phys. Rev. D 101 (2020). https://doi.org/10.1103/PhysRevD.101.076015
A. De Simone, T. Jacques, Guiding new physics searches with unsupervised learning. Eur. Phys. J. C 79(4), 289 (2019). https://doi.org/10.1140/epjc/s10052-019-6787-3. arXiv:1807.06038 [hep-ph]
L. de Oliveira, M. Kagan, L. Mackey, B. Nachman, A. Schwartzman, Jet-images–deep learning edition. JHEP 07, 069 (2016). https://doi.org/10.1007/JHEP07(2016)069. arXiv:1511.05190 [hep-ph]
A. Schwartzman, M. Kagan, L. Mackey, B. Nachman, L. De Oliveira, Image processing, computer vision, and deep learning: new approaches to the analysis and physics interpretation of LHC events. J. Phys. Conf. Ser. 762(1), 012035 (2016). https://doi.org/10.1088/1742-6596/762/1/012035
M. Kagan, Ld Oliveira, L. Mackey, B. Nachman, A. Schwartzman, Boosted jet tagging with jet-images and deep neural networks. EPJ Web Conf. 127, 00009 (2016). https://doi.org/10.1051/epjconf/201612700009
A.J. Larkoski, I. Moult, B. Nachman, Jet substructure at the large hadron collider: a review of recent advances in theory and machine learning. Phys. Rep. 841, 1–63 (2020). https://doi.org/10.1016/j.physrep.2019.11.001
G. Louppe, K. Cho, C. Becot, K. Cranmer, QCD-aware recursive neural networks for jet physics. arXiv:1702.00748 [hep-ph]
C. Shimmin, P. Sadowski, P. Baldi, E. Weik, D. Whiteson, E. Goul, A. Søgaard, Decorrelated jet substructure tagging using adversarial neural networks. Phys. Rev. D 96(7), 074034 (2017). https://doi.org/10.1103/PhysRevD.96.074034. arXiv:1703.03507 [hep-ex]
P. Baldi, K. Bauer, C. Eng, P. Sadowski, D. Whiteson, Jet substructure classification in high-energy physics with deep neural networks. Phys. Rev. D 93(9), 094034 (2016). https://doi.org/10.1103/PhysRevD.93.094034. arXiv:1603.09349 [hep-ex]
D. Guest, J. Collado, P. Baldi, S.-C. Hsu, G. Urban, D. Whiteson, Jet flavor classification in high-energy physics with deep neural networks. Phys. Rev. D 94(11), 112002 (2016). https://doi.org/10.1103/PhysRevD.94.112002. arXiv:1607.08633 [hep-ex]
L.G. Almeida, M. Backović, M. Cliche, S.J. Lee, M. Perelstein, Playing tag with ANN: boosted top identification with pattern recognition. JHEP 07, 086 (2015). https://doi.org/10.1007/JHEP07(2015)086. arXiv:1501.05968 [hep-ph]
J. Barnard, E.N. Dawe, M.J. Dolan, N. Rajcic, Parton shower uncertainties in jet substructure analyses with deep neural networks. Phys. Rev. D 95(1), 014018 (2017). https://doi.org/10.1103/PhysRevD.95.014018. arXiv:1609.00607 [hep-ph]
G. Kasieczka, T. Plehn, M. Russell, T. Schell, Deep-learning top taggers or the end of QCD? JHEP 05, 006 (2017). https://doi.org/10.1007/JHEP05(2017)006. arXiv:1701.08784 [hep-ph]
A. Butter, G. Kasieczka, T. Plehn, M. Russell, Deep-learned top tagging with a lorentz layer. SciPost Phys. 5 (2018). https://doi.org/10.21468/SciPostPhys.5.3.028
K. Datta, A. Larkoski, How much information is in a jet? JHEP 06, 073 (2017). https://doi.org/10.1007/JHEP06(2017)073. arXiv:1704.08249 [hep-ph]
K. Datta, A.J. Larkoski, Novel jet observables from machine learning. JHEP 03, 086 (2018). https://doi.org/10.1007/JHEP03(2018)086. arXiv:1710.01305 [hep-ph]
K. Fraser, M.D. Schwartz, Jet charge and machine learning. J. High Energy Phys. 2018 (2018). https://doi.org/10.1007/JHEP10(2018)093
A. Andreassen, I. Feige, C. Frye, M.D. Schwartz, Junipr: a framework for unsupervised machine learning in particle physics. Eur. Phys. J. C 79 (2019). https://doi.org/10.1140/epjc/s10052-019-6607-9
S. Macaluso, D. Shih, Pulling out all the tops with computer vision and deep learning. J. High Energy Phys. 2018 (2018). https://doi.org/10.1007/JHEP10(2018)121
ATLAS Collaboration, T.A. collaboration, Performance of top quark and W boson tagging in run 2 with ATLAS. ATLAS-CONF-2017-064
CMS Collaboration, CMS Phase 1 heavy flavour identification performance and developments. CMS-DP-2017-013. https://cds.cern.ch/record/2263802
ATLAS Collaboration, Optimisation and performance studies of the ATLAS \(b\)-tagging algorithms for the 2017-18 LHC run. Tech. Rep. ATL-PHYS-PUB-2017-013, CERN, Geneva (2017). http://cds.cern.ch/record/2273281
ATLAS Collaboration, Identification of hadronically-decaying w bosons and top quarks using high-level features as input to boosted decision trees and deep neural networks in ATLAS at \(\sqrt{s}\) = 13 TeV. Tech. Rep. ATL-PHYS-PUB-2017-004, CERN, Geneva (2017). https://cds.cern.ch/record/2259646
CMS Collaboration, Heavy flavor identification at CMS with deep neural networks. https://cds.cern.ch/record/2255736
ATLAS Collaboration, Identification of jets containing \(b\)-hadrons with recurrent neural networks at the ATLAS experiment. Tech. Rep. ATL-PHYS-PUB-2017-003, CERN, Geneva (2017). https://cds.cern.ch/record/2255226
ATLAS Collaboration, Quark versus gluon jet tagging using jet images with the ATLAS detector. Tech. Rep. ATL-PHYS-PUB-2017-017, CERN, Geneva (2017). https://cds.cern.ch/record/2275641
CMS Collaboration, New developments for jet substructure reconstruction in CMS. https://cds.cern.ch/record/2275226
P. Baldi, K. Cranmer, T. Faucett, P. Sadowski, D. Whiteson, Parameterized neural networks for high-energy physics. Eur. Phys. J. C 76(5), 235 (2016). https://doi.org/10.1140/epjc/s10052-016-4099-4. arXiv:1601.07913 [hep-ex]
S. Chang, T. Cohen, B. Ostdiek, What is the machine learning? Phys. Rev. D 97 (2018). https://doi.org/10.1103/PhysRevD.97.056009
T. Cohen, M. Freytsis, B. Ostdiek, (Machine) Learning to do more with less. JHEP 02, 034 (2018). https://doi.org/10.1007/JHEP02(2018)034. arXiv:1706.09451 [hep-ph]
J. Brehmer, K. Cranmer, G. Louppe, J. Pavez, A guide to constraining effective field theories with machine learning. Phys. Rev. D 98 (2018). https://doi.org/10.1103/PhysRevD.98.052004
J. Brehmer, K. Cranmer, G. Louppe, J. Pavez, Constraining effective field theories with machine learning. Phys. Rev. Lett. 121 (2018). https://doi.org/10.1103/PhysRevLett.121.111801
J. Brehmer, G. Louppe, J. Pavez, K. Cranmer, Mining gold from implicit models to improve likelihood-free inference. Proc. Natl. Acad. Sci. 117, 5242–5249 (2020). https://doi.org/10.1073/pnas.1915980117
T. Roxlo, M. Reece, Opening the black box of neural nets: case studies in stop/top discrimination. arXiv:1804.09278 [hep-ph]
M. Paganini, L. de Oliveira, B. Nachman, CaloGAN: simulating 3D high energy particle showers in multilayer electromagnetic calorimeters with generative adversarial networks. Phys. Rev. D 97(1), 014021 (2018). https://doi.org/10.1103/PhysRevD.97.014021. arXiv:1712.10321 [hep-ex]
L. de Oliveira, M. Paganini, B. Nachman, Controlling physical attributes in GAN-accelerated simulation of electromagnetic calorimeters, in 18th International Workshop on Advanced Computing and Analysis Techniques in Physics Research (ACAT 2017) Seattle, WA, USA, August 21–25, 2017 (2017). arXiv:1711.08813 [hep-ex]
M. Paganini, L. de Oliveira, B. Nachman, Accelerating science with generative adversarial networks: an application to 3D particle showers in multilayer calorimeters. Phys. Rev. Lett. 120(4), 042003 (2018). https://doi.org/10.1103/PhysRevLett.120.042003. arXiv:1705.02355 [hep-ex]
F.F. Freitas, C.K. Khosa, V. Sanz, Exploring the standard model EFT in VH production with machine learning. Phys. Rev. D 100(3), 035040 (2019). https://doi.org/10.1103/PhysRevD.100.035040. arXiv:1902.05803 [hep-ph]
J. Brehmer, F. Kling, I. Espejo, K. Cranmer, MadMiner: machine learning-based inference for particle physics. arXiv:1907.10621 [hep-ph]
J. Brehmer, S. Dawson, S. Homiller, F. Kling, T. Plehn, Benchmarking simplified template cross sections in \(WH\) production. JHEP 11, 034 (2019). https://doi.org/10.1007/JHEP11(2019)034. arXiv:1908.06980 [hep-ph]
NNPDF Collaboration, R.D. Ball et al., Parton distributions for the LHC Run II. JHEP 04, 040 (2015). https://doi.org/10.1007/JHEP04(2015)040. arXiv:1410.8849 [hep-ph]
S. Forte, L. Garrido, J.I. Latorre, A. Piccione, Neural network parametrization of deep inelastic structure functions. JHEP 05, 062 (2002). https://doi.org/10.1088/1126-6708/2002/05/062. arXiv:hep-ph/0204232
J. Neyman, E.S. Pearson, On the problem of the most efficient tests of statistical hypotheses. Philos. Trans. R. Soc. Lond. Ser. A Containing Papers of a Mathematical or Physical Character 231, 289–337 (1933) . http://www.jstor.org/stable/91247
S.S. Wilks, The large-sample distribution of the likelihood ratio for testing composite hypotheses. Ann. Math. Stat. 9(1), 60–62 (1938). https://doi.org/10.1214/aoms/1177732360
A. Wald, Tests of statistical hypotheses concerning several parameters when the number of observations is large. Trans. Am. Math. Soc. 54(3), 426–482 (1943)
G. Cowan, K. Cranmer, E. Gross, O. Vitells, Asymptotic formulae for likelihood-based tests of new physics. Eur. Phys. J. C 71, 1554 (2011). https://doi.org/10.1140/epjc/s10052-011-1554-0, https://doi.org/10.1140/epjc/s10052-013-2501-z. arXiv:1007.1727 [physics.data-an]. [Erratum: Eur. Phys. J. C 73, 2501 (2013)]
D.P. Kingma, J. Ba, Adam: a method for stochastic optimization. arXiv:1412.6980 [cs.LG]
F. Chollet, Keras (2017). https://github.com/fchollet/keras
M. Abadi et al., Tensorflow: Large-scale machine learning on heterogeneous systems (2015). https://www.tensorflow.org/
G. Kasieczka, B. Nachman, D. Shih, Official Datasets for LHC Olympics 2020 Anomaly Detection Challenge. https://doi.org/10.5281/zenodo.3596919
G. Kasieczka, B. Nachman, D. Shih, “R&D Dataset for LHC Olympics 2020 Anomaly Detection Challenge,”. https://doi.org/10.5281/zenodo.2629073
DarkMachines Collaboration, LHC simulation Project. https://doi.org/10.5281/zenodo.3685861
M. Shilling, Multivariate two-sample tests based on Neares neighbors. J. Am. Stat. Assoc. 81, 799–806 (1986)
N. Henze, A multivariate two-sample test based on the number of nearest neighbor type coincidences. Ann. Stat. 16, 772–783 (1988)
Q. Wang, S. Kulkarni, S. Verdú, Divergence estimation of continuous distributions based on data-dependent partitions. IEEE Trans. Inf. Theory 51, 3064–3074 (2005)
J.H. Collins, K. Howe, B. Nachman, Extending the search for new resonances with machine learning. Phys. Rev. D 99(1), 014038 (2019). https://doi.org/10.1103/PhysRevD.99.014038. arXiv:1902.02634 [hep-ph]
J. Alwall, M. Herquet, F. Maltoni, O. Mattelaer, T. Stelzer, MadGraph 5: going beyond. JHEP 06, 128 (2011). https://doi.org/10.1007/JHEP06(2011)128. arXiv:1106.0522 [hep-ph]
T. Sjostrand, S. Mrenna, P.Z. Skands, PYTHIA 6.4 physics and manual. JHEP 05, 026 (2006). https://doi.org/10.1088/1126-6708/2006/05/026. arXiv:hep-ph/0603175
DELPHES 3 Collaboration, J. de Favereau, C. Delaere, P. Demin, A. Giammanco, V. Lemal̂tre, A. Mertens, M. Selvaggi, DELPHES 3, A modular framework for fast simulation of a generic collider experiment. JHEP 02, 057 (2014). https://doi.org/10.1007/JHEP02(2014)057. arXiv:1307.6346 [hep-ex]
M. Farina, G. Panico, D. Pappadopulo, J.T. Ruderman, R. Torre, A. Wulzer, Energy helps accuracy: electroweak precision tests at hadron colliders. Phys. Lett. B 772, 210–215 (2017). https://doi.org/10.1016/j.physletb.2017.06.043. arXiv:1609.08157 [hep-ph]
A. Alloul, N.D. Christensen, C. Degrande, C. Duhr, B. Fuks, FeynRules 2.0—a complete toolbox for tree-level phenomenology. Comput. Phys. Commun. 185, 2250–2300 (2014). https://doi.org/10.1016/j.cpc.2014.04.012. arXiv:1310.1921 [hep-ph]
CMS Collaboration, A. Sirunyan et al., Performance of the CMS muon detector and muon reconstruction with proton-proton collisions at \(\sqrt{s}=\) 13 TeV. JINST 13(06), P06015 (2018). https://doi.org/10.1088/1748-0221/13/06/P06015. arXiv:1804.04528 [physics.ins-det]
Acknowledgements
MP and GG are supported by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (Grant Agreement No. 772369). We acknowledge partial support from the Swiss National Science Foundation under contract 200021-178999. RTD acknowledges support by the Munich Institute for Astro- and Particle Physics (MIAPP) which is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy EXC-2094-390783311. RTD acknowledges support by KITP, through the National Science Foundation under Grant No. NSF PHY-1748958.
Author information
Authors and Affiliations
Corresponding author
Appendix: Effects of reference sample’s mis-modelling
Appendix: Effects of reference sample’s mis-modelling
For this technique to be applied to a New Physics search on real data one needs to carefully match the reference sample to the data. Possible sources of mis-modelling need to be studied and corrected.
The method presented in this work aims at catching discrepancies between the data and the reference, i.e. the best possible description of the SM predictions. At this stage, no distinction is made upon the source of such discrepancies. Therefore a similar response is expected to effects which arise from systematic errors affecting the reference sample and those originated from New Physics phenomena. In the case systematics uncertainties are not properly assessed and coped with, the method would likely lead to type I errors, e.g. false positives.
As already mentioned in Sect. 6, the method can indeed be extended to include and treat systematic uncertainties as nuisance parameters; the details about this procedure are being worked out and will be properly documented in a future publication [26]. In this appendix we verify the aforementioned hypothesis about how a bias in the reference sample would impact the final result.
The benchmark examples addressed in Sects. 4 and 5 are again considered, introducing this time an artificial mis-modelling. In order to represent a realistic systematic uncertainty, a mis-calibration of the muon momentum scale is assumed; the relative error is typically of the order of \(0.1\%\), see for instance [93]; still, larger values are also considered in the following, to encompass the cases with final state objects measured with worse accuracy than muons. The mis-calibration is applied separately to the central (\(|\eta |<1.2\)) and the forward (\(1.2<|\eta |<2.4\)) pseudorapidity regions; while the effects are treated as fully correlated, the magnitude in the forward region is assumed three times larger than in the central part. Furthermore, as the decay of the Z boson to muons is usually exploited as a “candle” for in situ calibration, those events are excluded from the analysis, selecting the cases where the mass of the lepton pair is larger than 100 GeV.

Test statistic distributions for toys generated accordingly to the Standard Model, in the case of \(-0.1\%\) (yellow), \(0.5\%\) (red) and \(-0.5\%\) (green) mis-calibration of the momentum scale

Test statistic distributions for toys generated with New Physics signals: \(Z'\) on the left, a EFT signal on the right. The colours of the histograms represent respectively the cases of no mis-modelling (yellow), \(0.5\%\) (red) and \(-0.5\%\) (green) mis-calibration of the muon momentum scale
The response of our test statistic to artificially injected bias is checked both for toys generated according to the Standard Model and for toys containing New Physics. As far as the former are concerned, mis-calibrations of the momentum scale of \(-0.1\%\) and \(\pm 0.5\%\) have been tested (with those values referring to the central pseudorapidity region): as can be seen from the plot in Fig. 13, a mis-modeling at the per mil level is not revealed by the algorithm, whereas for larger biases higher values of the test statistics are found and thus a smaller p-value; as expected, the method yields a false positive.
Testing toy datasets including New Physics effects against a mis-modelled reference sample results in the test statistic distributions shown in Fig. 14. We consider a \(Z'\) signal (plot on the left) similar to what used for previous tests, corresponding to a reference significance of about \(10\sigma \), yielding an observed significance of \(4\sigma \) when tested against the unbiased reference sample. If a mis-calibration of \(\pm 0.5\%\) on the momentum scale is introduced, the discrepancy between the reference sample and the New Physics toys increases, leading to larger values of the test statistics. The same happens when an EFT signal (with \(c_W=10^{-6}\) TeV\(^{-2}\)) is injected and compared to the reference sample: the mis-modelling of the latter enhances the significance of the signal.
In conclusion, systematic errors in the description of the SM reference sample lead to type I errors; in the case New Physics is present in the data, the corresponding signal is not hidden by the mis-modelling (i.e. we do not incur into false negatives), on the contrary its significance increases.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3
About this article

Cite this article
D’Agnolo, R.T., Grosso, G., Pierini, M. et al. Learning multivariate new physics. Eur. Phys. J. C 81, 89 (2021). https://doi.org/10.1140/epjc/s10052-021-08853-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-021-08853-y