
Abstract
In this work, we will be testing four different general f(R)-gravity models, two of which are the more realistic models (namely the Starobinsky and the Hu–Sawicki models), to determine if they are viable alternative models to pursue a more vigorous constraining test upon them. For the testing of these models, we use 359 low- and intermediate-redshift Supernovae Type 1A data obtained from the SDSS-II/SNLS2 Joint Light-curve Analysis (JLA). We develop a Markov Chain Monte Carlo (MCMC) simulation to find a best-fitting function within reasonable ranges for each f(R)-gravity model, as well as for the Lambda Cold Dark Matter (\(\varLambda \)CDM) model. For simplicity, we assume a flat universe with a negligible radiation density distribution. Therefore, the only difference between the accepted \(\varLambda \)CDM model and the f(R)-gravity models will be the dark energy term and the arbitrary free parameters. By doing a statistical analysis and using the \(\varLambda \)CDM model as our “true model”, we can obtain an indication whether or not a certain f(R)-gravity model shows promise and requires a more in-depth view in future studies. In our results, we found that the Starobinsky model obtained a larger likelihood function value than the \(\varLambda \)CDM model, while still obtaining the cosmological parameters to be \(\varOmega _{m} = 0.268^{+0.027}_{-0.024}\) for the matter density distribution and \({\bar{h}} = 0.690^{+0.005}_{-0.005}\) for the Hubble uncertainty parameter. We also found a reduced Starobinsky model that are able to explain the data, as well as being statistically significant.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Since the proposition of the theory of general relativity (GR) by Einstein, it has developed into the accepted theory to explain gravity. What made GR useful was that it was not only able to explain extreme gravity phenomena, but was also able to reduce back to a Newtonian description of gravity in a weak gravitational field. Due to the ability of GR to explain the expansion of the Universe [1], the Hot Big Bang theory was developed using GR as its mathematical basis. However, in recent times, it was discovered that the expansion of the Universe was accelerating [2], which is not in line with the GR predictions. Therefore, an unknown pressure force acting out against gravity, called “dark energy” (\(\varLambda \) \(\sim \) cosmological constant) was added to explain why gravity on cosmological scales were not able to slow down the expansion [3]. By using the Einstein–Hilbert action, which tries to extremize the path between two time-like points in spacetime, with the inclusion of dark energy, one can derive the cosmological field equations. From the cosmological field equation, the Friedmann equations can be derived, with these equations being able to explain the accelerated expansion of the Universe in the Big Bang model, and is given by [4, 5]
where \(H(t) = \frac{{\dot{a}}(t)}{a(t)}\) is the Hubble parameter with a(t) the scale factor describing the relative size of the Universe at a certain time, \(\rho (t)\) is the energy density, P(t) is the isotropic pressure, and \(\kappa \) is the 3D (spacial) curvature. Furthermore, to derive these particular Friedmann equations, we had to assume we have a Friedmann–Lemaître–Robertson–Walker (FLRW) spacetime metric, as well as normalizing the system by using a geometric unit description where \(c=1=8\pi G\). To close the Friedmann equation system, we had to use the equation of state parameter \(\omega \), by relating \(\rho \) and P. We also assumed a perfect fluid, therefore \(\omega \) is constant [6].Footnote 1 This closed system is called the Lambda Cold Dark Matter (\(\varLambda \)CDM) model.
However, since dark energy is an unknown pressure force, this poses a problem: What is dark energy and why does it account for the majority content of the Universe (\(\sim \) 68%) [7]? Other questions that also arises within the \(\varLambda \)CDM model, is the Horizon and Flatness problems that stem from an early-time accelerated expansion epoch, called the Inflation epoch [9,10,11,12]. Other known problems in the \(\varLambda \)CDM model are the magnetic monopole problem and the matter/anti-matter ratio problem [12, 13]. Due to these problems, it has been previously suggested that we need to modify our theory of gravity. One such theory is f(R)-gravity. This theory makes the modification within the Einstein–Hilbert action by changing the Ricci scalar R to a generic function dependent on (R), therefore replacing the dark energy term with arbitrary free parameters [14, 15]. Re-deriving the Friedmann equations with this modification, we obtain [4, 11, 16]
where \(f = f(R)\), with \(f^{\prime }\) and \(f^{\prime \prime }\) being the first- and second- derivatives of the generic function w.r.t. R.
2 Supernovae cosmology and MCMC simulations
2.1 Supernovae cosmology
To test Eq. 3, we will use Supernovae Type 1A data. This class of supernovae is the resultant of a white dwarf (WD) star accreting a low-mass companion star until the accreted Hydrogen outer-layer, from the companion star, is compressed to the point that the WD explodes [17]. Since this process is always the same, their luminosities are relatively similar and can therefore be regarded as standard candles [18, 19]. Their measured flux is therefore only dependent on the distance to the particular supernova. We will use redshift (z) to approximate the distance. This will allow us to use the distance modulus function to test the expansion of the Universe, since the distance to the supernovae is changing. For simplicity, we will assume a flat universe (\(\varOmega _{k}=0\)), with a negligible radiation density (\(\varOmega _{r}\approx 0\)). The distance modulus function we obtain, by using the combination of different distance definitions found in [20], is given asFootnote 2
where m is the apparent magnitude and M is the absolute magnitude of the measured supernova, while per definition we have the Hubble uncertainty parameter as \({\bar{h}} = \frac{H(z)}{100\frac{km}{s.Mpc}}\) with H(z) is the Hubble parameter. Now that we have a model, we will use 359 low- and intermediate redshift supernovae data obtained from the SDSS-II/SNLS3 joint light-curve analysis (JLA). Usually, using only Supernovae Type 1A data means that we will not be able to fully constrain the Hubble uncertainty parameter, due to \(H_{0}\) being degenerate with the absolute magnitude M of the particular supernovae [21]. To break this degeneracy, Cepheid variable star data are required to make the necessary corrections to the distance modulus [22, 23], since the absolute magnitude is for the supernovae are unknown and a value for each supernova’s M needs to be predicted. However, we did not used predicted absolute magnitudes. We used the absolute magnitudes calculated for the B-filter in the research papers [24,25,26].Footnote 3 In their calculations they already did the neccesary corrections. Meaning, that we can use these absolute magnitudes as is. However, it must be noted that is limits the number of data points to 359 as mentioned above, where the original JLA dataset has over 700 data points.
The reason for using low- and intermediate redshift data is to have within our data the transition phase between the decelerated expansion (matter dominated) epoch and the late-time acceleration (dark energy) epoch which only started at around \(z\approx 0.5\) [27, 28]. This method is called supernovae cosmology.
2.2 Markov chain Monte Carlo (MCMC) simulation
To find the best-fitting distance modulus for each model, we will use MCMC simulations. These simulations are able to search for the most probable free parameter value, given certain physical constrains. In particular, we will be using the Metropolis–Hastings (MH) algorithm [29, 30], which starts by calculating the likelihood for each initial chosen free parameter’s distance modulus. The simulation then takes a random step for each parameter away from the initial conditions, but within the physical constrains. It then calculates the likelihood for each possible combination between the initial conditions and the random parameter values, to find the combination that has the largest likelihood of occurring.
The simulation then finds an acceptance ratio between the initial condition likelihood and the new largest likelihood combination. If the new combination has a acceptance ratio value large than 1, it is accepted. If it is lower than 1, a chance is created for the second combination to still be accepted in ratio to the probability for each combination to occur. After the acceptance or rejection of a certain combination, the algorithm starts at the top again. Since, we need a probability distribution to be able to calculated the likelihood for each parameter value’s distance modulus, we assume, for simplicity, a Gaussian distribution.
We use the EMCEE Hammer Python package (developed by [31]) to execute the MCMC simulation. This package uses different random walkers (in most cases we will use 100), each executing the MH algorithm and all starting at the same initial parameter values and converging on the most probable parameter values. The last iteration then creates a Gaussian distribution based on each random walker’s ending parameter values. Using the average values for each probability distribution for each parameter, we will have on average the best-fitting parameter value and its 1\(\sigma \)-deviation for each free parameter.
2.3 AIC and BIC statistical analysis
To test whether or not these f(R)-gravity models are able to explain the data, we will use the Akaike information criterion (AIC) and the Bayesian/Schwarz information criterion (BIC) selection methods [32]. These selection criteria uses the likelihood function value of each of the best-fitting models, while taking into account the amount of free parameters the model use. This is important, since a model that uses more free parameters can fit the data more precisely (has more freedom to change the shape of the function), but might not be as valuable as another model that uses less free parameters. The AIC and BIC selections are given as
where \(\chi ^{2}\) is calculated by using the model’s Gaussian likelihood function \({\mathcal {L}}({\hat{\theta }} |data)\) value, K is the amount of free parameters for the particular model, while n is the amount of data points in our dataset. Since the AIC and BIC selection values can be any positive value, we need to compare the particular f(R)-gravity model’s AIC and BIC values to that of a “true model” (in this case the \(\varLambda \)CDM model) [33], by finding the difference between them. This method was also used in the studies for different f(T)-gravity models [34, 35], with the latter also using the EMCEE Hammer Python package [31]. We will be using the Jeffrey’s scale in order to make conclusions about the f(R) model. It should be noted that this scale is not exclusive and should be handled with care [36]. The Jeffreys scale ranges are:
3 Results
3.1 The \(\varLambda \)CDM model
We will use the \(\varLambda \)CDM model to calibrate our MCMC simulation, as well as use it as our “true model” to which we can compare the f(R)-gravity models against to find if they are viable alternative models. By assuming a flat universe with negligible radiation density, we can find a normalized Friedmann equation for the \(\varLambda \)CDM model in terms of redshift, with the substitution \(\varOmega _{\varLambda } =1-\varOmega _{m}\) [37, 38], as
To execute the MCMC simulation for the \(\varLambda \)CDM model, we need to combine Eq. 11 with Eq. 5. The MCMC simulation gave the cosmological parameter values, shown in Fig. 1, for the \(\varLambda \)CDM model based on our test supernovae dataset, as \(\varOmega _{m} = 0.268^{+0.025}_{-0.024}\) for the matter density distribution and \({\bar{h}} = 0.697^{+0.005}_{-0.005}\) for the Hubble uncertainty parameter. These values are in line with other Supernovae Type 1A cosmological results, even though they are not within \(1\sigma \) from the Planck2018 results that were determined on the cosmic microwave background (CMB) radiation data. This discrepancy between early-time data, such as the CMB, and the late-time data, such as the supernovae events, have been shown to exist [12, 39]. Therefore, after finding possible viable f(R)-gravity models using only the one dataset and possibly finding a model that can alleviate this \(H_{0}\) tension, we must continue in testing those potential models on different datasets for a more comprehensive in-depth study for constraining these alternative models.

MCMC simulation results for the \(\varLambda \)CDM-model’s (Eq. 30) cosmological free parameters (\(\varOmega _{m}\) and \({\bar{h}}\)), with “true” values (blue lines: \(\varOmega _{m}=0.315\) and \({\bar{h}} = 0.674\)) provided by the Planck 2018 collaboration data release [7]. We used 100 random walkers and 25 000 iterations
This discrepancy is not only limited to these two methods of calculating the cosmological parameter values. In a paper by [40], they showed that different experiments resulted in different \(H_{0}\) values. With all the local measurements, such as eclipsing binaries in the Large Magellanic Clouds or Cepheid stars within the Milky Way, tend to result in higher values for the Hubble constant, while the early-time data tended to give a lower Hubble constant value. In future work, we can combine Supernovae Type 1A with CMB data to be able to show this discrepancy. It will also be worth it to test our potential viable f(R)-gravity models on other datasets, such as H(z) and BAO [41], to see how the different f(R)-gravity model lead to different contributions from the matter and dark energy densities distributions within the Universe [38, 42].
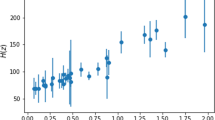
Now that we have discussed the MCMC results and have shown that the results are in line with expectation, we can make a plot for the best-fitting \(\varLambda \)CDM model on the Supernovae Type 1A data, to which we can the compare the f(R)-gravity models to. This is shown in Fig. 2.

The \(\varLambda \)CDM model’s best-fit to the Supernovae Type 1A data (top panel), with the cosmological parameter values as \(\varOmega _{m} = 0.268^{+0.025}_{-0.024}\) (constrained) and \(H_{0} = 69.7^{+0.5}_{-0.5}\frac{km}{s.Mpc}\), respectively. Furthermore, the residuals between the model’s predicted distance modulus values and the actual data points are also shown (bottom panel)
From Fig. 2, we can also confirm that the MCMC simulation’s calibration was done correctly, since the \(\varLambda \)CDM model fits the data with quite a high accuracy, as well as not having an over- or under-estimation at various different redshifts. As a note for the rest of the models, the average residual value that is shown on the residuals graphs shows the average amount the model over- or under-estimates the distance modulus (Mpc) for each supernovae. Therefore, the \(\varLambda \)CDM under-estimates the supernovae distance modulus, on average, with \({\bar{x}}_{res} = -0.0387\) Mpc, and the standard deviation of the data on this average distance is \(\sigma _{res} =0.21480\), showing that this is a very tight relation. Furthermore, in terms of constraining the parameters, the MCMC simulation were able to constrain both the cosmological parameters.
3.2 f(R)-gravity model results
We can now advance to the testing of various f(R)-gravity models. We will use two toy models, namely \(f(R) = \beta R^{n}\) and \(f(R) = \alpha R+\beta R^{n}\) [4], as well as two realistic models, namely the Starobinsky and Hu–Sawicki models, which are given by [43,44,45]
respectively, with \(\alpha \), \(\beta \) and n being the arbitrary free parameters and \(R_{c}\) parametrises the curvature scale. For each model, different analytical constraints on these parameters is discussed in more detail in the papers by [2, 4, 43,44,45,46]. We also used the effective cosmological constant term (\(\varLambda \equiv \frac{\beta R_{c}}{2})\) to mimic dark energy, to allow us to solve these realistic models [38, 43]. The reason for not only using the two realistic model, but also using toy models, is to test how the MCMC simulation and the method holds up against models that have disadvantages, such as the first toy model not being supported by observations or even valid for GR when \(n\not = 1\) [47]Footnote 4. This will give as another indication on how well the method and MCMC simulation works.
To our knowledge, this is the first work done on the two toy models with the JLA Supernovae Type 1A dataset, while the Starobinsky and Hu-Sawicki models were examined on the full dataset JLA dataset, by predicting the absolute magnitudes of each supernova (unlike our case where we use the calculated absolute magnitudes), in combination with BAO datasets in the research paper by [33]. Both these models were also examined on a combined dataset, that includes the JLA, BAO, CMB and H(z) data, using a different method by invoking different functions of f(R)-function by [16].
Even though only four models are listed, we ended up with eight different models that we have tested, since we found that except for the first toy model, the models become analytically unsolvable. Therefore, we assumed fixed n-values for the second toy model, to which we found four different solvable models. We then tried this approach for the two realistic models and were unsuccessful in this approach. This led us to incorporate a numerical optimization method into the MCMC simulation to find an approximated \(H^{2}\)-value at a particular z-value. Using this method, we were then able to build a solution map for different approximated \(H^{2}\)-values at different redshift values between \(0\le z\le z^{\prime }\). Using the solution map, we were then able to numerically integrate over z using the Simpson integration rule. From here on out the MCMC simulation were able to calculate the approximated distance modulus value for each supernova. Due to the resolution of the numerical methods, we found that for the Starobinsky model, 3 of the free parameters, did not effect the outcome of the predicted model. This led us to also try to fit a reduced version of the Starobinsky model.
A question that may arise at this stage is: How were we able to write the f(R)-gravity Friedmann equation (currently a function of the scale factor) into a normalized Friedmann equation form (a function of redshift), while having measurable quantities that we can use as free parameters, as was done for Eq. 11 (e.g. by using \(\varOmega _{m} = \frac{\rho _{m}}{3H^{2}_{0}}\)). To answer this, we firstly had to rewrite Eq. 3 into a more usable form (shown in Appendix: A), since we did not have a measurable quantity for some on the terms in Eq. 3 (e.g \({\dot{R}}\) and \({\ddot{H}}\)). After using the definitions of the Hubble parameter, the Ricci scalar, the Deceleration parameter, and the Jerk parameter, namely \(H = \frac{{\dot{a}}}{a}\), \(R = 6\big ({\dot{H}}+2H^{2}\big )\), \(q = -\frac{\ddot{a}a}{{\dot{a}}^{2}}\), and \(j = \frac{\dddot{a}a^{2}}{{\dot{a}}^{3}}\), we were able to rewrite Eq. 3 into the form
We were now able to substitute the different f(R)-gravity models into Eq. 14 and then solve for \(H^{2}(t)\). However, this Friedmann equation, for each specific f(R)-gravity model, is still a function of the scale factor and need to switched to a function of redshift. Therefore, we will need to use a parametrisation in terms of redshift for the cosmographic series terms [12]. We decided to use the parametrisations for these parameters as given in [48]. They defined the deceleration parameter as
while the jerk parameter was given as a function of the deceleration parameter
where \(q_{0}\) is the current deceleration parameter value and \(q_{1}\) is correction term. After the insertion of the cosmographic terms, as well as various other changes that were also needed for the \(\varLambda \)CDM model, the model can then be normalised to find the normalised Friedmann equation, which can then be used by the distance modulus (shown in Appendix: B). Therefore, up to this point we have not used any simplification, just pure substitution of different definitions equations to get it into a measurable form, with the only exception being the arbitrary parametrisation of the cosmographic terms. But these parametrisations are just one set, others can be used but the more complex they become the more free parameters appear in the model. It must be noted that this is a same method as the one presented in [33]. They just went the route of finding a free parameter (b) to encapsulate all of the free parameters, while we kept all of the different parameters.
We are now able to find the best-fitting function for each of the different f(R)-gravity models, however, due to space limitations we will only present the models that seemed to be able to explain the supernovae data to an extend. Starting in the order that were given above, our first model to show promise is the second toy model, where we assumed \(n=0\). Therefore, we have \(f(R) =\alpha R+\beta \). The MCMC simulation results for this model are shown in Fig. 3, while the best-fitting model on the supernovae data is shown in Fig. 4.
As a side note, due to the increasing number of free parameters, the MCMC variable comparison plots become larger and take up a lot of space, while they all show the same type of results, namely that some parameters are fully constrained, such as \(\alpha \) and \(\beta \) in Fig. 3 by forming a Gaussian distribution, or unreliably constrained, such as \(\varOmega _{m}\) obtaining a one-sided tail of a Gaussian distribution showing that some values are more desirable than others, but has not found the peak (the best-fitting parameter value). And lastly, a uniform type of distribution, similar to the \({\bar{h}}\), where there is no clear desirable parameter value. These parameters are considered unconstrained. Going on, we will only plot the best-fitting function on the supernovae data, and make comments describing the MCMC simulation results to save space.

MCMC simulation results for the second toy model’s, with \(n=0\), cosmological parameters (\(\varOmega _{m}\), \({\bar{h}}\)), as well as the model’s arbitrary free parameters (\(\alpha \) and \(\beta \)). The “true” values for \(\varOmega _{m}\) and \({\bar{h}}\) (blue lines) are provided by Planck 2018 collaboration data release [7]. We used 100 random walkers and 10,000 iterations. The blue lines for arbitrary free parameter values are to show their initial chosen starting point for the MCMC simulation

The second toy model (with \(n=0\)) fitted to the Supernovae Type 1A data. With cosmological parameter values calculated by the MCMC simulation as \(\varOmega _{m}=0.317^{+0.061}_{-0.101}\) (unreliably constrained) and \(H_{0} = 71.5^{+6.0}_{-7.2}\frac{km}{s.Mpc}\) (unconstrained), while the arbitrary free parameters were calculated to be \(\alpha = 1.202^{+0.397}_{-0.392}\) (constrained) and \(\beta =-5.265^{+1.698}_{-1.315}\) (constrained)
It is interesting that this particular model is able to explain the data, since this model resembles the \(\varLambda \)CDM model. By this we mean that if \(f(R) = R-2\varLambda \) (therefore \(\alpha =1\) and \(\beta = 2\varLambda \)), it would be exactly the same as the \(\varLambda \)CDM model [38]. An important difference between these two models is the fact that the MCMC simulation was only able to fully constrain the arbitrary free parameters and not the cosmological parameters for this f(R)-gravity model, while fully constraining both the cosmological parameter for the \(\varLambda \)CDM model. We did also determined the cosmological constant for this model, if we were to rewrite this model to resemble the \(\varLambda \)CDM model and found \(\varLambda = 2.190^{+1.011}_{-0.900}\). Since this is almost double the value of the cosmological constant, it shows us the impact of the free parameters. The second model that were able to explain the supernovae data, is also part of the second toy model group, where we fixed \(n=2\). This particular model \(f(R) = \alpha R+\beta R^{2}\) is also one of the original models developed by Starobinsky to explain the early time expansion [4, 9]. Furthermore, this model obtained a positive and a negative solution. We will be showing the negative solution. The best-fitting model is shown in Fig. 5.

The second toy model (with \(n=2\) - negative solution) fitted to the Supernovae Type 1A data. With cosmological parameter values calculated by the MCMC simulation as \(\varOmega _{m}=0.249^{+0.102}_{-0.101}\) (unconstrained), \(H_{0} = 63.8^{+4.6}_{-2.7}\frac{km}{s.Mpc}\) (unreliably constrained), \(q_{0}=-0.575^{+0.040}_{-0.046}\) (constrained), and \(q_{1}=-0.633^{+0.081}_{-0.049}\) (unreliably constrained), while the arbitrary free parameters were calculated to be \(\alpha = 19.642^{+2.967}_{-1.753}\) (unreliably constrained) and \(\beta =0.903^{+0.070}_{-0.107}\) (unreliably constrained)
Similar to the second toy model where \(n=0\), the fixation of \(n=2\), is also able to explain the data with no over- or under-estimations, although only the deceleration parameter was fully constrained. It is though worth mentioning that this result is somewhat in agreement with the results found by [10], where they showed that this model fits the observational data excellently. Even though only the deceleration parameter is the only parameter that were fully constrained, the other parameter results were realistic. This includes the lower than usual Hubble constant (which is still within \(1\sigma \) from the CMB results). The last three models that were able to explain the data, was the Starobinsky (with its reduced version) and the Hu–Sawicki model. These were solved using the numerical method. The first potential viable model of these three numerically calculated results is the Starobinsky model, which actually obtained a larger likelihood probability prediction than the \(\varLambda \)CDM model, as well as being our overall best-fitting f(R)-gravity model. The best-fitting Starobinsky model is shown in Fig. 6.

The Starobinsky model fitted to the Supernovae Type 1A data. With cosmological parameter values calculated by the MCMC simulation as \(\varOmega _{m} = 0.268^{+0.027}_{-0.024}\) (constrained), \(H_{0} = 69.0^{+0.5}_{-0.5}\frac{km}{s.Mpc}\) (constrained), \(q_{0}=-0.512^{+0.328}_{-0.265}\) (unconstrained), and \(q_{1}=0.037^{+0.991}_{-1.050}\) (unconstrained), while the arbitrary free parameters were calculated to be \(\beta = 5.284^{+3.191}_{-2.981}\) (unconstrained) and \(n =4.567^{+3.346}_{-2.899}\) (unconstrained)
From Fig. 6, it is clear that the Starobinsky model fits the data with a high precision. Furthermore, we can also assume that this model is quite stable, since the error bars on this model, just like the \(\varLambda \)CDM model is very small, therefore the MCMC simulation is certain that the predicted best-fit for this model is correct. The only problem faced by this result is the fact that only the cosmological parameters were constrained, while all the remaining free parameters were left unconstrained. Furthermore, due to the model being able to explain the data quite well, we can come to the conclusion that the basic shape of the function is dependent on the cosmological parameters, while the fine-tuning of the function’s shape is done by the arbitrary free parameters. However, due to the resolution of the numerical method this fine-tuning is not as effective. This led us to try and find a reduced Starobinsky model with fewer parameters. To reduces this model, we fixed the correctional deceleration parameter to be \(q_{1}=0\) (based on the Starobinsky model results). We also fixed \(\beta =1\) and \(n=1\), after we saw that their error bars are large, but did not translate to large errors in the best-fitting Starobinsky model. Even though this model did not find the accuracy of its counterpart, it was still the third best-fitting model (including the \(\varLambda \)CDM model) that we found. The results for this reduced Starobinsky model is shown in Fig. 7.

The reduced Starobinsky model fitted to the Supernovae Type 1A data. With cosmological parameter values calculated by the MCMC simulation as \(\varOmega _{m} = 0.266^{+0.026}_{-0.024}\) (constrained), \(H_{0} = 69.4^{+1.8}_{-0.6}\frac{km}{s.Mpc}\) (constrained), and \(q_{0}=-0.697^{+0.173}_{-0.138}\) (unconstrained)
Due to the fewer free parameters in the reduced Starobinsky model, we can see in Fig. 7 that this model is less stable compared to the original model. Therefore, a small change in one of the remaining parameters, can result in a completely different predicted model. It is this fact makes the \(\varLambda \)CDM model interesting, since it only has 2 free parameters and were still predicting a best-fit model with small errors. We did notice that the deceleration parameter MCMC results were not as uniformed as for the Starobinsky model, suggesting that due to the fewer free parameters the smaller resolution from the numerical method is not as restricting as in the previous case. Lastly, we have the Hu–Sawicki model, which to our surprise did not fair as well or even better than the Starobinsky model, but were still able to explain the supernovae data. The best-fitting Hu–Sawicki model results on the supernovae data is shown in Fig. 8.

The Hu–Sawicki model fitted to the Supernovae Type 1A data. With cosmological parameter values calculated by the MCMC simulation as \(\varOmega _{m} = 0.238^{+0.043}_{-0.049}\) (constrained), \(H_{0} = 73.7^{+9.0}_{-4.6}\frac{km}{s.Mpc}\) (unreliably constrained), \(q_{0}=-0.486^{+0.300}_{-0.285}\) (unconstrained), and \(q_{1}=-0.036^{+1.018}_{-0.968}\) (unconstrained), while the arbitrary free parameters were calculated to be \(\alpha = 5.196^{+2.322}_{-2.073}\) (constrained), \(\beta = 6.923^{+2.120}_{-2.732}\) (unreliably constrained), and \(n=2.262^{+0.800}_{-0.724}\) (unconstrained)
From Fig. 8, we can see that even though the Hu–Sawicki model did fit the data, the error region is just as large as the best-fitting function for the \(n=0\) second toy model and that was a toy model. This, however, might be an effect of the resolution of the numerical methods, since the Hu-Sawicki model used 7 free parameter, therefore the optimization approximations might have struggled within the MCMC simulation. This is why we kept this model within the group, since it might still be a viable model. For this particular model, we found two constrained parameters, however, only one of the two we a cosmological parameter, namely the matter density distribution parameter. The last three models that we tested, namely the first toy model and the second toy model with \(n=\frac{1}{2}\) and \(n=1\), obtained best-fitting models that were not able to explain the data.
Since we used the two realistic models, namely the Starobinsky and Hu-Sawicki models, we were able to compare them to the results in the research paper by [33], where they used the full JLA dataset, as well as BAO data, cosmic chronometer data and \(H_{0}\) observational data, on a state-of-the-art Monte Carlo program, called CLASS, in Python. They found their cosmological parameter values for the Starobinsky model as \(\varOmega _{m} = 0.269^{+0.050}_{-0.042}\) and \({\bar{h}} = 0.714^{+0.030}_{-0.028}\), while for the Hu-Sawicki model they found it to be \(\varOmega _{m} = 0.264^{+0.059}_{-0.055}\) and \({\bar{h}} = 0.722^{+0.042}_{-0.033}\), respectively. However (as mentioned), in this particular paper they used a singular free parameter (b) to encapsulate the remaining free parameters, therefore we were not able to compare our arbitrary free parameters to theirs. This, however, remains a significant result, since we found that even with our small testing dataset, our results are within \(1\sigma \) from their results.
All of the MCMC simulation best-fitting parameter value results are shown in Table 1. Now that we went through the results of the five best-fitting f(R)-gravity models, we can compare them and the three models that were not successful in explaining the data against the \(\varLambda \)CDM model. To do this we created a theoretical residuals plot between the distance modulus function of the \(\varLambda \)CDM model and the different f(R)-gravity models. This residual plot is shown in Fig. 9.
As excepted, the first toy model shows a divergence from the \(\varLambda \)CDM model for low-redshift due to its incompatibility with GR, with the exception of \(n=1\). For the second toy model, however, we have different outcomes. Firstly, we see that for \(n=\frac{1}{2}\) and \(n=1\), they are not even close to matching the \(\varLambda \)CDM model in the matter-dominated epoch, however, they do converge rapidly onto the \(\varLambda \)CDM model, especially for the \(n=1\) model, that joins up with the Starobinsky model for low-redshift (\(z<0.04\)). Therefore, in low-redshift, the second toy model for \(n=1\) can explain the data. This is not unexpected, since this form is just a strange way of writing the Einstein gravity model. It is though still rejected statistically due to its large over-estimation on the distance modulus for the intermediated-redshift supernovae. As for the \(n=\frac{1}{2}\) model, it does converge on the \(\varLambda \)CDM model, but then over-correct and end up being the model that has the largest under-estimation for the distance modulus of the supernovae data in comparison with the \(\varLambda \)CDM model.
For \(n=0\), as noted above, it is simply the \(\varLambda \)CDM model in terms of arbitrary free parameters, and we do see that is is almost perfectly parallel to the \(\varLambda \)CDM model, even though it is over-estimating the particular distance modulus with less the 0.1 Mpc relative to the \(\varLambda \)CDM model. For \(n=2\), which is the simplified form of the Starobinsky inflationary model [9], this model converges to the \(\varLambda \)CDM model for the intermediate redshift, and the entering the dark energy epoch it follows the trend set by the \(\varLambda \)CDM model, as expected, since this model was developed for an accelerating universe. It under-estimates the distance modulus with about \(\sim 0.1\) Mpc for the late-time acceleration with regards to the \(\varLambda \)CDM model. The Hu–Sawicki model follows the same trend as the second toy model for \(n=2\), with the exception that it diverges away from the \(\varLambda \)CDM model while in the matter-dominated epoch, and then almost matches the simplified Starobinsky inflationary model for the dark-energy epoch.
This leaves us then with the the two Starobinsky models. It is clear from Fig. 9, that this two models, matches the \(\varLambda \)CDM model the most closely from all of the different f(R)-gravity models. Both these models start almost identically in the matter-dominated epoch, however, at the transition phase, the reduced Starobinsky model diverges a bit from the original Starobinsky and \(\varLambda \)CDM model. This can be due to the limitations we added manually to the Starobinsky model to simplify it without any physical reason, only to see how the model will be affected by reduction in the number of free parameters. However, it is still the third best-fitting model, including the \(\varLambda \)CDM model. Both of the Starobinsky models under-estimates the distance modulus of the \(\varLambda \)CDM model with less than 0.05 Mpc.
3.3 Statistical analysis

Theoretical residuals comparing the different tested models against the \(\varLambda \)CDM model. The two most successful models are shown with a “dashed-dot” line, while the models that showed promise, were plotted with “dashed” lines. The unsuccessful models are shown with “dotted” lines
We are now able to do a statistical analysis on all the different f(R)-gravity models, to firstly find their goodness of fit, and secondly to determine whether they are statistically viable alternative models to explain the expansion of the Universe. Using all of the criteria from Sect. 2.3, we can set-up Table 2.
From Table 2, we see that the two Starobinsky models obtained likelihood function values that are close of even better than the \(\varLambda \)CDM model, and only obtained a percentage deviation on the goodness of fit of \(\approx 1.14\%\) and \(\approx 1.73\%\) respectively. However, based on the goodness of fit from the reduced \(\chi ^{2}\), the \(\varLambda \)CDM model still fits the supernovae data better than the two Starobinsky models. The other 3 models that were shown in the previous section, can still be considered good fits, since their \(\chi ^{2}\)-values are still relatively close to the \(\varLambda \)CDM model, with the weakest fit (second toy model with \(n=2\)) between these 5 models having an \(\approx 30\%\) deviation on the “true model’s” goodness of fit. It must be noted that by weakest fit, we do not say that the model does not explain the data, it is just not the best. For example, it was statistically rejected, but its \(\chi ^{2}\)-value on its own is still an excellent fit. It is also evident is the residuals plot Fig. 5, where its average over-estimation of the distance modulus compared to the supernovae is \({\bar{x}}_{res} = 0.0509\) Mpc, which is very small compared to the distances these supernovae are measured on. Therefore, this is still in agreement with the finding of [10]. It just shows you that there are models that do explain the data better. For the last three models, this percentage deviation, based on the goodness of fit, increases exponentially.
From the criteria selection, only the two Starobinsky models were deemed viable, with both obtaining a category 2 status for the AIC: “less support w.r.t. ‘true model”’. However, only the reduced Starobinsky model obtained the category 2 status for the BIC, with the rest all being statistically rejected, even though some were able to fit the data.
Furthermore, we found that the models that obtained constrained parameters, tended to fare better than the models that we left unconstrained. In particular, the five best-fitting models, including the \(\varLambda \)CDM model all obtained two constrained parameter, while the next best three only obtained one constrained parameter each and the remaining model (not fitting the data at all) did not constrain any free parameters. We also noticed that the models that constrained that cosmological parameters fared better than the models that only constrained the arbitrary free parameters, with the only exception being for the second toy model with \(n=0\). This model performed better than the Hu–Sawicki model, even though one of the 2 constrained parameters the Hu–Sawicki model obtained, is the matter-density distribution. However, this might be related to the fact that this particular toy model is in essence the \(\varLambda \)CDM model, just in terms of f(R) gravity. We can, from this knowledge, make the conclusion that the cosmological parameters control the shape of the function while the arbitrary free parameters are used to fine-tune the function to fit the data with a higher precision.
We have now obtained a few different models (five to be exact) through testing whether or not they might be viable alternative models, with the Starobinsky and Hu-Sawicki models obtaining cosmological parameter values that are within \(1\sigma \) from the results found in [33]. Using different techniques such as increasing our JLA dataset to the full version to improve our statistics, or using other datasets as seen in the research papers of [49], or even trying to reduce the number of free parameters like we have done with the reduced Starobinsky model can be done in future work to constrain this group of potential viable f(R)-gravity models.
4 Conclusions
In this work, we looked at how GR can be used to explain the expansion of the Universe through the usage of the Friedmann equations. This particular set of Friedmann equations, called the \(\varLambda \)CDM model, had to include the dark energy term to explain the late-time acceleration of the expansion. We then discussed how this model introduces problems due to an early-time acceleration, as well as posing the dark energy problem since it is an unknown pressure force. We then discussed possible alternative modifications to the GR model, which are able to explain the accelerated late-time expansion of the Universe with the exclusion of dark energy. One of these alternative theories is called f(R)-gravity.
Following the f(R)-gravity model’s theory, we looked at how we will be able to find a best-fitting model for different f(R) models. This led us to develop a MCMC simulation to fit the distance modulus for each f(R) model to Supernovae Type 1A data and find the cosmology parameters (\(\varOmega _{m}\) and \({\bar{h}}\)). We used the \(\varLambda \)CDM model to determine whether or not the MCMC simulation was correctly set-up. We also used the \(\varLambda \)CDM as a “true model” to compare the f(R)-gravity models to it.
By comparing, firstly, just the residuals of the various tested f(R)-gravity models to the \(\varLambda \)CDM model, we already noticed that the models that tended to be more realistic, such as the original Starobinsky (and its reduced version) and the Hu-Sawicki model had a similar trend than the \(\varLambda \)CDM model’s distance modulus. We also saw that the particular models based on the second toy model, that had a connection to realistic models, such as to either the \(\varLambda \)CDM model and the Starobinsky inflationary model, obtained similar distance modulus functions as the \(\varLambda \)CDM model, albeit over-or under-estimating it a bit, it also follow the \(\varLambda \)CDM model’s distance modulus trend. While the first toy model continues diverging away from the \(\varLambda \)CDM model in the dark energy epoch and the other two toy models have very large over-estimations (up to at least 0.5 Mpc) for the matter dominated epoch.
Statistically, we found the same five different f(R)-gravity models that were able to explain the data. In fact the Starobinsky model obtained a larger likelihood of occurring than the \(\varLambda \)CDM model, however had a slightly worse goodness of fit, with a deviation of \(\approx 1.14\%\) w.r.t. to the \(\varLambda \)CDM model. Therefore, Starobinsky model was only given a category 2 on the Jeffery’s scale for the AIC selection, while being statistically rejected by the BIC selection. The reduced Starobinsky had a smaller likelihood of occurring, and a slightly worse fit with a \(\approx 1.73\%\) deviation w.r.t. the \(\varLambda \)CDM model. This model though was the only model to receive a category 2 status on both the AIC and BIC selections. Therefore, its the only model that fits the data and have some statistical significance. The other three models were able to fit to the data, but were statistically rejected.
By comparing the residuals between the data and the tested models, theoretical residuals between the \(\varLambda \)CDM model and the tested models, as well as doing a statistical analysis on these models, we found insights into how these f(R)-gravity models compare numerically, not only to the \(\varLambda \)CDM model, but also how they themselves explain the data. Even though we knew from the beginning that only the realistic models are worth investigating, by testing models that had disadvantages, we were able to test whether the method and the MCMC simulation that we used were successful. Since this method was able to show that these models does not explain the data as expected, we can argue that this method does indeed work. Therefore, the models that the MCMC simulation gave as potential models to explain the data has more validity.
In terms of constraining these five model’s parameter values, we found that the models that obtained more constrained parameters, especially the cosmological parameters, tended to fit the data better that the models with fewer constrained parameters. Therefore, if we are to use a more efficient computer software in the future, where we can constrain all the parameters on different datasets, we will be able to constrain these potential viable models with a higher accuracy. However, it is worth noting that we were able to compare the Starobinsky and Hu-Sawicki models with results from more advance studies and we still found our cosmological parameter values to be within \(1\sigma \) from their results. Therefore, we will need to use the different datasets and a more efficient program just to fine-tune constrain our tested models.
The last 3 models that we investigated were not able to explain the data and were subsequently statistically rejected. Therefore, in future work it will not be necessary to work with them.
Lastly, we can, however, not make a conclusion on whether these f(R)-gravity models alleviate the tension between the supernovae results and the CMB results (as noted earlier), since we only used only one type of dataset and can, therefore, not constrain the parameters as accurately as other studies. However, it is worth mentioning that the two of the best-fitting f(R)-gravity models, namely the starobinsky model and its reduced version, gave Hubble constants that are lower (even though not by much) than the one predicted for the \(\varLambda \)CDM model on our dataset. Therefore, these two are closer to the CMB results than our predicted best-fitting \(\varLambda \)CDM model and it will be worth looking further into this potential alleviating the \(H_{0}\) tension result.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: The data we used is a reduced version of the full JLA data set, that can be found freely online, with the absolute magnitudes obtained from NASA’s Extragalactic Database. Therefore, it is not our own data and would recommend you to use the original data set.]
Notes
We will be using the distance modulus function in terms of Mpc.
These absolute magnitudes can also be found on NASA’s Extragalactic Database (NED).
In this paper using observational constraints, they determined that for \(f(R) = R^{1+\delta }\) to be valid in a GR spacetime, \(\delta \) is constrained to lie within the range \(0\le \delta <7.2\times 10^{-19}\) [47].
We left out the dependencies, such as \(f\rightarrow f(R)\), due to the long nature of these equations, but we did take them into account in the mathematical manipulations that we used to determine h(z) for each model.
References
R.P. Kirshner, Hubbles diagram and cosmic expansion. Proc. Natl. Acad. Sci. 101, 8–13 (2004). https://www.pnas.org/content/101/1/8
S. Nojiri, S.D. Odintsov, V.K. Oikonomou, Modified gravity theories on a nutshell: inflation, bounce and late-time evolution. Phys. Rep. 692, 1–104 (2017). https://doi.org/10.1016/j.physrep.2017.06.001
S. Capozziello, O. Luongo, R. Pincak et al., Cosmic acceleration in non- at f(T) cosmology. Ge. Relativ. Gravit. 50, 53 (2018). https://doi.org/10.1007/s10714-018-2374-4
A. Abebe, Beyond concordance cosmology. Ph.D. thesis University of Cape Town (2013)
J. Arnau Romeu, Derivation of the Friedman equations (2014). http://hdl.handle.net/2445/59759
M. Trodden, S. M. Carroll, TASI lectures: introduction to cosmology (2004). arXiv:astro-ph/0401547
N. Aghanim, Y. Akrami, M. Ashdown, et al., Planck 2018 results. VI. Cosmological parameters (2018). arxiv:1807.06209
L.G. Jaime, M. Jaber, C. Escamilla-Rivera, New parametrized equation of state for dark energy surveys. Phys. Rev. D 98, 083530 (2018). https://doi.org/10.1103/PhysRevD.98.083530
A.A. Starobinsky, A new type of isotropic cosmological models without singularity. Phys. Lett. B 91, 99 (1980). https://doi.org/10.1016/0370-2693(80)90670-X
A.H. Guth, Inflationary universe: a possible solution to the horizon and flatness problems. Phys. Rev. D, 23, 347–356 (1981). https://link.aps.org/doi/10.1103/PhysRevD.23.347
A. De Felice, S. Tsujikawa, f(R) theories. Living Rev. Relativ. 13, 3 (2010). https://doi.org/10.12942/lrr-2010-3
S. Capozziello, R. D’Agostino, O. Luongo, Extended gravity cosmography. Int. J. Mod. Phys. D 28, 1930016 (2019). https://doi.org/10.1142/S0218271819300167
F.J. Amaral Vieira, Conceptual problems in cosmology (2011). arXiv:1110.5634
M. Akbar, R. Cai, Thermodynamic behavior of field equations for f(R) gravity. Phys. Lett. B 648, 243–248 (2007). https://doi.org/10.1016/j.physletb.2007.03.005
S. Tsujikawa, K. Uddin, R. Tavakol, Density perturbations in f(R) gravity theories in metric and Palatini formalisms. Phys. Rev. D 77, 043007 (2008). https://doi.org/10.1103/PhysRevD.77.043007
J. Pérez-Romero, S. Nesseris, Cosmological constraints and comparison of viable f(R) models. Phys. Rev. D 97, 023525 (2018). https://doi.org/10.1103/PhysRevD.97.023525
R.J. Tayler, The Stars: Their Structure and Evolution, 2nd edn. (Cambridge University Press, Cambridge, 1994)
R. Barbon, F. Ciatti, L. Rosino, On the light curve and properties of Type I Supernovae. Astron. Astrophys. 25, 241–248 (1973)
D. Richardson, D. Branch, D. Casebeer et al., A comparative study of the absolute magnitude distributions of supernovae. Astron. J. 123, 745 (2002). https://doi.org/10.1086/338318
M.M. Deza, E. Deza, Encyclopaedia of distances. In: Encyclopaedia of Distances, pp. 1–583. Springer, Berlin (2009). https://doi.org/10.1007/978-3-642-00234-2_1
E. Ó. Colgáin, A hint of matter underdensity at low z? J. Cosmol. Astropart. Phys. (2019). https://doi.org/10.1088/1475-7516/2019/09/006
A.G. Riess, L. Macri, S. Casertano et al., A redetermination of the Hubble constant with the Hubble Space Telescope from a differential distance ladder. Astrophys. J. 699, 539–563 (2009). https://doi.org/10.1088/0004-637X/699/1/539
A.G. Riess, L. Macri, S. Casertano et al., A 3% solution: determination of the Hubble constant with the Hubble Space Telescope and Wide Field Camera 3. Astrophys. J. 730, 119 (2011). https://doi.org/10.1088/0004-637X/730/2/119
M. Hicken, P. Challis, S. Jha et al., CfA3: 185 Type Ia Supernova light curves from the CfA. Astrophys. J. 700, 331–357 (2009). https://doi.org/10.1088/0004-637X/700/1/331
J.D. Neill, M. Sullivan, D.A. Howell et al., The local hosts of Type Ia Supernovae. Astrophys. J. 707, 1449–1465 (2009). https://doi.org/10.1088/0004-637X/707/2/1449
A. Conley, J. Guy, M. Sullivan et al., Supernova constraints and systematic uncertainties from the first three years of the Supernova Legacy Survey. Astrophys. J. Suppl. Ser. 192, 1 (2010). https://doi.org/10.1088/0067-0049/192/1/1
E.V. Linder, Understanding the optimal redshift range for the supernovae Hubble diagram. Astrophysics (2001). arXiv:astro-ph/0108280
S. Capozziello, Ruchika, A.A. Sen, Model-independent constraints on dark energy evolution from low-redshift observations. Mon. Not. R. Astron. Soc. 484, 4484–4494 (2019). https://doi.org/10.1093/mnras/stz176
G.O. Roberts, A.F.M. Smith, Simple conditions for the convergence of the Gibbs sampler and Metropolis-Hastings algorithms. Stoch. Process. Appl. 49, 207–216 (1994). https://doi.org/10.1016/0304-4149(94)90134-1
S. Chib, I. Jeliazkov, Marginal likelihood from the Metropolis–Hastings output. J. Am. Stat. Assoc. 96, 270–281 (2001). https://doi.org/10.1198/016214501750332848
D. Foreman-Mackey, D.W. Hogg, D. Lang et al., emcee: the MCMC Hammer. Astron. Soc. Pac. 125, 306–312 (2013). https://doi.org/10.1086/670067
K.P. Burnham, D.R. Anderson, Multimodel inference: understanding AIC and BIC in model selection. Sociol. Methods Res. 33, 261–304 (2004). https://doi.org/10.1177/0049124104268644
R.C. Nunes, S. Pan, E.N. Saridakis, et al., New observational constraints on f(R) gravity from cosmic chronometers. J. Cosmol. Astropart. Phys. 2017, 005 (2017). https://doi.org/10.1088/1475-7516/2017/01/005
S. Basilakos, S. Nesseris, F.K. Anagnostopoulos et al., Updated constraints on f(T) models using direct and indirect measurements of the Hubble parameter. J. Cosmol. Astropart. Phys. 2018, 008 (2018). https://doi.org/10.1088/1475-7516/2018/08/008
F.K. Anagnostopoulos, S. Basilakos, E.N. Saridakis, Bayesian analysis of f(T) gravity using f8 data. Phys. Rev. D 100, 083517 (2019). https://doi.org/10.1103/PhysRevD.100.083517
S. Nesseris, J. García-Bellido, Is the Jeffreys’ scale a reliable tool for Bayesian model comparison in cosmology? J. Cosmol. Astropart. Phys. 2013, 036 (2013). https://doi.org/10.1088/1475-7516/2013/08/036
C.L. Bennett, D. Larson, J.L. Weiland et al., The 1% concordance Hubble constant. Astrophys. J. 794, 135 (2014). https://doi.org/10.1088/0004-637X/794/2/135
S.D. Odintsov, D. Saez-Chillon Gomez, G.S. Sharov, Is exponential gravity a viable description for the whole cosmological history? Eur. Phys. J. C 77, 862 (2017). https://doi.org/10.1140/epjc/s10052-017-5419-z
A.G. Riess, L.M. Macri, S.L. Hoffmann et al., A 2.4% determination of the local value of the Hubble constant. Astrophys. J. 826, 58 (2016). https://doi.org/10.3847/0004-637X/826/1/56
E. Mörtsell, S. Dhawan, Does the Hubble constant tension call for new physics? J. Cosmol. Astropart. Phys. 2018, 025 (2018). https://doi.org/10.1088/1475-7516/2018/09/025
S.L. Cao, X.W. Duan, X.L. Meng et al., Cosmological model-independent test of \(\Lambda \)CDM with two-point diagnostic by the observational Hubble parameter data. Eur. Phys. J. C 78, 313 (2018). https://doi.org/10.1140/epjc/s10052-018-5796-y
S.D. Odintsov, D. Saez-Chillon Gomez, G.S. Sharov, Testing logarithmic corrections on \(R^2\)-exponential gravity by observational data. Phys. Rep. 99, 024003 (2019). https://doi.org/10.1103/PhysRevD.99.024003
A.A. Starobinsky, Disappearing cosmological constant in f(R) gravity. J. Exp. Theor. Phys. Lett. 86, 157–163 (2007). https://doi.org/10.1134/S0021364007150027
S. Tsujikawa, Observational signatures of f(R) dark energy models that satisfy cosmological and local gravity constraints. Phys. Rev. D 77, 023507 (2008). https://doi.org/10.1103/PhysRevD.77.023507
V.F. Cardone, S. Camera, A. Diaferio, An updated analysis of two classes of f(R) theories of gravity. J. Cosmol. Astropart. Phys. 2012, 30 (2012). https://doi.org/10.1088/1475-7516/2012/02/030
H. Motohashi, Consistency relation for \({R}^{p}\) inflation. Phys. Rev. D 91, 064016 (2015). https://doi.org/10.1103/PhysRevD.91.064016
T. Clifton, J.D. Barrow, The power of general relativity. Phys. Rev. D 72, 103005 (2005). https://doi.org/10.1103/PhysRevD.72.103005
J.V. Cunha, J.A.S. Lima, Transition redshift: new kinematic constraints from supernovae. Mon. Not. R. Astron. Soc. 377, L74–L78 (2007). https://doi.org/10.1111/j.1365-2966.2008.13640.x
R. D’Agostino, R.C. Nunes, Probing observational bounds on scalar–tensor theories from standard sirens. Phys. Rev. D 100, 044041 (2019). https://doi.org/10.1103/PhysRevD.100.044041
R.T. Hough, Constraining modified gravity models with cosmological data. Masters dissertation, North-West University (2019). http://hdl.handle.net/10394/34763
R.T. Hough, A. Abebe, S.E.S. Ferreira, Constraining f(R)-gravity models with recent cosmological data, in SAIP Conference Proceedings (2019) (submitted)
A.M. Swart, R.T. Hough, S. Sahlu, et al., Unifying dark matter and dark energy in Chaplygin gas cosmology, in SAIP Conference Proceedings (2019) (submitted)
Acknowledgements
Renier Hough acknowledge funding through a National Astrophysical and Space Science Program (NASSP) and National Research Foundation (NRF) scholarship (Grant Number 117230). Amare Abebe and Stefan Ferreira acknowledge that this work is based on the research support in part by the NRF (with grant numbers 109257/112131 and 109253 respectively). We also acknowledge the help received from the Centre for Space Research at the North-West University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Masters dissertation
The work presented in this article is based on the findings in the Masters dissertation of Renier Hough [50]. Furthermore, an early results conference proceedings based on this work was submitted [51]. The MCMC simulation developed in the Masters dissertation, was also used in a group project that were also published in a conference proceedings [52].
Appendices
Appendices
Appendix A: Finding a usable form for the f(R)-gravity Friedmann equation
Starting with Eq. 3, and substituting the expressions for the Ricci scalar and its first-order derivative \({\dot{R}} = 6({\ddot{H}}+4H{\dot{H}})\), into this Friedmann equation, we findFootnote 5
We can then use the following known expressions for the Hubble parameter, which is given as:
By substituting these Hubble parameter definitions into Eq. 17 and simplifying, we obtain
By using the definition of the Jerk parameter, we can mathematically manipulate the first term in the bracket to find \(\frac{{\dot{a}}\dddot{a}}{a^{2}}=jH^{4}\), while using the deceleration parameter on the second term in the bracket to find \(\frac{{\dot{a}}^{2}\ddot{a}}{a^{3}} = - qH^{4}\). We can then substitute these expression into Eq. 19, as well as simplifying the equation to obtain
Since we assumed a flat universe (\(\varOmega _{k}=0\)) for simplicity, we know that \(\kappa = 0\). Therefore, we obtain
Appendix B: Finding h(z) for the Starobinsky inflationary toy model
In this section we will present the mathematical steps necessary to find f(R)-gravity Friedmann equation in terms of redshift (H(z)), as well as the normalized Friedmann equation for the second toy model (with \(n=2\)), namely the inflationary Starobinsky model. Starting of with just the general second toy model
You then need to re-parametrise this function, to obtain a dimensionless equation. This is given in [4] as
We then need to find the first and second order derivatives, in accordance with Eq. 14. This we obtain as
We can then substitute Eqs. 23 and 24 into Eq. 14 and obtain
We can now substitute the definition equation for the Ricci scalar into Eq. 25, to obtain
We can now solve for \(H^{2}(t)\) using the Maple mathematics program and obtain
Since this equation is not analytically solvable, we insert \(n=2\) into eq. 27. We then simplify using Maple to find
When solving for \(H^{2}\), we obtain 4 different solutions given by
The first solution is a stationary universe, while the second is only a function of the free parameters, which does not help us in being able to compare the cosmological parameters of the various model. Using the 3rd and the 4th solutions, we can determine the normalised Hubble parameter as a function of time. This we find to be
To change the dependency of time to redshift, we need to use \(\varOmega _{m}(t)=\varOmega _{m} (1=z)^{3}\), as well as the parametrised cosmographic series terms as defined in Eqs. 15 and 16. By substituting these terms into Eq. 30, to obtain
We showed the MCMC simulation’s result for the negative solution.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3
About this article

Cite this article
Hough, R.T., Abebe, A. & Ferreira, S.E.S. Viability tests of f(R)-gravity models with Supernovae Type 1A data. Eur. Phys. J. C 80, 787 (2020). https://doi.org/10.1140/epjc/s10052-020-8342-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-020-8342-7