
Abstract
We apply the generalized Lomb–Scargle (LS) periodogram to independently confirm the claim by Sturrock et al. (Astropart Phys 84:8. https://doi.org/10.1016/j.astropartphys.2016.07.005, 2016) of an oscillation at a frequency of 11/year in the decay rates of \(\mathrm {^{90}Sr/^{90}Y}\) from measurements at the Physikalisch Technische Bundesanstalt (PTB), which however has been disputed by Kossert and Nahle (Astropart Phys 69:18. https://doi.org/10.1016/j.astropartphys.2015.03.003, 2015). For this analysis, we made two different ansatze for the errors. For each peak in the LS periodogram, we evaluate the statistical significance using non-parametric bootstrap resampling. We find using both of these error models evidence for 11/year periodicity in the \(\mathrm {^{90}Sr/^{90}Y}\) data for two of the three samples, but at a lower significance than claimed by Sturrock et al. [1].
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the past two decades, there have been a number of works starting with Falkenberg [3] pointing out that the beta decay rates are variable and depend on various environmental parameters. Some of the environmental influences proposed for this variability include solar rotation, other ancillary dynamics in the inner solar core [4, 5], solar flares [6], Earth–Sun distance [7], lunar influence etc [8]. However, these results have been disputed by other authors (eg. [9,10,11,12]) and no common consensus has emerged. A summary of some of these claims as well as their rebuttals are reviewed in Refs. [1, 2, 9].
In this work we concentrate on settling the contentious claim of one such result regarding the decay rates of \(\mathrm {^{90}Sr/^{90}Y}\) from one specific experiment, between two groups of authors. Parkhomov [8] and Sturrock et al. [4] found evidence for annual and monthly oscillations in the decay rates of \(\mathrm {^{90}Sr/^{90}Y}\) measured at Institute for Time Nature Explorations, Moscow State University. Furthermore, Sturrock et al. [4] also found correlations between these decay rates and r-mode oscillations inside the Sun.
These results were contested by Kossert and Nahle [2] (hereafter, KN15). They showed using long-term measurements of the decay rates with a custom-built liquid scintillator at the Physikalisch-Technische Bundesanstalt (PTB), that there is no evidence for any periodic modulations in the decay rates of \(\mathrm {^{90}Sr/^{90}Y}\). The results of KN15 were in turn rebuked by Sturrock et al. [1] (hereafter, S16), who reanalyzed the same PTB data from KN15 and found evidence for statistically significant peaks at 11/year. S16 further argued that this oscillation frequency is indicative of a solar influence.
S16 used a likelihood procedure [13] analogous to the Lomb–Scargle periodogram to analyze the data and found peaks at the same location as KN15. However, the p-values they obtained (of the peaks been a random fluctuation) were much smaller than in KN15, implying an enhanced statistical significance for the peaks. One criticism of the KN15 paper by S16 was that KN15 incorrectly calculated the significance of each peak as \(\exp (-\sqrt{S})\), instead of \(\exp (-S)\), where S is the LS power. The significance of the peaks was also independently validated by S16 using a shuffle test [14].
Here, we focus on adjudicating the above conflict between KN15 and S16 regarding the oscillations in the decay rates of \(\mathrm {^{90}Sr/^{90}Y}\) at PTB, which remains unresolved, using an independent analysis and with a slight variant of their analysis. For this purpose, we use a modified version of the Lomb–Scargle periodogram called “Generalized Lomb–Scargle periodogram” (or floating-mean periodogram) to analyze the same dataset and evaluate the significance using bootstrap resampling. The same procedure was previously used in particle physics to assess the significance of periodicity in solar neutrino flux measured in Super-Kamiokande and SNO experiments [16]. However, this generalized periodogram is routinely used throughout astronomy (for example, see [17]).
The outline of this paper is follows. The generalized Lomb–Scargle periodogram is introduced in Sect. 2. Our analysis of the PTB is described in Sect. 3. A comparison of our results with those of Sturrock et al. can be found in Sect. 4. We then address the question of whether the observed data is purely stochastic in Sect. 5. We conclude in Sect. 6.
2 Generalized Lomb–Scargle periodogram
The Lomb–Scargle (hereafter, LS) [18, 19] (see Ref. [20] for a recent review) periodogram is a widely used technique in astronomy and particle physics to look for periodicities in unevenly sampled datasets, and has been applied to a large number of astrophysical datasets. Here, for our analysis, we shall apply a slight variant of the normal LS periodogram. We first provide a bare-bones introduction to the normal LS periodogram and then briefly outline the modification proposed by Zechmeister and Kurster [21], which is known in the literature as the generalized LS periodogram [21, 22] or the floating mean periodogram [20, 23, 24] or the Date-Compensated Discrete Fourier Transform [25]. More details are outlined in Refs. [20, 26] and references therein.
The goal of the LS periodogram is to determine the angular frequency (\(\omega \)) of a periodic signal in a time-series dataset y(t) given by:
It can be obtained as an analytic solution, while solving the problem of fitting for a sinusoidal function by \(\chi ^2\) minimization, and hence is a special case of the maximum likelihood technique for symmetric errors [27]. The LS periodogram calculates the power as a function of frequency, from which one needs to infer the presence of a sinusoidal signal.
One premise in calculating the LS periodogram [18, 19] is that the data are pre-centered around the mean value of the signal. This pre-centering is done using the sample mean, which is computed from the existing data. One ansatz implicitly made is that this is a good estimate for the mean value of the fitted function. This assumption breaks down if the data does not uniformly sample all the phases, or if the dataset is small and does not extend over the full duration of the sample. Such errors in estimating the mean can cause aliasing problems [21]. Therefore, to circumvent these issues, the LS periodogram was generalized to add an arbitrary offset to the mean values [21] as follows:
where \(y_0(f)\) is an offset term added to the sinusoidal model at each frequency We refer to this modification as the “generalized” LS periodogram in the remainder of this work. But as mentioned earlier, this modification is also referred elsewhere in literature as the floating-mean periodogram. The resulting equations for the generalized LS power can be found in Eq. 20 in Ref. [21]. It has been shown that the generalized LS periodogram is more sensitive than the normal one in detecting periodicities, in case the data sampling overestimates the mean [20, 21, 28]. In this work, we shall use the generalized LS periodogram for all the analyses.
If the observed data show any sinusoidal modulations at a given frequency, one would expect a peak in the LS periodogram at that frequency. To assess the significance of such a peak, we use the bootstrap method, in which for the same temporal coordinates as the data, we draw points randomly with replacements from the observed values and recompute the periodograms. Such a non-parametric bootstrap resampling procedure can reproduce any empirical distribution along with extreme-value methods to account for the tails [29]. To assess the significance of any peak, we shall compute the significance using 1000 bootstrap resamples of the data.
3 Analysis
3.1 Dataset
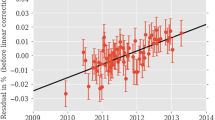
The PTB dataset consists of three samples of \(\mathrm {^{90}Sr/^{90}Y}\) denoted as S2, S3, and S4. This is supplemented by a blank sample (S1) for monitoring the background effects. The radioactivity estimates have been made using the Triple-To-Double coincidence ratio method [2]. The beta decay rates are parameterized by the normalized activity rates as shown in Figures 4, 5 and 6 of KN15. The normalization takes into account the triple coincidence rate and counting efficiency. More details of the sample preparation and the PTB measurements can be found in KN15.

Plot showing representative activity values and representative time instances of all the 240 bins for each of the three samples. The plot also shows the error in each bin assuming standard error of the mean
3.2 Power spectrum analysis
We have used the generalized Lomb–Scargle periodogram to detect a possible periodicity in the unevenly sampled activity data. The activity data from PTB contain many time periods without any data. The data were organized into bins and clustered. Contiguous data points were grouped into a single bin. All the data points in a bin were clustered, that is, the data points were replaced with a single value representative of all the points in that bin. After clustering the data, we obtained 240 time bins. Since there were no error bars provided per data point, we computed the periodogram by positing two different error models: For the first analysis we assumed that the error in each bin is given by the standard error of the mean, which is similar to the analysis done in S16. A time series representation of the data for all the three samples with this error model is shown in Fig. 1. We also redid this analysis assuming an error of 0.03% per data point. This is the average error estimated by KN15 (Table 1), from a quadrature sum of the different sources of systematic errors. We note however that it is not explicitly stated in KN15 as to whether this particular error budget has been used for their periodograms for the three samples. We also couldn’t find any information on the bin size used for the periodogram analysis carried out in KN15. On the other hand, S16 grouped the data into 50 bins of equal occupancy.
We computed the generalized LS periodogram using the lomb_scargle routine from the astroML [26] Python library. From the LS power at different frequencies, we need to estimate the significance at that frequency. The minimum and maximum frequencies have to be carefully chosen. The spacing between the frequencies has to be chosen so as to not miss any peaks. The choice of minimum frequency is straight-forward, \(f_{min}=1/T\), where T is the total time spanned by the set of observations. For all practical purposes, the minimum frequency is chosen to be zero. The maximum frequency is suggested as \((1/T_{med})\), where \(T_{med}\) is the median of the difference of the representative time instances of each bin [20]. The median time between consecutive bins after choosing a time bin to be the contiguous data is equal to approximately 1.006 days. The reason for the slight variation in this value for different samples is due to a very small variation in the bin sizes and time instances corresponding to the different data points.
Since our main goal is to resolve the conflicting claims in two papers, we restrict ourselves to a maximum frequency of \(20 \ \mathrm{year}^{-1}\), as in KN15 and S16 instead of the maximum permissible frequency. The spacing between the successive frequencies is chosen to be 1 / (5T) and is equal to \(5.87 \times 10^{-9}\) Hz. Note that there is a slight variation of this value for different samples due to a very small variation in the bin sizes and time instances corresponding to these data points. (For more details on these recommendations, see Vanderplas [20] and references therein).
So, the recommended minimum and maximum values of angular frequency \(\omega \), which we use are: \(\omega _{min}=(2\pi /T)\) and \(\omega _{max}=2\pi f_{max}\), where \(f_{max}= 20 \ \mathrm{year}^{-1}\). We choose the value of \(\omega _{min}\) very close to zero (\(1 \times 10^{-9}\) rad/s) here, instead of zero exactly, because the LS routine does not return a valid value for zero frequency. The total number of frequencies at which the power is computed is equal to \((\omega _{max} - \omega _{min})/(2\pi /5T)\). The total number of frequencies at which power is computed corresponds to 108, 108 and 107 for samples S2, S3 and S4 respectively.
We now report results from both these analyses.
3.2.1 Analysis assuming 0.03% error per data point
For the first error model, the representative activity value of each bin was calculated from the weighted mean of the observed data, wherein each data point is weighted by the inverse square of the error. The representative activity value (\(a_{b}\)) and time instance (\(t_b\)) of a given bin are computed as:
where N is the number of data points in the bin; \(e_i\) is the error per data point; and \(t_i\) is the time instance corresponding to data point \(d_i\).
The average activity error in each time bin (\(\sigma _i\)) is computed by propagating the uncertainty in each data point:
Using the above error budget, we then construct the LS periodogram for each of the three samples S2, S3, and S4. For each of these samples, we show the LS power and a horizontal line representing the False-Alarm Probability (FAP) of the most significant peak using 1000 bootstrap resamples. From the FAP, one can obtain an assessment of the statistical significance of any peak in the periodogram. For a peak to be statistically significant indicative of any oscillations, FAP should be as small as possible.
Figures 2, 3 and 4 show the corresponding LS periodogram (power vs frequency in units of \(\mathrm {year^{-1}}\)) with these assumptions for samples S2, S3, and S4 respectively. A tabular summary of these results can be found in Table 1.

Power spectrum of PTB Sample 2, assuming an error of 0.03% per data point. Note that the periodograms have been normalized according to Ref. [26]. To recover the LS powers in KN15 [2] and Sturrock [1], one needs to multiply by \((N-1)/2\). The dotted horizontal line corresponds to a false alarm probability (FAP) of a random fluctuation equal to 17.2% and represents the FAP of the largest peak in the LS periodogram. In this case, this peak is at about 11.4 \(\mathrm{year^{-1}}\). However, the FAP at this peak is consistent with it been a noise fluctuation

Power spectrum of PTB Sample 3, assuming an error of 0.03% per data point. See Fig. 2 for more details about the labels. The dotted horizontal line corresponds to a FAP 28.2% and is not significant

Power spectrum of PTB Sample 4, assuming an error of 0.03% per data point. See Fig. 2 for more details about the labels. The dotted horizontal line corresponds to a FAP of 20.5% and is consistent with noise. Here, there is no observed peak at 11.5 \(\mathrm{year}^{-1}\)
This normalization of the LS power (which follows the convention originally proposed by Lomb [18]), differs from that used in KN15 and S16, (which follows Scargle’s convention [19]) by a factor of \((N-1)/2\) for N data points. With this assumption, the values for the LS power fall between 0 and 1. A tabular summary of these results can be found in Table 1.
Despite using different bin sizes, the locations of the peak frequencies in all the periodograms with this error model is same as in KN15 and S16. For S2, the periodogram is peaked at about 11.4 /year (with FAP of about 17.2%). S3 and S4 show peaks at 17 per year with FAPs of 28.2 and 20.5% respectively. Therefore, the significance of all these peaks (based on the FAP) is marginal and cannot be construed as statistically significant evidence for oscillations at any frequency. If there is any influence from the solar interior on the beta decay rates, then all the three samples should show statistically significant peaks around 11 per year, which we do not find. The FAPs we obtain are much higher than S16 and are consistent with noise.
3.2.2 Analysis assuming standard error of mean
We now re-calculate the periodogram by positing that the error in each bin is the standard error of the mean, which is similar to the analysis done in S16. However in S16, 50 bins were chosen in such a way that the number of data points in each bin were the same, whereas for our analysis, the bins represent contiguous periods of data. In this case, the representative activity value (\(a_b\)) as well as the central time in each bin (\(t_b\)) were taken to be the mean of the activity values in a bin:
We note that \(t_b\) is calculated in the same way as in our previous analysis. The error in each bin, which in this case is the standard error SE is computed as follows:
where \(\sigma \) is the standard deviation of the data points in a given bin, \(\mu \) is the mean of the data points in a given bin and N is the total number of data points in a given bin.

Power spectrum of PTB Sample 2, assuming standard error of mean. See Fig. 2 for more details about the labels. The dotted horizontal line corresponds to a FAP of 2.6% and corresponds to a significance of 1.94\(\sigma \)

Power spectrum of PTB Sample 3, assuming standard error of mean. See Fig. 2 for more details about the labels. The dotted horizontal line corresponds to a FAP of 41.4% and is consistent with noise

Power spectrum of PTB Sample 4, assuming standard error of mean. See Fig. 2 for more details about the labels. The dotted horizontal line corresponds to a FAP of 74.1% and is consistent with noise
Using this error budget for each data point, we then construct the LS periodograms in the same way as before. These periodograms can be found in Figs. 5, 6 and 7 respectively. A tabular summary of the results with this model for the error budget can be found in Table 1. This time, we find that both S2 and S3 show peaks at a frequency of approximately 11/year. S4 shows a peak at about 1.3 per year. Therefore, the location of the peak frequencies in samples S3 and S4 is different than our previous analysis in Sect. 3.2.1 as well as with the results from KN15 and S16. However, even in this case none of the peaks are statistically significant. The FAP of the peaks for S2, S3, and S4 are 2.6, 41.4 and 74.1%. The lowest FAP is for the S2 equal to 2.6%, which corresponds to \(1.94\sigma \) (using Gaussian one-sided significance [30]) and is therefore only marginally significant.
Therefore, even with this model for the errors, we do not see any uniformity in the location of the peak frequencies across the three samples. However, in the S2 sample we do see a peak at 11/year similar to S16 and KN15, but with a lower significance than S16.
4 Comparison with Sturrock et al
In this section, we check if we can reproduce the results in Section 2 of S16, where they dispute the significance calculation of KN16. For this purpose, we only focus on the data from only the S2 sample, since this sample has the largest LS power at 11/year. We used the same binning procedure as our earlier analysis. Since the exact error model or the binning used to obtain LS power of 8.42 is not specified, we used both the error models. To compare our results with theirs, we use the same normalization for the LS power as in KN15 and S16 (which follows Scargle’s convention [19]), by multiplying the power shown Figs. 2, 3, 4, 5 and 6 by \((N-1)\)/2. We also calculate significance in the same way as Sect.2 of S16, which is given by \(\exp (-S)\), where S is the LS power using this normalization. This significance quantifies the false alarm probability of the null hypothesis and is equivalent to a p-value. In addition to the generalized LS periodogram, we also calculate the normal LS power and its significance, to mimic the results of S16 as closely as possible.
Our results are shown in Table 2. By positing an error model of 0.03% per data point, we get a value for our significance about 100 times larger than that obtained in S16. The results don’t differ much between normal and LS periodogram. However, using standard error of the mean, we get a significance value about one order of magnitude smaller than that in S16 of about \(1.6 \times 10^{-5}\). Taken at face value, this would correspond to \(4.1\sigma \) significance. Therefore, the actual value of the significance is also sensitive to the choice of the error model used. Since the actual error model used in Section 2 of S16 is not explicitly specified, we cannot do a direct comparison of our significance with theirs.
However, we can see that the statistical significance of the peak at 11/year becomes enhanced compared to S16, using the second error model.
5 Is the data completely stochastic?
Although our FAP is higher than S16, from Figs. 2 and 5, we do find a peak visible to the naked eye in the S2 data sample for both the choice of error models at the same frequency as S16. This raises the question of whether the observed data are purely stochastic.
Therefore, to test if the data is consistent with pure noise without any sinusoidal modulations, we carried out numerical experiments with synthetic data, using both the error models. We replaced the activity data of the sample S2 with Gaussian distributed random numbers (which are proxy for the activity counts) at the same time instances when S2 had data, and carried out the power spectrum analysis and calculation of FAP in the same way as for real data. We generated random numbers with mean of zero and standard deviation of unity. We then replicated the above procedure of generating synthetic data and analyzing using LS periodogram 1000 times and constructed a histogram of the LS power from each such realization. The LS power for each iteration was chosen as the maximum LS power in the frequency range between 11/year and 11.5/year. Figures 8 and 9 depict the histograms of the LS power with \(0.03\%\) error per data point and with standard error of the mean respectively. We also note that our results do not change much, if we use the standard deviation of the original data.
We found that the random LS power rarely crosses the observed LS power. After 1000 trials, we find that this maximum LS power value exceeds the observed LS power at 11/year, for about 8 and 10 different realizations, for the 0.03% error model and the standard error of mean error models respectively. Therefore, these numerical experiments with synthetic noise data demonstrate that the observed data are not completely stochastic and the observed LS power in the S2 data sample are indicative of marginal hints for periodicity of 11 years.

Histogram representing the distribution of LS powers over 1000 iterations with random data. The black vertical dotted line represents the observed LS power with the data of sample S2. The above plot represents the analysis with \(0.03\%\) error per data point as the error model. The probability of getting a peak larger than the observed value from these simulations is about 0.8%

Histogram representing the distribution of LS powers over 1000 iterations with random data. The black vertical dotted line represents the observed LS power with the data of sample S2. The above plot represents the analysis with Standard error of the mean as the error model. The probability of getting a peak larger than the observed value from these simulations is about 1%
6 Conclusions
The aim of this work was to resolve the controversy between two groups (S16 and KN15) regarding the influence of solar processes on nuclear beta decay rates of \(\mathrm {^{90} Sr/^{90}Y}\) measured at the PTB. We would like to verify using these measurements, whether this decay mode shows sinusoidal variations with a frequency of 11/year as claimed by S16 (but disputed by KN15), which could be indicative of a solar influence.
For this purpose, we have used the generalized or floating-mean LS periodogram to search for periodicity in the PTB activity data for three different samples, for which measurements span a period of 400 days. This generalized LS periodogram has been shown to be more sensitive than the normal periodogram, in case the data do not encompass the full phase coverage of a putative periodic signal [20]. We grouped the activity data into 240 bins, with each bin containing contiguous activity data points. We obtained the periodograms using two different assumptions about the errors as follows:
-
0.03% error per data point (in accord with the error budget calculated in KN15).
-
Standard error of mean in each bin (similar to the analysis done in S16).
The significance of each peak was evaluated using bootstrap resampling with 1000 samples, using the method proposed by Suveges [29]. The generalized LS periodograms for all the three samples are shown in Figs. 2, 3, 4, 5, 6 and 7. Table 1 summarizes the results of the generalized LS analysis carried out on S2, S3, and S4 using the above mentioned error models.
To compare our results with Sturrock et al., we then estimated the significance of the peak in the S2 sample using the same method as S16 with both the error models. Our results from this exercise are shown in Table 2. We then addressed the question of whether the data are purely stochastic by conducting 1000 numerical experiments of activity time series, which are drawn from a normal distribution using the same time-binning as the observed data. Histograms of the LS power at frequencies close to 11/year can be found in Figs. 8 and 9.
Our conclusions about these analyses are as follows:
-
The peak frequencies and their significances slightly change for some of the samples with different error models.
-
We do not find a peak in the periodograms close to 11/year in all the three samples using either of the two error models.
-
The sample S2 has a peak at about 11 \(\mathrm{year^{-1}}\) with FAP values of 17.2 and 2.6% assuming 0.03% error per data point and standard error of mean respectively. The FAP of 2.6% corresponds to a significance of 1.94\(\sigma \), and its statistical significance is smaller than that claimed in S16.
-
The only other sample with a peak frequency close to 11/year is S3, assuming a standard error of the mean. However, its FAP of 41.4% is consistent with a noise fluctuation.
-
None of the remaining peaks found in the other samples have FAP less than 10% with either of the two error budgets. Therefore, none of them can be considered as evidence for sinusoidal variations in the beta decay rates.
-
We obtain a significance of 0.4 and 0.0016%, using the same formula used by S16 for the 0.03% error per point and standard error of the mean models respectively. These values are about ten times larger and smaller respectively than the significance of 0.02% estimated in Section 2 of S16.
-
For purely stochastic time-series, we would obtain the probability of getting the LS power greater than the one observed at 11/year to be about 1%.
Hence in conclusion, we see that the differently prepared chemical samples S2, S3, and S4 do not exhibit any consistent periodic oscillations in their activity. However, we do see a marginally significant peak in the S2 data sample at the same frequency as S16 (11 per year), but with a higher false alarm probability. More data is needed for the S2 sample, along with a detailed error budget to ascertain if this peak at 11/year persists and is significant.
References
P.A. Sturrock, G. Steinitz, E. Fischbach, A. Parkhomov, J.D. Scargle, Astropart. Phys. 84, 8 (2016). https://doi.org/10.1016/j.astropartphys.2016.07.005
K. Kossert, O.J. Nähle, Astropart. Phys. 69, 18 (2015). https://doi.org/10.1016/j.astropartphys.2015.03.003
E.D. Falkenberg, Apeiron 8(2), 32 (2001)
P.A. Sturrock, A.G. Parkhomov, E. Fischbach, J.H. Jenkins, Astropart. Phys. 35, 755 (2012). https://doi.org/10.1016/j.astropartphys.2012.03.002
P.A. Sturrock, G. Steinitz, E. Fischbach. (2017). arXiv:1705.03010
J.H. Jenkins, E. Fischbach, Astropart. Phys. 31, 407 (2009). https://doi.org/10.1016/j.astropartphys.2009.04.005
J.H. Jenkins, E. Fischbach, J.B. Buncher, J.T. Gruenwald, D.E. Krause, J.J. Mattes, Astropart. Phys. 32, 42 (2009). https://doi.org/10.1016/j.astropartphys.2009.05.004
A.G. Parkhomov, J. Mod. Phys. 2(11), 1310 (2011)
S. Pommé, G. Lutter, M. Marouli, K. Kossert, O. Nähle, Astropart. Phys. 97, 38 (2018). https://doi.org/10.1016/j.astropartphys.2017.10.011
E. Bellotti, C. Broggini, G. Di Carlo, M. Laubenstein, R. Menegazzo, Phys. Lett. B 710(1), 114 (2012)
E. Bellotti, C. Broggini, G. Di Carlo, M. Laubenstein, R. Menegazzo, Phys. Lett. B 720, 116 (2013). https://doi.org/10.1016/j.physletb.2013.02.002
E. Bellotti, C. Broggini, G. Di Carlo, M. Laubenstein, R. Menegazzo, Phys. Lett. B 780, 61 (2018). https://doi.org/10.1016/j.physletb.2018.02.065
P.A. Sturrock, D.O. Caldwell, J.D. Scargle, M.S. Wheatland, Phys. Rev D. 72(11), 113004 (2005). https://doi.org/10.1103/PhysRevD.72.113004
J.N. Bahcall, W.H. Press, Astrophys. J. 370, 730 (1991). https://doi.org/10.1086/169856
S. Pommé, K. Kossert, O. Nähle, Solar Phys. 292, 162 (2017). https://doi.org/10.1007/s11207-017-1187-z
S. Desai, D.W. Liu, Astropart. Phys. 82, 86 (2016). https://doi.org/10.1016/j.astropartphys.2016.06.004
M. Süveges, R.I. Anderson, Astron. & Astrophys. 610, A86 (2018). https://doi.org/10.1051/0004-6361/201628870
N.R. Lomb, Astrophys. Space Sci. 39, 447 (1976). https://doi.org/10.1007/BF00648343
J.D. Scargle, Astrophys. J. 263, 835 (1982). https://doi.org/10.1086/160554
J.T. VanderPlas, Astrophys. J. Suppl. Ser. 236(1), 28 (2018). https://doi.org/10.3847/1538-4365/aab766
M. Zechmeister, M. Kürster, Astron. Astrophys. 496, 577 (2009). https://doi.org/10.1051/0004-6361:200811296
G.L. Bretthorst, in Bayesian Inference and Maximum Entropy Methods in Science and Engineering, American Institute of Physics Conference Series, vol. 568, ed. by A. Mohammad-Djafari, American Institute of Physics Conference Series, vol. 568, pp. 246–251, (2001). https://doi.org/10.1063/1.1381889
A. Cumming, G.W. Marcy, R.P. Butler, Astrophys. J. 526, 890 (1999). https://doi.org/10.1086/308020
J.T. VanderPlas, Ž. Ivezić, Astrophys. J. 812, 18 (2015). https://doi.org/10.1088/0004-637X/812/1/18
S. Ferraz-Mello, Astron. J. 86, 619 (1981). https://doi.org/10.1086/112924
Ž. Ivezić, A. Connolly, J. Vanderplas, A. Gray, Statistics, Data Mining and Machine Learning in Astronomy (Princeton University Press, Princeton, 2014)
G. Ranucci, Phys. Rev. D 73(10), 103003 (2006). https://doi.org/10.1103/PhysRevD.73.103003
J. Vanderplas, A. Connolly, Ž. Ivezić, A. Gray, in Conference on Intelligent Data Understanding (CIDU) (2012), pp. 47 –54. https://doi.org/10.1109/CIDU.2012.6382200
M. Süveges. (2012). arXiv:1212.0645S
S. Ganguly, S. Desai, Astropart. Phys. C 94, 17 (2017). https://doi.org/10.1016/j.astropartphys.2017.07.003
Acknowledgements
We are grateful to Karsten Kossert for providing us the data for the PTB measurements analyzed in KN15 and answering our queries, which enabled us to do this analysis. All the plots in this work have been made using the astroML library [26, 28]. We also thank the anonymous referee for detailed critical feedback on our manuscript. We also acknowledge Jake Vanderplas for useful correspondence.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
Tejas, P., Desai, S. Generalized Lomb–Scargle analysis of \(\mathrm {^{90}Sr/^{90}Y}\) decay rate measurements from the Physikalisch–Technische Bundesanstalt. Eur. Phys. J. C 78, 554 (2018). https://doi.org/10.1140/epjc/s10052-018-6040-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-018-6040-5