
Abstract
The extent to which pricing executives consider consumer perceptions of deception, fairness, and social justice is positioned within an emerging area of research that triangulates the dynamic between legal constraints, ethical considerations, and algorithmic models to make pricing decisions. This paper builds a conceptual model from an analysis of literature describing how companies couple organizational and technology factors into the price-setting process. The legal frameworks of antitrust, data privacy, and antidiscrimination are tethered to the ethical frameworks of deception, fairness, and social justice to form a foundation of relevant organizational factors. A qualitative study is proposed to test the validity of the conceptual model. The primary contribution of this paper is to catalyze practitioner discussion and spur empirical research into the implications of personalized pricing using algorithmic models.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Pricing is a tremendously important component of the organizational marketing mix (Borden 1964). Decision-making within the pricing function has evolved from an individual clerical task driven by instinct to a cross-functional team activity that drives strategic value (Mitchell 2012). Evidence supports the assertion that developing significant pricing capabilities positively impacts overall firm performance (Dutta et al. 2003). Liozu and Hinterhuber (2014) suggest a causal model of specific capabilities that includes “robust internal processes related to price setting, pricing tools, and training” (p. 153). Such processes could incorporate a combination of data-mining techniques to harness inferential analytics (Furnas 2012) and information asymmetries to exploit behavioral discrimination (Ezrachi and Stucke 2016a).
A paucity of descriptive research obscures the extent to which executives implement pricing strategies consistent with theoretical models and determinants (Noble and Gruca 1999; Rao and Kartono 2009). Data science has enabled “black box” algorithmic decision-making (Pasquale 2013), replete with technical complexity and secrecy, representing an evolution from classical pricing approaches and making a compelling case for price conditioning in certain industries (Acquisti and Varian 2005). The extent to which consumers develop an awareness of discriminatory pricing practices leads to a “culture of suspicion and envy,” illuminating a growing social concern (Turow 2006, p. 182). The specific mechanisms underpinning the competitive necessity of price discrimination take place largely in secret, beyond the current reach of effective regulation and the larger conversation in academic discourse. Miller makes an admirable first effort to codify various ethical concerns related to common forms of price discrimination (2014, pp. 99–101), and this paper seeks to build upon his call for public debate.
Throughout this paper, we refer to algorithms, algorithmic models, and algorithmic decision-making interchangeably, although we acknowledge a technical distinction between these terms. For simplicity, we use these terms to describe the broader ecosystem of four interrelated algorithm technologies (Treleaven et al. 2019):
Artificial intelligence (AI): the program that interprets and analyzes the data without explicit coding, makes predictions, and executes decisions to maximize a utility function (or goal). We limit our scope of AI to the subset of machine learning where programs learn to change when exposed to new data.
Blockchain: provides the data processing and storage infrastructure via a decentralized and distributed ledger of blocks (records) linked using cryptography. Blockchain also enables the creation and execution of smart contracts that guarantee performance of credible transactions.
Internet of Things (IoT): provides raw data through the extension of enabled processors, sensors, and communications hardware into physical devices and everyday objects. IoT devices communicate through a shared access point or directly between other connected devices.
Big data analytics: the process of cleaning, structuring, and analyzing (mining) raw data to discern patterns, preferences, and trends. AI requires the raw data provided through analytics to learn how to make better decisions.
Popular literature is replete with examples debating the extent to which opaque and non-auditable algorithms should require regulation and oversight (Bostrom 2014; O’Neil 2016; Pasquale 2015). Accordingly, academia must more robustly examine the potential anticompetitive dynamics and possible predatory abuses where our locations and interactions can be quantified to accurately model our behaviors and preferences (Ezrachi and Stucke 2016b; Mayer-Schönberger and Cukier 2013; Papandropoulos 2007). Perhaps more poignant for analysis are instances where the lack of transparency in algorithmically determined personalized pricing creates a potential for exclusion facilitating actual discrimination (Executive Office of the President 2015; Pasquale 2015). Brunk (2012) operationalizes a construct for consumer perceived ethicality (CPE) to describe individual perception of moral organizational disposition, acknowledging this may differ from actual organizational behavior. The research concludes “that, contrary to philosophical scholars’ exclusively consequentialist (teleological) or non-consequentialist (deontological) positions, a consumer’s ethical judgment of a company or brand can be a function of both evaluation principles, sometimes applied simultaneously” (p. 562). The pluralistic implication of this construct provides one possible reconciliation of consumers’ paradoxical attitudes toward privacy versus their demonstrated ‘anti’-privacy behaviors (Brown 2001; Norberg et al. 2007). Despite outward attitudes of concern about infringement of personal private data, anecdotal and empirical evidence suggests that consumers willingly divulge such information in return for a relatively small immediate benefit. Acquisti (2004) concludes “it is unlikely that individuals can act rationally in the economic sense when facing privacy sensitive decisions …. [and] even ‘sophisticated’ individuals may under certain conditions become privacy ‘myopic’” (p. 22). While government policymakers might favor regulatory oversight on evidence of collective privacy concerns, contradictory behaviors weaken the justification for such action. Kokolakis (2017) conducts a laudable review of the literature to tentatively resolve the paradox, concluding that contradictory research findings to explain the relationship between privacy attitudes and behaviors suggests a complex rather than paradoxical phenomenon. Categorization of research findings depends upon the theoretical background, methodological approach, and specific context of study. Interestingly, Kokolakis’ literature review specifically and directly excluded the body of literature relating to ethical and legal aspects of the information privacy paradox. We contend that in consideration of a complex system, the corpus of literature under review should be inclusive of probable ethical considerations and legal constraints.
Drawing on extant literature and supported by extensive practitioner experience, we propose a concept model to describe how personalized price levels may derive from a combination of organizational and technology factors. The model retains its grounding in liberal economic theory wherein businesses may establish or change price levels freely within a subjective and utility-based conception of value (Bigwood 2003). Yet competition requires competitors to make independent actions, and Gal (2019) suggests that “with the advent of algorithms and the digital economy, it is becoming technologically possible for computer programs to autonomously coordinate prices and trade terms” (p. 18). Potential legal constraints emerge when “algorithms are designed independently by competitors to include decisional parameters that react to other competitors’ decisions in a way that strengthens or maintains a joint coordinated outcome” (p. 19). Businesses race to convert mountains of data into generative insights to improve personalization-centered retail practices. They deploy internally developed and acquired technology factors that enable the marketing function to bridge from customer segmentation to individual personalization. Turow (2017) alludes to the consideration of ethical constructs as retailers use algorithms as a tool of social discrimination, sending customers “different messages, even different prices, based on profiles retailers have created about them—profiles that the individuals probably don’t know exist and, if they could read them, might not even agree with” (pp. 247–248).
The ethical and legal constructs we have adopted into our concept model are informed by Nissenbaum’s contextual integrity theory, positing that technology-based practices affecting flows of personal data evolve within distinctive contexts of informational norms (Nissenbaum 2010). Miller (2014) adopts this view within the specific context of using personal information to fuel algorithms that explore legal and ethical principles in retail pricing, yet this analysis predates the emerging ubiquity of both artificial intelligence and data science methods that enable autonomous decision-making within the pricing function. Deployment of algorithms to tailor pricing and promotions in real-time is the highest reported use case (40%) among retailers already adopting AI technology. Projected increases in hiring data scientists approach 50% over the next 3 years as companies seek to integrate direct and indirect channels of personal data to better train AI-based algorithmic models on unified platforms leveraging data-driven capabilities (Deloitte Consulting & Salesforce 2018). Our concept model lays the foundation for future empirical studies to evaluate how companies address considerations of ethics and mitigate legal constraints by using algorithmic pricing models in conjunction with human judgment.
Research questions
Transdisciplinary research encircles technology factors, ethical considerations, and legal constraints as a triumvirate defining the broad context within which algorithmic models set (often dynamic) personalized pricing levels. We propose a concept model to suggest how firms reconcile the predictive value of algorithmic decision-making with organizational factors offering human judgment in consideration of consumer ethical interests and the legal and regulatory policy consequences of informational wrongdoing. We further propose multiphased qualitative research based on consumer focus groups and entrenched case studies at firms utilizing algorithmic models to make pricing decisions. Our objective from this research is to address the following research questions:
- 1.
What factors contribute to consumers’ ethical and legal schemata when confronting situational contexts of algorithmic personalized pricing?
- 2.
What contributes to the organizational schema that firms consider when adopting algorithmic price-setting models? What feedback mechanisms impact the price-changing decision?
Key implications of our research may extend to both the scholarly and practitioner communities to provide generative insights about the extent of congruence between firm practices and consumer perceptions of personalized pricing using algorithmic models. We seek to address the paucity of empirical literature that considers the complexity of organizational and technological factors concurrent with algorithmic decision-making. We further anticipate contributing to a call by policymakers to determine suitable remedies where secrecy of black box algorithms may enable harmful use of aggregated personal information to make pricing decisions.
Conceptual model and literature review
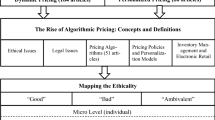
Informed by the literature and significant practitioner experience, the following preliminary conceptual model is offered as a framework for the proposed qualitative studies (Fig. 1).

Preliminary conceptual model
A constructivist grounded theory method (Charmaz 2014) formed the basis for our literature review and subsequent development of the conceptual model. This approach provides for methodological flexibility, dismissing certain rules, recipes, and requirements that force preconceived ideas and theories on acquired data. Instead, it invites the researcher to draw interpretive understandings and “follow leads that [researchers] define in the data, or design another way of collecting data to pursue our initial interests” (p. 32). The method is further substantiated as a precursor to our proposed qualitative research study in which a goal of data collection is to elucidate the meanings, beliefs, and values—the lived experiences—of research participants (Maxwell 2013).
Our systematic literature review utilizes the dynamic, reflexive, and integrative (DRI) zipper framework (El Hussein et al. 2017) that supports the intent of the constructivist grounded theory method. Classical and contemporary grounded theorists utilize systematic exploration to audit and appraise acquired data (Corbin and Strauss 2015; Stebbins 2001). The DRI zipper framework extends this interpretation to provide “traceable evidence to support [stated] generalizations and to justify the need to conduct the study” (El Hussein et al. 2017, p. 1207). Therefore, we approach the literature review as a concatenated activity (Stebbins 2001) that incorporates theoretical sensitivity (Glaser and Strauss 1999) to think “across fields and disciplines …. without letting it stifle [our] creativity or strangle [our] theory” (Charmaz 2014, p. 308).
Introduction to the literature review
We identify the relevant literature informing our conceptual model by drawing from the following key theories transcending fields of management, economics, and moral and political philosophy: behavioral theory of the firm (Cyert and March 1992), organizational decision-making theory (March 1994; March and Simon 1993 [1958]), ethical pluralism (James 2016 [1908]; Ross 2002 [1930]), and social contract theory (Hobbes 1982 [1651]; Locke 1980 [1690]; Rawls 1971).
We begin with a construction of the legal constraints and ethical considerations within which firms struggle to balance pressures and temptations that ultimately define the organizational factors influencing the decision-making process. Kaptein (2017) models the dimensions, conditions, and consequences of ethics struggles, proposing that greater ethical gaps created between opposing forces consequently require greater struggle. The multilevel model facilitates mutual interaction between individual and organizational units of analysis, allowing interdependent struggle through interactive combat. Nissenbaum’s (2010) theoretical framework of contextual integrity embraces the dynamicity of resulting ethical norms, thus bridging between organizational and technology factors by contextualizing the extent to which algorithmic models use flows of personal information that conform to consumers’ expectations. Accordingly, the process of personalized price setting depends both on algorithmic models and human judgement derived, in part, from a consideration of whether personal data are properly appropriated for use in a specific context.
Having described the broad theoretical framework from which our conceptual model is informed, we now briefly discuss each elemental component.
Legal constraints: conceptual foundations
The tenets of economic liberalism emerged from the Enlightenment-era to repudiate the feudal privileges and traditions of aristocracy. Smith (1975 [1776]) surmises that a laissez-faire philosophy incorporating minimal government intervention leads businesses, via unseen market forces, to distribute wealth “in the proportion most agreeable to the interest of the whole society” (p. 630). Recognizing the complexity of a knowledge-based society, Hayek (2011 [1960]) places some boundary conditions upon Smith’s invisible hand by arguing for modest yet limited government to create and enforce a general rule of law serving as individuals’ guardian of personal freedom. Liberty in the contemporary era is the result of an empirical and evolutionary view of politics wherein government creates and preserves the conditions to allow free markets to flourish. Friedman extends a somewhat tepid supposition, concluding that on a case-by-case basis, government intervention may mitigate negative externalities (as he terms, “neighborhood effects”), but cautions that mediating a market failure with legislative action likely increases other external costs (1978, 2012 [1962], pp. 30–32). Common within the economic liberalist tradition is the preservation of laissez-faire capitalism, yet many foundational proponents recognize limited government intervention as an antecedent to preserve individual liberty. The conditions and extent to which the political environment should provoke free markets remain a matter of considerable debate.
Antitrust as a legal constraint
Within the United States, the Department of Justice Antitrust Division maintains investigatory, enforcement, and prosecutorial jurisdiction over statutes related to both the illegal commercial restraint of fair competition and monopolistic practices (United States Department of Justice 2018, pp. II-1–II-25). Of particular importance, the Robinson-Patman Act (1936) specifically prohibits certain forms of wholesale discriminatory pricing, yet Robert Bork persuasively argues it is “the misshapen progeny of intolerable draftsmanship coupled to wholly mistaken economic theory” (1978, p. 382). At issue is the Act’s protection of competitors rather than competition—an antithetical and misguided approach to antitrust policy—by making unlawful the discrimination “in price between different purchasers of commodities of like grade and quality … and where the effect of such discrimination may be substantially to lessen competition or tend to create a monopoly in any line of commerce” (15 U.S.C. § 13(a)). Consequently, the phenomenon considered by the Act is not price discrimination, but rather, price difference—and it fails to consider those legitimate price differentials wholesalers may offer to their customers that in turn drive lower prices for consumers (Blair and DePasquale 2014). A novel empirical study of court cases involving consideration of the Robinson-Patman Act was conducted by Bulmash (2012) demonstrating how complainants in “secondary line” injury cases (purchasers of price-discriminated goods operating in a resale context) result in coordinated competition among suppliers, harming both consumers and competition. Despite historical recommendations for significant revision (Neal et al. 1968) and a contemporary call for outright repeal (Antitrust Modernization Commission 2007), the Act persists despite widespread abandonment of prosecutorial application in “primary line” injury claims (competitors of the price-discriminating firm).
While the effect of antitrust law seeks largely to prevent second-degree price discrimination through “acquisition or exercise of market power” (Fisher III, 2007, p. 14), Kochelek (2009) considers whether the Sherman Act indirectly applies in those cases where data-mining-based price discrimination may exert monopolistic or oligopolistic restraints on trade (15 U.S.C. §§ 1-2). While disfavoring such practices, the emergence of “data-mining-based price discrimination schemes fall into a gap between antitrust doctrine and the policies underlying the doctrine … [resulting in] reduce[d] consumer welfare, waste[d] resources, and reduce[d] allocative efficiency in exchange for increased producer profits that are insufficient to justify their cost” (Kochelek 2009, p. 535). Miller (2014) concurs, arguing that existing antitrust doctrine serves to limit a single firm to the extent they exert market power to raise price levels for most customers, yet data-mining-based price discrimination specifically targets unlikely defectors with higher prices without requiring widespread market influence. Effectively, classical antitrust laws are incompatible with modern methods of pricing discrimination.
Notwithstanding this limitation, the specter of seemingly unintentional collusion could result from algorithms that “are designed independently by competitors to include decisional parameters that react to other competitors’ decisions in a way that strengthens or maintains a joint coordinated outcome …. and the combination of these independent coding decisions leads to higher prices in the market” (Gal 2019, p. 19). As opposed to first-generation ‘adaptive’ algorithms that estimate and optimize price objectives subject to prior data, second-generation ‘learning’ algorithms use machine learning to condition their strategies upon experience (Calvano et al. 2019). Over time, independent algorithms may conclude that collusion is profitable, ultimately factoring competitive behavior as one among many changing market environmental variables. A small number of such cases have progressed through the judicial process (notably, “U.S. v. David Topkins,” 2015), but each is ultimately the result of algorithms designed by programmers (at the direction of managers) with collusive intent. Calvano et al. (2019) posit that the nature of learning algorithms to outperform humans in other contexts may result in collusive pricing that is hard to detect, presenting significant challenges to effective antitrust regulation.
Proposition 1
Antitrust factors are not legal constraints presently considered by firms that deploy algorithmic pricing models.
Antidiscrimination as a legal constraint
The extent to which discriminatory schemes in pricing are addressed in US federal law is largely embodied within the Civil Rights Act of 1964 mandating that “[A]ll persons shall be entitled to the full and equal enjoyment of the goods, services, facilities, privileges, advantages, and accommodations of any place of public accommodation, … without discrimination or segregation on the ground of race, color, religion, or national origin” (42 U.S.C. § 2000a). Spurred by California’s Unrah Civil Rights Act (Cal. Civ. Code, § 51), state-level legislation has extended such equal protection to include gender, language, and other factors easily detected and exploited by a price discrimination algorithm. Yet evidence suggests that even when states expand civil and equal rights doctrine, illegal discriminatory pricing schemes persist and prohibitions are broadly unenforced (Massachusetts Post Audit and Oversight Bureau, 1997). Federal opinion is mixed—the Federal Trade Commission suggests plentiful examples how big data can exploit underserved populations (2016, pp. 9–12), yet offers a counterpoint from the Executive Office of the President stipulating “if historically disadvantaged groups are more price-sensitive than the actual consumer, profit-maximizing differential pricing should work to their benefit” in competitive markets (2015, p. 17). Distinguishing between the aforementioned disparate treatment and disparate impact, the Presidential report “suggests that policies to prevent inequitable application of big data should focus on risk-based pricing in high-stakes markets such as employment, insurance, or credit provision” (p. 17).
The European Union extends legislation to prohibit “discrimination on grounds of nationality of the recipient or national or local residence” (Directive 2006/123/EC, Article 20), as demonstrated by a 2016 settlement reached between the European Commission and Disneyland Paris to settle allegations of inconsistent booking practices across member states (Abele 2016). Despite enforcement efforts, an extensive 2016 review of 10,537 e-commerce websites conducted by the European Commission (European Commission 2016) demonstrated the extensive practice of “geo-blocking” in 63% of cases to effectively limit interstate commerce. The resulting regulation “seeks to address direct, as well as indirect discrimination” (Regulation 2018/302), and, while not prohibiting price discrimination per se, eliminates one conduit through which such practices are facilitated.
Proposition 2
Antidiscrimination doctrine is a legal constraint considered by firms that deploy algorithmic pricing models.
Data privacy as a legal constraint
As described by Acquisti et al., “personal privacy is rapidly emerging as one of the most significant public policy issues” (2016, p. 485) and both social and behavioral science literature conclude that individual concerns are driven by uncertainty, context dependence, and malleability of privacy preferences (Acquisti et al. 2015). The Identity Theft and Assumption Deterrence Act of 1998 (18 U.S.C. § 1028) considers the surreptitious theft of personal data, but largely depends upon a consumer-initiated complaint to launch an investigative inquiry. To spur proactivity in those cases arising from organizational data vulnerabilities, individual states have adopted disclosure laws requiring firms to report security and privacy breaches, yet evidence indicates this leads to a minimal decrease in widespread data theft (Romanosky et al. 2011). Several studies further indicate that the financial impact of firm disclosures of security and data privacy breaches are negligible (Acquisti et al. 2006; Campbell et al. 2003). This breadth of research suggests that while legal doctrine and disclosure requirements may minimally reduce data theft, financial impacts to the firm are minimal and the graver concern to data privacy is the burden placed on consumers to wrestle with an apparent dichotomy between privacy attitudes and privacy behaviors (Berendt et al. 2005).
A 2009 study indicates that American consumers overwhelmingly reject behavioral targeting, yet express widespread erroneous views about the breadth and durability of existing privacy laws (Turow et al. 2009). While online users often seek anonymity at the application level (e.g., a website), broad anonymity is subject to technology and governmental factors that make it hard to achieve (Kang et al. 2013). Owing to the complexity of coexisting factors, this observed dichotomy is likely attributable to consumer perceptions of risk versus trust (Norberg et al. 2007) and behavioral heuristics (e.g., endowment effect) (Acquisti et al. 2013). Roberds and Schreft (2009) even argue that some loss of data privacy (and, by analogy, some degree of identity theft) enables the efficient sharing of information necessary for our modern payment systems. The debate over how best to preserve privacy while acknowledging the benefit of information sharing exacerbates a considerable wedge between proponents of regulation versus self-regulation of consumer data. At one extreme, Solove recommends a regulatory “architecture that establishes control over the data security practices of institutions and that affords people greater participation in the uses of their information” (2003, p. 1266). The template for such regulation could model the OECD Privacy Framework (2013) requiring radical continuous transparency about what information is being shared, a participatory interface for consumers to verify, amend, limit, or remove erroneous information, and accountability mandates for entrusted entities. At the opposite extreme, Rubin and Lenard (2002) argue forcefully for industry self-regulation, pointing to their study indicating that imposition of regulation adds unnecessary economic costs absent justification of an existing market failure.
The United States and European Union have approached the data privacy debate from different angles, with the latter opting to enact a considerable regulatory framework with the 2016 General Data Protection Regulation (GDPR) (Regulation 2016/679). The GDPR broadened its scope far beyond the 1995 EU Data Protection Directive (Directive 95/46/EC), widely targeting even foreign firms that collect, use, and maintain personal data of EU citizens. The regulation obliges both controllers (GDPR Article 4(7)) and processors (GDPR Article 4(8)) of personal data to meet certain quality requirements including demonstrable consent of the subject for a specified and legitimate purpose (GDPR Articles 5(1) & 6(1)). Inge Graef succinctly describes the contextual requirements for price discrimination. “…in order to engage in personalized pricing, which is a form of profiling, a controller must have the explicit consent of the data subject involved. Once the controller has obtained consent of the data subject and has met the data quality requirements, it is free to engage in personalized pricing under data protection law” (2018, p. 551).
Proposition 3
Data privacy doctrine is a legal constraint considered by firms that deploy algorithmic pricing models.
Ethical considerations: conceptual foundations
In a world increasingly observed by a triangulation of biometric surveillance, embedded sensors, and dynamic decision-making algorithms, it is unsurprising that academic discourse spars over the degree to which such panoptic technologies pose a moral hazard risking an inherent loss of freedom (Gandy 1993; Reiman 1995). The specter of Bentham’s Panopticon (2015 [1843]) as reference to a prison supervised by an insidious all-knowing overseer seems oddly applicable to our time, in a way reminiscent of Foucault (1979) and Orwell (2017 [1949]). As it relates to price discrimination, fairness is an ethical framework often considered. A conceptual framework capturing the perceptions of price fairness is nicely outlined by Xia et al. (2004), concluding that personalized pricing approaches may diminish trust if unmitigated by certain factors like product differentiation. A multidimensional view of trust by Garabino and Lee supports this assertion, concluding that such pricing schemes reduce the trust consumers perceive in the benevolence of the firm (2003). Yet, what constitutes “fairness” is subjectively defined, and firms have an incentive to reframe economic exchanges (e.g., transforming personalized pricing into a norm) in such a way to make them seem more fair (Kahneman et al. 1986).
Other ethical considerations addressed by the literature include the degree to which deception (or perceived deception) creates individual harm. Analogously, information asymmetry and negative externalities caused by price discrimination can result in widespread social injustice. Although now over a decade old, a research study conducted at the University of Pennsylvania in 2005 revealed a majority of US adults recognize their online behavior is tracked, but 65% reasoned that they know what is required to prevent exploitation of this data. Upon taking a short true/false assessment, no statistical difference was noted between those expressing or lacking such confidence—and the overall scores were abysmally poor, averaging 63–72% incorrect on questions relating to legal rights and privacy policy (Turow et al. 2005). Given this wide perceptual schism, it is unsurprising that concerns of deception, fairness, and social justice have attracted widespread attention.
Deception as an ethical consideration
US legal doctrine articulates that a sellers’ non-disclosure of a fact (e.g., that a lower price may exist via alternative channels) is only equivalent to an assertion that the fact does not exist in severely limited cases, notably that the fact “would correct a mistake of the other party as to a basic assumption on which that party is making the contract” (Restatement (Second) of Contracts § 161(b), 1981). As elaborated by Miller (2014), unless a seller has publically advertised a price, a buyer is rarely positioned to claim that uniformity of prices represented the grounding assumption upon which they entered into the transaction.
The rise of algorithmic pricing to exploit individual preferences and behavioral discrimination increases the magnitude of information asymmetry, and to the extent that pricing is personalized, minimizes the benefit consumers may receive from price comparison websites (Kannan and Kopalle 2001). Danna and Gandy Jr. (2002) illuminate the process of data mining to demonstrate how algorithmic decision-making may segment high-value from low-value customers, allowing firms to better maximize the difference between customer acquisition cost and lifetime value. Yet “techniques that create and exploit consumers’ high search costs undermine the ability to compare prices and can lower overall welfare and harm consumers” (Miller 2014, p. 80) leading some to recommend that broadened disclosure laws are necessary to inform consumers when individual data profiles are mined to personalize pricing. In particular, Solove and Hoofnagle (2006) conceptualize a “Model Regime” to mitigate gaps and limitations in existing legal doctrine, ultimately arguing for widespread expansion of the Fair Credit Reporting Act (15 U.S.C. § 1681 et seq.) to apply whenever data brokers use personal information—not altogether dissimilar from the European Union’s GDPR requirements.
Some seek to address discriminatory pricing within the framework of the Uniform Commercial Code’s unconscionability provision (U.C.C. § 2-302), serving as a roundabout alternative to ill-effective antitrust regulation (e.g., the Robinson-Patman Act) by labeling price discrimination as an egregiously deceptive trade practice (Darr 1994; Klock 2002). Yet the practicality of such application is questionable, yielding to the freedom to contract in which multiple parties seek to maximize their utility within the transaction. Klock concurs with this limitation, yet points to seemingly applicable state-level statutes (Ala. Code § 8-31 et seq.; Tex. Bus. & Com. Code § 17 et seq.) that could prohibit unconscionable discriminatory pricing actions. Aside from questionable applicability (e.g., the Alabama law applies only during a state of emergency), the widespread practice of price discrimination among online merchants across interstate boundaries makes the application of state statute unlikely.
Proposition 4
Deception is an ethical framework considered by firms that deploy algorithmic pricing models.
Fairness as an ethical consideration
Price fairness in a sales transaction has been defined in literature as “the extent to which sacrifice and benefit are commensurate for each party involved” (Bolton et al. 2003, p. 475) premised on a principle of dual entitlement stipulating that buyers are entitled to the terms of a reference transaction and sellers are entitled to a reference profit (Kimes 1994). To determine the perceived fairness of the reference profit, buyers often rely upon past prices (Briesch et al. 1997; Jacobson and Obermiller 1990), in-store comparative prices (Rajendran and Tellis 1994), and competitive prices (Kahneman et al. 1986). Yet, it has been demonstrated how consumers underestimate inflation, ignore in-store comparative cost categories beyond cost of goods sold, and attribute competitive price differences to profit rather than cost (Bolton et al. 2003). Regardless of the attribution, consumers are far less likely to make a purchase when they perceive the price as both unfair and personally unfavorable (Richards et al. 2016).
To the extent that different prices result from personalized or dynamic pricing, Garbarino and Lee (2003) empirically demonstrate the loss of benevolent trust in the firm on behalf of customers. Fisher (2007) and Cox (2001), for example, illustrate the exceptional wrath incurred by Amazon and Microsoft when loyal trusting customers learned of discriminatory schemes offering new buyers most favored pricing opportunities. Such recognition by technology-savvy customers drives their adoption of watchdog tools (Mikians et al. 2012) and false identities (Acquisti and Varian 2005) to seek the lowest possible prices. Trust is thereby replaced with attentive suspicion and preemptive measures to avoid discrimination.
Proposition 5
Fairness is an ethical framework considered by firms that deploy algorithmic pricing models.
Social justice as an ethical consideration
Walzer (1983) argues that distributive justice is a practice of allocating goods appropriately given a complex equality. An injustice occurs when that complex equality is provoked by a tyrannical force that unhinges the pluralist trinity of free exchange, desert (being deserving), and need. Miller links the concept of social justice to price discrimination: “[W]e are not talking about the distribution of products or services as such. Rather, we are discussing the distribution of price advantages and disadvantages—the opportunities to buy the same product at a discount or exclusion from these opportunities. Price discrimination challenges the idea of free market exchange as a just distributional criterion for goods in the market sphere because it distorts the price system” (Miller 2014, p. 91).
On the one hand, most online users freely provide private information through credit card transactions, social media outlets, online services, and loyalty card patronage, yet the inequity between consumer costs and firm benefits represents a market inefficiency imposing considerable negative externalities on the marketplace (Baumer et al. 2003; Bergelson 2003). Those consumers identified by a firm as “low value” may give private information more frequently, but find themselves at a relative disadvantage to “high-value” customers who contribute very little. On the other hand, if volunteering private information yields a significant benefit, those withholding it encounter the issue of adverse selection wherein negative consequences accrue to non-participants. The issue broadens when fueled by vast quantities of information available without voluntary disclosure—constructed from opaque integrated information systems that facilitate the unjust allocation of price advantages.
Proposition 6
Social justice is an ethical framework considered by firms that deploy algorithmic pricing models.
Discussion
Aside from individual negotiation as a tool for personalized pricing, loyalty card programs are considered an early form of using IT systems to provide real-time individualized point-of-sale promotions (Henschen 2011). These early efforts expedited big data’s foray into the retail sector, but limited applicability to future purchases. With the proliferation of big data analytics and artificial intelligence, companies shifted their technological approach to exploit consumers’ preferences shared within the online environment, providing fertile opportunities to offer mass customized offerings with personalized pricing (Ghose and Huang 2009). Current technology extends into the former realm of science fiction where in-store video monitors use facial recognition (McDonald 2015) and Wi-Fi triangulation maps foot traffic throughout a venue (Kopytoff 2014). The data are tracked, mined, aggregated at an individual customer level, and used to optimize behavioral advertisements and personalize pricing (Ezrachi and Stucke 2016b).
Aside from the retail context, broad dissemination of consumer data increases individual exposure to potentially predatory pricing practices that are currently unregulated (most notably within the United States). Genetic test-kit provider, 23andMe, is particularly notable for sharing its accumulated data with pharmaceutical partners Genentech (Herper 2015) and GlaxoSmithKline (Roland 2019). A reported 80% of customers explicitly consent to sharing their private (albeit anonymized) data for research purposes. Studies demonstrate how individuals learning they carry genetic markers indicative of high risk for certain diseases purchase long-term care insurance to mitigate the potential risk (Taylor et al. 2010; Zick et al. 2005). The resulting information asymmetry between insurance carriers and their customers could impact pricing of insurance premiums. Erlich and Narayanan (2014) demonstrate the bi-directionality of information asymmetry by illustrating the relative ease in which a technically sophisticated adversary can exploit certain techniques using quasi-identifiers or metadata to trace individual identity. While in the United States, the Genetic Information Nondiscrimination Act (a.k.a. GINA, Pub. L. No. 110-233) prohibits the use of genetic information when underwriting health insurance premiums, no federal antidiscrimination protection exists for life or long-term care insurance. Klitzman (2018) proposes some possible solutions, but acknowledges that each results in an uncertainty underlying the price level.
The dynamic element
Implementation of a dynamic element in conjunction with targeted pricing in competitive industries can yield additional profit (Chen and Zhang 2009), but also lead to potential peril for companies, as consumers (and governments) are wary of the issue of “fairness” in relation to price discrimination (UK Competition and Markets Authority 2015). Rayna et al. describe how consumer willingness to disclose information can provide for the design of personalized pricing that is economically advantageous to both the firm and customer (2015), but in many cases, consumers lack a robust awareness of whether, when, and how their information is being used to set prices (Consumers Council of Canada 2017). A thought-provoking suggestion is introduced by Ezrachi and Stucke whereby the delineation between personalized and dynamic pricing will disappear as firms use behavioral discrimination to accelerate information asymmetry and increase consumers’ search costs for a “true” market price (2016a).
Researchers at Boston Consulting Group (BCG) (2019) tout the inevitability of “progressive pricing,” a variant of dynamic pricing in which value is shared with rather than extracted from [customers]” (p. 8). Progressive pricing builds upon price optimization and yield management, using algorithmic models to capture additional consumer surplus both through raising prices for those with a higher willingness to pay and lowering prices to increase penetration toward those previously unserved market segments. This strategy of “optimizing a continuum of prices” (p. 3) is gaining traction to expand markets and increase profits. A large retail bank uses the approach to personalize interest rates on checking account deposits by monitoring customers’ cash transfers to secondary savings banks and deploying algorithms as a predictive barometer of the interest rate necessary to prevent such withdrawals. Ridesharing services are renowned for surge pricing, pool discounts, and leveraging algorithms to offer nudges that target specific customers’ sensitivities to promotional pricing incentives (Ke 2018). BCG claims that an imperative of progressive pricing is that “firms must redefine fairness and make the case that the criteria that drive price differences are fair …. [o]ne example is supply and demand” (2019, p. 8). Yet redefining fairness can be difficult when an algorithm mistakes misfortune for missed opportunity. During 2 days, November 8–9, 2018, following the initial breakout of California’s deadliest wildfire, online price trackers noted that the Amazon.com direct (not third party) prices for a First Alert fire extinguisher and ResQLadder fire escape ladder increased by 18.3% and 22%, respectively. A spokesperson for Amazon.com dismissed the possibility of surge pricing, yet no price fluctuations were reported for similar products listed on Amazon.com.uk (Ke 2018). BCG reports that “progressive pricing is inevitable …. to any individual customer or segment of one who opts into share personal real-time data” (pp. 6–7), which underscores the importance of examining the degree of congruence between consumer perceptions of ethical or legal pricing practices with the algorithmic decision-making processes deployed by firms to make pricing decisions.
Algorithmic development
The evolution from revenue management in targeted industries (e.g., airlines, car rentals, and so on) to scenarios where firms simultaneously price abundant varieties of goods and services requires a cost-effective AI-based model incorporating flexible demand modeling and a revenue optimization algorithm (Shakya et al. 2010). Given the preponderance of personalized pricing in online marketplaces, revenue optimization further requires consideration of supply availability (in nearby warehouses) and fulfillment costs to the customer’s doorstep (Lei et al. 2018). The ubiquity of embedding sensors into IoT devices is driving the collection of massive data relating to consumer behavior (Manyika et al. 2011), creating a third-party market for data aggregation and opportunities for firms to maintain a competitive advantage through the evolution from ‘adaptive’ to ‘learning’ pricing algorithms that exploit real-time active improvements to optimize decision-making (Ezrachi and Stucke 2016b).
The transition to machine learning as the basis for algorithmic modeling requires a substantial increase in available data for training, validation, and testing (Heath 2018). Yet raw data used for training reflect human bias—whether explicit or by omission. A Google image search for “parents” yields photos of predominantly heterosexual couples, and a similar search for “nurse” results in a preponderance of women (Steimer 2018). Etlinger (2017) describes how algorithmic bias seeps into popular press by presenting several sensationalist news headlines from September 2017: “Computers can tell if you’re gay from photos,” “Google allowed advertisers to target people searching racist photos,” and “Amazon suggests users purchase dangerous item combinations” (p. 8). A McKinsey Quarterly report (2019) describes five key pain points that businesses should address to mitigate AI-based risks, emphasizing a distinction between factors that enable AI (data, technology, and security) and those inherent to the execution of AI (algorithmic models and human–computer interaction). Control mechanisms remain nascent, but center upon structured identification of the most critical risks, execution of broad enterprise-level governance, and reinforcement of specific protocols within critical infrastructure. Admittedly, incorporation of controls can decrease the predictive power of algorithmic models, but concurrently increases transparency to improve confidence in human judgement.
Reactions from the public sector
European governmental bodies are leading efforts to regulate privacy rights and ensure well-functioning markets. Whereas it has been asserted that the European Union’s General Data Protection Regulation (GDPR) equally applies to personalized pricing (Zuiderveen Borgesius and Poort 2017), precedent has yet been established at the Court of Justice of the European Union. The Consumers Council of Canada has outlined a comprehensive Consumer Protection Framework, advocating consumer education as a mitigation factor against dynamic pricing, but also acknowledges that consumers have false overconfidence and a constrained ability to adequately convey their privacy needs (2017). The USA has perhaps the least well-defined official articulation in response to the increased prevalence of personalized pricing, inferring that while monitoring the application of big data is necessary, most issues of competition and consumer privacy abuse can be managed through existing legal frameworks and regulatory policies (Executive Office of the President 2015).
As public-sector regulations begin emerging to address legal and ethical issues relating to data privacy, scholars debate the extent to which AI as a broader concept should fit into various frameworks of oversight. Treleaven et al. (2019) propose a multidimensional framework consisting of “when-to regulation, where-to jurisdiction, and how-to technology” (pp. 32–33). They further advocate for technology-oriented solutions that include algorithm testing (verification and cross-validation), certification (comprehensive audit), and circuit breakers (fail-safe mechanisms deployed during unexpected system difficulties). The European Commission (2019) has established an independent High-Level Expert Group on Artificial Intelligence (AI HLEG) to support the implementation of a vision enabling Europe to emerge as the world leader in ethical AI and related technologies. Central to this vision is “trustworthy AI” (p. 5) which must be lawful, ethical, and robust (in both the technical context and social sense in which AI shall not cause unintentional harm). The emerging field of explainable AI (XAI) may perhaps hold significant value by eliminating the black box stigma-associated algorithmic modeling. However, the nature of machine learning (more specifically, neural network and deep learning approaches) makes interpretability a significant challenge.
Conclusion: a research challenge
The pricing function grows increasingly complex with algorithmic models utilizing personal data to make sophisticated predictions to optimize price levels. Made in conjunction with human judgement and reasonable controls that account for ethical considerations and legal constraints, artificial intelligence at the heart of decision-making can provide win–win outcomes for both organizations and consumers. Without relevant oversight, as denoted by countless dystopian headlines, algorithms are subject to bias, discriminatory predictions, third-party tampering, and autonomous collusion. Our conceptual model, informed by extant literature and practitioner experience, seeks to build a foundation from which subsequent qualitative research can compare consumers’ ethical and legal schemata when confronting algorithmic personalized pricing with the organizational schema considered by firms adopting such practices.
Accordingly, we conclude our discussion by outlining a qualitative study that uses our preliminary conceptual model to address our core research questions.
Proposed study
To begin examining these crucial issues, we propose a two-phase qualitative study using a hermeneutic phenomenological analysis method to determine what constraints, considerations, and factors influence the decision schema in the context of using algorithmic pricing models. Phenomenological analysis is an appropriate method for the researcher to describe what is real through the direct lived experience and essence of participants’ perceptions (Merleau-Ponty 1962). Gadamer (1976) elaborates that hermeneutic reflection requires that researcher prejudgments and preunderstanding remain “constantly at stake” (p. 38) so that prejudices may be set aside based on “what the text says to us” (p. xviii).
The first phase of this study will use a focus group technique (Krueger 1994) to examine the attitudes and perceptions of retail consumers toward the ethical considerations of deception, fairness, and social justice in pricing. The second phase of this study will couple the legal constraints hypothesized by the conceptual model to those emergent ethical considerations from the consumer focus groups. A series of semi-structured interviews will illustrate the lived experiences of senior pricing managers and top executives who make price-setting or price-changing decisions. Transcripts from the interviews will be coded (through open, axial, and selective phases) to elicit common themes and categories that will serve as validation or refutation of our hypotheses. The overall objective of this research effort is to reveal whether firms avoid potential unethical or illegal behavioral targeting through a manifested process within their pricing function.
Implications for future research
Without speculating toward the far future, there are some natural extensions of algorithmic pricing techniques that warrant further research. As noted by Ezrachi and Stucke, the appeal for ex-ante monitoring of algorithm design may become feasible as the proficiency of auditors develops toward a higher degree of sophistication (2016b). A further consideration could acknowledge the use of countervailing technologies to disrupt the cycle of algorithmic self-learning or negate its impact altogether.
Many questions deserve consideration following the implementation of GDPR. It is possible that consumers’ behaviors toward reviewing privacy policies have changed, or that third parties have utilized transparency disclosures to illuminate the prevalence and salience of personalized pricing algorithms. There also remains a dearth of literature on the potential discriminatory impacts of personalized pricing—particularly in combination with big data analytics, AI, and machine learning algorithms. Finally, recognizing the growing complexity and creeping normality of personalized pricing, it seems that further consideration of consumer attitudes toward discriminatory pricing techniques is warranted.
References
Abele, K. 2016. Disneyland Paris: kommission begrüßt Änderung der preispolitik. https://ec.europa.eu/germany/news/disneyland-paris-kommission-begr%C3%BC%C3%9Ft-%C3%A4nderung-der-preispolitik_de.
Acquisti, A. 2004. Privacy in electronic commerce and the economics of immediate gratification. Paper presented at the 5th ACM conference on electronic commerce, New York, NY. https://doi.org/10.1145/988772.988777.
Acquisti, A., L. Brandimarte, and G. Loewenstein. 2015. Privacy and human behavior in the age of information. Science 347 (6221): 509–514.
Acquisti, A., A. Friedman, and R. Telang. 2006. Is there a cost to privacy breaches? An event study. Paper presented at the international conference on information systems, Milwaukee, WI.
Acquisti, A., L.K. John, and G. Loewenstein. 2013. What is privacy worth? The Journal of Legal Studies 42 (2): 249–274.
Acquisti, A., C. Taylor, and L. Wagman. 2016. The economics of privacy. Journal of Economic Literature 54 (2): 442–492.
Acquisti, A., and H.R. Varian. 2005. Conditioning prices on purchase history. Marketing Science 24 (3): 367–381.
Alabama Unconscionable Pricing Act. Ala. Code § 8-31 et seq.
Antitrust Modernization Commission. 2007. Report and recommendations. https://govinfo.library.unt.edu/amc/report_recommendation/amc_final_report.pdf.
Baumer, D.L., J.B. Earp, and P.S. Evers. 2003. Tit for tat in cyberspace: consumer and website responses to anarchy in the market for personal information. North Carolina Journal of Law & Technology 4 (2): 217–274.
Bentham, J. 2015. Panopticon, constitution, colonies, codification. In The works of Jeremy Bentham, ed. J. Bowring, vol. 4.
Berendt, B., O. Günther, and S. Spiekermann. 2005. Privacy in e-commerce: Stated preferences vs. actual behavior. Communications of the ACM 48 (4): 101–106.
Bergelson, V. 2003. It’s personal, but is it mine? Toward property rights in personal information. UC Davis Law Review 37 (2): 379–452.
Bigwood, R. 2003. Exploitative contracts. Oxford: Oxford University Press.
Blair, R.D., and C. DePasquale. 2014. “Antitrust’s least glorious hour”: The Robinson-Patman Act. The Journal of Law & Economics 57 (S3): S201–S215.
Bolton, L.E., L. Warlop, and J.W. Alba. 2003. Consumer perceptions of price (un)fairness. Journal of Consumer Research 29 (4): 474–491.
Borden, N.H. 1964. The concept of the marketing mix. Journal of Advertising Research 4 (2): 2–7.
Bork, R.H. 1978. The antitrust paradox: A policy at war with itself. New York: Basic Books.
Bostrom, N. 2014. Superintelligence: Paths, dangers, strategies. Oxford: Oxford University Press.
Briesch, R.A., L. Krishnamurthi, T. Mazumdar, and S.P. Raj. 1997. A comparative analysis of reference price models. Journal of Consumer Research 24 (2): 202–214.
Brown, B. 2001. Studying the internet experience (HPL-2001-49). https://www.hpl.hp.com/techreports/2001/HPL-2001-49.pdf.
Brunk, K.H. 2012. Un/ethical company and brand perceptions: Conceptualising and operationalising consumer meaning. Journal of Business Ethics 111 (4): 551–565. https://doi.org/10.1007/S10551-012-1339-X.
Bulmash, H. 2012. An empirical analysis of secondary line price discrimination motivations. Journal of Competition Law & Economics 8 (2): 361–397.
Calvano, E., G. Calzolari, V. Denicolò, and S. Pastorello. 2019. Algorithmic pricing what implications for competition policy? Review of Industrial Organization. 55: 155–171.
Campbell, K., L.A. Gordon, M.P. Loeb, and L. Zhou. 2003. The economic cost of publicly announced information security breaches: Empirical evidence from the stock market. Journal of Computer Security 11 (3): 431–448.
Cavusoglu, H., B. Mishra, and S. Raghunathan. 2004. The effect of internet security breach announcements on market value: Capital market reactions for breached firms and internet security developers. International Journal of Electronic Commerce 9 (1): 69–104.
Charmaz, K. 2014. Constructing grounded theory, 2nd ed. Thousand Oaks: SAGE Publications.
Cheatham, B., Javanmardian, K., and Samandari, H. 2019. Confronting the risks of artificial intelligence. McKinsey Quarterly (April). https://www.mckinsey.com/~/media/McKinsey/Business%20Functions/McKinsey%20Analytics/Our%20Insights/Confronting%20the%20risks%20of%20artificial%20intelligence/Confronting-the-risks-of-artificial-intelligence-vF.ashx.
Chen, Y., and Z.J. Zhang. 2009. Dynamic targeted pricing with strategic consumers. International Journal of Industrial Organization 27 (1): 43–50.
Civil Rights Act of 1964. Pub. L. No. 88-352, 78 Stat. 241.
Consumers Council of Canada. 2017. Dynamic pricing—Can consumers achieve the benefits they expect. https://www.consumerscouncil.com/site/consumers_council_of_canada/assets/pdf/809323_ccc_dynamic_pricing_final_report_web.pdf.
Corbin, J., and A. Strauss. 2015. Basics of qualitative research: Techniques and procedures for developing grounded theory, 4th ed. London: SAGE Publications.
Cox, J.L. 2001. Can differential prices be fair? Journal of Product & Brand Management 10 (5): 264–275.
Cyert, R.M., and J.G. March. 1992. A behavioral theory of the firm, 2nd ed. Malden: Blackwell Publishers.
Danna, A., and O.H. Gandy Jr. 2002. All that glitters is not gold: Digging beneath the surface of data mining. Journal of Business Ethics 40 (4): 373–386.
Darr, F.P. 1994. Unconscionability and price fairness. Houston Law Journal 30 (5): 1819–1861.
Deloitte Consulting, & Salesforce. 2018. Consumer experience in the retail renaissance. https://c1.sfdcstatic.com/content/dam/web/en_us/www/documents/e-books/learn/consumer-experience-in-the-retail-renaissance.pdf.
Dutta, S., M.J. Zbaracki, and M. Bergen. 2003. Pricing process as a capability: A resource-based perspective. Strategic Management Journal 24 (7): 615–630.
El Hussein, M.T., A. Kennedy, and B. Oliver. 2017. Grounded theory and the conundrum of literature review: Framework for novice researchers. The Qualitative Report 22 (4): 1198–1210.
Erlich, Y., and A. Narayanan. 2014. Routes for breaching and protecting genetic privacy. Nature Reviews Genetics 15 (6): 409–421. https://doi.org/10.1038/nrg3723.
Etlinger, S. 2017. The customer experience of AI: Five principles to foster engagement, innovation and trust.
European Commission. 2016. Mystery shopping survey on territorial restrictions and geo-blocking in the European digital single market. https://ec.europa.eu/info/sites/info/files/geoblocking-final-report_en.pdf.
European Commission. 2019. Ethics guidelines for trustworthy AI. https://ec.europa.eu/digital-single-market/en/news/ethics-guidelines-trustworthy-ai.
European Union Data Protection Directive. Directive 95/46/EC.
European Union General Data Protection Regulation. Regulation 2016/679.
European Union Regulation on Unjustified Geo-blocking. Regulation 2018/302.
European Union Services Directive. Directive 2006/123/EC.
Executive Office of the President. 2015. Big data and differential pricing. https://obamawhitehouse.archives.gov/sites/default/files/whitehouse_files/docs/Big_Data_Report_Nonembargo_v2.pdf.
Ezrachi, A., and M.E. Stucke. 2016a. The rise of behavioural discrimination. European Competition Law Review 37 (12): 484–491.
Ezrachi, A., and M.E. Stucke. 2016b. Virtual competition: The promise and perils of the algorithm-driven economy. Cambridge: Harvard University Press.
Fair Credit Reporting Act. 15 U.S.C. § 1681 et seq.
Federal Trade Commission. 2016. Big data: A tool for inclusion or exclusion? Understanding the issues. https://www.ftc.gov/system/files/documents/reports/big-data-tool-inclusion-or-exclusion-understanding-issues/160106big-data-rpt.pdf.
Fisher III, W.W. 2007. When should we permit differential pricing of information? UCLA Law Review 55 (1): 1–38.
Foucault, M. 1979. Discipline and punish: The birth of the prison. New York: Vintage.
Friedman, M. 1978. The role of government in a free society. Milton Friedman Speaks. Stanford, CA: Stanford University.
Friedman, M. 2012. Capitalism and freedom, 40th anniversary ed. Chicago: University of Chicago Press.
Furnas, A. 2012. Everything you wanted to know about data mining but were afraid to ask. https://www.theatlantic.com/technology/archive/2012/04/everything-you-wanted-to-know-about-data-mining-but-were-afraid-to-ask/255388/.
Gadamer, H.-G. 1976. Philosophical hermeneutics, ed. D.E. Linge. Berkeley, CA: University of California Press.
Gal, M.S. 2019. Illegal pricing algorithms. Communications of the ACM 62 (1): 18–20. https://doi.org/10.1145/3292515.
Gandy Jr., O.H. 1993. The panoptic sort: A political economy of personal information. Boulder: Westview Press.
Garbarino, E., and O.F. Lee. 2003. Dynamic pricing in internet retail: Effects on consumer trust. Psychology & Marketing 20 (6): 495–513.
Ghose, A., and K.-W. Huang. 2009. Personalized pricing and quality customization. Journal of Economics & Management Strategy 18 (4): 1095–1135.
GINA (a.k.a. Genetic Information Nondiscrimination Act of 2008). Pub. L. No. 110-233.
Glaser, B.G., and A.L. Strauss. 1999. The discovery of grounded theory: Strategies for qualitative research. New York: Transaction Publishers.
Graef, I. 2018. Algorithms and fairness: What role for competition law in targeting price discrimination towards end consumers? Columbia Journal of European Law 24 (3): 541–560.
Hayek, F. A. 2011. The constitution of liberty (R. Hamowy Ed. The definitive ed.). Chicago, IL: University of Chicago Press.
Heath, N. 2018. Four ways machine learning is evolving, according to Facebook’s AI engineering chief. https://www.techrepublic.com/article/four-ways-machine-learning-is-evolving-according-to-facebooks-ai-engineering-chief/.
Henschen, D. 2011. Catalina marketing aims for the cutting edge of ‘big data’. https://www.informationweek.com/big-data/big-data-analytics/catalina-marketing-aims-for-the-cutting-edge-of-big-data/d/d-id/1099971?print=yes.
Herper, M. 2015. Surprise! With $60 million Genentech deal, 23andMe has a business plan. https://www.forbes.com/sites/matthewherper/2015/01/06/surprise-with-60-million-genentech-deal-23andme-has-a-business-plan/.
Hobbes, T. 1982. Leviathan, 4th ed. London: Penguin Classics.
Identity Theft and Assumption Deterrence Act of 1998. Pub. L. No. 105-318, 112 Stat. 3007, codified at 18 U.S.C. § 1028.
Izaret, J.-M., and J. Schürmann. 2019. Why progressive pricing is becoming a competitive necessity. https://www.bcg.com/publications/2019/why-progressive-pricing-becoming-competitive-necessity.aspx.
Jacobson, R., and C. Obermiller. 1990. The formation of expected future price: A reference price for forward-looking consumers. Journal of Consumer Research 16 (4): 420–432.
James, W. 2016. A pluralistic universe, Reprinted ed. Sydney: Wentworth Press.
Kahneman, D., J.L. Knetsch, and R. Thaler. 1986. Fairness as a constraint on profit seeking: Entitlements in the market. American Economic Review 76 (4): 728–741.
Kang, R., S. Brown, and S. Kiesler. 2013. Why do people seek anonymity on the internet? Informing policy and design. Paper presented at the proceedings of the SIGCHI conference on human factors in computing systems, Paris, France.
Kannan, P.K., and P.K. Kopalle. 2001. Dynamic pricing on the internet: Importance and implications for consumer behavior. International Journal of Electronic Commerce 5 (3): 63–83.
Kaptein, M. 2017. The battle for business ethics: A struggle theory. Journal of Business Ethics 144 (2): 343–361. https://doi.org/10.1007/s10551-015-2780-4.
Ke, W. 2018. Power pricing in the age of AI and analytics. https://www.forbes.com/sites/forbesfinancecouncil/2018/11/02/power-pricing-in-the-age-of-ai-and-analytics/.
Kimes, S.E. 1994. Perceived fairness of yield management. Cornell Hotel and Restaurant Administration Quarterly 35 (1): 22–29. https://doi.org/10.1177/001088049403500102.
Klitzman, R. 2018. Ethics, insurance pricing, genetics, and big data. Pension Research Council of the University of Pennsylvania. https://repository.upenn.edu/prc_papers/7/.
Klock, M. 2002. Unconscionability and price discrimination. Tennessee Law Review 69 (2): 317–383.
Kochelek, D.M. 2009. Data mining and antitrust. Harvard Journal of Law & Technology 22 (2): 515–535.
Kokolakis, S. 2017. Privacy attitudes and privacy behaviour: A review of current research on the privacy paradox phenomenon. Computers & Security 64: 122–134. https://doi.org/10.1016/J.COSE.2015.07.002.
Kopytoff, V. 2014. By sniffing out phones, stores follow visitors. MIT Technology Review 117 (1): 64–65.
Krueger, R.A. 1994. Focus groups: A practical guide for applied research, 2nd ed. Thousand Oaks: SAGE Publications.
Lei, Y., S. Jasin, and A. Sinha. 2018. Joint dynamic pricing and order fulfillment for e-commerce retailers. Manufacturing & Service Operations Management 20 (2): 269–284.
Liozu, S.M., and A. Hinterhuber. 2014. Pricing capabilities: The design, development, and validation of a scale. Management Decision 52 (1): 144–158.
Locke, J. 1980. Second treatise of government. Indianapolis: Hackett Publishing Company.
Manyika, J., M. Chui, B. Brown, J. Bughin, R. Dobbs, C. Roxburgh, and A.H. Byers. 2011. Big data: The next frontier for innovation, competition, and productivity. https://www.mckinsey.com/~/media/McKinsey/Business%20Functions/McKinsey%20Digital/Our%20Insights/Big%20data%20The%20next%20frontier%20for%20innovation/MGI_big_data_full_report.ashx.
March, J.G. 1994. A primer on decision making: How decisions happen. New York: The Free Press.
March, J.G., and H.A. Simon. 1993. Organizations, 2nd ed. Cambridge: Blackwell Publishers.
Massachusetts Post Audit and Oversight Bureau. 1997. Shear discrimination: Bureau finds wide price bias against women at Massachusetts hair salons despite anti-discrimination laws. https://archive.org/details/sheardiscriminat00mass.
Maxwell, J.A. 2013. Qualitative research design: An interactive approach, 3rd ed. Thousand Oaks: SAGE Publications.
Mayer-Schönberger, V., and K. Cukier. 2013. Big data: A revolution that will transform how we live, work, and think. Boston: Houghton Mifflin Harcourt.
McDonald, C. 2015. Almost 30% of retailers use facial recognition technology to track consumers in store. https://www.computerweekly.com/news/4500253499/Almost-30-of-retailers-use-facial-recognition-technology-to-track-consumers-in-store.
Merleau-Ponty, M. 1962. Phenomenology of perception. London: Routledge.
Mikians, J., L. Gyarmati, V. Erramilli, and N. Laoutaris. 2012. Detecting price and search discrimination on the internet. Paper presented at the proceedings of the 11th ACM workshop on hot topics in Networks, Redmond, Washington.
Miller, A.A. 2014. What do we worry about when we worry about price discrimination? The law and ethics of using personal information for pricing. Journal of Technology Law & Policy 19 (1): 41–104.
Mitchell, K. 2012. The next frontier of the pricing profession. In Innovation in pricing: Contemporary theories and best practices, ed. A. Hinterhuber and S.M. Liozu, 403–409. New York: Routledge.
Neal, P.C., W.F. Baxter, R.H. Bork, C.H. Fulda, W.K. Jones, D.G. Lyons, and S.P. Posner. 1968. Report of the White House task force on antitrust policy. Antitrust Law & Economics Review 2 (2): 11–52.
Nissenbaum, H. 2010. Privacy in context: Technology, policy, and the integrity of social life. Stanford: Stanford University Press.
Noble, P.M., and T.S. Gruca. 1999. Industrial pricing: Theory and managerial practice. Marketing Science 18 (3): 435–454.
Norberg, P.A., D.R. Horne, and D.A. Horne. 2007. The privacy paradox: Personal information disclosure intentions versus behaviors. Journal of Consumer Affairs 41 (1): 100–126.
O’Neil, C. 2016. Weapons of math destruction: How big data increases inequality and threatens democracy. New York: Crown Publishing.
Organisation for Economic Co-Operation and Development. 2013. The OECD privacy framework. http://www.oecd.org/sti/ieconomy/oecd_privacy_framework.pdf.
Orwell, G. 2017. Nineteen eighty-four. New York: Houghton Mifflin Harcourt.
Papandropoulos, P. 2007. How should price discrimination be dealt with by competition authorities? Institut de droit de la concurrence. http://ec.europa.eu/dgs/competition/economist/concurrences_03_2007.pdf.
Pasquale, F. 2013. The emperor’s new codes: Reputation and search algorithms in the finance sector. https://governingalgorithms.org/wp-content/uploads/2013/05/2-paper-pasquale.pdf.
Pasquale, F. 2015. The black box society: The secret algorithms that control money and information. Cambridge: Harvard University Press.
Rajendran, K.N., and G.J. Tellis. 1994. Contextual and temporal components of reference price. Journal of Marketing 58 (1): 22–34.
Rao, V.R., and B. Kartono. 2009. Pricing objectives and strategies: A cross-cultural survey. In Handbook of pricing research in marketing, ed. V.R. Rao, 9–36. Northampton: Edward Elgar Publishing Inc.
Rawls, J. 1971. A theory of justice, Original ed. Cambridge: Harvard University Press.
Rayna, T., J. Darlington, and L. Striukova. 2015. Pricing music using personal data: Mutually advantageous first-degree price discrimination. Electronic Markets 25 (2): 139–154.
Reiman, J.H. 1995. Driving to the panopticon: A philosophical exploration of the risks to privacy posed by the highway technology of the future. Santa Clara High Technology Law Journal 11 (1): 27–44.
Restatement (Second) of Contracts. 1981.
Richards, T.J., J. Liaukonyte, and N.A. Streletskaya. 2016. Personalized pricing and price fairness. International Journal of Industrial Organization 44: 138–153. https://doi.org/10.1016/j.ijindorg.2015.11.004.
Roberds, W., and S.L. Schreft. 2009. Data security, privacy and identity theft: The economics behind the policy debates. Federal Reserve Bank of Chicago Economic Perspectives 33 (Q1): 22–30.
Robinson-Patman Act (a.k.a. Anti-Price Discrimination Act of 1936). Pub. L. No. 74-692, 49 Stat. 1526, codified at 15 U.S.C. § 13.
Roland, D. 2019. How drug companies are using your DNA to make new medicine. https://www.wsj.com/articles/23andme-glaxo-mine-dna-data-in-hunt-for-new-drugs-11563879881.
Romanosky, S., R. Telang, and A. Acquisti. 2011. Do data breach disclosure laws reduce identity theft? Journal of Policy Analysis & Management 30 (2): 256–286.
Ross, D. 2002. The right and the good, 2nd ed. Oxford: Oxford University Press.
Rubin, P.H., and T.M. Lenard. 2002. Privacy and the commercial use of personal information. New York: Springer.
Shakya, S., C.M. Chin, and G. Owusu. 2010. An AI-based system for pricing diverse products and services. Knowledge-Based Systems 23 (4): 357–362.
Sherman Act (a.k.a. Sherman Antitrust Act of 1890). 15 U.S.C. §§ 1-7.
Smith, A. 1975. An inquiry into the nature and causes of the wealth of nations. Eds. R.H. Campbell and A.S. Skinner (Glasgow ed.). Oxford, UK: Oxford University Press.
Solove, D.J. 2003. Identity theft, privacy, and the architecture of vulnerability. Hastings Law Journal 54 (4): 1227–1276.
Solove, D.J., and C.J. Hoofnagle. 2006. A model regime of privacy protection. University of Illinois Law Review 2006 (2): 357–404.
Stebbins, R.A. 2001. Exploratory research in the social sciences, vol. 48. Thousand Oaks: Sage Publications.
Steimer, S. 2018. Your AI’s ethical lapses could be causing CX disasters. https://medium.com/ama-marketing-news/your-ais-ethical-lapses-could-be-causing-cx-disasters-8bb06c315c26.
Taylor, D.H., R.M. Cook-Deegan, S. Hiraki, J.S. Roberts, D.G. Blazer, and R.C. Green. 2010. Genetic testing For Alzheimer’s and long-term care insurance. Health Affairs 29 (1): 102–108. https://doi.org/10.1377/hlthaff.2009.0525.
Texas Deceptive Trade Practices Act. Tex. Bus. & Com. Code § 17 et seq.
Treleaven, P., J. Barnett, and A. Koshiyama. 2019. Algorithms: Law and regulation. Computer 52 (2): 32–40. https://doi.org/10.1109/MC.2018.2888774.
Turow, J. 2006. Niche envy: Marketing discrimination in the digital age. Cambridge: MIT Press.
Turow, J. 2017. The aisles have eyes: How retailers track your shopping, strip your privacy, and define your power. New Haven: Yale University Press.
Turow, J., L. Feldman, and K. Meltzer. 2005. Open to exploitation: America’s shoppers online and offline. https://repository.upenn.edu/cgi/viewcontent.cgi?referer=&httpsredir=1&article=1035&context=asc_papers.
Turow, J., J. King, C.J. Hoofnatle, A. Bleakley, and M. Hennessy. 2009. Americans reject tailored advertising and three activities that enable it. Annenberg School of Communication, University of Pennsylvania. https://repository.upenn.edu/cgi/viewcontent.cgi?referer=&httpsredir=1&article=1138&context=asc_papers.
U.K. Competition and Markets Authority. 2015. The commercial use of consumer data. London. https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/435817/The_commercial_use_of_consumer_data.pdf.
U.S. v. David Topkins, No. CR 15-00201 (U.S. District Court, Northern District of California 2015).
Uniform Commercial Code; Unconscionable contract or clause. U.C.C. § 2-302.
United States Department of Justice. 2018. Antitrust division manual. Washington, DC. https://www.justice.gov/atr/file/761166/download.
Unrah Civil Rights Act. Cal. Civ. Code, § 51.
Walzer, M. 1983. Spheres of justice: A defense of pluralism and equality. New York: Basic Books.
Xia, L., K.B. Monroe, and J.L. Cox. 2004. The price is unfair! A conceptual framework of price fairness perceptions. Journal of Marketing 68 (4): 1–15.
Zick, C.D., C.J. Mathews, J.S. Roberts, R. Cook-Deegan, R.J. Pokorski, and R.C. Green. 2005. Genetic testing for Alzheimer’s disease and its impact on insurance purchasing behavior. Health Affairs 24 (2): 483–490. https://doi.org/10.1377/hlthaff.24.2.483.
Zuiderveen Borgesius, F., and J. Poort. 2017. Online price discrimination and EU data privacy law. Journal of Consumer Policy 40 (3): 347–366.
Acknowledgements
The authors thank the Guest Editorial team and anonymous referees for their comments, suggestions, and insight that strongly improved this paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gerlick, J.A., Liozu, S.M. Ethical and legal considerations of artificial intelligence and algorithmic decision-making in personalized pricing. J Revenue Pricing Manag 19, 85–98 (2020). https://doi.org/10.1057/s41272-019-00225-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1057/s41272-019-00225-2