
Abstract
We consider the problem of finding common behavioral patterns among travelers in an airline network through the process of clustering. Travelers can be characterized at relational or transactional level. In this article, we focus on the transactional level characterization; our unit of analysis is a single trip, rather than a customer relationship comprising multiple trips. We begin by characterizing a trip in terms of a number of features that pertain to the booking and travel behavior. Trips thus characterized are then grouped using an ensemble clustering algorithm that aims to find stable clusters as well as discover subgroup structures within groups. A multidimensional analysis of trips based on these groupings leads us to discover non-trivial patterns in traveler behaviour that can then be exploited for better revenue management.










Similar content being viewed by others



Notes
Please note that the word segment is also used in the context of a flight segment in the airline domain; the meaning implied will become clear from the context of its usage in this article.
Since the groups discovered by the clustering algorithm are the segments we wish to find, the words cluster, segment and group can be used interchangeably in the context of this discussion.
References
Bodea, T. and Ferguson, M. (2014) Segmentation, Revenue Management and Pricing Analytics. New York, USA: Routledge.
Bottou, L. and Bengio, Y. (1995) Convergence properties of the k-means algorithm. In: G. Tesauro and D.S. Touretzky (eds.) Advances in Neural Information Processing Systems. Denver, Colorado, USA: MIT Press.
Fred, A. and Jain, A.K. (2002) Evidence accumulation clustering based on the K-means algorithm. In: T. Caelli, A. Amin, R.P.W. Duin, M. Kamel and D. de Ridder (eds.) Proceedings of the International Workshops on Structural and Syntactic Pattern Recognition. Windsor, Canada: Springer-Verlag.
Huang, Z. (1998) Extensions to the k-means algorithm for clustering large datasets with categorical values. Data Mining and Knowledge Discovery 2(3): 283–304.
Jain, A.K., Murthy, M.N. and Flynn, P.N. (1999) Data clustering: A review. ACM Computing Surveys 31(3): 264–323.
Khan, S.S. and Kant, S. (2007) Computation of initial modes for K-modes clustering algorithm using evidence accumulation. In: R. Sangal, H. Mehta and R.K. Bagga (eds.) Proceedings of the 20th international joint conference on Artifical intelligence. Hyderabad, India: Morgan Kaufmann Publishers Inc.
Leick, R. (2007) Building Airline Passenger Loyalty Through an Understanding of Customer Value: A Relationship Segmentation of Airline Passengers. Ph.D. thesis, Cranfield, UK: Cranfield University.
Liu, B., Xia, Y. and Yu, P.S. (2000) Clustering via decision tree construction. In: A. Agah, J. Callan, E. Rundensteiner and S. Gauch (eds.) Conference on Information & Knowledge Management. McLean, VA, USA: ACM.
Maulik, U. and Bandyopadhyay, S. (2002) Performance evaluation of some clustering algorithms and validity indices. IEEE Transactions on Pattern Analysis And Machine Intelligence 24(12): 1650–1654.
Ramakrishnan, J., Sundararajan, R. and Singh, P. (2009) Behavioural segmentation of credit card customers. In: 1st IIMA International Conference on Advanced Data Analysis, Business Analytics and Intelligence. Ahmedabad, India: IIM.
Ratliff, R. and Gallego, G. (2013) Estimating sales and profitability impacts of airline branded-fares product design and pricing decisions using customer choice models. Journal of Revenue and Pricing Management 12(6): 509–523.
Sculley, D. (2010) Web-scale k-means clustering. In: M. Rappa and P. Jones (eds.) Proceedings of the World Wide Web Conference (WWW). Raleigh, NC, USA: ACM.
Shebalov, S. (2014) Customer segmentation: Revisiting customer centricity for better analysis. Ascend (4).
Teichert, T., Shehu, E. and von Wartburg, I. (2008) Customer segmentation revisited: The case of the airline industry. Transportation Research Part A: Policy and Practice 42(1): 227–242.
Vinod, B. (2008) The continuing evolution: Customer-centric revenue management. Journal of Revenue and Pricing Management 7(1): 27–39.
Westermann, D. (2006) (Realtime) dynamic pricing in an integrated revenue management and pricing environment: An approach to handling undifferentiated fare structures in low-fare markets. Journal of Revenue & Pricing Management 4(4): 389–405.
Westermann, D. (2013) The potential impact of IATAs new distribution capability (NDC) on revenue management and pricing. Journal of Revenue and Pricing Management 12(6): 565–568.
Yankelovich, D. and Meer, D. (2006) Rediscovering market segmentation. Harvard Business Review 84(2): 122–131.
Acknowledgements
This work presented in this article was done when Aditya Kothari was employed with Sabre Airline Solutions.
Author information
Authors and Affiliations
Corresponding author
Additional information
1currently leads the Vehicle Intelligence team at Ather Energy. At the time of submission, he was a Senior Operations Research Analyst in the Pricing & Revenue Management group at Sabre Travel Technologies. Apart from data analytics, he has also worked on problems in the area of simulation and data visualization. He holds a B.Tech. from the Indian Institute of Technology Madras, India and lives in Bangalore.
2is a Senior Operations Researcher in the Airline Solutions OR Team at Sabre Inc. She holds a PhD and M.S. in Industrial Engineering from Penn State. She received her Bachelor’s degree in Electronics and Communication Engineering from Jawaharlal Nehru Technological University, India. Her research interests include Decision Support System, Data Mining, Machine Learning, Disaster management, Agent Based modeling and Complex Networks.
3is a Principal with the Operations Research group of Sabre Airline Solutions in Bangalore, India. He holds a bachelor’s degree in Information Systems from the Birla Institute of Technology & Science, Pilani, India, and a doctorate in Information Systems from the Indian Institute of Management, Kolkata, India. He has over 13 years of experience in applying machine learning/data mining techniques to a variety of problems in the area of finance, healthcare, energy and aviation, first at GE Global Research between 2003–2014 and now at Sabre since August 2014.
APPENDIX
APPENDIX
Clustering algorithm descriptions
This Appendix contains a more detailed description of the clustering algorithms used in the segmentation process. The key algorithms are k-means (and some variants thereof), clustering using classification trees and hierarchical clustering.
A.1 The k-means algorithm and its variants
There exist a number of clustering algorithms for numeric data sets, the most popular of which is the k-means algorithm, which discovers (a pre-determined number) k groups in the data by iteratively adjusting randomly initialized cluster centers to move toward the population centers in the data. Its advantages include scalability, versatility (in dealing with varied data types) and simplicity of implementation. The algorithm is defined as follows:
-
1
Data: Let X m × n be a data set where each row X i.=(X i1…X in ) represents a data point and is comprised of a set of n real-valued features. We wish to partition these m data points into k clusters.
-
2
Initialization: Pick a set of k points at random from the data set as initial cluster centers
 . Other initialization methods exist as well.
. Other initialization methods exist as well. -
3
Iteration: For p=1…P do:
 . Other initialization methods exist as well.
. Other initialization methods exist as well.-
a)
Allocation: Allocate each point in the data set to its closest cluster center. The result of this step is an allocation vector a 1…a m, a i ∈{1…k}, where the distance from a given cluster center is defined using Euclidean distance:

In case one wishes to consider the relative importance of features while clustering, equation (1) can be rewritten as the square root of a weighted summation of the squared distance along the various features, with the weights normalized so that they add up to 1.It is also possible, through an intelligent weighting scheme, to impose a specific hierarchy among the clusters along certain dimensions. For instance, by setting a high weight to the cabin relative to the other features, one can ensure that each of the resulting clusters cover either premium or economy cabins exclusively.
-
b)
Updation: Once points are allocated to cluster centers, adjust the cluster centers such that each cluster center equals the median of the points allocated to that center.


This algorithm has a computational complexity of O(kmn), which is better than a number of other clustering algorithms available; this explains its popularity among data mining practitioners. However, this may not be sufficient for really large data sets. A reasonably good and efficient approximation to k-means exists in the form of the mini-batch k-means algorithm (Sculley, 2010), which derives from the stochastic gradient descent version of k-means (Bottou and Bengio, 1995). This method is described as follows:
-
1
Data: Let X m × n be a data set with m data points, each described using n real-valued features. We wish to partition this data set into k clusters.
-
2
Initialization: Pick a set of k points at random from the data set as initial cluster centers
 . Also, initialize a vector (α
1…α
k
) to 0, where α
ℓ
represents the number of points seen so far that belong to cluster ℓ.
. Also, initialize a vector (α
1…α
k
) to 0, where α
ℓ
represents the number of points seen so far that belong to cluster ℓ.
 . Also, initialize a vector (α
1…α
k
) to 0, where α
ℓ
represents the number of points seen so far that belong to cluster ℓ.
. Also, initialize a vector (α
1…α
k
) to 0, where α
ℓ
represents the number of points seen so far that belong to cluster ℓ.-
3. Iteration: For p=1…P do:
-
(d) Sampling: Select a mini-batch S b × n of b points drawn randomly from X.
-
(e) Allocation: Allocate each point in the data set to its closest cluster center, using the same formula as in equation (1). The result of this step is an allocation vector a 1…a b , a i ∈{1…k}.
-
(f) Updation: Once points are allocated to cluster centers, iterate through the mini-batch again and adjust the center after seeing each point. The extent of adjustment is a function of the data point being considered, the existing center it is allocated to and the number of points seen so far (across mini-batches) that have been allocated to this cluster center. Iterate through the following steps for each element i=1…b in the mini-batch:

This algorithm is clearly more efficient than k-means when the mini-batch size b<<m. It has been shown to produce comparable results to k-means, which suggests that the improvement in efficiency does not come at the cost of effectiveness. Other variants to k-means deal with categorical data (Huang, 1998), adding weights to features to indicate their importance to the decision maker and so on. We use an amalgam of these variants tailored to deal with categorical data. The algorithm, which we call mini-batch k-modes, is described below:
-
1
Data: Let X m × n be a data set, where each row X i. =(X i1…X in ) represents a data point and is comprised of a set of n categorical features (X ij ∈{1…v j }, ∀j=1…n). We wish to partition this data set into k clusters.
-
2
Initialization
-
a)
Pick a set of k points at random from the data set as initial cluster centers
 .
. -
b)
Initialize the discrete probability distribution vectors
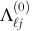 that represent the relative frequencies of the category values seen so far in feature j, among points assigned to cluster ℓ. The initial distribution will be degenerate, with only
that represent the relative frequencies of the category values seen so far in feature j, among points assigned to cluster ℓ. The initial distribution will be degenerate, with only 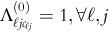 . Each cluster center in this algorithm is represented as a vector if the frequency distributions of the various categories, that is,
. Each cluster center in this algorithm is represented as a vector if the frequency distributions of the various categories, that is,  .
. -
c)
Also, initialize a vector (α 1…α k ) to 0, where α ℓ represents the number of points seen so far that belong to cluster ℓ=1…k.
 .
.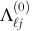 that represent the relative frequencies of the category values seen so far in feature j, among points assigned to cluster ℓ. The initial distribution will be degenerate, with only
that represent the relative frequencies of the category values seen so far in feature j, among points assigned to cluster ℓ. The initial distribution will be degenerate, with only 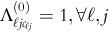 . Each cluster center in this algorithm is represented as a vector if the frequency distributions of the various categories, that is,
. Each cluster center in this algorithm is represented as a vector if the frequency distributions of the various categories, that is,  .
.-
3. Iteration: For p=1…P do:
-
(d) Sampling: Select a mini-batch S b × n of b points drawn randomly from X.
-
(e) Allocation: Allocate each point in the data set to its closest cluster center. The result of this step is an allocation vector a 1…a b , a i ∈{1…k}. The distance used is not the Euclidean distance as in equation (1), nor is it the overlap distance (number of features where the category values overlap between a given cluster center and data point). The distance measure, instead, is a sum of the Hellinger distance between the relative frequency of category values for each cluster center, and that of the new data point (which is degenerate):

As with k-means, in case one wishes to consider the relative importance of features while clustering, equation (4) can be rewritten as a weighted summation of the Hellinger distance along the various features, with the weights normalized so that they add up to 1.
-
(f) Updation: Once points are allocated to cluster centers, iterate through the mini-batch again and adjust the center after seeing each point. The extent of adjustment is a function of the data point being considered, the existing center it is allocated to and the number of points seen so far (across mini-batches) that have been allocated to this cluster center. Therefore, ∀i=1…b:


The drawbacks of k-means and its variants include sensitivity to cluster center initialization, the requirement to specify the number of clusters k and inability to find subgroup hierarchies in the data. These are addressed through our proposed ensemble approach.
A.2 Clustering using classification trees
CLTree is a clustering technique based on a supervised learning method, decision trees (Liu et al, 2000). Decision tree is a popular supervised learning technique which iteratively cuts the feature space into sub regions such that each sub-region contains only one label using the information gain criteria. The intuition behind decision tree-based clustering approach is that clusters are non-random groupings of data in the feature space. Therefore, a classifier that would distinguish between uniformly distributed (artificially generated) data and non-random (actual) data would automatically find clusters.
The decision tree-based approach tries to recursively partition the region into sub-regions based on a greedy approach. This approach, when used for clustering results in two issues: First, the best cut might split a cluster, and second, the resulting cluster might have embedded empty regions. In order to address the above issues the authors modified the best cut evaluation method to incorporate relative density and a simple look-ahead mechanism. The overall method is described below:
-
1
Data: Let X m × n be the data set to be clustered.
-
2
Initialization: Initialize a tree T with the root node containing all points in X.
-
3
Recursive partitioning: Recursively partition/cut X into sub-regions (each new sub-region is a child of the original parent region) until termination criteria is reached. Let L i be the child region with lower relative density and b i the boundary value of region under study for feature i. The relative density of a region is the ratio of number of original data points to number of artificial data points. Evaluation of best cut can be broadly split into three steps described below. The algorithm is described in Algorithm 1.
-
a)
Initial cut: Identify the initial best cut for the feature i based on information gain. If no information gain can be achieved by making a cut, feature i is ignored.
-
b)
Look ahead: On the basis of the first cut we find better cuts along the same feature i that satisfy the following objectives – (i) Do not split a cluster, and (ii) Split a cluster if there are embedded relatively empty region.
-
c)
Picking the best cut: Pick the cut that results in lowest relative density across all features.
-
a)
-
4
Termination condition: Recursive partitioning (Step 3) will terminate if any of the following criteria are met. If the number of data points in child region is less than a minimum number and gain achieved by splitting the parent region is less than a minimum gain value.
-
5
Cluster Identification: The resulting tree consists of a set of leaf nodes. We pick the leaf nodes with high relative density as cluster nodes. The original data points in the remainder leaf nodes are assigned to closest cluster nodes. In addition, we also extended the existing CLTree-based algorithm to incorporate categorical data types.
The resulting tree provides both cluster definitions (path from root leading to cluster nodes) and feature importance. This algorithm can handle diverse data types numeric and categorical (nominal and ordinal). Furthermore, it is ideal for full-space and sub-space clustering. One of the byproducts of this algorithm is that the empty spaces can be used for anomaly and outlier detection.
However, this algorithm can only produce hyper-rectangular regions as it can only make cuts that are parallel to the feature space. The cuts generated are very sensitive to input data. In addition, we cannot customize feature importance and incorporate that aspect while deciding on the feature to split a node.

A.3 Hierarchical agglomerative clustering
The standard agglomerative method for constructing hierarchical clusters is as follows:
-
1
Data: Let X m × n be the data set to be clustered.
-
2
Leaf nodes: Consider each point in the data set to be a leaf node in a tree. The tree shall now be constructed from the bottom-up. Think of each leaf node as a cluster with one point.
-
3
Recursive agglomeration: Repeat until only one cluster remains:
-
a)
Linkage: For each pair of clusters A, B currently remaining:
-
i
Calculate the set of pairwise distances d(a, b)∀a∈A, b∈B. The distance can be calculated using any metric of choice that suits the problem.
-
ii
Calculate the linkage between the two clusters A, B as an aggregation of the pairwise distances. Multiple linkage methods exist. For instance:

-
(a) Finding the best pair: Find the pair A*, B* that are closest to each other, according to the linkage measure defined above.
-
(b) Merging: Merge A* and B* into a single cluster.
It is clear from the algorithm described above that, while it is perfectly suited to the requirement of finding sub-group structures, it has polynomial complexity as it requires the computation of pairwise distance between all points in X. Therefore, it does not scale very well with large data size. The size problem is therefore addressed by compressing the data set into groups discovered through the evidence accumulation technique.
Rights and permissions
About this article

Cite this article
Kothari, A., Madireddy, M. & Sundararajan, R. Discovering patterns in traveler behaviour using segmentation. J Revenue Pricing Manag 15, 334–351 (2016). https://doi.org/10.1057/rpm.2016.33
Published:
Issue Date:
DOI: https://doi.org/10.1057/rpm.2016.33