
Abstract
We present a theoretical and computational study of the impact of inserting a new attribute and removing an old attribute in a data envelopment analysis (DEA) model. Our objective is to obviate a portion of the computational effort needed to process such model changes by studying how the efficient/inefficient status of decision-making units (DMUs) is affected. Reducing computational efforts is important since DEA is known to be computationally intensive, especially in large-scale applications. We present a comprehensive theoretical study of the impact of attribute insertion and removal in DEA models, which includes sufficient conditions for identifying efficient DMUs when an attribute is added and inefficient DMUs when an attribute is removed. We also introduce a new procedure, HyperClimb, specially designed to quickly identify some of the new efficient DMUs, without involving LPs, when the model changes with the addition of an attribute. We report on results from computational tests designed to assess this procedure's effectiveness.


Similar content being viewed by others

References
Ali AI (1993). Streamlined computation for data envelopment analysis. Eur J Opl Res 64: 61–67.
Application Development Tools (1994). IMSL Stat Library. Visual Numerics, Inc.: Houston, TX.
Banker RD, Charnes A and Cooper WW (1984). Some models for estimating technological and scale inefficiencies in data envelopment analysis. Mngt Sci 30: 1078–1092.
Charnes A, Cooper WW, Golany B, Seiford L and Stutz J (1985). Foundations of data envelopment analysis for Pareto–Koopmans efficient empirical production functions. J Econ 30: 91–107.
Charnes A, Cooper WW and Rhodes E (1978). Measuring the efficiency of decision making units. Eur J Opl Res 2: 429–444.
Charnes A, Cooper WW and Thrall RM (1991). A structure for classifying and characterizing efficiency and inefficiency in data envelopment analysis. J Prod Anal 2: 197–237.
Dulá JH and Hickman BL (1997). Effects of excluding the column being scored from the DEA envelopment LP technology matrix. J Opl Res Soc 48: 1001–1012.
Dulá JH and López FJ (2006). Algorithms for the frame of a finitely generated unbounded polyhedron. INFORMS J Comput 18: 97–110.
Dulá JH and Thrall RM (2001). A computational framework for accelerating DEA. J Prod Anal 16(1): 63–78.
Dulá JH, Helgason RV and Hickman BL (1992). Preprocessing schemes and a solution method for the convex hull problem in multidimensional space. In: Balci O. (ed). Computer Science and Operations Research: New Developments in Their Interfaces 1992. Pergamon Press: UK, pp. 59–70.
López FJ (2005). Generating random points (or vectors) while controlling the percentage of them that are extreme in their convex (or positive) hull. J Math Model Algorithms 4: 219–234.
Acknowledgements
The contribution of the first author was partially funded by a Summer research grant from the College of Business Administration at UTEP.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Result 1
-
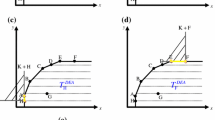
A data point that is on the boundary of the production possibility set in dimension m is on the boundary of the production possibility set in dimension m+1.
Proof
-
We present the demonstration for the VRS model and then explain how to adapt it for the other returns to scale assumptions.
Let 𝒜 be a set of n data points in ℛm. Assume that a j*∈𝒜 is on the boundary of the production possibility set generated by the VRS model in dimension m. Then, there exist 0≠π *∈ℛm, π *⩾0, and β∈ℛ such that
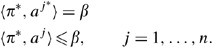
Thus, for âj*∈ℛm+1 and π m+1 *=0,
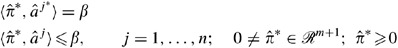
Then, âj* is on the boundary of the production possibility set in dimension m+1. □
The proofs for the IRS and the DRS follow immediately by adding above the constraint β⩾0, or β⩽0, respectively. For the CRS, the demonstration is as above with β=0.
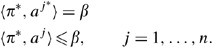
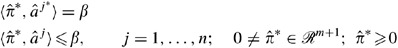
Result 2
-
An extreme point of the production possibility set in ℛm is extreme in ℛm+1.
Proof
-
Let
 be an extreme point of the production possibility set in
be an extreme point of the production possibility set in  . Then there exists a supporting hyperplane
. Then there exists a supporting hyperplane  such that
such that  is the only element of the support set. That is:
is the only element of the support set. That is: 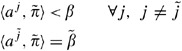
Construct the vector
 . Then
. Then 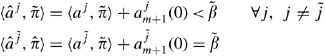
This means that the hyperplane
 in
in  supports the higher-dimensional VRS production possibility set (with support set an unbounded face). The point
supports the higher-dimensional VRS production possibility set (with support set an unbounded face). The point  is necessarily extreme since it is the only point in that face. Since
is necessarily extreme since it is the only point in that face. Since  is an extreme point of this face it is an extreme point of the full polyhedral set. □
is an extreme point of this face it is an extreme point of the full polyhedral set. □The proofs for the IRS, the DRS, and the CRS follow immediately by adding above the constraints β⩾0, β⩽0, or β=0 respectively.
 be an extreme point of the production possibility set in
be an extreme point of the production possibility set in  . Then there exists a supporting hyperplane
. Then there exists a supporting hyperplane  such that
such that  is the only element of the support set. That is:
is the only element of the support set. That is: 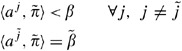
 . Then
. Then 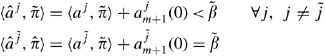
 in
in  supports the higher-dimensional VRS production possibility set (with support set an unbounded face). The point
supports the higher-dimensional VRS production possibility set (with support set an unbounded face). The point  is necessarily extreme since it is the only point in that face. Since
is necessarily extreme since it is the only point in that face. Since  is an extreme point of this face it is an extreme point of the full polyhedral set. □
is an extreme point of this face it is an extreme point of the full polyhedral set. □Result 4
-
Let a j*∈𝒜 be a boundary element of the production possibility set. Assume that there exists a hyperplane
 that supports the hull at a
j* such that, w.l.o.g.,
that supports the hull at a
j* such that, w.l.o.g.,  is the only coordinate of
is the only coordinate of  that is zero. Then a
j* is efficient when removing the mth attribute from the DEA model. If, in addition a
j*, is the only element of the support set in dimension m, then it is extreme efficient in the lower dimension.
that is zero. Then a
j* is efficient when removing the mth attribute from the DEA model. If, in addition a
j*, is the only element of the support set in dimension m, then it is extreme efficient in the lower dimension.
 that supports the hull at a
j* such that, w.l.o.g.,
that supports the hull at a
j* such that, w.l.o.g.,  is the only coordinate of
is the only coordinate of  that is zero. Then a
j* is efficient when removing the mth attribute from the DEA model. If, in addition a
j*, is the only element of the support set in dimension m, then it is extreme efficient in the lower dimension.
that is zero. Then a
j* is efficient when removing the mth attribute from the DEA model. If, in addition a
j*, is the only element of the support set in dimension m, then it is extreme efficient in the lower dimension.Proof
-
Since
 supports the hull at a
j* if follows that
supports the hull at a
j* if follows that 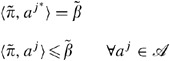
This implies that
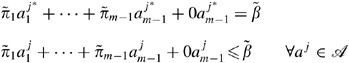
Hence

Since
 , it follows that a
j* if efficient when the mth attribute is removed from the DEA model.
, it follows that a
j* if efficient when the mth attribute is removed from the DEA model.It is obvious that if a j* is the only element of the support set in dimension m, then it is extreme efficient when removing the mth attribute. □
 supports the hull at a
j* if follows that
supports the hull at a
j* if follows that 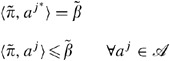
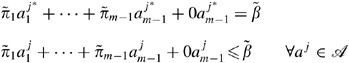

 , it follows that a
j* if efficient when the mth attribute is removed from the DEA model.
, it follows that a
j* if efficient when the mth attribute is removed from the DEA model.The proofs for the IRS, the DRS, and the CRS follow immediately by adding above the constraints β⩾0, β⩽0, or β=0 respectively.
Rights and permissions
About this article
Cite this article
López, F., Dulá, J. Adding and removing an attribute in a DEA model: theory and processing. J Oper Res Soc 59, 1674–1684 (2008). https://doi.org/10.1057/palgrave.jors.2602505
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1057/palgrave.jors.2602505