
Abstract
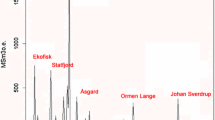
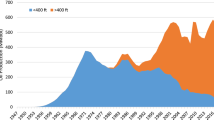
Various models have been used to estimate the amount of oil recoverable from an oil province and the likely sequence of discoveries from any further exploration programme, often with significantly different results. One particular type of model, the discovery-process model, considers oil exploration as a sampling process without replacement, with the underlying size distribution of oilfields determined by the maximum likelihood method. In this paper we consider one example of this type of model, the O'Carroll model, which was previously dismissed as misspecified because of the apparently unrealistic results it gave from early North Sea data. We re-examine this model, solving the integer-constrained maximum likelihood problem in a novel way—as an allocation problem in dynamic programming. Our conclusion is that this model gives a robust estimate of the oil potential in the UK Continental Shelf and a credible distribution of fields yet to be found.
Similar content being viewed by others
Author information
Authors and Affiliations
Rights and permissions
About this article
Cite this article
Fryer, M., Greenman, J. Estimating the Oil Reserve Base in the UK Continental Shelf. J Oper Res Soc 41, 725–733 (1990). https://doi.org/10.1057/jors.1990.101
Published:
Issue Date:
DOI: https://doi.org/10.1057/jors.1990.101