
Abstract
Heatwaves and dry spells are major climate hazards with far-reaching implications for health, economy, agriculture, and ecosystems. The frequency of compound hot and dry summers in Europe has risen in recent years. Here we present an examination of past extreme summers and compare them to future climate conditions. We use reanalysis data (2001–2022) and model data at three global warming levels: +1.2 °C, +2 °C, and +3 °C for nine selected sub-regions. Key findings indicate a significant increase in the frequency of most extreme past occurrences under 2 °C and 3 °C warming scenarios. For specific summers, the occurrence probability rises by up to 5–6 times from 2 °C to 3 °C. Moreover, our analysis reveals a notable northward shift in the climatology of hot and dry summers under 3 °C warming. The hot and dry climate observed in Eastern Europe under current conditions is anticipated to extend into substantial parts of the Baltic coast, Finland, and Scandinavia.
Similar content being viewed by others


Introduction
Prolonged periods of heatwaves and droughts substantially affect human health, the economy, agriculture, and natural ecosystems. Compounding events—two or more joint hazards—are the ones that are known to cause high impacts1,2. In recent years, Europe has experienced a series of compounding hot and dry summers (CHDs), e.g. 2003, 2015 and 20183,4, each of which has caused increased mortality5,6, economic losses due to crop yield reduction, blockage of river transportation due to low flow, worker productivity decrease7, and posed extreme stress on the natural ecosystems.
Quantifying the probability of historical CHDs is challenging due to the atmospheric and hydrological interrelation of temperature and precipitation8. Extreme heat and the absence of precipitation share the same atmospheric large-scale drivers as anticyclonic conditions, which lead to reduced cloudiness. Moreover, there is a self-intensifying feedback between hot and dry conditions9,10: with the onset of a heatwave, soil dries, and when falling below a certain threshold, a larger fraction of solar radiation is transformed into sensible heat. This leads to an increase in air temperature and evaporative demand, which in turn dries the soil even more and reduces precipitation due to lower evapotranspiration11,12. During CHDs, the Bowen Ratio of sensible heat to latent heat is enhanced compared to non-compound summers in large parts of Europe, and lower soil moisture conditions are present13. Previous studies have shown that seasonal summer temperatures and precipitation in Europe are highly correlated1,14, meaning that a higher number of CHDs happen than one would expect when looking at univariate probabilities and assuming independence. Moreover, looking to the future, rising summer average temperatures15 and a drying trend16 in the European summers might favour the intensification of the feedback mechanisms under changing climatic conditions17,18.
Quantifying the changes in probability of historical CHDs for different global warming levels (GWLs) is essential for many reasons. Determining the probability of historical CHDs under future conditions and comparing it to the present probability gives us insight into what we might expect to experience, contingent upon GWLs we might reach. This knowledge is invaluable for stakeholders like policy-makers, politicians, engineers, and farmers when managing water resources, adjusting agricultural practices or adapting to changing ecological minimum flow conditions19. A significant increase in probability strengthens the need for impact mitigation20. For instance, if CHDs should become a frequent feature of the European climate, there is a need to develop alternative solutions for cooling of thermal power plants, as they heavily depend on cooling water from natural resources21, implementation of measures to conserve water22,23, establishment of alternative transportation methods to shipping in summer and building green spaces like parks to reduce the urban heat island and urban sprawl effects to not additionally worsen the conditions in cities due to man-made issues24,25.
Thus, the probability of occurrence of CHDs is essential to assess; however, they are complex and multivariate in terms of drivers and feedback and happen rarely by definition. The probability quantification based on observational data is limited due to its temporal length. Applying a Single Model Initial Condition Large Ensemble (SMILE)26 allows overcoming these limitations by providing a robust statistical estimation of extremes. A SMILE consists of a multitude of simulations (ensemble members), each of which has the same forcing and the same physical model but differing initial conditions27. This allows to distinguish between the signal delivered by the internal chaotic nature of climate (natural climate variability) and a forced response due to effects like climate change. We argue for the application of SMILEs for probability quantification of extremes. Past studies have confirmed the usefulness of SMILEs for investigating compound extremes4,13,27,28.
In this study, we want to identify the most extreme CHDs on the European and regional scale of the past two decades, 2001–2022. For those CHDs, we aim to quantify the probability of occurrence given the current climate and how this probability changes under projected GWLs of +2K or +3K (GWL2 or GWL3, respectively). Seneviratne et al. and Gampe et al. used GWLs to communicate climate change impacts at temperature targets relevant to policy and decision-making29,30. Moreover, they allow to compare results across forcing scenarios. In the study, we estimate the probability of the most extreme historical CHD of the two past decades, 2001–2022, in the European climate reanalysis dataset ERA531 by comparing it to a 50-member regional large ensemble, the Canadian Regional Climate Model, version 5, Large Ensemble (CRCM5-LE)32 under RCP8.5. For the most extreme CHD in the ERA5 dataset, we quantify the probability for those seasons to happen by using the following three periods out of CRCM5-LE:
-
PRES: +1.2K GWL model world representing the present conditions. It corresponds to the model years 2001–2020.
-
GWL2: +2K GWL model world representing the optimistic target set by the Paris Agreement; model years 2021–2040.
-
GWL3: +3K GWL model world, representing the realistic perspective following the current trend; model years 2042–2061.
We inspect temperature and precipitation and use seasonal summer averages of June–July–August (JJA) for the CHD definition. With the summer-season-based definition of CHD for Europe, we follow previous research13,33,34,35. The three-month timescale for JJA has been shown to be of the most impact relevance, e.g. for crops36. Previous research by Lhotka et al. has shown that the median length of the dry-hot season lasts at least from late spring to August in Europe37. Due to the interrelation of those two variables, we cannot inspect those in univariate terms, but we have to model their interdependence using copulas8. In recent years, copulas have been widely used to study the interrelation between multiple variables13,33,38.
Multivariate copulas are especially useful for assessing the occurrence probability and return periods of compound extremes39,40,41. Following Aghakouchak et al. with the application on hot and dry seasons39, we use the Survival Kendall probability pSK, which estimates the probability of having an event at least as rare in probability as the one observed42. The pSK-isolines dividing the probability space are shown for one arbitrary grid cell in Fig. 1. By spatially clustering the resulting yearly pSK spatial maps of CRCM5-LE PRES, we identify nine European sub-regions most likely to experience a simultaneous CHD: SWE: South-West Europe, CMD: Central Mediterranean, BP: Balkan Peninsula, AC: Atlantic Coast, CE: Central Europe, EE: Eastern Europe, NBS: North and Baltic Sea, NEE: North-East Europe and NSC: North Scandinavia. We use the sub-regions to calculate local probabilities by averaging temperature and precipitation and then computing the pSK probability for each region. Figure 2 displays the entire European domain and sub-regions. More details can be found in 'Methods'.

Black triangles for CRCM5-LE data, red dots for ERA5 data. pSK isolines in the probability space are shown in red.

The orography [m] over the European domain of the CRCM5-LE in 0.11 deg resolution in (a) and the sub-regions obtained by clustering CHDs that are used in the analysis in (b).
Results
Identifying most extreme historical CHD on the European scale
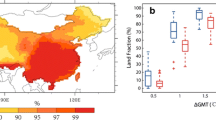
We first focus on identifying the most extreme CHD in the past two decades (2001–2022) on the European scale. By transferring the historical summers based on the ERA5 reanalysis to the CRCM5-LE space (see 'Methods' section), we assess the extremeness of the joint temperature and precipitation conditions during 2001–2022. Therefore, we calculate the bivariate exceedance probability pSK for all grid cells over the European land domain (see Fig. 1). The average of pSK per year over the whole European land domain is presented in Fig. 3, where the exceptional rarity of the summer of 2003 is confirmed on the continental scale with a probability close to zero in the entire affected area. Moreover, to gain insight into which proportion of the domain is experiencing an extreme CHD, we plot in red the fraction of land with a pSK value below the threshold of 10%, 5% and 1%. The pSK values for the latter case are calculated for every grid cell part of the domain. Also, 2003 is the most extreme summer in this measure, with over 20%, 15% and 10% of the grid cells affected, respectively.

The bivariate exceedance probability of hot and dry summers averaged over the whole European land domain pSK is shown in grey. In red the fraction of land is presented which is experiencing a pSK below a threshold noted in the legend. The vertical black line highlights the CHD with the least pSK.
Additionally, we inspect the most extreme CHD on the regional scale. Therefore, we repeat the same analysis, averaging temperature and precipitation over the chosen sub-regions. The results can be seen in Fig. 4. We obtain that 2003 was also the most extreme in the southern parts of the domain, such as SWE, CMD, AC and CE. Moreover, we find 2012 for BP, 2015 in EE, 2018 in NBS, 2006 in NEE and 2002 in NSC as additional CHDs to be inspected. One extraordinary heatwave that is not part of the analysis is the 2010 Russian heatwave. That can be explained by the fact that it has its hotspot to a considerable extent outside of the domain boundary43. NEE region is most affected by it. 2010 has a bigger spatial extent than the chosen CHD of 2006 but is less extreme in pSK, as seen in Fig. 4.

Sub-regions ordered from South to North from West to East in (a–i). The bivariate exceedance probability of hot and dry summers averaged over the land area of the whole region pSK is shown in grey. In red, the fraction of land is presented, which is experiencing an extremely rare CHD in the year. The vertical black line highlights the CHD with the least pSK.
We present the probability maps for the six extraordinary CHDs in the European domain in Fig. 5. The displayed maps confirm the spatial extremity of the year 2003. No other CHD had a comparable spatial extent. We calculate the probabilities of occurrence in the three chosen periods for the areas where the CHD are most extreme. The probabilities in % for the affected regions are displayed in Table 1. The probabilities for all CHDs are extremely low in the current climate, underlining the extraordinarity of the chosen summers. In the present climate conditions, the probability lies between 2.2% for NEE in 2006 and NBS in 2018 and 0.002 % for the 2012 summer for the Balkan Peninsula. The estimated probabilities correspond to return periods between 45 and more than 10, 000 years. Moreover, we inspect the change in probability to GWL2 and GWL3; we see a diverging pattern. CHDs of 2002, 2003 and 2018 are projected to become a frequent feature of the future European climate as the probabilities rise to 46% for GWL3, while other CHDs like 2006, 2012 and 2015 experience only a slight rise in probability, remaining a rare feature of the climate in the future.

2002, 2003, 2006, 2012, 2015, 2018 in (a–f).
To better understand where the change in probability originates on the European scale, we look at the underlying distribution of temperature and precipitation in Fig. 6. The two thick lines encircle 95% and 50% of the data and are obtained by kernel density estimation44. In the following, we compare the CHD to future temperature and precipitation distributions under GWL2 and GWL3. We see that what used to be the most extreme CHD in the PRES period lies closer to the centre of the distributions in the future periods of GWL2 and GWL3. The change is very pronounced, especially in temperature. The extreme temperatures during the 2003 summer are below the 95th percentile in GWL2 and would be considered a rather cold summer under GWL3. Although very much dominated by temperature, drying also contributes to the CHD’s intensification. The dryness of 2003 will become less extreme and below the 95th percentile in negative precipitation (above the 5th percentile in precipitation) under GWL2 and GWL3. Hence, the identified CHDs will become more common and less exceptional in the warmer climates, both in terms of temperature and precipitation. To ensure the reliability of the results, we perform the same analysis using another regional European large ensemble, CESM-CCLM, which consists of 21 members45,46,47. Hereafter, only CCLM. The analysis performed on CCLM that is displayed in Supplementary Fig. S1 confirmed the previously described findings in terms of the allocation of the most extreme past events in the temperature and precipitation distribution. CRCM5 shows a higher warming for GWL3 at the European level (95th percentile on 4K compared to 3.6K in CCLM). Also, the drying is stronger in absolute numbers, although it has to be noted that CCLM generally displays a narrower distribution in precipitation. More details can be seen in the regional distributions discussed in the next section.

The two lines encircle 95% and 50% of the data and are obtained by kernel density estimation. ERA5 years 1959–2022 shown with black dots. Most extreme years from the previous analysis are notified with black text. The most extreme year of 2003 for the whole domain is highlighted with black horizontal and vertical lines. Marginal distributions of temperature anomaly for the three periods are displayed in the upper plot; negative precipitation anomaly in the right plot. Dashed lines in the marginal plots indicate the 95th percentile of the corresponding distribution.
Distributional shifts on the regional scale
Additionally, we investigate the changes in the distribution of temperature and precipitation anomaly on the regional scale. The results are displayed in Fig. 7. We also inspect the empirical univariate probabilities shown in Table 1 under ptas and ppr.

Sub-regions ordered from South to North from West to East in (a–i). The most extreme historical CHD based on pSK is highlighted with a black line.
In terms of general change in climatology, we observe a two-fold pattern. Firstly, in the northern regions, such as NBS, NSC and NEE, changes are primarily driven by shifts in temperature, while precipitation is projected to change only slightly. Meanwhile, in the South and Central European regions, including Southern Western Europe (SWE), Central Mediterranean (CMD), Balkan Peninsula (BP), Atlantic Coast (AC), Central Europe (CE), and Eastern Europe (EE), the temperature-induced climatic alterations are further compounded by a pronounced decrease in precipitation. Therefore an increase in probability of CHDs roots in compound drying and warming for those regions. The analysis of CCLM, shown in Supplementary Fig. S2, shows a drying and warming for all sub-regions.
On the seasonal level, we can now determine where the diverging intensification of CHD probabilities comes from. The CHDs of 2012 in BP and 2015 in EE are characterised by extremely low precipitation, which is quantified by the univariate probability ppr below 0.6% in PRES, as can be seen in the distribution plot in Fig. 7 and Table 1. In those regions, the drying in GWL2 and GWL3 is less pronounced. Therefore, even under future climate conditions, those CHDs are not to be expected more frequently than once in 20 years or with a pSK ≤ 5%. For the summer of 2003 in SWE, CMD, and AC, temperature is found to be the dominant extreme driver, which is significantly rising in those regions under GWL2 and GWL3. The summers of 2002, 2003, and 2018 are expected to be exceeded with a probability above 5% already under GWL2. For the summer of 2003 in CE, rising temperatures and drying both contributed to heightened probability under GWL2 and GWL3.
When comparing to CCLM, CRCM5 is showing a comparable or weaker warming for all the regions but NSC for GWL2 (see Supplementary Fig. S3). For GWL3, CRCM5 shows stronger warming for all the regions except CE (see Supplementary Fig. S4). At the same time, CCLM shows a comparable drying for central and northern regions CE, EE, NBS, NEE and NSC for both GWL2 and GWL3. In the southern regions like SWE, CMD, BP and AC, CCLM demonstrates a more narrow spread of the precipitation distribution and a smaller change in the future periods when compared with CRCM5.
These findings shed light on the potential long-term changes in extreme CHD probabilities, suggesting that certain summers may define the new normal while others stay extreme in future expected climates.
Future CHD climatology
We evaluated in previous sections that historical extreme CHDs will become more frequent in the expected future climate. Further, we ask the question: For the hot and dry summer conditions of a given region under GWL3, can we identify another region reflecting similar conditions in the present climate already? To find those analogues, we take the distribution of GWL3 CHDs with pSK < 5% and try to find the most similar region in the present climate regarding extreme temperature and precipitation distribution. By doing this, we can say that under GWL of +3K, CHDs in, e.g. South Germany will be like they are nowadays in Eastern Europe in terms of their seasonal temperature and precipitation characteristics. Read more on the applied climatology in 'Methods'.
The clustered regions include various climatic zones, e.g. the Alps and vast parts of Germany are part of the same cluster. Therefore, we chose a representative point/grid cell for the region in PRES time frame and used the CHD distribution at that point for further analysis. The distribution of the chosen representative points is shown in Fig. 8a. NSC has the least intense hot and dry summers compared to other regions’ distribution (as we define CHDs based on local conditions). All the other regions are closer connected with the representative point in BP demonstrating the hottest and driest climate. The geographical location of the chosen representative points is displayed in Fig. 8b in black-edged dots.

a Distribution of the chosen representative point for every geographical cluster in CRCM5-LE PRES data. b Results of matching the representative point and grid cell values for CRCM5-LE PRES. Black-edged pink dots: location of the representative points. c Results of grid-cell-wise matching between the CHD distribution in CRCM5-LE GWL3 and representative points in CRCM5-LE PRES.
Given the substantial climatic variations within geographical clusters, we choose to first calculate the matched climatologies of present-present (Fig. 8b) to then compare the results to the future (Fig. 8c). The comparison reveals a noteworthy northward shift of most hot and dry climatologies, as exemplified by BP, which is expected to cover most of Southern Europe and, under GWL3, expand into more northern territories. Previously confined to the Balkan Peninsula, it extends into huge parts of the Iberian Peninsula, South France, Italy and Eastern Europe under GWL3. The area in the Alps, that is currently experiencing a relatively wet and cold NSC climate, shrinks, shifting in parts to a CE climate. Furthermore, the EE climate is gradually extending its presence into substantial parts of Central Europe and the Baltic Sea coast, including southern Sweden and Finland. These findings collectively indicate a substantial northward shift in all hot and dry climate zones under GWL3. In Supplementary Fig. S5, we show the most probable values for a CHD with pSK = 5% for every region’s chosen representative point. The figure confirms the shifts in climatic zones we see in Fig. 8, as, e.g. the GWL3 value of CE representative point is close to the PRES values of AC and EE. This is a change we can also see in Fig. 8c.
Discussion
Our study highlights the substantial implications of future climate conditions on CHDs in Europe. As a first step, we identify 9 typical spatial patterns of European CHDs by means of spatial clustering. For those regions, we identify the most extreme hot and dry summers of the past 22 years of European climate: 2002 for NSC, 2003 for SWE, CMD, AC, CE; 2006 for NEE; 2012 for BP; 2015 for EE; and 2018 for CE. We confirm that the most extreme historical CHDs will become more frequent features of the European climate under both scenarios—GWL2 and GWL3. For some CHDs, the annual probability of occurrence rises 500–600% from GWL2 to GWL3 and up to 46% under GWL3, translating into almost every second summer. This underlines the importance of limiting the global warming to +2°. Moreover, we see a twofold pattern. Some past CHDs are characterised by an extremity mainly in precipitation, as those in 2006, 2012, and 2015. Those CHDs will experience a moderate rise in frequency; however, they will remain extreme and rare even under future climate conditions for GWL2 and GWL3. Other past CHDs, such as 2002, 2003, and 2018, are projected to become immensely more frequent, with probabilities of up to 46%, as in the case of 2003 for CMD for GWL3. Additionally, our analysis reveals a notable northward shift in the climatology of CHDs under GWL3: the extremely hot and dry climate currently observed in BP is expected to extend into substantial parts of the spatial EE cluster, the relatively moist and cold NSC region in the Alps are contracting, while the EE CHD climate extends northward, reaching regions as far as the Baltic Sea and Scandinavia.
Our study contributes three key findings to the scientific field: (1) We show the utility of a high-resolution large ensemble for compound extreme investigation, as it is able to robustly relate to past experienced CHDs due to the amount of data and to resolve heterogeneities, e.g. for the investigation of the climatology shifts. We see the topography and the proximity to coastlines as governing effects on the hot and dry summer climates, which GCMs could not show due to the coarse resolution32,48. Investigating climatology changes in extremes is best possible with the application of an SMILE, as no other datasets provide enough data on extremes. As such, this work represents a valuable contribution that can inform compound extremes research and enhance the communication efforts of stakeholders from science and policy. (2) Our study presents a methodology to quantify probabilities of historical CHDs with large ensembles, using an extreme definition via Survival Kendall probability. (3) Last but not least, we see our contribution in presenting the shifts in the climatology of CHDs for GWL3. The spatial analysis of hot and dry climate patterns and spatial shifts while evolving towards GWL3 are vital tools for illustrating the potential consequences of climate change.
A study by Ionita et al. confirms the chosen extreme compound hot and dry summers33: according to the study, 2003 ranks the hottest year over northern Spain, France, and south Germany; 2015 the driest over east Europe, 2012 the hottest in South-Eastern Europe and 2006 and 2018 as one of the other extreme summers in Europe. The correspondence is remarkable, as Ionita uses a different event definition, built out of criteria on the minimum length of the heatwave, temperature bigger than the 90th percentile, and 3 months Standardised Precipitation Index smaller than minus one. The study confirms our CHD definition approach, as it uses a different dataset and a different definition yet arrives with a similar CHD set. The only exception is 2002, which is not included in the list of CHD. However, the NSC region is small; therefore, the results might vary on a differently cut domain.
To our knowledge, no studies exist that quantify the probability for all of the identified CHD in bivariate terms. According to Charpentier et al.49, for 2003, the return period is estimated to be 115–37 years, corresponding to 0.8–2.7% in annual exceedance probability, depending on the model and heatwave definition. However, it must be noted that probabilities were calculated in univariate terms in the study. Our results show a smaller probability, which is reasonable, as we include the extremity in precipitation. Rousi et al. find a probability of a summer like 2018 of 96% in a 2 °C warmer world by looking at the distribution of accumulated heat3. Our approach shows a four-fold (from 2.2% to 9%) increase in the probability of occurrence between PRES and GWL2 and reaches a return period of only once in 10 years in contrast to almost every year (96% under GWL2). Hence, the heat accumulation and spatial event definition might lead to those differences. Given that the reported impacts of the 2018 summer are linked to both drought and heat50,51, it is important to investigate extremes in multivariate terms to provide a realistic probability estimation. A study by Boehnisch et al. confirms that sticking to GWL2 might reduce extreme CHD occurrences multiple times13. The study also quantified compound hot and dry summer occurrences; however, using only CRCM5-LE13. Another study confirmed that changes in CHD probability in Europe are driven by changes in temperature52. In terms of changes in climatic zones of hot and dry extremes, our study presents to our knowledge novel results by demonstrating shifts to be expected in future under GWL3. We can compare the spatial patterns and shifts to a study by Beck et al., which quantified the changes in climate by the end of the century using the Köppen-Geiger classification. This classification is based on monthly temperature and precipitation values and describes changes in the mean climate53. The general trend found by our study can be confirmed, disregarding the difference in the definitions we see the same effect for, e.g. the climate present in the Iberian Peninsula spreading into Central European regions.
The findings of this study should be viewed in the context of certain limitations. The summer-season-based definition of CHD could lead to omitting certain hot and dry seasons that begin earlier than June or extend beyond the conventional summer boundaries37. Moreover, our analysis could include seasons that had a high variability in temperature and precipitation, e.g. one wet and cold month and two very warm and dry. In the study, we chose a definition of CHD relative to local climatology. It is the best choice when examining impacts on local ecology, as the ecological system adjusts to the values it is experiencing. At the same time, if we e.g. would like to examine human mortality due to hot and dry seasons, other definitions, such as those based on absolute thresholds, would be more advisable. In our definition, a CHD in NSC does not have the same impact on human mortality as a CHD in SWE due to lower temperatures and dryness.
Moreover, as with the results of any model biases might occur. CanESM2-CRCM5 shows a signal on the warmer and drier range for summer temperature and precipitation change between 1980–2009 and 2070–2090 when compared to other EURO-CORDEX models54. We scaled the chosen future climate via GWLs, which accounts for the rather high climate sensitivity of the CanESM2. Still, the regional warming signals over Europe for the given GWL3 are stronger than in the CCLM model to which we compared the results. At the same time, it has to be accounted, that previous research has shown that future changes in spatial patterns of hot and dry seasons are driven primarily by the global climate model37. Many of the driving models of EURO-CORDEX are part of CMIP5, which are known to underestimate the likelihood of hot and dry seasons for the period between 1950 and 1999 in Europe35. At the same time, there is high inter-CMIP5 uncertainty in the projection of the hot and dry seasons with regard to future periods35. Therefore, further research is needed to inspect other high-resolution large ensembles, particularly the effects induced by the new-generation CMIP6 models.
Focusing on two variables alone means that the summers may also have been extreme in other variables, e.g. wind, which could affect their probability. Moreover, the probabilities always rely on the extreme definition, and different definitions will undoubtedly lead to other probabilities and return periods for CHD occurrence. A model-related limitation lies within the missing two-way coupling of the dynamical downscaling between the RCM and the GCM. The high-resolution CRCM5-LE does not feed into the driving CanESM2. Therefore, the higher-resolution land-atmosphere interaction cannot affect the boundary conditions of the driving climate model. Moreover, the GWL approach assumes independence from the chosen model scenario, which must be validated further.
Looking forward, there are several avenues for future research. As indicated in the previous paragraph, there is potential for future research on compound hot and dry events on a monthly basis to assess CHDs for impacts like human health or energy consumption. Moreover, we have estimated the probability of occurrence of CHDs in the future. However, there is still a need for research on future factors leading to the formation and evolution of extremes. Our study on probability estimation can serve as a blueprint for analysing other compound extremes. Furthermore, there is potential in the analysis of shifts in climate zones, which could be applied to different types of extremes as well as to studies on the mean climate.
Methods
Bivariate probability assessment based on Survival Kendall probability and Copulas
In this study, we are investigating compound hot and dry extremes. We characterise them by temperature and precipitation. Those variables are highly interrelated. Therefore, we cannot calculate the probability in univariate terms, as this would disregard their bivariate structure38,39. Consequently, we use Copulas to describe the interrelation of the variables. Moreover, for the extreme CHD definition, we use the Survival–Kendall-hazard scenario40, which has previously proven its usefulness for the application on CHDs39. This approach divides the probability space into safe and potentially dangerous extremes. All extremes on the separating line share the same probability and return period.
We calculate our Survival Kendall probability using the following relationship:
where \({\bar{F}}_{X}(x)\) and \({\bar{F}}_{Y}(y)\) are the marginal survival functions of the two variables, t the critical probability and \(\hat{C}\) the survival copula. \({\bar{F}}_{X}(x)=1-{F}_{X}(x)\) and \({\bar{F}}_{Y}(x)=1-{F}_{Y}(y)\), where FX(x) and FY(y) correspond to the marginal cumulative distribution functions.
With the application on compound dry and hot extremes, we follow a previous study on the 2014 Californian drought39.
We use the VineCopula package in R55 for the calculation. Therefore, we first estimate the marginal probability functions and then transform those to uniform distributions. For precipitation, we use the empirical probability distribution with the Weibull plotting position formula, which is argued to be the best suited for extreme value analysis56. For temperatures above the 95th percentile, we use a Generalised Pareto distribution fit to get a higher accuracy for extremes. Below the 95th percentile, we are using the empirical probability distribution of the data. Different copula families exist that could be applied to bivariate structures. We fit 15 different copula families and use the Bayesian information criterion (BIC) to choose the best-fitting copula for the grid-cell-wise and regionally averaged temperature and precipitation values. All selected copulas pass the goodness-of-fit test based on Kendall’s process57,58 on α = 0.05 significance level.
Data sets
Assessing the occurrence probabilities of extremes requires an abundant database. To do this, we use seasonally averaged temperature and precipitation for June–July–August (JJA) originating from a SMILE, the Canadian Regional Climate Model 5 Large Ensemble (CRCM5-LE). The CRCM5-LE has been produced within the scope of the ClimEx Project32 on a European and a North American domain at a spatial resolution of 0.11° (12 km) for the years 1950–2099. We use the European domain for our analysis, which is displayed in Fig. 2. In the data production, dynamical downscaling via CRCM5-LE is applied on the global atmospheric 50-member initial-condition model—Canadian Earth System Model 2 (CanESM2)59. After a few years, the 50 members are losing their dependency due to the chaotic nature of the weather while maintaining its greenhouse gas forcing. The model is driven by historical greenhouse gas emissions up to 2005. Starting from the year 2006, the RCP8.5 forcing scenario is used. For the analysis, we are using the data from the three time periods: 2001–2020 (PRES), 2021–2040 (GWL2) and 2042–2061 (GWL3). We use 20 years from the 50 members, which results in 1000 years per period available for analysis.
The distributions of temperature and precipitation are compared to CCLM (0.44°), which is driven by CESM. The model ensemble consists of 21 members and covers the years 1950–2100, driven by the RCP8.5 scenario since 200645,46,47,60. For the analysis, we are using the data from the three time periods: 2001–2020 (PRES), 2033–2052 (GWL2) and 2052–2071 (GWL3) for temperature and precipitation61,62.
To assess the observed CHDs, we use the fifth generation of the ECMWF atmospheric reanalysis ERA531. We use linear interpolation on the European domain to make the data comparable with the grid from CRCM5-LE. For the fits, we are using the data for 1959–2022.
Temperatures in all three datasets are linearly detrended for each period individually. This is done to ensure comparability between the data from the beginning of the period and the end, which will have demonstrated an enhanced warming due to rising greenhouse gas concentration until the end of the period. ERA5 is detrended to the 2001–2020 level to ensure comparability with CRCM5 PRES. As shown by Schwalm et al., observed emissions in the years 2006–2020 are best represented by the RCP8.5 scenario63. As there is a model bias, we transfer ERA5 into the model worlds by transferring it according to its quantile and statistically evaluating whether the transformed data represent the univariate and bivariate structure well38. The authors argue in favour of this approach, in contrast to proceeding as usual and using the historical data as a reference, which would require three transformations on three periods of model data: GWL2, GWL3 and PRES. This would introduce a transformation error, as we have a limited historical data record of only 1959–2022. Moreover, for copula-based probability calculation, only ranks (hence quantiles) are used; therefore, no matter to which of the two datasets quantile mapping is applied there is no difference in the resulting probabilities in the analysis. The performed tests described below confirm that the resulting data is a good representation.
We test via Kolmogorov-Smirnov if both marginal distributions are well represented after the quantile mapping when inspecting ERA5 and CRCM5-LE64, and we perform a test of the bivariate structures via the TwoCop test in R. The latter test was developed by Rémillard and Scaillet65. It is designed to assess whether the empirical copulas between two distributions could belong to the same underlying distribution. Therefore, we can use it to evaluate whether they significantly deviate from one another. All the statistical tests have been performed on the α = 0.05 significance level. Here follow the methodology of Zscheischler et al.38
For the Supplementary Figs. S1 and S2 ERA5 are transferred into the CCLM world by using the same procedure as applied for CRCM5.
Global warming levels
GWLs have proven useful in science communication for calculating climate change-induced impacts at levels relevant for policy and decision-makers in various fields. The approach is less dependent on the choice of model and scenario. GWLs are calculated as mean surface air temperature anomalies referencing the historical conditions 1850–190029. They refer to the 20 years from the first year where the intended level was measured.
For our analysis, we follow the results of a previous study13 that used the anomalies from the CanESM2 driving model from 1850–1900 and used the same three periods:
-
1.
Present period 2001–2020 with GWL = +1.2 °C (PRES)
-
2.
Future I period 2021–2040 with GWL = +2 °C (GWL2)
-
3.
Future II period 2042–2061 with GWL = +3 °C (GWL3)
Finding regions where CHDs happen via Clustering
We apply the clustering technique to obtain regions to analyse CHDs. We aim to have regions experiencing CHDs simultaneously, with a high spatial and temporal interrelation in their occurrence. This study uses per grid cell and summer season calculated pSK-probability of occurrence as input to the agglomerative hierarchical clustering algorithm. We define the distance measure for the algorithm as
where r and q refer to two summers for which we are calculating the distance and cs to the cosine similarity measure66,67. We only include grid cells with pSK < 0.1 for the clustering to include only extreme occurrences. Only CHDs that have a spatial extent of at least 500 grid cells (≈1% of the land area) are analysed. We estimate the optimal number of clusters by applying the elbow method68. We apply a majority cluster filtering method introduced in a previous study67 and arrive at 9 clusters used as regions for the CHD probability quantification. The resulting clusters are displayed in Fig. 2, right.
Estimating future CHD climatology
To estimate the future CHD climatology, we take all the summers from the PRES and GWL3 period and filter pSK > 5% to obtain the distribution of CHDs per grid cell.
For the construction of a distance measure, we use the symmetrical Kullback–Leibler divergence69. The study by Perez et al. showed that it is possible to calculate the measure based on an empirical estimation from the samples using KD trees and nearest neighbours69. We use the Python implementation from Robert Kern70. As the Kullback–Leibler divergence is a non-symmetric measure, we symmetrise it by calculating the distance D via: D = 0.5KL(p, q) + 0.5KL(q, p), where p and q are bivariate distributions of two different grid cells.
To find the representative points for each cluster, we calculate the sum of the distance of every point to every other point in the spatial cluster. The point with the smallest summed distance is taken as a representative point for the spatial cluster. The distribution of the chosen points is shown in Fig. 8.
Data availability
The data is retrieved from the CRCM5-LE and freely available via https://www.climex-project.org/en/data-access/. The ERA5 data is freely available from https://cds.climate.copernicus.eu/. CESM-CCLM output is available upon request directed at erich.fischer@env.ethz.ch.
Code availability
All codes used are direct implementations of standard methods, publically available packages, and techniques, as described in detail in 'Methods'.
References
Zscheischler, J. et al. Future climate risk from compound events. Nat. Clim. Change 8, 469–477 (2018).
Masson-Delmotte, V. et al. Climate change 2021: the physical science basis. In Proc. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change, Vol. 2 (IPCC, 2021).
Rousi, E. et al. The extremely hot and dry 2018 summer in central and northern Europe from a multi-faceted weather and climate perspective. Nat. Hazards Earth Syst. Sci. 23, 1699–1718 (2023).
Sedlmeier, K., Feldmann, H. & Schädler, G. Compound summer temperature and precipitation extremes over central Europe. Theor. Appl. Climatol. 131, 1493–1501 (2018).
Robine, J.-M., Cheung, S. L., Le Roy, S., Van Oyen, H. & Herrmann, F. R. Report on excess mortality in Europe during summer 2003. EU Community Action Program. Public Health Grant Agreem. 2005114, 28 (2007).
Robine, J.-M. et al. Death toll exceeded 70,000 in Europe during the summer of 2003. Comptes Rendus Biol. 331, 171–178 (2008).
Barriopedro, D., Fischer, E. M., Luterbacher, J., Trigo, R. M. & García-Herrera, R. The hot summer of 2010: redrawing the temperature record map of Europe. Science 332, 220–224 (2011).
Zscheischler, J. & Seneviratne, S. I. Dependence of drivers affects risks associated with compound events. Sci. Adv. 3, e1700263 (2017).
Miralles, D. G., Gentine, P., Seneviratne, S. I. & Teuling, A. J. Land–atmospheric feedbacks during droughts and heatwaves: state of the science and current challenges. Ann. N. Y. Acad. Sci. 1436, 19 (2019).
O, S. et al. The role of climate and vegetation in regulating drought-heat extremes. J. Clim. 1, 1–21 (2022).
Vogel, M. M., Zscheischler, J. & Seneviratne, S. I. Varying soil moisture–atmosphere feedbacks explain divergent temperature extremes and precipitation projections in central Europe. Earth Syst. Dyn. 9, 1107–1125 (2018).
Seneviratne, S. I. et al. Investigating soil moisture–climate interactions in a changing climate: a review. Earth Sci. Rev. 99, 125–161 (2010).
Böhnisch, A., Felsche, E., Mittermeier, M., Poschlod, B. & Ludwig, R. Future hotspots of compound dry and hot summers emerge in European agricultural areas. Authorea Preprints (2023).
Trenberth, K. E. & Shea, D. J. Relationships between precipitation and surface temperature. Geophys. Res. Lett. 32 (2005). https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1029/2005GL022760
Thompson, V. et al. The most at-risk regions in the world for high-impact heatwaves. Nat. Commun. 14, 2152 (2023).
Böhnisch, A., Mittermeier, M., Leduc, M. & Ludwig, R. Hot spots and climate trends of meteorological droughts in Europe–assessing the percent of normal index in a single-model initial-condition large ensemble. Front. Water 3, 716621 (2021).
Almendra-Martn, L. et al. Analysis of soil moisture trends in Europe using rank-based and empirical decomposition approaches. Glob. Planet. Change 215, 103868 (2022).
Perkins-Kirkpatrick, S. E., Fischer, E. M., Angélil, O. & Gibson, P. B. The influence of internal climate variability on heatwave frequency trends. Environ. Res. Lett. 12, 044005 (2017).
Owen, A. L., Conover, E., Videras, J. & Wu, S. Heat waves, droughts, and preferences for environmental policy. J. Policy Anal. Manag. 31, 556–577 (2012).
Bittner, M.-I., Matthies, E. F., Dalbokova, D. & Menne, B. Are European countries prepared for the next big heat-wave? Eur. J. Public Health 24, 615–619 (2014).
Kromp-Kolb, H. et al. Climate change: assessment of the vulnerability of nuclear power plants and approaches for their adaptation. Organisation for Economic Co-Operation and Development (NEA, 2021).
Rossi, G., Cancelliere, A. & Giuliano, G. Case study: multicriteria assessment of drought mitigation measures. J. Water Resour. Plan. Manag. 131, 449–457 (2005).
Lowe, D., Ebi, K. L. & Forsberg, B. Heatwave early warning systems and adaptation advice to reduce human health consequences of heatwaves. Int. J. Environ. Res. Public Health 8, 4623–4648 (2011).
Ward, K., Lauf, S., Kleinschmit, B. & Endlicher, W. Heat waves and urban heat islands in Europe: a review of relevant drivers. Sci. Total Environ. 569, 527–539 (2016).
Habibi, S. & Asadi, N. Causes, results and methods of controlling urban sprawl. Procedia Eng. 21, 133–141 (2011).
Deser, C. et al. Insights from earth system model initial-condition large ensembles and future prospects. Nat. Clim. Change 10, 277–286 (2020).
Bevacqua, E. et al. Advancing research on compound weather and climate events via large ensemble model simulations. Nat. Commun. 14, 2145 (2023).
Poschlod, B., Zscheischler, J., Sillmann, J., Wood, R. R. & Ludwig, R. Climate change effects on hydrometeorological compound events over southern Norway. Weather Clim. Extrem. 28, 100253 (2020).
Seneviratne, S., Zhang, X., Adnan, M. et al. Chapter 11: weather and climate extreme events in a changing climate. climate change 2021: the physical science basis. In Proc.Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change (Cambridge, UK: Cambridge University Press, 2021).
Gampe, D. et al. Applying global warming levels of emergence to highlight the increasing population exposure to temperature and precipitation extremes. EGUsphere 2023, 1 (2023).
Hersbach, H. et al. The era5 global reanalysis. Q. J. R. Meteorol. Soc. 146 (2020).
Leduc, M. et al. The ClimEx Project: A 50-member ensemble of climate change projections at 12-km resolution over Europe and Northeastern North America with the Canadian Regional Climate Model (CRCM5). J. Appl. Meteorol. Clim. 58, 663–693 (2019).
Ionita, M., Caldarescu, D. E. & Nagavciuc, V. Compound hot and dry events in Europe: variability and large-scale drivers. Front. Clim. 3, 688991 (2021).
De Luca, P., Messori, G., Faranda, D., Ward, P. J. & Coumou, D. Compound warm–dry and cold–wet events over the Mediterranean. Earth Syst. Dyn. 11, 793–805 (2020).
Wu, X. et al. Projected increase in compound dry and hot events over global land areas. Int. J. Climatol. 41, 393–403 (2021).
Zscheischler, J., Orth, R. & Seneviratne, S. I. Bivariate return periods of temperature and precipitation explain a large fraction of European crop yields. Biogeosciences 14, 3309–3320 (2017).
Lhotka, O., Bešt’áková, Z. & Kyselý, J. Prolongation of compound dry–hot seasons over Europe under climate change scenarios. Earth’s. Future 11, e2023EF003557 (2023).
Zscheischler, J. & Fischer, E. M. The record-breaking compound hot and dry 2018 growing season in Germany. Weather Clim. Extrem. 29, 100270 (2020).
AghaKouchak, A., Cheng, L., Mazdiyasni, O. & Farahmand, A. Global warming and changes in risk of concurrent climate extremes: Insights from the 2014 California drought: Global Warming and Concurrent Extremes. Geophys. Res. Lett. 41, 8847–8852 (2014).
Salvadori, G., Durante, F., De Michele, C., Bernardi, M. & Petrella, L. A multivariate copula-based framework for dealing with hazard scenarios and failure probabilities. Water Resour. Res. 52, 3701–3721 (2016).
Zscheischler, J. & Lehner, F. Attributing compound events to anthropogenic climate change. Bull. Am. Meteorol. Soc. 103, E936–E953 (2022).
Salvadori, G., Durante, F. & De Michele, C. Multivariate return period calculation via survival functions. Water Resour. Res. 49, 2308–2311 (2013).
Russo, S., Sillmann, J. & Fischer, E. M. Top ten European heatwaves since 1950 and their occurrence in the coming decades. Environ. Res. Lett. 10, 124003 (2015).
Waskom, M. L. Seaborn: statistical data visualization. J. Open Source Softw. 6, 3021 (2021).
Fischer, E. M., Beyerle, U. & Knutti, R. Robust spatially aggregated projections of climate extremes. Nat. Clim. Change 3, 1033–1038 (2013).
von Trentini, F., Aalbers, E. E., Fischer, E. M. & Ludwig, R. Comparing internal variabilities in three regional single model initial-condition large ensembles (smile) over Europe. Earth Syst. Dyn. Discuss. 2019, 1–27 (2019).
Brönnimann, S. et al. Changing seasonality of moderate and extreme precipitation events in the Alps. Nat. Hazards Earth Syst. Sci. 18, 2047–2056 (2018).
Bevacqua, E., Zappa, G., Lehner, F. & Zscheischler, J. Precipitation trends determine future occurrences of compound hot–dry events. Nat. Clim. Change 12, 350–355 (2022).
Charpentier, A. On the return period of the 2003 heat wave. HAL Working Papers 109, 245–260 (2010).
Bastos, A. et al. Direct and seasonal legacy effects of the 2018 heat wave and drought on European ecosystem productivity. Sci. Adv. 6, eaba2724 (2020).
Dirmeyer, P. A., Balsamo, G., Blyth, E. M., Morrison, R. & Cooper, H. M. Land-atmosphere interactions exacerbated the drought and heatwave over northern Europe during summer 2018. AGU Adv. 2, e2020AV000283 (2021).
Manning, C. et al. Increased probability of compound long-duration dry and hot events in Europe during summer (1950–2013). Environ. Res. Lett. 14, 094006 (2019).
Beck, H. E. et al. Present and future köppen-Geiger climate classification maps at 1-km resolution. Sci. Data 5, 1–12 (2018).
von Trentini, F., Leduc, M. & Ludwig, R. Assessing natural variability in RCM signals: comparison of a multi model euro-cordex ensemble with a 50-member single model large ensemble. Clim. Dyn. 53, 1963–1979 (2019).
Nagler, T. et al. Vinecopula: statistical inference of vine copulas. R package version 2 (2019).
Makkonen, L. Plotting positions in extreme value analysis. J. Appl. Meteorol. Climatol. 45, 334–340 (2006).
Wang, W. & Wells, M. T. Model selection and semiparametric inference for bivariate failure-time data. J. Am. Stat. Assoc. 95, 62–72 (2000).
Genest, C., Quessy, J.-F. & Rémillard, B. Goodness-of-fit procedures for copula models based on the probability integral transformation. Scand. J. Stat. 33, 337–366 (2006).
Martynov, A. et al. Reanalysis-driven climate simulation over CORDEX North America domain using the Canadian Regional Climate Model, version 5: model performance evaluation. Clim. Dynam. 41, 2973–3005 (2013).
Addor, N. & Fischer, E. M. The influence of natural variability and interpolation errors on bias characterization in RCM simulations. J. Geophys. Res. Atmos. 120, 10,180–10,195 (2015).
Holland, M. M. et al. New model ensemble reveals how forcing uncertainty and model structure alter climate simulated across CMIP generations of the community earth system model. Geosci. Model Dev. 17, 1585–1602 (2024).
Lin, L., Gettelman, A., Fu, Q. & Xu, Y. Simulated differences in 21st century aridity due to different scenarios of greenhouse gases and aerosols. Clim. Change 146, 407–422 (2018).
Schwalm, C. R., Glendon, S. & Duffy, P. B. Rcp8. 5 tracks cumulative co2 emissions. Proc. Natl Acad. Sci. 117, 19656–19657 (2020).
Berger, V. W. & Zhou, Y. Kolmogorov–Smirnov test: overview. Wiley statsref: statistics reference online (2014).
Rémillard, B. & Scaillet, O. Testing for equality between two copulas. J. Multivar. Anal. 100, 377–386 (2009).
Cheng, X. & Wallace, J. M. Cluster analysis of the northern hemisphere wintertime 500 hpa height field: spatial patterns. J. Atmos. Sci. 50, 2674–2696 (1993).
Felsche, E., Böhnisch, A. & Ludwig, R. Inter-seasonal connection of typical European heatwave patterns to soil moisture. NPJ Clim. Atmos. Sci. 6, 1 (2023).
Jung, Y., Park, H., Du, D.-Z. & Drake, B. L. A decision criterion for the optimal number of clusters in hierarchical clustering. J. Glob. Optim. 25, 91–111 (2003).
Pérez-Cruz, F. Kullback-leibler divergence estimation of continuous distributions. In Proc. 2008 IEEE international symposium on information theory, 1666–1670 (IEEE, 2008).
Kern, R. Kullback-leibler divergence. https://gist.github.com/atabakd/ed0f7581f8510c8587bc2f41a094b518 (2011).
Acknowledgements
The CRCM5-LE was created within the ClimEx project, which was funded by the Bavarian State Ministry for the Environment and Consumer Protection. Computations of the CRCM5-LE were made on the SuperMUC supercomputer at the Leibniz Supercomputing Centre of the Bavarian Academy of Sciences and Humanities. We acknowledge Environment and Climate Change Canada for providing the CanESM2-LE driving data. We acknowledge Erik van Meijgaard for providing access to 16-member KNMI RACMO-EC-EARTH, which was used for comparisons not included in the study. We thank Erich Fischer for providing access to CESM-CCLM.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
E.F. designed the research under the supervision of R.L., E.F., A.B. and B.P. regularly feedbacked the results and provided ideas for further development. E.F. performed the data analysis and led the writing of the paper. E.F. prepared all the figures. All authors contributed to the interpretation of the findings and revision of the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval
All collaborators of this study have fulfilled the criteria for authorship required by Nature Portfolio journals and have been included as authors. Their participation was essential for the design and implementation of the study. Roles and responsibilities were agreed among collaborators ahead of the research. This research does not result in stigmatization, incrimination, discrimination or personal risk to participants. Local and regional research relevant to our study was taken into account in citations.
Peer review
Peer review information
Communications Earth & Environment thanks Ondr^ej Lhotka and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Primary Handling Editors: Akintomide Akinsanola, Heike Langenberg. A peer review file is available
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Felsche, E., Böhnisch, A., Poschlod, B. et al. European hot and dry summers are projected to become more frequent and expand northwards. Commun Earth Environ 5, 410 (2024). https://doi.org/10.1038/s43247-024-01575-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s43247-024-01575-5
- Springer Nature Limited