
Abstract
This study aimed to develop a machine learning (ML)-based tool for early and accurate prediction of in-hospital mortality risk in patients with spontaneous intracerebral hemorrhage (sICH) in the intensive care unit (ICU). We did a retrospective study in our study and identified cases of sICH from the MIMIC IV (n = 1486) and Zhejiang Hospital databases (n = 110). The model was constructed using features selected through LASSO regression. Among five well-known models, the selection of the best model was based on the area under the curve (AUC) in the validation cohort. We further analyzed calibration and decision curves to assess prediction results and visualized the impact of each variable on the model through SHapley Additive exPlanations. To facilitate accessibility, we also created a visual online calculation page for the model. The XGBoost exhibited high accuracy in both internal validation (AUC = 0.907) and external validation (AUC = 0.787) sets. Calibration curve and decision curve analyses showed that the model had no significant bias as well as being useful for supporting clinical decisions. XGBoost is an effective algorithm for predicting in-hospital mortality in patients with sICH, indicating its potential significance in the development of early warning systems.
Similar content being viewed by others


Introduction
Spontaneous intracerebral hemorrhage (sICH) is a critical neurological event characterized by bleeding within the intracerebral parenchyma, leading to a sudden and potentially life-threatening medical emergency1. Despite notable advancements in medical care, the overall prognosis of sICH remains poor, primarily attributed to inflammatory responses, oxidative stress, and other mechanisms, resulting in a significant proportion of patients succumbing during hospitalization2,3. Accurate prediction of in-hospital mortality holds paramount importance in guiding clinical decision-making and optimizing resource allocation. Therefore, there is an urgent need for an advanced model that can help predict the prognosis of patients with sICH.
In recent years, there has been a growing interest in the application of machine learning (ML) techniques to investigate various clinical diseases4,5,6,7,8. Compared to traditional statistics, ML exhibits characteristics such as handling complex nonlinear data, offering high flexibility, and enabling continuous learning and improvement9,10. Prior attempts have been made in the field of sICH11,12. However, there is still a pressing need for models that can accurately predict severe sICH cases in ICU.
The interpretability of machine learning models is crucial for enhancing trust among healthcare professionals. Therefore, Shapley Additive exPlanations (SHAP), a game-theoretic technique pioneered by Lundberg and Lee, effectively mitigates the black-box nature of ML models by offering consistent interpretability. This powerful method has been successfully applied in various contexts, including predicting the prognosis of patients with non-traumatic subarachnoid hemorrhage13, forecasting the onset of acute kidney injury following cardiac surgery14, and anticipating the development of sepsis in patients with COVID-1915.In this study, our objective is to develop and validate aML-based predictive model for in-hospital mortality among sICH patients. By utilizing a comprehensive set of clinical and demographic features, we aim to provide clinicians with a robust tool to accurately assess the risk of mortality in real-time, thus facilitating timely interventions and improving patient care.
Methods
Database and ethics
The Medical Information Mart for Intensive Care-IV (MIMIC-IV) is an open and freely accessible critical care database that contains comprehensive clinical data of patients admitted to a tertiary academic medical center in Boston, MA, USA, from 2008 to 2019. The database includes essential patient information, vital signs, laboratory indicators, treatment details, and survival data. The usage of data from MIMIC-IV has been granted approval by the Institutional Review Boards of Beth Israel Deaconess Medical Center (Boston, MA) and Massachusetts Institute of Technology (MIT; Cambridge, MA). As all personal data in this database is encrypted, informed consent was waived. One of the authors (Mao, Baojie) obtained access to the database and was responsible for data extraction (certification number 46148427). In addition, we recruited patients with cerebral hemorrhage who were admitted to ICU from December 2018 to February 2023 in Zhejiang Hospital. The study protocol was approved by the Ethics Review Committee of Zhejiang Hospital (No. 2023 Pro-examination (58 K)). All methods and procedures were carried out in accordance with the Declaration of Helsinki. All patient data were anonymized. No patient-identifiable data were recorded throughout the study. Given that this study was purely observational, written consent from patients was not required.
Data extraction and outcomes
Clinical and laboratory variables were meticulously collected within 24 h of admission to the Intensive Care Unit (ICU). In the case of variables with multiple measurements, mean values were calculated and utilized for analysis. A total of forty-six variables were included in the data collection process. These encompassed patient characteristics (age, gender), vital signs (respiratory rate, blood pressure, heart rate, oxygen saturation, and temperature), laboratory data (routine blood analysis, renal function, coagulation, and blood gases), as well as comorbidities identified based on recorded International Classification of Diseases ICD-9 and ICD-10 codes. The comorbidities considered were hypertension, diabetes mellitus, chronic obstructive pulmonary disease (COPD), congestive heart failure, renal disease, liver disease, and malignancy. Furthermore, information regarding the usage of anticoagulant and vasoactive drugs, surgical status, Glasgow Coma Scale (GCS), Sequential Organ Failure Assessment (SOFA) scores, mechanical ventilation, and renal replacement therapy (RRT) was gathered. Due to the limited number of patients with missing data, we opted to exclude them from the analysis rather than attempting to estimate the missing values. The primary endpoint was all-cause in-hospital mortality.
Cohort selection
-
1.
Patients must be admitted to the ICU for the first time.
-
2.
Patients must have a confirmed diagnosis of sICH.
-
3.
Patients’ age should fall within the range of 18–90 years.
-
4.
Patients must have an ICU length of stay exceeding 1 day.
-
5.
Patients must have complete clinical data.
The flowchart for patient recruitment is shown in Fig. 1.

Model development process and flowchart of the study.
Feature selection
We applied Lasso regression, a regularization technique, on the preprocessed dataset. Lasso performs feature selection by shrinking the coefficients of less important features to zero, effectively eliminating them from the model. The optimal regularization parameter (λ) for Lasso was determined using the coordinate descent algorithm. Following Lasso regression, the variables were ranked based on their corresponding non-zero coefficients. The final predictive model included the top 14 variables with the highest absolute coefficient values.
Statistical analysis
The normality of the distribution was evaluated using the Kolmogorov–Smirnov test. Continuous variables were presented as mean with standard deviation if they followed a normal distribution, or as median with 25–75th percentile if they deviated from normality. The Student's t-test or Mann–Whitney test was applied accordingly to analyze the continuous variables. Categorical variables were presented as counts and percentages, and the chi-square test was utilized to compare the distributions.
In this study, we employed five different ML algorithms to develop models: Logistic regression (LR), K-nearest neighbors (KNN), Adaptive boosting (AdaBoost), Random forest (RF) and eXtreme Gradient Boosting algorithms (XGBoost). The MIMIC IV dataset was initially partitioned into a training set (70%) and an internal validation set (30%). Furthermore, we utilized the Zhejiang Hospital dataset as an external validation set. The validation process employed a bootstrap resampling technique with 1000 iterations to evaluate the model's performance. The area under the curve (AUC) and 95% confidence intervals (CI) were calculated. Furthermore, several evaluation metrics, including accuracy, sensitivity, specificity, Youden index, and F1 score, were computed. The performance of the model is assessed by conducting tenfold cross-validation and obtaining the average value. For hyperparameter selection, grid search methods were utilized.
To assess the performance and clinical applicability of the predictive model, we generated calibration curves and clinical decision curves. Calibration curves were used to evaluate the predictive accuracy and calibration of the model by comparing the predicted probabilities with actual observations. On the other hand, clinical decision curves were employed to determine the model's sensitivity and specificity at various decision thresholds, thus optimizing its predictive performance for clinical decision-making. After selecting the optimal model, we utilized the SHAP package in Python to demonstrate the importance of each feature. Subsequently, we developed a web-based visual interface using Streamlit to demonstrate the functionality of the selected machine learning model. Users can input relevant data parameters or upload datasets for real-time model evaluation. The model processes the input data, generating predictive outcomes based on the underlying learning patterns.
Statistical significance was set at P < 0.05, and all tests were two-tailed. Statistical analyses were performed using R software (version 4.3.1) or Python software (version 3.11).
Result
Baseline characteristics
The present study involved a total of 1596 patients, including 1486 patients from the internal cohort extracted from the MIMIC-IV database and 110 patients from the external cohort extracted from the Zhejiang Hospital database. In the internal cohort, there were 349 in-hospital deaths (23.48%), whereas the external cohort had 18 in-hospital deaths (16.36%). Table 1 provides an overview of the baseline characteristics for both the internal and external cohorts.
Key variables
Within the training set, LASSO regression was applied for automated feature selection as illustrated in Fig. 2. Lasso regression is a method for regression analysis that reduces unnecessary model complexity by introducing a regularization term (λ) for variable selection and complexity adjustment. From the initial pool of 46 candidate variables, we identified the top 14 based on their importance and integrated them into the final model. The selected variables encompassed: use of anticoagulants, use of mannitol, use of vasoactive drugs, mechanical ventilation, temperature, surgical intervention, serum potassium, heart failure, blood oxygen saturation, SOFA, GCS, serum sodium, RDW and serum chloride.

Demographic and clinical feature selection. The automated feature selection process for 46 clinical factors was executed utilizing the LASSO, aiming to minimize the binomial deviance loss function, shrink coefficients, and generate some zero coefficients to facilitate efficient feature selection (A). Subsequently, the algorithm identified and retained 14 filtered features with non-zero coefficients for integration into the model generation process (B).
Model performance
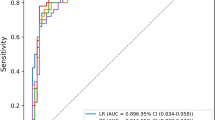
The discriminative ability of all models to predict mortality is shown in Fig. 3 and Table 2. In the training set, XGBoost, KNN, LR, RF, and AdaBoost models were built, and the AUCs of the internal validation set were 0. 907, 0.808, 0.851, 0.897, and 0.900, respectively. Note that the prediction performance of the XGBOOST model was the highest among these five models (AUC 0.907; 95% CI 0.875–0.939; accuracy: 0.874; sensitivity: 0.582). In the external validation set, the XGBoost model demonstrated predictive power with an AUC of 0.788, second only to the LR model, which achieved an AUC of 0.790.

Area under the receiver operating characteristic curve for machine learning models in the internal validation queue (A) and external validation queue (B). ROC receiver operate characteristics, CI confidence intervals.
Figure 4A shows the calibration plots for all five models. The calibration curve analysis showed that XGBoost was accurately calibrated in predicting the risk of in-hospital death, with no significant over or underestimation (Fig. 4B). In addition, the Decision Curve Analysis (DCA) for XGBoost has the highest net benefit across risk thresholds compared to all other models, as shown in Fig. 4C,D.

Calibration plots of five ML models in the internal validation queue (A,B). Decision curve analysis for five ML models in the internal validation queue (C,D).
The importance of features derived from XGBoost model is shown in Fig. 5. GCS score was the most influential feature followed by SOFA score, use of anticoagulants, use of mannitol, oxygen saturation, body temperature, serum sodium, serum potassium, RDW, mechanical ventilation, heart failure, serum chloride, use of vasoactive drugs and surgical intervention.

Scatter plot of variables for SHAP analysis (A) and importance ranking plot (B) of the XGBoost. A visual representation illustrates the importance of each feature in the XGBoost model, depicting the relationship between them. The color scale indicates the variable values, with red denoting higher values and blue indicating lower values.
Application of the model
Additionally, a web-based computational tool using the XGBoost algorithm model has been developed to enable clinicians in real-time prediction of the prognosis for patients with severe sICH. (accessible at https://sich-mimic.streamlit.app/). Figure 6 shows an example of using a real-time prediction tool for web pages. This example highlights the patient's heightened risk of in-hospital mortality and indicates that variables such as temperature, medications, and other factors serve as prognostic risk factors. Clinicians are advised to promptly regulate the patient's temperature, consider conservative anticoagulant therapy, and evaluate the discontinuation of mannitol if deemed feasible and suitable.

Case of website usage. Enter input values to determine the prognosis for sICH, and show the contribution of the variable shap value to the prediction. An in-hospital mortality rate of 44.812% was predicted. Additionally, factors including body temperature, non-utilization of anticoagulants, and mannitol usage were linked to a unfavorable prognosis in patients with sICH.
Discussion
In this retrospective study, we developed and validated a clinical feature-based machine learning algorithm for predicting in-hospital mortality in critically ill patients with sICH.Among the tested models, the XGBOOST model demonstrated the highest prediction performance. Through advanced machine learning techniques, we successfully identified several key clinical features strongly associated with in-hospital mortality, including GCS score, SOFA score, use of mannitol medication, use of anticoagulant medication, vital signs, serum electrolytes, RDW, among others. These findings are significant and warrant further investigation. Additionally, we have created an easy-to-use web-based calculator to assist clinicians in making informed decisions regarding further treatment.
Among various types of strokes, cerebral hemorrhage is characterized by a relatively high in-hospital mortality rate, especially in patients admitted to ICU. The in-hospital mortality rate of patients varies based on both the location and volume of the hematoma. Previous studies have reported an early mortality rate of 40% and a long-term mortality rate as high as 60% for sICH patients16,17,18.Marika Fallenius et al. analyzed patients admitted to the ICU with severe cerebral hemorrhage and found a mortality rate of 42% for supratentorial sICH patients and 49% for infratentorial sICH patients19. Additionally, researchers investigated a 30-day mortality rate of up to 54% for patients with severe sICH in the southern region of Spain, and this rate increased to 60% for patients with hematoma volumes exceeding 30 ml20. The mortality rate observed in our study was lower compared to the case-fatality rates reported in previous studies. This difference may be attributed to our exclusion of patients admitted for less than one day or those automatically discharged, as well as differences in medical conditions.
In this study, we employed five distinct ML methods to develop predictive models. The performance evaluation of these algorithms was based on six common metrics (AUC, F1 score, accuracy, sensitivity, specificity and Youden Index). Notably, the results unequivocally indicate that the XGBoost model exhibits the most superior performance and predictive stability, which contrasts with previous findings favoring the Random Forest model21. XGBoost is an efficient, flexible, and scalable ML algorithm, renowned for its classification capabilities. To mitigate overfitting and optimize its performance, XGBoost employs techniques such as improved subsampling rates, learning rates, and maximum tree depth control22. Zhu et al. evaluated data from ICU patients who were intubated due to respiratory failure and received mechanical ventilation. They utilized seven learning algorithms to predict in-hospital mortality, with XGBoost demonstrating the best overall performance23. Similarly, Hu et al. incorporated data from 8817 sepsis patients into seven models to predict in-hospital mortality, and they also found that the XGBoost model exhibited the most effective predictive ability24.
Despite the success of algorithms in this field, one of the current challenges lies in the need to interpret the “black box” of ML. Thus, we utilized the visualization function in SHAP to identify the impact of specific variable values on the model output. As anticipated, the GCS score takes the top position in the SHAP importance ranking. The GCS is a widely used scale for assessing the level of consciousness, with scores ranging from 3 to 15. Previous studies have consistently demonstrated the importance of the GCS score in evaluating the severity of neurological disorders21,25,26. The SOFA score serves as a valuable tool for quantifying the extent of organ dysfunction or failure at the point of ICU admission and has found widespread application in predicting in-hospital mortality in this setting27,28,29. It has been observed that the SOFA score exhibits superior predictive performance compared to other scoring systems when it comes to infection-related in-hospital mortality in ICU patients30. The use of anticoagulants in patients with cerebral hemorrhage and the timing of anticoagulant use remain controversial, and some studies have suggested that anticoagulants have a positive effect on patient prognosis. This might be because the use of anticoagulants in critically ill patients reduces complications such as thromboembolism and does not significantly increase bleeding complications31. Currently, the primary non-surgical treatment for cerebral hemorrhage involves the use of drugs like mannitol to reduce intracranial pressure. However, our study revealed that the use of mannitol may lead to a poor prognosis for patients with this disease. According to current guidelines, hypertonic saline demonstrates superior efficacy in managing cerebral edema associated with cerebral hemorrhage compared to mannitol32. Mannitol, which can elevate the risk of intracranial hemorrhage, may be less preferable in such cases. Oximetry ranked fifth in importance in our model. However, contrary to clinical expectations, we observed that oxygen saturation was lower in survivors compared to non-survivors in the internal cohort (97.22% vs. 98.34%) at baseline. It is possible that over-oxygenating ICU patients within normal oxygen saturation levels can lead to unfavorable prognoses and more adverse outcomes33. Moreover, prior research has established that electrolyte disturbances represent an independent risk factor for an unfavorable prognosis in stroke patients34,35,36. Lastly, to our surprise, the study indicates that in critically ill patients, surgical treatment may not hold significant importance. The low rate of surgery in sICH in the internal MIMIC dataset (8.60–11.96%) may be due to the fact that we included both critically and mildly ill patients, leading to a weakening of the influence of surgical intervention as an important factor, as it is known that surgical treatment may be more effective in patients with high bleeding volumes. This study holds significant clinical and methodological implications. Firstly, we implemented an external validation set to mitigate the risk of model overfitting. Secondly, the model was developed using readily available data collected within 24 h of patient admission, enabling early and accurate mortality prediction. This provides clinicians with more time to adjust treatment strategies accordingly. Thirdly, the study sheds light on previously overlooked factors, such as anticoagulant use and RDW, which are now identifiable. Integrating these factors with machine learning methods enhances the predictive performance significantly. Lastly, to facilitate bedside use by clinicians, a user-friendly calculator based on the model was developed.
Limitation
However, our study has several limitations that need to be acknowledged. Firstly, it was a retrospective and observational study, which may introduce certain research biases. Secondly, as our study was focused on patients with sICH, we did not include information on radiologic variables, such as hematoma volume or location, which could potentially provide additional insights into the disease. Thirdly, the complexity of the model with 14 inputs may pose challenges for practical implementation in clinical settings, suggesting the necessity of integrating the algorithms with electronic medical record systems. Fourthly, variations in data collection methods between the open dataset and the local dataset may introduce realistic discrepancies. Lastly, the diversity of patient populations across different ICUs, as evidenced by differing death rates between hospitals, may impact the generalizability of the study findings, highlighting the importance of considering regional factors in result interpretation. It is possible that the local dataset represents a subgroup of critical care cases within the larger open dataset.
Conclusion
The XGBoost model demonstrated superior performance in predicting short-term mortality among sICH patients. Our findings indicate that factors such as GCS, SOFA score, mannitol use, anticoagulant use, oxygen saturation, time of ICU admission, temperature, serum sodium, mechanical ventilation, and serum potassium are strongly associated with in-hospital mortality in sICH patients. This newly developed risk model is expected to serve as a convenient tool for risk stratification.
Data availability
The datasets and code used in the present study are available from the corresponding authors on reasonable request.
Abbreviations
- sICH:
-
Spontaneous intracerebral hemorrhage
- ICU:
-
Intensive care unit
- ML:
-
Machine learning
- LR:
-
Logistic regression
- KNN:
-
K-nearest neighbors
- AdaBoost:
-
Adaptive boosting
- RF:
-
Random forest
- XGBoost:
-
eXtreme Gradient Boosting
- AUC:
-
Area under the curve
- SHAP:
-
SHapley Additive exPlanations
- GCS:
-
Glasgow Coma Scale
- SOFA:
-
Sequential Organ Failure Assessment
- RDW:
-
Red blood cell distribution width
- MIMIC-IV:
-
Medical Information Mart for Intensive Care-IV
- COPD:
-
Chronic obstructive pulmonary disease
- RRT:
-
Renal replacement therapy
- CI:
-
Confidence intervals
- DCA:
-
Decision curve analysis
References
Qureshi, A. I. et al. Spontaneous intracerebral hemorrhage. N. Engl. J. Med. 344, 1450–1460 (2001).
Aronowski, J. & Zhao, X. Molecular pathophysiology of cerebral hemorrhage: Secondary brain injury. Stroke 42, 1781–1786 (2011).
Wang, J. Preclinical and clinical research on inflammation after intracerebral hemorrhage. Prog. Neurobiol. 92, 463–477 (2010).
Esteva, A. et al. Dermatologist-level classification of skin cancer with deep neural networks. Nature 542, 115–118 (2017).
Ambale-Venkatesh, B. et al. Cardiovascular event prediction by machine learning: The multi-ethnic study of atherosclerosis. Circ. Res. 121, 1092–1101 (2017).
Nomura, A., Noguchi, M., Kometani, M., Furukawa, K. & Yoneda, T. Artificial intelligence in current diabetes management and prediction. Curr. Diab. Rep. 21, 61 (2021).
Huang, B. et al. Mortality prediction for patients with acute respiratory distress syndrome based on machine learning: A population-based study. Ann. Transl. Med. 9, 794 (2021).
Huang, T., Le, D., Yuan, L., Xu, S. & Peng, X. Machine learning for prediction of in-hospital mortality in lung cancer patients admitted to intensive care unit. PloS One 18, e0280606 (2023).
Raita, Y. et al. Emergency department triage prediction of clinical outcomes using machine learning models. Crit. Care Lond. Engl. 23, 64 (2019).
Manz, C. R. et al. Validation of a machine learning algorithm to predict 180-day mortality for outpatients with cancer. JAMA Oncol. 6, 1723–1730 (2020).
Bunney, G. et al. Predicting early seizures after intracerebral hemorrhage with machine learning. Neurocrit. Care 37, 322–327 (2022).
Rusche, T. et al. Machine learning for onset prediction of patients with intracerebral hemorrhage. J. Clin. Med. 12, 2631 (2023).
Gu, L. et al. Machine learning predictors of risk of death within 7 days in patients with non-traumatic subarachnoid hemorrhage in the intensive care unit: A multicenter retrospective study. Heliyon 10, e23943 (2024).
Tseng, P.-Y. et al. Prediction of the development of acute kidney injury following cardiac surgery by machine learning. Crit. Care 24, 478 (2020).
Tang, G. et al. Prediction of sepsis in COVID-19 using laboratory indicators. Front. Cell. Infect. Microbiol. 10, 586054 (2021).
Van Asch, C. J. et al. Incidence, case fatality, and functional outcome of intracerebral haemorrhage over time, according to age, sex, and ethnic origin: A systematic review and meta-analysis. Lancet Neurol. 9, 167–176 (2010).
Sacco, S., Marini, C., Toni, D., Olivieri, L. & Carolei, A. Incidence and 10-year survival of intracerebral hemorrhage in a population-based registry. Stroke 40, 394–399 (2009).
Poon, M. T. C., Fonville, A. F. & Al-Shahi Salman, R. Long-term prognosis after intracerebral haemorrhage: Systematic review and meta-analysis. J. Neurol. Neurosurg. Psychiatry 85, 660–667 (2014).
Fallenius, M. et al. Spontaneous intracerebral hemorrhage. Stroke 50, 2336–2343 (2019).
Rodríguez-Fernández, S. et al. Validation of the ICH score in patients with spontaneous intracerebral haemorrhage admitted to the intensive care unit in Southern Spain. BMJ Open 8, e021719 (2018).
Nie, X. et al. Mortality prediction in cerebral hemorrhage patients using machine learning algorithms in intensive care units. Front. Neurol. 11, 610531 (2020).
Xu, Y. et al. Predicting ICU mortality in rheumatic heart disease: Comparison of XGBoost and logistic regression. Front. Cardiovasc. Med. 9, 847206 (2022).
Zhu, Y. et al. Machine learning prediction models for mechanically ventilated patients: Analyses of the MIMIC-III database. Front. Med. 8, 662340 (2021).
Hu, C. et al. Interpretable machine learning for early prediction of prognosis in sepsis: A discovery and validation study. Infect. Dis. Ther. 11, 1117–1132 (2022).
Teasdale, G. & Jennett, B. Assessment of coma and impaired consciousness. A practical scale. Lancet Lond. Engl. 2, 81–84 (1974).
Agrawal, N. et al. Comparison of admission GCS score to admission GCS-P and FOUR scores for prediction of outcomes among patients with traumatic brain injury in the intensive care unit in India. Acute Crit. Care 38, 226–233 (2023).
Ferreira, F. L. Serial evaluation of the SOFA score to predict outcome in critically ill patients. JAMA 286, 1754 (2001).
Vincent, J.-L. et al. The SOFA (Sepsis-related Organ Failure Assessment) score to describe organ dysfunction/failure: On behalf of the working group on sepsis-related problems of the European society of intensive care medicine (see contributors to the project in the appendix). Intensive Care Med. 22, 707–710 (1996).
Cárdenas-Turanzas, M. et al. Cross-validation of a Sequential Organ Failure Assessment score–based model to predict mortality in patients with cancer admitted to the intensive care unit. J. Crit. Care 27, 673–680 (2012).
Raith, E. P. et al. Prognostic accuracy of the SOFA score, SIRS criteria, and qSOFA score for in-hospital mortality among adults with suspected infection admitted to the intensive care unit. JAMA 317, 290 (2017).
Kuramatsu, J. B. & Huttner, H. B. Management of oral anticoagulation after intracerebral hemorrhage. Int. J. Stroke Off. J. Int. Stroke Soc. 14, 238–246 (2019).
Cook, A. M. et al. Guidelines for the acute treatment of cerebral edema in neurocritical care patients. Neurocrit. Care 32, 647–666 (2020).
Barbateskovic, M. et al. Higher versus lower fraction of inspired oxygen or targets of arterial oxygenation for adults admitted to the intensive care unit. Cochrane Database Syst. Rev. https://doi.org/10.1002/14651858.CD012631.pub2 (2019).
Bales, J. et al. The effect of hyponatremia and sodium variability on outcomes in adults with aneurysmal subarachnoid hemorrhage. World Neurosurg. 96, 340–349 (2016).
Matano, F. et al. Serum glucose and potassium ratio as risk factors for cerebral vasospasm after aneurysmal subarachnoid hemorrhage. J. Stroke Cerebrovasc. Dis. Off. J. Natl. Stroke Assoc. 28, 1951–1957 (2019).
Sadan, O., Samuels, O., Asbury, W. H., Hanfelt, J. J. & Singbartl, K. Low-chloride versus high-chloride hypertonic solution for the treatment of subarachnoid hemorrhage-related complications (The ACETatE trial): Study protocol for a pilot randomized controlled trial. Trials 19, 628 (2018).
Acknowledgements
We would like to thank all the participants and investigators that took part in this study.
Funding
This work was supported by the grants from Special Support Program for High Level Talents of Zhejiang Province (2022R52038), Key Research and Development Project of Zhejiang Provincial Department of Science and Technology (2021C03105), Natural Science Foundation of Zhejiang Province (LY21H090008) and Medical Health Science and Technology Project of Zhejiang Provincial Health Commission (WKJ-ZJ-2340).
Author information
Authors and Affiliations
Contributions
S.W. and M.W. designed the work. B.J.M., Y.H.P., R.Z. and W.N.Z. extracted and analyzed the datasets. B.J.M. and Y.F.S. wrote this paper. B.J.M., L.C.L., W.L., Y.N.L., S.H.X. and J.W. interpreted the results and helped to revise the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mao, B., Ling, L., Pan, Y. et al. Machine learning for the prediction of in-hospital mortality in patients with spontaneous intracerebral hemorrhage in intensive care unit. Sci Rep 14, 14195 (2024). https://doi.org/10.1038/s41598-024-65128-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-65128-8
- Springer Nature Limited