
Abstract
Predicting postpartum hemorrhage (PPH) before delivery is crucial for enhancing patient outcomes, enabling timely transfer and implementation of prophylactic therapies. We attempted to utilize machine learning (ML) using basic pre-labor clinical data and laboratory measurements to predict postpartum Hemoglobin (Hb) in non-complicated singleton pregnancies. The local databases of two academic care centers on patient delivery were incorporated into the current study. Patients with preexisting coagulopathy, traumatic cases, and allogenic blood transfusion were excluded from all analyses. The association of pre-delivery variables with 24-h post-delivery hemoglobin level was evaluated using feature selection with Elastic Net regression and Random Forest algorithms. A suite of ML algorithms was employed to predict post-delivery Hb levels. Out of 2051 pregnant women, 1974 were included in the final analysis. After data pre-processing and redundant variable removal, the top predictors selected via feature selection for predicting post-delivery Hb were parity (B: 0.09 [0.05–0.12]), gestational age, pre-delivery hemoglobin (B:0.83 [0.80–0.85]) and fibrinogen levels (B:0.01 [0.01–0.01]), and pre-labor platelet count (B*1000: 0.77 [0.30–1.23]). Among the trained algorithms, artificial neural network provided the most accurate model (Root mean squared error: 0.62), which was subsequently deployed as a web-based calculator: https://predictivecalculators.shinyapps.io/ANN-HB. The current study shows that ML models could be utilized as accurate predictors of indirect measures of PPH and can be readily incorporated into healthcare systems. Further studies with heterogenous population-based samples may further improve the generalizability of these models.
Similar content being viewed by others


Introduction
Postpartum hemorrhage (PPH) is a critical global issue in obstetrics, representing the foremost cause of maternal morbidity and mortality worldwide, contributing to nearly one-third of deaths among pregnant and postpartum women. In the United States, PPH rates are on the rise, complicating almost 3% of deliveries1. Recent decades have witnessed advancements in PPH treatment, including compression sutures2,3, and changes in fibrinogen and blood transfusion strategies4,5. However, the limited availability of these advanced treatments in primary and secondary centers impedes widespread use, underscoring the pivotal role of timely intervention.
Notwithstanding the utilization of advanced therapeutic modalities, postpartum hemorrhage (PPH) continues to exert a pivotal influence on maternal mortality rates. While maternal death is relatively rare in the United States, blood transfusion following hemorrhage, a condition 50 times more prevalent than mortality, is the primary diagnosis linked to severe maternal morbidity6,7. The complexity of obstetric care settings, with varying levels of resources and expertise across different healthcare facilities, presents additional challenges in early identification and management of individuals at risk of requiring blood transfusion. In some cases, delayed recognition of hemorrhage or insufficient access to timely interventions may exacerbate the need for blood transfusion and increase the risk of adverse maternal outcomes. This underscores the imperative need for the development of effective methodologies aimed at identifying high-risk patients. Predicting PPH before delivery is crucial for enhancing patient outcomes, enabling timely transfer to higher levels of care, advanced preparation, and implementation of prophylactic therapies8.
Despite historical studies on risk factors related to PPH, predicting the occurrence of PPH remains challenging. Risk factors such as abnormal placentation, placental abruption, severe preeclampsia, and intrauterine fetal demise have been identified9, but predicting a woman's risk of PPH upon labor admission involves incorporating known risk factors and approximating the probability using a risk strata scheme. In addition, a significant portion of PPH cases involve patients lacking known risk factors, presenting a challenge for traditional models that often fall short in predicting such instances10,11.
Some studies have developed PPH prediction models based on hemoglobin (Hb) levels and blood transfusion needs. Visual estimates of blood loss are deemed inaccurate12, and the gravimetric method for measuring blood loss has been validated in various studies13. Hb levels, especially concentrations below 80 g/L, appear to be a more accurate factor for evaluating and predicting PPH14.
Current risk-based stratification guidelines endorsed by The American College of Obstetricians and Gynecologists (ACOG) and California Maternal Quality Care Collaborative (CMQCC) utilize decision tree algorithms based on clinical consensus, expert opinion, and prior observational data15,16,17. However, a validated clinical prediction model suitable for deployment on labor and delivery units for PPH is currently lacking18. Traditional statistical methods historically formed the basis for risk prediction. However, the current literature indicates a shift towards embracing machine learning (ML) driven by advanced computer algorithms, particularly for individuals lacking conventional risk factors19. ML models efficiently automate the processing of non-additive relationships and incorporating complex interaction between factors that otherwise require specialized statistical expertise and time-consuming exploratory data analysis. This holds promising potential for accurately identifying women at the highest risk of PPH, potentially improving obstetric decision-making and clinical outcomes20,21,22,23. In this study, we attempted to construct an accurate machine-learning model using pre-labor clinical data and basic laboratory measurements to predict postpartum Hb levels in non-complicated singleton pregnancies.
Methods
This retrospective cohort study was conducted on pregnant women hospitalized in the maternity department of Mahdieh and Arash Hospitals in Tehran, Iran, from February 2016 to October 2019. This study included term pregnant women receiving standard of care and delivering within 24 h with a gestational age of more than 36 weeks and a singleton pregnancy. Exclusion criteria were defined as follows: Patients with Hb decline secondary to trauma, those with hemoglobinopathies, recent smoking, pre-delivery infection, hereditary and acquired coagulopathy and dysregulated coagulation profile (International normalized ratio > 1.5, activated partial thromboplastin time > 35 s) and anticoagulant use, inflammatory and rheumatic diseases, congenital and ischemic heart diseases, familial and congenital liver disease and cirrhosis, ketoacidosis, sepsis, or whole blood and blood product transfusion throughout the study.
Baseline demographics, obstetrics, and laboratory data, including age, gestational age, BMI, gravidity, parity, and abortion history, past medical history, past vaginal or cesarean delivery, labor cause, interval since last pregnancy, placenta location, perioperative blood product transfusion (as exclusion criteria), and baseline blood cell count and serum fibrinogen levels were obtained from patient medical records and paper-based questionnaires. Maternal and neonatal outcomes other than post-delivery maternal Hb levels were documented but not considered for the current study. Placental orientation was determined using ultrasound reports on sessions performed throughout the pregnancy.
Hb levels were routinely checked twice for each pregnant woman admitted to the study center; with the latter used as the main endpoint of the study. Two venous blood samples obtained in supine position were procured from each participant during distinct time intervals. The first sample was drawn within 24 h before the onset of labor to obtain serum and plasma measurements for complete blood count and laboratory measurements, while the second sample was collected 24 h post-delivery to evaluate Hb changes as a surrogate outcome for perioperative delivery and PPH. Samples were collected in vacutainer tubes containing 0.129 mol/L sodium citrate for coagulation assays, platelet count, fibrinogen, and other blood sample characteristics. Cell count was performed using automated hematology analyzers. Fibrinogen levels were assessed using the clot-based functional assay (Clauss method) using standard clinical laboratory kits. The local reference range for fibrinogen was 250-450 mg/dL.
Informed written consent to include anonymized laboratory and clinical patient data was obtained from all participants meeting the inclusion criteria. The proposal for this research has been approved by the Ethics Committee of Infertility and Reproductive Health Research Center (IRHRC), Shahid Beheshti University of Medical Sciences (2014, SBMU, REC 299). Study procedures have been performed in accordance with the Declaration of Helsinki.
Statistical analysis
Percentages were calculated for categorical variables, whereas mean and standard deviation were calculated for continuous variables. The association between pre-labor variables in the dataset with significant hemodynamic changes throughout the labor was evaluated by comparing the distribution of the aforementioned characteristics in those with or without significant Hb decline (≥ 2.5 g/dL) using independent t-test for continuous variables and chi-square tests for categorical variables as appropriate. Considering the lack of clinical relevance for absolute decline in hemoglobin within the normal range, linear Hb values were prioritized as the outcome of choice. To investigate the extent of association with post-delivery Hb levels, the input of ML models chosen using the feature selection approach described further below were incorporated in a multivariate linear regression model, alongside their crude estimates. All statistical analyses were carried out using Stata version 18.0. Alpha was set a priori at 0.05.
Data preparation and feature selection
The data was first split randomly into training and test datasets with an 8:2 ratio. To establish a consistent workflow and reproducible and comparable results, a preprocessing and feature selection pipeline was devised before evaluating the predictive accuracy of each included model. Preprocessing and data preparation were carried out by first removing variables with zero or near zero variances in the training dataset. Missing data was then imputed using bagged tree models for each predictor. Continuous data was scaled down between 0 and 1 to improve the predictive accuracy of dependent algorithms. Feature selection was performed using recursive feature selection based on random Forest and elastic net regularization algorithms with tenfold repeated (n = 3) cross-validation on training data by sequentially eliminating variables with least importance. The optimal model predictors for various combinations of independent variables were fitted to the remaining folds to assess the predictive accuracy of the selected model using the root mean squared error (RMSE) measure. The top five sets of predictors, chosen based on lower error rates, were then incorporated into the ML models.
Algorithm training and validation
To achieve optimal predictive accuracy, a comprehensive evaluation of various ML algorithms for regression output was conducted. The evaluated algorithms included Linear Regression (LR), Support Vector Machine with a linear kernel (SVM; implemented using the e1071 package), Multilayer Perceptron/Artificial Neural Networks with a single hidden layer employing resilient backpropagation and weight backtracking (ANN; implemented using the Neuralnet package). Additionally, Extreme Gradient Boosting with a linear base learner and regularization (XGBM; implemented using the xgboost package and gblinear booster) and Regression Tree (RT; implemented using the rpart package) models were considered.
Hyperparameter tuning and initial model evaluation were performed on the training dataset using a fivefold cross-validation strategy. The optimal hyperparameter values for each model were determined through the grid search approach implemented in the Caret package in R to obtain lowest RMSE. After determining optimized hyperparameters for each algorithm, the models were retrained on the whole training dataset. The accuracy of each model was evaluated using mean absolute error, RMSE, RMSE-standard deviation ratio (RSR), percent bias (PBIAS), and R-squared (R2) on validation dataset.
To further enhance the precision of the final model, two meta-ensemble models were developed. These ensembles incorporated the predicted values from the top three performing predictive algorithms from the earlier steps into a Generalized Linear Model (GLM) and a Random Forest algorithm, respectively. The retraining of the model with these meta-ensembles followed the same process as described earlier. The model with the most accuracy was chosen to be utilized in the interactive web platform. Preprocessing and algorithm training was carried out in the R programming language (version 4.3.1) and Caret (Version 6.0) framework24,25.
Interactive platform
An AI interactive platform was created using the RShiny app development platform to provide the most accurate estimation of post-delivery Hb levels. Users can input selected features, which were previously identified, and customize them as input parameters. The platform calculates predicted Hb values along with average 95% prediction intervals derived from the 2.5% and 97.5% percentiles of predictive errors observed in the test subset.
A subsequent one-tailed test will be conducted to examine whether predicted Hb value is comparable to 8g/dL cut point, if so, it is flagged as a high likelihood of requiring post-delivery red blood cell transfusion. Additionally, if the user inputs values outside the range of the training dataset, the platform issues a cautionary warning along with the predicted values, ensuring users are aware of potential limitations in extrapolating predictions beyond the training dataset range. This approach enhances user awareness and promotes cautious interpretation of predictions, contributing to the platform's overall reliability.
Results
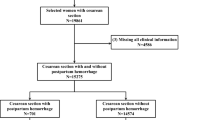
After exclusion of 77 patients, a total of 1974 patient were included in the analyses. The average age (± SD) and BMI of women participating in the study was 27.76 ± 5.76 years and 25.13 ± 3.42 kg/m2, respectively. Patients were most likely to deliver past the 37 weeks’ gestation. Hypertension and gestational diabetes mellitus (GDM) were observed in 6.2 and 7.8%, of the participants (Table 1). Average post-delivery hemoglobin was 10.97 ± 1.25 g/dL. Data on delivery type was available on 1966 patient, based on which, 1075 women underwent natural vaginal delivery. Mean duration of labor was 5.09 ± 4.54 h in participants with natural vaginal delivery.
In crude analyses, age, gestational age, past delivery type, and hypertension were baseline characteristics associated with significant drop in Hb. The use of progesterone vaginal suppository was also linked with hb decline < 2.5 g/dL. Gravidity, parity, cesarean delivery, delivery indications, anterior placenta location, and pre-delivery Hb and platelet were among obstetrics factors linked with 2.5 g/dL decline in secondary Hb (Table 2).
Variable selection and model training
The overall workflow of the current study is illustrated in Fig. 1. The initial phase of preprocessing involved the removal of variables with zero and non-zero variance towards the study outcome. The remaining variables to be assessed for subsequent stage were as follows: age, BMI, gravidity, parity, gestational age, placental orientation, delivery indication, primary (pre-labor) Hb, primary platelet count, serum fibrinogen, GDM, hypertension, suppository progesterone use throughout the pregnancy.

Flow diagram of included participants and overall workflow of the study.
Following comprehensive preprocessing and data splitting, the variables in the training dataset were further examined in the recursive feature elimination stage by evaluating their predictive accuracy, in conjunction with other variables, to determine the more accurate combination of predictors explaining the secondary Hb level variance. The top 5 predictors identified using the elastic net regression were as follows: primary Hb, serum fibrinogen, gestational age, primary platelet count, and parity. These selected predictors constitute the final set employed for algorithm training (Fig. 2). Interestingly, while cesarean section was associated with significant drop in Hb, the type of delivery was not correlated to linear changes in post-delivery Hb level.

Feature selection and variable importance investigated using Random Forest and Elastic Net Regression. The top 5 predictors identified in the Elastic Net model were chosen as input for all subsequent machine learning models.
Multivariate regression model revealed that increasing gestational age is associated with a marginal increase in secondary hemoglobin (− 0.31g/dL reduction in secondary Hb in 40 weeks compared 36 weeks gestation). Expectedly, pre-delivery laboratory values including primary Hb, platelet count, and serum fibrinogen were linked with higher secondary Hb. Moreover, increasing parity was associated with higher post-delivery Hb levels (Table 3).
Next, we constructed 5 ML models based on the selected variables and the algorithms visualized in Fig. 1. The optimal hyperparameters for SVM were epsilon-type regression with 0.25 constant of regularization term. Regression tree was fit with a complexity parameter of 0.003. XGBM was trained using 50 max boosting iterations and 0.1 L2 regularization term on weights. No interaction constraints were imposed. The neural network used in this work was a simple fully-connected network with one hidden layer with three nodes and sigmoid activation function and a single output node with linear activation function. The ensemble models utilized the results of the top predictive algorithms in meta generalized linear and random forest models.
Validation and deployment
The accuracy of models is provided in detailed in Table 4. All models performed with acceptable predictive precision. Nevertheless, the use of ANN was associated with marginally improved results compared to other models (Fig. 3). Training time was the longest for XGBM followed by ANN, and SVM due to a greater number of tunable hyperparameters. Utilizing ensemble models did not result in a considerably improved fit to observed values compared to ANN and were not taken into consideration. The mean absolute error of the final model was 0.622 g/dL, indicating high accuracy of the model in predicting post-delivery Hb level. The RSR for this model was close to 0.5, which provides a standardized measure that further confirms the high precision of the model. The model was deployed in https://predictivecalculators.shinyapps.io/ANN-HB/ as a standalone interactive webpage, which calculates the predicted value along with the 95% prediction intervals as the measure of model uncertainty.

Predictive accuracy and error of all evaluated algorithms. Artificial neural network/Multilayer perceptron had a marginal improvement over other included models. Expectedly, predictive accuracy was lower within lower and upper bounds of post-delivery hemoglobin.
Discussion
This investigation was undertaken utilizing an extensive dataset procured from two tertiary care hospitals with the aim of constructing a predictive model for postpartum hemoglobin (Hb) levels subsequent to childbirth. The dataset originally encompassed a multitude of variables, acquired both prenatally and postnatally, in the context of both normal vaginal delivery (NVD) and cesarean section (CS). All variables assessed either prior to or early within labor were examined for predictive value using both a statistical and a semi-automated workflow displayed throughout the work.
Consistent with previous studies26,27, there was a positive correlation between primary and secondary Hb values, as well as serum fibrinogen levels and platelet count with secondary Hb. Fibrinogen plays a crucial role in the coagulation cascade and serves as the central element in clot formation. During pregnancy, fibrinogen levels experience a gradual rise of up to 50%, correlating with advancing gestational age and reaching their peak in the third trimester. This elevation in fibrinogen levels is a fundamental aspect of the coagulation system's adaptive response, strategically aimed at mitigating the potential risks of adverse hemorrhagic outcomes during pregnancy28. Since evaluating fibrinogen level is characterized by expeditiousness, simplicity, and cost-effectiveness, it can be easily used before labor for predicting hematological outcomes after delivery. Anticipating transfusion needs based on pre-labor fibrinogen levels enables healthcare facilities to optimize resource allocation. This includes ensuring the availability of blood products and skilled medical staff, leading to more efficient and cost-effective maternal healthcare delivery.
Among variables associated with both linear and categorical hemoglobin outcome, gestational age emerged as a significant variable exhibiting a pronounced association with the decline in hemoglobin levels post-delivery. Consistent with our findings, analogous results have been reported in other studies, collectively suggesting that patients with a later gestational age at delivery are at an elevated risk of postpartum hemorrhage29. The association between gravidity and parity and a diminished likelihood of hemoglobin decline following delivery is also not unexpected considering the elevated risk of PPH among nulliparous women30. Notably, our investigation also demonstrated that the utilization of vaginal suppositories containing Progesterone is associated with a reduction in postpartum hemorrhage. This phenomenon is hypothesized to be attributed to the modulatory influence of progesterone on myometrial contractility, resulting in enhanced uterine contraction and subsequently diminished postpartum bleeding31.
Given the substantial global impact of PPH on maternal mortality, there is a pivotal need to delineate a predictive variable for hemorrhage and associated volume loss32,33. A universally accepted definition of postpartum hemorrhage (PPH) remains elusive, as multiple definitions are presently employed globally34,35. Although common definitions facilitate cross-country comparisons of PPH incidence rates, the clinical significance of quantified blood loss in otherwise robust and healthy parturient women is subject to skepticism32,36. Assessing the prevalence of clinically severe hemorrhage may prove more pertinent, taking into account the rate, total volume of blood loss, need of transfusion, post-delivery Hb and the efficacy of therapeutic interventions37. The gravity of PPH is contingent upon the maternal response to treatment, the pace and magnitude of blood loss, and the overall health of the patient, including pre-existing conditions which renders individuals more susceptible to decompensation in the presence of peripartum bleeding. Predicting the post-delivery Hb would play an essential role in clinical management of postpartum hemorrhage, volume loss and transfusion need. ML algorithms bring unprecedented analytical capabilities to the realm of maternal healthcare that may be specifically trained for this task. By processing vast datasets encompassing diverse patient profiles, ML models can discern intricate patterns and relationships within the data and may achieve higher predictive accuracy than experts within the same field.
Conclusion
This work demonstrated that both ML and statistical models demonstrate a high level of accuracy in predicting Hb level within 24 h post-delivery based on data accessible upon admission for labor including fibrinogen level. This study employs an analytical approach that has not been extensively explored or applied in obstetrics. However, it is crucial to note that this “proof of concept” must undergo prospective testing in larger population-based studies with heterogeneous sample sizes to validate its effectiveness. Despite the aforementioned factors, this study was limited by the omission of cases with allogenic blood product transfusion and other laboratory coagulation factors which could have given a more comprehensive profile and potentially improved the predictive accuracy of the model. While, the removal of non-complicated cases, traumatic cases, coagulopathies, and rare occurrences of factors strongly associated with intrapartum blood loss and PPH such as placental abruption in this study provided a more uniform distribution of participants, this choice may limit the generalizability of the results and preclude the predictive capability of the models for a general and geographically-distinct population. Overall, the results underscore the potential of machine learning methodologies to enhance clinical prediction and optimizing patient outcomes in the field of obstetrics.
Data availability
The dataset analyzed during the current study available from the corresponding author on reasonable request and with permission of the research and ethics committee of the study centers.
References
Callaghan, W. M., Kuklina, E. V. & Berg, C. J. Trends in postpartum hemorrhage: United States, 1994–2006. Am. J. Obstet. Gynecol. 202(4), 353.e1–6 (2010).
Allam, M. S. & B-Lynch, C. The B-Lynch and other uterine compression suture techniques. Int. J. Gynaecol. Obstet. 89(3), 236–41 (2005).
Hayman, R. G., Arulkumaran, S. & Steer, P. J. Uterine compression sutures: Surgical management of postpartum hemorrhage. Obstet. Gynecol. 99(3), 502–506 (2002).
Ahmed, S. et al. The efficacy of fibrinogen concentrate compared with cryoprecipitate in major obstetric haemorrhage—An observational study. Transfus. Med. 22(5), 344–349 (2012).
Phillips, L. E. et al. Recombinant activated factor VII in obstetric hemorrhage: Experiences from the Australian and New Zealand Haemostasis Registry. Anesth. Analg. 109(6), 1908–1915 (2009).
Callaghan, W. M., Mackay, A. P. & Berg, C. J. Identification of severe maternal morbidity during delivery hospitalizations, United States, 1991–2003. Am. J. Obstet. Gynecol. 199(2), 133.e1–8 (2008).
Creanga, A. A. et al. Maternal mortality and morbidity in the United States: Where are we now?. J. Womens Health (Larchmt) 23(1), 3–9 (2014).
Petersen, E. E. et al. Vital signs: Pregnancy-related deaths, United States, 2011–2015, and strategies for prevention, 13 states, 2013–2017. MMWR Morb. Mortal Wkly. Rep. 68(18), 423–429 (2019).
Akazawa, M., Hashimoto, K., Katsuhiko, N. & Kaname, Y. Machine learning approach for the prediction of postpartum hemorrhage in vaginal birth. Sci. Rep. 11(1), 22620 (2021).
Practice Bulletin No. 183: Postpartum hemorrhage. Obstet. Gynecol. 130(4), e168–e186 (2017).
Atallah, F. & Goffman, D. Improving healthcare responses to obstetric hemorrhage: Strategies to mitigate risk. Risk Manag. Healthc. Policy 13, 35–42 (2020).
Hancock, A., Weeks, A. D. & Lavender, D. T. Is accurate and reliable blood loss estimation the “crucial step” in early detection of postpartum haemorrhage: An integrative review of the literature. BMC Pregnancy Childbirth 15, 230 (2015).
Schorn, M. N. Measurement of blood loss: Review of the literature. J. Midwifery Womens Health 55(1), 20–27 (2010).
Liumbruno, G., Bennardello, F., Lattanzio, A., Piccoli, P. & Rossetti, G. Recommendations for the transfusion of red blood cells. Blood Transfus. 7(1), 49–64 (2009).
Kramer, M. S. et al. Incidence, risk factors, and temporal trends in severe postpartum hemorrhage. Am. J. Obstet. Gynecol. 209(5), 449.e1–7 (2013).
Main, E. K. et al. National partnership for maternal safety: Consensus bundle on obstetric hemorrhage. Obstet. Gynecol. 126(1), 155–162 (2015).
Wetta, L. A. et al. Risk factors for uterine atony/postpartum hemorrhage requiring treatment after vaginal delivery. Am. J. Obstet. Gynecol. 209(1), 51.e1–6 (2013).
Helman, S. et al. Revisit of risk factors for major obstetric hemorrhage: Insights from a large medical center. Arch. Gynecol. Obstet. 292(4), 819–828 (2015).
Cuocolo, R., Perillo, T., De Rosa, E., Ugga, L. & Petretta, M. Current applications of big data and machine learning in cardiology. J. Geriatr. Cardiol. 16(8), 601–607 (2019).
Goto, T., Camargo, C. A. Jr., Faridi, M. K., Freishtat, R. J. & Hasegawa, K. Machine learning-based prediction of clinical outcomes for children during emergency department triage. JAMA Netw. Open 2(1), e186937 (2019).
Escobar, G. J. et al. Automated early detection of obstetric complications: Theoretic and methodologic considerations. Am. J. Obstet. Gynecol. 220(4), 297–307 (2019).
Fohner, A. E. et al. Assessing clinical heterogeneity in sepsis through treatment patterns and machine learning. J. Am. Med. Inform. Assoc. 26(12), 1466–1477 (2019).
Venkatesh, K. K. et al. Machine learning and statistical models to predict postpartum hemorrhage. Obstet. Gynecol. 135(4), 935–944 (2020).
Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 28(5), 1–26 (2008).
Team RC. R: A language and environment for statistical computing. R Foundation for Statistical Computing. (No Title). (2013).
Salomon, C. et al. Haematological parameters associated with postpartum haemorrhage after vaginal delivery: Results from a French cohort study. J. Gynecol. Obstet. Hum. Reprod. 50(9), 102168 (2021).
van Dijk, W. E. M. et al. Platelet count and indices as postpartum hemorrhage risk factors: A retrospective cohort study. J. Thromb. Haemost. 19(11), 2873–2883 (2021).
Cortet, M. et al. Association between fibrinogen level and severity of postpartum haemorrhage: Secondary analysis of a prospective trial. Br. J. Anaesth. 108(6), 984–989 (2012).
Butwick, A. J. et al. Association of gestational age with postpartum hemorrhage: An international cohort study. Anesthesiology 134(6), 874–886 (2021).
Durmaz, A. & Komurcu, N. Relationship between maternal characteristics and postpartum hemorrhage: A meta-analysis study. J. Nurs. Res. 26(5), 362–372 (2018).
Shynlova, O., Nadeem, L. & Lye, S. Progesterone control of myometrial contractility. J. Steroid Biochem. Mol. Biol. 234, 106397 (2023).
Abdul-Kadir, R. et al. Evaluation and management of postpartum hemorrhage: Consensus from an international expert panel. Transfusion 54(7), 1756–1768 (2014).
Zhang, W. H., Alexander, S., Bouvier-Colle, M. H. & Macfarlane, A. Incidence of severe pre-eclampsia, postpartum haemorrhage and sepsis as a surrogate marker for severe maternal morbidity in a European population-based study: The MOMS-B survey. BJOG 112(1), 89–96 (2005).
ACOG Practice Bulletin. Clinical management guidelines for obstetrician-gynecologists number 76, October 2006: Postpartum hemorrhage. Obstet. Gynecol. 108(4), 1039–1047 (2006).
Rath, W. H. Postpartum hemorrhage–update on problems of definitions and diagnosis. Acta obstetricia et gynecologica Scandinavica. 90(5), 421–428 (2011).
WHO Guidelines Approved by the Guidelines Review Committee. WHO Guidelines for the Management of Postpartum Haemorrhage and Retained Placenta. Geneva: World Health Organization Copyright © 2009, World Health Organization (2009).
Prevention and management of postpartum haemorrhage: Green-top guideline No. 52. Bjog. 124(5), e106–e49. https://doi.org/10.1111/1471-0528.14178 (2017).
Acknowledgements
The authors would like to thank the Clinical Research Development Unit (CRDU) of Emam Ali Hospital, Alborz University of Medical Sciences, Karaj, Iran for their support, cooperation and assistance throughout the study.
Funding
This study did not receive funding, grant, or sponsorship from any individuals or organization.
Author information
Authors and Affiliations
Contributions
S.A.: Methodology, Software, Validation, Writing—Original Draft, Visualization K.J.: Visualization, Writing—Original Draft, Writing—Review and Editing. M.A.: Resources, Writing—Review and Editing, Writing—Original Draft F.M.: Writing—Original Draft. M.B.B.: Resources, Supervision N.S.: Resources, Supervision. S.S.G.: Resources, Writing—Review and Editing. M.B.: Conceptualization, Methodology, Validation, Formal Analysis, Writing—Review and Editing, Project Administration.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aghajanian, S., Jafarabady, K., Abbasi, M. et al. Prediction of post-delivery hemoglobin levels with machine learning algorithms. Sci Rep 14, 13953 (2024). https://doi.org/10.1038/s41598-024-64278-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-64278-z
- Springer Nature Limited