
Abstract
This research was carried out to predict daily streamflow for the Swat River Basin, Pakistan through four deep learning (DL) models: Feed Forward Artificial Neural Networks (FFANN), Seasonal Artificial Neural Networks (SANN), Time Lag Artificial Neural Networks (TLANN) and Long Short-Term Memory (LSTM) under two Shared Socioeconomic Pathways (SSPs) 585 and 245. Taylor Diagram, Random Forest, and Gradient Boosting techniques were used to select the best combination of General Circulation Models (GCMs) for Multi-Model Ensemble (MME) computation. MME was computed via the Random Forest technique for Maximum Temperature (Tmax), Minimum Temperature (Tmin), and precipitation for the aforementioned three techniques. The best MME for Tmax, Tmin, and precipitation was rendered by Compromise Programming. The DL models were trained and tested using observed precipitation and temperature as independent variables and discharge as dependent variables. The results of deep learning models were evaluated using statistical performance indicators such as root mean square error (RMSE), mean square error (MSE), mean absolute error (MAE), and coefficient of determination (R2). The TLANN demonstrated superior performance compared to the other models based on RMSE, MSE, MAE, and R2 during training (65.25 m3/s, 4256.97 m3/s, 46.793 m3/s and 0.7978) and testing (72.06 m3/s, 5192.95 m3/s, 51.363 m3/s and 0.7443) respectively. Subsequently, TLANN was utilized to make predictions based on MME of SSP245 and SSP585 scenarios for future streamflow until the year 2100. These results can be used for planning, management, and policy-making regarding water resources projects in the study area.
Similar content being viewed by others

Introduction
Pakistan is facing major consequences of climate change although it produces a small portion of the global carbon footprint. Pakistan is 5th climate vulnerable country. Pakistan has lost thousands of precious human lives and suffered 3.8 billion USD owing to climate change from 1999 to 2018. Global warming has changed air temperature and precipitation patterns. Pakistan will face a significant rise in precipitation under SSP370 and SSP585 in comparison to SSP126 and SSP245 scenarios1. Future annual mean air temperature will rise by 1.4–4.9 °C over Pakistan under SSP126, SSP245, and SSP585scenarios2. Precipitation and air temperature will gradually increase in the future for all SSPs across Pakistan3. Mean annual precipitation and air temperature will significantly increase in the near future (2021–2050) in comparison to the far future (2071–2100) under various SSPs scenarios4. The above discussion shows that meteorological are changing throughout Pakistan which can pose challenges for water resources management. This motivated the authors to assess the impacts of meteorological parameter alteration on streamflow under various SSP scenarios.
Global Climate Models (GCMs) are complex mathematical models that simulate the intricate earth’s climate system utilizing land surface, atmosphere, sea ice, and oceans5. The Coupled Model Intercomparison Project Phase 6 (CMIP6) is a joint venture of climatologists to improve and compare GCMs through the latest developments in climate science6. The SSPs complement GCMs through a set of future scenarios that describe various socioeconomic pathways assisting scientists to examine the effects of anthropogenic activities on greenhouse gas emissions and the earth’s climate system. GCMs, CMIP6, and SSPs provide a comprehensive framework for understanding future climate change and assist policymakers in making informed decision regarding potential impacts of climate change on various sectors. This motivated the authors to use various GCMs of CMIP6 under SSP245 and SSP585 scenarios for future streamflow estimation.
Hydrological models are the simplification of intricate real-world systems namely groundwater, surface water, soil water, etc. These models help in predicting, understanding, and managing water systems. Hydrological models are widely used for water quality and streamflow simulations7. Hydrological models assess the watershed response to meteorological and terrestrial factors and produce historical and future streamflow which can be used for a variety of purposes including water allocation, water budgeting, and flood mapping8. The results of hydrological models are sophisticated, but they are data-intensive and time-consuming. However, there is no universally superior hydrological model capable of accurately simulating watershed responses to the intricate challenges posed by anthropogenic activities and climate change9. Data-driven models are extensively used for streamflow simulation as they need less input metrological parameters. However, data-driven models fail to capture the hidden nonlinearity of river flow. Recent advancements have significantly enhanced the capability of deep learning models in gauging long-term memory and temporal dependency in streamflow data10,11,12,13. Moreover, LSTM, FFANN, SANN, and TLANN models have the capability of simulating streamflow data having long-term dependency, nonlinearity, seasonality, and time delays. The aforementioned attributes of deep learning models motivated the authors to assess the impacts of climate change on streamflow under various SSP scenarios.
Deep learning is a subset of machine learning which are extensively used in hydrology for translating meteorological parameters into streamflow. DL models have been employed for bias correction of GCM and long-term rainfall forecasting14. Literature shows that ML models are used for streamflow forecasting under various CMIP5 and CMIP6 scenarios15,16. However, studies of this nature are limited for hilly basins, primarily due to constraints related to data availability. Reference17 employed LSTM and Random Forest models with CMIP5 data for the Langtang basin. However, they encountered different challenges, particularly in simulating extreme runoff scenarios. Leveraging CMIP6 data can mitigate uncertainty, owing to enhanced simulated data of precipitation and temperature, thereby providing a more comprehensive insight into future hydrology. Despite this, there is a noticeable literature gap that integrates LSTM, SANN, FFANN, and TLANN models with CMIP6 data for predicting streamflow in hilly basins. The aforementioned models are chosen for streamflow simulations owing to the following reasons; LSTM handles long-term sequential data which capture intricate patterns in hydrological data. SANN is sophisticated in simulating seasonality inherent in hydrological data. FFANN having layered architecture is sophisticated in simulating nonlinear relationship in hydrological data. TLANN is based on time lags which enhance its capability to take into account delays in the hydrological response. The aforementioned capabilities of the deep learning techniques motivated the authors to capture complex, non-linear relationships and intricate patterns inherent in hydrological data.
The prime aim of this study is to evaluate the performance of DL techniques in simulating future streamflow in the Swat River basin. Firstly, the Taylor Diagram, Random Forest, and Gradient Boosting techniques were used to select the best combination of bias-corrected GCMs that closely resemble the observed data. Secondly, MME was computed for all three combinations of GCMs for Tmax, Tmin, and precipitation using the Random Forest technique where the best combination of GCMs was selected via compromise programming. Thirdly, deep learning model selection was carried out based on statistical performance indicators. Subsequently, the selected model was used for forecasting future flow under two different SSP scenarios (SSP 245 and 585) of CMIP6. The findings of this study will be used for regional water policy formulation.
Research methodology
Flow chart shown, depicting detailed research methodology. This flow chart presents a systematic approach for conducting research, encompassing all critical steps to enhance the reliability and validity of the study.

Study area
District Swat is located in the north of Khyber Pakhtunkhwa province, Pakistan. As of the 2023 Census, the district has 2,687,384 residents; its area is 5337 km2, with a population density of 503.5/km218. The annual population change from 2017 to 2023 was 2.6%. Swat, which is located at an average elevation of about 980 m, has a wetter and colder climate. It is located in the downhills of the Hindukush Mountains and has a latitude between 34°-40′ and 35° N, and a longitude between 72′ and 74°-6′ E.
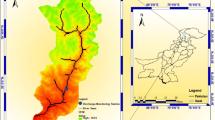
Swat Valley encounters seasonal variations in precipitation, with a mean annual rainfall of approximately 700–800 mm. There is heavy rainfall in summer (June to September) while winter is dry (December–February). Air temperature varies from season to season. The typical summertime temperature varies from 20 and 30 °C19. The study area, illustrated in Fig. 1, was delineated using Quantum Geographic Information System (QGIS) version 3.32, a free, open-source, and publicly available tool used for viewing, editing, printing, and analyzing geospatial data in a range of data formats20.

Study area of the present study.
Data acquisition, data pre-processing, model development and model evaluation
Data acquisition
Observed hydroclimatic data
Daily meteorological data which includes precipitation and air temperature (maximum and minimum) was acquired from the Pakistan Meteorological Department from 1993 to 2020. Additionally, daily streamflow data for the years 1993 to 2020 was provided by the Water and Power Development Authority.
Meteorological forcing
In this study, daily Tmax, Tmin, and precipitation data from 10 Global Climate Models (GCMs) were retrieved from the CMIP6 repository, with detailed information available in Table 1. This study employed a comprehensive selection process to identify the most relevant scenarios for capturing a range of potential future climate conditions. The Shared Socioeconomic Pathways (SSP) scenarios SSP 585 and SSP 245, representing high-emission and moderate-emission pathways respectively, as outlined by the Intergovernmental Panel on Climate Change (IPCC), were utilized. These scenarios were chosen to reflect both worst-case and more optimistic mitigation efforts, ensuring a robust and comprehensive assessment of climate change impacts on streamflow.
Historical climate data from 1993 to 2020 provided a reliable baseline for comparison. The climate model projections (GCM) were selected based on an extensive literature review, with particular reference to studies by Ref.19, who employed these GCM models in their climate impact assessments. The selection was also influenced by the models' ability to accurately simulate extreme weather events. This approach ensured alignment with the most current and relevant scientific data, providing actionable insights for climate resilience planning.
By leveraging a range of scenarios and projections, this study offers a thorough examination of the potential impacts of climate change on streamflow, supporting informed decision-making and effective climate resilience strategies. The future dataset includes two different SSP scenarios, integral to exploring various potential futures of socioeconomic development and their implications for greenhouse gas emissions and climate change impacts. Each scenario used in this study is discussed in detail to provide a clear understanding of their respective roles in climate change research and analysis.
SSP245 SSP245 depicts a scenario characterized by concerted global efforts towards sustainable development, underscored by moderate mitigation endeavors aimed at curbing greenhouse gas emissions, thereby yielding reductions in comparison to baseline projections. Positioned as a "middle-of-the-road" trajectory, this scenario envisages moderate economic expansion, population growth, and technological advancements. Notably, it anticipates a global temperature rise of approximately 2.5 °C above pre-industrial levels by the year 2100, reflecting the cumulative impacts of ongoing societal, economic, and environmental dynamics within this framework of sustainable development pathways.
SSP245 is characterized by:
-
Medium population growth (around 9.5 billion by 2100)
-
Medium economic growth (around 2% annual GDP growth)
-
Continued technological progress, but at a moderate pace
-
Gradual improvements in energy efficiency and carbon intensity
SSP585 SSP585 delineates a scenario marked by elevated emissions and constrained mitigation endeavors, culminating in a trajectory typified by escalating concentrations of greenhouse gases and heightened manifestations of climate change impacts. Positioned as a "high-end" projection, this scenario envisages rapid economic expansion, substantial population growth, and restricted technological advancement. Projections under SSP585 anticipate a stark global temperature surge, with temperatures soaring by approximately 5.5 °C above pre-industrial levels by the year 2100, reflecting the compounded effects of persistent socioeconomic trends and limited mitigation measures within this framework.
SSP585 is characterized by:
-
High population growth (around 12 billion by 2100)
-
High economic growth (around 3% annual GDP growth)
-
Limited technological progress and slow improvements in energy efficiency
-
Continued high energy demand and fossil fuel dependence
These scenarios are used to assess the potential impacts of climate change on various sectors, such as extreme weather events, and ecosystem changes, and to evaluate the effectiveness of different mitigation and adaptation strategies.
In this study, Two SSPs, SSP245 and SSP585 projections are utilized to represent contrasting socioeconomic and emissions pathways and assess their potential impacts on hydrological processes, particularly streamflow patterns.
Digital elevation model
The Digital Elevation Model, having a resolution of 30 m by 30 m, was retrieved from the NASA webpage https://www.earthdata.nasa.gov/. This data was used to delineate the study area's watershed.
Data pre-processing
As shown in Table 2, provides a detailed summary of the input and output parameters utilized in the study. It encompasses historical observed data and GCM model projections for each scenario, specifically SSP 585 and SSP 245, the input parameters include three key climate variables: Tmax (°C), Tmin (°C), and Precipitation (mm). The output parameter exclusively consists of Discharge (m3/s). These climate parameters are instrumental in evaluating the impacts of different emission scenarios on streamflow modeling within the study area and in devising strategies to address changing climate conditions.
GCMs bias correction and multi-model ensemble (MME) computation
In this research, the linear scaling technique was used for bias correction to remove discrepancies from the GCMs data and make it significant for streamflow prediction. After bias correction, the Taylor Diagram, Random Forest, and Gradient Boosting techniques were used to select the best combination of GCMs that closely resemble the observed data. The details of each technique are as follows:
(I) Taylor diagram
The Taylor diagram is a graphical technique that compares various GCMs with observed data21. It offers a comprehensive visualization of key statistical metrics, including correlation coefficient (r) and standard deviation (SD), enabling a holistic assessment of model performance in replicating observed patterns. This diagram effectively identifies GCMs that closely match the observed data. The correlation coefficient (r) and standard deviation (SD) are both important statistical measures used to analyze data.
(a) Correlation coefficient (r)
The correlation coefficient measures the strength and direction of the linear relationship between two variables. It ranges from − 1 to 1, where 1 indicates a perfect positive linear relationship, − 1 indicates a perfect negative linear relationship, and 0 indicates no linear relationship. The sign of the correlation coefficient indicates the direction of the relationship (positive or negative), while the magnitude indicates the strength.
The correlation coefficient (r) between two variables XX and YY can be calculated using the following formula:
where \(Xi\) and \(Yi\) are individual data points, \(\overline{X}\) and \(\overline{Y}\) are the means of X and Y respectively,
(b) Standard deviation (SD):
The standard deviation measures the dispersion or variability of a set of values around their mean (average). A low standard deviation indicates that the data points tend to be close to the mean, while a high standard deviation indicates that the data points are spread out over a wider range. Standard deviation is particularly useful in understanding the spread of data and identifying outliers.
The standard deviation (SD) of a set of n data points × 1, × 2,…, xn can be calculated using the following formula:
where Xi represents individual data points, \(\overline{\text{X} }\) is the mean of the data points.
In this study, a Python script was developed using Anaconda Spyder version 5.4.3, a free and open-source scientific environment22. Its primary objective was to generate a Taylor diagram, which facilitates the assessment of similarity between observed and modeled datasets in terms of correlation coefficient and standard deviation.
First, the necessary libraries such as Pandas (version 2.0.3), Matplotlib (version 3.7.2), and NumPy (version 1.24.3) were imported. The script then reads data from an Excel file located at a specified path using pandas.
It defines a function called taylor_diagram to plot the Taylor diagram, which calculates correlation coefficients and standard deviations between multiple climate models with observed data and visualizes them on a chart. Using Matplotlib, a subplot is created, and data from different climate models is compared against observed data using the Taylor_diagram function. Each model is depicted by a distinct marker style and color on the diagram,
In the context of climate model selection, the top three models were selected based on the highest correlation coefficients and the lowest standard deviations. The models were ranked primarily by their correlation coefficients, with standard deviation serving as a tie-breaker.
(II) Gradient Boosting and Random Forest
In this study, Gradient Boosting and Random Forest algorithms were utilized to compute feature importance scores for General Circulation Models (GCMs). The model development was conducted using Anaconda Spyder version 5.4.3, a free and open-source scientific environment22,23. To ensure robust and accurate modeling, several comprehensive libraries were employed, including:
pandas Version 2.0.3: Utilized for data manipulation and analysis, specifically for loading data from Excel files and managing data frames.
scikit-learn Version 1.3.0: A versatile machine learning library used for:
GradientBoostingRegressor and RandomForestRegressor: Employed to create and train the Gradient Boosting and Random Forest models.
train_test_split Used to divide the dataset into training and testing sets.
matplotlib Version 3.7.2: A plotting library used to create static, interactive, and animated visualizations in Python, specifically applied here for plotting feature importance scores.
The aforementioned machine-learning models were trained on historical meteorological data. The GCMs bearing high scores show a good resemblance with the observed data.
The aforementioned techniques highlighted three combinations of GCMs for each meteorological parameter namely Tmax, Tmin, and precipitation. The MME was computed using Orange software version 3.36.3, a free and open-source environment for machine learning model tasks24 for all three combinations of GCMs for Tmax, Tmin, and precipitation using the Random Forest and Gradient Boosting technique. The performance of these techniques was assessed via statistical performance indicators. The best combination of GCMs for Tmax, Tmin, and precipitation was highlighted using Compromise Programming. The Compromise Programming is based on statistical performance indicators. The superior combination for Tmax, Tmin, and precipitation was used for SSP245 and SSP585 projections. The projected Tmax, Tmin, and precipitation were later used for streamflow projections.
Input and output parameters
Table 2 provides a detailed summary of the input and output parameters utilized in the study. It encompasses historical observed data and GCM model projections for each scenario, specifically SSP 585 and SSP 245, the input parameters include three key climate variables: Tmax (°C), Tmin (°C), and Precipitation (mm). The output parameter exclusively consists of Discharge (m3/s). These climate parameters are instrumental in evaluating the impacts of different emission scenarios on streamflow modeling within the study area and in devising strategies to address changing climate conditions.
Model development
In this study, the hydro-meteorological data was normalized using a min–max scaling approach, utilizing the ‘MinMaxScaler’ library from ‘scikit-learn’. Following this, the observed hydro-meteorological data was divided into training (70% from 1993 to 2012) and testing (30% from 2013 to 2020) sets for model development. The selection criteria for the training and testing periods are grounded in a comprehensive literature review, which reveals a consensus among prominent researchers such as25,26,27,28 that 70% of the total data should be allocated for training, and the remaining 30% reserved for testing when training and testing different machine learning models.
In the next step, the architecture of the LSTM, FFANN, SANN, and TLANN models was designed. The structure of the aforementioned models consists of an input layer, hidden layers, an optimizer, a transfer function, batch size, and an output layer. These models were meticulously optimized via a trial-and-error method using ‘TensorFlow’ and ‘Keras’ libraries. Hidden layers configuration was explored, ranging from 4 to 512 neurons, using the ‘Adam’ optimizer. The learning rate was varied from 0.001 to 0.01. Epochs and batch size were varied from 10 to 1200, and 16 to 128, respectively. This process was repeated for all deep learning (DL) models. The number of hidden layers, optimizer, learning rate, epochs, and batch size of the best-performing DL model was noted. For the same attributes, the remaining DL models were rerun and their statistical performance indicators were compared. The one that produced superior results was used for streamflow forecasting using SSP245 and SSP585 scenarios.
In this study, Anaconda Spyder version 5.4.3 software was utilized for model development. Spyder is a free and open-source scientific environment written in Python, designed by and for scientists, engineers, and data analysts. To ensure robust and accurate modeling, several comprehensive libraries were employed. The names and versions of the package programs and libraries used in the study are as follows:
pandas Version 2.0.3 for data manipulation and analysis.
numpy Version 1.24.3 for numerical operations.
scikit-learn Version 1.3.0 for machine learning models and tools.
TensorFlow Version 2.15.0 for the deep learning framework.
matplotlib Version 3.7.2 for data visualization.
Common underlying theory of all models
All these models are types of artificial neural networks (ANNs), which are computational models inspired by the human brain. ANNs consist of interconnected nodes (neurons) organized into layers. Each connection between nodes has an associated weight, which is adjusted during the learning process to minimize errors in predictions or classifications. The basic operation involves taking inputs, processing them through the network using weighted connections and activation functions and producing an output.
Advantages of the selected models
The LSTM, SANN, TLANN, and FFANN are selected for streamflow simulation owing to their distinct advantages. The LSTM model captures intricate long-term patterns in hydrometeorological data making it suitable for future streamflow estimation. The SANN model is specifically designed to capture seasonal patterns in hydrometeorological data making it beneficial for streamflow modeling where seasonality is dominant. The TLANN model is designed to make use of time-lagged meteorological inputs, making it well-suited to assess the impacts of past observations on future streamflow. The FFANN model has simple architecture which is easy to train while simulating streamflow.
Long short-term memory (LSTM)
General description
LSTM is the advanced form of the Recurrent Neural Network model. LSTM handles long-term sequential data which capture intricate patterns in hydrological data12. Due to long-term dependency, LSTM models are excessively used for streamflow modeling29. LSTM architecture comprises three gates and a memory cell. The three gates comprise input, forget, and output gates. The prime function of the aforementioned memory cell and three gates is to regulate the flow of information by selectively allowing the retention and attrition of data over time. LSTM architecture is very useful for hydrological modeling as it captures inherent intricate temporal patterns, non-linear relationships, and dependencies within hydrological data30. The LSTM functions are as follows:
xt: input vector to the LSTM unit; ft: forget gate's activation vector; it: input/update gate's activation vector; ot: output gate's activation vector; ht: hidden state vector also known as output vector of the LSTM unit; Ćt: cell input activation vector; Ct: cell state vector; σ: sigmoid function; tanh: hyperbolic tangent function.
LSTM hyper parameterization
In this study, the hydro-meteorological data was normalized using a min–max scaling approach. Following, the observed hydro-meteorological data was divided into training (70% from 1994 to 2012) and testing (30% from 2013 to 2020) sets for model development. The LSTM analysis was carried out in the Keras library. The LSTM generally comprises various components namely neurons, dropout, batch size, epochs, activation functions, and optimizers. In this study, the LSTM architecture consists of 512 neurons and an activation function named rectified linear unit (ReLU) as demonstrated in Fig. 2. A dropout of 0.5 was adopted to generalize the LSTM model and avoid overfitting in neural networks. The subsequent hidden layers exhibit a progressive reduction in the number of neurons, ranging from 512 to 4. The output layer consists of only one neuron. The LSTM model is based on the Adam optimizer with a learning rate of 0.001 and a mean squared error loss function. Moreover, the model undergoes 1000 epochs with a batch size of 128.

Depicts different layers, neurons, dropouts, and activation functions of LSTM.
Feedforward artificial neural network (FFANN)
General description
The FFANN is a type of neural network in which information flows in one direction i.e. from the input to the output layer. The flow of information occurs in a forward direction without looping back like RNN31. The main components of FFANN consist of the input layer, a hidden layer, weights and biases, an activation function, and an output layer. The FFANN function is given below:
where Ø is the activation function, w is the weight matrix, x is the input vector and b is the bias vector.
FFANN hyper parameterization
In this study, the hydrometeorological data was normalized using a min–max scaling approach. Following, the observed hydrometeorological data was divided into training (70% from 1994 to 2012) and testing (30% from 2013 to 2020) sets for model development. The FFANN analysis was carried out in the Keras library. FFANN model's architecture starts with an initial densely connected layer of 512 neurons using the rectified linear unit (ReLU) as the activation function as demonstrated by Fig. 3. A dropout rate of 0.5 was applied to avoid model overfitting. The subsequent hidden layers exhibit a progressive reduction in the number of neurons, ranging from 512 to 4. The output layer consists of only one neuron. The FFANN model is based on the Adam optimizer with a learning rate of 0.001 and a mean squared error loss function. Moreover, the model undergoes 1000 epochs with a batch size of 128. FFANN architecture has a strong capability of capturing complex patterns within input data.

Depicts different layers, neurons, dropouts, and activation functions of FFANN.
Seasonal artificial neural network (SANN)
General description
The SANN technique is suitable for predicting time series data having seasonal patterns. Seasonality in time series data exhibits regular cyclic patterns. In the initial stage, a seasonality factor is introduced to the dataset. The SANN function is given below:
where Ø is the activation function, w is the weight matrix, xt is the input vector at the time “t”, St is seasonal components at the time “t” and b is the bias vector.
SANN hyper parametrization
In this research, the hydrometeorological data was normalized using a min–max scaling approach. Following, the observed hydro-meteorological data was divided into training (70% from 1994 to 2012) and testing (30% from 2013 to 2020) sets for model development. The SANN analysis was carried out in the Tensor Flow Keras library. The SANN model's architecture starts with an initial densely connected layer of 512 neurons using the rectified linear unit (ReLU) as the activation function as demonstrated by Fig. 4. A dropout rate of 0.5 was applied to avoid model overfitting. The subsequent hidden layers exhibit a progressive reduction in the number of neurons, ranging from 512 to 4. The output layer consists of only one neuron. The SANN model is based on the Adam optimizer with a learning rate of 0.001 and a mean squared error loss function. Moreover, the model undergoes 1000 epochs with a batch size of 128.

Depicts different layers, neurons, dropouts, and activation functions of SANN.
Time lag artificial neural network (TLANN)
General description
Data-driven models generally produce sophisticated results when input–output variables have a strong associative relationship. However, in hydrology abstraction losses delay the flow response which uncertain the associative relationship. This necessitates the time lag adjustment to seek an adequate relationship between the input and target variable.
where Ø is the activation function, w is the weight matrix, k is the number of time lags, xt-k represent the input at time t − k and b is the bias vector.
TLANN hyper parametrization:
In this study, the hydro-meteorological data was normalized using a min–max scaling approach. Following, the observed hydro-meteorological data was divided into training (70% from 1994 to 2012) and testing (30% from 2013 to 2020) sets for model development. After normalization, the feature lagging was applied for three days. The TLANN model's architecture starts with an initial densely connected layer of 512 neurons using the rectified linear unit (ReLU) as the activation function as demonstrated by Fig. 5. A dropout rate of 0.5 was applied to avoid model overfitting. The subsequent hidden layers exhibit a progressive reduction in the number of neurons, ranging from 512 to 4. The output layer consists of only one neuron. The TLANN model is based on the Adam optimizer with a learning rate of 0.001 and a mean squared error loss function. Moreover, the model undergoes 1000 epochs with a batch size of 128.

Depicts different layers, neurons, dropouts, and activation functions of TLANN.
Model evaluation
The performance assessment of all four deep learning (DL) models encompassed evaluations in both testing and training phases, employing four key statistical indicators: Mean Absolute Error (MAE), Root Mean Square Error (RMSE), Mean Squared Error (MSE), and the coefficient of determination (R2). These metrics hold widespread acceptance and serve as standard measures in regression tasks, facilitating the assessment of accuracy and the goodness of fit of machine learning models. The selection criteria for MAE, RMSE, MSE, and R2 are grounded in an exhaustive literature review, which underscores a consensus among esteemed researchers such as32,33,34,35,36 affirming their utility and relevance in evaluating model performance. There is no predefined range for MAE, RMSE, and MSE, however, among the comparison of results of models, smaller values mean smaller errors indicating a better model’s performance. In contrast, the coefficient of correlation (R2) ranges from 0 to 1, where 0 indicates poor model performance and 1 indicates perfect performance.
These metrics provide a comprehensive understanding of the model's performance in terms of error magnitude, variance, and goodness of fit:
Mean squared error (MSE):
The MSE is the average squared difference between the model and observed values. The MSE is demonstrated by Eq. (1):
Root mean squared error (RMSE):
The RMSE is equal to the square root of the MSE. The RMSE is demonstrated by Eq. (2):
Mean absolute error (MAE):
The MAE is equal to the average absolute difference between the recorded and predicted values. The MAE is demonstrated by Eq. (3):
Coefficient of determination (R2):
The coefficient of determination, also known as R2, is the proportion of the dependent variable's variance that is explained by independent variables. A better fit is indicated by a value closer to 1. The R2 is demonstrated by Eq. (4):
The range for the selection of the model is generally considered as R2:
-
Excellent: > 0.9
-
Good: 0.7–0.9
-
Fair: 0.5–0.7
-
Poor: < 0.5
While efficiency parameters like computational time, memory usage, and convergence rate are important, they may not be directly relevant to evaluating the model's predictive performance. In selecting models, a combination of metrics is commonly used, and the choice of metrics may depend on the specific problem and dataset.
Results and Discussion
GCMs data preprocessing
After downscaling and bias correction, the best combinations of GCMs were highlighted for Tmax, Tmin, and precipitation using the Taylor diagram, Random Forest, and Gradient Boosting techniques as demonstrated in Fig. 6a–i.


(a) GCMs selection for Tmax by using the Taylor diagram technique. (b) GCMs selection for Tmin by using the Taylor diagram technique. (c) GCMs selection for Precipitation by using Taylor diagram technique. (d) GCMs selection for Tmin by using the Random Forest technique. (e) GCMs selection for Tmax by using the Random Forest technique. (f) GCMs selection for Precipitation by using the Random Forest technique. (g) GCMs selection for Tmin by using the Gradient Boosting technique. (h) GCMs selection for Tmax by using the Gradient Boosting technique. (i) GCMs selection for Precipitation by using the Gradient Boosting technique.
In detail, for precipitation, Random Forest analysis revealed MRI-ESM2-0, EC-Earth3-Veg-LR, and CNRM-CM6-1 with respective feature importance scores of 0.157243, 0.135147, and 0.109728. Similarly, Gradient Boosting highlighted MRI-ESM2-0, CNRM-CM6-1, and EC-Earth3-Veg-LR, with feature importance scores of 0.276222, 0.219612, and 0.132509, respectively.
For Minimum Temperature, MRI-ESM2-0, NESM3, and EC-Earth3-Veg-LR were identified as the optimal models. Random Forest analysis indicated feature importance scores of 0.485070, 0.119726, and 0.107643, respectively. Similarly, Gradient Boosting assigned the highest importance to MRI-ESM2-0 (0.277700), followed by EC-Earth3-Veg-LR (0.255183) and NESM3 (0.188819).
Regarding maximum temperature (Tmax), the top three models were determined from the Tayler diagram based on correlation coefficients and standard deviations. CNRM-ESM2-1, NESM3 and CNRM-CM6-1 emerged as the leading models, with correlation coefficients of 0.623, 0.623, and 0.623, and standard deviations of 11.048, 11.182, and 11.211, respectively, as presented in Table 3.
These models exhibited the highest correlation coefficients and, had the lowest standard deviation, making them the best choice among all the GCM models. This selection ensures that the chosen models provide robust and reliable predictions for Tmax based on their performance metrics. The superior combination for Tmax, Tmin, and precipitation was used for SSP245 and SSP585 projections. The projected Tmax, Tmin, and precipitation were later used for streamflow projections.
MME was computed using Random Forest, Ada Boost, Tree, and Gradient Boost techniques for each combination of GCMs. The performance of each technique was assessed via statistical performance indicators where Random Forest performed better than others in each case. Among the three combinations for each parameter, as shown in Table 4, the superior combination was selected using Compromise Programming. Based on this approach, Gradient Boosting and Random Forest models emerged as the top performers for precipitation and Tmin, while the Taylor diagram method emerged as the top performer for Tmax as shown in Table 5. Feature importance scores from Random Forest and Gradient Boosting models further elucidated the significance of each GCM in predicting precipitation patterns.
Evaluation of DL models
This research was carried out to predict streamflow using four DL models namely LSTM, SANN, FFANN, and TLANN. These prediction models used streamflow data as the target variable and Precipitation, Tmax & Tmin as input variables. The observed data was divided into training (70%) and testing (30%). The aforementioned model’s performance was assessed using statistical performance measures such as MSE, RMSE, MAE, and R2, to assess how better these models’ simulated streamflow. The results demonstrated that TLANN outperformed the remaining models. The training and testing results are demonstrated in Figs. 7 and 8 respectively.

Observed versus predicted streamflow during the training phase for (a) FFNN, (b) LSTM, (c) SANN, and (d) TLNN models.

Observed versus predicted streamflow during the testing phase for (a) FFNN, (b) LSTM, (c) SANN, and (d) TLNN models.
Figures 7 and 8 likely depict plots comparing observed streamflow data with predicted streamflow values generated by various models over time. These plots are instrumental in assessing the accuracy of the models in capturing observed streamflow patterns.
Interpreting these plots involves evaluating the alignment between predicted and observed streamflow values:
-
1.
For FFANN (Figs. 7a and 8a), it is evident that the model consistently fails to reach peak values, indicating an underestimation of streamflow patterns. This suggests that the FFANN predictions fall short of the observed values.
-
2.
Similarly, for LSTM (Figs. 7b and 8b), the model also does not reach peak values, indicating an underestimation of streamflow patterns.
-
3.
In the case of SANN (Figs. 7c and 8c), a similar underestimation of peak values is observed, suggesting that the SANN model also falls short in capturing the full range of streamflow patterns.
-
4.
However, for TLANN (Figs. 7d and 8d), it is evident that the TLANN model strives to capture observed peak values, aligning/overlapping closely with observed streamflow patterns. While achieving perfect alignment, indicating 100% accuracy, is practically impossible, however, the TLANN model demonstrates a remarkable level of agreement between observed and predicted values. This superior performance suggests that the TLANN model outperforms other models evaluated in this study.
The SANN model performance assessment
The SANN model predictive performance was assessed using four statistical assessment indicators namely R2, MSE, MAE, and RMSE. The results of R2, MSE, MAE, and RMSE during the training and testing phase are (0.6557, 7275.85 m3/s, 60.563 m3/s, and 85.30 m3/s) and (0.6504, 7022.54 m3/s, 59.151 m3/s, and 83.80 m3/s) respectively as documented in Table 6.
The results demonstrated that the SANN model's performance is satisfactory during both the training and testing phases as obvious from Fig. 9.

Scatter plot between observed and predicted streamflow of SANN model during training and testing.
In Fig. 9, Observed streamflow values are plotted against the predicted streamflow values generated by the models. Each point on the scatter plot represents a specific observation, where the x-coordinate corresponds to the observed streamflow value and the y-coordinate represents the predicted streamflow value. By comparing the position of each point relative to the 1:1 line (the diagonal line), it can be determined whether the model under-predicts or over-predicts streamflow values. Points below the 1:1 line indicate under-prediction (the model predicts lower values than observed), while points above the line signify over-prediction (the model predicts higher values than observed). In the case of SANN the R2 value for training is 0.6557 and for testing is 0.6504, Given that both R2 values are close to each other and relatively high (above 0.5), it suggests that the model explains a significant portion of the variance in the observed streamflow values. Therefore, the model neither consistently under-predicts nor consistently over-predicts. Instead, it provides a reasonable fit to the observed data during both training and testing phases. Statistical assessment indicators collectively suggest that the SANN model performed well in predicting streamflow. However, its performance is lower than the other competing models, a decision has been made to exclude it in this study for future predictions.
The LSTM model performance assessment
The predictive capability of the LSTM model in simulating streamflow is evaluated using statistical performance metrics namely R2, MSE, MAE, and RMSE. The results of R2, MSE, MAE, and RMSE during the training and testing phase are (0.6924, 6499.47 m3/s, 58.463 m3/s, and 80.62 m3/s) and (0.6764, 6500.18 m3/s, 58.651 m3/s, and 80.62 m3/s) respectively as documented in Table 6. The LSTM model performed well during training and testing, attaining the desired degree of accuracy in streamflow prediction, as demonstrated by Fig. 10.

Scatter plot between observed and predicted streamflow of LSTM model during training and testing.
Figure 10 illustrates the relationship between observed streamflow values and the corresponding values predicted by the models. In the case of LSTM (Fig. 10), the R2 value for training is 0.6924, and for testing, it is 0.6764. Both R2 values are relatively high, exceeding 0.5, and closely aligned, indicating that the model effectively captures a substantial portion of the variability in the observed streamflow values. Like the SANN model, the model demonstrates balanced performance, neither consistently underestimating nor overestimating, but rather providing a satisfactory fit to the observed data during both training and testing phases.
However, despite its reasonable performance, the LSTM model was not employed for future streamflow prediction. This decision was based on its comparatively lower performance when compared to other competing models.
The FFANN model performance assessment
The forecasting power of the FFANN model was thoroughly evaluated in streamflow using statistical measures in both the training and testing phases. The results of R2, MSE, MAE, and RMSE during the training and testing phase are (0.7225, 5863.87 m3/s, 54.205 m3/s, and 76.58 m3/s) and (0.6949, 6129.37 m3/s, 54.896 m3/s, and 78.29 m3/s) respectively as documented in Table 6.
The results indicate that the FFANN model performed well during both the training and testing phases. As a whole, the FFANN model can forecast streamflow data with a fairly desirable degree of accuracy and reliability, as demonstrated by Fig. 11.

Scatter plot between observed and predicted streamflow of FFANN model during training and testing.
In Fig. 11, the correlation between observed streamflow values and the corresponding predictions from the FFANN model is depicted. With a focus on the FFANN model, its R2 value for training stands at 0.7225, while for testing, it reaches 0.6949. These R2 values are notably high, surpassing the threshold of 0.5, and exhibit close alignment, indicating the model's proficiency in capturing a significant portion of the variability in observed streamflow values.
Similar to the LSTM and SANN models, the FFANN model showcases balanced performance, avoiding consistent underestimation or overestimation and providing a satisfactory fit to the observed data across both training and testing phases. However, due to relatively lower performance in comparison to competing models in simulating streamflow data, a decision has been made to exclude it in this study for future predictions.
The FFANN model effectively captured patterns and trends in the training data, demonstrating reasonable accuracy and forecasting capability in the testing phase. Importantly, The FFANN model performed better in streamflow prediction in comparison to the LSTM model.
The TLANN model performance assessment
The forecasting power of the TLANN model was thoroughly checked in streamflow prediction using statistical measures in both the training and testing phases. The results of R2, MSE, MAE, and RMSE during the training and testing phase are (0.7978, 4256.97 m3/s, 46.793 m3/s, and 65.25 m3/s) and (0.7443, 5192.95 m3/s, 51.363 m3/s, and 72.06 m3/s) respectively as documented in Table 6.
The findings reveal that the TLANN model exhibited superior performance in both the training and testing phases, demonstrating a remarkable level of accuracy in streamflow prediction. The TLANN model outperformed the other competing models in predicting streamflow based on statistical performance indicators. The experimental results showcase TLANN's exceptional performance, achieving the highest R2 value and the lowest RMSE, MAE, and MSE among all assessed algorithms. With its strong performance in regression error metrics (RMSE, MAE, and MSE) and performance evaluation parameters R2, TLANN stands out as the leading algorithm. Consequently, it is highly recommended that TLANN be prioritized as the machine learning regression algorithm of choice for streamflow prediction applications. In Table 6, the selection criteria for identifying the superior TLANN model over others may consider various performance evaluation metrics, including MAE, RMSE, MSE, and R2. Superiority can be determined by TLANN's ability to demonstrate lower values of MAE, RMSE, and MSE compared to alternative models, indicating enhanced accuracy and precision in streamflow prediction. Additionally, a higher R2 value for the TLANN model would signify a better fit to the observed data, further reinforcing its superior predictive performance. The TLANN model effectively captured the inherent intricate patterns and trends in streamflow as shown in Fig. 12.

Scatter plot between observed and predicted streamflow of TLANN model during training and testing.
Figure 12 depicts the correlation between observed streamflow values and the corresponding predictions generated by the FFANN model. Highlighting the performance of the FFANN model, its R2 value for training is reported at 0.7978, while for testing, it reaches 0.7443. These R2 values are notably high, surpassing those of other models, and exhibit close alignment, indicating the model's proficiency in capturing a significant portion of the variability in observed streamflow values.
The TLANN model demonstrates commendable performance in both the training and testing phases, as evidenced by the majority of data points lying near or on the 1:1 line in the scatter plot shown in Fig. 12. This proximity indicates that the predicted values closely match the observed values. Due to its superior performance compared to competing models, the TLANN model was selected for future streamflow prediction based on SSP245 and SSP585 scenarios.
Future streamflow prediction under SSP245 and SSP585 scenarios
Future streamflow forecasting was carried out using the outperformed model, TLANN, under two different scenarios i.e. SSP245 and SSP585 until the year 2100. It is worth notable that the predicted streamflow of SSP585 is higher in comparison to SSP245. Moreover, SSP585 has more flow spikes in comparison to SSP245 as obvious from Figs. 13 and 14. Overall, the observed and future streamflow under both SSP scenarios follows the same seasonal flow pattern. Two major factors that affect the streamflow in the study area are the air temperatures and the amount of precipitation. Together, these climate shifts increase the total amount of water in the streams, which affects the hydrological system. Snowmelt is caused by air temperature, and overland flow is caused by precipitation, which adds water to river systems. The anticipated variations in streamflow are essential for planning regional water resources. Effective adaptation strategies must be developed in light of the potential changes in streamflow. It also emphasizes how crucial it is to take climate change scenarios and the uncertainties they entail into account when organizing and managing future water resources. Policymakers and other stakeholders can benefit greatly from these predicted changes in streamflow, which will help them formulate strategies that will effectively address the expected changes in the hydrological patterns of the study area.

Predicted streamflow for the year 2021–2100 under SSP-245.

Predicted streamflow for the year 2021–2100 under SSP-585.
Discussion
Future streamflow estimation is extremely important for water policy formulation in a climate change context. This study concluded that the TLANN model outperformed the remaining three models. Many researchers assessed alterations in meteorological parameters in Pakistan. Reference37 found that in the Swat River Basin, the mean temperature increased by 0.90 °C, the Tmax by 0.40 °C, and the mean Tmin by 0.50 °C. This rise in temperatures has resulted in water stress, and glacier retreat, and has significantly impacted permafrost conditions at higher altitudes in the region. Reference38 analyzed precipitation variability across 15 stations in the Swat River Basin, Pakistan, covering a period of 51 years from 1961 to 2011. Utilizing nonparametric Mann–Kendall and Spearman’s rho tests, precipitation trends were identified. The findings revealed that the Saidu Sharif Swat station recorded the most significant monthly precipitation events, followed by Abazai, Khairabad, and Malakand. Additionally, there was a notable shift in seasonal trends from summer to autumn, with Saidu Sharif exhibiting the highest annual increase in precipitation at 7.48 mm/year. Throughout the analysis, the Mann–Kendall and Spearman’s rho tests consistently demonstrated reliability at the verified significance level. A study conducted by39 on Mid-century climate changes in the Swat River Basin revealed significant temperature increases. Areal and Dir experienced a 2 °C rise in annual maximum temperature (2041–2060), while Swat Kalam, Swat Malam Jabba, and Swat Saidu Sharif saw a 1 °C increase. Precipitation also exhibited notable changes, with approximately a 12% increase in annual maximum and seasonal precipitation, particularly in summer and autumn, across all scenarios. However, the RCP 4.5 scenario stood out with a higher increase, indicating a 20% rise in summer precipitation and a substantial 32% increase in autumn precipitation. Reference40 found a substantial increase in air temperature in the upper Indus basin. Reference41 found that precipitation will increase in Pakistan under various RCP scenarios. Literature shows that many researchers assessed the impacts of climate change on streamflow in Pakistan. Reference42 found that river flow will increase under SSP245. The study conducted by Ref.43 on the Swat River Basin reveals that climate change impacts under the RCP4.5 and RCP8.5 scenarios will lead to significant increases in river flow by the end of the century. Specifically, Under the RCP8.5 scenarios, deviations of 908.8, 1091.2, and 1064.5 cubic meters per second (cumecs) are projected during the early, mid, and late intervals of these seasons, respectively. In contrast, under the RCP4.5 scenarios, the expected deviations are 299.7, 689.4, and 750.9 cumecs for the same intervals. These significant deviations underscore the pronounced impact of climate change on hydrological patterns, particularly during the monsoon and autumn seasons. The study conducted by19 on the Swat River Basin reveals that future streamflow projections indicate an increase in mean annual streamflow between the 2050s and 2080s. Specifically, the projections range from an increase of 3.26 to 7.52% for the SSP245 scenario and from 3.77 to 13.55% for the SSP585 scenario. These findings suggest a notable rise in streamflow in response to different greenhouse gas concentration pathways, reflecting the potential impacts of climate change on the region's hydrological patterns. Reference44 concluded that streamflow will enhance by 27.4% and 34.8% under SSP2 and SSP5 in the Mohmand Dam Catchment. Reference45 found that future streamflow will increase in the Upper Indus River and Kabul River. Reference46 found that future streamflow will increase by 13.8% and 16.3% under different SSP2 and SSP5 scenarios. The above discussion shows that the impacts of climate change on streamflow under SSP5 outweigh SSP2. Moreover, it is also noted that streamflow will increase in the future under SSP2 and SSP5 scenarios. The findings of the present study are parallel with the literature. Any variations in streamflow have significant impacts on downstream hydropower and agriculture production. Therefore, it is suggested to consider climate change effects on streamflow while formulating water policy to bring sustainability to the water environment.
Implications for regional water policy and impact on water resources management, agriculture, and water structures
The analysis conducted in this study carries significant implications across multiple critical sectors, including environmental engineering, water resources policy, and sustainable development. Informed decision-making in areas such as crop irrigation, water resource allocation, hydropower generation, and the management of extreme events relies heavily on accurate hydrological forecasting. Leveraging CMIP6 scenarios and machine learning models, this research aims to enhance hydrological prediction by translating meteorological variables into key hydrological parameters like snowmelt, river stage, and streamflow.
The findings offer valuable insights for water resource managers and stakeholders, facilitating the formulation of proactive strategies for water management, the design of climate-resilient infrastructure, and the preservation of ecosystems in the face of shifting climatic conditions. Specifically, the projected changes in streamflow outlined in this research carry significant implications for water resource management and flood risk assessments. The anticipated increase in streamflow and the heightened risk of flash floods underscore the urgent need for effective flood mitigation and adaptation strategies.
The findings of this study hold profound implications for water resources management, agriculture, and water structures:
-
1.
Water resources management: With the projected increases in precipitation and river flow, water resources management strategies will need to adapt to accommodate these changes. This might involve adjusting water allocation plans, enhancing flood management systems, and updating infrastructure to mitigate potential risks associated with increased water availability. Additionally, managing the quality of the increased water flow will be crucial to ensure its suitability for various uses, such as drinking water supply, industrial processes, and ecosystem health.
-
2.
Agriculture: The anticipated rise in precipitation and river flow can both benefit and challenge agricultural practices. Increased water availability could potentially support crop irrigation, leading to improved agricultural productivity in some regions. However, careful management will be required to prevent waterlogging and soil erosion. Farmers may need to adjust planting schedules and crop varieties to optimize yields in response to changing precipitation patterns. Moreover, adaptation strategies such as water-saving irrigation techniques and soil conservation practices may become increasingly important to sustain agricultural production under evolving climate conditions.
-
3.
Water structures: Infrastructure for water storage, distribution, and flood control will need to be reevaluated and potentially upgraded to cope with the projected changes in precipitation and river flow. Dams, reservoirs, and levees may need to be modified to accommodate increased water volumes and variability while ensuring resilience against extreme events such as floods and droughts. Furthermore, incorporating climate change projections into the design and planning of new water structures will be essential to ensure their long-term effectiveness and sustainability.
This study underscores the urgency of integrating climate change considerations into water resources management, agricultural practices, and water infrastructure planning. Proactive measures and adaptive strategies will be essential to harness the opportunities and address the challenges posed by the projected changes in precipitation and river flow, ultimately ensuring the resilience and sustainability of water-related systems and sectors.
Conclusions
In this research, four DL models namely LSTM, SANN, FFANN, and TLANN were used to predict the daily streamflow in the Swat River Basin. The aforesaid model performance was evaluated using four statistical indicators namely RMSE, MSE, MAE, and R2. The TLANN model outperformed the other three competing models based on statistical measures namely RMSE, MSE, MAE, and R2 during training (65.25 (m3/s), 4256.97 (m3/s), 46.793 (m3/s) and 0.7978) and testing (72.06 (m3/s), 5192.95 (m3/s), 51.363 (m3/s) and 0.7443) respectively. Subsequently, TLANN was utilized to forecast future streamflow until the year 2100. These findings indicate that the TLANN model can be effectively used to reliably forecast daily streamflow for the Swat River.
The current research findings are significant as they utilize Multiple Model Ensemble (MME) data from 10 Global Climate Models (GCMs) to forecast streamflow under different socio-economic scenarios (SSP245 and SSP585). Despite the statistical significance of the results, it's essential to acknowledge certain limitations. The study is confined to a specific dataset, and the efficacy of Deep Learning (DL) models can be influenced by data intricacies and complexity. Thus, there's a clear need for further improvements in model performance, especially when tailoring them for specific water resource management contexts. This underscores the necessity for ongoing research and adaptability to meet evolving demands in water resource forecasting and management.
While the chosen methodology aligns with existing literature and has undergone peer review, it's crucial to recognize the remaining limitations. Notably, DL models require extensive data for effective training, unlike physical-based models, which don't face such constraints. Consequently, in scenarios with limited data availability, physical-based models might be preferable. Another drawback is the DL models' challenge in predicting values outside their training scope, emphasizing the importance of training them on longer records and incorporating variables relevant to extreme flow values. Additionally, since streamflow is influenced by climate variables, it can impact forecast model accuracy, warranting further consideration.
For future endeavors, incorporating the most recent data beyond the 1993–2020 timeframe could yield more realistic insights into recent climate changes.
Data availability
The hydrometeorological data used in this study is available from the corresponding author upon reasonable request. The Python code can be provided upon request to the corresponding author.
References
Jamal, K. et al. Bias correction and projection of temperature over the altitude of the Upper Indus Basin under CMIP6 climate scenarios from 1985 to 2100. J. Water Clim. Change 1, 1 (2023).
Karim, R., et al. Future changes in seasonal temperature over Pakistan in CMIP6 (2021).
Ali, Z. et al. A novel approach for evaluation of CMIP6 GCMs in simulating temperature and precipitation extremes of Pakistan. Int. J. Climatol. 1, 1–12 (2024).
Adnan, M. et al. Estimation of changes in runoff and its sources in response to future climate change in a critical zone of the Karakoram mountainous region, Pakistan in the near and far future. Geomat. Nat. Haz. Risk 15(1), 2291330 (2024).
Gettelman, A., & Rood, R.B. Demystifying climate models: A users guide to earth system models (Springer Nature, 2016).
Almazroui, M. et al. Projected changes in temperature and precipitation over the United States, Central America, and the Caribbean in CMIP6 GCMs. Earth Syst. Environ. 5, 1–24 (2021).
Haleem, K. et al. Hydrological impacts of climate and land-use change on flow regime variations in upper Indus basin. J. Water Clim. Change 13(2), 758–770 (2022).
Debbarma, S. et al. Simulation of flood inundation extent by integration of HEC-HMS, GA-based rating curve and cost distance analysis. Water Resour. Manag. 1, 1–21 (2024).
Yang, Q. et al. Dynamic runoff simulation in a changing environment: A data stream approach. Environ. Model. Softw. 112, 157–165 (2019).
Adnan, M. S. G. et al. The effects of changing land use and flood hazard on poverty in coastal Bangladesh. Land Use Policy 99, 104868 (2020).
Fu, B. et al. Short-lived climate forcers have long-term climate impacts via the carbon–climate feedback. Nat. Clim. Chang. 10(9), 851–855 (2020).
Rahimzad, M. et al. Performance comparison of an LSTM-based deep learning model versus conventional machine learning algorithms for streamflow forecasting. Water Resour. Manage 35(12), 4167–4187 (2021).
Ghobadi, F. & Kang, D. Improving long-term streamflow prediction in a poorly gauged basin using geo-spatiotemporal mesoscale data and attention-based deep learning: A comparative study. J. Hydrol. 615, 128608 (2022).
Singh, D. et al. Machine-learning-and deep-learning-based streamflow prediction in a hilly catchment for future scenarios using CMIP6 GCM data. Hydrol. Earth Syst. Sci. 27(5), 1047–1075 (2023).
Adib, M. & Harun, S. Metalearning approach coupled with CMIP6 multi-GCM for future monthly streamflow forecasting. J. Hydrol. Eng. 27(6), 05022004 (2022).
Fu, Y. et al. Assessment and prediction of regional climate based on a multimodel ensemble machine learning method. Clim. Dyn. 1, 1–20 (2023).
He, Q. et al. Spatiotemporal analysis of meteorological drought across China based on the high-spatial-resolution multiscale SPI generated by machine learning. Weather Clim. Extremes 40, 100567 (2023).
Sarfaraz, Q. et al. Flood frequency analysis of river swat using easyfit model and statistical approach. Pak. J. Eng. Appl. Sci. 1, 1 (2021).
Ullah, B., et al. Futuristic streamflow prediction based on Cmip6 scenarios using machine learning models (2023).
Moyroud, N., & Portet, F. Introduction to QGIS. 1–17 (2018).
Taylor, K. E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. 106(D7), 7183–7192 (2001).
Rolon-Merette, D. et al. Introduction to Anaconda and Python: Installation and setup. Quant. Methods Psychol. 16, S3–S11 (2020).
Naik, P., & Oza, K. Python with Spyder: An Experiential Learning Perspective (2019).
Ishak, A. et al. Orange software usage in data mining classification method on the dataset lenses. IOP Conf. Ser. Mater. Sci. Eng. 1003, 012113 (2020).
Nguyen, Q. et al. Influence of data splitting on performance of machine learning models in prediction of shear strength of soil. Math. Probl. Eng. 1, 1 (2021).
Mijwil, M. & Aljanabi, M. A comparative analysis of machine learning algorithms for classification of diabetes utilizing confusion matrix analysis. Baghdad Sci. J. 21, 1 (2023).
Oribhabor, C. & Anyanwu, C. Research Sampling and Sample Size Determination: A practical Application. 2, 47–56 (2019).
Odiakaose, C. A comparative analysis of machine learning algorithms: A case study of a higher institution (2021).
Feng, D., Fang, K. & Shen, C. Enhancing streamflow forecast and extracting insights using long-short term memory networks with data integration at continental scales. Water Resour. Res. 56(9), 1 (2020).
Ullah, B. et al. Futuristic streamflow prediction based on CMIP6 scenarios using machine learning models. Water Resour. Manag. 1, 1 (2023).
Sazli, M. A brief review of feed-forward neural networks. Commun. Fac. Sci. Univ. Ankara 50, 11–17 (2006).
Zhao, X., Jing, W. & Zhang, P. Mapping fine spatial resolution precipitation from TRMM precipitation datasets using an ensemble learning method and MODIS optical products in China. Sustainability 9, 1912 (2017).
Bag, A. A comparative study of regression algorithms for predicting graduate admission to a university (2020).
Khan, M. & Noor, S. Performance analysis of regression-machine learning algorithms for predication of runoff time. 8, 187 (2019).
Chen, F. Design and implementation of machine learning algorithms in automatic grading of students’ assignments. J. Electr. Syst. 20, 899–919 (2024).
Adil, K., et al. Machine learning and deep learning based students’ grades prediction (2023).
Khan, S. et al. Climate change impacts and adaptation to flow of Swat River, Glaciers and Permafrost in Hindukush Ranges, Swat District, Pakistan (2004–2013). J. Sci. Technol. 38, 19–36 (2014).
Ahmad, I. et al. Precipitation trends over time using Mann-Kendall and Spearman’s rho tests in Swat River Basin Pakistan. Adv. Meteorol. 2015, 1–15 (2015).
Ali, W. et al. Mid-century change analysis of temperature and precipitation maxima in the Swat River Basin. Pakistan. Front. Environ. Sci. 10, 1 (2022).
Ali, S. et al. Twenty first century climatic and hydrological changes over Upper Indus Basin of Himalayan region of Pakistan. Environ. Res. Lett. 10(1), 014007 (2015).
Ikram, F. et al. Past and future trends in frequency of heavy rainfall events over Pakistan. Pak. J. Meteorol. 12(24), 1 (2016).
Haleem, K. et al. Evaluating future streamflow patterns under SSP245 scenarios: Insights from CMIP6. Sustainability 15(22), 16117 (2023).
Haq, W. et al. Climate change investigation of swat river using HEC-HMS hydrological model. Int. J. Res. Appl. Sci. Eng. Technol. 11, 479–487 (2023).
Masood, M. U. et al. Appraisal of land cover and climate change impacts on water resources: A case study of Mohmand Dam Catchment, Pakistan. Water 15(7), 1313 (2023).
Rizwan, M. et al. Simulating future flood risks under climate change in the source region of the Indus River. J. Flood Risk Manag. 16(1), e12857 (2023).
Hassan, S. et al. Investigating the effects of climate and land use changes on Rawal Dam reservoir operations and hydrological behavior. Water 15(12), 2246 (2023).
Acknowledgements
The authors are thankful to the Deanship of Graduate Studies and Scientific Research at Najran University for funding this work under the Growth Funding Program grant code (NU/GP/SERC/13/239-1). The authors also would like to express their gratitude to the supporting staff and management of WAPDA, PMD, and the Irrigation Department of Khyber Pakhtunkhwa for their valuable assistance in facilitating and supplying the necessary data. Their contributions were instrumental in completing this study.
Funding
Open access funding provided by Lulea University of Technology. The authors are thankful to the Deanship of Graduate Studies and Scientific Research at Najran University for funding this work under the Growth Funding Program grant code (NU/GP/SERC/13/239-1).
Author information
Authors and Affiliations
Contributions
Conceptualization, writing—original draft, writing review and editing, formal analysis, methodology: HA, BU, AUK; writing review and editing, data curation, investigation; ATBT, TN, MUB, AAJG, MI; supervision: AUK, AAJG.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Anwar, H., Khan, A.U., Ullah, B. et al. Intercomparison of deep learning models in predicting streamflow patterns: insight from CMIP6. Sci Rep 14, 17468 (2024). https://doi.org/10.1038/s41598-024-63989-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-63989-7
- Springer Nature Limited