
Abstract
Demographic health surveys (DHS) contain in-depth information about the demographic characteristics and the factors affecting them. However, fertility rates which are the important indicators of population growth have been estimated by utilizing the design-based approaches. Model-based approach, on the other hand, facilitates efficient predictive estimates for these rates by utilizing the demographic and other family planning related characters. In this article, we first attempt to observe the effect of various socio-demographic and family planing related factors on births counts by fitting different regression models to Pakistan Demographic Health Survey 2017–2018 data under classical as well as Bayesian frameworks. The births occurred during the time periods of 1-year, 3-years and 5-years are taken as the responses and modeled using different non-linear models. The model-based approach is then used for estimation of the fertility measures including age-specific fertility rates, total fertility rate, general fertility rate, and gross reproduction rate for ever-married women in Pakistan. The performance of the model-based estimators is examined using a bootstrapped sampling algorithm. While the age-specific fertility rates are over-estimated for some age groups and under-estimated for others. The model-based fertility estimates are recommended for estimating the demographic indicators at national and sub-national levels when survey data contains incomplete or missing responses.
Similar content being viewed by others

Introduction
Measuring fertility indicators using household surveys such as the Demographic Health Surveys (DHS) and the Multiple indicator Cluster Surveys (MICS) is challenging especially in developing countries like Pakistan, where updated vital registration systems (VRS) are very poor or are not available at all. Such measures are needed to evaluate the progress of the United Nations (UN) Sustainable Development Goals (SDGs), which is especially to ”Ensure healthy lives and promote well-being for all at all ages ”, for the improvement of maternal, newborn, and child health1,2. Fertility measures as an important indicator of the above stated SDG needs to be estimated for evaluation of the progress on SDGs. The direct fertility indicators estimation methods were initially utilized by the practitioners in World Fertility Survey (WFS), which was conducted during 1972–19843,4, and afterward in the DHS surveys. The approaches utilized by WFS and DHS have been documented in many articles like5,6,7. The approaches have later been used for estimation of fertility indicators by other household surveys (HS) programs, such as the MICS. In direct estimation methods, data about the births occurred during 3 or 5 years are gathered and used for the calculation of fertility indicators8. The DHS program mostly uses the census and survey processing system and other typical statistical packages such as STATA, SAS, SPSS, or R, etc. to produce the fertility measures, and other DHS statistics under direct methods9,10,11. The results on fertility indicators obtained from PDHS 2017–2018 data, using DHS.rates package12 (constructed by13), are given in PDHS 2017–2018 report14. The report covers a cross tabulation and visual display of the relationship between the fertility indicators and other demographic and socio-economic factors (Region, Sex, Marital Status, Age, Education, etc). Apart from reaching to a valid statistical inference, estimation of parameters, and constructing confidence intervals based on estimated rates, one can also develop regression models for the number of births and estimate them to observe the relationship between the number of births and its candidate determinants15.
Etiological studies utilize the regression models for establishing cause and effect relationship between number of births and its determinants. However, the births history includes discrete variables where the linear models cannot be applied as the normality of residual errors does not fulfill16,17. Generalized Linear Models (GLMs) are fitted for prediction in situations where outcome variables have a distribution other than normal. Because GLMs involve categorical variables of interest such as “Yes”/“No” responses; or belonging to Groups A or B and, therefore, do not have full range i.e. \(-\infty \) to \(+\infty \). Hence, the relationship between the response variable and the predictors may not be linear. Some examples of GLMs used for birth history data include logistic regression model18, Poisson regression model19 and event history methods20. Although the principle has rarely been described in demographic analysis manuals, regression methods, especially Poisson regression, can still be practiced to calculate the classical demographic measures such as total fertility rate (TFR) and other fertility rates21,22. Some new developments and applications on fertility estimation and casual inference are available in23,24,25,26,27,28. Reference29 used 1998–1999 Burkina Faso DHS data to explain the estimation of TFR and ASFRs using individual data with Poisson regression. The number of births over a 5-years period preceding the interview (variable predefined in the DHS women recode file PKIR71) is taken as the response variable and the age groups as dummy regressors in the model controlling for the length of exposure (5-years corresponding to each woman) using a term (offset)30,31. The average number of births is obtained by exponentiating the coefficients for each of the seven age groups without introducing an intercept and computing the TFR as the sum of the rates multiplied by five. Recently32, obtained pooled estimate of the TFR in sub-Saharan Africa using (2010–2018) DHS data.
The classical linear regression provides estimate of the model parameters based on the sampled data alone. However, if the sample size is small, one might express the estimate as a distribution of possible values of the parameter given the sample information. This is the situation where Bayesian regression is needed. Bayesian regression is widely used in estimation, inference and prediction purpose in wide variety of non-linear setups33,34. In Bayesian regression parameter estimation is done using Markov Chain Monte Carlo (MCMC) method35. Reference35 warned about the programming errors and the problems that occur in estimation routines during MCMC. However, Bayesian framework is still preferred due to the flexibility in model construction, statistical inference, and assessment of the fitted model than the classical approaches36. Reference37 also pointed out two main concerns with the employment of the MCMC algorithms: mixing and convergence and suggested to confirm that the algorithm results in a Markov chain that “converges” to the appropriate posterior density and “mixes” well throughout the values of the density. When these conditions met, Bayesian regression nicely models the linear as well as non linear relationship between the response variable and covariate with an effective prediction38,39.
The literature on fertility estimation emphasizes on observing the relationship between the birth counts and their determinants as well as utilizing the estimated models for obtaining more accurate estimates at national and sub-national levels. However, the model-based predictive estimation method aids in efficiency by utilizing the model relationship between the study variable and the available socio-demographic variables40,41. However, the response variables are the birth counts which, we cannot proceed with linear regression setup. For obtaining a precise estimates of fertility measures, we establish the model-based estimators of fertility measures using the classical as well as the Bayesian count regression models. The model-based approach increase efficiency of the estimators by including information available on related covariates. We are able to produce estimates on different fertility measures with age sex distribution at national as well as sub-national levels for fixed values of covariates. Based on the suggested estimation algorithm we can produce fertility estimates for fixed values of other significant socio-demographic and family planning variables. For example, we can produce estimates on fertility indicators based on Wealth Index (WI), education level of women, contraceptive usage etc. An etiological analysis on number of birth is conducted in Section “Model estimation and inference for birth counts”. Section “Model-Based Estimation of Fertility Indicators” covers the model-based estimation of different fertility rates. Section “Conclusion” summarizes the article with some concluding remarks (Fig. 1).

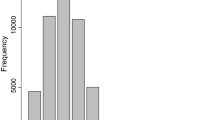
(a) Bar chart for birth counts during 1-year period. (b) Bar chart for birth counts during 3-year period. (c) Bar chart for birth counts during 5-years period; X-axis consists of birth counts and Y-axis corresponding frequencies.
Model estimation and inference for birth counts
We first briefly introduce fertility indicators and methods of their calculation following5. The Age Specific Fertility Rate (ASFR) is the average count of births that occurred during a given reference period per 1,000 women exposed to the risk of fertility, in 1- year, 3-years, or 5-years age groups. For any age group \(g= 1, 2,...,7\) for 5-years grouping), \(B_{g}\), and \(E_g\) denote the total births given by the women and women-years of exposure in age group g for the referenced period respectively. The ASFR in age group g is expressed as:
where 1000 is multiplied to show the rate per 1000 women-years of exposure. The data about the exact Date of Birth (DoB) of the child from DHS data was utilized for directly calculating the numerator \(B_{g}\). For calculating the denominator \(E_g\), the exact DoB of each woman was used for summing up the number of women-years of exposure in g, because a woman can participate in atleast two age groups for a given referenced period. For details about computation of the women-years of exposure, readers are referred to11. The Total Fertility Rate (TFR) is used to measure women’s fertility hypothetically42. It can be described as the total children who would be born per 1,000 women if they went through their reproductive age according to a given schedule of ASFR subject to no mortality. The TFR is computed on the basis of \(ASFR_{g}\) for \(g=0,1,...,6\) as follows
The General Fertility Rate (GFR), which is the mean count of births that a woman gives during her whole reproductive period, is obtained by dividing the total number of births during a specified period by the total number of women exposed to the risk of fertility, during the same specific period. The standard formula for GFR is given by
Similarly, Gross Reproduction Rate (GRR) is computed based on ASFR and sex ratio at birth during that period. Like TFR, GRR assumes that the hypothetical group (cohort) of women pass from birth over their reproductive age with no mortality. This assumption is valid when one is interested in comparing levels of fertility over time. The GRR is expressed as
where \(P_{g}\) is the proportion of female births to the women in age group g. The birth data file (PKBR71FL.DTA) from PDHS 2017-18 was taken for analysis. The detail about the data collection mechanism, fieldwork, training of staff and pretest is available in43. The key variables including demographic characteristics, socioeconomic variables, and variables related to family planning were taken as the predictors and described in Table 1 along with the response variables. Figure 2 shows bar-charts corresponding to three responses and one can observe that all three responses depict highly departure from symmetry. Also one can observe that the number of births for 1 year includes the highest number of zeros than the other two counts. The number of births during the 5-year period tends to follow a Poisson distribution without access to zeros.
Birth count regression models
Let y be the observed response corresponding to a random variable Y whose values are unknown for a finite population of size N indexed as \(\mathcal {U}=\{1,2,3,....,N\}\). In matrix notation, let \(\varvec{y}=(y_{i}, i \in U)\) be the realizations of the stochastic vector \(\varvec{Y}=(\varvec{Y}_{i}, i \in \mathcal {U} )\) under model-based approach. Suppose a sample \(S=\{1,2,3,...,n\}\) of size n is drawn from finite population \(\mathcal {U}\) using a Sampling Design (SD) and \(r=(1,2,3,...,N-n)\) be the set of index attached to the values of units that are not indexed in s. For a given sample s, we can rearrange the population vector as \(\varvec{y}=(\varvec{y}^{T}_{s},\varvec{y}^{T}_{r})^{T}\), where \(\varvec{y}_{s}\) and \(\varvec{y}_{r}\) be the vectors of n sampled and \((N-n)\) non-sampled values of the study variable respectively. Let \(\mathcal {M}\) be the true underlying model expressed as
where \(\varvec{X}\) is the data matrix containing p regressors including intercept and \(\varvec{\epsilon }\) be the vector of random errors assumed to be distributed normally with mean vector \(\varvec{0}\) and variance-covariance matrix \( \varvec{\Sigma }\). When the response variable is the number of occurrences of an event, the distribution of counts is discrete and is bound to non-negative integered values. While applying an ordinary linear regression model to such data, researchers may face one of the following two issues. (i) Often such count data has positively skewed distribution with many observations having value 0 as in Fig. 2. With a large number of zeros in the data set, one cannot transform such skewed distributions into normal. (ii) It is quite possible that the regression model produces negative predicted values which contradicts with theory44. The following sub-sections cover some generalized linear regression models which we use as a working model for births per woman during 1, 3, and 5-years periods before the interview.
Poisson regression model
A Poisson Regression Model (PRM) assumes that the error term has Poisson distribution instead of a normal distribution. Further, it uses the natural logarithm of the response variable as a linear function of the coefficients rather than simply modeling the response variable as a linear function of the regression coefficients. To proceed it is assumed that the logarithm of the mean values (rates) can be modeled into a linear form with some unknown parameters. The mathematical form of PRM is given by
where vector \(\varvec{\beta }\) is obtained using maximum likelihood estimation (MLE). Let \(\mu \) be the rate parameter which is also the dispersion parameter of Poisson distribution and Equation (5) can be expressed as:
The exponent of the coefficient \(\beta _{j}\) (jth component of \(\varvec{\beta }\) for \(j=0,1,2,...,p\)) for an explanatory variable \((X_{j})\) thus shows the relationship between the number of births per woman for which the explanatory variable has a specified value and the number of births per woman for which the variable has the specified value minus one, all other things remain constant. Readers can find more details about Poisson regression model from45.
Negative binomial regression model
The PRM assumes that the error term, consequently responses for fixed covariate values, has the same mean and variance which is not usually true in practice. In many cases we face problem of over dispersion i.e. the variance of the error is larger than its mean. An alternative method for modeling the data with an over-dispersed error term is to fit a Negative Binomial Regression Model (NBRM)46. In negative binomial distribution the parameter of the distribution is considered as a random variable. The variation in the parameter can be considered as the variance of the data that is larger than the mean. We need more parameterization in NB distribution to get a form that is appropriate to our model. Following the notations given in47, we parameterize the NB density for the ith observation with parameters \(P_{i}\) and r. The former is known as the success parameter, and for the ith observation it is defined as \(P_{i}=\frac{r}{r+\mu _{i}}\), where \(\mu _{i}\) satisfies the relation given in Equation (7). The latter is the over-dispersion parameter \((\ge 0)\), which is equal to 1 in the Poisson distribution (i.e. there is no over-dispersion). The maximum likelihood estimates of the coefficients are obtained using the MASS package in R. The detail about parameter estimation, model assumptions, and validity of estimates can be found in48, Page 326 and49.
Zero-inflated poisson model
In the cases with responses having a large variance, many zeros as well as a few very large values, the negative binomial model as an extension of Poisson handles the extra variance. However, sometimes there may exist too many zeros than a Poisson would expect to predict. In such cases, a better option is to use Zero-Inflated Poisson (ZIP) model50. In a ZIP model, we assume that some zeros occur by a Poisson process and some were not even able to have the event occur. Hence two processes work in ZIP – where one determines whether the individual is eligible for a non-zero response, and the other finds the count of that response for eligible individuals. The ZIP model consists of two regression models both working simultaneously. A logistic (or probit) model is used to determine the probability of being eligible for a positive count and a Poisson model is used to model the size of the counts for eligible individuals with positive value. Both models utilize the same predictors, but with separate estimates for their coefficients. In this way, the predictor variables can have quite different effects on the processes. While a ZIP model needs it to be theoretically reasonable that some individuals are not eligible for a count. Zero-Inflation Poisson (ZIP) for response y is defined as
where \(\theta \) is the probability of occurring false values (zeros). Hence there are two models coupled together (a mixture model) to give an overall probability: (1)-when a response is zero (i.e. \( y_{i}=0\)), it is the probability of getting a zero plus the probability of a true value times probability of choosing a value of zero from a Poisson distribution with parameter \(\mu \) and (2)-when a response is greater than 0, it is the probability of true value times the probability of drawing that value from a Poisson distribution with parameter \(\mu \).
This definition indicates that the Poisson parameter \(\mu \) is the same for both zero and non-zero components. The model of zero values (i.e. \( y_{i}=0\)) is used for essentially investigating whether the likelihood of false zeros is related to the linear predictors. The greater than zero (i.e. \( y_{i}\ge 0\)) model, then, investigate whether the counts (non-zero responses) are related to the linear predictors. The expected value and the variance of the response y for a ZIP model are \(E(y_{i})=\mu (1-\theta )\) and \(Var(y_{i})=\mu (1-\theta )\times (1+\theta \mu ^2)\) respectively. The model building involves an iterative process which is performed using the MASS package in R. The detail about derivation and application of ZIP model to count responses is available in48. To model birth counts, we use four different regression models namely Poisson, NB, ZIP, and ZIP inflation on full data obtained from PDHS-2017-18. We obtain 3 different models corresponding to 3 responses as follows;
-
Model 1: Taking 1-year births as responses
-
Model 2: Taking 3-years births as responses
-
Model 3: Taking 5-years births as responses.
For data with count responses, the regression model utilizes the maximum likelihood (ML) method for estimation of the parameters. Reference51 provided a practically understandable introduction of ML estimation. The estimates of all coefficients are obtained by using an iterative set of procedures for estimating parameters. All the ML estimation results are converged and found a unique set of values for each coefficient.
Birth count regression models under classical approach
After screening different possible determinants of birth from DHS dataset, we select significant variables for fitting final Poisson, NB, ZIP and ZINB models. The estimated coefficients for Models-1, 2, and 3 are presented in Tables 2, 3, and 4 respectively to quantify the impact of different determinants on the number births. The predictor ’region’ is included to obtain the estimates and making comparison of different regions in terms of fertility measures. Other predictors includes the most significant indicators10 after excluding the insignificant determinants available in PDHS 2017-18. The standard error for estimated coefficients are reported in parentheses with different codes of significance (Significance codes: 0 ’***’ 0.001 ’**’ 0.01 ’*’ 0.05 ’.’ 0.1 ’ ’ 1). The results provide sufficient evidence that the estimated coefficients for all variables except Sindh, Prof\(\_\)tech, and Prof\(\_\)Agr have a significant effect on the number of 1-year births. The variables Res\(\_\)Age, Residence, and Age\(\_\)husbund show negative estimated coefficients for the Poisson model which supports the argument that the number of births during 1-year period to a woman decreases with the age of mother and is also higher for rural areas. The number of births for urban areas is \(\exp {(-0.1021)}=0.903\) times the number of births in rural areas assuming no changes in other factors. The likelihood value and its transformations (like AIC and BIC) are used for comparison of the fitting power of competing models44. The variable on the region of the respondent is reconstructed into 5 dummies leaving Punjab as the base category. For interpreting the dummies, we follow recommendations given in52. The dummy variable corresponding to the province Khyber Pakhtunkhwa (KPK) has negative estimated coefficient \((-0.0926)\) with a standard error of 0.035 indicating lower birth exposure in KPK (KPK=1) as compared to Punjab (KPK=0) assuming all other factors as fixed. While the coefficients are \(-0.088\) and \(-0.05\) with standard errors 0.021 and 0.015 for Poisson Model 2 and 3 respectively. Similarly, one can distill from Tables 2, 3 and 4 that, after adjusting other variables, the average births during 1, 3 and 5-year period are respectively exp(\(-0.0926) = 0.9115\), exp(\(-0.088) = 0.92\) and exp(−0.05) = 0.96 times of the average births in Punjab. The 95 % confidence intervals for the true effects are \( (-0.1612, -0.024)\), \((-0.12916, -0.04684)\) and (\(-0.079, -0.021\)) for Poisson Models 1, 2 and 3 respectively. The 95% confidence intervals for the relative rates (exponentiated estimates) are (0.851, 0.976), (0.879, 0.954) and (0.924, 0.98).
The regression coefficient associated with the wealth index (WI) is approximately −0.13 for all models. As WI is dummy coded, the negative sign shows that the average number of births for those who have positive WI is smaller than for those who have negative WI. Similarly, for all three responses, the coefficients for all dummies corresponding to different groups of the contraceptive methods turn negative denoting the number of births for those who use any one of the contraceptive methods is smaller than those who use no contraceptive method. For example, the average births to the women who use contraceptive pills have exp(\(-0.358)=0.70\) times of the average number of births to the women who don’t use any method at all. Further, the ratio of births during 1-year period between those who use male contraceptives and those who use female contraceptives is 0.2383 with exp(\(-0.102+0.77885) = 1.97\) showing that the number of births during 1-year period for those who use male contraceptive method have more birth than those who use a female contraceptive method. The same interpretation for the coefficients corresponding to contraceptive methods can be done with a slight change in the estimated values and standard errors. Further, the average number of 1, 3, and 5-year births to women belonging to an agriculture background are respectively 1.07, 1.06, and 1.123 times higher than those who do not work. However, the regression coefficient for dummy corresponding to pregnancy termination (Preg_term_new) is insignificant. The (1-\(\alpha \))% confidence interval corresponding to each exponentiated coefficient can be constructed after obtaining confidence interval for the coefficients given in Tables 2.
The method introduced in52 for interpreting dummy variables cannot be extended for the interpretation of the coefficients corresponding to the continuous predictors. For the education level variable, the regression coefficient is 0.095. To see one level change in education level, we put \(\triangle =1\) into the formula \(100 \times [0.095 \times 1-1] = 10\) indicating that there is a \(10\%\) (\(7.6\%\) for 3-years births and \(5.6\%\) for 5-years) increase in the expected number of 1-year births for a unit increase in education level. For the number of children already living in the same household, the regression coefficient is 0.025 with \(100\times [exp(0.025\times 1)-1]= 25.3\) showing that there is a \(25.3 \%\) increase in the average number of 1-year births with increase of one child in the family. The percentage changes in births during 3-years and 5-years periods before the interview have not been reported to reduce the length of the article. Similarly, the percentage change in the expected births during 1-year period with one unit change in the variable Res_age, Age_husbnd, Num_daughter, MTFBI are 9.7%, 1.64%, 2.5%, 26.905%, and 0.5% respectively. The percentage change in the expected births during 3-years period with one unit change in the variable Res_age, Age_husbnd, Num_daughter, MTFBI are 8.9%, 1.41% 2.14%, 23%, and 0.5% and the percentage change in the expected births during 5-years period with one unit change in the variable Res_age, Age_husbnd, Num_daughter, MTFBI are 7.9%, 1.14%, 1.78% 22.4%, and 0.435084% respectively.

Display of exponentiated estimated coefficients for Poisson models.
Figure 2 displays the effect of factors on birth counts for the 3 models. The length of bars shows the dispersion in the estimates while the center shows the exponentiated average change in births. The vertical line on the center divides the variables with negative and positive coefficients. The variables with insignificant effects are very close to the vertical line. The bars corresponding to 1-year births for Con_IUD and Con_Female show a highly significant decrement in birth while using these contraceptive methods.
A comparison of Poisson, NB, and ZIP are provided in Table 5 for three different responses. The minimum, maximum and mean residuals for each model are reported. The minimum residual is observed at extreme (i.e. -1.0731, -1.7707, and -2.6435) for the ZIP model. While maximum residual is observed at extreme (i.e. 51.793, 15.0487, and 9.5761) for NB. Further to see the model performance -2logliklihood and AIC values are also reported. The AIC values are observed smaller for ZIP as compared to other models considered in this study (Table 5).

Illustration of birth history data on a Lexis diagram (each birth can fall in one of the given categories then person-years are calculated according to these categories) is given in Fig. 3. Years spent by respondents before interview are shown on X-axis in 3-year periods. While age of respondents are shown on Y-axis the first arrow begins from 15 years age and end at 20 years inferring that birth falling in this category, i.e. area between first and second arrows before the first vertical line corresponding to 3, are counted as exposure for group 15-19.
Birth count regression models under bayesian framework
In this section, we analyze the birth history data using the PRM, previously run under frequentist’s point of view in a Bayesian framework by adding a normal prior on the coefficients of the linear log-mean function as given in (6) i.e. \(\beta _{j}\sim N(0,1\times 10^{-3})\) for all \(j=0,1,2,...,24\). The analysis is done in R-library (rjags) Just Another Gibbs Sampler (JAGS) taking three chains. We initialize the model and run the burn-in period and the model is updated 100 times and the number of iterations is taken 1,000. We take relatively fewer iterations as the number of nodes is 50,495 which leads to a longer time in running the complete model. After deciding the burn-in period, we simulate the samples that will keep. We re-run the model for checking the convergence and to see the auto-correlation. The deviance information criterion is also obtained for each model.
The 2nd, 5th and 8th columns of Table 6 give the posterior means of each coefficient, 3rd, 6th and 9th columns provide their standard deviation (standard errors), and 4th, 7th and 10th columns give effective sample sizes. One can notice that the posterior means almost match with the estimated coefficients corresponding to each variable with a slight reduction in standard error. The standard error for the “Residence” variable with Poisson model with 1-year period births as the response is 0.0242 while the corresponding posterior standard deviation for the same coefficient under MCMC is 0.0228. After running MCMC, we need to confirm whether MCMC sampler covers the parameter space efficiently, i.e. it does not accept or reject too many proposals. A detail discussion of MCMC diagnostics can be found in53,54 and55 etc. If the MCMC rejects too many proposals, we need a large number of simulations to generate a considerable number of parameter samples. On the other end, if a large number of proposals are accepted, we cannot find much information about the parent distribution. Trace plots are the important tools for assessing the mixing of a chain. Figures 9, 10, 11, 12, 13, 14, 15 show the trace plots corresponding to each coefficient which provide evidence of the presence of randomness (lack of pattern) in data. The trace plots corresponding to intercept \(\beta _{0}\), and two coefficients \(\beta _{1}\) and \(\beta _{3}\) reflect a slight lack of randomness while the trace plots corresponding to all other coefficients provide enough evidence of randomness. We provide the trace plot corresponding to the model for the births during 1-year period. Density plots are smoothed histograms of the samples, i.e. they show the function that we are trying to explore. Observing Figures 9, 10, 11, 12, 13, 14,15 one can also see the behavior of posterior densities for each coefficient through density plots. An alternative way to check for convergence of the estimates is to look at the auto-correlations among the samples obtained from MCMC. The lag-l auto-correlation is the correlation between every sample and the sample l steps earlier (which become smaller as l increases) i.e. considering samples as independent. On the other hand, if this auto-correlation remains constant (high) for higher values of l too, then the situation depicts a higher correlation between every sample and the sample l steps before. The autocorrelation plots corresponding to each coefficient for the three models are obtained from MCMC sampling. The plots for the model with 1-year period births as response variable are reported in Appendix.
The autocorrelation plots are displayed in Figs. 4, 5, 6, 7, 8 (see Appendix). It can be noticed that the auto-correlation goes down for all coefficients with increase in l. However, the auto-correlation plots corresponding to the intercept and the coefficient of age indicate the presence of auto-correlation. This auto-correlation can be reduced by thinning the MCMC chains, i.e. by discarding n samples for every sample that we keep. The thinning of the MCMC chain is not of much use unless we want to reduce the memory and storage space in long chains. With this argument, one should keep only one out of ten samples instead of thinning the chain because this is more efficient, concerning the Effective Sample Size (ESS), to run only one chain 10 times as long, it will take 10 times more storage space. A more reliable estimate for burn-in cut-off is through the ESS. An ESS is the number of independent samples with the same estimation power as the number of autocorrelated samples. The burn-in samples are the samples that have not much information, and if the period of burn-in is estimated to be short enough then this will lead to a reduction in the ESS. On contrary, if the period of burn-in is estimated to be much longer, again causes in reduction of the ESS as informative samples are being isolated. An increase in ESS should be with the optimal estimate of the burn-in are highly recommended in practical estimation procedures. The burn-in samples can be assessed from the trace plots and ESS. Table 6 shows that the ESS all coefficients, except \(\beta _{0}\), \(\beta _{1}\) and \(\beta _{3}\) which are 38.7, 36.3, and 32.75 respectively, are large enough to continue. The ESS for the coefficient of Cont_Inj is maximum with 1,855. Finally, we see the predictive power of our models by checking at deviances. The most widely used tool for checking the predictive power of a model is the Deviance Information Criterion (DIC). It is an estimate of the expected predictive error of the model. Table 7 gives the mean deviances for the three models. The DIC value is least (i.e. 43,015) for the model with the number of birth during 1-year period as the response. The penalized deviance for the same model with the penalty of 24.08 is 43,039 which is slightly larger than the deviance without penalty.
Model-based estimation of fertility indicators
In PDHS final report43, ASFRs are obtained according to the formula given in Equations (1) and (2) for each age group. The mother’s age is computed, in century month code (CMC) format, by taking the difference of the date of the interview and the mother’s date of birth. Births are then tabulated by age group after converting the ages into years. Similarly, the denominator in ASFR is women-years of exposure in the five-year age group during the 3-years time-period. A woman can expose to several age groups in the given period, with varying lengths of the period. For the 3-years period, a woman will contribute to at most two five-year age groups during the 36-months period. For further details related to the allocation of women to the extreme age groups (higher and lower), readers are referred to43.
We developed R codes for estimating ASFR under a model-based approach after converting the individual (IR) data to person-year data. For tabulation of person-years, each woman is tallied twice, once in the lower age group aggregating lower age group exposure and once according to the higher age group summing the exposure she contributes to the higher age group. In computing fertility rates, we use only ever-married samples without taking the “all-women factor” under a model-based approach. Hence the interpretation of the rates is done based on birth per ever-married woman only. The total exposure in each age group is the sum of the exposure in each age group tallying from the first and second. After obtaining ASFR, it is straightforward to obtain TFR, GFR, and GRR using formulae given in Equations (2), (3) and (4). We obtained fertility measures i.e. ASFR, TFR, GFR, and GRR using predicted responses obtained from the regression models after partitioning data into sampled and non-sampled parts. A bootstrap sampling procedure was used to study the design-based properties of the estimated fertility rates PDHS 2017-18 women re-coded data. The calculations are documented in the following algorithm.

Boot-strapped algorithm for birth rates estimation
Model-based ASFRs for Pakistan at national and sub-national levels for an ever-married sample along with their RMSE are presented in Table 8, and Tables 9-10 respectively under four different working models. The expected ASFR with the smallest RMSE among four (obtained under four alternative models) is bolded corresponding to each age group for the sub-national and national levels. In majority of the cases, the ZIP model gives relatively smaller RMSE at both national and sub-national levels. Comparing the estimated ASFR with the ASFR obtained from full data in the last column of Tables 8-10, we can notice that the ASFR for age groups 1, 2, 6, and 7 are upward biased for all models i.e. they are estimated larger than the ASFER obtained from full data. The discrepancies in results occurred due to the use of person time data for estimating ASFRs. As for smaller and elder ages we are not able to exactly find the exposure to births and denominator in ASFR might be counted below the actual exposure time. Which can be considered as major limitation of this approach. The expected ASFR with the smallest difference (bias) with the ASFR obtained from full data among four is underlined corresponding to each age group at both national and sub-national levels. For example, the closest estimate for age group 1 is obtained under NB model in Punjab province. From ASFR based on full PDHS data, one can observe that for age group 15-19 the highest average number of births is observed for FATA and the lowest for KPK. Similarly, ASFR can be compared across regions based on full data.
The TFR, GFR, and GRR for ever-married women are provided at sub-national and national levels in Tables 11, 12 and 13 respectively. The TFR for the ever-married sample is observed highest in ICT with 6.26 and lowest in Punjab with 5.44 per 1000 ever-married women. While the TFR for all women given in PDHS 2017-18 report is observed highest in FATA. The TFR obtained for all women using the DHS.rates package are given in Appendix. The estimates obtained under NB, ZIP, and ZINB are more accurate than the ones observed for Poisson which can be noticed from RMSE in Table 11 corresponding to each region. The smallest RMSE is observed at the national level when ZIP is used to model births i.e. 0.0617. Similarly, the predictive estimate for GFR at the sub-national and national level is observed highest for ever-married women in KPK which is 174.95.6 (NB as it is more precise than the other three estimates) births per 1000 married women. The lowest GFR is observed for Punjab with 162 children per 1000 ever-married women. The RMSE is observed highest when the Poisson regression model is used for modeling births in KPK. While for other regions continuing with Poisson, ZIP and NB give almost similar RMSE for estimating GFR at sub-national and national levels. The GFR for full data without model fitting is obtained in the last column of Table 12. The GRR is computed using the proportion of female births (PF) from all age groups using the sex ratio of male to female from full data (PF from census or administrative records can be used for obtaining sex ratio). The GRR is observed higher in Balochistan, Punjab, and KPK as compared to other regions replacement of 2 or more daughters per woman before the death of their mother. RMSE is smaller for Punjab, Sindh, and KPK when the NB model is used for prediction. While it is smaller for the remaining regions when the ZIP model is employed.
The model-based estimates on ASFR, TFR, GFR and GRR are obtained in this study using three responses (birth history during 1, 3 and 5 years preceding the interview). Interpretations are made on the basis of most suitable one (with smallest RMSE) from the estimates obtained under four different methods. The highest ASFR is estimated in Age group 25–29 and lowest is observed in 45-49 at national level. Same results for ASFR is obtained for Punjab, KPK and FATA. However, in Sindh, Balochistan and ICT highest ASFR is obtained for age group 20–24. The total TFR is estimated highest in ICT with 6.23 (about 6 births per woman) and lowest in Pubjab region with 5.45. TFR is estimated 5.8 (aorund 6 per woman during their whole reproductive age) at National level. The GFR is estimated highest in KPK with 175 per 1000 women and lowest in FATA with 153 per 1000 women. The GFR is estimated 168 per 1000 women at national level. Similarly, the GRR is obtained highest in ICT with 2.8 per married woman and lowest in Balochistan with 2.4.
Conclusion
Estimation and inference of fertility rates posses severe challenges when surveys consist of missing responses on birth counts. Model-based approach by utilizing available data on related covariates aids in efficiency of estimated fertility rates. This article covers an etiological analysis of PDHS 2017-18 data on birth history to observe its significant determinants followed by construction of the model-based estimators on fertility rates including ASFR, TFR, GFR, and GRR. Estimation and inference of birth counts are considered under classical as well as Bayesian frameworks. The bootstrapped study reveals that the model-based estimators of fertility rates provide efficient results when relevant auxiliary data are available from the census at unit or cluster level. It is important to mention that the data about the majority of covariates considered for prediction in this study is not easy in practical situations at the individual level. However, data might be available for clusters through Civil Registration of Vital events (CRVE) or from previously conducted surveys. The predictive approach is suggested here in constructing rates in case of missing responses on birth and for small area estimation. However, in case of model failure the proposed estimation method would not work well and a more robust model assisted strategy is needed. Same authors are working on constructing the same rates using model assisted strategies.
References
United Nations Inter-agency Group for Child Mortality Estimation (UN IGME). Levels & Trends in Child Mortality: Report 2018, Estimates developed by the United Nations Inter-agency Group for Child Mortality Estimation. New York: United Nations Children’s Fund. (2018).
Abel, G. J., Barakat, B., Samir, K. C. & Lutz, W. Meeting the Sustainable Development Goals leads to lower world population growth. Proc. Natl. Acad. Sci. 113(50), 14294–14299 (2016).
Lightbourne, J. R., Singh, S. & Green, C. P. The world fertility survey: Charting global childbearing. Popul. Bull. 37(1), 1–55 (1982).
Chamratrithirong, A., Kamnuansilpa, P. & Knodel, J. Contraceptive practice and fertility in Thailand: Results of the third contraceptive prevalence survey. Stud. Fam. Plann. 17(6 Pt 1), 278–287 (1986).
Croft, T. N., Marshall, A. M. J., Allen, C. K., et al. Guide to DHS statistics. Rockville, Maryland, USA: ICF; [cited 2019 January 29]. Available from: https://www.dhsprogram.com/publications/publicationDHSG1-DHS-Questionnaires-and-Manuals.cfm (2018).
Moultrie, T. A. Direct estimation of fertility from survey data containing birth histories. In: Moultrie, T. A., Dorrington, R. E., Hill, A. G., Hill, K., Timæus, I. M., & Zaba, B, (eds). Tools for Demographic Estimation. Paris: International Union for the Scientific Study of Population; [cited 2019 January 29]. Available from: http://demographicestimation.iussp.org/content/introduction-child-mortality-analysis. (2013).
Hill, K. Introduction to child mortality analysis. In: Moultrie, T. A., Dorrington, R. E., Hill, A. G., Hill, K., Timæus, I. M., & Zaba B, (eds). Tools for Demographic Estimation. Paris: International Union for the Scientific Study of Population; [cited 2019 January 29]. Available from: http://demographicestimation.iussp.org/content/introduction-child-mortality-analysis. (2013).
United Nations, Department of Economic and Social Affairs, Population Division (2011). Mortality Estimates from Major Sample Surveys: Towards the Design of a Database for the Monitoring of Mortality Levels and Trends. The Technical Paper series; (Technical Paper No. 2011/2).
ICF. The DHS Program STATcompiler. Funded by USAID; (2012) [cited 2019 January 29]. Available from: http://www.statcompiler.com.
Schoumaker, B. A Stata module for computing fertility rates and TFRs from birth histories: tfr2. Demogr. Res. 28, 1093–1144 (2013).
Masset, E. SYNCMRATES: Stata module to Compute Child Mortality Rates Using Synthetic Cohort Probabilities. 2016 [cited 2019 January 29]. Available from: https://EconPapers.repec.org/RePEc:boc:bocode:s458149. (2016).
Elkasabi, M. Calculating fertility and childhood mortality rates from survey data using the DHS. rates R package. PLoS ONE 14(5), e0216403 (2019).
Elkasabi M. DHS.rates: Calculates demographic indicators. R package version 0.7.0; Available from: https://cran.r-project.org/web/packages/DHS.rates/index.html (2018).
PAKISTAN Demographic and Health Survey 2017-18 key indicators report, National Institute of Population Studies Islamabad, Pakistan The DHS Program ICF Rockville, Maryland, USA August 2018 https://www.nips.org.pk/abstract_files/PDHS%20-%202017-18%20Key%20indicator%20Report%20Aug%202018.pdf
Tomal, J. H., Khan, J. R. & Wahed, A. S. Weighted Bayesian Poisson regression for the number of children ever born per woman in Bangladesh. J. Stat. Theory Appl. 21, 79–105. https://doi.org/10.1007/s44199-022-00044-2 (2022).
Gardner, W., Mulvey, E. P. & Shaw, E. C. Regression analyses of counts and rates: Poisson, over-dispersed Poisson, and negative binomial models. Psychol. Bull. 118(3), 392 (1995).
Long, J. S. Regression models for categorical and limited dependent variables (Vol. 7). Advanced quantitative techniques in the social sciences. (1997).
Angeles, G., Guilkey, D. K. & Mroz, T. A. Purposive program placement and the estimation of family planning program effects in Tanzania. J. Am. Stat. Assoc. 93(443), 884–899 (1998).
Mencarini, L. An analysis of fertility and infant mortality in South Africa based on 1993 LSDS data. In Third African Population Conference, African Population in the 21st Century(pp. 109-128). (1999).
Raftery, A. E., Lewis, S. M. & Aghajanian, A. Demand or ideation? Evidence from the Iranian marital fertility decline. Demography 32(2), 159–182 (1995).
Powers, D. A. & Xie, Y. Statistical Methods for Categorical Data Analysis (Acad, San Diego, 2000).
Zeileis, A., Kleiber, C. & Jackman, S. Regression models for count data in R. J. Stat. Softw. 27(8), 1–25 (2008).
Tiwari, A. K., Singh, B. P. & Patel, V. Retrospective study of investigation of possible predictors for total fertility rate in India. J. Sci. Res. Rep. 26(9), 111–119 (2020).
Sethi, N., Jena, N. R. & Loganathan, N. Does financial development influence fertility rate in South Asian economies? An empirical insight. Business Strategy Dev. 4(2), 94–108 (2021).
Ermisch, J. English fertility heads south. Demogr. Res. 45, 903–916 (2021).
Bu, N. & Wang, J. Economic geography and cross-region fertility revisited. Appl. Econom. Lett., 1-4. (2022).
Rezaee, M., Faraji Sabokbar, H. A. & Tahmasbi, S. Spatial smoothing of fertility rate in rural areas of Iran (2011–2016). J. Rural Res. 12(4), 734–749 (2022).
Kamal, S. M. & Ulas, E. Child marriage and its impact on fertility and fertility-related outcomes in South Asian countries. Int. Sociol. 36(3), 362–377. https://doi.org/10.1177/0268580920961316 (2021).
Schoumaker, B. & Hayford, S. R. A person-period approach to analysing birth histories. Population 59(5), 689–702 (2004).
Ganesan, N. A. B. A. G., & Othman, N. S. The determinants of fertility rate in Malaysia. In Proceedings of The 2 nd Conference on Managing Digital Industry, Technology and Entrepreneurship (CoMDITE 2021) (p. 237).
Sarker, M. M. R., Nishat, N. I., Parvin, M. M. & Fagun, A. N. Determinants of fertility trend at district, divisional and regional levels and policy implication for poverty alleviation. Int. J. Health Econom. Policy 6(3), 92–99 (2021).
Tesfa, D. et al. The pooled estimate of the total fertility rate in sub-Saharan Africa using recent (2010–2018) Demographic and health survey data. Front. Public Health 10, 1053302 (2023).
Muth, C., Oravecz, Z. & Gabry, J. User-friendly Bayesian regression modeling: A tutorial with rstanarm and shinystan. Quant. Methods Psychol. 14(2), 99–119 (2018).
Wang, S., Sun, X. & Lall, U. A hierarchical Bayesian regression model for predicting summer residential electricity demand across the USA. Energy 140, 601–611 (2017).
Hamra, G., MacLehose, R. & Richardson, D. Markov chain Monte Carlo: An introduction for epidemiologists. Int. J. Epidemiol. 42(2), 627–634. https://doi.org/10.1093/ije/dyt043 (2013).
Leknes, S., & Løkken, S. A. Flexible empirical Bayes estimation of local fertility schedules: Reducing small area problems and reserving regional variation (No. 953). Discussion Papers. (2021).
Lynch, S. M. Evaluating Markov Chain Monte Carlo Algorithms and Model Fit. In Introduction to Applied Bayesian Statistics and Estimation for Social Scientists. Statistics for Social and Behavioral Sciences (ed. Lynch, S. M.) (Springer, New York, NY, 2007).
Hill, J. L. Bayesian nonparametric modeling for causal inference. J. Comput. Graph. Stat. 20(1), 217–240 (2011).
Hahn, P. R., Murray, J. S. & Carvalho, C. M. Bayesian regression tree models for causal inference: Regularization, confounding, and heterogeneous effects (with discussion). Bayesian Anal. 15(3), 965–1056 (2020).
Ahmed, S. & Shabbir, J. On the use of ranked set sampling for estimating super-population total: Gamma population model. Scientia Iranica 28(1), 465–476 (2021).
Ahmed, S., & Shabbir, J. (2021). A novel basis function approach to finite population parameter estimation. Scientia Iranica.
Kato, H. Total Fertility Rate, Economic-Social Conditions, and Public Policies in OECD Countries. In Macro-econometric Analysis on Determinants of Fertility Behavior (pp. 51-76). Springer, Singapore. (2021).
PAKISTAN Demographic and Health Survey 2017-18 final report, National Institute of Population Studies Islamabad, Pakistan, The DHS Program ICF Rockville, Maryland, USA January 2019 http://nips.org.pk/abstract_files/PDHS%202017-18%20-%20key%20%20findings.pdf
Cameron, A. C. & Trivedi, P. K. Regression Analysis of Count Data (Cambridge University Press, New York, NY, 1998).
Stefany, C., West S. G. & Aiken, L. S. The analysis of count data: A gentle introduction to Poisson regression and its alternatives, J. Personality Assess, 91(2), 121-136, https://doi.org/10.1080/00223890802634175 .
Jay, M. V. H. & Peter, L. B. Quasi-Poisson vs. neagtive binomial regression: How should we model overdispersed count data?. Ecology 88, 2766–2772 (2007).
Jackman, S. Estimation and inference via Bayesian simulation: An introduction to Markov chain Monte Carlo. Am. J. Political Sci. 44(2), 375–398 (2000).
Cameron, A. C. & TrivediP, K. Regression Analysis of Count Data 2nd edn. (Cambridge Univ. Press, Cambridge, 2013).
Hilbe, J. Negative Binomial Regression (Cambridge University Press, Cambridge, 2011). https://doi.org/10.1017/CBO9780511973420.
Atkins, D. C., Baldwin, S., Zheng, C., Gallop, R. J. & Neighbors, C. A tutorial on count regression and zero-altered count models for longitudinal addictions data. Psychol. Addict. Behav. 27, 166177. https://doi.org/10.1037/a0029508 (2013).
Enders, C. K. Maximum likelihood estimation. In Encyclopedia of Behavioral Statistics (eds Everitt, B. & Howell, D. C.) 1164–1170 (Wiley, West Sussex, England, 2005).
Atkins, D. C. & Gallop, R. J. Rethinking how family researchers model infrequent outcomes: A tutorial on count regression and zero-inflated models. J. Fam. Psychol. 21(4), 726 (2007).
Mengersen, K. L., Robert, C. P. & Guihenneuc-Jouyaux, C. MCMC convergence diagnostics: A review. Bayesian Stat. 6, 415–440 (1999).
Boone, E. L., Merrick, J. R. & Krachey, M. J. A Hellinger distance approach to MCMC diagnostics. J. Stat. Comput. Simul. 84(4), 833–849 (2014).
Vats, D., Robertson, N., Flegal, J. M., & Jones, G. L. (2019). Analyzing MCMC Output. arXiv preprint arXiv:1907.11680.
Acknowledgements
The authors are very grateful to DHS program for providing data on PDHS 2017-18. The authors are grateful to the handling editor and reviewers for their insightful comments that lead in improvement of the paper.
Author information
Authors and Affiliations
Contributions
S.A.: wrote the main manuscript text and all the analysis O.A.: Revised J.S.: reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
See Figs. 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, and 15.

Auto Correlation of coefficients Plot 1.

Auto Correlation of coefficients Plot 2.

Auto Correlation of coefficients Plot 3.

Auto Correlation of coefficients Plot 4.

Auto Correlation of coefficients Plot 5.

Trace Plot 1-A.

Trace Plot 1-B.

Trace Plot 1-C.

Trace Plot 1-D.

Trace Plot 1-E.

Trace Plot 6.

Trace Plot 7.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ahmed, S., Albalawi, O. & Shabbir, J. A novel approach for estimating fertility rates in finite populations using count regression models. Sci Rep 14, 1879 (2024). https://doi.org/10.1038/s41598-024-51734-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-51734-z
- Springer Nature Limited