
Abstract
The partitioned Dual Maclaurin symmetric mean (PDMSM) operator has the supremacy that can justify the interrelationship of distinct characteristics and there are a lot of exploration consequences for it. However, it has not been employed to manage “multi-attribute decision-making” (MADM) problems represented by picture fuzzy numbers. The basic inspiration of this identification is to develop the novel theory of picture fuzzy PDMSM operator, and weighted picture fuzzy PDMSM operator and to identify their important results (Idempotency, Monotonicity, and Boundedness). Further, to identify the best decision, every expert realized that they needed the best way to find the beneficial optimal using the proper decision-making procedure, for this, we diagnosed the MADM tool in the consideration of deliberated approaches based on PF information. Finally, to drive the characteristics of the invented work, several examples are utilized to test the manifest of the comparative analysis with various more existing theories, which is a fascinating and meaningful technique to deeply explain the features and exhibited of the proposed approaches.
Similar content being viewed by others


Introduction
The aim of the decision-making (DM) sciences is to identify the massive dominant decision from a group of expected ones. MADM is a critical and crucial component of these sciences. In genuine DM strategy, the dilemma requires resolving the provided decisions by many classes like single or interval evaluation investigations. However, in many awkward scenarios, it is very challenging for the expert to reduce their decisions to a classical number. To establish it, Zadeh1 exposed the mathematical framework of fuzzy set (FS) by proposing a new function, called membership degree (MD)  defined from universal set \(X\) to \(\left[0, 1\right]\). If we are taking any arbitrary element \(x\in X\) and assigning it to a value
defined from universal set \(X\) to \(\left[0, 1\right]\). If we are taking any arbitrary element \(x\in X\) and assigning it to a value  , then the resultant value should belong to \(\left[0, 1\right]\). In many cases, the meaningful theory of FS has been unsuitable, when an expert copes with information that contains yes or no. Then for this, one of the most suitable and meaningful theories which easily manage awkward and complicated data arising in real life was invented by Atanassov2, 3, called intuitionistic FS (IFS) by including a new function, called non-membership degree (NMD) \(\eta_ {{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \) defined from universal set \(X\) to \(\left[\mathrm{0,1}\right]\). If we are taking any arbitrary element \(x \in X\) and assigning it to a function \(\eta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right)\), then the resultant value should belong to \(\left[ {0,1} \right]\) with \(0 \le \zeta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right) + \eta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right) \le 1\). Unrelatedly, the informative idea of IFSs has been utilized in various areas. Still, there is a diversity of circumstances in which IFS theory can’t be employed. For instance, casting a vote and managing dilemmas like yes, abstinence, no, and refusal, which bounded the implementation of IFS theory. Then for this, one of the most suitable and meaningful theories which easily manage difficult and intricate data occurring in real life was invented by Cuong4, called picture FS (PFS) by including a new function, called abstinence degree (AD) \(\wp_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \) defined from universal set \(X\) to \(\left[\mathrm{0,1}\right]\). If we are taking any arbitrary element \(x \in X\) and assigning it to a function \(\overline{\wp }_ {{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }}\left( x \right)\), then the resultant value should belong to \(\left[\mathrm{0,1}\right]\) with \(0 \le \zeta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right) + \wp_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right) + \eta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} }} \left( x \right) \le 1\).
, then the resultant value should belong to \(\left[0, 1\right]\). In many cases, the meaningful theory of FS has been unsuitable, when an expert copes with information that contains yes or no. Then for this, one of the most suitable and meaningful theories which easily manage awkward and complicated data arising in real life was invented by Atanassov2, 3, called intuitionistic FS (IFS) by including a new function, called non-membership degree (NMD) \(\eta_ {{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \) defined from universal set \(X\) to \(\left[\mathrm{0,1}\right]\). If we are taking any arbitrary element \(x \in X\) and assigning it to a function \(\eta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right)\), then the resultant value should belong to \(\left[ {0,1} \right]\) with \(0 \le \zeta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right) + \eta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right) \le 1\). Unrelatedly, the informative idea of IFSs has been utilized in various areas. Still, there is a diversity of circumstances in which IFS theory can’t be employed. For instance, casting a vote and managing dilemmas like yes, abstinence, no, and refusal, which bounded the implementation of IFS theory. Then for this, one of the most suitable and meaningful theories which easily manage difficult and intricate data occurring in real life was invented by Cuong4, called picture FS (PFS) by including a new function, called abstinence degree (AD) \(\wp_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \) defined from universal set \(X\) to \(\left[\mathrm{0,1}\right]\). If we are taking any arbitrary element \(x \in X\) and assigning it to a function \(\overline{\wp }_ {{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }}\left( x \right)\), then the resultant value should belong to \(\left[\mathrm{0,1}\right]\) with \(0 \le \zeta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right) + \wp_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} \left( x \right) + \eta_{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{{\underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle\cdot}$}}{\text{Y}} }} }} \left( x \right) \le 1\).
Literature review
Because of the importance and significance of the FS, numerous researchers worked in this area. Saha et al.5 devised a similarity-based arrangement with the Archimedean Dombi aggregation operator (AO) in the setting of fuzzy information. Babuska and Verbruggen6 deduced techniques for FS and Hullermeier7 employed techniques for FS in machine learning. The fuzzy technique of MADM was interpreted by Nazari et al.8. Deni et al.9 deduced another fuzzy technique of MADM and named it the SAW technique. The key concept of L-FS was diagnosed by Goguen10 and the major concept of bipolar soft sets was invented by Mahmood11. The fuzzy soft sets (FSSs) were developed by Ali12 and the topological structure of FSS was exposed by Tanay and Kandemir13. More, the main idea of interval-valued FS was utilized by Feng et al.14. The portfolio investigation based on fuzzy entropy measures was diagnosed by Qin et al.15 and two different types of entropy measures for fuzzy data were utilized by Bi et al.16.
The desire to address ambiguity and vagueness in decision-making, create workable solutions for genuine issues, and enhance the theoretical underpinnings of this fuzzy set extension motivates researchers in the subject of IFSs. They are working to develop tools that are more reliable and adaptable for dealing with uncertainty in diverse situations. Xu and Yager17 devised geometric AOs within intuitionistic fuzzy (IF) information and Xu18 deduced AOs under the setting of IF information. The generalized AOs within IFS were devised by Zhao et al.19. Xia et al.20 deliberated various AOs under IF information by employing Archimedean t-conorm and t-norm. The weighted Maclaurin symmetric mean (MSM) operators within IFS were revealed by Shi and Xiao21. Wang et al.22 devised an IF PDMSM operator for coping with MADM dilemmas. Liu and Qin23 deduced MSM operators in the environment of linguistic IF set. Garg and Arora24 devised generalized MSM operators in the environment of the IF soft set. Further, various researchers developed various approaches within IFS such as Ecer25 devised the technique of MAIRCA for IFS, Chen, and Tsao26 devised the technique of TOPSIS for IFS, Zhao et al.27 devised a method of IF MABAC Chatterjee et al.28 devised the VIKOR procedure for IFS, and Zhang et al.29 interpreted a technique of MULTIMOORA for IFS. The entropy and similarity measures based on IFS were utilized by Thao and Chou30 and the histogram equalization based on IFS was presented by Jebadass and Balasubramaniam31. The main model for the evaluation of three-way approximation using IFS was anticipated by Yang et al.32.
In the area of PFSs, various researchers interpreted new AOs, approaches, and applications to cope with complex vague, and uncertain data in numerous fields. Garg33 and Wei34 devised various AOs within picture fuzzy (PF) information. Jan et al.35 devised Dombi AOs within PF information and Wei36 interpreted Hamacher AOs under the setting of PF information. Ullah37 devised MSM operators for PF information. Various researchers developed numerous approaches in the environment of PFS like Simic et al.38 devised a multi-criteria DM (MCDM) approach for PFS, Jin et al.39 devised a technique of TOPSIS for PF information, Meksavang et al.40 interpreted an approach of VIKOR for PFS, Liang et al.41 deduced method of EDAS-ELECTRE for PF information, Akram et al.42 devised COPRAS approach for IFS and Tian et al.43 interpreted a technique of MULTIMOORA for IF information.
Motivation
The theory of MSM was deduced by Maclaurin44 and then modified by DeTemple and Roberston45. The MSM and dual MSM (DMSM) differ from typical aggregation operators in that they take into account the interactions between many input parameters. Because of this, the MSM and DMSM excel at delivering flexible and reliable data combinations, making it especially useful for dealing with (MADM) scenarios where the characteristics are distinct from one another. Further, to organize and optimize data storage and retrieval, a collection must be partitioned. Combining similar information, cutting down on duplication, and enhancing query efficiency, enables effective data management. Partitioning can also boost parallel processing capacities, resulting in quicker data processing and better system scalability. From the above-mentioned discussion, we observed that there are no AOs under the setting of PF information which is based on DMSM and can cope with the partitioned collection. Thus, in this manuscript, we will try to utilize PDMSM operators in the setting of PF information. The PDMSM operators in the environment of PF information have the supremacy that can justification of the interrelationship of distinct characteristics and there are a lot of exploration consequences for it. Moreover, there is no such MADM approach in the literature under PF information that can employ the PDMSM operator and cope with MADM dilemmas. So further, in this manuscript, we devise a MADM method under PF information relying on the invented PDMSM operators. The basic inspiration for this identification is described below:
-
(1)
To develop the novel theory of PFPDMSM operator, WPFPDMSM operator and identified their important results (Idempotency, Monotonicity, Boundedness).
-
(2)
To identify the best decision, every expert realized that they needed the best way to find the beneficial optimal using the proper decision-making procedure, for this, we diagnosed the MADM tool in the consideration of deliberated approaches based on PF information.
-
(3)
To drive the characteristics of the invented work, several examples are utilized to test the manifest of the comparative analysis with various more existing theories, which is a fascinating and meaningful technique to deeply explain the features and exhibited of the proposed approaches.
Organization of the paper
Various and main important of this analysis are organized the shape: In Sect. "Preliminaries", we revised the concept of PF data along with their operational laws. Further, we also recalled the theory of Maclaurin symmetric mean (MSM), dual MSM (DMSM), and PDMSM operators and their related results which are very helpful for the invented work. In Sect. "PDMSM Operators Based on PFNs", we established the novel theory of PFPDMSM operator, and WPFPDMSM operator and identified their important results (Idempotency, Monotonicity, Boundedness). In Sect. "Application (“MADM Process”)", we identified the best decision, every expert realized that they needed the best way to find the beneficial optimal using the proper decision-making procedure, for this, we diagnosed the MADM tool in the consideration of deliberated approaches based on PF information. Finally, to drive the characteristics of the invented work, several examples are utilized to test the manifest of the comparative analysis with various more existing theories, which is a fascinating and meaningful technique to deeply explain the features and exhibited of the proposed approaches. In Sect. "Conclusion", we concluded some remarks.
Preliminaries
The major impact of this scenario is to revise the theory of PF set and its operational rules. Further, we also recalled the theory of Maclaurin symmetric mean (MSM), dual MSM (DMSM), and PDMSM operators and their related results which are very helpful for the invented work.
Definition 1:
4 A PFS \(\widehat{\mathcal{M}}\) on \(\widetilde{X}\) is deliberated by:
with \(0\le {\zeta }_{\mathcal{M}}\left(x\right)+{\wp }_{\mathcal{M}}\left(x\right)+{\eta }_{\mathcal{M}}\left(x\right)\le 1\). Where \({\zeta }_{\mathcal{M}}\left(x\right),{\wp }_{\mathcal{M}}\left(x\right), {\eta }_{\mathcal{M}}\left(x\right)\in \left[0, 1\right]\) denote the MD, AD and NMD respectively, the triplet \(\left({\zeta }_{\mathcal{M}}\left(x\right),{\wp }_{\mathcal{M}}\left(x\right), {\eta }_{\mathcal{M}}\left(x\right)\right)\) is termed PFN. In short, PFN written as \(\widehat{\mathcal{M}}=\left(\zeta ,\wp ,\eta \right)\). Further, let \({\widehat{\mathcal{M}}}_{1}=\left({\zeta }_{1}, {\wp }_{1}, {\eta }_{1}\right)\) and \({\widehat{\mathcal{M}}}_{2}=\left({\overline{\zeta }}_{2}, {\overline{\wp } }_{2}, {\overline{\eta }}_{2}\right)\) be two PFNs, \(\mathrm{\mho }\) be a positive real number, then
Moreover, using Eqs. (2)–(5), we obtain the following theories, such that.
(1) \({\widehat{\mathcal{M}}}_{1}\oplus {\widehat{\mathcal{M}}}_{2}={\widehat{\mathcal{M}}}_{2}\oplus {\widehat{\mathcal{M}}}_{1},\)
(2) \({\widehat{\mathcal{M}}}_{1}\otimes {\widehat{\mathcal{M}}}_{2}={\widehat{\mathcal{M}}}_{2}\otimes {\widehat{\mathcal{M}}}_{1},\)
(3) \(\mathrm{\mho }\left({\widehat{\mathcal{M}}}_{1}\oplus {\widehat{\mathcal{M}}}_{2}\right)={\mathrm{\mho }\widehat{\mathcal{M}}}_{1}\oplus {\mathrm{\mho }\widehat{\mathcal{M}}}_{2},\mathrm{ \mho }>0,\)
(4) \({\mathrm{\mho }}_{1}{\widehat{\mathcal{M}}}_{1}\oplus {{\mathrm{\mho }}_{2}\widehat{\mathcal{M}}}_{1}=\left({\mathrm{\mho }}_{1}+{\mathrm{\mho }}_{2}\right){\widehat{\mathcal{M}}}_{1},{\mathrm{\mho }}_{1},{\mathrm{\mho }}_{2}>0,\)
(5) \( {\widehat{\mathcal{M}}}_{1}^{{\mho_{1} }} \otimes {\widehat{\mathcal{M}}}_{1}^{{\mho_{2} }} = \left( {{\widehat{\mathcal{M}}}_{1} } \right)^{{\mho_{1} + \mho_{2} }} ,{ }\mho_{1} ,\mho_{2} > 0, \)
(6) \( \left( {\widehat{\mathcal{M}}}_{1} \otimes {\widehat{\mathcal{M}}}_{2} \right)^{\mho } = {\widehat{\mathcal{M}}}_{1}^{\mho } \otimes {\widehat{\mathcal{M}}}_{2}^{\mho } ,{ }\mho > 0 \)
Additionally, finding the ranking between any PFNs is a very challenging task for experts, for this, we revise the score value (SV) and accuracy value (AV), such that
Then by employing Eqs. (6) and (7), we diagnose.
1. If \({\mathbb{S}}\left({\widehat{\mathcal{M}}}_{1}\right)>{\mathbb{S}}\left({\widehat{\mathcal{M}}}_{2}\right)\) then \({\widehat{\mathcal{M}}}_{1}>{\widehat{\mathcal{M}}}_{2}\)
2. If \({\mathbb{S}}\left({\widehat{\mathcal{M}}}_{1}\right)={\mathbb{S}}\left({\widehat{\mathcal{M}}}_{2}\right)\) then.
3. If \(\mathop {\text{A}}\limits^{ \vee } \left( {{\widehat{\mathcal{M}}}_{1} } \right) > \mathop {\text{A}}\limits^{ \vee } \left( {{\widehat{\mathcal{M}}}_{2} } \right)\) then \({\widehat{\mathcal{M}}}_{1} > {\widehat{\mathcal{M}}}_{2}\)
4. If \(\mathop {\text{A}}\limits^{ \vee } \left( {{\widehat{\mathcal{M}}}_{1} } \right) = \mathop {\text{A}}\limits^{ \vee } \left( {{\widehat{\mathcal{M}}}_{2} } \right)\) then \({\widehat{\mathcal{M}}}_{1} = {\widehat{\mathcal{M}}}_{2}\)
Definition 2:
44 For any specified positive real numbers \({\mathcal{M}}_{{t}}\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right),\) and \({{\mathbb{F}}}=1, 2, \ldots .,{{\mathbbm{f}}}\), The MSM operator initiated by:
The DMSM operator initiated by:
where \(\left({{t}}_{1}, {{t}}_{2},\ldots ,{{t}}_{{\mathbbm{F}}}\right)\) covers all the b-tuple combination of \(\left(1, 2, . . ,{{\mathbbm{f}}}\right)\) and \({\mathfrak{B}}_{{\mathbbm{f}}}^{{\mathbb{F}}}=\frac{{{\mathbbm{f}}}!}{{{\mathbb{F}}}!\left({{\mathbbm{f}}}-{{\mathbb{F}}}\right)!}\), with various properties, such that.
-
(1)
If \({\mathcal{M}}_{{t}}=\mathcal{M}\left({t}=1, 2,\ldots,{{\mathbbm{f}}}\right),\) then \(DMS{M}^{({{\mathbb{F}}})}\left({\mathcal{M}}_{1}, {\mathcal{M}}_{2}, \ldots, {\mathcal{M}}_{{\mathbbm{f}}}\right)=\mathcal{M},\)
-
(2)
If \({\mathcal{M}}_{{t}}\le {\gamma }_{{t}}\left({t}=1, 2,\ldots,{{\mathbbm{f}}}\right)\), then \(DMS{M}^{({{\mathbb{F}}})}\left({\mathcal{M}}_{1}, {\mathcal{M}}_{2}, \ldots, {\mathcal{M}}_{{\mathbbm{f}}}\right)\le DMS{M}^{({{\mathbb{F}}})}\left({\gamma }_{1}, {\gamma }_{2}, \ldots , {\gamma }_{{\mathbbm{f}}}\right)\), \(\underset{{t}}{\mathrm{min}}\left\{{\mathcal{M}}_{{t}}\right\}\le DMS{M}^{\left({{\mathbb{F}}}\right)}\left({\mathcal{M}}_{1}, {\mathcal{M}}_{2}, \ldots, {\mathcal{M}}_{{\mathbbm{f}}}\right)\le \underset{{t}}{\mathrm{max}}\left\{{\mathcal{M}}_{{t}}\right\}.\)
Definition 3:
22 The PDMSM operator would be deduced as:
where \(\left({{t}}_{1}, {{t}}_{2},\ldots ,{{t}}_{{\mathbb{F}}}\right)\) holds all the b-tuple combination of \(\left(1, 2, . . ,{\varsigma }_{{r}}\right)\) and \({\mathfrak{B}}_{{\varsigma }_{{r}}}^{{\mathbb{F}}}=\frac{{\varsigma }_{{r}}!}{{{\mathbb{F}}}!\left({\varsigma }_{{r}}-{{\mathbb{F}}}\right)!}\), with some results, such that.
Proposition 1:
22 (Idempotency) Let \({\mathcal{M}}_{1}= {\mathcal{M}}_{2}= \cdots={\mathcal{M}}_{{\mathbbm{f}}}=\mathcal{M}.\) Then.
Proposition 2:
22 (Monotonicity) Let \({\chi }_{{t}},{\mathcal{M}}_{{t}}\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\) be two sets of non-negative real numbers and \({\chi }_{{t}}\le {\mathcal{M}}_{{t}},{t}=1, 2,\dots ,{{\mathbbm{f}}},\) then.
when the parameter \({{\mathbb{F}}}\) is fixed.
Proposition 3:
22 (Boundedness) Let \({\mathcal{M}}_{{t}}\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\) be a group of non-negative real numbers, \({\mathcal{M}}^{-}=\underset{{t}}{\mathrm{min}}\left\{{\mathcal{M}}_{{t}}\right\}\) and \({\mathcal{M}}^{+}=\underset{{t}}{\mathrm{max}}\left\{{\mathcal{M}}_{{t}}\right\}\), then.
PDMSM operators based on PFNs
PDMSM operator has the supremacy which can take justification of interrelationship of distinct characteristics and there are a lot of exploration consequences on it. However, it has not been employed to manage MADM dilemmas represented by PFNs. The basic inspiration for this identification is to develop the novel theory of the PFPDMSM operator, and WPFPDMSM operator and identify their important results (Idempotency, Monotonicity, Boundedness).
Definition 4:
Let a gathering of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\). Then the underneath expression.
demonstrate PFPDMSM operators. Where \({\acute{c}} \) reveals number of partitions \({\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}{1} , {\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{2} , \ldots , {\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{{\acute{c}}}\), \({{\mathbb{F}}}=1, 2, . . . .,\) is a parameter, \(\varsigma_{r}\) is the amount of attributes in \(P_{r}\),\(\left({{t}}_{1}, {{t}}_{2},. . . ,{{t}}_{{\mathbb{F}}}\right)\) covers all the b-tuple combination of \(\left(1, 2, . . ,{\varsigma }_{{r}}\right)\) and \({\mathfrak{B}}_{{\varsigma }_{{r}}}^{{\mathbb{F}}}=\frac{{\varsigma }_{{r}}!}{{{\mathbb{F}}}!\left({\varsigma }_{{r}}-{{\mathbb{F}}}\right)!}\).
Theorem 1:
Let a gathering of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\overline{\zeta }}_{{t}}, {\overline{\wp } }_{{t}}, {\overline{\eta }}_{{t}}\right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\). Then by employing Eq. (14), we get.
Proof:
Using the operational laws of PFNs, we have.
and
Then we get
And
So, we can get
Next, we show
To develop AOs that adhere to specific logical and mathematical principles, monotonicity, boundedness, and idempotency serve as a foundation. This improves the usefulness and interpretability of the aggregated data. For aggregation operators to guarantee the dependability and significance of the aggregation process, the properties of monotonicity, boundedness, and idempotency are essential. Monotonicity preserves the intuitive idea that more substantial contributions should result in a bigger aggregate by ensuring that as input values grow, the aggregated output does not decrease. Extreme outliers are prevented from unduly affecting the conclusion by boundedness, which ensures that the aggregate result stays within a certain range. Idempotency guarantees that the same outcome is produced when the AOs are applied again to the same set of data, improving the stability and predictability of the aggregate process. Together, these characteristics provide consistency, precision, and control over the aggregation process, which qualifies it for a variety of applications including statistical analysis, decision-making, and data summarization.
Proposition 4:
(Idempotency) Let a gathering of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\). If \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)=\widehat{\mathcal{M}}=\left(\zeta , \wp , \eta \right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right),\) then
Proof:
By using Eq. (15), we have.
Proposition 5:
(Commutativity) Let a gathering of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\left({t}=1, 2,\dots ,{{\mathbb{F}}}\right)\). Then if \({\widehat{\mathcal{M}}}_{{t}}^{\prime}=\left( {\zeta }_{{t}}^{\prime}, {\wp }_{{t}}^{\prime}, {\eta }_{{t}}^{\prime}\right)\) is any permutation of \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\forall {t}\) then,
Proof:
By using Eq. (15), we get.
Because \({\widehat{\mathcal{M}}}_{{t}}^{\prime}=\left({\zeta }_{{t}}^{\prime}, {\wp }_{{t}}^{\prime}, {\eta }_{{t}}^{\prime}\right)\) is any permutation of \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\forall {t}\) So we have \(PFPDMS{M}^{\left({{\mathbb{F}}}\right)}\left({\widehat{\mathcal{M}}}_{1}, {\widehat{\mathcal{M}}}_{2}, . . ., {\widehat{\mathcal{M}}}_{{\mathbbm{f}}}\right)=PFPDMS{M}^{\left({{\mathbb{F}}}\right)}\left({\widehat{\mathcal{M}}}_{1}^{\prime}, {\widehat{\mathcal{M}}}_{2}^{\prime}, . . ., {\widehat{\mathcal{M}}}_{{\mathbbm{f}}}^{\prime}\right)\).
Proposition 6:
(Monotonicity) Let two gatherings of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\) and \({\widehat{\mathcal{M}}}_{{t}}^{\prime}=\left({\zeta }_{{t}}^{\prime},{\wp }_{{t}}^{\prime}, {\eta }_{{t}}^{\prime}\right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\). If \({\zeta }_{{t}}\ge {\zeta }_{{t}}^{\prime}\),\({\wp }_{{t}}\le {\wp }_{{t}}^{\prime}\),\({\eta }_{{t}}\le {\eta }_{{t}}^{\prime} \forall {t}\) then,
when \({{\mathbb{F}}}\) is fixed.
Proof:
Let \(PFPDMS{M}^{\left({{\mathbb{F}}}\right)}\left({\widehat{\mathcal{M}}}_{1}, {\widehat{\mathcal{M}}}_{2}, . . ., {\widehat{\mathcal{M}}}_{{\mathbbm{f}}}\right)=\widehat{\mathcal{M}}=\left(\zeta , \wp , \eta \right)\) and \(PFPDMS{M}^{\left({{\mathbb{F}}}\right)}\left({\widehat{\mathcal{M}}}_{1}^{\prime}, {\widehat{\mathcal{M}}}_{2}^{\prime}, . . ., {\widehat{\mathcal{M}}}_{{\mathbbm{f}}}^{\prime}\right)={\widehat{\mathcal{M}}}^{\prime}=\left({\zeta }^{\prime}, {\wp }^{\prime}, {\eta }^{\prime}\right)\), then.
because \({\zeta }_{{t}}\ge {\zeta }_{{t}}^{\prime}\),\({\wp }_{{t}}\le {\wp }_{{t}}^{\prime}\),\({\eta }_{{t}}\le {\eta }_{{t}}^{\prime}\)
which shows \({\zeta }_{{t}}\ge {\zeta }_{{t}}^{\prime}\),\({\wp }_{{t}}\le {\wp }_{{t}}^{\prime}\) and \({\eta }_{{t}}\le {\eta }_{{t}}^{\prime}\) , then \(\widehat{\mathcal{M}}\ge {\widehat{\mathcal{M}}}^{\prime}\). So
Proposition 7:
(Boundedness) Let a gathering of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\left({t}=1, 2,\dots ,{{\mathbb{F}}}\right)\). If \({\widehat{\mathcal{M}}}^{-}=\underset{{t}}{\mathrm{min}}\left\{{\widehat{\mathcal{M}}}_{{t}}\right\}\) and \({\widehat{\mathcal{M}}}^{+}=\underset{{t}}{\mathrm{max}}\left\{{\widehat{\mathcal{M}}}_{{t}}\right\},{t}=1, 2,\dots ,{{\mathbbm{f}}}\) then
Proof:
Owing to \({\widehat{\mathcal{M}}}^{-}=\underset{{t}}{\mathrm{min}}\left\{{\widehat{\mathcal{M}}}_{{t}}\right\}\le {\widehat{\mathcal{M}}}_{{t}}\), also by propositions 4 and 6, we have,
and
So, we have.
Let \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\) be PFNs partitioned into \(\acute{c} \) distinct partitions \({\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}{1} , {\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{2} , \ldots , {\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{\acute{c}}\) weight of PFNs \({\widehat{\mathcal{M}}}_{{t}}\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\) is \(\raisebox{2.1pt}{$\upomega$}\kern-2.3pt\rotatebox{80}{\tiny $\smile$}_{{t}}\), holds \(\raisebox{2.1pt}{$\upomega$}\kern-2.3pt\rotatebox{80}{\tiny $\smile$}_{{t}}\in \left[0, 1\right]\) and \(\sum_{{t}=1}^{{\mathbb{F}}}\raisebox{2.1pt}{$\upomega$}\kern-2.3pt\rotatebox{80}{\tiny $\smile$}_{{t}}=1, {{\mathbb{F}}}=1, 2, . . . .,{\varsigma }_{{r}}, {\varsigma }_{{r}}\) is the amount of attributes in \({\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{{r}}.\)
Definition 5:
Let a gathering of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\). Then the underneath expression.
demonstrate WPFPDMSM operators. Where \(\acute{c} \) reveals the number of partitions \({\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{1},{\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{2}, . . .,{\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{\acute{c} }\), \({{\mathbb{F}}}=1, 2, . . . .,{\varsigma }_{{r}}\) is a parameter, \({\varsigma }_{{r}}\) is the amount of attributes in \({\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{{r}}\),\(\left({{t}}_{1}, {{t}}_{2},. . . ,{{t}}_{{\mathbb{F}}}\right)\) contains all the b-tuple combinations of \(\left(1, 2, . . ,{\varsigma }_{{r}}\right)\) and \({\mathfrak{B}}_{{\varsigma }_{{r}}}^{{\mathbb{F}}}=\frac{{\varsigma }_{{r}}!}{{{\mathbb{F}}}!\left({\varsigma }_{{r}}-{{\mathbb{F}}}\right)!}\).
Theorem 2:
Let a gathering of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\overline{\zeta }}_{{t}}, {\overline{\wp } }_{{t}}, {\overline{\eta }}_{{t}}\right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\). Then by employing Eq. (20), we get.
Proof:
Omitted.
Additionally, we diagnose some properties, such that.
Proposition 8:
(Commutativity) Let a gathering of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\). If \({\widehat{\mathcal{M}}}_{{t}}^{\prime}=\left({\zeta }_{{t}}^{\prime}, {\wp }_{{t}}^{\prime}, {\eta }_{{t}}^{\prime}\right)\) is any permutation of \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\forall {t}\), then
Proposition 9:
(Monotonicity) Let two gatherings of PFNs \({\widehat{\mathcal{M}}}_{{t}}=\left({\zeta }_{{t}}, {\wp }_{{t}}, {\eta }_{{t}}\right)\) and \({\widehat{\mathcal{M}}}_{{t}}^{\prime}=\left({\zeta }_{{t}}^{\prime},{\wp }_{{t}}^{\prime}, {\eta }_{{t}}^{\prime}\right)\left({t}=1, 2,\dots ,{{\mathbbm{f}}}\right)\). If \({\zeta }_{{t}}\ge {\zeta }_{{t}}^{\prime}\), \({\wp }_{{t}}\le {\wp }_{{t}}^{\prime}\), \({\eta }_{{t}}\le {\eta }_{{t}}^{\prime} \forall {t}\) then,
when \({{\mathbb{F}}}\) is fixed. Further, if we choose the value of \(\acute{c} =1,\) then we get
Application (“MADM process”)
MADM is a crucial and essential part of the decision-making sciences whose aim is to recognize the massive dominant decision from the group of expected ones. In a genuine decision-making strategy, the problem needs to resolve the provided decisions by many classes like single or interval evaluation investigations. However, in many awkward scenarios, it is very challenging for the expert to reduce their decisions to a classical number. However, it has not been employed to manage MADM dilemmas represented by PFNs. The basic inspiration for this identification was to develop the novel theory of PFPDMSM operator, and WPFPDMSM operator and identify their important results (Idempotency, Monotonicity, Boundedness).
The primary goal of this section is to identify the best decision, every expert realized that they needed the best way to find the beneficial optimal using the proper DM procedure, for this, we diagnosed the MADM tool in the consideration of deliberated approaches based on PF information. Finally, to drive the characteristics of the invented work, several examples are utilized to test the manifest of the comparative analysis with numerous more prevailing theories, which is a fascinating and meaningful technique to deeply explain the features and exhibited of the proposed approaches.
Decision-making technique
In this scenario, we aim to diagnose a new MADM process based on the environment for solving DM dilemmas. For this, we assume \(\mathfrak{T}=\left\{{\mathfrak{T}}_{1}, {\mathfrak{T}}_{2},. . . , {\mathfrak{T}}_{ \underline{{\text{n}}} }\right\}\), and \(\Xi =\left\{{\Xi }_{1},{\Xi }_{2},. .. ,{\Xi }_{{\mathbb{F}}}\right\}\) be a group of alternatives and attributes with \(\raisebox{2.1pt}{$\upomega$}\kern-2.3pt\rotatebox{80}{\tiny $\smile$}=\left\{\raisebox{2.1pt}{$\upomega$}\kern-2.3pt\rotatebox{80}{\tiny $\smile$}_{1},\raisebox{2.1pt}{$\upomega$}\kern-2.3pt\rotatebox{80}{\tiny $\smile$}_{2},. . .,\raisebox{2.1pt}{$\upomega$}\kern-2.3pt\rotatebox{80}{\tiny $\smile$}_{{\mathbbm{f}}}\right\}\), representing the weight vectors such that \(\sum_{{t}=1}^{{\mathbb{F}}}\raisebox{2.1pt}{$\upomega$}\kern-2.3pt\rotatebox{80}{\tiny $\smile$}_{{t}}=1, {{\mathbb{F}}}=1, 2, . . ., {{\mathbbm{f}}}\). Using PFNs DMs evaluate the \({\mathfrak{T}}_{{t}}\) concerning the attribute \({\Xi }_{\mathbb{Y}}\) and represent it as \({\widehat{\mathcal{M}}}_{{{t}}_{\mathbb{Y}}}=\left({\zeta }_{{{t}}_{\mathbb{Y}}}, {\wp }_{{{t}}_{\mathbb{Y}}}, {\eta }_{{{t}}_{\mathbb{Y}}}\right)\) where \({\zeta }_{{{t}}_{\mathbb{Y}}}, {\wp }_{{{t}}_{\mathbb{Y}}}, {\eta }_{{{t}}_{\mathbb{Y}}}\in \left[0, 1\right]\) and \(0\le {\zeta }_{{{t}}_{\mathbb{Y}}}+{\wp }_{{{t}}_{\mathbb{Y}}}+ {\eta }_{{{t}}_{\mathbb{Y}}}\le 1\). We can acquire a decision matrix \(\mathcal{Y}={\left[{\widehat{\mathcal{M}}}_{{{t}}_{\mathbb{Y}}}\right]}_{ \underline{{\text{n}}} \times {{\mathbbm{f}}}}\) ,\(1\le {t}\le \underline{{\text{n}}} , 1\le {\mathbbm{y}}\le {{\mathbbm{f}}}\). Let \(\mathfrak{T}=\left\{{\mathfrak{T}}_{1}, {\mathfrak{T}}_{2},. . . , {\mathfrak{T}}_{ \underline{{\text{n}}} }\right\}\) is partitioned into \(\acute{c} \) distinct groups \({\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{1}, {\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{2}, . . .,{\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{\acute{c} }\). Therefore, to identify the best decision, every expert realized that they needed the best way to find the beneficial optimal using the proper decision-making procedure. For this, we computed the procedure, whose main steps are defined below.
Step 1 In DM dilemmas there are two various sort of attributes, that is cost sort and benefit sort, to abolish the effect of different attribute types, transform the decision matrix \(\mathcal{Y}={\left[{\widehat{\mathcal{M}}}_{{{t}}_{\mathbb{Y}}}\right]}_{ \underline{{\text{n}}} \times {{\mathbbm{f}}}}\) into \({\mathcal{Y}}^{\prime}={\left[{\widehat{\mathcal{M}}}_{{{t}}_{\mathbb{Y}}}^{\prime}\right]}_{ \underline{{\text{n}}} \times {{\mathbbm{f}}}},1\le {t}\le \underline{{\text{n}}} , 1\le {\mathbbm{y}}\le {{\mathbbm{f}}}\). To normalize the decision matrix use the given formula:
where \(1\le {t}\le \underline{{\text{n}}} , 1\le {\mathbbm{y}}\le {{\mathbbm{f}}}\).
Step 2 Using the developed WPFPDMSM operator to get
Noted that \({\widehat{\mathcal{M}}}_{{t}}^{\prime}\) is the preference argument of alternative \({\mathfrak{T}}_{{t}}\), \({t}=1, 2,. . ., \underline{{\text{n}}} \)
Step 3 Obtained values \({\mathbb{S}}\left({\widehat{\mathcal{M}}}_{{t}}^{\prime}\right)\) and \(\check{{\rm A}}\left({\widehat{\mathcal{M}}}_{{t}}^{\prime}\right)\) of aggregated outcomes \({\widehat{\mathcal{M}}}_{{t}}^{\prime}\left({t}=1, 2,. . ., \underline{{\text{n}}} \right).\)
Step 4 Make a comparison between \({\mathbb{S}}\left({\widehat{\mathcal{M}}}_{1}^{\prime}\right), {\mathbb{S}}\left({\widehat{\mathcal{M}}}_{2}^{\prime}\right),. . . .,{\mathbb{S}}\left({\widehat{\mathcal{M}}}_{ \underline{{\text{n}}} }^{\prime}\right)\) and \(\check{{\rm A}}\left({\widehat{\mathcal{M}}}_{1}^{\prime}\right), \check{{\rm A}}\left({\widehat{\mathcal{M}}}_{2}^{\prime}\right),. . .,\check{{\rm A}}\left({\widehat{\mathcal{M}}}_{ \underline{{\text{n}}} }^{\prime}\right)\), then ranking all the alternatives to get the finest one.
Numerical example
Assume the five suitable enterprise resource management (ERP) schemes expressed by \(\left\{{\mathfrak{T}}_{1}, {\mathfrak{T}}_{2},{\mathfrak{T}}_{3},{\mathfrak{T}}_{4},{\mathfrak{T}}_{5}\right\}\) denoted the collection alternatives, which require to be resolved by decision-makers. For this, ERP schemes are resolved based on the four attributes expressed by \(\left\{{\Xi }_{1},{\Xi }_{2},{\Xi }_{3},{\Xi }_{4}\right\}\), represented by:\({\Xi }_{1}\): Technical Achievement;\({\Xi }_{2}\): Human Recourse; \({\Xi }_{3}\): Economic benefits and \({\Xi }_{4}\): constructions of the enterprises. For every attribute, the expert gives their opinion in the shape of a weight vector like 0.4, 0.3, 0.2, and 0.1. Therefore, the selection process of the ERP scheme is evaluated with the help ofthe above procedure.
Step 1 In DM issues there are two various sort of attributes, that is cost sort and benefit sort,, to abolish the effect of different attribute types, transform the decision matrix \(\mathcal{Y}={\left[{\widehat{\mathcal{M}}}_{{{t}}_{\mathbb{Y}}}\right]}_{ \underline{{\text{n}}} \times {{\mathbbm{f}}}}\) into \({\mathcal{Y}}^{\prime}={\left[{\widehat{\mathcal{M}}}_{{{t}}_{\mathbb{Y}}}^{\prime}\right]}_{ \underline{{\text{n}}} \times {{\mathbbm{f}}}},1\le {t}\le \underline{{\text{n}}} , 1\le {\mathbb{Y}}\le {{\mathbbm{f}}}\), explained in Table 1.
To normalize the decision matrix use the given formula:
where \(1\le {t}\le \underline{{\text{n}}} , 1\le {\mathbb{Y}}\le {{\mathbbm{f}}}\). But the information given in Table 1, does not required to be normalized.
Step 2 Using the developed WPFPDMSM operator, we obtained the information given in Table 2, with \({\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{1}=\left\{{\Xi }_{3},{\Xi }_{4}\right\}\) and \({\rm P}\kern-5pt \raisebox{8.5pt}{\rotatebox{180}{J}}_{2}=\left\{{\Xi }_{1},{\Xi }_{2}\right\}\).
Step 3 Obtained values \({\mathbb{S}}\left({\widehat{\mathcal{M}}}_{{t}}^{\prime}\right)\) and \(\check{{\rm A}}\left({\widehat{\mathcal{M}}}_{{t}}^{\prime}\right)\) of aggregated result \({\widehat{\mathcal{M}}}_{{t}}^{\prime}\left({t}=1, 2,. . ., \underline{{\text{n}}} \right)\), illustrated in Table 3.
Step 4 Make a comparison between \({\mathbb{S}}\left({\widehat{\mathcal{M}}}_{1}^{\prime}\right), {\mathbb{S}}\left({\widehat{\mathcal{M}}}_{2}^{\prime}\right),. . . .,{\mathbb{S}}\left({\widehat{\mathcal{M}}}_{ \underline{{\text{n}}} }^{\prime}\right)\) and \(\check{{\rm A}}\left({\widehat{\mathcal{M}}}_{1}^{\prime}\right), \check{{\rm A}}\left({\widehat{\mathcal{M}}}_{2}^{\prime}\right),. . .,\check{{\rm A}}\left({\widehat{\mathcal{M}}}_{ \underline{{\text{n}}} }^{\prime}\right)\), then ranking all the alternatives to choose the best one, such that
From the above, we get the best optimal in the shape of \({\mathfrak{T}}_{2}\).
Comparative analysis
Comparative analysis is an old technique, used for comparing two or more theories. As a main theme of this analysis, we described the advantages and disadvantages of the invented work with the help of comparison among any two or more theories. For this, we suggested various existing theories, described as.
-
AOs for IF information, deduced by Xu18.
-
MSM operators under IF information, which are interpreted by Shi and Xiao21.
-
PDMSM operators in the setting of IF information which are deduced by Wang et al.22.
-
AOs for PFSs which was utilized by Garg33.
-
AOs based on generalized t-norm and t-conorm for PFSs which were presented by Wei34,
-
Dombi AOs for PF information which were utilized by Jana et al.35
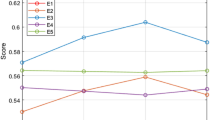
Now reconsider the MADM dilemma solved in Sect. "Numerical example" and apply the existing and diagnosed theories. The final result of the diagnosed and prevailing operators is demonstrated in the shape of Table 4.
The prevailing theories investigated by Xu18, Shi and Xiao21, and Wang et al.22 failed to tackle the PF information because these theories are in the structure of IFS and the notion of IFS merely copes with MD and NMD and can’t consider the AD while, the theory of PF information consider MD, NMD and AD. Thus, the invented theory is more generalized and modified than the prevailing one. The diagnosed AOs can also reduce the notion of IFS by just taking AD equal to zero. Moreover, the information in Table 4 represented that if we choose the information of the invented work, we obtained the finest decision in the form of \({\mathfrak{T}}_{2}\), but if we considered the information in Ref.33, 35, we obtained the best decision in the shape of \({\mathfrak{T}}_{4}\) and the information given in Ref.34 gives the final result in the shape of \({\mathfrak{T}}_{1}\). Consequently, the anticipated operators are more beneficial and practicable than prevailing operators33,34,35. From the above discussion, it is obvious that the diagnosed AOs have the capability of tackling PF information, IF information, and fuzzy information, and these operators can transform to IFS and FS as.
-
In the diagnosed AOs, take AD equal to zero, and the AOs will transform in the model of IFS.
-
In the diagnosed AOs, take AD and NMD equal to zero, the AOs will transform in the model of FS.
Ethical approval
The authors state that this is their original work and it is neither submitted nor under consideration in any other journal simultaneously.
Conclusion
Using the advantages of the PDMSM operator, where the PDMSM operator has the supremacy which can take justification of interrelationship of distinct characteristics and there is a lot of exploration consequence on it. However, it has not been employed to manage MADM dilemmas represented by picture fuzzy numbers (PFNs). So, in this manuscript, first of all, we deduced AOs such as PDMSM and weighted PDMSM operators in the setting of PF information and called them PFPDMSM and WPFPDMSM operators. We also investigated the related axioms of invented operators such as idempotency, monotonicity, and boundedness. After the development of these AOs, we diagnosed a technique of MADM by employing the deduced PFPDMSM and WPFPDMSM operators in the environment of PF information and we identified the best enterprise resource management scheme that is \({\mathfrak{T}}_{2}\) from the collection of considered 5 schemes with the assistance of the developed technique of MADM within PF information. At the end of the manuscript, we compared the deliberated theory with a few prevailing theories to reveal how the deduced AOs and MADM technique is better and beneficial than certain prevailing theories. We also demonstrated that the diagnosed AOs can transform in the setting of IFS and FS.
In the future, we will revise the fundamental theory of bipolar complex fuzzy set47, 48, bipolar complex fuzzy soft set49, and complex hesitant fuzzy set49 and will try to expand this work in these theories.
Data availability
The data will be available on reasonable request to corresponding author.
References
Zadeh, L. A. Fuzzy sets. Inf. Control 8(3), 338–353 (1965).
Atanassov, K. Intuitionistic fuzzy sets, VII ITKR’s Session, Sofia (1983).
Atanassov, K. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 20, 87–96 (1986).
Cuong, B. C. Picture fuzzy sets, a new concept for computational intelligence problems, in Proceedings of the third world congress on information and communication technologies, pp. 1–6. (Hanoi, 2013).
Saha, A., Reddy, J. & Kumar, R. A fuzzy similarity based classification with Archimedean-Dombi aggregation operator. J. Intell. Manag. Decis. 1(2), 118–127 (2022).
Babuška, R. & Verbruggen, H. Neuro-fuzzy methods for nonlinear system identification. Annu. Rev. Control. 27(1), 73–85 (2003).
Hüllermeier, E. Fuzzy methods in machine learning and data mining: Status and prospects. Fuzzy Sets Syst. 156(3), 387–406 (2005).
Nazari, A., Salarirad, M. M. & Aghajani Bazzazi, A. Landfill site selection by decision-making tools based on fuzzy multi-attribute decision-making method. Environ. Earth Sci. 65, 1631–1642 (2012).
Deni, W., Sudana, O. & Sasmita, A. Analysis and implementation fuzzy multi-attribute decision making SAW method for selection of high achieving students in faculty level. Int. J. Comput. Sci. Issues (IJCSI) 10(1), 674 (2013).
Goguen, J. A. L-fuzzy sets. J. Math. Anal. Appl. 18(1), 145–174 (1967).
Mahmood, T. A novel approach towards bipolar soft sets and their applications. J. Math. 2020, 46908085 (2020).
Ali, M. I. A note on soft sets, rough soft sets and fuzzy soft sets. Appl. Soft Comput. 11(4), 3329–3332 (2011).
Tanay, B. & Kandemir, M. B. Topological structure of fuzzy soft sets. Comput. Math. Appl. 61(10), 2952–2957 (2011).
Feng, F., Li, Y. & Leoreanu-Fotea, V. Application of level soft sets in decision making based on interval-valued fuzzy soft sets. Comput. Math. Appl. 60(6), 1756–1767 (2010).
Qin, Z., Li, X. & Ji, X. Portfolio selection based on fuzzy cross-entropy. J. Comput. Appl. Math. 228(1), 139–149 (2009).
Bi, L., Zeng, Z., Hu, B. & Dai, S. Two classes of entropy measures for complex fuzzy sets. Mathematics 7(1), 96 (2019).
Xu, Z. & Yager, R. R. Some geometric aggregation operators based on intuitionistic fuzzy sets. Int. J. Gen. Syst. 35(4), 417–433 (2006).
Xu, Z. Intuitionistic fuzzy aggregation operators. IEEE Trans. Fuzzy Syst. 15(6), 1179–1187 (2007).
Zhao, H., Xu, Z., Ni, M. & Liu, S. Generalized aggregation operators for intuitionistic fuzzy sets. Int. J. Intell. Syst. 25(1), 1–30 (2010).
Xia, M., Xu, Z. & Zhu, B. Some issues on intuitionistic fuzzy aggregation operators based on Archimedean t-conorm and t-norm. Knowl. -Based Syst. 31, 78–88 (2012).
Shi, M. & Xiao, Q. Intuitionistic fuzzy reducible weighted Maclaurin symmetric means and their application in multiple-attribute decision making. Soft Comput. 23, 10029–10043 (2019).
Wang, H., Liu, Y., Liu, F. & Lin, J. Multiple attribute decision-making method based upon intuitionistic fuzzy partitioned dual Maclaurin symmetric mean operators. Int. J. Comput. Intell. Syst. 14(1), 1–20 (2021).
Liu, P. & Qin, X. Maclaurin symmetric mean operators of linguistic intuitionistic fuzzy numbers and their application to multiple-attribute decision-making. J. Exp. Theor. Artif. Intell. 29(6), 1173–1202 (2017).
Garg, H. & Arora, R. Generalized Maclaurin symmetric mean aggregation operators based on Archimedean t-norm of the intuitionistic fuzzy soft set information. Artif. Intell. Rev. 54(4), 3173–3213 (2021).
Ecer, F. An extended MAIRCA method using intuitionistic fuzzy sets for coronavirus vaccine selection in the age of COVID-19. Neural Comput. Appl. https://doi.org/10.1007/s00521-021-06728-7 (2022).
Chen, T. Y. & Tsao, C. Y. Experimental analysis of the intuitionistic fuzzy TOPSIS method on distance measures. Inf. Sci. 2007, 1057–1063 (2007).
Zhao, M., Wei, G., Chen, X. & Wei, Y. Intuitionistic fuzzy MABAC method based on cumulative prospect theory for multiple attribute group decision making. Int. J. Intell. Syst. 36(11), 6337–6359 (2021).
Chatterjee, K., Kar, M. B., & Kar, S. Strategic decisions using intuitionistic fuzzy VIKOR method for information system (IS) outsourcing. In 2013 International Symposium on Computational and Business Intelligence 123–126. (IEEE, 2013).
Zhang, C., Chen, C., Streimikiene, D. & Balezentis, T. Intuitionistic fuzzy MULTIMOORA approach for multi-criteria assessment of the energy storage technologies. Appl. Soft Comput. 79, 410–423 (2019).
Thao, N. X. & Chou, S. Y. Novel similarity measures, entropy of intuitionistic fuzzy sets and their application in software quality evaluation. Soft Comput. 26(4), 2009–2020 (2022).
Jebadass, J. R. & Balasubramaniam, P. Low light enhancement algorithm for color images using intuitionistic fuzzy sets with histogram equalization. Multimed. Tools Appl. 81(6), 8093–8106 (2022).
Yang, J., Yao, Y. & Zhang, X. A model of three-way approximation of intuitionistic fuzzy sets. Int. J. Mach. Learn. Cybern. 13(1), 163–174 (2022).
Garg, H. Some picture fuzzy aggregation operators and their applications to multicriteria decision-making. Arab. J. Sci. Eng. 42(12), 5275–5290 (2017).
Wei, G. Picture fuzzy aggregation operators and their application to multiple attribute decision making. J. Intell. Fuzzy Syst. 33(2), 713–724 (2017).
Jana, C., Senapati, T., Pal, M. & Yager, R. R. Picture fuzzy Dombi aggregation operators: application to MADM process. Appl. Soft Comput. 74, 99–109 (2019).
Wei, G. Picture fuzzy Hamacher aggregation operators and their application to multiple attribute decision making. Fundam. Inform. 157(3), 271–320 (2018).
Ullah, K. Picture fuzzy maclaurin symmetric mean operators and their applications in solving multiattribute decision-making problems. Math. Probl. Eng. 2021, 1098631. https://doi.org/10.1155/2021/1098631 (2021).
Simić, V., Soušek, R. & Jovčić, S. Picture fuzzy MCDM approach for risk assessment of railway infrastructure. Mathematics 8(12), 2259 (2020).
Jin, J., Zhao, P. & You, T. Picture fuzzy TOPSIS method based on CPFRS model: An application to risk management problems. Sci. Program. 2021, 1–15 (2021).
Meksavang, P., Shi, H., Lin, S. M. & Liu, H. C. An extended picture fuzzy VIKOR approach for sustainable supplier management and its application in the beef industry. Symmetry 11(4), 468 (2019).
Liang, W. Z., Zhao, G. Y. & Luo, S. Z. An integrated EDAS-ELECTRE method with picture fuzzy information for cleaner production evaluation in gold mines. IEEE Access 6, 65747–65759 (2018).
Akram, M., Ramzan, N. & Feng, F. Extending COPRAS method with linguistic Fermatean fuzzy sets and Hamy mean operators. J. Math. 2022, 1–26 (2022).
Tian, C., Peng, J. J., Long, Q. Q., Wang, J. Q. & Goh, M. Extended picture fuzzy MULTIMOORA method based on prospect theory for medical institution selection. Cognit. Comput. 14(4), 1446–1463 (2022).
Maclaurin, C. A second letter to Martin Folkes, Esq.; concerning the roots of equations, with demonstration of other rules of algebra. Philos. Trans. R. Soc. Lond. Ser. A 36, 59–96 (1729).
DeTemple, D. W. & Robertson, J. M. On generalized symmetric means of two variables. PublikacijeElektrotehničkogfakulteta. SerijaMatematikaifizika 634/677, 236–238 (1999).
Mahmood, T. & Ur Rehman, U. A novel approach towards bipolar complex fuzzy sets and their applications in generalized similarity measures. Int. J. Intell. Syst. 37(1), 535–567 (2022).
Mahmood, T., ur Rehman, U. & Ali, Z. Analysis and application of Aczel-Alsina aggregation operators based on bipolar complex fuzzy information in multiple attribute decision making. Inf. Sci. 619, 817–833 (2023).
Mahmood, T., Rehman, U. U., Jaleel, A., Ahmmad, J. & Chinram, R. Bipolar complex fuzzy soft sets and their applications in decision-making. Mathematics 10(7), 1048 (2022).
Mahmood, T., Ur Rehman, U., Ali, Z. & Mahmood, T. Hybrid vector similarity measures based on complex hesitant fuzzy sets and their applications to pattern recognition and medical diagnosis. J. Intell. Fuzzy Syst. 40(1), 625–646 (2021).
Acknowledgements
The study was funded by Researchers Supporting Project number (RSPD2023R749), King Saud University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
T.M., U.R. and Z.A. wrote the original draft of the paper and validate the results. W.E. mam drew all figures, tables, checked language issues of the manuscript and managed other requirements. H.W. proofread the manuscript and corrected the issues (language, calculations etc.) arises during proofreading.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mahmood, T., Rehman, U.u., Emam, W. et al. Partitioned dual Maclaurin symmetric mean operators based on picture fuzzy sets and their applications in multi-attribute decision-making problems. Sci Rep 13, 20834 (2023). https://doi.org/10.1038/s41598-023-44344-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-44344-8
- Springer Nature Limited