
Abstract
This study developed a machine learning algorithm to predict gestational diabetes mellitus (GDM) using retrospective data from 34,387 pregnancies in multi-centers of South Korea. Variables were collected at baseline, E0 (until 10 weeks’ gestation), E1 (11–13 weeks’ gestation) and M1 (14–24 weeks’ gestation). The data set was randomly divided into training and test sets (7:3 ratio) to compare the performances of light gradient boosting machine (LGBM) and extreme gradient boosting (XGBoost) algorithms, with a full set of variables (original). A prediction model with the whole cohort achieved area under the receiver operating characteristics curve (AUC) and area under the precision-recall curve (AUPR) values of 0.711 and 0.246 at baseline, 0.720 and 0.256 at E0, 0.721 and 0.262 at E1, and 0.804 and 0.442 at M1, respectively. Then comparison of three models with different variable sets were performed: [a] variables from clinical guidelines; [b] selected variables from Shapley additive explanations (SHAP) values; and [c] Boruta algorithms. Based on model [c] with the least variables and similar or better performance than the other models, simple questionnaires were developed. The combined use of maternal factors and laboratory data could effectively predict individual risk of GDM using a machine learning model.
Similar content being viewed by others


Introduction
Gestational diabetes mellitus (GDM) is one of the most common medical complications of pregnancy, and its prevalence has increased significantly worldwide1. The pooled global standardized prevalence of GDM was 14.0% in 20222, and it is expected to continue to increase in the future. However, the prevalence of GDM is also highly variable due to racial, ethnic, and population diversity, as well as heterogeneous screening tools and diagnostic strategies3. Several studies have found that Asian women have a higher risk of GDM than other ethnic groups, despite having a relatively lower body mass index (BMI)4,5. In a meta-analysis of Eastern and Southeastern Asian populations, the prevalence of GDM was found to be 10.1%6 to 20%2,7. The prevalence of GDM in South Korea was reported to be 8% to 11.1% in 2012–2016 and it continues to increase3,6.
Hyperglycemia in pregnancy can be harmful to the fetus and lead to several neonatal complications8. GDM is also known to be associated with an increased risk of type II diabetes and cardiovascular disease in the mother in later life9,10 and obesity, diabetes, and metabolic syndrome in the childhood period of offspring11.
Although there is no clear consensus on the best screening method for GDM12, early detection may prevent or reduce the risk of adverse pregnancy outcomes13,14. A multicenter Randomized Controlled Trial is underway to evaluate the benefits of early screening and management of GDM; and it suggests that early screening may help improve prognosis15. Although early pregnancy risk stratification may help to promote lifestyle modification aimed at reducing the risk of GDM16, there is no consensus on the optimal screening algorithms. Further research is needed to determine when screening tests should be performed, which tests are the most accurate, and which individuals should be tested17.
Recently, various clinical prediction models have been developed to identify women at increased risk of GDM18,19, and several machine learning methods have demonstrated robust self-learning capabilities with improved GDM prediction accuracy20,21,22. Therefore, this study aimed to develop a machine learning algorithm for prediction of GDM in Asian women according to gestational period that can be applied to Korean women to calculate individualized risk of GDM.
Methods
Data
Data were extracted from the perinatal database for women who delivered between January 2009 and December 2020 at seven hospitals in four areas of South Korea, under the authority of The Catholic University of Korea. Data on maternal demographic characteristics, body mass index (BMI), blood pressure (BP) measurements, blood and urine laboratory tests, diagnoses recorded by physicians, and medications prescribed were collected from the hospitals’ databases via electronic medical records. Data were confirmed, and missing data were abstracted from chart reviews by two obstetricians (J.H.W. and H.S.K.). The Institutional Review Board of The Catholic University of Korea approved the present study (XC20WIDI0103). Since this study analyzed retrospective cohort data, which were anonymized, informed consent was waived by the Institutional Review Board of The Catholic University of Korea.
Study population and outcome definition
In medical centers of The Catholic University of Korea, GDM is diagnosed by a two-step procedure performed routinely for all women at 24–28 weeks of pregnancy, in accordance with NIH guidelines23,24. In the first step, a 1-h, 50-g, glucose challenge test (GCT) is performed; women with glucose levels > 200 mg/dl receive a GDM diagnosis. Women with a GCT value > 140 mg/dl are referred to a second step, in which an additional 100-g, 3-h oral glucose tolerance test (OGTT) is performed. Women with two glucose measurements above the Carpenter and Coustan criteria (thresholds of 95, 180, 155, and 140 mg/dl) under fasting conditions (zero), 1, 2, and 3 h after glucose intake, respectively, also receive a GDM diagnosis25. In women with risk factors such as a family history of diabetes or history of GDM in a previous pregnancy, GDM screening is sometimes performed in the first trimester. In some women with a 50-g GCT value ≤ 140 mg/dl, at 24–29 weeks’ gestation, but with a fetus suspected to be large for gestational age, (> 90th percentile) during the second or third trimester, a 100-g OGTT was performed and GDM was diagnosed using the Carpenter and Coustan criteria. We also included pregnancies with GDM based on the ICD code during pregnancy (ICD9 codes in O24.4 or O24.9), after excluding women with a prepregnancy record of diabetes, defined as any of the ICD9 codes in O24.0–24.3, or E12–14, or prescription codes for insulin or other medication for diabetes.
Machine learning
Data preparation
We followed the guidelines for the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis for Establishing Prediction models26. Based on these guidelines, all anonymized data from 34,387 subjects were included in the data set used for this study. The subjects were divided into two groups based on their parity status: nulliparity (n = 18,023) and multiparity (n = 16,184). To ensure a balanced distribution of the target variable, a 7:3 stratified split was performed to divide the data into training and test sets for each of the three cohorts: the whole cohort, nulliparity cohort, and multiparity cohort. Each cohort of training and test data was analyzed by dividing it into GDM and non-GDM groups.
Variables used to develop the gestational diabetes prediction models
Four sets of variables were used to develop the GDM prediction models, including variables from different time periods: (1) baseline variables, which were obtained solely from maternal questionnaires completed during the first hospital visits; (2) early pregnancy (E0) variables, collected from the first visit until 10 weeks of gestation; (3) 1st trimester (E1) variables, collected from 11 to 13 weeks of gestation; and (4) 2nd trimester (M1) variables, collected from 14 to 24 weeks of gestation. The variables included age, parity, underlying diseases, family history, reproductive history, physical examinations, laboratory results, and obstetric histories of the previous pregnancy in parous women. All sets included age, parity, underlying diseases, reproductive history, obstetric histories of the previous pregnancy, physical examination, and family history. The baseline set included physical examinations, but laboratory results were excluded. This resulted in inclusion of 165 variables in the nulliparous women and 199 variables in the parous women. The E0 set included physical examinations and laboratory test results before the first trimester serum screening, which resulted in inclusion of 222 variables in the nulliparous women and 254 variables in the parous women. The E1 set included data from maternal serum Down screening tests of human chorionic gonadotropin (HCG) and pregnancy associated plasma protein-A (PAPP-A), which resulted in inclusion of 224 variables in the nulliparous women and 256 variables in the parous women. The M1 set included the 50-g GCT laboratory test results, which resulted in inclusion of 324 variables in the nulliparous women and 361 variables in the parous women. The whole cohort used the same sets of variables as those used for the multiparity cohort, according to each time point.
Machine learning algorithms
In this study, two tree-based algorithms were compared: the light gradient boosting machine (LGBM) and extreme gradient boosting (XGBoost) algorithms. Both algorithms implement the gradient boosting method, which is widely recognized as the state of the art for predicting tabular data27,28. Additionally, these algorithms have built-in methods for handling missing values, making it possible to use data with missing values in the machine learning process29.
Evaluation of algorithms
To determine the best algorithm to use, the split data set was fed into each algorithm and its performance was evaluated using the metrics of area under the receiver operating characteristic curve (AUC) and area under precision-recall curve (AUPR). The performances of LGBM and XGBoost across the whole data set, nulliparity, and multiparity cohorts, at four different stages (baseline, E0, E1, and M1), were compared and a final algorithm was selected for prediction.
Model interpretations
In order to explain the output from complex machine learning models, Shapley values were used to indicate how much influence each variable had in determining model output. The Shapley value is the average value of all the contribution of every variables in a coalition, according to the presence or absence of the each variable. We used a SHapley Additive exPlanations (SHAP) values to calculate and visualize the Shapley values of the prediction models30.
Simplified model evaluation and validation
For clinical application, three models were developed with simplified features. Model [a] used variables suggested by the American College of Obstetricians and Gynecologists (ACOG) and the American Diabetes Association (ADA) as GDM risk factors for early pregnancy screening24,31. Model [b] used variables with high ranked SHAP values up to 40 variables. Model [c] utilized the Boruta algorithm to select important variables for the machine learning model32. The Boruta algorithm is a variable selection algorithm based on the random forest and decision trees. Removing variables that are less relevant to the result than their shadowed variable by a statistical test can reduce the misleading impact of random fluctuations and correlations and reduce the undesirable effect of over-fitting32,33. The performance of these three models was evaluated by AUC and AUPR and validated in the test sets. Questionnaires for clinical application were developed based on the model performance and convenience.
Ethical approval
The Institutional Review Board of The Catholic University of Korea approved the present study (XC20WIDI0103).
Results
Data set
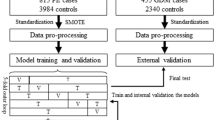
The final study cohort included 34,387 pregnancies after subtracting women with exclusion criteria from among 35,098 pregnancies during the study period (Fig. 1). GDM was diagnosed in 3,103 pregnancies (9.02%) in the entire cohort, which were 2,172 and 931 pregnancies in the training and test sets, respectively.

Participant selection process. GDM, gestational diabetes.
Algorithm selection
When all the original variables were used, XGBoost outperformed LGBM in most cohorts and at most time points, except for the E1 time point in the whole and multiparity cohort (Fig. 2). Therefore, XGBoost was selected for subsequent analysis.

Performance comparison between LGBM and XGBoost algorithms, using original variables. (a) AUC performance at each time point in the whole cohort, (b) AUC performance at each time point in the nulliparity cohort, (c) AUC performance at each time point in the multiparity cohort. LGBM, light gradient boosting machine; XGBoost, extreme gradient boosting.
Predictive model evaluation
A prediction model with original variables achieved an AUC of 0.711 at baseline, 0.720 at E0, 0.721 at E1 and 0.804 at M1, and an AUPR of 0.246 at baseline, 0.256 at E0, 0.262 at E1, and 0.442 at M1, for the whole cohort (Fig. 3). In the nulliparous cohort, a prediction model with original variables achieved an AUC of 0.664 at baseline, 0.678 at E0, 0.672 at E1, and 0.782 at M1, and an AUPR of 0.211 at baseline, 0.229 at E0, 0.226 at E1, and 0.413 at M1. In the multiparous cohort, a prediction model with original variables achieved an AUC of 0.708 at baseline, 0.723 at E0, 0.720 at E1, and 0.798 at M1, and an AUPR of 0.260 at baseline, 0.274 at E0, 0.240 at E1, and 0.424 at M1.

Predictive model evaluation with original variables. (a) AUC curves at each time point in the whole cohort, (b) AUC curves at each time point in the nulliparity cohort, (c) AUC curves at each time point in the multiparity cohort, (d) AUPR curves at each time point in the whole cohort, (e) AUPR curves at each time point in the nulliparity cohort, (f) AUPR curves at each time point in the multiparity cohort.
There was no improvement in predictive power in the E1 period compared to the E0 period, even though more variables were added. Accordingly, the subsequent analysis was conducted at the three time points of baseline, E0, and M1. Feature importance with high SHAP values up to 20 variables in the whole cohort are presented in Fig. 4. BMI before pregnancy, history of previous GDM, history of endocrine disease, maternal age, and family history of DM were identified as the most predictive features at baseline and E0. At M1, the variables that were identified as the most predictive features were the 50-g GCT results, HbA1C levels, BMI before pregnancy, history of previous GDM, and family history of DM.

Feature importance of the top 20 contributing features in the whole cohort. Each graph illustrates the importance of the top 20 items among 40 items with a high cut-off value extracted through SHAP importance. The red bar indicates high positive importance, and the blue bar means high negative importance. (a) baseline, (b) E0 period, (c) M1 period. BMI, body mass index (kg/m2); DM, diabetes; GDM, gestational diabetes; LGA, large for gestational age; SBP, systolic BP; DBP, diastolic BP; WBC, white blood cell; HDL, high density lipoprotein; ALT, alanine aminotransferase; AST, aspartate aminotransferase; OGTT, oral glucose tolerance test; HbA1C, glycated hemoglobin; FBS, fasting blood sugar; HCG, multiples of median values of human chorionic gonadotropin; MAP, mean arterial pressure.
Feature selections for a simplified prediction model
For clinical application, we compared the performance of the three models using GDM risk factors recommended by ACOG, top 40 features based on SHAP value, and the Boruta algorithm. We evaluated the performance of each model and compared the results to determine which features and models yielded the best performance for GDM prediction. GDM risk factors recommended by ACOG include being overweight or obese, being physically inactive, having GDM in a previous pregnancy, having a very large baby (9 pounds or more) in a previous pregnancy, high BP, a history of heart disease, and polycystic ovary syndrome (PCOS)24. The top 40 variables with the highest SHAP values were identified for each cohort (Fig. 4 and Supplementary Fig. S1), and variables were also determined using the Boruta algorithm (Fig. 5 and Supplementary Fig. S2). The Boruta algorithm selected similar features to the top 40 features identified by SHAP values, but the number of features determined by the Boruta algorithm was 10 at baseline and 20 at E0 and M1 (Figs. 4 and 5). The minimum and maximum SHAP importance of variables identified by the Boruta algorithm are provided in Supplementary Table S3, and the SHAP summary plots are shown in Supplementaty Fig. S4.

SHAP importance of variables identified by the Boruta algorithm in the whole cohort. (a) baseline, (b) E0 period, (c) M1 period. BMI, body mass index (kg/m2); DM, diabetes; GDM, gestational diabetes; LGA, large for gestational age; SBP, systolic BP; DBP, diastolic BP; WBC, white blood cell; HDL, high density lipoprotein; AST, aspartate aminotransferase; OGTT, oral glucose tolerance test; HbA1C, glycated hemoglobin; FBS, fasting blood sugar; HCG, multiples of median values of human chorionic gonadotropin.
Performance evaluation of simplified models by feature selection methods
At baseline, the model with GDM risk factors determined by ACOG displayed the lowest performance in the whole, nulliparity, and multiparity cohorts. The performance of the models using SHAP values and the Boruta algorithm were similar at each time point (Table 1). Consequently, we developed simplified 12-point (baseline) and 20-point(E0) and 18-point (M1) questionnaires that corresponds to the variables identified by the Boruta algorithm for clinical use (Table 2).
Discussion
Principal findings
In this study, we developed a machine learning algorithm for prediction of GDM in Asian women, especially Korean women, according to gestational period. The XGBoost algorithm displayed better performance than the LGBM algorithm in most cohorts and at most time points. After analyzing the performance of the machine learning model with original variables, we developed three models with simplified features for clinical application. At baseline, the model with GDM risk factors recommended by ACOG displayed the lowest performance for the whole cohort and subcohorts. Although the performance of the models employing SHAP values and the Boruta algorithm was similar at each time point, the model with variables determined by the Boruta algorithm was selected for clinical application, because the number of features was less than in the model using SHAP values. Finally, we developed questionnaires for clinical application at baseline, at E0, and at M1.
Because the first trimester maternal serum aneuploidy screening markers, PAPP-A and HCG, which were added as variables in E1, did not improve the prediction performance for GDM, we set the three time points for prediction as baseline, E0, and M1. As expected, the prediction performance for GDM in the M1 period, which included the results of the 50-g OGTT and HbA1C levels, displayed significant improvement, with the highest SHAP importance of these two variables. Measurement of HbA1C is not included in routine screening tests during pregnancy. However, in South Korea abdominal obesity, assessed using waist circumference in women of 20–49 years old, has increased from 9% in 2013 to 12.2% in 202134. In 2020, the prevalence of diabetes and prediabetes was reported as 14.3% and 22.5% in women of 30–49 years old35. Although the high SHAP importance of HbA1C might be associated with its measurement in a limited number of women, routine screening and insurance cover of HbA1C measurements need to be considered in pregnant women and/or further studies of the criteria for pregnant women who require HbA1C measurement are required.
Several studies have attempted to use traditional statistical methods to predict GDM, based on risk factors33,34, but such models have not yet been employed clinically. In recent years, there have been attempts to achieve the same goal using cutting-edge, machine learning technology22,36. Some studies, like this one, have focused on predicting GDM using early pregnancy information, and the predictive power has been reflected by an AUC of 0.7–0.937,38,39,40,41. Although these studies included subjects from various racial backgrounds, including Asians, there was a limited number of Asian participants, and specific studies focusing on Asian women, particularly Korean women, were scarce. Therefore, the current study is significant, as GDM varies greatly across ethnicities and geographical regions, and is particularly influenced by specific regional environments41. Some studies have evaluated additional biomarkers42,43 and genetics44,45,46, in addition to the routine data collected during antenatal care. In this study, only the basic information and laboratory tests collected during routine antenatal care were used as variables, yet the machine learning models still demonstrated moderate to high performance in early and mid-pregnancy, and have the advantage of being cost-effective.
Strengths and limitations
Since machine learning methods are continuously evolving, numerous types of new machine learning algorithms are being developed. In this study, we used two gradient boosting algorithms. The LGBM has demonstrated good performance with bioinformatics tasks47,48, and XGBoost is fast to run and scalable, allows parallel computing, and solves many scientific problems accurately27,28,49. Following the development of a prediction model using the XGBoost algorithm with all variables included, we extracted the variables with high SHAP values or identified by the Boruta algorithm. The final simplified prediction model, which utilizes the key variables identified by the Boruta algorithm, may be more clinically practical.
One limitation is that this is a retrospective study and we conducted internal validation only, in the test set. For this reason, some data are missing and there may be bias because some tests were not performed in all populations. However, this study is based on data collected from seven centers that use the same electronic health record system and that are located in various geographical locations in Korea. Thus, our study has the strength of including various regional characteristics. In order to overcome any limitations of retrospective data, prospective cohorts for validation are currently being registered. In particular, prospective data are also being collected for the top 40 variables with high importance in SHAP value, in addition to the abbreviated variables adopted from the Boruta algorithm in this analysis. Lastly, this study evaluated the model performance not only in the whole cohort, but also in subcohorts of nulliparous and multiparous women, to improve the precision in each cohort. Our findings are predicted to be a cornerstone for developing a better algorithm and identify possible future research to validate the algorithm developed in the current study.
Conclusion
On the basis of our study, we propose a machine learning algorithm for reliably predicting GDM in Asian women, especially Korean women. Indeed, using a machine learning model to analyze a combination of maternal factors and laboratory data may effectively predict individual risk of GDM, although further studies with prospective cohorts and external data sets may be needed for further validation.
Data availability
All relevant data are within the paper and its Supporting Information files.
References
American Diabetes Association. Management of diabetes in pregnancy: Standards of medical care in diabetes—2021. Diabetes Care 44, S1200–S1210 (2021).
Wang, H. et al. IDF diabetes atlas: Estimation of global and regional gestational diabetes mellitus prevalence for 2021 by international association of diabetes in pregnancy study group’s criteria. Diabetes Res. Clin. Pract. 183, 109050 (2022).
Jung, C. H. et al. Gestational diabetes in Korea: Temporal trends in prevalence, treatment, and short-term consequences from a national health insurance claims database between 2012 and 2016. Diabetes Res. Clin. Pract. 171, 108586 (2021).
Yang, S. J. et al. Insulin secretion and insulin resistance in Korean women with gestational diabetes mellitus and impaired glucose tolerance. Korean J. Intern. Med. 28, 306–313 (2013).
Yoon, K. H. et al. Epidemic obesity and type 2 diabetes in Asia. Lancet 368, 1681–1688 (2006).
Nguyen, C. L., Pham, N. M., Binns, C. W., Duong, D. V. & Lee, A. H. Prevalence of gestational diabetes mellitus in eastern and southeastern Asia: A systematic review and meta-analysis. J. Diabetes Res. 2018, 6536974 (2018).
Lee, K. W. et al. Prevalence and risk factors of gestational diabetes mellitus in Asia: A systematic review and meta-analysis. BMC Pregnancy Childbirth 18, 494 (2018).
Wu, Y. T. et al. Early prediction of gestational diabetes mellitus in the Chinese population via advanced machine learning. J. Clin. Endocrinol. Metab. 106, e1191–e1205 (2021).
Bianco, M. E. & Josefson, J. L. Hyperglycemia during pregnancy and long-term offspring outcomes. Curr. Diabetes Rep. 19, 143 (2019).
Lowe, W. L. Jr. et al. Hyperglycemia and adverse pregnancy outcome follow-up study (HAPO FUS): Maternal gestational diabetes mellitus and childhood glucose metabolism. Diabetes Care 42, 372–380 (2019).
Chung, H. R. et al. Maternal hyperglycemia during pregnancy increases adiposity of offspring. Diabetes Metab. J. 45, 730–738 (2021).
Bimson, B. E. et al. Current trends in the diagnosis and management of gestational diabetes mellitus in the United States. J. Matern. Fetal Neonatal Med. 30, 2607–2612 (2017).
Koivusalo, S. B. et al. Gestational diabetes mellitus can be prevented by lifestyle intervention: The Finnish gestational diabetes prevention study (RADIEL): A randomized controlled trial. Diabetes Care 39, 24–30 (2016).
Wang, C. et al. A randomized clinical trial of exercise during pregnancy to prevent gestational diabetes mellitus and improve pregnancy outcome in overweight and obese pregnant women. Am. J. Obstet. Gynecol. 216, 340–351 (2017).
Simmons, D. et al. Hyperglycaemia in early pregnancy: The treatment of booking gestational diabetes mellitus (TOBOGM) study. A randomised controlled trial. Med. J. Aust. 209, 405–406 (2018).
Huhn, E. A., Rossi, S. W., Hoesli, I. & Göbl, C. S. Controversies in screening and diagnostic criteria for gestational diabetes in early and late pregnancy. Front. Endocrinol. (Lausanne) 9, 696 (2018).
Kuo, C. H. & Li, H. Y. Diagnostic strategies for gestational diabetes mellitus: Review of current evidence. Curr. Diabetes Rep. 19, 155 (2019).
Naylor, C. D., Sermer, M., Chen, E. & Farine, D. Selective screening for gestational diabetes mellitus. Toronto Trihospital gestational diabetes project investigators. N. Engl. J. Med. 337, 1591–1596 (1997).
van Leeuwen, M. et al. Estimating the risk of gestational diabetes mellitus: A clinical prediction model based on patient characteristics and medical history. BJOG 117, 69–75 (2010).
Artzi, N. S. et al. Prediction of gestational diabetes based on nationwide electronic health records. Nat. Med. 26, 71–76 (2020).
Chen, X. et al. A machine learning-based model for predicting gestational diabetes mellitus. Sci. Rep. 11, 11192 (2021).
Mushtaq, S. et al. A novel machine learning approach for early prediction of gestational diabetes mellitus. Sci. Rep. 10, 12497 (2021).
Vandorsten, J. P. et al. NIH consensus development conference: Diagnosing gestational diabetes mellitus. NIH Consens. State Sci. Statements 29, 1–31 (2013).
Gestational diabetes mellitus. ACOG practice bulletin No. 190. American college of obstetricians and Gynecologists. Obstet. Gynecol. 131, e49–e64 (2018).
Cheng, Y. W., Block-Kurbisch, I. & Caughey, A. B. Carpenter-Coustan criteria compared with the national diabetes data group thresholds for gestational diabetes mellitus. Obstet. Gynecol. 114, 326–332 (2009).
Moons, K. G. M. et al. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): Explanation and elaboration. Ann. Intern. Med. 162, W1–W73 (2015).
Chen, C., Dong, D., Qi, B., Peterson, I. R. & Rabitz, H. Quantum ensemble classification: A sampling-based learning control approach. IEEE Trans. Neural Netw. Learn. Syst. 28, 1345–1359 (2017).
Mateo, J., Rius-Peris, J. M., Maraña-Pérez, A. I., Valiente-Armero, A. & Torres, A. M. Extreme gradient boosting machine learning method for predicting medical treatment in patients with acute bronchiolitis. Biocybern. Biomed. Eng. 41, 792–801 (2021).
Pedregosa, F. et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Proc. Syst. 30, 4765–4774 (2017).
American Diabetes Association. Classification and diagnosis of diabetes. Diabetes Care 40, S11–S24 (2017).
Kursa, M. & Rudnicki, W. Feature selection with the Boruta package. J. Stat. Softw. 36, 1–13 (2010).
Kursa, M. & Rudnicki, W. The all relevant feature selection using random forest. CoRR. abs/1106.5112. https://arxiv.org/abs/1106.5112 (2011). Accessed 24 Jan 2023.
Statistics Korea. https://kosis.kr/index/index.do
Diabetes fact sheet in Korea (2022).
Mennickent, D. et al. Machine learning-based models for gestational diabetes mellitus prediction before 24–28 weeks of pregnancy: A review. Artif. Intell. Med. 132, 102378 (2022).
van Hoorn, F. et al. Prognostic models versus single risk factor approach in first-trimester selective screening for gestational diabetes mellitus: A prospective population-based multicentre cohort study. BJOG 128, 645–654 (2021).
Battarbee, A. N. & Yee, L. M. Association of fast food and supermarket density with neonatal outcomes of pregnancies affected by gestational diabetes. Am. J. Perinatol. 36, 1405–1411 (2019).
Naylor, C. D. et al. Selective screening for gestational diabetes mellitus. N Engl J Med 337, 1591–1596 (1997).
Bourdages, M. et al. First-trimester abdominal adipose tissue thickness to predict gestational diabetes. J Obstet Gynaecol Can. 40, 883–887 (2018).
Gabbay-Benziv, R., Doyle, L. E., Blitzer, M. & Baschat, A. A. First trimester prediction of maternal glycemic status. J. Perinat. Med. 43, 283–289 (2015).
Enquobahrie, D. A. et al. Maternal early pregnancy serum metabolites and risk of gestational diabetes mellitus. J. Clin. Endocrinol. Metab. 100, 4348–4356 (2015).
Liu, J. et al. Predictive values of serum metabolites in early pregnancy and their possible pathways for gestational diabetes: A nested case-control study in Tianjin. China. J. Diabetes Complicat. 35, 108048 (2021).
Popova, P. V. et al. Association of common genetic risk variants with gestational diabetes mellitus and their role in GDM prediction. Front. Endocrinol. 12, 628582 (2021).
Sørensen, A. E. et al. The predictive value of miR-16,-29a and-134 for early identification of gestational diabetes: A nested analysis of the DALI cohort. Cells 10, 170 (2021).
Dziedziejko, V., Safranow, K., Tarnowski, M. & Pawlik, A. Common type 2 diabetes genetic risk variants improve the prediction of gestational diabetes. Horm. Metab. Res. 51, 655–660 (2019).
Ke, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. Proceedings of the 31st International Conference on Neural Information Processing Systems, 3149–3157 (2017).
Guyon, I. et al. (eds.) Advances in Neural Information Processing Systems, vol. 30, 3146–3154 (Curran Associates, Inc., 2017).
Chen, W. et al. Radar emitter classification for large data set based on weighted-xgboost. IET Radar, Sonar Navig. 11, 1203–1207 (2017).
Acknowledgements
This work was financially supported by Korea Health Industry Development Institute, grant number: HI21C1300.
Author information
Authors and Affiliations
Contributions
Author H.S.K. conceived and designed the study. Author S.U.L., S.H., S.K.C., S.K.C., J.E.S., J.H.W., Y.S.J., Y.H.K., K.K. and Y.H.C. collected and verified the data. Author K.J. and Author H.H. developed the machine learning algorithm. Author B.S.K. and Author H.H. wrote the initial draft of the manuscript. Author B.S.K., H.H., I.Y.P. and Author H.S.K. revised the manuscript for intellectual content. All authors reviewed and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kang, B.S., Lee, S.U., Hong, S. et al. Prediction of gestational diabetes mellitus in Asian women using machine learning algorithms. Sci Rep 13, 13356 (2023). https://doi.org/10.1038/s41598-023-39680-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-39680-8
- Springer Nature Limited
This article is cited by
-
The role of machine learning algorithms in detection of gestational diabetes; a narrative review of current evidence
Clinical Diabetes and Endocrinology (2024)