
Abstract
While the development of prehospital diagnosis scales has been reported in various regions, we have also developed a scale to predict stroke type using machine learning. In the present study, we aimed to assess for the first time a scale that predicts the need for surgical intervention across stroke types, including subarachnoid haemorrhage and intracerebral haemorrhage. A multicentre retrospective study was conducted within a secondary medical care area. Twenty-three items, including vitals and neurological symptoms, were analysed in adult patients suspected of having a stroke by paramedics. The primary outcome was a binary classification model for predicting surgical intervention based on eXtreme Gradient Boosting (XGBoost). Of the 1143 patients enrolled, 765 (70%) were used as the training cohort, and 378 (30%) were used as the test cohort. The XGBoost model predicted stroke requiring surgical intervention with high accuracy in the test cohort, with an area under the receiver operating characteristic curve of 0.802 (sensitivity 0.748, specificity 0.853). We found that simple survey items, such as the level of consciousness, vital signs, sudden headache, and speech abnormalities were the most significant variables for accurate prediction. This algorithm can be useful for prehospital stroke management, which is crucial for better patient outcomes.
Similar content being viewed by others

Introduction
Early treatment of stroke with large vessel occlusion (LVO) requires rapid transport to a thrombectomy-capable hospital for early recanalization1,2. Similarly, timely transport to specialized facilities is critical for treating subarachnoid haemorrhage (SAH) and intracerebral haemorrhage (ICH), as it can significantly improve patient outcomes3,4. The American Stroke Association recommends recognizing stroke accurately, activating emergency medical services (EMS), triaging to the appropriate hospital, and designating a competent stroke centre5. However, accurately diagnosing stroke in prehospital settings can be challenging for EMS personnel due to resource constrains and similarity of symptoms between different types of strokes, potentially leading to delays in hospital arrival or misdiagnosis. To address this issue, various prehospital scales targeting LVO have been developed to aid in determining indications for thrombectomy6,7,8,9, and the prehospital diagnosis of SAH and ICH is also important for acute stroke treatment10,11. Moreover, recent advances in machine learning (ML) and deep learning (DL) models have shown promising results in improving prehospital diagnosis scales12,13,14.
In the medical field, ML and DL models have demonstrated their potential in computer-aided diagnosis, helping healthcare professionals make accurate and timely diagnoses. For instance, DL-based image classification has been used to diagnose diseases such as pneumonia, breast cancer and lung cancer15,16,17. The ML-driven segmentation of medical images has enabled the detection of regions of interest18, and feature extraction techniques have been used to extract relevant features from medical images or other data for developing diagnostic tools19,20. ML models, as decision support systems, have been developed and used to assist clinicians in diagnosing and treating diseases [e.g., heart diseases21]. To improve the accuracy of machine learning models, there are generally three methods of hyperparameter optimization. Grid Search, Random Search, and Bayesian Optimisation. Grid search is simple and easy to implement. However, it is computationally expensive when the hyperparameter space is large, and it doesn't learn adaptively from previous iterations. Random search allows to explore the hyperparameter space more efficiently compared to grid searching. But because it's random, there is no guarantee that the best hyperparameter combination will be found. Bayesian optimization efficiently explores the hyperparameter space by using a probabilistic model to guide the search. It adapts the search based on previous evaluations, improving efficiency. It uses a learning function to select the next hyperparameter configuration to evaluate, balancing exploration and exploitation.
Building upon these recent advances, our study aimed to develop an ML-driven decision support system to help EMS personnel diagnose patients with consistent accuracy. We collected stroke-related information from the records of patients with suspected stroke who were transported by EMS to a single secondary medical care area as part of the Smart119 project. In our previous paper, we analysed the data using ML models and presented a stroke prediction scale that includes the diagnosis of stroke categories22. In this work, considering that the prehospital selection of patients requiring surgical treatment, rather than the diagnosis of stroke subtypes, would contribute to more appropriate transport, we examined the prehospital predictive diagnosis of patients who actually required surgical intervention based on case data from the Smart119 project. Our findings suggest that by integrating ML into prehospital decision support for EMS personnel, it is possible to improve patient outcomes by enabling appropriate and timely transport of patients requiring stroke surgical treatment.
Results
Baseline characteristics and outcomes
Patient characteristics and clinical findings in the study model are shown in Tables 1, 2, 3, S1–S3. There was no significant difference in patient background between the two groups; however, the intervention group had a significantly shorter time from onset to command (Table 1). In terms of the level of consciousness, treatment intervention was less common in patients with code alerts (Japan Coma Scale [JCS] 0, Glasgow Coma Scale [GCS] E4V5M6) and significantly more common in patients with codes JCS 3–100 and GCS E3/V2/M4-5 (Table 2). Vital signs and symptoms that required considerably more intervention were sudden headache, vomiting, hemiparesis, conjugate deviation, aphasia, and dysarthria (Table 3).
Prediction of prehospital stroke surgical intervention
Four popular ML algorithms were used to predict the need for stroke surgical intervention: eXtreme Gradient Boosting (XGBoost), Logistic Regression, Random Forest, and Support Vector Machine (SVM) as a representative of a gradient boosting algorithm, linear algorithm, tree algorithm, and dimensionality reducer and classifier (Table S4). In the training cohort, analysis using Random Forest predicted surgical intervention in stroke patients with high performance (an area under the receiver operating characteristic curve [AUROC] of 0.882, a sensitivity of 0.862, and a specificity of 0.746). When applied to the test cohort, the XGBoost model performed the best and predicted surgical intervention with higher scores than other models, achieving an AUROC of 0.802 (sensitivity 0.719, specificity 0.774) (Table 4, Fig. 1). The Shapley Additive exPlanation (SHAP) summary plot revealed that the major predictive contributors for stroke intervention were “Japan Coma Scale”, “dysarthria”, “heart rate”, “age”, “sudden headache and/or unconsciousness”, “Glasgow coma scale (V)”, “time from onset to emergency call”, “body temperature”, “aphasia”, and “oxygen saturation” (Fig. 2).

Area under the receiver operating characteristic curves of machine learning models. The receiver operating characteristic curve of prehospital prediction algorithms for stroke requiring surgical intervention is depicted with 1-specificity on the x-axis and sensitivity on the y-axis using the training cohort (a) and the test cohort (b). The 95% confidence interval of the AUROC is also shown. AUROC area under the receiver operating characteristic curve.

SHAP value of stroke surgical intervention. The impact of the features on the model output was expressed as the SHAP value. The features are placed in descending order according to their importance. The association between the feature value and SHAP value indicates a positive or negative impact of the predictors. The extent of the value is depicted as red (high) or blue (low) plots. SHAP SHapley Additive exPlanation.
Discussion
The present study demonstrated that a prehospital scale could predict stroke requiring surgical intervention with high accuracy. Although prehospital stroke diagnostic scales have been published in many countries and scales have been developed to determine the severity of stroke23,24, to the best of our knowledge, this is the first scale that predicts the need for surgical intervention. When surgical intervention is needed for any type of stroke, rapid transport is necessary, and hospitals need to be prepared for this. Therefore, this scale, which can predict the need for surgical intervention before hospital arrival, is very useful for rapid patient transport.
The most important variables for diagnosis were found to be JCS, vitals (pulse, temperature, oxygen saturation), age, time from onset to emergency call, headache, and speech abnormalities. Interestingly, a detailed neurological examination was not among them (Fig. 3). These variables identified as most important variables are simple survey items, and we believe that the scale is composed of easily obtainable data that EMS teams routinely observe. Regarding the absence of a detailed neurological examination including paresis, it is interesting to note that the focus should be on other items that reflect disease severity since paresis and neurological deficits are observed even in minor strokes that do not require surgical intervention.

Feature importance. The impact of the features on the model output is expressed as the average of the absolute SHAP value. The larger the value, the more important is the feature for predicting stroke surgical intervention. SHAP SHapley Additive exPlanation.
The prehospital stroke scales that have been published to date have enabled the diagnosis of LVO with high accuracy and stroke subtypes. However, in all of the scales, stroke-specific survey items were important, such as conjugate deviation and hemispatial neglect25,26,27. As noted above, these items were not included in the key variables in this scale, suggesting that its usefulness could be maintained even when these items were missing, such as in cases in which stroke was not suspected.
The novel prehospital scale developed in this study can predict the need for surgical intervention across all stroke diseases. In comparison, the Shonan Prehospital Scale (SPSS) is a score used at the municipal level to predict surgical intervention. The SPSS evaluates severe headache, impaired consciousness (JCS ≥ 10), and local symptoms (hemiplegia, facial paralysis, or abnormal speech), scoring 1 point if the onset is severe and 2 points if it is sudden onset. Comparative validation of the two models using the present data revealed that the newly developed model was superior to the other with an AUROC of 0.652 (sensitivity 0.880, specificity 0.425) (Table S5).
The patient information system utilized in the Smart119 project stores patient data gathered by EMS personnel via tablets. The interface of the system is equipped with an application that enables prehospital stroke diagnosis. We believe that the inclusion of this program into the existing system would reduce the time required for hospital selection and contribute to prompt and appropriate emergency transport.
This study has some limitations. First, the decision to initiate therapeutic intervention was made by the neurosurgeons at each participating hospital, which may have introduced variability across institutions. Second, although this was a multicentre study, the study was limited to a single metropolitan area in Japan. Hence, it is crucial to validate the algorithm’s high predictive value in other regions with distinct characteristics to increase its applicability across Japan. Fortunately, the medical region where this study was conducted (Chiba Prefecture) comprises diverse types of medical organizations, including urban type with multiple hospitals, independent type with one hospital as the main hospital, and depopulated type with no central hospital. The algorithm will be expanded to Chiba Prefecture as a whole and will be demonstrated in the future.
In conclusion, our algorithm serves as a prehospital stroke scale that can be easily completed by EMS personnel to predict the need for surgical intervention in patients with stroke. We firmly believe that our machine-learning-based scale holds significant value as predicting stroke intervention is important in determining a suitable transport destination considering their medical care system.
Methods
Study design and patient population
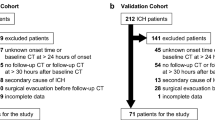
From September 2019 to January 2022, we conducted a study of patients who were transported by EMS for suspected stroke. The destination hospitals included all 12 medical institutions within the secondary care area that were equipped to transport stroke patients. We developed a surgical intervention prediction scale by retrospectively examining 1143 patients whose diagnosis and treatment plan could be ascertained at the transport site.
Surgical intervention was defined as aneurysmal neck clipping or coil embolization for SAH, haematoma removal, haematoma or ventricular drainage for ICH, administration of intravenous tissue plasminogen activator (tPA), mechanical thrombectomy, or other endovascular treatment for acute ischaemic stroke. The decision to perform interventions was made at the discretion of the neurosurgeon at each institution.
The Chiba University Hospital Certified Clinical Research Review Board approved this study (No. 2733) and waived the need for written informed consent in conformity with the Ethical Guidelines for Medical and Health Research Involving Human Subjects in Japan. We posted information about this study in each ambulance. We promptly excluded the collected data when a patient or family indicated that they did not wish to participate in this study.
Selected variables
The survey items for analysis included patients’ characteristics, vital signs, symptoms, level of consciousness, and the 7 key parameters proposed by the Japanese Stroke Association. Details are as follows: (i) patients’ characteristics: age, sex, time from onset to emergency call, onset timing; (ii) vital signs: pulse, blood pressure (systolic/diastolic), body temperature, oxygen saturation; (iii) symptoms: vomiting, dizziness, cramps, numbness; (iv) level of consciousness: JCS, GCS (E, V, M); (v) previous medical history; (vi) important stroke parameters: conjugate deviation, hemispatial neglect by 4-finger method25, aphasia (call of glasses/clock), pulse irregularity, dysarthria, facial paralysis, upper and lower hemiparesis.
Missing values
As our data had missing values, we performed imputations before building the ML models. First, we used domain knowledge to impute pairs of groups of features including (i) conjugate deviation and visual field defects (ii) dysarthria and facial paralysis; (iii) aphasia, GCS, JCS and other consciousness-related features; (iv) systolic and diastolic blood pressure values; and (v) paralysis-related features. For other numerical features, such as heart rate, body temperature, oxygen saturation, and time from onset to emergency call, we imputed with the median value of each feature. The rest of the features with missing values (all of them are categorical features) were left as they were since boosting models such as XGBoost support missing values and treat them as a separate category.
Machine learning model development
We developed ML models using four different algorithms: XGBoost, Random Forest, Logistic Regression and SVM. To ensure a balanced distribution of surgical intervention categories, we randomly assigned 765 cases (70%) to a training cohort and 378 cases (30%) to a test cohort. The stroke types were classified into SAH, ICH, LVO, and other ischaemic stroke in both cohorts. The number of cases and the number of surgical interventions for each type are shown in Fig. S1.
The hyperparameters of the ML models were tuned by using an open-source hyperparameter optimization software framework called Optuna that employs Bayesian optimization algorithm techniques. Optuna helps us to find the best combination of parameters that maximize the model score by iterating the choice of parameters and evaluating the models obtained with those parameters. In each iteration, an evaluation of a model was performed with the scoring method AUROC through fivefold cross-validation.
Statistical analysis
Model performance was measured in terms of the AUROC, sensitivity, specificity, and F1 score. Furthermore, the SHAP algorithm of the XGBoost model, which outperformed all other models, wa employed to interpret the contribution of each variable to the predictive model28. In this algorithm, the SHAP values are calculated by measuring the difference in model output resulting from the inclusion of a variable into the algorithm, providing insights into the impact of each variable on the output. In the SHAP plots, a violin plot was created for all data points associated with each feature, with higher values appearing red and lower values appearing blue. The violin plot is aligned with the SHAP value as the x-axis. Thus, the red/blue violin plot on the right (i.e., higher positive SHAP values) suggests that the higher/lower the value of that feature, the better the model predicts towards positive/negative effects.
Continuous values were expressed as medians (interquartile ranges), and categorical values were presented as absolute numbers and percentages. Two-sided P values less than 0.05 were considered indicative of statistical significance.
Analyses were performed using the open-source Python 3.7.15 package, XGBoost 1.5.1, Sciki-learn 1.0.2, Pandas 1.3.5, Optuna 2.10.1, and SHAP 0.41.0 package. (Python Licence: https://docs.python.org/3/license.html, XGBoost: https://github.com/dmlc/xgboost/blob/master/LICENSE, Scikit-learn: https://github.com/scikit-learn/scikit-learn/blob/main/COPYING, Pandas:http://pandas.pydata.org/pandasdocs/stable/getting_started/overview.html?highlight=license, Optuna: https://github.com/optuna/optuna/blob/master/LICENSE, SHAP: https://github.com/slundberg/shap/blob/master/LICENSE. All figures in this study were drawn using Matplotlib (3.2.2)20,21, a Python visualization package.
Data availability
The datasets used and analysed during our study are available from the corresponding author upon reasonable request.
Abbreviations
- LVO:
-
Large vessel occlusion
- EMS:
-
Emergency medical services
- SAH:
-
Subarachnoid haemorrhage
- ICH:
-
Intracerebral haemorrhage
- JCS:
-
Japan coma scale
- GCS:
-
Glasgow coma scale
- XGBoost:
-
EXtreme gradient boosting
- AUROC:
-
Area under the receiver operating characteristic curve
- tPA:
-
Tissue plasminogen activator
- SHAP:
-
SHapley Additive exPlanation
References
Goyal, M. et al. Endovascular thrombectomy after large vessel ischaemic stroke: A meta-analysis of individual patient data from five randomized trials. Lancet 387, 1723–1731 (2016).
Nogueira, R. G. et al. Thrombectomy 6 to 24 hours after stroke with a mismatch between deficit and infarct. N. Engl. J. Med. 378, 11–21 (2018).
Kowalski, R. G. et al. Initial misdiagnosis and outcome after subarachnoid hemorrhage. JAMA 291, 866–869 (2004).
Gioia, L. C. et al. Prehospital systolic blood pressure is higher in acute stroke com- pared with stroke mimics. Neurology 86, 2146–2153 (2016).
Adeoye, O. et al. Recommendations for the establishment of stroke systems of care: A 2019 update. Stroke 50, e187-210 (2019).
Gong, X. et al. Conveniently-grasped field assessment stroke triage (CG-FAST): A modified scale to detect large vessel occlusion stroke. Front. Neurol. 10, 390 (2019).
Václavík, D. et al. Prehospital stroke scale (FAST PLUS Test) predicts patients with intracranial large vessel occlusion. Brain Behav. 8, e01087 (2018).
Scheitz, J. F. et al. Clinical selection strategies to identify ischemic stroke patients with large anterior vessel occlusion: results from SITS-ISTR (Safe implementation of thrombolysis in stroke international stroke thrombolysis registry). Stroke 48, 290–297 (2017).
Hastrup, S., Damgaard, D., Johnsen, S. P. & Andersen, G. Prehospital acute stroke severity scale to predict large artery occlusion: Design and comparison with other scales. Stroke 47, 1772–1776 (2016).
Uchida, K. et al. Clinical prediction rules to classify types of stroke at prehospital stage. Stroke 49, 1820–1827 (2018).
Uchida, K. et al. Simplified prehospital prediction rule to estimate the likelihood of 4 types of stroke: The 7-item japan urgent stroke triage (JUST-7) score. Prehospital Emerg. Care 7, 1–10 (2020).
Heo, J. et al. Machine learning-based model for prediction of outcomes in acute stroke. Stroke 50, 1263–1265 (2019).
Nishi, H. et al. Predicting clinical outcomes of large vessel occlusion before mechanical thrombectomy using machine learning. Stroke 50, 2379–2388 (2019).
Uchida, K. et al. Development of machine learning models to predict probabilities and types of stroke at prehospital stage: The Japan urgent stroke triage score using machine learning (JUST-ML). Transl. Stroke Res. 13, 370–381 (2022).
Okeke, S., Mangal, S., Uchenna, J. M. & Do-Un, J. an efficient deep learning approach to pneumonia classification in healthcare. J. Healthc Eng. 2019, 4180949 (2019).
Teresa, A. et al. Classification of breast cancer histology images using Convolutional Neural Networks. PLoS ONE 12, e0177544 (2017).
Jinsa, K. & Gunavathi, K. Lung cancer classification using neural networks for CT images. Comput. Methods Programs Biomed. 113, 202–209 (2014).
Lin, M., Bao, G., Sang, X. & Wu, Y. Recent advanced deep learning architectures for retinal fluid segmentation on optical coherence tomography images. Sensors (Basel) 22, 3055 (2022).
Wu, P. et al. AGGN: Attention-based glioma grading network with multi-scale feature extraction and multi-modal information fusion. Comput. Biol. Med. 152, 106457 (2023).
Li, H., Zeng, N., Wu, P. & Clawson, K. Cov-Net: A computer-aided diagnosis method for recognizing COVID-19 from chest X-ray images via machine vision. Expert Syst. Appl. 207, 118029 (2022).
Pooja, R., Rajneesh, K., Nada, M. O. S. A. & Anurag, J. A decision support system for heart disease prediction based upon machine learning. J. Reliab. Intell. Environ. 7, 263–275 (2021).
Hayashi, Y. et al. A prehospital diagnostic algorithm for strokes using machine learning: A prospective observational study. Sci. Rep. 11, 20519 (2021).
de la Pérez, O. N. et al. Design and validation of a prehospital stroke scale to predict large arterial occlusion:the rapid arterial occlusion evaluation scale. Stroke 45, 87–91 (2014).
Katz, B. S., McMullan, J. T., Sucharew, H., Adeoye, O. & Broderick, J. P. Design and validation of a prehospital scale to predict stroke severity: Cincinnati prehospital stroke severity scale. Stroke 46, 1508–1512 (2015).
Suzuki, K. et al. Emergent large vessel occlusion screen is an ideal prehospital scale to avoid missing endovascular therapy in acute stroke. Stroke 49, 2096–2101 (2018).
Ohta, T. et al. Optimizing in-hospital triage for large vessel occlusion using a novel clinical scale (GAI2AA). Neurology 93, e1997-2006 (2019).
Okuno, Y. et al. Field assessment of critical stroke by emergency services for acute delivery to a comprehensive stroke center: FACE2AD. Transl. Stroke Res. 11, 664–670 (2020).
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2, 56–67 (2020).
Acknowledgements
We thank all contributors to this study, especially the following investigators: Chiba Emergency Medical Center (Akihiro Miyata), Chiba Medical Center (Iwao Yamakami), Chiba Chuo Medical Center (Motoki Sato), Chiba Neurosurgical Hospital (Takuji Igarashi), National Hospital Organization Chiba Medical Center (Hiroaki Ozaki), Chiba Aoba Municipal Hospital (Yasumasa Morita), Mitsuwadai General Hospital (Masahiko Kasai), Japan Community Health Care Organization Chiba Hospital (Noriyoshi Murotani), Sannou Hospital (Tune Yajima), Kashiwado Hospital (Toshihiro Saito), Kajita M C (Masahito Kajita), and Chiba City Fire Department (Hideki Shinhama).
Funding
This research was supported by the Japan Agency for Medical Research and Development under Grant Number #JPhe1502001. The funder had no role in the study design, analysis of the data, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
Study concept and design: T.N., Y.Y. (Yoshida), Y.Y. (Yamao), Acquisition of data: T.N., N.H., T.S., Y.H., S.T., Drafting of the manuscript: T.N., Y.Y. (Yoshida), R.M., Critical revision of the manuscript for important intellectual content: Y.Y. (Yoshida), Y.H., T.S., N.H., K.T., R.M., Y.Y. (Yamao), Y.T., Y.I., T.N., Statistical analysis: T.N., Y.Y. (Yoshida), Y.Y. (Yamao), R.M., Supervision: T.N., All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
TN and YY (Yamao) are inventors and have submitted patents related to this work. TN and YY (Yamao) serve as directors and hold shares in Smart119 Inc. REM serves as a chief scientist in Smart119 Inc. The remaining authors have disclosed that they do not have any conflicts of interest.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yoshida, Y., Hayashi, Y., Shimada, T. et al. Prehospital stroke-scale machine-learning model predicts the need for surgical intervention. Sci Rep 13, 9135 (2023). https://doi.org/10.1038/s41598-023-36004-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-36004-8
- Springer Nature Limited