
Abstract
Nowadays, Transit-Oriented Development (TOD) plays a vital role for public transport planners in developing potential city facilities. Knowing the necessity of this concept indicates that TOD effective parameters such as network accessibility (node value) and station-area land use (place value) should be considered in city development projects. To manage the coordination between these two factors, we need to consider ridership and peak and off-peak hours as essential enablers in our investigations. To aim this, we conducted our research on Chengdu rail-transit stations as a case study to propose our Node-Place-Ridership-Time (NPRT) model. We applied the Multiple Linear Regression (MLR) to examine the impacts of node value and place value on ridership. Finally, K-Means and Cube Methods were used to classify the stations based on the NPRT model results. This research indicates that our NPRT model could provide accurate results compared with the previous models to evaluate rail-transit stations.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Introduction
Public transit operations have now become a logical substitution for private transportation to eliminate the drawbacks such as air pollution and traffic congestion. Transport planners benefit from high-speed trains, subways, and BRTs to implement their cities' Transit-Oriented Development (TOD) concepts. Policymakers, governments, and municipal mayors look forward to providing better access to public transport systems in high-density cities. Thus, comprehensive models for transport planners sound essential. In the past, researchers investigated the potential approaches to match the rail-transit supply and demand. Network accessibility and land use have been considered stem factors to provide the Node-Place (NP) model1,2. Researchers define node value based on transport access, network design and structure, and other related network variables. In contrast, they determine place value by assessing the number, diversity, and interaction of urban economic, social, or cultural activities.
The NP model is a regional scaled model concentrating on the rail-transit networks and stations to classify TOD typologies. One of the fundamental ideas of this model is providing the accessibility and conditions for the location to develop the transportation provision. In turn, increasing the demand for transport leads to enhancing the location growth and transport system. The relationship between node value and place value was mentioned in past research3. However, it seems there are two more dimensions as necessary as node and place values, which have not been considered yet. Ridership refers to the possibility of using transit centers and infrastructures by public transport takers, which relates to land use and time. To obtain a comprehensive model, we need to collect the data at peak and off-peak hours since the mentioned parameters and ridership are functionally linked with time. Analyzing the coordination between node-place-ridership-time (NPRT) values can better understand this model for transport planners.
As an Asian city and a developing area in China, Chengdu benefits from multiple subway lines, high-speed trains, BRTs, and mono-rails. This brings us an idea to select Chengdu city as our case study to propose a comprehensive model for city planners and municipal government. It sounds beneficial for policymakers to apply an extensive model and know the interaction between NPRT values to provide strategic transit plans. Thus, we aimed to add ridership and time values as third and fourth dimensions to the previous node-place model and proposed a new model to evaluate transit stations.
We structured the remainder of this research to derive our proposed NPRT model and check the accuracy of existing models. In the next section, the previous node-place model and also current research works are reviewed. Section “Methodology and data” covers the methodological approaches and data acquisition. Section “Results and discussion” presents the results, model evaluation, and discussion. Finally, we provide the central conclusion of this research in “Conclusion”.
Literature review
Peter Calthorpe introduced Transit-Oriented Development (TOD) concept in his book "The Next American Metropolis"4. TOD refers to mixed-use and walkable neighborhoods that provide easy access to public transit for people5. TOD neighborhoods include transit stations, public centers, high-density residential and commercial buildings, and walkable streets. Classifying station areas based on their similar functional characteristics and set of morphological is the meaning of TOD classification. Distinguishing the types of TOD is a significant concern described in Calthorpe's book4. He defined neighborhood TOD and urban TOD according to the spatial orientation of the area functions. Knowing the importance of accessible stations in TOD neighborhoods, many researchers researched how stations can be efficient and reachable.
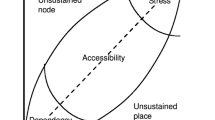
A Node-Place (NP) model was proposed to categorize and evaluate public transit stations in 1999 using node value and place value1. As we mentioned before, balancing land use with transportation is the principal aim of the NP model. This model was conveyed in a two-dimensional diagram, as shown in Fig. 1. In this diagram, the station-area land use corresponds to \(x\)-axis (Place). Place content of an area indicates how human interaction is affected by the diversity of urban activities. Besides, \(y\)-axis (Node) belongs to the accessibility of the node, which refers to the relationship between people and their interaction. Based on this diagram, five possible situations can be found.

The Node-place model and five ideal–typical situations for a location1.
The middle diagonal line area indicates the "Balance" area (1), which means if the node value and place value are similar and equally strong, that station is considered as an accessible or balanced station. In the Balance zone, infra-systems and land use match each other without any stress to maintain the environment and the system. The "Stress" area (2) shows that the diversity of transportation and activities is over-configurated, and the vital node has maximal physical human interaction, making a substantial place value. A station located in the Stress zone has numerous and realized potential facilities to provide a more efficient land use. The "Dependence" area (3) represents stations where the node and place values are matched but under-configuration. In this zone, the demand for public transportation is deficient. There are enough free spaces, but due to the low demand for public transit, there's no reasonable need for infra-system developments. A station is an "Unbalanced node" (4) if transportation facilities are more available than urban activities. In this area, the land use facilities are relatively lower than the public transit flow supply, leading to jammed traffic, massive transit lines, and environmental degradation. A station is considered an "Unbalanced place" (5) if the opposite situation is actual. Land use activities are more available compared to public transportation systems' supply.
A review of the previous research shows that a two-dimensional (node-place) model cannot cover all of the analysis aspects of a station. According to the node-place model, increasing or decreasing the node and/or place value(s) would bring an unbalanced station in the balance area6,7. There should be more values to have a comprehensive model since a station with balanced node and place values cannot be efficient or advantageous. In contrast, it does not have a good ridership value. Moreover, the coordination between node, place, and ridership value might not remain steadily constructive in peak and off-peak hours. Therefore, the relationship between node, place, and ridership values should be defined following the time to consider a comprehensive function, including practical values. Engineers and transport planners should design structures and networks concerning the critical situation. Thus, time is as essential as node, place, and ridership values. This research considered all four mentioned values (node, place, ridership, and time) to create our NPRT model to evaluate the efficiency of rail-transit stations.
The node value of a station in the node-place model proposed by Bertolini1 is defined as the station's network accessibility, including daily service frequency, the number of stations located in the area within 45 min of traveling, and the number of accessible directions at the station. Other researchers added some indexes to measure the station's node value. Proximity to CBD area by Chorus and Bertolini8 and congestion index by Olaru et al.9 were added to the node value. At a station, network accessibility includes two significant factors: the accessible opportunities by a station and the transport possibilities to access the opportunities10,11,12,13. Zhejing Cao et al. recently added accessible opportunities and network centrality into the node value14.
Bertolini measured the place value in his proposed node-place model by the station-area land use and the number of residents and employees in economic areas1. After Bertolini, other researchers added more indicators to the place value, such as population density, land prices, unemployment rate, number of flats, and core urban area15,16. Although density and diversity of activities are primary factors in place value measurement, it seems necessary to consider other essential indicators such as parking areas, fed buses at stations, and walking areas. The built environment features were also included in the place value by Zhejing Cao et al.14. Moreover, they studied and considered ridership as the third dimension of node-place value and created the node-place-ridership model.
A comprehensive study on the subway stations and CBDs in Chengdu showed that applying the previous node-place and node-place-ridership models couldn't provide a fair and balanced class for stations. In most case study locations, during weekdays, many people need to change the line, go to work, or come back from their working areas. For example, the subway stations called "South Railway Station" and "Chunxi Road" face a lack of trains and enough space for the riders in the mornings from 6:00 to 9:00 and evenings from 17:00 to 20:00. It's due to the high-frequency trips, in the morning and evening, to and from the working destinations which can be reached via this subway station. Moreover, Chunxi Road is one of the CBDs in Chengdu. There are many shopping malls, offices, consulates, visa centers, and training schools at Chunxi Road station. Let's consider the previous models of node-place and node-place-ridership, in which Time was not considered a leading dimension. It's not possible to justify the reason for these unbalanced stations. These subway stations were designed and categorized without considering time as a significant factor. It can be seen that a station classification might change from balanced to unbalanced several times during the day. A fair comparison and investigation of the existing models proved that it's vital to provide a new and more accurate model for city planners, traffic policymakers, and governments to apply a constructive model to classify the stations based on the needs and demands of the society.
This research work's main contribution and novelty present the Node-Place-Ridership-Time (NPRT) method and the Cube model with 27 classes to provide accurate classifications for rail-transit stations during different time-spans. The NPRT model provides a new contribution to the TOD concept, leading to a more progressive and beneficial policy for cities. To obtain the NPRT model, we added a fourth dimension of Time into the node-place-ridership model to evaluate and classify the transit stations. The coordination between ridership and time influences stations' classification to know which stations are balanced and unbalanced. Without a comprehensive model, we would not establish the relative position of a transit station in the urban regional network. This would assist the city planners and governments in updating their applied policies.
Methodology and data
Approach
We consider all of Chengdu city as our case study. First, the Chengdu transit system and the study area are presented in this research. Next, we provide a list of node, place, and ridership indicators. To make our research more accurate, we divide the time into four classes to determine the effect of time on ridership at peak, peak-off, weekend, and other regular hours. Different data resources were used to collect the information for our target variables. We apply the Min–Max Normalization method to normalize our data. Afterward, we apply Information Entropy Weighting (IEW) to combine all indicators and create composite nodes and places. Then, to investigate the relationship between four facets of node, place, ridership, and time, we apply the Multiple Linear Regression (MLR) method. This method investigates the relations between different parameters and factors in scientific research works17,18. Afterward, we propose a comprehensive Node-Place-Ridership-Time (NPRT) model. We apply the NP and NPR models proposed by other previous researchers and our proposed NPRT model to evaluate our research work. In this comparison, we use the same database and check all models' accuracy.
K-Means method
K-Means clustering is one of the most popular unsupervised machine learning algorithms. It is an extensively used technique for data cluster analysis. The goal of this algorithm is to find groups in the data, with the number of groups represented by the variable \(K\). The algorithm works iteratively to assign each data point to one of \(K\) groups based on the provided features. Data points are clustered based on feature similarity. The steps of K-Means are as follows:
Step 1: Give the parameter \(K,\) which means the number of groups we want the points to be assigned to.
Step 2: Randomly select \(K\) points as the initial cluster centers \({c}_{1}, {c}_{2},\cdots ,{c}_{K}\).
Step 3: Calculate the distance between each point and each cluster center, then assign it to its nearest center, based on the squared Euclidean distance.
where \(x\) is the point that needs to be assigned to one group.
Step 4: After assigning all the points to the groups, recompute the coordinates of the cluster center, which means replacing the cluster center with the new cluster center.
where \({G}_{i}\) means the \(i-th\) group, \(|{G}_{i}|\) means the number of points in \({G}_{i}\) and \({x}_{i}\) means the \(i-th\) point in \({G}_{i}\).
Step 5: Repeat Step3 and Step4 until a stopping criterion is met (i.e., no data points change clusters, the sum of the distances is minimized, or some maximum number of iterations is reached).
\(K\) value indicates the number of clusters and is a pre-defined value. In this research, we used the Elbow method to select \(K\) for the K-Means algorithm19. Based on Fig. 2, we can find the value of \(K\) where the Sum of Squared Errors \((SSE)\) decreases sharply \((K=5)\).

Elbow method and parameter \(K\) for the K-Means algorithm.
Cube method
To classify our stations, we also applied the Cube method, which is made of 3 dimensions: node value, place value, and ridership regarding the time. According to the Cube method, there are three main layers on each node, place, and ridership measurement value, which are Low Balanced (LB), Balanced (B), and High Balanced (HB), as shown in Fig. 3. The combination of layers on the node, place, and ridership values, leads to 27 classes. Class 1 denotes LB stations in all three values, while class 27 represents HB stations. Cluster 14 means the station is balanced in all three dimensions during the defined time-span. This 3-Dimension illustration provides more understandable coordination between mentioned values and layers compared to the previous models.

Low Balanced (LB), Balanced (B), and High Balanced (HB) classes of the Cube Method.
Moreover, the Cube method also shows the density of stations in or around critical classes. Therefore, policymakers and city planners can easily understand if their plans need to be revised to improve the efficiency of LB and HB stations. An accurate classification result from 1 to 27 would prove the efficiency of this method, as shown in Appendixes B and C.
To understand the relationship between node, place, ridership, and time values, we applied the K-Means method19 using the "sklearn.cluster.KMeans" measure of Python and also the Cube method on NP, NPR, and our proposed NPRT models to classify Chengdu rail-transit stations, shown in Appendixes B to F.
As can be extracted from Fig. 4, our research has four main steps. We apply unique methods to prepare, compose, and analyze our data to approach our NPRT model in each step. Table 1 summarizes the application of all the methods used in this research work.

Research structure and applied methods.
The case study area and Chengdu rail transit network
The Chengdu Metro system is considered the rapid rail-transit network of the capital city of Sichuan province, China, with a daily passenger flow of 5,906,123 rides. The system includes twelve subway lines and one light rail line, operated by Chengdu Rail Transit Group Company. Table 2 presents brief information about Chengdu subway lines. Figure 5 presents the Chengdu rail-transit stations.

Chengdu rail-transit network and stations.
Node, place, ridership, and time indicators
Node indicators
We measure a station's node value by four facets: station facility, accessible transits, accessible destinations, and network centrality. Eight node indicators under these four facets are presented in Table 3.
The station facility is measured by the number of entrances and exits (N1) in each metro station. The accessible transits are measured by the number of metro stations (N2) that one station can reach within 20 min, the number of the station to CBD (Chunxi Road) (N3), and the number of stations to CBD (3rd Tianfu Street) (N4). It is well known that there are 2 CBDs in Chengdu: Chunxi Road and 3rd Tianfu Street. Therefore, we calculate the number of stations and the distance to Chunxi Road and 3rd Tianfu Street. The distance measures the accessible destinations to the CBDs Chunxi Road and 3rd Tianfu Street indicated by (N5) and (N6), respectively. The network centrality consists of degree centrality (N7) and closeness centrality (N8).
Based on the graph modeling, we applied the network centrality to capture the impedance of a station in the transit network20. To translate the Chengdu rail-transit network into a graph \(G = \left( {V,E} \right),\) we assign \(V\) of vertices to indicate our stations, and the set \(E\) of edges is for the station linkages. The transit traveling distance is used to weigh the \(E\)21. We measure Chengdu network degree centrality (N7) of a transit station \(v \in V\) by the number of links connected to station \(v\) in Eq. (3), wherein \(L_{vt}\) represents the linkage between station \(v\) and station \(t \in V\), and \(K\) shows the number of all stations in set \(V\)22:
Closeness centrality reflects the node's proximity and reachability within the network component. We measure the closeness centrality (N8) of station \(v\) by the inverse of the sum of shortest transit distances from station \(v\) to all other stations in set \(V\) in Eq. (4), wherein \(d_{vt}\) denotes the shortest transit distance between station \(v\) and station \(t \in V\):
Table 4 presents the node indicators values of some stations.
Place indicators
We use a 500-m and 1000-m radius to define the transit catchment area in Chengdu, considering the low-density context of some areas. We measure the station's place value by three facets: design, density, and diversity. Nine place indicators under three facets are presented in Table 3. Table 5 provides the place indicators values of some stations.
The design is measured by the average price of office land inside the 1000 m-radius catchment area (P1), the average price of commercial land inside the 1000 m-radius catchment area (P3), the average price of residential land inside the 1000 m-radius catchment area (P5), the number of parking lots inside the 500 m-radius catchment area (P8) and the number of buses stops inside the 500 m-radius catchment area (P9). The design is measured by the number of offices within 1000 m (P2), the number of shops within 1000 m (P4), and the number of residences within 1000 m (P6). The diversity consists of public facilities (parks, cultural facilities, schools, hospitals) inside the 1000 m-radius catchment area (P7).
Ridership and time indicators
Because the NPR model's limitation does not consider the implication of time and ignores the difference in ridership about departure and coming, we record the tapped-in and tapped-out arrival trips and construct an NPRT model by considering different conditions.
As we mentioned before, ridership has a direct relationship with time. Therefore, we categorized the passenger traffic into two groups: inbound traffic (I) and the second group for outbound traffic (O). We also divided the time into peak hours, off-peak hours, regular hours, and weekends (T1 to T4). Therefore, we get eight different conditions. IT1 means inbound traffic during working hours, IT2 means inbound traffic during off-hours, IT3 means inbound traffic during the rest of the working day, and IT4 means inbound traffic on two weekend days. OT1 means the ridership of passengers leaving the station during working hours, OT2 means the ridership of passengers leaving the station during off-hours, OT3 means the ridership of passengers leaving the station during the rest of the working day, and OT4 means the ridership of passengers leaving the station on two days of the weekend.
The definition of each class and time-spans from IT1 to OT4 is written in Table 6.
Table 7 shows the ridership values of some stations during eight time-spans mentioned above.
As for data sources and processing, the number of entrances and exits, offices, shops, residences, parking lots, and bus stops was acquired from Amap (https://www.amap.com/) and SOSO (https://map.qq.com/). The number of stations that one station can reach within 20 min and stations to CBDs (https://www.chengdurail.com/index_en.html), the distance to CBDs, and closeness centrality could be required and calculated via the API of Chengdu Metro Website (https://www.chengdurail.com/index_en.html). The degree of centrality was acquired from a map of Chengdu Metro Station in 2021 in Fig. 5. The average price of office, commercial, and residential land was acquired from Anjuke (https://chengdu.anjuke.com/) and Fang (https://cd.newhouse.fang.com/). We collected ridership of all stations from Chengdu Metro. Each station counts both tapped-in departure trips and tapped-out arrival trips for the station's ridership statistics. All the data was acquired in March 2021.
Information entropy weighting (IEW)
To practice our data analysis and compose the indicators, we applied Information Entropy Weighting (IEW)23 to provide a composite node or place value index. We use the IEW method to integrate \(N1 - N8\) into one Node value and \(P1 - P9\) into one Place value.
First, the decision matrix should be constructed, shown in Eq. (5). \(m\) stations and \(n\) node value indicators have consisted in \(X\). Moreover, \(X_{pq}\) indicates the value of indicator \(q\) at station \(p\). We apply Eq. (6) to normalize the decision matrix:
Then, \(R_{pq}^{^{\prime}}\) computes the proportion of station \(p\) for indicator \(q\):
We can calculate the entropy value \(e_{q}\) of indicator \(q\) in Eq. (8), knowing that if \(R_{pq}^{^{\prime}} = 0\), then \(\ln R_{pq}^{^{\prime}} = 0.\)
In the next step, we need to calculate the imbalance coefficient using Eq. (9):
\(W_{q}\) is the weight of indicator \(q\), which can be extracted from Eq. (10). Then, to compose the node value index \(N_{p}\) for station \(p\), we can apply Eq. (11):
Afterward, we need to normalize the node value index between 0 and 1. In Eq. (12), \(N\) indicates the array of node value index, \(m\) is the number of stations, and \(p\) is the target station:
Results and discussion
Equations
We obtain the equations through Multiple Linear Regression (MLR). Table. 8 provides a list of constants and variables coefficients of our equations. The results of our MLR models are presented in Table 9.
The general format of our MLR equations is as follows:
where \(\alpha\) is the equation constant, and \(\beta\) and \(\gamma\) are the coefficient of node value and place value, respectively.
To better understand how a station's node value and place value impact its ridership at different times, we must analyze our eight MLR models below. Concerning the parameters of eight MLR models, we can know that the number of entrances and exits, the number of stations to CBD (3rd Tianfu Street), the distance to CBD (Chunxi Road), closeness centrality, and the number of residences within 1000 m are negatively associated with ridership in all facets of time. The number of stations to CBD (Chunxi Road), the distance to CBD (3rd Tianfu Street), degree of centrality, the average price of commercial land, the number of shops within 1000 m, and the number of parking lots and bus stops inside the 500 m-radius catchment area are positively associated with ridership in all facets of time.
The number of stations that one station can reach within 20 min is positively associated with ridership of stations in off-peak hours, is positively associated with ridership of getting outstations in other hours on working days, and is negatively associated with ridership in other times. The average price of office land and the number of public facilities are positively associated with ridership of getting in stations in peak hours, are positively associated with ridership of getting outstations in off-peak hours, and are negatively associated with ridership in other times. The number of offices within 1000 m and the average price of residential land are negatively associated with ridership of getting in stations in peak hours, are negatively associated with ridership of getting outstations in off-peak hours, and are positively associated with ridership in other times.
The distance to CBD (Chunxi Road) is significantly negatively associated with ridership of getting in stations in peak hours and ridership of getting outstations in off-peak hours. The number of offices within 1000 m is significantly positively associated with ridership of getting in stations in off-peak hours and ridership of getting outstations on other working days. The number of shops is incredibly positively associated with the ridership of getting in peak hours and the ridership of getting outstations in off-peak hours.
Using Table 8 in the MLR Eq. (13), we have eight equations from \({\text{IT}}1\) to \({\text{OT}}4.\) For instance, the equation of Inbound traffic during working hours from 6:00 a.m. to 9:00 a.m. would be as follows:
All variables have been 0–1 normalized by Min–Max Normalization for the model input, shown in Appendix A. The variance inflation factor (VIF) is approximately equal to 10, indicating no severe multicollinearity. The adjusted R2 and R2 are more extensive than 0.25, showing that the results are promising in model fitting. When using 0.05 as a significance level threshold, F-test shows that our MLR models are significant. The T-Test shows the number of stations to CBD (3rd Tianfu Street), the distance to CBD (Chunxi Road), degree of centrality, the number of offices within 1000 m, the number of shops within 1000 m, the average price of residential land and the number of bus stops are significant with equation IT1. The distance to CBD (Chunxi Road), degree of centrality, the number of offices, and the number of residences are significant with equation IT2. The number of entrances and exits, degree of centrality, the number of offices, and the number of shops are significant with equations IT3, IT4, and OT1. The number of stations to CBD (3rd Tianfu Street), the distance to CBD (Chunxi Road), degree centrality, and the number of shops are significant with equation OT2. The distance to CBD (3rd Tianfu Street), the number of offices, and the number of residences are significant with equation OT3. The number of entrances and exits, degree of centrality, the number of offices, and the number of shops are significant with equation OT4.
Methods and classification results
The coordination between ridership and time influences stations' classification to know which stations are balanced and unbalanced.
Regarding the node value, place value, and ridership extracted in four time-spans, five classes resulted from the K-Means method. Figure 6 summarizes the classification results extracted from the K-Means method for our proposed NPRT model.

Number of stations in K-Means classification method for NPRT model.
In each model from IT1 to OT4, shown in Appendix B, F, and Fig. 6, based on the NPRT values, the results show that some stations can be balanced or unbalanced; low, medium, high, or extremely high ridership; stress or dependent.
For example, in the model IT1, Xipu station with the result of [0.4523, 0.2703, 1.0] for the node value, place value, and ridership is categorized in class 4, with high ridership and balanced, while Chunxi Road station with the values of [0.5185, 0.8886, 0.1691], is in class 5, low ridership and unbalanced place. Compared to the IT4 model, on weekends, Xipu station is medium ridership and balanced class 4, with the NPR values of [0.4523, 0.2703, 0.4807]. Chunxi Road station for the same model indicates the results of [0.5185, 0.8886, 1.0], falling into class 5, extremely high ridership, and an unbalanced place. Therefore, it can be seen that although the node and place values are essential factors in our classifications model, the ridership at different time-spans can significantly change the results.
As already mentioned, in both K-Means and Cube methods, the concept of ridership is influenced by time. The relationship between ridership and time can also be proved by analyzing the results of the Cube Method. The number of stations in each class of the Cube method is presented in Fig. 7. Based on Fig. 3, class 1 has a low node, place, and ridership values, while class 27 comprises high node, place, and ridership values.

Number of stations in Cube classification method for NPRT model.
Regarding Appendix C, F, and Fig. 7, class 2 includes 52.8% to 58.04% of Chengdu rail-transit stations. In contrast, some other classes, such as class 1, have 0% of the stations. This difference is not only because of the low or high node and place value, but the time as a significant factor in ridership caused the differences as mentioned. Some stations have good status on node and place values. If we only consider the ridership value as a constant value during our investigation, the results would be different from the reality. Stations can be balanced at 1 h but unbalanced at another hour. As an instance, in the OT1 model, Chunxi Road, for NPR values of [0.5185, 0.8886, 1.0] is classified in cluster 27, high node, place, and ridership value, whereas this station in the IT1 model is in class 9, [0.5185, 0.8886, 0.1691], high node and place value, but low ridership. Chunxi Road is one of the CBDs of Chengdu. It is surrounded by many shopping malls, companies, institutions, consulates and visa centers, and headquarters. During the time-span OT1, 6:00–9:00 a.m. on weekdays (Table 6), the number of passengers going to work in the Chunxi Road area is considerably higher than the number of people traveling from this location to the other part of the city (IT1 model). Therefore, we can find the influence of time on the ridership and, consequently, on the classification of a station.
To compare our proposed NPRT model with the NP model by Bertolini1 and the NPR model by Zhejing Cao14, we also applied our case study area and rail-transit stations to the NP and NPR models, presented in Appendixes D to F.
Regarding many subway stations in Chengdu and the massive number of classification results, we provided the results of four stations in Table 10 as a sample. Table 10 shows the station classifications resulting from the K-Means method and Cube model, using NP, NPR, and NPRT. The results prove that Chunxi Road was classified as an unbalanced station with high NPR values over different time-spans, while the Financial City is a balanced station during OT3 (class 14 of the Cube model). According to our previous discussion about Fig. 2, there are five classes in the K-Means method (K = 5). In comparison, the Cube model provides 27 classes, leading to more accurate classifications. For instance, in Table 10, the K-Means method for the Chunxi Road station has the same result (class 5) during the time-spans IT1 and IT2, whereas the Cube method puts this station at class 9 during IT1 and class 27 over IT2. The results of the Xipu station experience the same situation for the time-spans IT1, IT2, OT3, and OT4.
Moreover, the results show that the classification result to check the station efficiency would not be accurate without considering the relationship between ridership value and time. For example, comparing Chunxi Road station in three different models, we can see the node value, place value, and the ridership in NP, NPR, and NPRT IT1 models are [0.5185, 0.8886, –-], [0.5185, 0.8886, 1.0], and [0.5185, 0.8886, 0.1691], respectively. This station's ridership for the NPR model is extremely high, although it is low for the NPRT IT1 model. This situation is true for some other stations, such as North Railway Station, Wenshu Monastery, Tianfu Square, Sichuan Gymnasium, Hi-Tech Zone, Financial City, and Century City. Therefore, as one of the most important factors in policymaking, the ridership should be considered regarding the critical time-spans, from IT1 to OT4.
The periods IT1 to OT4, NPRT method, and Cube model can assist the policymakers and city planners update their applied policies. We can consider the Chunxi Road station as an example. The NPR values at the time-span OT1, [0.5185, 0.8886, 1.0], and its class 27 would let the municipal government know this location needs some charter trains at the time-span OT1. The charter trains would travel directly between the high frequently-demanded stations to the Chunxi Road. The Chengdu Metro Co. can calculate the frequency and number of required charter trains by knowing the number of riders during the critical time-span.
Moreover, since the Chunxi Road station is located at the junction of lines 2 and 3, the Chengdu Metro Co. would be able to find the Low Balanced (LB) stations on lines 2 and 3 at the time-spans T1. Therefore, every second train can stop at the LB stations during the time-span T1. Southwest Jiaotong University is almost a steady station (class 6). Since this station is located in the Jinniu district, the Jinniu municipal government would be able to apply the results of this study in their potential plans to enhance the classification of this station toward cluster 14, which creates a fully balanced station.
These are some examples of potential revised policies based on this study's innovation in developing the station classifications. Regarding the 27 classes from the Cube model and the NPRT method, governments can access the accurate classification results of the stations during critical time-spans T1 to T4 to implement appropriate policies and enhance the rail-transit network efficiency.
Conclusion
In this research, we conducted a case study on Chengdu rail-transit stations to present the relationship between node, place, and ridership. Since the number of riders during the daytime and over the week is not constant, we divided our investigation into four time-spans. It was proved that ridership has a direct relationship with time. So, we included this factor in our study. After collecting the data and providing all the influential parameters, Multiple Linear Regression (MLR) was applied to create our Node-Place-Ridership-Time (NPRT) equations. MLR is a constructive method to model the coordination and relationship between the effective parameters on the NPRT model. We developed our classifications using k-Means and Cube methods and analyzed the results. Stations with exemplary node and place values can not be necessarily balanced or efficient since the ridership and time-span play essential roles on the other side. The policymakers, city planners, and governments need to apply NPRT models to analyze the efficiency of transit stations. Compared with Node-Place (NP) and Node-Place-Ridership (NPR) models presented by previous researchers, our proposed NPRT model provides more accurate results.
Possible directions for future studies
This research investigated the impact of node, place, and time values on ridership to present the NPRT model for classifying rail-transit stations. However, the effect of ridership on node and place values which leads to the bi-directional relationship between the dependent and independent variables would be an open discussion for future studies. Moreover, the effect of the economy, ecology, and sociodemographic characteristics (such as transit mode share, household going-out rate, and age composition) on the NPRT model would be essential for future studies.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Bertolini, L. Spatial development patterns and public transport: The application of an analytical model in the Netherlands. Plan. Pract. Res. 14(2), 199–210 (1999).
Bertolini, L. Station Areas as Nodes and Places in Urban Networks: An Analytical Tool and Alternative Development Strategies 35–57 (Railway Development. Physica-Verlag, 2008).
Wingo, L. Transportation and Urban Land (Routledge, 2016).
Calthorpe, P. The Next American Metropolis: Ecology, Community, and the American Dream (Princeton Architectural Press, 1993).
Feudo, F. L. How to build an alternative to sprawl and auto-centric development model through a TOD scenario for the North-Pas-de-Calais region? Lessons from an integrated transportation-land use modeling. Transp. Res. Procedia 4, 154–177 (2014).
Lyu, G., Bertolini, L. & Pfeffer, K. Developing a TOD typology for Beijing metro station areas. J. Transp. Geogr. 55(2016), 40–50. https://doi.org/10.1016/j.jtrangeo.2016.07.002 (2016).
Zemp, S., Stauffacher, M., Lang, D. J. & Scholz, R. W. Classifying railway stations for strategic transport and land use planning: Context matters!. J. Transp. Geogr. 19(2011), 670–679. https://doi.org/10.1016/j.jtrangeo.2010.08.008 (2011).
Chorus, P. & Bertolini, L. An application of the node place model to explore the spatial development dynamics of station areas in Tokyo. J. Transp. Land Use 4(1), 45–58 (2011).
Olaru, D. et al. Place vs. node transit: Planning policies revisited. Sustainability 11(2), 477 (2018).
Guy, C. M. The assessment of access to local shopping opportunities: A comparison of accessibility measures. Environ. Plann. B 10(2), 219–237 (1983).
Bhat, C. et al. Development of an Urban Accessibility Index: Literature Review (University of Texas at Austin, 2000).
Geurs, K. T. & Ritsema van Eck, J. R. Accessibility Measures: Review and Applications. Evaluation of Accessibility Impacts of Land-Use Transportation Scenarios, and Related Social and Economic Impact (National Institute for Public Health and the Environment Ministry of Health, Welfare and Sport, 2001).
Geurs, K. T. & Van Wee, B. Accessibility evaluation of land-use and transport strategies: Review and research directions. J. Transp. Geogr. 12(2), 127–140 (2004).
Cao, Z., Asakura, Y. & Tan, Z. Coordination between node, place, and ridership: Comparing three transit operators in Tokyo. Transp. Res. Part D 87(2020), 102518. https://doi.org/10.1016/j.trd.2020.102518 (2020).
Reusser, D. E. et al. Classifying railway stations for sustainable transitions–balancing node and place functions. J. Transp. Geogr. 16(3), 191–202 (2008).
Ivan, I., Boruta, T., Horak, J., 2012. Evaluation of railway surrounding areas: the case of Ostrava city. Urban Transport XVIII-Urban Transport and the Environment in the 21st Century. WIT Press, Southampton, pp. 141–152.
Pishro, A. A. et al. Application of artificial neural networks and multiple linear regression on local bond stress equation of UHPC and reinforcing steel bars. Sci. Rep. 11, 15061. https://doi.org/10.1038/s41598-021-94480-2 (2021).
Pishro, A. A., Feng, X., Ping, Y., Dengshi, H. & Shirazinejad, R. S. Comprehensive equation of local bond stress between UHPC and reinforcing steel bars. Constr. Build. Mater. 262, 119942. https://doi.org/10.1016/j.conbuildmat.2020.119942 (2020).
Hartigan, J. A. & Wong, M. A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C 28(1), 100–108 (1979).
Caset, F., Vale, D. S. & Viana, C. M. Measuring the accessibility of railway stations in the Brussels Regional Express Network: A node-place modeling approach. Netw. Spatial Econ. 18(3), 495–530 (2018).
Papa, E. & Bertolini, L. Accessibility and transit-oriented development in European metropolitan areas. J. Transp. Geogr. 47, 70–83 (2015).
Freeman, L. C. Centrality in social networks conceptual clarification. Soc. Netw. 1(3), 215–239 (1978).
Shannon, C. E. & Weaver, W. The Mathematical Theory of Communication (University of Illinois Press, 1949).
Acknowledgements
The authors would like to acknowledge the Sichuan University of Science and Engineering, Southwest Jiaotong University, Sichuan University, and Université Paris Nanterre.
Author information
Authors and Affiliations
Contributions
A.A.P. designed the research plan, analyzed the data, and wrote the main manuscript text. He is the first author. Y.Q. conceived the mathematical model. Z.S. and H.D. supervised the numerical parts of this paper. M.A.P., Z.Z., Z.Y., and V.P. collected the data and prepared Appendix A. L.W. prepared Appendix F. All authors reviewed the manuscript. The authors would like to acknowledge the Sichuan University of Science and Engineering, Southwest Jiaotong University, Sichuan University, and Université Paris Nanterre.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Amini Pishro, A., Yang, Q., Zhang, S. et al. Node, place, ridership, and time model for rail-transit stations: a case study. Sci Rep 12, 16120 (2022). https://doi.org/10.1038/s41598-022-20209-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-20209-4
- Springer Nature Limited
This article is cited by
-
An Overview of TOD Level Assessment Around Rail Transit Stations
Urban Rail Transit (2024)