
Abstract
The existing F-test for two counts data from the Poisson distribution under classical statistics can be applied only when the counts in the data are exact or not intervals. The existing test cannot be applied when the count data is indeterminate, in the interval, and uncertain. In this paper, the F-test for two counts data from the Poisson distribution under classical statistics is designed. The test for two counts recording at the same time or different times is presented. The daily and the monthly number of records broken data in the U.S from the weather department is selected for the application of the proposed test. The application and comparison studies show the efficiency of the proposed test. The proposed test was found to be informative, flexible, and appropriate to be applied in an uncertain environment.
Similar content being viewed by others
Introduction
The Poisson distribution has only one parameter which is also known as the mean of the distribution. The Poisson distribution is applied when the events have occurred in a specified time such as the number of defective items produced in a day or the number of weather broken records. In such a situation, it is quite interested to investigate the significance of the difference between two counts that came from the Poisson distribution. The F-test for two counts of data is applied to test the null hypothesis that there is no statistical difference in two counts vs. the alternative hypothesis that there is a statistical difference in two counts. Usually, the F-test for two counts data is applied under the assumption that the counts follow the Poisson distribution and counts should be recorded at the same time of occurrence. Kanji1 discussed F-test for two counts data under the classical statistics. Krishnamoorthy and Thomson2 worked on the test for testing two means of Poisson distribution. Hilbe3 applied the test for count data in education. Puig and Weiß4 presented the goodness of fit test with real application. More applications of such tests can be seen in5,6,7,8,9,10.
The statistical methods and tests have been widely applied for testing the normality and estimation of wind speed data. Several authors introduced various statistical models for the wind speed data. References11,12,13,14,15,16,17,18,19,20 used various statistical techniques in the area of metrology.
The existing tests under classical statistics are applied when the count’s data is determined. Viertl21 stated that “statistical data are frequently not precise numbers but more or less non-precise, also called fuzzy. Measurements of continuous variables are always fuzzy to a certain degree”. The statistical tests designed under fuzzy logic are applied when uncertainty is found in the data. References22,23,24,25,26,27,28,29 introduced statistical tests using fuzzy logic.
According to Smarandache30, the fuzzy logic is not efficient as neutrosophic logic in terms of the measure of indeterminacy. Smarandache31 proved the efficiency of neutrosophic logic over interval-based analysis and fuzzy logic. References32,33,34,35,36 presented several applications of neutrosophic logic. Smarandache37 introduced the extension of classical statistics is known as neutrosophic statistics. The neutrosophic statistics can be applied when uncertainty is found in the data. References38,39 introduced the methods to deal with neutrosophic data. The statistical tests under neutrosophic statistics were introduced by references40,41,42.
The F-test under classical statistics applied under the assumption that all observations in the data are determined and précised. Therefore, the existing F-test for two counts data from the Poisson distribution can be applied only when the counts are determined. In real life, it is not always necessary that the counts are determined. In this situation, the existing F-test for two counts data may mislead the decision-makers. In addition, the use of the existing F-test on the data having uncertain observations does not give information about the measure of indeterminacy. The literature study shows that F-test to deal with the neutrosophic in counts data is not available. In this paper, the F-test for two counts data having uncertainty will be introduced originally. The operational procedure and statistic of the proposed test will be introduced. The proposed test will be applied in testing weather records at two different times. It is expected that the proposed test will be efficient and informative than the existing test under classical statistics.
Methods
The existing F-test for two counts data from the Poisson distribution under classical statistics can be applied only when all counts in the data are determined, clear, and exact, see1. When the count data is the interval, the existing F-test for count data cannot be applied for testing the significance between two counted results. In this situation, the F-test for two count data under neutrosophic statistics can be applied. In this section, the methodology of the proposed F-test under indeterminacy will be presented. The main objective of the proposed F-test for the count data is to investigate the difference between two counted results having minimum and maximum counts in the data. The proposed F-test for the count data will be applicable under the assumptions that counts are from the Poisson distribution (rare events) and in addition, both samples of count data are recorded under uniform conditions. Let us assume that \(N_{1N} = N_{1L} + N_{1U} I_{1N} ;I_{1N} \epsilon \left[ {I_{1L} ,I_{1U} } \right]\) and \(N_{2N} = N_{2L} + N_{2U} I_{2N} ;I_{2N} \epsilon \left[ {I_{1L} ,I_{2U} } \right]\) be neutrosophic forms of count data from the first and second populations, respectively. Note that \(N_{1L}\) and \(N_{2L}\) are the determined parts in neutrosophic forms and \(N_{1U} I_{1N}\) and \(N_{2U} I_{2N}\) are the indeterminate parts of neutrosophic forms. Note also that \(I_{1N} \epsilon \left[ {I_{1L} ,I_{1U} } \right]\) and \(I_{2N} \epsilon \left[ {I_{1L} ,I_{2U} } \right]\) are the measure of indeterminacy associated with counts in the first and second population, respectively. The information about the neutrosophic numbers can be seen in43,44,45,46,47,48,49. Suppose that \(\mu_{1N}\) and \(\mu_{2N}\) be the means of the first and second population, respectively. To test the null hypothesis that \(H_{0N} :\mu_{1N} = \mu_{2N}\), the F-test, say \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) based on neutrosophic counts \(N_{1N} \epsilon \left[ {N_{1L} ,N_{1U} } \right]\) and \(N_{2N} \epsilon \left[ {N_{2L} ,N_{2U} } \right]\) is defined as
The statistic \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) follows the neutrosophic F-distribution with \(\left( {2\left( {N_{2N} + 1} \right),2N_{1N} } \right)\) degree of freedom, see Aslam40. It is worth noting that the statistic was given in Eq. (1) can be applied when two counts are recorded in the same period of time \(\left( {t_{1} = t_{2} } \right)\). The neutrosophic form of the proposed statistic \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) can be expressed as
The proposed statistic \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) is a generalization of the existing F-test for two counts data. The statistic \(F_{L1}\) presents the existing F-test for two counts data. Note that \(F_{U1} I_{{F_{N1} }} ;I_{{F_{N1} }} \epsilon \left[ {I_{{F_{L1} }} ,I_{{F_{U1} }} } \right]\) present the indeterminate part and \(I_{{F_{N1} }} \epsilon \left[ {I_{{F_{L1} }} ,I_{{F_{U1} }} } \right]\) is a measure of uncertainty associated with \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\). The proposed statistic \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) becomes the existing statistic when \(I_{{F_{L1} }} = 0\).
When the counts are noted over the different period’s time \(t_{1}\) and \(t_{2}\), the counting rates \(N_{1N} /t_{1}\) and \(N_{2N} /t_{2}\) are obtained. For this situation, the proposed statistic \(F_{N2} \epsilon \left[ {F_{L2} ,F_{U2} } \right]\) is defined as
The neutrosophic form of the proposed statistic \(F_{N2} \epsilon \left[ {F_{L2} ,F_{U2} } \right]\) can be expressed as
The proposed statistic \(F_{N2} \epsilon \left[ {F_{L2} ,F_{U2} } \right]\) is a generalization of the existing F-test for two counts data. The statistic \(F_{L2}\) presents the existing F-test for two counts data. Note that \(F_{U2} I_{{F_{N2} }} ;I_{{F_{N2} }} \epsilon \left[ {I_{{F_{L2} }} ,I_{{F_{U2} }} } \right]\) present the indeterminate part and \(I_{{F_{N1} }} \epsilon \left[ {I_{{F_{L1} }} ,I_{{F_{U1} }} } \right]\) is a measure of uncertainty associated with \(F_{N2} \epsilon \left[ {F_{L2} ,F_{U2} } \right]\). The proposed statistic \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) become the existing statistic when \(I_{{F_{L2} }} = 0\).
Application
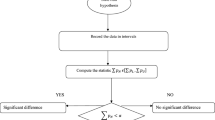
Now, we will discuss the application of the proposed F-test for count data recorded from a subset of stations in the Global Historical Climatological Network. The weather data is selected from https://www.ncdc.noaa.gov/cdo-web/datatools/records on January 07, 2021. The U.S daily records broken are shown in Table 1 and U.S monthly records broken are shown in Table 2. From Tables 1–2, it can be seen that record counting is in intervals rather than the exact values. From such counting data, the existing F-test for two counts data under classical statistics cannot be applied. The proposed test is an alternative to the existing test. From Tables 1–2, it can be seen that two counts are recorded in the same period of time \(\left( {t_{1} = t_{2} } \right)\), therefore, the statistic \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) is suitable to apply. The values of \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) are also shown in Tables 1–2. The proposed test is implemented in the following steps.
-
Step 1 State \(H_{0N} :\mu_{1N} = \mu_{2N}\) vs. \(H_{1N} :\mu_{1N} \ne \mu_{2N}\).
-
Step 2 Set the level of significance at \(\alpha\) = 5% and select the critical value from F-table at \(\alpha\) = 5% which is 1.
-
Step 3 The values of \(F_{N1}\) for last 30 days is computed as \(F_{N1} = \frac{{\left[ {115,597} \right]}}{{\left[ {152,1484} \right]}}; F_{N1} \epsilon \left[ {0.1923,0.1024} \right]\). Similarly, the other values of \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) in Table 1 and Table 2 can be computed.
-
Step 4 Accept \(H_{0N} :\mu_{1N} = \mu_{2N}\) for the U.S daily and monthly records as \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) for both datasets are smaller than 1.
From the study, it is concluded that there is no statistical difference between the two counts of U.S daily records and U.S monthly records.
Comparative study
The proposed F-test for two counts data is reduced to F-test for two counts data under classical statistics when the counts are determined or not in intervals and no indeterminacy is recorded in counts. The comparison of the proposed test is given over the existing F-test for two counts data in terms of chance of uncertainty. The neutrosophic analyses of \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) of both data sets along with the measures of indeterminacy are shown in Table 3. The neutrosophic forms consist of the statistic of the existing test and indeterminate part. Note that the symbols of statistic \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) represent the corresponding number of days. For example, for the records in the last 30 days, the neutrosophic form is \(F_{N1} = 0.1923 - 0.1024I_{N130D} ;I_{N130D} \left[ {0,0.87} \right]\), where the value of statistic 0.1923 presents the existing test when \(F_{L1}\) = 0 and \(0.1024I_{N130D}\) is an indeterminate part and the measure of uncertainty associated with \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) is 0.87. It means that for the proposed test, the value of \(F_{N1}\) can be expected from 0.1923 to 0.1024. From the analysis, it can be seen that under uncertainty, the proposed test gives the values of statistic \(F_{N1} \epsilon \left[ {F_{L1} ,F_{U1} } \right]\) is a range rather than the exact value. Therefore, the proposed test is quite effective and flexible to apply in uncertainty. Similarly, other neutrosophic forms given in Table 3 can be interpreted. Based on the information, the proposed test can be interpreted as for \(\alpha\) = 5%, the chance of accepting \(H_{0N} :\mu_{1N} = \mu_{2N}\) is 0.95, the chance of committing a type-I error (the probability of rejecting \(H_{0N}\) when it is true) is 0.05 and the chance of uncertainty about the acceptance of \(H_{0N} :\mu_{1N} = \mu_{2N}\) is 0.87. It is clear that for the real example, the chance of indeterminacy is high; therefore, the decision-makers should be careful in making the decision about the acceptance of \(H_{0N} :\mu_{1N} = \mu_{2N}\). The proposed test under neutrosophic statistics is also a generalization of interval-based analysis. The interval analysis uses intervals instead of crisp numbers in order to approximate/capture the data inside the intervals. On the other hand, the neutrosophic statistics analysis uses set analysis (any type of set, not only intervals) in order to approximate/capture the data inside intervals. The results obtained from the proposed test can also be compared with the results obtained from the interval data analysis. From the data analysis, the value of \(F_{N1}\) from the interval analysis is 0.1923 to 0.1024. In addition, from the neutrosophic form \(F_{N1} = 0.1923 - 0.1024I_{N130D} ;I_{N130D} \left[ {0,0.87} \right]\), it can be seen that \(F_{N1}\) is also better structured since we know that \(0.1923\) is the determinate part and \(0.1024I_{N130D}\) is the fluctuating part around \(0.1923\). From the comparison, it can be seen that the interval-based analysis provides the results in an interval without the information about the measure of indeterminacy. From the study, it can be concluded that the proposed F-test is efficient than the existing F-test under classical statistics and interval-based analysis in terms of information and flexibility. Therefore, under indeterminacy, it is recommended to apply the proposed test for testing the daily recodes and monthly records data.
Concluding remarks
In this paper, the F-test for two counts data from the Poisson distribution under classical statistics was designed. The tests for two counts time are the same or different was presented. The procedure to test two counts from the same or different times is equal or not was discussed. The application of the proposed was given using the weather records data. The application of the proposed test showed that the proposed test is flexible and informative to apply in uncertainty. In addition, the proposed test gives the results in indeterminate intervals. Based on the study, it is recommended to apply the proposed test when the counts are recorded in an indeterminate environment. The proposed test using double sampling can be considered as future research. The application of the proposed test for big data can be considered as future research.
Data availability
The data is given in the paper.
Change history
04 July 2022
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1038/s41598-022-15750-1
References
Kanji, G. K. 100 Statistical Tests (Sage, 2006).
Krishnamoorthy, K. & Thomson, J. A more powerful test for comparing two Poisson means. J. Stat. Plan. Inference 119, 23–35 (2004).
Hilbe, J. M. The statistical analysis of count data/El análisis estadístico de los datos de recuento. Cult. Educ. 29, 409–460 (2017).
Puig, P. & Weiß, C. H. Some goodness-of-fit tests for the Poisson distribution with applications in Biodosimetry. Comput. Stat. Data Anal. 144, 106878 (2020).
White, G. C. & Bennetts, R. E. Analysis of frequency count data using the negative binomial distribution. Ecology 77, 2549–2557 (1996).
Coxe, S., West, S. G. & Aiken, L. S. The analysis of count data: A gentle introduction to Poisson regression and its alternatives. J. Pers. Assess. 91, 121–136 (2009).
Salinas-Rodriguez, A., Manrique-Espinoza, B. & Sosa-Rubi, S. G. Statistical analysis for count data: Use of healthcare services applications. Salud Publica Mex. 51, 397–406 (2009).
Pham, T. V. & Jimenez, C. R. An accurate paired sample test for count data. Bioinformatics 28, i596–i602 (2012).
Hawinkel, S., Rayner, J., Bijnens, L. & Thas, O. Sequence count data are poorly fit by the negative binomial distribution. PLoS ONE 15, e0224909 (2020).
Böhning, D. & Sangnawakij, P. Count outcome meta-analysis for comparing treatments by fusing mixed data sources: comparing interventions using across report information. AStA Adv. Stat. Anal. 105, 75–85 (2021).
Akpinar, E. K. & Akpinar, S. A statistical analysis of wind speed data used in installation of wind energy conversion systems. Energy Convers. Manag. 46, 515–532 (2005).
Yilmaz, V. & Çelik, H. E. A statistical approach to estimate the wind speed distribution: the case of Gelibolu region. Doğuş Üniversitesi Dergisi 9, 122–132 (2011).
Ali, S., Lee, S.-M. & Jang, C.-M. Statistical analysis of wind characteristics using Weibull and Rayleigh distributions in Deokjeok-do Island-Incheon, South Korea. Renew. Energy 123, 652–663 (2018).
Arias-Rosales, A. & Osorio-Gómez, G. Wind turbine selection method based on the statistical analysis of nominal specifications for estimating the cost of energy. Appl. Energy 228, 980–998 (2018).
Akgül, F. G. & Şenoğlu, B. Comparison of wind speed distributions: a case study for Aegean coast of Turkey. Energy Sour. Part A Recov. Util. Environ. Eff. https://doi.org/10.1080/15567036.2019.1663309 (2019).
ul Haq, M. A., Rao, G. S., Albassam, M. & Aslam, M. Marshall-Olkin Power Lomax distribution for modeling of wind speed data. Energy Rep. 6, 1118–1123 (2020).
Bludszuweit, H., Domínguez-Navarro, J. A. & Llombart, A. Statistical analysis of wind power forecast error. IEEE Trans. Power Syst. 23, 983–991 (2008).
Brano, V. L., Orioli, A., Ciulla, G. & Culotta, S. Quality of wind speed fitting distributions for the urban area of Palermo, Italy. Renew. Energy 36, 1026–1039 (2011).
Katinas, V., Gecevicius, G. & Marciukaitis, M. An investigation of wind power density distribution at location with low and high wind speeds using statistical model. Appl. Energy 218, 442–451 (2018).
Zaman, B., Lee, M. H. & Riaz, M. An improved process monitoring by mixed multivariate memory control charts: An application in wind turbine field. Comput. Ind. Eng. 142, 106343 (2020).
Viertl, R. Univariate statistical analysis with fuzzy data. Comput. Stat. Data Anal. 51, 133–147 (2006).
Filzmoser, P. & Viertl, R. Testing hypotheses with fuzzy data: the fuzzy p-value. Metrika 59, 21–29 (2004).
Tsai, C.-C. & Chen, C.-C. Tests of quality characteristics of two populations using paired fuzzy sample differences. Int. J. Adv. Manuf. Technol. 27, 574–579 (2006).
Taheri, S. M. & Arefi, M. Testing fuzzy hypotheses based on fuzzy test statistic. Soft. Comput. 13, 617–625 (2009).
Jamkhaneh, E. B. & Ghara, A. N. in 2010 International Conference on Intelligent Computing and Cognitive Informatics. 86–89 (IEEE).
Chachi, J., Taheri, S. M. & Viertl, R. Testing statistical hypotheses based on fuzzy confidence intervals. Aust. J. Stat. 41, 267–286 (2012).
Kalpanapriya, D. & Pandian, P. Statistical hypotheses testing with imprecise data. Appl. Math. Sci. 6, 5285–5292 (2012).
Montenegro, M., Casals, Ma. R., Lubiano, Ma. A. & Gil, Ma. A. Two-sample hypothesis tests of means of a fuzzy random variable. Inf. Sci. 133, 89–100 (2001).
Park, S., Lee, S.-J. & Jun, S. Patent big data analysis using fuzzy learning. Int. J. Fuzzy Syst. 19, 1158–1167 (2017).
Smarandache, F. Neutrosophy. Neutrosophic probability, set, and logic, proquest information & learning. Ann Arbor Mich. USA 105, 118–123 (1998).
Smarandache, F. Introduction to neutrosophic measure, neutrosophic integral, and neutrosophic probability. DOI: 10.5281/zenodo.8843 (Infinite Study, 2013).
Broumi, S. & Smarandache, F. Correlation coefficient of interval neutrosophic set. Appl. Mech. Mater. 436, 511–517 (2013) (Trans Tech Publ).
Guo, Y. & Sengur, A. N. C. M. Neutrosophic c-means clustering algorithm. Pattern Recogn. 48, 2710–2724 (2015).
Broumi, S., Bakali, A., Talea, M. & Smarandache, F. Bipolar neutrosophic minimum spanning tree. SSRN Electr. J. https://doi.org/10.2139/ssrn.3127519 (2018).
Abdel-Baset, M., Chang, V. & Gamal, A. Evaluation of the green supply chain management practices: A novel neutrosophic approach. Comput. Ind. 108, 210–220 (2019).
Abdel-Basset, M., Mohamed, M., Elhoseny, M., Chiclana, F. & Zaied, A.E.-N.H. Cosine similarity measures of bipolar neutrosophic set for diagnosis of bipolar disorder diseases. Artif. Intell. Med. 101, 101735 (2019).
Smarandache, F. Introduction to neutrosophic statistics. DOI:https://doi.org/10.13140/2.1.2780.1289 (Infinite Study, 2014).
Chen, J., Ye, J. & Du, S. Scale effect and anisotropy analyzed for neutrosophic numbers of rock joint roughness coefficient based on neutrosophic statistics. Symmetry 9, 208 (2017).
Chen, J., Ye, J., Du, S. & Yong, R. Expressions of rock joint roughness coefficient using neutrosophic interval statistical numbers. Symmetry 9, 123 (2017).
Aslam, M. Neutrosophic analysis of variance: application to university students. Complex Intell. Syst. 5, 403–407 (2019).
Aslam, M. & Albassam, M. Application of neutrosophic logic to evaluate correlation between prostate cancer mortality and dietary fat assumption. Symmetry 11, 330 (2019).
Aslam, M. A new method to analyze rock joint roughness coefficient based on neutrosophic statistics. Measurement 146, 65–71 (2019).
Ye, J. Multiple-attribute group decision-making method under a neutrosophic number environment. J. Intell. Syst. 25, 377–386 (2016).
Liu, P. & Liu, X. The neutrosophic number generalized weighted power averaging operator and its application in multiple attribute group decision making. Int. J. Mach. Learn. Cybern. 9, 347–358 (2018).
Zheng, E., Teng, F. & Liu, P. Multiple attribute group decision-making method based on neutrosophic number generalized hybrid weighted averaging operator. Neural Comput. Appl. 28, 2063–2074 (2017).
Pramanik, S.; Roy, R.; Roy, T.K. Teacher selection strategy based on bidirectional projection measure in neutrosophic number environment. In Neutrosophic Operational Research; Smarandache, F., Abdel-Basset, M., El-Henawy, I., Eds.; Pons Publishing House: Bruxelles, Belgium, 2, 2017; ISBN 978-1-59973-537-5.
Maiti, I., Mandal, T. & Pramanik, S. Neutrosophic goal programming strategy for multi-level multi-objective linear programming problem. J. Ambient. Intell. Humaniz. Comput. 11, 3175–3186 (2019).
Mondal, K., Pramanik, S., Giri, B. C. & Smarandache, F. NN-Harmonic mean aggregation operators-based MCGDM strategy in a neutrosophic number environment. Axioms 7, 12 (2018).
Pramanik, S. & Banerjee, D. Neutrosophic number goal programming for multi-objective linear programming problem in neutrosophic number environment. Curr. Res. Rev. 1, 135–141 (2018).
Acknowledgements
The authors are deeply thankful to the editor and reviewers for their valuable suggestions to improve the quality and presentation of the paper.
Funding
No.
Author information
Authors and Affiliations
Contributions
M.A wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The author declares no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1038/s41598-022-15750-1
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aslam, M. RETRACTED ARTICLE: Neutrosophic statistical test for counts in climatology. Sci Rep 11, 17806 (2021). https://doi.org/10.1038/s41598-021-97344-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-97344-x
- Springer Nature Limited
This article is cited by
-
Saddlepoint p-values for a class of location-scale tests under randomized block design
Scientific Reports (2024)
-
The run test for two samples in the presence of uncertainty
Journal of Big Data (2023)
-
Estimating Latent Linear Correlations from Fuzzy Frequency Tables
Communications in Mathematics and Statistics (2022)