
Abstract
Large-scale crop yield estimation is, in part, made possible due to the availability of remote sensing data allowing for the continuous monitoring of crops throughout their growth cycle. Having this information allows stakeholders the ability to make real-time decisions to maximize yield potential. Although various models exist that predict yield from remote sensing data, there currently does not exist an approach that can estimate yield for multiple crops simultaneously, and thus leads to more accurate predictions. A model that predicts the yield of multiple crops and concurrently considers the interaction between multiple crop yields. We propose a new convolutional neural network model called YieldNet which utilizes a novel deep learning framework that uses transfer learning between corn and soybean yield predictions by sharing the weights of the backbone feature extractor. Additionally, to consider the multi-target response variable, we propose a new loss function. We conduct our experiment using data from 1132 counties for corn and 1076 counties for soybean across the United States. Numerical results demonstrate that our proposed method accurately predicts corn and soybean yield from one to four months before the harvest with an MAE being 8.74% and 8.70% of the average yield, respectively, and is competitive to other state-of-the-art approaches.
Similar content being viewed by others


Introduction
The use of satellites and other remote sensing mechanisms has proven to be vital in monitoring the growth of various crops both spatially and temporally1. Common uses of remote sensing are to extract various descriptive indices such as normalized difference vegetation index (NDVI), temperature condition index, enhanced vegetation index, and leaf area index2. This information can be used for drought monitoring, detecting excessive soil wetness, quantifying weather impacts on vegetation, the evaluation of vegetation health and productivity, and crop yield forecasting3,4,5. Moreover, a large-scale collection of environmental descriptors such as surface temperature and precipitation can also be identified from satellite images6,7.
Accurate and non-destructive identification of crop yield throughout a crop’s growth stage enables farmers, commercial breeding organizations, and government agencies to make decisions to maximize yield output, ultimately for a nation’s economic benefit. Early estimations of yield at the field/farm level play a vital role in crop management in terms of site-specific decisions to maximize a crop’s potential. Numerous approaches have been applied for crop yield prediction, such as manual surveys, agro-meteorological models, and remote sensing based methods8. However, given the size of farming operations, manual field surveys are neither efficient nor practical. Moreover, modeling approaches have limitations due to the difficulty in determining model parameters, the scalability to large areas, and the computational resources necessary9.
Recently, satellite data has become widely available in various spatial, temporal, and spectral resolutions and can be used to predict crop yield over different geographical locations and scales10. The availability of Earth observation (EO) data has created new ways for efficient, large-scale agricultural mapping11. EO data enables a unique mechanism to capture crop information over large areas with regular updates to create maps of crop production and yield. Nevertheless, due to the high spatial resolution needed for accurate yield predictions, Unmanned Aerial Vehicles (UAV) have been promoted for data acquisition12. Although UAV platforms have demonstrated superior image capturing abilities, without the assistance of a large workforce, accurately measuring the yield for large regions is not feasible.
Indeed, advances in technology have made yield prediction more accessible and accurate both through machine learning and statistical approaches. Historically, common methods to predict crop yield include random forests, linear regression, and ensemble approaches13,14,15. However, recently crop yield predictions have been dominated by deep learning approaches. Recent works have applied multi-layer perceptrons to predict yield in wheat, corn, and strawberry yield by combining observed phenotypic data and environmental data16,17,18,19. Moreover, there is an increasing amount of literature combining convolutional neural networks and yield prediction from UAV imagery20,21,22. It is evident from recent works that no matter the data acquisition mechanism, there is an apparent shift in utilizing deep neural networks for crop yield predictions.
In regards to the scope of our paper, remote sensing capabilities have been extensively used for estimating crop yield around the world of various scales (field, county, state). Various studies have been performed using different vegetation indices to estimate yield in maize, wheat, grapes, rice, corn, and soybeans using random forests, neural networks, multiple linear regression, partial least squares regression, and crop models23,24,25,26,27,28,29,30,31. Similar to tabular yield data and UAV imagery, remote sensing yield predictions were historically dominated by traditionally machine learning and statistical approaches. However, there is a recent trend towards combining convolutional neural networks with satellite imagery for crop yield predictions32,33,34. These research papers showcase the potential, power, and accuracy deep learning and remote sensing have on estimating yield at a large scale.
For this paper, we consider two main crops in the Midwest United States (US), corn (Zea mays L.) and soybeans (Glycine max). According to the United States Department of Agriculture, in 2019, 89.7 million and 76.1 million acres of corn and soybean were planted, respectively. The combination of these two crops makes up approximately 20% of active US farmland35. Given the sheer size of these farming operations combined with the growing population, actions must be taken to maximize yield. With the help of remote sensing, government officials, as well as farmers, can monitor crop growth (at various scales) to ensure proper crop management decisions are made to maximize the yield potential.
Although approaches exist to estimate yield with various means, current models are limited in that they only estimate yield for a single crop. That is, there does not exist any model making use of remote sensing data to predict the yield of multiple crops simultaneously. More specifically, the scientific question we answer in this paper is determining how to extract transferable information about the yield prediction of one crop to be used for the yield prediction of another crop. Moreover, because individual models need to be constructed for each crop, long computational times prevent machine learning methods from being adopted over large areas36,37. One way to alleviate these issues is by considering simultaneous (multi-target) regression of yield. By predicting multiple response variables simultaneously, interaction effects are considered between response variables leading to improved accuracy, and computational performance is reduced due to having a single model predict multiple outputs as opposed to multiple models predicting multiple outputs.
Multi-target regression using support vector regression has been successful in estimating different biophysical parameters from remote sensing images outperforming single-target regression techniques both in terms of computational performance and accuracy38. Additionally, a multi-target Gaussian regressor created to identify canopy biomass in rice paddies was shown to obtain superior accuracy when compared to a single-target Gaussian regression39. Indeed, across a variety of domains and applications, simultaneous regression of multiple responses has shown promise with improved accuracy and computational performance40,41,42.
Given the promising attributes of a multi-target regression model, we apply this approach to our remote sensing use case. Having such a model would, hopefully, result in more accurate predictions by considering the interactions between crops and estimating yields accordingly. Additionally, because predictions are simultaneous, the results are less computationally intensive than computing a model for each crop. Therefore, we propose a new deep learning framework called YieldNet utilizing a novel deep neural network architecture. This model makes use of a transfer learning methodology that acts as a bridge to share model weights for the backbone feature extractor. Moreover, because of the uniqueness associated with simultaneous yield prediction for two crops, we propose a new loss function that can handle multiple response variables. Specifically, the novelties of our approach include:
-
1.
A new model that extracts transferable information from both corn and soybean to improve the yield prediction of both crops simultaneously.
-
2.
The proposed method utilizes transfer learning through sharing weights of the backbone feature extractor among multiple crops, therefore, improving computational efficiency. To the best of our knowledge, this is the first deep learning approach combining multi-target regression, convolutional neural networks, and remote sensing data for crop yield prediction.
-
3.
A new loss function is proposed to consider the multi-target response variable.
-
4.
The weight sharing property of the proposed method substantially decreases the number of model parameters and subsequently helps the training process despite having limited labeled data.
-
5.
The effectiveness of our proposed method is demonstrated on large-scale geospatial data from 1132 counties for corn and 1076 counties for soybean covering 13 states across the United States.
Methodology
The goal of this paper is to simultaneously predict the average yield per unit area of two different crops (corn and soybean) both grown in regions of interest (US counties) based on a sequence of images taken by satellite before harvest. Let \(I^t_{l,k} \in {\mathbb {R}}^{H\times W \times d}\) and \(Y_{l,k}^{c} \in {\mathbb {R}}^+\) denote, respectively, the remotely sensed multi-spectral image taken at time \(t \in \{1, \dots , T\}\) during the growing season and the ground truth average yield of crop type \(c \in \{1,2\}\) planted in location l at year k, where H and W are the image’s height and width and d is the number of bands (channels). Thus, the dataset can be represented as
where L and K are the numbers of locations and years, respectively.
For our approach, we do not use end-to-end training due to the main following reasons: (1) the number of labeled training data is limited, and (2) inability to use transfer learning from popular benchmark datasets such as Imagenet43 due to domain difference and multi-spectral nature of satellite images. Therefore, we reduce the dimensionality of the raw remote sensing images under the permutation invariance assumption which states the average yield mostly depends on the number of different pixel types rather than the position of the pixels in images due to the infeasibility of end-to-end training. Similar approaches have been used in other studies34,44. As a result, we separately discretize the pixel values for each band of a multi-spectral image \(I^t_{l,k}\) into b bins and obtain a histogram representation \(h^t_{l,k}\in {\mathbb {R}}^{b \times d}\). If we obtain histogram representations of the sequence of multi-spectral images denoted as \((h_{l,k}^1,h_{l,k}^2, \ldots ,h_{l,k}^T)\) and concatenate them through time dimension, we can produce a compact histogram representations \(H_{l,k}\in {\mathbb {R}}^{T\times b \times d}\) of the sequence of multi-spectral images taken during growing season. As such, the dataset D can be re-written as the following and we will use this notation throughout the rest of the paper:
Given the above dataset, this paper proposes a deep learning based method, named YieldNet, that learns the desired mapping \(H_{l,k}\in {\mathbb {R}}^{T\times b \times d} \mapsto (Y_{l,k}^1,Y_{l,k}^2)\) to predict the yields of two different crops simultaneously.
Network architecture
Crop yield is a highly complex trait that is affected by many factors such as environmental conditions and crop genotype which requires a complex model to reveal the functional relationship between these interactive factors and crop yield.
We propose a novel convolutional neural network architecture which is a highly non-linear and complex model. Convolutional neural networks belong to the class of representation learning methods which automatically extract necessary features from raw data without the need for any handcrafted features45,46. Figure 1 outlines the architecture of the proposed method. Table 1 shows the detailed architecture of the proposed model. We use a 2-D convolution operation which is performed over the ‘time’ and ‘bin’ dimensions while considering bands as channels. As such, convolution operation over the time dimension can help capture the temporal effect of satellite images collected over time intervals.

Outline of the YieldNet architecture. The input of the YieldNet is 3-D histograms \(H\in {\mathbb {R}}^{T\times b \times d}\) and the 2-D convolution operation is performed over the ‘time’ and ‘bin’ dimensions while considering bands as channels. The number under feature maps indicates the number of channels. Convolutional layers denoted with yellow color work as a backbone feature extractor and share weights for both corn and soybean yield predictions.
In our proposed network, the first five convolutional layers share weights for corn and soybean yield predictions which are denoted with yellow color in Fig. 1. These layers extract relevant features from input data for both corn and soybean yield predictions. The intuition behind using one common feature extractor is that it significantly decreases the number of parameters of the network, which helps training the model more efficiently given the scarcity of the labeled data. In addition, many low-level features captured by the comment feature extractor reflect general environmental conditions that are transferable between corn and soybean yields. All convolutional layers are followed by batch normalization47 and ReLU nonlinearities in our proposed network. Batch normalization is used to accelerate the training process by reducing internal covariate shifts and regularizing the network. We use two convolutional layers in both corn and soybean heads which are followed by two fully connected layers.
Network loss
To jointly minimize the prediction errors of corn and soybean yield forecasting, we propose the following loss function:
where \(Y_{i}^{c}\), \({\hat{Y}}_{i}^{c}\), \(Y_{i}^{s}\), \({\hat{Y}}_{i}^{s}\), \(N_c\), \(N_s\), \(\bar{Y}^c\), and \(\bar{Y}^s\) denote ith average ground truth corn yield, ith predicted corn yield, ith average ground truth soybean yield, ith predicted soybean yield, number of corn samples, number of soybean samples, average corn yield, and average soybean yield, respectively. Our proposed loss function is a normalized Euclidean loss which makes the corn and soybean losses to have the same scale. We use the maximum function in our proposed loss function to make the training process more stable and ensure that both corn and soybean losses are optimized.
Experiments and results
In this section, we present the dataset used in our study and then report the results of our proposed method along with other competing methods in corn and soybean yield predictions. We conducted all experiments in Tensorflow48 on an NVIDIA Tesla V100 GPU.
Data
The data analyzed in this study included three sets: yield performance, satellite images, and cropland data layers.
-
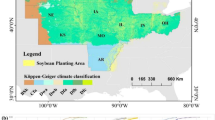
The yield performance dataset includes the observed county-level average yield for corn and soybean between 2004 and 2018 across 1132 counties for corn and 1076 for soybean within 13 states of the US Corn Belt: Indiana, Illinois, Iowa, Minnesota, Missouri, Nebraska, Kansas, North Dakota, South Dakota, Ohio, Kentucky, Michigan, and Wisconsin, where corn and soybean are considered the dominant crops49. Figures 2 and 4 depict the US Corn Belt and histogram of yields, respectively. The summary statistics of the corn and soybean yields are shown in Table 2.
-
Satellite data contains MODIS products including MOD09A1 and MYD11A2. MOD09A1 product provides an estimate of the surface spectral reflectance of Terra MODIS bands 1-7 at 500m resolution and corrected for atmospheric conditions50. The MYD11A2 product provides an average land surface temperature which has the day and night-time surface temperature bands at 1km resolution51. It is worth noting that MOD09Q1 data exists at 250m resolution, however, it encompasses only 2 reflectance bands. Thus, although higher resolution, the data contains less information52. Figure 3 depicts an example multispectral image of land surface temperature and surface spectral reflectance for Adams county in Illinois. These satellite images were captured at 8-days intervals and we only use satellite images captured during growing seasons (March–October). As such, satellite images are collected 30 times a year in our study. We discretize all multispectral images using 32 bins to generate the 3-D histograms \(H\in {\mathbb {R}}^{T\times b \times d}\), where \(T=30\), \(b=32\), and \(d=9\).
-
USDA-NASS cropland data layers (CDL) is crop-specific land cover data that are produced annually for different crops based on moderate resolution satellite imagery and extensive agricultural ground truth53. In this paper, cropland data layers are used for both corn and soybean to focus on only croplands within each county and exclude non-croplands such as buildings and streets from satellite images.

The map of US Corn Belt.

The multispectral images of surface spectral reflectance and land surface temperature for Adams county in Illinois captured on May 8th, 2011. Corn and soybean farmland images indicate cropland areas within the Adams county in Illinois in year 2011.

The histograms of the corn and soybean yields. The unit of yield is bushels per acre.
Design of experiments
We compare our proposed method with the following models to evaluate the efficiency of our method.
Random forest (RF)54
RF is a non-parametric ensemble learning method that is robust against overfitting. We set the number and the maximum depth of trees in RF to be 150 and 20, respectively. We tried different numbers and the maximum depth of trees and found that these hyperparameters resulted in the most accurate predictions.
Deep feed forward neural network (DFNN)
DFNN is a highly nonlinear model which stacks multiple fully connected layers to learn the underlying functional relationship between inputs and outputs. The DFNN model has nine hidden layers, each having 50 neurons. We used batch normalization for all layers. The ReLU activation function was used in all layers except the output layer. The model was trained for 120,000 iterations. Adam optimizer was used to minimize the Euclidean loss function.
3-dimensional convolutional neural network (3D-CNN)
3D-CNN is a highly non-linear model which employs 3-dimensional kernels in its convolution operations to capture spatio-temporal features in the data55. The 3D-CNN captures the temporal effects of remote sensing data as well as spatial and intra-band features extracted from the individual images56. In this paper, we used a homogeneous network architecture for the 3D-CNN which is found effective in other studies55,57. Table 3 shows the network architecture of the 3D-CNN.
Regression tree (RT)58
RT is a nonlinear model which does not make any assumption regarding the mapping function. We set the maximum depth of the regression tree to be 12 to decrease the overfitting.
Lasso59
Lasso adopts \(L_1\) norm to reduce the effect of unimportant features. A Lasso model also can be used as a baseline model to compare the linear and nonlinear effects of input features. We set the \(L_1\) coefficient of our Lasso model to be 0.05.
Ridge60
Ridge regression is similar to the Lasso model except it uses \(L_2\) norm as a penalty to reduce the effect of unimportant features. We set the \(L_2\) coefficient of our Ridge model to be 0.05.
Training details
YieldNet network was trained in an end-to-end manner. We initialized the network parameters with Xavier initialization61. To minimize the loss function defined in Eq. (1), we used Adam optimizer62 with a learning rate of 0.05% and a mini-batch size of 32. The network was trained 4000 iterations to convergence. We do not use dropout63 because batch normalization also has a regularization effect on the network.
Final results
After having trained all models, we evaluated the performances of our proposed method along with other competing models to predict corn and soybean yields. To completely evaluate all models, we took 3 years 2016, 2017, and 2018 as test years and predicted corn and soybean yields 4 times a year during the growing season on the 23rd day of July, August, September, and October. From a practical perspective, monitoring crop yield throughout the growing season is vital for optimal farm management practices (when to add fertilizer, apply pesticides, irrigate crops, etc). In addition, crop yield monitoring affects crop commodity market, which determines the future prices of crops. Therefore, our results emulate the situation where we are progressively predicting yield at the end of the growing season months earlier as a means of tracking expected crop growth. Tables 4 and 5 present the corn and soybean yield prediction results, respectively, and compare the performances of models with respect to the root–mean–square error (RMSE) evaluation metric which is defined as follows:
where, N, \(y_{i}\), and \({\hat{y}}_{i}\) denote the number of observations, the predicted yield for ith observation, and the ground truth yield for ith observation, respectively.
As shown in Tables 4 and 5, our proposed method outperforms other methods to varying extents. The Ridge and Lasso had comparable performances for soybean yield prediction, but, Lasso performed considerably better compared to the Ridge for corn yield prediction. DFNN showed a better performance than RF, RT, and Ridge for both corn and soybean yield predictions. DFNN had similar performance with Lasso for corn yield prediction while having higher prediction accuracy for soybean yield prediction. Despite the linear modeling structure, Lasso performed better than RF and RT for corn yield prediction, which indicates that RF and RT cannot successfully capture the nonlinearity of remote sensing data, resulting in poor performance compared to Lasso. RT had a weak performance compared to other methods due to being prone to overfitting. RF performs considerably better than RT because of using ensemble learning, which makes it robust against overfitting. 3D-CNN outperformed other models except for our proposed method due to capturing the temporal effects and spatial and intra-band features of remote sensing data. 3D-CNN performed slightly better than YieldNet in three cases for soybean and corn yield predictions. But, YieldNet outperformed the 3D-CNN on average for both corn and soybean yield predictions while having a smaller number of parameters and computation time.
Our proposed method outperformed the other methods due to multiple factors: (1) the convolution operation in the YieldNet model captures both the temporal effect of remote sensing data collected over growing season and the spatial information of bins in histograms, (2) the YieldNet network uses transfer learning between corn and soybean yield predictions by sharing the weights of the backbone feature extractor, and (3) using a shared backbone feature extractor in the YieldNet model substantially decreases the number of model’s parameters and subsequently helps training process despite having the limited labeled data. The prediction accuracy decreases as we try to make predictions earlier during the growing season (e.g. July and August) due to loss of information. All models except our proposed model do not show a clear decreasing pattern in performance accuracy as we go from October to July, which indicates they cannot fully learn the functional mapping from satellite images to the yield.
Table 6 compares the number of parameters and training time of the competing methods for crop yield prediction. As shown in Table 6, Lasso and Ridge have the lowest number of parameters compared to neural network based models such as DFNN, 3D-CNN, and YieldNet due to their linear modeling structure. Compared to the YieldNet model, other models should be trained separately for corn and soybean, which results in having twice the total number of parameters. 3D-CNN has the highest number of parameters among the neural network based models. From a computation time perspective, linear models and RT had the lowest training time. RF had the second longest training time after 3D-CNN compared to other models due to using ensemble learning. Among neural network based models, YieldNet had the shortest training time and 3D-CNN had the longest training time. The models were trained on an Intel i7-4790 CPU 3.60 GHz. The inference times of all methods are less than a second. However, the inference time of our model is less than that of the 3D-CNN model.
We also report the yield prediction performance of our proposed model with respect to another evaluation metric, mean absolute error (MAE), in Table 7. As shown in Table 7, our proposed method accurately predicted corn yield 1 month, 2 months, 3 months, and 4 months before the harvest with MAE being 9.92%, 8.88%, 8.36%, and 7.8% of the average corn yield, respectively. The proposed model also accurately predicted soybean yield one month, two months, three months, and four months before harvest with MAE being 10.05%, 9.06%, 8.01%, and 7.67% of the average soybean yield, respectively. The proposed model is slightly more accurate in soybean yield forecasting than corn yield forecasting, which is due to the higher variation in the corn yield compared to the soybean yield.
We visualized the error percentage maps for the corn and soybean yield predictions for the year 2018. As shown in Figs. 5 and 6, the error percentage is below 5% for most counties, which indicates that our proposed model provides a robust and accurate yield prediction across US Corn Belt.

The error percentage maps for the 2018 corn yield prediction which is done during growing season in July, August, September, and October. The counties with white color indicate the ground truth yield were not available for those counties in 2018.

The error percentage maps for the 2018 soybean yield prediction which is done during the growing season in July, August, September, and October. The counties with white color indicate the ground truth yield were not available for those counties in 2018.
To further evaluate the prediction results of our proposed model, we created the scatter plots of ground truth yield against the predicted yield for the year 2018. Figure 7 depicts the scatter plots for the corn yield prediction during the growing season in the months July, August, September, and October. The corn scatter plots indicate that the YieldNet model can successfully forecast yield months prior to harvesting.

The scatter plots for the 2018 corn yield prediction during the growing season in the months July, August, September, and October. MAE and r stand for mean absolute error and correlation coefficient, respectively. The unit of yield is bushels per acre.
Figure 8 depicts the scatter plots for the soybean yield prediction during the growing season in the months July, August, September, and October. The corn scatter plots indicate that the YieldNet model provides reliable and accurate yield months prior to the harvest.

The scatter plots for the 2018 soybean yield prediction during the growing season in months July, August, September, and October. MAE and r stand for mean absolute error and correlation coefficient, respectively. The unit of yield is bushels per acre.
Ablation study
In order to examine the usefulness of using a single deep learning model for simultaneously predicting the yield of two crops, we perform the following analysis. We train two separate models one for corn yield prediction and another for soybean yield prediction which are as follows:
\(\varvec{YieldNet}^{\varvec{corn}}\) This model has exactly the same network architecture as the YieldNet model except we removed the soybean head from the original YieldNet network. As a result, \(\textit{YieldNet}^{\textit{corn}}\) can only predict the corn yield.
\(\varvec{YieldNet}^{\varvec{soy}}\) This model has exactly the same network architecture as the YieldNet model except we removed the corn head from the original YieldNet network. As a result, \(\textit{YieldNet}^{\textit{soy}}\) can only predict the soybean yield.
Tables 8 and 9 compare the yield prediction performances of the above-mentioned models with the original YieldNet model.
As shown in Tables 8 and 9, the YieldNet model which simultaneously predicts corn and soybean yields outperforms individual \(\textit{YieldNet}^{\textit{corn}}\) and \(\textit{YieldNet}^{\textit{soy}}\) models. The YieldNet provides more robust and accurate yield predictions compared to the other two individual models, which indicates that transfer learning between corn and soybean yield prediction improves the yield prediction accuracy for both crops.
Discussion and conclusion
Our numerical results illustrate that our approach to simultaneously predicting yield for both corn and soybeans is possible and can achieve higher accuracy than individual models. By utilizing transfer learning between corn and soybean yield to share the weights of the backbone feature extractor, YieldNet was able to substantially decrease the number of learning parameters. Our transfer learning approach enabled us to save on computation resources while also maximizing our prediction accuracy. Moreover, the accuracy achieved using a 4-month look-ahead has a lot of important implications for crop management decisions. With accurate yield predictions at various time points, decision-makers now have the ability to change crop management practices to ensure yield is being maximized throughout its growth stage.
Although our approach highlighted corn and soybean in the US market, this approach is applicable to any number of crops in any region. Due to the strength of our deep learning framework in combination with a generalized loss function, our approach is ready for scale. To improve the accuracy of our methodology, more data can be gathered and this can be left as a future extension to this work, alongside more crops and more regions. It is the hope of this paper that our approach and results showcase the power deep learning for simultaneous yield prediction can have on the remote sensing community and the larger agricultural community as a whole.
Data availability
This data is publicly available and acquisition details are in “Data”.
References
Anastasiou, E. et al. Satellite and proximal sensing to estimate the yield and quality of table grapes. Agriculture 8, 94 (2018).
da Silva, C. A., Nanni, M. R., Teodoro, P. E. & Silva, G. F. C. Vegetation indices for discrimination of soybean areas: A new approach. Agron. J. 109, 1331–1343 (2017).
Quarmby, N., Milnes, M., Hindle, T. & Silleos, N. The use of multi-temporal ndvi measurements from avhrr data for crop yield estimation and prediction. Int. J. Remote. Sens. 14, 199–210 (1993).
Kogan, F., Gitelson, A., Zakarin, E., Spivak, L. & Lebed, L. Avhrr-based spectral vegetation index for quantitative assessment of vegetation state and productivity. Photogramm. Eng. Remote. Sens. 69, 899–906 (2003).
Singh, R. P., Roy, S. & Kogan, F. Vegetation and temperature condition indices from noaa avhrr data for drought monitoring over india. Int. J. Remote Sensing 24, 4393–4402 (2003).
Liou, Y.-A. & Kar, S. K. Evapotranspiration estimation with remote sensing and various surface energy balance algorithms—A review. Energies 7, 2821–2849 (2014).
Song, L., Liu, S., Kustas, W. P., Zhou, J. & Ma, Y. Using the surface temperature-albedo space to separate regional soil and vegetation temperatures from aster data. Remote. Sens. 7, 5828–5848 (2015).
Geipel, J., Link, J. & Claupein, W. Combined spectral and spatial modeling of corn yield based on aerial images and crop surface models acquired with an unmanned aircraft system. Remote. Sens. 6, 10335–10355 (2014).
Van Wart, J., Kersebaum, K. C., Peng, S., Milner, M. & Cassman, K. G. Estimating crop yield potential at regional to national scales. Field Crop. Res. 143, 34–43 (2013).
Battude, M. et al. Estimating maize biomass and yield over large areas using high spatial and temporal resolution sentinel-2 like remote sensing data. Remote. Sens. Environ. 184, 668–681 (2016).
Fieuzal, R., Sicre, C. M. & Baup, F. Estimation of corn yield using multi-temporal optical and radar satellite data and artificial neural networks. Int. J. Appl. Earth Observ. Geoinf. 57, 14–23 (2017).
Sagan, V. et al. Uav-based high resolution thermal imaging for vegetation monitoring, and plant phenotyping using ici 8640 p, flir vue pro r 640, and thermomap cameras. Remote. Sens. 11, 330 (2019).
Sellam, V. & Poovammal, E. Prediction of crop yield using regression analysis. Indian J. Sci. Technol. 9, 1–5 (2016).
Shahhosseini, M., Martinez-Feria, R. A., Hu, G. & Archontoulis, S. V. Maize yield and nitrate loss prediction with machine learning algorithms. Environ. Res. Lett. 14, 124026 (2019).
Suresh, G., Kumar, A. S., Lekashri, S. & Manikandan, R. Efficient crop yield recommendation system using machine learning for digital farming. Int. J. Mod. Agric. 10, 906–914 (2021).
Chu, Z. & Yu, J. An end-to-end model for rice yield prediction using deep learning fusion. Comput. Electron. Agric. 174, 105471 (2020).
Nassar, L., Okwuchi, I. E., Saad, M., Karray, F., Ponnambalam, K., & Agrawal, P. Prediction of strawberry yield and farm price utilizing deep learning. In 2020 International Joint Conference on Neural Networks (IJCNN), 1–7 (IEEE, 2020).
Bhojani, S. H. & Bhatt, N. Wheat crop yield prediction using new activation functions in neural network. Neural. Comput. Appl. 1–11 (2020).
Khaki, S., Wang, L. & Archontoulis, S. V. A cnn-rnn framework for crop yield prediction. Front. Plant Sci. 10, 1750 (2020).
Chang, A., Jung, J., Yeom, J., Maeda, M. M., Landivar, J. A., Enciso, J. M., Avila, C. A. & Anciso, J. R. Unmanned Aircraft System-(UAS-) Based High-Throughput Phenotyping (HTP) for Tomato Yield Estimation. J. Sens. (2021).
Zhou, J. et al. Yield estimation of soybean breeding lines under drought stress using unmanned aerial vehicle-based imagery and convolutional neural network. Biosyst. Eng. 204, 90–103 (2021).
Apolo-Apolo, O., Martínez-Guanter, J., Egea, G., Raja, P. & Pérez-Ruiz, M. Deep learning techniques for estimation of the yield and size of citrus fruits using a uav. Eur. J. Agron. 115, 126030 (2020).
Rischbeck, P. et al. Data fusion of spectral, thermal and canopy height parameters for improved yield prediction of drought stressed spring barley. Eur. J. Agron. 78, 44–59 (2016).
Kuwata, K. & Shibasaki, R. Estimating corn yield in the united states with modis evi and machine learning methods. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 3(8), 131–136 (2016).
Leroux, L. et al. Maize yield estimation in west africa from crop process-induced combinations of multi-domain remote sensing indices. Eur. J. Agron. 108, 11–26 (2019).
Gómez, D., Salvador, P., Sanz, J. & Casanova, J. L. Potato yield prediction using machine learning techniques and sentinel 2 data. Remote. Sens. 11, 1745 (2019).
Zhuo, W. et al. Assimilating soil moisture retrieved from sentinel-1 and sentinel-2 data into wofost model to improve winter wheat yield estimation. Remote. Sens. 11, 1618 (2019).
Awad, M. M. Toward precision in crop yield estimation using remote sensing and optimization techniques. Agriculture 9, 54 (2019).
Ballesteros, R., Intrigliolo, D. S., Ortega, J. F., Ramírez-Cuesta, J. M., Buesa, I. & Moreno, M. A. (2020). Vineyard yield estimation by combining remote sensing, computer vision and artificial neural network techniques. Precis. Agric. 21, 1242–1262 (2020).
Wang, Y., Zhang, Z., Feng, L., Du, Q. & Runge, T. Combining multi-source data and machine learning approaches to predict winter wheat yield in the conterminous united states. Remote. Sens. 12, 1232 (2020).
Maimaitijiang, M. et al. Soybean yield prediction from uav using multimodal data fusion and deep learning. Remote. Sens. Environ. 237, 111599 (2020).
Cao, J. et al. Integrating multi-source data for rice yield prediction across china using machine learning and deep learning approaches. Agric. For. Meteorol. 297, 108275 (2021).
Paudel, D. et al. Machine learning for large-scale crop yield forecasting. Agric. Syst. 187, 103016 (2021).
Sun, J. et al. Multilevel deep learning network for county-level corn yield estimation in the us corn belt. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 13, 5048–5060 (2020).
USDA. USDA long-term agricultural projections. https://www.usda.gov/oce/commodity/projection (2019).
Jin, X. et al. A 315 review of data assimilation of remote sensing and crop models. Eur. J. Agron. 92, 141–152 (2018).
Zhu, B. et al. A regional maize yield hierarchical linear model combining landsat 8 vegetative indices and meteorological data: Case study in jilin province. Remote. Sens. 13, 356 (2021).
Tuia, D., Verrelst, J., Alonso, L., Pérez-Cruz, F. & Camps-Valls, G. Multioutput support vector regression for remote sensing biophysical parameter estimation. IEEE Geosci. Remote. Sens. Lett. 8, 804–808 (2011).
Alebele, Y. et al. Estimation of canopy biomass components in paddy rice from combined optical and sar data using multi-target gaussian regressor stacking. Remote. Sens. 12, 2564 (2020).
Santana, E. J. et al. Predicting poultry meat characteristics using an enhanced multi-target regression method. Biosyst. Eng. 171, 193–204 (2018).
da Silva, B. L. S., Inaba, F. K., Salles, E. O. T. & Ciarelli, P. M. Outlier robust extreme machine learning for multi-target regression. Expert. Syst. Appl. 140, 112877 (2020).
Xiao, X. & Xu, Y. Multi-target regression via self-parameterized Lasso and refactored target space. Appl. Intell. 1–9 (2021).
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K. & Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248–255 (IEEE, 2009).
You, J., Li, X., Low, M., Lobell, D. & Ermon, S. Deep gaussian process for crop yield prediction based on remote sensing data. In Thirty-First AAAI Conference on Artificial Intelligence (2017).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Goodfellow, I., Bengio, Y., Courville, A. & Bengio, Y. Deep Learning Vol. 1 (MIT Press Cambridge, 2016).
Ioffe, S. & Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 (2015).
Abadi, M. et al. Tensorflow: A system for large-scale machine learning. In 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), 265–283 (2016).
Usda—National agricultural statistics service quickstats. https://quickstats.nass.usda.gov/. (Accessed 12–30, 2020).
Vermote, E. MOD09A1 MODIS/terra surface reflectance 8-day l3 global 500m sin grid v006. NASA EOSDIS Land Process. DAAC https://doi.org/10.5067/MODIS/MOD09A1.006 (2015).
Wan, Z., Hook, S. & Hulley, G. MOD11A2 MODIS/Terra land surface temperature/emissivity 8-day l3 global 1km sin grid v006. NASA EOSDIS Land Process. DAAC https://doi.org/10.5067/MODIS/MOD11A2.006 (2015).
Vermote, E. MOD09Q1 MODIS/terra surface reflectance 8-day l3 global 250m sin grid v006. NASA EOSDIS Land Process. DAAC.
USDA-NASS. USDA national agricultural statistics service cropland data layer. (2020).
Breiman, L. Random forests. Mach. Learning 45, 5–32 (2001).
Tran, D., Bourdev, L., Fergus, R., Torresani, L. & Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, 4489–4497 (2015).
Li, Y., Zhang, H. & Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3d convolutional neural network. Remote. Sens. 9, 67 (2017).
Nevavuori, P., Narra, N., Linna, P. & Lipping, T. Crop yield prediction using multitemporal uav data and spatio-temporal deep learning models. Remote. Sens. 12, 4000 (2020).
Breiman, L., Friedman, J., Stone, C. J. & Olshen, R. A. Classification and Regression Trees (CRC Press, 1984).
Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 58, 267–288 (1996).
Hoerl, A. E. & Kennard, R. W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 12, 55–67 (1970).
Glorot, X. & Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 249–256 (2010).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I. & Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958 (2014).
Funding
This work was partially supported by the National Science Foundation under the LEAP HI and GOALI programs (Grant number 1830478) and under the EAGER program (Grant number 1842097).
Author information
Authors and Affiliations
Contributions
S.K., H.P., and L.W. conceived the study. S.K. implemented the computational experiments. S.K., H.P., and L.W. wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khaki, S., Pham, H. & Wang, L. Simultaneous corn and soybean yield prediction from remote sensing data using deep transfer learning. Sci Rep 11, 11132 (2021). https://doi.org/10.1038/s41598-021-89779-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-89779-z
- Springer Nature Limited
This article is cited by
-
Multi-source information fusion-driven corn yield prediction using the Random Forest from the perspective of Agricultural and Forestry Economic Management
Scientific Reports (2024)
-
Predicting wheat yield from 2001 to 2020 in Hebei Province at county and pixel levels based on synthesized time series images of Landsat and MODIS
Scientific Reports (2024)
-
Assessment of the relevance of features associated with corn crop yield prediction in Colombia, a country in the Neotropical zone
International Journal of Information Technology (2024)
-
End-to-end 3D CNN for plot-scale soybean yield prediction using multitemporal UAV-based RGB images
Precision Agriculture (2024)
-
Acre-Scale Grape Bunch Detection and Predict Grape Harvest Using YOLO Deep Learning Network
SN Computer Science (2024)