
Abstract
Valid and reliable measurement of an individual’s knowledge and risk perception is pivotal to monitor and evaluate the effectiveness of interventions aimed at preventing cardiovascular diseases (CVDs). The recently developed Attitudes and Beliefs about Cardiovascular Disease (ABCD) knowledge and risk questionnaire is shown to be valid in England. In this study, we evaluated the psychometric properties of the modified and Dutch (Flemish)-translated ABCD questionnaire using both the classical test and item response theory (IRT) analysis. We conducted a community-based survey among 525 adults in Antwerp city, Belgium. We assessed the item- and scale-level psychometric properties and validity indices of the questionnaire. Parameters of IRT, item scalability, monotonicity, item difficulty and discrimination, and item fit statistics were evaluated. Furthermore, exploratory and confirmatory factorial validity, and internal consistency measures were explored. Descriptive statistics showed that both the knowledge and risk scale items have sufficient variation to differentiate individuals’ level of knowledge and risk perception. The overall homogeneity of the knowledge and risk subscales was within the acceptable range (> 0.3). The exploratory and confirmatory factor analyses of the risk scale supported a three-factor solution corresponding to risk perception (F1), perceived benefits and intention to change physical activity (F2), and perceived benefit and intention to change healthy dietary habit (F3). The two parametric logistic (2—PL) and rating scale models showed that the item infit and outfit values for knowledge and risk subscales were within the acceptable range (0.6 to 1.4) for most of the items. In conclusion, this study investigated the Dutch (Flemish) version of the ABCD questionnaire has good psychometric properties to assess CVD related knowledge and risk perception in the adult population. Based on the factor loadings and other psychometric properties, we suggested a shorter version, which has comparable psychometric properties.
Similar content being viewed by others


Introduction
Cardiovascular diseases (CVDs) are the leading cause of adult morbidity and mortality worldwide, accounting for an estimated 18.6 million deaths and 393 million disability adjusted life years (DALYs) in 20191,2. Similarly, 4 million deaths each year and 25% of all-cause DALYs in Europe are due to CVDs, so being the major cause of disease burden than any other condition3,4. The proportion of total deaths due to CVD greatly varies among countries in Europe, with over a twofold difference between Bulgaria (62%) and France (26%)5. In Belgium, CVDs account for 28% of all deaths and 14.2% of total DALYs4,6.
The relationship between lifestyle and CVD is well established. Physical inactivity, unhealthy dietary habit, tobacco use, excessive alcohol consumption, and stress have all been identified as independent risk factors of CVD7,8,9. The adoption of a healthy lifestyle has also been shown to reduce CVD risk10. In this regard, active involvement of the target population is crucial for CVD preventive interventions aiming at improving such healthy lifestyles. Likewise, knowledge of behavioral risks is essential for behavior change and individuals who perceive themselves to have a higher risk of CVD are more likely to adopt a healthy lifestyle11,12. Moreover, knowledge of the risk factors in comparison with one’s own lifestyle may form the risk perception13, which is a central psychological construct that could affect adoption of healthy lifestyle and maintenance14,15. As a result, improving knowledge and risk perception is an integral part of behavioral interventions aimed at reducing incidence of CVD15,16,17.
Poor knowledge and the gap between actual risk and the risk perception of the general population impedes the attainment of better health outcomes. Therefore, measurement of a person’s CVD knowledge and risk perception is essential to develop a healthy lifestyle intervention and to evaluate undergoing preventive activities. However, valid and reliable tools to measure CVD knowledge and risk perception among the adult population are scant. Few studies assessed risk perception using a single question18,19, which is not sufficient to assess multiple dimensions thereof20. The Heart Disease Fact Questionnaire (HDFQ) is put forward as a comprehensive measure of CVD risk knowledge, however, the focus is on measuring knowledge among patients with diabetes and it does not measure the risk perception21. In response, Woringer et al. developed a questionnaire to measure CVD knowledge and risk perception in England22. The study used an extensive scale development procedure and found a significant correlation between perceived risk measured by the questionnaire and predicted risk of CVD. Moreover, the tool has shown to have acceptable psychometric validity to be used in practice. They named the questionnaire Attitudes and Beliefs about Cardiovascular Disease Risk Questionnaire, or in short the ABCD questionnaire. The questionnaire consists of 26 items grouped into four scales: Knowledge of CVD Risk and Prevention (eight items), Perceived Risk of Heart Attack/Stroke (eight items), Perceived Benefits and Intention to Change Behavior (seven items) and Healthy Eating Intentions (three items).
The multi-country CVD prevention study named ‘SPICES’—Scaling-up Packages of Interventions for Cardiovascular diseases in Europe and Sub-Saharan Africa identified the ABCD questionnaire as a potential instrument to measure CVD knowledge and risk perception prior to and after the planned intervention. However, the questionnaire was not translated and validated in the Belgium context. Therefore, this study aimed to psychometrically investigate a modified and Dutch (Flemish) translated ABCD questionnaire, in terms of validity and reliability, using both the classical test (CTT) and item response theory (IRT) approach.
Methods
Study setting
This study is part of the ongoing SPICES project, and we particularly used data collected during the baseline population survey in the city of Antwerp, Belgium. The city of Antwerp is subdivided into 9 districts with over half a million inhabitants. The SPICES project in Belgium targets a vulnerable population based on the principle of ‘proportionate universalism’, in which assessments and interventions are universal, not targeted, but with a scale proportionate to the level of vulnerability23. Hence, instead of stratifying people on an individual level vulnerability, we rather focused on target ‘vulnerable districts’ based on the socioeconomic deprivation index, access to primary healthcare, density of households with social support, and density of elderly inhabitants. Using the aforementioned criteria, two districts, Deurne Noord and Borgerhout Intramuros, were selected.
Study sample and procedure
Data were collected using postal and online platforms on randomly selected adults in the two selected districts of Antwerp from February to July 2020. We obtained a stratified random sample of inhabitants from the Antwerp city administration based on the probability proportional to size (PPS) sampling technique. The stratification was based on age group (5-year interval), sex and statistical sector (the lowest administrative unit). The inclusion criteria were: being a registered resident of Antwerp and aged 18 years or older. To remediate a high non-response rate, we used a matched substitution technique for non-respondents, which is shown to have acceptable external validity24. Substitutes were matched based on age, sex and geographical location, in substitution phases. In order to increase the response rate, we sent a reminder for participants who did not respond within ten days as recommended by several studies25,26. Out of 1,512 invited, 543 participants responded to the survey. During data processing, four questionnaires indicated that the participant could not fill it due to cognitive impairment (noted on the questionnaire), 14 participants had missing responses in all the required items, hence, leading to a total of 525 participants included in this validation analysis.
Measures
Adaptation of the original ABCD questionnaire
We made minor modifications to the original ABCD questionnaire, next to the translation to Dutch (Flemish). The knowledge scale in the original tool has 8 items. We added one item about smoking “People who smoke have an increased risk of cardiovascular diseases”. In addition, question 7 in the original questionnaire was phrased as “HDL refers to ‘good’ cholesterol, and LDL refers to ‘bad’ cholesterol”. Hence, we modified this question into “There is 'good' cholesterol and there is 'bad' cholesterol” since the relevance of the English acronyms LDL and HDL in the questionnaire are considered to be minimal. Similarly in the risk scale, we added two items in order to have more insight on healthy diet intentions and phrased these items as “I am considering eating at least 5 servings of fruit and vegetables a day and “I intend, or want, to eat at least 5 servings of fruit and vegetables a day”.
The Dutch (Flemish) translated ABCD questionnaire
First, independent translation of the modified ABCD questionnaire was performed by language professionals who had experience in translation of medical questionnaires. Next, the Dutch (Flemish) version was back translated to English by experts in Linguapolis, University of Antwerp language institute. Then, the investigators discussed both versions of the questionnaire to check for consistency. Afterwards, a lay-man translation was performed to enhance understanding of the questionnaire. The knowledge scale consists of 9 statements about CVD risks, with response options being ‘true’, ‘false’ and ‘I don’t know’. For each item, the correct answer was scored as 1 and the incorrect or ‘I don’t know’ answers were both scored as 0. The Flemish version of the ABCD risk questionnaire consists of 20-items and response options were presented on a 4-point scale ranging from 1 ‘strongly disagree’ to 4 ‘strongly agree’, while items 6, 13 and 20 were reverse coded. Both the English and the Dutch (Flemish) translated questionnaire are available in the supplementary material.
Statistical analyses
Upon checking for completeness, data were entered in the Research Electronic Data Capture (REDCap) database system. Then, we downloaded it as a CSV file and exported to the free R software package version 4.0.2 for further processing and analysis.
We followed a scale validation protocol for applied health research as suggested by Dima AL27. Descriptive statistics and Spearman rank correlations (rs) between items were examined. We evaluated the monotonicity and scalability of items using a Mokken Scaling Analysis (MSA)28. Coefficients of scalability (H), monotonicity and invariant item ordering were examined and H > = 0.30 were considered to be scalable. As a rule of thumb, Mokken28 proposed a cutoff for H as follows: a scale is considered weak if 0.3 ≤ H < 0.4, moderate if 0.4 ≤ H < 0.5, and strong if H > 0.5.
To study the dimensionality of items of the risk scale in more detail, we performed an exploratory (EFA) and confirmatory factor analysis (CFA). We evaluated the sample and data adequacy for factor analysis using Kaiser–Meyer–Olkin (KMO) and Bartlett’s test of sphericity. EFA was performed using the maximum likelihood extraction and Oblimin rotation method on random half-sample (n = 262). We determined the adequate number of factors using a scree plot and parallel analysis. Then, to test the consistency of factors, we performed a CFA on the remaining half-sample (n = 263). We evaluated the model fit of the CFA using; the X2 test, the Tucker-Lewis and Comparative Fit Indexes and the root mean square error of approximation (RMSEA)29. Detailed procedures on EFA and CFA are available in the supplementary material.
We further examined the item properties of each scale using the parametric IRT analysis, which accounts for item difficulty and/or discrimination30. For the dichotomous knowledge scale, we fitted a Rasch model31 and a two-parameter logistic (2-PL) model, using conditional maximum likelihood (CML) estimation. We also provided a graphical illustration of the estimated item parameters using Item Characteristic Curves (ICCs). On the other hand, for the polytomous risk scale we used the Rating Scale Model, an extension of the Rasch model32. Diagnostics including item fit, global model fit, and joint ICCs were computed and results thereof are available in the supplementary material.
We computed the reliability analysis measures including Cronbach's alpha, Guttman’s lambda-6, beta, and omega. Furthermore, we compared psychometric properties of the short version we proposed with the original ABCD questionnaire.
Ethics and participant consent
Along with the whole project, the protocol of this population survey was approved by the ethical committee of the University of Antwerp hospital (Approval No: B300201940009). Upon detailed description of study aim and procedures, informed consent was obtained from all study participants. The study was in accordance with the principles of the declaration of Helsinki.
Results
Socioeconomic characteristics of participants
The mean age of participants was 49.9 years (SD: 15.9). Majorities (57.7%) were females and 81 (15.5%) were born in non-European countries. Above half (56.2%) were married, whereas 62 (12.1%) attended less than 10 years of education.
Item descriptives
Almost all items had sufficient variation to differentiate respondents’ level of knowledge. The correlation matrix indicated that a strong correlation between item 1 (‘Stress is one of the main causes of heart attacks and strokes’) and 5 (‘Managing one’s stress levels will help to manage blood pressure’) (Spearman’s rho (rs) = 0.76), and item 2 (‘Walking and gardening are considered types of exercise that can lower the risk of having a heart attack or stroke’) and 3 (‘Moderately intense activity of 2½ hours a week will reduce your chances of having a heart attack or stroke.’) (rs = 0.72). Similarly, all response options of the risk scale were well-represented except for item 4 (‘The chance that I will have a heart attack or stroke within the next ten years is high’) and 5 (‘I will probably have a heart attack or stroke because of my past and/or current lifestyle behavior’) with below 10 responses in the ‘strongly agree’ category. The correlation matrix indicated that strong correlation between item 16 (‘I am considering eating at least 5 servings of fruit and vegetables a day’) and reverse-coded item 20 (’I am not thinking eating at least 5 servings of fruit and vegetables a day’) (rs = 0.84), and item 10 (‘I am considering exercising 30 min for at least 5 times a week’) and reverse-coded item 13 (‘I am not thinking exercising 30 min for at least 5 times a week’) (rs = 0.86). Details on the frequencies of individual response options and correlation plots are available in the supplementary material.
Exploratory and confirmatory factor analysis of the risk scale
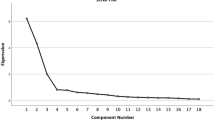
Our analysis demonstrated that the data was adequate for factor analysis based on the KMO (0.88) and Bartlett’s test of sphericity (2699.8, p < 0.001). Using the scree plot (Fig. 1a), and parallel analysis, a three-factor solution emerged, which accounted for 68.5% of the total variance. The very simple structure (Fig. 1b) also showed a three-factor solution was optimal (Velicer’s Minimum Average Partial test = 0.02).The pattern of factor loadings in our analysis slightly varied from the original subscales. The domains in the original subscales were risk perception, benefit finding and healthy eating intentions. Whereas in our analysis the domains are somehow similar with different loading patterns and we named them as; factor1—risk perception, factor2- perceived benefit and intention to change PA, and factor3—perceived benefit and intention to change dietary habit (Table 1). We performed a CFA and the results indicated that the model fit was moderately acceptable (X2 = 560.7, df = 167, p < 0.001; CFI = 0.92; TLI = 0.91; RMSEA = 0.07, 95% confidence interval (CI) (0.06, 0.8); SRMR = 0.04). Standardized covariances ranged from 0.10 (p < 0.01) between factor 1 and 2 to 0.25 (p < 0.001) between factor 2 and 3. Extended results of the CFA are available in the supplementary material.

Scree plot (a) and very simple structure (b) of the exploratory factor analysis of the risk scale.
Mokken scaling analysis
The MSA showed that the coefficient of homogeneity (H) for the whole knowledge scale was 0.38 (standard error (SE) = 0.03), which is a weak but acceptable scalability. However, individual item coefficients showed that items 6 (‘Drinking large amounts of alcohol can increase your cholesterol and other blood fats’) and 7 (‘There is 'good' and there is 'bad' cholesterol’) had H below 0.3, which violates the criterion of scalability. Furthermore, these items also showed deviation from monotonicity.
The H for the entire risk scale was 0.44 (SE = 0.03), indicating a moderate accuracy. However, the individual H values and monotonicity indices indicated violation of homogeneity and monotonicity for some items. Then, we performed the MSA on each subscale of the risk scale separately based on the results of EFA. Hence, the overall H was 0.64 (SE = 0.02), 0.71 (SE = 0.02) and 0.72 (SE = 0.02) for risk perception, perceived benefit of PA, and dietary habit, respectively. Moreover, all items in the respective subscales had H positive and above 0.3, which is an acceptable level of homogeneity. Details of the MSA of the knowledge scale and each domain of the risk scale are available in the supplementary material.
Rasch and two-parametric logistic (2-PL) model of the knowledge scale
We compared the performance of the Rasch and 2-PL model using the Likelihood-Ratio (LR) test and the fit was significantly different (p < 0.001), indicating that the more complex 2-PL model performed better than the Rasch model. Hence, the results of the 2-PL model are summarized in Table 2 and the ICCs are displayed in Fig. 2. The result showed that question 9 was the easiest (%Correct = 92.0%; δ = − 2.65; SE = 0.41) and question 8 was the most difficult item (%Correct = 27.8%; δ = 0.87; SE = 0.11). The discrimination parameters also showed heterogeneity, question 3 and 6 respectively had the highest (α = 3.82; SE 0.77) and the lowest (α = 0.86; SE = 0.14) discrimination. The model fit was adequate, with average infit and outfit mean square statistics (MSQ) around 1.00. The infit and outfit MSQs for all individual items were within the acceptable range, except for item 3, in which the infit and outfit value was 0.34 and 0.49 (below 0.6). The person-item map showed that item saturation around average levels of the latent trait and beyond ± 2, and item deficiency in between ± 1 to ± 2 (Fig. 3).

The joint Item Characteristic Curves (ICCs) of the two—parametric logistic model of ABCD-knowledge scale.

The person-item map of the Rasch model of ABCD-knowledge scale.
The estimated difficulty parameters of the Rasch model are roughly comparable to those from the 2-PL model with strong correlation in between (Pearson correlation coefficient (r) = 0.94). Details of the Rasch estimates, ICCs and LR parameters are provided in the supplementary material.
Rasch Rating Scale Model (RSM) of the risk scale
Table 3 presents the summary of item parameter estimates and infit and outfit statistics for each domain of the risk scale. We investigated whether τi1 ≤ τi2, and τi2 ≤ τi3 for each item and the result indicates the thresholds were ordered as expected given the ordinal rating scale categories for all items in all three subscales. Moreover, infit and outfit values for all the items were between 0.6 and 1.4, except for items 11 and 16 which fall slightly below 0.6, indicating that these items had less variation in the observed response pattern than expected by the model. Further details of individual ICCs, person-item maps for risk scale are available in the supplementary material.
Reliability analysis
The knowledge scale showed acceptable internal consistency with Cronbach’s alpha of 0.75; Guttman’s lambda-6 = 0.90; Beta = 0.58; and Omega = 0.74 (95% CI 0.70–0.78). The reliability statistics if item deleted showed no major change except for minimal increase in Cronbach’s alpha from 0.75 to 0.77 when item 7 was dropped. We computed reliability indices for each of the subscales of the risk scale and the Cronbach’s alpha coefficients were 0.93, 0.88 and 0.84 for risk perception, intention to change PA, and dietary habit, respectively, indicating an excellent internal consistency. Similarly, no major changes were observed in the reliability statistics when items deleted. Details of the reliability statistics for both knowledge and each domain of the risk scale are available in the supplementary material.
Short scale version
We also tested the reliability of a short version of ABCD questionnaire. Based on the factor loadings, psychometric properties (CTT and IRT), and subjective judgement, we selected seven items from the knowledge scale, and five items from each construct of the risk scale. The shorter version of the knowledge scale (7-items) provided a good internal consistency (Cronbach’s alpha = 0.76; Guttman’s lambda-6 = 0.79; Beta = 0.54; and Omega = 0.71 (95% CI 0.65, 0.78)). The correlation with the original version was sufficient (r = 0.95). Similarly, the shorter version of risk perception, perceived benefit of PA and dietary habit showed an excellent internal consistency (Cronbach’s alphas equal to 0.91, 0.85, and 0.82, respectively) with strong correlation with their original versions. Details are available in the supplementary material.
Discussion
With the continuing burden of CVDs, targeting knowledge and risk perception of adults is vital to improve healthy lifestyle. In response to the need for a valid and reliable tool to measure CVD knowledge and risk perception, Woringer and her colleagues developed the ABCD questionnaire. To the best of our knowledge, the ABCD questionnaire is not translated and validated to be used in Belgium. Therefore, we conducted a validation study on a random sample of adults in selected districts to examine the psychometric properties of the Dutch (Flemish) version of the questionnaire. Our analyses demonstrated that both the knowledge and each domain of the risk scale have good psychometric properties. Hence, the Flemish version of ABCD questionnaire could be a valuable tool for researchers, public health and clinical practitioners to assess an individual’s level of CVD knowledge, self-perceived risk to take appropriate measures accordingly. Furthermore, it can be utilized to monitor and evaluate the effectiveness of interventions and programs aimed at improving CVD risks awareness, perception and intention to change. For coaching and intervention purposes specific items might be considered as some items more emphasize on the perceived benefit, whereas some others focus on intention to change and self-efficacy measures.
We confirmed a three-factor structure for the 20-item risk scale comprising risk perception, perceived benefit and intention to change PA, and perceived benefit and intention to change dietary habits. These three factors accounted for 68.5% of the total variance. The pattern of factor loadings in our analysis was slightly different from the original subscales. The original subscales were risk perception, benefit finding and healthy eating intentions. The Hungarian version of ABCD questionnaire also replicated the same constructs as the original ones, however, the pattern of factor loadings somewhat varied33. In our analysis the factor loading of the two latent constructs are slightly different from the original subscales. Item 14 (‘When I eat at least five portions of fruit and vegetables a day I do something good for the health of my heart.’), which was in factor 2 showed a better loading to factor 3 in our analysis. The two additional items related to healthy dietary habit also loaded to factor 3 along with three items of the original subscale (health eating intention). We tested the factorial structure using CFA and the model fit was better. The two added items have similar construct with the 3 items of healthy eating intentions (factor-3) of the original subscales and item 14 which is logically related to healthy diet intention rather than PA. Furthermore, the difference in ordering of the questions could also contribute to the variation in factorial structure34,35.
As demonstrated in the MSA, most of the items in the knowledge scale have good scalability and monotonicity coefficients, except for items 6 and 7, which might not be applicable as a unidimensional scale with other items. This implies that these items might have a different underlying construct compared to the rest of the items. Hence, using these items along with other items to measure CVD knowledge might be misleading. Whereas, the rest of the knowledge scale items are homogenous and unidimensional. Likewise, each domain of the risk scale showed a good scalability property, indicating that the subscales are sufficiently homogenous and the application of risk subscales by adding the individual item scores could be suitable to measure underlying constructs.
The 2-PL model showed that the infit and outfit statistics of most of the knowledge items were within the acceptable range, implying that the items have sufficient contribution to the overall score of knowledge. Furthermore, the model also showed that items differ not only in difficulty but also in discriminatory potential. However, items of the knowledge scale are saturated around the average levels of knowledge, indicating the need for additional items to better locate individuals’ CVD risk knowledge level. In this regard, the Rasch model also indicated on average, the respondents were located higher than the knowledge scale, suggesting that the items might be relatively easy for participants. Thus, adding more difficult items of various dimensions on the knowledge scale is recommended to provide a better insight in the individual’s CVD knowledge level and to differentiate participants sufficiently in this regard.
The Rasch rating scale model for each domain of the risk scale showed that infit and outfit statistics for all the items were within the acceptable range, except for item 11 and 16, which fall below 0.6, showing items had less variation in the observed response pattern and might have strong correlation with other items. This signifies the possibility of item modification or reduction in the risk scale.
Our reliability analysis indicated that the knowledge scale has moderate internal consistency with Cronbach’s alpha of 0.75, which is higher than the result shown in the previous validation study in Hungary and Australia33,36. The reliability indices for each subscales of the risk scale showed a good internal consistency, which is coherent with the findings of the original study, the Hungarian version and a revalidation in Australia, though the loadings vary to some extent22,33,36.
We reduced the items and tested the psychometric properties of a short version of the ABCD questionnaire. The shorter version of the knowledge scale (7-item) is almost as good as the original one based on the internal consistency measures and it also has sufficient correlation with the original scale. However, internal consistency measures might not always be a good indicator as smaller number of items usually resulted in a better consistency. Moreover, as indicated in the Rasch analysis, the knowledge items are relatively easy and not sufficient at each level of participants’ latent ability. Hence, we recommend changing item 6 and 7 as well as adding more items of the knowledge in order to measure multiple dimensions of CVD knowledge. The shorter version of risk perception, perceived benefit and intention to change of physical activity, and diet showed an excellent internal consistency and strong correlation with the scores of respective longer versions. Therefore, this study showed that the ABCD questionnaire could be applicable in future studies, clinical and public health practices to measure an individual’s CVD knowledge and risk perception.
The present study has limitations that need to be considered in interpretation of findings. First, due to the nature of postal and online surveys, we had a high rate of non-response. However, the use of matched substitution technique helped the survey to have a prefixed net sample sizes within age groups, sex and geographical location that improved the representativeness across socioeconomic groups. Second, we did not measure other variables such as family history of CVD and self-perceived health, which might theoretically be related to dietary and physical activity behaviors.
In conclusion, results of the psychometric investigation suggest that the Flemish version of ABCD risk questionnaire has an acceptable property to assess an individual’s CVD risk perception, perceived benefit and intention to change physical activity and dietary habit. Hence, the measure is acceptable to be used among adults in Belgium, particularly Flanders context. Moreover, with minor contextual modifications, the questionnaire could be employed in the Netherlands and other areas where Dutch-speaking communities live. Similarly, the ABCD knowledge scale also showed good psychometric property, however, the item was relatively easy and it might not be comprehensive to assess many aspects of CVD risk factors. Therefore, we recommend addition of more items in order to have a better insight on knowledge and to be able to differentiate participants well. Since we did not use a French or German version of the questionnaire, the results might not be generalizable to French- and German-speaking communities within Belgium.
Data availability
Data will be available on reasonable request.
References
WHO. A global factsheet on cardiovascular diseases 2017 [Jan 20, 2020]. https://www.who.int/news-room/fact-sheets/detail/cardiovascular-diseases-(cvds).
Roth Gregory, A. et al. Global burden of cardiovascular diseases and risk factors, 1990–2019. J. Am. Coll. Cardiol. 76(25), 2982–3021. https://doi.org/10.1016/j.jacc.2020.11.010 (2020).
WHO regional office for Europe. Cardiovascular Diseases; Data and Statistics [Feb 1, 2020]. http://www.euro.who.int/en/health-topics/noncommunicable-diseases/cardiovascular-diseases/data-and-statistics.
Townsend, N. et al. Cardiovascular disease in Europe: Epidemiological update 2016. Eur. Heart J. 37(42), 3232–3245. https://doi.org/10.1093/eurheartj/ehw334 (2016).
Timmis, A. et al. European society of cardiology: Cardiovascular disease statistics 2017. Eur. Heart J. 39(7), 508–579. https://doi.org/10.1093/eurheartj/ehx628 (2018).
EUROstat. Causes of death — diseases of the circulatory system, residents 2016. https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Causes_of_death_statistics.
Arsenault, B. J. et al. Physical inactivity, abdominal obesity and risk of coronary heart disease in apparently healthy men and women. Int. J. Obes. (Lond.) 34(2), 340–347. https://doi.org/10.1038/ijo.2009.229 (2010).
Kromhout, D. Diet and cardiovascular diseases. J. Nutr. Health Aging. 5(3), 144–149 (2001).
Silverman, A. L., Herzog, A. A. & Silverman, D. I. Hearts and minds: Stress, anxiety, and depression: Unsung risk factors for cardiovascular disease. Cardiol. Rev. 27(4), 202–207. https://doi.org/10.1097/crd.0000000000000228 (2019).
Fang, J., Moore, L., Loustalot, F., Yang, Q. & Ayala, C. Reporting of adherence to healthy lifestyle behaviors among hypertensive adults in the 50 states and the District of Columbia, 2013. J. Am. Soc. Hypertens. 10(3), 252–62.e3. https://doi.org/10.1016/j.jash.2016.01.008 (2016).
Sheeran, P., Harris, P. R. & Epton, T. Does heightening risk appraisals change people’s intentions and behavior? A meta-analysis of experimental studies. Psychol. Bull. 140(2), 511–543. https://doi.org/10.1037/a0033065 (2014).
Lynch, E. B., Liu, K., Kiefe, C. I. & Greenland, P. Cardiovascular disease risk factor knowledge in young adults and 10-year change in risk factors: The Coronary Artery Risk Development in Young Adults (CARDIA) Study. Am. J. Epidemiol. 164(12), 1171–1179. https://doi.org/10.1093/aje/kwj334 (2006).
Homko, C. J. et al. Cardiovascular disease knowledge and risk perception among underserved individuals at increased risk of cardiovascular disease. J. Cardiovasc. Nurs. 23(4), 332–337. https://doi.org/10.1097/01.JCN.0000317432.44586.aa (2008).
Ko, Y. & Boo, S. Self-perceived health versus actual cardiovascular disease risks. Jpn. J. Nurs. Sci. 13(1), 65–74. https://doi.org/10.1111/jjns.12087 (2016).
Imes, C. C. & Lewis, F. M. Family history of cardiovascular disease, perceived cardiovascular disease risk, and health-related behavior: A review of the literature. J. Cardiovasc. Nurs. 29(2), 108–129. https://doi.org/10.1097/JCN.0b013e31827db5eb (2014).
Albarqouni, L. et al. Patients’ knowledge about symptoms and adequate behaviour during acute myocardial infarction and its impact on delay time: Findings from the multicentre MEDEA Study. Patient Educ. Couns. 99(11), 1845–1851 (2016).
Liu, Q. et al. Association between knowledge and risk for cardiovascular disease among older adults: A cross-sectional study in China. Int. J. Nurs. Sci. 7(2), 184–190. https://doi.org/10.1016/j.ijnss.2020.03.008 (2020).
Claassen, L., Henneman, L., van der Weijden, T., Marteau, T. M. & Timmermans, D. R. Being at risk for cardiovascular disease: Perceptions and preventive behavior in people with and without a known genetic predisposition. Psychol Health Med. 17(5), 511–521. https://doi.org/10.1080/13548506.2011.644246 (2012).
DeSalvo, K. B. et al. Cardiac risk underestimation in urban, black women. J Gen. Intern. Med. 20(12), 1127–1131. https://doi.org/10.1111/j.1525-1497.2005.00252.x (2005).
Wilson, R. S., Zwickle, A. & Walpole, H. Developing a broadly applicable measure of risk perception. Risk Anal. 39(4), 777–791. https://doi.org/10.1111/risa.13207 (2019).
Wagner, J., Lacey, K., Chyun, D. & Abbott, G. Development of a questionnaire to measure heart disease risk knowledge in people with diabetes: The Heart Disease Fact Questionnaire. Patient Educ. Couns. 58(1), 82–87. https://doi.org/10.1016/j.pec.2004.07.004 (2005).
Woringer, M. et al. Development of a questionnaire to evaluate patients’ awareness of cardiovascular disease risk in England’s National Health Service Health Check preventive cardiovascular programme. BMJ Open 7(9), e014413. https://doi.org/10.1136/bmjopen-2016-014413 (2017).
Marmot, M. & Bell, R. Fair society, healthy lives. Public Health 126, S4–S10 (2012).
Demarest, S. et al. Sample substitution can be an acceptable data-collection strategy: The case of the Belgian Health Interview Survey. Int. J. Public Health 62(8), 949–957. https://doi.org/10.1007/s00038-017-0976-3 (2017).
Blumenberg, C. et al. The role of questionnaire length and reminders frequency on response rates to a web-based epidemiologic study: A randomised trial. Int. J. Soc. Res. Methodol. 22(6), 625–635. https://doi.org/10.1080/13645579.2019.1629755 (2019).
Christensen, A. I. et al. The effect of multiple reminders on response patterns in a Danish health survey. Eur. J. Pub. Health 25(1), 156–161. https://doi.org/10.1093/eurpub/cku057 (2014).
Dima, A. L. Scale validation in applied health research: Tutorial for a 6-step R-based psychometrics protocol. Health Psychol. Behav. Med. 6(1), 136–161. https://doi.org/10.1080/21642850.2018.1472602 (2018).
Mokken RJ. A theory and procedure of scale analysis: With applications in political research: Walter de Gruyter; 2011.
Hu, L. T. & Bentler, P. M. Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Struct. Equ. Model. Multidiscip. J. 6(1), 1–55. https://doi.org/10.1080/10705519909540118 (1999).
van Schuur, W. H. Mokken scale analysis: Between the guttman scale and parametric item response theory. Polit. Anal. 11(2), 139–163. https://doi.org/10.1093/pan/mpg002 (2003).
Rasch G. Probabilistic models for some intelligence and attainment tests: ERIC; 1993.
Andrich, D. A rating formulation for ordered response categories. Psychometrika 43(4), 561–573. https://doi.org/10.1007/BF02293814 (1978).
Martos, T. et al. Cardiovascular disease risk perception in a Hungarian community sample: Psychometric evaluation of the ABCD Risk Perception Questionnaire. BMJ Open 10(7), e036028. https://doi.org/10.1136/bmjopen-2019-036028 (2020).
Lavrakas, P. Encyclopedia of survey research. Methods https://doi.org/10.4135/9781412963947 (2008).
Royal, K. D. The impact of item sequence order on local item dependence: An item response theory perspective. Surveill. Soc. 9(4), 1–7 (2016).
Obamiro K, Lee S, Cooper A, T B. The ABCD Risk Questionnaire: Further evidence of validity and reliability using a Facebook sample. JMIR Preprints. 2019. https://doi.org/10.2196/preprints.16839.
Acknowledgements
We express our gratitude to the administration of the city of Antwerp, particularly, Daniel Van Nijlen and Jerry Ruys for providing us the random samples and constructive suggestions on the postal and online survey procedures.
Funding
This work was supported by the European Commission through the Horizon2020 research and innovation action, grant agreement ID: 733356.
Author information
Authors and Affiliations
Contributions
H.Y.H., H.B. and S.A. conceived and designed the study. H.Y.H. performed the statistical analysis and interpretation of findings with close supervision of H.B. and S.A. H.Y.H., H.B., N.A. and S.A. contributed to the development of the questionnaire and reviewing literature. S.D. and D.M. supported the statistical analysis and survey methodology. H.Y.H. wrote the first draft. All authors critically reviewed the manuscript for the intellectual content. All authors contributed to the design of the study, read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hassen, H.Y., Aerts, N., Demarest, S. et al. Validation of the Dutch-Flemish translated ABCD questionnaire to measure cardiovascular diseases knowledge and risk perception among adults. Sci Rep 11, 8952 (2021). https://doi.org/10.1038/s41598-021-88456-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-021-88456-5
- Springer Nature Limited
This article is cited by
-
Translation and validation of the Chinese ABCD risk questionnaire to evaluate adults’ awareness and knowledge of the risks of cardiovascular diseases
BMC Public Health (2022)
-
Level of cardiovascular disease knowledge, risk perception and intention towards healthy lifestyle and socioeconomic disparities among adults in vulnerable communities of Belgium and England
BMC Public Health (2022)
-
Psychometric properties of the Chinese version of Attitudes and Beliefs about Cardiovascular Disease Risk Perception Questionnaire
Scientific Reports (2022)