
Abstract
Automatic and reliable segmentation of the hippocampus from magnetic resonance (MR) brain images is extremely important in a variety of neuroimage studies. To improve the hippocampus segmentation performance, a local binary pattern based feature extraction method is developed for machine learning based multi-atlas hippocampus segmentation. Under the framework of multi-atlas image segmentation (MAIS), a set of selected atlases are registered to images to be segmented using a non-linear image registration algorithm. The registered atlases are then used as training data to build linear regression models for segmenting the images based on the image features, referred to as random local binary pattern (RLBP), extracted using a novel image feature extraction method. The RLBP based MAIS algorithm has been validated for segmenting hippocampus based on a data set of 135 T1 MR images which are from the Alzheimer’s Disease Neuroimaging Initiative database (adni.loni.usc.edu). By using manual segmentation labels produced by experienced tracers as the standard of truth, six segmentation evaluation metrics were used to evaluate the image segmentation results by comparing automatic segmentation results with the manual segmentation labels. We further computed Cohen’s d effect size to investigate the sensitivity of each segmenting method in detecting volumetric differences of the hippocampus between different groups of subjects. The evaluation results showed that our method was competitive to state-of-the-art label fusion methods in terms of accuracy. Hippocampal volumetric analysis showed that the proposed RLBP method performed well in detecting the volumetric differences of the hippocampus between groups of Alzheimer’s disease patients, mild cognitive impairment subjects, and normal controls. These results have demonstrated that the RLBP based multi-atlas image segmentation method could facilitate efficient and accurate extraction of the hippocampus and may help predict Alzheimer’s disease. The codes of the proposed method is available (https://www.nitrc.org/frs/?group_id=1242).
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
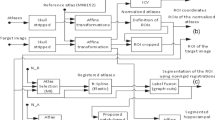
Accurate and automatic hippocampus segmentation from magnetic resonance (MR) brain images is important in several neuroimaging studies of brain disorders, such as brain cancer, epilepsy, and Alzheimer’s disease (AD)1,2,3. To achieve fully automated hippocampus segmentation, atlas-based methods have been proposed for hippocampus segmentation4. These methods typically adopt an atlas image with a manually labeled hippocampus and use a nonlinear image registration algorithm to align the atlas to the image to be segmented, referred to as a target image hereafter, and the segmentation of the target image is then achieved by propagating the atlas label to the target image space. However, there may be a limit to the performance of these techniques for a case in which there exists a large anatomic difference between the atlas and target images, which would make the image registration difficult.
To partially circumvent this problem, multi-atlas image segmentation (MAIS) methods have been proposed5,6. In contrast to the single-atlas image segmentation method, the MAIS methods generally comprise image registration and label fusion. In MAIS methods, each atlas image is first registered to the target image and the atlas label is propagated to the target image space accordingly7. The propagated label maps are then fused to get a final segmentation8. In some MAIS methods, a small number of atlas images that are better matched with the target image are selected instead of using all the available atlas images9,10,11,12.
In the MAIS methods, the label fusion step is a core component as it fuses the propagated atlas labels to obtain the image segmentation result. Several label fusion strategies have been developed, such as majority voting6 and weighted voting13. For better accounting for the image registration errors, nonlocal patch-based (NLP) methods were proposed14,15. In the NLP methods, for labeling a target image voxel a number of voxels in the searching region in each atlas image are considered and high weight factors are assigned to those more similar to the target image voxel. To improve the accuracy and robustness of the NLP methods, several label fusion methods have been proposed, including sparse representation16,17, dictionary learning18, manifold learning19,20,21,22, and joint label fusion (JLF)23. In addition to these methods, NLP methods have also been combined with statistical label fusion methods5, which have been highly successful24,25,26.
Recently, pattern recognition based label fusion methods have been developed and successfully applied to a variety of medical image segmentation problems10,27,28,29,30. These methods solve the image segmentation problem as a pattern recognition problem by considering registered atlas images as training data in order to build pattern recognition models for predicting the segmentation labels of images to be segmented. It has been demonstrated that feature extraction is important in pattern recognition based label fusion methods10,27. For example, image intensity and texture image features were adopted to train support vector machine (SVM) classifiers for predicting segmentation labels10,27, the random forest classification algorithm was adopted to construct classifiers for label fusion using local and contextual image features28,29, artificial neural networks were built for label fusion using statistical and textural features30. The studies on the aforementioned methods have demonstrated that MAIS algorithms could achieve improved performance by building pattern recognition models using rich image features.
In this paper, we propose a novel feature extraction method based on local binary pattern (LBP) features31,32, referred to as random local binary pattern (RLBP), for building linear regression models to achieve reliable and accurate label fusion in MAIS. We have illustrated that the proposed RLBP method is more robust to image noise than the LBP method and is capable of capturing discriminative information for the image segmentation. Our method is validated for segmenting hippocampi from MR brain images. In the validation experiment, we compared the proposed RLBP method with the LBP method32. The results showed that our method could provide more accurate segmentation results than the LBP method. We also compared our method with state-of-the-art label fusion methods, including NLP14,15, local label learning (LLL)10, JLF23, and nonlocal weighted voting with metric learning (NLW-ML)33. The results demonstrated that our RLBP method was competitive to state-of-the-art label fusion methods. In addition, we also performed a hippocampal volumetric analysis experiment. The obtained results demonstrated that our RLBP method performed well in detecting the volumetric differences of the hippocampus between AD, mild cognitive impairment (MCI), and normal control (NC) groups. Part of this work has been previously presented in34.
Materials and Methods
Imaging data
A dataset comprising 135 T1 MRI scans with manually labeled hippocampi from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (adni.loni.usc.edu/) was used for validating the proposed algorithm. The ADNI was launched in 2003 as a public-private partnership, led by Principal Investigator Michael W. Weiner, MD. The primary goal of ADNI has been to test whether serial magnetic resonance imaging, positron emission tomography, other biological markers, and clinical and neuropsychological assessment can be combined to measure the progression of mild cognitive impairment and early Alzheimer’s disease. For up-to-date information, see www.adni-info.org. The ADNI MRI scans were acquired using a sagittal 3D MP-RAGE T1-w sequence (TR = 2400 ms, minimum full TE, TI = 1000 ms, FOV = 240 mm, voxel size of \(1.25\times 1.25\times 1.2{{\rm{mm}}}^{3}\)).
Manual labeling of hippocampus
Hippocampus labels of the image data in the Neuroimaging Informatics Technology Initiative format were provided by the European Alzheimer’s Disease Consortium and Alzheimer’s Disease Neuroimaging Initiative harmonized segmentation protocol (EADC–ADNI)35, which can be publicly downloaded (www.hippocampal-protocol.net). The dataset consists of a preliminary release part with 100 subjects and a final release part with 35 subjects. In the preliminary release part, one subject’s hippocampus label missed several slices. In the final release part, the hippocampus labels and the images of three subjects are not well matched. Their subject identification numbers are 002_S_0938, 007_S_1304, 029_S_4279 and 136_S_0429 respectively. Such problems might be caused by imaging data format conversion. Figure 1 shows these MR brain scans and their corresponding hippocampus labels. We used the remaining 32 subjects in the final release part as a training data set and the remaining 99 preliminary release subjects as a testing data set in the present study.

MR brain images (top row) with problematic hippocampus labels (bottom row).
The training data set contains 14 NC, 11 MCI, and 7 AD subjects (see Table 1). The testing data set contains 29 NC, 34 MCI, and 36 AD subjects (see Table 2). The testing MCI subjects were further classified as stable MCIs (sMCI, n = 11) and progressive MCIs (pMCI, n = 21), according to the ADNI clinical data downloaded on July 17, 2017. However, 2 MCI subjects could not be assigned to either sMCI or pMCI groups due to missing data.
All the MR brain images were aligned along the line that passes through the anterior and posterior commissures of the brain, corrected for their bias field, and finally spatially normalized to the MNI152 template space using affine transformation35.
Atlas selection and registration
To reduce the computation cost and improve the registration accuracy, we identified two bounding boxes, one for the left hippocampus and the other for the right hippocampus. In particular, the sizes of the obtained bounding boxes were \(48\times 77\times 67\) and \(47\times 70\times 66\) for the left and right hippocampi respectively, which were large enough for covering the hippocampi of an unseen target image10,36. To improve the segmentation performance, we selected \(N\) atlases which were most similar to the target image based on normalized mutual information of the image intensities within the bounding box9. Then, we used a nonlinear, cross-correlation-driven image registration algorithm to register these atlas images to the target images to achieve a better local anatomy matching between the target image and each atlas image37. To further reduce the computation cost, the majority voting label fusion was performed to get an initial segmentation for the target image. We then applied the proposed method introduced in the following two subsections to segment voxels which did not receive a unanimous vote in the majority voting label fusion10.
Machine learning based MAIS
With atlas selection and image registration, we have \(N\) warped atlases \({A}_{i}=({I}_{i},{L}_{i}),\,i=1,2,\ldots ,N\), where \({I}_{i}\) is the i-th warped atlas image and \({L}_{i}\) is its warped label map. A machine learning based MAIS method is to infer the label map of the target image \(I\) by building prediction models based on the warped atlases such that the image segmentation problem is solved as a pattern recognition problem.
To label the target voxel x, a set of training voxels is identified in a cube-shaped searching neighborhood \(N(x)\) of size \((2{r}_{s}+1)\times (2{r}_{s}+1)\times (2{r}_{s}+1)\) of the corresponding voxel \(X\) from all atlas images, and a feature vector for each of the training voxels is extracted to characterize the local image information. By denoting the feature vector of the target voxel by \({f}_{x}\), the feature vector of voxel \(j\) of the \({i}^{th}\) atlas by \({f}_{i,j}\) and its corresponding segmentation label by \({l}_{i,j}\in \{-1,1\}\) where 1 represents the region of interest and −1 represents the background, we obtain a training set \({D}_{x}=\{({f}_{i,j},{l}_{i,j})|i=1,\mathrm{..},N,\,j\in N(x)\}\). A pattern recognition model is finally built by using the training set \({D}_{x}\) to predict the segmentation label of the test sample \({f}_{x}\).
RLBP feature extraction method
To characterize each image voxel, a new feature extraction method is developed based on the LBP image feature extraction method32. In particular, the LBP image feature extraction method was developed for 2D images. Given a \(3\times 3\) neighboring system as illustrated by Fig. 2, the LBP features are computed as
where \(s(x)=\{\begin{array}{c}1,\,x\ge 0\\ 0,\,x < 0\,\end{array}\), and \({g}_{c}\) and \({g}_{p}\) are the image intensity values of the center pixel and its neighboring voxels respectively. The binarization of the local image intensity difference makes LBP features robust to illumination and image contrast variations. However, it is sensitive to image noise38.

Illustration of the image neighborhood for computing LBP features.
In order to obtain more discriminative and robust image features, we propose an RLBP feature extraction method, as illustrated in Fig. 3. First, we extend the LBP method to be applicable to 3D images. Thus, for a voxel \(C\) in a 3D image with a cubic image patch centered at itself with \((2{r}_{p}+1)\times (2{r}_{p}+1)\times (2{r}_{p}+1)\) voxels, a difference image intensity vector is computed using
where \({x}_{i},\,i=1,\ldots ,n\) is the image intensity value of a voxel in the cubic image patch, and \({x}_{c}\) is the image intensity value of the voxel \(c\).

Illustration of the computation of RLBP features.
Then, we constructed a large number of random transformation functions to generate RLBP features with the following formula,
where \({h}_{j}(\overrightarrow{y})=s({\overrightarrow{w}}_{j}\cdot \overrightarrow{y})=\{\begin{array}{c}1,\,{\overrightarrow{w}}_{j}\cdot \overrightarrow{y}\ge 0\\ 0,\,{\overrightarrow{w}}_{j}\cdot \overrightarrow{y} < 0\end{array},\,j=1,\ldots ,L\), “·” represents the dot multiplication of vectors, and \({\overrightarrow{w}}_{j}\in {R}^{n}\) is a random vector whose values are uniformly distributed in \([-1,1]\). Using the RLBP feature extraction method, a feature vector \(\overrightarrow{f}(c)=h(\overrightarrow{y})\) is obtained for the given voxel \(c\).
The LBP method obtains the binarized values directly from the sign of the differences between the adjacent pixels and the center pixel regardless of the absolute value of the differences. It has been demonstrated that small pixel difference is vulnerable to noise38. In contrast to the LBP method, the proposed RLBP method adopts a large number of random weights to obtain weighed sums of the image difference vectors before the binarization. The random combination processing increases the robustness of the image difference as illustrated by the example shown in Fig. 4. Particularly, Fig. 4 shows a 2D image patch and a version of it that is corrupted by noise. Their LBP features are (\(01110111\)) and (\(11011111)\), which are different in 3 out of 8 bits. By setting \({\rm{L}}=20\) (the dimension of the generated RLBP feature is 20) for 100 computations, the RLBP features of these two image patches are the same in 68 computations, different in 1 bit in 24 computations, different in 2 bits in 7 computations, and different in 3 bits in 1 computation, thus illustrating that the RLBP features are statistically more robust to image noise than the LBP features.

Example image patch, the version of it that is corrupted by noise, and the histogram of the differences between the RLBP features, for 100 computations.
Linear regression with RLBP features for label fusion
Based on the generated RBLP features \({\overrightarrow{f}}_{i,j}\) and the corresponding label \({l}_{i,j}\), we use the following linear regression model to predict the label of target voxel,
where \(\Vert \cdot \Vert \) is the L2 norm and \(C\) is a balance parameter between the data fitting cost and the regularization term.
To solve the optimization problem of Eq. (4), we let the gradient of \(F(\overrightarrow{\beta })\) be equal to zero,
By reorganizing Eq. (5), we obtain
where \(I\) is an identity matrix. We then obtain
and estimate the label of the target voxel as
Parameter optimization
There are five parameters in our method, including the number of selected atlases (\(N\)), the dimension of the generated RLBP feature \((L)\), balance parameter \((C)\) in the linear regression model, search radius \(({r}_{s})\), and patch radius \(({r}_{p})\). We first chose the best value of \(N\) from {5, 10, 15, 20, 25, 30} using the baseline majority voting label fusion method. We fixed the searching radius to \({r}_{s}=1\), since a nonlinear image registration algorithm was used to warp the atlas images to the target image 10,33, and selected the best value of \(L\) from {100, 500, 1000, 1500, 2000}. Finally, we determined the other two parameters \(C\) and \({r}_{p}\) empirically from {\({4}^{-5},{4}^{-4},\ldots ,{4}^{0}\)} and \(\{1,2,3,4,5\}\) using a grid-searching strategy. We performed leave-one-out cross-validation experiments based on the training set for optimizing these parameters.
Evaluation metrics for segmentation results
The segmentation accuracy of the proposed method was evaluated by using the test dataset. We evaluated the image segmentation results using six segmentation evaluation metrics that measure differences between the automatic segmentation results and their corresponding manual segmentation labels in different aspects, including Dice coefficient (Dice), Jaccard, Precision, Recall, volume difference (dVol), and mean distance (MD). These metrics are defined as,
where \(A\) is the manual segmentation, \(B\) is the automated segmentation, \(\bar{A}\) and \(\bar{B}\) are the complements of \(A\) and \(B\), \(V(X)\) is the volume of \(X\), \(\partial A\) is a set of the boundary voxels of \(A\), and \(d(\cdot ,\cdot )\) is the Euclidian distance between two voxels.
The correlation coefficients between the hippocampal volumes estimated using the manual segmentation and the automatic segmentation methods were also computed.
Comparison of the proposed method with state-of-the-art algorithms
The proposed method was compared with state-of-the-art label fusion methods, including NLP14, LLL10, JLF23 and NLW-ML33. The parameters of all these methods were also optimally selected according to the results of leave-one-out cross-validation experiments on the training set. As in the case of the RLBP, the searching radius rs was fixed as 1 (searching neighborhood V with a size of 3 × 3 × 3) for all these methods.
The NLP method comprises two additional parameters, which include patch radius \({r}_{p}\) and \({\sigma }_{x}\) in the Gauss function. \({\sigma }_{x}\) was set as \({\sigma }_{x}=mi{n}_{{x}_{s,j}}\{{\Vert P(x)-P({x}_{s,j})\Vert }_{2}+\varepsilon \},\,s=\mathrm{1..}N,\,j\in V\), where \(\varepsilon =1e-20\) used to ensure numerical stability14,15. The best value of \({r}_{p}\) was selected from {1, 2, 3, 4}. For the LLL method, the parameter C in the sparse linear SVM classifiers was set to its default vaule (C = 1). The patch radius \({r}_{p}\) and the number of training samples \(k\) were determined from {1, 2, 3, 4} and {300, 400, 500} using the grid-searching strategy. For the JLF method, the patch radius \({r}_{p}\) and parameter \(\beta \) were determined from {1, 2, 3} and {0.5, 1, 1.5, 2} using the grid-searching strategy. For the NLW-ML method, the best values of two parameters \({r}_{p}\) and \(k\) were selected from {1, 2, 3} and {3, 9, 27} using the grid-searching strategy.
The proposed method (RLBP) was also compared with LBP features for label fusion using the same linear regression model to illustrate the effectiveness of the proposed RLBP feature extraction method. As the only difference between the RLBP and LBP methods is that a large number of random combinations are used in the RLBP method before binarization, parameters of the same values were used in the LBP method as RLBP.
Hippocampal volumetric analysis
A hippocampal volumetric analysis was performed based on the test dataset. As the hippocampal volume varies with the brain size, we corrected the hippocampal volumes according to the intracranial volumes estimated using SPM12 (http://www.fil.ion.ucl.ac.uk/spm/). The hippocampal volumes were then corrected using the following equation
where ICV is the intracranial volume of the testing subject whose hippocampal volume is to be corrected, and \({{\rm{ICV}}}_{mean}\) is the mean intracranial volume of all testing subjects. All volumes in formula (7) were measured in cm3.
In order to investigate the sensitivity of each method in detecting the volumetric differences of the hippocampus between the different groups including NC, MCI, and AD, we computed the Cohen’s d effect size based on the corrected hippocampal volumes. Cohen’s d effect size is defined as Cohen’s \({\rm{d}}=\frac{{m}_{1}-{m}_{2}}{S{D}_{Pooled}},\) \(S{D}_{Pooled}=\sqrt{\frac{S{D}_{1}^{2}+S{D}_{2}^{2}}{2}},\) where \(m\) and \(SD\) are the mean and standard deviation respectively 39. Based on a conventional operational definition of Cohen’s d, small, medium, and large effect sizes were defined as \({\rm{d}} < 0.5,\,0.5 < {\rm{d}} < 0.8,\) and \({\rm{d}} > 0.8\), respectively19,39.
We also carried out classification experiments to distinguish AD patients (n = 36) from NC subjects (n = 29) as well as to distinguish stable MCI (sMCI, n = 11) subjects from progressive MCI (pMCI, n = 21) subjects. The latter was served as an experiment for prediction of MCI conversion. To assess each segmentation method with respect to its classification performance, we trained and tested linear support vector machine (SVM) classifiers40 built upon the age of each subject, as well as the left and right hippocampal volume measures derived from its segmentation results. The SVM classifier was built using MATLAB (R2012a) functions with default parameter (C = 1) based on a leave-one-out (LOO) cross-validation procedure. The classification performance was evaluated based on receiver operating characteristic (ROC) curves, summarized by area under the ROC curve (AUC).
Experimental results
Parameter optimization results
The left subfigure of Fig. 5 shows the mean Dice values of segmentation results obtained by majority voting label fusion method with different number of atlases, which illustrates that n = 20 could obtain the optimal segmentation results. The right subfigure of Fig. 5 shows the mean Dice values of segmentation results obtained by the RLBP method with different values L, which demonstrates that the proposed method could perform well when L > 500, and it could obtain the best segmentation results when L was between 1000 and 1500. Thus, we chose L = 1000 for the computational efficiency. Table 3 shows the average segmentation accuracy of the RLBP method with different parameters measured in terms of the Dice index, and it can be observed that the optimal values were \(C={4}^{-4}\) and \({r}_{p}=4\). For the NLP method, the optimal value of \({r}_{p}\) was \(1\). For the LLL method, the best parameters were \({r}_{p}=3\) and \(\,k=300\). For the JLF method, the best parameters were \({r}_{p}=1\) and \(\beta =1\). For the NLW-ML method, the optimal parameters were \({r}_{p}=1\) and \(k=9\).

Mean Dice values of segmentation results obtained by majority voting label fusion method with different number of atlases (left), random local binary pattern method with different values of parameter L (right).
Segmentation accuracy results
Figure 6 shows a 2D visualization of the segmentation results of a randomly selected subject obtained using different methods, including the NLP, LLL, JLF, NLW-ML and RLBP methods. Table 4 summarizes six segmentation accuracy metrics (mean ± std) of the segmentation results of the test images obtained using the segmentation methods under comparison, including NLP, LBP, LLL, JLF, NLW-ML and RLBP methods. For each metric, the best value was highlighted in bold. The results illustrated that the proposed RLBP method performed statistically better than the NLP, LBP, and LLL methods (pair-wise Wilcoxon signed rank tests, p < 0.05) in most of the metrics used for evaluating their segmentation results. The performance of the RLBP method was comparable to that of the state-of-the-art JLF and NLW-ML algorithms. Figure 7 shows box plots of Dice, dVol and MD indexes of the segmentation results obtained using different methods, while Fig. 8 shows relative improvement of Dice values (%) achieved by RLBP method compared with other label fusion methods. Both of these figures illustrate that the RLBP method achieved competitive performance.

Hippocampus segmentation results of a randomly selected subject using different methods.

Comparison of various methods for segmenting left hippocampus (top row) and right hippocampus (bottom row) in terms of the Dice, dVol and MD indexes. In each box, the central line is the median, and the central diamond is the mean. The edges of each box are the 25th and 75th percentiles.

Relative improvement (%) achieved by our method compared with alternative state-of-the-art methods in terms of Dice index values of individual testing images. The relative improvement rates of individual testing images were ranked separately for different methods.
Figure 9 shows the scatter plots of the hippocampal volumes estimated using manual segmentation and the automatic segmentation methods, and the correlation coefficients are summarized in Table 5. All automatic segmentation methods obtained the Pearson Correlation coefficients larger than 0.93, with one-tailed p < 0.001.

Volumetric comparison of hippocampus segmentation results obtained on using the automatic methods and manual labeling. The black line represents the unity line. From top to bottom: NLP versus RLBP method, LBP versus RLBP method, LLL versus RLBP method, JLF versus RLBP method, and NLW-ML versus RLBP method. The hippocampal volumes were corrected using the total intracranial volumes. The x and y axes are volume measures (cm3) of hippocampi segmented by different methods.
Hippocampal volumetric analysis results
The corrected volumes of the left and right hippocampi by groups are summarized in Table 6, indicating that the AD subjects had smaller hippocampus than the MCI and NC subjects, and the MCI subjects had smaller hippocampus than the NC subjects. Table 7 summarizes the Cohen’s effect sizes of the hippocampal volumes between various groups. These results indicated that the hippocampal volumes estimated by different methods were sensitive in capturing the differences between AD and NC as well as between MCI and NC groups. However, all the methods, including the manual segmentation method, had median or low effect sizes between the MCI and AD groups. For the left hippocampus, LLL and RLBP methods obtained medium effect sizes (between 0.5 and 0.8), while NLP, LBP, JLF, NLW-ML methods obtained small effect sizes (smaller than 0.5). For the right hippocampus, all methods obtained small effect sizes. However, the proposed RLBP method got the largest effect size.
The performance of different SVM classifiers built upon the age of each subject, as well as the left and right hippocampal volume measures estimated by different methods is shown in Fig. 10. DeLong statistical test was further used to compare the ROC curve of the RLBP method with other methods41. Table 8 lists the AUC values, their standard errors, and p-values of the statistical tests. It can be observed that the RLBP method obtained the best AUC value for distinguishing AD from NC subjects, and the JLF and RLBP methods obtained the best AUC for distinguishing pMCI from sMCI subjects. In particular, the RLBP method was better than NLP, LBP and NLW-ML in distinguishing pMCI from sMCI subjects (p < 0.05).

ROC curves of the SVM classifiers built upon the age of each subject and hippocampal volume measures estimated by different methods under comparison. Left panel shows ROC curves for distinguishing AD patients from NC subjects, right panel shows ROC curves for distinguishing sMCI from pMCI subjects.
Computational cost
The NLP, LLL, NLW-ML, and RLBP methods were implemented using MATLAB 7.14 on a personal computer with a four-core 3.4-GHZ CPU, and the JLF method was implemented using C + + . On average, the RLBP method required approximately 8.0 min to segment one side of the hippocampus, while the NLP, LLL, NLW-ML, and JFL methods required approximately 4.0 min, 6.0 min, 20 min, and 0.5 min respectively to segment one side of the hippocampus. Note that, this is the time for feature extraction and segmentation excluding image registration.
Discussion and conclusions
Machine learning based multi-atlas label fusion methods have obtained great success in a variety of image segmentation problems. In these methods, feature extraction plays an important role10,27. In this study, we presented an RLBP feature extraction method for machine learning based label fusion. In contrast to the original LBP feature extraction method, the proposed RLBP method computes a large number of random combinations before the binarization. It is known that a small pixel difference is vulnerable to image noise, which may degrade the pattern recognition performance when the LBP features are used to build prediction models as the LBP method treats large and small differences in the same way. Benefiting from the random combination processing, the large difference will contribute more in the binarized features, which makes the proposed RLBP method more robust to image noise than LBP method. The random combination weights in the RLBP feature extraction method can be seen as random texture feature filters. Using a large number of random texture feature filters, the statistical properties of the image patches can be captured efficiently. The experiment results demonstrated that the proposed RLBP feature extraction method was more effective than the LBP method when using the same linear regression model in multi-atlas based hippocampus segmentation.
The comparison experiments with start-of-the-art multi-atlas label fusion methods demonstrated that the proposed RLBP method exhibited superior or comparable segmentation results, which were evaluated using by a variety of image segmentation metrics. It is worth noting that hippocampal volumes estimated by the automatic segmentation methods were highly correlated with the manual labeling results. The volumetric analysis experiments demonstrated that all the hippocampus segmentation methods under comparison achieved promising performance for distinghusing NC from AD and MCI subjects based on their hippocampal volume measures. We further used a linear SVM classifier with the age of each subject as well as left and right hippocampal volume measures estimated by each method as features to distinguish AD patients from NC subjects (diagnosis study) and distinguishing sMCI from pMCI subjects (prognosis study). The results showed that the RLBP method obtained the best AUC values for distinguishing AD from NC subjects, as well as for distinguishing pMCI from sMCI subjects. However, because of the limited samples, the RLBP method was only statistically better than NLP, LBP and NLW-ML for distinguishing pMCI from sMCI subjects (p < 0.05).
In the present study, linear regression models were built by using RLBP features to achieve multi-atlas label fusion. In our experiments, we also tested sparse linear SVM classifiers with RLBP features for multi-atlas label fusion. However, the results were not as good as thosed obtained by the linear regression models. Compared with training a nonlinear SVM classification model27,33, the computational cost of training a linear regression model is much lower. Thus, the proposed RLBP method was faster than the existing nonlinear SVM classification based label fusion methods27,33. The RBLP based label fusion method achieved a segmentation accuracy similar to NLW-ML with a faster computation speed33. The proposed method could be further improved by incorporating deep learning techniques in order to extract more discriminative image features42,43,44,45,46,47,48,49,50,51,52,53,54.
The proposed method is a learning-based technique, and therefore, its performance is bounded by the quality of the training and testing data. In this study, we adopted the EADC-ADNI dataset for both training and testing35. Particularly, 68 1.5 T and 67 3 T volumetric structural ADNI scans from different subjects were segmented using five qualified harmonized protocol tracers, the absolute interrater intraclass correlation coefficients of which were 0.953 and 0.975 (left and right).
As a multi-atlas segmentation method, a major issue is the high computational cost of nonlinear image registration. To reduce the computational cost, several methods have been proposed, such as the enhanced atlas-based segmentation method55, optimized patch match label fusion method56, and multi-atlas learner fusion method57. In this study, we adopted an atlas selection strategy for selecting the most similar atlases for reducing the computational cost of the nonlinear image registration9,10. However, it would be interesting to combine the proposed method with the enhanced atlas based segmentation method, the optimized patch match label fusion method, and the multi-atlas learner fusion method to further improve the computational speed. A very promising direction for improving both the computational efficiency and segmentation accuracy by utilizing deep learning techniques has been reported in recent papers42,43,44,45,46,47,48,49,50,51,52,53,54. By using deep learning techniqures, more discriminative image features can be extracted to achieve improved segmentation performance.
In conclusion, we have proposed a novel RLBP method to extract image features for building prediction models to fuse labels in the framework of multi-atlas segmentation. The results of the evaluation experiments showed that the proposed RLBP method could achieve hippocampus segmentation accuracy competitive to or comparable with that of state-of-the-art label fusion methods.
References
Wolz, R. et al. Robustness of automated hippocampal volumetry across magnetic resonance field strengths and repeat images. Alzheimer’s & Dementia 10(430–438), e432 (2014).
Akhondi-Asl, A., Jafari-Khouzani, K., Elisevich, K. & Soltanian-Zadeh, H. Hippocampal volumetry for lateralization of temporal lobe epilepsy: automated versus manual methods. NeuroImage 54, S218–S226 (2011).
Kazda, T. et al. Left hippocampus sparing whole brain radiotherapy (WBRT): A planning study. Biomedical Papers 161, 397–402 (2017).
Hosseini, M. P. et al. Comparative performance evaluation of automated segmentation methods of hippocampus from magnetic resonance images of temporal lobe epilepsy patients. Medical physics 43, 538–553 (2016).
Warfield, S. K., Zou, K. H. & Wells, W. M. Simultaneous truth and performance level estimation (STAPLE): an algorithm for the validation of image segmentation. Medical Imaging, IEEE Transactions on 23, 903–921 (2004).
Rohlfing, T., Brandt, R., Menzel, R. & Maurer, C. R. Jr Evaluation of atlas selection strategies for atlas-based image segmentation with application to confocal microscopy images of bee brains. NeuroImage 21, 1428–1442 (2004).
Doshi, J. et al. MUSE: MUlti-atlas region Segmentation utilizing Ensembles of registration algorithms and parameters, and locally optimal atlas selection. NeuroImage 127, 186–195 (2016).
Iglesias, J. E. & Sabuncu, M. R. Multi-atlas segmentation of biomedical images: A survey. Medical image analysis 24, 205–219 (2015).
Aljabar, P., Heckemann, R., Hammers, A., Hajnal, J. & Rueckert, D. Multi-atlas based segmentation of brain images: Atlas selection and its effect on accuracy. NeuroImage 46, 726–738 (2009).
Hao, Y. et al. Local label learning (LLL) for subcortical structure segmentation: Application to hippocampus segmentation. Human brain mapping 35, 2674–2697 (2014).
Dill, V., Klein, P. C., Franco, A. R. & Pinho, M. S. Atlas selection for hippocampus segmentation: Relevance evaluation of three meta-information parameters. Computers in biology and medicine 95, 90–98 (2018).
Zaffino, P. et al. Multi atlas based segmentation: Should we prefer the best atlas group over the group of best atlases? Physics in Medicine & Biology 63, 12NT01 (2018).
Artaechevarria, X., Munoz-Barrutia, A. & Ortiz-de-Solorzano, C. Combination strategies in multi-atlas image segmentation: Application to brain MR data. Medical Imaging, IEEE Transactions on 28, 1266–1277 (2009).
Coupé, P. et al. Patch-based segmentation using expert priors: Application to hippocampus and ventricle segmentation. NeuroImage 54, 940–954 (2011).
Rousseau, F., Habas, P. A. & Studholme, C. A supervised patch-based approach for human brain labeling. Medical Imaging, IEEE Transactions on 30, 1852–1862 (2011).
Wu, Y. et al. Prostate segmentation based on variant scale patch and local independent projection. Medical Imaging, IEEE Transactions on 33, 1290–1303 (2014).
Zu, C. et al. Robust multi-atlas label propagation by deep sparse representation. Pattern Recognition 63, 511–517 (2017).
Tong, T. et al. Segmentation of MR images via discriminative dictionary learning and sparse coding: Application to hippocampus labeling. NeuroImage 76, 11–23 (2013).
Li, X. W., Li, Q. L., Li, S. Y. & Li, D. Y. Local manifold learning for multiatlas segmentation: application to hippocampal segmentation in healthy population and Alzheimer’s disease. CNS neuroscience & therapeutics 21, 826–836 (2015).
Pang, S. et al. Hippocampus Segmentation based on Iterative Local Linear Mapping with Representative and Local Structure-preserved Feature Embedding. IEEE transactions on medical imaging (2019).
Pang, S. et al. Hippocampus segmentation based on local linear mapping. Scientific reports 7, 45501 (2017).
Sanroma, G. et al. Learning non-linear patch embeddings with neural networks for label fusion. Medical image analysis 44, 143–155 (2018).
Wang, H. et al. Multi-atlas segmentation with joint label fusion. Pattern Analysis and Machine Intelligence, IEEE Transactions on 35, 611–623 (2013).
Asman, A. J. & Landman, B. A. Formulating spatially varying performance in the statistical fusion framework. Medical Imaging, IEEE Transactions on 31, 1326–1336 (2012).
Commowick, O., Akhondi-Asl, A. & Warfield, S. K. Estimating a reference standard segmentation with spatially varying performance parameters: Local MAP STAPLE. Medical Imaging, IEEE Transactions on 31, 1593–1606 (2012).
Asman, A. J. & Landman, B. A. Non-local statistical label fusion for multi-atlas segmentation. Medical image analysis 17, 194–208 (2013).
Bai, W., Shi, W., Ledig, C. & Rueckert, D. Multi-atlas segmentation with augmented features for cardiac MR images. Medical image analysis 19, 98–109 (2015).
Han, X. Learning-Boosted Label Fusion for Multi-atlas Auto-Segmentation. Proc. MLMI, 17–24 (2013).
Ren, X., Sharp, G. & Gao, H. Automated Segmentation of Head‐And‐Neck CT Images for Radiotherapy Treatment Planning Via Multi‐Atlas Machine Learning (MAML). Medical physics 43, 3321–3321 (2016).
Amoroso, N. et al. Hippocampal unified multi-atlas network (HUMAN): protocol and scale validation of a novel segmentation tool. Physics in medicine and biology 60, 8851 (2015).
Ahonen, T., Hadid, A. & Pietikainen, M. Face description with local binary patterns: Application to face recognition. Pattern Analysis and Machine Intelligence, IEEE Transactions on 28, 2037–2041 (2006).
Ojala, T., Pietikäinen, M. & Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognition 29, 51–59 (1996).
Zhu, H., Cheng, H., Yang, X. & Fan, Y. & Alzheimer’s Disease Neuroimaging Initiative. Metric Learning for Multi-atlas based Segmentation of Hippocampus. Neuroinformatics 15, 41–50 (2017).
Zhu, H., Cheng, H. & Fan, Y. Random local binary pattern based label learning for multi-atlas segmentation. SPIE Medical Imaging 9413, 94131B-94131B–94138 (2015).
Boccardi, M. et al. Training labels for hippocampal segmentation based on the EADC-ADNI harmonized hippocampal protocol. Alzheimer’s & Dementia 11, 175–183 (2015).
Morra, J. H. et al. Validation of a fully automated 3D hippocampal segmentation method using subjects with Alzheimer’s disease mild cognitive impairment, and elderly controls. NeuroImage 43, 59–68 (2008).
Avants, B. B., Epstein, C. L., Grossman, M. & Gee, J. C. Symmetric diffeomorphic image registration with cross-correlation: evaluating automated labeling of elderly and neurodegenerative brain. Medical image analysis 12, 26–41 (2008).
Ren, J., Jiang, X. & Yuan, J. Noise-resistant local binary pattern with an embedded error-correction mechanism. IEEE Transactions on Image Processing 22, 4049–4060 (2013).
Zandifar, A. et al. A comparison of accurate automatic hippocampal segmentation methods. NeuroImage 155, 383–393 (2017).
Cristianini, N. & Shawe-Taylor, J. An introduction to support vector machines and other kernel-based learning methods. (Cambridge university press, 2000).
DeLong, E. R., DeLong, D. M. & Clarke-Pearson, D. L. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 44, 837–845 (1988).
Manjón, J. V. & Coupé, P. Hippocampus subfield segmentation using a patch-based boosted ensemble of autocontext neural networks. International Workshop on Patch-based Techniques in Medical Imaging, 29–36 (2017).
Chen, Y. et al. Hippocampus segmentation through multi-view ensemble ConvNets. 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), 192–196 (2017).
Ataloglou, D., Dimou, A., Zarpalas, D. & Daras, P. Fast and Precise Hippocampus Segmentation Through Deep Convolutional Neural Network Ensembles and Transfer Learning. Neuroinformatics, 1–20 (2019).
Chen, Y. et al. Accurate and consistent hippocampus segmentation through convolutional LSTM and view ensemble. International Workshop on Machine Learning in Medical Imaging, 88–96 (2017).
Cao, L. et al. Multi-task neural networks for joint hippocampus segmentation and clinical score regression. Multimedia Tools and Applications 77, 29669–29686 (2018).
Xie, Z. & Gillies, D. Near Real-time Hippocampus Segmentation Using Patch-based Canonical Neural Network. arXiv preprint arXiv:1807.05482 (2018).
Thyreau, B., Sato, K., Fukuda, H. & Taki, Y. Segmentation of the hippocampus by transferring algorithmic knowledge for large cohort processing. Medical image analysis 43, 214–228 (2018).
Folle, L., Vesal, S., Ravikumar, N. & Maier, A. Dilated deeply supervised networks for hippocampus segmentation in MRI. Bildverarbeitung für die Medizin 2019, 68–73 (2019).
Shi, Y., Cheng, K. & Liu, Z. Hippocampal subfields segmentation in brain MR images using generative adversarial networks. Biomedical engineering online 18, 5 (2019).
Jiang, H. & Guo, Y. Multi-class multimodal semantic segmentation with an improved 3D fully convolutional networks. Neurocomputing (2019).
ZHU, H. et al. Dilated Dense U-net for Infant Hippocampus Subfield Segmentation. Frontiers in Neuroinformatics 13, 30 (2019).
Roy, A. G., Conjeti, S., Navab, N., Wachinger, C. & Initiative, A. S. D. N. QuickNAT: A fully convolutional network for quick and accurate segmentation of neuroanatomy. NeuroImage 186, 713–727 (2019).
Zhao, X. et al. A deep learning model integrating FCNNs and CRFs for brain tumor segmentation. Medical image analysis 43, 98–111 (2018).
Sdika, M. Enhancing atlas based segmentation with multiclass linear classifiers. Medical physics 42, 7169–7181 (2015).
Giraud, R. et al. An Optimized PatchMatch for multi-scale and multi-feature label fusion. NeuroImage 124, 770–782 (2016).
Asman, A. J., Huo, Y., Plassard, A. J. & Landman, B. A. Multi-atlas learner fusion: An efficient segmentation approach for large-scale data. Medical image analysis 26, 82–91 (2015).
Acknowledgements
This work was supported in part by the National Key Basic Research and Development Program (No. 2015CB856404), the National High Technology Research and Development Program of China (No. 2015AA020504), the National Natural Science Foundation of China (Nos 61602307, 61877039, 61902047, 61502002, 61473296, and 81271514), National Institutes of Health grants (Nos EB022573 and CA189523), and Natural Science Foundation of Zhejiang Province (No. LY19F020013). Data collection and sharing for this project was funded by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol-Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann-La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.
Author information
Authors and Affiliations
Contributions
H.C. Zhu, Z.Y. Tang, Y.H. Wu and Y. Fan developed the method, H.W. Cheng performed data preprocessing. All authors contributed to the preparation of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhu, H., Tang, Z., Cheng, H. et al. Multi-atlas label fusion with random local binary pattern features: Application to hippocampus segmentation. Sci Rep 9, 16839 (2019). https://doi.org/10.1038/s41598-019-53387-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-019-53387-9
- Springer Nature Limited
This article is cited by
-
How segmentation methods affect hippocampal radiomic feature accuracy in Alzheimer’s disease analysis?
European Radiology (2022)