
Abstract
In recent years, the landscape of computer-assisted interventions and post-operative surgical video analysis has been dramatically reshaped by deep-learning techniques, resulting in significant advancements in surgeons’ skills, operation room management, and overall surgical outcomes. However, the progression of deep-learning-powered surgical technologies is profoundly reliant on large-scale datasets and annotations. In particular, surgical scene understanding and phase recognition stand as pivotal pillars within the realm of computer-assisted surgery and post-operative assessment of cataract surgery videos. In this context, we present the largest cataract surgery video dataset that addresses diverse requisites for constructing computerized surgical workflow analysis and detecting post-operative irregularities in cataract surgery. We validate the quality of annotations by benchmarking the performance of several state-of-the-art neural network architectures for phase recognition and surgical scene segmentation. Besides, we initiate the research on domain adaptation for instrument segmentation in cataract surgery by evaluating cross-domain instrument segmentation performance in cataract surgery videos. The dataset and annotations are publicly available in Synapse.
Similar content being viewed by others


Background & Summary
Following the technological advancements in surgery, operation rooms are evolving into intelligent environments. Context-aware systems (CAS) are emerging as pivotal components of this evolution, empowered to advance pre-operative surgical planning1,2,3, automate skill assessment4,5,6,7,8, support operation room planning9,10,11, and interpret the surgical context comprehensively12. By enabling real-time alerts and offering decision-making support, these systems prove invaluable, especially but not only for less-experienced surgeons. Their capabilities extend to the automatic analysis of surgical videos, encompassing functions like indexing, documentation, and generating post-operative reports13. The ever-increasing demand for such automatic systems has sparked machine-learning-based approaches to surgical video analysis.
Cataract Surgery, renowned as the most commonly conducted ophthalmic surgical procedure and one of the most demanding surgeries worldwide, is a major operation where deep learning can be of great benefit. Cataract, characterized by the opacification of the eye’s natural lens, is often attributed to aging and leads to impaired visual acuity, reduced brightness, visual distortion, double vision, and color perception degradation. Globally, cataracts stand as the primary cause of blindness14. Owing to the aging demographic and increased lifespans, the World Health Organization forecasts a surge in cataract-related blindness cases, estimating the number to reach 40 million by the year 202514. This prevalent disease can be remedied through cataract surgery involving the substitution of the eye’s natural lens with a synthetic counterpart known as an intraocular lens (IOL). Advancements in technology have driven the evolution of cataract surgery techniques. This evolution spans from intracapsular cataract extraction (ICCE) in the 1960s and 1970s to extracapsular cataract extraction (ECCE) in the 1980s and 1990s. Today, the primary method involves sutureless small-incision phacoemulsification surgery with an injectable intraocular lens (IOL) implantation. Throughout this paper, the term “Cataract Surgery” is synonymous with “Phacoemulsification Cataract Surgery”. Due to the widespread occurrence of cataract surgery and its substantial influence on patients’ quality of life, a significant focus has been directed towards the analysis of cataract surgery content using deep learning methodologies over the past decade. In particular, Surgical phase recognition and scene segmentation are joint building blocks in various applications related to cataract surgery video analysis13. These applications include but are not limited to relevance detection15, relevance-based compression16, irregularity detection17,18, and surgical outcome prediction. The current public datasets for cataract surgery either provide annotations for a particular sub-task such as instrument recognition19, scene and relevant anatomical structure segmentation15,20,21,22,23, or offer small multi-task datasets targeting specific problems such as intraocular lens (IOL) irregularity detection17. As a result of the lack of a comprehensive dataset, there exists a considerable gap in exploring deep-learning-based approaches and frameworks to enhance cataract surgery outcomes. To facilitate the development of such systems and models, there is a compelling need for large-scale datasets that encompass multi-task annotations.
This paper introduces the largest cataract surgery video dataset, including 1000 videos of cataract surgery recorded in Klinikum Klagenfurt, Austria, between 2021 and 2023. We provide large-scale ground-truth annotations for the semantic segmentation of different instruments and relevant anatomical structures, as well as surgical phases. Besides, the dataset features two subsets for major irregularities in cataract surgery, which affect surgical workflow, including intraocular lens (IOL) rotation, and pupil contraction in cataract surgery. Together, these 1000 videos, annotated datasets, and irregularity subsets form a complete dataset to empower computer-assisted interventions (CAI) in cataract surgery.
Methods
This work is performed under ethics committee approval (EK 28/17) from Ethikkommission Kärnten24. All patients have given written consent to the video recording and open publication.
Dataset acquisition
Cataract surgery is performed utilizing a binocular microscope, which offers a three-dimensional magnified and illuminated view of the eye, ensuring precise observation of the patient’s eye. The surgeon manually adjusts the microscope’s focus to optimize visual clarity during the procedure. Additionally, a mounted camera within the microscope captures and archives the entire surgical process, facilitating subsequent analysis for various post-operative purposes.
Cataract-1K dataset description
The Cataract-1K dataset consists of 1000 videos of cataract surgeries conducted in the eye clinic of Klinikum Klagenfurt from 2021 to 2023. The videos are recorded using a MediLive Trio Eye device mounted on a ZEISS OPMI Vario microscope. The Cataract-1K dataset comprises videos conducted by surgeons with a cumulative count of completed surgeries ranging from 1,000 to over 40,000 procedures. On average, the videos have a duration of 7.12 minutes, with a standard duration of 200 seconds. In addition to this large-scale dataset, we provide surgical phase annotations for 56 regular videos and relevant anatomical plus instrument pixel-level annotations for 2256 frames out of 30 cataract surgery videos. Furthermore, we provide a small subset of surgeries with two major irregularities, including “pupil reaction” and “IOL rotation,” to support further research on irregularity detection in cataract surgery. Except for the annotated videos and images, the remaining videos in the Cataract-1K dataset are encoded with a temporal resolution of 25 fps and a spatial resolution of 512 × 324. Table 1 provides a comparison between the annotated subsets in the Cataract-1K dataset and currently existing datasets for semantic segmentation and phase recognition in cataract surgery. We delineate the challenges and annotation procedures for each subset in the following paragraphs.
Phase recognition dataset
Crafting an approach to detect and classify significant phases within these videos, considering frame-by-frame temporal details, presents considerable challenges due to several factors:
-
As shown in Fig. 1, phase recognition datasets for cataract surgery are extremely imbalanced, as the longest phase (phacoemulsification) and the shortest phase (incision) cover 28.72% and 2.1% of the annotations, respectively.
Fig. 1 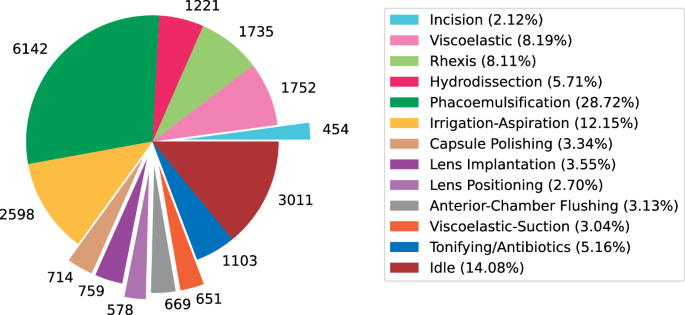
Total duration of the annotated phases in the 56 annotated cataract surgery videos (in seconds).
-
Videos may exhibit defocus blur stemming from manual camera focus adjustments25.
-
Unintentional eye movements and rapid instrument motions close to the camera result in motion blur, impairing distinctive spatial details.
-
As illustrated in Fig. 2, instruments, which play a fundamental role in distinguishing between relevant phases, share a substantial resemblance in certain phases, leading to a narrow variation between different classes in a trained classification model.
Fig. 2 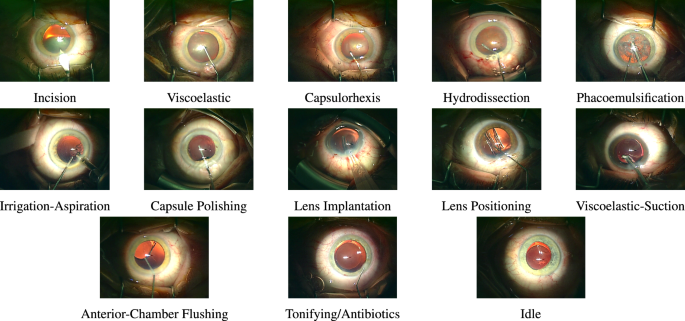
Sample frames from different phases in a regular cataract surgery.
-
Lack of metadata in stored videos precludes additional contextual information.
-
Variances in patients’ eye visuals generate substantial inter-video distribution disparities, demanding ample training data to build networks with generalizable performance.


As shown in Fig. 2, regular cataract surgery can include twelve action phases, including incision, viscoelastic, capsulorhexis, hydrodissection, phacoemulsification, irrigation-aspiration, capsule polishing, lens implantation, lens positioning, viscoelastic-suction, anterior-chamber flushing, and tonifying/antibiotics. Besides, the idle phases refer to the time spans in the middle of a phase or between two phases when the surgeons mainly change the instruments and no instrument is visible inside the frames. We provide a large annotated dataset to enable comprehensive studies on deep-learning-based phase recognition in cataract surgery videos. Table 2 visualizes the phase annotations corresponding to 56 regular cataract surgery videos, with a spatial resolution of 1024 × 768, a temporal resolution of 30 fps, and an average duration of 6.45 minutes with a standard deviation of 2.04 minutes. This dataset comprises patients with an average age of 75 years, ranging from 51 to 93 years, and a standard deviation of 8.69 years. The videos present in the phase recognition dataset correspond to surgeries executed by surgeons with an average experience of 8929 surgeries and a standard deviation of 6350 surgeries.
Semantic segmentation dataset
Figure 3 visualizes pixel-level annotations for relevant anatomical objects and instruments. As illustrated in Fig. 3, semantic segmentation in cataract surgery videos poses the following challenges:
-
Variations in color, shape, size, and texture in pupil.
-
Transparency and deformations in the artificial lens,
-
Smooth edges and color variations in iris,
-
Occlusion, motion blur, reflection, and partly visibility in instruments,
-
Visual similarities between different instruments in case of multi-class instrument segmentation,

Visualization of pixel-based annotations corresponding to relevant anatomical structures and instruments in cataract surgery and the challenges associated with different objects.
The semantic segmentation dataset includes frames from 30 regular cataract surgery videos with a spatial resolution of 1024 × 768 and an average duration of 6.52 minutes with a standard deviation of two minutes. Frame extraction is performed at the rate of one frame per five seconds. Subsequently, the frames featuring very harsh motion blur or out-of-scene iris are excluded from the dataset. We provide pixel-level annotations for three relevant anatomical structures, including the iris, pupil, and intraocular lens, as well as nine instruments used in regular cataract surgeries, including slit/incision knife, gauge, spatula, capsulorhexis cystome, phacoemulsifier tip, irrigation-aspiration, lens injector, capsulorhexis forceps, and katana forceps. All annotations are performed using polygons in the Supervisely platform, and exported as JSON files. Within this dataset, the included individuals possess an average age of 74.5 years, spanning from 51 to 90 years, with a standard deviation of 8.43 years. Additionally, the videos contained in the semantic segmentation dataset depict surgeries conducted by surgeons whose collective experience averages 8033 surgeries, with a standard deviation of 3894 surgeries. The provided dataset enables a reliable study of segmentation performance for relevant anatomical structures, binary instruments, and multi-class instruments.
Irregularity detection dataset
This dataset contains two small subsets of major intra-operative irregularities in cataract surgery, including pupil reaction18 and lens rotation17.
-
Pupil Contraction: During the phacoemulsification phase, where the occluded natural lens is fragmented and suctioned, there exists a heightened risk of causing damage to the delicate iris. Even very subtle trauma to the tissue can lead to undesirable pupil constriction26. These sudden reactions in pupil size can lead to serious intra-operative implications. Especially during the phacoemulsification phase, where the instrument is deeply inserted inside the eye, sudden changes in pupil size may lead to injuries to the eye’s tender tissues. Besides, achieving precise IOL alignment or centration becomes challenging in cases where intraoperative pupil contraction (miosis) occurs. Particularly in multifocal IOLs, minor displacements or tilts, which might be negligible for conventional mono-focal IOLs, can significantly compromise visual performance. In the case of toric IOLs, precise alignment of the torus is crucial, as any deviation diminishes the IOL’s effectiveness. Detection of unusual pupil reactions and severe pupil contractions during the surgery can highly contribute to the overall outcomes of cataract surgery and provide important insight for further post-operative investigations. Figure 4-top demonstrates an example of severe pupil contraction during cataract surgery. Pupil contraction can be automatically detected via accurate segmentation of the pupil and cornea, and tracking the relative area of the pupil over time18.
Fig. 4 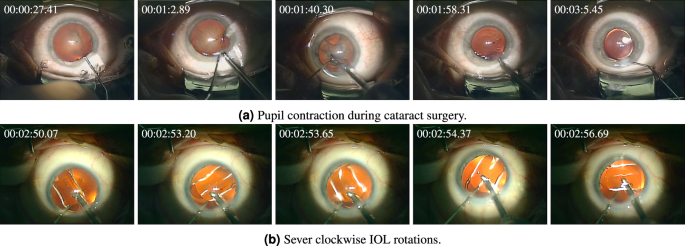
Intra-operative irregularities in cataract surgery.
-
IOL Rotation: Although aligned and centered upon surgery’s conclusion, the IOL may rotate or dislocate following the surgery. Even slight deviations, such as minor misalignments of the torus in toric IOLs or the slight displacement and tilting of multifocal IOLs, can result in significant distortions in vision and leave patients dissatisfied. The sole way to address this postoperative complication is follow-up surgery, which entails added costs, heightened surgical risks, and patient discomfort. Identification of intra-operative indicators for predicting and preventing post-surgical IOL dislocation is an unmet clinical need. It is argued that intra-operative rotation of IOLs during cataract surgery is the leading cause of post-operative misalignments27. Hence, automatic detection and measurement of intra-operative lens rotations can effectively contribute to preventing post-operative IOL dislocation. Figure 4-bottom represents fast clockwise rotations of IOL during unfolding, which occur in less than seven seconds. While intra-operative IOL rotation is a serious irregularity, its occurrence within cataract surgery videos is relatively infrequent. Consequently, conventional classification techniques designed to discriminate videos exhibiting IOL rotation struggle due to the considerable class imbalance present in the training data. Indeed, lens rotation computation entails more complicated frameworks and accurate computation of lens rotation necessitates more intricate methodologies. In our extensive investigation into predicting post-operative IOL dislocation, we have introduced, implemented, and assessed a robust framework for precisely calculating IOL rotation. This framework incorporates advanced techniques such as phase recognition, semantic segmentation, and object localization networks to precisely measure the sum of absolute rotations of the IOL after lens unfolding28.

Experimental settings for phase recognition
Network architectures
We adopt a combined CNN-RNN framework for phase recognition. The CNN component, serving as the backbone model, is responsible for the extraction of distinctive features from individual frames within the video sequence. To achieve this, two different pre-trained CNN architectures, VGG16 and ResNet50, are employed. The output feature map of the CNN is fed into a recurrent neural network (RNN). The RNN component focuses on capturing temporal features from the input video clip. We compare the performance of four different RNN architectures, including LSTM, GRU, BiLSTM, and BiGRU.
Training settings
We adopt a one-versus-rest strategy to evaluate phase recognition performance15,29. Accordingly, we segment all videos corresponding to each phase into three-second clips with an overlap of one second. Afterward, the entire dataset is split into two categories: the designated target phase and the remaining phases (the “rest” class). We apply offline augmentations to the videos across all categories. Typically, the number of clips in the target category is significantly lower than in the rest category. To rectify this imbalance problem, we employ a random selection process from the “rest” category, aligning it with the clip count in the target category. This strategy ensures an equivalent number of clips in both classes. The employed augmentations include gamma and contrast adjustments with a factor of 0.5, Gaussian blur with a sigma of 10, random rotation up to 20 degrees, brightness within a range of [−0.3, 0.3], and saturation within a range of [0.5, 1.5]. To maximize diversity within our training set, we employ a random sampling strategy during training. Specifically, we configure the network’s input sequence to comprise 10 frames randomly selected from 90 frames within each three-second clip. In all settings, the backbone network employed for feature extraction is pre-trained on the ImageNet dataset. The RNN component is constructed with a single recurrent layer comprising 64 units. This is followed by a dense layer with 64 units, and finally, a two-unit layer with a Softmax activation function. To mitigate the risk of overfitting, the last four layers of the CNN component are kept frozen during training, and dropout regularization with a rate of 0.5 is applied to the output feature map of the recurrent layer. All models are trained on 32 videos and tested on non-overlapping clips from the remaining videos. We use a binary cross-entropy loss function and Adam optimizer, a learning rate equal to 0.001, and a batch size of 16. The network’s input dimensions are set to 224 × 224. We compare the performance of the trained models using accuracy and F1 score.
Experimental settings for semantic segmentation
Network architectures
We perform experiments to validate the robustness of our pixel-level annotations using several state-of-the-art baselines targetting general images, medical images, and surgical videos. The specifications of the baselines are listed in Table 3.
Training settings
For all neural networks, the backbones are initialized with ImageNet’s pre-trained parameters30. We train all networks with a batch size of eight and set the initial learning rate to 0.001, which decreases during training using polynomial decay \(lr=l{r}_{init}\times {\left(1-\frac{iter}{total-iter}\right)}^{0.9}\). The input size of the networks is set to 512 × 512. We apply cropping and random rotation (up to 30 degrees), color jittering (brightness = 0.7, contrast = 0.7, saturation = 0.7), Gaussian blurring, and random sharpening as augmentations during training, and use the cross entropy log dice loss during training as in Eq. (1),
where \({{\mathscr{X}}}_{true}\) denotes the ground truth binary mask, and \({{\mathscr{X}}}_{pred}\) denotes the predicted mask \(\left(0\le {{\mathscr{X}}}_{pred}(i,j)\le 1\right)\). The parameter λ ∈ [0, 1] is set to 0.8 in our experiments, and \(\odot \) refers to the Hadamard product (element-wise multiplication). Besides, the parameter σ is the Laplacian smoothing factor, which is added to (i) prevent division by zero and (ii) avoid overfitting (in experiments, σ = 1). We compare the performance of baselines using average dice and average intersection over union (IoU).
Data Records
All datasets and annotations including the 1000 raw videos, phase recognition set, semantic segmentation set, and irregularity detection set are publicly released in Synapse31.
Frame-level annotations for phase recognition are provided in CSV files, determining the first and the last frames for all action phases per video. The preprocessing codes to extract all action and idle phases from a video using the CSV files are provided in the GitHub repository of the paper. Table 2 visualizes our phase annotations for 56 cataract surgery videos. Furthermore, Fig. 1 demonstrates the total duration of the annotations corresponding to each phase from 56 videos.
Pixel-level annotations are provided in two formats: (1) Supervisely format, for which we provide Python codes for mask creation from JSON files, and (2) COCO format, which also provides bounding box annotations for all pixel-level annotated objects. The latter annotations can be used for object localization problems. The preprocessing codes to create training masks for “anatomy plus instrument segmentation”, “binary instrument segmentation”, and “multi-class instrument segmentation” are provided in the GitHub repository of the paper. We have formed five folds with patient-wise separation, meaning every fold consists of the frames corresponding to six distinct videos. Table 4 compares the number of instances and their appearance percentage in the frames. Besides, Table 5 lists the average number of pixels per frame corresponding to each label.
Technical Validation
In this section, we bolster the quality control of our multi-task annotations by rigorously training several state-of-the-art neural network architectures for each task. We meticulously evaluate the performance of the trained models using relevant metrics to ensure the accuracy and reliability of our annotations.
Table 6 showcases the phase recognition performance of several CNN-RNN architectures. In our evaluations, we have combined the phases of viscoelastic and anterior-chamber flushing due to their shared visual features. The collective findings reveal commendable and satisfactory phase recognition performance across diverse backbones and recurrent network setups. Notably, the incorporation of bidirectional recurrent layers has consistently amplified detection accuracy and F1-Score across all configurations. Furthermore, networks leveraging the ResNet50 backbone display marginally superior performance compared to those utilizing VGG16. This outcome can be attributed to the deeper architecture of ResNet50, facilitating the extraction of intricate features essential for accurate recognition. The results also reveal the distinguishability of different phases in cataract surgery. Precisely, the phacoemulsification phase consistently attains the highest accuracy and F1 score, attributed to the distinctive phacoemulsification instrument and the unique texture of the pupil during this phase. Conversely, the least robust detection performance aligns with the viscoelastic/AC flushing phases, accentuating the visual resemblances shared between these phases and other phases within cataract surgery videos.
Table 7 provides a quantitative analysis of “anatomy plus instrument” segmentation performance for various neural network architectures. The results notably highlight that segmenting the relevant anatomical structures emerges as a comparatively less challenging task than instrument segmentation for all networks. Specifically, the best performance corresponds to pupil segmentation, attributable to its distinct features and sharp boundaries. In contrast, lens segmentation demonstrates relatively lower performance due to its transparent nature and an inherent imbalance issue (outlined in Table 4). The segments involving instruments, however, confront significant challenges. This class is marked by major distortions, encompassing motion blur, reflections, and occlusions, collectively contributing to the relatively low performance of the networks. The best performance corresponds to the DeepPyramid network with a VGG16 backbone, consistently yielding optimal results across all classes.
Figure 5 visually compares the Dice and IoU metrics’ averages and standard deviations across five folds for the evaluated neural networks. According to the results, DeepPyramid, AdaptNet, and ReCal-Net are the three best-performing networks for anatomy and instrument segmentation in cataract surgery videos.

Average and standard deviation of “anatomy plus instrument” segmentation results for neural network architectures listed in Table 3.
Within Table 8, a thorough comparison is made between the performance of various neural network architectures concerning intra-domain and cross-domain scenarios. These architectures are trained using our binary instrument annotations. The results clearly indicate statistical differences between Cataract-1k and CaDIS datasets. Concretely, the average dice coefficient for binary instrument segmentation equals 77% within the Cataract-1k dataset. However, this performance metric markedly contracts, remaining confined to around 67% (with AdaptNet illustrating 66.23%) when extended to the CaDIS dataset. This considerable variance starkly underscores the substantial domain shift inherently present between these two datasets. These results demonstrate the necessity of strategically exploring semi-supervised and domain adaptation techniques to elevate instrument segmentation performance in cataract surgery videos with cross-dataset domain shifts32.
Usage Notes
The datasets are licensed under CC BY. For further legal details, we kindly request the readers to refer to the complete license terms. Besides, anyone can view the sample videos and images from the dataset and access the GitHub repository for dataset preparation codes.
Code availability
We provide all code for mask creation using JSON annotations and phase extraction using CSV files, as well as the training IDs for four-fold validation and usage instructions in the GitHub repository of the paper (https://github.com/Negin-Ghamsarian/Cataract-1K).
References
Ma, L. et al. Simulation of postoperative facial appearances via geometric deep learning for efficient orthognathic surgical planning. IEEE Transactions on Medical Imaging 42, 336–345, https://doi.org/10.1109/TMI.2022.3180078 (2023).
Quon, J. et al. Deep learning for automated delineation of pediatric cerebral arteries on pre-operative brain magnetic resonance imaging. front surg 2020; 7 (2020).
Xiao, D. et al. Estimating reference bony shape models for orthognathic surgical planning using 3d point-cloud deep learning. IEEE Journal of Biomedical and Health Informatics 25, 2958–2966, https://doi.org/10.1109/JBHI.2021.3054494 (2021).
Yanik, E. et al. Deep neural networks for the assessment of surgical skills: A systematic review. The Journal of Defense Modeling and Simulation 19, 159–171 (2022).
Lam, K. et al. Machine learning for technical skill assessment in surgery: a systematic review. NPJ digital medicine 5, 24 (2022).
Wang, Z. & Majewicz Fey, A. Deep learning with convolutional neural network for objective skill evaluation in robot-assisted surgery. International journal of computer assisted radiology and surgery 13, 1959–1970 (2018).
Wang, Z. & Fey, A. M. Satr-dl: improving surgical skill assessment and task recognition in robot-assisted surgery with deep neural networks. In 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 1793–1796 (IEEE, 2018).
Soleymani, A. et al. Surgical skill evaluation from robot-assisted surgery recordings. In 2021 International Symposium on Medical Robotics (ISMR), 1–6 (IEEE, 2021).
Aksamentov, I., Twinanda, A. P., Mutter, D., Marescaux, J. & Padoy, N. Deep neural networks predict remaining surgery duration from cholecystectomy videos. In Medical Image Computing and Computer-Assisted Intervention- MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, September 11-13, 2017, Proceedings, Part II 20, 586–593 (Springer, 2017).
Twinanda, A. P., Yengera, G., Mutter, D., Marescaux, J. & Padoy, N. Rsdnet: Learning to predict remaining surgery duration from laparoscopic videos without manual annotations. IEEE transactions on medical imaging 38, 1069–1078 (2018).
Marafioti, A. et al. Catanet: predicting remaining cataract surgery duration. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part IV 24, 426–435 (Springer, 2021).
Ghamsarian, N. Deep-learning-assisted analysis of cataract surgery videos, (2021).
Ghamsarian, N. Enabling relevance-based exploration of cataract videos. In Proceedings of the 2020 International Conference on Multimedia Retrieval, ICMR’20, 378–382, https://doi.org/10.1145/3372278.3391937 (2020).
Burton, M. J. et al. The lancet global health commission on global eye health: vision beyond 2020. The Lancet Global Health 9, e489–e551 (2021).
Ghamsarian, N., Taschwer, M., Putzgruber-Adamitsch, D., Sarny, S. & Schoeffmann, K. Relevance detection in cataract surgery videos by spatio- temporal action localization. In 2020 25th International Conference on Pattern Recognition (ICPR), 10720–10727 (2021).
Ghamsarian, N., Amirpourazarian, H., Timmerer, C., Taschwer, M. & Schöffmann, K. Relevance-based compression of cataract surgery videos using convolutional neural networks. In Proceedings of the 28th ACM International Conference on Multimedia, 3577–3585 (2020).
Ghamsarian, N. et al. Lensid: A cnn-rnn-based framework towards lens irregularity detection in cataract surgery videos. In de Bruijne, M. et al. (eds.) Medical Image Computing and Computer Assisted Intervention – MICCAI 2021, 76–86 (Springer International Publishing, Cham, 2021).
Sokolova, N. et al. Automatic detection of pupil reactions in cataract surgery videos. Plos one 16, e0258390 (2021).
Al Hajj, H. et al. Cataracts: Challenge on automatic tool annotation for cataract surgery. Medical image analysis 52, 24–41 (2019).
Grammatikopoulou, M. et al. Cadis: Cataract dataset for surgical rgb-image segmentation. Medical Image Analysis 71, 102053 (2021).
Ghamsarian, N. et al. Recal-net: Joint region-channel-wise calibrated network for semantic segmentation in cataract surgery videos. In Mantoro, T., Lee, M., Ayu, M. A., Wong, K. W. & Hidayanto, A. N. (eds.) Neural Information Processing, 391–402 (Springer International Publishing, Cham, 2021).
Ghamsarian, N., Taschwer, M., Sznitman, R. & Schoeffmann, K. Deeppyramid: Enabling pyramid view and deformable pyramid reception for semantic segmentation in cataract surgery videos. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 276–286 (Springer, 2022).
Ghamsarian, N., Wolf, S., Zinkernagel, M., Schoeffmann, K. & Sznitman, R. Deeppyramid+: medical image segmentation using pyramid view fusion and deformable pyramid reception. International journal of computer assisted radiology and surgery 1–9 (2024).
Ethikkommission kärnten. https://www.ethikkommission-kaernten.at/ueber-uns/kommission
Ghamsarian, N., Taschwer, M. & Schoeffmann, K. Deblurring cataract surgery videos using a multi-scale deconvolutional neural network. In 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), 872–876 (2020).
Mirza, S. A., Alexandridou, A., Marshall, T. & Stavrou, P. Surgically induced miosis during phacoemulsification in patients with diabetes mellitus. Eye 17, 194–199, https://doi.org/10.1038/sj.eye.6700268 (2003).
Oshika, T. et al. Prospective assessment of plate-haptic rotationally asymmetric multifocal toric intraocular lens with near addition of +1.5 diopters. BMC Ophthalmology 20, 454, https://doi.org/10.1186/s12886-020-01731-3 (2020).
Ghamsarian, N. et al. Predicting postoperative intraocular lens dislocation in cataract surgery via deep learning. IEEE Access 1–1, https://doi.org/10.1109/ACCESS.2024.3361042 (2024).
Nasirihaghighi, S., Ghamsarian, N., Stefanics, D., Schoeffmann, K. & Husslein, H. Action recognition in video recordings from gynecologic laparoscopy. In 2023 IEEE 36th International Symposium on Computer-Based Medical Systems (CBMS), 29–34, https://doi.org/10.1109/CBMS58004.2023.00187 (2023).
Deng, J. et al. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248–255 (Ieee, 2009).
Ghamsarian, N. et al. Cataract-1k. Synapse https://doi.org/10.7303/syn52540135 (2024).
Ghamsarian, N. et al. Domain adaptation for medical image segmentation using transformation-invariant self-training. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 331–341 (Springer, 2023).
Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N. & Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Transactions on Medical Imaging 39, 1856–1867, https://doi.org/10.1109/TMI.2019.2959609 (2020).
Feng, S. et al. Cpfnet: Context pyramid fusion network for medical image segmentation. IEEE Transactions on Medical Imaging 39, 3008–3018, https://doi.org/10.1109/TMI.2020.2983721 (2020).
Gu, Z. et al. Ce-net: Context encoder network for 2d medical image segmentation. IEEE Transactions on Medical Imaging 38, 2281–2292, https://doi.org/10.1109/TMI.2019.2903562 (2019).
Chen, X., Zhang, R. & Yan, P. Feature fusion encoder decoder network for automatic liver lesion segmentation. In 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), 430–433, https://doi.org/10.1109/ISBI.2019.8759555 (2019).
Roy, A. G., Navab, N. & Wachinger, C. Recalibrating fully convolutional networks with spatial and channel “squeeze and excitation” blocks. IEEE Transactions on Medical Imaging 38, 540–549 (2019).
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F. & Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), 801–818 (2018).
Xiao, T., Liu, Y., Zhou, B., Jiang, Y. & Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European conference on computer vision (ECCV), 418–434 (2018).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, 234–241 (2015).
Acknowledgements
We would like to thank Daniela Stefanics for helping us in annotating the datasets to the highest quality. This work was funded by Haag-Streit Foundation Switzerland and the FWF Austrian Science Fund under grant P 32010-N38.
Author information
Authors and Affiliations
Contributions
N.G. wrote the original draft. R.S., M.Z., S.W., K.S., Y.E. and D.P. acquired the projects’ funding. R.S. and K.S. were responsible for the projects’ supervision. N.G. and K.S. organized the annotation process. Y.E. and D.P. provided expert information on the cataract surgery phases, relevant anatomical structures, and instruments used in regular cataract surgery videos. N.G. and D.P. partly annotated the datasets and reviewed and corrected the remaining annotations. N.G. designed, implemented, and evaluated semantic segmentation experiments of the technical validation. N.G. and S.N. designed phase recognition experiments of technical validation. S.N. implemented and evaluated phase recognition experiments of technical validation. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ghamsarian, N., El-Shabrawi, Y., Nasirihaghighi, S. et al. Cataract-1K Dataset for Deep-Learning-Assisted Analysis of Cataract Surgery Videos. Sci Data 11, 373 (2024). https://doi.org/10.1038/s41597-024-03193-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03193-4
- Springer Nature Limited