

Abstract
Biodiversity faces unprecedented threats from rapid global change1. Signals of biodiversity change come from time-series abundance datasets for thousands of species over large geographic and temporal scales. Analyses of these biodiversity datasets have pointed to varied trends in abundance, including increases and decreases. However, these analyses have not fully accounted for spatial, temporal and phylogenetic structures in the data. Here, using a new statistical framework, we show across ten high-profile biodiversity datasets2,3,4,5,6,7,8,9,10,11 that increases and decreases under existing approaches vanish once spatial, temporal and phylogenetic structures are accounted for. This is a consequence of existing approaches severely underestimating trend uncertainty and sometimes misestimating the trend direction. Under our revised average abundance trends that appropriately recognize uncertainty, we failed to observe a single increasing or decreasing trend at 95% credible intervals in our ten datasets. This emphasizes how little is known about biodiversity change across vast spatial and taxonomic scales. Despite this uncertainty at vast scales, we reveal improved local-scale prediction accuracy by accounting for spatial, temporal and phylogenetic structures. Improved prediction offers hope of estimating biodiversity change at policy-relevant scales, guiding adaptive conservation responses.
Similar content being viewed by others


Main
Accelerating rates of species extinction are driving global changes in biodiversity, threatening ecosystems and the services they provide1. In an attempt to reverse biodiversity declines, world leaders, policymakers and academics have called for action12. Evidence-based actions require long-term datasets and rigorous modelling to reliably detect and attribute biodiversity change through time13,14. At present, some of the most influential estimates of biodiversity change are calculated using datasets such as BioTIME2, the Living Planet15 or the North American Breeding Bird Survey3. Inferences from these abundance datasets have shaped policy16 and are considered by some to be a key pillar of global biodiversity monitoring17.
Biodiversity datasets are complex and typically subject to one or more sources of non-independence across the axes of time, space and evolution. This presents a challenge for analysis, as omission of even one of these sources of non-independence from a statistical model can lead to underestimation of uncertainty, incorrect trends and poorly resolved prediction, and ultimately undermines current interpretation of wildlife abundance trends18,19,20. A unifying feature of previous studies is that they are characterized by the consistent omission of one or more of these dependencies from their analysis. This imposes a risk that past estimates of abundance change—pointing to declines15,21, no net change18,22,23 and recovery24—may be unreliable.
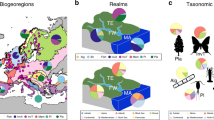
Non-independence can be classified in a variety of ways, which we split into two core types: hierarchical, for which observations are pseudoreplicated or nested (for example, multiple trends for a given species, site or region in time); and correlative, for which observations become increasingly correlated (sometimes termed autocorrelation) when close in time25, space26 or phylogeny27. Under correlative non-independence, we may expect sequential abundance values in a time series to be more similar, and trends should be similar when near in space or in closely related species (Fig. 1). Although studies commonly account for hierarchical non-independence using features such as random effects in mixed models, a literature review covering hundreds of papers published in high-impact journals since 2010 revealed that studies rarely account for correlative non-independence across space (accounted for in 7% of studies), phylogeny (14%) or time (32%; Supplementary Table 1). Further, no biodiversity model has yet been formalized to account for all three sources of correlative non-independence at the same time.
Here we show that ignoring non-independence has serious consequences for inference of biodiversity trends. We introduce the correlated effect model, which incorporates hierarchical non-independence and all three sources of correlative non-independence, and apply it to ten high-profile, multi-species datasets that have been used to infer abundance trends in global biodiversity2,3,4,5,6,7,8,9,10,11. Combined, these datasets describe the abundance (including relative abundance and densities) patterns of more than 30,000 populations, representing about 3,100 species and about 6,000 unique locations, and are considered some of the best biodiversity monitoring datasets available.

The text and images show the objective, implicit and key features of large-scale abundance datasets, current approaches for analysis, the problem, its implications and the solution.
Non-independence increases uncertainty
We compared our correlated effect model with two mixed-effect modelling frameworks that are commonly used and account only for hierarchical non-independence: random intercept and random slope (both described in Fig. 1). Across the 44 relevant studies identified in a literature search spanning 282 published papers, 43% (n = 19) used a version of the random intercept model and 50% (n = 22) used a version of the random slope model (Supplementary Table 1). Comparing these commonly applied approaches to the correlated effect model, we detect a pronounced shift in collective abundance trends (that is, the model-derived average rate of change in abundance across all species and locations), and show that existing approaches underestimate collective trend uncertainty and can misestimate direction (Fig. 2).

Abundance trend projections across ten high-profile datasets under three different models. Circles represent the collective trend (the coefficient describing the change in abundance over time averaged across all species and locations) for each dataset in our three models (from left to right): random intercept, random slope and the correlated effect model that simultaneously accounts for temporal, spatial and phylogenetic correlative non-independence. We specify four categories of trend: significant increase—coefficient is positive and significant; non-significant increase—coefficient is positive but not significant (that is, no detectable change); non-significant decrease—coefficient is negative but not significant (that is, no detectable change); significant decrease—coefficient is negative and significant. Significance indicates that the coefficient does not overlap zero at a 50% credible interval. Coefficients and 95% credible intervals are available in Supplementary Table 4. We use the collective trend coefficient and 50% credible intervals (represented by shading) to produce abundance projections for each model in each dataset from an arbitrary baseline abundance of 100. Abundance projections cover the time span of the observed data and are presented on the log10 scale.
Collective abundance trend uncertainty (that is, the standard deviation (s.d.) around the abundance–time coefficient) was underestimated in all ten datasets in both the random intercept and random slope models. These underestimates are large, with uncertainty in the correlated effect model 26 times greater [95% confidence interval (CI): 14–47] than that in the random intercept model and 3.4 times greater [95% CI: 1.8–6.2] than that in the random slope model. Further, after accounting for correlative non-independence, we find instances in which the trend direction shifts and even reverses (for example, from negative to positive). For instance, in the Living Planet dataset, a decreasing trend in the random intercept model shifts to a stable trend in the random slope model, before shifting back to a sharp albeit uncertain decrease after accounting for correlative non-independence. In three databases—the Living Planet, RivFishTIME and Atlantic reef fishes—the mean trends were more extreme under the correlated effect model, shifting away from zero (that is, no net change in abundance), although still highly uncertain. Across the three models, we observed complete agreement in trend direction and significance status (50% credible intervals) in only four of the datasets. At 95% credible intervals, we found no instances in which models agreed on trend direction and significance status.
Collective abundance trend uncertainty is likely to be underestimated when hierarchical terms (for example, random effects) fail to effectively represent the complex spatial, phylogenetic and temporal structures in the data (Extended Data Fig. 1). This is an apparently common phenomenon given all ten datasets underestimate uncertainty, and across the ten datasets, we find that correlative terms proportionally account for approximately one-third of the variation in the data (spatial: mean = 0.34 s.d. = 0.3; phylogeny: mean = 0.41, s.d. = 0.28), relative to the combined variance captured by the respective hierarchical and correlated terms. There is no comparable metric for the temporal term that describes the correlation between abundances instead of covariance between trends. Notably, the stark increase in uncertainty is not a consequence of simply introducing additional correlated terms. This is because uncertainty tends to increase substantially only when the correlated terms are capturing a high proportion of variance (β = 1.00, 95% CI: −0.19 to 2.21, P = 0.09; Extended Data Fig. 1). Through iteratively introducing the correlated terms into the random slope model (exploring six further model structures), it is apparent that uncertainty increases most after the inclusion of spatial correlation (Extended Data Fig. 2).
Predicting biodiversity change
Counterintuitively, accounting for correlative non-independence improves our capacity to make predictions ‘out of sample’—that is, for a withheld subset of data not used to develop the model—despite the large uncertainty at the level of the collective trend. Part of the value of these abundance trends is that they can be used to estimate which species and locations are likely to be declining or recovering, and when. To evaluate whether the correlated effect model improves our ability to make local-scale predictions, we tested each model’s ability to forecast new abundance observations and estimate population trends. For each dataset, we removed the final abundance observation in 50% of the population abundance time series and then evaluated each of the three models’ ability to predict this value. Next, we conducted leave-one-out cross-validation to assess trend prediction, removing a population time series (that is, trend) from each dataset and testing each model’s ability to recover this population’s abundance trend. We repeated this cross-validation 50 times for each of the 10 datasets. In each dataset, we report predictive accuracy for each of these approaches as the percentage error (PE), a metric describing the median of the absolute percentage difference between predicted and observed values; for example, with a 5% error, an abundance on the log scale of 1 would become 1.05. Summarizing across datasets, we report the mean and s.d.
Across the 10 datasets, the correlated effect model estimated the final abundance observation with 16.1% error (s.d. = 7.5%), 1.51 times more accurately than the random intercept model (mean = 24.4%, s.d. = 16.2%) and 1.13 times more accurately than the random slope model (mean = 18.3%; s.d. = 10.5%). The correlated effect model also performed best when estimating missing population trends, with an error of 18.3% (s.d. = 11.6%), 1.35 times more accurate than the random slope model (mean = 28.9%; s.d. = 25.5%). In one case, using the correlated effect model to capture the spatial, temporal and phylogenetic structures halved the trend prediction error, relative to the random slope model. The random slope model had a lower prediction error than the correlated effect model in only one dataset in the abundance assessment, and two datasets in the trend assessment.
The improved prediction in the correlated effect model is a consequence of handling temporal, spatial and phylogenetic non-independence. For the Living Planet data, recognizing temporal correlation between sequential abundance values (ρ = 0.52) introduces nonlinearity (residual variability in linear trends) in temporal trends, and more closely represents realistic population dynamics (Fig. 3, population level). Comparably, temporal non-independence in the Living Planet data was higher than the average across the ten datasets (ρ = 0.31, s.d. = 0.42, range: −0.65 to 0.99). Accounting for this temporal structure in population trends can also influence trend direction and uncertainty of species-level and site-level trends, relative to the random slope model (Fig. 3, site level). At the global level, the presence of temporal, spatial (proportion of variance captured by spatial correlation term = 0.30) and phylogenetic (proportion of variance captured by phylogenetic correlation term = 0.34) structures elevated the uncertainty around the overall trend (Extended Data Fig. 2), ultimately leading to more robust inference.

a–c, Example of how the three models (random intercept (a), random slope (b) and correlated effect (c)) describe abundance patterns at different ecological scales (finer ecological scales on the left). The population-level column showcases how each of the three models produce different estimates of abundance trends (lines are the median values with 95% credible interval shading) for all three bat species (genus Myotis) with data in a given location, with data points representing the observed abundance values. The site-level column depicts how the species’ trends, under different models, influence the site-level trend (that is, a trend for a given location; black), in which the line and 95% credible intervals describe the median trend and variability in trend (respectively) across all species in the given location. At the collective level, the median trend for each unique site is represented by a faded grey line, and the median collective trend coefficient and 95% credible intervals are depicted by the coloured line and shading. At the site and collective levels, credible intervals solely describe uncertainty in the main parameter of interest, the rate of change coefficient, not the intercept. The final column describes how a hypothetical population would change under the median collective trend coefficient and 50% credible intervals projected from a relative baseline abundance of 100. This example is based on data in the Living Planet. In each plot, we restrict the time frame to the temporal extent of the population-level trends (1987–2015), instead of the total temporal extent of our Living Planet sample.
The presence of the observed spatial and phylogenetic structures also has the added benefit of allowing us to make predictions beyond the species and location data (Fig. 4), offering important insight into species and locations most likely to exhibit declines and recoveries. Our ability to predict a given species trend is dependent on the species being contained and accurately described in a phylogeny. Efforts continue to expand the breadth and quality of phylogenetic information28, and across our 10 datasets, we were able to obtain phylogenetic information for 80% of species.

Evidence of abundance change at different significance thresholds (for example, at an 80% CI threshold, dark red indicates evidence of declines whereas dark blue indicates evidence of increases). a, For the phylogeny, the species-level trends were derived by summing across hierarchical taxonomic random effects and phylogenetic correlation terms. Asymptotic species-level confidence thresholds were derived using uncertainty in phylogenetic predictions at multiple z-scores. To improve visualization, phylogenetic branch lengths are log transformed. b, For space, we take taxonomic and phylogenetic information from a for one iconic and abundant North American species, the American robin Turdus migratorius, and combine this with hierarchical and correlative spatial terms to make population-level predictions across terrestrial space. Asymptotic confidence thresholds were derived at the population scale (for example, species in a given site) using multiple z-scores. These predictions are drawn from the correlated effect model and BioTIME data (Supplementary Table 1).
Implications for biodiversity science
The abundance datasets we analyse are influential in policy, tracking progress towards biodiversity targets at national and international scales16,17,29, and so it is vital that any inference gained is both valid and reliable. Our work shows that when biodiversity change datasets are analysed without accounting for correlative non-independence among phylogeny, time and space, there is a substantial risk that trend uncertainty could be underestimated, trend direction misestimated and policy misinformed. Further, once uncertainty is appropriately attributed in the correlated effect model, we failed to detect a single significant trend in collective abundance across the 10 datasets under 95% credible intervals. This pervasive pattern points to a highly uncertain status in collective abundance trends; that is, it is unclear how biodiversity is changing across vast spatial and taxonomic scales once uncertainty is appropriately estimated.
The random intercept model, used by 43% of studies, underestimated trend uncertainty 26-fold. The random slope model, used by 50% of studies, performs better but still underestimates uncertainty 3.4-fold. This underestimated uncertainty has a substantial impact on trend inference, for which 9 datasets have significant trends at 50% credible intervals in the random intercept model compared to 7 datasets in the random slope model, and just 4 datasets in the correlated effect model. At 95% credible intervals, we found 8 significant collective trends in the random intercept model, 4 significant trends in the random slope model and zero significant trends in the correlated effect model. This raises questions about the robustness of existing estimates of abundance change in the literature.
Past estimates of abundance change have pointed to declines15,21, no net change18,22,23 and recovery24. This high variability across studies and datasets could be well founded given their different spatial, temporal and taxonomic scales, but it is also paradoxical given the expectation that biodiversity has declined under intense and widespread global change1. In the correlated effect model, we partially resolve this variability between datasets, as our results generalize under the common feature of substantial uncertainty. However, the absence of significant trends in the correlated effect model also further emphasizes the paradox of failing to detect biodiversity loss despite rapid global change. Ours is not the first study to fail to detect declining abundances. For instance, previous work has shown that most abundance trends exhibit no net change23, and that the magnitude of decline reduces after accounting for extreme values18 and random abundance fluctuations19. Other work suggests the current data collection infrastructure is too small and biased to detect a trend reliably30. Similarly, analyses of BioTIME suggest that declines are unlikely because environmental change generates winners as well as losers2,22, whose opposing population trends may cancel each other out at global scales.
All things considered, it seems likely that collective abundance trends over varied taxa exhibiting varied responses to varied degrees of environmental change may not present as significant even with vast quantities of data. Perhaps a more considered approach is necessary, focused on describing which taxonomic groups and specific locations are declining and recovering, and why. The correlated effect model is particularly well placed for exploring this question, as the integration of space and phylogeny allows us to explore the particular locations and clades for which abundance trends shift from stable to decline. Although the high uncertainty around collective trends limits our general understanding of abundance changes, we observe an increase in accuracy of abundance forecasts and trend predictions under the correlated effect model, delivering a much-needed improvement in prediction at local scales (Fig. 4). The more complex representation of space, time and phylogeny is key to this improved prediction, for which, as an example, a priori information on evolutionary history can help predict which species are likely to decline and recover. Our new methods offer the hope of greater clarity in biodiversity trend estimation across different datasets and geographies, to inform and guide adaptive conservation policy responses.
Despite failing to detect a decline in collective abundance across the ten datasets at 95% credible intervals, our results do not necessarily mean that wildlife abundances have not declined, or that the current estimates of trends are incorrect. It is possible that abundances may have increased on average, or perhaps declines have been far more extreme than we have previously imagined; simply, the uncertainty is too high to know. With this in mind, we re-emphasize calls to urgently expand data collection and improve trend detectability, but this will only help to estimate current and future biodiversity trends. Given the large uncertainty associated with our estimates of abundance change, it seems that past abundance patterns are lost and undetectable at present. A shift towards causal frameworks of detection and attribution is probably necessary to estimate past biodiversity change14.
In our study, we have solely focused on deriving the collective abundance trend given its potential political importance17, but the core statistical framework could be applied to other biodiversity data types (for example, occupancy data), adapted to other metrics (for example, species richness) and integrated into a global biodiversity observation system14. For instance, the species trend coefficients could be extracted from the model and used alongside estimates of absolute species abundance to determine the absolute change in populations31. Weightings could be included to increase the influence of common species, allowing us to reconcile and test for differences between collective abundance trends, biomass decline and individuals lost. Precise and accurate estimates of abundance change in time and space also underpin a variety of policy-relevant facets of biodiversity, including ecosystem function through abundance-weighted functional diversity32,33, energy flux, and population stability and resilience34.
The implications of our findings extend beyond biodiversity change. Spatial, temporal and phylogenetic data structures are common in ecological and evolutionary research. Under the presence of correlative non-independence, there is a potentially pervasive risk in the field that we have mis-specified our statistical models, violating data independence assumptions, and producing unreliable inference. However, this also presents an opportunity, as the correlative effect model could be adapted for a wide array of settings, improving inference across ecology and evolution. The model could also streamline workflows by simultaneously capturing spatial, phylogenetic and temporal structures, avoiding the need to capture terms in multiple separate analyses.
Our analytical advance offers new potential in predictive ecology, but given the severity of the potential implications of biodiversity loss35, it is vital that we continue to expand and improve these methods. We offer a general framework for addressing spatial, temporal and phylogenetic non-independence, but further advances are necessary, considering underlying issues around time-series length36, bias and non-probability37, nonlinearity and varied responses to environmental change38, modern data collection philosophies39 and rigorous analysis approaches40. This combination of improved methods and data has the potential to reveal patterns of biodiversity change and disentangle the complex processes shaping our ecosystems.
Methods
Data
We compiled ten datasets that describe population abundances through time2,3,4,5,6,7,8,9,10,11,41. These datasets represent some of the most influential in ecology and conservation biology, forming a basis for influential reports such as the Living Planet15, as well as a series of high-profile and highly cited publications (see Supplementary Table 2 for a full summary). For each dataset, we extracted the population abundance estimates, the accompanying time-stamps, the scientific names of the species, the name of the site (location) where the population was sampled and any site coordinates. For datasets to be included, they had to be open access, and contain multiple abundance time series for a selection of species and locations. Although these datasets are vital in biodiversity science, many of the datasets are prone to biases (for example, lacking tropical representation, and contain few plant and invertebrate species). The datasets have been compiled from a variety of methods, realms and systems, covering a vast array of spatial, taxonomic and temporal scales. Further, there is probably some overlap in data between datasets where population time series may occur in more than one dataset. We take no action to correct or acknowledge these biases and features, as our analysis is designed to show how model choice can have a substantial influence on inference in a variety of datasets, rather than to derive a consensus trend across datasets.
To account for correlative non-independence introduced by species’ shared evolutionary past, we extracted a phylogeny for each dataset. We used synthetic trees from the Open Tree of Life42,43 and estimated missing branch lengths using Grafen’s approach44 from the compute.brlen function in the R package ape45. The Open Tree of Life identified a phylogeny for 80% of species (n = 23,871); all other species were removed from the analysis. For studies with the overall aim of assessing biodiversity change, removing species could be problematic, as the collective trend would not be representative of all species. However, in our case, in which the aim is to assess how collective trend inference changes under a variety of modelling approaches, trimming the data to species with an accompanying phylogeny has no impact on our conclusions. Regardless, in sensitivity analyses in the Supplementary Information section entitled Phylogeny, we investigated this trade-off, and found that more than 1,000 species would have to be excluded from the data if higher-quality phylogenies were used (Supplementary Table 3). Further, inference is generally consistent across the datasets regardless of phylogeny quality (Supplementary Figs. 6 and 7).
After removing species not present in the Open Tree of Life topology, we further trimmed the data to include only higher-quality time series, removing the following: time series that contained zeros (which we considered extreme cases of extinctions or recolonizations) and time series with missing abundance values for a given year throughout the sampling duration (that is, we required consecutive abundance estimates). In all datasets except the two smallest ones—Atlantic reef fishes and Large carnivores—we further trimmed the datasets to keep only time series that had greater than or equal to the median number of abundance observations (that is, including the longest 50% of time series in each dataset). In some cases, this cutoff was not sufficient as the median number of observations in the time series equalled two. With only two abundance observations, trends are highly exposed to error purely driven by random fluctuations in abundance19. To partially address this issue, we imposed a further cutoff on these datasets, ensuring that each time series had at least five observations. These datasets are characterized in Supplementary Table 2. With our trimmed dataset, we derived a mean abundance in each year (in cases for which there were more than one observation per year) for each time series. In some datasets, there is a possibility that some species will have overlapping populations measured at different scales (for example, a national trend and a regional trend).
Modelling
We explored which models have been used in the literature to infer abundance change. We focused on studies that characterized the average change in abundances over time, rather than studies assessing how many species are declining or increasing, as this avoids discretizing a numeric value; that is, we avoid having to define what change is necessary to be classified as a decline. To evaluate the diversity of approaches used to model abundance change over time in multi-species and/or multi-location datasets, we conducted a literature search in a selection of high-profile ecology journals over the past 13 years (Supplementary Information). Our search identified 282 research papers, 28 of which described approaches to model abundance change across multi-species and/or multi-location datasets. A further 16 methods were not detected in the literature search but were known priori to the authorship team, resulting in 44 different studies and/or methods. Models of abundance change varied in complexity, each containing their own assumptions, with no clear ‘standard’ approach for deriving the rate of change in abundance. However, across the 44 studies and/or methods that we compiled (Supplementary Table 1), five general approaches were present, as follows.
-
1.
Abundance average: The simplest models derive an average or total abundance across all species or sites in a given year, and then regress average abundance against time. This approach fails to recognize any of the hierarchical structures in the data.
-
2.
Trend average: A slightly more complex model, which estimates abundance change per population by fitting a series of log-linear modes of abundance against year; averaging over the extracted slope coefficients. This approach fails to propagate uncertainty in average rates of change of each population, and ignores the implicit spatial and taxonomic structures in the data, inducing pseudoreplication.
-
3.
Random intercept: Some studies partially address the aforementioned pseudoreplication (for example, certain sites or species having multiple estimates) with mixed models, regressing log-linear abundance against year across all populations, while specifying that populations belong to a site and/or species. However, often this mixed model structure extends only to random intercepts, which only acknowledge that mean abundance can differ between sites, species and locations, and assumes that the abundance trends will all remain the same. This is a particularly common approach among the indicators from population monitoring schemes that shape policy46.
-
4.
Random slope: In the scientific literature, it is common to use more complex models, with a similar structure to the random intercept model, but now also capturing the differences in abundance trends (not only mean abundances) across populations, sites and species with random slope terms.
-
5.
Decomposition: This is the rarest of the approaches and deviates from the linear mixed model methods. Instead, the decomposition approach involves fitting generalized additive models through each time series to smooth abundance estimates and reduce noise. The smoothed time series is then decomposed into a time series of rates of change (or λ values), which are then averaged across species and biomes to derive estimates of the average change in abundance for each year across all of the time series.
The most common approaches were the random intercept and random slope models, used 19 and 23 times, respectively. The abundance average, trend average and decomposition approaches were rare, used just five, two and three times, respectively. Not all studies adopted just one approach, sometimes splitting their model into two steps (for example, using a random intercept model to estimate a given species trend across locations, which could then be aggregated across broader taxonomies with a random slope model). Further, all approaches regularly failed to account for temporal, spatial and phylogenetic structures (that is, closely related species are likely to have more similar trends than distant species), with only 14 of the 44 approaches accounting for temporal autocorrelation. Studies that accounted for phylogenetic or spatial covariance were comparably rarer—included in just six and three studies, respectively. Four studies attempted to account for two sources of correlative non-independence in their models, by first deriving population trends while accounting for temporal autocorrelation of abundances in time series, and then using phylogenetic least squares to aggregate these trends. However, no study captured more than one of these covariances simultaneously (for example, spatio-temporal models). Further, no study attempted to account for all three sources of correlative non-independence.
Given the apparent rarity of the abundance average, trend average and decomposition approaches in the literature, we focus on understanding how the dominant approaches (that is, the random intercept and random slope models) compare to our newly developed correlated effect model. Full model equations are available in the Supplementary Information.
Model 1 (random intercept)
In model 1, we fit a linear mixed-effect model between the natural logarithm of abundance and year, with five random intercepts: population (the unique time series), site (unique locations), region (broader spatial category to nest sites; flexibly determined on the basis of the spatial extent of the dataset), species (unique species) and genus (broader taxonomic category to nest species; measured as the parent node to the species tip). In the model, we do not specify any nesting of the population in the site and species random intercepts as the hierarchical structure of the data is poorly defined (for example, although populations always occur in a species and site, some species are nested in sites, and some sites are nested in species, creating a crossed random effect design). Model 1 assumes all populations, sites, regions, species and genera have the same trend in abundance.
Model 2 (random slope)
In model 2, we develop a linear mixed-effect model, in which we regress the natural logarithm of abundance against year, including population, site, region, species and genus all as random slopes. This builds on the random intercept model by allowing abundance–year slope coefficients to vary for each category in each random slope term (for example, each species can have a different slope)—not simply differing intercepts as in model 1. Unlike in model 1, we centre the year and abundances of each population time series at zero (for example, subtracting each year by the mean year in each population, and subtracting the log of each abundance by the mean log abundance value in each population). This centring fixes the y and x intercepts at zero for each slope, and is a convenient solution to account for variance captured by the random intercepts without increasing the number of parameters. To all intents and purposes, assuming that the objective is to characterize the abundance–year coefficient, the random slope model is equivalent to a model with random intercepts and slopes.
Model 3 (correlated effect)
Model 3 is structurally similar to model 2, but accounts for correlative non-independence. For temporal non-independence, we model the population level time series with a discrete first-order autoregressive temporal process, which assumes that sequential abundance observations in a time series will be more similar. To capture the spatial and phylogenetic correlative non-independence, we focus on non-independence across time-series trends (instead of abundance observations), assuming that trends in population abundances through time will be more similar in neighbouring sites and more closely related species. In models 1 and 2, we try to capture this non-independence with grouping categories (genus and region). However, in the correlated effect model, we more explicitly describe shared correlations between every species and site by specifying the covariance structures of our site and species random slopes. The site covariance matrix was derived by taking each site’s coordinates and estimating the pairwise Haversine (spherical) distance between the sites (for example, how far is every site from every other site). This was then converted into a matrix, normalized between 0 and 1, with values close to 1 indicating neighbouring sites, whereas values approaching 0 indicate distant sites. The species covariance matrix was derived by converting the phylogeny into a variance–covariance matrix, in which phylogenetic branch lengths describe the evolutionary distance between species.
All models were developed using Bayesian Integrated Nested Laplace Approximation (INLA)47 in R v.4.0.5 (ref. 48). We describe our model priors in the Supplementary Information section entitled Priors and validate our model assumptions in the Supplementary Information section entitled Assumptions (Supplementary Figs. 1–5). We also conduct additional sensitivity analyses exploring how phylogeny quality and how the addition of each correlative component (space, time or phylogeny) affect inference (see the Supplementary Information sections entitled Phylogeny and Component importance). We compiled the data using the following R packages: tidyverse49, countrycode50, janitor51, here52 and arrow53. Figures were produced using the following R packages: ggplot254, ggtree55 and ape45.
Outputs
Measuring non-independence
We assess whether correlative terms capture a meaningful proportion of variance in the data, by dividing the proportion of variance captured by the correlated slopes (for example, spatial covariance) by the combination of the variance captured by the correlated and independent slopes (for example, spatial covariance + site random slope + region random slope). This was carried out separately for the spatial and phylogenetic terms. As the spatial and phylogenetic components each contain three terms (an independent species or location slope, an independent genera or region slope and a correlated species or location slope), a proportional variance captured of 0.33 would indicate that the correlative slope captures an equal proportion of variance compared to the two independent slopes. A value greater than 0.33 indicates that correlative slopes account for more variation than independent random slopes. We measure temporal non-independence as the degree of correlation between sequential abundances (ρ).
Differing inference between the models
Using the mean and 50% credible intervals of the global trend (overall abundance–time coefficients), we display abundance projections for each model in each dataset. These projections are based on an arbitrary baseline abundance of 100, set at the first year of available data in each dataset, and this abundance would change according to the overall coefficients and credible intervals. For instance, with a 1% annual rate of change, an abundance in year zero of 100 would become 101 in year 1, and 164 in year 50. The purpose of these projections is to showcase varying abundance trajectories under different model complexities. We also report the fold change in the collective trend s.d. of the correlated effect model, relative to the random intercept and random slope models. This involved regressing fold change against category (for example, correlated effect versus random intercept) in a linear model. We report the mean fold change and 95% CIs. Model outputs are reported in Supplementary Tables 4 and 5.
Predictive performance
We assess the predictive performance of the different models by determining their ability to predict final observations in time series, and their ability to predict population trends of a given species in a given location. To test the predictive accuracy for the final observation in the time series, we removed the final observation from half of the time series in each dataset and predicted the missing values using each of the three models on the log scale. We report the percentage error (PE), a metric describing the median of the absolute percentage difference between predicted and observed values (for example, with a 5% error, an abundance on the log scale of 1 would become 1.05). This is calculated by finding the absolute difference between the true value and prediction, divided by the true value, before being multiplied by 100 and converted to an absolute error.
To test the accuracy of the population trend prediction, we conducted leave-one-out cross-validation, removing one population time series (or trend) from each dataset, and estimating the missing trend using the random slope and correlated effect models. We solely removed population time series with a trend not overlapping zero at 95% credible intervals (that is, populations changing significantly), to test our ability to identify which populations are changing or not. We repeated this process 50 times per dataset and compare the predicted trends to trends from a simplified correlated effect model, which contains a population-level slope and accounts for temporal autocorrelation, but does not include the spatial and phylogenetic correlation terms or any of the hierarchical terms, which have no influence on the required population-level inference. We measured trend-predictive performance using the same approaches as above (PE). In the random slope model, the population trend coefficients were derived by adding the species, location, genus, region and overall coefficients together, meaning that missing population trends can still be informed by other hierarchical information. For the correlated effect model, the population trend is informed by the phylogenetic and spatial variance–covariance matrices, as well as all hierarchical information in the random slope model. Prediction accuracy for each dataset is reported in Supplementary Tables 6 and 7.
Phylogenetic and spatial distribution of abundance change
To plot abundance change across a phylogeny, we derived species-level rates of change in abundance from the taxonomic (species and genera) and phylogenetic random effects. We incorporate uncertainty in species-level trend prediction by estimating the CI threshold by which a species would be considered to have increased or decreased. For instance, a negative trend at an 80% CI threshold would be considered stronger evidence of decline than a negative trend at a 20% interval threshold. We derive four asymptotic CI thresholds (20%, 40%, 60% and 80%) using the uncertainty (s.d.) from the phylogenetic random effect and a series of z-scores (0.25, 0.52, 0.84 and 1.28).
To plot abundance change across space, we focus solely on one abundant and iconic species, the American robin T. migratorius, as site-level trend variability is high at the community level (that is, community trends across space are rarely significant). To produce abundance change predictions for the American robin across space, we expanded the BioTIME spatial Haversine distance matrix (describing distances between each time series) by supplementing it with a gridded extent covering North America. This new grid had a latitudinal range of 20 to 60 and 1° spacing (for example, 15, 16 and so on), and longitudinal range of −130 to −60 with 1° spacing. This new matrix allows us to estimate expected covariance (similarity) in abundance trends for any pair of 1° cells across North America. We then derived the average rate of change in abundance across all hierarchical and correlative random effects, and used population-level trend uncertainty to derive the selection of CI thresholds described above.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All of the data used in the study are publicly available and accessible from the following links: RivFishTIME (https://doi.org/10.1111/geb.13210), North American Breeding Birds (https://doi.org/10.5066/P97WAZE5), BioTIME (https://doi.org/10.1111/geb.12729), Living Planet (https://www.livingplanetindex.org/data_portal), CaPTrends (https://doi.org/10.1111/geb.13587), ReSurveyGermany (https://doi.org/10.25829/idiv.3514-0qsq70), UK Fish Counts (https://environment.data.gov.uk/dataset/ce2618db-d507-4671-bafe-840b930d2297), FishGlob (https://doi.org/10.31219/osf.io/2bcjw), TimeFISH (https://doi.org/10.1002/ecy.3966), Pilotto (https://zenodo.org/records/10638241). See comprehensive data descriptions in Supplementary Table 2 and data_compile.Rmd (https://zenodo.org/records/10638241). Source data are provided with this paper.
Code availability
All code is available at https://zenodo.org/records/10638241.
References
Summary for Policymakers of the Global Assessment Report on Biodiversity and Ecosystem Services of the Intergovernmental Science-Policy Platform on Biodiversity and Ecosystem Services (IPBES, 2019).
Dornelas, M. et al. BioTIME: a database of biodiversity time series for the Anthropocene. Glob. Ecol. Biogeogr. 27, 760–786 (2018).
Sauer, J. R. et al. The first 50 years of the North American Breeding Bird Survey. Condor 119, 576–593 (2017).
Pilotto, F. et al. Meta-analysis of multidecadal biodiversity trends in Europe. Nat. Commun. 11, 3486 (2020).
Comte, L. et al. RivFishTIME: a global database of fish time-series to study global change ecology in riverine systems. Glob. Ecol. Biogeogr. 30, 38–50 (2021).
Freshwater Fish Counts (UK Government, 2021, accessed 1 May 2023); https://environment.data.gov.uk/dataset/ce2618db-d507-4671-bafe-840b930d2297.
Johnson, T. F., Cruz, P., Isaac, N. J. B., Paviolo, A. & González-Suárez, M. CaPTrends: a database of large carnivoran population trends from around the world. Glob. Ecol. Biogeogr. 31, 2475–2482 (2022).
Living Planet Index Database (LPI, 2023, accessed 1 May 2023); https://www.livingplanetindex.org/data_portal.
Maureaud, A.A., Palacios-Abrantes, J., Kitchel, Z. et al. FISHGLOB_data: an integrated dataset of fish biodiversity sampled with scientific bottom-trawl surveys. Sci. Data 11, 24 (2024).
Quimbayo, J. P. et al. TimeFISH: Long-term assessment of reef fish assemblages in a transition zone in the Southwestern Atlantic. Ecology 104, e3966 (2023).
Jandt, U. et al. More losses than gains during one century of plant biodiversity change in Germany. Nature 611, 512–518 (2022).
Ripple, W. J. et al. World scientists’ warning to humanity: a second notice. BioScience 67, 1026–1028 (2017).
Pereira, H. M. et al. Essential biodiversity variables. Science 339, 277–278 (2013).
Gonzalez, A., Chase, J. M. & O’Connor, M. I. A framework for the detection and attribution of biodiversity change. Philos. Trans. R. Soc. B 378, 20220182 (2023).
Living Planet Report 2020 - Bending the Curve of Biodiversity Loss (WWF, 2020).
Ledger, S. E. H. et al. Past, present, and future of the Living Planet Index. npj Biodivers. 2, 12 (2023).
Geldmann, J., Byaruhanga, A., Gregory, R., Visconti, P. & Xu, H. Prioritize wild species abundance indicators. Science 380, 591–592 (2023).
Leung, B. et al. Clustered versus catastrophic global vertebrate declines. Nature 588, 267–271 (2020).
Buschke, F. T., Hagan, J. G., Santini, L. & Coetzee, B. W. T. Random population fluctuations bias the Living Planet Index. Nat. Ecol. Evol. 5, 1145–1152 (2021).
Loreau, M. et al. Do not downplay biodiversity loss. Nature 601, E27–E28 (2022).
van Klink, R. et al. Meta-analysis reveals declines in terrestrial but increases in freshwater insect abundances. Science 368, 417–420 (2020).
Dornelas, M. et al. A balance of winners and losers in the Anthropocene. Ecol. Lett. 22, 847–854 (2019).
Daskalova, G. N., Myers-Smith, I. H. & Godlee, J. L. Rare and common vertebrates span a wide spectrum of population trends. Nat. Commun. 11, 4394 (2020).
Haase, P. et al. The recovery of European freshwater biodiversity has come to a halt. Nature 620, 582–588 (2023).
Dornelas, M. et al. Quantifying temporal change in biodiversity: challenges and opportunities. Proc. R. Soc. B 280, 20121931 (2013).
Browning, E., Freeman, R., Boughey, K. L., Isaac, N. J. B. & Jones, K. E. Accounting for spatial autocorrelation and environment are important to derive robust bat population trends from citizen science data. Ecol. Indic. 136, 108719 (2022).
Dinnage, R., Skeels, A. & Cardillo, M. Spatiophylogenetic modelling of extinction risk reveals evolutionary distinctiveness and brief flowering period as threats in a hotspot plant genus. Proc. R. Soc. B 287, 20192817 (2020).
Parks, D. H. et al. Recovery of nearly 8,000 metagenome-assembled genomes substantially expands the tree of life. Nat. Microbiol. 2, 1533–1542 (2017).
Status of Priority Species: Relative Abundance (Department for Environment, Food & Rural Affairs, 2023).
Valdez, J. W. et al. The undetectability of global biodiversity trends using local species richness. Ecography 2023, e06604 (2023).
Rosenberg, K. V. et al. Decline of the North American avifauna. Science 366, 120–124 (2019).
Sol, D. et al. The worldwide impact of urbanisation on avian functional diversity. Ecol. Lett. 23, 962–972 (2020).
Oliver, T. H. et al. Declining resilience of ecosystem functions under biodiversity loss. Nat. Commun. 6, 10122–10122 (2015).
Capdevila, P., Noviello, N., McRae, L., Freeman, R. & Clements, C. F. Global patterns of resilience decline in vertebrate populations. Ecol. Lett. 25, 240–251 (2022).
Rockström, J. et al. A safe operating space for humanity. Nature 461, 472–475 (2009).
White, E. R. Minimum time required to detect population trends: the need for long-term monitoring programs. BioScience 69, 40–46 (2019).
Boyd, R. J., Powney, G. D. & Pescott, O. L. We need to talk about nonprobability samples. Trends Ecol. Evol. 38, 521–531 (2023).
Elmqvist, T. et al. Response diversity, ecosystem change, and resilience. Front. Ecol. Environ. 1, 488–494 (2003).
Meng, X.-L. Statistical paradises and paradoxes in big data (I): low of large populations, big data paradox, and the 2016 US presidential election. Ann. Appl. Stat. 12, 685–726 (2018).
Wauchope, H. S. et al. Protected areas have a mixed impact on waterbirds, but management helps. Nature 605, 103–107 (2022).
Jandt, U. et al. ReSurveyGermany: vegetation-plot time-series over the past hundred years in Germany. Sci. Data 9, 631 (2022).
OpenTree. Open Tree of Life Synthetic Tree version 13.4 https://doi.org/10.5281/zenodo.3937741 (2019).
Michonneau, F., Brown, J. W. & Winter, D. J. rotl: an R package to interact with the Open Tree of Life data. Methods Ecol. Evol. 7, 1476–1481 (2016).
Grafen, A. & Hamilton, W. D. The phylogenetic regression. Philos. Trans. R. Soc. B 326, 119–157 (1989).
Paradis, E. & Schliep, K. ape 5.0: an environment for modern phylogenetics and evolutionary analyses in R. Bioinformatics 35, 526–528 (2019).
Breeding Bird Survey (BTO, 2020, accessed May 1st 2023); https://doi.org/10.5066/P97WAZE5.
Rue, H., Martino, S. & Chopin, N. Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J. R. Stat. Soc. Ser. B 71, 319–392 (2009).
R Core Team. R: A Language and Environment for Statistical Computing. http://www.R-project.org/ (R Foundation for Statistical Computing, 2020).
Wickham, H. et al. Welcome to the Tidyverse. J. Open Source Softw. 4, 1686 (2019).
Arel-Bundock, V., Enevoldsen, N. & Yetman, C. countrycode: an R package to convert country names and country codes. J. Open Source Softw. 3, 848 (2018).
Firke, S. janitor: Simple Tools for Examining and Cleaning Dirty Data https://sfirke.github.io/janitor/authors.html (2024).
Müller K. here: A Simpler Way to Find Your Files Version 1.0.1 https://here.r-lib.org/ (2020)
Richardson, N. et al. arrow: Integration to ‘Apache’ ‘Arrow’ Version 15.0.0 https://github.com/apache/arrow/ (2024).
Wickham H. ggplot2: Elegant Graphics for Data Analysis https://ggplot2.tidyverse.org (Springer, 2016).
Yu, G., Smith, D. K., Zhu, H., Guan, Y. & Lam, T. T. ggtree: an R package for visualization and annotation of phylogenetic trees with their covariates and other associated data. Methods Ecol. Evol. 8, 28–36 (2017).
Acknowledgements
We thank: the contributors to BioTIME; the Living Planet team, including R. Freeman and L. McRae; all scientists and volunteers that contributed to the North American Breeding Bird Survey; FishGlob; RivFishTIME; the UK environment agency; TimeFISH; ReSurveyGermany; as well as contributors to the European biodiversity data, including A. Verstraeten, J. Neirynck, G. Van Ryckegem, G. Van Hoey, B. Nikolov, V. Evtimova, R. Stanchev, P. Haase, I. Kronck, J. Meyer, J. Creveceour, M. Janssen, A. Thimonier, F. Pilotto, I. Kappel Schmidt, D. Oro, J. Poyry, K. Huttunen, T. Muotka, R. Paavola, L. Barboro, E. Camatti, M. Pansera, R. Alber, S. Vorhauser, A. Skula, G. Springe, B. J. Ens, M. E. Visser, T. Bongard, T. Jensen, K. A. E. Baekkelie, T. C. Jensen, M. Pardal, F. Martinho, T. Pipan, M. Aljancic, F. Gabrovsek, H. Kalivoda, L. Halada, S. David, U. Grandin, D. Monteith, S. Rennie, J. Adamson, R. Anderson, C. Andrews, J. Bater, N. Bayfield, K. Beaton, D. Beaumont, S. Benham, V. Bowmaker, C. Britt, R. Brooker, D. Brooks, J. Brunt, G. Common, R. Cooper, S. Corbett, N. Critchley, P. Dennis, J. Dick, B. Dodd, N. Dodd, N. Donovan, J. Easter, M. Flexen, A. Gardiner, D. Hamilton, P. Hargreaves, M. Hatton-Ellis, M. Howe, J. Kahl, M. Lane, S. Langan, D. Lloyd, B. McCarney, Y. McElarney, C. McKenna, S. McMillan, F. Milne, L. Milne, M. Morecroft, M. Murphy, A. Nelson, H. Nicholson, D. Pallett, D. Parry, I. Pearce, G. Pozsgai, R. Rose, S. Schafer, T. Scott, L. Sherrin, C. Shortall, R. Smith, P. Smith, R. Tait, C. Taylor, M. Taylor, M. Thurlow, C. Tilbury, A. Turner, K. Tyson, H. Watson, M. Whittaker, C. Wood, I. Winfield, M. I. Di Fonzo, B. Collen, A. L. M. Chauvenet, G. M. Mace, L. Comte, Q. J. Carvajal, P. A. Tedesco, X. Giam, U. Brose, T. Erős, A. F. Filipe, M. J. Fortin, K. Irving, C. Jacquet, S. Larsen, J. R. Sauer, D. K. Niven, J. E. Hines, D. J. Ziolkowski, K. L. Pardieck Jr, J. E. Fallon, W. A. Link, S. J. Thackeray, M. Dornelas, L. H. Antão, F. Moyes, A. E. Bates, A. E. Magurran, S. P. R. Greenstreet, M. Moriarty, S. D. Batten, S. Seibold, W. Weisser, M. Gossner, E. Pasalic, M. Lange, M. Turke, S. N. Gallenberger and M. Staab. This work was financially supported by the UK Research and Innovation–Natural Environment Research Council grant NE/T003502/1.
Author information
Authors and Affiliations
Contributions
Conceptualization: T.F.J., A.P.B., D.Z.C., R.P.F.; data curation: T.F.J., T.J.W., C.A.G.; analysis: T.F.J., P.C., R.P.F.; visualization: T.F.J.; writing: T.F.J., A.P.B., D.Z.C., R.P.F.; editing: T.F.J., A.P.B., D.Z.C., T.J.W., K.L.E., C.A.G., P.C., C.F.C., M.B., R.D.G., G.H.T., E.D., R.P.F.; mentoring: A.P.B., D.Z.C., R.P.F.; funding acquisition: A.P.B., R.P.F., D.Z.C., C.F.C., K.L.E., T.J.W., G.H.T.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature thanks Henrique Pereira and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Impact of phylogenetic and spatial signal on inference.
Fold change in the standard deviation of the abundance-time coefficient between the correlated effect and random slopes model, plotted against the mean signal. Mean signal is calculated by finding the mean of the phylogenetic signal (variance captured by the phylogeny divided by the sum of the phylogenetic and non-phylogenetic variance) and spatial signal (as in the phylogeny). n = 10 with each point representing a dataset. Shading represents 95% confidence intervals from a linear model.
Extended Data Fig. 2 Contribution of spatial, temporal and phylogenetic components to collective trend uncertainty.
Relative fold change in the standard deviation of the collective trend as additional components (space, time or phylogeny) are added to the random slope model. Models are compared to the standard deviation of the collective trend in the random slope model. In each model comparison (y-axis), n = 10 with each point representing a dataset. The larger point and error bar represents the mean change and associated standard deviation around this mean.
Supplementary information
Supplementary Information
Supplementary text and data, Figs. 1–7 and Tables 1–7.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Johnson, T.F., Beckerman, A.P., Childs, D.Z. et al. Revealing uncertainty in the status of biodiversity change. Nature 628, 788–794 (2024). https://doi.org/10.1038/s41586-024-07236-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-024-07236-z
- Springer Nature Limited