
Abstract
Demand modeling is an important part of the setup of a traffic model for a city. All travel demand models rely on land use data as the demand for traveling fundamentally stems from activities occurring at different locations; however, many cities lack these data, or experience in estimating travel demand in their region. In response, this study develops a methodology for generating highly detailed land use data in the form of points of interest (POIs) specifically aimed at travel demand estimation purposes. The framework includes a procedure to extract, clean, enhance, and categorize freely available land use data from OpenStreetMap (OSM) into different POI categories, such as residences, schools, and shops. These residential and activity POIs, which are typical origins and/or destinations of trips, serve as the starting point for estimating travel demand. This paper demonstrates the framework’s utility through three case studies across different cities in Belgium. It validates the effectiveness of OSM-derived POIs for travel demand estimation by replicating Antwerp’s existing demand model, examines the POIs classification’s suitability for various travel demand purposes in Leuven, and assesses the transferability of correlations between OSM data and travel demand from Antwerp to Ghent. Beyond the applications illustrated in this paper, the framework provides opportunities for future research on the consistent disaggregation of existing zonal demand estimates and design-based research in which future demand is estimated given the development of POIs. The framework is openly available as a Python tool called Poidpy.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
An essential component of a traffic model is the travel demand in the region. For modeling travel demand, there are multiple approaches in literature and practice, of which the most known are trip-based [1] and activity-based [2] demand modeling. Although these methods vary in their methodology, they all rely on land use data for estimating demand. This is because the demand for traveling fundamentally stems from activities occurring at different locations. Therefore, regardless of the method used, understanding the land use and distribution of activity locations or points of interest (POIs) is essential for accurately estimating travel demand within a region.
The traditional trip-based demand models, also known as the 4-step model, represent travel demand by estimating the number of trips originating and ending in a certain area, called production and attraction within a traffic analysis zone (TAZ) [1]. The reliance on these TAZs in traditional models stems from the use of spatial data available only at an aggregate level, typically derived from government-provided census data. However, the need for more detailed travel demand estimates becomes apparent, particularly for the planning of emerging and adaptable transportation services such as micro-mobility and demand-responsive systems. More detailed spatial data is required to accurately capture the complexities of travel patterns by these systems.
This paper provides a methodology for generating highly detailed land use data in the form of POIs specifically aimed at travel demand estimation purposes. For this purpose, the developed framework leverages OpenStreetMap (OSM) for gathering spatial data as it is free and available worldwide. The framework includes an automated process of extracting, cleaning and categorizing the OSM data in different types of POIs. The framework is generic in the sense that these classified POIs can be used as input for any type of demand model and can be applied to any region in the world.
The remainder of the paper is structured as follows. Section 2 provides background information about OSM, and states the contribution of this paper compared to the literature. In section 3, the developed framework is presented, and the methodology for collecting, cleaning and categorizing the data is explained. In section 4, the applicability of the framework is showcased through three case studies in which demand models are estimated, and their performance is evaluated. Finally, the paper ends with a discussion and conclusion.
2 Literature and contribution statement
Volunteer-based geographic information (VGI) systems like OpenStreetMap (OSM) have become increasingly popular. OSM is the most comprehensive open database that contains geographical features representing physical objects worldwide, such as roads, buildings, POIs and land use data [3]. Operating as a key-value database, each object in OSM is assigned a unique ID for identification, with additional information added through tags attached to the object. These tags consist of a key and an associated value [4]. For example, the tag “building” = ‘school’ indicates that the building is used for educational purposes.
In this way, OSM provides open access to POI information, revealing highly disaggregated geospatial data about the built environment and land use in a region. An advantage of OSM over other static data sources is that it is a living data source, ensuring it remains up to date while land use and mobility habits evolve. Moreover, the availability of these OSM data, at a highly disaggregated scale for any region of choice, can reduce dependency on heterogeneous governmental data sources, which simplifies the process and enhances its portability to other regions.
The global and cost-free accessibility of OSM, facilitated by VGI crowdsourced data, has benefited numerous applications in transport planning. For instance, previous studies have leveraged OSM data for the generation of a road network required in traffic simulation [5, 6]. Also for travel demand estimation purposes, OSM has been consulted. Valdes et al. [7] used a subset of POIs data from OSM in combination with demographic information to estimate the demand for electric charging. More recently, Klinkhardt et al. [8] developed and validated a methodology for calculating the attractiveness of travel demand models from OSM data and national trip generation guidelines. Similarly, Li et al. [9] employed OSM POIs and standard trip generation rates to estimate travel demand using the traditional 4-step model.
Despite its popularity, the reliability and fitness for use of crowdsourced data can be questioned as the quality depends on the diligence of the local contributors [10, 11]. There exists a large body of literature on quality assessment of VGI systems [12] and the International Organization for Standardization (ISO) has defined a set of measures for evaluating the quality of geographic data [13]. Relevant quality aspects of OSM include completeness (i.e., the extent to which the map data covers all geographic features within a given area) [14, 15], positional accuracy of features [16], topological consistency between features [17, 18], temporal quality [19], attribute completeness [17, 20], and attribute accuracy [20].
Research shows that building completeness exhibits notable variability across regions and urban contexts with relatively high completeness observed in Europe & Central Asia (71%) and North America (64%), while regions such as Latin America & Caribbean (20%), East Asia & Pacific (20%), Middle East & North Africa (12%), and South Asia (9%) exhibit lower completeness values [15]. Moreover, the latter study observed substantial variations in building completeness within individual urban areas, highlighting disparities even within the same cityscape [15].
Furthermore, the completeness of attributes remains low, even in areas with extensive coverage of building geometries. Overall, OSM includes more than 96,000 attributes and more than 150,000 distinct tags [4]. At most 20% of buildings were labeled with their building type, while 4.6% had tags indicating the number of levels, and merely 2.9% included height information [20]. The authors of [17] observed comparable rates of omissions in building types and noted that these omissions are significantly higher than those observed for road or rail types. Nonetheless, despite the low attribute completeness, the accuracies for building type reached up to 84.4%, and building levels achieving up to 72.2% accuracy [20]. The analysis of land use data in [21] revealed a similar trend indicating low completeness in most countries but relatively high accuracy.
On top of the low attribute completeness, there is a large difference in tag usage [17]. For example, 7868 different values are used for specifying the building type, and 99.9% of these values yield usage rates less than 0.5% [4]. This underscores the challenges in data completeness and heterogeneity within OSM, attributed to its VGI nature, where it relies on the contributions of local mappers and is subject to regional cultural and language differences.
While initial efforts have been made to use OSM data for travel demand generation, few publications address the challenges posed by low attribute completeness, large attribute variability and topological inconsistencies of OSM data for this application. Moreover, the highly heterogeneous quality of OSM buildings across regions has hindered the development of an automated process for acquiring detailed land use data from OSM for travel demand estimation.
This paper addresses these gaps by developing a framework for meticulous gathering, cleaning and categorizing OSM data in the form of POIs for application in any travel demand model. Previous methodologies (proposed by Klinkhardt et al. [8] and Li et al. [9]) select OSM data based on a specific selection of tags. This means that spatial objects that have incomplete labeling (which often occurs in OSM) might be ignored. To address this, the framework presented here uses only a selection of keys instead of tags, i.e., keys and values. Later in our process, a tag list is used to drop specific objects and, in this way, limit the pollution in the dataset. Additionally, while previous efforts primarily focused on attractiveness in travel demand models, in this study, we also want to identify residential buildings (residential POIs) as they form the origins of most trips. Especially for identifying residences, more than for activity POIs, the information in OSM is missing because the completion rate of relevant tags is very low. Furthermore, inconsistencies in the multilayered dataset, such as overlapping building polygons or overrepresentation (for example, a shop can be included as a point with the tag “shop” = “supermarket” as well as a polygon with the tag “building” = ‘supermarket’), are resolved and flattened to one layer. In this layer, building polygons serve as the unit of analysis, to which the relevant information of the contained POIs and surrounding land use is added. This approach is an effective step to (1) take into account and categorize incompletely labeled or unlabeled objects and (2) avoid double counting.
Furthermore, our contribution lies in providing a fully automated, open-source Python toolkit for data gathering, cleaning, and categorization. In contrast, existing methods required manual data retrieval and multiple software tools for visualization. Klinkhardt et al. [8] proposed a manual methodology that requires the use of multiple available tools. In their suggestions for future research, they acknowledge the added value of an automated process for faster estimation of travel demand and for easier updating of existing models based on an updated OSM dataset. Moreover, automating the estimation process benefits portability to other regions. The toolkit includes a built-in module for data retrieval and allows customization of attributes and values based on regional differences. Furthermore, visualizations of the OSM data and model performance are integrated within the tool.
This paper shows the applicability of the framework by applying it for three case studies on three different cities in Belgium. The first case study validates the effectiveness of POIs data generated from OSM for travel demand estimation by reproducing travel demand of an existing trip-based demand model of Antwerp. Further, the correspondence between the chosen POIs classification and different travel demand purposes is analyzed through a second case study on the city of Leuven. In the third case study the model estimated for Antwerp is applied to Ghent to analyze to which extent the correlations found between OSM data and travel demand found for one city can be extrapolated to a different but comparable region or city.
3 Poidpy framework
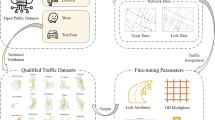
The methodology developed in this paper is incorporated in a tool called Poidpy. The core idea of Poidpy is that POIs, i.e., activity locations and residences, form the origins and destinations of trips and hence can be used to estimate travel demand within and between regions. The overall Poidpy framework is presented in Fig. 1.

Poidpy Framework
The Poidpy framework consists of two submodules: POI data extraction and preprocessing, and POI categorization. They are, respectively, related to gathering and categorizing the data from OSM.
In the next subsections, the submodules in Fig. 1 will be discussed in more detail. PoidpyFootnote 1 is openly available as a Python package and includes code, documentation and example notebooks.
3.1 POI data extraction and preprocessing
This section describes the design choices made concerning the data downloaded from OSM as well as the preprocessing methods applied to attain a consistent dataset of POIs. An overview is given in Fig. 2. Four preprocessing steps are considered. First, relevant data are downloaded from OSM. Second, objects that are irrelevant for travel demand estimation are removed from the downloaded dataset. Third, inconsistencies in the data are resolved. Finally, the information of objects representing the same building in reality is combined. Moreover, this information is further enhanced by including details of the surrounding land use type. All four steps are discussed in more detail below.

POI data extraction and preprocessing
To download the data, the OSMNx package [22] is utilized to interact with the OSM API. To query the OSM data, different parameters are specified in the OSM download module. Spatial data in OSM exist in three geometry types: points, linestrings and polygons. For identifying activity locations and residences, only points (e.g., a POI) and polygons (e.g., a building) are of interest and hence downloaded from OSM, assuming that a line feature, such as a street, is not a POI that contributes to travel demand.
Because of the low level of completeness in OSM and the large heterogeneity in tags, we did not choose to download objects based on specific key-value pairs (as in previous research), as this could result in an underestimation of objects in the study area. Instead, the approach developed in this paper extracts all the information from OSM within the specified study area that is relevant for classifying residences and activity locations.
Nonetheless, downloading all relevant information from OSM while limiting the inclusion of irrelevant data is challenging because of the large heterogeneity in tag usage. Therefore, a selection of relevant keys (without specified values) is passed on as a parameter in the OSM download module instead of as a list of specific tags. The keys used are land use, building, amenity, shop, office, leisure, sport and tourism. These are among the most commonly used attributes in the OSM database [23] and were chosen based on previous research [24]. This process results in a multilayered dataset (visualized in Fig. 3a) that includes points representing POIs, polygons representing buildings, and polygons providing general information on land use. Via this approach, unlabeled buildings can also be classified with the additional extracted information of these contained POIs or surrounding land use polygons.

a Data downloaded from OSM and b an example of points (waste bin, bench and electric charger) and polygons (parking and parking spots) dropped from the dataset
Only in the subsequent step, a list of tags to ignore is used to drop objects that are irrelevant for travel demand estimation from the downloaded dataset. The ignore-tags might, for example, include “landuse” = ‘flowerbed’, “building” = ‘garage’, “amenity” = ‘waste_basket’, and “leisure” = ‘outdoor_seating’, as these objects do not represent residential or activity locations. An example of a set of dropped data points is shown in Fig. 3b. The full list of attribute-value pairs that are ignored in the case studies presented in this paper is shown in Appendix A, Table 9.
Ideally, the multilayered spatial data extracted from OSM are accurate and consistent; unfortunately, this is not the case. There could be faulty or inaccurate mappings that make the layer spatially inconsistent. In the third step, two types of inconsistencies are handled: contained polygons and overlapping polygons. Two types of polygon features are distinguished: (1) objects with a value for the building key (building polygons or, in short, buildings) and (2) objects without a value for buildings but with a value for the land use key or other tags referring to the land use within the polygon (called contour polygons). The contour polygons are selected based on the tag list included in Table 10 in Appendix. Examples of buildings and contour polygons are shown in Fig. 4.

The building and contour polygons representing the land use in the region
Examples of overlapping and contained building and contour polygons are shown in Fig. 5. For buildings, it is impossible to have more than one structure at the same location. Having another function inside a building is possible, but the structure as such consists of only one building or two individual nonoverlapping buildings. Similarly for contour polygons, an area with a specific land use should not contain a zone with another land use, since this implies a new land use consisting of the combination of the others which is an unwanted situation. To resolve these inconsistencies and avoid double counting, two possibilities are put forward: (1) removing the contained or smallest polygon, keeping only the larger polygon or (2) cutting out the contained or smallest polygon from the larger one, keeping both as individual nonoverlapping polygons in the dataset. The contained buildings are removed. For overlapping buildings, the smallest polygon is always cut from the largest polygon. The same pragmatic approach is used for overlapping and contained contour polygons: the smallest or contained polygon is always cut out from the largest or surrounding contour polygon. In this way, the most informative land use type is used to infer the function of buildings located inside the contour polygon.

Examples of a contained buildings and b contour polygons
As a final cleaning step, a threshold for a minimal building surface is specified. For the Belgian case studies considered in this paper, this threshold is set to 40 m2 because permission is needed for constructing buildings in Belgium that are larger than this threshold. In this way, most garden sheds and garages are successfully removed from the building layer, as shown in Fig. 6.

An example of buildings removed from the dataset based on the minimum surface threshold
Finally, although already consistent, the multilayered dataset still needs to be flattened to only one layer where all the object information is combined. For this purpose, the procedure considers the building polygons as the unit of analysis and adds all the information to these polygons. This is because most activities (including residential activity) are hosted inside a building. One exception is outside leisure activities such as soccer pitches or running tracks. As these will also attract trips, they are taken into account as a separate category in the categorization module (which will be explained in more detail in the next subsection).
The flattening of the multilayered data is an important contribution of the framework developed in this paper. It is important for two reasons: (1) to avoid doubled counting and (2) to be able to classify unlabeled buildings. First, places for certain activities are often included in OSM both as points and polygons (see Fig. 7a). It also happens, although less frequently, that an activity is included as an extra polygon in addition to the building polygon. Second, combining information from the different layers enables the classification of unlabeled buildings. For example, in Fig. 7, buildings with the tag “building” = ‘yes’ can be classified by the information of the points located within (Fig. 7a) and based on the land use polygons around it (Fig. 7b). For both reasons, the information of points and nonbuilding polygons lying within the building polygons and of the surrounding contour polygons are added to the building polygons. The exact use of this combined information for classifying the building polygons in the subsequent categorization step is explained in the next section.

Examples of building polygons with a points located inside and b surrounding contour polygons
3.2 POI categorization
The next step uses these preprocessed data to identify activities and residential locations (called POIs hereafter) that attract or produce trips and categorize them. The following categorization was used: Small residential, Large residential, Health, Services, Shops, Industry, Catering, Leisure, Leisure areas, School, Tourism and Others. To identify the POIs, two separate procedures are developed for residential POI categories and activity POI categories (as discussed in Sects. 3.2.1 and 3.2.2, respectively). Both procedures assign a probability between zero and one, indicating the likelihood of any POI belonging to the POI categories. Note that buildings can be of mixed use and can receive a probability for both a residential and an activity category and that their sum can be greater than one. Once the probabilities are assigned, these values are multiplied by the polygon area (in squared meters) to take the size of the residence and activity location into account. In this way, not only the existence of a POI of a certain type but also its degree of attractiveness or trip-generating potential are taken into account.
Note that OSM has a building-level tag, but because it is rarely used (in approximately 2% of all polygons in OSM this is not considered [4, 20]). However, as explained below, we heuristically increase the area inside city centers for some activities to account for the effect that buildings inside city centers tend to be multistoried buildings.
3.2.1 Residential function
To obtain all the residential POIs, the categorization procedure starts from a layer containing only building polygons. Fig. 20 in Appendix B depicts the full procedure that is used to assign a residential function to a building depending on the available information.
The process starts by selecting geometries with specific attribute values directly referring to residences. The considered attribute-value pairs are, for example, “building” = ‘house’ classified as Small residential with a probability of one and “building” = ‘apartments’ with a probability of one for Large residential. The full list of considered attribute-value pairs is presented in Table 11 in Appendix B. Similarly, buildings that clearly have nonresidential purposes according to tags such as “building” = ‘church’, “amenity” = ‘university’, “leisure” = ‘sports-centre’, “office” = ‘government’ and “tourism” = ‘hotel’ are labeled nonresidential. These buildings are selected based on the tag list presented in Table 12.
However, many features (for example, 92.2% of the buildings presented in Fig. 8) lack detailed information to immediately label them residential or nonresidential, such as features with the tag “building” = ‘yes’. Moreover, buildings can be of mixed use. A clear example is buildings in the city center that have a shop on the ground floor and apartments on the floors above. Therefore, if the labeling of objects is incomplete, some additional basic decision rules are used, which are briefly explained below.

Result of the residential categorization step
One strategy used to classify buildings is to look at the surrounding contour polygons, providing information on the land use. For this purpose, three types of land use contours are differentiated: nonresidential, unlikely residential and residential. On the one hand, features inside a nonresidential land use contour are classified as nonresidential (zero probability), as these features are highly unlikely to be residences. An example of a nonresidential land use contour is “landuse_outer” = ‘cemetery’. Other nonresidential land use contours are identified according to the tags presented in Table 13 in Appendix B. On the other hand, buildings located inside unlikely residential land areas (e.g., “landuse_outer” = ‘farmyard’, “landuse_outer” = ‘retail’ and other presented in Table 14) have a small probability of having a residential function because they are most likely to represent an activity POI but could also be of mixed use and hence host a residence. Finally, buildings inside residential land use polygons (“landuse_outer” = ‘residential’) are more likely to be purely residential. Nonetheless, because they could also be of mixed use, this rule is also combined with other rules (extra tags, polygon area) in the categorization algorithm to define the residential probability.
-
Extra tags: Having extra tags (e.g., “shop”, “amenity”, “office”) in addition to a building tag decreases the likelihood of a building being a residence.
-
Polygon area: Buildings larger than the maximal residential building area threshold are less likely to be residences. As the average size of a house varies by region and country, this threshold is a changeable parameter in the tool (here 600 m2).
-
City center: Buildings inside the city center are more likely to be of mixed use.
-
Inner point or polygon info: when a building intersects with another feature (point or polygon), its likelihood of being solely residential decreases. By considering the tags of these intersecting features, in combination with the other rules, a probability for the residential function is assigned.
As a result, all buildings will receive a probability representing the likelihood of the building being a Large or Small residence. An example of such a result is visualized in Fig. 8.
3.2.2 Activity categories
This section describes the approach for classifying POIs according to their activity type. The following nine activity categories are considered: School, Health, Services, Industry, Catering, Shops, Leisure, Tourism and Others.
The algorithm starts by classifying each building according to all its attribute-value pairsFootnote 2, including the tags derived from the information of contained or surrounding points and polygons. All considered pairs associated with any activity category are shown in Table 15 in Appendix C. Some examples of classifications are listed in Table 1. If a building has multiple tags that are part of different activity categories, this building receives a probability for each of these categories. For example, a stadium is assigned to both the Leisure and Tourism categories. In the case studies presented in this paper, all activity categories receive equal probability.
For building polygons not yet classified and only having “building” = ‘yes’ as tag, an additional step is performed in which information on the surrounding land is used to infer the activity type. For example, “landuse_outer” = ‘education’ or ‘industrial’. All considered land use tags per activity category are listed in Table 16.
After all the buildings are classified into activity categories, their trip-generating potential or degree of attractiveness are considered based on the building surface. As a building can belong to multiple categories (specified by its probabilities), the building surface is divided into different categories proportional to its probabilities of belonging to the different activity categories. Two refinements are implemented. First, for example, a sports hall or museum often also host a cafe. As Catering is not the main function of the building at these locations, an extra correction is applied to its surface. Specifically, for any building that is categorized as Catering and has an additional function, the part of the building surface allocated to the Catering function is reduced. In this way, the majority of the surface of a building being an activity location will be categorized according to the primary function and with Catering as the secondary function. The second refinement added to the categorization algorithm is that the surface area of buildings categorized as Services, such as offices, is increased when located in the city center. As building-level information is scarce in OSM (approximately 2% of all polygons in OSM [4, 20 ]), this pragmatic rule is included because offices are often multistoried buildings within a city center.
The previously mentioned categorization rules were applied to buildings. In addition, the categorization also considers leisure polygons. The latter represents the location of activities that are not taking place inside a building, for example, a soccer pitch. As these activities also attract trips, they are important to consider as well. These leisure polygons are identified as polygons not having a building-tag value but having a tag, such as “leisure” = ‘soccer_pitch’. All the attribute value pairs in the nonbuilding activities list are presented in Table 17. Individuals belonging to this class are classified as belonging to a separate leisure category called leisure areas because these activities can cover large areas but typically attract fewer trips per square kilometer than, e.g., a fitness center included in the category Leisure. In the next steps within the framework, separating this category from the Leisure category (only including buildings) allows the model to estimate different trip rates for both.
The results of the categorization steps presented above are visualized in Fig. 9. In this example, 33.3% of the activity buildings could be classified based on information obtained from the tags of the surrounding contour polygons and points and polygons located inside the building polygons. Again, this proves that the approach taken in this paper is more suitable than the approach taken in previous research in which POIs are downloaded and classified based on specific key-value pairs inherently available in OSM only.

Result of the activity categorization step
3.2.3 Flexibility of the Poidpy tool
Although the keys, tag lists and specified parameters used in the preprocessing and categorization steps presented in this paper follow from extensive research on multiple case studies in addition to previous research [24] and information from OSM Wiki and tag info [4, 23], it is important to note that the parameters are changeable, the tag lists are dynamic, and values can be included or excluded depending on the regional context. The fine-tuning of tag lists and parameters, such as the minimal building surface threshold, the maximum residential building surface threshold and the building level multiplier, is especially encouraged when applying the framework to a region to which it has not yet been applied. To accommodate this fine-tuning, all the parameters and tag lists used within the downloading, cleaning, and categorization steps are stored and can be easily accessed by the user via the Poidpy tool. For example, after both the residential and activity categorization steps, the tool provides a list of tags that were not considered in the classification rules but some objects in the study area poses. This allows the user to evaluate the list of unused tags and, if necessary, add these tags to the appropriate activity class in the categorization lists so that these objects will be classified after rerunning the categorization steps.
For the case studies presented in this paper, the pragmatic rules and specific parameters were defined and evaluated based on extensive research of personally well-known regions in Leuven, Heverlee and Korbeek-Lo. Based on the latter region, the figures presented above were also created.
4 Applications
To showcase and evaluate the applicability of the Poidpy framework in travel demand modeling, the extracted and classified POIs are used as input for the trip generation step of the classic 4-step model. It starts from the idea that for each zone, the total number of trips produced and attracted is the sum of the zone characteristics, as shown in Eq. 1.
where \({X}_{ni}\) is the numerical value of characteristic n for zone i and \({\beta }_{A,n}\) and \({\beta }_{P,n}\) are the corresponding β parameters for this characteristic for attraction and production, respectively. The intercept is considered to be zero because when there are no POIs in a zone, no production or attraction is expected.
One way to setup this trip generation model is through calibration, where given the attraction and production per zone (e.g., obtained from a reference OD matrix), a multiple linear regression finds the trip rate coefficients for the different POI classes. These trip rate coefficients represent the number of trips produced or attracted per square meter. This method is used in the first case study to reproduce existing estimates of the travel demand in Antwerp. In this paper, the ordinary least squares method is used for this calibration.
Depending on the data used, the meanings of the β coefficients differ. The trip rate coefficients correspond to the same dimension of the given production and/or attraction numbers. For example, they can be differentiated by trip purpose, mode of travel and time of day. This allows us to analyze how trip production and attraction of different POI types vary by travel purpose, mode choice and time of day. In the second case study, for Leuven, the correlations between the different POI categories and demand data for specific trip purposes are analyzed and purpose-specific attraction models are estimated. To further evaluate the relevance of the chosen POI categorization, the POI category-specific trip rate coefficients per purpose are compared. These differences in β coefficients will reveal whether calibrating models based on OSM adequately capture the logical differences in travel demand-generating potential between the different POI categories across travel purposes.
Instead of calibrating the β coefficients, these coefficients can come from standard guidelines such as those proposed by Klinkhardt et al. [8] and Li et al. [9]. Nonetheless, those coefficients are not always available for the study area. In practice, to resolve this, trip generation rates of other regions are used. Similarly, these coefficients can come from previous calibrations with Poidpy data on a comparable city with known travel demand estimates and can be used on a set of POIs from a new city where no former demand is known. In the third case study, the transferability of coefficients is tested by estimating travel demand in Ghent using the calibrated model of Antwerp.
For all three case studies, available OD matrices generated from the strategic person model Flanders v4.2.2 (developed by the Department of “Mobiliteit en Openbare Werken” (MOW) of the Flemish government) are used as ground truth [25]. The dataset includes an OD matrix for the year 2020 for all of Flanders, including external zones that represent the neighboring areas. The reference itself is not a direct and perfect observation of all trips in the region (which does not exist), but it is the result of a demand generation exercise using all sorts of relevant data such as the regional household travel survey, national statistics on person mobility and other official governmental data sources. It does not consider OSM.
4.1 Antwerp case study
Figure 10 visualizes the study area and zoning. The zones covering the port of Antwerp as well as the airport of Antwerp (Deurne) are excluded because these zones possess specific characteristics different from those of the mixed land use in the other zones. In this case study, the person travel demand between 7 and 8 a.m., including all trip purposes, was selected. The ground-truth production and attraction per zone (Fig. 10) are calculated by summing the values of each row (origin) and of each column (destination) in the MOW OD matrix.

Reference zonal a production and b attraction (in number of trips)
4.1.1 Trip generation models
The goal of the production and attraction regression models is to predict zonal production and attraction based on the information included in the categorized POIs. The classified POIs extracted from OSM are shown in Fig. 11. Note that for visualization purposes, the surface of the POIs, and therefore the value of the corresponding category, is ignored.

a Residences and b activity locations
Production in the morning peak is most dependent on people leaving their home to go to work and school. Therefore, zonal production is mainly based on buildings categorized as Small or Large residences. Nonetheless, the activity POIs were also considered regressors in the production model. An analysis of the correlations between total production and the different POI categories revealed that zonal production was mostly correlated with the surface of Small (0.41) and Large (0.43) residences, followed by the Others category (0.22). The other activity categories show correlations with production below 0.08, reaching − 0.24 with the Industry category. The latter value seems logical because industrial areas typically have a lower density of residential properties. Correlations between the different POI categories never exceeded 0.35 except for the correlations between Services and Tourism (0.43), Catering and Tourism (0.38), Leisure and Leisure areas (0.44), Large residential and Catering (0.43), and Industry and Shops (0.41). These correlations between the POI categories and morning peak production are highly plausible and provide confidence in the categorization method and useful information for the next step.
Next, multiple linear regression was used to test whether the considered residential and activity categories significantly predicted production (P) on a 5-percent significance level. By performing “leave one out cross-validation”, a model that included small residential (\({X}_{SR}\)), and large residential (\({X}_{LR}\)) models was found to perform best in terms of the uncentered R2, root mean squared error (RMSE) and mean absolute error (MAE) values. The production model structure is as follows:
Performing statistical outlier analyses revealed six zones that biased the regression results. After these influential observations were dropped, a significant regression equation was found with an (uncentered) R2 of 0.941 and an RMSE of 180.08 (with outliers)Footnote 3. The estimated coefficients and model performance are reported in Table 2.
The R2 value shows that the model describes a substantial part of the relationship between the number of different types of POIs and the number of produced trips. The estimated coefficients indicate that a large residential building (\({X}_{LR}\)) produces more trips per square meter than does a single residential building (\({X}_{SR}\)), which is logical.
For modeling zonal attraction, mainly activity POIs are considered. Following the same analogy as used for zonal production, activities can be considered the main destinations of morning peak trips. Additionally, adding an aggregate variable representing Small and Large residential POIs together improved the model. The reasons for this might be that morning peak trips also include trips made for visiting people and for performing activities, such as home care. Additionally, some activities can be shorter than the 1-h period considered, such that the return home is indeed part of the demand. Moreover, intuitively, it seems logical that a zone with a higher population will also have more activities in its neighborhood. Additionally, a correlation analysis confirms the intuitive assumptions made above. In contrast to the correlations with production, the categories Services, Shops, Catering and School are more correlated to attraction, showing correlations between 0.30 and 0.37, whereas the correlation between attraction and Small residential areas decreases to 0.03.
Multiple linear regression was used to test whether the total surface area of POIs in each activity category (School, Services, Health, Shops, Catering, Industry, Leisure, Leisure areas, Tourism and Others) and total residential (\({X}_{TR}\)) significantly predicted attraction (A) on a 5-percent significance level. By performing “leave one out cross-validation”, the following model structure was found to perform best:
Outlier analysis revealed seven zones that strongly influenced the regression results. We obtained a significant regression equation with an (uncentered) R2 of 0.835 and an RMSE of 368.03 (with outliers)3. The estimated coefficients and model performance are reported in Table 2.
The R2 value shows that the selected POI types (School, Services, Catering, Industry, Others, and TR—aggregate residential) indeed explain a large part of the variation in the number of attracted trips. Categories Health, Shops, Leisure, Leisure area and Tourism were found not to be significantly predicting Attraction on a 5-percent significance level. This might be explained by the fact that these activities are typically not performed between 7 and 8 a.m. in the morning but rather during the day and in the evening. The coefficients for Catering and Others might seem unintuitively high. However, this might be explained by the fact that activities such as cafés, restaurants (Catering) and churches (Others) are often located within city centers, i.e., areas that are rich in activities. Additionally, School and Services produce a considerable number of trips, which is as expected during the morning peak. Industry produces fewer trips per square meter than, e.g., a school. This seems reasonable, as often large parts of these buildings are filled with machines and large storage spaces. Moreover, only person travel is taken into account in the reference OD matrix used in this case study. It is expected that this category will be of greater importance when freight transport is also considered.
4.1.2 Calibration performance
Next, the performance of the trip generation models is evaluated. The model estimated that 92,947 trips (88,570 without outliers) are produced by all zones together, whereas the actual total production is equal to 97,462 (89,854 without outliers). Regarding attraction, the model has a similarly satisfactory performance in terms of estimating total attraction. The model estimates that, in total, 112,009 trips (103,482 without outliers) are attracted compared to the actual total attraction of 116,296 (104,632 without outliers). This is an underestimation of 4.63% (1.43% without outliers) for production and 3.61% (1.10% without outliers) for attraction.
A scatterplot comparing the true production and attraction with the estimated number of trips is shown in Fig. 12. This plot confirms the strong correlation of 0.941 between true and estimated production and of 0.835 between true and estimated attraction. Figure 13 shows the distribution of the estimation errors for production and attraction. Of course, the predictions for the highly influential zones that were excluded from the model showed the largest errors. Moreover, the production of all the outlying zones is underestimated, whereas for attraction, three out of the seven outlying zones are overestimated.

Scatterplot of true versus predicted a production and b attraction (in number of trips)

Distribution of estimation errors (in number of trips): a production and b attraction
Figure 14 spatially visualizes the estimation error per zone. There is a general trend of underestimating both the number of trips produced and the number of trips attracted by zones within the city center, whereas zonal production and attraction outside the city center are overestimated. One possible explanation could be that the surfaces of buildings tend to decrease when located closer to the city center, e.g., a detached house in the surrounding urban areas and a terraced house within the city center, although the travel demand-generating potential may not be different. Another contributing factor might be that a similar-size store within the city center may attract more people than a similar activity outside the city center because of the difference in population density. Moreover, building heights tend to increase, implying more travel demand-generating potential per square meter ground surface. These factors are not (or for the latter factor: only limited) taken into account in the current model; further research into the travel demand-generating potential depending on the urban environment and the role of building heights in this demand generation framework is suggested, as it is expected that this would improve the estimation performance.

Estimation errors (predicted—true number of trips): a production and b attraction
Table 3 reports on the performance in different classes, representing the full range of production and attraction values (including outliers). The reported error measures include the bias, the MAE, the RMSE and the mean absolute percentage error (MAPE). The MAPE metric shows that there is an error of 20–30%, except for the least producing or attracting zones, which is merely a consequence of the metric structure that strongly inflates for errors on small values. The bias metric confirms the general underestimation of both production and attraction. In general, most of the producing and attracting zones are underestimated on average, whereas the inverse is true for fewer producing and attracting zones. Considering the very limited POI information used as input to the procedure, it is remarkable that so much of the structure of the aggregated demand can be captured.
It should be noted that not all deviations from the reference matrix are necessarily errors in the new model. As mentioned before, the reference itself is, after all, not a direct, perfect observation of trips in the region but rather the result of earlier, more extensive demand generation and calibration exercise. Fine-tuning to improve the fit between the assigned flows and link-count data might have introduced overfitting bias into the reference OD matrix. This is one possible explanation for the larger errors between our generated demand and the reference data. Similarly, we have reason to believe that the ‘outliers’ observed in our model fit result from overfitting biases in the reference data for the following reasons: (1) Upon closer investigation of the detected outlying zones, we found that these zones are nearby and encompass areas such as highways and large interchanges. Adjusting the production and attraction of these zones offers quick fixes for misalignment in highway traffic counts without impacting traffic counts on lower-level roads and roads further away. (2) Furthermore, we confirmed that the POI data does not exhibit any notable deviations that explain the divergent estimation.
4.2 Leuven case study
To further evaluate the usability of OSM-generated POIs and the chosen POI classification for travel demand estimation, the relationships between POI categories and purpose-specific demand are analyzed. For each of the following purposes—Work & Business, School & Education, Shopping & Groceries, and Leisure—, the zonal attraction within the city of Leuven is investigated (Fig. 15).

Purpose-specific zonal attraction (in number of trips)
The correlations between the different POI types and the number of trips attracted per zone for each purpose are presented in Table 4. From this overview, it is clear that most activity categories (except for those that are underrepresented within the study area, indicated in italic) correlate most strongly with the most reasonable trip purpose (indicated in bold). These findings support the success of the developed categorization method.
For each purpose, a multiple linear regression model was calibrated, including the most logical POI categories as regressors. The estimated coefficients and model performances are presented in Table 5. These results suggest that the models can explain a substantial part of the purpose-specific demand. In each model, including the aggregated residential POIs increased the performance.
Figure 16 visualizes the estimation errors over the study area. For all purposes, it seems that only a handful of zonal attractions are poorly estimated, whereas the majority of zonal attractions are predicted within the error margin of 300 trips, which is approximately 30%. These outlying predictions are often for zones with strongly dedicated land use, which is in contrast to the mixed use in most zones. For example, the zone for which the number of work and business trips was estimated the worst is a zone with mainly large office buildings (Fig. 16a). The zone for which the number of school commutes was largely overestimated covered almost exclusively a large university campus (Fig. 16b). Nonetheless, the travel behavior of students is inaccurately included and underrepresented in the demand data used as ground truths, which can partly explain the overestimation. Perhaps, in this specific case, the Poidpy estimation may be closer to reality than the reference matrix. A clear outlier in Fig. 16c is another zone with highly dedicated land use for which attraction is underestimated. This zone covers almost exclusively the main shopping street in the city center of Leuven.

Estimation error (predicted—true number of trips) per zone for each purpose
Finally, this paper investigates the performance of a model in which purpose-specific coefficients are combined to estimate the total number of trips attracted for all purposes combined. For comparison, an additional model is directly calibrated based on the total zonal attraction. Both models are presented in Table 6. For the combination of purpose-specific models, the coefficients of each POI category are summed. For calibration of the second model, the activity categories with a negative coefficient were dropped from the model. The (uncentered) adjusted R2 values indicate that both models are capable of explaining a large part of the variation in zonal attraction.
Table 7 compares the performances of both models. The model calibrated directly on the zonal attraction, including all purposes, scored better on the RMSE than the model combining the purpose-specific coefficients (RMSE of 1270.57 compared to 1527.95). Nonetheless, the difference in performance remains relatively small. Both models exhibit a MAPE of approximately 30%. Moreover, from a modeler perspective, the combination of purpose-specific models is preferred because of its interpretability. In the second model, the coefficients of many activity categories proved to be negative. A negative coefficient indicates that the presence of an associated activity decreases the number of trips to the zone. Moreover, some activity categories, such as Catering and Tourism, dominate other relevant activity types and have unexplainably high coefficients, with coefficients of 0.7162 and 0.8346, respectively. Both findings are reasons why one might prefer a model in which purpose-specific coefficients are combined, despite the slightly lower performance.
4.3 Ghent case study
To test the hypothesis on the transferability of coefficients, the coefficients of Antwerp are used for estimating the travel demand in Ghent, a different but comparable region. Given the calibrated Antwerp model, which is defined by the β coefficients and used categories, together with the surfaces for each category of POI classes per zone, the attraction and production in Ghent is estimated for each zone. To evaluate the performance, the reference production and attraction values are calculated from the MOW OD matrix representing person travel in the morning peak (7 a.m.–8 a.m.). The reference zonal production and attraction in Ghent are visualized in Fig. 17. Like in Antwerp, the harbor zones were removed from the study area.

Reference zonal a production and b attraction (in number of trips)
After generating demand, the (uncentered) R2 values between the predicted and reference values are 0.786 for production and 0.663 for attraction. The correlation between the true and predicted values is visualized in Fig. 18. The reference and predicted total produced and attracted trips over all zones are 57,382 and 62,900, respectively (+ 9.62% error), and 74,210 and 100,574, respectively (+ 35.53% error). There is a general overestimation, which could have been expected, as Ghent’s population density is only 64% of that in Antwerp. A certain activity POI in Antwerp will attract more people than in Ghent because of the higher population density. A similar observation was already made above: a certain activity POI in the city center of Antwerp might attract more people than in suburbs because of the higher population density within the city center. Multiplying the estimated attraction coefficients by a density ratio of 64% (expect for the total residential coefficient) would reduce the overall overestimation of attraction to 6.55%. For production, the model is more or less able to correct for the lower population because there are fewer residential POIs. The remaining overestimation might be explained by apartment buildings in Antwerp being generally taller than those in Ghent.

Scatterplot of true versus predicted a production and b attraction (in number of trips)
The general overestimation trend is confirmed by the bias metric in Table 8. The MAPE metric exhibits values mostly between 20% and 30% but sometimes up to 50% for production and up to 60% for attraction for the different classes, representing the full range of production and attraction values. Figure 19 shows for which zones the model predictions of production and attraction were most off. Within these figures, the same trend, i.e., an underestimation in the city center, as in the case of Antwerp is clearly visible (see the explanation discussed for Antwerp). Still, the demand structure is largely captured by the model.

Estimation errors (predicted—true number of trips): a production and b attraction
4.4 Other applications of POI-based travel demand modeling
The performed case studies serve as a first proof of concept of the Poidpy framework, but many others can be imagined. The usage of POIs for travel demand modeling purposes, is intended to extend beyond travel demand estimation purposes shown in the case studies above.
The framework is not only useful for estimating the current demand but also enables the exploration of other and future scenarios with changed locations and number of POIs. One can easily adjust the set of POIs according to planned changes of land use, e.g., new urban development with residences, which can be consistently transformed into corresponding demand changes using this tool. This makes Poidpy even useful in design-based research, where the location and number of POIs are land use design decisions and their impact on travel demand, mode choice, etc., are of interest.
Additionally, POI-based demand generation can serve as a consistent disaggregation method for trip-based models. This could be done by splitting the demand of a zone into multiple smaller zones according to (travel demand-generating potential) POI density or hotspots of POIs in an area. Ultimately, trips could be modeled at the POI level, which removes the notion of zoning and thus eliminates the notion of intra- and interzonal trips and hence the related modeling issues. In this way, the spatial resolution in already existing and calibrated trip-based demand models can be increase.
5 Conclusion and suggestions for future research
The case studies presented above prove that it is possible to estimate travel demand using the Poidpy framework, i.e., demand modeling based on categorized POIs extracted from OSM data. Even though the data of OSM is rather limited in direct translation to demand, the results showed that large parts of demand can indeed be explained and generated from widely and freely available POI data extracted from OSM. Moreover, the second case study showed that the categorization used matches the different purposes for travel demand rather well and yields logical, interpretable travel demand generation coefficients. These findings give confidence in the developed framework for extracting, pre-processing and categorizing POI land use data aimed at travel demand estimation, even though the accuracy of the generated land use POIs was not explicitly validated. Moreover, the fully automated process allows the framework to be easily applied to other regions for generating POIs data as we have implicitly shown by performing the case studies each on a different city.
Still, there are important aspects to keep in mind when applying the Poidpy framework to other cities or regions. OSM remains a VGI system, hence the quality and labeling of OSM data depends on the diligence of the local contributors and can vary widely between and within regions. To generate land use data with Poidpy for another region, the tool already facilitates to extend the tag lists and adapt the parameters used throughout the categorization. Still, the extent to which the variability in completeness of OSM data affects the effectiveness of the Poidpy tool and the usefulness of OSM data for travel demand estimation represents an interesting direction for future in-depth research.
Further, the third case study even showed that the correlations found between OSM data and travel demand found for one city can be extrapolated to a different but comparable city or region. However, when transferring the calibrated model from one city or region to another, it is crucial to consider whether cities are comparable. It depends on factors such as city scale (e.g., population density, size of buildings), city importance (e.g., international vs. provincial cities, national vs. regional cities), and travel behavior, which is largely determined by land use and spatial planning practices. How the transferability of coefficients depends on the comparability of cities is another interesting direction for follow-up research.
Additionally, there was a general trend of underestimating travel demand within the city centers in all three case studies. Future efforts could improve model accuracy by better accounting for building heights and the difference in travel demand-generating potential of POIs depending on the urban environment (e.g. population density). Follow-up research could also explore whether more differentiated POI categories can improve the performance. Because the chain of required steps has been completed, the open-source tool Poidpy can be used for sensitivity analysis to anticipate the effect of improvements on the results, which helps prioritize potential model refinements.
Finally, the highlighted opportunities of POI-based modeling for design-based research and consistent disaggregation of existing zonal travel demand estimates prove to be promising avenues for future research. As the Poidpy tool is openly available anyone is able and welcome to contribute.
Availability of data and code
Map data copyrighted OpenStreetMap contributors and available from https://www.openstreetmap.org. Poidpy is a public available tool which has notebooks with code for every case study presented in this paper. Dana Borremans of the Flemish Ministry of Mobility and Public Works (MOW) is acknowledged for providing travel demand data of Flanders. This ground truth demand data is licensed. Therefore, those data are not openly available. However, access to the data can be requested through MOW. The Poidpy version used in this paper is accessible through the following link: https://gitlab.kuleuven.be/ITSCreaLab/publications/poidpy-1.0. Future updates will always be accessible through: https://gitlab.kuleuven.be/ITSCreaLab/public-toolboxes/poidpy.
Notes
These include the tags added to the building polygons derived from the information of points and nonbuilding polygons laying within the building and of the surrounding contour polygons (as explained at the end of Sect. 3.1).
The regression model was estimated without outliers but the reported performance metrics are calculated with outliers included.
References
de Ortúzar J, Willumsen LG. Modelling transport. 4th ed. Wiley; 2011.
Axhausen KW, Gärling T. Activity-based approaches to travel analysis: conceptual frameworks, models, and research problems. Transp Rev. 1992;12:323–41. https://doi.org/10.1080/01441649208716826.
Map features—OpenStreetMap Wiki. https://wiki.openstreetmap.org/wiki/Map_features. Accessed 19 July 2022.
OpenStreetMap Taginfo. https://taginfo.openstreetmap.org/. Accessed 19 July 2022.
Ortmann P, Tampère CMJ. dyntapy: dynamic and static traffic assignment in Python. J Open Source Softw. 2022;7:4593. https://doi.org/10.21105/JOSS.04593.
Ziemke D, Kaddoura I, Nagel K. The MATSim Open Berlin Scenario: a multimodal agent-based transport simulation scenario based on synthetic demand modeling and open data. Procedia Comput Sci. 2019;151:870–7. https://doi.org/10.1016/J.PROCS.2019.04.120.
Valdes J, Wuth J, Zink R, et al. Extracting relevant points of interest from open street map to support E-mobility infrastructure models. Bavarian J Appl Sci. 2018;4:323–41. https://doi.org/10.25929/BJAS.V4I1.51.
Klinkhardt C, Woerle T, Briem L, et al. Using OpenStreetMap as a data source for attractiveness in travel demand models. Transp Res Rec. 2021;2675:294–303. https://doi.org/10.1177/0361198121997415.
Li A, Zhou X, Kim T. grid2demand: a tool for generating zone-to-zone travel demand based on grid cells or external TAZs; 2022
Neis P, Zielstra D. Zipf A (2013) Comparison of Volunteered Geographic Information Data Contributions and Community Development for Selected World Regions. Future Intern. 2013;5:282–300. https://doi.org/10.3390/FI5020282.
Basiri A, Haklay M, Foody G, Mooney P. Crowdsourced geospatial data quality: challenges and future directions. Int J Geogr Inf Sci. 2019;33:1588–93. https://doi.org/10.1080/13658816.2019.1593422.
Senaratne H, Mobasheri A, Ali AL, et al. A review of volunteered geographic information quality assessment methods. Int J Geogr Inf Sci. 2017;31:139–67. https://doi.org/10.1080/13658816.2016.1189556.
International Organization for Standardization (ISO) (2023) ISO 19157–1:2023—Geographic information—data quality. https://www.iso.org/standard/78900.html. Accessed 17 Apr 2024.
Zhou Q, Zhang Y, Chang K, Brovelli MA. Assessing OSM building completeness for almost 13,000 cities globally. Int J Digit Earth. 2022;15:2400–21. https://doi.org/10.1080/17538947.2022.2159550.
Herfort B, Lautenbach S, Porto de Albuquerque J, et al. A spatio-temporal analysis investigating completeness and inequalities of global urban building data in OpenStreetMap. Nat Commun. 2023;2023(14):1–14. https://doi.org/10.1038/s41467-023-39698-6.
Brovelli MA, Zamboni G. A new method for the assessment of spatial accuracy and completeness of OpenStreetMap building footprints. ISPRS Int J Geo Inf. 2018;7:289. https://doi.org/10.3390/IJGI7080289.
Zacharopoulou D, Skopeliti A, Nakos B, et al. (2021) Assessment and visualization of OSM consistency for European cities. ISPRS Int J Geo Inf. 2021;10:361. https://doi.org/10.3390/IJGI10060361.
Touya G, Brando-Escobar C. Detecting level of detail inconsistencies in VGI datasets. Cartographica. 2013;48:134–43. https://doi.org/10.3138/carto.48.2.1836ï.
Minghini M, Frassinelli F. OpenStreetMap history for intrinsic quality assessment: is OSM up-to-date? Open Geospatial Data Softw Std. 2019;4:1–17. https://doi.org/10.1186/S40965-019-0067-X.
Biljecki F, Chow YS, Lee K. Quality of crowdsourced geospatial building information: a global assessment of OpenStreetMap attributes. Build Environ. 2023;237: 110295. https://doi.org/10.1016/J.BUILDENV.2023.110295.
Zhou Q, Wang S, Liu Y. Exploring the accuracy and completeness patterns of global land-cover/land-use data in OpenStreetMap. Appl Geogr. 2022;145: 102742. https://doi.org/10.1016/J.APGEOG.2022.102742.
Boeing G. OSMnx: New methods for acquiring, constructing, analyzing, and visualizing complex street networks. Comput Environ Urban Syst. 2017;65:126–39. https://doi.org/10.1016/J.COMPENVURBSYS.2017.05.004.
OpenStreetMap Wiki. https://wiki.openstreetmap.org/wiki/Main_Page. Accessed 19 July 2022.
Griffiths HM, Tampère CMJ, Verstraete J. A new method for determining traffic demand using open data. KU Leuven; 2020.
Vanderhoydonc Y, Borremans D (2020) Strategische Verkeersmodellen Vlaanderen versie 4.2.1: Overzichtsrapportage
Funding
This research was part of the Flemish DUET pilot (EU Horizon 2020; grant agreement No.870697) and is partly funded by the FWO SB fellowship on “Design-based research of integrated automated mobility services” (Project Number: 1S80623N).
Author information
Authors and Affiliations
Contributions
The authors confirm their contributions to the paper as follows: Notelaers Lotte: methodology, software, validation, formal analysis, writing—original draft, visualization. Jeroen Verstraete: methodology, software, validation, writing—review & editing. Pieter Vansteenwegen: conceptualization, writing—review & editing, supervision. Tampère Chris: conceptualization, writing—review & editing, supervision. All authors reviewed the results and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This declaration is not applicable as no animal or human studies are performed.
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 A: POI data extraction and preprocessing
Irrelevant features are dropped based on a predefined tag list that includes specific attribute value pairs (ignore-tag list) (see Tables 9, 10).
1.2 B: Residential categorization
See Fig. 20, Tables 11, 12, 13, 14.


Residential function allocation
1.3 C: Activity categories
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Notelaers, L., Verstraete, J., Vansteenwegen, P. et al. A travel demand modeling framework based on OpenStreetMap. Discov Civ Eng 1, 26 (2024). https://doi.org/10.1007/s44290-024-00020-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44290-024-00020-y