
Abstract
Accurate localization is critical for lunar rovers exploring lunar terrain features. Traditionally, lunar rover localization relies on sensor data from odometers, inertial measurement units and stereo cameras. However, localization errors accumulate over long traverses, limiting the rover’s localization accuracy. This paper presents a metric localization framework based on cross-view images (ground view from a rover and air view from an orbiter) to eliminate accumulated localization errors. First, we employ perspective projection to reduce the geometric differences in cross-view images. Then, we propose an image-based metric localization network to extract image features and generate a location heatmap. This heatmap serves as the basis for accurate estimation of query locations. We also create the first large-area lunar cross-view image (Lunar-CV) dataset to evaluate the localization performance. This dataset consists of 30 digital orthophoto maps (DOMs) with a resolution of 7 m/pix, collected by the Chang’e-2 lunar orbiter, along with 8100 simulated rover panoramas. Experimental results on the Lunar-CV dataset demonstrate the superior performance of our proposed framework. Compared to the second best method, our method significantly reduces the average localization error by 26% and the median localization error by 22%.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
As the closest extraterrestrial body to the Earth, the Moon serves as a starting point for exploration beyond our planet. Throughout history, lunar exploration has relied primarily on lunar orbiters to collect data about the lunar surface. This invaluable information has provided us with profound insights into lunar topography, geology, and various other features [1, 2]. Currently, lunar rovers provide us with the critical edge in high-resolution exploration, rendering them indispensable in our current efforts to explore the lunar surface.
Throughout the lunar rover mission, accurate localization is essential for lunar rovers [3, 4], allowing rovers to plan their path, approach targets and guard against hazards. However, localization on the Moon is not as easy as it is on the Earth. Traditional global positioning systems such as BeiDou [5] and GPS [6], which rely on complex artificial satellite networks, cannot meet the requirements of lunar localization.
To address this challenge, the industry has adopted two different methods of lunar localization: relative lunar localization and absolute lunar localization. Relative localization involves discerning an entity’s location in relation to the rover [7, 8]. Notable techniques include dead reckoning and visual station localization methods employed by the Yutu and Yutu-2 lunar rovers. Absolute localization, on the other hand, involves determining the rover’s position within the global lunar coordinate system. Pioneering endeavors, exemplified by the Spirit and Opportunity Mars rovers, determine the rover’s absolute position on the Martian surface by receiving signals from the Mars orbiters or from the Earth [9].
Although the above methods have been successful, some challenges remain. In the case of relative localization, the most significant obstacle is the cumulative error. Although existing methods mitigate this error by integrating multiple sensors such as inertial measurement units (IMUs), gyroscopes, and accelerometers, complete elimination remains elusive. Moreover, for absolute localization, the accuracy and real-time of localization are uncertain due to the limited number of satellites in orbit. To address the issues of cumulative error in relative localization and the limited real-time performance of absolute localization, we explore the application of cross-view metric localization (CVML). When the approximate global location of a rover is known, aerial images can be obtained from orbital digital orthophoto maps (DOMs). By leveraging CVML, we can accurately determine the rover’s location by estimating the location of ground images captured by the rover within these aerial images.
However, existing CVML techniques are primarily tailored for terrestrial environments, and there are two major differences when applied to lunar environments. First, the lunar environment, characterized by its openness and desolation without any buildings, offers fewer natural and man-made textures as landmarks. Second, the resolution of lunar DOMs is significantly lower than terrestrial DOMs, making effective matching with high-resolution terrestrial query images difficult. To address these challenges, our approach begins with perspective projection based on the planar assumption, aimed at bridging the gap between different viewpoints. Then, we introduce an image-based metric localization (IML) network. This network features a heterogeneous feature extraction mechanism and a coarse-to-fine contrastive loss function, designed to mitigate performance degradation due to the low spatial resolution. The major contributions of this paper include the following:
-
1)
We introduce a cross-view alignment technique termed perspective projection. This technique employs a geometric transformation to project the image from ground camera coordinates to pseudo-aerial image coordinates. This reduces domain differences between ground images and aerial images.
-
2)
We present a pre-processing strategy, query-based random context exploration (QRCE). QRCE aims to allow the arbitrary distribution of query locations within the candidate regions of the aerial image.
-
3)
We introduce a cross-view metric localization network termed the IML network. This network leverages heatmap generation to capture both coarse-grained and fine-grained information in cross-view images effectively.
-
4)
We create the first large-area lunar cross-view image (Lunar-CV) dataset to evaluate localization performance. Experimental results on the Lunar-CV dataset clearly demonstrate the superiority of our framework.
2 Related works
In this section, we conduct a comprehensive review of the relevant literature in the fields of lunar rover localization and cross-view image geo-localization.
2.1 Lunar rover localization
Lunar rovers typically employ multiple localization methods, as exemplified by the Yutu rover [7, 8]. This lunar explorer utilizes three distinct localization techniques. The on-board guidance, navigation, and control system integrates a dead-reckoning system, which continuously localizes the rover on the lunar surface by processing data from the IMUs and wheel odometer. However, dead-reckoning often yields relatively large localization errors due to wheel slippage and IMU drift. These errors inevitably accumulate over extended rover traverses [10]. To reduce error accumulation, the Chang’e-3 mission incorporates two image-based methods: cross-site visual localization and DOM matching.
Cross-site visual localization involves several steps: First, the corresponding regions between navigation camera images are extracted from adjacent sites using initial localization results from the dead-reckoning system. These corresponding regions are subjected to sparse keypoint matching [11, 12] to extract tie points, with gross errors removed using a RANSAC algorithm [13]. The tie points are then used to construct an image mesh, and bundle adjustment is performed to achieve accurate localization results for the current site relative to the previous site. This stepwise localization process routinely supports rover teleoperation.
DOM matching is performed to further reduce accumulated localization errors and enhance accuracy during long rover traverses. This involves matching the DOMs derived from the navigation camera stereo images at each waypoint with the previously generated landing site DOM. The matching process relies primarily on scale-invariant feature transform (SIFT), although manual matching is occasionally employed when SIFT matching encounters difficulties.
2.2 Cross-view image geo-localization
Cross-view image geo-localization aims to determine the location of a query point based on ground-based images and geotagged aerial images. Depending on the level of localization, cross-view image geo-localization can be broadly categorized into two branches: cross-view image retrieval [14–19] and CVML [20–25].
Cross-view image retrieval focuses on identifying a satellite patch that encompasses the query point. Polar transformation methods are designed to generate pseudo-ground images from aerial imagery, aiming to address the challenges of cross-view image retrieval. For example, techniques such as SAFA [14] employes polar coordinate transformation to warp satellite images into ground-level perspectives. Ref. [16] not only applied polar coordinate transformation but also considered the scenario where the azimuth of the ground map was unknown. Refs. [15, 19] use in-batch reweighting triplet loss to emphasize the positive effect of hard samples during training. Moreover, S2SP [17] employs height map learning to project satellite images to ground-level viewpoints, and an alternative approach in Ref. [18] maps satellite image pixels to the ground plane using geometric constraint projection.
CVML represents a branch of localization methods that uses information from a ground view to determine the exact location of an object or entity in an aerial view. Additional generative models have been frequently employed in handling CVML. They commonly focus on converting ground perspective features into aerial perspectives, with particular emphasis on elements characterized by substantial height variations, such as vehicles, trees, and buildings. Notably, methods [20–22] such as BEVFormer utilize techniques such as transformers [26] to establish mappings from multiple in-car camera views to aerial-view representations, facilitating aerial semantic segmentation inference. In addition, some approaches such as cross-view regression (CVR) [24] generate global image descriptors to predict query coordinates on satellite images, while MCC [25] leverages denser local descriptors of satellite images to generate heatmaps capturing multi-modal localization distribution features. These approaches have shown impressive performance in earth-based CVML applications.
We note that while the additional generative modeling methods have demonstrated remarkable results, they primarily study objects that are not typically found in lunar surface images. Moreover, the natural flatness of the lunar surface and the absence of complex structures or buildings result in a markedly limited presence of altitude-related features. Consequently, these methods cannot be directly applied to lunar environments.
3 Methodology
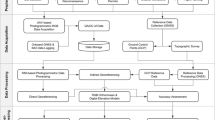
Given a ground image \(I_{\mathrm{g}}\in \mathbb{R}^{H_{\mathrm{g}}\times W_{\mathrm{g}} \times 3}\) and an aerial image \(I_{\mathrm{a}}\in \mathbb{R}^{L_{\mathrm{a}}\times L_{\mathrm{a}} \times 3}\), the primary objective is to estimate the rover’s location \(\zeta \in [1, L_{\mathrm{a}}]^{2}\), which corresponds to pixel coordinates within \(I_{\mathrm{a}}\), as it is related to \(I_{\mathrm{g}}\). To accomplish this objective, we present a comprehensive solution comprising pre-processing and a localization network, as illustrated in Fig. 1. Initially, the perspective projection transforms \(I_{\mathrm{g}}\) to generate a pseudo-aerial image \(I_{\mathrm{pa}}\in \mathbb{R}^{L_{\mathrm{a}}\times L_{\mathrm{a}} \times 3}\). Meanwhile, the QRCE processes aerial candidate regions to augment \(I_{\mathrm{a}}\). Next, both \(I_{\mathrm{pa}}\) and \(I_{\mathrm{a}}\) are fed into the IML, which generates a location heatmap represented by \(\mathcal{M}\in \mathbb{R}^{(L_{\mathrm{a}}/4)\times (L_{\mathrm{a}}/4)}\), thereby facilitating precise estimation of the rover’s location. Details of each component are presented as follows.

An overview of the proposed framework. First, the perspective projection is employed to transform the ground image \(I_{\mathrm{g}}\) into a pseudo-aerial image \(I_{\mathrm{pa}}\). Then, the image-based metric localization network extracts dense scene features from the \(I_{\mathrm{pa}}\) and aerial image \(I_{\mathrm{a}}\) for similarity retrieval. Next, a location heatmap \(\mathcal{M}\) is generated by calculating the cosine similarity between the extracted features, and the peak location in \(\mathcal{M}\) is considered the predicted location. During the training phase, query-based random context exploration (QRCE) is employed to achieve an arbitrary distribution of query locations within \(I_{\mathrm{a}}\). The coarse-to-fine contrastive loss \(\mathcal{L}_{\mathrm{CF}}\) optimizes \(\mathcal{M}\) to capture spatial information across scales. \(L_{\mathrm{a}}\) represents the pixel size of \(I_{\mathrm{a}}\)
3.1 Pre-processing
3.1.1 Perspective projection
Since the imaging angles of \(I_{\mathrm{g}}\) and \(I_{\mathrm{a}}\) are nearly vertical, there is a large domain difference in their features. To mitigate this domain difference between these two cross-view images, we propose a geometric transformation perspective projection to project \(I_{\mathrm{g}}\) from the ground-level image to pseudo-aerial image coordinates.
Given the unique lunar environment, characterized by the absence of objects such as trees or buildings that can be used as landmarks to mark the sharp changes in elevation, coupled with the relatively flat lunar surface, we can reasonably assume that aerial pixels correspond to points on the lunar surface. This fundamental assumption enables us to establish direct geometric correspondences between images captured from diverse viewpoints. Leveraging this inherent layout correspondence, we can employ perspective projection on \(I_{\mathrm{g}}\) to effectively produce \(I_{\mathrm{pa}}\), which faithfully simulates the aerial perspective.
As illustrated in Fig. 2, the projection between the pseudo-aerial pixel coordinates \((u^{\mathrm{pa}}, v^{\mathrm{pa}})\) and the ground-level camera coordinates \((x, y, z)\) can be described as a parallel projection [17, 27]:
where \((u^{\mathrm{pa}}_{0}, v^{\mathrm{pa}}_{0}) = (L_{\mathrm{a}}/2, L_{ \mathrm{a}}/2)\) indicates the center of \(I_{\mathrm{pa}}\). λ, the resolution of \(I_{\mathrm{pa}}\), is used to achieve scale alignment with \(I_{\mathrm{a}}\). Here \(u^{\mathrm{pa}}\) and x point to the north.

Illustration of the pixel-by-pixel latent geometric correspondence between the \(I_{\mathrm{pa}}\) and panoramic \(I_{\mathrm{g}}\). Ground camera coordinates \((x , y , z)\) and pseudo-aerial pixel coordinates \((u^{\mathrm{pa}}, v^{\mathrm{pa}})\) are shown. θ and φ represent the pitch and azimuth angles of the ground camera, respectively. The pixel \((u_{i}^{\mathrm{g}}, v_{i}^{\mathrm{g}})\) on \(I_{\mathrm{g}}\) corresponds to \((x_{i}, y_{i}, z_{i})\) in camera coordinates and to \((u_{i}^{\mathrm{pa}}, v_{i}^{\mathrm{pa}})\) on \(I_{\mathrm{pa}}\)
Assuming that the panoramic \(I_{\mathrm{g}}\) is captured on a spherical imaging plane, we represent this plane using a spherical coordinate system \((\theta , \varphi , r)\), where we set \(r=1\). The mapping between \((\theta , \varphi )\) and \((x, y, z)\) is computed as
The center of \(I_{\mathrm{g}}\) is \((u^{\mathrm{g}}_{0}, v^{\mathrm{g}}_{0})=(H_{\mathrm{g}}/2, W_{ \mathrm{g}}/2)\). The mapping between \((\theta , \varphi )\) and ground pixel coordinates \((u^{\mathrm{g}}, v^{\mathrm{g}})\) is computed as
Combining Eqs. (1), (2) and (3), the corresponding relationships between \((u^{\mathrm{g}}, v^{\mathrm{g}})\) and \((u^{\mathrm{pa}}, v^{\mathrm{pa}})\) are computed as
where \(u^{\prime}=u^{\mathrm{pa}}-u^{\mathrm{pa}}_{0}\) and \(v^{\prime}=v^{\mathrm{pa}}-v^{\mathrm{pa}}_{0}\). h is the altitude of the ground-level camera. Through the aforementioned operation, we are able to project \(I_{\mathrm{g}}\) onto an imaging plane parallel to \(I_{\mathrm{a}}\).
3.1.2 Query-based random context exploration
Data diversity plays a pivotal role in enhancing the model’s generalization capabilities. In previous research, owing to the limited availability of high-precision DOM data, a common approach is to sample the DOM data by utilizing a fixed step-size in the latitudinal and longitudinal directions [24]. Nevertheless, this sampling strategy cannot guarantee the equilibrium of the distribution of query points over the satellite patches. Consequently, the network may be biased toward certain areas within the query location, resulting in reduced performance when serving queries located in other regions.
To enhance the robustness of lunar rover localization, we propose a data augmentation technique, query-based random context exploration (QRCE). As illustrated in Fig. 1, during the training phase, we create square aerial candidate regions centered on the query location. Within these regions, we randomly sample \(L_{\mathrm{a}} \times L_{\mathrm{a}}\) patches as training data \(I_{\mathrm{a}}\). The range of queries within the training data \(I_{\mathrm{a}}\) is constrained by the size of the candidate localization region. For instance, queries can be distributed freely within \(I_{\mathrm{a}}\) for the \(2L_{\mathrm{a}} \times 2L_{\mathrm{a}}\) candidate region. This approach enhances the diversity in the distribution of query locations within satellite patches, potentially bolstering the model’s generalization capabilities.
3.2 Image-based metric localization network
With the pseudo-aerial image \(I_{\mathrm{pa}}\) and the aerial image \(I_{\mathrm{a}}\) at hand, we design an IML network to accurately estimate the rover’s location. The IML network comprises two key components: a heterogeneous feature extraction network and a similarity heatmap constructor for precise localization. In a nutshell, the feature extraction network captures distinctive features from cross-view images, and these features are then used in the similarity heatmap constructor to build the heatmap for precise localization. A comprehensive breakdown of this progress is provided below.
3.2.1 Heterogeneous feature extraction network
In order to achieve pixel-level matching on aerial images, we utilize a heterogeneous network to extract features from cross-view images. As illustrated in Fig. 1, \(I_{\mathrm{pa}}\) is encoded as a global descriptor \(F_{\mathrm{g}} \in \mathbb{R}^{1\times 1\times D}\), where \(D = 256\). We utilize ResNet50 [28] as the backbone of the ground network. Specifically, we retain the ResNet50 architecture up to the second residual layer (inclusive) for feature extraction. To reduce computational cost, we replace the following layers with four convolutional layers.
\(I_{\mathrm{a}}\) is encoded as a high-resolution feature volume \(F_{\mathrm{a}} \in \mathbb{R}^{(L_{\mathrm{a}}/4) \times (L_{ \mathrm{a}}/4) \times D}\). The feature of each spatial location in \(F_{\mathrm{a}}\) represents the fine-grained scene layout information of the local receptive field centered on the location. UNet [29] can be the backbone of the aerial network to generate \(F_{\mathrm{a}}\). However, considering the potential mismatch of heterogeneous networks, we choose Res-UNet [30], which combines UNet and ResNet as the backbone of the aerial network. As a result, the spatial resolution of \(F_{\mathrm{a}}\) is reduced to 1/4 of that of \(I_{\mathrm{a}}\).
3.2.2 Similarity heatmap for localization
To pinpoint the rover’s location in \(I_{\mathrm{a}}\), we propose indexing the location of \(F_{\mathrm{g}}\) within \(F_{\mathrm{a}}\), thereby establishing the relative location of \(I_{\mathrm{pa}}\) with respect to \(I_{\mathrm{a}}\). To this end, we segment \(F_{\mathrm{a}}\) along the spatial dimension, resulting in multiple feature vectors. Subsequently, we compute the cosine similarity between each aerial feature vector and \(F_{\mathrm{g}}\). Next, we reorganize these feature vectors corresponding to their spatial locations in \(F_{\mathrm{a}}\), facilitating the construction of the spatially-aware heatmap \(\mathcal{M}\in \mathbb{R}^{ (L_{\mathrm{a}}/4) \times (L_{\mathrm{a}}/4) }\), which is calculated as
where \((ij)\) represents the segmented cell coordinates. Once \(\mathcal{M}\) is computed, the location of its peak point is identified as the predicted localization point, and this point is then scaled to \(I_{\mathrm{a}}\) to yield the final localization result ζ,
where γ is the scaling factor.
In the real scene, we determine the geographic location (latitude and longitude) of the query based on the geotagged \(I_{\mathrm{a}}\) and ζ, and finally locate the rover with the meter-level unit of measurement.
3.2.3 Coarse-to-fine contrastive loss
Common CVML methods [25] use infoNCE loss \(\mathcal{L}^{\prime}\) [31] to monitor the localization specified by \(\mathcal{M}\):
where \((ij^{\mathrm{GT}} )\) represents the ground truth (GT) coordinates of \(\mathcal{M}\) and the hyperparameter τ is used as a reference to control the sensitivity of the model to difficult candidate regions. Nonetheless, within the vicinity of the GT point, there exists a gradual spatially-aware similarity, rather than a one-hot-like similarity observed in \(\mathcal{L}^{\prime}\).
We note that the contrastive loss \(\mathcal{L}_{\mathrm{C}}\) imparts spatial awareness to \(\mathcal{M}\) by incorporating a Gaussian smoothing strategy. Specifically, \(\mathcal{L}_{\mathrm{C}}\) generates a Gaussian label distribution centered on the GT location. It denotes the part of the Gaussian probability density function (PDF) exceeding the threshold hyperparameter η as positive and the rest as negative. Finally, the Gaussian weighting of \(\mathcal{L}^{\prime}\) is applied exclusively to the positive regions to obtain \(\mathcal{L}_{\mathrm{C}}\):
where \((i j^{+} )\) are the coordinates of the positive regions centered on the GT location, and \(w_{i j^{+}} \) is the re-normalized value of the Gaussian PDF for the positive regions.
Due to the requirement of both large-scale information (such as terrain contours) and fine-grained information (such as lunar craters) in CVML, we propose a coarse-to-fine contrastive loss \(\mathcal{L}_{\mathrm{CF}}\) to guide the model training. As seen in Fig. 1, we apply max-pooling with strides s of 1, 2, 4, 8 and 16 to \(\mathcal{M}\), resulting in a series of pooled heatmaps \(\mathcal{M}_{s}\). We apply the same max-pooling to the \((L_{\mathrm{a}}/4) \times (L_{\mathrm{a}}/4)\) Gaussian label distribution map and use the fixed η to distinguish the positive and negative regions. \(\mathcal{L}_{\mathrm{CF}}\) is computed as
where \((i j_{s}^{+} )\) are the coordinates of the positive regions in \(\mathcal{M}_{s}\). The coarse-grained cells capture the maximum values of the fine-grained cells within their coverage range, that is, the positive area of the low-resolution Gaussian-weighted heatmap is larger than that of the high-resolution case.
With the introduction of the coarse-to-fine training strategy, the model exhibits rapid convergence during the initial training phases, primarily guided by the coarse-grained labels. As training progresses, the \(\mathcal{L}_{\mathrm{CF}}\) guides \(\mathcal{M}\) to comprehensively perceive the fine-grained and coarse-grained spatial information, thereby improving the model’s tolerance for subtle label errors. Compared with \(\mathcal{L}_{\mathrm{C}}\), \(\mathcal{L}_{\mathrm{CF}}\) can guide the IML network to learn pixelwise-discriminative feature representations, which are more suitable for lunar localization scenarios.
4 Lunar large-area cross-view image dataset
To evaluate the performance of different CVML methods, we create the Lunar-CV dataset in this paper. This dataset contains an aerial perspective, with 30 orbital DOMs captured by the Chang’e-2 (CE-2) lunar orbiter, each with a resolution of 7 m/pix. Within each DOM, we have meticulously segmented 225 satellite patches. From rover’s perspective, this dataset consists of 2700 query points, with three ground panoramas for each query point, for a total of 8100 ground images. In the following sections, we will present the details of the Lunar-CV dataset and explain the meticulous preparation process.
4.1 Sampling of satellite patches
To obtain the ground coordinates from an orbital perspective with acceptable computational requirements, we need to segment satellite patch \(I_{\mathrm{a}}\) from the DOM with known coordinates. An intuitive approach involves aligning the edges of neighboring \(I_{\mathrm{a}}\) patches to ensure a seamless patch coverage. However, for the case where the query is at the edge of \(I_{\mathrm{a}}\), too few overlapping regions of cross-view images increase the difficulty of localization. Therefore, we use the sampling method of the VIGOR dataset [24]. The \((L_{\mathrm{a}}/2) \times (L_{\mathrm{a}}/2) \) central region of \(I_{\mathrm{a}}\) is called the “positive” region, and the remaining region is called “semi-positive” region (Fig. 3(b)). As depicted in Fig. 3(c), we sample the orbital DOM along the latitudinal and longitudinal directions, with an overlap of 50% for the seamless connection of “positive” regions. \(I_{\mathrm{a}}\) and \(I_{\mathrm{g}}\), which are located in the “positive” region, are called “positive” samples. In general, we can determine the localization error range of the rough coordinates and use \(I_{\mathrm{a}}\) with a larger coverage to ensure the size of the overlapping region. This allows us to pay more attention to the “positive” samples when performing CVML.

The sampling strategy employed in the Lunar-CV dataset, with stars indicating query locations. In (a), stars denote query points that are either not covered by satellite patches or are on the edge of a satellite patch. In (b), red stars denote query points in the “positive” region, while blue stars represent query points in the “semi-positive” region. \(L_{\mathrm{a}}\) represents the pixel size of \(I_{\mathrm{a}}\)
4.2 Ground query sampling
The ground image \(I_{\mathrm{g}}\) plays a pivotal role in accomplishing CVML. We generate three-dimensional terrain data of the lunar surface utilizing the digital elevation model and DOM data from the CE-2 mission. This process enables us to create \(I_{\mathrm{g}}\) at the designated altitude and location. To evaluate the localization performance under different field of view (FoV) conditions, we synthesize \(I_{\mathrm{g}}\) as a panoramic image.
We note that the VIGOR dataset does not take into account the correlation between different ground images \(I_{\mathrm{g}}\), which limits its ability to support only single image localization. In order to evaluate the performance of continuous image localization methods on the Lunar-CV dataset, we sample 90 query locations in each orbital DOM, which can be divided into nine groups. Each group consists of 10 adjacent locations, and the interval between two adjacent locations is approximately 100 m, as shown in Fig. 4. For each query, we generate \(I_{\mathrm{g}}\) at altitudes of 25 m, 100 m and 500 m. However, due to the constraints of the resolution of orbital DOMs, lower altitudes result in progressively blurred details. Therefore, we suggest placing greater emphasis on the analysis of the localization performance of \(I_{\mathrm{g}}\) at an altitude of 500 m, where the details are relatively well-preserved. The sizes of the orbital DOMs and \(I_{\mathrm{g}}\) are \(4096\times 4096\) and \(1500\times 3000\), respectively. \(L_{\mathrm{a}}\) is 512, which means that one DOM can hold 225 patches. Figure 4 also shows an example of the adjacent \(I_{\mathrm{g}}\), in which the red bar points to the north.

The sampling trajectory of query locations in the orbital digital orthophoto map and an example of an adjacent ground image \(I_{\mathrm{g}}\). The red bar indicates the north direction
4.3 Dataset comparison
Table 1 shows a comparison between the Lunar-CV dataset and previous benchmark datasets. The orbital DOM of the Earth is obtained from DOM providers such as Google Maps with a resolution of less than 0.25 m/pix. In the CVACT and CVUSA datasets, \(I_{\mathrm{g}}\) is aligned with the center of the corresponding \(I_{\mathrm{a}}\), which limits them to support only image retrieval methods. However, in the real world, there might not always be an \(I_{\mathrm{a}}\) perfectly aligned with the \(I_{\mathrm{g}}\). To overcome this limitation, the VIGOR allows \(I_{\mathrm{g}}\) to appear anywhere within \(I_{\mathrm{a}}\), introducing meter-level localization error evaluation. The KITTI-CVL dataset [27] is specifically designed for vehicle autonomous navigation and serves as a benchmark for video-based localization methods by providing a sequence of continuous images.
The Lunar-CV dataset aims to achieve large-area localization of lunar rovers, and therefore, we select 30 orbital DOMs to evaluate localization performance under various terrain conditions. We construct \(I_{\mathrm{g}}\) in the form of continuous images. This approach makes the Lunar-CV dataset highly operable and suitable for image retrieval, single image metric localization, and continuous image metric localization.
5 Experiments
In this section, we first introduce the evaluation metrics. We then offer detailed insights into the implementation of each experiment. Next, we conduct a comparative analysis of our method against other mainstream approaches using the Lunar-CV dataset. Finally, we present a series of comprehensive ablation experiments to demonstrate the effectiveness of each individual component.
5.1 Evaluation metrics
We use the mean and median of the localization error as evaluation metrics. The localization error is the distance between the predicted location in \(I_{\mathrm{a}}\) and the GT location over all samples. The resolution of \(I_{\mathrm{a}}\) in our released Lunar-CV dataset is 7 m/pix. Because all the compared localization methods do not alter the size of the satellite patches, we measure the localization error using the Euclidean distance (both in pixels and meters). The mean localization error represents the overall accuracy of the localization, while the median localization error provides a more robust reference for localization performance. Similar to other retrieval works, we present the (cumulative) error distribution to demonstrate the localization accuracy of different methods at different thresholds.
5.2 Implementation details
The pixel size of \(I_{\mathrm{a}}\) in the Lunar-CV dataset is \(L_{\mathrm{a}} \times L_{\mathrm{a}} = 512 \times 512\), and the \(I_{\mathrm{g}}\) pixel size is \(H_{\mathrm{g}} \times W_{\mathrm{g}} = 1500 \times 3000\). Both \(I_{\mathrm{pa}}\) and \(I_{\mathrm{a}}\) are resized to \(512\times 512\) before they are fed into the network. For ground feature extraction, we use ResNet50 as the backbone and replace the remainder of the second residual block with four convolution layers. This generates a global descriptor in \(8\times 8\times 4\) size, which is then flattened into a 256-dimensional \(F_{\mathrm{g}}\). In the process of aerial feature extraction, we utilize Res-Unet as the backbone. The resolution of the deepest layer is down-scaled to \(1/16\) of the original resolution, yielding a \(F_{\mathrm{a}}\) with the dimensions of \(128\times 128\times 256\).
We use models trained on the VIGOR dataset as the pre-trained models. Next, we evaluate the localization performance on the Lunar-CV dataset using three-fold cross-validation. In each fold, we select 20 orbital DOMs and their corresponding images \(I_{\mathrm{g}}\) as the training data. The remaining 10 orbital DOMs are processed using the sampling strategy in Fig. 3(c) to obtain \(I_{\mathrm{a}}\) and \(I_{\mathrm{g}}\) as test data. During training, we apply various data augmentation techniques, including image flipping, \(I_{\mathrm{pa}}\) Cutout [34], hue adjustment and our proposed QRCE.
For hyperparameter selection, τ for the \(\mathcal{L}_{\mathrm{CF}}\) is set to 0.1. The loss is optimized using the Adam optimizer [35] with a learning rate of \(1.0\times 10^{-5}\). η for discriminating between positive and negative regions is set to 0.01.
5.3 Baselines
In order to demonstrate the effectiveness of the IML network, we choose the existing representative works in CVML as the baselines and compare them with the IML network. These works including the following methods.
-
1)
Center-only. This technique [25] involves using the center of \(I_{\mathrm{a}}\) as the prediction. It is used to illustrate the localization accuracy achieved by successful image retrieval alone.
-
2)
SIFT-based image localization (SIFT-IL). This method [10] extracts SIFT descriptors from the image, establishes descriptor correspondence with the K-nearest neighbor (KNN) match algorithm, and uses RANSAC to eliminate incorrect matches, resulting in the determination of the image location via the homography matrix.
-
3)
Visual cross-view metric localization with dense uncertainty estimates (MCC). This method [25] utilizes dense satellite descriptors, performs similarity matching at the bottleneck, and provides a dense spatial distribution as the output to effectively address multi-modal localization ambiguities. It represents the state-of-the-art approach on the VIGOR dataset.
For all methods involved in the experiment, we resize the pixel size of \(I_{\mathrm{g}}\) to \(320\times 640\), and adjust \(I_{\mathrm{a}}\) to \(512\times 512\). MCC utilizes a VIGOR pre-trained model and conducts a three-fold cross-validation for evaluation. To demonstrate the effectiveness of the proposed pre-processing strategy, we use the prefix “Proj-” to indicate perspective projection and the suffix “†” to indicate data augmentation, thereby introducing control groups.
Due to the limited resolution of \(I_{\mathrm{a}}\), the \(I_{\mathrm{g}}\) simulated at lower altitudes contains blurrier near-field information. Therefore, our analysis primarily focuses on \(I_{\mathrm{g}}\) at 500 m altitude, where most of the details are preserved. Furthermore, our main evaluation will be based on “positive” samples, as they represent the majority of real-world scenarios where rough location priors are obtained through image retrieval or relative localization methods. Both the IML and MCC experiments are performed using PyTorch. To ensure a fair evaluation of localization errors and runtime efficiency, all these methods are tested on one GeForce RTX 3090 GPU.
5.4 Experimental results
The experiment primarily evaluates the localization performance of all methods under various test scenarios. These scenarios encompass four distinct working conditions: (1) FoV panoramas, representing the ideal working condition; (2) limited horizontal field of view (HFoV) panoramas, which is representative scenarios with horizontal angle constraints; (3) limited vertical field of view (VFoV) panoramas, reflecting conditions where vertical angle limitations are imposed; (4) panoramas captured at different altitudes. The performance results are detailed below.
Localization with full FoV panoramas
We have conducted experiments using our Lunar-CV dataset to evaluate the localization performance of various methods on panoramic images \(I_{\mathrm{g}}\) at 500 m altitude. As shown in Table 2, the following observations are reported.
-
1)
Without the pre-processing methods we have introduced, SIFT-IL struggles to achieve effective localization, while MCC has higher mean and median errors compared to the “center-only” baseline. However, upon implementing our perspective projection pre-processing and data augmentation technique for all the methods, we have observed a significant improvement in the localization accuracy of each method. This improvement underscores the effectiveness of our proposed approach in bridging the domain difference between different views. Consequently, we incorporate our pre-processing methods into all the CVML methods. For an intuitive understanding of the performance of each method, we provide localization examples under different experimental conditions, as shown in Fig. 5.
Figure 5 
Qualitative evaluation of all the methods. In each sub-figure, the upper left portion represents \(I_{\mathrm{g}}\), the lower left portion represents \(I_{\mathrm{pa}}\) and the right portion represents \(I_{\mathrm{a}}\), which overlaps with the results of all methods. Yellow shading indicates greater heat value at that location. GT represents the ground truth location of the query \(I_{\mathrm{g}}\) within \(I_{\mathrm{a}}\). (a)-(d) are from the “positive” cases. (c) and (d) are from the “semi-positive” cases. (a), (b), (e) and (f) all use panoramic image \(I_{\mathrm{g}}\), (c) uses 120∘ HFoV \(I_{\mathrm{g}}\), and (d) uses 120∘ VFoV \(I_{\mathrm{g}}\). IML: image-based metric localization; SIFT, scale-invariant feature transform; SIFT-IL, SIFT-based image localization; MCC: visual cross-view metric localization with dense uncertainty estimates. HFoV: limited horizontal field of view; VFoV: vertical field of view
-
2)
For the “positive” samples, our method’s mean error is reduced by 26% compared to the second best Proj-MCC† (30.45 pix vs. 41.20 pix), and our median error is reduced by 22% compared to the second best Proj-SIFT-IL (17.05 pix vs. 21.91 pix). For the “positive + semi-positive” samples, all methods show an increase in localization errors. When the GT location is located at the edge of \(I_{\mathrm{a}}\), the overlap between the cross-view images is significantly reduced. Each method can only determine the location based on a partial FoV of the panoramic image \(I_{\mathrm{g}}\), increasing the risk of localization failure. Figure 5(f) shows an example of localization failure in Proj-MCC† , where the GT location is close to the lower-left corner of the \(I_{\mathrm{a}}\), and only approximately 1/4 of the \(I_{\mathrm{pa}}\) overlaps with the \(I_{\mathrm{a}}\).
-
3)
As the region to be localized has limited discriminative features, Proj-SIFT-IL fails to accurately capture the corresponding points between \(I_{\mathrm{pa}}\) and \(I_{\mathrm{a}}\), resulting in significant deviation in the results (Fig. 5(b)). The predicted location of the Proj-MCC† also deviates to some extent.
-
4)
The error distributions in Fig. 6 demonstrate that our method outperforms the other methods. Our method shows improvements of 16% (75% vs. 87%) relative to Proj-MCC† and 21% (72% vs. 87%) relative to Proj-SIFT-IL in terms of achieving 50-pixel level accuracy.
Figure 6 
Error distribution records for “positive” samples using panoramic image \(I_{\mathrm{g}}\) at 500 m altitude


These improvements highlight the superiority of the proposed IML network architecture. The experiments demonstrate that Proj-IML† can estimate the rover’s location at 16 frames per second on a GeForce RTX 3090. Next, we will discuss the localization performance in response to variations in the characteristics of \(I_{\mathrm{g}}\).
Localization with limited HFoV panoramas
In practice, the number of images captured by the rover at each location varies, resulting in an inconsistent FoV for the stitched images. As a result, localization methods need to adapt to \(I_{\mathrm{g}}\) with different FoVs. We have investigated the quantitative and qualitative localization performance of \(I_{\mathrm{g}}\) with different HFoVs. The experimental results are summarized as follows.
-
1)
As depicted in Fig. 7, the model trained using \(I_{\mathrm{g}}\) with diverse HFoVs (between 120∘ and 360∘) demonstrates enhanced capability in feature extraction from limited HFoV images, surpassing the model trained solely with panoramic image \(I_{\mathrm{g}}\). This translates into superior localization performance. Hence, we have opted to train Proj-IML† and Proj-MCC† using \(I_{\mathrm{g}}\) with diverse HFoVs for this purpose.
Figure 7 
Comparison of the performance of \(I_{\mathrm{g}}\) with diverse HFoVs under two training strategies for our framework. 360∘ denotes training using \(I_{\mathrm{g}}\) with full HFoV. \(120^{\circ}-360^{\circ}\) denotes training using \(I_{\mathrm{g}}\) with HFoVs between 120∘ and 360∘. The red line shows the situation before adjusting the strategy. The localization error of the model under the \(120^{\circ}-360^{\circ}\) training strategy (the blue line) increases slightly when testing \(I_{\mathrm{g}}\) with an HFoV of 360∘ compared to the 360∘ training strategy (the red line)
-
2)
As depicted in Fig. 7, after adjusting the training strategy, the localization errors of Proj-IML† and Proj-MCC† increase slightly when evaluated on panoramic image \(I_{\mathrm{g}}\), in contrast to their training on panoramic image \(I_{\mathrm{g}}\). We consider a slight increase to be within an acceptable range.
-
3)
As presented in Table 3, the localization error of each method increases monotonically as the HFoV of the ground images decreases. Our method outperforms the other methods when the HFoVs are 360∘, 300∘, and 240∘. When the HFoV is 180∘ or 120∘, Proj-SIFT-IL shows better performance. Figure 5(c) shows the case with \(\text{HFoV}=120^{\circ}\), where the limited HFoV increases localization uncertainty and suppresses the performance of our method. However, our method still outperforms Proj-MCC† .
Table 3 Comparison of the performances of \(I_{\mathrm{g}}\) with different horizontal fields of view (HFoVs). The best results are highlighted in bold

Localization with limited VFoV panoramas
We have also investigated the localization performance when the VFoV of \(I_{\mathrm{g}}\) is limited. We adopt the same training strategy as in the limited HFoV experiment. Based on the experimental results, we have the following observation.
-
1)
According to the quantitative results presented in Table 4, as the VFoV decreases, the localization error for each method consistently increases. In particular, Proj-IML† exhibits superior localization robustness compared to the other methods over a wide range of conditions.
Table 4 Comparison of the performances of \(I_{\mathrm{g}}\) with different vertical fields of view (VFoVs). The best results are highlighted in bold -
2)
Fig. 5(d) illustrates the case in which \(\text{VFoV}=120^{\circ}\), and the optical axis of the \(I_{\mathrm{g}}\) acquisition camera is parallel to the ground plane. The limited VFoV of \(I_{\mathrm{g}}\) causes the loss of near-field information. As a result, the center of the generated \(I_{\mathrm{pa}}\) appears as a circle without information.
Localization with different altitude panoramas
The above experiments are conducted using \(I_{\mathrm{g}}\) at 500 m altitude. \(I_{\mathrm{g}}\) can preserve the details of the nearby scenery. In addition, a higher altitude provides a broader field of view, enabling the generation of an \(I_{\mathrm{pa}}\) with a resolution similar to that of the input \(I_{\mathrm{a}}\). In practical scenarios, the ground details may vary considerably based on the altitude. As a result, we conduct localization performance tests using \(I_{\mathrm{g}}\) captured at altitudes of 500 m, 100 m, and 25 m, respectively. This assessment aims to evaluate the effectiveness of different methods under substantial disparities in resolution between \(I_{\mathrm{g}}\) and \(I_{\mathrm{pa}}\). Based on the experimental results, we have made the following observation.
-
1)
Figure 8 shows examples of the localization results using \(I_{\mathrm{g}}\) at different altitudes at the same query location. As the altitude decreases, the details in the synthesized ground images become blurrier, requiring the generation of \(I_{\mathrm{pa}}\) with a larger coverage to provide discriminative information. However, the far-field information with more pronounced altitude variations breaks the perspective projection assumption and leads to distortion in the \(I_{\mathrm{pa}}\), which suppresses localization performance.
Figure 8 
Localization examples for different altitudes of \(I_{\mathrm{g}}\) for the same query location. GT represents the ground truth location of the query \(I_{\mathrm{g}}\) within \(I_{\mathrm{a}}\). Proj-SIFT-IL fails in (c)
-
2)
In Fig. 8(c), Proj-SIFT-IL fails to find corresponding points between \(I_{\mathrm{pa}}\) at 25 m altitude and \(I_{\mathrm{a}}\). In response to this situation, we use the image center as the predicted result for the quantitative evaluation.
-
3)
As evident from the quantitative results presented in Table 5, the performances of all methods decrease as the altitude decreases. At a ground altitude of 100 m, the distortion in \(I_{\mathrm{pa}}\) remains relatively manageable. Nonetheless, both Proj-SIFT-IL and Proj-MCC† exhibit a substantial decrease in performance when compared to the case in the 500 m scenario. In sharp contrast, Proj-IML† stands out for its significantly better results, highlighting the potential of our framework for achieving accurate localization in low-resolution base maps.
Table 5 Comparison of the performances of \(I_{\mathrm{g}}\) at different altitudes. The best results are highlighted in bold

5.5 Ablation studies
In this section, we discuss the effect of perspective projection, data augmentation and coarse-to-fine contrastive loss on performance. All the following experiments use panoramic image \(I_{\mathrm{g}}\) acquired at 500 m altitude and their corresponding “positive” \(I_{\mathrm{a}}\) as input.
Perspective projection
The effect of perspective projection is shown in Table 6. Without perspective projection, more IML† and MCC† localization errors are found than in the “center-only” case, indicating a localization failure. This clearly demonstrates the critical role of perspective projection in lunar cross-view localization tasks.
Data augmentation
The performance of our framework under different conditions, including using data augmentation, excluding specific augmentation methods, and not using data augmentation at all, is shown in Table 7. We observe the minimum localization error when all the augmentation methods are used, indicating that each method has a positive impact on the localization performance. The exclusion of the proposed QRCE leads to the most significant performance degradation, further validating the effectiveness of the proposed augmentation method.
Coarse-to-fine contrastive loss
In our framework, we apply max-pooling with strides s of \([s_{1}=16,s_{2}=8,\dots ,s_{5}=1]\) to \(\mathcal{M}\) for \(\mathcal{L}_{\mathrm{CF}}\) computation. We examine the localization performance using either the specific \(s_{i}\) or the complete \(\mathcal{L}_{\mathrm{CF}}\) for loss computation. As shown in Table 8, an increase of i in \(s_{i}\) generally leads to a decrease in localization error, with a significant decrease observed from \(s_{2}\) to \(s_{3}\). However, from \(s_{4}\) to \(s_{5}\), there is no apparent decrease in localization error, perhaps because the extremely fine-grained GT labels do not adequately guide the network to perceive coarse-grained information. In contrast, \(\mathcal{L}_{\mathrm{CF}}\) guides the network to simultaneously focus on both coarse and fine-grained information, resulting in the best localization performance.
6 Conclusion
In this study, we present a metric localization framework for lunar rovers. Our framework is designed for precise absolute localization for lunar rovers by exploiting the synergy between ground-level images and geotagged satellite patches. First, we introduce the perspective projection and QRCE techniques for processing ground and aerial images, respectively. Perspective projection effectively mitigates domain differences between cross-view images. Moreover, QRCE increases the robustness of localization. Then, our IML network extracts features and generates heatmaps, revealing the probability distribution of localization predictions. To capture both coarse and fine-grained image details, the coarse-to-fine contrastive loss is adopted for network optimization. In this way, the accuracy of the localization is effectively promoted. Finally, extensive experiments on the Lunar-CV dataset demonstrate the effectiveness of our framework. Future work will address joint localization with multiple ground images.
Data availability
The dataset generated by this work is not publicly available due to institutional policy. Access to the data may be granted on a case-by-case basis upon request.
Abbreviations
- CVML:
-
cross-view metric localization
- DOM:
-
digital orthophoto map
- FoV:
-
field of view
- GT:
-
ground truth
- HFoV:
-
horizontal field of view
- IML:
-
image-based metric localization network
- IMU:
-
inertial measurement unit
- Lunar-CV:
-
lunar large-area cross view image
- MCC:
-
visual cross-view metric localization with dense uncertainty estimates
- PDF:
-
probability density function
- QRCE:
-
query-based random context exploration
- SIFT:
-
scale-invariant feature transform
- SIFT-IL:
-
SIFT-based image localization
- VFoV:
-
vertical field of view
References
Nozette, S., Rustan, P., Pleasance, L. P., Kordas, J. F., Lewis, I. T., Park, H. S., et al. (1994). The Clementine mission to the Moon: scientific overview. Science, 100(5192), 1835–1839.
Zhao, B., Yang, J., Wen, D., Gao, W., Chang, L., Song, Z., et al. (2011). Overall scheme and on-orbit images of Chang’E-2 lunar satellite CCD stereo camera. Science China. Technological Sciences, 54(9), 2237–2242.
Liu, J., Ren, X., Yan, W., Li, C., Zhang, H., Jia, Y., et al. (2019). Descent trajectory reconstruction and landing site positioning of Chang’E-4 on the lunar farside. Nature Communications, 10(1), 4229.
Wu, W., Yu, D., Wang, C., Liu, J., Tang, Y., Zhang, H., et al. (2020). Technological breakthroughs and scientific progress of the Chang’E-4 mission. Science China. Information Sciences, 63(10), 1–14.
Yang, Y., Gao, W., Guo, S., Mao, Y., & Yang, Y. (2019). Introduction to BeiDou-3 navigation satellite system. Navigation, 66(1), 7–18.
El-Rabbany, A. (2002). Introduction to GPS: the global positioning system. Norwood: Artech House.
Liu, Z., Di, K., Li, J., Xie, J., Cui, X., Xi, L., et al. (2020). Landing site topographic mapping and rover localization for Chang’e-4 mission. Science China. Information Sciences, 63(4), 140901.
Liu, Z., Di, K., Peng, M., Wan, W., Liu, B., Li, L., et al. (2015). High precision landing site mapping and rover localization for Chang’e-3 mission. Science in China. Physics, Mechanics and Astronomy, 58(1), 1–11.
Ali, K. S., Vanelli, C. A., Biesiadecki, J. J., Maimone, M. W., Cheng, Y., Martin, A. M. S., et al. (2005). Attitude and position estimation on the Mars exploration rovers. In Proceedings of the IEEE international conference on systems, man and cybernetics (pp. 20–27). Piscataway: IEEE.
Di, K., Liu, Z., & Yue, Z. (2011). Mars rover localization based on feature matching between ground and orbital imagery. Photogrammetric Engineering and Remote Sensing, 77(8), 781–791.
Ng, P. C., & Henikoff, S. (2003). SIFT: predicting amino acid changes that affect protein function. Nucleic Acids Research, 31(13), 3812–3814.
Fu, Z., Guo, Y., & An, W. (2018). Simultaneous context feature learning and hashing for large scale loop closure detection. In Proceedings of the 24th international conference on pattern recognition (pp. 1689–1694). Piscataway: IEEE.
Chum, O., Matas, J., & Kittler, J. (2003). Locally optimized RANSAC. In B. Michaelis & G. Krell (Eds.), Proceedings of the 25th DAGM symposium on pattern recognition (pp. 236–243). Berlin: Springer.
Shi, Y., Liu, L., Yu, X., & Li, H. (2019). Spatial-aware feature aggregation for image based cross-view geo-localization. In H. M. Wallach, H. Larochelle, A. Beygelzimer, et al. (Eds.), Proceedings of the 33rd international conference on neural information processing systems (pp. 10090–10100). Red Hook: Curran Associates.
Cai, S., Guo, Y., Khan, S. H., Hu, J., & Wen, G. (2019). Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 8390–8399). Piscataway: IEEE.
Shi, Y., Yu, X., Campbell, D., & Li, H. (2020). Where am I looking at? Joint location and orientation estimation by cross-view matching. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 4063–4071). Piscataway: IEEE.
Shi, Y., Campbell, D., Yu, X., & Li, H. (2022). Geometry-guided street-view panorama synthesis from satellite imagery. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(12), 10009–10022.
Shi, Y., Yu, X., Liu, L., Campbell, D., Koniusz, P., & Li, H. (2023). Accurate 3-DoF camera geo-localization via ground-to-satellite image matching. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3), 2682–2697.
Guo, Y., Choi, M., Li, K., Boussaïd, F., & Bennamoun, M. (2022). Soft exemplar highlighting for cross-view image-based geo-localization. IEEE Transactions on Image Processing, 31, 2094–2105.
Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., et al. (2022). BEVFormer: learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In S. Avidan, G. J. Brostow, M. Cissé, et al. (Eds.), Proceedings of the 17th European conference on computer vision (pp. 1–18). Cham: Springer.
Reiher, L., Lampe, B., & Eckstein, L. (2020). A sim2real deep learning approach for the transformation of images from multiple vehicle-mounted cameras to a semantically segmented image in bird’s eye view. In Proceedings of the 23rd IEEE international conference on intelligent transportation systems (pp. 1–7). Piscataway: IEEE.
Zhou, B., & Krähenbühl, P. (2022). Cross-view transformers for real-time map-view semantic segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 13750–13759). Piscataway: IEEE.
Wang, J., Zhang, Y., Di, K., Chen, M., Duan, J., Kong, J., et al. (2021). Localization of the Chang’e-5 lander using radio-tracking and image-based methods. Remote Sensing, 13(4), 590.
Zhu, S., Yang, T., & Chen, C. (2021). VIGOR: cross-view image geo-localization beyond one-to-one retrieval. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 3640–3649). Piscataway: IEEE.
Xia, Z., Booij, O., Manfredi, M., & Kooij, J. F. P. (2022). Visual cross-view metric localization with dense uncertainty estimates. In S. Avidan, G. J. Brostow, M. Cissé, et al. (Eds.), Proceedings of the 17th European conference on computer vision (pp. 90–106). Cham: Springer.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., et al. (2017). Attention is all you need. In I. Guyon U. von Luxburg, S. Bengio, et al. (Eds.), Proceedings of the 31st international conference on neural information processing systems (pp. 5998–6008). Red Hook: Curran Associates.
Shi, Y., Yu, X., Wang, S., & Li, H. (2022). CVLNet: cross-view semantic correspondence learning for video-based camera localization. In L. Wang, J. Gall, T. Chin, et al. (Eds.), Proceedings of the 16th Asian conference on computer vision (pp. 123–141). Cham: Springer.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778). Piscataway: IEEE.
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: convolutional networks for biomedical image segmentation. In N. Navab, J. Hornegger, W. M. Wells, et al. (Eds.), Proceedings of the 18th international conference on medical image computing and computer assisted intervention (pp. 234–241). Cham: Springer.
Xiao, X., Lian, S., Luo, Z., & Li, S. (2018). Weighted Res-UNet for high-quality retina vessel segmentation. In Proceedings of the 9th international conference on information technology in medicine and education (pp. 327–331). Piscataway: IEEE.
Van den Oord, A., Li, Y., & Vinyals, O. (2018). Representation learning with contrastive predictive coding. arXiv preprint. arXiv:1807.03748.
Liu, L., & Li, H. (2019). Lending orientation to neural networks for cross-view geo-localization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5624–5633). Piscataway: IEEE.
Zhai, M., Bessinger, Z., Workman, S., & Jacobs, N. (2017). Predicting ground-level scene layout from aerial imagery. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4132–4140). Piscataway: IEEE.
Devries, T., & Taylor, G. W. (2017). Improved regularization of convolutional neural networks with cutout. arXiv preprint. arXiv:1708.04552.
Kingma, D. P., & Ba, J. (2014). Adam: a method for stochastic optimization. arXiv preprint. arXiv:1412.6980.
Funding
This work was partially supported by the Shenzhen Key Laboratory of Navigation and Communication Integration (No. ZDSYS20210623091807023).
Author information
Authors and Affiliations
Contributions
ZC conceived the initial ideas, conducted detailed experiments, and drafted the paper. KL suggested the use of perspective projection for ground image pre-processing and improved the research ideas. HL carefully revised the experimental design and drafted the paper. ZF revised the manuscript. HZ created the Lunar-CV dataset for experimental evaluation. YG systematically refined the research framework, experimental design, and provided guidance throughout the writing process. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, Z., Li, K., Li, H. et al. Metric localization for lunar rovers via cross-view image matching. Vis. Intell. 2, 12 (2024). https://doi.org/10.1007/s44267-024-00045-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44267-024-00045-y