
Abstract
Few-shot relation extraction is one of the current research focuses. The key to this research is to fully extract the relation semantic information through very little training data. Intuitively, raising the relation semantics awareness in sentences can improve the efficiency of the model to extract relation features to alleviate the overfitting problem in few-shot learning. Therefore, we propose an enhanced relation semantic feature model based on prototype network to extract relations from few-shot texts. Firstly, we design a multi-level embedding encoder with position information and Transformer, which uses local information in the text to enhance the relation semantics representation. Secondly, the encoded relation features are fed into the novel prototype network, which designs a method that utilizes query prototype-level attention to guide the extraction of supporting prototypes, thereby enhancing the prototypes representation to better classify the relations in query sentences. Finally, through experimental comparison and discussion, we prove and analyze the effectiveness of the proposed multi-level embedding encoder, and prototype-level attention can enhance the stability of the model. Furthermore, our model has substantial improvements over baseline methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The knowledge graph is a complex network composed of nodes and edges. The node and edge named entity and relation have actual semantic information [1, 2]. Extracting entities and relations from unstructured text is one of the most important steps in the process of knowledge graph construction [3,4,5,6]. This paper mainly studies the extraction of the relation between given entity pairs by text description. As Table 1 shows, according to the description of the support set, the relation (expressed as “?”) between the head entity and the tail entity in the query set is classified, to achieve the purpose of relation extraction [7, 8].
With the more in-depth study of relation extraction, there has been a problem of wasting a lot of human resources to annotate sentences, so the cost of corpus annotation has attracted more and more attention [9,10,11,12]. Researchers who study relation extraction have found a new solution to the problem of corpus annotation, which makes full use of a small number of labeled samples for training so that the model has better generalization ability. Therefore, they proposed the few-shot relation extraction task, which extracts the relation between two entities in a sentence with very few annotations. The few-shot relation extraction model represents the relation semantics of the sentence category without learning the specific features of each relation, which can effectively alleviate the long-tail distribution [13, 14], thus solving the overfitting problem. Consequently, the key to building a model that can quickly learn the relation features through few labeled data is how to train very few category samples for accurate relational classification.
The metric-based prototype network is typically used in the few-shot relation extraction tasks [15, 16]. It mainly regards the center of each sample category as the prototype representation of the category and then analyzes the category of the target by comparing the distance between the target and each center [17]. However, considering the influence of the complexity and diversity of relation semantic information in sentences on prototype classification [18], we propose two key points for enhancing relation semantics. (1) The contextual semantics of relations are easily ignored, resulting in the loss of local relation features in the sentence. As shown in Table 1, local relation semantic words (marked as italic) appear in the front, middle, or back position of the head entity (marked as bold) and the tail entity (marked as bolditalic). Therefore, emphasizing the local relation feature is conducive to the mining of complex relation semantics. (2) There are multiple relation semantics in the sentence [19, 20]. For example, in Table 1, an instance with the relation “Place_of_birth” contains two kinds of semantic information of birthplace and place of life. Therefore, the impact of deviation caused by multiple relation semantics on relation prototype representation should be avoided.
Given the above keys, a prototype network model that can enhance relation semantic information is proposed. We designed a multi-level embedding encoding method to further capture the data distribution. In this method, the phrase of the same relation with position information is fed into the Transformer to emphasize important local relation features. After encoding the sentence embeddings, we use the query prototype to assist the construction of the support prototype in the form of attention weight, to strengthen the classification ability to the query sentence. The main contributions of our proposed model can be summarized as:
-
1.
A multi-level embedding encoder with position information and Transformer module is designed to identify and emphasize local relation semantic information, so that the encoded sentence embeddings can obtain more accurate relation features, as well as the model can adapt to few-shot relation extraction tasks.
-
2.
In the prototype network, query information participates in the extraction of support prototypes in a way of prototypes-level attention, to suppress the semantic deviation caused by noise and enhance the representation ability of relation semantics, thereby extracting the more reliable prototype to classify query sentences and then improving the stability of the model.
-
3.
The proposed model is compared with its ablation variants and the most advanced models in the experiment. The comparison results show that innovations play an important role in the proposed model, and our model achieves the most advanced results compared with the baseline model.
In summary, the proposed encoding method is actually a feature capturer that finds important relation information from the feature distribution. Local information in sentences are multi-level encoded because they are beneficial to the understanding of relation semantics, and then using context to enhance the relation semantic features is the key to current research. In addition, we improve the prototype extraction method from the perspective of prototype-level attention to adapt to the relation extraction task in few-shot scenarios.
The structure of this paper is as follows: related work in Sect. 2. Section 3 defines the background and problem setting of few-shot relation extraction tasks. Section 4 describes the proposed model and its algorithm in detail. Section 5 compares and discusses the experimental results, and analyzes the role of each module. Finally, Sect. 6 summarizes and looks forward to future work.
2 Related Works
Since the relational triples in most scenarios obey the long tail distribution, the training of available sample features is easy to overfit. In addition, the number of available samples is limited by the size of data in professional fields. In this paper, the purpose of the few-shot relation extraction task is to effectively improve the model learning ability by embedding representation, and then make better use of a limited number of training samples to obtain satisfactory relation extraction performance. Next, this section mainly introduces the related work of few-shot relation extraction based on feature representation from three perspectives: the relation extraction method based on embedding representation learning, few-shot learning research, and the few-shot relation extraction models.
The method based on embedding representation learning projects the input into embeddings and describes the structure of the dataset with relatively low dimensions. The neural network-based method uses its powerful computing power to learn word embedding to improve the performance of the relation extraction model. Lin et al. [21] proposes an attention mechanism on the sentence-level relation features, aiming at the problem of excessive noise caused by label propagation in distant supervision scenarios to improve the model effect. The R-BERT model [22] use the pre-trained model BERT to perform sentence-level coding and achieved good results. Its main contribution is to take the lead in using BERT for relation extraction tasks and to explore the combination of the entity and their location attributes in the large pre-trained model. Models based on embedding representation can learn relation semantics from a large number of features. However, in the face of data whose relation obeys the long-tail distribution, the embedding model cannot give full play to the ability of feature learning representation. In this regard, the multi-level embedding representation proposed is more suitable for feature mining of long-tail relations.
The few-shot learning studies the realization of task goals with a small amount of data. Existing few-shot learning models can be divided into three directions: 1. The Model-Based research aims to quickly update parameters on a small number of samples by the design of model structures. Santoro et al. [23] proposed a memory enhancement method to solve the few-shot learning task, which adjusts bias through weight updating and caches to memory quickly. 2. The Metric-Based research is to model the distance distribution between samples. Siamese Network [24] trains the model in a supervised way to learn weights and then reuses the features extracted from the network for the few-shot learning. 3. Optimization-Based research focuses on gradient optimization for model parameters. Finn et al. [25] proposed the Model-Agnostic Meta-Learning method to train the initial parameters so that the model can achieve the optimal effect after a few steps of gradient. The three research methods solve the feature sparse problem in few-shot tasks from different perspectives. The Metric Based method, which can model the distance distribution between samples, can match the relation classification requirements in the few-shot relation extraction task. However, this method still faces the problem of distance deviation caused by multi-relational semantic noise.
The research content of the task on FewRel 1.0 first proposed by Han et al. [26] is the problem of few-shot learning on the relation extraction. Then, improving the effectiveness of the relation extraction model in few-shot platforms has attracted more and more attention from researchers. The few-shot relation extraction based on Prototype Network [27] represents the relation by learning the center of data distributions in instances. The Matching the Blanks method [28] proposes that there are similar relation types in the same entity pair, and then uses a large amount of unsupervised data for pre-training. The Multi-Level Matching Aggregation Network (MLMAN) proposed by Ye et al. [29] uses word-level and instance-level attention mechanisms to perform multi-level matching aggregation for query instances and support sets. To solve the problem of being susceptible to noisy instances in few-shot learning, Gao et al. [30] proposed a prototype network based on hybrid attention, the model designs instance-level and feature-level attention to highlight key sample instances and features. These models can mine effective relation features from a small number of training samples to adapt to the few-shot relation extraction task. However, they ignore the different influences of information around the relation, resulting in the relation semantics is not fully explored.
In summary, referring to the problems encountered in related work, we use representation learning and Metric Based Prototype Networks as technical support to further improve the performance of few-shot relation feature extraction.
3 Background
Meta-learning is one of the methods used in few-shot learning. It performs transfer learning from a large number of classification problems learned using labeled samples, so that it can quickly learn new tasks on the basis of acquiring existing knowledge. Prototype Network is the branch of metric-based method in meta-learning platform, which calculates the distance between the support set and the query set mapped in a consistent embedding space through the metric function, and then classifies the instance in the query set.
Few-shot relation extraction based on prototype network is actually the N way K shot classification task. The data in this task is divided into support set and query set, and the support set is defined as:
N is the number of relations in the support set, and K is the number of instances with the same relation. Each instance is denoted as \(i_{n, k}=\{s, h, t, r\}_{n, k}\), \(1 \le n \le N\), \(1 \le k \le K\). s is the sequence of words, namely sentence. h and t refer to the head and tail entities, respectively, and r refers to the relation.
The few-shot relation extraction model predicts the relation type of each instance in the query set by the few training data. In the design part of the task, while extracting K support instances from one way, Q query instances are also extracted, and \(Q=K\). Therefore, N, K, and Q are set to small numbers, as detailed in Sect. 5.2.
4 Methods
4.1 Model Framework
We design a prototype network framework based on multi-level embedding representation. As shown in Fig. 1, The left panel is the overall framework of the model, and the right panel is a detailed description of the framework.

The overall framework of a few-shot relation extraction model is composed of a multi-level embedding encoder with position and Transformer and an improved prototype network. The model enhances relation representation through word-level, phrase-level and sentence-level coding processes, and then uses the prototype network to extract relation features from 1 way 3 shot instances
The model is mainly divided into three layers: the input layer, the encoder layer, and the prototype network layer.
The input layer is mentioned in Sect. 3, the number of instances in the Support set (denoted as \({\mathcal {S}}\)) is \(N*K\), and the number of instances in the Query set (denoted as \({\mathcal {Q}}\)) is \(N*Q\).
The encoding layer is a multi-level embedding encoding process: firstly, the initial encoding of words in the instance. Secondly, we propose a phrase embedding encoding method with position and attention information to enhance local relation semantic information. Thirdly, the phrase embedding in each instance is fused by convolution to obtain sentence embeddings.
In the prototype network layer, we compute the prototype representation of the query instances obtained by the encoder and use it in the form of weight information to extract the support prototype, which can enhance the ability of the prototype to express the corresponding relation. Then measure the distance from the support set instance to the query prototype, and finally train the model through the loss function.
4.2 A Multi-level Embedding Encoding Method
The Encoder panel in Fig. 1 describes the encoding of three support sentences with the same relation. A square represents d-dimensional embeddings. Firstly, to obtain the contextual semantic information of the relation, we divide the sentences into phrases according to the position of the entity and then fuse the word embeddings in each phrase into phrase embeddings. Secondly, we allow the position embeddings for each phrase position of the sentence sequence and feed phrase embeddings with the position in one way into the Transformer to enhance local relation semantics. Finally, we fuse word embeddings with position and attention information into sentence embeddings by multi-layer convolution. The model encoder is described in detail below.
We first use the Bert method to initialize the word-level features, so that the initial word embeddings can obtain global semantic information, and the obtained word embedding matrix is defined as \(\{\textbf{w}_{1}, \textbf{w}_{2}, \ldots , \textbf{w}_{m}\} \in {\mathbb {R}}^{l \times d}\), in which a sentence is fixed to be composed of l word embeddings.Although the Bert can enable words to learn semantic features in the sentence, it is limited by the single encoding unit and then ignores the Local relation semantic information, resulting in incomplete relation expression. So, we divide sentences according to the location of head and tail entities to get the phrase representation in front of the head entity \(p_{f}=f_{p}(\textbf{w}_{1}, \ldots , \textbf{w}_{i-1})\), \(\textbf{e}_{h}\), the phrase representation in the middle of the head and tail entity \(p_{m}=f_{p}(\textbf{w}_{i+1}, \ldots , \textbf{w}_{j-1})\), \(\textbf{e}_{t}\), and the phrase representation in back of the tail entity \(p_{b}=f_{p}(\textbf{w}_{j+1}, \ldots , \textbf{w}_{m})\), where i and j are indexes of the head entity and the tail entity, respectively. Where \(\textbf{w}_{i}=\textbf{e}_{h}\)and \(\textbf{w}_{j}=\textbf{e}_{t}\), \(f_{p}\)is the average operation for the word-level embeddings in each phrase.
We define the phrase embeddings set in a sentence as \(m_{k}=\{p_{f}, \textbf{e}_{h}, p_{m}, \textbf{e}_{t}, p_{b}\}\), \(m_{k} \in {\mathbb {R}}^{5 \times d}\), and phrase-level matrix set in n-th way as \(M=(m_{1}, \ldots m_{K})\), \(M \in {\mathbb {R}}^{K \times 5 \times d}\), where \(m_{k}\) is a sequence. \(x_{i} \in m_{k}\) is the phrase embeddings. We adopt the position encoding method commonly used in Transformer to generate a fixed position representation \(p_{i}\) to preserve the sequence position of phrases in the sentence. The formula is as follows :
where \(x_{i}^{p o s}\) is the phrase embeddings with position information, thus ensuring permutation and translation invariance. And phrase-level matrix set with position information in one way is \(M^{pos} \in {\mathbb {R}}^{5 K \times d}\), the phrases embeddings in \(M^{pos}\) describe the same relation semantics. Therefore, we feed \(M^{pos}\) into a stack of Transformers, which can enhance the important local semantics feature with the same relation in one way. This process can be expressed as:
where, \(M_{T}^{pos} \in {\mathbb {R}}^{5 K \times d}\) is phrase embeddings set with position and attention information in one way K shot. In the training process of the model, the sentence embeddings with different relations can be distinguished by adjusting the weight parameters in the vector space, thus enhancing the relation semantic expression of the sentence with the same relation and increasing the difference of prototypes to build a more reliable prototype network.
We fuse \(M_{T}^{pos}\) in a convolution way to represent K sentence embeddings. The convolution process is shown in the following Fig. 2.

It is a process of fusing phrase-level embeddings into sentence-level embeddings in the encoder, which contains two layers of convolution with different kernels
Finally, the features of the \(M_{T}^{pos}\) are fused by 2-layer convolution, to get K sentence embeddings denoted as \(S=\{\mathbf {s_{1}}, \cdots , \mathbf {s_{K}}\}\), \(S \in {\mathbb {R}}^{K \times d}\). Through this encoding method, the important relation semantic information is highlighted in each way, which increases the distance between sentence embeddings with different relations in the embedding space, so as to make the different relation representations more easily distinguished.
4.3 Prototype Network with Query Prototype-Level Attention Weight
The few-shot relation extraction model based on the prototype network expresses the mean value of sentence embeddings in the embedding space as the prototype, so the task is regarded as the nearest neighbor classification problem in the space. The typical method for calculating the prototype is as follows:
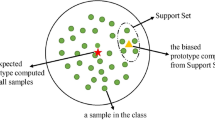
where \((\textbf{s}_{1}, \cdots , \textbf{s}_{K})_{n}\) is K shot sentence-level embeddings set, and \({\mathcal {P}}_{n} \in {\mathbb {R}}^{d}\) is a prototype in n-th way. However, before calculating the support set prototype, there is no information interaction between the support set and the query set, which leads to the support prototype containing some features that have no effect on classified query sentences [30, 31]. Therefore, we joint query information to assist the calculation support prototype. Furthermore, as shown in Eq. (3), the representation of the prototype is determined by K sentence embeddings in n-th way. As a matter of fact, there are a small number of sentence embeddings that are far away from other sentences with the same relation in the space. These sentence embeddings with noise features can cause the support prototype semantic deviation. Hence, we use the query prototype instead of query sentences to mitigate the impact of this problem. We calculate the query prototype \({\mathcal {P}}_{n}^{({\mathcal {Q}})}\) in n-th way by Eq. (3) and input it into the following formulas:
where, \(W^{(1)} \in {\mathbb {R}}^{d \times d}\) and \(W^{(2)} \in {\mathbb {R}}^{d \times d}\) are the learning weight parameters. Different from the previous model that involved the query set in the calculation of the support prototype, we take the point multiplication between the query prototype-level attention weight and the corresponding support embeddings to realize the support prototype with query information. The main reason is that the query prototype can reduce the noise features in the query set, and then alleviate the deviation effect of the query sentence, so as to enhance the relation semantic representation ability of the support prototype.
After obtaining the support prototype, we use the Euclidean distance formula to calculate the distance \(d({\mathcal {P}}_{n}^{({\mathcal {S}})}, S^{({\mathcal {Q}})})\) between the support prototype and the query sentences. All the distances from query sentences to support prototypes are normalized. The following formula shows :
The normalizing distance \({\mathcal {D}}_{R} \in {\mathbb {R}}^{N^{*} Q}\) between the query prototype and support sentences can also be obtained. Finally, we input \({\mathcal {D}}\) and correspond \(label^{({\mathcal {Q}})}\) to the following loss function to calculate the loss L of the whole model.
Ultimately, we summarize the training process of our model for the few-shot relation extraction in Algorithm 1:

5 Experiments
5.1 Dataset
FewRel 1.0 dataset is constructed based on the Wikipedia corpus and the Wikidata knowledge graph, which contains 100 relations, and each relation contains 700 instances. It is the largest fine-label dataset in the field of relation extraction. The FewRel 1.0 is used not only in classical supervised or remote-supervised relation extraction but also in the emerging few-shot learning tasks. In FewRel 1.0, the training sets with 64 relations, the evaluation sets with 16 relations, and the test sets with 20 relations are extracted from the same domain [32].
5.2 Implementation Details
Our model is trained on a machine with 3 T V100 32GB GPUs and gets results. the results of the baseline model are obtained in related papers. Hyperparameters of the model are set as follows: The maximum length (l) of the sequence of the word in a sentence is set to 64, and the initial embedding dimension (d) is 768. We randomly select N relations from the training set, each relation contains the K instance sample, N selected from 5, 10, and K selected from 1, 5, namely 10 way 5 shot, 10 way 1 shot, 5 way 5 shot, and 5 way 1 shot. In the model optimization part, AdamW is used for the training strategy, and the learning rate (lr) is set to \(2e-5\). The number of training iterations is 20000.
5.3 Results Comparison
The accuracy of correct prediction is typically used as the evaluation metric of the few-shot relation extraction model, which is obtained by calculating the ratio of the number of predictions and the total number of predictions.The Baseline models used are as follows:
ProtoNet is originally applied in the field of the image. The backbone of the model is to use the mean value of features as the prototype representation of the class center, which is widely used in the few-shot learning.
Proto_HATT is an improved model based on ProtoNet to adapt to the relation extraction task, and this model has a more prominent performance than the original ProtoNet.
LM-ProtoNet [33] is a model that can enhance the reliability of relation classification. Considering the impact of sentence coding, a new loss function is designed to alleviate the impact, which has achieved outstanding performance.
MLMAN is a model that calculates the matching information between query instances and support instances through MLP. The matching score between query instance representation and prototype can be well calculated by metrics different from the prototype network.
BERT-PAIR is a sentence classification model based on Bert. Each query sentence is paired with all support sentences, and each pair is connected as a sequence. Finally, the scores of two sentences in the same relation are obtained.
TPN [34] is a model that combines Transformer to enhance prototype representation, to extract more distinctive relation feature dimensions. And the model also uses Bert as the initial encoder.
APN [35] is a model that can increase the generalization ability of few-shot relation extraction. The author designs the adaptive prototype network with labels and the loss function that can joint representation learning.
RBERTI-Proto [36] is a model that model stratifies pre-training knowledge through backdoor adjustment based on causal intervention.
In Table 2, the experiment results are shown in the valid/test format, and the best results of our model and baseline models on four experiments are identified in bold. Experimental results on the FewRel 1.0 dataset demonstrate that the proposed method achieves superior performance in most experiments, so our model has made progress in few-shot relation extraction tasks. However, the valid metric of the 5 Way 1 Shot is worse than that of the BERT-PAIR model, and the test metric on the 5 Way 5 Shot is worse than that of TPN. We speculate that this might be due to the BERT-PAIR model encoding two sentences together, which is conducive to information fusion, and TPN fully exploits the advantage of the encoders in increasing distances between different prototypes. While the prototype network-based model relies on more support instances to get a better prototype. By comparing the above results, we conclude that our model can present advanced experimental results on the FewRel1.0 dataset and effectively promote the development of few-shot relation extraction.
5.4 Discussion
5.4.1 Discussion on Model Comparison Results
This part mainly discusses feeding the encoded sentence embeddings to the nonparametric estimation model to improve the performance of the prototype network in meta-learning. We find that the multi-level embedding encoding method is sufficient to capture the key local information in the sentence. There are similarities between the current multi-level encoding method and the LM-ProtoNet model encoded by Fine-grained Features, indicating that the phrase-level features contribute to the understanding of relation semantics. However, the main difference between our encoder and the LM-ProtoNet model encoding is attributed to the fact that the attention weighting of Transformer can emphasize important relation semantics. The research on Transformer applied to few-shot relation extraction task is in accord with MLMAN and TPN, but we provide the position modeling of phrase in a relation class, which has a stronger ability to distinguish and extract the relation features. In Sect. 5.5.1, we further explain the influence of the improvement of the encoder on the effect of few-shot relation extraction. Hence, different from the single coding and prototype acquisition methods in BERT-PAIR and other baseline models based on ProtoNet. Our model proves the effectiveness of the relation semantics enhancement for few-shot relation extraction tasks from the perspective of relation feature diversity to alleviate the long-tail distribution problem of the data.
The experimental data results presented are obtained from experiments and literatures, which are authentic and reliable. These data contribute to a clearer understanding of the limitations of our model. One concern about the findings is that our model does not perform significantly on few-shot data in 5 way. Two types of accounts could be proposed for the unexpected findings. The first account assumes that relation semantic differentiation is not clearly distinguished by the attention in the encoder due to fewer relation categories. The second account assumes that the advantage of the prototype-level attention method that reduces instance bias cannot be exerted, especially when there is only one instance. Notwithstanding these limitations, the contribution of this paper still has an enlightening effect on the few-shot relation extraction field. On the one hand, we first propose to enhance the relation semantics method in a way with the same relation to solve the problem of sparse features in few-shot learning. On the other hand, we propose an improved idea for the metric-based prototype network, which is commonly used in few-shot platforms, to improve the reliability of prototype extraction by the interaction between the support prototype and the query prototype.
5.4.2 Discussion on the Model Robustness
During the experiment, the support instances are wrong-labeled to perform robustness experiments on the model, where the probability of wrong-labeling is Noise Rate. In Table 3, with the increase in Noise Rate, the downward trend of the results of our model is not as obvious as that of the ProtoNet model and Proto_HATT model. This proves that our model is more robust to face noise data. This robustness performance is mainly attributed to the identification of wrong-labeling instances by the query prototype, thereby resisting the impact of noise data. And Transformer can also play a role in filtering redundant information.
5.5 Module Analysis
5.5.1 Analysis of Encoder with Position and Transformer
We designed a set of comparative experiments for ablation research of encoder: 1. The phrase embeddings are directly fused into the sentence embeddings by convolution. 2. we add position information to the phrase embeddings in each sentence and then fuse the phrase embeddings with the position feature into sentence embeddings. 3. After adding position information, we feed the phrase embeddings in one shot into the Transformer module, and then fuse the phrase embeddings with position and attention information into the sentence embeddings. 4. We feed the phrase embeddings in K shot into the Transformer module. The high-dimensional phrase embedding representation generated by four encoding methods is visualized by the PCA model. Fig. 3a–d correspond to the comparative experiments 1, 2, 3 and 4, respectively. The scatters in the figures represent the feature distribution of phrase embeddings after dimension reduction in 10 way 5 shot task.

It is an ablation study of the encoder. a Remove Transformer and position. b Add position information to phrase in a sentence. c Add position information to phrase in a way. d Experimental results of our encoder. By observing the results of four figures, it can be found that with the addition of innovation, the distribution of scatter points is more excellent
In Fig. 3a, although some scatter with some relations are compact, the distances between each relation class are close and there are many mixed nodes. It can be observed that the scatter distribution effect of Fig. 3a is the worst compared with the other three figures. Therefore, the addition of position and attention information can make the model better perform relation classification. The scatters of different colors in Fig. 3b are more distinguishable than those in (a), but any scatters of different colors are too close or even mixed. So adding position features to phrase embeddings in each sentence can help them learn more useful features. Both Fig. 3c and d equip with the Transformer based on (b), and the experimental difference between the two figures is the input phrase form. It can be observed from Fig. 3c and d that the scatters with the same color are relatively compact and not mixed, but the distance of each scatter class in Fig. 3d is farther than that in Fig. 3c. We attribute this ability to feeding the K shot phrase embeddings into the Transformer module to increase the distance between the scatter classes with different relations by training the model. In summary, we conclude that the encoder with the position and Transformer module can reduce the distance between the scatters with the same relation, and the attention weight added in the K shot phrase embedding can increase the distance between different classes, which can distinguish confusing data, to achieve good performance in few-shot relation extraction tasks.
5.5.2 Analysis of Sentence Embeddings Fusion Method
We try the following experiments to fuse the phrase embeddings with position and attention information into sentence embeddings and show the influence of different phrase-level feature fusion methods in the encoder on the experimental results. 1. The vanilla approach to computing the sentence embeddings is to average 5 phrase embeddings in a sentence. 2. Based on PCNN (Piece-Wise-CNN) feature fusion method, the piecewise max pooling method is used to splice and merge phrase embedding to obtain sentence embeddings. 3. We use a two-level convolution method to map word embedding into sentence embedding. We verified the three methods through a group of experiments, and the results are shown in Fig. 4.

The effects of three phrase-level feature fusion methods are compared, namely averaging, Piece-Wise-CNN, and two-layer convolution. By comparing the results we chose a two-layer convolution method to fuse phrase-level features into sentence embeddings
We observe that the result of aggregated phrase embeddings by Averaging is the worst in the three experiments, and the coding effect of CNN in our encoder is the best. This proves that the two-layer convolution can better retain the position and attention information to emphasize the important local relation semantic features compared with the other two methods in the process of fusing phrase embeddings into sentence embeddings. PCNN retains phrase-level position information to a certain extent by using piecewise max pooling. Moreover, CNN and PCNN have similar results in the 5 way experiment, because one shot is not enough to play the advantages of the Transformer.
5.5.3 Analysis of Query Information Involved in Supporting Prototype Extraction
In order to enable the support prototype to obtain more features related to the query set, the query information is used to assign weight to the support sentence, and the query prototype is involved in the extraction of the support prototype to solve the problem of semantic deviation caused by query information. Therefore, we designed the following three experiments to prove that innovation has a positive impact on the model. 1. We adopt the traditional prototype network, directly calculate the support prototype, and measure the distance from the query sentence to the support prototype. 2, we take each query sentence embeddings as sentence-level attention (sla) information to weight the support sentence embeddings and then calculate the support prototype. 3 Our method is to replace the query sentence embeddings in 2 with the query prototype, then support sentence embeddings weighted by prototype-level attention (pla). Table 4 shows the effects of three experiments on the model results on the valid set and the test set.
It is observed from Table 4 that the effect of assigning weights to support instances by the query prototype-level attention is the best, and the performance of the ProtoNet-sla is better than that of the original ProtoNet. Therefore, we draw a conclusion that generating a prototype with query information contributes to relation extraction, and replacing query sentence-level attention with query prototype-level attention can reduce noise effects on the support prototype.
In addition, to further illustrate the effect of the query prototype-level attention on the support prototype, we calculate the average Euclidean distance between query sentence embeddings and the support prototype, and the results show that when using query prototype-level attention, the minimum average distance between sentence embedding and prototype is 7.1, and when using query sentence-level attention, the minimum average distance is 11.5. Therefore, the query prototype-level attention makes sentences closer to the corresponding prototype.
6 Conclusion
This paper proposes a prototype network model that can enhance the semantic representation of relations in the sentence for few-shot relation extraction tasks. The K shot phrase embeddings with position information are fed into the Transformer so that the model encoder can emphasize the local relation semantic information in the sentence and further capture the feature distribution of the data. In the prototype network, the query prototype-level attention is used to construct a reliable support prototype representation, and then accurate relation features are extracted from very few training data. We evaluate and analyze the model on common datasets, and the results show that each innovation point can improve the performance of the model in few-shot relation extraction tasks. Our future work may consider further enhancing information interaction between query sets and support sets, such as adding feature-level attention to make full use of information in a small amount of data to extract relation features more accurately.
Availability of data and materials
Not applicable.
References
Nayak T, Majumder N, Goyal P, Poria S. Deep neural approaches to relation triplets extraction: a comprehensive survey. Cogn Comput. 2021;13:1215–32.
Mintz M, Bills S, Snow R, Jurafsky D. Distant supervision for relation extraction without labeled data. Singapore. 2009.
Bram S, Gilles V, Michael W. Ink: knowledge graph embeddings for node classification. Data Min Knowl Discov. 2022;48.
Yang Z, Wang L, Ma B, Yang Y, Dong R, Wang Z. Rtjtn: relational triplet joint tagging network for joint entity and relation extraction. Comput Intell Neurosci. 2021.
Legrand J, Toussaint Y, Raïssi C, Coulet A. Syntax-based transfer learning for the task of biomedical relation extraction. J Biomed Semant. 2021.
Yi Q, Zhang G, Zhang S. Utilizing entity-based gated convolution and multilevel sentence attention to improve distantly supervised relation extraction. Comput Intell Neurosci. 2021.
Wang Y, Bao J, Liu G, Wu Y, He X, Zhou B, Zhao T. Learning to decouple relations: few-shot relation classification with entity-guided attention and confusion-aware training. Coling. 2020.
Song S, Sun Y, Di Q. Multiple order semantic relation extraction. Neural Comput Appl. 2019;4563–76.
Wang D, Tiwari P, Garg S, Zhu H, Bruza PD. Structural block driven enhanced convolutional neural representation for relation extraction. Appl Soft Comput. 2020;1568–4946.
Shao Y, Li H, Gu J, Qian L, Zhou G. Extraction of causal relations based on sbel and bert model. Database. 2021.
Qiu Q, Xie Z, Ma K, Chen Z, Tao L. Spatially oriented convolutional neural network for spatial relation extraction from natural language texts. Transactions in GIS. 2021.
Stanley O, Nazife D, Arif A. Chemical disease relation extraction task using genetic algorithm with two novel voting methods for classifier subset selection. Turk J Electr Eng Comput Sci. 2020;1179–96.
Woohwan J, Kyuseok S. T-rex: a topic-aware relation extraction model. Assoc Comput Mach. 2020;2073–6.
Abu-Salih B, Al-Tawil M, Aljarah I, Faris H, Wongthongtham P. Relational learning analysis of social politics using knowledge graph embedding. Data Min Knowl Discov. 2021.
Fan S, Zhang B, Zhou S, Wang M, Li K. Few-shot relation extraction towards special interests. Big Data Res. 2021;2214–5796.
Vinyals O, Blundell C, Lillicrap T, Wierstra D. Matching networks for one-shot learning. Adv Neural Inform Process Syst. 2016.
Qu M, Gao T, Xhonneux L-P, Tang J. Few-shot relation extraction via bayesian meta-learning on relation graphs. ICML. 2020.
Hui B, Liu L, Chen J, Zhou X, Nian Y. Few-shot relation classification by context attention-based prototypical networks with bert. EURASIP J Wirel Commun Netw. 2020.
Deng S, Zhang N, Kang J, Zhang Y, Zhang W, Chen H. Meta-learning with dynamic-memory-based prototypical network for few-shot event detection. Assoc Comput Mach. 2020;151–9.
Fangchao L, Xinyan X, Lingyong Y, Hongyu L, Xianpei H, Dai D, Hua W, Le S. From learning-to-match to learning-to-discriminate: global prototype learning for few-shot relation classification. Chin Comput Linguist. 2021.
Lin Y, Shen S, Liu Z, Luan H, Sun M. Neural relation extraction with selective attention over instances. 2016;2124–33.
Shanchan W, Yifan H. Enriching pre-trained language model with entity information for relation classification. 2019.
Adam S, Sergey B, Matthew B, Daan W, Timothy L. One-shot learning with memory-augmented neural networks. In: 33nd international conference on machine learning. 2016.
Gregory K, Zemel R, Salakhutdinov R. Siamese neural networks for one-shot image recognition. 2015;2.
Chelsea F, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks. 2017.
Han X, Zhu H, Yu P, Wang Z, Yao Y, Liu Z, Sun M. Fewrel: a large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. EMNLP. 2018.
Jake S, Swersky K, Zemel R. Prototypical networks for few-shot learning. Adv Neural Inform Process Syst. 2017.
Livio BS, Nicholas F, Jeffrey L, Tom K. Matching the blanks: distributional similarity for relation learning. ACL. 2019.
Ye Z, Ling Z. Multi-level matching and aggregation network for few-shot relation classification. ACL. 2019.
Gao T, Han X, Liu Z, Sun M. Hybrid attention-based prototypical networks for noisy few-shot relation classification. 2019;6407–14.
Wang K, Liew JH, Zou Y, Zhou D, Feng J. Panet: few-shot image semantic segmentation with prototype alignment. IEEE; 2019.
Gao T, Han X, Zhu H, Liu Z, Li P, Sun M, Zhou J. Fewrel 2.0: towards more challenging few-shot relation classification. EMNLP. 2019;2124–33.
Fan M, Bai Y, Sun M, Li P, Bai Y, Sun M, Li P. Large margin prototypical network for few-shot relation classification with fine-grained features. Assoc Comput Machin. 2019;2353–6.
Wen W, Liu Y, Ouyang C, Lin Q, Chung T. Enhanced prototypical network for few-shot relation extraction-sciencedirect. Inform Process Manage. 2021.
Xiao Y, Jin Y, Hao K. Adaptive prototypical networks with label words and joint representation learning for few-shot relation classification. CoRR. 2021.
Li Z, Ouyang F, Zhou C, He Y, Shen L. Few-shot relation classification research based on prototypical network and causal intervention. IEEE Access. 2022;10:36995–7002.
Funding
This work was supported by the Science and Technology Project of Hebei Education Department under Grant, Nos. QN2021145. Zhongyuanyingcai program-funded to central plains science and technology innovation leading talent program, No. 204200510002.
Author information
Authors and Affiliations
Contributions
HN contributed in writing, methodology of the study and programming. HH and JF assisted with report improvement and review, as well as providing guidance on manuscript drafting. QW and QW assisted with performing the experiments and data collection. All authors examined the results and gave final approval to the manuscript’s final version.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare they have no competing interests.
Consent for publication
The authors hereby consent to publication of the work.
Ethical approval and consent to participate
This article does not contain any studies with animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
He, H., Niu, H., Feng, J. et al. A Prototype Network Enhanced Relation Semantic Representation for Few-shot Relation Extraction. Hum-Cent Intell Syst 3, 1–12 (2023). https://doi.org/10.1007/s44230-022-00012-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s44230-022-00012-0