
Abstract
Understanding the determinants underlying variations in urban health status is important for informing urban design and planning, as well as public health policies. Multiple heterogeneous urban features could modulate the prevalence of diseases across different neighborhoods in cities and across different cities. This study examines heterogeneous features related to socio-demographics, population activity, mobility, and the built environment and their non-linear interactions to examine intra- and inter-city disparity in prevalence of four disease types: obesity, diabetes, cancer, and heart disease. Features related to population activity, mobility, and facility density are obtained from large-scale anonymized mobility data. These features are used in training and testing graph attention network (GAT) models to capture non-linear feature interactions as well as spatial interdependence among neighborhoods. We tested the models in five U.S. cities across the four disease types. The results show that the GAT model can predict the health status of people in neighborhoods based on the top five determinant features. The findings unveil that population activity and built-environment features along with socio-demographic features differentiate the health status of neighborhoods to such a great extent that a GAT model could predict the health status using these features with high performance. The results also show that the model trained on one city can predict health status in another city with high performance, allowing us to quantify the inter-city similarity and discrepancy in health status. The model and findings provide novel approaches and insights for urban designers, planners, and public health officials to better understand and improve health disparities in cities by considering the significant determinant features and their interactions.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Understanding the effects of urban neighborhood factors on residents' health is one critical factor for addressing health disparities in cities. In particular, understanding the extent to which urban features can explain the risk of disease within and across cities is an essential tool for integrated urban design that promotes public health. Previous literature has considered a wide range of determinants of health status, but the majority of existing studies consider only limited types of determinants. For example, (Galiatsatos et al., 2018) examined social-economic determinants to explain the relationship with health outcomes at the neighborhood level. (Subramanian & Kawachi, 2003) examine the association between state income inequality and poor self-rated health. This study compared physician use in Ontario and the midwestern and northeastern United States for persons of different socioeconomic status and health field (Katz et al., 1996). (Mason et al., 2018) reported the connection between high densities of physical activity facilities and lower obesity for adults in mid-life. (Farmer & Ferraro, 2005) examine health disparities between white and black adults and whether the SES/health gradient differs across the two groups in the USA. (Michael et al., 2014) evaluates the effect of a neighborhood-changing intervention on changes in obesity among older women. (Tang et al., 2022) performs principal component regression (PCR) to assess the relationship between the built environment and both self-rated physical health and mental health. (Hasthanasombat & Mascolo, 2019) proposes an approach to link the effects of neighborhood services on citizen health using a technique that attempts to highlight the cause-effect aspects of these relationships. (Wang et al., 2017) links four models to evaluate the effects of both international exports and interprovincial trade on PM pollution and public health across China. Recently, a number of studies have used urban human mobility data as determinants of public health status. (Bauer & Lukowicz, 2012) described a machine learning-based system that estimated well-being measures using geographically aggregated objective and subjective measures gleaned from mobile data in the United Kingdom. (Lai, et al., 2019) reviews relevant work aiming at measuring human mobility and health risk in travelers using mobile geo-positioning data. (Bauer & Lukowicz, 2012) describes the initial results of an ongoing project to use mobile phone sensors to detect stress-related situations. (Canzian & Musolesi, 2015) seeks to answer whether mobile phones can be used to unobtrusively monitor individuals affected by depressive mood disorders by analyzing only their mobility patterns from GPS traces. These early findings motivate a deeper evaluation of the contribution of population activity and mobility features to health disparity in cities.
Another limitation of the existing literature is the lack of consideration of non-linear interactions among features that could modulate the health status of urban neighborhoods. The existing spatial statistics methods assume a linear relationship between features, such as public parks (Liu et al., 2017). Non-linear interactions refer to the way different types of urban features (such as socio-demographic attributes, people's activity and mobility, and built environmental features) influence health outcomes in both directly and also in interaction with other features. These interactions could involve complex relationships where the effect of one variable on health outcomes changes depending on the level of another variable. For example, the impact of green space on physical activity levels may differ based on the socio-economic status of the neighborhood, illustrating a non-linear interaction between these features. Besides, even though spatial models such geographically weighted regression, spatial lag models, and others can address spatial heterogeneity, but they still assume underlying linear relationships among the features or fail to capture the full complexity of the extent to which features interact across different spatial areas. This limitation could be effectively addressed by spatial graph deep-learning techniques which could capture heterogeneous features of neighborhoods as well as their spatial interactions. Also, existing approaches do not provide a quantitative way to examine the similarities and discrepancies in the determinants of health disparities across different cities. The ability to juxtapose the determinants of health disparity across different cities could inform the transferability of urban design and planning strategies across different cities.
Recognizing these gaps, in this study, Graph Attention network model is applied, which can model complex, non-linear interactions among a wide range of urban features at different scales, and also consider the spatial information, which offering a more nuanced understanding of how these features collectively influence health outcomes. we examine features related to the built environment, population activities and mobility, and socio-demographics in training and testing graph attention network (GAT) models which could predict four major preventable threats to public health: obesity, diabetes, cancer, and heart disease. Population activity and human mobility data are collected from commercial location intelligence providers (Spectus and SafeGraph) and contain anonymized and aggregated data related to population visitations to points of interest (POI) as well as micro-mobility characteristics (such as average distance traveled and radius of gyration). In addition to population activity and mobility, we considered built environment features related to the density of facilities in neighborhoods, as well as air pollution and socio-demographic features. The GAT models treat the census tracts as nodes and edges, a construct which represents the spatial adjacency of the census tracts. The models were trained and tested in five U.S. cities across the four disease types. The models trained on a particular city were evaluated in other cities to evaluate the inter-city transferability of urban health determinants. Also, we conducted the GraphLIME method to rank the important features to specify the top five determinant features for each city and disease type. We also performed cross-city comparisons to reveal similarities and discrepancies in determinants of inter-city health disparity.
2 Data collection and data processing
In this study, we focused on metropolitan counties in the United States. The selections were made based on population size, geographic distribution, and dataset availability. First, counties should have a population that is large enough to have intra-city health status variation. Second, the selected counties should be located in different regions in the United States to capture geographic variations. Finally, we chose Cook County (Chicago metro) in Illinois, Wayne County (Detroit metro) in Michigan, Fulton County (Atlanta metro) in Georgia, Suffolk County (Boston metro) in Massachusetts, and Queens County in New York (New York metro). For capturing population activity and mobility features in these counties, we selected the period of February 2020 which represents a steady-state period with no events that could influence population activity and mobility. Since human mobility data for the period before 2019 is either not available or very sparse and, because patterns of population activity and mobility are stable in cities and do not change from year to year, we used the February 2020 data for specifying the features.
Public health data Obesity, Diabetes, Cancer, Heart Disease
Public health data were collected from CDC (the Centers for Disease Control and Prevention). The dataset contains all United States at county, place, census tract, and ZIP Code Tabulation Area (ZCTA) levels. The dataset includes 29 health measures: 4 chronic disease health risk behaviors, 13 health outcomes, 3 health status, and 9 on preventive services. This study uses the data at the census tract (CT) level and used the four most common health conditions as dependent variables: obesity, diabetes, cancer, and heart disease. All health conditions were captured for adults aged older than 18 years in each census tract: obesity rate, percentage of diagnosed diabetes, percentage of cancer (excluding skin cancer), and percentage of coronary heart disease. The latest public health data released in 2021 is based upon 2019 Behavior Risk Factor Surveillance System (BRFSS) data (Behavioral Risk Factor Surveillance System, 2020). In this study, health outcomes were stratified into four distinct categories based on uniform quartile distribution: the 25th percentile, the 50th percentile, and the 75th percentile. Such stratification facilitates the classification of each census tract into four levels of health outcome prevalence, ranging from level 1 (indicating the lowest disease prevalence) to level 4 (indicating the highest disease prevalence). The adoption of quartile categorization for health outcomes ensures that each category distinctly represents a distinct level of disease prevelance, thereby offering a statistically significant and coherent overview of health outcomes across the demographic spectrum. The utilization of quantiles serves as an efficacious strategy for mitigating the impact of outliers and skewed distributions, which frequently occur in health data due to the variable prevalence of diseases. A critical analysis of the balance between granularity and simplicity led to the conclusion that the delineation of five or more clusters would render the analysis and interpretation overly complex without providing additional significant insights. Conversely, a reduction to fewer clusters (e.g., four) would result in an oversimplification of the data, potentially concealing critical distinctions between distinct population segments. Therefore, a four-cluster approach is deemed optimal for ensuring that findings are both insightful and readily interpretable.
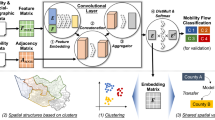
Figure 1 illustrates an overview of the feature groups considered in this study. We extracted these health status features for each city at the census tract (CT) level. In addition to population activity and mobility features as inputs, we also considered features related to the built environment, environmental air pollution, and socio-demographics as reported in the literature. In particular, we considered the density of types of POIs in census tracts, as the density of POIs has been shown to have effects on health status. For example, (Galiatsatos et al., 2018) reported the relationship between social-economic status, tobacco store density, and health outcomes at the neighborhood level in a large urban community, and (Mason et al., 2018) shows strong associations between high densities of physical activity facilities and lower obesity for adults in mid-life. (Hasthanasombat & Mascolo, 2019) discussed the effect of the number of sports facilities on health status. (Horn, et al., 2021) revealed the relationship between the fast-food environment and health status. which gives us some ideas to explore some other common facilities that could affect health status. Unlike these papers just find the effect of the neighborhood areas. Based on the existing literature, we define various features obtained from different datasets as inputs to our models (Table 1).

Illustration of the analytical framework. The framework comprises two components: (1) feature groups and labels, and (2) training and testing process and three other analyses. The upper part of the figure is a schematic overview of feature groups and labels. The features and labels were collected at the census tract level. Each health status is labeled by the extent level. The lower part of the figure shows the training and testing process and three other analyses. (1) Using the trained GAT model to classify the extent of four health outcomes among five counties. (2) We used GraphLIME to identify the top five important determinants through input features and predicted classification results. (3) Analyze the model similarity across different counties by applying the original model and the transfer model
Socio-Demographic Age, Income, Minority
The socio-demographic data were retrieved from American Community Survey database administrated by (US Census Bureau, 2020). Age represents the percentage of people older than 65. Income stands for household income. Minority captures the percentage of minorities; Here minority groups refer to African Americans, American Indians, Alaska Natives, Asians, Native Hawaiian, and other Pacific Islanders.
POI density N(grocery), N(health), N(restaurant), N(rec)
The enumeration of Point of Interest (POI) establishments within each census tract (CT) was executed through the utilization of the SafeGraph POI dataset (SafeGraph, 2020). The SafeGraph dataset provides the geographical coordinates and NAICS (North American Industry Classification System) codes corresponding to the POIs. It is updated on a monthly basis, ensuring that any alterations such as the opening or closure of stores are promptly reflected. For the purposes of this study, the SafeGraph dataset was acquired in February 2020, thereby encompassing all pertinent updates for the year 2019. By cross-referencing the NAICS codes assigned to each POI, it becomes feasible to categorize them accordingly. A pre-established NAICS code table (as depicted in Table SI-1 of the supplemental information) facilitates this categorization process. Specifically, our analysis centered on four primary POI categories: grocery facilities, health facilities, restaurants, and recreation centers. Subsequently, leveraging the spatial geometry data, each POI was allocated to its respective Census Tract (CT).
Air pollution Emission
We used PM 2.5 emission data, a measure of particulate matter, released by Centers for Disease Control and Prevention (CDC). The dataset provides modeled predictions of PM 2.5 levels. It contains an estimated mean predicted concentration at the census tract (CT) level.
Micro-mobility CT_Avg_Time, CT_Avg_Trips, CT_Avg_Distance, CT_Avg_ROG
All measurements of micro-mobility are made at the level of individual residents of a census tract. The micro-mobility dataset is derived from visitation metrics supplied by Spectus. These primary visitation statistics encompass identifiers (cuebiq id), dwell time, dates, times, and the spatial information of the destinations. Within this dataset, each 'cuebiq id' represents a distinct individual, with 'dwell time' documenting the duration of stay for each trajectory. The inclusion of date and time stamps provides insights into the timing of these movements, whereas the spatial data elucidates the geographical positioning of destinations, enabling the identification of the corresponding census tract. By arranging the data sequentially according to 'cuebiq id', date, and time, it is possible to reconstruct the ordered trajectories undertaken by each individual.
Furthermore, the dataset incorporates variables such as CT_Avg_Time, which denotes the average duration of travel to destinations within each census tract; CT_Avg_Trips, reflecting the mean number of visits to each census tract; and CT_Avg_Distance, indicating the average journey length across tracts which can be calculated by the geometry information across different destinations. Additionally, CT_Avg_ROG (Radius of Gyration) is employed to gauge the scope of mobility within these areas. The Radius of Gyration serves as a quantitative measure of human mobility, calculated through a specified equation. Selection criteria for participants include those whose centroid falls within a census tract, thereby representing the mobility characteristics of that tract. It can be calculated by the following equations:
where \({p}_{i}\) is the ith position for the specific person, p_centroid is the central position of the people according to his moving trajectories. M is the number of trips completed by a user. N is the number of users in this census tract.
Visitation features V(grocery), V(health), V(restaurant), V(rec)
Furthermore, in addition to the micro-mobility characteristics, the frequency of visits to each facility can be indicative of the health status within a given area. To standardize these visitations, we normalized them by dividing the total visits by the population count of the respective census tract, thereby mitigating the influence of varying population sizes across tracts. Consequently, these adjusted visitations to different types of Point of Interest (POI) facilities constitute another set of population activity features.
The visitation data primarily originates from the dataset provided by the location intelligence firm, Spectus. Spectus aggregates data from approximately 15 million daily active cell phone users across the United States. Notably, data points equipped with highly precise GPS information offer insights into travelers' routes and destinations. This accuracy is instrumental in delineating detailed visitation patterns. Spectus's primary database is constructed from data gathered by third-party applications, which acquire cell phone location data with user consent. On a daily basis, these applications collect over 100 data points per individual. Each POI in the database is associated with the coordinates of longitude and latitude corresponding to its location. Importantly, Spectus anonymizes location data to safeguard user privacy.
To ascertain human visitation to POI facilities, the process necessitated identifying the home location of each anonymous user at the census-tract level. Human residence data were extracted from the device table within the core Spectus database. A location was designated as an individual's home if their recorded stay duration exceeded 12 h. Subsequently, Spectus's stop table was utilized to delineate the visitation patterns for each anonymous device ID. Stops are registered in the dataset when individuals remain at a location for a significant duration, providing information such as the stop's location coordinates, date, and time. Given the absence of NAICS code information within the Spectus dataset to differentiate the types of POIs, we augmented the dataset with information from SafeGraph. As previously stated, SafeGraph data comprises NAICS codes and polygonal data for each POI. By leveraging location coordinates as reference keys, the polygonal data from Spectus and the poi information from SafeGraph were merged, which will add the NAICS code information into each stop point. It enables us to tag each visited POI with a unique NAICS code. Subsequently, for users residing in each census tract, weekly visits to each POI were aggregated.
Both the micro-mobility and visitation features were computed utilizing data from February 2020. This choice of timeframe is deliberate, as it represents the most recent period prior to the onset of the COVID-19 pandemic in the United States. Given that the emergence of COVID-19 occurred after March 2020, the temporal lag between the data collection period and the pandemic's onset ensures minimal influence on the analysis. Notably, urban mobility patterns exhibit relatively stable characteristics from year to year preceding the COVID-19 pandemic, thus mitigating the impact of temporal disparities on the analytical outcomes.
Active index
The active index is calculated using the following equation:
Here, i is the ith census tract. In_degree is the number of users who visit this census tract. Out_degree is the number of users who leave this census tract. The active index is calculated by the normalized human flows. A larger active index indicates that the census tract is more active.
3 Method
3.1 GAT
The graph attention network model (Velickovic, et al., 2017) is a novel approach to processing graph-structured data by neural networks, leverages attention over a node's neighborhood. GAT is shown to achieve state-of-the-art results on various networked data, such as transudative citation network tasks and an inductive protein–protein interaction task. In this study, GATs utilize the spatial information of the node directly during the learning process. In this analysis, the node is a vector of features for each Census Tract, the link is the connection if two Census Tracts are neighboring (spatial adjacency). The first step performed by the graph attention layer is to apply a linear transformation-Weighted matrix W to the feature vectors of the nodes to compute the attention coefficients \({{\text{e}}}_{{\text{ij}}}\). It indicates the importance of node j’s features to node i. \({{\text{h}}}_{{\text{i}}}\) is a set of node features for node i, \({{\text{h}}}_{{\text{j}}}\) is a set of node features for node j.
Due to the complicated connections between nodes, each node may have a different number of neighbors. To keep the same scale across all neighbors, the attention coefficients need to be normalized by using the softmax function and then activated by a non-linear activate function LeakyReLU function, where \({N}_{i}\) is the number of neighborhoods of node i.
In this way, the new node’s features can be represented by:
To improve the stability of the learning process, multi-head attention is employed. We computed multiple different attention maps and finally aggregated all the learned representations on one node, where K is the number of independent attention maps used:
Initially, each node's features are linearly transformed using a shared weight matrix. This step is crucial for embedding the features into a space where relationships between them can be more effectively captured, serving as a foundation for modeling non-linear interactions. The core of GAT's ability to handle non-linear interactions lies in its attention mechanism. For each node, the model computes attention coefficients with all its neighbors, including itself. These coefficients indicate the importance or relevance of a neighbor's features to the given node. The attention function is typically a single-layer feedforward neural network, applying a non-linear activation (like LeakyReLU) to the concatenated features of the node pair. This mechanism allows the model to dynamically prioritize certain nodes over others based on their feature relationships, capturing non-linearity in the process. After computing the attention coefficients, GAT aggregates the neighbors' features for each node, weighted by the computed attention scores. This weighted sum ensures that more relevant features have a greater influence on the node’s new feature representation, inherently modeling the non- linear interactions between the node and its neighbors. GAT often employs multi-head attention, where multiple independent attention mechanisms process the inputs simultaneously. The results from these heads can be concatenated or averaged, leading to more stable and rich representations. This ensemble-like approach allows the model to capture different aspects of non-linear interactions among features from various perspectives. Finally, non-linear activation functions (LeakyReLU) can be applied to the aggregated feature representations. This step is essential for introducing non-linearity into the model, allowing it to learn complex patterns and relationships in the data beyond what linear models could capture.
3.2 GraphLIME
An important step in adopting deep learning models for urban design and planning purposes is to ensure that models are sufficiently explainable to inform plans and decisions about the importance of different features. In this study, we adopt GraphLIME as an instrumental role for specifying the features’ importance in the models. (Huang, 2022) proposed GraphLIME, a local interpretable model for graphs using the Hilbert–Schmidt Independence Criterion (HSIC) Lasso (Climente-Gonzalez et al., 2019). Unlike some methods that aim to explain model behavior globally, GraphLIME focuses on providing explanations for individual predictions. It seeks to answer why a model made a specific prediction for a specific node in a graph. It captures non-linear relationships between features and predictions, using a local surrogate model that approximates the behavior of the complex GNN model in the vicinity of the node being explained. First, we identify the target node for which we want to generate an explanation regarding the model's prediction. Second, for the selected node, we identify a set of neighboring nodes that influence its prediction. Third, the analysis extracts the feature vectors of the selected neighboring nodes. Given that node features in graphs can be high-dimensional, GraphLIME applies a dimensionality reduction technique, often using techniques like Hilbert–Schmidt Independence Criterion (HSIC) Lasso, to select a subset of features that are most relevant for explaining the prediction locally. Forth, with the reduced feature set, the analysis trains a simple, interpretable model (the surrogate) to approximate the predictions of the original complex GNN for the target node and its neighbors. Decision trees are common choices for the surrogate model, as they provide clear insight into how input features relate to the output. Finally, the analysis uses the surrogate model to interpret the contribution of each selected feature to the prediction of the target node.
In this study, we focus primarily on the top five features, this focus was informed by our reliminary analysis, which indicated that these features stood out in terms of their importance scores, suggesting a stronger influence on health status predictions. By narrowing our examination to these top features, we aimed to provide a more in-depth and meaningful analysis of the most influential factors affecting health status, rather than diluting our insights across a broader but potentially less impactful feature set. Accordingly, we examine whether population activity and mobility features are among the most important. The rationale behind our specific interest in population activity and mobility features stems from their potential relevance to public health outcomes and their limited consideration in the existing literature. Recent studies have highlighted the extent to which changes in population activity features shape health trends within populations (Bauer & Lukowicz, 2012) (Lai, et al., 2019) (Canzian & Musolesi, 2015). By investigating whether these features rank among the most important, our study seeks to contribute to the understanding of how mobility and activity patterns can be significant predictors of health status in the context of GAT models.
3.3 Cross-county similarity
To understand the extent to which the health determinants identified in one urban area are universal across other cities, this study employs a unique approach using Graph Attention Network (GAT) models. For each studied county, we create a GAT model to identify key predictors of health issues like obesity, diabetes, cancer, and heart disease. The method is to see if these models, when trained with data from one city, can accurately predict the health outcomes in different cities. We do this by comparing how well the models perform when applied to different cities (i.e., model transferability analysis), by evaluating both model performances using F-1 score or how their predictions match the actual spatial distribution of these outcomes in the new settings. This approach helps us tease apart which health determinants are universal and which are specific to certain urban environments, guiding the development of health interventions and urban planning efforts that can be adapted to different cities.
4 Results
In this section, we present the results of multiple experiments to answer the following research questions: 1) to what extent population activity, human mobility, built environments, and air pollution features can predict the status of urban-scale health? 2) what is the importance of population activity and mobility features in predicting the health status of neighborhoods across the four diseases? 3) to what extent do models trained in one city could transfer to other cities to inform about the transferability of urban design and plans to promote urban health?
4.1 Prediction performance
In this study, we gave each census tract a label indicating the extent of disease prevalence, with level 1 indicating the lowest percentage, and level 4, the highest. With the labels and input features, we trained the GAT model with all node features and complete adjacency matrix, but randomly chose 70% of the nodes as a training set for the supervised learning. In addition, to keep the robustness of the model, we use fivefold cross validation technique. We set four hyperparameters in total: the number of hidden layers, the number of heads, the number of epochs, and the learning rate. The number of hidden layers and the number of heads can enrich the model capacity and stabilize the learning process. The learning rate controls how quickly the model adapts to the problem. We tuned these hyperparameters of the model: hidden layers (5, 10, 15), heads (3, 4, 5), and learning rate (0.025, 0.05). We use the F-1 score to measure the model performance, which considers both precision and recall of the testing set, Precision is the number of correct positive results divided by the number of all positive results, and recall is the number of correct positive results divided by the number of positive results that should have been returned. The F1 score can be understood as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 (perfect precision and recall) and worst at 0. Taking the example of Wayne County, for each disease type, we classified the census tracts into four clusters by their quantiles. Figure 2(a) shows the process of training and the improvement across the epochs for all nodes. The x-axis is the number of epochs; the y-axis is the F-1 score. We can see from the figure that models with different hyperparameter sets converged to the highest F-1 score at different speeds. F-1 score across epochs in different hyperparameter sets was greater than 0.6. Figure 2b gives an example of classification results for the obesity rate in Wayne County by the confusion matrix. Each cell on the diagonal shows the accuracy on the test set for each class. As shown in the figure, the GAT model has a good performance; clusters 1, cluster 3, and cluster 4 have an accuracy greater than 0.8. Even though the performance for cluster 3 lacks the accuracy of the other clusters. The model can still predict more than half of the nodes precisely. By observing F-1 score in different hyperparameter sets, we chose the hyperparameter sets that show the highest for our model. In this way, the extent of health status by using the defined feature groups can be quantified.

F-1 score for obesity in Wayne County between different hyperparametric sets. a. Results of F-1 score across 1000 epochs for 12 different hyperparameter sets. It indicates that the GAT model has a good performance by using defined feature groups to predict different health statuses. b. The confusion matrix. (The model used here is selected with the highest F-1 score according to a.)
Table 2 summarizes the model performance in counties across four health statuses. Even while some F-1 score is less than 0.6, the majority of them are greater than 0.6, which further demonstrates how successfully the input features combined with their non-linear relationships to predict the four main diseases at the census-tract level.
4.2 Feature analysis
In the next step, we examined the importance of features in predicting the health status across different diseases to examine whether population activity and human mobility features are among the top features. We first trained the model by using each single feature group as input separately. We used the aforementioned hyperparameter set to train the model. The outcomes of predicting obesity across five counties are shown in Table 3. (The outcomes related to other health statuses can be found in the supplemental information (Tables SI-2, SI-3, and S-4). We found that the performance of the models using some single-feature groups, such as the POI density feature in Fulton County for obesity, even outperforms than using all features in predicting health status; however, the difference is not significant and the models with more features provide better explainability about features to inform urban design and planning to promote urban health. We also notice that in most cases among four diseases, models with socio-demographic features result in the best performance. This result confirms health disparity in urban areas. Evaluating disease prevalence based on sociodemographic data, however, provides limited insights for urban design and planning to promote urban health. The differences between the best feature groups in predicting health statuses motivated us to explore the combination of features in different feature groups as input features, but to focus on more than a single feature group, so that the models and their feature importance can inform urban design and planning to promote urban health.
In the next step, we used GraphLIME as a method to provide a deep insight into feature importance in the prediction results. Generally speaking, each node (census tract) gives us a list of ranked features according to its contribution weight. Aggregating the contribution weight by all nodes in one county gives the overall feature importance. Fig. 3(a-d) show examples of feature importance for Wayne County regarding obesity. The x-axis is the contribution weight for prediction; the y-axis shows the name of the features. Each box includes 601 aggregated nodes, which is the number of census tracts in Wayne County. Figure 3 depicts the ranked feature importance for obesity. We can see the top five features are the percentage of people older than 65, the percentage of minorities, the total income, radius of gyration, and the number of restaurants in census tracts. This result shows that some population activity and mobility features are among the most important factors alongside socio-demographic features.

Feature importance in different disease types in Wayne County: (a) obesity, (b) diabetes, (c) cancer, and (d) heart disease. Each box shows the median and variation of contribution weight. The importance of features in each health status is sorted from largest to smallest
By picking the top five important features to predict health status, model performance is very close to using all features as input. We can conclude that the top five features are enough to depict health status (see supplemental information, Table SI-5). By seeing Table 4, for obesity, we can observe that the minority feature is an important feature in all counties. This indicates that there exists a very strong relationship between the percentage of minorities and obesity, which is an evidence of health inequality for racial minorities in terms of obesity. Total income appears as an important feature in models of four counties, percentage of emissions, and active index appear in models of three counties. When we add the emission feature to the other top five features for each model, the model prediction improves. This result indicates that there is a strong relationship between emission and other top five features in predicting health status. Except for these features, the number of grocery stores and the number of recreation centers (such as gyms) appear twice in the models. CBG_Avg_Trips and CBG_Avg_ROG just show up once among the top five important features across all models. These results show the importance of socio-demographic features and the built environment features (number of certain POIs) in predicting obesity.
For diabetes, the percentage of minorities is an important feature in all five counties. The percentage of people older than 65 and total income appears four times in the top five features. Visits to health facilities, number of grocery stores, and active index appear twice. Visits to recreational centers, the number of recreational centers, the number of restaurants, emission, CBG_Avg_Time appears only once. Based on the result, minority, income, age, visits to health facilities, number of grocery stores, and active index are the most important features in predicting diabetes prevalence. CBG_Avg_Time, emission, the number of grocery stores, the number of restaurants, and visits to recreation centers are not major features in predicting diabetes. Compared with obesity, except for the socio-demographic features, visits to health facilities become more important, and emissions become less important. This result is intuitive as areas with more prevalence of diabetes would have a greater number of visits to health facilities since diabetes is known to exacerbate other health conditions.
For cancer, the number of minorities is the most important feature in all five counties. Total income and number of grocery stores appear four times. The active index shows up three times. Emissions, the number of recreational centers, and the percentage of people older than 65 appear twice. Visits to restaurants, visits to health facilities, and CBG_Avg_ROG only appear once. Based on these results, minority, income, number of grocery stores, active index, age, emissions, number of grocery stores, and number of recreation centers are the important features in predicting cancer. Different from the other disease types, the density of POIs is shown to be an important determinant in the prevalence of cancer across urban areas.
For heart disease, the percentage of minorities is still the most important feature. The total income and the percentage of people older than 65 appear four times. Emissions appears three times. Visits to grocery stores and active index show up twice. Visits to health facilities, recreation centers, and restaurants, the number of recreation centers, CBG_Avg_ROG just appears once. Based on the result, the percentage of minorities, the total income, age, emission, visits to grocery stores, and active index are important features in predicting heart disease. Health research has shown the significance of diet for heart disease. Visits to grocery stores could capture aspects of people’s diet patterns. It is noteworthy to find visits to grocery stores among the top five important features for heart disease prediction.
In conclusion, the interactions among minority, age, income, POI density and POI visitations provide reliable predictions for all four disease types. The visitation features are more important in predicting diabetes and heart disease. For cancer, except for socio-demographic features, POI density is an important determinant for improving prediction performance. In addition, we also found that compared with other disease types, the model performance of obesity is the highest, and the distribution of important features is very concentrated, basically gathered in socio-demographic and POI density. For heart disease, the model performance of the model is the lowest, and the distribution of important features is very scattered, basically involving all feature groups.
4.3 Cross-county similarity of determinants among health status
Till now, we have illustrated that we can use socio-demographic population activity, human mobility, built environments, and air pollution features to predict urban-scale health status. Also, we have found the top five significant features for each health status for different counties. What if just one model were used, and the chosen top five features developed in one city applied to multiple cities? It is apparent that health status in different cities has distinct determinants. Nevertheless, this might be different in high-dimensional space, which can capture a more complex structure among the determinants of health status. Identifying the similarities of the determinants of health status is useful for examining the transferability of urban design and planning strategies that promote urban health across different cities. As shown above, the GAT model can capture complex non-linear relationships with different features with different health status between cities, which prompts us to explore the similarity of the top five determinants in different health status among different cities by implementing the original model and the transfer model.
First, we compared the spatial distributions of the clusters by using the original model and the transfer model. Figure 4 depicts some examples of spatial distribution of obesity by implementing the original model and the transfer model for different disease types. For instance, as shown in Fig. 4(a), the original model was trained in Wayne County, and the transfer model was trained in Queens County. We can find that the majority of the pairs of areas are assigned in the same clusters for Wayne County. The lower rate of obese people is clustered in the south and northwest parts, while the higher rate of obesity is in the northeast part of Wayne County. Similarly, the results shown in Fig. 4 (b) indicate that most pairs of areas are assigned in the same clusters. However, in Fig. 4(c), we can find some different spatial distributions in the south and the northwest part of Cook County. In this case, the Queens County model does not share similar health status determinants with Cook County according to the spatial distribution plot. The same results can be observed in Fig. 4(d). Since the geographical structures differ significantly by using the original model and transfer model, it would be impractical to apply the same policies from Queens County to Cook County. These findings also encourage us to determine the degree to which the geographical structures of other counties are comparable.

Geospatial and Statistical Analysis of Health Outcomes Across Various Counties (a) Geospatial classification of obesity prevalence in Wayne County, using a locally developed model, contrasted with results from a model transferred from Queens County. (b) Mapping of diabetes prevalence in Queens County, using a native model, alongside outcomes from a Suffolk County model applied to Queens County. (c) Visual representation of cancer prevalence in Cook County, based on a local model and a model adapted from Queens County. (d) Obesity prevalence in Suffolk County depicted through the application of a Suffolk-specific model, with comparison to a model imported from Queens County. (e) Box plots representing the predictive F-1 score of transferred models for various health conditions (obesity, diabetes, cancer, heart disease) across five counties. The central line indicates the median F-1 score, while the box denotes the interquartile range
Next, we explored quantifying the degree of similarity among cities in terms of different health statuses. As mentioned in the Method section, we first trained a GAT model in one county, for example, Cook County, until the model performance reaches the criteria requirements. This GAT model will be defined as a transfer model and later applied to the other four counties. We use the F-1 score of the transfer model to measure the extent of cross-county determinants similarity. In this way, we have four values in each box, each value representing the transfer model performance in the other four counties. Figure 4(e) provides strong evidence that the cross-county model can capture the complex non-linear relationships among the determinant features in predicting health status with more than 50% accuracy. In other words, cities have 50% to 70% similarity in terms of the top five feature determinants predicting obesity and diabetes rate, 45% to 60% similarity for cancer, and 40% to 55% similarity for heart disease. Among all disease types, obesity shares the most similarity in terms of the determinants across the five-county model, and heart disease has the least similarity. At the county level, Suffolk County shares a large number of similarities with other counties regarding obesity, diabetes, and heart disease. Fulton County shares a number of similarities with other counties for cancer. These results may be influenced by the selection of counties in our study and may change with the addition of more counties. In conclusion, the results show the capability of the proposed method to explore cross-county similarities in examining the determinants of urban health disparity in high dimensional space. Besides, the transfer model could provide a comparison regarding the extent of similarities and differences in the determinants of health status among different cities.
5 Discussion
In this study, we presented a graph deep learning approach for unveiling the determinants of urban health disparities. The findings of this study show that the combination of socio-demographic, POI density, and population activity features and their interactions are the main determinants in predicting the prevalence of obesity, diabetes, cancer, and heart disease. The results also show population activity features (point of interest visitation) are more important in predicting diabetes and heart disease, and POI density is an important feature for cancer prediction. Finally, the results related to the assessment of cross-city transferability show that, to a great extent, the core determinants of four disease types are similar; a model trained in one city can predict the spatial structure of disease prevalence in other cities.
This study presented in this paper provides important advancements in the way urban health disparity is examined. First, departing from the existing studies, which focus primarily on socio-demographic and environmental exposure features, our model captures heterogeneous features related to population activity and mobility, as well as POI facility density to specify the extent to which these urban characteristics contribute to the prediction of major disease types. Second, the GAT model provides a novel approach for examining urban health disparities as an emergent property arising from interaction among various heterogeneous urban features. Third, the approach used in this study provides a quantitative way to compare urban health disparity and the similarity of important determinants across different cities. Such quantitative approach is essential for evaluating the transferability of urban design and planning strategies, as well as public health policies across different cities. Through these advancements, the model and results presented in this study enable more integrated urban design strategies to promote health equity in cities. For example, the results of this study could inform urban design policies related to facility distribution and facility visitation as they are shown to be among the important determinants of disease prevalence. Broadly, this study contributes to the growing field of urban artificial intelligence (urban AI) for integrated urban design.
Some limitations within this study, which would need to be overcome in the future. First, additional urban features could be considered in the models. In this study, we focused on features related to population activity and POI facility density, since there was a dearth of studies examining these features and their contribution to urban health status. Future studies can expand the type and number of features to enhance the model presented in this paper. Second, the explainability of graph deep learning models is still a technical challenge to be solved. We used the state-of-the-art method of GraphLIME to specify feature importance. However, GraphLIME cannot specify the important feature interactions Our analysis also considers the feature interaction when revealing the feature importance. While GraphLIME excels at identifying important features for individual predictions, its ability to capture complex interactions between these features is limited because it treats features independently during the explanation generation process. The primary utility of GraphLIME is to identify which features of a node and its neighborhood are most influential for the model's prediction concerning that node. This can include identifying the importance of specific node features or the roles of neighboring nodes. However, GraphLIME itself is focused more on highlighting the importance or contribution of features to the model's prediction rather than directly determining the sign (positive or negative impact) of each feature. It would be very challenging to explain what the feature sign and its relation to the health status. With further advancements in the field of explainable graph deep learning, future studies could further examine the sign of determinants of urban health status and specify the important feature interactions to inform policies. Third, during the process of model training, we found that performance would be improved if the urban area had more nodes, in other words, more census tracts. Future research should focus on collecting data with a larger sample of census tracts. Future studies can include linear spatial model like Geographically Weighted Regression (GWR) and Spatial Lag Models (SLM) to compare with GAT model to reveal the differences between linear and non-linear model.
Availability of data and materials
The data that support the findings of this study are available from SafeGraph and Spectus, but restrictions apply to the availability of these data, which were used under license for the current study. The data can be accessed upon request submitted to the data provides. Other data we use in this study are all publicly available.
References
Bauer, G., & Lukowicz, P. (2012). Can smartphones detect stress-related changes in the behaviour of individuals? In 2012 IEEE International Conference on Pervasive Computing and Communications Workshops (pp. 423–426) IEEE.
Behavioral Risk Factor Surveillance System. (2020). Available from: https://www.cdc.gov/brfss/index.html.
Canzian, L., & Musolesi, M. (2015). Trajectories of depression: unobtrusive monitoring of depressive states by means of smartphone mobility traces analysis. In Proceedings of the 2015 ACM international joint conference on pervasive and ubiquitous computing (pp. 1293–1304)
Climente-Gonzalez, H., et al. (2019). Block HSIC Lasso: Model-free biomarker detection for ultra-high dimensional data. Bioinformatics, 35(14), i427–i435.
Farmer, M. M., & Ferraro, K. F. (2005). Are racial disparities in health conditional on socioeconomic status? Social Science & Medicine, 60(1), 191–204.
Galiatsatos, P., et al. (2018). Neighbourhood characteristics and health outcomes: Evaluating the association between socioeconomic status, tobacco store density and health outcomes in Baltimore City. Tobacco Control, 27(e1), e19–e24.
Hasthanasombat, A., & Mascolo, C. (2019). Understanding the Effects of the Neighbourhood Built Environment on Public Health with Open Data. In The World Wide Web Conference (pp. 648–658)
Horn, A. L., et al. (2021). Investigating mobility-based fast food outlet visits as indicators of dietary intake and diet-related disease. medRxiv.
Huang, Q., et al. (2022). GraphLIME: Local Interpretable Model Explanations for Graph Neural Networks. IEEE Transactions on Knowledge and Data Engineering (pp. 1–6)
Katz, S. J., Hofer, T. P., & Manning, W. G. (1996). Physician use in Ontario and the United States: The impact of socioeconomic status and health status. American Journal of Public Health, 86(4), 520–524.
Lai, S., et al. (2019). Measuring mobility, disease connectivity and individual risk: a review of using mobile phone data and mHealth for travel medicine. Journal of Travel Medicine, 26(3), p.taz019.
Liu, H., et al. (2017). The relationships between urban parks, residents’ physical activity, and mental health benefits: A case study from Beijing. China. J Environ Manage. 190, 223–230.
Mason, K. E., Pearce, N., & Cummins, S. (2018). Associations between fast food and physical activity environments and adiposity in mid-life: Cross-sectional, observational evidence from UK Biobank. The Lancet Public Health, 3(1), e24–e33.
Michael, Y. L., et al. (2014). Does change in the neighborhood environment prevent obesity in older women? Social Science & Medicine, 102, 129–137.
Subramanian, S. V., & Kawachi, I. (2003). The association between state income inequality and worse health is not confounded by race. International Journal of Epidemiology, 32(6), 1022–1028.
Tang, J., et al. (2022). The Effect of Built Environment on Physical Health and Mental Health of Adults: A Nationwide Cross-Sectional Study in China. International Journal of Environmental Research and Public Health, 19(11), 6492.
United States Census Bureau. (2020). Available from: https://data.census.gov/cedsci/.
Wang, H., et al. (2017). Trade-driven relocation of air pollution and health impacts in China. Nature Communications, 8(1), 738.
Velickovic, Petar, et al. (2017). Graph attention networks. stat 1050.20 (2017): 10–48550.
SafeGraph, SafeGraph (2020).
Acknowledgements
The authors also would like to acknowledge that Spectus and SafeGraph provided mobility and population activity data. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of Texas A&M University, Spectus, and SafeGraph.
Code availability
The code that supports the findings of this study is available from the corresponding author upon request.
Funding
This material is based in part upon work supported by Texas A&M University X-Grant 699.
Author information
Authors and Affiliations
Contributions
C.L and A.M designed research; A.M and C.L collected data; C.L analyzed data; C.L, A.M and C.F wrote and revised the paper.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
This article does not contain any studies with human participants performed by any of the authors.
Consent for publication
The author has given the informed consent to publish this article in Urban Informatics if accepted.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, C., Fan, C. & Mostafavi, A. Graph attention networks unveil determinants of intra- and inter-city health disparity. Urban Info 3, 18 (2024). https://doi.org/10.1007/s44212-024-00049-5
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44212-024-00049-5