
Abstract
In this paper we consider a new class of asymmetric logistic distribution that contains both the type I and type II generalized logistic distributions of Balakrishnan and Leung (Commun Stat Simul Comput 17(1):25–50, 1988) as its special cases. We investigate some important properties of the distribution such as expressions for its mean, variance, characteristic function, measure of skewness and kurtosis, entropy etc. along with the distribution of its order statistics. A location-scale extension of the distribution is defined and discussed the maximum likelihood estimation of its parameters. Further, two real life medical data sets are utilized for illustrating the usefulness of the model and a simulation study is conducted for examining the performance of the maximum likelihood estimators of the parameters of the distribution.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The logistic distribution has been found several applications in various fields such as public health (Grizzle [8]), survival analysis (Plackett [13]), biology (Pearl and Reed [12]), bioassay problems (Berkson [3,4,5]) etc. For a detailed account of properties and applications of various forms of logistic distributions, refer Balakrishnan [1]. Several generalised distributions have been studied in the literature. Balakrishnan and Leung [2] studied three types of generalized logistic distributions. Wahed and Ali [18] introduced the skew logistic distribution (SLD). An extension of SLD was proposed by Nadarajah [11]. A flexible class of skew logistic distribution was studied by Kumar and Manju [10].
A continuous random variable X is said to have the standard logistic distribution (LD) if its probability density function (PDF) is of the following form, for \(x\in R=\left( -\infty ,+\infty \right)\).
The cumulative distribution function (CDF), \(F_{1}(.)\) of the LD is
for \(x\in\) R. Balakrishnan and Leung [2] introduced and studied two generalized classes of logistic distributions namely the generalized logistic distribution of type I \((denoted\; by \;LD_{I})\) and type II \((denoted\; by\; LD_{II})\) respectively through the following PDFs \(f_2 \left( {.} \right)\) and \(f_3 \left( {.} \right)\), for \(x\in R\), \(\alpha > 0\) and \(\beta >0\).
The CDFs corresponds to the \(LD_{I}\) and the \(LD_{II}\) are respectively
and
Clearly, when \(\alpha =\beta =1\) in (5), the CDF of \(LD_{I}\) reduces to that of the LD and when \(\alpha =1\) in (6), the CDF of \(LD_{II}\) reduces to that of the LD. Both these classes of distributions have applications in several areas of scientific research. Through the present paper we attempt to unify both these classes of distributions and termed it as “the gamma generalized logistic distribution (GGLD)”, which is not available any where in the existing literature . The objective of the present work is to develop a more flexible class of distribution which can handle asymmetric distributions and derive some of its important properties. The paper is organized as follows. In Sect. 2, we present the definition of the GGLD and describe some important properties. A location scale extension of the GGLD is considered in Sect. 3 and in Sect. 4, two real life medical data sets are considered for illustrating the usefulness of the model compared to the LD, \(LD_{I}\) and \(LD_{II}\). In Sect. 5, a generalized likelihood ratio test procedure is suggested for testing the significance of the parameters of the GGLD and a simulation study is conducted to test the efficiency of the maximum likelihood estimators (MLEs) of the distribution in Sect. 6 . We have the following representations from Gradshteyn and Ryzhik [7] , those we need in the sequel.
-
(i)
For \({Re (\mu )\; > - 1},\)
$$\begin{aligned} \quad \int \limits _0^1 {x^{\mu - 1} \ln \left( {1 - x} \right) } dx =- \frac{1}{\mu }\left[ {\psi \left( {\mu + 1} \right) -\psi (1)} \right] =- \frac{1}{\mu }\left[ {\psi \left( {\mu + 1} \right) +C} \right] , \end{aligned}$$(7)in which \(\Psi \left( a \right) = \frac{{d\log \Gamma a}}{{da}}\) and C is the Euler’s constant.
-
(ii)
For \(u^2 < 1,\)
$$\begin{aligned} \left[ {\ln \left( {1 - u} \right) } \right] ^2 =2 \sum \limits _{j = 1}^\infty {\frac{{ u^{j + 1} }}{{j + 1}}} \sum \limits _{i = 1}^j {\frac{1}{i}} \end{aligned}$$(8)
2 Definition and Properties
In this section, first we present the definition of the GGLD and discuss some of its important properties. A continuous random variable X is said to follow gamma generalized logistic distribution if its CDF is of the following form, in which \(x\in R\) , \(\alpha > 0\), \(\gamma > 0\) and \(\beta > 0\).
On differentiating (9) with respect to x, we have the probability density function (PDF) of GGLD as
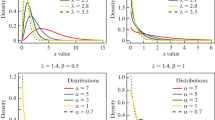
The distribution of a random variable with CDF (9) or PDF (10) is hereafter we denoted by \(GGLD\left( \alpha , \beta , \gamma \right)\). Clearly, when \(\gamma =1\), the GGLD reduces to the \(LD_{I}\) and when \(\alpha =\beta =1\), the GGLD reduces to \(LD_{II}\) with parameter \(\gamma .\) The PDF plots of \(GGLD\left( \alpha , \beta ,\gamma \right)\) for particular choices of its parameters \(\alpha , \beta\) and \(\gamma\) is given in Fig. 1. From the figure it is clear that for fixed \(\alpha\) and \(\beta\), the distribution is positively skewed for \(\gamma < 1\) and negatively skewed for \(\gamma > 1\). Furthermore, as \(\gamma\) increases the kurtosis is also increases for fixed \(\alpha\) and \(\beta\).
Proposition 1
The characteristic function \(\Phi _X \left( t \right)\) of \(GGLD\left( \alpha , \beta ,\gamma \right)\) with PDF (10) is the following, for \(t\in R\), where B(.,.) is the beta function.
Proof
Let X follows \(GGLD\left( \alpha , \beta ,\gamma \right)\) with PDF (10). Then by the definition of characteristic function, we have the following for any \(t\in R\) and i=\(\sqrt{-1}\).
substitute \(\frac{1}{{\left( {1 + e^{ -\beta x} } \right) ^{\alpha + 1} }} = u\) in (12), to obtain
Now applying binomial expansion of \(\left( 1- u^\alpha \right) ^{\gamma - 1}\) in (13) and rearranging the terms to get the following.
which gives (11), by the definition of beta integral. \(\square\)
Proposition 2
The mean and variance of \(GGLD\left( \alpha , \beta ,\gamma \right)\) with PDF (10) are respectively
and
where \(\eta _{k,\alpha }(a) = (\alpha + \alpha k + a)^{-1}\) and \(\psi \left( a \right)\) is as defined in (7).
Proof
By definition, the mean of \(GGLD\left( \alpha , \beta ,\gamma \right)\) is
by putting \(u=\left( {1 + e^{ - \beta x} } \right) ^{ - 1}.\) Now by binomial expansion of \(\left( {1 - u^\alpha } \right) ^{\gamma - 1}\), we obtain the following.
Applying (7) in the second integral term of (17) and by using integration by parts in the first integral term, one can obtain (15).
By definition, the variance of \(GGLD\left( \alpha , \beta ,\gamma \right)\) gamma generalized logistic distribution (GGLD) is
in which
by taking \(u = \frac{{1 }}{{1 + e^{ -\beta x} }}\). By applying binomial expansion of \(\left( {1 - u^\alpha } \right) ^{\gamma - 1}\), in (19), we obtain the following.
where
and
Now, by using integration by parts we have the following from (21).
In a similar way, we obtain the following from (22).
Applying (8) in (23), \(I_3\) becomes,
Thus, from (18) and (20) we get (16), in the light of (24), (25) and (26). \(\square\)
Proposition 3
The quantile of \(GGLD\left( \alpha , \beta ,\gamma \right)\) of order c, \(X_{c}\) is given by
Proof
By inverting (9), one can obtain (27). \(\square\)
Proposition 4
Measure of skewness \(g_a\) and kurtosis \(L_0\) of \(GGLD\left( \alpha , \beta ,\gamma \right)\) with PDF (10) are given by
and
in which \(\delta _c = [(1 - c^{1/\gamma } )^{-1/\alpha } -1]\).
Proof
Galton [6] introduced the percentile oriented measure of skewness as
so that \(0< g_a <\infty\). Note that \(g_a=1\) indicates symmetry, \(g_a<1\) indicates skewness to left while \(g_a>1\) is interpreted as skewness to right. Schmid and Trede [17] defined the percentile oriented measure of kurtosis \(L_0\) as the product of the measure of tail \(T =\frac{{x_{0.975} - x_{0.025} }}{{x_{0.875} - x_{0.125} }}\) and the measure of peakedness \(P =\frac{{x_{0.875} - x_{0.125} }}{{x_{0.75} - x_{0.25} }}\) . That is,
Now the proof of (28) and (29) follows form (27), (30) and (31). It is quite interest to note that both skewness and kurtosis depends only on \(\alpha\) and \(\gamma\). From Appendix it is clear that the the skewness of this distribution ranges from 0.67 to 1.82. From Fig. 1 also it is evident that this is a moderately skewed distribution. The computed values of skewness and kurtosis for different values of the parameters are given in Appendix . \(\square\)
Proposition 5
The PDF of the kth order statistics \(X_{k:n}\) of \(GGLD\left( \alpha , \beta ,\gamma \right)\) is
Proof
Let \(X_{1},X_{2}, ...,X_{n}\) be a random sample of size n from the \(GGLD\left( \alpha , \beta ,\gamma \right)\) and let \(X_{k:n}\) be the \(k^{th}\) order statistic for k = 1, 2, ..., n. Let \(F_{x_{k:n}}(x)\) and \(f_{x_{k:n}}(x)\) denotes the CDF and the PDF of \(X_{k:n}\) respectively. Then
for \(x\in\) R. Now, by applying (9) and (10) in (33) to obtain (32). \(\square\)
From Proposition (5), we have the following Corollaries.
Corollary 1
The distribution of the smallest order statistic \(X_{1:n}\) based on a random sample of size n taken from a population following \(GGLD\left( \alpha , \beta ,\gamma \right)\) is \(GGLD\left( \alpha , \beta ,n\gamma \right)\).
Corollary 2
The PDF of the largest order statistics \(X_{n:n}\) is
for x \(\in\) R, which reduces to \(LD_{I}\left( \alpha n, \beta \right)\) when \(\gamma =1\).
Proposition 6
The Renyi entropy of \(GGLD\left( \alpha , \beta ,\gamma \right)\) is given by
Proof
For \(0< \theta \ne 1\) the Renyi entropy \(I_R \left( \theta \right)\) is defined as
On substituting \(\frac{1}{{1 + e^{ - x} }}\; = u\) in (36) we have
by applying binomial expansion in \(\left( {1 - u^\alpha } \right) ^{\theta \left( {\gamma - 1} \right) }.\) Thus we have
which gives (35). \(\square\)
Proposition 7
The survival function is given by
Proposition 8
The hazard function is given by
The proof follows directly from the definition of survival function and hazard function and hence, omitted. The curve of hazard function is given in Fig. 2. From the curve it is seen that when \(\alpha , \beta \; \text {and} \; \; \gamma\) are more than 1, the curve has a point of inflection between 0.5 and 1 , and thereafter it remains stable. The point of inflection increases as any one of the parameters takes a value less than one.
3 Location Scale Extension
In this section we define an extended form of \(GGLD\left( \alpha ,\; \beta ,\;\gamma \right)\) by introducing the location parameter \(\mu\) and scale parameter \(\sigma\) and discuss the maximum likelihood estimation of the parameters of extended form of \(GGLD\left( \alpha ,\; \beta ,\;\gamma \right)\).
Definition
Let Z follows the \(GGLD\left( \alpha , \;\beta ,\; \gamma \right)\) with PDF (10). Then \(X = \mu +\;\sigma Z\) is said to have an “extended GGLD with parameters \(\mu ,\; \sigma ,\; \alpha ,\;\beta\) and \(\gamma\)”, denoted by “\(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\)”. The PDF of \(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\) is
in which \(x\in R\), \(\mu \in R\), \(\alpha> 0,\; \beta > 0\) and \(\gamma >0\). Next we discuss the maximum likelihood estimation of \(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\). Let \(X_{1},\; X_{2},\; .\; .\; .\; ,X_{n}\) be a random sample from a population having \(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\) with the PDF (38). Let \(L (\mu ,\;\sigma ;\;\alpha \; ,\beta ,\;\gamma )\) denote the likelihood function, the log-likelihood function \(l = \ln L (\mu ,\;\sigma ;\;\alpha ,\;\beta ,\;\gamma )\) of the random sample is
On differentiating (39) with respect to parameters \(\mu ,\; \sigma ,\; \alpha ,\; \beta ,\; \gamma\) and equating to zero, we obtain the following likelihood equations, in which \(z_i = \frac{{x_i - \mu }}{\sigma }\), for each i = 1, 2, . . . , n and \(\Omega _j = \left[ {1 + e^{-\beta \left( {\frac{{x_i - \mu }}{\sigma }} \right) } } \right] ^j\), for j=1 or \(\alpha\).
When these likelihood equations donot always have solutions, the maximum of the likelihood function is reached at the border of the parameter domain. Since the MLE of the unknown parameters \(\mu ,\; \sigma ,\; \alpha ,\; \beta ,\; \gamma\) cannot be obtained in closed forms, there is no way to derive the exact distribution of the MLE. Therefore, we derived the second order partial derivatives of the log-likelihood function with respect to the parameters \(\mu ,\; \sigma ,\; \alpha ,\; \beta ,\; \gamma\) using MATHLAB software and noticed that these gave negative values for \(\mu>0,\; \sigma>0,\;\alpha>0,\; \beta>0,\; \gamma >0\). Hence the maximum likelihood estimators of the parameters of \(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\) can be obtained by solving the above system of Eqs. (40)–(44) with the help of mathematical softwares such as MATLAB, MATHCAD, MATHEMATICA, R etc.
4 Applications
For numerical illustration we consider the following two data sets .
Data set 1. Myopia Data data set available in “https://www.umass.edu//statdata”. This data set is also used by Hosmer et al. [9]. The dataset is a subset of data from the Orinda Longitudinal Study of Myopia (OLSM), a cohort study of ocular component development and risk factors for the onset of myopia in children. Data collection began in the 1989–1990 school year and continued annually through the 2000–2001 school year. All data about the parts that make up the eye (the ocular components) were collected during an examination during the school day. Data on family history and visual activities were collected yearly in a survey completed by a parent or guardian. The dataset used in this text is from 618 of the subjects who had at least 5 years of follow-up and were not myopic when they entered the study. All data are from their initial exam and the dataset includes 17 variables. We have taken the continuous variable vitreous Chamber depth (VCD) in mm of 618 patients. VCD is the length from front to back of the aqueous-containing space of the eye in front of the retina.
Data set 2. Rosner’s FEV Data set available in “http://biostat.mc.vanderbilt.edu//DataSets". The data set contains determinations of forced expiratory volume (FEV) on 654 subjects in the age group of 6–22 years who were seen in the childhood respiratory disease study in 1980 in East Boston, Massachusetts. Forced expiratory volume (FEV), a measure of lung capacity, is the variable of interest. We obtain the maximum likelihood estimators (MLEs) of the parameters of the \(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\) by using the ‘nlm()’ package in R software. The values of Kolmogrov–Smirnov Statistic (KSS), Akaike information criterion (AIC), Bayesian information criterion \(\left( BIC \right)\), Consistent Akaike information criterion \(\left( CAIC \right)\) and Hannan Quinn information criterion \(\left( HQIC \right)\) are computed for comparing the model \(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\) with the existing logistic models—\(LD(\mu ,\sigma )\), \(LD_{ I}(\mu ,\sigma ,\alpha ,\beta )\), \(LD_ {II} (\mu ,\sigma ,\alpha )\). Moreover, the distribution is compared with another family of distribution, double lindely distribution (DLD) of Kumar and Jose [16] having distribution function
\(x\in R=\left( -\infty , +\infty \right) \,\,and\;\;\theta > 0\)
From Table 1, it is seen that the KSS, AIC, BIC, CAIC and HQIC values are minimum for \(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\) compared to other models. Figures 3 and 4 also confirm this result. These observations reveals that the \(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\) is relatively a better model compared to the existing models.
5 Testing of Hypothesis
In this section we discuss certain generalized likelihood ratio test procedures for testing the parameters of the \(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\) and attempt a brief simulation study. Here we consider the following tests. Test 1. \(H_{01}:\gamma = 1\) against \(H_{11} :\gamma \ne 1\) Test 2. \(H_{02}:\alpha =1,\; \beta = 1\) against \(H_{12} :\alpha \ne 1,\; \beta \ne 1\) Test 3. \(H_{03}:\alpha = 1,\; \beta = 1,\; \gamma = 1\) against \(H_{13}:\alpha \ne 1, \; \beta \ne 1, \; \gamma \ne 1\) In this case, the test statistic is,
where \(\mathop \Omega \limits ^ \wedge\) is the maximum likelihood estimator of \(\Omega = \left( {\mu ,\;\sigma ,\;\alpha ,\;\beta ,\;\gamma } \right)\) with no restriction, and \(\mathop \Omega \limits ^{ \wedge * }\) is the maximum likelihood estimator of \(\Omega\) when \(\gamma = 1\) in case of Test 1, \(\alpha = 1,\; \beta = 1\) in case of Test 2 and \(\alpha = 1,\;\beta =1,\; \gamma =1\) in case of Test 3 respectively. The test statistic \(- 2\ln \Lambda\) given in (45) is asymptotically distributed as \(\chi ^{2}\) with one degree of freedom for test 1, 2 degree of freedom for test 2 and 3 degree of freedom for test 3 [14]. The computed values of \(lnL( {\mathop \Omega \limits ^ \wedge ;y|x}), \;ln L( {\mathop \Omega \limits ^{ \wedge * } ;y|x})\) and test statistic in case of the two data sets are listed in Table 2. Since the critical values at the significance level 0.05 and degree of freedom one, two and three for the two tailed test are 5.024, 7.378 and 9.348 respectively the null hypothesis is rejected in all cases, which shows the appropriateness of the EGGLD to both the data sets.
6 Simulation
To assess the performance of the estimates of the parameters of
\(EGGLD\left( \mu ,\;\sigma ;\;\alpha ,\; \beta ,\;\gamma \right)\), we have conducted a brief simulation study based on values of the following sets of parameters.
-
(i)
\(\alpha =1.335 ,\; \beta =0.399,\; \gamma =2.668,\;\mu =0.489,\; \sigma = 0.575\) (negatively skewed).
-
(ii)
\(\alpha =5.335 ,\; \beta =0.400,\; \gamma =0.668,\; \mu =0.490,\; \sigma = 0.576\) (positively skewed).
Here we adopt the inverse transform method of Ross [15] for generating random numbers. The computed values of bias and mean square errors (MSE) corresponding to sample sizes 30, 100, 200 , 300 and 500 respectively are given in Table 3. From Table 3 it can be seen that both the absolute bias and MSEs in respect of each parameters of the EGGLD are in decreasing order as the sample size increases.

Plots of PDF of the GGLD for varying values of \(\alpha\) and \(\beta\) and \(\gamma\)

Hazard rate function of GGLD for varying values of \(\alpha\) and \(\beta\) and \(\gamma\)

Empirical distribution of the data set1 along with the fitted CDFs

Empirical distribution of the data set2 along with the fitted CDFs
7 Discussion
While considering practical applications, most of the real life data sets are not symmetric in nature. So, in the present work we developed certain wide classes of asymmetric logistic distributions through the names “generalized gamma logistic distribution (GGLD)” and “extended generalized gamma logistic distribution (EGGLD)”. The EGGLD has been fitted to two medical data sets and shown that the EGGLD gives best fit to both the data sets compared to the existing models such as LD, LDI and LDII, DLD based on various measures such as the KSS, AIC, BIC, CAIC and HQIC values. Figures 3 and 4 also supports in favour to the EGGLD as the best model.
8 Conclusion
In this paper, we have developed a wide class of generalised logistic distribution GGLD, which will be suitable for asymmetric data sets compared to the existing models. This model is a generalized class of both the LDI and LDII models. Some of the important characteristics of the distribution have been discussed via deriving mean, variance, characteristic function, measures of skewness and kurtosis, entropy etc. along with the distribution of its order statistics and maximum likelihood estimation of its parameters. Two real life medical data sets are utilized for illustrating the usefulness of the model and a simulation study is conducted for examining the performance of the maximum likelihood estimators of the parameters of the distribution. Several inferential aspects as well as structural properties of the model are yet to study.
Availability of data and material
Data set 1. Myopia Data data set available in https://www.umass.edu//statdata". Data set 2. Rosner’s FEV Data set available in http://biostat.mc.vanderbilt.edu//DataSets".
Abbreviations
- AIC:
-
Akaike information criterion
- BIC:
-
Bayesian information criterion
- CAIC:
-
Consistent Akaike information criterion
- CDF:
-
Cumulative distribution function
- EGGLD:
-
Extended gamma generalized logistic distribution
- GGLD:
-
Gamma generalized logistic distribution
- HQIC:
-
Hannan–Quinn information criterion
- KSS:
-
Kolmogrov Smirnov statistic
- LD:
-
Logistic distribution
- LDI:
-
Logistic distribution of type I
- LDII:
-
Logistic distribution of type II
- DLD:
-
Double lindely distribution
- MLEs:
-
Maximum likelihood estimators
- MSE:
-
Mean square error
- PDF:
-
Probability density function
References
Balakrishnan, N.: Handbook of Logistic Distribution. Dekker, New York (1992)
Balakrishnan, N., Leung, M.Y.: Order statistics from the type I generalized logistic distribution. Commun. Stat. Simul. Comput. 17(1), 25–50 (1988)
Berkson, J.: Application of the logistic function to bioassay. J. Am. Stat. Assoc. 37, 357–365 (1944)
Berkson, J.: Why I prefer logits to probits. Biometrics 7, 327–339 (1951)
Berkson, J.: A statistically precise and relatively simple method of estimating the bio-assay with quantal response, based on the logistic function. J. Am. Stat. Assoc. 48, 565–599 (1953)
Galton, F.: Application of the method of percentiles to Mr. Yule’s data on the distribution of pauperism. J. R. Stat. Soc. 59, 392–396 (1896)
Gradshteyn, I.S., RyzhiK, I.M.: Tables of Integrals, Series and Products, 6th edn. Academic Press, San Diego (2000)
Grizzle, J.E.: A new method of testing hypothesis and estimating parameters for the logistic model. Biometrics 17, 372–385 (1961)
Hosmer, D.W., Lemeshow, S., Sturdivant, R.X.: Applied Logistic Regression. Wiley, New York (2000)
Kumar, C.S., Manju, L.: A flexible class of skew logistic distribution. J. Iran. Stat. Soc. 14(2), 71–92 (2015)
Nadarajah, S.: The skew logistic distribution. AStA Adv. Stat. Anal. 93, 187–203 (2009)
Pearl, R., Reed, L.J.: Studies in Human Biology. Williams and Wilkins, Baltimore (1924)
Plackett, R.L.: The analysis of life test data. Technometrics 1, 9–19 (1959)
Rao, C.R.: Linear Statistical Inference and Its Applications. Wiley, New York (1973)
Ross, S.M.: Simulation, 2nd edn. Academic Press Inc, New York (1997)
Satheesh, Kumar C., Jose, R.: On double Lindley distribution and some of its properties. Am. J. Math. Manag. Sci. 38(1), 23–43 (2019)
Schmid, F., Trede, M.: Simple tests for peakedness, fat tails and leptokurtosis based on quantiles. Comput Stat Data Anal 43, 1–12 (2003)
Wahed, A.S., Ali, M.M.: The skew-logistic distribution. J. Stat. Res. 35, 71–80 (2001)
Acknowledgements
The authors are very much thankful to the reviewers for their valuable inputs to bring this research paper to this form.
Funding
Nil.
Author information
Authors and Affiliations
Contributions
CSK: conceptualization, methodology, supervision, validation, writing-review and editing. LM: writing-original draft, investigation, Methodology, software, visualization, Data curation.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare they have no conflicts of interest.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Appendix
Appendix
See Table 4.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kumar, C.S., Manju, L. Gamma Generalized Logistic Distribution: Properties and Applications. J Stat Theory Appl 21, 155–174 (2022). https://doi.org/10.1007/s44199-022-00046-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s44199-022-00046-0