
Abstract
The terrible operating constraints of many real-world events cause systems to malfunction regularly. The failure of systems to perform their intended duties when they reach their lowest, highest, or both extreme operating conditions is a phenomenon that researchers rarely focus on. The multi-stress strength reliability \(R = P(W<X<Z)\) is deemed in this study for a component whose strength X falls between two stresses, W, and Z, where X, W, and Z are independently inverted Kumaraswamy distributed. Both maximum likelihood and maximum product spacing procedures are employed to obtain the reliability estimator under simple random sampling (SRS) and ranked set sampling (RSS) methodologies. Four scenarios for reliability estimators are considered. The reliability estimator in the first and second cases can be determined by applying the same sample design (RSS/SRS) to the strength and stress distributions. When the sample data for W and Z originate from RSS while those for X are acquired from SRS, the third reliability estimator is calculated. The drawn data of the strength and stress random variables, which are obtained from SRS and RSS, respectively, are taken into consideration in the final scenario. The effectiveness of the suggested estimators is compared using a comprehensive computer simulation. Lastly, three real data sets have been used to determine reliability estimators.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In several situations, when we try to gather information on the environmental inquiry, several types of issues come up. Due to the lack of sample selection, it might be challenging in the majority of cases to acquire a simple random sample (SRS). It is likewise challenging to make free decisions about where to gather observations following a predetermined plan. An effective foundation for estimating the parameters of environmental variables may be found in ranked set sampling (RSS). Under extremely certain conditions, such as when sample units can be readily and cheaply obtained and ranked among themselves, but it is relatively expensive to measure them properly, RSS can offer an observational economy. Ranking may be done visually about the research variable or by using any simple, economical way. For instance, ranking a small group of trees according to their heights visually is simple if the goal is to estimate the average height of trees. The RSS approach was initially proposed by [1] for estimating pasture and forage yields. The RSS approach entails selecting m sets of size m each at random from a population and visually ranking the units in each set or using some other low-cost method. The unit with the lowest ranking among the first m units is chosen for actual quantization. The unit ranked second lowest among the second batch of m units is picked for actual quantification. The procedure is repeated up until the mth set’s largest-ranked unit is selected for actual quantification. The one-cycle RSS of m samples of size m is represented as follows:
where \({X_{\left( {i:m} \right) j}}\) represents the \({i^{th}}\) order statistic from the \({j^{th}}\) SRS of size m. The observed sample \({\text {Y }} = \left( {{Y_1},{Y_2},\ldots ,{Y_m}} \right)\) is called a one-cycle RSS of size m. In a sample of size m, it marginally, \({Y_{\left( i \right) }}\) has the same distribution as the probability density function (PDF) given below (see [2])
The process of determining precisely how reliable a system or a component is called reliability estimate. Reliability estimate is essential in today’s technologically advanced environment to make sure systems function as intended and reduce failure risk. It entails gathering performance data from the system, evaluating the data, and forecasting future performance. Recent studies in this estimating technique can be found in [3,4,5,6]. In some situations, the life of a component with a random strength X and a random stress Y is described by the stress strength (SS) model. This idea emerged in the context of the traditional SS reliability when the person is interested in predicting the probability \(P\left( {Y < X} \right)\) which can be seen as the probability that a component would fail when applied stress Y is larger than its strength (see [7]). This model has several uses in a variety of fields, especially in engineering, such as building structures, the aging of concrete pressure vessels, and the deterioration of rocket engines. There are several more significant studies in this field as well, such as those by Refs. [8,9,10,11,12] among others. Several studies in recent years have taken into account SS model inferential statistics using the RSS method. The unbiased estimator for R where X and Y are from an exponential distribution was discovered by Sengupta and Mukhuti [13]. It was applied to the Weibull distribution, respectively, by [14]. More recent studies can be found in [15,16,17,18,19,20,21,22,23,24,25].
The multi-stressstrength systems model, which is also an essential SS model in which component fails when exposed to extreme lower and upper working environments, that is, \(R = P\left( {Y< X < Z} \right)\), where Y and Z are the component stresses (lower and upper), and X is the strength of the component, is given much fewer spotlights. Reference [26] was the ones who initially presented the primary concept of this methodology. For instance, many gadgets are incapable of operating in both extremely hot and low temperatures. Similar to this, a person’s systolic and diastolic blood pressure has two limitations, and it should stay within these ranges. In a related manner, numerous devices are unworkable in two extremes of stress.
In the literature, the estimate of \(R = P\left( {{X_1}< Y < {X_2}} \right)\) where \({X_1},Y,\) and \({X_2}\) are exponentially distributed was covered by Ref. [27]. Singh [28] explored the uniform minimum variance unbiased estimators (UMVUEs) and the maximum likelihood estimators (MLEs) of \(R = P\left( {X< Y < Z} \right)\), where X, Y, and Z are independent random variables that have a normal distribution. The MLE and UMVUE of R were given by Ivshin [29] when X, Y, and Z are either random variables that are exponential or uniform. Guangming et al. [30] constructed a statistical inference for R under the assumption that the three samples were independent. Reference [31] has offered an estimation of R for independent Weibull distributions with k outliers. Recently, studies on R in complete samples were presented by Hameed et al. [32] for inverted Kumaraswamy distribution (IKwD). References [33, 34] investigated several strategies for estimating R for the inverse Rayleigh distribution. When data are observed from independent Kumaraswamy distributions, Ref. [35] provided classical and Bayesian estimates of R. The Bayesian and non-Bayesian estimates of R from the exponentiated exponential distribution were supplied by Yousef et al. [36] based on generalized progressive hybrid censoring.
Only one recent work has examined the estimation issue of \(R = P(W<X<Z)\) under RSS methodology in the literature, assuming that both stresses and strength random variables follow generalized inverse exponential distributions [37]. Here, the primary goal is to handle the the estimation issue of \(R = P(W<X<Z)\) in light of RSS method. This concentration’s idea came from the variety of areas that apply the RSS strategy. Additionally, compared to the SRS design, the RSS design provides more efficient estimators for a given sample size. Assume the stresses and strength random variables follow the IKwD, due to the significance of this distribution and its wide range of applications. In addition, this study uses the maximum product of the spacing (MPS) estimation approach as an additional estimation technique in comparison to the work previously offered by Hassan et al. [37]. Consequently, the following is a summary of this effort:
-
The MLE and MPS estimator (MPSE) of \(R = P(W<X<Z)\) are derived under four situations for RSS and SRS methods.
-
The MLE and MPSE of \(R = P(W<X<Z)\) are generated when the stresses(W, Z), and strength (X) have the same sampling design (RSS/RSS) as done in the first and second scenarios.
-
The MLE and MPSE of \(R = P(W<X<Z)\) are determined when the observed samples of the stresses (W, Z) are taken from RSS, whereas the observed samples of strength (X) are taken from SRS in the third scenario.
-
In the last case, the reliability estimators are produced when the observed samples of the stresses are gathered from SRS, whereas observed samples of the strength are taken from RSS.
-
Extensive simulations were done to compare the two approaches, and the dataset was assessed for better clarification.
The following is an outline for this article. The model description and its reliability expression are included in Sect. 2. When both stresses and strength distributions have the same sampling design, Sects. 3 and 4 deduce the MLE and MPSE of R. As demonstrated in Sect. 5, the estimator of R is determined when stresses have the SRS and strength has the RSS using both estimation methods. The estimator of R is deduced when stresses have the RSS and strength has the SRS using the proposed estimation methods, as documented in Sect. 6. Sections 7 and 8 provide, respectively, techniques for simulating and analyzing real data. In Sect. 9 we conclude the paper.
2 Description of the Model and Its Reliability
In this section, a description of the model is explained and an expression of \(R = \,P[W< X < Z]\) is obtained, where independent random variables X, W, and Z adhere to the IKwD.
The inverse of the probability distributions is useful for examining further characteristics of the phenomena. Inverted distributions have been demonstrated to be useful in research based on econometrics, biological and engineering sciences, survey sampling, medical applications, and life testing issues. Recently, Abd AL-Fattah et al. [38] provided the IKwD for a random variable \(X = (1/Y) - 1\), where the random Y has a Kumaraswamy distribution. The PDF, survival function (SF) and hazard rate function (HRF) of the IKwD are, represented, by:
and
where, \(\lambda\) and \({\rho _1}\) are the shape parameters. The PDF (1) comprises some distributions for some choices of \(\lambda\) and \({\rho _1}\). At \({\rho _1} = 1,\) the PDF (1) provides the Lomax distribution; at \(\lambda = 1,\) the PDF (1) gives beta Type II distribution. Also, at \(\lambda = {\rho _1} = 1,\) the PDF (1) reduces to log-logistic distribution. The PDF (1) gives the inverse Weibull distribution when \({\rho _1} \rightarrow \infty ,\) and the generalized exponential distribution when \(\lambda \rightarrow \infty .\) Figures 1 and 2 display the PDF and HRF of the IKwD for some choices of parameters. From Figs. 1 and 2, we can note that the PDF of the IKwD can be unimodal, decreasing and right skewed, but the HRF can be decreasing, reversed J-shaped and up-side-down.

Plots of the PDF of the IKwD

Plots of the HRF of the IKwD
The IKwD yields beneficial estimates of rare occurrences happening in the right tail of the distribution when compared to other distributions, making it useful for long-term reliability predictions [39]. Compared to other commonly used distributions, the IKwD has a longer right tail, which has a beneficial impact on the distribution’s capacity to match the infrequent occurrences that occur in the right tail, or outlier data in the right tail. In place of the widely used Weibull distribution, the IKwD was employed for modelling wind speed data [40]. Using dual generalized order statistics, Ref. [41] determined the shape parameters, SF, and hazard function of IKwD. The Bayesian estimation of mixed IKwD with application to 56 observations related to the burning velocity of different chemical materials was examined by [42]. Reference [43] examined several estimate techniques for the IKwD parameters using RSS and applied them to the waiting periods between 65 successive eruptions of the Kiama Blowhole. For more studies of the IKwD in life testing experiment [44, 45].
Expression of \(R = P[W< X < Z],\) is derived, where the strength \(X\sim\)IKwD\((\lambda ,{\rho _1})\) and the two stress random variables \(W\sim\)IKwD\((\lambda ,{\rho _2})\) and \(Z\sim\)IKwD\((\lambda ,{\rho _3})\) are independent. Reference [28] argued that the SS model’s reliability \(R = \,P[W< X < Z],\) formula has the following structure:
where \({{\bar{H}}_Z}\left( x \right)\) is the SF of stress Z at x, and \({G_W}\left( x \right)\) is the cumulative distribution function of W at x. Consequently, based on (4), we obtain R as follows:
Note that formula (5), depends on the parameters \({\rho _1},{\rho _2}\) and \({\rho _3}\).
3 Estimator of \({R_1} = \,P[{W_{SRS}}< {X_{SRS}} < {Z_{SRS}}]\)
This section discusses, the MLE and MPSE of \({R_1},\) designed respectively by \({{\hat{R}}_1},\) and \({{\tilde{R}}_1},\) when the observed samples for both stresses and strength are taken from SRS.
3.1 MLE of \({R_1}\)
Let \({X_1},{X_2},\ldots ,{X_{m_1^*}}\), \({W_1},{W_2},\ldots ,{W_{m_2^*}},\) and \({Z_1},{Z_2},\ldots ,{Z_{m_3^*}},\) are independent IKwD with parameters \((\lambda ,{\rho _{1}}),\) \((\lambda ,{\rho _2}),\) and \((\lambda ,{\rho _3}),\) respectively, under SRS. First, we acquire the MLE of \({\rho _1},{\rho _2},{\rho _3}\) and \(\lambda\), then use that information to derive the MLE of \({R_1}\) following the invariance property. The likelihood function of SRS is
where \(\Psi \equiv ({\rho _1},{\rho _2},{\rho _3},\lambda ).\) The log-likelihood function, say \({\ell _1}(\Psi ),\) is as follows:
where, \(A({x_{{j_1}}},{w_{{j_2}}},{z_{{j_3}}}) = \sum \nolimits _{{j_1} = 1}^{m_1^*} {\log } \,(1 + {x_{{j_1}}}) + \sum \nolimits _{{j_2} = 1}^{m_2^*} {\log } \,(1 + {w_{{j_2}}}) + \sum \nolimits _{{j_3} = 1}^{m_3^*} {\log } \,(1 + {z_{{j_3}}}),\) \({H_1}({x_{{j_1}}},\lambda ) = \left[ {1 - {{\left( {1 + {x_{{j_1}}}} \right) }^{ - \lambda }}} \right] ,\) \({H_2}({w_{{j_2}}},\lambda ) = \left[ {1 - {{\left( {1 + {w_{{j_2}}}} \right) }^{ - \lambda }}} \right] ,\) and \({H_3}({z_{{j_3}}},\lambda ) = \left[ {1 - {{\left( {1 + {z_{{j_3}}}} \right) }^{ - \lambda }}} \right] .\) The equations following are produced by differentiating (6) concerning the population parameters.
where, \(\frac{\partial }{{\partial \lambda }}{H_k}({\upsilon _{{j_k}}},\lambda ) = {H'_k}({\upsilon _{{j_k}}},\lambda ) = {\left( {1 + {\upsilon _{{j_k}}}} \right) ^{ - \lambda }}\log \left( {1 + {\upsilon _{{j_k}}}} \right) ,{\upsilon _{{j_k}}} \equiv \left( {{x_{{j_1}}},{w_{{j_2}}},{z_{{j_3}}}} \right) ,k = 1,2,3.\) Set Eq. (7) with zero gives the MLEs of \({\rho _1},{\rho _2}\) and \({\rho _3},\) say \({{\hat{\rho }} _1},\,\,{{\hat{\rho }} _2}\) and \({{\hat{\rho }} _3},\) as a function of \(\lambda\) as seen below:
Inserting (9) in (8) provides us with
where, \({{\hat{\rho }} _i}(\lambda ),\,i = 1,2,3\) defined in (9). The MLE of \(\lambda\), say \({\hat{\lambda }}\), is determined from (10), by using a reasonable approximation approach. Consequently, \({{\hat{\rho }} _1},\,\,{{\hat{\rho }} _2}\) and \({{\hat{\rho }} _3}\) are produced by incorporating \({\hat{\lambda }}\) in Eq. (7). Therefore, \({{\hat{R}}_1},\) is supplied by including \({{\hat{\rho }} _1},\,\,{{\hat{\rho }} _2}\) and \({{\hat{\rho }} _3}\) in (5) as follows:
3.2 MPSE of \({R_1}\)
Reference [46] proposed the MPS technique, a potent alternative method for calculating the population parameters of continuous distributions. Consider the ordered items \({X_{(1)}},{X_{(2)}},\ldots ,{X_{(m_1^ * )}}\), \({W_{(1)}},{W_{(2)}},\ldots ,{W_{({m_2^*})}},\) and \({Z_{(1)}},{Z_{(2)}},\ldots ,{Z_{({m_3^*})}},\) constitute an SRS of sizes \(m_1^ *,{m_2}^ *,{m_3}^ *\), drawn from independent IKwD with parameters \((\lambda ,{\rho _1}),\) \((\lambda ,{\rho _2}),\) and \((\lambda ,{\rho _3}),\) respectively. Hence, the uniform spacings are defined by:
where,
where \({i_j} = 1,2,...,m_j^* ,{\upsilon _{{i_j}}} \equiv \left( {{x_{{i_1}}},{w_{{i_2}}},{z_{{i_3}}}} \right) ,j = 1,2,3.\) The MPSEs of the unknown parameters \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) denoted by \({{\tilde{\rho }} _1},{{\tilde{\rho }} _2},{{\tilde{\rho }} _3},\) and \({\tilde{\lambda }}\) can be obtained by maximizing, with respect to \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) the following function:
where, \({K_j}({\upsilon _{({i_j})}},\lambda ) = \left[ {1 - {{\left( {1 + {\upsilon _{({i_j})}}} \right) }^{ - \lambda }}} \right] ,\) \(K_{_j}^ * ({\upsilon _(}_{{i_j} - 1)},\lambda ) = \left[ {1 - {{\left( {1 + {\upsilon _{({i_j} - 1)}}} \right) }^{ - \lambda }}} \right] ,\) and \({\upsilon _{({i_j})}} = ({x_{{i_1}}},{w_{{i_2}}},{z_{{i_3}}}), j = 1,2,3.\) Equivalently these estimators can be obtained by differentiating (12) concerning \({\rho _j},j = 1,2,3,\) and \(\lambda\) as below:
where, \({{\ddddot{K}}_j}({\upsilon _{({i_j})}},\lambda ) = \frac{\partial }{{\partial \lambda }}{\left[ {{K_j}({\upsilon _{({i_j})}},\lambda )} \right] ^{{\rho _j}}} = {\rho _j}{\left[ {{K_j}({\upsilon _{({i_j})}},\lambda )} \right] ^{{\rho _j} - 1}}{\left( {1 + {\upsilon _{({i_j})}}} \right) ^{ - \lambda }}\log \left( {1 + {\upsilon _{({i_j})}}} \right) ,\) and \(\ddddot K_j^*({\upsilon _{({i_j} - 1)}},\lambda ) = \frac{\partial }{{\partial \lambda }}{\left[ {K_j^ * ({\upsilon _{({i_j} - 1)}},\lambda )} \right] ^{{\rho _j}}} = {\rho _j}{\left[ {{K_j}({\upsilon _{({i_j} - 1)}},\lambda )} \right] ^{{\rho _j} - 1}}{\left( {1 + {\upsilon _{({i_j} - 1)}}} \right) ^{ - \lambda }}\log \left( {1 + {\upsilon _{({i_j} - 1)}}} \right) .\)
Equating the above derivatives with zero and solving them numerically, we obtain the MPSE of parameters. Inserting \({{\tilde{\rho }} _1},{{\tilde{\rho }} _2},{{\tilde{\rho }} _3},\) and \({\tilde{\lambda }}\) in (5), we can obtain the MPSE of \({R_1}\) as follows:
4 Estimation of \({R_2} = \,P[{W_{RSS}}< {X_{RSS}} < {Z_{RSS}}]\)
In this section, the MLE and MPSE of \({R_2},\) designed respectively by \({{\hat{R}}_2},\) and \({{\tilde{R}}_2},\) are established when the observed samples for both stresses and strength are collected from RSS.
4.1 MLE of \(R_2\)
Let \({X_t}_{\left( t \right) u}\), represents the \({t^{th}}\) order statistics (OS) of the \({t^{th}}\) sample, \(t = 1,2, \ldots ,{m_1}\), in the \({u^{th}}\) cycle, \(u = 1,2, \ldots , {s_x}\), \(m_1^ * = {m_1}{s_x}\) from IKwD \((\lambda ,{\rho _1}).\) Let \({W_k}_{\left( k \right) b}\), be the kth OS from IKwD \((\lambda ,{\rho _2})\) of \({k^{th}}\) sample, \(k = 1,2, \ldots ,{{m_2}}\), in the \({b^{th}}\) cycle, \(b = 1,2, \ldots , {s_w},\) \({m_2}^ * = {{m_2}}{s_w}\). Also, suppose that \({z_q}_{\left( q \right) b}\) \({Z_q}_{\left( q \right) d}\), be the \({q^{th}}\) OS from IKwD \((\lambda ,{\rho _3})\) of \({q^{th}}\) sample, \(q = 1,2, \ldots ,{{m_3}}\), in the \({d^{th}}\) cycle, \(d =1,2,\ldots , s_z\), \({m_3}^ * = {{m_3}}{s_z}\). Here, \({s_x},{s_w},\) and \({s_z}\) are the number of cycles, \(m_1\), \({m_2}\), and \({m_3}\) are the set sizes. For the sake of clarity, we refer to \({X_{tu}},{W_{kb}},\) and \({Z_{qd}}\) throughout the rest of the work rather than \({X_t}_{\left( t \right) u},{W_k}_{\left( k \right) b},\) and \({Z_q}_{\left( q \right) d}\). It’s important to note that the PDFs of the \({X_t}_{\left( t \right) u},{W_k}_{\left( k \right) b},\) and \({Z_q}_{\left( q \right) d}\) are, respectively, the PDFs of the \({t^{th}},{k^{th}}\) and \({q^{th}}\) OS, which were obtained as
where, \({\Upsilon _{tu}}(\lambda ) = \left[ {1 - {{\left( {1 + {x_{tu}}} \right) }^{ - \lambda }}} \right] ,\) \({\Xi _{kb}}(\lambda ) = \left[ {1 - {{\left( {1 + {w_{kb}}} \right) }^{ - \lambda }}} \right] ,\) and \({\textrm{B}_{qd}}\left( \lambda \right) = \left[ {1 - {{\left( {1 + {z_{qd}}} \right) }^{ - \lambda }}} \right] .\)
In this instance, the likelihood function \({L_2}(\Psi )\) is as follows:
The log-likelihood function, say \({\ell _2}(\Psi ),\) based on RSS, is given by:
The MLEs of \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) are given by:
The MLEs of \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) could be obtained by setting (15)–(18) to zero and solving numerically, then obtaining \({{\hat{R}}_2}\) by plugging these MLEs into (5).
4.2 MPSE of \(R_2\)
Consider the ordered items \({X_{(1:m_{1}^*)}},{X_{(2:m_{1}^*)}},\ldots ,{X_{(m_{1}^*:m_{1}^*)}},\) \({W_{(1:m_2^*)}},{W_{(2:m_2^*)}},\ldots ,{W_{(m_2^*:m_2^*)}},\) and \({Z_{(1:m_3^*)}}\),
\({Z_{(2:m_3^*)}},\ldots ,{Z_{({m_3^*}:m_3^*)}},\) be RSS with sizes \(m_1^* = {m_1}{s_x}\), \(m_2^* = {{m_2}}{s_w}\) and \(m_3^* = {{m_3}}{s_z},\) respectively, where \({m_1},{{m_2}},{{m_3}}\) are set sizes while \({s_x},{s_w},{s_z}\) are cycles numbers drawn from independent IKwD with parameters \((\lambda ,{\rho _1}),\) \((\lambda ,{\rho _2}),\) and \((\lambda ,{\rho _3}).\) Hence, the uniform spacings
where,
and \({i_j} = 1,2,\ldots ,m_j^* ,{\omega _{({i_j}:m_j^*)}} \equiv \left( {{x_{({i_1}:m_1^ * )}},{w_{({i_2}:m_2^* )}},{z_{({i_3}:m_3^* )}}} \right) ;j = 1,2,3.\) The following function can be maximized with respect to \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) to yield the MPSEs of the unknown parameters \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\)
where \(A{K_j}({\omega _{({i_j}:m_j^*)}},\lambda ) = \left[ {1 - {{\left( {1 + {\omega _{({i_j}:m_j^*)}}} \right) }^{ - \lambda }}} \right] ,\) \(AK_{j}^ * ({\omega _(}_{{i_j} - 1:m_j^*)},\lambda ) = \left[ {1 - {{\left( {1 + {\omega _{({i_j} - 1:m_j^*)}}} \right) }^{ - \lambda }}} \right] .\)
Equivalently these estimators can be obtained by differentiating (20) concerning \({\rho _j},j = 1,2,3,\) and \(\lambda\) as below:
where
and
Equating the above derivatives with zero and solving them numerically, we obtain the MPSE of parameters, and then by inserting these estimators in (5), we can obtain the MPSE of \({R_2}.\)
5 Estimation of \({R_3} = \,P[{W_{RSS}}< {X_{SRS}} < {Z_{RSS}}]\)
The MLE and MPSE for the situation where the strength data for X is obtained from SRS and the stress data for W and Z are obtained from RSS design are given in this section. Assuming that X, W, and Z are all independent IKwD with parameters \((\lambda ,{\rho _1}),\) \((\lambda ,{\rho _2}),\) and \((\lambda ,{\rho _3}),\) respectively.
5.1 MLE of \(R_3\)
Let \({X_1},{X_2},\ldots ,{X_{m_1^*}},\) be a SRS observed from IKwD \((\lambda ,{\rho _1}).\) Let \({W_{kb}},\,\,k = 1,2, \ldots ,{{m_2}}\), \(b = 1,2, \ldots {s_w},\) and \(m_2^* = {{m_2}}{s_w}\) be the selected RSS from IKwD \((\lambda ,{\rho _2})\). Also, suppose that \({Z_{qd}},\,\,q = 1,2, \ldots ,{{m_3}}\), \(d = 1,2, \ldots {s_z},\) and \(m_3^* = {{m_3}}{s_z}\) from IKwD \((\lambda ,{\rho _3}).\) The likelihood function \({L_3}(\Psi )\) in this case is as follows:
The log-likelihood function, symbolized by \({\ell _3}(\Psi ),\) is presented as follows:
By maximizing \({\ell _3}(\Psi )\) with respect to \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\), the MLEs of them are obtained. The first partial derivatives of \({\rho _1},{\rho _2},{\rho _3}\) are derived in (7), (16) and (17). The first partial derivative of \(\lambda\) is:
The MLEs of \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) are created by equating (7), (16), (17) and (23) to zero and numerically solving these equations. These MLEs are then inserted into (5) to produce \({{\hat{R}}_3}\).
5.2 MPSE of \(R_3\)
Consider \({X_{(1)}},{X_{(2)}},\ldots ,{X_{(m_{1}^*)}}\) be the ordered SRS of strength X of size \(m_{1}^*\) from IKwD \(\sim (\lambda ,{\rho _1}).\) Let \({W_{(1:m_2^*)}},{W_{(2:m_2^*)}},\ldots ,{W_{(m_2^*:m_2^*)}},\) and \({Z_{(1:m_3^*)}},{Z_{(2:m_3^*)}},\ldots ,{Z_{(m_3^*:m_3^*)}},\) be RSS of sizes \(m_2^* = {{m_2}}{s_w}\) and \(m_3^* = {{m_3}}{s_z},\) respectively, where \({m_2}, {m_3}\) are set sizes while \(s_w\), \(s_z\) are cycles numbers drawn from IKwD\(\sim (\lambda ,{\rho _2})\) and IKwD \(\sim (\lambda ,{\rho _3})\) where X, W, and Z all operate independently. Hence, the uniform spacing in this case is as below:
where, \({D_{{i_1}}}(\lambda ,{\rho _1}),\) is defined in (11) for \(j=1\), \({\Delta _{{i_2}}}(\lambda ,{\rho _2})\) and \({\Delta _{{i_3}}}(\lambda ,{\rho _3})\) are defined in (19). The MPSEs of the unknown parameters \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) can be obtained by maximizing, with respect to \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) the following function:
Equivalently these estimators can be obtained by differentiating (25) with respect to \({\rho _j},j = 1,2,3,\) and \(\lambda\). Note that MPSE of \({\rho _j},\) is obtained in (13) for \(j =1\), and (21) for \(j=\)2 and 3. The MPSE of \(\lambda\) is given by
Equating the derivatives in (13),(21) and(26) with zero and solving them numerically, we obtain the MPSE of parameters, then by inserting these estimators in (5), we can obtain the MPSE of \(R_3\).
6 Estimation of \({R_4} = \,P[{W_{SRS}}< {X_{RSS}} < {Z_{SRS}}]\)
In this section, the MLE and MPSE estimator of \(R_4\) are produced using data from the RRS design for X and the SRS design for W and Z. Assuming that X, W, and Z are independent, where \(X\sim\)IKwD\((\lambda ,{\rho _1}),\) \(W \sim\)IKwD\((\lambda ,{\rho _2}),\) and \(Z\sim\)IKwD\((\lambda ,{\rho _3}).\)
6.1 MLE of \(R_4\)
Let \({X_{tu}},t = 1,2, \ldots ,{m_1},u = 1,2, \ldots {s_x},\) be RSS from IKwD \((\lambda ,{\rho _1})\). Also, suppose that \({w_1},{w_2},\ldots ,{w_{m_2^*}},\) and \({z_1},{z_2},\ldots ,{z_{m_3^*}},\) are SRS from the IKwD with parameters \((\lambda ,{\rho _2})\), and \((\lambda ,{\rho _3})\) respectively. The likelihood function in this case is given by:
The log-likelihood function, say \({\ell _4}(\Psi ),\) is given by:
The first partial derivatives of \({\rho _1},\) is provided in (15) and \({\rho _2},{\rho _3}\) are supplied in (7). The partial derivative of \(\lambda\) results in the following
Setting (7), (15) and (27) to zero and solving numerically yields the MLEs of \({\rho _1},{\rho _2},{\rho _3}\) and \(\lambda\), as a result, \({{\hat{R}}_4}\) is determined after putting the resulted MLEs in (5).
6.2 MPSE of \(R_4\)
Let \({x_{(1:m_{1}^*)}},{x_{(2:m_{1}^*)}},\ldots ,{x_{(m_{1}^*:m_{1}^*)}}\), be RSS of size drawn from IKwD\(\sim (\lambda ,{\rho _1})\). Consider the ordered SRS items \({w_{(1)}},{w_{(2)}},\ldots ,{w_{m_2^*}}\) and \({z_{(1)}},{z_{(2)}},\ldots ,{z_{m_3^*}}\) of size \(m_2^*\) and \(m_3^*\) drawn from IKwD\(\sim (\lambda ,{\rho _2})\) and IKwD\(\sim (\lambda ,{\rho _3})\) where X, W, and Z operate independently. Hence, the uniform spacing
where, \({\Delta _{{i_1}}}(\lambda ,{\rho _j})\) for \(j=1\) is in defined (19), \({D_{{i_2}}}(\lambda ,{\rho _2}),\) and \({D_{{i_3}}}(\lambda ,{\rho _3})\) given in (11). The MPSEs of the unknown parameters \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) can be obtained by maximizing, with respect to \({\rho _1},{\rho _2},{\rho _3},\) and \(\lambda\) the following function:
Equivalently these estimators can be obtained by differentiating (29) with respect to \({\rho _j},j = 1,2,3,\) and \(\lambda\). Note that MPSE of \({\rho _j}\) are obtained in (13) for \(j =2, 3,\) and (21) for \(j=1\). The MPSE of \(\lambda\) is given by:
Equating the above derivatives with zero and solving them numerically, we obtain the MPSE of parameters, then by inserting these estimators in (5), we can obtain the MPSE of \(R_4\).
7 Simulation Investigation
This section conducts a thorough simulation study to examine how different estimators behave when subjected to the specified sampling techniques. For the ML and MPS estimation methods, the mean squared error (MSE) and the absolute bias (AB) were used as precision measurements. The relative efficiency (RE) is also used to compare each example to Case 1 in each instance. The algorithm can be broken down into the following phases using the MathCAD program:
-
1.
The true parameters values of \(({\rho _1},{\rho _2},{\rho _3},\lambda )\) are selected as (2.5, 0.8, 5, 0.5), (1.5, 0.5, 6, 0.5) and (2, 0.2, 12, 0.5). The corresponding values of R are 0.456, 0.563, and 0.768 respectively.
-
2.
The SRS of X, W, and Z, represented by \({x_1},{x_2},\ldots ,{x_{m_1^*}},\) \({w_1},{w_2},\ldots ,{w_{m_2^*}},\) and \({z_1},{z_2},...,{z_{m_3^*}}\) where \((m_{^2}^ *,m_{^1}^ *,m_{^3}^ * ) =\) (10,10,10), (20,20,20), (30,30,30), (20,10,20), (30,10,30), (10,20,10), (10,30,10), (30,20,30), (20,30,20).
-
3.
The corresponding RSSs of X, W, and Z are represented, respectively by:
-
(a)
\({X_t}_{\left( t \right) u}\), where \(t = 1,2, \ldots ,{m_1}\), in the \({u^{th}}\) cycle, \(u = 1,2, \ldots {s_x}\), \(m_1^ * = {m_1}{s_x}\),
-
(b)
\({W_k}_{\left( k \right) b}\), where \(k = 1,2, \ldots ,{{m_2}}\), in the \({b^{th}}\) cycle, \(b = 1,2, \ldots {s_w}\), \(m_2^ * = {{m_2}}{s_w}\),
-
(c)
\({Z_q}_{\left( q \right) d}\), where \(q = 1,2, \ldots ,{{m_3}}\), in the \({d^{th}}\) cycle, \(d = 1,2, \ldots {s_z}\), \(m_3^ *= {{m_3}}{s_z}\),
where set sizes; \(({{m_2}},{m_1},{{m_3}}) =\) (2,2,2), (4,4,4), (6,6,6), (4,2,4), (6,2,6), (2,4,2), (2,6,2), (6,4,6), and (4,6,4), number of cycles \({s_x} = {s_w} = {s_z} = 5\). Hence, the sample sizes are \((m_{^2}^ *,m_{^1}^ *,m_{^3}^ *) =\) (10,10,10), (20,20,20), (30,30,30), (20,10,20), (30,10,30), (10,20,10), (10,30,10), (30,20,30), (20,30,20).
-
(a)
-
4.
Generate 1000 SRS and RSS of \(X\sim\)IKwD\(({\rho _1},\lambda )\), \(W\sim\)IKwD\(({\rho _2},\lambda )\) and \(Z\sim\)IKwD\(({\rho _3},\lambda )\) using inversion method.
-
5.
Four sampling cases are studied such that:
-
(a)
Case 1: \(P({W_{SRS}}< {X_{SRS}} < {Z_{SRS}})\).
-
(b)
Case 2: \(P({W_{RSS}}< {X_{RSS}} < {Z_{RSS}})\).
-
(c)
Case 3: \(P({W_{RSS}}< {X_{SRS}} < {Z_{RSS}})\).
-
(d)
Case 4: \(P({W_{SRS}}< {X_{RSS}} < {Z_{SRS}})\).
-
(a)
-
6.
The parameter estimates, together with their reliability estimates \({{\hat{R}}_1},{{\hat{R}}_2},{{\hat{R}}_3}\) and \({{\hat{R}}_4}\), are computed for ML method and \({{\tilde{R}}_1},{{\tilde{R}}_2},{{\tilde{R}}_3}\) and \({{\tilde{R}}_4}\) are calculated for MPS method.
-
7.
The efficiencies of different estimates under selective schemes with respect to SRS are defined by,
\(R{E_2}({\hat{R}}) = \frac{{ML\,MS{E_{{R_1}}}}}{{ML\,MS{E_{{R_2}}}}},\) \(R{E_3}({\hat{R}}) = \frac{{ML\,MS{E_{{R_1}}}}}{{ML\,MS{E_{{R_3}}}}},\) and \(R{E_4}({\hat{R}}) = \frac{{ML\,MS{E_{{R_1}}}}}{{ML\,MS{E_{{R_4}}}}}.\)
Also,
\(R{E^*}_2({\tilde{R}}) = \frac{{MPS\,MS{E_{{R_1}}}}}{{MPS\,MS{E_{{R_2}}}}},\) \(R{E^*}_3({\tilde{R}}) = \frac{{MPS\,MS{E_{{R_1}}}}}{{MPS\,MS{E_{{R_3}}}}},\) and \(R{E^*}_4({\tilde{R}}) = \frac{{MPS\,MS{E_{{R_1}}}}}{{MPS\,MS{E_{{R_4}}}}},\)
Finally, relative efficiency of \({\hat{R}}\) with respect to \({\tilde{R}}\) are also calculated. Tables 1, 2, 3, 4, 5, and 6 provide a summary of the AB, MSE, and RE values.
The numerical results shown in Tables 1, 2, 3, 4, 5, 6 and Figs. 3, 4, 5, 6, 7, 8, 9, 10 allow us to draw the following conclusions:
-
1.
Tables 3 and 5 show that reliability estimates acquired using the RSS technique are often more effective than reliability estimates obtained using the SRS scheme, where \(R=\) 0.456, 0.563 and 0.768.
-
2.
The MSEs of \({{\hat{R}}_3} = P\left( {{W_{RSS}}< {X_{SRS}} < {Z_{RSS}}} \right)\) are often more efficient than \({{\hat{R}}_4} = P\left( {{W_{SRS}}< {X_{RSS}} < {Z_{SRS}}} \right)\) at true value R = 0.563, (Table 4).
-
3.
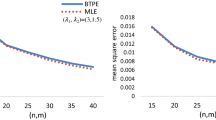
Figures 3 and 4 show that, in the majority of circumstances, the MSEs of \({{\tilde{R}}_1},{{\tilde{R}}_2},{{\tilde{R}}_3}\) and \({{\tilde{R}}_4}\) decrease as sample size increases. Additionally, we note that Case 1 has the highest MSE values compared to the others.
-
4.
As seen in Fig. 4, Case 3 has the lowest MSE values at true value R = 0.768 when compared to the other cases.
-
5.
The MSE of the system reliability \({{\tilde{R}}_3}\) has the least MSE at R =0.563 when \((m_2^*,m_1^ *,m_3^* ) =\) (20,20,20) and (30,30,30) as shown in Fig. 3.
-
6.
The MSE of the system reliability \({{\tilde{R}}_3}\) has the least MSE at R = 0.768 at sample sizes (10,10,10), (20,20,20) and (30,30,30) as shown in Fig. 4.
-
7.
The MSE of \({{\hat{R}}_1},{{\hat{R}}_2},{{\hat{R}}_3},{{\hat{R}}_4}\) decreases as the actual value of R increases as seen in Figs. 5 and 6.
-
8.
As illustrated in Figs. 5 and 6, the MSE in Case 1 of \({{\hat{R}}_1}\) has the largest values when compared to the other cases.
-
9.
Figure 5 shows that the system reliability \({{\hat{R}}_3}\) has the least MSE at R = 0.456 and 0.768 at sample sizes (10,10,10), while Fig. 6 shows that the MSE of the system reliability \({{\hat{R}}_3}\) has the least MSE at R = 0.456 and 0.563 at sample sizes (30,10,30).
-
10.
For chosen sample size values (20, 20, 20) and different real values of R under the MPS method, we conclude that using RSS strengths and stress random variables (Case 2) is more efficient than the others, as illustrated in Fig. 7.
-
11.
The RE for \({\hat{R}}\) increases as the sample size increases at R = 0.456 and R = 0.563 respectively (see for example Fig. 8).
-
12.
Figure 8 indicates that Case 2 is the most efficient at sample sizes (10,10,10), (20,20,20) while Case 3 is the most efficient at sample sizes (30,30,30).
-
13.
Figure 9 explains that case C2 is the most efficient at sample sizes (20,20,20) and (30,30,30) while Case 3 is the most efficient at sample size (10,10,10).
-
14.
Figure 10 shows that MLE of R has a smaller MSE than the MPSE at R = 0.768 for sample size (30,30,30), also it indicates that case 2 has the least MSE compared to the other cases for both MLE and MPSE.
-
15.
It is clear from Tables 7, 8 and 9 that the ML method is preferred than the MPS method in most of the situations except at true value \(R =0.456\) when the observed samples from stresses and strength data are all drawn from RSS (Case 2).

MSE of \({{\tilde{R}}_1},{{\tilde{R}}_2},{{\tilde{R}}_3},{{\tilde{R}}_4}\) at R = 0.563

MSE of \({{\tilde{R}}_1},{{\tilde{R}}_2},{{\tilde{R}}_3},{{\tilde{R}}_4}\) at R = 0.768

MSE of \({{\hat{R}}_1},{{\hat{R}}_2},{{\hat{R}}_3},{{\hat{R}}_4}\) for different values of R at (10, 10, 10)

MSE of \({{\hat{R}}_1},{{\hat{R}}_2},{{\hat{R}}_3},{{\hat{R}}_4}\) for different values of R at (30, 10, 30)

MSE of \({{\tilde{R}}_1},{{\tilde{R}}_2},{{\tilde{R}}_3},{{\tilde{R}}_4}\) for sample size (20, 20, 20) at different values of R

\(RE({\hat{R}})\) comparison of different sample sizes at R = 0.456

\(RE({\hat{R}})\) comparison of different sample sizes at R = 0.563

MSE comparison of different cases at R = 0.768 and sample size (30,30,30)
8 Application
This section considered and described in details three data sets to illustrate the usefulness of the proposed models. The first application is a real data set obtained from [47]. It consists of thirty successive values of March precipitation (in inches) in Minneapolis/St Paul. The second data application was given by [48]. The data set refers to the time between failures for repairable items. The third data application is the vinyl chloride data obtained from clean upgrading, and monitoring wells in mg/L; this data set was used by [49].
Data Set I: X \(m_1^*\; = \;30\)
0.77 | 1.74 | 0.81 | 1.2 | 1.95 | 1.2 | 0.47 | 1.43 | 3.37 | 2.2 |
3 | 3.09 | 1.51 | 2.1 | 0.52 | 1.62 | 1.31 | 0.32 | 0.59 | 0.81 |
2.81 | 1.87 | 1.18 | 1.35 | 4.75 | 2.48 | 0.96 | 1.89 | 0.9 | 2.05 |
Data Set II: W \(m_2^*\; = \;30\)
1.43 | 0.11 | 0.71 | 0.77 | 2.63 | 1.49 | 3.46 | 2.46 | 0.59 | 0.74 |
1.23 | 0.94 | 4.36 | 0.4 | 1.74 | 4.73 | 2.23 | 0.45 | 0.7 | 1.06 |
1.46 | 0.3 | 1.82 | 2.37 | 0.63 | 1.23 | 1.24 | 1.97 | 1.86 | 1.17 |
Data Set III: Z \(m_3^*\; = \;34\)
5.1 | 1.2 | 1.3 | 0.6 | 0.5 | 2.4 | 0.5 | 1.1 | 8 | 0.8 | 6.8 | 0.2 |
0.4 | 0.6 | 0.9 | 0.4 | 2 | 0.5 | 5.3 | 3.2 | 2.7 | 2.9 | 1.2 | 0.4 |
2.5 | 2.3 | 1 | 0.2 | 0.1 | 0.1 | 1.8 | 0.9 | 2 | 4 |
The three data sets were tested by Ref. [50] who showed that the IKwD fits this data well. Based on the foregoing theoretical conclusions, the analysed real data sets are sampled using both the RSS and SRS techniques. The reliability estimates from the IKwD are shown in Table 10 for various set size values based on five cycles and four various scenarios. The R-package RSS sampling is used to create the RSS and SRS using data sets I, II, and III. Based on these data sets I, II and III, the initial PDF shapes using the non-parametric kernel density estimation approach are shown in Figs. 11, 12 and 13. From these figures, it can be seen that the obtained PDF has an asymmetric shape. The quantile-quantile (QQ) plot is used to examine the normality condition (see Figs. 11, 12 and 13). The boxplot can also be used to identify outliers, as can be seen in Figs. 11, 12 and 13

Some non-parametric plots for the data set I

Some non-parametric plots for the data set II

Some non-parametric plots for the data set III
9 Summary and Conclusion
Systems usually perform badly in several real-world scenarios because of the demanding operational circumstances. Researchers generally pay little attention to the fact that systems usually fail to carry out their intended functions when they are in their most extreme functioning states lower, higher, or both. This article’s goal is to construct an inference for the reliability function in situations where SS variables have inverted Kumaraswamy distributions based on RSS and SRS methodologies. As a result, the issue of ML and MPS procedures are used in estimating the SS function, R, if W, X, and Z are drawn from three separate independent inverted Kumaraswamy distributions under four cases; that is, case 1: \({R_1} = \,P[{W_{SRS}}< {X_{SRS}} < {Z_{SRS}}]\), Case 2: \({R_2} = \,P[{W_{RSS}}< {X_{RSS}} < {Z_{RSS}}]\), Case 3: \({R_3} = \,P[{W_{RSS}}< {X_{SRS}} < {Z_{RSS}}]\) and Case 4: \({R_4} = \,P[{W_{SRS}}< {X_{RSS}} < {Z_{SRS}}]\); for both methodologies is the subject of this article. To assess the effectiveness of the reliability estimators of the four models, a numerical study is conducted, and it is discovered that all reliability estimates perform better as the set sizes increase in the four cases. In general, we may deduce that models including the reliability estimators (Case 2, 3, and 4) via RSS are superior to the reliability estimator in Case 1 via SRS methodology for both methods, in the majority of situations. The efficiency of the SS reliability function improves as the set size increases. Application to real data has been analyzed for more information. Further research will consider the Bayesian estimation technique of \(R=P(W<X<Z\)) in case of imperfect ranking.
Availability of Data and Materials
Any data that supports the findings of this study is included in the article.
References
McIntyre, G.A.: A method for unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 3(4), 385–390 (1952)
Takahasi, K., Wakimoto, K.: On unbiased estimates of the population mean based on the sample stratified by means of ordering. Ann. Inst. Stat. Math. 20(1), 1–31 (1968)
Lone, S.A., Panahi, H., Shah, I.: Bayesian prediction interval for a constant-stress partially accelerated life test model under censored data. J. Taibah Univ. Sci. 15(1), 1178–1187 (2021). https://doi.org/10.1080/16583655.2021.2023847
Sindhu, T.N., Colak, A.B., Lone, S.A., Shafiq, A.: Reliability study of generalized exponential distribution based on inverse power law using artificial neural network with Bayesian regularization. Qual. Reliab. Eng. Int. 39(6), 2398–2421 (2023)
Shafiq, A., Colak, A.B., Lone, S.A., Sindhu, T.N.: Reliability modeling and analysis of mixture of exponential distributions using artificial neural network. Math. Methods Appl. Sci. 47(5), 3308–3328 (2024). https://doi.org/10.1002/qre.3352
Lone, S.A., Panahi, H., Anwar, S., Sana, S.: Inference of reliability model with burr type XII distribution under two sample balanced progressive censored samples. Phys. Scr. (2024). https://doi.org/10.1088/1402-4896/ad1c29
Birnbaum, Z.W., McCarty, R.C.: A distribution-free upper confidence bound for Pr[\(Y<X\)], based on independent samples of X and Y. Ann. Math. Stat. 29(2), 558–562 (1958)
Kundu, D., Gupta, R.D.: Estimation of P[\(Y<X\)] for Weibull distributions. IEEE Trans. Reliab. 55(2), 270–280 (2006)
Rezaei, S., Tahmasbi, R., Mahmoodi, M.: Estimation of P[\(Y<X\)] for generalized Pareto distribution. J. Stat. Plan. Inference 140(2), 480–494 (2010)
Babayi, S., Khorram, E., Tondro, F.: Inference of R=P[\(X<Y\)] for generalized logistic distribution. Statistics 48(4), 862–871 (2014)
Hassan, A.S., Abd-Allah, M., Nagy, H.F.: Estimation of P(\(Y<X\)) using record values from the generalized inverted exponential distribution. Pak. J. Stat. Oper. Res. 14(3), 645–660 (2018)
Anwar, S., Lone, S.A., Khan, A., Almutlak, S.: Stress-strength reliability estimation for the inverted exponentiated Rayleigh distribution under unified progressive hybrid censoring with application. AIMS Electron. Res. Arch. 31(7), 4011–4033 (2023). https://doi.org/10.1002/qre.3352
Sengupta, S., Mukhuti, S.: Unbiased estimation of P(\(X>Y\)) using ranked set sample data. Statistics 42(3), 223–230 (2008)
Akgul, F.G., Senoglu, B.: Estimation of P(\(X<Y\)) using ranked set sampling for the Weibull distribution. Qual. Technol. Quant. Manag. 14(3), 296–309 (2017)
Al-Omari, A.I., Almanjahie, I.M., Hassan, A.S., Nagy, H.F.: Estimation of the stress-strength reliability for exponentiated Pareto distribution using median and ranked set sampling methods. CMC Comput. Mater. Continua 64(2), 835–857 (2020)
Hassan, A.S., Al-Omari, A., Nagy, H.F.: Stress-strength reliability for the generalized inverted exponential distribution using MRSS. Iran. J. Sci. Technol. Trans. A Sci. 45(2), 641–659 (2021)
Esemen, M., Gurler, S., Sevinc, B.: Estimation of stress-strength reliability based on ranked set sampling for generalized exponential distribution. Int. J. Reliab. Qual. Saf. Eng. 28(2), 2150011 (2021). https://doi.org/10.1142/S021853932150011X
Hassan, A.S., Elshaarawy, R.S., Onyango, R., Nagy, H.F.: Estimating system reliability using neoteric and median RSS data for generalized exponential distribution. Int. J. Math. Math. Sci. (2022). https://doi.org/10.1155/2022/2608656
Hassan, A.S., Nagy, H.F.: Reliability estimation in multicomponent stress strength for generalized inverted exponential distribution based on ranked set sampling. Gazi Univ. J. Sci. 35(1), 314–331 (2022)
Bhushan, S., Kumar, A., Lone, S.A.: On some novel classes of estimators using ranked set sampling. Alex. Eng. J. 61(7), 5465–5474 (2022)
Yousef, M.M., Hassan, A.S., Al-Nefaie, A.H., Almetwally, E.M., Almongy, H.M.: Bayesian estimation using MCMC method of system reliability for inverted Topp–Leone distribution based on ranked set sampling. Mathematics 10(17), 3122 (2022). https://doi.org/10.3390/math10173122
Hassan, A.S., Nagy, H.F.: Reliability estimation in multicomponent stress-strength for generalized inverted exponential distribution based on ranked set sampling. Gazi Univ. J. Sci. 35(1), 314–331 (2022)
Hassan, A.S., Almanjahie, I.M., Al-Omari, A.I., Alzoubi, L., Nagy, H.F.: Stress-strength modeling using median-ranked set sampling: estimation, simulation, and application. Mathematics 11(2), 318 (2023). https://doi.org/10.3390/math11020318
Alsadat, N., Hassan, A.S., Elgarhy, M., Chesneau, C., Mohamed, R.E.: An efficient stress-strength reliability estimate of the unit Gompertz distribution using ranked set sampling. Symmetry 15(5), 1121 (2023). https://doi.org/10.3390/sym15051121
Hassan, A.S., ElShaarawy, R., Nagy, H.F.: Estimation study of multicomponent stress-strength reliability using advanced sampling approach. Gazi Univ. J. Sci. (2024). https://doi.org/10.35378/gujs.1132770
Chandra, S., Owen, D.B.: On estimating the reliability of a component subject to several different stresses (strengths). Nav. Res. Logist. Q. 22(1), 31–39 (1975)
Dutta, K., Sriwastav, G.L.: An n-standby system with P(\(X<Y<Z\)). Indian Assoc. Prod. Qual. Reliab. 12(1–2), 95–97 (1986)
Singh, N.: On the estimation of P(\(X_1<Y<X_2\)). Commun. Stat. Theory Methods 9(15), 1551–1561 (1980)
Ivshin, V.V.: On the estimation of the probabilities of a double linear inequality in the case of uniform and two-parameter exponential distributions. J. Math. Sci. 88(6), 819–827 (1998)
Guangming, P., Xiping, W., Wang, Z.: Nonparametric statistical inference for P(\(X<Y<Z\)). Sankhya A 75(1), 118–138 (2013)
Hassan, A.S., Elsayed, A.E., Shalaby, R.M.: On the estimation of P(\(X<Y<Z\)) for Weibull distribution in the presence of k outliers. Int. J. Eng. Res. Appl. 3(6), 1728–1734 (2013)
Hameed, B.A., Salman, A.N., Kalaf, B.A.: On estimation of in cased inverse Kumaraswamy distribution. Iraqi J. Sci. 61(4), 845–853 (2020)
Kalaf, B.A., Raheem, S.H., Salman, A.N.: Estimation of the reliability system in model of stress-strength according to distribution of inverse Rayleigh. Period. Eng. Nat. Sci. (PEN) 9(2), 524–533 (2021)
Abd Elfattah, A.M., Taha, M.A.: On the estimation of P(\(Y<X<Z\)) for inverse Rayleigh distribution in the presence of outliers. J. Stat. Appl. Probab. Lett. 8(3), 181–189 (2021)
Yousef, M.M., Almetwally, E.M.: Multi stress-strength reliability based on progressive first failure for Kumaraswamy model: Bayesian and non-Bayesian estimation. Symmetry 13(11), 2120 (2021). https://doi.org/10.3390/sym13112120
Yousef, M.M., Hassan, A.S., Alshanbari, H.M., El-Bagoury, A.-A.H., Almetwally, E.M.: Bayesian and non-bayesian analysis of exponentiated exponential stress-strength model based on generalized progressive hybrid censoring process. Axioms 11(9), 455 (2022). https://doi.org/10.3390/axioms11090455
Hassan, A.S., Alsadat, N., Elgarhy, M., Chesneau, C., Nagy, H.F.: Analysis of P[\(Y<X<Z\)] using ranked set sampling for a generalized inverse exponential model. Axioms 12(3), 302 (2023). https://doi.org/10.3390/axioms12030302
Abd AL-Fattah, A.M., El-Helbawy, A.A., Al-Dayian, G.R.: Inverted Kumaraswamy distribution: properties and estimation. Pak. J. Stat. 33(1), 37–61 (2017)
Mohie El-Din, M.M., Abu-Moussa, M.: On estimation and prediction for the inverted Kumaraswamy distribution based on general progressive censored samples. Pak. J. Stat. Oper. Res. 14(34), 717–736 (2018)
Bagci, K., Arslan, T.E., Celik, H.: Inverted Kumarswamy distribution for modeling the wind speed data: Lake Van, Turkey. Renew. Sustain. Energy Rev. 135, 110110 (2021)
AL-Dayian G.R., EL-Helbawy, A.A., Abd AL-Fattah, A.M.: Statistical inference for inverted Kumaraswamy distribution based on dual generalized order statistics. Pak. J. Stat. Oper. Res. 16(4), 649–660 (2020)
Noor, F., Masood, S., Zaman, M,, Siddiqa, M., Wagan, R.A., Khan, I.U., Sajid, A.: Bayesian Analysis of Inverted Kumaraswamy Mixture Model with Application to Burning Velocity of Chemicals. Recent Trends Adv. Robot. Syst. 2021, 5569652. https://doi.org/10.1155/2021/5569652
Nagy, H.F., Al-Omari, A.I., Hassan, A.S., Alomani, G.A.: Improved estimation of the inverted Kumaraswamy distribution parameters based on ranked set sampling with an application to real data. Mathematics 10, 4102 (2022). https://doi.org/10.3390/math10214102
Yousef, M.M., Alyami, S.A., Hashem, A.F.: Statistical inference for a constant-stress partially accelerated life tests based on progressively hybrid censored samples from inverted Kumaraswamy distribution. PLoS One 17(8), e0272378 (2022). https://doi.org/10.1371/journal.pone.0272378
Yousef, M.M., Alsultan, R., Nassr, S.G.: Parametric inference on partially accelerated life testing for the inverted Kumaraswamy distribution based on Type-II progressive censoring data. Math. Biosci. Eng. 20(2), 1674–1694 (2023)
Cheng, R., Amin, N.: Maximum product of spacings estimation with application to the lognormal distribution (Mathematical Report 79–1). University of Wales IST, Cardiff (1979)
Hinkley, D.: On quick choice of power transformation. J. R. Stat. Soc. Ser. C (Appl. Stat.) 26(1), 67–69 (1977)
Murthy, D.N.P., Xie, M., Jiang, R.: Weibull Models. Wiley, New York (2004)
Bhaumik, D.K., Kapur, K., Gibbons, R.D.: Testing parameters of a gamma distribution for small samples. Technometrics 51(3), 326–334 (2009)
EL-Helbawy, A.A.-A., AL-Dayian, G.R., Abd AL-Fattah, A.M.: Statistical inference for inverted Kumaraswamy distribution based on dual generalized order statistics. Pak. J. Stat. Oper. Res. 16(4), 649–660 (2020)
Acknowledgements
This research is supported by researchers Supporting Project number (RSPD2024R548), King Saud University, Riyadh, Saudi Arabia.
Funding
This research was funded by King Saud University, grant number RSPD2024R548.
Author information
Authors and Affiliations
Contributions
A.S.H., N.A., M.E., H.A. and H.F.N., these authors contributed equally to all parts of this research.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no Conflict of interest.
Ethics approval and consent to participate
Ethics approval and consent to participate.
Consent for publication
All the authors agreed to publish this research.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hassan, A.S., Alsadat, N., Elgarhy, M. et al. On Estimating Multi- Stress Strength Reliability for Inverted Kumaraswamy Under Ranked Set Sampling with Application in Engineering. J Nonlinear Math Phys 31, 30 (2024). https://doi.org/10.1007/s44198-024-00196-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44198-024-00196-y