
Abstract
The Internet of Things (IoT) has been extensively utilized in domains such as smart homes, healthcare, and other industries. With the exponential growth of Internet of Things (IoT) devices, they have become prime targets for malicious cyber-attacks. Effective classification of IoT traffic is, therefore, imperative to enable robust intrusion detection systems. However, IoT traffic data contain intricate spatial relationships and topological information, which traditional methods for traffic identification lack the capability to fully extract features and capture crucial characteristics. We propose a multi-scale convolutional feature fusion network augmented with a Convolutional Block Attention Module (MCF-CBAM) for accurate IoT traffic classification. The network incorporates three critical innovations: (1) Parallel convolution extracts multi-scale spatial features from traffic data. The 1 × 1 convolution operation reduces the amount of parameters and calculations of the network, thereby improving work efficiency. (2) The attention module suppresses less informative features while highlighting the most discriminative ones, enabling focused learning on decisive features. (3) Cross-scale connections with channel jumps reuse features from prior layers to enhance generalization. We evaluate the method extensively on three widely adopted public datasets. Quantitative results demonstrate MCF-CBAM establishes new state-of-the-art performance benchmarks for IoT traffic classification, surpassing existing methods by a significant margin. Qualitative visualizations of the learned attention weights provide intuitive insights into how the network automatically discovers the most decisive spatial features for identification. With its strong empirical performance and interpretable attention mechanisms, this work presents a promising deep learning solution to augment real-world IoT intrusion detection systems against growing cybersecurity threats.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
As a core technology of the fourth industrial revolution, the Internet of Things has found widespread applications in logistics and transportation, industrial processing, smart homes, healthcare, and various other fields [1,2,3,4]. While simplifying human lifestyles and work processes, it also introduces network security risks, an increasing number of IoT devices have been deployed worldwide. IoT devices are typically resource-constrained and have insufficient protection capabilities, making them vulnerable to cyber-attacks [5]. In 2016, the Mirai botnet infected massive IoT devices to launch powerful distributed denial-of-service (DDoS) attacks on DNS servers in the US, causing significant service disruptions [6]. In addition, privacy breaches through IoT devices like smart cameras and speakers are also on the rise [7]. Given the severe security threats posed by IoT systems, it is imperative to develop tailored solutions to safeguard them.
Among various security techniques, network traffic analysis and classification play a vital role in IoT intrusion detection systems (IDS). By inspecting network traffic patterns, malicious activities such as DDoS attacks and unauthorized access can be identified in a timely manner [8]. In smart homes, IoT devices often face vulnerabilities like unauthorized access and control. Network traffic analysis can effectively detect the communication patterns of smart home devices to identify abnormal or malicious activities while ensuring the security and normal operation of these intelligent living spaces [9]. The security concerns associated with smart cities primarily encompass the integrity, accuracy, and confidentiality of urban data, as well as the safety of life and property and personal privacy of urban residents. Network traffic analysis and classification technology can comprehensively scrutinize the network, protocols, and data pertaining to each subsystem within a smart city in order to identify potential attacks against such cities while ensuring their secure and efficient operation [10]. In the context of the Industrial Internet of Things, efficient traffic classification methods play a crucial role in enabling enterprises to detect and mitigate unauthorized intrusions, safeguarding their equipment and data. This not only enhances the comprehensiveness and precision of product testing but also expedites product launch [11]. Furthermore, by facilitating identification of malicious attacks and activities, traffic analysis and classification assist enterprises in gaining deeper insights into the condition of their devices and data. Consequently, administrators are prompted to undertake timely maintenance and repairs, thereby augmenting project productivity [12].
Existing IoT traffic analysis methods can be divided into signature-based and anomaly-based [13]. Signature-based methods rely on pre-defined attack signatures to detect known threats. However, these methods require constant database update and fail to identify new attacks [14]. In contrast, anomaly-based methods build models using machine learning algorithms to detect anomalies. Although deep learning models like CNNs and RNNs can automatically extract features [15, 16], they lack the ability to fully capture the complex spatial relationships and topological information within IoT traffic data [17]. In addition, the traditional stacked network structure lacks the ability to effectively extract key features, resulting in limited feature representation capabilities and affecting the classification effect [18]. Existing deep learning models for IoT intrusion detection usually only consider the accuracy of the model and ignore the time required for the model to run, resulting in low work efficiency.
To address these limitations, we propose a multi-scale convolutional feature fusion network augmented with a Convolutional Block Attention Module (MCF-CBAM) for robust IoT traffic classification. Use parallel convolutional structures to extract multi-scale features. An attention mechanism is introduced to adaptively adjust feature weights to better extract key features, and enrich feature extraction through feature reuse. To test the effectiveness of the proposed model, experiments are conducted on traffic data sets of different network environments, and we have evaluated MCF-CBAM with other common traffic classification algorithms. Furthermore, we compared MCF-CBAM with advanced IDS-based models. Experiments show that the MCF-CBAM model is better than common traffic classification algorithms and other IDS models.
The main contributions of this study are listed below:
-
(1)
Considering the complex semantic relationships between different IoT traffic features, a parallel convolution structure is designed to extract multi-scale traffic features and increase the diversity of feature extraction. Using 1 × 1 convolution operation reduces the parameter amount and calculation amount of the network, thereby reducing runtime and improving work efficiency.
-
(2)
An attention mechanism is introduced to make the model pay more attention to important traffic characteristics. Integrate CBAM that acts on the channel domain and spatial domain into MCF to increase the weight of important features and suppress insignificant ones.
-
(3)
Side classifiers with channel jump connection for feature reuse, so that low-level features and high-level features work together on the classifier. This structure can be used to extract more global and important features.
-
(4)
State-of-the-art performance and strong robustness validated by experiments on three datasets.
The remainder of this paper is structured as follows. Section 2 surveys related work on IoT intrusion detection using machine learning. Section 3 presents the proposed methodology in detail. The results are provided in Sect. 4. Some key issues are discussed in Sect. 5, followed by conclusions in Sect. 6. Section 7 describes future work.
2 Related Work
In the context of IoT network environments, network attack types exhibit a high degree of complexity and diversity. Deep learning models have demonstrated their proficiency in traffic detection, primarily due to their exceptional automatic feature extraction capabilities. Consequently, researchers in the field of intrusion detection are shifting their focus from traditional machine learning to deep learning methodologies. In this section, we will delve into a detailed exploration of various traffic classification and identification methods utilized in the realm of intrusion detection.
2.1 A. Traditional Supervised Machine Learning Methods
SVM-based IoT Intrusion Detection [19]: Birnbach et al. harnessed Support Vector Machine (SVM) technology to craft an IoT intrusion detection system tailored for identifying sensor data within smart home devices and validating the authenticity of physical events generated by sensors. However, this approach had an inherent limitation—it struggled to differentiate fake physical event reports sent by attackers.
Hybrid Machine Learning Detection [20]: Bhatt and his contemporaries pioneered a hybrid machine learning detection system by integrating the Gaussian mixture model with the isolation forest algorithm. Their approach focused on identifying and detecting anomalies by analyzing the timing characteristics inherent in IoT-generated traffic patterns.
IoT-Argos Multi-stage Anomaly Detection [21]: IoT-Argos adopted a multi-stage anomaly detection methodology, with the initial stage employing five lightweight machine learning techniques to detect and filter a subset of attacks. This strategic choice aimed to reduce the computational load on resource-constrained IoT devices, minimizing CPU and memory consumption.
Deep Learning and K-Means Clustering [22]: Ravi and fellow researchers proposed a unique amalgamation of deep learning and machine learning techniques. Their approach utilized a deep feed-forward neural network (DFNN) for feature extraction and leveraged the K-means clustering algorithm for classification. However, due to the intricate nature of IoT traffic, K-means clustering struggled to effectively partition corresponding clusters, rendering it less suitable for IoT intrusion detection.
Feature Selection Algorithm with PIO [23]: Alazzam et al. introduced an innovative feature selection algorithm grounded in Pigeon Inspired Optimization (PIO). This algorithm expedited model convergence by incorporating cosine similarity and leveraged decision trees (DT) as classifiers. While well-suited for processing large-scale IoT datasets, this method exhibited a propensity for overfitting, resulting in model accuracy falling below the 90% threshold.
Two-Layer Dimensionality Reduction [24]: Pajouh and colleagues introduced an anomaly intrusion detection system featuring a two-layer dimensionality reduction strategy complemented by two-layer classification. However, the primary focus of this method was the detection of common attacks primarily concentrated in low-frequency bands, such as R2L (Remote-to-Local) and U2L (User-to-Local).
Lightweight SVM Intrusion Detection [25]: Jan et al. conceived a lightweight SVM-based intrusion detection model that relied solely on extracting average, median, and minimum values of packet arrival rates as feature inputs. This limited feature scope resulted in vulnerabilities to certain attack vectors.
In summary, traditional machine learning methods, while excelling in terms of runtime efficiency, tend to focus primarily on binary classification for detecting abnormal traffic. These methods often fall short in conducting a detailed analysis of specific attack types. Recognizing the importance of promptly identifying and mitigating various attack types underscores the necessity for more comprehensive intrusion detection techniques.
2.2 B. Advanced Deep Learning Approaches
The increasing prevalence of IoT devices has led to a surge in network attacks, posing severe security threats. Traditional machine learning methods have been widely adopted for IoT intrusion detection, but they often suffer from limitations such as binary classification, handcrafted feature engineering, and limited generalization capability.
Deep learning has emerged as a promising solution for IoT intrusion detection due to its superior automatic feature extraction capabilities. Deep learning methods for IoT intrusion detection are widely used in smart homes and industrial production. Some notable examples include:
-
(1)
A supervised intrusion detection system [26]: This method proposes a three-layer intrusion detection model that can automatically differentiate smart home devices. Identify and classify malicious packets when a device receives a malicious attack.
-
(2)
Self-Configurable Cyber-Physical [27]: This method considers both traffic data and smart home underlying physical data. Use unsupervised learning to automatically update parameters for intrusion detection based on changes in the surrounding network environment.
-
(3)
Robust detection for network intrusion [28]: This method uses an ensemble model of multiple convolutional neural networks (CNN) to process one-dimensional feature data and then fuses them together to improve the accuracy of the classifier. However, this method was only tested on one data set and cannot prove the strong robustness of the model.
-
(4)
Communication efficient federated learning [29]: This method combines a convolutional neural network with a long short-term memory network to detect abnormal industrial traffic. And reduce resource consumption through the gradient compression mechanism. However, when faced with low-dimensional industrial traffic data, detection efficiency will be affected.
-
(5)
Hierarchical federated learning [30]: This method uses federated learning to build an intrusion detection model, and deep reinforcement learning to train local models, achieving high accuracy and low latency. However, this method relies on high-dimensional industrial flow data, and the detection accuracy needs to be improved.
Existing deep learning methods for IoT intrusion detection can be broadly categorized into two groups:
-
(1)
Feature selection-based deep learning: These methods typically employ deep neural networks to extract discriminative features from traffic data, followed by a classifier to perform attack detection.
-
(2)
Feature fusion-based deep learning: These methods combine multiple features from traffic data, extracted using different techniques, to improve detection performance.
Some notable examples of feature selection-based deep learning methods for IoT intrusion detection include:
-
(1)
Feature Selection with Deep Learning [31]: This method uses a deep learning model to learn a robust feature subspace for attack detection.
-
(2)
Deep Learning for Feature Selection [32]: This method combines deep learning with decision trees to learn a feature subspace with high discriminative power.
-
(3)
Fog Computing Framework [33]: This method uses advanced feature selection techniques and recurrent neural networks to identify attack traffic in the fog paradigm.
Some notable examples of feature fusion-based deep learning methods for IoT intrusion detection include:
-
(1)
Multi-Level Feature Fusion [34]: This method fuses hierarchical features from traffic statistics, timing, and bytes to improve detection performance.
-
(2)
Attention-Based Multi-scale Convolutional Feature Fusion Network [Ours]: This method proposes a novel attention-based multi-scale convolutional feature fusion network to extract and fuse multi-scale spatial features for enhanced representation.
Despite the promising results achieved by deep learning methods, there are still some major problems that need to be addressed, such as:
-
(1)
Many deep learning models for IoT intrusion detection usually utilize high-level features deep in the network and discard secondary traffic features. However, secondary features may contain valuable information. How to make reasonable use of features is an important issue.
-
(2)
Existing deep learning models for IoT intrusion detection often employ single-stacked networks, which may lead to suboptimal utilization of traffic characteristics.
-
(3)
Most deep learning models for IoT intrusion detection usually do not prioritize significant traffic features. In theory, key features should play a more important role in the traffic identification process. How to make the network model pay more attention to the key characteristics of traffic has become a major issue in IoT intrusion detection.
-
(4)
At present, most researchers in the field of IoT intrusion detection end the research process with the final experimental results, while ignoring further explanation and analysis of the deep learning model. Furthermore, there is no universally accepted evaluation protocol for deep learning models for IoT intrusion detection.
In this paper, we propose an attention-based multi-scale convolutional feature fusion network tailored for IoT intrusion detection. Our network addresses the aforementioned challenges by:
-
(1)
Extracting and fusing multi-scale spatial features: Our network uses a parallel convolutional structure to extract multi-scale spatial features for enhanced representation.
-
(2)
Incorporating channel and spatial attention modules: Our network incorporates channel and spatial attention modules to adaptively highlight decisive traffic features.
-
(3)
Using side classifiers with channel jump connections: Our network uses side classifiers with channel jump connections to achieve feature reuse and improve generalization.
-
(4)
Visual feature maps and feature weights help further explain deep learning models.
We conduct extensive experiments on diverse IoT traffic datasets to demonstrate the effectiveness of our proposed model. Our results show that our model achieves state-of-the-art performance in terms of both classification accuracy and efficiency.
3 Materials and Methods
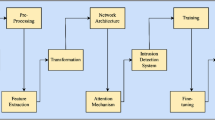
Multi-scale feature extraction and attention mechanism enhance the diversity and key feature mining capabilities of the network, respectively, thereby improving its ability to analyze diverse traffic data. The proposed MCF-CBAM model mainly consists of a multi-scale feature extraction layer, a feature fusion layer, an attention module, and a side classifier. The side classifier assists the main classifier in completing the classification task. During the training process, the sum of the side classifier's partial loss and the main classifier's loss is backpropagated to optimize the model using the Adam algorithm. Figure 1 illustrates the overall framework of the model.

Overall framework of MCF-CBAM model. The network mainly consists of multi-scale feature extraction layer, multi-scale feature fusion layer, attention mechanism layer and side classifier
3.1 Multi-scale Feature Extraction
Early studies showed that shallow CNNs could only extract low-level features, prompting researchers to deepen the network to extract more abstract high-level features [35]. However, while increasing the number of network layers could enhance the feature extraction ability, it also made deep neural networks prone to the problems of gradient vanishing and explosion [36]. Numerous studies have demonstrated that increasing model width can effectively compensate for the lack of network depth, meaning that a reasonable increase in model width can also improve classification performance [37, 38]. This is because increasing the network model's width increases the number of channels in the feature map, thereby obtaining richer and more diverse feature information, effectively avoiding the negative impact of increasing model depth.
To avoid the loss of feature extraction diversity caused by using only one scale of convolutional kernel, we appropriately deepen the network width and use 1 × 1, 3 × 3, and 5 × 5 multi-scale convolutional kernels to extract flow features in parallel. However, using multi-scale convolutional kernels to extract features will increase the number of model training parameters, which may lead to overfitting and affect classification performance. To address this, we used extensive 1 × 1 convolution operations, which not only reduces the dimension of the channel and the number of model parameters, but also reduces the running time of the model and improves the execution efficiency. Additionally, we combine multiple feature maps to integrate feature information between different channels. Figure 2 illustrates this process.
where \(a^{l}\) represents the output of layer \(l\) and the input of layer \(l + 1\) in the network; \(w^{l + 1}\) represents the weight matrix of layer \(l + 1\); The nonlinear activation function ReLU (\(f\)) is used to learn complex nonlinear features. Parallel multi-scale convolution is employed, and the final output is the combination of the outputs of each convolution operation, given by:

Multi-scale convolution feature extraction
3.2 Side Classifier
Broadly speaking, traffic features can be divided into shallow, middle, and high-level features. High-level features are generally used as important elements for classification, which leads to the underutilization of middle and shallow features. To fully exploit the features and enable the network to capture richer features, we propose a side classifier, as shown in Fig. 3.

Internal structure of side classifier
The side classifier uses input from the previous layer and passes its corresponding feature map to the adjacent subsequent layer at each layer. These curved skip connections allow the input features of the previous neuron to be effectively transmitted to the next adjacent neuron, achieving feature reuse. Studies have shown that skip connections between adjacent layers enable neurons to quickly access gradients from input data, which reduces information transmission between neurons and effectively overcomes the gradient vanishing problem [39]. Therefore, the side classifier can not only use shallow features, but also overcome the gradient vanishing problem.
Unlike traditional network structures, the side classifier has 2L connections instead of L connections in a network with L layers. Each module includes a 3 × 3 convolutional operation, ReLU activation function, and a feature skip connection operation. Its input is the output of the multi-scale feature extraction layer of the main network, denoted as F. When the convolutional operation is performed, if the size and number of channels of the output matrix are the same as those of the input matrix F, the output feature map is added directly to F and then sent to the activation function. This is represented as follows:
When the size and channel number of \(a^{l}\) and the output matrix are different, \(a^{l}\) needs to be adjusted to the same structure as the output matrix by corresponding convolution operations \(t\). This is expressed as follows:
3.3 Attention Mechanism
The attention mechanism adaptively selects important features by adjusting the weights of different feature maps. We embed two attention mechanisms, Squeeze-and-Excitation (SE) and Convolutional Block Attention Module (CBAM), into MCF to obtain MCF-SE and MCF-CBAM, respectively. CBAM is a further improvement of SE.
3.4 (1) SENet (Channel Attention Mechanism)
The Squeeze-and-Excitation (SE) module explicitly models inter-channel dependencies [40]. It constructs useful features by fusing spatial and channel information within the local receptive field. It adaptively adjusts feature weights between channels, enhancing CNN representation ability. The structure of the SE module is shown in Fig. 4.

Architecture of SE attention
The SE module consists of four steps:
a) Extract flow features from a single flow grayscale image. The resulting feature map has dimensions of [C, H, W], where C is the number of channels, H is the height, and W is the width.
b) Perform maximum or average pooling on the spatial dimensions (H, W) of the feature map, reducing its size from [C, H, W] to [C, 1, 1]. Denote the cth element of the pooled feature map as \({{\text{Z}}}_{{\text{c}}}\). This can be understood as a weight for the cth channel.
c) The feature vector [C, 1, 1] can be interpreted as the weight of each channel, indicating how each channel affected the feature extraction process. After global pooling, the vector passes through the MLP network to obtain the channel weights, denoted as \({{\text{S}}}_{{\text{c}}}\), which represent the importance of each channel in the final feature representation.
d) After obtaining the weight of each channel C in the previous steps, we apply the weight to the feature map [C, H, W], multiplying each channel by its own weight. The final output is denoted as \({{\text{u}}}_{{\text{c}}}^{\mathrm{^{\prime}}}\). This means that when the weight is large, the value of the feature map of that channel will increase, and its influence on the final output will also increase. Conversely, when the weight is small, the value of the feature map of that channel will be smaller, and its influence on the final output will also decrease.
where \(\delta\) is Sigmoid function, \(f\) is ReLU function, \(W_{1}\) and \(W_{2}\) are parameters of two fully connected layers. Then, a corresponding weight \(s_{c}\) is assigned to each feature channel. The final output feature map \(u_{c}{\prime}\) is the product of \(s_{c}\) and \(u_{c}\).
3.5 (2) CBAM Attention Mechanism
CBAM is a simple and effective feed-forward convolutional neural network attention module [41]. It consists of two sequential attention modules: a channel attention module and a spatial attention module. The channel attention module learns to focus on informative channels by assigning higher weights to them. The spatial attention module learns to focus on informative spatial regions by assigning higher weights to them. The combination of channel attention and spatial attention allows CBAM to learn more discriminative features.
CBAM uses a combination of max pooling and average pooling to generate a channel weight vector, which is then used to modulate the feature map along the channel dimension. This is achieved using a fully connected layer or a one-dimensional convolution. CBAM also uses a combination of max pooling and average pooling to generate a spatial weight map, which is then used to modulate the feature map along the spatial dimensions. This is achieved using a two-dimensional convolution. The structure of CBAM is shown in Fig. 5.

Architecture of CBAM attention
Given a feature map \(F\) as input, utilizing CBAM produces a one-dimensional channel attention map \(M_{c}\) and a two-dimensional spatial attention map \(M_{s}\) sequentially. The overall attention process can be represented as:
where \(\otimes\) represents element-wise multiplication and \(F^{^{\prime\prime}}\) is the final output feature.
Figures 6 and 7 illustrate the design process of the channel attention module and the spatial attention module in CBAM, respectively. The details of each attention module are described below.

Channel attention module in CBAM

Architecture of spatial attention in CBAM attention
-
a)
The feature map is passed through MaxPool and AvgPool to generate two [C, 1, 1] weight vectors.
-
b)
The two weight vectors are processed by the same MLP network to obtain the weights for each channel.
-
c)
The mapped weights are added together and passed through a Sigmoid function to output the final channel attention weights.
-
d)
The channel attention weights are multiplied with the original feature map along each channel to obtain the final output.
The calculation formulas for the above process are found in (14, 15).
where \(\sigma\) denotes the Sigmoid function,\(W_{0} \in R^{C/r \times C}\), \(W_{1} \in R^{C \times C/r}\) and \(r\) is a reduction ratio used to reduce parameter overhead. Note that the weight matrices \(W_{0}\) and \(W_{1}\) of the MLP are shared for both inputs, and a ReLU activation function is applied after \(W_{0}\).
-
a)
The feature map is passed through MaxPool and AvgPool to generate two [1, H, W] weight vectors by channel-wise max pooling and average pooling operations. This reduces the number of channels from [C, H, W] to [1, H, W].
-
b)
The two weight vectors are stacked together to form a [2, H, W] spatial attention feature map.
-
c)
A convolutional layer is applied to transform the [2, H, W] feature map into a [1, H, W] feature map. This [1, H, W] feature map represents the importance of each point on the original feature map, with larger values indicating higher importance.
-
d)
The spatial attention weight [1, H, W] is multiplied with the original feature map [C, H, W] element-wise. Specifically, each point on the [H, W] plane of the feature map is assigned a corresponding weight.
The final output can be represented as:
where \(\sigma\) denotes the Sigmoid function, \(f^{7 \times 7}\) denotes a convolution operation with a filter size of 7 × 7.
In general, attention mechanisms allow models to adaptively assign weights to features, so that the most important features play a major role in the classification process. The main difference between SE and CBAM is that SE modules assign different weight coefficients to each feature map, while CBAM modules assign weights to both feature maps and each pixel of feature maps. Theoretically, CBAM should perform better than SE.
3.6 Model Execution Process
Figure 8 shows the overall process of traffic classification and identification. The dataset is preprocessed and divided into training and test sets in a 7:3 ratio. The training data are then passed through ordinary convolution and pooling operations to extract simple features, followed by the multi-scale feature extraction module to extract rich and complex spatial features.

Overall model execution process
The output of the first multi-scale feature fusion module is fed to the side classifier and the attention module. The attention module adaptively assigns weights to features based on their importance. The side classifier loss is added to the main classifier loss by a certain proportion. The sum of the two losses is used to update the network parameters using the Adam optimizer. It is important to note that the model used for testing does not include the side classifier.
4 Results
4.1 Dataset
In this work, we used three datasets: KDDCUP99 [42], UNSW-NB15 [43], and N-BaIoT [44].
4.2 A. KDDCUP99
KDDCUP99 is a large public dataset containing a variety of network traffic attacks. It was created by the US Department of Defense Advanced Planning Agency in 1999 for the Knowledge Discovery and Data Mining (KDD) Cup competition. The dataset contains over 4 million network traffic records, each labeled as either normal or attack traffic. The attack traffic is further classified into four categories: denial of service (DoS), probe, remote to user (R2L), and user to root (U2R).
4.3 B. UNSW-NB15
UNSW-NB15 is another large public dataset containing network traffic attacks. It was created by the Australian Network Security Center (ACCS) in 2015 and is designed to be more realistic and challenging than KDDCUP99. The dataset contains over 2.5 million network traffic records, labeled as either normal or attack traffic. The attack traffic is further classified into nine categories: DoS, generic, exploitation, fuzzer, malware, reconnaissance, analysis, backdoor, and shellcode.
4.4 C. N-BaIoT
N-BaIoT is a public dataset containing IoT traffic attacks. It was collected from 9 IoT devices infected by two different botnets: Mirai and BASHLITE. The dataset contains over 1.3 million network traffic records, labeled as either normal or attack traffic. The attack traffic is further classified into six categories: Mirai, BASHLITE, Scan (Mirai), Scan (BASHLITE), DoS, and TCP flooding (Table 1).
KDDCUP99 is an older dataset with a simpler data structure than UNSW-NB15 and N-BaIoT. It is suitable for training models to solve general traffic problems. UNSW-NB15 is a comprehensive dataset with a large number of features and a complex structure. N-BaIoT was created specifically for studying botnets in the IoT environment. It contains more novel attack types and more than 100 basic features, making it more challenging for network models than KDDCUP99 and UNSW-NB15.
In this paper, we focus on the N-BaIoT dataset, not only performing binary classification to identify abnormal traffic, but also using multi-classification to identify different attack types. We chose these three datasets to verify the generality of our proposed method, which performs well in intrusion detection in both IoT and general Internet environments.
4.5 Data Preprocessing
Since the datasets have different specifications and data distributions, directly running experiments on them will significantly impact the outcomes. Therefore, it is necessary to preprocess the datasets before model training to transform them to the same specification or a particular distribution. The main steps of data preprocessing are as follows:
a) Convert character features in the dataset to numeric features: This is necessary because most machine learning algorithms cannot directly process character features.
b) Numeric normalization: This step is performed to reduce the weight difference between different features and prevent some features from having a significant impact on the outcomes. It also converts data with varied attributes to data with a similar scale for comparison and analysis, which increases the accuracy and reliability of the data analysis. The calculation formulas for numeric normalization are as follows:
where \(x_{ij}\) represents the data matrix, \(ij\) represents the row index and column index, respectively; \(avg_{j}\) represents the mean value; \(stad_{j}\) represents the mean absolute deviation, which has better robustness than the standard deviation \(\sqrt {\frac{{\sum {(x_{ij} - \mathop {x_{j} }\limits^{ - } )^{2} } }}{n - 1}}\) for outliers. In the above calculation, some judgments need to be made. If \(avg_{j}\) = 0, then \(x_{ij}{\prime}\) = 0; if \(stad_{j}\) = 0, then \(x_{ij}{\prime}\) = 0.
c) Numeric normalization: Numeric normalization is a data preprocessing technique that compresses sample data to between 0 and 1. This eliminates the differences in dimensions and numerical values between different variable samples, making them comparable. The two most common numeric normalization methods are min–max normalization and z-score normalization. Min–max normalization scales the data to a range of 0 to 1 by subtracting the minimum value from each data point and then dividing by the range of values. The calculation formula is as follows:
After the above data preprocessing, we convert each row of data in the dataset into a two-dimensional matrix form as follows:
4.6 Experimental Setup
Experiments were conducted on three datasets: N-BaIoT, KDDCUP99, and UNSW-NB15, using three different models: MCF, MCF-SE, and MCF-CBAM. On N-BaIoT, binary classification, ternary classification, and multi-classification were performed to evaluate the models' performance in identifying different types of attacks. On KDDCUP99 and UNSW-NB15 datasets, only binary classification was performed. The best experimental results were compared with those of recent similar works. All confusion matrices listed in the experiment are generated by the MCF-CBAM network. Through repeated experiments, our selection of some key parameters is shown in Table 2. The main parameter we improved is the size of the convolution kernel. We use parallel 1 × 1, 3 × 3 and 5 × 5 convolution kernels to extract multi-scale features, which has not been paid attention to in previous research.
In classification tasks, the following terms are used:
-
a)
True positive (TP): A positive sample that is correctly predicted as positive.
-
b)
True negative (TN): A negative sample that is correctly predicted as negative.
-
c)
False positive (FP): A negative sample that is incorrectly predicted as positive.
-
d)
False negative (FN): A positive sample that is incorrectly predicted as negative.
The four most commonly used classification metrics are accuracy, precision, recall, and F1-score.
-
a)
Accuracy: The proportion of samples that are correctly predicted.
-
b)
Precision: The proportion of positive predictions that are correct.
-
c)
Recall: The proportion of positive samples that are correctly predicted.
-
d)
F1-score: A harmonic mean of precision and recall.
Accuracy is a good overall measure of performance, but it can be misleading in imbalanced datasets, where one class is much more common than the other. Precision and recall are more informative in these cases. Precision is important for tasks where it is costly to misclassify negative samples, such as spam detection. Recall is important for tasks where it is costly to miss positive samples, such as fraud detection.
The F1-score is a good balance of precision and recall. It is often used as the primary evaluation metric for classification tasks. The calculation formulas for Accuracy, Precision, Recall, and F1-Score are as follows:
4.7 Binary and Multi-class Classification on the N-BaIoT Dataset
A more comprehensive experiment was conducted on the N-BaIoT dataset. Initially, the focus was on identifying abnormal network traffic, leading to the dataset's division into two main categories: normal and abnormal traffic. Subsequently, within the abnormal traffic, two distinct types of botnet attacks were discerned. Furthermore, a detailed analysis was performed to identify various attack types emanating from these two botnets, totaling nine unique attack types in total. The specific process is illustrated in Fig. 9.

N-BaIoT classification process
4.7.1 Binary Classification of the N-BaIoT Dataset
Binary classification only needs to identify anomalous traffic, without further analyzing the attack type. Figure 10 shows the best classification results and scores of our model on the N-BaIoT dataset. As shown in Fig. 10(a), The MCF-CBAM network outperforms both MCF-SE and MCF in all performance indicators. This superiority can be attributed to the dual mechanisms of channel attention and spatial attention implemented by CBAM, which endow the MCF-CBAM network with a stronger ability to select key features compared to MCF-SE and MCF. In contrast, the absence of an attention mechanism in MCF leads to inaccurate discrimination between important and secondary features, resulting in lower performance indicators than those achieved by both MCF-CBAM and MCF-SE. Figure 10(b) illustrates the specific classification of normal traffic and abnormal traffic, where 0 represents normal traffic while 1 represents abnormal traffic. Only a few traffic samples are misclassified, which may be due to extremely similar traffic characteristics.

The best classification results and scores of our model for binary classification, (a) two-class classification performance on N-BaIoT dataset, (b) two-class confusion matrix on N-BaIoT dataset
4.7.2 Ternary Classification of the N-BaIoT Dataset
The N-BaIoT dataset comprises two distinct types of botnet network traffic, namely Mirai and Gafgyt. Ternary classification further extends our ability to identify specific botnet attacks within the malicious traffic.
Our model exhibits outstanding performance in ternary classification on the N-BaIoT dataset, as demonstrated in Fig. 11. Figure 11a presents the scores of various performance indicators for ternary classification. The results prominently highlight the exceptional performance of all three networks in ternary classification, with MCF-CBAM consistently achieving the best results. Notably, its accuracy reaches an impressive 99.94%, albeit slightly lower than that achieved in binary classification, likely due to the slightly greater complexity of the classification task. Figure 11b provides a visual breakdown, where 0 represents normal traffic, 1 represents Mirai, and 2 represents Gafgyt. This visualization aids in a clearer understanding of our model's classification outcomes and the distribution of different categories in ternary classification. It can be seen from the figure that the detection rates of FP and FN in the MCF-CBAM network are relatively low, making the prediction results very accurate.

The best classification results and scores of our model for ternary classification, a ternary classification performance on N-BaIoT dataset; b ternary classification confusion matrix on N-BaIoT dataset
4.7.3 Ten-Class Classification of the N-BaIoT Dataset
The N-BaIoT dataset can be further refined into ten distinct data categories, with nine of them representing different attack types. This expansion builds upon the foundation of ternary classification, which initially focused on identifying botnet attacks but now delves deeper into classifying and distinguishing between these specific attack types. The overarching performance of three different networks on the N-BaIoT dataset is thoughtfully presented in Fig. 12.

The best classification results and scores of our model for ten-class classification, a ten-Class classification performance on N-BaIoT dataset, b ten-class classification confusion matrix on N-BaIoT dataset, c ten-Class classification index score on N-BaIoT dataset
As illustrated in Fig. 12a, the networks consistently demonstrate robust performance in multi-classification. Similar to the results obtained in binary and ternary classifications, MCF-CBAM consistently outperforms MCF and MCF-SE, emphasizing the substantial improvement brought about by the attention mechanism. It is worth noting that the CBAM module proves superior to the SE module in enhancing model performance.
Figure 12b offers a visual representation of MCF-CBAM's classification effectiveness, where 0 signifies normal traffic, and 1–9 correspond to ack, Mirai-scan, syn, udp, udpplain, combo, junk, gafgyt-scan, and tcp/udp, representing the nine distinct attack types. This visual breakdown facilitates a more intuitive understanding of the classification outcomes. The figure shows that combo and junk are easily confused. Although a few instances are misclassified due to extremely similar traffic characteristics, it is worth noting that even under such challenging circumstances, the performance indicators of MCF-CBAM still surpass those of both MCF-SE and MCF. Therefore, this method exhibits promising potential for effectively identifying categories with high similarity.
In Fig. 12c, we provide a detailed breakdown of performance indicators for each category within MCF-CBAM, revealing an impressive accuracy score of 0.9966. In addition, most of the other indicators of each category exceed 0.99, which further demonstrates the huge advantages brought by the attention mechanism, feature reuse and multi-scale feature extraction. It is important to note that multi-classification scenarios inherently possess higher complexity compared to binary and ternary classifications. Therefore, the slightly lower accuracy observed in multi-classification is entirely reasonable and expected.
This comprehensive analysis underscores the efficacy of our approach in effectively classifying and identifying different types of attacks within the N-BaIoT dataset, offering valuable insights for network security applications.
Finally, we conducted a comparative analysis of MCF-CBAM against other methods for IoT botnet traffic anomaly detection. Based on the provided metrics, MCF-CBAM clearly outperforms other methods in binary, ternary, and ten-class classification tasks, as summarized in Table 3.
Table 3 demonstrates that our proposed MCF-CBAM model achieves accuracy rates of 99.96%, 99.94%, and 99.66% in binary, ternary, and ten-class classification tasks, respectively, surpassing other comparative methods. Compared with the MCF-CBAM model, other methods only use high-level features for traffic analysis and identification, lacking the ability to capture key features and make full use of features. This is the reason why the accuracy of the MCF-CBAM model is higher than other methods. This series of high-precision results validates the exceptional performance of MCF-CBAM in detecting and classifying IoT botnet attacks and anomalies. The model's robust performance across various multi-class tasks highlights the effectiveness of our approach in identifying a wide range of IoT botnet threats.
4.8 Binary Classification of the UNSW-NB15 Dataset
To evaluate the enhancement effects of our proposed attention mechanisms on network intrusion detection, we conducted binary classification experiments on the UNSW-NB15 dataset.
Figure 13 shows the performance metrics of MCF and networks based on two different attention mechanisms on the UNSW-NB15 dataset. It can be seen that whether it is accuracy or other metrics, their values have reached more than 98%, indicating good classification effects for each model. Although all three networks achieved good results, differences in classification accuracy still exist due to different attention modules. In the classification process, the SE module mainly assigns different weight coefficients to each feature map, while the CBAM module considers the weights of both feature maps and individual pixels within them. Therefore, theoretically the CBAM module may have better classification performance.

Comparison of various evaluation indicators of MCF, MCF-SE and MCF-CBAM on the data set UNSW-NB15, a accuracy comparison chart, b precision comparison chart, c F1-score comparison chart, d recall comparison chart
This conjecture is validated—Fig. 13a shows MCF-CBAM reaches the highest accuracy of 98.78% in the 10th round of training, surpassing the other two networks. This demonstrates the CBAM mechanism does improve model classification capability. Finally, we compared MCF-CBAM's classification performance on UNSW-NB15 with other methods. As shown in Table 4, MCF-CBAM achieves higher accuracy and F1-score compared to other models tested on this dataset in recent years. Compared to stacked networks CNN4-1D [41], RGB [42] and DNN4Layers [43], the MCF-CBAM network utilizes the fusion and reuse of features to achieve higher accuracy. In addition, this network has the ability of multi-scale feature extraction and effective feature selection. Therefore, MCF-CBAM produced the best results on the UNSW-NB15 dataset compared to other methods. This highlights the advantages of our proposed attention-enhanced network for network intrusion detection.
4.9 Binary Classification of the KDDCUP99 Dataset
In the context of binary classification on the KDDCUP99 dataset, we turn our attention to the performance of MCF, MCF-SE, and MCF-CBAM, as depicted in Fig. 14. Notably, MCF-CBAM emerges as the top performer, achieving an impressive accuracy rate of 99.92%. Comparing this performance to Fig. 13, it is evident that the model's metrics on the KDDCUP99 dataset surpass those on the UNSW-NB15 dataset, underscoring its robustness.

Comparison of various evaluation indicators of MCF, MCF-SE and MCF-CBAM on the data set KDDCUP99, a accuracy comparison chart, b precision comparison chart, c F1-score comparison chart, d recall comparison chart
To provide a broader perspective, let us compare our results on the KDDCUP99 dataset with those of state-of-the-art methods, as showcased in Table 4. RENOIR [45] This model is composed of a neural network and an autoencoder, and determines traffic categories by calculating the distance between spatial features.
MINDFUL [40] This method is divided into two modules: unsupervised and supervised. The unsupervised module mainly trains autoencoders. The supervised module uses multi-channel convolution operations to obtain the spatial characteristics of samples, and improves the classification performance of the model through the dependencies between different samples.
MCLDM [46] not only designs supervised and unsupervised learning modules, but also introduces contrastive learning methods. By comparing the similarities between samples of the same type and the differences between samples of different types, the learning ability of the model is further improved.
Our proposed MCF-CBAM network is deeper than MCLDM [46], RENOIR [45] and MINDFUL [40] and is more prone to the vanishing gradient problem. But MCF-CBAM showed the best performance, with accuracy and F1-score reaching 99.92% and 99.84%, respectively. This shows that the MCF-CBAM network can almost perfectly distinguish between normal and abnormal traffic and does not face gradient disappearance.
Compare Tables 4 and 5. Interestingly, the classification accuracy of various existing methods on the KDDCUP99 dataset outpaces their performance on the UNSW-NB15 dataset. Furthermore, when stacked against other approaches, our proposed method consistently outperforms them on the KDDCUP99 dataset. This not only highlights the exceptional performance of MCF-CBAM but also emphasizes the dataset-dependent nature of intrusion detection methodologies. Our method not only excels on the KDDCUP99 dataset but also underscores the potential for tailored solutions to yield superior results on specific datasets.
4.10 Comparison of MCF-CBAM and Common Classifiers
To further prove the performance of the MCF-CBAM network, we compared MCF-CBAM with some common classifiers on the N-BaIoT data set, as shown in Fig. 15.

Compared MCF-CBAM with some common classifiers on the N-BaIoT dataset, a binary classification results of each model on the N-BaIoT, b ten-class classification results of each model on the N-BaIoT
Figure 15a illustrates the binary classification results of each model on N-BaIoT, where every performance metric of MCF-CBAM outperforms other models. In Fig. 15b, we present ten-class classification outcomes for each model on N-BaIoT data set. Similar to two-class results, MCF-CBAM achieved the highest score. Overall, two-class classification outcomes are superior to those of ten-class classification for all models considered here. Traditional stacked networks (CNN and MLP) lack feature extraction and key feature capturing abilities in complex IoT datasets; hence their classification performance is inferior to that of MCF-CBAM.
4.11 Time Performance Test
The 1 × 1 convolution operation facilitates the integration of cross-channel information, leading to a reduction in network parameters and computations, thereby decreasing model training time. We conducted ten rounds of training on MCF-CBAM and common classifiers using one hundred thousand pieces of N-BaIoT data. The average time consumption is depicted in Fig. 16.

Average time consumption of MCF-CBAM network and common classifiers on the data set N-BaIoT data, a average time consumption in the training and testing phases of the MCF-CBAM network with 1 × 1 convolution operation and the MCF-CBAM network without 1 × 1 convolution operation, b the average time taken by the MCF-CBAM network and other common classifiers in the training and testing phases
As shown in Fig. 16a, the training time is significantly longer than the testing time due to continuous optimization parameter updates during training. Notably, models with 1 × 1 convolution operations consume less time compared to those without such operations, both during training and testing phases.
Furthermore, we compared the time consumption of the MCF-CBAM network with 1 × 1 convolution operation against common classifiers, as shown in Fig. 16b. In both the training and testing phases, the MCF-CBAM network takes less time than other classifiers. Combined with the conclusion of Fig. 15, it further shows that our proposed MCF-CBAM network can achieve higher accuracy in a shorter time, thereby significantly improving the productivity of the project. This is especially important for projects that need to process large amounts of traffic data or complete intrusion detection within a limited time.
4.12 The Relationship Between Attention Weight and Accuracy
In order to delve into the correlation between classification accuracy and attention feature weights, we conducted a visualization of these feature weights, as depicted in Fig. 17. Notably, in Fig. 17a–e, we observe distinct variations in the distribution of feature weights throughout the model's continuous training process.

Visualization of attention feature weights; relationship between standard deviation of attention feature weights and model accuracy, a–e are distributions of attention feature weights, f is the relationship between standard deviation of attention feature weights and model accuracy
Upon closer examination, it becomes evident that as the standard deviation among the feature weights increases, there is a gradual enhancement in model accuracy, as illustrated in Fig. 17f. The standard deviation serves as a metric to quantify the level of data dispersion. It is expressed as follows:
where \(s\) represents the sample standard deviation, \(n\) represents the number of sample data, \(x_{i}\) represents the \(i\) th data, and \(\mathop x\limits^{ - }\) represents the mean of sample data.
The observed connection between accuracy and weight standard deviation reveals that the attention module consistently discerns primary features from secondary ones, assigning varying weights accordingly. This dynamic process results in a progressively more dispersed distribution of feature weights, leading to an increasing standard deviation of these weights.
This phenomenon indicates that the network continually updates feature weights through attention mechanisms during the training process, gradually enhancing the model's accuracy. In essence, the attention module plays a crucial role in refining the model's ability to focus on pertinent features, ultimately contributing to improved classification performance.
4.12.1 Feature Visualization and Interpretation
In the context of feature visualization, the brightness within the feature maps serves as an indicator of feature importance for the classification task at hand. In Fig. 18, we compare the feature maps generated by the model both with and without an attention mechanism.

Feature visualization results, a feature map with attention mechanism, b feature map without attention mechanism
Figure 18a reveals a feature map with a more intricate brightness distribution, indicating that the attention mechanism assigns varying degrees of importance to different features. This complexity in the brightness distribution signifies the model's capability to distinguish and emphasize different features based on their relevance.
On the other hand, Fig. 18b showcases the feature map generated by the network without an attention mechanism. Here, although the network may pay some special attention to certain features, it does not differentiate significantly among most other features. Consequently, the feature map exhibits a relatively uniform color difference distribution.
These visualizations provide valuable insights into how the attention mechanism aids in feature selection and interpretation, ultimately contributing to the model's ability to focus on salient features for improved classification performance.
Through the comprehensive analysis conducted above, we gain a visual perspective on the effectiveness of the attention mechanism and its remarkable capability to represent traffic features. This effectiveness is further underscored by the comparison of various performance indicators across different networks in Sect. 4.
In essence, the attention mechanism plays a pivotal role in enhancing the model's ability to discern and prioritize relevant features, as evidenced by the visual feature maps and the substantial performance improvements observed. This validation from both a visual and quantitative standpoint reinforces the significance of the attention mechanism in traffic feature representation.
5 Discuss
In our study, the robustness of the model was validated using KDDCUP99, UNSW-NB15, and N-BaIoT datasets. The experimental results demonstrate the exceptional performance of the model on each dataset. However, variations exist among different models. Networks with attention mechanisms outperform MCF, and specifically MCF-CBAM performs better than MCF-SE. This highlights that attention mechanisms can indeed enhance model performance; CBAM, obtained by enhancing the SE module, exhibits greater advantages in feature extraction.
In IoT intrusion detection projects, the efficiency and accuracy of model training directly impact project productivity. The 1 × 1 convolution operation in the MCF-CBAM network reduces parameter count and computation load, thereby decreasing runtime and improving work efficiency. This is particularly crucial for projects dealing with large volumes of traffic data or requiring timely intrusion detection within limited timeframes, significantly boosting overall project productivity.
Although comparative evaluations consistently demonstrate the superiority of the MCF-CBAM network over other models, it still possesses certain limitations. Some aspects addressed in this article primarily focus on ensuring good robustness for MCF-CBAM to detect various types of traffic with high accuracy; however, indicators such as space complexity and time complexity were not considered. Given that IoT devices have limited resources available to them, future work should aim at minimizing resource consumption while enhancing detection efficiency. Additionally, experiments conducted using real traffic datasets would provide more convincing evidence.
6 Conclusion
In the era of rapid Internet of Things (IoT) technology development, IoT intrusion detection technology based on deep learning has been widely used in smart homes, smart medical and industrial IoT. The landscape of network traffic has become increasingly complex, marked by intricate spatial features and intricate semantic relationships between these features. The conventional stacked network structures often fall short in effectively extracting crucial multi-scale features, which poses significant challenges in identifying malicious traffic within the IoT ecosystem.
In our research, we introduce the MCF-CBAM network to address these challenges. First and foremost, we acknowledge the constraints posed by IoT device resources. Consequently, we use 1 × 1 convolution operation to significantly reduce the number of training parameters, thereby reducing resource consumption and network running time, which is beneficial to improving project productivity. Furthermore, our adoption of a multi-scale parallel convolution structure and feature skip connections empowers the network to extract spatial information across varying scales effectively. Additionally, the incorporation of the attention mechanism serves to magnify the significance of critical features, further enhancing the network's ability to differentiate and prioritize vital information. The inclusion of feature reuse within the side classifier unites low-level and high-level features, bolstering the network's overall generalization capacity.
We have substantiated the effectiveness of our approach through comprehensive experiments conducted across datasets representing diverse network environments. Comparative evaluations with other network models consistently demonstrate the superior performance and robustness of our MCF-CBAM network in traffic classification tasks.
Moreover, we employ the standard deviation as a tool to establish the relationship between network accuracy and attention weight. By generating attention feature maps, we offer a visual perspective on the pivotal role of the attention mechanism in our network architecture.
In conclusion, our MCF-CBAM network represents a noteworthy advancement in IoT traffic classification. Its resource-efficient design, multi-scale feature extraction capabilities, and attention-driven focus on crucial features collectively contribute to its effectiveness and robustness. As IoT technology continues to evolve, our work serves as a foundation for further research in enhancing network security and traffic classification in this dynamic and complex landscape.
7 Future Work
With the rapid development of the Internet of Things, fog computing and edge computing are gradually emerging. In future work, we will consider applying both to traffic identification tasks in order to achieve resource-constrained IoT intrusion detection with reduced resource consumption. Additionally, feature reduction and reconfiguration will be thoroughly studied to overcome the problem of limited resources on IoT devices, thereby improving work efficiency. Finally, more effort will be devoted to studying unknown traffic detection by developing a real-time updatable traffic detection model that makes the traffic analysis process more intelligent.
Availability of data and materials
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Guan C. Design of a coupling model for sustainable development in industry 4.0. Iete J Res. 1–12 (2022)
Luo, L., Chen, F.: Multi-objective optimization of logistics distribution route for industry 4.0 using the hybrid genetic algorithm. Iete J Res. 1–11 (2022)
Mohan, T.R., Preetha Roselyn, J., Annie Uthra, R.: Anomaly detection in machinery and smart autonomous maintenance in industry 4.0 during covid-19. Iete J Res. 68(6), 4679–4691 (2022)
Fang, B.: Method for quickly identifying mine water inrush using convolutional neural network in coal mine safety mining. Wirel. Pers. Commun. 1–18 (2021)
Zarpelão, B.B., Miani, R.S., Kawakani, C.T.: A survey of intrusion detection in Internet of Things. J. Netw. Comput. Appl. 84, 25–37 (2017)
Antonakakis, M., April, T., Bailey, M., et al.: Understanding the mirai botnet. 26th USENIX security symposium (USENIX Security 17), pp.1093–1110 (2017)
Guo, Z., Lin Z., Li, P., et al.: SkillExplorer: Understanding the Behavior of Skills in Large Scale. 29th USENIX Security Symposium (USENIX Security 20), pp.2649–2666 (2020)
Kumar, P., Bagga, H., Netam, B.S., et al.: Sad-iot: Security analysis of ddos attacks in iot networks. Wirel. Pers. Commun. 122(1), 87–108 (2022)
Azath, H., Devi Mani M., Prasanna Venkatesan, G.K.D., et al.: Identification of iot device from network traffic using artificial intelligence based capsule networks. Wirel. Pers. Commun. 123(3), 2227–2243 (2022)
Verma, A., Ranga, V.: Machine learning based intrusion detection systems for IoT applications. Wirel. Pers. Commun. 111, 2287–2310 (2020)
Lakshminarayana, S.K., Basarkod, P.I.: Unification of K-Nearest Neighbor (KNN) with Distance Aware Algorithm for Intrusion Detection in Evolving Networks Like IoT. Wirel. Pers. Commun. 132(3), 2255–2281 (2023)
Al-Qurabat, A.K.M., Mohammed, Z.A., Hussein, Z.J.: Data traffic management based on compression and MDL techniques for smart agriculture in IoT. Wirel. Pers. Commun. 120(3), 2227–3225 (2021)
Khraisat, A., Alazab, A.: A critical review of intrusion detection systems in the internet of things: techniques, deployment strategy, validation strategy, attacks, public datasets and challenges. Cybersecurity. 4, 1–27 (2021)
Aljabri, M., Aljameel, S.S., Mohammad, R.M.A., et al.: Intelligent techniques for detecting network attacks: review and research directions. Sensors. 21(21), 7070 (2021)
Zhou, X., Hu, Y., Liang, W., et al.: Variational LSTM enhanced anomaly detection for industrial big data. IEEE Trans. Industr Inform. 17(5), 3469–3477 (2020)
Xu, C., Shen, J., Du, X.: A method of few-shot network intrusion detection based on meta-learning framework. IEEE Trans. Inf. Forensics Secur. 15, 3540–3552 (2020)
Gao, M., Wu, L., Li, Q., et al.: Anomaly traffic detection in IoT security using graph neural networks. J. Inf. Secur. 76, 103532 (2023)
Om Kumar, C.U., Marappan, S., Murugeshan, B., et al.: Intrusion Detection Model for IoT Using Recurrent Kernel Convolutional Neural Network. Wirel. Pers. Commun. 129(2), 783–812 (2023)
Birnbach, S., Eberz, S., Martinovic, I.: Haunted house: physical smart home event verification in the presence of compromised sensors. ACM trans. internet things. 3(3), 1–28 (2022)
Bhatt, P., Morais, A.: HADS: Hybrid anomaly detection system for IoT environments. international conference on internet of things, embedded systems and communications (IINTEC). pp. 191–196. IEEE.(2018)
Wan, Y., Xu, K., Xue, G., et al.: Iotargos: A multi-layer security monitoring system for internet-of-things in smart homes. IEEE INFOCOM 2020-IEEE Conference on Computer Communications. pp. 874–883. IEEE. (2020)
Ravi, N., Shalinie, S.M.: Semisupervised-learning-based security to detect and mitigate intrusions in IoT network. IEEE Internet Things J. 7(11), 11041–11052 (2020)
Alazzam, H., Sharieh, A., Sabri, K.E.: A feature selection algorithm for intrusion detection system based on pigeon inspired optimizer. Expert Syst. Appl. 148, 113249 (2020)
Pajouh, H.H., Javidan, R., Khayami, R., et al.: A two-layer dimension reduction and two-tier classification model for anomaly-based intrusion detection in IoT backbone networks. IEEE Trans. Emerg. Topics Comput. 7(2), 314–323 (2016)
Jan, S.U., Ahmed, S., Shakhov, V., et al.: Toward a lightweight intrusion detection system for the internet of thing. IEEE access. 7, 42450–42471 (2019)
Anthi, E., Williams, L., Słowińska, M., et al.: A supervised intrusion detection system for smart home IoT devices. Internet Things J. 6(5), 9042–9053 (2019)
Heartfield, R., Loukas, G., Bezemskij, A., et al.: Self-configurable cyber-physical intrusion detection for smart homes using reinforcement learning. IEEE Trans. Inf. Forensics Secur. 16, 1720–1735 (2020)
Li, Y., Xu, Y., Liu, Z., et al.: Robust detection for network intrusion of industrial IoT based on multi-CNN fusion. Measurement 154, 107450 (2020)
Liu Y, Kumar N, Xiong Z, et al. Communication-efficient federated learning for anomaly detection in industrial internet of things. IEEE Global Communications Conference (GLOBECOM). pp. 1–6. IEEE. (2020)
Wang, X., Garg, S., Lin, H., et al.: Toward accurate anomaly detection in industrial internet of things using hierarchical federated learning. IEEE Internet Things J. 9(10), 7110–7119 (2021)
Sharma, B., Sharma, L., Lal, C., et al.: Anomaly based network intrusion detection for IoT attacks using deep learning technique. Comput. Electr. Eng. 107, 108626 (2023)
Simon, J., Kapileswar, N., Polasi, P.K.: Hybrid intrusion detection system for wireless IoT networks using deep learning algorithm. Comput. Electr. Eng. 102, 108190 (2022)
Syed, N.F., Ge, M., Baig, Z.: Fog-cloud based intrusion detection system using Recurrent Neural Networks and feature selection for IoT networks. Comput. Netw. 225, 109662 (2023)
Lin, K., Xu, X., Xiao, F.: MFFusion: A multi-level features fusion model for malicious traffic detection based on deep learning. Comput. Netw. 202, 108658 (2020)
Tao, Y., Xu, M., Lu, Z., Zhong, Y.: DenseNet-based depth-width double reinforced deep learning neural network for high-resolution remote sensing image per-pixel classification. Remote Sens. 10(5), 779 (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
Zagoruyko, S., Komodakis, N.: Wide Residual Networks. Procedings of the British Machine Vision Conference. British Machine Vision Association (2016)
Tan, M., Le, Q.: Efficientnet: Rethinking model scaling for convolutional neural networks. International conference on machine learning (PMLR). pp. 6105–6114 (2019)
Tong, W., Chen, W., Han, W., Li, X., Wang, L.: Channel-attention-based DenseNet network for remote sensing image scene classification. IEEE J-STARS. 13, 4121–4132 (2020)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7132–7141 (2018)
Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: Cbam: Convolutional block attention module.Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018)
Tavallaee, M., Bagheri, E., Lu, W.: A detailed analysis of the KDD CUP 99 data set. IEEE symposium on computational intelligence for security and defense applications. pp. 1–6 (2009)
Moustafa, N., Slay, J.: UNSW-NB15: a comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). military communications and information systems conference (MilCIS). pp. 1–6.IEEE. (2015)
Meidan, Y., Bohadana, M., Mathov, Y.: Network-based Detection of IoT Botnet Attacks Using Deep Autoencoders. IEEE Pervasive Comput. 17, 12–22 (2018)
McDermott, C.D., Majdani, F., Petrovski, A.V.: Botnet detection in the internet of things using deep learning approaches. international joint conference on neural networks (IJCNN). pp 1–8.IEEE. (2018)
Nguyen, H.T., Ngo, Q.D., Le, V.H.: IoT botnet detection approach based on PSI graph and DGCNN classifier. international conference on information communication and signal processing (ICICSP). pp 118–122. IEEE. (2018)
Kumar, A., Lim, T.J.: EDIMA: Early detection of IoT malware network activity using machine learning techniques. 5th World Forum on Internet of Things (WF-IoT). pp. 289–294. IEEE. (2019)
Gao, X., Shan, C., Hu, C., Niu, Z., Liu, Z.: An adaptive ensemble machine learning model for intrusion detection. IEEE Access. 7, 82512–82521 (2019)
Shi, W.C., Sun, H.M.: DeepBot: a time-based botnet detection with deep learning[J]. Soft. Comput. 24, 16605–16616 (2020)
Abu Al-Haija, Q., Zein-Sabatto, S.: An efficient deep-learning-based detection and classification system for cyber-attacks in IoT communication networks. Electronics 9(12), 2152 (2020)
Jung, W., Zhao, H., Sun, M., Zhou, G.: IoT botnet detection via power consumption modeling. Smart Health. 15, 100103 (2020)
Ashraf, J., Keshk, M., Moustafa, N., Abdel-Basset, M., Khurshid, H., Bakhshi, A.D., Mostafa, R.R.: IoTBoT-IDS: A novel statistical learning-enabled botnet detection framework for protecting networks of smart cities. Sustain. Cities Soc. 72, 103041 (2021)
Abu Al-Haija, Q., Al Badawi, A., Bojja, G.R.: Boost-Defence for resilient IoT networks: A head-to-toe approach. Expert. Syst. 39(10), 12934 (2022)
Abu Al-Haija, Q., Al-Dala’ien, M.A.: ELBA-IoT: an ensemble learning model for botnet attack detection in IoT networks.J. Sens. Actuator Netw. 11(1), 18 (2022)
Andresini, G., Appice, A., Di Mauro, N., Loglisci, C., Malerba, D.: Multi-channel deep feature learning for intrusion detection. IEEE Access. 8, 53346–53359 (2020)
Lopez-Martin, M., Carro, B., Sanchez-Esguevillas, A., Lloret, J.: Shallow neural network with kernel approximation for prediction problems in highly demanding data networks. Expert Syst. Appl. 124, 196–208 (2019)
Kim, T., Suh, S.C., Kim, H., Kim, J., Kim, J.: An encoding technique for CNN-based network anomaly detection. In International Conference on Big Data. pp. 2960–2965. IEEE. (2018)
Vinayakumar, R., Alazab, M., Soman, K.P., Poornachandran, P., Al-Nemrat, A., Venkatraman, S.: Deep learning approach for intelligent intrusion detection system. IEEE Access. 7, 41525–41550 (2019)
Yang, Y., Zheng, K., Wu, C., Niu, X., Yang, Y.: Building an effective intrusion detection system using the modified density peak clustering algorithm and deep belief networks. Appl. Sci. 9(2), 238 (2019)
Andresini, G., Appice, A., Malerba, D.: Autoencoder-based deep metric learning for network intrusion detection. Inf. Sci. 569, 706–727 (2021)
Luo, J., Zhang, Y., Wu, Y., Xu, Y., Guo, X., Shang, B.: A Multi-Channel Contrastive Learning Network Based Intrusion Detection Method. Electronics 12(4), 949 (2023)
Vigneswaran, R.K., Vinayakumar, R., Soman, K.P., Poornachandran, P.: Evaluating shallow and deep neural networks for network intrusion detection systems in cyber security. 9th International conference on computing, communication and networking technologies (ICCCNT) pp. 1–6. IEEE.(2018)
Andresini, G., Appice, A., Paolo Caforio, F., Malerba, D.: Improving cyber-threat detection by moving the boundary around the normal samples. Machine Intelligence and Big Data Analytics for Cybersecurity Applications. 105–127 (2021)
Andresini, G., Appice, A., Di Mauro, N., Loglisci, C., Malerba, D.: Exploiting the auto-encoder residual error for intrusion detection. In European Symposium on Security and Privacy Workshops (EuroS&PW). pp. 281–290. IEEE.(2019)
Acknowledgements
This work has received support from the 2021 Graduate Practical Innovation and Entrepreneurial Ability Improvement Project "Research and Design of Traffic Classification Method Based on Deep Integrated Learning" (No. 6080201-000101204) from Changsha University of Science and Technology.
Funding
There is no financial support for this study.
Author information
Authors and Affiliations
Contributions
Liao and Guan contributed to the design and implementation of the study and writing part of the paper.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liao, N., Guan, J. Multi-scale Convolutional Feature Fusion Network Based on Attention Mechanism for IoT Traffic Classification. Int J Comput Intell Syst 17, 36 (2024). https://doi.org/10.1007/s44196-024-00421-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-024-00421-y