
Abstract
With the demands for light deep networks models in various front-end devices, network compression has attracted increasing interest for reducing model sizes yet without sacrificing much model accuracy. This paper presents a multifarious knowledge transfer network (MKTN) that aims to produce a compact yet powerful student network from two complementary teacher networks. Instead of learning homogeneous features, the idea is to pre-train one teacher to capture generative and low-level image features under a reconstruction objective, and another teacher to capture discriminative and task-specific features under the same objective as the student network. During knowledge transfer, the student learns multifarious and complementary knowledge from the two teacher networks under the guidance of the proposed adversarial loss and feature loss respectively. Experimental results indicate that the proposed training losses can effectively guide the student to learn spatial-level and pixel-level information as distilled from teacher networks. On the other hand, our study over a number of widely used datasets shows that transferring multifarious features from complementary teachers equipped with different types of knowledge helps to teach a compact yet powerful student effectively.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In recent years, deep neural networks (DNNs) have achieved much improved performance in various computer vision tasks such as image classification, image segmentation, object detection, etc [1,2,3,4,5,6]. On the other hand, the performance gain comes at the price of heavy computation and large models with a huge amount of network parameters. The large model size has become a bottleneck to various edge-computing devices, where resources in data storage and computational power are often too constrained to accommodate large deep network models.
Researchers have investigated different approaches for compressing deep network models. The existing works fall into four broad categories: (1) network pruning [7,8,9,10], (2) network quantization [11, 12], (3) compact network design [13, 14], and (4) knowledge transfer [15,16,17,18,19,20,21]. Network pruning and network quantization deal with existing large networks by removing less informative network parameters and reducing the number of bits used to represent the network parameters, respectively. Compact network design is more elegant, which directly designs light and efficient network architectures (e.g., MobileNet) from the scratch.

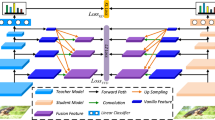
The architecture of the proposed adversarial-based multifarious knowledge transfer network MKTN. Firstly, the first teacher (Teacher1) is trained for image reconstruction aiming to learn generative and low-level features such as bird’s boundary; The second teacher (Teacher2) is trained with the same task as the student aiming to learn discriminative yet task-specific features such as bird’s head. Secondly, both teacher networks transfer the learned features to the student under the guidance of adversarial loss and feature loss, respectively. Here, ‘C’ denotes the ConvBlock module for feature alignment
Knowledge transfer (KT) compresses networks by transferring distilled knowledge from one or multiple teacher networks to a compact student network. Inspired by Hinton’s pioneer work on network distillation, several works have been carried out largely to address constrain of softmax function in [22], e.g., by transferring intermediate features [15,16,17, 23] or optimizing the student initialization [24, 25]. On the other hand, the aforementioned methods typically employed a single teacher network, which tend to learn homogeneous instead of multifarious knowledge. Several works did employ multiple teacher networks [26,27,28] or an assistant teacher [29] to learn richer knowledge in recent years, but they trained the teacher networks under similar objectives and still tend to learn homogeneous instead of complementary and multifarious features.
We present an adversarial-based knowledge transfer network (MKTN) that transfers multifarious features from two complementary teachers to train a compact yet powerful student network. The design is motivated by the observation that a student often learns and becomes a master of a subject by absorbing comprehensive instead of solely subject-specific knowledge, e.g., many champions in the International Physics Olympiad often have very strong foundation in mathematics. We hence utilize two teacher networks in MKTN as illustrated in Fig. 1, one pre-trained under an image reconstruction objective and the other pre-trained under the same objective as the student network. The hypothesis is that the reconstruction task guides to learn more generative features in scene layouts and object structures (e.g., the bird’s contour) which are complementary to the discriminative and task specific features (e.g., the bird’s head). For knowledge transfer to the student, we introduce adversarial learning to transfer more spatial and structural features as well as the performance of robustness from the reconstruction teacher, and distill discriminative features before the full connected layer from the second teacher. Extensive experiments demonstrate the effectiveness of our proposed multifarious knowledge transfer network.
The contributions of this work can be summarized in three aspects. First, it proposes a multifarious knowledge transfer network that employs two complementary teachers pre-trained under different objectives to train a compact yet powerful student. Second, it introduces an adversarial learning strategy for optimal knowledge transfer from a teacher network pre-trained under reconstruction objective. Third, extensive evaluations verify our hypothesis − generative features can complement discriminative features in image classification and semantic segmentation tasks. Furthermore, combining the two types of complementary features helps train a compact and accurate student network effectively.
2 Related Works
2.1 Offline Knowledge Transfer
Knowledge transfer (KT) aims to train a smaller yet compact student network by transferring knowledge from one or multiple powerful teacher(s). There have been plenty of KT researches based on one teacher and one student, such as attention transfer (AT) [16], neuron selectivity transfer (NST) [30] and factor transfer (FT) [17], that will not be covered in detail here. Our work is more related to the multiple teacher applied KT methods. As a comparison, Yin et al. [26] pre-trains multiple teachers with the same architecture to make respective policy distillation on a specific task, and Zhang et al. [28] distills knowledge of multiple self-supervised teacher models from soft probability distribution and internal representation. In [29], Mirzadeh employs a teacher assistant to achieve multi-step knowledge distillation. While these methods provide fairly good performance improvements, they neglect the complementarity and multifarious between the transferred features. To alleviate this problem, in this paper, we propose a novel MKTN that attempts to transfer multifarious knowledge from two complementary teacher networks to empower a compact yet powerful student.
2.2 Reconstruction Learning
Auto-encoder as a neural network based feature extraction method has achieved great success in capturing abstract image features. Hinton proposes that auto-encoder can learn sufficient information for reconstructing the input images in [31]. Recently, many studies prove that auto-encoder can produce better classification accuracy via learning generative features. For example, Shin et al. [32] demonstrates that stacked auto-encoder can learn classification related features effectively over complex datasets and Ng et al. [33] introduces an auto-encoder based method for learning a set of features with better classification capabilities. Additionally, existing works [34,35,36] have demonstrated that reconstruction task can be applied for improving the classification accuracy via providing additional detailed features in large-scale image classification [34], domain adaptation [35] and open-set classification [36]. Inspired by the above related work, we incorporate a reconstruction module in Teacher1 network to generate the reconstructed image of the input, targeting to learn the reconstruction sensitive yet classification related features in an unsupervised way.
2.3 Adversarial Learning
Generative adversarial learning [37] is proposed to generate realistic-looking images by using a generator and discriminator to compete with each other while training simultaneously. Several researches [38,39,40] employ adversarial loss to measure the feature difference between the teacher and student networks trained with the same task. Specifically, the teacher and student model applied in [38, 40] should have the same number of blocks, limiting the network application. In this work, we introduce a discriminator to discriminate the difference between the transferred Teacher1’s generative features and the student’s task-specific output. An advantage of adversarial learning is that the generator, i.e., the student network in the proposed MKTN, attempts to produce similar features as Teacher1 that the discriminator cannot differentiate.
On the other hand, existing work [41,42,43,44,45,46] applied adversarial learning in their model for robustness learning and transferring. In particular, Liu et al. [41] proposed an Adversarial Collaborative Knowledge Distillation (ACKD) method to bulid a more powerful student with attention mechanism. Tang et al. [42] introduced Adversarial Variational Knowledge Distillation (AVKD) via estimating the KL-divergence term between a prior p(x) over the latent variables and an approximate generative model \(q(x\vert y)\). Wang et al. [43] designed a novel Harmonized Dense Knowledge Distillation (HDKD) training method for multi-exit architecture by incorporating all possible beneficial supervision information. Maroto et al. [44] presented Adversarial Knowledge Distillation (AKD) to boost a model’s robust performance by consisting on adversarially training a student on a mixture of the original labels and the teacher outputs. Dong et al. [45] employed an adversarial-based learning strategy as supervision to guide and optimize the lightweight student network to recover the knowledge of teacher networks, and enable the discriminator module to distinguish the feature of teacher and student simultaneously. Ham et al. [46] proposed a new knowledge distillation, named NEO-KD, reducing adversarial transferability in the network while guiding the output of the adversarial examples to closely follow the ensemble outputs of the neighbor exits of the clean data, and significantly improving the overall adversarial test accuracy.
Inspired by the relevant work above, the discriminator designed in our MKTN is trained to empower the student with the distilled knowledge as well as the ability of robustness.
3 Proposed Method
Compared with the deeper teacher network, the student does not have sufficient capacity to capture the rich and comprehensive image features. Take the interested image classification task as an example, the student could classify images better when it is equipped with generative yet latent features, as well as the classification sensitive features.
Following the aforementioned intuitions, we put forward the architecture MKTN with the following steps: (1) a candidate teacher network is first modified by adding reconstruction modules and ConvBlock module respectively, as Teacher1 and Teacher2 shown in Fig. 1. (2) Two teacher networks are pre-trained with reconstruction loss and task-specific loss respectively. The reconstruction loss, calculated by minimizing the distance between the input and generated images, drives to learn generative reconstruction representations in an unsupervised manner. The task-specific loss drives to learn task-specific features with discriminative information. (3) Once the teacher networks are pre-trained well, the distilled diverse yet complementary features are fed into the corresponding student output with adversarial loss and feature loss, enabling the student to learn this knowledge and mimic the performance of its teachers thoroughly.
3.1 Generative Features Learning
Given a labeled dataset (X, Y), \(\tilde{X_{i}} = T_{1}(X_{i})\) denotes the reconstruction output of Teacher1, which has the same size as the input image \(X_{i}\). Here, i=\(1,2,\dots ,M\), M is the number of objects.
Instead of using \(L_{1}\) or \(L_{2}\) to directly calculate the pixel-level distance between \(\tilde{X_{i}}\) and \(X_{i}\), we attempt to model their respective feature space as the probability distribution before evaluating the similarity. As Maaten et al. proposed in [47], the conditional probability distribution expresses the probability of each sample via selecting each of its neighbors, applying this method is expected to better facilitate the image reconstruction via describing the local regions between \(\tilde{X_{i}}\) and \(X_{i}\). Furthermore, we employ the cosine similarity based affinity metric to be the kernel \(K_{\mathrm{cosine}}\), which can be formulated as:
Therefore, the conditional probability distribution for the input image \(X_{i}\) is defined as:
while for the generated image \(\tilde{X_{i}}\) as:
The conditional probabilities are delimited to [0, 1] and sum to 1, i.e., \(\Sigma ^{M}_{i=0, i\ne j}p_{i \mid j}\) = 1 and \(\Sigma ^{M}_{i=0, i\ne j}q_{i \mid j}\) = 1. \(\sigma\) is the parameters of kernel K. \(X_{m}\) means the mth input image. While training \(T_{1}\), the Kullback–Leibler (KL) divergence metric is applied to calculate the reconstruction loss formulated as:
3.2 Discriminative Features Learning
In Teacher2 network, we first add a convolutional layer with batch normalization to align the transferred features. This is followed by an averaged pooling and fully connected layer to produce the classification probabilities. Similar to the conventional metric in classification work, we apply cross-entropy function C against labels Y to evaluate the classification result:
where \(T_{2}(X)\) denotes the output after fully connected layer in Teacher2 network and \(L_{T_{2}}\) is the task-specific training loss for Teacher2 network.
3.3 Complementary Features Transferring
Once \(T_{1}\) and \(T_{2}\) converge, their parameters are frozen and the student network S is trained with the transferred knowledge, that actually correspond to the generative reconstruction features \(T^{f}_{1}(X)\) before the deconvolution layers in \(T_{1}\) and informative classification features \(T^{f}_{2}(X)\) before the pooling layer in \(T_{2}\). As illustrated in Fig. 1, student S is trained with the adversarial loss, feature loss, and task-specific loss simultaneously.
To calculate the adversarial loss \(L_{D}^{s}\) between \(T_{1}\) and S, an adversarial-based learning strategy is introduced to assimilate the distilled knowledge \(T^{f}_{1}(X)\). The discriminator D attempts to classify its input \(\bar{x}\) by maximizing the following objective [37]:
where \(\bar{x}\) is the concatenated result of \(T_{1}^{f}(X)\) and the corresponding output \(S^{f}(X)\) before the fully connected layer in S. At the same time, S attempts to generate similar features which will fool the discriminator by minimizing \(L_{D}^{s}\). D is consisted of three fully connected layers with ReLu operation, that works by generating more valuable gradient for S. The last layer with 2 hidden neurons is responsible for identifying the input features of \(T_{1}\) or S.
To calculate the feature loss \(L_{\mathrm{fea}}^{s}\) between \(T_{2}\) and S, we first normalize (denoted as \(\eta (\cdot )\)) the transferred knowledge \(T^{f}_{2}(X)\) and \(S^{f}(X)\). Then, the feature metric is formulated as:
where the feature metric d can be evaluated by either \(L_{1}\) or \(L_{2}\) distance.
Therefore, the student can be trained with adversarial loss \(L_{D}^{s}\), feature loss \(L_{\mathrm{fea}}^{s}\) and task-specific loss \(L_{\mathrm{cls}}^{s}\) as follows:
where \(\alpha\) and \(\beta\) are weight parameters. C(S(X), Y) is a common item used in the classification task which calculates the cross-entropy between the student output S(X) and ground-truth labels Y. During the student’s learning process, gradients are computed and propagated back within S, guiding it to learn the two teachers’ knowledge in Eq. (9).
4 Experiments and Analysis
This section verifies the validity of our proposed knowledge transfer network including (1) datasets and evaluation metrics, (2) implementation details, (3) comparisons with the state-of-the-art, (4) ablation studies and (5) discussion, more details to be described in the following subsections.
4.1 Datasets and Evaluation Metrics
The proposed MKTN is evaluated over four datasets, which have been widely used to study the knowledge transfer challenge in [17,18,19, 21, 38, 48, 49]. CIFAR10 [50] and CIFAR100 [51] are two publicly accessible classification datasets. Both datasets have 50,000 training images and 10,000 test images, with 10 and 100 image classes respectively. All images in the two datasets have 32 \(\times\) 32 pixel with RGB colors. ImageNet refers to the LSVRC 2015 classification dataset [52] which consists of 1.2 million training images and 50,000 validation images of 1000 image classes. PASCAL VOC 2012 dataset [53] is a standard instance segmentation benchmark with 1,464 pixel-level image annotations for training. We use an augmentation of the dataset provided by the extra annotations in [54] as employed in the baseline paper [55].
For evaluation metrics, we use Top-1/5 mean classification error (%) and mean Intersection over Union (mIoU) on classification and semantic segmentation task, respectively. To measure the computation cost in model inference stage, floating point operations (FLOPs) is adopted in the discussion section.
4.2 Implementation Details
We compare MKTN with several state-of-the-art KT methods including knowledge distillation (KD) [22], attention transfer (AT) [16], neuron selectivity transfer (NST) [30], factor transfer (FT) [17], activation boundaries (AB) [25] and OFD [56]. For KD, the temperature of softened softmax is fixed to 4 as in [22]. Following [16, 30], \(\beta\) of AT and NST is set to 1000 and 0.01 respectively. In MKTN, the balance weight \(\alpha\) of adversarial loss is set to 100 consistently, and \(\beta\) of feature loss is set to 100 for CIFAR and 10 for ImageNet. On classification data, teacher networks are pre-trained with an initial learning rate of 0.1 and a batchsize of 64. On segmentation data, all models are trained for 50 epochs, and the learning rate schedule is the same as the baseline paper [55]. All experiments are implemented by PyTorch on GPU devices.
4.3 Comparisons with the State-of-the-Art
CIFAR10 and CIFAR100: Several experiments are designed to compare the proposed MKTN with the state-of-the-art methods over CIFAR10 and CIFAR100. Specifically, different combinations of the backbone architectures ResNet [3], Wide ResNet (WRN) [57] and PyramidNet (PYN) [58] are employed for testing various situations as shown in Tables 1 and 2, where the numbers in parentheses are the network parameter sizes in Millions. Teacher1 noted with * is modified with reconstruction modules based the same backbone of Teacher2.
According to Tables 1 and 2, four conclusions can be drawn as follows: (1) while trained from scratch, Teacher2\(\dagger\) obtains lower Top-1 mean classification error rate than Student\(\dagger\) as expected, largely due to its deeper network structures and/or larger amounts of network parameters. (2) The student trained with the compared transfer methods AT, KD, NST, FT, AB and OFD (i.e., trained by transferring unitary features from a single teacher) perform better than the corresponding ‘Student\(\dagger\)’, demonstrating that the student could significantly improve its performance if equipped or empowered with more knowledge and features. On the other hand, the compared models unsteadily show better or worse performances than others depending on the network pair used. (3) On CIFAR10 as shown in Table 1, MKTN outperforms all the compared methods consistently regardless of the type of network used, no matter whether the student and teacher networks are of different depth (ResNet20/ResNet56), having different type (ResNet20/WRN40-1), or having large depth gap (WRN16-1/WRN40-1, WRN16-2/WRN40-2). (4) On CIFAR100 as shown in Table 2, it can be observed that when the depth of the student network reduces from 56 to 32, both of the two MKTN-trained students outperform the Teacher2\(\dagger\) that has much deeper network architecture. It shows that a small network trained with proper knowledge distillation could have the similar or even better representation capacity than a large one. In addition, this clearly suggests the potential scalability of our proposed knowledge transfer network architecture. These outstanding performances are largely due to the complementary instead of unitary feature transfer in MKTN, where student effectively learns multifarious and complementary knowledge including both generative and discriminative features.
ImageNet: To demonstrate the potential of MKTN to transfer more complex information, we conduct a large-scale experiment over the ImageNet LSVRC 2015 classification task. The student’s performance is validated based on Top-1 and Top-5 mean classification error rate as shown in Table 3 (following page). By absorbing the complementary features from the two diverse teachers, MKTN-trained student consistently makes better performance. As the results shown in Table 3, it helps to lower about 1.82% of MKTN-trained student’s (ResNet18) Top-1 error compared to the same network trained from scratch in Student\(\dagger\). This clearly demonstrates the potential adaptability of our proposed MKTN method, making promising performance even on the more complex dataset.
4.4 Ablation Studies
Two sets of experiments are conducted to evaluate the MKTN, where the first set aims to study the advantages of knowledge transfer from two complementary teachers and the second set aims to study the effects of different loss composition in knowledge transfer.
Transfer with One or Two Teachers:
To make the study solid, we employ different scenarios to evaluate the transfer performance where the student and teacher network have the same architecture but different depths (ResNet56/ResNet110) or have different network architectures (VGG13/WRN46-4). As Table 4 shows, in both setups, MKTN(T1,T2)-trained student transferred from two teachers (1) clearly outperforms both MKTN(T2) and MKTN(T1) trained students that learned from a single teacher alone, and (2) achieves even lower error than the Teacher\(\dagger\) that employs larger network architecture. The promising results indicate the great benefits of transferring both the generative features from Teacher1 and discriminative task-specific features from Teacher2, that complement with each other for guiding a small yet compact student network effectively.
Transfer Losses and Transfer Strategies: By including the reconstruction Teacher1 only as shown at the top part of Table 5, it shows using a discriminator to calculate adversarial loss (as denoted as \(L_{D}\) ) between Teacher1 and student features achieves the better performance than directly using \(L_1\) or \(L_2\) to calculate the pixel-level distances. The good performance is largely attributed to the discriminator which can empower the student model with good robustness and interpret the spatial information in transferred features. While including the task-specific Teacher2 only as shown in the middle of Table 5, using \(L_{1}\) to calculate the feature loss before the fully connected layer outperforms \(L_{2}\) clearly with 0.39 decrease in Top-1 classification error over CIFAR10. Nevertheless, it shows clearly worse performance if using \(L_{1}\) to calculate the feature loss after the fully connected layer (as denoted as ‘\(L_{1}^{\diamond }\)’). This again illustrates that the fully connected layer shares the commonality that dimension reduction would result in the loss of informative knowledge and features. In general, the lowest error rate is achieved when adversarial loss \(L_{D}\) and \(L_{1}\) loss are used together for knowledge transfer.
4.5 Discussion
Inference efficiency: MKTN is efficient during both training and inference stages. During training over CIFAR100, the MKTN-trained student learns multifarious features and knowledge and converges much faster than the student trained from the scratch as illustrated in Fig. 2. During inference, the MKTN-trained students (using ResNet56 and ResNet32) achieve similar even better accuracy as the teacher (using ResNet101) but consumes much less energy (lower FLOPs) and shorter inference time as shown in Table 6.

Comparison of training loss curves over CIFAR100 while the student networks trained with the proposed MKTN or from scratch

Visualizations of validation images from the ImageNet dataset by t-SNE. We randomly sample 10 classes within 1000 classes. Left is the single model result trained from scratch. Right is the result of our MKTN-trained student
Feature visualization: We visualize the distribution of features from the MKTN-trained student and the plain student trained from the scratch. Figure 3 shows the t-SNE visualization [59] of 10 randomly selected ImageNet classes. It is obvious that the distribution of the MKTN-trained student has smaller intra-class variations and larger inter-class distances as compared with the plain student in Student*. Figure 4 further illustrates the learnt features with four sample images. As Fig. 4 shows, Teacher1 learns more generative features (e.g., bird’s boundary, car’s outline) while Teacher2 learns more discriminative features (e.g., bird’s head, car’s wheels). The MKTN-trained student learns multifarious features that capture more useful information than that of the plain student in Student*. All these illustrations align perfectly with the quantitative image classification results in Tables 1, 2 and 3.

Activation feature maps from different teachers and students in ResNet56/ResNet110 pair. The results in Teacher1, Teacher2, MKTN-Student and Student\(\dagger\) columns correspond to the output before deconvolution modules in Teacher1, as well as the output before the classifier layer in Teacher2, MKTN-trained student and the student trained from scratch, respectively
Semantic segmentation: We select the latest study, DeepLabV3+ [55] as the base model to perform semantic segmentation on PASCAL VOC 2012 data [53]. Specifically, DeepLabV3+ based on ResNet101 and ResNet18/MobileNetV2 are utilized as the teacher and student networks respectively. Similar to previous work, the student is initialized to the same one pre-trained on ImageNet. Results are shown in Table 7, where MKTN significantly improves the performance of student network. In particular, MKTN-trained MobileNetV2 performs better with 2.39 improvements in mIoU. Besides classification task, MKTN shows potential ability in semantic segmentation with promising results.
Compare against the multiple teachers applied KT method: We didn’t compare with [26, 28] as the two methods tackle deep reinforcement learning and video classification tasks. We performed a new experiment by comparing MKTN with TAKD [29] that employs assistant teachers and tackles the image classification task similarly. As the results shown in Table 8, with ResNet26 as teacher, the TAKD-trained ResNet8 and ResNet14 (under the assistant teacher ResNet14 and ResNet20) obtained 11.99% and 8.77% classification error, respectively, for CIFAR100. Our MKTN-trained ResNet8 and ResNet14 obtained lower classification error rate of 11.02% and 7.59%, respectively, under the same setup. This again demonstrates the potential capability of our knowledge transfer network architecture MKTN equipped with complementary teacher networks for transferring multifarious features.
5 Conclusion
Reconstruction task learns generative and low-level image representations, whereas recognition task learns discriminative and task-specific representations. The features learned by the two tasks capture different characteristics of images which are usually complementary to each other. This paper presents a multifarious knowledge transfer network (MKTN) that employs two complementary teachers to transfer generative features and discriminative features to train a compact yet powerful student network. On the other hand, the distilled features from teacher networks can be effectively transferred to a student network under the proposed adversarial loss and feature loss, that guide the student to learn spatial-level and pixel-level information, respectively. Extensive experiments show that our MKTN-trained student achieves superior performance despite its much smaller model size. We will adapt the MKTN idea for other vision tasks such as object detection and recognition in our future work.
Data Availability Statement
All dataset used in experiment are available on public platform.
Abbreviations
- MKTN:
-
Multifarious knowledge transfer network (our proposed method)
- DNNs:
-
Deep neural networks
- KT:
-
Knowledge transfer
- KD:
-
Knowledge distillation
- WRN:
-
Wide ResNet
- PYN:
-
PyramidNet
- mIoU:
-
Mean intersection over union
- FLOPs:
-
Floating point operations
- AT:
-
Attention transfer (the compared method)
- NST:
-
Neuron selectivity transfer (the compared method)
- FT:
-
Factor transfer (the compared method)
- AB:
-
Activation boundaries (the compared method)
- OFD:
-
Overhaul of feature distillation (the compared method)
- TAKD:
-
Knowledge distillation via teacher assistant (the compared method)
References
Tsiakmaki, M., Kostopoulos, G., Kotsiantis, S., Ragos, O.: Transfer learning from deep neural networks for predicting student performance. Appl. Sci. 10(6), 2145 (2020)
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going Deeper with Convolutions. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, USA, Jun 7–12, pp. 1–9 (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, Jun 26–Jul 1, pp. 770–778 (2016)
Zhang, X., Gong, H., Dai, X., Yang, F., Liu, N., Liu, M.: Understanding pictograph with facial features: end-to-end sentence-level lip reading of Chinese. In: Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, USA, Jan 2–Feb 1, pp. 9211–9218 (2019)
Madan, P., Singh, V., Chaudhari, V., Albagory, Y., Dumka, A., Singh, R., Gehlot, A., Rashid, M., Alshamrani, S.S., AlGhamdi, A.S.: An optimization-based diabetes prediction model using CNN and bi-directional LSTM in real-time environment. Appl. Sci. 12(8), 3989 (2022)
AlBadani, B., Shi, R., Dong, J., Sabri, R.A., Moctard, O.B.: Transformer-based graph convolutional network for sentiment analysis. App. Sci. 12(3), 1316 (2022)
Li, H., Kadav, A., Durdanovic, I., Samet, H., Graf, H.P.: Pruning filters for efficient ConvNets. In: Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, May 2–4, pp. 1–15 (2016)
Mariet, Z., Sra, S.: Diversity networks: neural network compression using determinantal point processes. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, May 2–4, pp. 1–13 (2016)
Luo, J., Wu, J., Lin, W.: ThiNet: a filter level pruning method for deep neural network compression. In: Proceedings of IEEE International Conference on Computer Vision (ICCV), Venice, Italy, Oct 22–29, pp. 5068–5076 (2017)
Molchanov, P., Tyree, S., Karras, T., Alia, T., Kautz, J.: Pruning convolutional neural networks for resource efficient transfer learning. In: Proceedings of International Conference on Learning Representations (ICLR), Toulon, France, Apr 24–26, pp. 1–17 (2017)
Courbariaux, M., Hubara, I., Soudry, D., Ran, E.Y., Bengio, Y.: Binarized neural networks: training deep neural networks with weights and activations constrained to +1 or -1. arXiv:1602.02830 (2016)
Rastegari, M., Ordonez, V., Redmon, J., Farhadi, A.: XNOR-Net: ImageNet classification using binary convolutional neural networks. In: Proceedings of the 21st ACM Conference on Computer and Communications Security, Berlin, Germany, May 30–Jun 3, pp. 525–542 (2016)
Iandola, F.N., Han, S., Moskewicz, M.W., Ashraf, K., Dally, W.J., Keutzer, K.: SqueezeNet: AlexNet-level Accuracy with 50x Fewer Parameters and \(\le\)0.5MB model size. arXiv:1602.07360 (2016)
Howard, A.G., Zhu, M., Chen, B.: MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861 (2017)
Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: FitNets: hints for thin deep nets. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, USA, May 7–9, pp. 1–15 (2015)
Zagoruyko, S., Komodakis, N.: Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer. In: Proceedings of International Conference on Learning Representations (ICLR), Toulon, France, Apr 24–26, pp. 1–13 (2017)
Kim, J., Park, S., Kwak, N.: Paraphrasing complex network: network compression via factor transfer. In: Proceedings of Conference on Neural Information Processing Systems (NIPS), Montréal, Canada, Dec 3–8, pp. 2760–2769 (2018)
Zhang, X., Lu, S., Gong, H., Luo, Z., Liu, M.: AMLN: adversarial-based mutual learning network for online knowledge distillation. In: Proceedings of European Conference on Computer Vision (ECCV), Online Virtual, Aug 23–28, pp. 158–173 (2020)
Zhang, X., Lu, S., Gong, H., Liu, M., Liu, M.: Training lightweight yet competent network via transferring complementary features. In: Proceedings of the Internationale Conference on Neural Information Processing, Lagos, Nigeria, Aug 13–14, pp. 571–579 (2020)
Zhang, P., Li, Y., Wang, D., Wang, J.: RS-SSKD: self-supervision equipped with knowledge distillation for few-shot remote sensing scene classification. Sensors 21(5), 1566 (2021)
Blakeney, C., Huish, N., Yan, Y., Zong, Z.: Simon says: evaluating and mitigating bias in pruned neural networks with knowledge distillation. arXiv:2106.07849 (2021)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. In: Proceedings of Annual Conference on Neural Information Processing Systems (NIPS), Barcelona Spain, Dec 5–10, pp. 1–9 (2016)
Zhang, L., Song, J., Gao, A., Chen, J., Bao, C., Ma, K.: Be Your own teacher: improve the performance of convolutional neural networks via self distillation. In: Proceedings of IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, Oct 27–Nov 2, pp. 1–10 (2019)
Chen, T., Goodfellow, L., Shlens, J.: Net2Net: accelerating Learning via knowledge transfer. In: Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, May 2–4, pp. 1–10 (2016)
Heo, B., Lee, M., Yun, S., Choi, J.Y.: Knowledge transfer via distillation of activation boundaries formed by hidden neurons. In: Proceedings of AAAI Conference on Artificial Intelligence, Honolulu, USA, Jan 2–Feb 1, pp. 3779–3787 (2019)
Yin, H., Pan, S.J.: Knowledge transfer for deep reinforcement learning with hierarchical experience replay. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, USA, Feb 4–9, pp. 1640–1646 (2017)
You, S., Xu, C., Xu, C., Tao, D.: Learning from multiple teacher networks. In: Acm Sigkdd International Conference, Halifax, Canada, Aug 13–17, pp. 1285–1294 (2017)
Zhang, C., Peng, Y.: Better and faster: knowledge transfer from multiple self-supervised learning tasks via graph distillation for video classification. In: Proceedings of International Joint Conference on Artificial Intelligence, pp. 1135–1141. Stockholm (2018)
Mirzadeh, S.I., Farajtabar, M., Li, A., Levine, N., Matsukawa, A., Ghasemzadeh, H.: Improved knowledge distillation via teacher assistant. In: Proceedings of AAAI Conference on Artificial Intelligence, New York, USA, Feb 7–12, vol. 34(4) (2020)
Huang, Z., Wang, N.: Like what you like: knowledge distill via neuron selectivity transfer. arXiv:1707.01219 (2017)
Hiton, G.E., Salakhutdinov, R.R.: Reducing the dimensionality of data with neural networks. Appl. Sci. 313(5786), 504–507 (2006)
Shin, H.C., Orton, R.W., Collins, J.D.: Stacked autoencoders for unsupervised feature learning and multiple organ detection in a pilot study using 4D patient data. IEEE Trans. Pattern Anal. Mach. Intell. 35, 1930–1943 (2013)
Ng, W.W.Y., Zeng, G., Zhang, J.: Dual autoencoders features for imbalance classification problem. Pattern Recognit. 60, 875–889 (2016)
Zhang, Y., Lee, K., Lee, H.: Augmenting supervised neural networks with unsupervised objectives for large-scale image classification. In: Proceedings of International Conference on Machine Learning (ICML), New York, USA, Jun 19–24, pp. 612–621 (2016)
Ghifary, M., Kleijn, W.B., Zhang, M., Balduzzi, D., Li, W.: Deep reconstruction-classification networks for unsupervised domain adaptation. In: Proceedings of European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, Oct 10–16, pp. 597–613 (2016)
Yoshihashi, R., Shao, W., Rei, K., You, S., Iida, M., Naemura, T.: Classification-reconstruction learning for open-set recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Angeles, USA, Jun 16–20, pp. 4011–4020 (2019)
Goodfellow, I.J., Pouget-A., J., Mirza, M., Xu, B., Warde-F., D.: Generative adversarial nets. In: Proceedings of the 28nd Conference on Neural Information Processing Systems, Montreal, Canada, Dec 8–13, pp. 2672–2680 (2014)
Shen, Z., He, Z., Xue, X.: MEAL: multi-model ensemble via adversarial learning. In: Proceedings of AAAI Conference on Artificial Intelligence, Honolulu, USA, Jan 2–Feb 1, pp. 4886–4893 (2019)
Xu, Z., Hsu, Y.C., Huang, J.: Training student networks for acceleration with conditional adversarial networks. British Machine Vision Association, Northumbria University, North East of England, Sept 3–6, pp. 1–10 (2018)
Shu, C., Li, P., Xie, Y., Qu, Y., Dai, L., Ma, L.: Knowledge squeezed adversarial network compression. arXiv:1904.05100 (2019)
Liu, Z., Huang, C., Liu, Y.: Improved knowledge distillation via adversarial collaboration. arXiv:2111.14356 (2021)
Tang, X., Lin, T.: Adversarial variational knowledge distillation. In: Proceedings of the 30th International Conference on Artificial Neural Networks, pp. 558–569 (2021)
Wang, X., Li, Y.: Harmonized dense knowledge distillation training for multi-exit architectures. In: Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada, Feb 2–9, pp. 10218–10226 (2021)
Maroto, J., Jimenez, G.O., Frossard, P.: On the benefits of knowledge distillation for adversarial robustness. arXiv:2203.07159 (2022)
Dong, N., Zhang, Y., Ding, M., Xu, S., Bai, Y.: One-stage object detection knowledge distillation via Ddversarial learning. Appl. Intell. 52(4), 4582–4598 (2022)
Ham, S., Park, J., Han, D., Moon, J.: NEO-KD: knowledge-distillation-based adversarial training for robust multi-exit neural networks. In: Proceedings of the 37th Conference on Neural Information Processing Systems, https://openreview.net/forum?id=Z7Cz9un2Fy (2023)
Maaten, L.V.D., Hinton, G.: Visualizing data using t-sne. J. Mach. Learn. Res. 9, 2575–2605 (2008)
Chen, D., Mei, J.P., Wang, C., Chen, C.: Online knowledge distillation with diverse peers. In: Proceedings of AAAI Conference on Artificial Intelligence, New York, USA, Feb 7–12, pp. 3430–3437 (2020)
Nikolaos, P., Tefas, A.: Learning deep representations with probabilistic knowledge transfer. In: Proceedings of European Conference on Computer Vision (ECCV), Munich, Germany, Sept 8–14, pp. 8–14 (2018)
Krizhevsky, A., Hinton, G.: Learning Multiple Layers of Features from Tiny Images (CIFAR10), 1, pp. 1–60. University of Toronto (2012)
Krizhevsky, A., Hinton, G.: Learning Multiple Layers of Features from Tiny Images (CIFAR100), 1, pp. 1–60. University of Toronto (2012)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Proceedings of Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, Dec 12–17, pp. 1097–1105 (2013)
Everingham, M., Eslami, S.M.A., Gool, L.V., Williams, C.K.I., Winn, J., Zisserman, A.: The pascal visual object classes challenge: a retrospective. Int. J. Comput. Vis. 111, 98–136 (2015)
Hariharan B., Arbelaez P., Bourdev L., Maji, S., Malik, J.: Semantic contours from inverse detectors. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, Nov 6–13, pp. 991–998 (2011)
Chen, L.C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder–decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of European Conference on Computer Vision (ECCV), Munich, Germany, Sep 8–14, pp. 833–851 (2018)
Heo, B., Kim, J., Yun, S., Park, H., Kwak, N., Choi, J.Y.: A comprehensive overhaul of feature distillation. In: Proceedings of IEEE/CVF International Conference on Computer Vision, Montreal, Canada, Oct 10–17, pp. 1921–1930 (2021)
Zagoruyko, S., Komodakis, N.: Wide residual networks. In: Proceedings of British Machine Vision Conference, York, England, UK, Sept 19–22, pp. 19–22 (2016)
Han, D., Kim, J., Kim, J.: Deep pyramidal residual networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Hawaii, USA, Jul 21–26, pp. 6307–6315 (2017)
Maaten, L.V.D., Hinton, G.: Visualizing data using t-sne. J. Mach. Learn. Res. 11, 1–5 (2008)
Acknowledgements
The authors are grateful to all the anonymous reviewers for their suggestions and comments.
Funding
This research has been supported by National Social Science Fund Project, China (21BXW057).
Author information
Authors and Affiliations
Contributions
XZ completed the main work of this paper, including conceptualization, methodology, writing—original draft, experimental finishing. HC and YH implemented the work of writing—checking, editing and manuscript modification. DC planned the empirical study, and supervised during the writing process. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Yes.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, X., Chang, H., Hao, Y. et al. MKTN: Adversarial-Based Multifarious Knowledge Transfer Network from Complementary Teachers. Int J Comput Intell Syst 17, 72 (2024). https://doi.org/10.1007/s44196-024-00403-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-024-00403-0