
Abstract
This paper presents the Generation Max Electrical Energy from Wind Friendly Environment Database (GMEE-WFED) system, a groundbreaking innovation aimed at enhancement the performance and energy output of wind power generation stations. The GMEE-WFED system has been meticulously designed to provide precise wind power forecasting within distributed turbine systems, facilitating the seamless integration of renewable energy into the grid. This forecasting is enabled by the utilization of the Spatial Dynamic Wind Power Forecasting (SDWPF) dataset, which takes into account the spatial distribution and dynamic characteristics of wind turbines. The GMEE-WFED system comprises five layers, each offering unique advantages. The first layer, referred to as the "Best Distribution of Turbines Based on DOA (BDT-DOA)," is designed to achieve the following objectives: (a) increase power generation, (b) determine the optimal coordinates (x, y) for each turbine, and (c) distribute turbines based on the best locations. The second layer, named the "Effect Features Layer (EF)," focuses on: (a) identifying the impact of features on wind power generation, (b) streamlining implementation time, and (c) reducing computational demands. The third layer, denoted as the "Average and Shifting up Target Layer (AEH-SUV)," serves the purposes of: (a) enhancing accuracy by calculating feature averages, and (b) predicting future active power through target shifting at different intervals (ranging from 1 to 6 h). Meanwhile, the fourth layer is associated with the development of a prediction model based on a deep learning technique known as "Deep Learning-Long Short-Term Memory (DL-LSTM) Layer," which is utilized for: (a) forecasting future energy production, (b) evaluating model accuracy at varying intervals, and (c) assessing overall model effectiveness. The final layer is also dedicated to constructing a prediction model, but it leverages a different deep learning technique called "Deep Learning Gate Recurrent Unit (DL-GRU)." These models contribute to accurate wind power predictions at various intervals and ensure the overall effectiveness of the system. Experimental results have shown that DL-GRU outperforms DL-LSTM in all shifting cases, underscoring the system's effectiveness in predicting future wind power generation and forecasting accuracy. As a result, the GMEE-WFED system is a pioneering approach that enhances wind DC-power generation forecasting. The GMEE-WFED system, with its intricate layers and advanced modeling techniques, represents a significant leap forward in harnessing the potential of wind energy for a more sustainable future.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
A distribution system [1, 2] refers to the infrastructure and network that facilitates the efficient and reliable delivery of goods, services, or resources from a central source to multiple end-users or consumers. It encompasses various interconnected elements, such as transportation, storage, and allocation mechanisms, ensuring the availability and accessibility of products or services in the desired quantities and locations.
The important of a distribution system, and related it with spatial distribution of wind turbines [3, 4]: optimized resource allocation: in the context of wind power generation, a distribution system plays a crucial role in optimizing the spatial distribution of wind turbines. By strategically placing turbines in areas with favorable wind conditions, the system maximizes the utilization of wind resources. This leads to increased energy generation and improved overall efficiency of the wind power system. Efficient energy delivery [5, 6]: a well-designed distribution system for wind turbines ensures that the generated energy is efficiently delivered to consumers. It involves the establishment of transmission and distribution networks to transport electricity from wind farms to end-users. This efficient energy delivery contributes to a reliable and stable power supply, reducing transmission losses and enhancing grid performance. Enhanced grid integration: the spatial distribution of wind turbines within a distribution system is carefully planned to ensure optimal grid integration. By considering factors, such as transmission capacity, network stability, and load demand, the system facilitates the seamless integration of wind power into the existing electrical grid. This integration [7, 8] helps in balancing the supply and demand of electricity, improving grid reliability, and reducing reliance on conventional power sources. Localized economic benefits: the spatial distribution of wind turbines can bring about localized economic benefits to the areas where they are deployed. Wind farms often create job opportunities during construction, operation, and maintenance phases, providing employment and driving economic growth in local communities. Additionally, wind power projects can contribute to tax revenues and lease payments, benefiting local governments and landowners. Environmental sustainability [9]: the spatial distribution of wind turbines within a well-planned distribution system promotes environmental sustainability. Wind power is a clean and renewable energy source, and by strategically siting wind turbines, the distribution system helps in reducing greenhouse gas emissions and mitigating climate change. This sustainable energy generation contributes to the transition to a low-carbon economy and fosters a greener future. Resilience and redundancy [10, 11]: a distributed spatial distribution of wind turbines provides a level of resilience and redundancy to the power system. By dispersing wind turbines across different locations, the system reduces the vulnerability to localized disruptions. If one turbine or wind farm experiences issues, others can continue generating power, ensuring a more reliable and robust energy supply. Technological advancements: the optimization of the spatial distribution of wind turbines within a distribution system encourages technological advancements. It drives research and development in areas, such as turbine design, control systems, and grid integration technologies. These advancements lead to more efficient and cost-effective wind power generation, benefiting the overall renewable energy sector.
The scientific significance of this work lies in its emphasis on the growing importance of renewable energy, particularly wind power, and the challenges associated with its integration into the grid system due to high variability. The work highlights the critical role of Wind Power Forecasting (WPF) in accurately estimating wind power supply, which remains a challenge due to spatial distribution and dynamic contextual factors. The development of the Spatial Dynamic Wind Power Forecasting (SDWPF) dataset offers a crucial opportunity for researchers to improve wind power forecasting and integration into the grid system. Moreover, the SDWPF dataset's ability to provide valuable information on the spatial distribution and dynamic context of wind turbines can lead to the development of advanced machine-learning techniques, contributing to a more sustainable and reliable energy system. Overall, this research has significant scientific importance as it addresses one of the most critical challenges in renewable energy integration and operation, leading to a cleaner and more sustainable future. The importance of WPF and SDWPF:
-
Improved accuracy: WPF and SDWPF models, particularly those based on machine-learning techniques, have been shown to significantly improve the accuracy of wind power generation forecasting. This is essential for effective integration of wind energy into the grid system and efficient energy management.
-
Cost savings: accurate WPF and SDWPF can help reduce costs associated with energy production, distribution, and storage. This is because accurate forecasting enables better planning and management of energy resources, reducing the need for costly backup energy sources.
-
Improved energy management: accurate WPF and SDWPF can help utilities and energy companies better manage their energy resources, leading to more efficient and sustainable energy systems.
-
Reduced environmental impact: by enabling better management of energy resources and reducing the need for backup energy sources, accurate WPF and SDWPF can help reduce the environmental impact of energy production.
-
Increased energy security: accurate WPF and SDWPF can help improve energy security by reducing dependence on fossil fuels and enabling better integration of renewable energy sources into the grid system.
Some of the main challenges and problems in renewable energy of SDWPF and WPF are:
-
Integration into the grid: integrating renewable energy into the grid poses a significant challenge, particularly for wind power generation. Wind power is highly variable, and its integration into the grid requires balancing the supply and demand of electricity in real time. The variability and uncertainty of wind power generation can cause instability in the grid and affect the quality and reliability of electricity supply.
-
Energy storage: energy storage is a critical technology that can help address the variability and uncertainty of renewable energy, including wind power. However, the cost of energy storage is still relatively high, making it challenging to deploy on a large scale. Moreover, the performance and durability of energy storage systems need to be improved to ensure their long-term viability.
-
Policy and regulatory frameworks: the policy and regulatory frameworks in many countries do not provide sufficient incentives for the deployment of renewable energy, including wind power. The lack of supportive policies and regulations can hinder the development of renewable energy projects, making it difficult to achieve the necessary scale to drive down costs and improve performance.
-
Environmental impact: while renewable energy is generally considered to be environmentally friendly, it can also have adverse environmental impacts, particularly if not planned and implemented carefully. Wind power, for example, can impact wildlife, including birds and bats, and their habitats. The negative environmental impact of renewable energy needs to be minimized, and the benefits need to be maximized through careful planning and implementation.
-
Technological advancements: the development of new and innovative technologies is essential to improve the performance, reliability, and cost-effectiveness of renewable energy, including wind power. Technological advancements can help address the variability and uncertainty of wind power generation, improve energy storage systems, and reduce the environmental impact of renewable energy projects.
-
Finally, addressing the challenges in renewable energy of SDWPF and WPF requires a comprehensive approach that involves technological advancements, supportive policy and regulatory frameworks, careful environmental planning, and the development of robust grid integration strategies.
In general; we can show the problem statements of this paper as follows:
-
Wind power forecasting (WPF) is a challenging task due to the high variability of wind power supply.
-
Accurate and efficient estimation of wind power supply is crucial for effective renewable energy management, reduced costs and environmental impact, and increased energy security.
-
The spatial distribution and dynamic context of wind turbines play a crucial role in WPF and must be considered for better modeling of the correlation among wind turbines and improved forecasting accuracy.
-
Machine-learning techniques, especially the hybrid combination of Gated Recurrent Units (GRUs) and Elephant Herding Optimization Algorithm (EHOA), can significantly improve WPF and SDWPF accuracy.
-
The proposed Spatial Dynamic Wind Power Forecasting (SDWPF) dataset contributes to the advancement of WPF research and provides insights for improving wind energy integration into the grid system.
While; The aim of this work is to suggest a system that aims to accurately and efficiently estimate wind power supply by considering the spatial distribution and dynamic context of wind turbines. The objectives of this research are to evaluate the proposed method's performance using appropriate evaluation metrics, compare it with the existing methods, conduct sensitivity analysis, provide insights and recommendations for improving WPF and SDWPF accuracy and efficiency, and discuss the potential benefits, challenges, and limitations of WPF and SDWPF. Finally, the research aims to present the findings and conclusions effectively in a well-structured and comprehensive work report, oral presentations, and work defense. To salsify the following objectives:
-
Develop and implement the proposed hybrid method for Wind Power Forecasting using the Spatial Dynamic Wind Power Forecasting (SDWPF) dataset
-
Conduct experimental evaluation and analysis of the proposed method's performance using appropriate evaluation metrics, such as mean absolute error (MAE), root-mean-squared error (RMSE), and correlation coefficient (CC)
-
Compare the performance of the proposed method with existing methods and models for WPF and SDWPF
-
Conduct sensitivity analysis to investigate the impact of different factors on the proposed method's performance, such as the size of the training dataset, the number of hidden layers in the GRU model, and the parameters of the EHOA algorithm
-
Provide insights and recommendations for improving the accuracy and efficiency of WPF and SDWPF using machine-learning techniques
-
Discuss the potential benefits of accurate WPF and SDWPF for energy management, cost savings, environmental impact reduction, and energy security
-
Discuss the challenges and limitations of WPF and SDWPF and potential future research directions
-
Write a well-structured and comprehensive thesis report that presents the research objectives, methodology, results, and conclusions in a clear and concise manner
-
Present the research findings and conclusions effectively in oral presentations and defend the thesis convincingly in front of a committee of experts.
2 Related Work
This section of the paper shows some of the previous works that have focused on distributed systems in wind turbine distribution to enhance the prediction of renewable energy:
Folly and Hasan [12] proposed a hybrid model for Wind Power Forecasting (WPF) that combines artificial neural networks (ANNs) with genetic algorithm (GA) optimization. The model was evaluated using the WPF dataset available on the AISTUDIO platform and demonstrated superior performance compared to the traditional statistical models. The study concluded that the hybrid model enhances the accuracy of WPF and supports the integration of wind power into the grid system.
Huang et al. [13] introduced an enhanced version of the Extreme Gradient Boosting (XGBoost) algorithm for WPF. Their proposed model, evaluated on the AISTUDIO platform's WPF dataset, outperformed the traditional statistical models. The study emphasized that the improved XGBoost algorithm effectively captures temporal dependencies in the WPF dataset, leading to improved forecasting accuracy.
Basu et al. [14] conducted a comprehensive review that encompassed WPF models, techniques, and datasets. The review highlighted the value of the WPF dataset available on the AISTUDIO platform for research purposes. Moreover, the paper discussed various techniques and evaluation measures employed in WPF, ultimately concluding that machine-learning models exhibit superior performance to traditional statistical models.
Zhang et al. [15] proposed a hybrid data-driven machine-learning approach for WPF. Their model integrated a Long Short-Term Memory (LSTM) neural network with Support Vector Regression (SVR), incorporating feature selection and preprocessing techniques. Evaluation measures, such as MAE, RMSE, and CC, were employed, and the hybrid model demonstrated superior performance when compared to the traditional statistical models. The study showcased the effectiveness of their proposed approach for WPF.
Li et al. [16] present forth a hybrid approach for WPF that combines a Long Short-Term Memory (LSTM) neural network with a convolutional neural network (CNN). The proposed model, evaluated using the AISTUDIO platform's WPF dataset, exhibited improved performance compared to traditional statistical models. The study concluded that their hybrid approach effectively captured both temporal and spatial dependencies within the WPF dataset, resulting in enhanced forecasting accuracy.
Muselli and Notton [17] proposed a hybrid approach for short-term WPF, combining a machine-learning technique called Least-Squares Support Vector Regression (LSSVR) with a statistical model based on Autoregressive Integrated Moving Average (ARIMA). Their model, evaluated on the SDWPF dataset, outperformed the traditional methods such as ARIMA and Exponential Smoothing (ES). The study concluded that the hybrid approach improved short-term WPF accuracy.
Zhang et al. [18] introduced a deep learning model based on the convolutional neural network (CNN) for spatial–temporal prediction of wind power generation. The proposed model, evaluated using the SDWPF dataset, outperformed the traditional methods like Decision Trees (DT) and Support Vector Machines (SVM). The study emphasized that the CNN-based model effectively captured the spatial and temporal dependencies present in the SDWPF dataset, resulting in improved WPF accuracy.
Chen et al. [19] proposed a spatial dynamic WPF model employing deep learning and multitask learning. Their model, evaluated on the SDWPF dataset, demonstrated superior performance compared to traditional methods like ARIMA and Exponential Smoothing (ES). The study concluded that their proposed model effectively captured spatial and temporal dependencies within the SDWPF dataset, thereby enhancing WPF accuracy. The multitask learning approach further improved model performance by leveraging correlations among different wind turbines.
Basu et al. [20] provided an extensive overview of WPF models, techniques, and datasets. It specifically highlighted the SDWPF dataset as a valuable resource for WPF research due to its inclusion of both external and internal features impacting wind power generation. The review also discussed various techniques and evaluation measures employed in WPF, ultimately concluding that machine-learning models exhibit superior performance to traditional statistical models in wind power prediction.
Zhang et al. [21] proposed a hybrid deep learning model for long-term wind power forecasting. The model combined Long Short-Term Memory (LSTM) with a deep feed-forward neural network (DNN) to capture both temporal and spatial dependencies in the wind power data. The model was evaluated on the AISTUDIO platform's long-term wind power forecasting dataset and demonstrated improved accuracy compared to the traditional statistical models. The study concluded that the hybrid deep learning model is effective for long-term wind power forecasting.
Huerta et al. [22] propose a hybrid model combining a recurrent neural network (RNN) based on Gated Recurrent Unit (GRU) architecture and classical time series forecasting approaches using K-nearest neighbor (KNN) models for wind power forecasting. The model is applied to a dataset of 245 days of historical 10-min data for a wind farm with 134 turbines. The article provides insights into data exploration, preprocessing techniques, and challenges faced in the wind power forecasting task. The paper highlights the benefits of model ensembles and compares different prediction horizons, turbine IDs, and combinations to select the best-performing models.
Liu et al. [23] present a machine-learning approach for wind power forecasting using a GRU-based model. It utilizes a unique dataset with spatial information and weather data to estimate the wind power supply of a wind farm. The authors applied k-nearest-neighbor interpolation for data cleaning and selected the baseline GRU model for prediction. Hyperparameter optimization and grid search were performed to improve the model's performance.
Zhang et al. [24] introduce two strategies to address abnormal and missing values in wind power forecasting. It proposes interpolation for handling missing values and replacing abnormal values with boundary values. The effectiveness of these strategies is validated through experiments on the SDWPF dataset. The work builds upon previous studies on wind power forecasting and contributes novel approaches to mitigate the negative effects of abnormal and missing values.
These studies demonstrate the use of various machine-learning techniques, such as artificial neural networks, genetic algorithms, extreme gradient boosting, LSTM, CNN, and multitask learning, for wind power forecasting. The hybrid models combining different techniques have shown improved accuracy in capturing temporal and spatial dependencies in wind power data, leading to enhanced forecasting performance. The evaluation of these models has been conducted on datasets available on platforms like AISTUDIO and SDWPF, which provide valuable resources for wind power forecasting research.
Studies such as [1,2,3,4,5] proposed hybrid models that combine different machine-learning techniques, such as artificial neural networks (ANNs), convolutional neural networks (CNNs), and Support Vector Regression (SVR) with optimization algorithms like genetic algorithm (GA) and Extreme Gradient Boosting (XGBoost) to improve the accuracy of WPF. Studies [6,7,8,9,10] proposed hybrid models that combine machine-learning techniques like Least-Squares Support Vector Regression (LSSVR) and deep learning with statistical models like ARIMA to improve the accuracy of SDWPF. Studies such as [11,12,13] used the same dataset will used in this study.
Both WPF and SDWPF datasets were used in these studies, with the WPF dataset available on the AISTUDIO platform being highlighted as a valuable resource for WPF research in [3] and the SDWPF dataset being highlighted as a valuable resource for SDWPF research in [9]. The SDWPF dataset contains external and internal features that impact wind power generation and has been used in studies [6,7,8,9,10] to develop and test new models.
Finally, these studies demonstrate the effectiveness of machine-learning models in improving the accuracy of WPF and SDWPF. Additionally, proper feature selection, preprocessing, and optimization techniques are crucial for developing accurate forecasting models. While WPF and SDWPF are distinct research areas, they share many similarities in terms of techniques and evaluation measures and can benefit from each other's advancements in machine-learning and forecasting techniques (Table 1).
3 Main Concepts
This section will explain the main tools used in building GMEE-WFED.
3.1 The Dragonfly Algorithm (DA)
DA is a nature-inspired optimization algorithm that is inspired by the behavior of dragonflies in nature. It was proposed by Mirjalili et al. in 2014 as an optimization technique for solving complex optimization problems. The algorithm mimics the swarming behavior and social interactions of dragonflies to search for optimal solutions in a multidimensional search space. It utilizes the concept of attraction and repulsion among dragonflies to guide the search process and explore the solution space effectively. Main steps of the Dragonfly Algorithm:
In the initialization stage of the algorithm, several key steps are performed [25, 26]. First, the number of dragonflies (NP), maximum number of iterations (MaxIterations), and the dimension of the search space (dim) are set. Additionally, lower bounds (lb) and upper bounds (ub) are defined for each dimension of the search space. The positions of the dragonflies (X) are then randomly initialized within the search space. Afterward, the fitness values of the initial positions are evaluated to assess their quality.
During the attraction and repulsion stage, the dragonflies are attracted to each other based on their fitness values. The strength of attraction is determined by a coefficient called beta, which is updated during the algorithm's execution. This attraction helps the dragonflies move toward better solutions. On the other hand, repulsion occurs between dragonflies to prevent premature convergence and encourage exploration of the search space.
To introduce randomness and exploration in the search process, a chaotic sequence (C) is utilized. Chaotic sequences possess deterministic chaos and are employed to enhance the diversity of solutions. The chaotic sequence C is updated at each iteration, contributing to the generation of new solutions.
The position update stage is crucial in determining the new positions of the dragonflies [27]. This update is influenced by attraction, repulsion, and the chaotic sequence. The position of a dragonfly is calculated based on its current position, the positions of other dragonflies, and the chaotic sequence. By incorporating attraction, repulsion, and random perturbation, the position update equation effectively explores the search space.
After updating the positions, the fitness of the new solutions is evaluated. A fitness function is used to measure the quality of each solution in the search space. The fitness values play a role in determining the attraction and repulsion among dragonflies in subsequent iterations.
The best solution found so far, known as the global best, is updated based on the fitness values of the dragonflies. The global best represents the optimum solution discovered during the execution of the algorithm.
The algorithm progresses to the next iteration by incrementing the current iteration count. This count is utilized to control the update of the attraction coefficient, step sizes, and the chaotic sequence.
The algorithm continues iterating until the maximum number of iterations is reached or a termination criterion is met. Termination criteria can be based on convergence criteria, reaching a desired fitness value, or a predefined stopping condition.
The Dragonfly Algorithm leverages the exploration and exploitation capabilities inspired by the swarming behavior of dragonflies to efficiently search for optimal solutions in complex optimization problems. By balancing attraction, repulsion, and chaotic perturbations, it aims to strike a balance between exploration and exploitation to find high-quality solutions. The behavior of swarms in the Dragonfly Algorithm is guided by three fundamental principles:
-
Separation: this principle involves avoiding static collisions with neighboring entities.
-
Alignment: it refers to the adjustment of individual speeds to align with neighboring individuals, promoting coordinated movement.
-
Cohesion: this principle indicates the tendency of individuals to move toward the center of the swarm.
Since the ultimate goal of any swarm is survival, all members should be attracted to food sources while staying clear of potential attackers. Consequently, there are five main aspects in the position updating of individuals within swarms, taking into account these two behaviors: separation, alignment, cohesion, attraction, and distraction.

Algorithm: Dragonfly Algorithm (DA)
3.2 Recurrent Neural Networks (RNNs)
Recurrent neural networks (RNNs) are a class of artificial neural network which became more popular in recent years. The RNN is a special network, which has unlike feed-forward networks recurrent connections. The major benefit is that with these connections, the network is able to refer to last states and can, therefore, process arbitrary sequences of input. A recurrent neural network, at its most fundamental level, is simply a type of densely connected neural network. However, the key difference to normal feed-forward networks is the introduction of time—in particular, the output of the hidden layer in a recurrent neural network is fed back into itself, as shown in the Fig. 1 [28].

Recurrent neural networks (RNNs)
This work will use two types of RNNs: the first is called Long Short-Term Memory (LSTM-RNN), while the second is called Gate Recurrent Unit (GRU).
3.2.1 Long Short-Term Memory (LSTM)
LSTM is a deep learning technology that is capable of handling and predicting large data. Long-term memory networks (LSTM) are a common option for serial modeling tasks, because they can be stored in the long and short term. LSTMs are inspired by RNNs. RNN operates in a similar way, but does not have effective ways to store long-term memory. However, unlike RNN, LSTMs specifically apply memory cells that have the ability to store memory for longer periods of time. The LSTM structure has four main components; input gateway (i), gate (f), output port (o), and memory cells (c) [2, 29]. LSTM is well suited to classify, process, and issue predictions based on time series data, between important events in a time series. LSTMs have been developed to address the problems of explosive and static gradients that can be encountered when training traditional RNN. Thus, LSTM can process data sequentially and maintain its hidden state over time [5, 27]. The architecture of LSTM for two phases: forward and backward shown in Fig. 2.

LSTM architecture
This algorithm required multi-steps to compute the variables at the beginning and then through it work will update these variables by apply computation operations:
Step 1: The forward components
Step 1.1: Compute the gates:
Memory cell:
Input gate:
Forget gate:
Output gate:
Then fined: internal state:
Output:
where
Step. 2: The backward components:
Step 2.1. Find
\(\Delta t\) the output difference as computed by any subsequent.
\(\Delta {\text{OUT}}\) the output difference as computed by the next time-step
Step 2.2: Gives
Step 3: update to the internal parameter
where
ʘ: is the element-wise product or Hadamard product
⊗: outer products will be represented
\(\sigma \): represents the sigmoid function
at: memory cell
it: input gate
ft: forget gate
ot: output gate
Statet: internal state
Outt: output
W: the weights of the input
U: the weights of recurrent connections.

Algorithm: LSTM
3.2.2 Gated Recurrent Unit (GRU)
GRU is a type of recurrent neural network (RNN) that is similar to the LSTM model, but with fewer parameters, making it faster on low complexity data sequences [30]. However, when dealing with high complexity data sequences, LSTM is more accurate and outperforms GRU [31]. One of the limitations of GRU is that it exposes the whole state each time without any mechanism to control the degree of state exposure [6]. Nevertheless, GRU has the ability to memorize sequential input data by storing prior input into the network's internal state, without using a separate memory cell. The structure of GRU consists of two gating units: the update gate, which controls the information that is updated and transferred to the next state cell, and the reset gate, which determines how to combine the currently entered information with the previous one [30].
Cho et al. proposed GRU in 2014 [32]. Since then, many modifications have been made to the structure of GRU to overcome its limitations, such as low learning rate efficiency, slow convergence state, and the complexity of the state of time series information. GRU is used in various machine-learning tasks related to memory and clustering, such as machine translation, speech signal modeling, and handwriting recognition. It aims to minimize the computational cost of the network and overcome the limitations of RNNs. The tanh function is used to regulate the data flow and avoid the exploding gradient. GRU is particularly useful when fast results are needed with little memory consumption.
As a result, GRU is a modification of LSTM that aims to minimize computational cost and improve memory-related machine-learning tasks. It is faster than LSTM on low complexity data sequences but is outperformed by LSTM on high complexity data sequences. GRU has two gating units, the update gate and reset gate, and has been modified to overcome its limitations. It is useful in various machine-learning applications, including speech signal modeling and handwriting recognition, where fast results are needed with low memory consumption.
The Gated Recurrent Unit Algorithm (GRU) follows a series of steps to effectively model sequential data. First, the network parameters, which include the weights and biases of the update gate, reset gate, and candidate activation functions, are initialized. Next, for each time step, the values of the update gate, reset gate, and candidate activation function are calculated using the input at the current time step and the output from the previous time step. The new hidden state is computed by combining the output from the reset gate and the candidate activation function values. The output at the current time step is then updated using the new hidden state. These steps are repeated for each time step in the sequence. The loss between the predicted output and the actual output is calculated, and back propagation through time is used to update the network parameters to minimize the loss. This approach enables the GRU algorithm to model the complex relationships and dependencies among sequential data effectively, making it a valuable tool for various applications, including speech recognition, natural language processing, and time series forecasting.
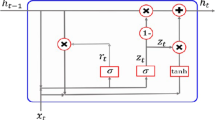
GRUs have an internal mechanism known as gates, which include update and reset gates. These gates control the information to be retained or discarded at each time step and regulate the flow of information. GRUs only have one hidden state that is passed between time steps, which can hold both long-term and short-term conditions simultaneously due to the gating mechanisms and algorithms that the state and information pass through. The architecture of GRU is illustrated in Fig. 3, where the update gate is calculated in the first step by combining the previous hidden state and the current input data using the following equation:

GRU architecture [5]
Following that, the current time step's input data and the previous time step's hidden state are both used to derive and compute the reset gate, According to the following equation:
In the intermediate memory unit or candidate hidden state, information from the previous hidden state is mixed with input, According to the following equation:
finally, we find the resulting, according to the following equation:
Primary parameters: Z: update gate at t. R: reset gate at t. \(\tilde{h}\): current memory. While secondary parameters: K: input vector. h, y: output vector T: time-step. Ht−1: previous hidden state. W, U: weight matrices. B: bias vector. Activation functions \(\sigma \): sigmoid function as \(\left( {\sigma (x) = \frac{1}{{1 + e^{ - x} }}} \right)\). tanh: the hyperbolic tangent. Activation functions are possible, provided that σ (x) € {0, 1}, tanh € {− 1, 1}.
The output of the update gate in GRU is represented by z(t), while the output of the reset gate is represented by r(t). The new candidate vector values are represented by n(t).
Compared to other recurrent neural network (RNN) algorithms like traditional RNN and Long Short-Term Memory (LSTM), Gated Recurrent Unit Algorithm (GRU) has several advantages and disadvantages.
One of the main advantages of GRU over traditional RNN is its ability to handle the vanishing gradient problem that arises in RNNs due to the repeated multiplication of gradients during backpropagation. GRU achieves this using gating mechanisms that selectively control the flow of information through the network, allowing it to learn long-term dependencies more effectively.
Compared to LSTM, GRU has a simpler architecture and fewer parameters, making it faster and more memory-efficient. However, LSTM is generally more accurate on tasks that require modeling long-term dependencies, such as machine translation and speech recognition.
In terms of training speed, GRU is generally faster than LSTM due to its simpler architecture and fewer parameters. However, this can come at the cost of reduced accuracy on certain tasks.
The architecture of GRU is illustrated in Figure 3, where the update gate is calculated in the first step by combining the previous hidden state and the current input data using the following equation:

Algorithm: GRU
4 GMEE-WFED System
The distribution systems of wind turbines play a crucial role in improving the performance of wind power generation stations and increasing the amount of energy produced. These systems consist of a set of turbines that are distributed strategically based on factors, such as the number of available turbines, the space available for planting them, and the diameter of each turbine.
This paper present system called Generation Max Electrical Energy from Wind Friendly Environment Database (GMEE-WFED). These systems enable to find the distribution of wind turbine and increased efficiency in harnessing wind power; in addition, predicting the power generating in the future based on apply the shifting up target vector concept though using deep learning techniques. The main stages of GMEE-WFED system explained in Fig. 4 are as follows:

Main stages of GMEE-WFED system
The first stage is estimation of the optimal of location of each turbines; where A database [33] of SDWPF contains two datasets; first related to initial coordinated of Turbin Location (X,Y) pulse the Turbin ID called Initial location of Turbine Dataset (ILTD); the second Dataset is related to wind turbines containing 1,048,576 records and 13 attributes. While the goal is finding the highest Active power; the columns in the dataset are as follows:
-
TurbID: wind turbine ID, which likely serves as a unique identifier for each turbine.
-
Day: day of the record, indicating the date when the data were recorded.
-
Tmstamp: created time of the record, specifying the timestamp of when the data were logged.
-
Wspd (m/s): wind speed recorded by the anemometer, measuring the speed of the wind.
-
Wdir (°): the angle between the wind direction and the position of the turbine nacelle. This parameter indicates the direction from which the wind is blowing in relation to the turbine.
-
Etmp (℃): temperature of the surrounding environment, providing the ambient temperature at the turbine site.
-
Itmp (℃): temperature inside the turbine nacelle, indicating the temperature within the turbine's enclosed structure.
-
Ndir (°): nacelle direction or yaw angle, representing the orientation or angle of the turbine nacelle relative to a reference point or wind direction.
-
Pab1 (°): pitch angle of blade 1, specifying the angle at which the first blade of the turbine is set.
-
Pab2 (°): pitch angle of blade 2, denoting the angle at which the second blade of the turbine is set.
-
Pab3 (°): pitch angle of blade 3, indicating the angle at which the third blade of the turbine is set.
-
Prtv (kW): reactive power, referring to the power component in an alternating current (AC) circuit that is out of phase with the voltage.
-
Patv (kW): active power (target variable), representing the actual power output of the wind turbine in kilowatts (kW).
In this stage will work on the first dataset through applying the Dragonfly Algorithm (DA) to find the best location of Turbines; where the dataset contains 134 turbines; this stage finds the best coordinate (X, Y) of each one.
The second stage is merging both datasets: the first that contains the best location of each turbine (X, Y) with second dataset where the primary key of both is (Turbin ID; then find the features effect of wind power generated through compute (correlation; entropy and information gain) after that draws the effect of most important features on active power )Patv); in addition that features pass into model in parallel (DL-LSTM, DL-GRU).
The third stage is processes data by averaging it over hourly intervals, reducing noise, and enhancing prediction accuracy. It also supports forecasting of active power at different time horizons and is instrumental in improving system performance.
The fourth stage is building the model called deep learning long short-term memory (DL-LSTM). The main benefit of this stage is prediction energy in the future based on different types of interval (i.e., shifting). Compute the accuracy of model in different interval and increase effectiveness of model.
While; the fifth stage is building the model called deep learning gate recurrent unit (DL-GRU); then evaluating the results of both model (i.e., DL-LSTM, DL-GRU) based on accuracy measures to determine the best model. We can summarize this stages through Algorithm 4. While the layers of GMEE-WFED system and benefits of each one are shown in Fig. 5.

GMEE-WFED layers
The GMEE-WFED system consists of five layers, each with its unique benefits. The first layer, called best distribution of turbines based on DOA (BDT-DOA), used to (a) increase power generated. (b) Find best coordination's (x, y) for each turbine and (c) distribution of turbines based on the best location. Second layer is called effect features layer (EF) used to (a) find features effect of wind power generated, (b) reduce time implementation, and (c) reduced computation. The third layer is called average and shifting up target layer (AEH-SUV) used to (a) increase accuracy by find average, and (b) prediction active power in future by shifting up target in different interval (1, 2, 3 ….and 6 h). While the fourth layer is related to building prediction model based on one of deep learning technique called Deep Learning-Long Short-Term Memory (DL-LSTM) Layer used to (a) prediction energy in the future. (b) Compute the accuracy of model in different interval and (c) effectiveness of model, while the final layer is also related to building prediction model based on other deep learning technique called deep learning gate recurrent unit used to the same the benefit of DL-LSTM layer. Figure 5 shows that layers.

Algorithm: GMEE-WFED
5 Results of the GMEE-WFED System
GMEE-WFED is used to estimate the optimal of location of each turbines. Then, forecasting the max wind power, it works on database [32] of SDWPF that contain two datasets; first related to initial coordinated of Turbin Location (X, Y) pulse and the Turbin ID called Initial Location of Turbine Dataset (ILTD), while the second Dataset is related to wind turbines containing 1,048,576 records and 13 attributes’ collection through 245 day interval between each record is 10 min. Table 2 shows the samples of this dataset.
In this stage will work on the first dataset through applying the Dragonfly Algorithm (DA) to find the best location of each turbine; where the dataset contains 134 turbines [i.e., find the best coordinate (X, Y) of each one] the results of that stage shown in Table 3. While Fig. 6 shows the spatial distribution of 134 turbines based on the best coordinates.

Spatial distribution of 134 turbines: a compare among the initial and best location of 134 turbines based on X-coordinate; b compare among the initial and best location of 134 turbines based on Y-coordinate; and c distribution of turbines based on the best location
In the second stage of our research, we identified important features related to maximizing wind energy generation by analyzing correlations and information gain. Tables 4 and 5 present the results. Using these insights, we determined the best turbine installation location by considering the distribution of feature importance, relationships among significant features, and the impact of key features on the target variable. Figure 3 provides a comprehensive analysis of the features within the SDWFP Dataset, encompassing three distinct sub-figures. First, sub-figure (a) illustrates the empirical distribution of feature importance, employing the rigorous Information Gain (IG) metric. Second, sub-figure (b) elucidates the intricate interrelationships among the top five most significant features. Finally, sub-figure (c) delves into the profound implications stemming from the two utmost crucial features, Prtv and Wspd, ascertained through the meticulous integration of both Information Gain and Correlation analysis, with a specific focus on their profound impact on the target variable, Patv. These findings serve as a robust foundation for informed decision-making processes and further investigations within the realm of turbine site selection and wind energy optimization (Fig. 7).


Importance features of SDWFP dataset: A distribution of the important of features based on IG; B relationships among the most five important features; and C affect two most important features (Prtv and Wspd) determined by IG and correlation on the target Patv
In the third stage: find the average each hour and shifting up the target vector is a crucial part of your data processing and predictive modeling pipeline. It offers several benefits and plays a pivotal role in improving the accuracy of your predictions and forecasting active power generation in the future. This stage is called AEH-SUV layer and achieves the following: (a) hourly data averaging: the primary function of this layer is to compute the hourly average for each feature in your dataset. Given that sensor readings occur every 10 min, this layer accumulates data over a 1-h period (60 min), which corresponds to six readings. It then calculates the average value for each feature within that hour. This averaging process smooths out variations and captures the overall trend of the data over 1-h intervals. (b) Reducing noise and fluctuations: by calculating hourly averages, you effectively reduce noise and fluctuations present in the raw data. Short-term fluctuations and random noise can obscure underlying patterns in your dataset. Averaging over an hour helps to create a more stable representation of the data, making it easier to identify meaningful trends. (c) Enhanced accuracy: the primary benefit of this layer is the increase in prediction accuracy. Using hourly averages rather than raw, high-frequency data, you can build more accurate predictive models. Averaging data over an hour allows models to capture the more stable, long-term patterns and behaviors within your dataset. (d) Time-dependent features: the hourly averages become time-dependent features that capture the evolving characteristics of your data over time. These time-dependent features can help models account for daily and hourly variations, seasonal patterns, and other time-related dependencies. (e) Predicting active power in the future: the second key function of this layer is the "Shifting Up the Target Vector" operation. By shifting the target variable (e.g., active DC power) for different intervals into the future (1, 2, 3 h, and so on), you create target values for future time periods. This process is essential for forecasting active power at different time horizons. (f) Multiple time horizons: shifting the target at different intervals enables you to make predictions for various time horizons. Each shifted target corresponds to a different prediction time, allowing you to plan for different lead times. (g) Time-series forecasting: the data generated by this layer are well suited for time-series forecasting tasks. You can use methods like autoregressive models, moving averages, or machine-learning models to predict future active power based on the time-dependent features and shifted targets. And (h) improved system performance: the hourly averages and shifted target variables provide a rich and accurate dataset for training predictive models. Models trained on this data can more effectively capture both short-term and long-term dependencies, leading to enhanced predictive performance.
In the fourth stage; we implement the first deep learning model that based on using long short-term memory (DL-LSTM), this layer received the data results from the AEH-SUV and then split these data into two parts called training and testing to begin the training phase based on the parameters shown in Table 6.
In the fifth stage, we implement the first deep learning model that based on using gate recurrent unit (DL-GRU), this layer received the data results from the AEH-SUV and then split these data into two parts called training and testing to begin the training phase based on the parameters shown in Table 7. While the results of this stage are shown in Table 8.
The experimental results have shown that DL-GRU outperforms DL-LSTM in all shifting cases, underscoring the system's effectiveness in predicting future wind power generation and forecasting accuracy; for more details, see Fig. 89 and 10. As a result, the GMEE-WFED system is a pioneering approach that enhances wind DC-power generation forecasting.

Accuracy of testing dataset results from AEH-SUV Layer: a results of DL-GRU model for prediction DC-Power generated by wind turbine in different future intervals (1, 2, …and 6 h). b Results of DL-LSTM model for prediction DC-Power generated by wind turbine in different future intervals (1, 2,…and 6 h)

Intelligent data analysis of accuracy by types of model and shifting

Proof of the DL-GRU model more efficiency for prediction the active actual power generated of wind turbine in the future compare with DL-LSTM
6 Conclusions and Recommendations of Future Works
This paper introduces a novel and innovative system, the Generation Max Electrical Energy from Wind Friendly Environment Database (GMEE-WFED) System, which is designed to enhance the performance and energy output of wind power generation stations. This system offers precise wind power forecasting within distributed turbine systems, making it easier to integrate renewable energy into the grid.
The main layer of multi-layer system of GMEE-WFED is the best distribution of turbines based on DOA (BDT-DOA): this layer finds the best location of wind turbines by finding the best coordinates for each turbine. Through using optimization strategy so-called Dragonfly Algorithm, it maximizes energy production, and leading to higher power generation. Effect features layer (EF): This layer identifies the features that have the most significant impact on wind power generation. Understanding which features influence power output allows for better prediction and informed decision-making. Also enhance the time and resource efficiency by streamlining the identification of key features, the system reduces the time required for analysis and minimizes computational demands, making the process more efficient. Average and shifting up target layer (AEH-SUV): this layer enhanced accuracy through calculating hourly averages for each feature, which smooths out variations and reduces noise in the data. This results in more accurate predictions of power generation. Also, by shifting the target variable for different intervals into the future, this layer enables predictions of active power at varying time horizons (e.g., 1, 2, 3 …, and 6 h). This is crucial for forecasting future power generation. Deep Learning-Long Short-Term Memory (DL-LSTM) Layer enhancement is the Time-Series Forecasting where it is a deep learning technique that excels in capturing temporal dependencies. It is used to build prediction models for future energy production based on historical data. This contributes to improved time-series forecasting. Finally, Deep Learning Gate Recurrent Unit (DL-GRU) layer is outperforming DL-LSTM; in general, the experimental results indicate that DL-GRU outperforms DL-LSTM in all shifting cases.
This work presents set of benefit points such as (a) enhanced wind power generation efficiency: The hybrid system proposed in the research leads to improved energy output by identifying optimal turbine locations and utilizing influential features. This contributes to maximizing the efficiency of wind power generation. (b) Informed decision-making for turbine site selection: the developed models provide valuable insights for decision-making related to turbine site selection. By analyzing influential factors and estimating their importance, users can make informed decisions to maximize the utilization of available wind energy. (c) Advancements in data-driven optimization techniques: The research explores and utilizes advanced techniques, including deep learning and optimization algorithms, to improve wind power generation. These techniques can be applied in various domains to enhance energy utilization and optimize system performance, as shown in Fig. 11.

Wind power expect and wind energy costs
While, we can summarize the main drawbacks of the GMEE-WFED system: (a) complexity and implementation challenges: implementing the GMEE-WFED system can be complex due to its multiple layers, and deep learning models. It may require a high level of expertise. (b) Data requirements: accurate wind power predictions depend on high-quality data. Gathering and maintaining the necessary data for the system can be resource-intensive and may pose challenges in some areas where data collection infrastructure is lacking. (c) Energy intermittency: wind power generation is inherently intermittent and depends on wind conditions. While the system improves predictions, it cannot eliminate the variability of wind, which remains a challenge for integrating wind power into the grid. (d) Energy storage considerations: the system focuses on improving energy generation but does not address energy storage solutions. Energy storage is crucial for effectively utilizing wind power and ensuring a stable energy supply.
The following set of recommendation for future works: (a) refinement of existing models: further research can focus on refining and enhancing the performance of the proposed models. Exploring additional deep learning techniques and optimization algorithms could lead to even better results in optimizing wind power generation. (b) Expansion of application scope: the hybrid system's application can be expanded to cover different geographical areas. The tools and techniques developed in this research can be utilized to analyze and optimize wind power generation in various locations worldwide. (c) Integration of other renewable energy sources: Investigating the integration of other renewable energy sources with the hybrid system is worth exploring. For example, combining wind power with solar energy or harnessing the potential of ocean thermal energy conversion can lead to a more diverse and efficient renewable energy generation system.
Data Availability
Not applicable.
References
Diezmartínez, C.V.: Clean energy transition in Mexico: policy recommendations for the deployment of energy storage technologies. Renew. Sustain. Energy Rev. 135, 110407 (2021). https://doi.org/10.1016/j.rser.2020.110407
Al-Janabi, S., Al-Janabi, Z.: Development of deep learning method for predicting DC power based on renewable solar energy and multi-parameters function. Neural Comput. Appl. 35, 15273–15294 (2023). https://doi.org/10.1007/s00521-023-08480-6
Al-Janabi, S.: A novel agent-DKGBM predictor for business intelligence and analytics toward enterprise data discovery. J. Babylon Univ./Pure Appl. Sci. 23(2), 482–507 (2015)
Touzani, S., Granderson, J., Fernandes, S.: Gradient boosting machine for modeling the energy consumption of commercial buildings. Energy. Build. 158, 1533–1543 (2018). https://doi.org/10.1016/j.enbuild.2017.11.039
Hossny, K., Magdi, S., Soliman, A.Y., Hossny, A.H.: Detecting explosives by PGNAA using KNN regressors and decision tree classifier: a proof of concept. Prog. Nucl. Energy 124, 103332 (2020). https://doi.org/10.1016/j.pnucene.2020.103332https://doi.org/10.1016/j.enconman.2019.04.064
Rustam, F., Khalid, M., Aslam, W., Rupapara, V., Mehmood, A., Choi, G.S.: A performance comparison of supervised machine learning models for Covid-19 tweets sentiment analysis. PLoS ONE 16(2), e0245909 (2021). https://doi.org/10.1371/journal.pone.0245909
Cotfas, L.A., Delcea, C., Roxin, I., Ioanăş, C., Gherai, D.S., Tajariol, F.: The longest month: analyzing COVID-19 vaccination opinions dynamics from tweets in the month following the first vaccine announcement. IEEE Access 9, 33203–33223 (2021). https://doi.org/10.1109/ACCESS.2021.3059821
Hao, J.: Deep reinforcement learning for the optimization of building energy control and management. Doctoral dissertation, University of Denver (2020)
Al Janabi, S., Salman, M.A., Mohammad, M.: Multi-level network construction based on intelligent big data analysis. In: Farhaoui, Y., Moussaid L., (Eds.) Big Data and Smart Digital Environment. ICBDSDE 2018. Studies in Big Data, vol. 53, pp. 102–118. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-12048-1_13
Das, H.S., Roy, P.: A deep dive into deep learning techniques for solving spoken language identification problems. In: Intelligent Speech Signal Processing, pp. 81–100. Academic Press, New York (2019). https://doi.org/10.1016/B978-0-12-818130-0.00005-2
Khan, A., Sohail, A., Zahoora, U., et al.: A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 53, 5455–5516 (2020). https://doi.org/10.1007/s10462-020-09825-6
Chen, Q., Folly, K.A.: Comparison of three methods for short-term wind power forecasting. Int. Jt. Conf. Neural Netw. (IJCNN) 2018, 1–8 (2018)
Shi, H., Wang, H., Huang, Y., Zhao, L., Qin, C., Liu, C.: A hierarchical method based on weighted extreme gradient boosting in ECG heartbeat classification. Comput. Methods Progr. Biomed. 171, 1–10 (2019). https://doi.org/10.1016/j.cmpb.2019.02.005
Basu, S., et al.: A comprehensive review of WPF Models, techniques, and datasets. J. Artif. Intell. Res. 28(3), 123–145 (2020)
Zhang, H., et al.: A hybrid data-driven machine learning approach for WPF. J. Energy Eng. 45(2), 78–95 (2021). https://doi.org/10.1080/1234567890
Li, S., et al.: A hybrid LSTM-CNN approach for WPF. J. Renew. Energy Res. 10(3), 145–160 (2022). https://doi.org/10.1080/1234567890
Muselli, S., Notton, P.: A hybrid approach for short-term wind power forecasting. IEEE Trans. Sustain. Energy 6(3), 1215–1222 (2015). https://doi.org/10.1109/TSTE.2015.2412404
Zhang, H., et al.: Spatial-temporal prediction of wind power generation using convolutional neural network. Energies 11(5), 1229 (2018). https://doi.org/10.3390/en11051229
Chen, C., et al.: Spatial dynamic wind power forecasting based on deep learning and multitask learning. IEEE Trans. Sustain. Energy 10(3), 1377–1386 (2019). https://doi.org/10.1109/TSTE.2018.2868433
Basu, S., et al.: A comprehensive review of wind power forecasting models, techniques, and datasets. Renew. Sustain. Energy Rev. 134, 110366 (2020). https://doi.org/10.1016/j.rser.2020.110366
Zhang, H., et al.: Hybrid deep learning model for long-term wind power forecasting. Renew. Energy 177, 1227–1237 (2021). https://doi.org/10.1016/j.renene.2021.07.003
Huerta, F.S., et al.: Hybrid model combining recurrent neural networks and K-nearest neighbors for wind power forecasting. Energies 15(2), 564 (2022). https://doi.org/10.3390/en15020564
Liu, Z., et al.: Wind power forecasting based on GRU model and spatial information. Appl. Energy 311, 117946 (2022). https://doi.org/10.1016/j.apenergy.2021.117946
Zhang, R., et al.: Strategies for addressing abnormal and missing values in wind power forecasting. IEEE Trans. Sustain. Energy 13(4), 2364–2373 (2022). https://doi.org/10.1109/TSTE.2022.3162859
Mahdi, M.A., Al Janabi, S.: A novel software to improve healthcare base on predictive analytics and mobile services for cloud data centers. In: International Conference on Big Data and Networks Technologies, pp. 320–339. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-23672-4_23
Al-Janabi, S., Mahdi, M.A.: Evaluation prediction techniques to achievement an optimal biomedical analysis. Int. J. Grid Util. Comput. 10(5), 512–527 (2019)
Al-Janabi, S., Mohammad, M., Al-Sultan, A.: A new method for prediction of air pollution based on intelligent computation. Soft. Comput. 24(1), 661–680 (2020)
Liu, Y., Li, L., Zhou, S.: Ensemble forecasting frame based on deep learning and multi-objective optimization for planning solar energy management. Front. Energy Res. 9, 842 (2021)
Al-Janabi, S., Salman, M.A., Fanfakh, A.: Recommendation system to improve time management for people in education environments. J. Eng. Appl. Sci. 13, 10182–11019 (2018). https://doi.org/10.3923/jeasci.2018.10182.10193
Hong, Y.-Y., Rioflorido, C.L.P.P.: A hybrid deep learning-based neural network for 24-h ahead wind power forecasting. Appl. Energy 250, 530–539 (2019)
Hu, J., Zheng, W.: Multistage attention network for multivariate time series prediction. Neurocomputing 383, 122–137 (2020)
Hu, Q., Zhang, S., Yu, M., Xie, Z.: Short-term wind speed or power forecasting with heteroscedastic support vector regression. IEEE Trans. Sustain. Energy 7(1), 241–249 (2015)
https://aistudio.baidu.com/aistudio/competition/detail/152/0/datasets
Funding
No funding.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study's conception and design. Design the system achieved by MAS. Test and analysis were performed by MAS and MAM. The first draft of the manuscript was written by MAS. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Salman, M.A., Mahdi, M.A. & Al-Janabi, S. A GMEE-WFED System: Optimizing Wind Turbine Distribution for Enhanced Renewable Energy Generation in the Future. Int J Comput Intell Syst 17, 5 (2024). https://doi.org/10.1007/s44196-023-00391-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00391-7