
Abstract
With the rapid development of the Internet-of-Things (IoT), a massive amount of transient data is transmitted in edge networks. Transient data are highly time-sensitive, such as monitoring data generated by industrial devices. Due to their inefficiency, traditional caching strategies in edge networks are inadequate for handling transient data. Thus, to improve the efficiency of transient data caching, we construct a freshness model of transient data and propose a maximum entropy Actor–Critic-based caching strategy, TD-MEAC-which can improve the freshness of cached data and reduce the long-term caching cost. Simulation results show that the proposed TD-MEAC achieves a higher cache hit rate and maintains a higher average freshness of cached transient data compared with the existing DRL and baseline caching strategies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the rapid advent of the Internet-of-Things era, there has been exponential growth in the number of devices at the edge network and the amount of data they generate [1]. The data generated by IoT devices are used in extensive applications across various domains [2]. Conventionally, IoT data are transmitted to a remote cloud where it is stored for long-term use and subjected to complex data analysis. However, this approach increases the traffic load in the cloud core network, as the cloud core network is responsible for carrying out data requests and responses for applications. Consequently, data acquisition becomes more costly, and transmission latency increases.
Edge caching has emerged as a promising solution in recent years to address these challenges [3]. Edge caching involves using idle storage resources by network edge nodes, such as small base stations, user devices, etc., to cache a portion of the data. Applications can retrieve the required data from edge nodes without explicit communication with the cloud or IoT devices, reducing the network traffic load and content retrieval latency.
In the edge network, data generated by IoT devices are transient and have different valid periods based on the application’s requirements [4]. For example, some health monitoring sensors produce specific health parameters that are only valid for a few minutes and become invalid. The invalid data can affect the reliability and accuracy of application decisions. Caching transient data at the edge network can accelerate response times and reduce network traffic, thereby improving Quality of Service (QoS) and Quality of Experience (QoE) [5, 6]. For instance, in a vehicle traffic monitoring system, collecting and timely updating the status data of the monitoring objects (such as congestion conditions at a particular road section at a specific time) is crucial. Caching this valid status data at the edge nodes eliminates the need for IoT devices to respond to data requests, thereby reducing the load on the return path. Additionally, for some latency-sensitive applications, such as intelligent power distribution monitoring systems, responding to requests by edge nodes can more quickly isolate device failures.
The transient nature of data significantly impacts caching operations in edge networks.
-
Data freshness. The caching of transient data needs to consider data freshness, which depends on the application’s timeliness and lifecycle requirements. Data become stale with time, resulting in freshness loss. Thus, caching transient data require balancing caching benefits and freshness loss.
-
Frequent replacements. Compared to long-lived data, the caching of transient data require more frequent cache replacements, which may increase the energy consumption of edge nodes [7].
In fact, most of related policies take little account of information freshness for cached contents, and how to tackle transient IoT data in content-centric networking is still an ignored but crucial issue [8]. Therefore, caching strategies for long-lived data are not suitable for transient data. Some studies have sought to improve traditional caching policies to consider data transience. For instance, Ref. [9] proposed a cache replacement strategy based on data freshness, which selects data with the shortest remaining lifespan for replacement when cache replacement occurs. Reference [10] proposed the expected validity of data lifecycles, which predicts the number of requests received by cached data in the remaining lifespan and evicts data with the lowest expected number of requests for cache replacement. Although these methods consider data transience, they require prior knowledge, such as popularity and network topology. However, edge networks are dynamic, with the position, connection status, resource distribution, application scenarios, and demands of IoT devices constantly changing [11], making it challenging to provide prior knowledge.
Deep reinforcement learning (DRL) [12] has recently attracted widespread attention as a new machine learning paradigm. DRL uses deep neural networks to represent and process high-dimensional state space, improving decision-making capabilities in large-scale state space. Without prior knowledge and state features of edge networks, DRL can generate a series of mappings between network states and caching actions through multi-round interactions with edge networks, making it an excellent method for solving the problem of caching transient data in edge networks [13].
This paper focuses on the freshness characteristics of transient data. It proposes a transient data caching strategy called TD-MEAC based on Maximum Entropy Actor–Critic, which can adapt to the dynamic nature of edge networks and make caching decisions without prior knowledge. The main contributions of this paper are as follows:
-
A caching strategy for transient data is proposed, considering the data lifecycle and propagation delay to construct a freshness model for the data. A cost function that balances the freshness loss of the data and the cost of acquiring data items is also presented, which can reduce the long-term acquisition cost of transient data.
-
Considering the practical limitations of the caching scenario, the caching replacement problem for transient data is formulated as Markov Decision Process (MDP). The freshness of data items is viewed as a part of the state space, and the efficiency function is applied to the reward function. The Actor–Critic algorithm with maximum entropy interacts with the environment and finds the optimal caching decision.
This paper compares the TD-MEAC with other approaches, including classical and DRL-based caching strategies. Simulation results show that the proposed TD-MEAC achieves a higher cache hit rate and maintains a higher average freshness of cached transient data.
2 Related Work
Network edge nodes such as routers and switches that cache certain content can reduce the number of requests from applications to cloud data centers, thereby reducing service latency and network load. In edge caching, various issues need to be considered, including content selection for caching, cache replacement, and cache performance evaluation [14]. Some studies have focused on passive caching. In references [15, 16], collaborative caching issues of edge nodes were considered, and the overall cache hit rate was improved by finding the optimal cache layout. Reference [17] proposed an active caching strategy based on machine learning for the IoT scenario of intelligent agriculture, which can cache planting data in advance. Regarding active edge caching, Ref. [18] used neural networks to predict the optimal cache location for data. Reference [19] designed a content caching strategy applicable to centralized and distributed scenarios, which does not require knowledge of file popularity. Reference [20] proposed a passive in-network caching strategy, which can select caching nodes in a named data network for IoT based on the popularity of the content. However, the above work only applies to data that remains valid in the long term. For IoT data, due to its transient nature, the data gradually become obsolete and invalid, posing new challenges to edge caching [21].Therefore, some studies have investigated the impact of the data’s lifecycle on caching. Reference [22] focused on the Vehicle to Everything scenario. It analyzed the freshness of transient data (such as parking availability, road congestion, and surrounding maps) based on the method of layered soft slicing to increase the reuse gain of smooth slicing. To enable the optimal caching strategy, Ref. [23] proposed an Active learning (AL) approach to learn the content popularities and design an accurate content request prediction model. Reference [24] considered caching transient data on routers, balancing the cost of multi-hop communication and data freshness to evaluate the feasibility of router caching. Reference [25] used the least recently used replacement strategy and considered the transient nature of the data to determine whether to cache it by setting a freshness threshold. The caching strategies for these transient data are usually static. However, the dynamic edge network environment makes it challenging to provide the prior knowledge required by static policies. Compared with static policies, DRL-based methods can better cope with dynamic environments. In Ref. [26], DRL was first used to solve the caching problem of transient data in edge networks. Likewise, to address the complex and dynamic control issues, Ref. [27] introduced a framework known as Federated Deep-Reinforcement-Learning-Based Cooperative Edge Caching (FADE). The objective of this framework is to enhance the hit rate, minimize performance loss and average delay, as well as offload backhaul traffic. An Actor–Critic method is trained in an asynchronous and parallel manner, allowing caching decisions to be made without a priori knowledge. Reference [28] proposed a hierarchical network architecture caching system, formulating the problem as MDP and designing a policy optimization solver to obtain the optimal policy. Reference [29] considered the limited caching capacity and used a distributed proximal policy optimization (DPPO) algorithm to optimize the allocation of cached data and improve training speed.
Unlike the above methods, this paper proposes a transient data cache strategy based on the Maximum Entropy Actor–Critic, TD-MEAC, which is based on the traditional Actor–Critic algorithm and considers the randomness of cache actions. It improves the exploration ability and can better adapt to the dynamic edge environment.
3 System Model
3.1 Network Architecture
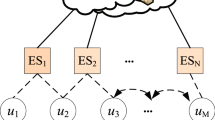
In the process of edge caching, caching of data items produces replicas in network nodes. In edge networks, the more data replicas there are, the greater the difficulty maintaining consistency among them. This is because the validity period of transient data is generally short, and some cached data items may become invalid and unable to respond to application requests. Network nodes must frequently update and maintain the cached content to maintain the validity of cached data. However, due to energy constraints, network nodes cannot continuously check the validity of data items to IoT devices or other nodes. This paper considers a centralized caching scenario for a group of IoT devices covered by edge nodes in edge networks, as shown in Fig. 1. This scenario consists of IoT devices, applications, and edge nodes.

The network architecture of edge caching
Edge Node refers to business platforms built at the network’s edge, such as edge controllers or servers. Typically composed of multiple units, an edge node covers all IoT devices within a given area. In the edge caching model, edge nodes act as gateways between IoT devices and applications. Due to limited storage capacity, edge nodes have a finite cache space.
IoT devices include sensors and intelligent machines that sense the environment and provide feedback. Data generated by IoT devices consist of three fields: static content identifiers, timestamps, and lifetimes. Static content identifiers represent the category of data items, timestamps indicate the moment when the IoT device generated the data item, and lifetimes indicate the duration of validity for the carried information after its generation.
IoT applications initiate data requests and process and analyze data. Applications that initiate requests may originate from the corresponding edge node, the cloud, or other edge nodes.
Edge nodes randomly distribute N IoT devices within their coverage area, with each IoT device capable of generating only one data item type. These data items can be cached on the corresponding edge node. When an IoT application sends a data request, the edge node checks its cache unit to see if there is a related data item. If there is, and the freshness of the data item meets the requirements, the edge node responds to the request. Otherwise, the edge node forwards the request to the corresponding IoT device, which generates a new data item and responds via the return link.
3.2 Freshness Model
Freshness reflects the staleness of transient data, and a lower freshness indicates a more stale data item. Worn data items can reduce the accuracy and timeliness of applications. Different types of applications have additional requirements for data freshness. Factors that affect data freshness include data collection and processing time, transmission delay, and timeliness of data processing. It is necessary to model the freshness of data to evaluate the quality and availability of cached data items.

Data item is valid

Data item is invalid
A static content identifier CID uniquely identifies the IoT data items. Different instances of IoT data items generated at other times share the same CID for the same IoT device. Each IoT data item i has a timestamp field \(t_\textrm{gen}^i\) and a lifecycle field \(t_\textrm{life}^i\). For a given time t, the data age of the data item i is defined as \(t_\textrm{age}^i = t - t_\textrm{gen}^i\), representing the time elapsed from the generation of the data item to the current time t.
The response delay of the edge node \(t_\textrm{del}^i\) consists of two parts: the delay of caching and retrieval after receiving the data request and the propagation delay of the data item from the edge node to the IoT application. The former is related to the computing and processing capacity of the edge node, and the latter is related to the distance between the edge node and the IoT application and the network latency. The larger the \(t_\textrm{del}^i\), the less fresh the data item.
As shown in Fig. 2, when \(t_\textrm{age}^i + t_\textrm{del}^i < t_\textrm{life}^i\), the data item is still valid, and its freshness is greater than 0, which can be used as a response to the request. In contrast, in Fig. 3, when \(t_\textrm{age}^i + t_\textrm{del}^i > t_\textrm{life}^i\), the freshness is 0, indicating that the cached data item has expired, and the carried information is invalid, thus cannot be used as a response to the request.
The more invalid data items cached in the edge node, the lower the cache hit rate. Therefore, improving the average freshness of cached data items for transient data can help enhance the overall cache hit rate.
3.3 Cost Function
The caching of transient data involves careful consideration of device energy consumption and network transmission delays and maintaining data freshness to reduce the cost of data acquisition. This paper introduces two cost functions to represent the cost of freshness loss and the acquisition of transient data. The caching of transient data at edge nodes results in a lag, causing the cached data to have a non-zero data age compared to directly acquired data from IoT devices. Consequently, the cache results in a loss of data freshness. The cost of freshness loss for a newly generated data item from IoT devices can be considered as zero, while the cost of freshness loss for a cached data item i is related to its data age. Therefore, the cost of freshness loss denoted as \(\text {Cost}{_\textrm{loss}}\) is defined as follows:
The acquisition cost of data, denoted as \(\text {Cost}{_g}\), depends on where the data are obtained. The cost of acquiring data from an edge node is denoted as \(\text {Cost}{_{g1}}\), while the cost of acquiring data from IoT devices is denoted as \(\text {Cost}{_{g2}}\). The generation of data items by IoT devices consumes device energy, and there is a transmission delay from IoT devices to edge nodes. Thus, it is generally true that \(\text {Cost}{_{g1}} < \text {Cost}{_{g2}}\).
When an edge node responds to a request, the cost consists of two parts: the cost of freshness loss \(\text {Cost}{_\textrm{loss}}\), and the cost of acquiring data items by the edge node \(\text {Cost}{_{g1}}\). When IoT devices respond to the request, there is only the cost of acquiring data items \(\text {Cost}{_{g2}}\). Both costs affect the benefit of caching transient data. To balance the two costs, the cost function, denoted as Cost, is defined as follows:
where \(\psi \) and \(\varrho \), respectively, denote the weighting coefficients for the cost of freshness loss and the acquisition cost of data items. To evaluate the effectiveness of caching, we define the benefit function U. Minimizing the cost is equivalent to maximizing the benefit since the cost of caching is inversely proportional to its benefit. To ensure that the benefit function is always non-negative, we define the constant \(\alpha \text {Cost}{_{g2}} + \beta \) as the baseline benefit value. Therefore, the benefit function is defined as follows:
One component of the edge node state is the freshness of the cached data items. In the next section, we describe how the benefit function is applied to the reward of caching actions, combined with the maximum entropy Actor–Critic algorithm, to determine the optimal caching strategy.
4 Maximum Entropy Actor–Critic-Based Caching Solution
4.1 Cache Replacement Process
Using DRL to handle transient data caching involves training a neural network to learn how to take caching actions that maximize cumulative caching rewards. During the caching process of transient data, edge nodes need to interact with the environment, observe the environment’s state, take caching actions, and obtain cache rewards. Hence, dealing with complex dynamic environments with continuous time and space is necessary. The framework provided by MDP is used to model the reinforcement learning problem. MDP stipulates that future states and rewards depend solely on the current state and action token, independent of prior conditions and actions. This simplifies the modeling of transient data caching, allowing edge nodes to take caching actions based only on the current state and rewards without considering history.
When an IoT application requests a data item, an edge node may face one of three scenarios: (1) the data item is already cached and still valid, in which case the edge node can directly respond to the request; (2) the data item is cached but has become invalid, so the edge node forwards the request to the IoT device, which collects the data and responds via a feedback link, and the edge node updates the cache and replaces the invalidated data item; and (3) the data item is not cached, and the IoT device collects the data and responds via a feedback link.
Since the edge node’s cache space is limited, data items must be selectively cached. In scenarios (1) and (2), the space occupied by the cache does not change. However, in scenario (3), the new data items can be cached if the cache space is not full. But if the cache space is full and new data items need to be cached, a cache swap replaces some cached data items with new ones.
The cache state of edge nodes is determined solely by the previous cache state and the previous caching action. Therefore, the cache replacement process can be represented as MDP. A typical MDP consists of a quintuple \(\left\{ {S,A,P,R,\gamma } \right\} \). In the transient data cache model, the number of requests processed by an edge node in a single time step is unknown. If the unknown number of requests is regarded as part of the MDP, the complexity of the model will increase exponentially. Therefore, this paper regards processing a single request by an edge node as a decision cycle and replaces the time step with a decision cycle. And the quintuple for the nth decision cycle can be represented as \(\left\{ {{s_n},{a_n},p({s_{n + 1}}\vert {s_n},{a_n}),{r_n},\gamma } \right\} \) (Fig. 4).

MDP in a decision cycle
The MDP for transient data caching is depicted as follows. The state space S represents a finite set of states for the caching process of edge nodes. The state features are split into two parts: the data items already cached in the cache space and the requests from IoT applications. The cache space size is defined as C, and C binary tuples can represent the data item features \({{\hat{d}}_i} = \left\{ {CI{D_i},\text {freshness}{_i}} \right\} \). The request is represented by \({{\hat{d}}_0} = \left\{ {CID,\text {requestTime}} \right\} \). Thus, the state \({s_n}\) for the nth decision cycle can be represented as \({s_n} = \left\{ {{{{\hat{d}}}_0},{{{\hat{d}}}_1},{{{\hat{d}}}_2} \ldots {{{\hat{d}}}_c}} \right\} \).
The action space A represents a finite set of caching actions for edge nodes. The action taken by the edge node in the nth decision cycle is represented by \({a_n}\). The size of the action space is proportional to the cache space and is related to the selected caching action. The larger the action space, the greater the computational complexity of the model. In resource-constrained edge nodes, to limit the size of the action space, it is stipulated that at most one cache replacement occurs in a decision cycle. The action space is represented as \(A = \left\{ {0,1,2,3, \ldots ,C} \right\} \). Here, \({a_n} = 0\) represents skipping the cache replacement process while represents replacing the new data item with the \({a_n}\)th data item in the cache space.
The state transition probability \(P\left( {{s_{n + 1}}{s_n},{a_n}} \right) \) represents the probability of the following decision cycle state \({s_{n + 1}}\) given the state-action combination \(\left\{ {{s_n},{a_n}} \right\} \).
The reward function R is an instantaneous utility function. \({r_n}\) represents the expected instantaneous reward for the state-action combination in the nth decision cycle. The utility function U serves as a suitable indicator for training DRL, balancing freshness loss cost and data acquisition cost. Define reward function R as
In addition to the immediate reward, the impact of future rewards on the current decision is also considered. A discount rate \({\gamma }\) is used to reconcile the cumulative rewards of the reward sequence. The smaller the \({\gamma }\) is, the more biased the immediate reward is. Define the cumulative rewards \({G_n}\) starting from the nth decision cycle as
The goal of MDP is to find an optimal caching policy that maximizes the long-term reward under this policy, as shown below:
Model-based approaches can handle MDP, but the quintuple must be known. However, in the actual transient data caching process, requests from IoT applications are unknown, and the state transition probability model P is also unknown. Therefore, model-based methods are not suitable for transient data caching processes. Moreover, in complex dynamic environments, it is not easy to manually extract all valuable features of the domain into a low-dimensional state space.
This paper uses a model-free DRL method to address the challenges above. Specifically, an Actor–Critic method based on maximizing entropy is used to find the optimal caching policy \({\pi ^{{{*}}}}\).
4.2 Implementation of TD-MEAC
Actor–Critic is a reinforcement learning approach that combines policy gradient and value function approximation. It has a faster update and convergence speed than pure policy gradient algorithms. To enhance the exploration capability of the strategy, the randomness of cached actions is considered when selecting them, and the maximum entropy policy is used to improve the solution to the problem. The improved optimal policy \({\pi ^{\mathrm{{*}}}}\) is defined as
Here, \(\pi (\cdot \vert {s_i})\) represents the probability distribution of cached actions taken under the marginal node state \({s_i}\). The function \(\pi (\cdot \vert {s_i})\) represents the entropy of the cached actions, which measures the randomness of the caching strategy. Increasing entropy can give the marginal node a more robust exploration capability and thus better discover potential high-reward policies. \(\alpha \) is the temperature parameter, which indicates the relative importance of the entropy term to the cumulative reward. The larger the \(\alpha \), the greater the weight of random exploration of cached actions.
To find the optimal policy \({\pi ^*}\), this paper defines the action value function \({Q^\pi }\left( {s,a} \right) \) and state value function \({V^\pi }\left( s \right) \). \({Q^\pi }\left( {s,a} \right) \) measures the expected cumulative reward obtained by the marginal node based on the caching policy \(\pi \), considering the entropy of the cached actions, and can be expressed as
\({V^\pi }\left( s \right) \) measures the expected cumulative reward obtained by the marginal node based on the caching policy \(\pi \) after executing the cached actions, considering the entropy of the cached actions, and can be expressed as
The cached actions for transient data at the marginal node are independent, so the action space is discrete. In the discrete action space, the Bellman equation can be used to express Eqs. (9) and (10) in the following form:

Actor network and critic network
As shown in Fig. 5, the Actor–Critic model consists of an Actor and a Critic. The Actor determines the cached action while the Critic evaluates the cached action. Typically, the optimization of the caching policy is achieved through alternating iterations of policy evaluation, which computes the value function of the policy, and policy improvement, which uses the value function to improve the policy. However, convergence through policy evaluation and improvement can be very challenging in a large-scale dynamic edge caching environment. Therefore, two independent neural networks are used to approximate the value function \({Q^\pi }\left( {s,a} \right) \) and the policy function \(\pi (\cdot \vert {s})\), denoted as \({Q_\omega }\left( {s,a} \right) \) and \({\pi _\theta }\left( {a{\vert }s} \right) \), respectively, where \(\omega \) and \(\theta \) are the parameters of the two networks. The policy network \({\pi _\theta }\left( {a{\vert }s} \right) \) outputs a-dimensional vector, representing the probability distribution of each cached action. The value network \({Q_\omega }\left( {s,a} \right) \) outputs a score for the cached action. The convergence objective is achieved through stochastic gradient descent during policy evaluation and improvement.
To mitigate the overestimation caused by bootstrapping during the neural network training process, this strategy employs two value networks, \({Q_{{\omega _1}}}\left( {s,a} \right) \) and \({Q_{{\omega _2}}}\left( {s,a} \right) \), and defines two target value networks, \({Q_{{{{\bar{\omega }} }_1}}}\left( {s,a} \right) \) and \({Q_{{{\bar{\omega }}_2}}}\left( {s,a} \right) \), with the same structure as the former but with different parameters (Fig. 6). To compute the TD target \({{\hat{y}}_n}\), the minimum value between the two target value networks is taken and denoted as

Neural network architecture of TD-MEAC
Therefore, the TD error, defined as \(\delta \), can be represented as the difference between the value network and the TD target, as shown below:
The specific algorithm implementation flow of the TD-MEAC strategy is given in the following subsection.
4.3 Strategy Implementation
The workflow of the TD-MEAC caching strategy is illustrated in Fig. 7 and described as follows.
-
(1)
Given the current state \({s_n}\), the edge node uses the policy network \({\pi _\theta }\left( {{\cdot \vert }{s_n}} \right) \) to obtain a cached action \({a_n}\). The agent executes the cached action, and the environment provides the reward \(r\left( {{s_n},{a_n}} \right) \) and the new state \({s_{n + 1}}\). The is then stored in the experience buffer D.
-
(2)
A batch of transitions T is randomly sampled from the experience buffer D, and the TD error of each transition is computed.
-
(3)
The value and policy network parameters are updated. When updating the parameters of the value network, the objective function is defined as follows:
$$\begin{aligned} J\left( {{Q_\omega }} \right){} & {} = E\Bigg [ \frac{1}{2}\big ({Q_\omega }\left( {{s_n},{a_n}} \right) \nonumber \\{} & {} - {{\left( {r\left( {{s_n},{a_n}} \right) + \gamma \left[ {{V^{{\bar{\omega }} }}\left( {{s_{n + 1}}} \right) } \right] } \right) }^2}{\vert }\left( {{s_n},{a_n}} \right) \sim T \Bigg ].\nonumber \\ \end{aligned}$$(15)
Here, \({V^{{\bar{\omega }} }}\left( {{s_{n + 1}}} \right) \) represents the expected action distribution obtained by sampling experiences from the experience buffer using the target value network and Eq. (11).
When updating the parameters of the policy network, the objective function is defined as follows:
The value network parameters \({\omega _1}\) and \({\omega _2}\) are updated using the stochastic gradient descent method based on Eqs. (11) and (12). Then, the target value network parameters \({{\bar{\omega }} _1}\) and \({{\bar{\omega }} _2}\) are updated using the weight-based method.

Workflow of TD-MEAC
The transient nature of data can cause rewards to change constantly, rendering the use of a fixed temperature parameter \(\alpha \) unreasonable and leading to instability throughout the training process. Therefore, different temperature parameters must be used depending on the exploration stage. When the policy has essentially completed the exploration of a region and the optimal action has been determined, \(\alpha \) should be reduced. Conversely, when the procedure begins exploring a new area, \(\alpha \) should be increased to explore more space in search of the optimal action. Consequently, during policy updates, the temperature parameter \(\alpha \) is updated synchronously with the constraint formula proposed in Ref. [30] to adjust automatically, as shown in Eq. (17):
Here, \({\bar{H}}\) is a constant vector that represents the hyperparameter of the target entropy.
Algorithm 1 describes the critical steps of the TD-MEAC strategy. First, TD targets are calculated using Eq. (13), and then the neural network parameters are updated using the stochastic gradient descent algorithm.

TD-MEAC:Transient Data Caching Strategy Based on Maximum Entropy Actor-Critic.
The time complexity of the TD-MEAC strategy primarily depends on the neural network structure and the amount of data processed per unit of time. Within the TD-MEAC strategy are four Actor networks and one Critic network. The parameter quantity for each network can be calculated based on the number of network layers and neurons in each layer. Assuming that the parameter quantity for the Actor networks is denoted as \({N_a}\), the parameter quantity for the Critic network as \({N_c}\), and the amount of data processed per unit of time as \({N_i}\), then the time complexity can be represented as \(O\left( {\left( {4*{N_a} + {N_c}} \right) *{N_i}} \right) \).
The space complexity of the TD-MEAC strategy mainly arises from storing the neural network parameters and experience pool data. Let \({N_d}\) denote the size of the experience pool, then the space complexity of the strategy can be expressed as \(O(\left( {4*{N_a} + {N_c}} \right) *{N_d}\).

Cache capacity vs cache hit ratio
5 Experiments and Evaluation
This section compares the TD-MEAC caching strategy with other caching schemes to verify the performance of the TD-MEAC caching strategy.
5.1 Simulation Setting
This section aims to evaluate the performance of the TD-MEAC caching strategy by comparing it with other caching schemes. The experimental environment was established using Python 3.8 and libraries such as Numpy, Torch, Gym, Pandas, and TensorFlow. The simulations were conducted on a workstation with an AMD Ryzen 7 3700X 8-Core CPU and 32 GB RAM. The caching scenario simulated in this study involved IoT devices initiating data requests, with the corresponding edge nodes receiving and determining whether to respond based on the cached content or forward the request to the IoT devices and then update the cache. It was assumed that each request received a response. The edge node’s cache space was set to 100 (C=100 ), with 200 IoT devices within the coverage range, and each device generated a data item with a unique CID. The data item’s lifespan was randomly sampled from 5 to 20 time steps, and the delay in network propagation was uniformly distributed between 1 and 3 time steps.
For IoT application requests, 50,000 requests were generated using the Zipf distribution for testing purposes. To avoid the impact of data request correlation on the results, these requests were generated using a variable Zipf parameter \(\epsilon \) ranging from 0.9 to 1.7.
Regarding the TD-MEAC neural network model, both the value and policy networks were set to two hidden layers. Each hidden layer had 64 neurons, and the relu function was the activation function between the layers. The learning rate was initialized at 0.0001, the discount rate \(\mathrm{{\gamma }}\) was set to 0.99, the initial value of the temperature parameter \(\alpha \) was 0.2, and the weight coefficient \(\psi \) of the cost was initialized to 0.6. Each batch contained 256 experiences during training, and the experience buffer size was set to 5000.
This study compared TD-MEAC with three representative caching schemes, including a baseline caching strategy: Least Fresh First (LFF) and two reinforcement learning-based caching strategies.
LFF was proposed in Ref. [9] as a baseline transient data caching strategy where the edge node records the freshness of each cached data item and selects the least fresh one for replacement.
DRL-Cache, proposed in the Ref. [24], was the first strategy to apply DRL to transient data caching. This scheme is based on Actor–Critic and trains the neural network online and offline, allowing it to find the optimal caching strategy without prior knowledge.
IoT-Cache, proposed in the Ref. [26], is a caching strategy for IoT data that uses DPPO to learn the best caching strategy for multi-objective decisions.

Cache capacity vs average freshness
5.2 Results and Discussion
This section analyzes the impact of different parameter indicators on cache strategies from multiple aspects, including cache capacity, number of requests, request frequency, and weight coefficients.
First, the impact of cache capacity is discussed in Fig. 8, where it can be observed that the cache hit rate of several strategies increases with the increase of cache capacity. For transient data, cache misses are likely to occur if the cache capacity is small, resulting in a low cache hit ratio. It is also observed that the cache strategy based on reinforcement learning performs significantly better than the LFF strategy. However, the performance of the proposed TD-MEAC strategy is still better than that of the DRL-Cache and IoT-Cache strategies. Part of the reason is that the TD-MEAC strategy uses the method of entropy regularization and the optimal strategy \({\pi ^{{{*}}}}\) used contains the entropy of the cache actions. Entropy regularization can encourage the model to balance the predicted distribution of outputs and improve the convergence speed of the model. In addition, the TD-MEAC strategy uses two independent value networks to reduce overestimation problems, making the learning process more stable.

Request counts vs cache hit ratio

Request counts vs average freshness
Therefore, under the same cache capacity, TD-MEAC can have better performance.
Figure 9 illustrates the impact of varying cache capacity on the average freshness of cached items. The results indicate that as cache capacity increases, the average freshness decreases. This is because transient data experiences freshness loss once it is cached until invalid. When the request rate is constant (at ten requests per time step), larger cache capacity results in fewer cache replacements, reducing the average freshness of cached items.
The relationship between cache hit rate, the average freshness of data items, and request quantity are recorded in Figs. 10 and 11. As the number of requests increases, the cache strategy based on reinforcement learning explores based on historical experience. Cache actions tend to become similar, resulting in an upward trend in both the cache hit rate and average freshness of data items. It can be seen from Figs. 10 and 11 that the TD-MEAC strategy is superior to the DRL-Cache and IoT-Cache strategies for the same number of requests. Especially when the number of requests is small, TD-MEAC, due to its more vital exploration ability, can reach convergence faster, and its advantage over DRL-Cache and IoT-Cache is more pronounced. In contrast, the cache decision of LFF is constant mainly because it is not affected by historical experience.

Request rate vs cache hit ratio
The request frequency of transient data items in IoT applications affects the performance of cache policies. To observe the impact of request frequency on cache decision-making, this study sets the request frequency from 2 requests/timestep to 14 requests/timestep. As depicted in Fig. 12, the cache hit rate of the cache strategy increases as the request frequency rises from 2 to 10 requests/timestep. This is because the data items in the cache space tend to expire when requests are less frequent. As the request frequency increases, the data items in the cache space are more likely to respond to requests before expiration, thus improving the cache hit rate. However, the cache hit rate will not continue to increase, and when the request frequency exceeds 10 requests/timestep, the cache hit rate tends to stabilize.

Request rate vs average freshness

Weight factor vs cache hit ratio
As shown in Fig. 13, the average freshness of cached data items increases as the request frequency increases. Due to the increase in request frequency, the number of cache replacements also increases, and invalidated cache data items are more likely to be replaced, thus increasing the average freshness. The average freshness stabilizes when the request frequency exceeds ten requests/timestep. Compared with other cache policies, the proposed TD-MEAC strategy performs better at different request frequencies.
The weight coefficients in the cost function of the transient data cache play an essential role in the performance of the cache strategy. In particular, the coefficients \(\psi \) and \(\varrho \) represent the weight assigned to the cost of freshness loss and the cost of data retrieval, respectively, where \(\psi + \varrho = 1\). By varying the value of \(\psi \), we can observe the cache preference of the TD-MEAC model. As shown in Fig. 14, the cache hit rate based on the reinforcement learning cache strategy decreases as \(\psi \) increases from 0 to 1. This is because the cache strategy tends to retrieve new data from the IoT devices to avoid the cost of freshness loss associated with using cached data. As \(\psi \) increases, more fresh data is generated by the IoT devices, which leads to a decrease in the cache hit rate.
Figure 15 presents a clear trend of the average freshness. As the proportion of fresh data retrieved from the IoT devices increases, the edge nodes replace cached data items with fresh ones of the same CID, resulting in an overall increase in the average freshness.

Weight factor vs average freshness

Life cycle vs cache hit ratio
From Figs. 14 and 15, we can observe that TD-MEAC outperforms other policies in the \(0.4 \le \psi \le 0.8\). Therefore, compared to DRL-Cache and IoT-Cache, the TD-MEAC strategy is more suitable for situations where the weight coefficient \(\psi \) is relatively balanced.
To investigate the inherent logic of different strategies in the transient data caching process, we recorded the response process of edge nodes to requests. We classified the requested data items according to their lifecycles. The cache hit rate is shown in Fig. 16. Data items with longer lifecycles tend to have higher cache hit rates. For data items with lifecycles between 10 and 16, the cache hit ratio of the TD-MEAC strategy is superior to that of DRL-Cache and IoT-Cache. As for data items with other lifecycles, the performance of the three DRL-based strategies is comparable.
Finally, we recorded the average cost as the number of requests changed. As shown in Fig. 17, the TD-MEAC strategy’s average cost converges to the lowest point at around 30,000 requests and maintains relatively stable performance afterward. TD-MEAC strategy outperforms DRL-Cache and IoT-Cache strategies in reducing long-term average cost.

Requests counts vs cost
In summary, we investigated the effects of four factors, namely cache capacity, request volume, request frequency, and weight coefficient, on cache hit rate and average data freshness. Simulation experiments showed that the DRL-based strategy performed significantly better than the baseline strategies for caching transient data. Compared to DRL-Cache and IoT-Cache, TD-MEAC was more suitable for caching data items with a medium lifespan due to its consideration of action randomness and overestimation. Consequently, TD-MEAC exhibited superior overall cache hit rate, data freshness, and long-term cost.
6 Conclusion
This paper addressed the issue of caching transient IoT data in edge networks. A freshness model was established based on the transient data’s lifespan and latency, and a cost function was proposed that integrated data freshness and retrieval Cost. To make the approach suitable for dynamic edge environments, we developed a maximum entropy Actor–Critic-based caching strategy, TD-MEAC, reducing reliance on prior knowledge. The performance of TD-MEAC was evaluated experimentally and compared to other strategies. Experimental results indicate that TD-MEAC is better than
other caching strategies regarding cache hit ratio, data freshness, and reducing long-term cache costs. In future work, the model of data freshness and cost can be further optimized to take more influencing factors into account and combine with other techniques to further improve the performance of the caching strategy.
Availability of Data
Data employed in this research were generated through the parameter settings in Section 5.1. For details, please contact the author: zhangy.03@qq.com
Abbreviations
- IoT:
-
Internet of things
- DRL:
-
Deep reinforcement learning
- QoS:
-
Quality of service
- QoE:
-
Quality of experience
- MDP:
-
Markov decision process
- DPPO:
-
Distributed proximal policy optimization
- LFF:
-
Least fresh first
References
Syed, A.S., Sierra-Sosa, D., Kumar, A., Elmaghraby, A.: Iot in smart cities: a survey of technologies, practices and challenges. Smart Cities 4(2), 429–475 (2021)
Imteaj, A., Thakker, U., Wang, S., Li, J., Amini, M.H.: A survey on federated learning for resource-constrained iot devices. IEEE Internet Things J. 9(1), 1–24 (2021)
Chiang, M., Zhang, T.: Fog and iot: an overview of research opportunities. IEEE Internet Things J. 3(6), 854–864 (2016). https://doi.org/10.1109/JIOT.2016.2584538
Samir, M., Sharafeddine, S., Assi, C.M., Nguyen, T.M., Ghrayeb, A.: Uav trajectory planning for data collection from time-constrained iot devices. IEEE Trans. Wirel. Commun. 19(1), 34–46 (2020). https://doi.org/10.1109/TWC.2019.2940447
Xia, X., Chen, F., He, Q., Grundy, J., Abdelrazek, M., Jin, H.: Online collaborative data caching in edge computing. IEEE Trans. Parallel Distrib. Syst. 32(2), 281–294 (2020)
Sun, X., Ansari, N.: Edgeiot: mobile edge computing for the internet of things. IEEE Commun. Mag. 54(12), 22–29 (2016). https://doi.org/10.1109/MCOM.2016.1600492CM
Wu, X., Li, X., Li, J., Ching, P.C., Leung, V.C.M., Poor, H.V.: Caching transient content for iot sensing: multi-agent soft actor–critic. IEEE Trans. Commun. 69(9), 5886–5901 (2021). https://doi.org/10.1109/TCOMM.2021.3086535
Feng, B., Tian, A., Yu, S., Li, J., Zhou, H., Zhang, H.: Efficient cache consistency management for transient iot data in content-centric networking. IEEE Internet Things J. 9(15), 12931–12944 (2022). https://doi.org/10.1109/JIOT.2022.3163776
Meddeb, M., Dhraief, A., Belghith, A., Monteil, T., Drira, K., Mathkour, H.: Least fresh first cache replacement policy for ndn-based iot networks. Pervasive Mob. Comput. 52, 60–70 (2019)
Fatale, S., Prakash, R.S., Moharir, S.: Caching policies for transient data. IEEE Trans. Commun. 68(7), 4411–4422 (2020). https://doi.org/10.1109/TCOMM.2020.2987899
Lim, W.Y.B., Luong, N.C., Hoang, D.T., Jiao, Y., Liang, Y.-C., Yang, Q., Niyato, D., Miao, C.: Federated learning in mobile edge networks: a comprehensive survey. IEEE Commun. Surv. Tutor. 22(3), 2031–2063 (2020). https://doi.org/10.1109/COMST.2020.2986024
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A.A., Veness, J., Bellemare, M.G., Graves, A., Riedmiller, M., Fidjeland, A.K., Ostrovski, G., et al.: Human-level control through deep reinforcement learning. Nature 518(7540), 529–533 (2015)
Heuillet, A., Couthouis, F., Díaz-Rodríguez, N.: Explainability in deep reinforcement learning. Knowl.-Based Syst. 214, 106685 (2021)
Yao, J., Han, T., Ansari, N.: On mobile edge caching. IEEE Commun. Surv. Tutor. 21(3), 2525–2553 (2019)
Maniotis, P., Thomos, N.: Viewport-aware deep reinforcement learning approach for 360\(^\circ \) video caching. IEEE Trans. Multimedia 24, 386–399 (2021)
Zhang, Y., Feng, B., Quan, W., Tian, A., Sood, K., Lin, Y., Zhang, H.: Cooperative edge caching: a multi-agent deep learning based approach. IEEE Access 8, 133212–133224 (2020)
Junior, F.M.R., Bianchi, R.A., Prati, R.C., Kolehmainen, K., Soininen, J.-P., Kamienski, C.A.: Data reduction based on machine learning algorithms for fog computing in iot smart agriculture. Biosys. Eng. 223, 142–158 (2022)
Wang, Y., Friderikos, V.: Network orchestration in mobile networks via a synergy of model-driven and ai-based techniques. In: 2020 IEEE Eighth International Conference on Communications and Networking (ComNet), pp. 1–5. IEEE (2020)
Zhong, C., Gursoy, M.C., Velipasalar, S.: Deep reinforcement learning-based edge caching in wireless networks. IEEE Trans. Cogn. Commun. Netw. 6(1), 48–61 (2020)
Naeem, M.A., Nguyen, T.N., Ali, R., Cengiz, K., Meng, Y., Khurshaid, T.: Hybrid cache management in iot-based named data networking. IEEE Internet Things J. 9(10), 7140–7150 (2021)
Stoyanova, M., Nikoloudakis, Y., Panagiotakis, S., Pallis, E., Markakis, E.K.: A survey on the internet of things (iot) forensics: challenges, approaches, and open issues. IEEE Commun. Surv. Tutor. 22(2), 1191–1221 (2020). https://doi.org/10.1109/COMST.2019.2962586
Zhang, S., Luo, H., Li, J., Shi, W., Shen, X.: Hierarchical soft slicing to meet multi-dimensional qos demand in cache-enabled vehicular networks. IEEE Trans. Wireless Commun. 19(3), 2150–2162 (2020)
Bommaraveni, S., Vu, T.X., Chatzinotas, S., Ottersten, B.: Active content popularity learning and caching optimization with hit ratio guarantees. IEEE Access 8, 151350–151359 (2020). https://doi.org/10.1109/ACCESS.2020.3014379
Vural, S., Wang, N., Navaratnam, P., Tafazolli, R.: Caching transient data in internet content routers. IEEE/ACM Trans. Netw. 25(2), 1048–1061 (2016)
Zhang, Z., Lung, C.-H., Lambadaris, I., St-Hilaire, M.: Iot data lifetime-based cooperative caching scheme for icn-iot networks. In: 2018 IEEE International Conference on Communications (ICC), pp. 1–7. IEEE (2018)
Zhu, H., Cao, Y., Wei, X., Wang, W., Jiang, T., Jin, S.: Caching transient data for internet of things: a deep reinforcement learning approach. IEEE Internet Things J. 6(2), 2074–2083 (2018)
Wang, X., Wang, C., Li, X., Leung, V.C.M., Taleb, T.: Federated deep reinforcement learning for internet of things with decentralized cooperative edge caching. IEEE Internet Things J. 7(10), 9441–9455 (2020). https://doi.org/10.1109/JIOT.2020.2986803
Wu, H., Nasehzadeh, A., Wang, P.: A deep reinforcement learning-based caching strategy for iot networks with transient data. IEEE Trans. Veh. Technol. 71(12), 13310–13319 (2022)
Sharma, S., Peddoju, S.K.: Iot-cache: Caching transient data at the iot edge. In: 2022 IEEE 47th Conference on Local Computer Networks (LCN), pp. 307–310. IEEE (2022)
Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., Kumar, V., Zhu, H., Gupta, A., Abbeel, P., et al.: Soft actor-critic algorithms and applications. arXiv preprint arXiv:1812.05905 (2018)
Acknowledgements
The authors wish to thank the funds for their support.
Funding
The research was supported by the National Natural Science Foundation of China (No. 62162003) and the Nanning Science and Technology project (No. 20221031).
Author information
Authors and Affiliations
Contributions
YZ: conceptualization, methodology, formal analysis, writing—original draft, and visualization. NC: conceptualization, supervision, funding acquisition, writing—review and editing. SY: investigation, supervision, and writing—review. LH: investigation and writing—-review.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Y., Chen, N., Yu, S. et al. Transient Data Caching Based on Maximum Entropy Actor–Critic in Internet-of-Things Networks. Int J Comput Intell Syst 17, 20 (2024). https://doi.org/10.1007/s44196-023-00377-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00377-5